
Abstract
Background
Vaginal birth after cesarean (VBAC) is generally regarded as a safe and viable birthing option for most women with prior cesarean delivery. Nonetheless, concerns about heightened risks of adverse maternal and perinatal outcomes have often dissuaded women from considering VBAC. This study aimed to assess the performance of an artificial intelligence (AI)-powered VBAC prediction system integrated into a decision-aid birth choice platform for shared decision-making (SDM).
Materials and Methods
Employing a retrospective design, we collected medical records from a regional hospital in northern Taiwan from January 2019 to May 2023. To explore a suitable model for tabular data, we compared two prevailing modeling approaches: tree-based models and logistic regression models. We subjected the tree-based algorithm, CatBoost, to binary classification.
Results
Forty pregnant women with 347 records were included. The CatBoost model demonstrated a robust performance, boasting an accuracy rate of 0.91 (95% confidence interval (CI): 0.86–0.94) and an area under the curve of 0.89 (95% CI: 0.86–0.93), surpassing both regression models and other boosting techniques. CatBoost captured the data characteristics on the significant impact of gravidity and the positive influence of previous vaginal birth, reinforcing established clinical guidelines, as substantiated by the SHapley Additive exPlanations analysis.
Conclusion
Using AI techniques offers a more accurate assessment of VBAC risks, boosting women’s confidence in selecting VBAC as a viable birthing option. The seamless integration of AI prediction systems with SDM platforms holds a promising potential for enhancing the effectiveness of clinical applications in the domain of women's healthcare.
Keywords
Introduction
Vaginal birth after cesarean (VBAC) is a safe and viable birthing option for the majority of women following a previous caesarean delivery (CD). 1 This choice not only offers potential benefits for the women, but also plays a crucial role in reducing unnecessary elective repeat cesarean delivery (ERCD), which is associated with an increased risk of adverse maternal and perinatal mortality and complications.2,3 Nevertheless, the decision-making processes regarding VBAC are complex and multifaceted, necessitating a careful consideration of various medical, obstetric, and individual factors.4,5
Artificial intelligence (AI) has emerged as a powerful tool in healthcare, offering the potential to support medical professionals and patients in making informed decisions.4,5 Drawing on previous research findings,6–9 we created an innovative web-based platform serving as the basis for a decision-aid (DA) system for birth choices aimed at fostering shared decision-making (SDM). 10 Through this DA platform, we strive to enhance understanding, boost confidence, and improve communication between medical professionals and pregnant women. The DA platform could be easily operated for pregnant women and healthcare professionals through mobile devices, such as smartphones, tablets, and computers. 10 The DA platform is equipped with essential features, including a video to introduce SDM, an overview of the functions and features of the birth DA, and comprehensive information on the risks and benefits of VBAC and ERCD. 10 Most importantly, the platform incorporates an AI calculator to empower SDM between healthcare providers and pregnant women by providing personalized, data-driven insights and risk assessments for VBAC. 10
Although several VBAC prediction models have been developed, their generalizability and applicability remain unclear4,5; thus, high-quality internal and external validation studies are needed. Most importantly, none of these VBAC prediction models intergrade the AI technique into the DA platform. Thus, this study aims to evaluate the performance of an AI-powered VBAC prediction system with a DA birth choice platform for SDM.
Materials and methods
Study design
We conducted a retrospective study with a quantitative and descriptive design. The DA platform was implemented on a cloud server with a responsive web design (RWD) to ensure the stability and reliability of the system.11,12 This platform consisted of four key components: an interactive web service (IWS) 13 for SDM; a responsive web design (RWD) for data collection and visualization; a cloud-based VBAC database for collaborative use among multiple users; and a VBAC prediction system enhanced with AI techniques (Figure 1). The VBAC prediction system leverages cloud-based AI to compute and employ a predictive model, which assesses the likelihood of a successful vaginal birth during pregnancy.
