
Abstract
Objectives
To evaluate the accuracy and clinical utility of GPT-4O in recognizing abnormal blood cell morphology, a critical component of hematologic diagnostics.
Methods
GPT-4O's blood cell morphology recognition capabilities were assessed by comparing its performance with hematologists. A total of 70 images from the Chinese National Center for Clinical Laboratories, External Quality Assessment (EQA) from 2022 to 2024 were analyzed. Two experienced hematology experts evaluated GPT-4O's recognition accuracy using a Likert scale.
Results
GPT-4O achieved an overall accuracy of 70% in blood cell morphology recognition, significantly lower than the 95.42% accuracy of hematologists (p < 0.05). For peripheral blood smears and bone marrow smears, GPT-4O's accuracy was 77.14% and 62.86% respectively. Likert scale evaluations revealed further discrepancies, with GPT-4O scoring 288.50 out of 350, compared to higher manual scores. GPT-4O accurately recognized certain intracellular inclusions such as Howell-Jolly bodies and Auer rods, while it misidentified fragmented red blood cells as neutrophilic metamyelocytes and oval-shaped red blood cells as sickle cells. Additionally, GPT-4O had difficulty accurately identifying intracellular granules and distinguishing cell nuclei and cytoplasm.
Conclusion
GPT-4O's performance in recognizing abnormal blood cell morphology is currently inadequate compared to hematologists. Despite its potential as a supplementary tool, significant improvements in its recognition algorithms and an expanded dataset are necessary for it to be reliable for clinical use. Future research should focus on enhancing GPT-4O's diagnostic accuracy and addressing its current limitations.
Introduction
Since its release in November 2022, ChatGPT (Chat Generative Pre-trained Transformer), an artificial intelligence-driven natural language processing tool, has garnered significant attention. Its latest iteration, GPT-4O (Generative Pre-trained Transformer 4 Omni), launched in May 2024, enhances its ability to generate human-like responses in conversational contexts based on input text. Despite its advanced capabilities, the application of ChatGPT in the field of medicine remains under-explored, primarily due to the limited use of biomedical data during its training process. This necessitates further evaluation and discussion with medical experts.
Previous studies have evaluated ChatGPT's performance in clinical decision-making scenarios across various medical conditions, including acute pancreatitis, 1 glaucoma, 2 and chronic obstructive pulmonary disease. 3 These studies, however, reported limited improvements. For example, while ChatGPT was able to retrieve medical knowledge rapidly and suggest common treatment options, it lacked the clinical nuance required for complex cases, particularly in handling patient histories and contextual decision-making. Specifically, in acute pancreatitis and chronic obstructive pulmonary disease (COPD) contexts, ChatGPT was found to be less reliable in accounting for comorbidities and patient-specific factors that influence diagnosis and treatment outcomes. Comparative studies have also evaluated ChatGPT's performance against that of human clinicians. While AI systems excel in speed and knowledge retrieval, they often underperform in individualized patient care. For instance, ChatGPT's clinical suggestions in conditions like infections, differential diagnoses, management, and treatment were found to be less precise and context-specific compared to human doctors, who could adjust treatment strategies based on subtle clinical cues and patient feedback.4,5 These comparisons highlight that while AI models like GPT-4O can serve as valuable decision-support tools, they cannot yet fully replace human judgment in clinical settings.
In addition to its role in clinical decision-making, ChatGPT and its successor models, including GPT-4O, have shown significant potential in other critical areas of healthcare, such as medical education and public health communication. ChatGPT has been applied in medical education, where it supports learning by simulating patient interactions, providing clinical case scenarios, and offering explanations on complex medical topics. 6 Furthermore, its use extends to assisting healthcare students and professionals in preparing for exams and improving their understanding of medical concepts. 7 This application broadens the scope of AI's utility in nurturing future healthcare professionals.
