
Abstract
Background and aim
Suicide is a global public health issue disproportionately impacting equity-deserving groups. Recent advances in Artificial Intelligence and increased access to a variety of digital data sources have enabled the development of novel and personalized suicide prevention strategies. However, standards on how to harness these data in a comprehensive and equitable way remain unclear. The primary aim of this study is to identify considerations for the collection and use of digital health data for suicide prevention and care. The results will inform the development of a data governance framework for a multinational suicide prevention mHealth platform.
Method
We used a modified Cochrane Rapid Reviews Method. Inclusion criteria focused on primary studies published in English from 2007 to the present that referenced the use of digital health data in the context of suicide prevention and care. Screening and data extraction was performed independently by multiple reviewers, with disagreements resolved through discussion. Qualitative and quantitative synthesis methods were employed to identify emergent themes.
Results
Our search identified 2453 potential articles, with 70 meeting inclusion criteria. We found little consensus on best practices for the collection and use of digital health data for suicide prevention and care. Issues of data quality, fairness and equity persist, compounded by inadequate consideration of key governance issues including privacy and trust, especially in multinational initiatives.
Conclusions
Recommendations for future research and practice include prioritizing engagement with knowledge users, establishing robust data governance frameworks aligned with clinical guidelines, and leveraging advanced analytics, such as natural language processing, to improve the quality of health equity data.
Introduction
Suicide is a serious global public health issue, with over 700,000 people losing their lives to suicide annually worldwide.1,2 It is also the second leading cause of death among young people1,3 and disproportionately impacts equity-deserving groups, or a community or demographic that has historically faced systemic barriers to equal opportunities, resources and representation. 4 These barriers may be based on race, ethnicity, gender, sexual orientation, disability, socioeconomic status or other factors.5,6 As rates of suicide continue to rise, there is an urgent need to develop comprehensive approaches to provide appropriate care and support for those who are experiencing suicidal thoughts and behaviours. 7 Recent research indicates that advances in Artificial Intelligence (AI) combined with increased access to a variety of digital data sources may have potential for the development of novel and personalized suicide prevention strategies. 8 For example, the increasing integration between electronic health records (EHRs) with wearable technologies (e.g. actigraphy), mobile applications (e.g. for self-reported symptoms and experience sampling) and machine learning methods (e.g. natural language processing (NLP) of unstructured clinical notes) offers promising opportunities to collect and triangulate these novel sources of data to support more effective, accessible and equitable interventions and outcomes.9–13 However, the guidelines for the collection and use of this data in suicide prevention and care remain unclear.
Suicidal ideation is highly sensitive and personal information. Collecting and using data on individuals’ thoughts of self-harm or suicide raises significant concerns.14,15 For example, existing regulatory and governance frameworks could expose these data to misuse, including sale and analysis outside of health systems. 16 Moreover, even when strong legal and governance frameworks are in place and adhered to, they do not guarantee social legitimacy. 17 In other words, digital technologies designed to collect, analyse and translate data into meaningful insights may face low uptake and poor user engagement when they transgress the social parameters of acceptable data usage. 18 Further, the number of mobile health (mHealth) platforms (app or web based) developed to support people experiencing suicidal ideation has increased exponentially over the last decade.19–22 While these digital technologies present unique opportunities to support care more globally, how the data might be collected and used is vague within this transnational context. 23 Finally, it remains unclear how or even if the data collected via these digital platforms (such as symptom reporting in a mobile app)24,25 might be integrated into clinical workflows to improve outcomes.20,26–28
As a result, there remain serious questions about the use and misuse of this data. For example, if a machine learning model predicts an individual is at risk of suicide, what actions should be taken and by whom? There is a risk that these tools might be used to justify unwanted preemptive interventions (e.g. increased surveillance, involuntary hospital admissions, child removal by children's services).29,30 These interventions could infringe on individuals’ well-being and rights 31 or reinforce mental health stigma and discrimination, which may inadvertently undermine help-seeking. 29 Finally, there are concerns about the potential for false positives/negatives32–34 and increasing evidence that without careful consideration, machine learning models often perpetuate and even amplify long-standing inequities in the provision and quality of suicide prevention services.34–37
Combined, these concerns provide compelling evidence for the importance of understanding the range of considerations for the collection and use of digital healthcare data for suicide prevention and care. 38 To explore such concerns, we conducted a rapid review, which is a form of knowledge synthesis designed to produce information in a timely manner. 39 Rapid reviews are especially useful in fields characterized by ongoing changes (e.g. AI) and when evidence is required to inform decision-making and practice. 40 Thus, the overall goal of this rapid review is to provide timely and relevant information about existing research gaps in the collection and use of digital health data in the context of suicide prevention and care. The more specific objectives are to: (1) inform the development of a data governance framework and the data collection strategy for a new multinational suicide prevention mobile health (mHealth) platform and (2) generate data use case scenarios to support meaningful knowledge user engagement activities, including individuals with lived/living experience of suicidal ideation, families/carers, service providers and researchers (including machine learning scientists), to inform the co-design of this mHealth platform.
Methods
Planning and research question
Healthcare systems in both the UK and Canada are experiencing similar challenges related to suicide prevalence, prevention and care, which presented a unique opportunity to share knowledge and expertise between our two contexts. Thus, this review is part of a larger collaboration between the University of Toronto, Oxford University, the Centre for Addiction and Mental Health and the NHS Oxford, designed to work together on innovative projects looking at suicide and suicide prevention taking a multinational approach. Another unique dimension of this work is the co-design of an mHealth platform, which was first advocated for by people with lived and living experience and their families. They recognized the need for accessible, personalized and mobile-based suicide safety plans. Suicide safety plans are an effective intervention strategy designed to help individuals at risk of suicide manage their thoughts and behaviours and seek support during times of crisis. 41 In particular, our group desired to know if there were similar mHealth platforms that could inform a multinational data governance framework for suicide prevention and care. These initial discussions resulted in a brief environmental scan of the literature, which suggested that this was a rapidly evolving field. 42 As a result, a rapid review was chosen over a systematic or scoping review as our overall goal was to produce evidence that could inform the governance framework and co-design of this platform. 39 Our research question for this review was: What is known from the existing academic literature about the key data governance considerations for the collection and use of digital health data in the context of suicide prevention and care?
