
Abstract
Objective
This study aimed to assessing usability of intelligent guidance chatbots (IGCs) in Chinese hospitals.
Methods
A cross-sectional study based on expert survey was conducted between August to December 2023. The survey assessed the usability of chatbots in 590 Chinese hospitals. One-way ANOVA was used to analyze the impact of the number of functions, human-like characteristics, number of outpatients, and staff size on the usability of the IGCs.
Results
The results indicate that there are 273 (46.27%) hospitals scoring above 45 points. In terms of function development, 581(98.47%) hospitals have set the number of functions between 1 and 5. Besides, 350 hospitals have excellent function implementation, accounting for 59.32%. In terms of the IGC's human-like characteristic, 220 hospitals have both an avatar and a nickname. Results of One-way ANOVA show that, the number of functions(F = 202.667, P < 0.001), human-like characteristics(F = 372.29, P < 0.001), staff size(F = 9.846, P < 0.001), and the number of outpatients(F = 5.709, P = 0.004) have significant impact on the usability of hospital IGCs.
Conclusions
This study found that the differences in the usability of hospital IGCs at various levels of the number of functions, human-like characteristics, number of outpatients, and staff size. These findings provide insights for deploying hospital IGCs and can inform improvements in patient's experience and adoption of chatbots.
Introduction
The practice of medical care exhibits significant variation across different systems and cultural contexts. 1 In China, for example, medical care system that is heavily specialized, patients access medical care services without a referral from a family doctor and do not know what specialty or provider they need to visit before arriving in the hospital's lobby. 1 In China, patients seeking medical care have several options for scheduling appointments with doctors, including in-person visits to hospitals, phone calls, or booking online. As information technology advances, a growing number of Chinese patients are turning to online platforms for appointments. Data from China's National Health Commission indicates that over 50% of appointments in Chinese tertiary hospitals are now made online. 2 With this shift trend, an issue arises that patients frequently make an appointment with incorrect departments or doctors online, necessitating a department or doctor change when they arrive at hospital's lobby. To enhance outpatient service quality and facilitate patient access to medical care, numerous hospitals have initiated the implement of intelligent medical guidance systems. This initiative forms a crucial part of the hospitals’ endeavor towards smart healthcare infrastructure. In this era of smart healthcare services, a range of intelligent applications are bridging the gap between patients and medical staff.3,4
Artificial intelligence (AI)-driven conversational agents, offering medical guidance, are increasingly becoming pivotal in the facilitation and access to medical services.5,6 These medical guidance agents, driven by conversational AI, leverage technologies such as natural language processing and machine learning. Such integration allows these systems to interpret and process human language, thereby enabling effective communication with patients and accurately discerning their needs to execute relevant tasks or provide appropriate responses. 7 In this research, we define these AI-driven conversational agents for medical guidance as intelligent guidance chatbots (IGCs; refer to Figure 1). Patients engage with these IGCs to acquire pre-visit information. During their conversation, patients can articulate symptoms to identify the most suitable medical department and arrange consultations with specialized physicians. These IGCs are instrumental in aiding patients to find the correct medical department or doctors and better comprehend patients’ health conditions prior to their doctor visits. 8 Additionally, these IGCs can address user inquiries regarding medication, diseases, and other medical information, as well as provide guidance on healthcare insurance policies, hospitalization instructions, and more. Moreover, if the hospital offers specialized services, such as scheduling appointments with renowned experts, users can also obtain relevant information by engaging in dialogue with the IGCs.

The interface of a medical guidance chatbot.
