
Abstract
Background
ChatGPT has the potential to enhance patient education by offering clear and accurate responses, but its reliability in providing precise medical information is still under investigation. This study evaluates the effectiveness in assisting healthcare professionals with patient inquiries about radioiodine therapy.
Methods
This study used OpenAI's GPT-4o and GPT-4 models, with each query submitted as a separate prompt. Chain-of-thought prompting was utilized to require the model to articulate its step-by-step reasoning prior to the final answer, thereby making the decision process transparent for qualitative evaluation. Three responses were generated per prompt and evaluated by three nuclear medicine doctors using a 4-point Likert scale across five aspects: Appropriateness, Helpfulness, Consistency, Validity of References, and Empathy. Normality test, Wilcoxon signed-rank test, and chi-square tests were used for analysis.
Results
A total of 126 paired responses from GPT-4 and GPT-4o were independently rated by three nuclear-medicine physicians. Both models performed similarly across the main dimensions—appropriateness, helpfulness, consistency, and validity of reference—with no statistically significant differences (Wilcoxon signed-rank, p ≥ 0.01). High-level ratings (score ≥ 3) were achieved in appropriateness for 90.4% of GPT-4 outputs and 84.9% of GPT-4o outputs, and in helpfulness for 92.1% of outputs from both models. Citation accuracy was limited: fully valid references were present in 20.6% of GPT-4 and 21.4% of GPT-4o responses. Empathy was judged present in 56.3% of GPT-4 and 66.7% of GPT-4o answers (χ², p > 0.05). There was low inter-rater agreement (Fleiss κ = 0.04).
Conclusion
The results suggest that ChatGPT can furnish generally appropriate and helpful answers to frequently asked questions in radioactive iodine treatment, yet citation accuracy remains limited, underscoring the need for clinician oversight. GPT-4o and GPT-4 demonstrated comparable performance, indicating that model selection within this family has minimal impact under the controlled conditions studied.
Keywords
Introduction
For decades, cancer has been the leading cause of mortality in Taiwan. Thyroid cancer has become the most common endocrine malignancy in the region, with an incidence rate of approximately 19.79% in 2021. 1 Of those diagnosed with thyroid cancer, a significant proportion received radioactive iodine therapy. 2 Given the exposure to radiation, dietary restrictions, and numerous precautions during the treatment process, clear and thorough education for patients before radioactive iodine therapy is essential. Despite the provision of oral instructions and written educational materials, the complexity of the whole process often makes it difficult to understand and retain information for patients and their families. In addition, health care providers often need to spend more time on repeated reminders and clarifications. As a result, we would like to seek a more efficient method or approach that could provide clear and accurate answers to patients’ questions about radioactive iodine therapy. This improvement not only improves patient understanding but also saves valuable time for health professionals.
Continuous advancements in Artificial Intelligence (AI)-assisted technology have attracted public attention, and ChatGPT (OpenAI, San Francisco, CA, USA) is one of the most notable advances. ChatGPT is an advanced language model developed by OpenAI, initially released as a prototype in November 2022. It represents a significant leap in natural language processing (NLP), enabling human-like interactions across various domains. Built on large-scale transformer architecture, ChatGPT leverages pretrained data and fine-tuning to perform tasks such as text generation, summarization, and conversational assistance.3–5 Since its inception, ChatGPT has become increasingly popular and has found applications in various professional fields. This widespread adoption is due not only to its ability to perform a wide range of tasks but also to providing users with rich and comprehensive feedback. People often use ChatGPT to ask for unknown or specialized knowledge and efficiently obtain concise and well-organized answers.
Chain-of-Thought (CoT) prompting is an approach designed to enhance the reasoning capabilities of large language models (LLMs). It involves explicitly instructing the model to generate intermediate, step-by-step reasoning processes leading to a final solution, rather than directly outputting an answer. By doing so, CoT prompting guides LLMs to systematically decompose complex problems into simpler, sequential steps, mirroring human cognitive processes. Empirical evidence indicates that this method significantly improves performance in tasks requiring multistep logical reasoning, including arithmetic, commonsense inference, and symbolic reasoning. Thus, CoT prompting not only boosts accuracy but also provides transparency into the model's decision-making process, facilitating better interpretability and verification of results.6–8
The medical field has shown considerable interest in ChatGPT as well. Applications such as medical record documentation, report interpretation, professional knowledge assessments, 9 patient education, and interactions10,11 have all been explored, with related studies and precedents in place. However, due to differences in models and training data used, the accuracy of responses generated by ChatGPT models may vary and may not always contain the latest information. Moreover, ChatGPT differs from dedicated medical chatbots in that it has not been specifically trained on a specialized data set curated by medical experts. As a result, the answers provided by the model may not always be completely accurate and could even generate false information or create nonexistent references.5,12 In this context, we aim to investigate whether ChatGPT combining CoT technique can help health professionals answer common questions about radioiodine therapy and provide sufficient accurate information.
Methods
Model selection
The study used the GPT-4 and GPT-4o models from OpenAI's ChatGPT (https://openai.com/chatgpt). GPT-4 was released on 14 March 2023, representing a significant step forward in NLP. GPT-4o (“omni”), launched in May 2024, is a native multimodal transformer that accepts text, image, audio, and video inputs. Compared with GPT-4 Turbo, GPT-4o offers markedly lower latency (∼200 ms end-to-end), faster generation speeds (≥100 tokens s⁻¹), and a 128 k-token context window.13,14 GPT-4 was preferentially used for scenarios requiring highly structured, multistep analysis, whereas GPT-4o was selected for tasks demanding rapid or interactive outputs, particularly when real-time or multimodal capabilities were advantageous.
Responses of ChatGPT
In this study, both models were prompted to generate responses using CoT reasoning. Questions were submitted separately in distinct sessions, with each session containing only the current question to eliminate any potential bias. To ensure consistency, the “regenerate-response” feature was used twice for every prompt, resulting in three responses per question. Furthermore, ChatGPT was instructed to incorporate references in its responses.