Study design
A rapid review was conducted with guidance from the Cochrane Rapid Reviews Method (CRRM) with modifications made where appropriate. The CRRM bypasses steps involved in a traditional systematic review to synthesize knowledge in a time sensitive manner 43 and roughly involves the following stages: defining the research question and eligibility criteria, conducting the search, selecting studies, extracting data, risk of bias assessment, synthesizing information and other considerations. Reporting was conducted in accordance with the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) 2020 guidelines, which allow for transparent reporting of the purpose, methods and findings of reviews. 44
Information sources and search strategy
A comprehensive search strategy was developed by a medical librarian (RB) in consultation with the research team. The development process involved identifying concepts from the research question. A list of related synonyms under the construct of (digital data collection, healthcare data) AND (suicide or self-harming behaviour) AND (suicide prevention within mobile applications, digital technologies) was prepared. Using these terms, a search strategy was drafted using a combination of keywords and database appropriate subject headings. The search strategy was validated by testing whether it would capture seven known relevant studies. All seven studies were identified in the final Medline strategy. The strategy was then adapted into selected databases. In addition to using bibliographic biomedical databases, a selection of Information Science, Technology and Interdisciplinary databases were searched given the specialty of the topic, which intersects health and technology subjects. Ovid MEDLINE: Epub Ahead of Print, In-Process & Other Non-Indexed Citations, Ovid MEDLINE® Daily and Ovid MEDLINE®, Ovid PsycINFO, Ovid Embase, EBSCOhost CINAHL, EBSCOhost Library, Information Science and Technology Abstracts (LISTA), ACM Digital Library and Web of Science's Core Science Collection databases were searched in April 2023. No further limits or filters were applied at this stage. A copy of the database strategies is available in Additional File 1.
Eligibility criteria
For inclusion and exclusion criteria, see Table 1. To improve the timeliness of this review, articles were limited to primary studies (excluding conference proceedings, dissertations, reviews) whose primary objective was related to suicide prevention or care. To be included, articles also had to refer to the use of digital data explicitly (e.g. online surveys, tablets, mobile apps) and in the context of healthcare. The results were limited from 2007 to present since the first smartphone, the first-generation iPhone was introduced this year. 45 Only studies published in English were included.
Inclusion and exclusion criteria.

Summary of the results.

Note. EHR: electronic health record; EMR: electronic medical record; AI: artificial intelligence.
Non-mutually exclusive category.
Selection process
Citations were exported into Covidence Systematic Review Management software and Paperpile reference software to support the management of records, including deduplication and screening. All article titles and abstracts were screened independently by two reviewers (LS, SK, LB-P, PS, NS, JS and DWJ) against the inclusion criteria. Disagreements were discussed and resolved via group discussion. Relevant articles were then read in full by six independent reviewers (LS, SK, LB-P, PS, NS and JS) and reviewed for a detailed inclusion assessment. Articles that were excluded and the reasons for exclusion were documented within Covidence.
Data extraction
Data were extracted from the included articles by six reviewers (LS, SK, LB-P, PS, NS, and JS), this was done using the extraction tool within Covidence. Articles were extracted by a single reviewer, and were validated by a second reviewer. Any disagreements that arose during the validation process were resolved through discussion between reviewers. A full extraction template is available in Additional File 2.
In brief, data extracted included general characteristics of the article, such as the year and country of publication, study design and the clinical context or planned use of the digital data in relation to suicide prevention and care. We also extracted characteristics used to describe the digital dataset, including the source of the data (e.g. EHRs), the size of the dataset (e.g. number of participants), the time scale of the dataset (e.g. number of years of data collected) and approach to data analysis (e.g. machine learning or statistical modelling). With increasing access to novel sources of data we also captured whether the dataset included structured or unstructured data types. For example, structured digital data is often highly organized and standardized across and within institutions to capture pre-determined categories, such as diagnostic codes. Unstructured data refers to data that largely lack a predetermined structure or organization, such as clinical notes, emails, social media posts and ecological momentary assessment data, or repeated sampling of behaviours and experiences in real time (e.g. sleep data).
As a research team interested in advancing digital health equity, we also extracted information about the range of sociodemographic features and social determinants of health captured in the dataset.46–48 In addition, we extracted known considerations for digital data collection and use including trust, privacy, fairness and health equity.15,34 To inform future knowledge user engagement activities, we also extracted information about whether researchers engaged any knowledge users, and if so, what type (e.g. clinicians) and how. Lastly, we also extracted information about any reference to specific data governance frameworks, guidelines or principles used to inform the collection and use of digital health data as it relates to suicide prevention and care.
Synthesis
Data analysis involved both quantitative and qualitative synthesis by a multidisciplinary team. As stated, a librarian with methodological expertise in knowledge syntheses conducted the searches with input from the larger research team. Three members of the team (LS, SK and LS) ensured that the context and key terms were relevant. In consultation with the wider research team, two members of the team with qualitative data analysis expertise (LS and NS) used their expertise to complete a qualitative content and thematic analysis. 49 First, we co-developed a combined deductive–inductive coding frame. 50 The deductive codes were selected first (e.g. fairness, health equity, trust, privacy, governance) as they are known considerations for the use of digital data in healthcare.15,51 Within each of these deductive codes we developed axial codes using a more open, inductive approach. 50 These overarching themes and their related axial codes were examined iteratively in a series of team meetings to conduct an exploratory analysis of emergent considerations and patterns of significance. 50 Finally, two members of the team with expertise in quantitative analysis used data extraction sheets to tabulate and compare descriptive information and to gather frequency statistics (SK and LB-P).
Results
Characteristics of included studies
Our search protocol produced 2452 potential articles for inclusion (see Figure 1). After a two-part screening process, we found 70 publications eligible for inclusion from 2010 to 2023, however 71% (n = 50/70) of the included studies were published between 2020 and 2022. The majority of the studies (n = 50/70; 71%) were conducted in the United States. A smaller number of studies were conducted in Spain (n = 4/70; 5.7%), the UK (n = 3/70; 4.3%) and Australia (n = 2/70; 2.9%). One study was conducted in each of the following countries: Canada, Denmark, Fiji, France, Germany, Israel, Korea, Mexico, Nepal, South Africa and Sweden. None reported on considerations around digital data collection and use from more than one country (see Table 2 for a summary of the results).

