
Abstract
Objective
This research explores the performance of ChatGPT, compared to human doctors, in bilingual, Mandarin Chinese and English, medical specialty exam in Nuclear Medicine in Taiwan.
Methods
The study employed generative pre-trained transformer (GPT-4) and integrated chain-of-thoughts (COT) method to enhance performance by triggering and explaining the thinking process to answer the question in a coherent and logical manner. Questions from the Taiwanese Nuclear Medicine Specialty Exam served as the basis for testing. The research analyzed the correctness of AI responses in different sections of the exam and explored the influence of question length and language proportion on accuracy.
Results
AI, especially ChatGPT with COT, exhibited exceptional capabilities in theoretical knowledge, clinical medicine, and handling integrated questions, often surpassing, or matching human doctor performance. However, AI struggled with questions related to medical regulations. The analysis of question length showed that questions within the 109–163 words range yielded the highest accuracy. Moreover, an increase in the proportion of English words in questions improved both AI and human accuracy.
Conclusions
This research highlights the potential and challenges of AI in the medical field. ChatGPT demonstrates significant competence in various aspects of medical knowledge. However, areas like medical regulations require improvement. The study also suggests that AI may help in evaluating exam question difficulty and maintaining fairness in examinations. These findings shed light on AI role in the medical field, with potential applications in healthcare education, exam preparation, and multilingual environments. Ongoing AI advancements are expected to further enhance AI utility in the medical domain.
Introduction
The technological revolution of the past decade has profoundly transformed our lives. During this process, the advancements in neural networks, deep learning, and artificial intelligence have shone brightly across numerous fields, including but not limited to manufacturing of consumer goods, finance, and healthcare. The evolution of these technologies has brought us unprecedented convenience and efficiency. Neural network and deep learning technologies have enabled us to now establish highly accurate classification and regression models. These models exhibit exceptional handling capabilities for various types of data, whether it be images, natural language, or audio, they can swiftly build models and perform analysis. Consequently, these technologies have been widely applied in diverse fields and applications. We can confidently assert that the progress of neural networks, deep learning, and artificial intelligence has completely altered our lifestyles and ways of working. Moreover, this is just the beginning.
While these technologies have made a significant impact on many fields, their application in clinical medicine is still somewhat limited. One of the reasons for this limitation is the vast amount of unstructured text in clinical settings, as well as the lack of interoperability between different medical information systems. These factors contribute to difficulties in standardizing structured imaging, thereby hindering the production of structured, machine-readable data required for deep learning algorithms. Even when algorithms suitable for clinical medicine are developed, the quality of collected data often varies. Therefore, except for a few exceptions, the application of artificial intelligence in modern clinical medicine, particularly in the field of medical imaging, remains relatively rare.
However, recent advancements in artificial intelligence have sparked revolutionary innovation in the field of digital healthcare, with large language models making significant contributions in the past 2 years. These large language models are deep neural network models with a vast parameter space, containing tens of billions of parameters. They represent a critical advancement in artificial intelligence, opening up new possibilities for understanding and generating natural language. Since the public release of ChatGPT in November 2022, this is the first time that such a complex large language model has been made available to the public in an accessible format.
Globally, the application of ChatGPT has gradually penetrated into many areas of healthcare.1,2 From conducting routine medical consultations to carrying out professional medical education training, ChatGPT plays an indispensable role. Many medical institutions have begun using ChatGPT for predicting and simulating medical examinations,3,4 thereby improving the accuracy and fairness of these exams. In this trend, we have chosen to undertake an interesting challenge in the field of Nuclear Medicine in Taiwan. Our goal is to use ChatGPT to test the specialty exam in Nuclear Medicine. This specialty exam is not straightforward; it consists of a mixture of Traditional Chinese and English, which undeniably poses a huge challenge to ChatGPT. Although English is the primary language of ChatGPT, we hold high expectations for its performance in such a multilingual environment.
We believe that this work will provide stability and quantitative feedback for ChatGPT performance. We will assess ChatGPT performance in this challenging multilingual medical specialty exam, while observing and documenting its responses and answers to various problems. This will not only assess its performance on specific healthcare issues but will also evaluate its performance in broader, more complex linguistic contexts.
Methods
The current study would evaluate the performance of ChatGPT in a complex multilingual medical specialty exam for Nuclear Medicine in Taiwan. In addition, chain-of-thoughts (COT) technology would also be tried to further improve the exam results by ChatGPT. All the ChatGPT results would be compared to the human doctors’ performance. Moreover, we would also analyze if there were differences of accuracy in knowledge categories of questions, length of questions, or ratio of languages between the responses of ChatGPT and human doctors.