Moreover, ChatGPT plays an increasing role in public health communication, particularly during health crises and in managing widespread health education efforts. AI models have been employed to convey public health information effectively, engage with diverse populations, and provide clear and timely guidance on disease prevention and health promotion. 8 Additionally, AI tools like GPT-4 have been integrated into public health systems to enhance communication strategies, ensuring accessibility of information to the public, especially in underserved communities. 9
In the realm of laboratory medicine, ChatGPT has been utilized to address clinical laboratory questions, spanning from basic knowledge queries to complex interpretations of laboratory data in clinical contexts. 10 Notably, the application of the GPT-4 model in pathology 11 and blood cell morphology recognition 12 has shown promise. Research indicates that GPT-4 achieves an 88% accuracy rate in recognizing normal blood cells and surpasses traditional manual methods by 49.5% in identifying abnormal cells. However, the limited sample size of only 44 images and concerns about GPT-4's capability in recognizing pathological images call for further validation to conclusively determine its proficiency in identifying abnormal cells.
Given the advancements in the GPT-4O version, it is anticipated that healthcare professionals and patients will increasingly rely on GPT-4O for interpreting laboratory test results. This study aims to evaluate the performance of GPT-4O in hematology recognition, assessing whether its identification capabilities are on par with or superior to traditional methods. Additionally, this research seeks to explore the potential of artificial intelligence methods, such as ChatGPT, to mitigate the impact of subjective judgments on diagnoses, thereby enhancing diagnostic efficiency. This direction warrants further in-depth investigation.
Methods
The blood cell morphology recognition capabilities of GPT-4O were assessed by comparing its judgments with those of hematologists based on a set of images. These images, sourced from the Chinese National Center for Clinical Laboratories, were distributed to participating laboratories for External Quality Assessment (EQA) in 2022, 2023, and 2024, resulting in a total of 70 images (all images are available in the supplementary material). The EQA process ensures the quality and accuracy of laboratory practices by comparing results from different laboratories against a pre-determined standard. In this study, the images used for EQA were selected to represent common abnormal cells found in peripheral blood and bone marrow (Table 1).