PRISMA diagram of study screening, review and inclusion.
The study types fell into three broad categories. The first group (n = 50/70; 71%) relied on at least one source of digital healthcare data to generate a dataset for their analyses of suicide prevention and care. A second group of studies (n = 13/70; 18.6%) engaged knowledge users in questions about the collection and use of digital data for suicide prevention and care. A third group (n = 7/70; 10%) of these studies had both a dataset and knowledge user engagement in their study (e.g. user engagement for a mobile app designed to collect data). Nearly one-third (n = 23/70; 32.9%) of the studies used a cohort-based study design. A smaller proportion of studies used a case–control method (n = 11/70; 15.7%), quasi-experimental methods (n = 10/70; 14.3%) and cross-sectional study designs (n = 8/70; 11.4%). Eight (11.4%) studies used mixed methods, such as a combination of user testing and interviews. Smaller numbers of studies used qualitative designs (n = 3/70; 4.3%), case report designs (n = 3/70; 4.3%), randomized control trials (n = 3/70; 4.3%) and a case crossover design (n = 1/70; 1.4%). See Additional File 3 for a complete list of included studies and their key characteristics.
Descriptive analysis
Clinical context and use cases
The majority (n = 35/70; 50%) of the studies described the collection and use of digital healthcare data for suicide prevention and planning in primary care. In these studies, the goal was to use digital data to improve the early detection of suicidal ideation in routine medical encounters, such as a checkup with a primary care physician or in a general (non-psychiatric) hospital ward.52–86 Ten studies (14.3%) examined the utility of collecting digital data within the context of in-patient settings, including emergency departments. These studies sought to improve suicide safety planning by either improving data collection processes with digitized documentation processes (e.g. self-report via tablets)87–91 or through the real-time monitoring of mood and behaviours (e.g. sleep) with smartphones and other wearable devices to support timelier interventions.92–96 Eight studies (11.4%) examined the collection and use of data for individuals with a diagnosis (e.g. major depressive disorder) but stable enough to receive care in an out-patient setting.97–104 Eight studies (11.4%) examined the collection and use of digital data via smartphone apps or digital tools in community settings for anyone who might be experiencing thoughts of suicidal ideation or self-harm.105–112 Five studies (7.1%) were focused on improving suicide prevention for high-risk and/or marginalized subgroups (children, youth, health care providers and Indigenous groups).113–117 Finally, four studies (5.7%) examined the utility of collecting digital data on suicidal ideation to support proactive and timelier emergency or public health planning at a population level.118–121
Digital dataset description
Dataset source(s)
Fifty-seven studies compiled a digital dataset from a variety of sources to complete their analyses. The majority (n = 40/57; 70.2%) of these studies relied on digital data from the EHR/electronic medical record.53,55,57–66,71,72,74–77,79–81,84,86,88,90,91,94,96,97,100,101, 103,109,114,115,117–119,121 Nearly a quarter (n = 13/57; 22.8%) of these studies collected the data via a mobile device or computer owned by the individual (e.g. online forms, self-reporting symptoms using a survey link on their phone or computer).60,65,67,82,92,95,98,99,102,104,107,110,112 A smaller number of studies collected their dataset from self-report data provided by clients via a device provided by the clinic (e.g. a tablet in the waiting room) (n = 6/57; 10.5%)52,60,87,89,92,121; from national or local databases (n = 5/57; 8.8%)53,57,73,120,121; directly from a mobile application (including metadata on user statistics) (n = 5/57; 8.8%)61,82,87,101,108; and from wearable devices (e.g. sleep patterns) (n = 2/57; 4%).92,95 Of these studies, a few contained (n = 7/57; 12.3%) multimodal datasets (e.g. obtained data from more than one source such as actigraphy from a wearable device combined with clinical data from the EHR).53,57,60,65,92,101,121
Dataset type
To characterize the digital dataset further we captured whether the data was described as either structured, unstructured or both. Our review found that nearly half of the data were structured only (n = 27/57; 47.4%).52,53,57–60,62,66,75–78,86,89,94,97–100,102,104,107,109,110,112,117,121 A smaller number of studies combined structured and unstructured data (n = 22/57; 38.6%)55,61,63–65,71,73,74,79,81,82,84,87,91,92,95,96,101,103,114,118,119 while few relied on unstructured data only (n = 8/57; 14%).67,72,80,88,90,108,115,120 These studies were primarily interested in processing narrative data contained in EHRs (e.g. clinical assessments) to improve machine learning models.67,72,80,88,90,108,115,122
Dataset size
The number of individual records or observations in the datasets varied greatly from one participant with continuous observations (via a wearable device) over a 10-day period 95 to over 1 million participants with multiple observations from the EHR.94,118,119 These very large datasets all came from Veterans Affairs (e.g. military personnel) in the United States. The most common number of individual records in each dataset was between 1 and 1000 participants (n = 25/57; 43.9%) and between 1001 and 10,000 (n = 15/57; 26.3%). Three studies (n = 3/57; 5.3%) only reported the number of observations (not individual records), which included the number of messages sent via a patient portal55,63 and the number of evaluations. 74
Digital dataset analysis
The most common analytical approaches to analysing this data were standard statistical techniques (n = 42/57; 73.7%), like linear regression or simple descriptive statistics.52,53,55,57–66,71,72,74–81,86–88,91,94–100,107–110,112,115,120,121 Some studies (n = 6/57; 10.5%) combined statistical modelling with qualitative approaches,82,84,89,114,117,118 while other studies (n = 5/57; 8.8%) combined statistical modelling with AI applications, including NLP and predictive modelling.67,73,90,92,104 A small number of studies (n = 4/57; 7%) relied on AI applications only, including NLP, and predictive modelling.101–103,119
Dataset time scale
The majority of the datasets contained data collected over 1–5 years (n = 34/57; 59.6%),52,53,55,58,59,61–67,71,74,76,78,79,84,86,88,89,94,96,98,100,104,108,109,112,114,115,119,121,123 while some contained data collected in a single year (n = 8/57; 14%).60,91,95,97,101,110,117,118 A smaller percentage of the datasets contained data for 11+ years (n = 7/57; 12.3%),57,72,73,75,90,103,120 and 6–10 years (n = 1/57; 1.8%). 77 In addition, most of the digital data was collected from 2011 to 2015 (n = 19/57; 33.3%),55,58,62,63,65,67,71,74,76,84,88,89,91,96,98,100,108,109,114 and 2016–2020 (n = 18/57; 31.6%),53,59–61,64,66,79,86,94,97,99,101,104,110,112,117,118,121 with smaller numbers of data collected between 2000 and 2005 (n = 6/57; 10.5%)52,57,75,103,115,120 and 2006 and 2010 (n = 5/57; 8.8%).72,77,78,90,119 Only one study reported on data collected from pre-2000 (1.8%). 73
