
Abstract
Objective
While current multimodal approaches in the diagnosis and severity assessment of pneumonia demonstrate remarkable performance, they frequently overlook the issue of modality absence—a common challenge in clinical practice. Thus, we present the robust multimodal transformer (RMT) model, crafted to bridge this gap. The RMT model aims to enhance diagnosis and severity assessment accuracy in situations with incomplete data, thereby ensuring it meets the complex needs of real-world clinical settings.
Method
The RMT model leverages multimodal data, integrating X-ray images and clinical text data through a sophisticated AI-driven framework. It employs a Transformer-based architecture, enhanced by multi-task learning and mask attention mechanism. This approach aims to optimize the model’s performance across different modalities, particularly under conditions of modality absence.
Results
The RMT model demonstrates superior performance over traditional diagnostic methods and baseline models in accuracy, precision, sensitivity, and specificity. In tests involving various scenarios, including single-modal and multimodal tasks, the model shows remarkable robustness in handling incomplete data. Its effectiveness is further validated through extensive comparative analysis and ablation studies.
Conclusion
The RMT model represents a substantial advancement in pediatric pneumonia severity assessment. It successfully harnesses multimodal data and advanced AI techniques to improve assessment precision. While the RMT model sets a new precedent in AI applications in medical diagnostics, the development of a comprehensive pediatric pneumonia dataset marks a pivotal contribution, providing a robust foundation for future research.
Introduction
Pediatric pneumonia remains a significant health challenge globally, especially in low- and middle-income countries.1–3 Despite advancements in medical imaging and diagnostics, accurately diagnosing and assessing the severity of pediatric pneumonia continues to be a substantial challenge.4–6 Traditional diagnostic and assessment methods, primarily based on chest X-rays, often serve as the initial investigative approach. However, these methods are constrained by limitations such as subjective interpretation, highlighting a critical need for more precise, objective, and automated diagnostic and severity assessment methods.7,8
The field of computer-aided diagnosis, especially with the use of convolutional neural networks (CNNs) for image analysis, has made significant strides in enhancing pneumonia diagnosis and assessment accuracy from chest X-ray images.9–13 This progress is largely attributed to evolving from basic deep learning optimizations to advanced techniques such as transfer learning with pre-trained CNN architectures and integrating multiple CNN models for superior feature extraction.14–18 Despite the remarkable classification accuracies through these innovative approaches,19–21 a notable gap persists: the predominant focus on single-modal data sources. These approaches overlook the rich, multifaceted nature of medical data, underscoring a critical need for methodologies that encompass a broader spectrum of diagnostic information.
In recent years, the development of multimodal diagnostic and severity assessment methods has marked a significant advancement in medical imaging. These methods overcome the constraints of single-modal approaches by combining diverse clinical data types, such as radiological images and blood testing results, allowing for a more holistic understanding of the patient’s condition. For instance, ConVIRT, 22 REFERS, 23 GLoRIA, 24 and CheXMed 25 have explored new frontiers in multimodal learning, ranging from unsupervised visual representation learning to sophisticated global-local representation learning frameworks. These approaches emphasize the importance of integrating different data types in medical diagnostics. Despite their advancements, a gap remains in fully addressing the challenges posed by the absence of certain modalities in diagnostic data which is a prevalent issue in real-world settings, such as lacking X-ray resources or refusing X-rays for children due to radiation concerns, and the absence of expert interpretation even when X-rays are available.
Therefore, in this article, we introduce the robust multimodal transformer (RMT) model, innovatively designed to tackle the real-world challenge of missing modalities in pediatric pneumonia severity assessment. It integrates and analyzes both X-ray images and medical record data, employing advanced techniques like multi-task learning and mask attention to handle modaility missing problems. This targeted approach allows RMT to maintain high performance in severity assessment, even in scenarios where traditional models falter due to incomplete data.
Furthermore, the RMT model is designed with scalability and adaptability in mind. Its transformer-based architecture allows for efficient handling of larger datasets, and its multimodal framework can be extended to other medical diagnostic tasks involving diverse data types, such as cardiovascular diseases and other conditions. This flexibility ensures that the RMT model can adapt to various clinical applications beyond pediatric pneumonia.
In a nutshell, the main contributions of this article are described as follows:
We introduce a robust multimodal transformer model, which demonstrates remarkable robustness in handling incomplete data, maintaining high performance even when certain modalities are absent, closely aligning with real-world scenarios. A pediatric pneumonia severity assessment dataset is developed through multiple acquisition and preprocessing steps, covering a total number of 5101 cases. This marks a substantial contribution to the field by providing a rich resource for future research. We conduct thorough validations, demonstrating superior accuracy and robustness compared to traditional diagnostic and severity assessment methods. Our findings, supported by ablation studies, underscore the effectiveness of the multi-task learning strategy and the mask attention mechanism.
Data overview
The cornerstone of driving superior performance in deep learning models, particularly in the medical domain, lies in the acquisition and preprocessing of high-quality data.26,27 This section delineates the thoughtfully designed process undertaken to construct a pediatric pneumonia multimodal dataset. This endeavor addresses the prevalent limitations in existing datasets such as CheXpert, 28 MIMIC-CXR, 29 and chest-Xray, 30 notably their focus on adult patients and exclusion of clinical records beyond radiological reports.
Data acquisition
The pediatric pneumonia multimodal dataset is compiled from the extensive records of the Children’s Hospital Zhejiang University School of Medicine, a leading tertiary care institution. Adhering strictly to medical ethics, a total of 37,579 pediatric pneumonia instances (20,932 outpatient and 16,647 inpatient cases), encompassing both X-ray images and detailed clinical narratives (including symptoms, medication history, etc.), are extracted from the period spanning 5 June 2019 to 28 October 2022.
To ensure the specificity and relevance of our study, we first excluded cases that were not related to pneumonia, such as those involving emphysema, lung cancer, and other conditions that, while requiring chest X-rays, fall outside the scope of our investigation. This step reduced the dataset to 20,932 cases (55.7% of the original data).
Next, we focused on distinguishing between severe and mild pneumonia cases. This task was particularly challenging as the severity was not always explicitly stated in the reports. To address this, we adopted standardized criteria: cases resulting in hospitalization were classified as severe, while those treated in outpatient settings were classified as mild. Additionally, we excluded cases where hospitalization was not due to pneumonia and, for cases with multiple days of hospitalization, only the record from the first day of admission was retained. After applying these criteria, we further reduced the dataset to 6703 cases (17.8% of the initial data).
In the final stage, we removed records that contained only lateral chest X-ray images to maintain consistency and ensure the effectiveness of our analysis. This rigorous selection process resulted in a refined dataset of 5101 high-quality cases (13.6% of the initial dataset), comprising 2537 mild cases and 2564 severe cases. This means