Although IGCs are still in the exploratory phase, this technology has improved the accessibility of medical services for patients, reduced their reliance on manual guidance during hospital visits, and optimized the medical care process. 9 IGCs support patients in seeking medical advice anytime and anywhere, 10 which provide real-time feedback, assisting patients in understanding their symptoms, learning about their health conditions, and offering diagnostic suggestions. 11 Such chatbots as virtual conversational agents, mimicking human interaction, and directly provide medical advice to patients in a timely and cost-effective manner. For instance, IGCs facilitate appointment scheduling and online consultations, guide patients in answering a series of questions about their symptoms for disease diagnosis, and help confirm the severity of a disease. 12 In the realm of medical queries, employing IGCs as tools for medical consultation provides relevant information and decision support, streamlining the consultation process by which medical staff consult with patients, and answering patient queries and resolving doubts. 13
Despite these potential benefits, similar to many other mobile health (mHealth) applications, IGCs have not yet been widely adopted by those who could benefit the most from this new technology. 14 Previous work has primarily focused on developing advanced algorithms to enhance the accuracy and effectiveness of the diagnostic capabilities of conversational agents.15,16 However, it is necessary to improve navigational aids, such as intelligent guidance chatbots (IGCs), to streamline information flow and enhance patient outcomes. There has been limited research on the real-world usage of IGCs. 17 Most of the previous studies focus on the use of medical conversational bots in controlled environments and have limited understanding of the deployment of IGCs in various medical institutions, and the potential barriers and challenges associated with patients’ use. 18
Health information technology has been widely applied in the field of medical care, with a rich variety of dimensions and tools available for its evaluation. However, currently, there is no mature evaluation framework to support the assessment of IGCs. Previous evaluations of conversational agents have provided theoretical references, and scholars have proposed numerous methods for assessing medical conversational robots. These include the heuristic evaluation method proposed by Nielsen, 19 the international standard of ISO/IEC 25010 and ISO 9241-11,20–23 and the use of questionnaires like SUS, UEQ, and Chatbottest.13,24 Based on research characteristics, methods such as constructing an evaluation system that involves metrics like system accuracy, similarity to human conversation, user's satisfaction and perceived of usefulness, are used to assess the usability of conversational agents.25–27 While previous research on health information technology evaluation is extensive in terms of dimensions and tools, an assessment framework specifically for IGCs has yet to be proposed.
To fill the aforementioned gap, we investigated the implement of IGCs in 590 tertiary grade-A hospitals in China, which is beneficial for understanding the usability of IGC in real-world settings, as well as the variations in usability under different technological conditions and organizational sizes. This study represents the first large-scale, real-world evaluation to investigate these issues. More specifically, we proposed the evaluation method to measure the usability of IGCs in these 590 tertiary hospitals. In addition, we highlighted the variations in usability under different technological and organizational conditions and the reasons for these variations, offering insights for optimizing medical guidance services and enhancing user experience.
Methods
Data sources and variables
An institution-based cross-sectional quantitative study was conducted at the China Three Gorges University, from August 31/2023 to December 01/2023. This study conducted a cross-sectional survey on whether the IGCs had been implemented by all 1651 tertiary grade-A hospitals in China (In Chinese medical system, hospitals are divided into multiple levels, among which the tertiary grade-A hospitals are the top medical institutions). 28 In this study, we initially compiled a list of 1651 hospitals. Subsequently, our team, comprising the three members who are also authors of this paper, conducted a preliminary assessment by systematically testing the IGCs in these hospitals. Through this process, we identified 603 hospitals that had implemented IGCs. However, during the subsequent data collection phase, we encountered usage issues with 13 of these hospitals, rendering it impossible to retrieve data from their IGCs. Therefore, we excluded these 13 hospitals from our final sample.
It was found that 590 hospitals had implemented intelligent guidance services and had complete data. Therefore, this study took the IGCs of these 590 tertiary grade-A hospitals in China as the research object. The required data was obtained from various sources such as the hospitals’ intelligent guidance systems, official government websites, and relevant news reports about the hospitals, with the data collection period ending on August 31, 2023. We confirm that ethical approval is not needed as we did not conduct research on human subjects. Informed consent was not necessary for all of the analysis data to be publicly available from the website. Thus, the Ethics Committee of China Three Gorges University waived the need for informed consent. The details of the sample and data acquisition were mainly divided into the following two stages.