Diversity and quantity of cell image types.
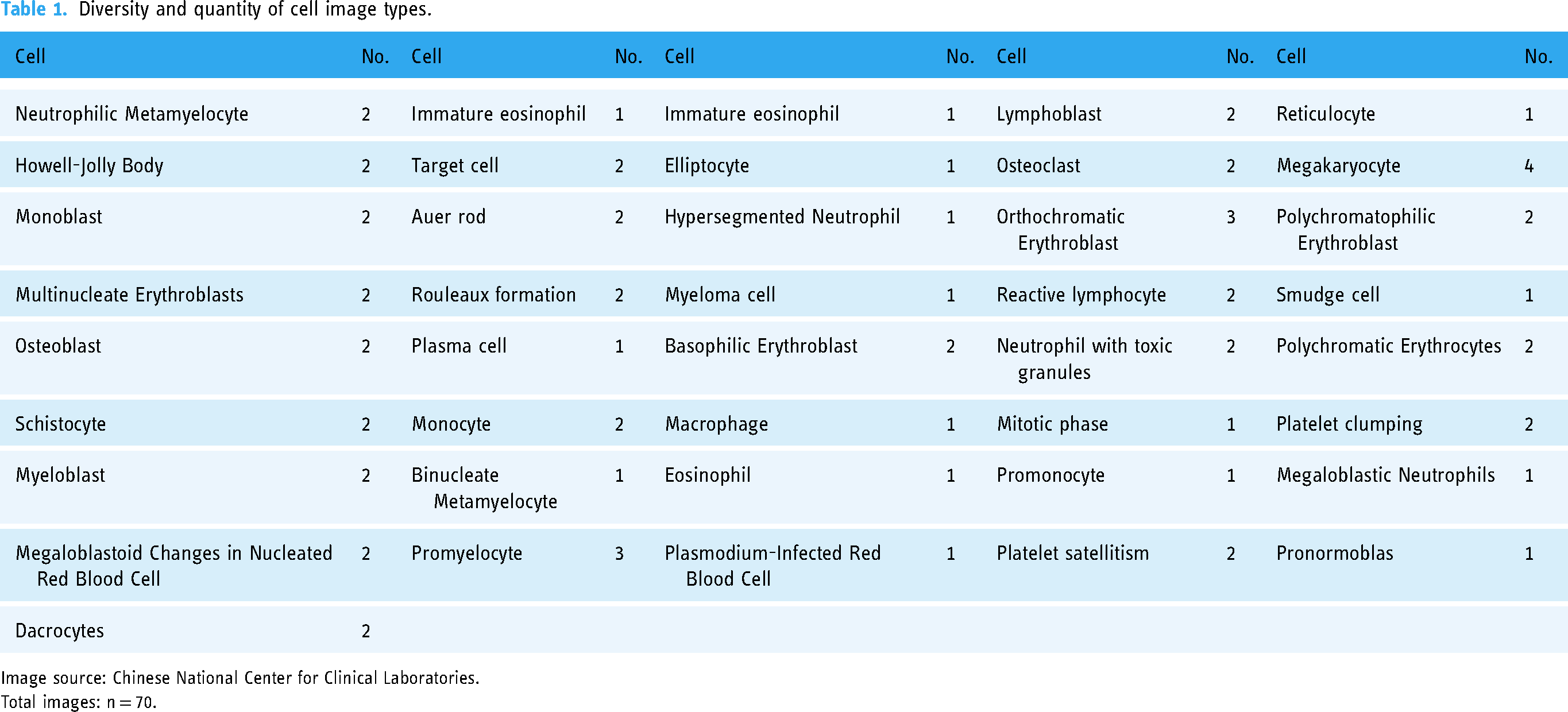
Image source: Chinese National Center for Clinical Laboratories.
Total images: n = 70.
External quality assessment (EQA) process
The EQA serves as a mechanism for evaluating laboratory performance on a standardized set of diagnostic tasks, in this case, the identification of blood cell morphology. Participating laboratories are provided with a set of test images and are asked to classify the cells according to defined criteria. The source of the images was the Chinese National Center for Clinical Laboratories, a recognized institution that regularly conducts EQA to ensure diagnostic accuracy across clinical laboratories in China. The evaluators involved in this process were hematologists with extensive experience in blood cell morphology, all qualified to issue clinical hematologic morphology reports. Their assessments formed the gold standard against which GPT-4O's performance was compared.
Likert scale assessment
To provide a nuanced evaluation of GPT-4O's performance, a Likert scale was employed. A Likert scale is a psychometric tool commonly used to measure attitudes or perceptions on a range from, for example, “strongly agree” to “strongly disagree”. In this study, the Likert scale allowed for more granular scoring by considering partial correctness in the identification of cell types. For each image, the recognition by GPT-4O was evaluated on a 5-point Likert scale as follows: 1 point indicates complete inaccuracy, such as incorrect identification of cell lineage, completely erroneous descriptions of the nucleus and cytoplasm, with no relevance to the correct answer. 2 points represent fundamental errors, with only partial correctness in descriptions. For example, partial correctness in cytoplasmic descriptions but incorrect lineage identification, mistaking the cell for common, easily confused cells (e.g., mistaking a polychromatic normoblast for a lymphocyte). 3 points indicate correct lineage identification but errors in cytoplasmic descriptions, like mistaking eosinophilic granules for basophilic granules. 4 points signify mostly accurate descriptions, with correct cell lineage identification but allowing for some errors in cytoplasmic descriptions, such as incorrectly identifying the cell stage (e.g., mistaking a neutrophilic metamyelocyte for a neutrophilic band cell). 5 points denote complete and accurate identification.