Subgroups of interest
The majority (n = 58/70; 82.9%) of the studies included in this review identified at least one ‘subgroup’ of interest in their study. The subgroup of interest was defined by the authors as a subset of a larger population that the study was focused on, either because they were defined as at high-risk of suicide (e.g. veterans) and/or an equity-deserving group (e.g. Trans youth). Over half of these studies (n = 41/70; 58.6%) focused on individuals with a mental health and/or substance use disorder.53–59,61–65,67,68,71,75–79,81–84,86,89,91–95,99,100,102–104,107,111,112,114,121 A quarter of all the studies (n = 17/70; 24.3%) identified children and youth as a subgroup of interest,52,57,61,64,70,79,81,84,91,96,97,99,101,108,113,114,121 while a smaller subset focused (n = 13/70; 18.6%) on active military personnel or veterans.53,66,71,72,76,83,94,100,103,115,118–120 A limited number of studies focused on the relationship between traumatic brain injury (n = 4/70; 5.7%) and suicide,71,72,75,88 and the specific needs of Indigenous communities (n = 3/70; 4.3%).109,113,116 One study each (n = 1/70; 1.4%) examined the experience of suicide for individuals with a history of violence or assault, 58 explored occupational stressors specific to clinicians 117 and used a mobile app (TransLife) to understand the short-term risk factors for suicide among transgender individuals. 106 Six studies (8.6%) did not mention any specific high-risk group or population of interest.60,69,73,74,87,98
Sociodemographic features and the social determinants of health
There was little consistency between how and which sociodemographic features were collected, used and analysed. The most frequently collected sociodemographic features were sex/gender (n = 54/70; 77.1%),52–55,57–68,71–75,77–84,86–90,93,94,96,99–104,108,109,111,112,114–121 age (n = 45/70; 64.3%)52,54–56,58,59,61,63,64,66–68,71,73–75,77,78,80–84,86–90,93,94,96–99,101,102,104,109,112,114,117–121 and race/ethnicity (n = 37/70; 52.9%).17,52,54–56,59–62,64–66,68,72,74,76–80,83,84,87,88,90,94,96,98,100,101,103,106,115,118–121 Of note, however, is that most studies defined both sex/gender and race/ethnicity poorly and/or used them interchangeably. Thus, in most cases, we were unable to distinguish between these constructs during extraction (for exceptions see Refs.71,119).
Socioeconomic status was also often collected but characterized by a wide range of features including marital or relationship status (n = 17/70; 24.3%),55,59,62,71,74,76,82,83,88,100,102,103,109,115,117,119,122 education level (n = 10/70; 14.3%),54,57,60,75,83,87,99,100,106,122 income/employment status (n = 10/70; 14.3%),57,59,75,82,88,100,102,106,109,112 military status, rank and/or history of active duty (n = 7/70; 10%),53,71,76,83,100,115,122 housing status (n = 5/70; 7.1%),71,76,88,100,119 insurance status (n = 4/70; 5.7%),52,57,88,114 geographic location (e.g. rural vs. urban) (n = 3/70; 4.3%),109,112,121 food insecurity (n = 2/70; 2.9%),71,119 religion (n = 2/70; 2.9%),53,109 language (n = 2/70; 2.9%),56,62 sexual orientation (n = 1/70; 1.4%), 99 disability (n = 1/70; 1.4%) 76 and country of birth (n = 1/70; 1.4%). 53
Sociodemographic features were collected for a variety of reasons. In most cases, the information was presented to describe the characteristics of the dataset. In other cases, the goal was to explicitly assess the relative representativeness of the dataset as compared to another population. For example, one study used this information to determine how their sample is proportionally related to the US military population overall. 122 In others, the goal was to examine known social determinants of mental health (such as racial discrimination, loneliness or socioeconomic disadvantage) and their relationship to suicide risk, prevention and care.62,103,113 Given that individuals are defined by more than one dimension of their identity, it is also worth noting that only one study (n = 1/70; 1.4%) reported that they completed an analysis comparing positive risk flags in the health record and access to care for military veterans using an intersectional lens (housing, relationship status, disability and gender). 71
Knowledge user engagement
About a quarter of the studies in our review (n = 20; 28.6%) engaged knowledge users to understand their perspectives on the collection, use, analysis and reuse of digital healthcare data in the context of suicide prevention. Amongst these, studies (n = 7/20; 35%) engaged knowledge users to obtain their perspectives on specific suicide prevention mobile apps,70,82,87,93,99,106,111 and a webpage (n = 1/20; 5%). 108 Other studies (n = 4/20; 20%) asked knowledge users about their perceptions on implementing EHR-based screening tools80,81 and EHR-based alerts.83,91
Four studies (20%) asked knowledge users about the automation of suicide risk prediction using a machine learning algorithm developed from EHR data.54,68,83,124 One study (5%) engaged knowledge users’ perspectives on the implementation of a Machine Learning algorithm (applied to structured data collected using follow-up forms) to inform follow-up care strategies for individuals identified at risk within a community-based surveillance system in White Mountain Apache Tribe. 116 Two studies (10%) used experimental paradigms; one tested the usability of a mobile app compared to paper-based clinical guidelines for suicide risk screening, 56 and the other conducted a randomized controlled trial to assess changes in individual's scores on suicidal ideation, depression and well-being questionnaires after using a suicide prevention app. 99 Two studies (10%) convened consensus meetings; one of these studies developed recommendations to help standardize the collection and analysis of clinical trial data related to suicidal ideation/suicidal behaviour, 105 while the other summarized the differences between suicide prediction models and clinicians’ predictions, evidence available for their concurrent use and identified future research priorities. 85 In one study (5%), researchers engaged youth in workshops to develop short narrative videos as a health promotion strategy. 113
Types of knowledge users engaged
The types of knowledge users engaged varied. Some studies engaged service users with prior suicidal ideation and/or attempt(s) (n = 9/20; 45%)68–70,82,83,87,93,99,111; fewer studies engaged service users from populations deemed at risk of suicidality (n = 3/20; 15%)106,108,113; and one study (5%) engaged service users of a primary care clinic. 80 About half of these studies (n = 8/20; 40%) engaged clinicians.54,56,68–70,81,91,116 Four of these studies (20%) engaged researchers as knowledge users, including data scientists.68,69,85,105 Three studies (15%) considered family members’ perspectives.68–70 Three studies (15%) engaged multiple groups of knowledge users, including service users, clinicians and families.68–70 Two studies (10%) engaged a bioethicist and health administrators68,69 while one included representatives from regulatory agencies and pharmaceutical companies. 105