In the first phase, following Nielsen's research which suggests that five evaluators are optimal for finding usability problem, 29 we invited five experts with interdisciplinary backgrounds in health and information technology who had undergone training in evaluation methods. Two of them hold PhD in medical informatics and are actively involved in research pertaining to medical information management, while three are IT technicians engaged in the development of medical information systems. These experts were tasked with assessing the usability of the IGCs of these hospitals. Each expert was responsible for evaluating approximately 120 IGCs, ensuring a manageable workload. Consequently, each IGC was rated by one expert rater.
Furthermore, to ensure the reliability of the ratings, we conducted a preliminary assessment of inter- and intra-rater agreements. Prior to the formal evaluation, we tested the consistency of the experts using a small sample. Specifically, after providing training to the experts, we randomly selected 20 IGCs from different hospitals. Each expert assessed these 20 IGCs twice, with a one-month interval between assessments. The results of our analysis demonstrated strong inter-rater reliability, with an intraclass correlation coefficient (ICC) of 0.91 (P < 0.001) for the first assessment and 0.94 (P < 0.001) for the second assessment. These findings indicate high consistency among the expert raters in their evaluations. Additionally, the intra-rater reliability was also robust, with ICC coefficients exceeding 0.75 (P < 0.001) for both the first and second assessments, indicating consistency in evaluations over time.
In the second phase, we analyzed the function development and the human-like characteristics of IGCs of these 590 hospitals. In terms of function development, the Chinese content, implementation and the number of functions were analyzed. The content of function denotes the collection of specific functions included in an intelligent guidance chatbot, such as department recommendation, medical queries, or vaccine information. The implementation of function refers to the extent to which a series of functions of the intelligent guidance chatbot can be realized. Whether the chatbot can navigate patients to the appropriate department based on their described symptoms, or answer questions about medications based on user queries. For human-like characteristics, we primarily focused on whether the sample IGCs had a nickname or an avatar. Additionally, we gathered data on the staff size and the number of outpatient of the sample hospitals, which had been published on their official websites. To simplify the data analysis process and enhance the effectiveness and reliability of data analysis, we conducted a group analysis of the following variables. The grouping details are as presented in Table 1. The grouping of the staff size and the number of outpatients are based on the distribution characteristics of the data sample in this study.
Variable definition and grouping.

These 590 hospitals are distributed across 31 provinces and municipalities in China (data from Hong Kong, Macau, and Taiwan not included). The diversity in geographical distribution and technological application among these hospitals makes them well-suited to meet the research needs.
Usability evaluation for IGCs
Usability is a key indicator of the quality of user experience. Usability assessments enable developers of medical information systems to promptly identify issues that arise during human-computer interactions. As a classic method for assessing usability, Nielsen's ten principles evaluate the usability of products or services from the user's perspective. It is important to note that Nielsen's principles represent a general evaluation framework. For this study, we have developed a usability evaluation scale for IGC of hospital based on Nielsen's usability heuristics, adapted to the domain-specific features and interface characteristics of these chatbots, as shown in Table 2. To quantitatively evaluate our study sample, each indicator is described and assigned a value, with the cumulative total of these values across the 10 indicators constituting the measure of usability.
Usability evaluation scale for IGCs.

Statistical analysis methods
To investigate the differences in the usability of intelligent guiding chatbots from technical and organizational aspects, we analyzed the impact of four variables: the number of functions, human-like characteristics, staff size, and the numbers of outpatient. First, we grouped each variable, then used SPSS 25.0 software to conduct tests for normality and homogeneity of variance test. And then, we performed analysis of variance (ANOVA) and used the Least Significant Difference (LSD) method to compare the significance of differences between sample groups. Modern statistical research and practice suggest that factor analysis of variance can be effectively performed when the sample size is sufficient and the data distribution is approximately normal. Therefore, in the process of performing normality tests, we conducted observation analysis by drawing Q-Q plots. Additionally, given the wide applicability of the Levene test, this study used the Levene test to examine the homogeneity of variances of the data, determining whether the variances of each sample group are equal to the variables.