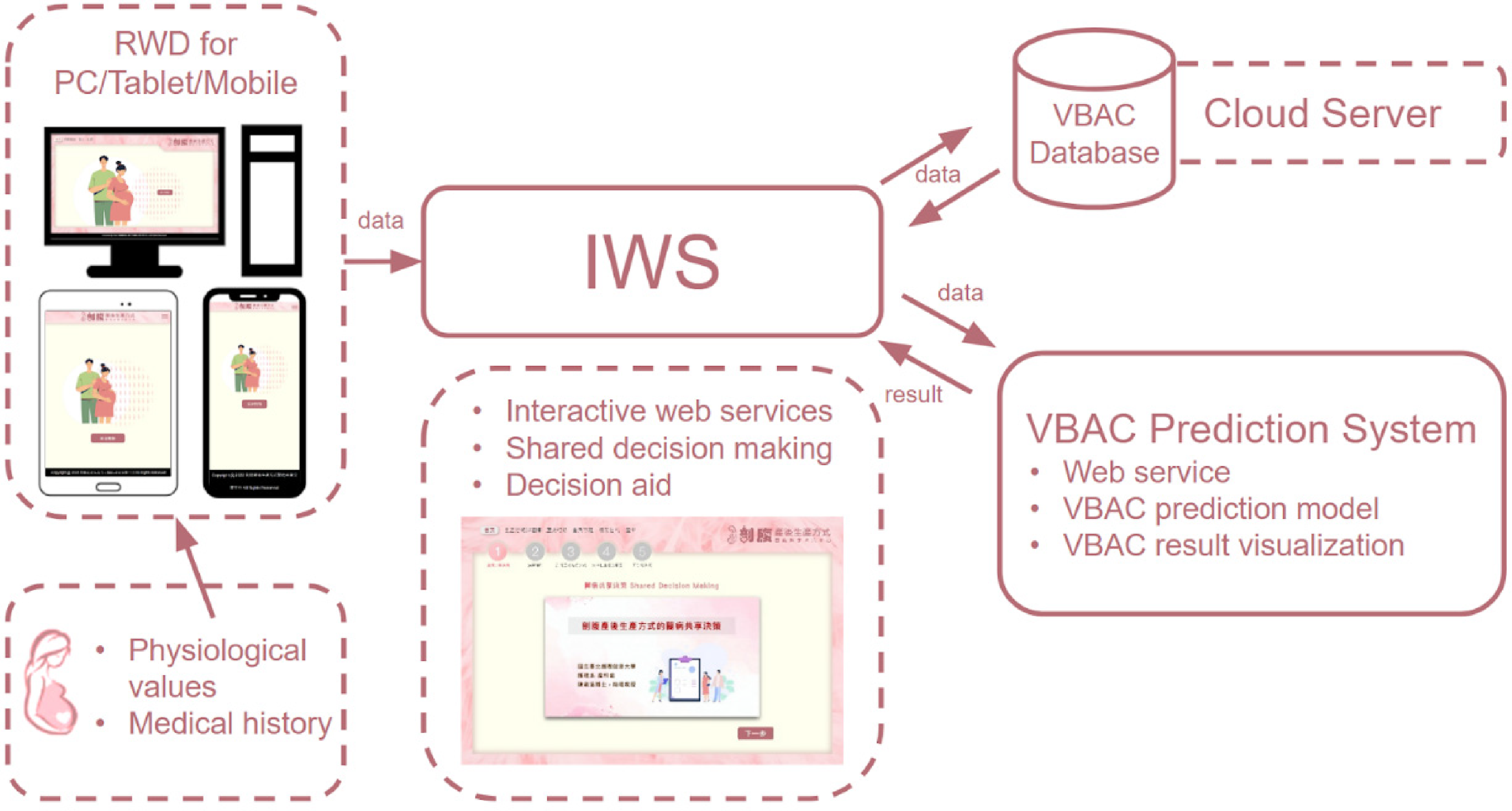
Web-based decision-aid platform comprising four components: The
The interactive web service (IWS) was tailored for AI-powered predictions, utilizing medical record data and a machine learning model, 14 notably CatBoost, with finely tuned hyperparameters. Its primary function is to anticipate the probability of a successful VBAC and identify potential birth-related risks for pregnant women. The seamless integration of AI and web services has empowered healthcare professionals to provide informed decision-making support to pregnant women (Figure 2).

AI prediction with medical record form and ML model.