Knowledge user engagement approach
The most common engagement method was the administration of a survey (n = 11/20; 55%). A smaller number of studies conducted interviews (n = 8/20; 40%), user-testing (n = 6/20; 30%) and focus groups (n = 5/20; 25%). Two studies (10%) convened consensus meetings with experts. Nearly half of the studies that consulted knowledge users (n = 9/20; 45%) relied on more than one method. For example, two studies used a combination of user testing, semi-structured interviews and surveys82,111; two employed user testing combined with interviews93,106; one combined user testing with advisory groups and surveys. 87 Two studies used a combination of focus groups, surveys and interviews.68,69 Lastly, one study used a survey followed by a consensus meeting, 105 while one other study used participatory workshops followed by a survey and exit interview. 113
Exploratory analyses
Digital data considerations: fairness and health equity
Equity, diversity and inclusion considerations
Few (n = 7/70; 10%) of the studies described any equity, diversity and inclusion-related issues in relation to the collection and use of digital data for suicide prevention. One study noted that the age distribution of smartphone use and ownership might bias the outcomes of any digital suicide prevention tool. 93 Another found that perceptions of what users of a mobile suicide prevention app found helpful when they disclosed suicidality varied by gender. 112 Four others noted that the social determinants of health are risk factors for suicidal ideation, attempt and death.57,66,103,119 These studies also noted that the failure to collect high quality and standardized sociodemographic data 60 presents challenges for the equitable use of digital data related to suicide prevention and care.
Fairness considerations
Fairness considerations refer to various techniques and strategies for addressing algorithmic bias in machine learning models. Very few of the studies (n = 7/70; 10%) discussed any fairness considerations related to the collection and use of digital data in relation to suicide prevention and care. The majority of these studies speculated about the possible discriminatory harms that might result from the collection and use of digital data, including the tendency of statistical and machine learning models to be biased towards a majority group.59,85,94 These studies advocated for greater consideration of the ways that the social determinants of health might impact data quality.59,112 As it relates to suicide prevention in particular, one qualitative study found that participants agreed that false negatives (e.g. missing individuals at risk of suicide) greatly outweighed the risk of false positives (e.g. falsely identifying individuals at risk of suicide). 68 Two studies examined potential opportunities to enhance fairness with AI applications.103,119 These studies used NLP to enrich data quality to better understand the social determinants of suicide risk. All of these studies emphasized the importance of collecting high-quality sociodemographic data to prevent inequities in care delivery and that AI introduces new risks and opportunities for health equity initiatives.
Digital data considerations: governance, trust and privacy
Data governance frameworks
Most of the studies obtained Research Ethics Board (REB) approval (n = 51/70; 73.9%); however, few (n = 5/70; 7.1%) of the studies we extracted explicitly referenced a specific local, national or global governance framework shaping the collection, use and analysis of digital data collected for suicide prevention and care59,67,92,98,112 and two explicitly called attention to the need to develop one.68,69 Another noted that the development of multimodal modelling (e.g. the integration of more than one data type) presents new governance, privacy and intellectual property issues that require further exploration. 92
Of the few studies that referred to any guiding principles, policies or guidelines, the majority emphasized data privacy, security and safety standards. Three studies cited national guidelines, including generic ‘privacy standards’ 92 ; ‘HIPPA Safe Harbor Provisions’, which de-identified data prior to storing it 59 ; and finally, the ‘Australian National Safety and Quality Digital Mental Health Standards’. 98 Only one study cited any framework that might apply to a global context 67 ; the ‘Declaration of Helsinki’, which is a statement of ethical principles for medical research involving identifiable human material made by the World Medical Association (WMA) and last updated in 2013. One study cited a corporate privacy policy, which specifies that anonymized data can be used for scientific research and that users could opt out of research. 112 Finally, as members of our team are based in Canada where the collection and use of First Nations, Metis and Inuit Peoples’ data require additional considerations, we also captured whether the studies described any policies or guidelines for collecting and using Indigenous Peoples’ data. Three studies from the United States reported that they obtained additional tribal approvals from the relevant Native American community to conduct their study and disseminate the findings.109,113,116
Trust
A limited number (n = 10/70; 7.0%) of papers included in this review discussed the notion of trust. Notably, only one study provided a definition of the word trust. 106 Within the subset of studies that discussed any aspect of trust, there were three overlapping themes: trust as reliance (n = 6/10; 60.0%), trust as a social process (n = 6/10; 60.0%) and the consequences of distrust (n = 2/10; 20.0%). Six studies discussed trust within the context of reliance on the outputs of a machine learning model or algorithm. Two of these studies highlighted that clinicians may not trust (or rely on) the recommendations given by algorithms given concerns about the possibility of false-positive rates and their possible negative consequences.54,116 Two of these studies emphasized that trust in mHealth platforms is required to ensure uniform uptake and adherence.106,111 The last two studies emphasized that model interpretability, or the degree to which humans can understand the causes underlying any given prediction, is essential for ‘building trust’ with an algorithm.101,116 However, these studies also noted that most data collection platforms (e.g. EHRs) lack the functionality to provide personalized insights about the features underlying model prediction.