Prompt development and CoT
Several rounds of pilot testing were conducted to optimize prompt clarity and ensure consistent CoT outputs. After iterative refinements, the following wording was adopted as the final prompt for all queries:
Final prompt
“Let's think about it step by step.
1. Use COT to explain the thinking process of answering the question.
2. List an integrated response at the end; each response must include three references in APA format.
Please write it out in Traditional Chinese and then translate it into English.”
This prompt explicitly instructed the model to (i) generate transparent, step-by-step reasoning in CoT format, (ii) produce a consolidated answer, and (iii) supply three APA-style references, first in Traditional Chinese and subsequently in English. Embedding these requirements served two purposes in our experimental design: (1) it standardized the structure of all model outputs, facilitating objective comparison across evaluation dimensions; and (2) it enabled qualitative assessment of both the reasoning trace and citation accuracy, which are critical for determining each model's suitability for patient-facing educational materials.
Evaluation procedure
Two qualified nuclear medicine doctors, each with more than five years of experience in the administration of I-131 treatments, and a third-year nuclear medicine resident, independently assessed ChatGPT's responses. The assessment criteria were based on previous related studies and classified into five main categories: “Appropriateness,” “Helpfulness,” “Consistency,” “Validity of References,” and “Empathy” (Table 1). 15 The evaluations were performed using a 4-point Likert scale to avoid neutral responses, and “Empathy” was assessed as a binary outcome (presence or absence). A reviewer also participated in the process. In addition, board-certified physicians reviewed the consistency of the three responses to each question and verified the accuracy of all references quoted.
The prompts are assessed according to the below categories.

Each meaning of the points is listed below.
Note: (1) The scoring criteria described in this table are used to evaluate prompts according to the specified categories. Each category is assessed using a defined numerical scale, with higher scores indicating better performance (e.g., 4 = highly appropriate for Appropriateness, 4 = Very helpful for Helpfulness). (2) Empathy is evaluated as a binary score (1 = Empathetic, 0 = Not empathetic). (3) The scores are assigned independently by evaluators based on the definitions provided in the table.
Questions and ethical considerations
Fourteen frequently asked questions about radioiodine therapy (Table 2) have been developed with simple, nontechnical language to improve patient understanding. The questions were not adapted from a previously validated instrument, nor have they undergone formal psychometric testing. Instead, they were developed through an expert-consensus approach involving four nuclear medicine specialists. Specifically, these specialists identified and consolidated common queries derived from patient-education materials as well as frequently asked questions encountered in clinical practice by patients and their family members.
Fourteen frequently asked questions about radioiodine therapy.

Note: This table lists 14 frequently asked questions (FAQs) about radioiodine therapy, compiled through an expert-consensus exercise involving four board-certified nuclear-medicine specialists. Overlapping items were merged, and wording was refined for patient readability, yielding a concise set that addresses the most common patient concerns. The questions collectively cover five key domains: indication, preparation, acute and late side-effects, fertility/lactation, and post-treatment precautions. This comprehensive FAQ set is intended to support patient education by providing clear, practical guidance throughout the treatment journey.
Since the study did not use patient data or included personal information, ethical approval was considered unnecessary. The work has been reported in line with the STROCSS criteria. 16
Statistical analysis
The mean and standard deviation for each physician across all aspects and questions, as well as the overall mean and standard deviation for all three physicians for each aspect and question, will be analyzed using descriptive statistics. The four aspects of the GPT-4 and GPT-4o responses will be compared using the normality test (Kolmogorov–Smirnov test, Shapiro–Wilk test) and Wilcoxon signed-rank test. A conservative threshold of p < 0.01 was adopted for statistical significance. As for empathy, being a categorical variable, it will be analyzed separately using a chi-square test.
Inter-rater reliability among the three nuclear medicine physicians was assessed to ensure consistency and robustness in the evaluations of GPT-4 and GPT-4o responses. Fleiss’ Kappa (κ) was calculated to measure overall agreement across all raters simultaneously, while pairwise Cohen's Kappa coefficients were used to evaluate the agreement between each pair of raters individually. Kappa statistics were interpreted using the Landis–Koch scale, where κ values between 0.01 and 0.20 indicate slight agreement, 0.21–0.40 fair agreement, 0.41–0.60 moderate agreement, 0.61–0.80 substantial agreement, and 0.81–1.00 almost perfect agreement. All calculations for inter-rater agreement were performed using IBM SPSS Statistics for Windows, Version 26.0 (IBM Corp., Armonk, NY, USA), with the corresponding confidence intervals and significance levels reported.
Results
Three physicians in nuclear medicine participated in the survey, assessing the responses generated by GPT-4 and GPT-4o models based on criteria such as appropriateness, helpfulness, consistency, validity of reference, and empathy. Each model underwent a total of 126 evaluations. All responses produced by GPT-4 and GPT-4o for the 14 evaluation questions are available in the supplementary file, Appendix Table S1. Figure 1 presents the complete distribution of Likert scores for each evaluation dimension. The average score and standard deviation of each category are shown in Table 3.