Data sources and collection
Prior to the commencement of the study, ethical approval was obtained from the Institutional Review Board of Fu Jen Catholic University (No. C111042). To conduct the training and testing verification of the AI model, this study collected and used retrospective medical record data from the regional hospital in northern Taiwan between Jan 2019 and May 2023. A total of 44 pregnant with 386 record data met the study criteria. The inclusion criteria were (1) pregnant women, (2) aged between 20 and 45 years, and (3) had a previous CD. The exclusion criteria were (1) multiple pregnancies and (2) previous classical CD or myomectomy surgery. These criteria were considered based on their potential impact on the outcomes of the study. After excluding cases with major fetal anomalies, intrauterine fetal demise, gestational weeks less than 12, and those with missing data, our final analysis included a total of 40 pregnant women with 347 recorded data points constituting 89.89% of the originally considered dataset (Figure 3). Among the trial of labor after cesarean (TOLAC) attempts, 117 (33.72%) led to a successful vaginal birth referred to as the ‘VBAC Success’ group, while 230 (66.28%) resulted in a failed TOLAC attempt designated as the ‘VBAC Failure’ group. The clinical information with statistically significant differences between these two groups can be found in Table 1. The variables in this study can be categorized into two main types: continuous variables and categorical variables. Continuous variables encompass maternal age, gestational week, and BMI, while categorical variables encompass gravidity, previous vaginal birth, prolonged labor, gestational diabetes, and chronic hypertension.
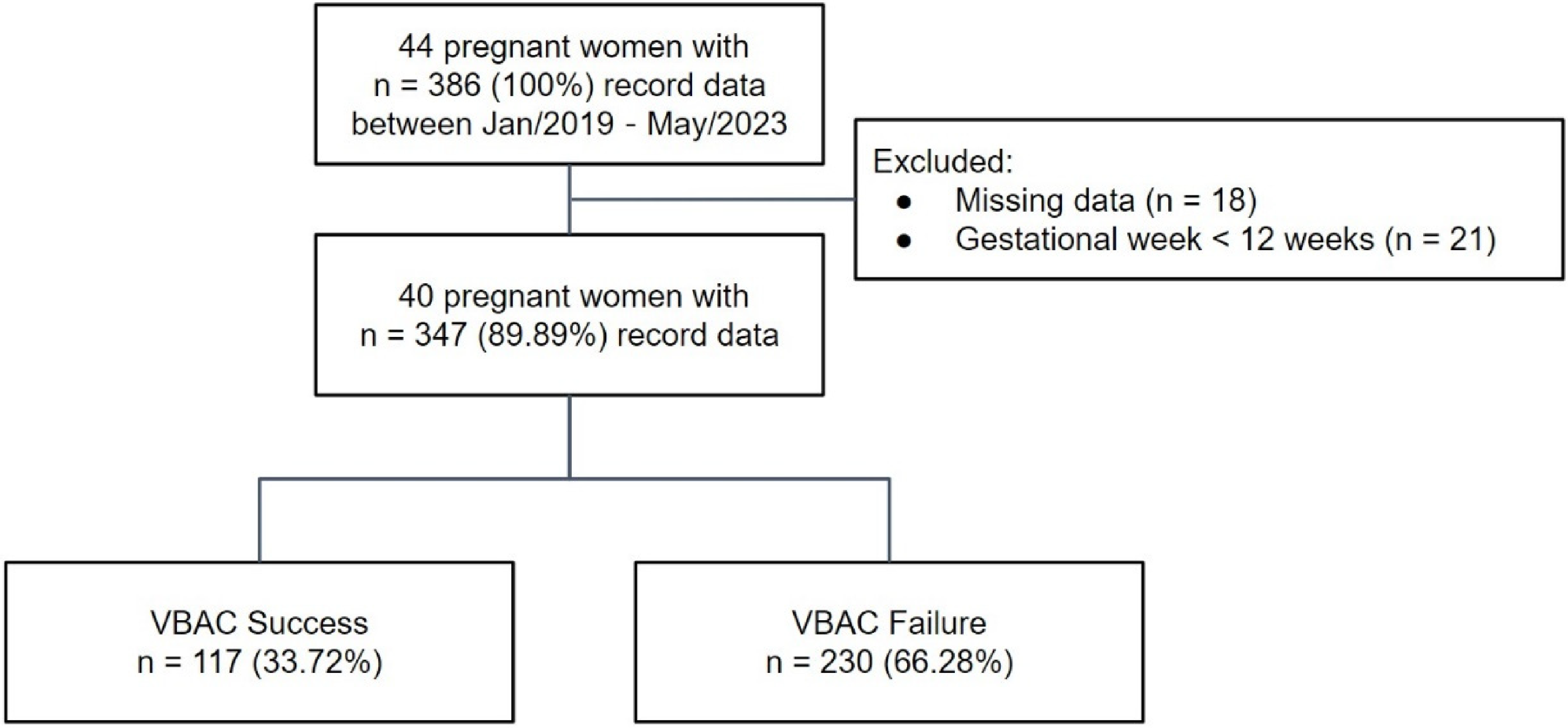
Recruitment flow chart for the AI model.