Data selection process for pediatric pneumonia cases. This flowchart illustrates the reduction of an initial set of 37,579 records to 5101 high-quality cases, balanced between 2537 mild and 2564 severe cases, after excluding non-pneumonia respiratory cases and those with unclear severity annotations.
Data preprocessing
The multimodal pediatric pneumonia dataset requires extensive preprocessing for optimal utility in model training.
Textual data handling
The dataset comprises two primary text modalities: “Clinical Diagnosis” and “Radiological Descriptions.” To prevent premature leakage of diagnostic conclusions into the model, all explicit diagnostic statements in “Clinical Diagnosis” are removed. The refined text is then concatenated with “Radiological Descriptions” to form a comprehensive textual representation. No augmentations were performed on the textual data. The textual data was preserved in its original form, with minimal preprocessing to ensure clarity and consistency.
Image modality processing
Chest X-ray images undergo a comprehensive standardization process. We standardize the images to a resolution of 224

Composite reapresentation of image processing stages for a chest X-ray. Panel (a) displays the original grayscale image. Panel (b) exhibits the enhanced clarity post histogram equalization, where the contrast adjustments elucidate finer details for diagnostic purposes. Panel (c) demonstrates a series of data augmentation techniques applied to (b).
During the training phase, we applied various data augmentation techniques to the X-ray images, including subtle rotations, scaling variations, and contrast adjustments, as illustrated in Figure 2(c), to simulate real-world variability in imaging conditions. For each original image, three augmented versions were dynamically generated, increasing the diversity of training samples. These augmentations were applied uniformly to both the mild and severe pneumonia classes, ensuring balanced representation across both categories.
Dataset formatting
The original dataset, initially stored in a CSV format containing extraneous information such as hospital numbers and personal identifiers, is reformatted into a Jsonl format, a decision driven by the format’s alignment with machine learning practices. The Jsonl format organizes data into a structured form: “id”: “[sample index],” “label”: [“mild” or “severe”], “image”: “[image file path],” “text”: “[combined clinical and radiological narrative],” thereby streamlining the integration into our analytical framework. Subsequently, the dataset is divided into training, validation, and testing subsets with a 7:2:1 ratio as illustrated in Table 1.
Training, validation, and testing dataset split.

Study sample characteristics
To ensure the robustness and generalizability of the proposed model, it is crucial to evaluate the diversity and representativeness of the dataset used for training and testing. In this section, we provide a comprehensive analysis of the study sample, including demographic information, as well as medical history and comorbidity diversity. These characteristics highlight the wide-ranging patient demographics and clinical conditions covered in the dataset, supporting the applicability of the model across diverse real-world scenarios.
Demographic analysis
The dataset comprises a total of 5101 pediatric pneumonia cases, evenly distributed between mild (2537 cases) and severe (2564 cases) pneumonia. We analyzed the age and gender distribution to better understand the demographic diversity of the sample.
Figure 3(a) shows the age distribution of patients with mild pneumonia, where the majority of cases are concentrated in the 0–3 age range, peaking at age 3. In contrast, Figure 3(b) illustrates the age and gender distribution for severe pneumonia cases, where the most prominent group is infants aged 0–1 years. Both male and female patients are well-represented across all age groups, with a balanced distribution between genders. This balance ensures that the model is trained and evaluated on a demographically representative population, particularly in terms of early childhood, where pneumonia incidence is typically higher.

Age and gender distribution of pediatric patients with mild and severe pneumonia. (a) The age and gender distribution for mild pneumonia cases; (b) the age and gender distribution for severe pneumonia cases.
These age and gender distributions indicate that the dataset effectively captures a broad range of pediatric pneumonia cases, from infants to older children, across both genders. Such diversity is essential for ensuring the model’s ability to generalize across different patient subgroups.
Medical history analysis
To further evaluate the clinical diversity of the dataset, we analyzed key clinical symptoms and comorbidities commonly associated with pediatric pneumonia. Table 2 presents the breakdown of fever severity, cough characteristics, and the 10 most frequent comorbidities observed in the dataset.
Fever, cough, and comorbidities diversity.