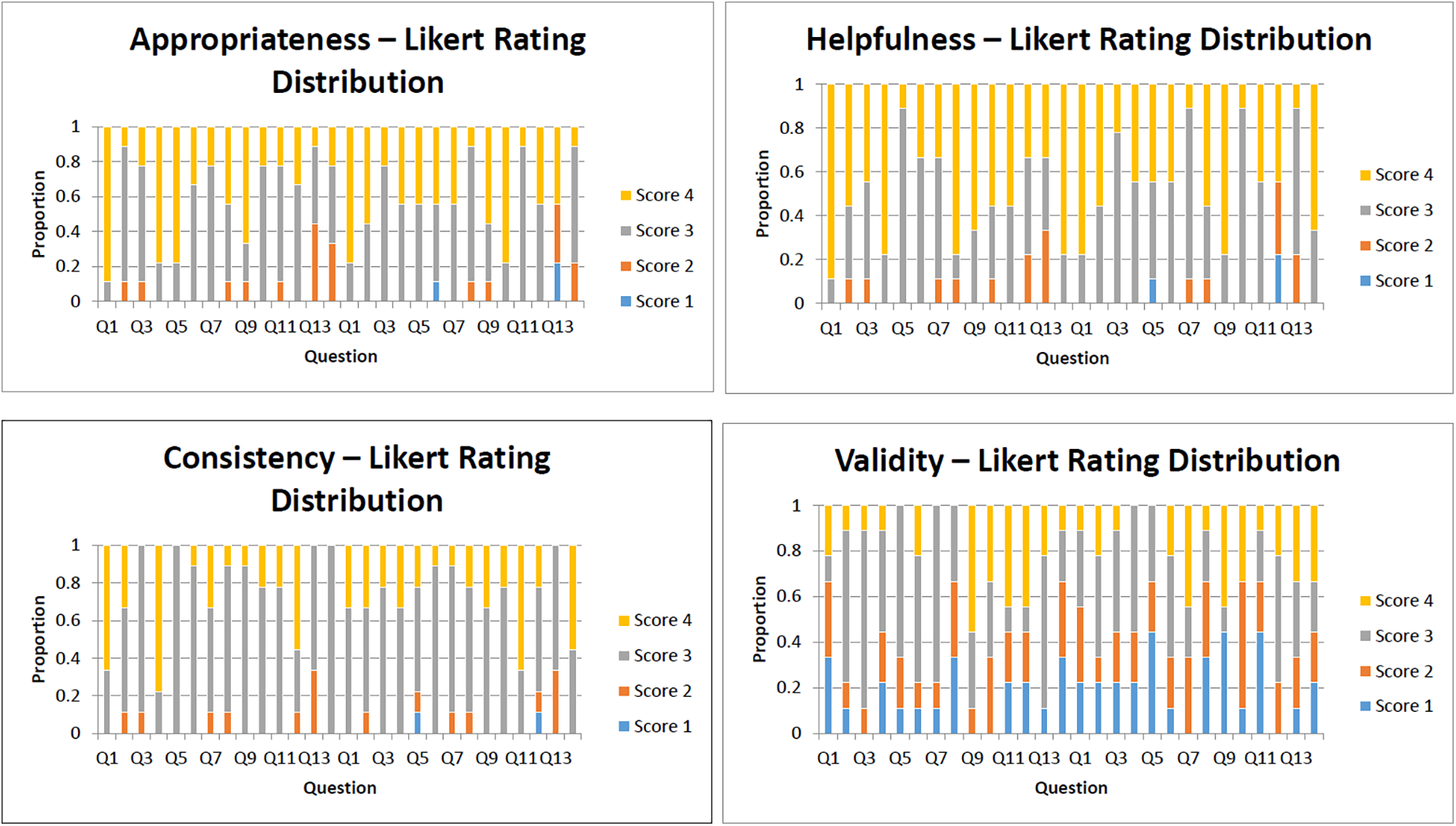
Likert score distributions for four evaluation dimensions (GPT-4 vs. GPT-4o).
Comparison of average scores (mean ± SD) across evaluation categories for GPT-4 and GPT-4o.
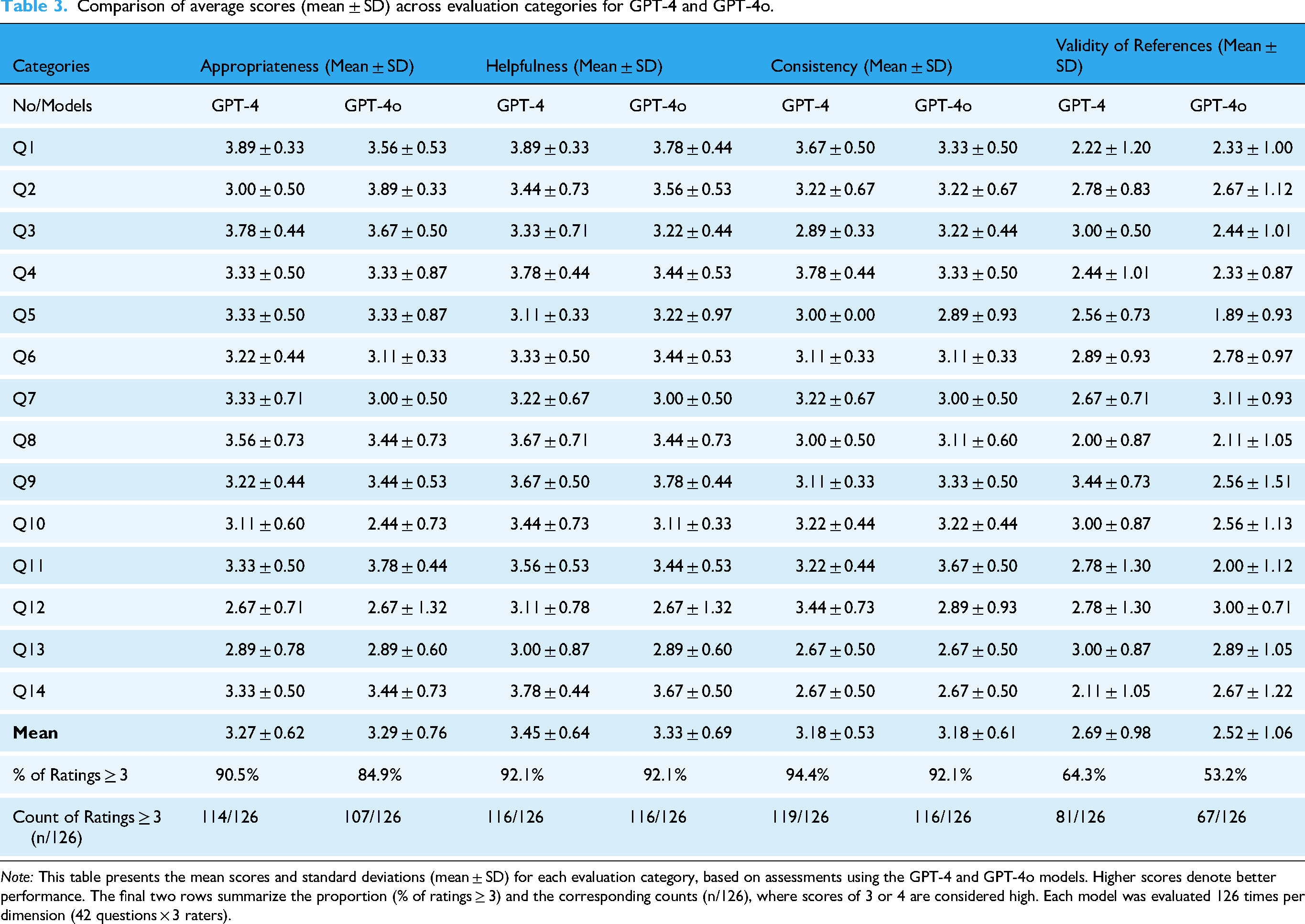
Note: This table presents the mean scores and standard deviations (mean ± SD) for each evaluation category, based on assessments using the GPT-4 and GPT-4o models. Higher scores denote better performance. The final two rows summarize the proportion (% of ratings ≥ 3) and the corresponding counts (n/126), where scores of 3 or 4 are considered high. Each model was evaluated 126 times per dimension (42 questions × 3 raters).