Clinical information with statistic difference between VBAC success and failure group.

Continuous variables are expressed as mean ± standard deviation and range, including maternal age, gestational week, and BMI.
Categorical variables are presented as number n (%), including gravidity, previous vaginal birth, prolonged labor, pregestational diabetes, and chronic hypertension.
CI: confidence interval; VBAC: vaginal birth after cesarean.
Development of machine learning models with hyperparameter design and architectural comparison
The model's input comprised seven variables, as referenced in a previous study. 30 These variables included maternal age, gravidity, BMI, previous vaginal birth, prolonged labor, gestational diabetes, and chronic hypertension. Furthermore, recognizing that the BMI naturally increases as the gestational weeks progress, a necessary adjustment was made to account for this variable. This adjustment involved dividing the BMI by the gestational week, ensuring that this variable did not disproportionately influence the model predictions across different gestational weeks and periods.
This research primarily focused on developing and refining machine learning models designed to predict outcomes using tabular data sources, as indicated in previous studies.15,16 The dataset analyzed displayed a tabular structure and had previously shown enhancements when utilized with tree-based models well-known for their ability to effectively classify data with diverse features. Drawing upon insights from prior studies, 17 we incorporated the boosting technique along with the GridSearch method. This strategic approach allowed us to finely tune the hyperparameters, ultimately optimizing the performance. As an example, we made adjustments to various hyperparameters, including depth, (e.g., CatBoost with choices [6, 8, 10]), learning rate (options: [0.01, 0.05, 0.1]), l2_leaf_reg (values: [2, 3, 4]), iterations (alternatives: [500, 1000]), and loss function (selections: [‘Logloss’]). This approach enabled us to incorporate non-linear parameter adjustments, which could potentially result in improved training outcomes. Additionally, the attributes within the tabular dataset used in this study were recognized for their relatively distinct and independent characteristics. Consequently, we conducted a comparative analysis between two widely adopted model categories: tree-based models and logistic regression. Specifically, we evaluated the performance of six distinct algorithms, namely, logistic regression and five tree-based models, that is, decision tree, random forest, 18 eXtreme gradient boosting (XGBoost), light gradient boosting machine (LightGBM), 19 and CatBoost, 20 employing them for the binary classification tasks. 21
Evaluation of model performance and interpretation with SHapley Additive exPlanations-based feature selection
In this phase, we assessed the performance of the VBAC models utilizing a range of machine learning algorithms, including logistic regression, decision tree, random forest, XGBoost, LightGBM, and CatBoost. We relied on two primary metrics, namely, accuracy and the area under the curve (AUC), as the key indicators to gauge the effectiveness of our optimized models. To enhance the interpretability of these models, we employed SHapley Additive exPlanations (SHAP)-based feature selection. This method was instrumental in identifying the most influential features contributing to the models’ predictions. 22 The SHAP values offer a unified measure of feature importance that can be consistently applied across different model types. 23 The feature selection procedure was carried out using the SHAP library in Python. To comprehensively evaluate the models’ performance, we employed a range of metrics, including accuracy, sensitivity, specificity, precision, positive likelihood ratio (LR + ), negative likelihood ratio (LR-), and AUC. 24 To assess the robustness and generalizability of the models, we conducted a bootstrapping testing procedure involving 1000 resamples of the testing dataset. This process enabled us to estimate the confidence intervals (CIs) related to the accuracy and AUC metrics, providing insights into the models’ stability and their ability to perform effectively on new and unseen data.