The diversity in fever severity ranges from mild (37–38 °C) to high (above 40 °C), with 578 cases falling within the 37–38 °C range and 632 cases between 38–39 °C, which ensures that the model is exposed to varying fever intensities, a critical factor in pneumonia diagnosis. In addition to fever, cough symptoms show significant variation, including cases with sputum retention (553 cases), barking cough (475 cases), and crowing cough (209 cases), adding to the range of clinical presentations the model encounters. Furthermore, the dataset includes a variety of comorbidities that often coexist with pneumonia, such as congenital laryngomalacia (82 cases), recent colds (65 cases), and respiratory failure (63 cases). Other comorbidities, such as pulmonary emphysema, COVID-19, and congenital heart defects, further enrich the dataset. This variety of clinical symptoms and comorbidities ensures that the model is trained on complex, real-world scenarios, allowing it to better generalize across different clinical conditions and patient profiles, ultimately enhancing its robustness and clinical relevance.
Method
Multimodal transformers are designed to integrate and process heterogeneous data types, including text, images, and audio, using unified attention mechanisms to handle inter-modal and intra-modal relationships. By embedding each modality into a shared representation space, multimodal transformers can jointly learn the semantic associations between diverse data types, enabling richer contextual understanding across tasks.
The existing supervised multimodal bi-transformer (MMBT) model represents a significant advancement in integrating multimodal data, expertly combining visual and textual elements. 31 Originally designed to leverage the strengths of both modalities, MMBT has shown its versatility in various applications. Nevertheless, its capacity to handle scenarios dominated by a single modality, particularly when one type of data is missing, falls short. This limitation becomes especially pronounced in the context of pediatric pneumonia assessment, where the availability and quality of multimodal data can vary significantly, posing challenges in accurately diagnosing and evaluating the condition.
To address the challenges of multimodal analysis in severity assessment, we introduce a robust multimodal transformer (RMT) model. Building on the MMBT framework, the RMT model is specifically designed to improve performance in pediatric pneumonia assessment, particularly in real-world scenarios where data from one modality may be incomplete or entirely missing. Figure 4 provides an overview of the RMT model’s architecture, highlighting its ability to process both text and image inputs.