We first evaluated the distribution of the rating data obtained for GPT-4 and GPT-4o across various question groups. Both the K-S and S-W tests revealed that almost all rating data across the question groups deviated significantly from normality (Tables 4, 5, 6, 7), indicating that the ratings do not follow a normal distribution. Accordingly, we determined that nonparametric statistical methods were most appropriate for further analysis.
Normality test for appropriateness ratings of GPT-4 and GPT-4o.
Note: * This is a lower bound of the true significance.
Lilliefors significance correction was applied for the Kolmogorov–Smirnov test.
Normality test for helpfulness ratings of GPT-4 and GPT-4o.
Note: * This is a lower bound of the true significance.
Lilliefors significance correction was applied for the Kolmogorov–Smirnov test.
Normality test for consistency ratings of GPT-4 and GPT-4o.
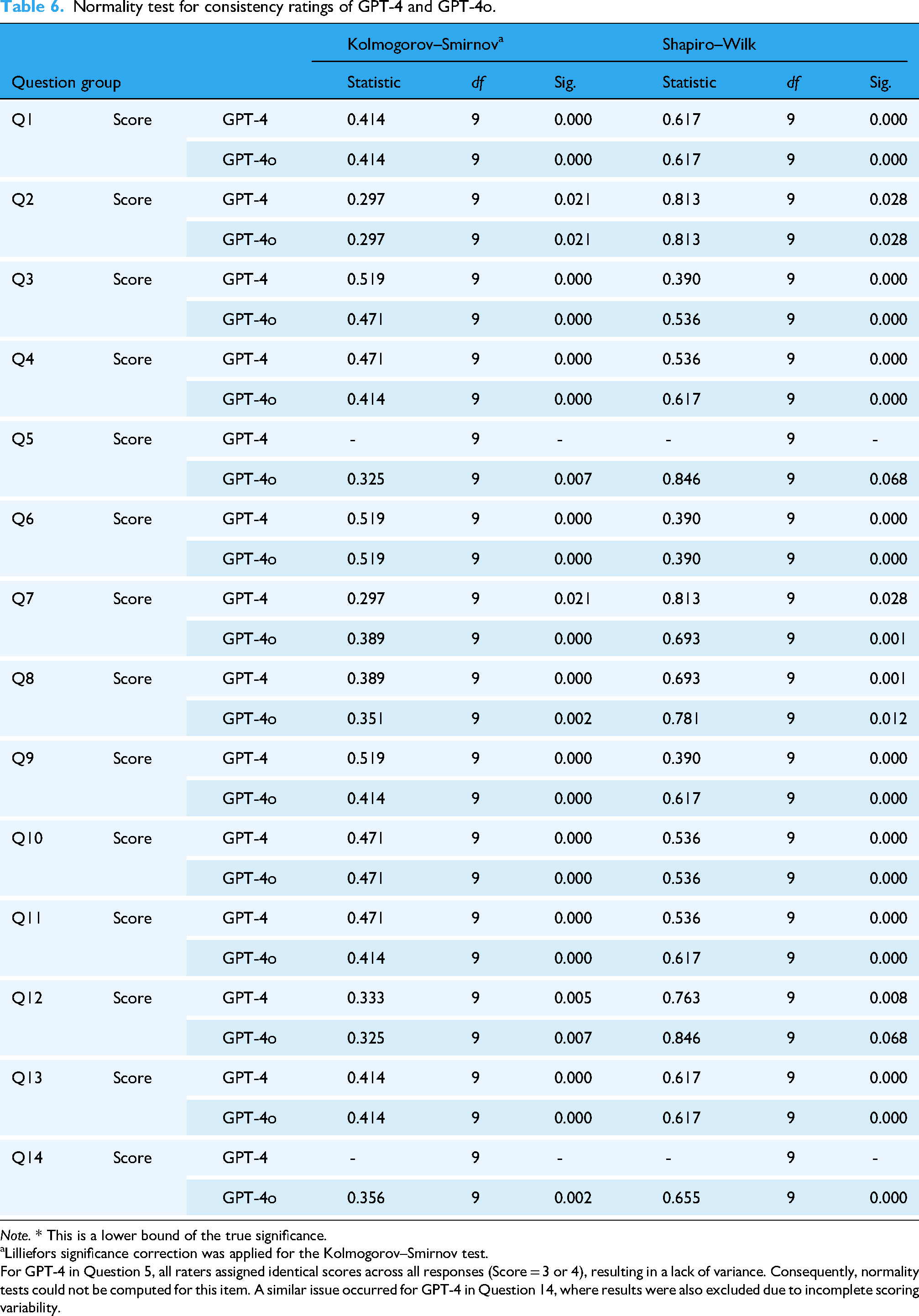
Note. * This is a lower bound of the true significance.
Lilliefors significance correction was applied for the Kolmogorov–Smirnov test.