Statistical analysis
Statistical analysis was conducted using SciPy modules version 1.11.2 in Python. To establish statistical significance, a significance level of p < 0.05 was applied for the two-tailed test. The evaluation of continuous variables, such as maternal age, gravidity, and BMI, was carried out using the Wilcoxon rank-sum test. Nominal categorical variables like previous vaginal birth, prolonged labor, pregestational diabetes, and chronic hypertension were assessed using the Fisher's exact test, and two-sided p-values were computed.
Results
Performance validation comparison between ML models
A total of 40 subjects with 347 data were included in the testing cohort (40, 89.89%). Seven variables were utilized as the input factors for the six ML methods of logistic regression, random forest, XGBoost, LightGBM, decision tree, and CatBoost. In Table 2, the CatBoost model demonstrated the utmost efficacy within the experimental framework, yielding a commendable accuracy of 0.91 (95% CIs: 0.86–0.94). In contrast, the alternative models of logistic regression, random forest, XGBoost, LightGBM, and decision tree achieved comparatively modest accuracy values of 0.69 (95% CIs: 0.65–0.74), 0.88 (95% CIs: 0.85–0.92), 0.82 (95% CIs: 0.78–0.85), 0.90 (95% CIs: 0.87–0.93), and 0.83 (95% CIs: 0.79–0.86), respectively, as discerned from the outcomes obtained within the testing cohort of the study and the AUC values of 0.57 (95% CIs: 0.54–0.6), 0.85 (95% CIs: 0.81–0.89), 0.80 (95% CIs: 0.76–0.85), 0.89 (95% CIs: 0.85–0.93), and 0.79 (95% CIs: 0.74–0.83). Confusion matrices for each ML model and ROC curves for the performance evaluation of each ML model were plotted in Figures 4 and 5, respectively. Furthermore, the sensitivity, specificity, precision, LR+ and LR− were calculated to further evaluate the performance of the six models. The results are also presented in Table 2. Despite not achieving the highest sensitivity among the various models examined, it is noteworthy that the CatBoost model's enhanced performance can be attributed to the intricate interplay of hyperparameters associated with the boosting technique, a phenomenon similarly observed in the case of XGBoost and LightGBM. To encapsulate the findings, when evaluating pivotal metrics, such as accuracy and AUC, the CatBoost model emerged as the discerning choice for the incorporation into our innovative decision-aid platform as the designated AI predictive model.

Confusion matrix for every ML model, including logistic regression, random forest, XGBoost, LightGBM, decision tree, and CatBoost. 0: VBAC failure group. 1: VBAC success group.

ROC curve for the performance evaluation at every ML model, including logistic regression, random forest, XGBoost, LightGBM, decision tree, and CatBoost.
Performance comparison for the VBAC classification based on different ML models. The ML models were six kinds of architecture, namely, logistic regression, random forest, XGBoost, LightGBM, decision tree, and CatBoost.