Overview of the robust multimodal transformer (RMT) model architecture.
To further illustrate how the RMT model manages these complexities, we next focus on how the model handles missing modality scenarios—a crucial aspect in clinical practice where data availability can be unpredictable. The RMT employs two core mechanisms, mask attention and multi-task learning, that ensure the model maintains high diagnostic accuracy, even when one of the modalities (either text or image) is partially or completely absent.
Handling missing modality scenarios
As shown in Figure 4, the model processes both textual and visual data through separate embedding layers, and utilizes classification tokens for each modality and the multimodal task. When a modality is missing, the mask attention mechanism selectively focuses on the available modality by setting the attention weights of the missing modality to zero. This ensures that the model concentrates solely on the present data. For instance, when image data is missing, attention related to the image is masked, allowing the model to focus entirely on textual information.
In addition to mask attention, the model integrates a multi-task learning strategy, which enhances the model’s performance across different tasks, including image-only, text-only, and multimodal tasks. By employing distinct classification tokens for each task, the RMT model is able to maintain high accuracy when one modality is missing. This strategy enables the model to effectively use the available modality, compensating for the absence of another.
These two mechanisms work together to ensure that the RMT model can handle missing data scenarios without a significant drop in performance. The following sections will delve deeper into the technical implementation of these mechanisms within the RMT model architecture, demonstrating their contributions to robust multimodal integration and handling of missing modality scenarios.
Model architecture
The RMT model, built upon the MMBT framework, is specifically designed for enhanced multimodal integration. Its architecture centers around a transformer encoder that adeptly processes inputs from both visual and textual modalities.
For textual data, each token is transformed into a 768-dimensional embedding
Simultaneously, for visual data, a pre-trained ResNet-152
32
model is utilized to extract feature vectors
Within the transformer encoder, the self-attention mechanism plays a pivotal role in integrating multimodal data. The mechanism’s sophistication lies in how it processes the concatenated embeddings from both textual and visual modalities to create a unified representation. This is achieved through the generation and interaction of the Query (
The self-attention mechanism computes attention scores by evaluating the dot product between each Query and all Keys, scaled by the square root of the Key’s dimension
Finally, the output of the self-attention layer for each Query is computed as a weighted sum of the Value vectors, determined by these attention weights:
After the self-attention processing is completed and the mask attention technique (detailed later) is incorporated, each classification token—enriched with modality-specific information—passes through a linear classifier. This classifier translates the integrated multimodal representation into a probabilistic distribution over target classes, culminating in the model’s final decision-making process.
Mask attention technique
Building upon the self-attention mechanism described in the model architecture section, the mask attention technique further enhances the model’s ability to handle missing modality scenarios by selectively ignoring irrelevant modal information. It achieves this by directly setting certain parts of the attention matrix to zero, effectively isolating the relevant modality’s features for focused processing.
For image-only tasks, the mask attention mechanism targets the image CLS token I. Figure 5(a) visualizes this, where the attention values related to text tokens
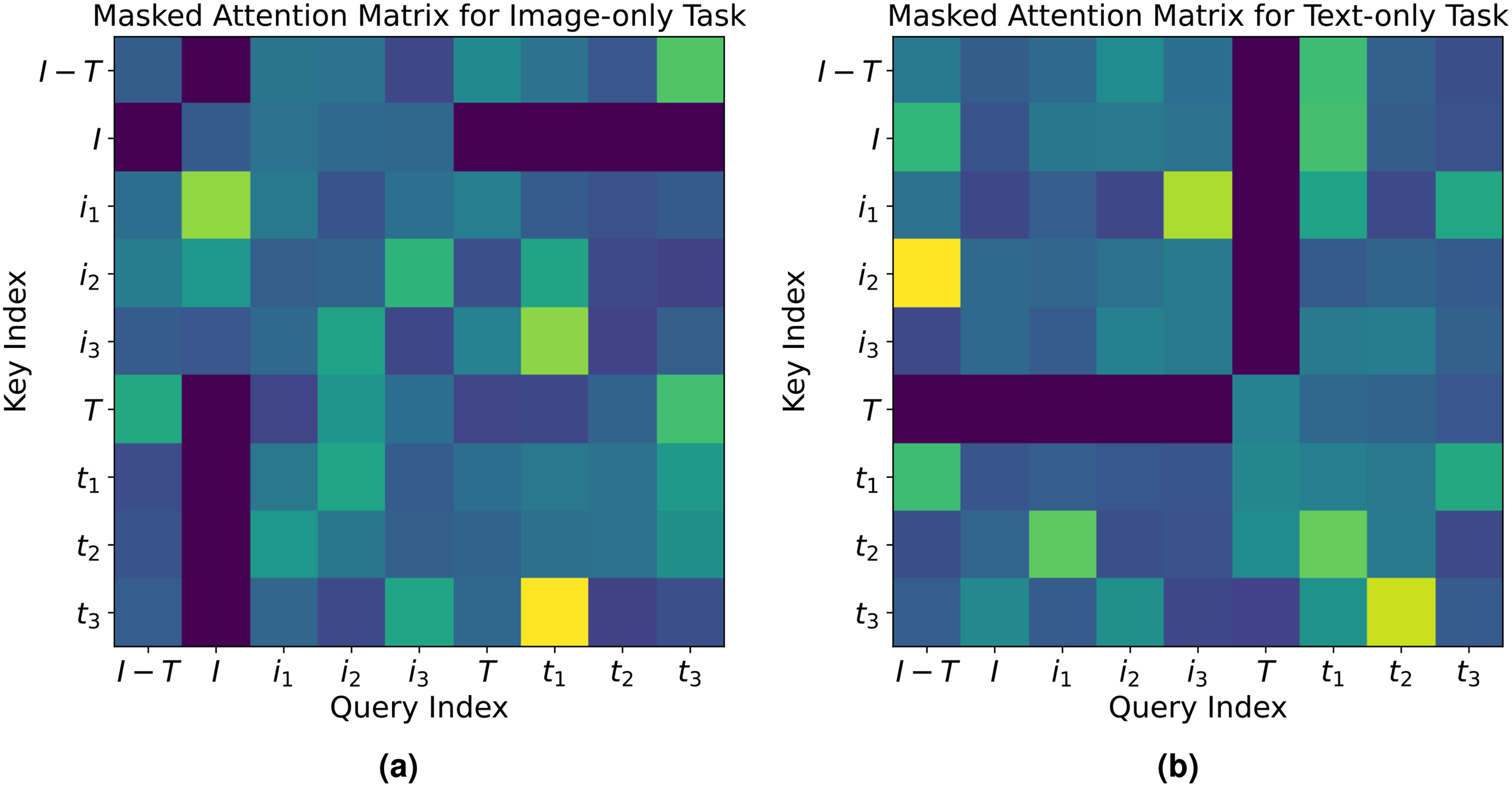
Visualization of the masked attention technique in the RMT model: (a) Masked attention matrix for image-only task. The matrix displays selective activation where the image CLS token (“
Conversely, in text-only tasks, the text CLS token T is the primary recipient of the model’s focus. As shown in Figure 5(b), attention values for image vectors are zeroed, which allows the text CLS token to focus on textual information from the clinical narratives without visual data interference.
This technique is mathematically represented in the attention matrix For image-only tasks: For text-only tasks:
Through the implementation of this zeroing-out strategy, the RMT model guarantees that the image and text CLS tokens scrutinize their respective modalities independently, shielding them from irrelevant modalities. This precise mechanism not only bolsters the model’s performance in unimodal tasks but also fortifies its dependability in scenarios with incomplete multimodal data.
In essence, the mask attention technique fine-tunes the RMT’s analytical capabilities, allowing for a more accurate assessment in tasks, where a clear and undistracted focus on one modality is essential.
Multi-task learning
The multi-task learning strategy works in tandem with the mask attention mechanism. When a modality is missing, the mask attention ensures that the model focuses on the available modality, while the multi-task learning strategy ensures that the model learns specialized representations for each modality-specific task, maintaining high accuracy even in unimodal scenarios.
To further elaborate on this, multi-task learning in the RMT framework is designed to enhance the model’s performance across three distinct tasks: image-only, text-only, and multimodal. This approach utilizes dedicated classification tokens (CLS tokens) for each task—image CLS token for image-only task, text CLS token for text-only task, and multimodal CLS token for multimodal task—facilitating specialized and simultaneous learning.
The multi-task learning strategy is implemented through a composite loss function that combines the individual cross-entropy loss functions from each task, which measure the difference between the true label distribution and the predicted probability distribution for each task. The image-only task cross-entropy loss 
Computational complexity
The RMT model integrates a ResNet-152 architecture for processing X-ray images and a BERT-based architecture for handling clinical text data. The computational complexity of ResNet-152 is primarily dictated by its depth and the dimensions of the input images, which can be expressed as
Despite the inherent computational demands, these complexities are manageable with current hardware. For instance, on an NVIDIA A40 GPU, the training phase of the RMT model consumes
Scalability and adaptability
The RMT model is designed with both scalability and adaptability in mind, leveraging its transformer-based architecture to handle larger datasets and accommodate different medical diagnostic tasks. Below, we detail the key aspects of the model that contribute to these capabilities.
One of the core strengths of the transformer architecture is its ability to process input data in parallel, as opposed to sequential processing in models such as recurrent neural networks (RNNs). 33 This parallelism ensures that the RMT model can efficiently scale to larger and more complex datasets, such as those found in real-world clinical applications involving thousands or even millions of patient records and medical images. In practice, this efficiency is further enhanced by techniques such as mixed-precision training, 34 which reduces the computational load by using lower-precision arithmetic for certain operations without compromising the accuracy of the model. Furthermore, the modular design of the RMT model allows for easy adjustments in the number of layers, attention heads, and hidden dimensions, providing flexibility to tailor the model to datasets of varying sizes and complexities. 35 This flexibility ensures that, as the size of the dataset increases, the model can maintain its performance by adapting its architecture to balance computational efficiency and prediction accuracy. 36
In addition to scalability, the RMT model is highly adaptable to different medical diagnostic tasks. Its modality-agnostic architecture allows it to process various forms of medical imaging data, such as X-rays, CT scans, and MRIs, in conjunction with textual clinical information. This flexibility ensures that the model is not limited to a specific type of data, making it applicable to a wide range of medical conditions that benefit from multimodal data integration, such as cardiovascular diseases, neurological disorders, or cancer. Furthermore, its adaptability can extends to diverse healthcare systems, ensuring broad applicability. Building on this flexibility, the RMT model can also be fine-tuned for new diagnostic tasks with minimal changes to its core architecture. 37 The transformer-based framework supports easy adaptation to different clinical scenarios, where the nature and availability of data may vary. This capability ensures the model remains effective across diverse medical environments, consistently meeting the need for accurate and efficient diagnosis. 38
Implementation details
The transformer encoder utilizes the bert-base-chinese model for its depth and robustness, featuring a 12-layer architecture with 768 hidden dimensions. Pretrained on Chinese Wikipedia, it captures a detailed understanding of the Chinese language, crucial for processing clinical and radiological narratives effectively. While the visual inputs are processed using a ResNet-152 model with ImageNet pretrained weights from PyTorch’s model zoo. The computational work is executed on Ubuntu Linux 20.04 with NVIDIA A40 Graphics Processing Units, backed by 503 GB of memory. Training is conducted with a batch size of 32 over 50 epochs, starting with a learning rate of 1
During the training phase, as shown in Figure 6(a), the model’s accuracy on both the training and validation datasets, calculated using equation (2), steadily increases, achieving substantial improvement by the fourth epoch with accuracy just under 80%. After the sixth epoch, the accuracy growth tapers off, indicating that the model’s learning has reached a stable plateau. Concurrently, Figure 6(b) illustrates that the model’s loss on training and validation datasets, computed according to equation (1), declines substantially before plateauing after the sixth epoch, signaling that the model has achieved convergence.