For GPT-4 in Question 5, all raters assigned identical scores across all responses (Score = 3 or 4), resulting in a lack of variance. Consequently, normality tests could not be computed for this item. A similar issue occurred for GPT-4 in Question 14, where results were also excluded due to incomplete scoring variability.
Normality test for validity of references ratings of GPT-4 and GPT-4o.
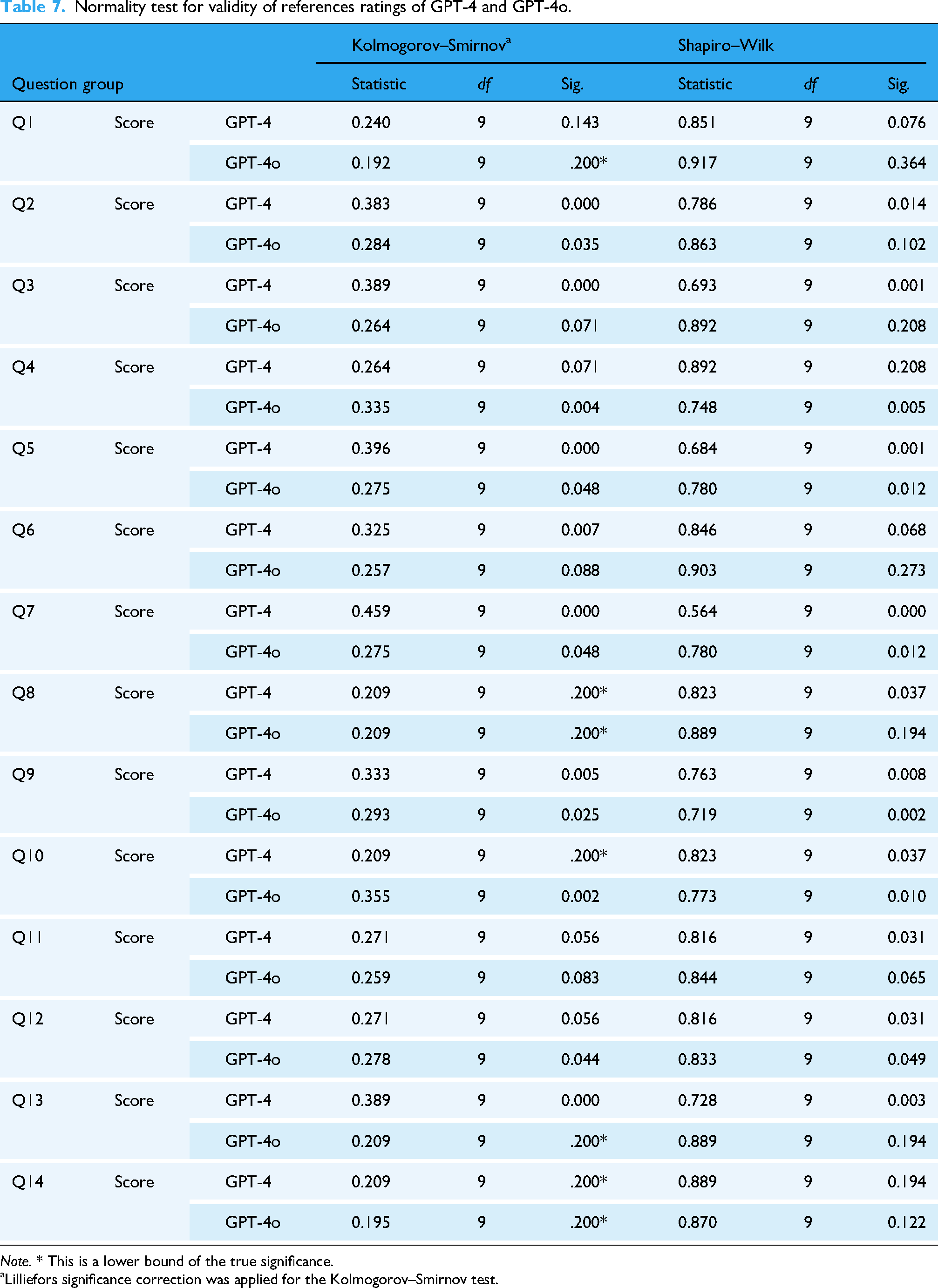
Note. * This is a lower bound of the true significance.
Lilliefors significance correction was applied for the Kolmogorov–Smirnov test.
Wilcoxon signed-rank tests were then conducted to compare GPT-4 and GPT-4o across four evaluation dimensions: Appropriateness, Helpfulness, Consistency, and Validity of References. As shown in Table 8 and 9, none of the comparisons reached statistical significance. The effect sizes across dimensions were generally small, suggesting minimal practical divergence between the two models. GPT-4o produced appropriate responses (“quite appropriate” or “fully appropriate”) in 84.9% (107/126) of the answers, while GPT-4 did so in 90.4% (114/126). Within the appropriateness category, the average score for several questions fell below 3, specifically for Q10, Q12, Q13 by GPT-4o, and Q12, Q13 by GPT-4, respectively.
Wilcoxon signed-rank test ranks for GPT-4 vs. GPT-4o.

Note: Negative ranks indicate items where GPT-4 outperformed GPT-4o; Positive ranks indicate items where GPT-4o outperformed GPT-4. Ties represent items with equal scores between models.
Wilcoxon signed-rank test and effect size comparing GPT-4 and GPT-4o across four evaluation dimensions.

Note: Negative Z values indicate GPT-4 > GPT-4o. Effect size r = Z/√N with N = 14. p < 0.05.
Regarding the category of “Helpfulness,” answers provided by both models were rated as “quite helpful” or “very helpful” in 92.1% of cases (116/126), demonstrating identical performance in this regard.
The scores of “Consistency” were similar for both models, indicating consistent results with minimal variation across different questions. Of the responses provided by GPT-4o, 92.1% (116/126) were considered both relevant and only minimally inconsistent, while GPT-4 achieved a rating of 94.4% (119/126) according to the same criteria.