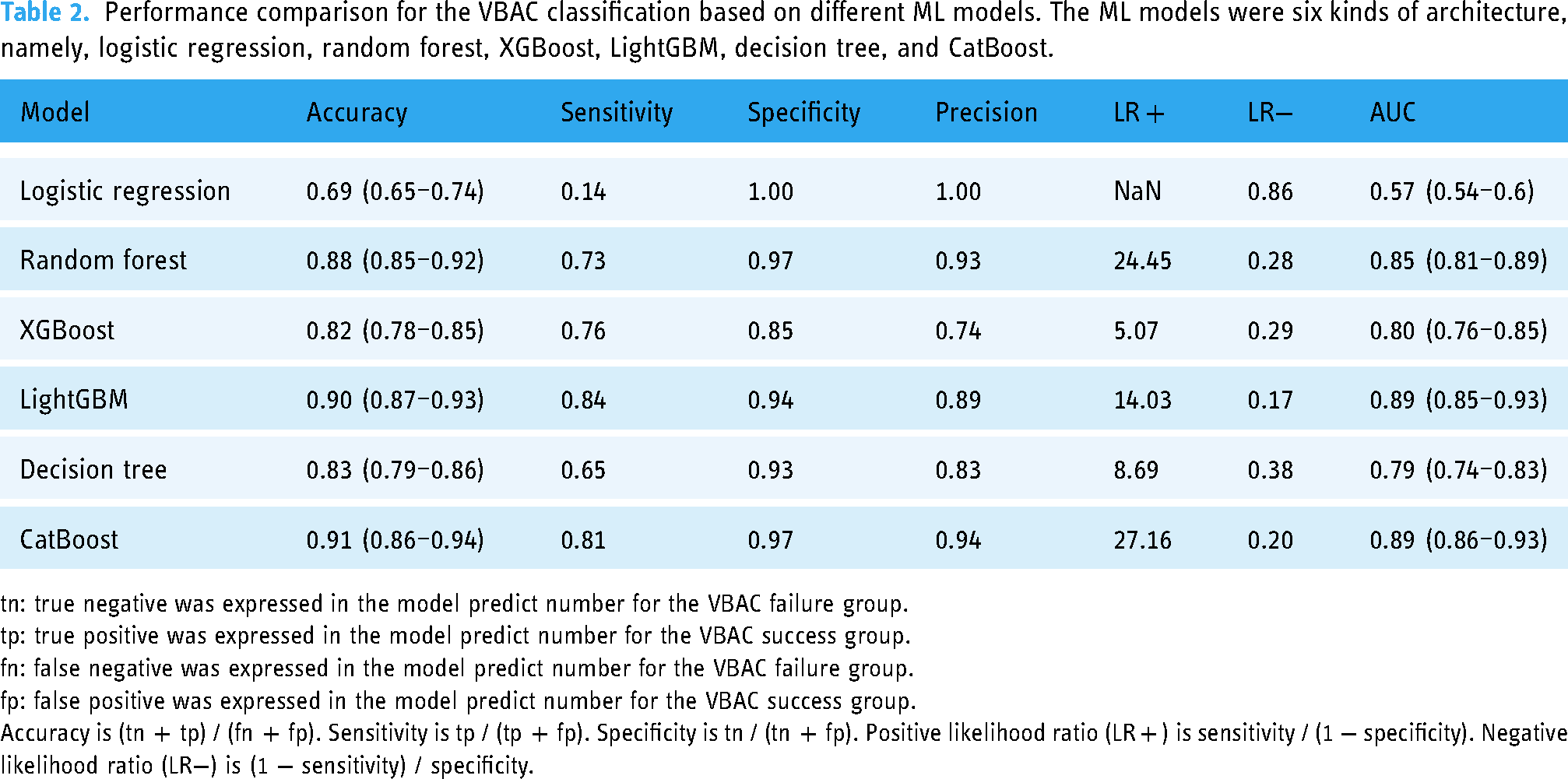
tn: true negative was expressed in the model predict number for the VBAC failure group.
tp: true positive was expressed in the model predict number for the VBAC success group.
fn: false negative was expressed in the model predict number for the VBAC failure group.
fp: false positive was expressed in the model predict number for the VBAC success group.
Accuracy is (tn + tp) / (fn + fp). Sensitivity is tp / (tp + fp). Specificity is tn / (tn + fp). Positive likelihood ratio (LR + ) is sensitivity / (1 − specificity). Negative likelihood ratio (LR−) is (1 − sensitivity) / specificity.
Model explainability comparison for each ML model
In this study, we aimed to provide a deeper understanding of the ML models used for predicting mortality by interpreting its black box using SHAP values. The SHAP summary plot ranks feature importance and is presented in Figure 6. On the right side of Figure 6, the top four most significant variables contributing to the model were identified as maternal age, gravidity, BMI, and previous virginal birth in random forest, XGBoost, LightGBM, and CatBoost. Additionally, gravidity emerged as the most significant variable in CatBoost, while maternal age held this distinction in random forest, XGBoost, and LightGBM. Notably, features like gestational diabetes were among the top four most significant variables in the logistic regression and decision tree models. As depicted on the left side of Figure 6, we present more detailed results regarding the top four most important clinical features categorized based on their positive and negative impact factors, which influence the predictive output of the ML models. Previous vaginal birth was the most positively significant variable in random forest, LightGBM, decision tree, and CatBoost. Conversely, gravidity had the most negative impact on logistic regression, while maternal age held the most positive significance in XGBoost.