Composite overview of the robust multimodal transformer (RMT) model’s performance. (a) Model accuracy over training epochs; (b) model loss over training epochs.
Experiments
Evaluation metrics
In the context of our study, evaluating the RMT model’s ability to assess pediatric pneumonia severity is pivotal. The performance metrics used to assess pediatric pneumonia severity include accuracy, sensitivity, specificity, and precision, each reflecting a unique aspect of the model’s diagnostic capability. We formulate these metrics as follows:
Accuracy, the model’s overall correctness, is defined as follows: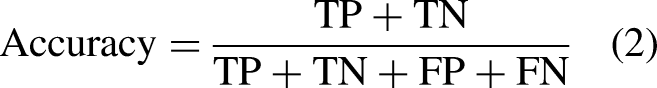



Efficacy evaluation
In this section, we conduct a fair comparison with carefully selected baseline models on the task of assessing the severity of pediatric pneumonia. Our experimental design is divided into three main parts. Initially, we compare baseline models that solely utilize the image modality, particularly ResNet-152, 32 known for its strong feature extraction capabilities in image recognition tasks. Subsequently, we compare baseline models that exclusively use the textual modality. Finally, we compare against multimodal models employing different fusion strategies. Through comprehensive and detailed experiments, we validate the superior performance of our RMT in assessing pediatric pneumonia severity.
Since the original baseline models might not be directly applicable to the binary classification task of pediatric pneumonia severity assessment, we implement a simple linear classifier in all cases. This approach maximizes the demonstration of the baseline models’ inherent capabilities, ensuring fairness in our experiments. The baseline models we employ are as follows:
In each case, we run five inference processes, taking the average as the final performance result. The experimental results of this part are mainly presented in Table 3.
Performance comparison across different modalities and classifiers.