Six studies discussed the social and political process of building trust with service users. Four highlighted the need for providers to provide an empathetic approach during data collection,16,82,83,100 while two others emphasized the importance of relying on evidence-based strategies 83 and established ethical frameworks to support these processes.69,82 Two studies discussed trust in relation to its absence (e.g. distrust). One study discussed the role of distrust in the health system more broadly, which stems from negative experiences with colonial and racist health systems for Alaskan Native Americans. 109 Another cautioned that it was crucial to move forward cautiously with predictive analytics as poor implementation might ‘sever’ the relationship with a trusted provider or health system. 68 In particular, this study found that patients worried their providers might trust a risk prediction score over the patient's own wishes, which might ultimately undermine efforts designed to foster help-seeking.
Privacy
Fourteen studies (n = 14/70; 20.0%) discussed privacy in relation to three key themes: the right to data protection and security (n = 7/14; 50.0%); the right to control how data is collected and used (n = 5/14, 36%) and privacy-enhanced data collection (n = 2/14; 14.3%). In the first theme, three studies described their approach to data security as being thoughtful about what data is being collected and/or how it is anonymized.59,97,121 One study noted that their data was stored according to their privacy policy 92 while another described that ‘safeguards’ are in place to protect the data being collected. 82 Lastly, two studies postulated that there may be low confidence in mobile apps specifically due to concerns about the security of their data on these platforms 106 and that these concerns may limit uptake of mHealth interventions. 68
The second theme primarily explored the rights of patients to control how any suicide risk-related data is collected, used and disseminated. These studies emphasized the possible negative consequences of data misuse. For example, the authors of one study suggested that the application of a predictive algorithm without consent might feel invasive, 116 while another cautioned against sharing risk scores ‘externally’ (externally was not defined). 69 Another suggested that a sense of privacy might be enhanced by grouping sensitive questions together at the end of an appointment. 79 Finally, one study examined privacy empirically by asking military veterans to rate a conversational script they might have with their provider about the use of predictive analytics in their care. 83 These participants expressed few privacy concerns as long as these tools were used to enhance the therapeutic alliance by centring the patient's expressed needs and concerns.
The final two studies referred to the privacy-enhancing features of different data collection procedures and digital devices. The first study discussed the necessity for a private space to collect data as nurses ask patients questions about suicide risk verbally prior to documenting electronically. 65 In the second study, researchers observed data quality on suicide risk varied according to how the data was collected. 110 For example, based on previous research 125 which found that participants only reported symptoms of suicidal ideation using a mobile device and not on paper, they hypothesized that mobile devices might enhance privacy as the screens are difficult to read by others in the waiting room and are unlikely to be misplaced by users.
Discussion
Our rapid review found that increased access to novel sources of digital health data, alongside the adoption of advanced analytical methods (e.g. machine learning models), is presenting researchers and health systems with a multitude of potential applications to enhance suicide prevention and care (see Additional File 4 for a synthesis of these use case scenarios). 9 Despite the potential of these applications there was little consensus on how best to adopt digital innovations and technology in the context of suicide prevention and care. While a few of the studies we extracted drew attention to the calls for more rigorous attention to how this data is collected and used throughout its lifecycle,68,69,126 we found little evidence of any reliance on established global or national governance frameworks meant to guide the collection and use of digital health data. 127 More critically, there was a lack of evidence to suggest that there was anything applicable to the collection and use of digital health data within a multinational context. Finally, very few studies considered any of the known challenges related to digital data collection and use for suicide prevention, including data quality, fairness and health equity, privacy, trust and data sovereignty. 15 Given the rapid evolution of this field, there is an urgent need for further research to keep pace with the latest developments, address emerging gaps in knowledge and identify evidence-based digital health applications to address a major global public health concern: suicide prevention and care. Below we outline a summary of a number of key questions for multinational data governance frameworks for digital health initiatives designed to support suicide prevention and care (see Figure 2).

A summary of the digital data considerations for suicide prevention and care.
Digital data considerations: data quality, fairness and health equity
Our findings highlight that there is little consensus on what kinds of data need collecting, how to define and collect high-quality data, and how this data might be effectively used to support suicide prevention and care safely and equitably. For example, there was no clear rationale provided for the best time scale for the collection or modelling window when using digital data or any possible decision-rule thresholds that might reduce a predictive model's fidelity over time (e.g. due to calibration drift). 128 Further, while some authors noted issues with data quality 110 there was little discussion about how missing data might reflect and reinforce existing social and systemic inequities. 129 For example, as secondary analysis of EHR data increasingly becomes the norm, there is a pressing need to better address the challenges in its use relating to missing data and associated biases. 130 In addition, there was almost no mention of the digital divide or discussion of how the benefits of new technologies are often unevenly distributed. 131 This was evidenced by the limited number of studies originating from outside the Global North (n = 4/70; 6%). This is particularly crucial as digital technologies are more widely disseminated than ever before, and may provide opportunities to narrow the global health gap in mental health care. 23 As a multinational research team, we were hoping to find studies that did this work; however, we found little, suggesting this is a major area of need.
We also found that most studies failed to adequately collect standardized sociodemographic features, which may impact the safety, effectiveness and evaluation of health equity of these new tools.132–134 Even when these features were collected they were often poorly defined (e.g. the conflation of sex with gender identity) or used as coarse proxies for other constructs (e.g. umbrella race categories),135–137 which often conceal meaningful inequities between and within groups defined by intersecting features (e.g. gender and race). 5 Further, few of the studies addressed the fact that suicidality is unevenly reported and managed, especially among equity-deserving groups. 33 In addition, many of the known social determinants of health that impact suicidal ideation, behaviours and outcomes were never captured at all.46,132 Finally, there were notably large gaps in the information available from the Global South, high-risk subgroups and the unique considerations introduced by novel and emergent use cases (e.g. actigraphy data). Bridging these data gaps by leveraging administrative and/or routinely collected clinical data will be crucial for improving care. 130 More critically, the lack of consensus about what constitutes a high-quality digital dataset and the concomitant impact on algorithmic biases and health equity is an area of research need with major policy and practice implications.