Results
Descriptive statistical analysis
Result of usability evaluation
According to the usability evaluation method for IGCs proposed in this study, the statistical results indicate that there are 273 (46.27%) hospitals scoring above 45 points (50 points is the maximum score), 307 (52.03%) hospitals scoring between 35 to 44 points, and 10 (1.7%) hospitals scoring below 35 points. Among hospitals that have implemented IGCs, the usability evaluation results show that some hospitals have developed their intelligent guidance chatbots well, the majority still need to strengthen their efforts. The horizontal comparison was made of the scores obtained by various hospitals across 10 indicators, as shown in Figure 2.

Comparison of the scores across 10 indicators of usability evaluation.
The results show that in the three indicators of aesthetics and minimalist design (589/590, number of hospitals with a score of 5/total sample size), flexibility and efficiency of use (570/590), and recognition rather than recall (584/590), the majority of these hospitals’ IGCs scored 5 points. Regarding the two indicators of consistency and standards (474/590) and help users recognize, diagnose, and recover from errors (447/590), about 80% of hospitals have achieved good performance. For the three indicators of visibility of system status (350/590), user control and freedom (377/590), and error prevention (387/590), about 60% of hospitals have achieved good performance. In addition, for indicators consistency and standards (293/590), help and documentation (232/590), around 50% of the hospitals’ chatbots have suboptimal scores.
Results of function development and human-like characteristics
Function development and human-like characteristics technically reflect the implement status of IGCs in hospitals. Sample analysis results indicate that the main functions of IGCs are appointment for hospital visits, medical enquiries, medical insurance guidelines, medical test result inquiries, inpatient guidelines, and vaccine searches. However, many hospitals have devised many functions in IGCs, these functions may not be implemented effectively. A statistical analysis was conducted on the number of functions and the implementation status of these functions of the 590 hospitals’ IGCs, with results presented in Figure 3. The implementation status of the IGCs’ functions was divided into five levels; the number of functions was counted based on what is displayed on the interface of the hospital's IGC. Overall, there are 76 hospitals with one function setting, 78 hospitals with two function settings, 30 hospitals with three function settings, 103 hospitals with four function settings, and 57 hospitals with five function settings, 98.47% (581/590) of hospitals have set the number of functions between 1 and 5. Besides, 350 hospitals have excellent function implementation, accounting for 59.32% (350/590).

Results of the implementation status and number of functions.
In terms of the IGC's human-like characteristic, 220 hospitals have both an avatar and a nickname, 103 have either an avatar or a nickname, and 267 have neither. We found that the more detailed the human-like characteristics of IGC, such as having a nickname or an avatar, the more advanced the system development tends to be. A well-crafted human-like characteristics of IGC enhance the user experience, making human-chatbot interaction more natural and appealing. Furthermore, it was found that nicknames often have characteristics like homogeneity, cuteness, and user-friendliness, with examples like ‘Xiao Mi’, ‘Xiao Rui’, ‘Xiao Die’, ‘Doctor Xiao Ci’, etc. The avatar, on the other hand, are mostly represented by cartoon robots, cartoon nurses, cartoon doctors, and other cartoon figures. The following are the nicknames and avatars of some of the IGCs, as shown in Figure 4.

Nicknames and avatars of some of the IGCs.
Results of number of outpatients and staff size of hospitals
There were approximately 8.04 billion outpatient visits nationwide in China, with around 3.88 billion of these occurring in hospitals across various regions. The statistics indicate that in the most recent year, the total number of outpatient visits in these 590 hospitals amounted to about 705 million. On average, these hospitals had about 1.1949 million outpatient visits per year, and the average staff size was approximately 2126 employees. Overall, the vast majority of hospitals had a large number of outpatient visits, resulting in high demand for outpatient consultation and a heavy workload of outpatient tasks.