Generative pre-trained transformer
Generative pre-trained transformer (GPT) was initially developed by OpenAI and is a powerful language model. GPT-3 achieved significant breakthroughs, becoming a leading language model, and introduced ChatGPT designed specifically for conversational and interactive scenarios. Based on GPT-3, ChatGPT possesses a natural fluency in conversations. GPT-4 further enhances its functionality and performance, bringing more potential to ChatGPT. 5
GPT-4 is a model based on the Transformer architecture, as shown in Figure 1, which was initially proposed by Google in 2017 and has made significant breakthroughs in the field of natural language processing. 6 Traditional deep learning architectures such as convolutional neural networks and recurrent neural networks have limitations when dealing with sequence-to-sequence tasks, while the Transformer addresses these limitations by introducing self-attention mechanisms. The key innovation of the Transformer lies in its use of self-attention, which allows it to simultaneously consider all positions in the sequence and capture the dependencies between different positions.

Transformer architecture.
ChatGPT has been widely applied across various domains, exerting a profound impact on industries. Particularly in the fields of natural language processing, machine translation, and text generation, ChatGPT plays a crucial role. In the healthcare sector, ChatGPT is utilized for medical consultations and professional training, providing accurate medical information and training resources to healthcare professionals, thereby enhancing the quality and efficiency of healthcare services. 7 In the education field, ChatGPT applications include automated assessment of student assignments and generating supplementary educational content, improving learning experiences and outcomes. 8 These applications have made ChatGPT an indispensable tool in today's society, bringing innovation and benefits to diverse industries.
ChatGPT has demonstrated exceptional performance and continues to undergo continuous updates. OpenAI released the technical report for GPT-4 in May 2023, 9 highlighting its outstanding performance in professional and academic tests across various domains, comparable to that of humans. GPT-4 has showcased excellent capabilities in a wide range of disciplines, including biology, history, economics, and psychology. Moreover, it has achieved excellent scores in university entrance exams and professional certification tests. These results demonstrate the interdisciplinary potential of GPT-4. Therefore, we have chosen to utilize GPT-4 in our research to thoroughly explore its applications and efficacy in different academic fields.
Chain-of-thoughts
COT is a method proposed by Jason Wei, a researcher at Google Brain, in January 2022, in a paper published on arXiv. 10 Its objective is to enhance the performance of question-answering systems by leveraging discrete prompt learning. COT not only provides answers to questions but, more importantly, focuses on offering the thought process involved in problem-solving. Its aim is to improve the quality of the answers by triggering and explaining the thinking process. To achieve this, question-answering systems need to possess a deep understanding of the questions and the ability to engage in relational reasoning. Furthermore, they should present the thought process to users in a coherent and logical manner.
COT operates differently from traditional question-answering systems. It not only trains the model to generate answers but also enhances the quality of the answers by triggering and explaining the thought process, as shown in Figure 2. This approach enables the question-answering system to provide more detailed and comprehensive explanations, helping users better understand the problem-solving approach. Additionally, COT provides an opportunity to evaluate the system reasoning capabilities and interpretability, thereby improving the overall effectiveness of the question-answering process. With the introduction of COT, users can gain a clearer understanding of the problem-solving process and critically examine the system reasoning, resulting in more reliable answers.

COT explaining the thought process. COT: chain-of-thoughts.
The introduction of COT has opened up new possibilities for question-answering systems. In addition to its applications in traditional question-answering scenarios, COT has a wide range of potential uses. It can be extended to the field of education, providing students with more inspiring and in-depth question-answering experiences to enhance their learning and understanding. Furthermore, COT can be applied to self-service solutions, assisting users in resolving various issues and uncertainties. Future research could focus on generating and explaining the thought process more effectively and exploring how to adapt COT to different domains and languages. With the continuous development of the COT concept, we can expect the application of more intelligent and user-friendly question-answering systems in various fields.
Nuclear medicine in Taiwan
Nuclear medicine is an important scientific field in the medical domain in Taiwan, focusing on the application of radioactive substances and nuclear medicine imaging techniques for disease diagnosis and treatment. Nuclear medicine integrates knowledge from nuclear physics, biology, and medicine to track physiological processes and pathological changes within the human body using radiopharmaceuticals. In Taiwan, the field of nuclear medicine has experienced significant development, with nuclear medicine physicians playing a crucial role in disease diagnosis, treatment planning, and treatment efficacy assessment. They utilize nuclear medicine imaging techniques such as single-photon emission computed tomography and Positron emission tomography to accurately observe the body functional and metabolic status, providing precise diagnostics and treatment monitoring, and driving the progress and innovation in nuclear medicine.