Digital data considerations: governance, trust and privacy
A data governance framework establishes how data is collected, stored, processed, accessed and used throughout its lifecycle.69,126 Unfortunately, we found reference to very few governance frameworks and most did not consider the unique factors related to suicide prevention and care.69,126 In particular, we found only one example from Australia of a national governance strategy for digital mental health tools more broadly. 138 Unlike our expectations, none referenced any international partnerships or working groups (e.g. the Global Digital Health Partnership, FAIR Data Principles) and few addressed the data governance considerations specific to suicide prevention and care. 127 It may be that the lack of global consensus reflects underlying differences in clinical guidelines, regulatory frameworks and competing health priorities across and within regions. 139 For example, in the UK, the national competence framework advises against any quantified risk ‘prediction’ or risk ‘assessment’ 140 yet much of the research we identified from other national contexts (e.g. USA) does exactly that.52,80,81,83,92 Further, there was almost no consideration for Indigenous data sovereignty principles such as the First Nations Principles of OCAP® (Ownership, Control, Access and Possession) 141 or the CARE (Collective Benefit, Authority to Control, Responsibility and Ethics) principles for Indigenous data governance. 142 Thus, there is a clear imperative for additional research within this space to ensure that Indigenous communities’ rights are respected and upheld. Despite these gaps, we did identify a small but growing body of research engaging underserved communities in the collection and use of digital data in the context of suicide prevention and care.69,70,116 These studies engaged diverse knowledge users, including patients from vulnerable groups and family members,67,68 clinicians,67,68,114 researchers, health system administrators and a bioethicist, 67 iteratively 67 and published their engagement materials (e.g. focus group guides).67,68,114 Such studies, along with recently developed tools that help define and evaluate meaningful patient engagement, 143 serve as a useful starting point for future engagement of knowledge users in this field.
Lastly, we completed an exploratory analysis of two factors considered essential for the successful collection and use of digital health: privacy and trust. However, we found that both of these constructs were often poorly defined and operationalized. For example, while ‘trust’ was defined as an essential element of successful digital data initiatives, very few of the studies discussed how one might develop trust in these systems and ensure appropriate reliance on these new tools.144–146 Information relating to privacy within the studies reviewed was even more limited. As privacy expectations, laws and social norms are highly variable within and between regions, more research is needed in this area to enable a wider understanding of privacy issues and concerns that focus on mitigation. Lessons from large data initiatives highlight the importance of engaging all knowledge users, especially the public, in fostering trust around data collection and re-use in clinical settings. Relying on a single social license, such as one for re-using EHR data, may be insufficient to secure consent for applying insights from predictive analytics generated from digital health tools. 17
While countries are in the process of modernizing the privacy and healthcare legislations and regulations to keep pace or stay ahead of the rapidly developing field, 147 there are other mechanisms to simultaneously build trust and identify how to preserve privacy of its constituents. At the data level, some proposed privacy-preserving approaches include using decentralized systems, federated learning systems, differential privacy and cryptographic techniques (i.e. homomorphic encryption, secure multi-party computation, garbled circuits and secret sharing). 148 At the organizational and systems level, there needs to be a data governance framework to define how AI systems collect, access and use health data – these often include access control policies, data sharing agreements, ethical guidelines, privacy impact assessments, consent and data management practices. 149 There is also a need to build capacity and awareness in the healthcare workforce, especially health professionals, as they are the most trusted knowledge user and are critical in maintaining public trust in the healthcare institution.150,151 There are also opportunities to adopt participatory approaches to engage the public to improve data literacy, education and awareness, which can enhance the trustworthiness and transparency of these digital data-driven initiatives. Moreover, these approaches offer an opportunity to move beyond the reliance on the passive mechanism of notice and choice, shifting towards informed choice or meaningful consent. 150 These efforts would benefit from bringing the spectrum of knowledge users together to navigate the ethical, equity and societal issues in minimizing the risk of harm. 152 For example, there is a growing trend of establishing ‘tribunals’, ‘data trusts’ or ‘civic trusts’ to help identify priority areas and ensure that AI initiatives align with societal interests. 153 In sum, addressing the translational gaps in digital health data governance frameworks, incorporating diverse perspectives from knowledge users and fostering trust through transparent approaches including meaningful consent and privacy-enabled data collection150,151 are essential for advancing digital health initiatives, particularly in the critical realm of suicide prevention and care. See Table 3 for a summary of our key recommendations and action items.
Key recommendations and action items for the collection and use of digital health data for suicide prevention and care.
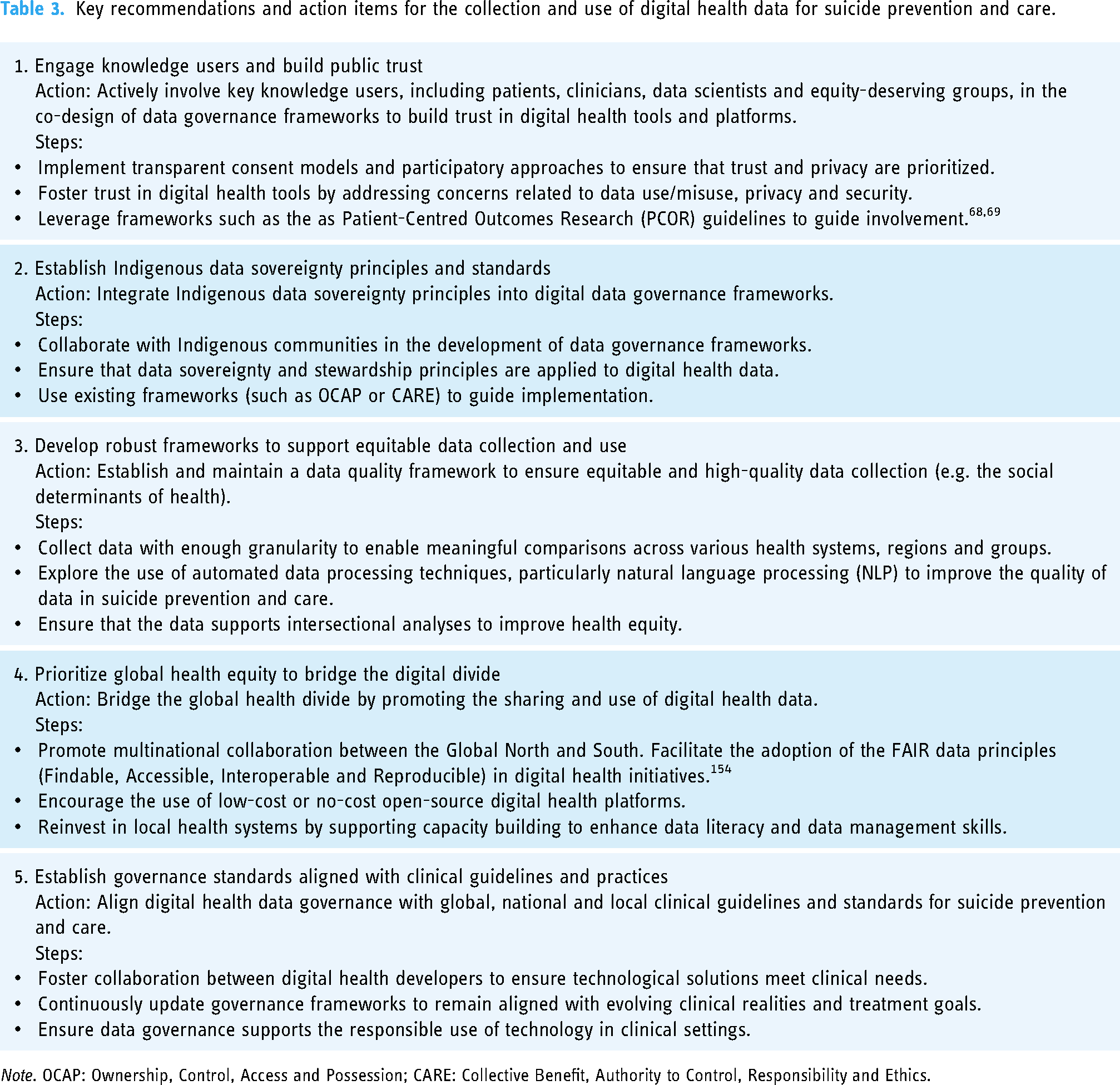
Note. OCAP: Ownership, Control, Access and Possession; CARE: Collective Benefit, Authority to Control, Responsibility and Ethics.