Feature importance based on SHAP for every ML model, including logistic regression, random forest, XGBoost, LightGBM, decision tree, and CatBoost.
Discussion
We developed an AI predictive model for VBAC, which was integrated into an innovative DA birth choice platform for SDM. 10 In contrast to conventional DA like booklets, video CDs, pamphlets, or computer-based tools commonly used to aid pregnant women in making birth choices after previous cesarean delivery,25–29 this platform integrates an AI predictive model. Through this model, women can input seven crucial factors—maternal age, gravidity, BMI, gestational week, history of previous vaginal birth, prolonged labor, gestational diabetes, and pregnancy-induced hypertension—to promptly ascertain their likelihood of achieving a successful VBAC. This groundbreaking advancement proves particularly advantageous in regions where hospital access is limited. While prior research predominantly focused on diverse variables concerning pregnant women and fetuses to validate models, often relying on datasets from later gestational stages (i.e., gestational week > 27 weeks), our model exhibited robust performance and strong validity across a broad spectrum of gestational weeks ranging from 12 to 40 weeks.
Addressing the common challenge of limited generalizability in AI-based healthcare applications, often stemming from inadequate training procedures and evaluation protocols, 30 we adopted a comprehensive approach. Our study distinguishes itself by achieving a comparable predictive performance with only seven parameters, a significant reduction compared to that in existing research.4,5 Our strategy consisted of a two-fold approach: during the training phase, we employed boosting techniques and applied bootstrapping for rigorous testing.31,32 Our results demonstrated that when analyzing tabular data, the tree-based models consistently outperformed the regression models. We assessed six different models and fine-tuned their hyperparameters through the boosting technique, leading us to identify CatBoost as the top-performing model in alignment with the findings of the study by Li et al. 19
We incorporated six variables (i.e., maternal age, pregnancy weight, height, arrest disorder, previous vaginal birth, and chronic hypertension) drawn from prior research by Grobman et al. 33 To enhance our model's predictive capability, we introduced two critical factors: gravidity and gestational diabetic status. Nonetheless, the influence of obstetric disease, such as chronic hypertension and gestational diabetes, remains intricate. While the incidence of obstetric disease in VBAC failed cases appears higher compared to VBAC success cases, 34 another study suggests that within the obstetric disease subgroup, both incidences of the chronic hypertension and pregestational diabetes of cases favor VBAC success over VBAC failed. 35 Moreover, both studies fail to establish significant statistical differences in obstetric disease. Recent efforts have sought to consolidate critical parameters through review and synthesis of studies. Surprisingly, amidst these endeavors, the significance of hypertension within obstetric disease appears less pronounced and evident. 4 To ensure the effective utilization of these influencing factors, our study employed a machine learning methodology rather than conventional statistical approaches, such as linear regression. Our findings indeed demonstrate that this addition significantly improved the accuracy of our model. Unlike previous studies that mainly focused on data beyond 37 weeks of gestation, 33 our research not only adjusted for BMI, but also extended its applicability to as early as 12 weeks into term gestation. Our substantial improvement in predictive performance was a result of transitioning from conventional regression to tree-based models. These tree-based models effectively managed both categorical and continuous variables, capturing intricate relationships. Consequently, our model exhibited a notable performance boost, achieving an AUC of 0.89 (95% CI: 0.86–0.93) and surpassing the AUC of 0.75 (95% CI: 0.74–0.77) reported in previous studies. 33 This advancement underscores the potential significance of our research in the realm of tabular data analysis for pregnancy-related outcomes.