The accuracy data for manual identification of blood cell morphology were obtained from the Chinese National Center for Clinical Laboratories. However, there were certain considerations, such as instances where immature basophils were classified as basophils, which were deemed incorrect according to the center's guidelines. The distinction between immature and mature basophils is clinically significant because these cell types can indicate different hematological conditions. Immature basophils may be indicative of certain bone marrow pathologies or dysregulated hematopoiesis, whereas mature basophils are associated with normal or reactive processes. There are clinical differences between immature eosinophils and mature eosinophils, however, in terms of morphological recognition, the two are merely adjacent stages in the development of basophils. Confusing immature basophils with mature basophils in morphological assessment cannot be considered a serious error. This limitation may have impacted the objective assessment of GPT-4O's cell morphology recognition capabilities. To address this, a Likert scale was introduced as an additional evaluation metric (Table 2), allowing for partial scoring in such cases. Specific scoring criteria can be referred to in the Likert Scale Assessment section. Two experienced experts, qualified to issue clinical hematologic morphology reports, evaluated GPT-4O's cell morphology descriptions and recognition capabilities using the Likert scale. Additionally, considering that GPT-4O can produce inconsistent results, we queried GPT-4O three times using the same prompt, and each result was scored by two experts. The final score was the average of the six scores.
Comparison of likert scale score for EQA and GPT-4 recognition abilities.
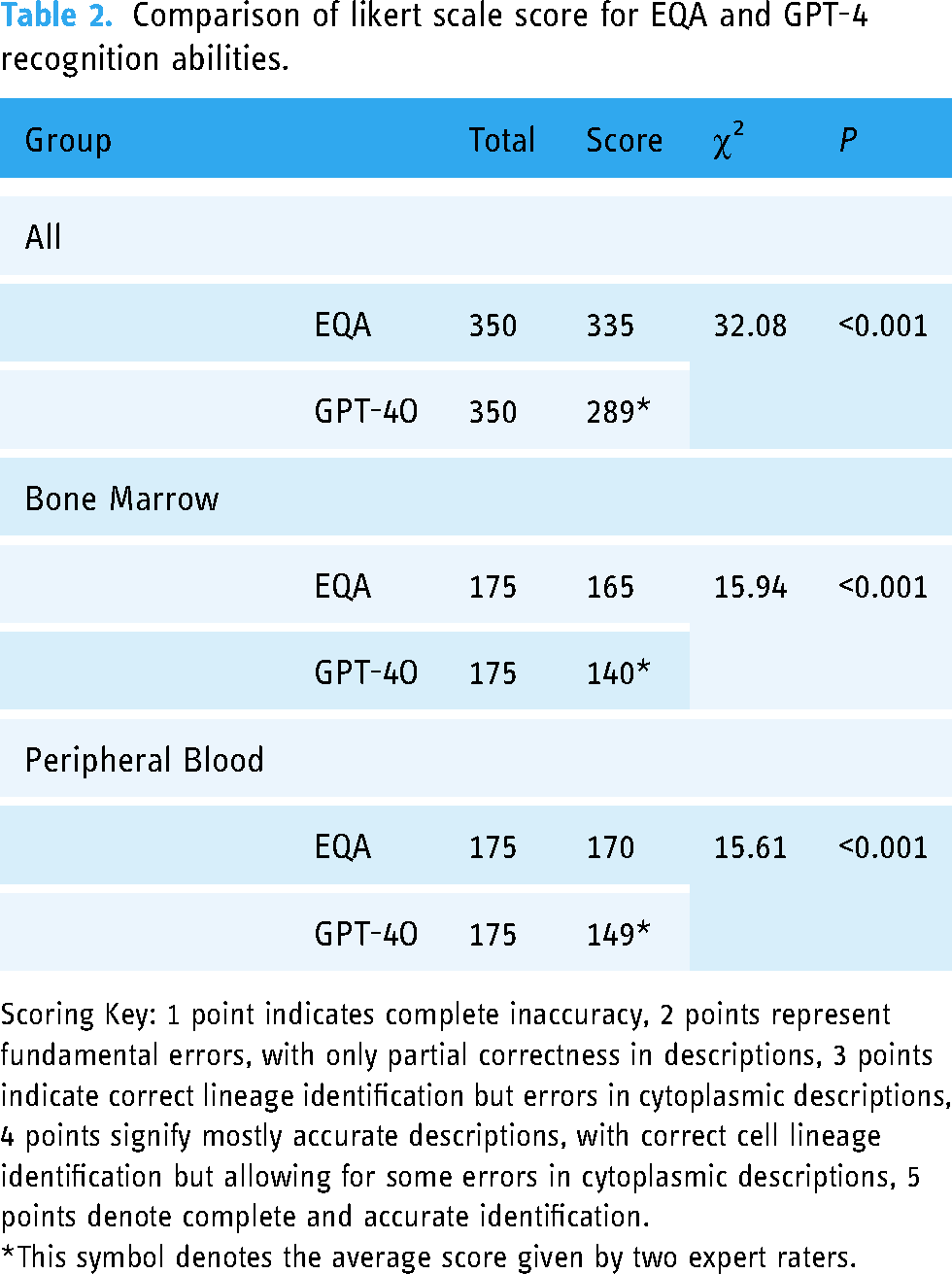
Scoring Key: 1 point indicates complete inaccuracy, 2 points represent fundamental errors, with only partial correctness in descriptions, 3 points indicate correct lineage identification but errors in cytoplasmic descriptions, 4 points signify mostly accurate descriptions, with correct cell lineage identification but allowing for some errors in cytoplasmic descriptions, 5 points denote complete and accurate identification.