Results of analysis of variance (ANOVA)
Normality test
Q-Q plots were generated using SPSS 25.0 to illustrate the usability of IGCs at various levels of four variables: the number of functions, human-like characteristics, staff size, and number of outpatients. The results are shown in Appendix 1 to 4. In these plots, the diagonal line represents the Q-Q line that would be expected if the usability of IGCs followed a normal distribution, and the blue dots represent the actual scatter plot of the usability of IGCs. From these graphs, it can be observed that the usability of IGCs with these four variables at different levels is concentrated near the normal Q-Q line, indicating that overall, they approximately follow a normal distribution.
Homogeneity of variance test
Before conducting a one-way analysis of variance (ANOVA), a test for homogeneity of variance was performed on the data. This test was applied to the four variables: number of functions, human-like characteristics, staff size, and number of outpatients. The test results, as shown in Table 3, indicate that all four variables had significance results greater than 0.05, demonstrating homogeneity of variances. Combined with the results of the normality test, these four variables meet the prerequisite conditions for conducting an ANOVA.
Levene test of homogeneity of variance.

Results of one-way analysis of variance
A one-way ANOVA was conducted on the four variables respectively, resulting in descriptions of samples with different distributions (see Table 4) and the results of ANOVA (see Table 5). Take the variable of number of functions as an example, it can be observed that the mean value of usability for Group 1 is 42.29, while for Group 2 it is 46.89, indicating a significant difference between the two groups. Further, as shown in Table 5, the P-value of the number of functions is less than the significance level α=0.05, and the F-value is also relatively high. This suggests that there is a significant difference in the overall mean values of the usability at different levels of the number of functions. The results of Tables 4 and 5 show that the four variables both have significant impact on the usability of IGCs.
Sample descriptions for different distributions of the four variables.

Results of the variance analysis for different distributions of the four variables.
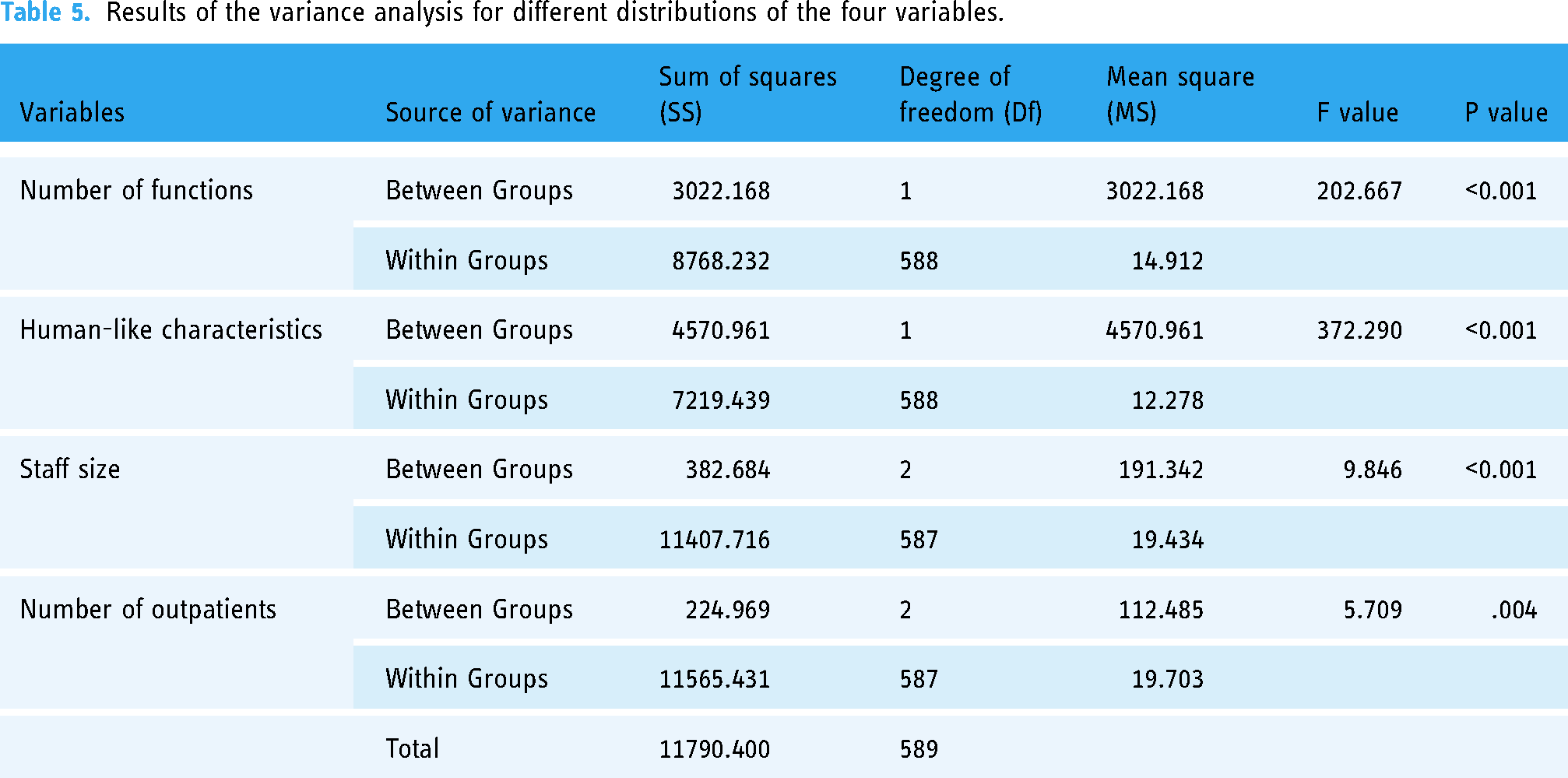