In the category “Validity of references,” both GPT-4o and GPT-4 underperformed compared to the categories mentioned above. GPT-4o received an average score of 2.69 ± 0.98, while GPT-4 had a slightly lower score of 2.52 ± 1.06. Fully valid responses were found only in 21.4% (27/126) of GPT-4o's outputs, compared to 20.6% (26/126) for GPT-4. In addition, 22.2% of the references generated by GPT-4o (28/126) were found invalid, compared to 15.9% (20/126) of GPT-4. Appendix Table S2 presents a detailed comparison of citation validity for GPT-4 and GPT-4o.
For the “empathy” category, 66.7% (84/126) of GPT-4o's responses were rated as empathetic by specialists, while GPT-4 achieved 56.3% (71/126). Statistical analysis indicated that there were no significant differences between the two models, with p values exceeding 0.05. Furthermore, weak correlations, as shown by Phi and Cramer's V, suggest that the difference in appropriateness scores between the models is negligible (Table 10).
Results of chi-square test of “empathy” category.

Note: (1) The Chi-square test results indicate no statistically significant difference between
aThe continuity correction is applied only for 2 × 2 tables as an adjustment for small sample sizes
Inter-rater reliability was quantified with Fleiss’ κ and pairwise Cohen's κ. Overall concordance among the three evaluators was low: Fleiss’ κ = 0.040, indicating only marginal agreement beyond chance. Pairwise agreement was similarly poor, with Cohen's κ values of 0.004 for Rater A versus B, 0.073 for A versus C, and 0.100 for B versus C (Table 11). According to the Landis–Koch scale (κ = 0.01–0.20, “slight agreement”), these findings demonstrate limited consistency across raters.
Inter-rater agreement among three evaluators based on Fleiss’ and Cohen's kappa statistics.

Note: Fleiss’ Kappa evaluates the overall consistency across all three raters, while Cohen's Kappa measures pairwise agreement. All values reflect categorical agreement on 4-point ratings.
Discussion
Our study compared the performance of GPT-4 and GPT-4o in terms of appropriateness, helpfulness, and consistency in responding to common questions about radioactive iodine therapy. In the “Appropriateness” category, both models perform similarly without significant differences in overall results and provide responses considered appropriate by physicians in nuclear medicine. In fact, more than 90% of the responses generated by GPT-4 were rated as “quite appropriate” and “fully appropriate.” Similar results are also seen in the “Helpfulness” category, in which the GPT-4o and GPT-4 score more than 3 average, and no significant difference is found between the 2 models. These results suggest that the models generally provide accurate information, in line with the standards expected by nuclear medicine experts. These findings confirm those of earlier studies, such as a study that investigated the role of ChatGPT in preparing patients for FDG PET/CT and explained their reports. In this study, ChatGPT provided satisfactory and useful responses to more than 90% of the questions from the perspective of experts in nuclear medicine. 15 Similar trends were also observed in other studies, in which ChatGPT provided averagely accurate answers to questions about Lu-177 PSMA-617 treatment, 17 or questions related to common cancers. 18
However, when examining ChatGPT's responses to individual questions, we found that the average score of “Appropriateness” was below 3 within some of them. For example, Q12 asks whether breastfeeding is allowed after undergoing radioiodine therapy. The correct response should indicate that the patients must stop breastfeeding. Nonetheless, all 6 of ChatGPT's answers failed to mention this and only recommended stopping breastfeeding for a few days or months. Our findings suggest that ChatGPT can still produce incorrect information or exhibit “hallucinations,” aligning with earlier studies. For example, Goodman and colleagues conducted a study in which ChatGPT responded to over 200 medical questions submitted by physicians from various specialties, and its accuracy and completeness were evaluated. While the overall accuracy and thoroughness were generally high, there were instances where ChatGPT's responses were unexpectedly incorrect. 19 Another research by Belge Bilgin and colleagues assessed the performance of ChatGPT and Google Bard in answering frequently asked patient questions about 177Lu-PSMA-617 therapy. They found that 16.6% (16 of 96) of the responses provided by GPT-4 were not entirely accurate. 17 Recently, a study by Zhou et al. examined how task difficulty alignment, the avoidance of specific tasks, and the consistency of prompt responses vary across different types of language models. Their findings indicated that even for relatively simple tasks, such as understanding geographical relationships between cities, language models do not consistently provide fully reliable answers. 20 Since patients may struggle to recognize incorrect responses from ChatGPT, this could pose risks to their health and safety. Thus, both patients and healthcare professionals must be cautious and aware when using ChatGPT. In light of this issue, we strongly recommend that all GPT-generated content—particularly information directly related to patient safety—undergo a thorough review by qualified healthcare professionals before it is shared with patients or their families.
The consistency of the responses between both models was comparable, with average scores exceeding 3. More than 90% of the answers provided by ChatGPT-4o and 4 were rated as “Relevant” or “Minor inconsistency,” indicating that there were minimal differences between the responses. The findings are also consistent with previous research. For example, Ana Suárez et al. found that ChatGPT provided answers to endodontic questions with an overall consistency rate of 85.44%. 21 In another study by Rahsepar et al., ChatGPT delivered consistent responses 90% of the time (36 out of 40 instances) when addressing common questions about lung cancer. 22 Our results further corroborate the ones of prior research. However, it is worth noting that the probabilistic nature of LLMs inherently leads to response variability, where different answers may be generated for the same question across multiple attempts. This characteristic stems from the model's design to identify and generate contextually relevant patterns rather than produce deterministic outputs. While this variability can be advantageous in generating diverse and adaptive responses, it also presents challenges in ensuring consistency. Future research should focus on developing strategies to reduce unnecessary variability while preserving the model's ability to generate diverse and contextually relevant outputs, thereby improving its reliability and applicability in healthcare settings.