*This symbol denotes the average score given by two expert raters.
Statistical analysis
Statistical analyses were conducted using SPSS software version 25.0 (SPSS Inc., Chicago, IL, USA). A Chi-square test was employed to determine whether there were significant differences in the accuracy of cell morphology recognition between manual identification by hematologists and GPT-4O's automated recognition. This test assessed the overall accuracy rates across different cell types to evaluate whether GPT-4O's performance was statistically comparable to human experts in a clinical setting. When the expected frequencies in some cells were less than 5 and total sample size greater than 40, a Chi-square test with Yates’ continuity correction was employed to reduce the bias of the Chi-square statistic and avoid overestimation of statistical significance. All tests were two sided, and p values < 0.05 were considered statistically significant.
Results
The accuracy of GPT-4O in identifying blood cell morphology across all smears (n = 70) (Table 1) was 70%, significantly lower compared to the hematologists accuracy of 95.42% (Figure 1). Specifically, the accuracy for peripheral blood smears was 77.14%, and for bone marrow smears, it was 62.86%. Both of these figures were markedly lower than those provided by human experts from the Chinese National Center for Clinical Laboratories. In all categories, including blood cell morphology smears, peripheral blood smears, and bone marrow smears, GPT-4O's accuracy showed a statistically significant difference compared to human experts (p < 0.05) (Table 3).

Comparison of GPT-4O and hematologists recognition accuracy.
Accuracy comparison between EQA and GPT-4O.

*The symbol denotes the integer value obtained by multiplying the average accuracy of all laboratories by the number of test images.
The symbol denotes the average value of the correctness of results generated by GPT-4 over three queries.
Using the Likert scale for an objective evaluation of GPT-4O's performance, GPT-4O achieved a score of 288.50 out of 350 across all images, with scores of 148.67 for peripheral blood smears and 139.83 for bone marrow smears. These scores were lower than those assigned by manual assessment. The differences in scoring rates across all categories, compared to manual recognition, were statistically significant (p < 0.05) (Table 2).
Discussion
The emergence of artificial intelligence (AI) models such as ChatGPT and other large language models like Bing has significantly impacted the field of medicine.13,14 Reports suggest that ChatGPT has surpassed traditional search engines like Google in terms of medical knowledge. 15 Numerous studies have explored ChatGPT's applications in pathology and laboratory education, including kidney pathology exams, 16 histopathologic descriptions, diagnosis of common diseases, 17 cancer pathology, 18 and digital pathology research. 19 However, these studies have also highlighted certain limitations, particularly in the analysis of histopathological images. Given the lack of specific research on ChatGPT's performance in recognizing abnormal blood cell morphology, it is crucial to assess its ability in this area. AI assistance may be utilized by patients or resident physicians for identifying and interpreting morphological reports.
This study revealed that GPT-4O demonstrated accurate recognition of intracellular inclusions such as Howell-Jolly bodies and Auer rods, achieving 100% accuracy in these images. Its recognition capability for common abnormal red blood cells, such as teardrop cells, target cells, and spherocytes, was also satisfactory. However, GPT-4O's identification of schistocyte as neutrophil band cell (Table 4) and elliptocyte as sickle cells suggests potential issues in recognizing cell outlines. These red blood cells do not contain any interfering particles within their cytoplasm, indicating that the recognition errors are perplexing.