RMT: robust multimodal transformer; CNNs: convolutional neural networks; MMBT: supervised multimodal bi-transformer; RF: random forest; XGB: extreme gradient boosting.
For single-modal image inference, the RMT model demonstrates a better accuracy to ResNet-152 in single-modal image inference (0.877 over 0.875), with a notable improvement in precision (0.922 over 0.855). This highlights RMT’s effectiveness in reducing false positives. However, its sensitivity (0.846) is marginally lower than ResNet-152 (0.876). In specificity, RMT excels, achieving a score of 0.913. When compared with CheXMed, RMT still maintains the best performance overall, particularly in precision. Overall, RMT outperforms both the ResNet-152 and CheXMed models in the single-modal image data scenario, likely due to its utilization of the multimodal transformer architecture, which has a stronger representation capability compared to traditional CNN architectures, enabling more effective feature extraction and inference from images.
For single-modal text inference, RMT achieves remarkable results, surpassing all baseline models with accuracy, precision, sensitivity, and specificity scores of 0.937, 0.962, 0.918, and 0.959, respectively. This superiority of RMT in processing natural language data can be attributed to its self-attention mechanism, which allows the model to establish direct dependencies between different parts of the text, thus effectively capturing semantic information and clinical relevance. Interestingly, we also note that deep learning models like CheXMed and Bert outperform traditional machine learning models like XGB and RF.
In multimodal inference, compared with models based on post-fusion strategies, ConcatBert and CheXMed, RMT is slightly behind MMBT in sensitivity but outperforms all other baseline models in accuracy, precision, and specificity. This underscores the RMT model’s ability to effectively integrate and interpret both visual and textual data, leveraging the strengths of the transformer architecture in feature extraction and inference. Overall, RMT, while modifying MMBT, still maintains or slightly exceeds MMBT’s excellent performance in this task.
Task weight variation analysis
In the multi-task learning framework for pediatric pneumonia severity assessment, the adjustment of task weights
Model performance under various task weight configurations.

Initially, the experiment establishes a baseline by setting the task weights to a near-equal distribution, achieving respectable accuracies across all modalities. This balance serves as a benchmark for assessing the impact of shifting emphasis towards specific modalities. When the weight is increased for image tasks (
A significant turning point in our analysis emerges when the task weight is predominantly allocated to text tasks (
The observation that textual data emerges as the dominant modality in this context serves as a springboard to a broader discussion on the variability of modality dominance across different datasets. It is plausible that other datasets may exhibit a different dominant modality, influenced by factors such as the nature of the tasks, the quality and type of data available, and the specific objectives of the model’s application. This variability underscores the importance of recognizing and adapting to the leading modality of a dataset to optimize model performance. Adjusting the trade-offs between task weights based on dataset characteristics becomes crucial, not only for enhancing model accuracy within a specific context but also for ensuring its robustness and generalizability across diverse applications.
Robustness analysis
To validate the superior robustness of our RMT over the standard supervised MMBT in handling modality absence, we conduct two sets of inference experiments. In one set, the model has access to complete image data and partial text data, assessing RMT’s robustness to text absence. In the other, it accesses complete text data and partial image data, to evaluate robustness to image absence. Our findings indicate that the RMT model demonstrates exceptional performance across various rates of modality absence.
Performance under text modality absence
As illustrated in Figure 7(a), even under significant text modality absence (with only 10% of text data available), RMT achieves an accuracy of 0.881, significantly surpassing MMBT’s 0.834. This not only highlights RMT’s independence and autonomy in processing image modality data but also its capability to effectively infer and recognize under severe data scarcity. Notably, at very low text visibility rates (10% and 30%), MMBT’s performance is even inferior to the image-only Resnet-152 model, suggesting MMBT’s potential performance degradation when integrating minimal textual information and highlighting its fragility under modality absence. As text visibility improves, both RMT and MMBT show enhanced accuracy, but RMT consistently outperforms MMBT under all comparative conditions. At a 90% text visibility rate, RMT’s accuracy improves to 0.949, still exceeding the performance of the MMBT model.

Comparative analysis of the RMT and MMBT models in different modality scenarios: (a) performance under varying rates of text data availability; (b) performance under varying rates of image data availability. RMT: robust multimodal transformer; MMBT: supervised multimodal bi-transformer.
Performance under image modality absence
In scenarios with missing image modality, the RMT model proves its superior robustness, as demonstrated in Figure 7(b). Even with severely limited image data (10% image visibility), RMT’s accuracy is significantly higher than that of MMBT, which is 0.878. Compared to the Bert model, which relies solely on textual modality, RMT consistently shows higher accuracy under all conditions of image absence. This underscores RMT’s independence and effectiveness in handling textual modality, maintaining high accuracy even with scant image data. It is noteworthy that although MMBT’s accuracy gradually improves with increased image information, it still demonstrates sensitivity to limited image data, possibly leading to performance instability.
RMT exhibits robustness under various conditions of modality absence, particularly excelling over unimodal baselines in situations of extreme modality scarcity, confirming its exceptional adaptability to incomplete inputs. This adaptability can be attributed to the innovative multi-task learning strategy and mask attention mechanism integrated into the RMT model. The multi-task learning approach, by considering various inference tasks during training, enhances the model’s understanding and processing capabilities across different data modalities. The mask attention mechanism plays a pivotal role in the model’s attention allocation, ensuring focus on the remaining modalities in the absence of one, thereby mitigating potential negative impacts of incomplete modality on inference performance. This is especially crucial in clinical settings where medical diagnosis often encounters incomplete data challenges. Models like RMT provide more flexible and reliable tools for supporting medical diagnostic decisions, thereby enhancing patient outcomes and holding significant value in real-world medical applications.
Ablation analysis
Our ablation experiments rigorously assess the roles of the multi-task learning strategy and mask attention technique in bolstering the robustness of the RMT model for the critical task of assessing the severity of pediatric pneumonia. For clarity, in our analysis, RMT-
Ablation analysis with text modality absence.