Moreover, given the significant impact of staff size on the usability of IGCs, it is necessary to perform post-hoc analyses to identify which specific groups exhibit significant differences. For this purpose, this paper employs the LSD test for post-hoc multiple comparison analysis. The test results, as shown in Table 6, indicate that there are significant differences in the impact on thstem and the real e usability of IGCs between Group 1 (small hospitals) and both Group 2 (medium-sized hospitals) and Group 3 (large hospitals). However, there is no significant difference between Group 2 and Group 3. Besides, we conducted the same test for the variable of the number of outpatients, as shown in Table 6. The results indicate significant differences in the impact on the usability of IGCs between Group 1 (<50) and both Group 2 (50∼150) and Group 3 (>150), while no significant difference exists between Group 2 and 3.
Multiple comparison results for different staff size distributions.

aP < 0.05.
Discussion
Principal findings
Nearly half of the sample hospitals have suboptimal scores for five indicators of IGC's usability
Analysis of the usability of IGCs in 590 hospitals shows that many hospitals have suboptimal performance in terms of visibility of system status, user control and freedom, error prevention, match between the system and the real world, and help and documentation. Approximately 40% of the hospitals’ chatbots exhibited average performance in the indicators of visibility of system status, user control and freedom, and error prevention. These indicators reflect issues in the system design of the IGCs. The average performance in visibility of system status can be attributed to inadequate interface interaction design and a lack of effective feedback mechanisms, making it difficult for users to perceive the current system status of the chatbot. The lower scores in user control and freedom are primarily due to a lack of flexible navigation options in the system, such as ‘undo’, ‘redo’, or ‘back’ steps, which can make users feel constrained during operation and unable to freely explore or correct errors. The lower scores in error prevention involve not fully considering possible user errors or lacking effective mechanisms to prevent errors.
Therefore, in the system design of IGCs, firstly, interfaces of chatbots should be easy to understand and use, offering clear status indicators such as progress bars and confirmation messages to enhance the visibility of the system's status. Secondly, it is crucial to ensure that users have sufficient control during their interactions with the chatbots, such as allowing them to interrupt operations at any time or providing a variety of choices for user-driven decision-making. Thirdly, error-tolerant interaction processes need to be designed, offering clear error messages and quick recovery options, enabling users to easily correct mistakes and return to the correct path.