When it comes to the category of “Validity of references,” GPT-4o and GPT-4 showed poorer performance compared to other categories. Fewer than 60% of the references supplied by GPT-4 and under 40% of those generated by GPT-4o could be successfully verified (Table 12). Additionally, many references were deemed invalid, suggesting that some may have been fabricated or nonexistent. Not only in this study but the accuracy of the references generated by ChatGPT has been a persistent concern. A systematic review published in 2024 examined 11 studies, covering a total of 471 references, and found that the precision rates for GPT-3.5 and GPT-4 were 9.4% and 13.4%, respectively. Furthermore, hallucination rates—defined as having errors in at least two of three fields (title, first author, or publication year), were 39.6% for GPT-3.5 and 28.6% for GPT-4. 23 A separate study evaluated the accuracy of GPT-3's responses to radiology-related queries. The model demonstrated a correctness rate of 67% (59 out of 88 responses). In addition, 63.8% (219 out of 343) of the references generated by GPT-3 could not be verified by an internet search, suggesting they were fabricated by the model. 24 Joseph Mugaanyi and colleagues conducted a study in which ChatGPT was asked to generate 10 topics, evenly divided between the natural sciences and humanities. In total, ChatGPT produced 102 citations, 55 of which were related to natural sciences and 47 to humanities. Of these, around 72.7% of the citations in the natural sciences and 76.6% in the humanities were found to be valid sources. 25 Considering the results of these studies, ChatGPT may help solve complex problems (e.g., common questions about radioactive iodine therapy), but its ability to accurately obtain relevant references still requires significant improvements. The aforementioned study by Zhou et al. also showed similar results, in which LLMs, including various versions of ChatGPT, often struggle with simpler tasks. In fact, none of the tested models achieved more than 60% accuracy in tasks of the lowest difficulty. Furthermore, fine-tuned models were found to produce more incorrect responses compared to their original versions, producing responses that appear convincing but are ultimately incorrect. 20 In conclusion, users should be cautious when requesting references from ChatGPT, as it may produce incorrect information and occasionally fabricate details, even with simpler tasks or questions.
Summary of reference validity comparison between GPT-4 and GPT-4o.
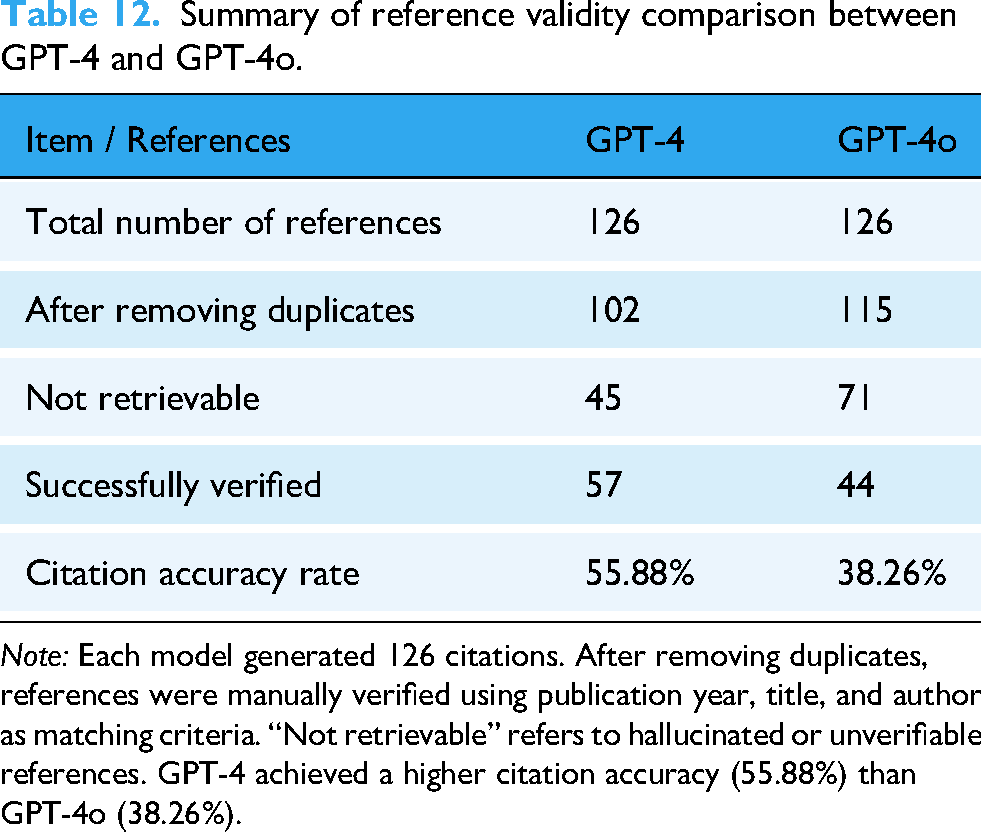
Note: Each model generated 126 citations. After removing duplicates, references were manually verified using publication year, title, and author as matching criteria. “Not retrievable” refers to hallucinated or unverifiable references. GPT-4 achieved a higher citation accuracy (55.88%) than GPT-4o (38.26%).
Our research found that over 60% of the responses from GPT-4o and 50% from GPT-4 were regarded as empathetic. Previous studies have shown that ChatGPT can generate responses perceived as emotional by human evaluators. In a study led by Schaaff et al., ChatGPT was tasked with rephrasing neutral sentences into six emotional tones: joy, anger, fear, love, sadness, and surprise. Three annotators evaluated the prompts to identify the most appropriate emotion, with more than 70% achieving unanimous agreement and only 1.7% assigned three different emotions. 26 Ayer et al. conducted another study using patient questions posted on the subreddit r/AskDocs from Reddit. They asked ChatGPT to generate answers to these questions. A group of healthcare professionals from various specialties then evaluated the original questions, the responses of ChatGPT, and the verified physician responses from the social media platform, assessing them for quality and empathy. The results showed that ChatGPT responses were considered significantly more empathetic compared to those of physicians. 27 Based on these results, ChatGPT is capable of providing empathetic responses, which could be potentially helpful in clinical applications. It may also reduce the sense of distance and formality that patients may feel.