The SHAP analysis provided valuable insights into the key factors driving prediction outcomes, making it a valuable tool for interpreting machine learning models in the medical field. 22 In this study, we demonstrated the efficacy of the SHAP method in interpreting the VBAC prediction models within the medical domain. By utilizing a game-theoretic approach, SHAP consistently and reliably estimated the importance of features, making it an ideal choice for analyzing medical data that combine both continuous and categorical variables. Previous research primarily relied on linear p-values to assess parameters in VBAC prediction. 33 However, our research uncovered that the VBAC prediction model trained with SHAP consistently upheld a coherent hierarchy of variable importance, closely mirroring the factors that influence clinical decision-making, similar to previous investigations.36,37 In the context of the SHAP analysis for the CatBoost model, the significance of gravidity as the most influential factor can be illuminated from multiple perspectives. Gravidity may intricately correlate with physiological elements, such as uterine status, uterine musculature elasticity, and ligamentous tension, all of which collectively influence the likelihood of a successful vaginal birth. 38 Furthermore, our current study's SHAP analysis demonstrated that a history of successful vaginal births significantly impacts the VBAC success. Women with such a history may possess more favorable birth canals, thereby increasing the likelihood of a successful current vaginal delivery. 39
Limitation and recommendation
This study has notable limitations that warrant acknowledgment. First, its single-hospital focus restricts its generalizability. To bolster external validity, future research should encompass multiple hospitals, particularly those with diverse geographical locations and healthcare systems. This broader approach would render the research more applicable and representative of real-world scenarios, facilitating a deeper understanding of its impact on clinical practices and outcomes. Second, the current sample may not adequately capture the population's diversity, potentially leading to oversights in comprehending the dynamics of decision-making regarding birth choices across various racial backgrounds. Expanding the inclusion of diverse racial and ethnic groups would contribute to a more comprehensive understanding of the phenomenon. Third, the timing of ERCD significantly influences birth outcomes, and it is vital to consider when women opt for cesarean sections. Integrating the timing of childbirth into the study parameters would offer a more accurate reflection of the decision-making processes during actual ERCD procedures. The timing of birth can substantially impact various aspects of maternal and neonatal outcomes, including complications and interventions. Incorporating data on childbirth timing would provide additional insights for a comprehensive analysis and inform evidence-based guidelines for optimizing obstetric care. Despite these limitations, implementing the study's findings into existing healthcare systems can enhance the effectiveness of encouraging pregnant women to attempt VBAC, providing valuable insights for clinical decision-making and ultimately improving the quality of care.
Conclusion
The integration of AI prediction systems into DA birth choice platform for SDM holds great potential for clinical practice. Our study successfully designed and deployed such a platform in clinical settings, which has been well-received by pregnant women. It has demonstrated a remarkable accuracy when using local hospital data, with tree-based models, particularly CatBoost, outperforming traditional regression models. The SHAP analysis further validated the model's effectiveness in grasping data intricacies and emphasized the importance of key variables like gravidity and vaginal birth history. This AI-powered VBAC prediction system substantially enhances the accuracy of AI models and is adaptable for use in the early stages of pregnancy. Its primary objective is to improve decision-making processes related to birth choice and enhance the overall pregnancy experience. This holds particular significance in addressing the extremely low VBAC rates in Taiwan, aiming to empower pregnant women to make well-informed decisions concerning their mode of birth.
Footnotes
Acknowledgements
We would like to express our sincere gratitude to Saint Paul's Hospital for providing the valuable data necessary for this research.
Contributorship
CCY contributed to conceptualization, methodology, data curation, funding acquisition, resource, and formal analysis. SWC contributed to conceptualization, methodology, formal analysis, supervision, project administration, and writing of the original draft, review, and editing. HWH contributed to conceptualization, methodology, formal analysis, and writing of the original draft. CFW contributed to conceptualization, methodology, formal analysis, and writing of the original draft. WML contributed to conceptualization, data curation, and formal analysis. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Ministry of Science and Technology (grant number MOST 110-2314-B-227-006-MY2).
Guarantor
SWC.
Research ethics and patient consent
This study was conducted under the approval of the Ethics Committee of Fu Jen Catholic University (REC number: C111042), adhering strictly to the Helsinki Declaration guidelines and regulations prior to commencement. As this was retrospective medical record data, the requirement for obtaining written informed consent from all participants was waived by the Ethics Committee of Fu Jen Catholic University.