Additionally, for the indicators of match between the system and the real world, and help and documentation, around 50% of the hospitals’ chatbots have suboptimal scores. The issue arises from the chatbots employing language that is too technical or specialized, or their manner of conversation not matching the linguistic habits and cultural background of the target user group, resulting in difficulties for users in understanding and communication. The low scores for the help and documentation are due to insufficient help resources, difficulty in accessing or using the help function, and delay in updating help documentation.
Studies have pointed out that there are differences in the reading level of different users,30,31 and it is recommended to use simpler words, shorter sentences, and remove complex medical terms in patient educational materials. 32 Therefore, in order to improve the efficiency of human-computer interaction, in the interaction interface with the chatbots, commands should be consistent with user language habits, avoiding technical jargon or complex commands. The help and documentation indicator is often overlooked. However, to enhance user understanding and empower users with self-service capabilities, it is crucial to strengthen the development of help systems and provide real-time, contextually relevant help information.
Function development significantly affects the usability of IGCs
In terms of function development, survey results indicate that the primary functions of IGCs in most hospital include department registration, medical inquiries, medical insurance guides, test result inquiries, inpatient guidelines, and vaccine searches. More than half of the hospitals have set 1 or 2 functions, and more than half have IGCs whose functions are well implemented. However, many hospitals have developed some functions, but these functions didn’t really work out. Looking at the current well-established IGCs, such as those at Union Hospital, Tongji Medical College, Huazhong University of Science and Technology, or Shanghai Ninth People's Hospital, their advantages primarily manifest in the mature development of various functions, all capable of providing medical guidance to assist patients in problem-solving or offering help. For example, if a patient's primary task is to find a specific department in hospital, the chatbot should offer a straightforward and direct appointment function for department registration. To enhance the function development level of IGCs and meet patients’ needs, it is crucial to conduct a detailed assessment of existing functions to identify issues and shortcomings, and to establish effective user feedback mechanisms to collect user opinions promptly. Furthermore, variance analysis results show that the number of functions significantly impacts the usability of IGCs. Although having a greater number of functions is not always better, the number setting of functions reflect the importance hospitals place on implementing IGCs.
Optimizing human-like characteristic design is beneficial for enhancing the usability of IGCs
In the aspect of human-like characteristic, among the 590 hospitals’ IGCs, nearly half lack both nickname and avatar. Even for those that nickname or avatar are set, there is a high degree of homogeneity in the nicknames and avatars of chatbots across different hospitals. Moreover, variance analysis results show that human-like characteristic significantly impacts the usability of IGCs. The presentation of human-like characteristic is conducive to shortening the psychological distance with patients and increasing patients’ trust and favorability in the hospital. 33 To highlight the human-like characteristics of chatbots, design elements could incorporate the hospital's history and the cultural features of its location. Alternatively, hospital staff, patients, and their families can be invited to participate in the design process of the chatbot's nickname and avatar through online surveys or social media interactions. Such user-involved design not only enhances the acceptance of the chatbots but also makes them more aligned with users’ preferences and needs.
Hospitals of vary sizes have different strategies in the implement of IGCs
From the perspective of hospital's staff size, variance analysis results demonstrate that staff size has a significant impact on the usability of IGCs. There are notable differences in the usability of IGCs between small hospitals and medium-to-large-sized hospitals. Overall, hospitals with larger staff sizes tend to have higher usability scores for their chatbots. This indicates that deployment strategies for chatbots should differ according to the scale of the hospital. Large hospitals, with more resources, can invest in more advanced technologies and higher quality IGCs. For smaller hospitals, where resources may be more limited, the design of chatbot systems should avoid overly complex functions. Instead, the focus should be on core functionalities that enhance efficiency and patient satisfaction, such as basic medical guidance and information inquiry, ensuring that the chatbot's functions match the hospital's scale and needs.