Wrong blood cell annotations of GPT-4O (as an example).

Additionally, GPT-4O's accuracy in identifying intracellular granules is imprecise. For instance, it incorrectly identifies immature eosinophils and immature basophils as metamyelocytes (Table 4), suggesting accurate discrimination during the cell differentiation stage but erroneous recognition of cytoplasmic granules. Other observations indicate issues with GPT-4O's recognition of cell nuclei and cytoplasm. For example, it misidentifies osteoclasts and osteoblasts in the bone marrow as megakaryocytes (Table 4) and orthochromatic erythroblast as plasma cells, despite these being cells that beginners often confuse in routine practice. Moreover, even when provided with ample clinical information and data necessary for hematologic disease diagnosis, such as immunology, cytogenetics, or molecular biology, GPT-4O's performance was unsatisfactory. Among the 10 well-informed questions presented, it achieved an accuracy rate of only 40%. Some errors were due to its tendency to provide only a general diagnosis, such as labeling a cell as a “blast cell” without further detail. In the external quality assessment conducted by the Chinese National Health Commission, such responses were deemed incorrect. Introducing the Likert scale for a more objective assessment of GPT-4O's performance revealed a significant gap in cell morphology recognition compared to manual identification, particularly in bone marrow cell morphology. The results indicate that GPT-4O cannot yet replace human expertise in identifying abnormal blood cell morphology, highlighting the need for further enhancement in its blood cell recognition capabilities.
However, this study has certain limitations. Firstly, the questions provided by the Chinese National Center for Clinical Laboratories mostly involved direct cell image-based inquiries to GPT-4O, without providing specific cases or additional clinical information. Therefore, the accuracy of GPT-4O without sufficient clinical context remains uncertain. Additionally, this preliminary study solely focused on GPT-4O as an expert in blood cell morphology, without providing an extensive dataset of cell morphology for training. The images used in this study from the Chinese National Health Commission's Clinical Inspection Center represented only abnormal cells and did not cover the full spectrum of abnormal and normal cells. Moreover, the overall sample size was limited to only 70 cases, which is relatively small. Further expansion of the sample size is necessary to provide a more comprehensive evaluation of GPT-4O's performance.
Conclusion
In conclusion, while GPT-4O shows potential as a supplementary tool in laboratory medicine, significant improvements are necessary before it can be considered a reliable alternative to human expertise in abnormal blood cell morphology recognition. Future research should focus on addressing these limitations and enhancing the model's diagnostic accuracy and reliability.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076241298503 - Supplemental material for Assessing the accuracy and clinical utility of GPT-4O in abnormal blood cell morphology recognition
Supplemental material, sj-docx-1-dhj-10.1177_20552076241298503 for Assessing the accuracy and clinical utility of GPT-4O in abnormal blood cell morphology recognition by Xinjian Cai, Lili Zhan and Yiteng Lin in DIGITAL HEALTH
Footnotes
Acknowledgments
We want to thank Qiuxia Lu and Huaqing Shen for their assistance in reviewing and scoring the accuracy of GPT-4O answers.
Authors’ contributions
All authors made equal contributions to the work reported, whether in the conception, study design, execution, acquisition of data, analysis and interpretation, or in all these areas. They participated in drafting, revising or critically reviewing the article, gave final approval of the version to be published, agreed on the journal to which the article was submitted, and agreed to be accountable for all aspects of the work.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author, Xinjian Cai, on reasonable request.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical statement
The Ethics Committee of the Chinese Academy of Medical Sciences and Peking Union Medical College Shenzhen Hospital waived the requirement for ethics approval and informed consent, as the study results were generated using artificial intelligence. Additionally, the peripheral blood smear images utilized in this research were publicly available and sourced from the Chinese National Center for Clinical Laboratories.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Supported by Sanming Project of Medicine in Shenzhen (No.SZSM202311002).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.