Additionally, the Society of Nuclear Medicine of the Republic of China organizes an annual specialized physician board examination to assess the professional competence in nuclear medicine in Taiwan. The purpose of this examination is to ensure that nuclear medicine practitioners possess the required knowledge and skills, providing high-quality nuclear medicine services. The examination encompasses fundamental theories of nuclear medicine, imaging, radiation protection, and other relevant areas. It’s consisting dozens of single-choice questions. By successfully completing this examination, physicians can obtain certification as a specialist in nuclear medicine, further enhancing their professional standing and employment prospects in the field. The board examination for nuclear medicine physician is designed for medical school graduates who have completed two years of general medical training after graduation and 4 years of residency training in nuclear medicine. Only after completing this training, they are eligible to participate in the annual board examination for nuclear medicine physicians. Those who pass the examination are granted a nuclear medicine physician license valid for 6 years. If they meet the continuing education requirements for extending the license's validity, they can receive another 6-year validity period. Those who fail the board examination or do not pass the extension requirements for the license can only attempt to obtain the license through the examination in the following year.
Therefore, the specialized physician board examination for nuclear medicine holds important significance for the development and professional talent cultivation in Taiwan. It promotes the standardization and recognition of the nuclear medicine profession while providing support for the growth and academic exchange of the discipline. This examination also offers a fair platform for assessing physicians’ professional competence in the field of nuclear medicine, ensuring their ability to provide safe and high-quality nuclear medicine services and driving the progress of this field.
Experimental data
In our recent experiment, we used written test questions from the nuclear medicine physician board examination in Taiwan as our test subjects. This undertaking not only posed a significant challenge for our AI model, ChatGPT, but also served as an exploration of the application of AI technology in the medical field. For this experiment, we selected one of the examinations that had taken place within the past decade as our benchmark. 11 The written test consisted of 50 single-choice questions, and each question had four possible choices. Both AI and human participants took the same set of test questions. Examinees would receive two points for selecting the correct option for each question; otherwise, they would receive zero points. Besides the list of qualified candidates and examination questions, the list of eligible candidates and examination results are not considered public information. Therefore, with the consent of the Society of Nuclear Medicine of the Republic of China, the presentation of examination results can be provided in a manner that removes direct identification or cross-referencing for reverse deduction, which therefore provided as an average score of all doctors (DrsAverage) to eliminate the possibility of retrievable information by means of knowing total number of candidates or their individual scores. The selected examination is highly representative as its questions cover all key areas within nuclear medicine. Comprehensive knowledge and understanding, both in breadth and depth, are prerequisites for passing the examination.
The stem and options in the questions encompass the fields of Radiophysics, Radiobiology, Radiation Protection, Nuclear Medicine Instrumentation, Radiopharmaceuticals, and Image Processing, which are categorized as Theory-based Questions. Questions associated with the management of radioactive preparations and adherence to radiation regulations fall under the classification of Medical Regulatory Questions. Questions pertaining to image interpretation, disease treatment, and medical quality are designated as Clinical Medicine Questions. In cases where the stem or option spans more than two categories from the initial three, it is classified as Integrated. The total number of questions in each category is listed in Table 1.
The total number of questions in each category.

Moreover, a unique feature of nuclear medicine physician board examination in Taiwan is its bilingual format: every multiple-choice question is composed in both Mandarin Chinese and English. This bilingual format reflects Taiwan's linguistic environment. As a predominantly Mandarin-speaking country, Taiwanese physicians typically undergo their professional training in a bilingual environment. This not only helps them to stay abreast of the latest advancements in global medical research, but also ensures smooth communication when interacting with the international medical community. This bilingual examination format undeniably poses a major challenge for our AI, ChatGPT. Although ChatGPT has demonstrated outstanding capabilities in understanding and generating language, the linguistic structure and specialized knowledge required in this experiment necessitate it to switch flexibly between Chinese and English, while maintaining high levels of precision. Importantly, such a bilingual environment is common in real-life situations. Hence, we hope that this experiment can realistically reflect ChatGPT performance under such circumstances, providing valuable insights for its future development and refinement.
Statistical analysis
As the examination results could only be provided as an average score of all doctors, neither parametric nor nonparametric statistical test was applicable. Only head-to-head comparison would be present.
Data availability statement
The dataset used in this study is held by the Society of Nuclear Medicine, Taiwan (R.O.C). Researchers who are interested can browse the dataset through the website of the Society of Nuclear Medicine. http://www.snm.org.tw/specialist/question_h.asp.