Limitations
Our review included 70 published sources to identify key considerations for the collection and use of digital health data in the context of suicide prevention and care. A limitation of our study is that the majority of the research we identified was conducted in the United States and nearly a quarter of these studies were focused on military personnel. As a result, a limited number of EHRs (e.g. Veterans Affairs) represent the digital datasets used in these studies. This is likely because Veterans Affairs was one of the earliest adopters of an integrated electronic health information system with national standards. 155 Another limitation for this study was that we limited our scope to suicide prevention only. Any relevant data governance frameworks that could be adapted based on lessons learned for other use cases in mental health, including substance use disorders, depression and/or anxiety may have been missed. In addition, while we extracted information about trust, privacy, fairness, governance frameworks and knowledge user engagement from the articles included in our review, these concepts and related synonyms were not part of our original search terms, which could have also resulted in certain studies being missed. Finally, as a rapid review we limited our search to published scholarly sources. However, a more comprehensive search of the grey literature (forms of evidence that are not often published such as conference proceedings, policy briefs, white papers) might provide a more holistic view of governance, trust and privacy as it relates to digital health data in the context of suicide prevention and care. 156 Future initiatives should monitor government documents, policy reports and white papers to build upon our findings.
Conclusion
In conclusion, our rapid review emphasizes the critical importance of robust data governance frameworks in the context of suicide prevention and care. Despite the vast potential of novel sources of digital health data alongside advanced analytical methods, such as machine learning models, our findings reveal a concerning lack of consensus on the optimal adoption of digital innovations in this sensitive context. Moreover, there is a notable absence of established global or national governance frameworks to guide the ethical collection and utilization of digital health data, particularly concerning suicide prevention and care, within a multinational context. Despite some efforts, the lack of global consensus on data governance specific to suicide prevention and care presents a significant obstacle to the responsible and equitable use of digital health data. Smaller health systems and organizations might overcome these hurdles by adopting the FAIR data principles (Findable Accessible Interoperable and Reproducible) to improve collaborative efforts across disciplines and national boundaries.
Key challenges highlighted in our review include the urgent need to address issues related to data quality, fairness and health equity. The absence of standardized sociodemographic data collection and inadequate consideration of known social determinants of health are likely to exacerbate existing inequities in access to care and outcomes, particularly among marginalized and underserved communities. Furthermore, our analysis demonstrates the critical importance of robust data governance frameworks that are aligned with clinical guidelines and patient and provider values (such as privacy expectations and norms). Our review highlights the need to address these translational gaps by engaging diverse knowledge users (patients, providers, data scientists) in these digital health initiatives. Finally, the glaring scarcity of studies originating from the Global South and high-risk subgroups is alarming. This lack of representation not only limits our understanding of the unique challenges faced by these populations but also undermines efforts to develop inclusive, globally relevant digital health solutions. In the context of suicide prevention and mental health care, this absence means that many at-risk communities are being left out of research that could inform tailored, life-saving interventions. Future initiatives must prioritize the inclusion of underrepresented regions and populations to build a more comprehensive evidence base that can improve care for those most in need. Addressing these disparities in research will not only foster better health outcomes but also ensure that digital health solutions are robust, scalable and accessible to all. By addressing these critical gaps we can harness the full potential of these digital data to improve suicide prevention and care worldwide.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241308615 - Supplemental material for Harnessing digital health data for suicide prevention and care: A rapid review
Supplemental material, sj-docx-1-dhj-10.1177_20552076241308615 for Harnessing digital health data for suicide prevention and care: A rapid review by Laura Bennett-Poynter, Sridevi Kundurthi, Reena Besa and Dan W. Joyce, Andrey Kormilitzin, Nelson Shen, James Sunwoo, Patrycja Szkudlarek, Lydia Sequiera, Laura Sikstrom in DIGITAL HEALTH
Footnotes
Acknowledgements
Contributorship
LS1, LS2, NS, LB-P, DWJ, AK and RB contributed to conception and design of the study. LS1, NS, LB-P, SK, JS and PS contributed to data extraction and analysis. LS1, LB-P and SK contributed to writing (original draft). LS2, LB-P, PS, AK, SK, NS and RB contributed to writing (review and editing). LS contributed to supervision. All authors reviewed and approved the final draft.
Data availability
All data and materials supporting the findings of this rapid review are available in the article or the supplementary material.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was jointly funded by the Centre for Addiction and Mental Health, Oxford University, the University of Toronto and the Oxford NHS Foundation Trust.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.