RMT: robust multimodal transformer; MMBT: supervised multimodal bi-transformer.
Ablation analysis with image modality absence.

RMT: robust multimodal transformer; MMBT: supervised multimodal bi-transformer.
Ablation analysis for multi-task learning strategy
The ablation study reveals a noticeable performance drop in RMT-
Ablation analysis for mask attention technique
The performance of RMT-
Case study
Following the experimental section, where the RMT model demonstrates its effectiveness in assessing pediatric pneumonia severity, we explore two specific cases to further illustrate the model’s practical application, as detailed in Table 7. These cases exemplify the model’s ability to integrate multimodal data for more accurate and confident diagnoses, surpassing traditional and partial approaches.
Two pediatric pneumonia cases are presented, with the first row dedicated to case 1 and the second row to case 2. Each case includes a chest X-ray image, clinical text descriptions, the models used for assessment, and their inference results, which display the predicted severity labels and associated probabilities. For instance, for case 1, ResNet-152 classifies the case as “severe” with a probability of 0.79 (P = 0.79).

RMT: robust multimodal transformer.
In the first case, a pediatric pneumonia condition is initially deemed “Severe” by the ResNet-152 model, which evaluates the chest X-ray image in isolation from clinical text. However, with the integration of clinical text, the RMT model reclassifies the condition as “Mild” achieving a probability of 0.87. This not only marks an improvement from RMT-
The second case involves a condition mislabeled as “Mild” by the Bert model, which only uses the clinical text for its assessment. Upon adding the chest X-ray data into the analysis, the RMT model adjusts the diagnosis to “Severe” with a probability of 0.89. This score is higher than both the RMT-
By comparing the performance of the RMT model with its variants, RMT-
Explainability and interpretability
Model interpretability is vital for clinician trust in medical applications. We applied two interpretability techniques in our multimodal transformer model: gradient-weighted class activation mapping (Grad-CAM) 45 and attention visualizations, to help clinicians understand how the model processes chest X-rays and reports for pneumonia diagnosis.
Grad-CAM for X-ray image interpretation
To provide spatial interpretability for the image modality, we employed Grad-CAM to visualize the areas of the X-ray image that contributed most to the model’s prediction. By applying Grad-CAM to the visual data, we generated a heatmap overlay that highlights the regions of the lung field most relevant to the classification decision.
As demonstrated in Figure 8, the Grad-CAM heatmap reveals that the model’s attention is concentrated on areas with increased and blurred pulmonary markings and scattered patchy areas of increased density, which align with the clinical findings stated in the report: “scattered areas of increased density.” This correspondence between the model’s focus and the clinician’s diagnosis enhances the model’s credibility in clinical practice.

Original X-ray alongside the gradient-weighted class activation mapping (Grad-CAM) heatmap. The red and yellow regions indicate where the model focuses its attention, providing an interpretable map of the regions that drive the diagnosis.
Attention mechanism visualization
The core of our model’s decision-making process relies on the self-attention mechanism inherent in the Transformer architecture. In this study, we employed BERT-base as the backbone of our multimodal Transformer, which consists of 12 layers, each containing 12 attention heads. To demonstrate how the model processes both image and text inputs, we conducted experiments analyzing attention maps across different layers and heads. Through these experiments, we observed that the information aggregation process within the model can be divided into three distinct stages. We then selected representative attention maps from these stages to provide insights into how the model integrates multimodal information.
Stage 1, initial self-attention
In the early stages of the model, Figure 9 (left) shows that attention is primarily focused on self-attention, where each token mainly attends to itself. This behavior is crucial for establishing an initial understanding of individual tokens, such as image features (e.g. “