The larger the amount of outpatient consultation the more necessary it is to enhancing the implement of IGCs
Regarding the number of outpatients, many hospitals in various regions have large numbers of outpatients, facing significant pressure in medical guidance. The variance analysis from this study shows that the number of outpatients significantly influences the usability of IGCs. There is a significant difference in usability between hospitals with fewer patients compared to those with more. Overall, hospitals with more outpatients tend to have higher usability scores for their chatbots. In hospitals with more outpatients, deploying IGCs is crucial to alleviate the pressure on medical consultation staff and improve service efficiency. On the one hand, technology is key to the effective functioning of chatbot systems, and continuous technological improvements and upgrades are essential to optimize outpatient medical consultation process and effectively handle the complex outpatient environment. On the other hand, increasing the acceptance of chatbots among hospital staff and patients is vital, which can be achieved through training or promotion, thereby enhancing users’ confidence and ability to use chatbots.
Limitations
This study primarily explored the application and deployment of intelligent guidance chatbots in hospitals from the perspective of usability. In addition to the analysis of function development, human-like characteristics, hospital staff size, and the number of outpatients, which mainly focuses on the technical and organizational aspects, other factors such as economic conditions, internet development in a region, and even hospitals’ attitudes towards technology can also influence their decision-making and deployment of IGCs in hospitals. For instance, medical organizations in economically prosperous areas may have more resources and funds to invest in new technologies. The economic environment of a hospital's location influences its decision-making regarding intelligent guidance chatbot adoption. Furthermore, in regions with well-developed internet infrastructures, high-speed and stable network connections provide the necessary foundation for the real-time operation and data exchange of IGCs. Therefore, in future research, we aim to explore the adoption behavior of hospitals towards IGCs from multiple perspectives. Besides, in terms of research methodology, we consider the use of regression analysis methods in the future to more comprehensively analyze the influencing factors of the usability of IGCs.
Conclusions
In China, an increasing number of outpatients are opting for online appointment scheduling, and AI-driven intelligent guidance chatbots are being adopted by more and more hospitals for outpatient appointment services. Previous research on intelligent guidance chatbots is not extensive. This paper analyzed the usability of IGCs in 590 tertiary hospitals in China. It is the first study to use a large-scale heterogeneous dataset to investigate the real-world usage of IGCs in hospitals. We assessed the usability of IGCs, function development, human-like characteristics of these 590 hospitals’ chatbots. Using variance analysis, we explored the differences in the usability of hospital IGCs at various levels of the number of functions, human-like characteristics, number of outpatients, and staff size. These findings provide insights for deploying hospital IGCs and can inform improvements in patient's experience and adoption of chatbots.
This study makes three significant contributions. Firstly, we provide a detailed analysis of the use of AI-driven IGCs in Chinese hospitals, which is a topic still underexplored in the health informatics community. Secondly, previous studies often focused on a single case, such as evaluating a specific chatbot or other health information technology. Building on this theoretical foundation, we proposed a method for assessing the usability of IGCs, aimed at evaluating the development status of hospital IGCs. Thirdly, We analyzed how the usability of IGCs varies at different levels of function development, human-like characteristics, staff size, and the number of outpatients. We identify challenges and barriers that hinder the adoption and usage of these chatbots and provide references for optimizing hospital outpatient appointment services, enhancing patient's experience with using chatbots, and alleviating pressure in outpatient triage.
Footnotes
Acknowledgements
The authors extend their gratitude to Lihua Chen, Siying He, and Yaping Ouyang for their invaluable assistance in data collection. We also express our sincere thanks to all the participants in this study.
Contributorship
YY, SL, and PL researched the literature and conceived the study. YY, SL LL and YT were involved in data analysis. YY, PL, and ZH wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Data availability
The datasets used and analyzed during the study are available from the corresponding author on reasonable request.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
We confirm that such approval is not needed as we did not conduct research on human subjects. Informed consent was not necessary for all of the analysis data to be publicly available from the website.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Guarantor
YY and PL.