Our findings indicate that GPT-4 and GPT-4o can streamline routine patient-education tasks, yet they must be positioned strictly as adjunct decision-support tools. All AI-generated material should undergo a concise “review-and-release” process in which nuclear-medicine staff confirm factual accuracy, dosing instructions, and safety advice before dissemination. For high-risk topics—such as radiation precautions, fertility, and breastfeeding—we recommend a dual-review procedure or automatic escalation to a senior physician, and we advise embedding explicit safety disclaimers in any written output provided to patients. Effective implementation also requires structured training to enhance clinicians’ digital literacy, enabling them to recognize common AI failure modes (e.g., hallucinations, outdated information), interpret outputs critically, and communicate residual uncertainties transparently. Looking forward, the multimodal capabilities of GPT-4o (e.g., image- or voice-based guidance) could be incorporated into telehealth follow-ups, provided that the same verification and safety checks are maintained. Collectively, these measures translate our performance data into practical safeguards that support the safe and responsible adoption of LLMs in nuclear-medicine clinics. Going forward, we recommend two complementary lines of investigation. First, consumer-centered evaluations—using methods such as surveys, focus groups, and usability testing—should be undertaken to gauge end-users’ comprehension of LLM-generated content, as well as their perceptions of its usefulness, trustworthiness, and influence on intended behaviors. Second, prospective, real-world studies that compare multiple LLMs across clinical and educational settings are needed to determine their effects on decision-making workflows and patient or learner outcomes.
Limitation
This study has several limitations. First, data collection and expert evaluation were confined to a single medical center, which may restrict external validity. Second, ratings were provided by only nuclear-medicine physicians, so the mean scores may not reflect wider clinician or patient perspectives. Future work will recruit patients with a history of thyroid cancer to provide consumer-level ratings and qualitative feedback. Third, all assessments represent a single time point; because ChatGPT is periodically updated, response drift over time cannot be excluded. Fourth, interactions occurred exclusively through the ChatGPT web interface, preventing control of generation parameters and thereby limiting reproducibility. Fifth, our analysis focused solely on textual output, leaving GPT-4o's multimodal (image and audio) capabilities untested. Sixth, the five-item rating scale—Appropriateness, Helpfulness, Consistency, Validity of References, and Empathy (binary yes/no)—has not undergone formal psychometric validation. Future multicenter investigations with larger panels of evaluators, validated assessment tools, longitudinal follow-up, and patient-centered outcome measures are needed.
Conclusion
In this study, GPT-4 and GPT-4o demonstrated comparable and high performance in answering common patient questions about radioactive iodine therapy. Prompted with CoT technique, responses from both models were rated as highly appropriate and helpful by nuclear medicine physicians. However, two critical weaknesses were identified. First, citation accuracy was poor, with only about 21% of references being fully verifiable and numerous instances of fabricated sources. Second, the models remained susceptible to significant factual errors, such as providing incorrect advice on breastfeeding and highlighting risks to patient safety. Furthermore, the low inter-rater reliability across all evaluation criteria underscores the inherent subjectivity in assessing AI-generated medical content.
In conclusion, when guided by a standardized CoT prompt, ChatGPT can deliver generally accurate and useful patient-education responses on radioactive iodine therapy, regardless of model version. Persistent reference inaccuracies and occasional factual errors nevertheless mandate clinician review before clinical deployment. Future work should focus on improving citation integrity, validating outputs in patient cohorts, and exploring multimodal capabilities to further streamline patient-education workflows in nuclear medicine practice.
Declaration of generative AI and AI-assisted technologies in the writing process
The authors declare that generative AI and AI-assisted technologies, including ChatGPT (o3, 4o) and Gemini (2.5 Pro), were employed during the writing process of this manuscript. Their application was strictly limited to refining the language, improving sentence structure, enhancing readability, and addressing grammatical issues. Crucially, these tools were not used for generating novel scientific content, performing data analysis, formulating interpretations, or drawing conclusions. The conceptualization, methodology, data collection, analysis, and interpretation of results remain the original intellectual contributions of the named authors. All presented information and arguments are based on the authors’ research and understanding, and the AI tools were utilized solely as linguistic aids to ensure the highest standard of written communication while upholding academic integrity and avoiding any form of plagiarism.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251357468 - Supplemental material for Optimizing patient education for radioactive iodine therapy and the role of ChatGPT incorporating chain-of-thought technique: ChatGPT questionnaire
Supplemental material, sj-docx-1-dhj-10.1177_20552076251357468 for Optimizing patient education for radioactive iodine therapy and the role of ChatGPT incorporating chain-of-thought technique: ChatGPT questionnaire by Chao-Wei Tsai, Yi-Jing Lin, Jing-Uei Hou, Shih-Chuan Tsai, Pei-Chun Yeh and Chia-Hung Kao in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251357468 - Supplemental material for Optimizing patient education for radioactive iodine therapy and the role of ChatGPT incorporating chain-of-thought technique: ChatGPT questionnaire
Supplemental material, sj-docx-2-dhj-10.1177_20552076251357468 for Optimizing patient education for radioactive iodine therapy and the role of ChatGPT incorporating chain-of-thought technique: ChatGPT questionnaire by Chao-Wei Tsai, Yi-Jing Lin, Jing-Uei Hou, Shih-Chuan Tsai, Pei-Chun Yeh and Chia-Hung Kao in DIGITAL HEALTH
Footnotes
Acknowledgements
This study was supported in part by China Medical University Hospital (DMR-114-001 and DMR-114-006).
Ethical considerations
This study is not a clinical trial nor a human trial; therefore, an IRB approval is not required. Therefore, the consent statement was not necessary.
Author contributions
Chao-Wei Tsai: Conceptualization, methodology, investigation, formal analysis, visualization, and writing – original draft. Yi-Jing Lin: Investigation and formal analysis. Jing-Uei Hou: Investigation and formal analysis. Shih-Chuan Tsai: Investigation and supervision. Pei-Chun Yeh: Data curation, investigation, formal analysis, validation, and visualization. Chia-Hung Kao: Conceptualization, resources, project administration, supervision, and writing – review & editing.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and material
All available data are presented in the text of the paper.
Guarantor
C-HK.
Supplemental material
Supplemental Material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.