Attention maps at three key stages of the model’s information aggregation process. From left to right: stage 1 represents self-attention focused on individual tokens, stage 2 shows a broadening of attention across neighboring tokens, and stage 3 highlights the final aggregation of global information where key tokens such as the textual modality are prioritized.
Stage 2, broadening attention across modalities
As the model progresses through the layers, we observed a significant broadening of attention, indicating an increased focus on contextual interactions between tokens, rather than solely self-attention. The attention map from layer 5, head 1, as depicted in Figure 9 (center), showcases this transition. Initially concentrated on individual tokens along the diagonal, the attention now spreads to include multiple neighboring tokens, both above and below each focal token.
This stage highlights a pivotal shift in the model’s processing strategy—moving from focusing mainly on individual token properties in early layers to a more integrated approach. Tokens begin to interact more substantially with their immediate neighbors, reflecting the model’s adaptation to a broader contextual understanding. This is particularly critical in settings where textual descriptions need to be closely linked with corresponding visual features in the images.
Stage 3, global information aggregation
In the final stage, we observed that the model’s attention becomes highly concentrated on specific tokens that play a pivotal role in the decision-making process. In layer 12, head 3, as shown in Figure 9 (right), attention is predominantly directed toward the token representing “
This attention map suggests that, in this particular head, the model is heavily focusing on the textual modality during the final phase, especially on key clinical terms such as “increased density” and “observed,” which are highly relevant for the diagnosis of pneumonia. While the model may appear to prioritize these text-based features in this head, it is likely because they provide explicit diagnostic details within the clinical report that are crucial for interpretation.
However, it is important to note that this focused attention on “
Future work
While our study demonstrates the effectiveness of the RMT model in assessing the severity of pediatric pneumonia, there are opportunities for further enhancement to maximize its impact in clinical practice.
One key avenue is ensuring the model’s generalizability across different healthcare institutions. Although the RMT model has shown robust performance using data from the Children’s Hospital of Zhejiang University School of Medicine, variations in healthcare environments and patient populations can affect its performance. Differences in medical equipment, diagnostic protocols, and patient demographics may impact the model when deployed elsewhere. To address this, we plan to collaborate with multiple institutions to validate and fine-tune the model using datasets from diverse regions and clinical workflows, ensuring it maintains diagnostic accuracy and fairness across varied environments.
Another promising direction is the clinical validation of the RMT model in real-world healthcare environments. Although we have utilized actual clinical data from the Children’s Hospital of Zhejiang University School of Medicine, implementing the model within live clinical workflows and conducting prospective clinical trials would provide deeper insights into its practical utility and reliability. This progression is essential for translating our research findings into tangible benefits for patient care.
Integrating the RMT model into existing hospital information systems and clinical workflows is another important consideration. Seamless adoption in clinical settings involves addressing challenges related to data integration and compatibility with electronic medical records. By developing standardized interfaces and designing intuitive tools that present the model’s results clearly to clinicians, we can facilitate smoother integration. Additionally, ensuring scalability and ease of maintenance through modular deployment can enhance the model’s adaptability across different healthcare institutions.
Addressing potential biases in the dataset is also crucial for enhancing the model’s fairness and generalizability. Factors such as demographic variations, uneven representation of patient subgroups, and the heterogeneity of clinical records are common challenges in the field of AI in healthcare. These biases may inadvertently influence the model’s performance across different patient populations. Expanding the dataset to include a more diverse patient population and additional modalities like lab results or respiratory sounds can further improve the model’s robustness and applicability in broader clinical settings.
Conclusion
The success of the RMT model in addressing pediatric pneumonia demonstrates the promising potential for AI-driven diagnostics in broader medical fields. In the future, multimodal AI models like RMT could be applied to a wide range of diseases beyond pneumonia, including cardiovascular disorders, cancers, and neurological conditions. By leveraging multiple types of clinical data, these models can offer more comprehensive diagnostic insights, enabling earlier detection and more effective interventions across various medical conditions.
Moreover, the ability of the RMT model to handle incomplete data scenarios has significant implications for real-world applications, particularly in low-resource settings or during telemedicine consultations. AI tools capable of delivering accurate diagnoses with partial or missing data can play a pivotal role in increasing access to healthcare, especially in remote or underserved regions where comprehensive diagnostic resources are scarce. This capability enhances the model’s utility in diverse medical contexts, addressing some of the most pressing challenges in global healthcare access.
As AI continues to integrate into clinical workflows, decision support systems based on models like the RMT will assist healthcare professionals by providing objective, data-driven insights. This can help reduce diagnostic errors and enhance consistency in medical assessments, particularly in complex or ambiguous cases. Additionally, AI systems that learn from vast patient datasets will be essential for advancing personalized medicine, where treatment strategies are tailored to the unique characteristics of each patient, potentially improving outcomes and reducing unnecessary interventions.
Footnotes
Acknowledgements
The authors acknowledge support from the National Key R&D Program of China, Leading Goose R&D Program of Zhejiang, Zhejiang Provincial NSF, the NSFC, Beijing Life Science Academy, Henan Institute of Chinese Engineering Development Strategies, and the Fundamental Research Funds for the Central Universities. The study was approved by the Medical Ethics Committee of Childrens Hospital (Approval Letter of IRB/EC, 2023-IRB-0287-P-01).
Contributorship
All authors contributed to the study conception and design. Data acquisition and preprocessing were performed by JL, GQQ, and GY. Code and experiments were conducted by ZAN, JLC, XKZ, and XL. The first draft of the article was written by SFL, YYW, and XYM. Required clinical knowledge was supported by YQW. All authors commented on previous versions of the article. All authors read and approved the final article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethics approval
This study was approved by the Medical Ethics Committee of Children’s Hospital (Approval Letter of IRB/EC, 2023-IRB-0287-P-01) and waived the need for written informed consent from patients, as long as the data of the patient remained anonymous. All of the methods were carried out in accordance with the Declaration of Helsinki.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key R&D Program of China (2023YFC2706400), Leading Goose R&D Program of Zhejiang (2024C01109), Zhejiang Provincial NSF (LR21F020005), the NSFC (62372404), the Key R&D Program of Zhejiang (2023C03101), Beijing Life Science Academy (BLSA: 2023000CB0020), Henan Institute of Chinese Engineering Development Strategies (2023HENZDB01), and the Fundamental Research Funds for the Central Universities (226-2024-00030).
Guarantor
GY.