Consent statement and ethical approval
This study is not a clinical trial nor a human trial; therefore, an IRB approval is not required. Therefore, the consent statement was not necessary.
Result
In this experiment, we leveraged the advanced capabilities of GPT-4, an impressive AI model developed by OpenAI. Importantly, we utilized two different versions of GPT-4, released in March and May, respectively. These two versions, while fundamentally based on the same model, possess subtly nuanced characteristics due to the adjustments and enhancements made during the intervening period. This distinction allowed us to delve into an intriguing exploration of the model evolution and performance enhancements over time. In addition to the standard model, we integrated the increasingly popular COT technology to further enhance GPT-4 performance. This innovative technology, making waves in the AI field, was expected to augment GPT-4 capabilities and yield even more precise results. We designed the experiment around four distinct objectives, each aimed at evaluating the performance of a different variant of the model. Our first objective was to collect statistical data on the average scores of the nuclear medicine physician candidates. The second and third objectives were focused on assessing the individual performances of the March and May versions of GPT-4, respectively. Finally, for the fourth objective, we examined the May version of GPT-4, which had been further enhanced by the integration of COT.
Our analysis began with an evaluation of the scores attained by four distinct candidates, labeled as DrsAverage, GPT4-March, GPT4-May, and ChatGPT4-May (COT). As illustrated in Figure 3, DrsAverage scored 71 points, GPT4-March garnered 72 points, GPT4-May achieved an impressive score of 82 points, while ChatGPT4-May (COT) topped the chart with an outstanding score of 84 points. It's worth noting that GPT-4, our AI candidate, unexpectedly achieved the highest score, thereby underlining its potential and capability. Upon examining these scores, it's clear that GPT-4 performance, particularly the May version enhanced with COT integration, was superior, underlining the significant strides made in AI technology.

The average score.
First, we delve into a comprehensive analysis of the four main sections of this examination: Theory-based Questions, Medical Regulatory Questions, Clinical Medicine Questions, and Integrated Question Type. Each section poses its own unique challenges to the candidates, testing their overall capabilities ranging from theoretical knowledge to practical applications, as well as the ability to tackle integrated questions.
First up is the Theory-based Questions section. The primary objective here is to assess concepts related to basic nuclear physics, radiochemistry, radiopharmaceuticals, radiation detection instruments, and radiobiology. As revealed by the data, the average correct rate for DrsAverage in this section is 68%. Meanwhile, the GPT4-March exhibits a correctness of 76%, showcasing GPT-4 fundamental competence in handling medical theory-based questions. Moving forward to GPT4-May, its correctness rate improved to 82%, with the ChatGPT4-May (COT) reaching as high as 88%. However, the scenario appears quite different for the Medical Regulatory Questions section. This part tests understanding and application of medical regulations, including the concepts of radiation protection, assessment and treatment of radiation injuries, and radiation protection regulations. Looking at the data, DrsAverage averaged a correctness rate of 57%, while all the AI scored 0%. Next, we have the Clinical Medicine Questions section, aimed at the knowledge about the distribution of radiopharmaceuticals in the human body, laboratory diagnosis, imaging diagnosis, and radionuclide therapy. Here, the doctors’ average correctness rate is 70%, whereas GPT4-March achieved a rate of 72%. It's evident that even in clinical medical questions, AI is performing comparably to doctors. Upon arriving at ChatGPT4-May and ChatGPT4-May (COT), the correctness rate was elevated to 83%. Lastly, in the Integrated Question Type section involving other topics that integrate the aforementioned three knowledge areas or are difficult to categorize specifically, we observed that DrsAverage achieved an average correctness rate of 100%. This is an astounding result, verifying doctors’ professional proficiency in handling questions involving multiple domains. Compared to this, GPT4-March had a correctness rate of 67%, whereas ChatGPT4-May and ChatGPT4-May (COT) maintained a rate of 100%, as shown in Figure 4.

Four main sections of this examination.
After conducting our research, we performed a meticulous analysis on the complexity of the question length, focusing on its impact on the accuracy of nuclear medicine physician candidates and AI. Worth mentioning is that our designed questions are of a mixed Chinese-English format. This not only increased the complexity of the analysis but also made the results more meaningful. We divided the complexity of question length into four equal parts on average: less than 53 words, 54–108 words, 109–163 words, and 164–218 words. Surprisingly, we found that within the 109–163 words range, nuclear medicine physician candidates and AI both achieved the highest accuracy in answering questions, as shown in Figure 5.
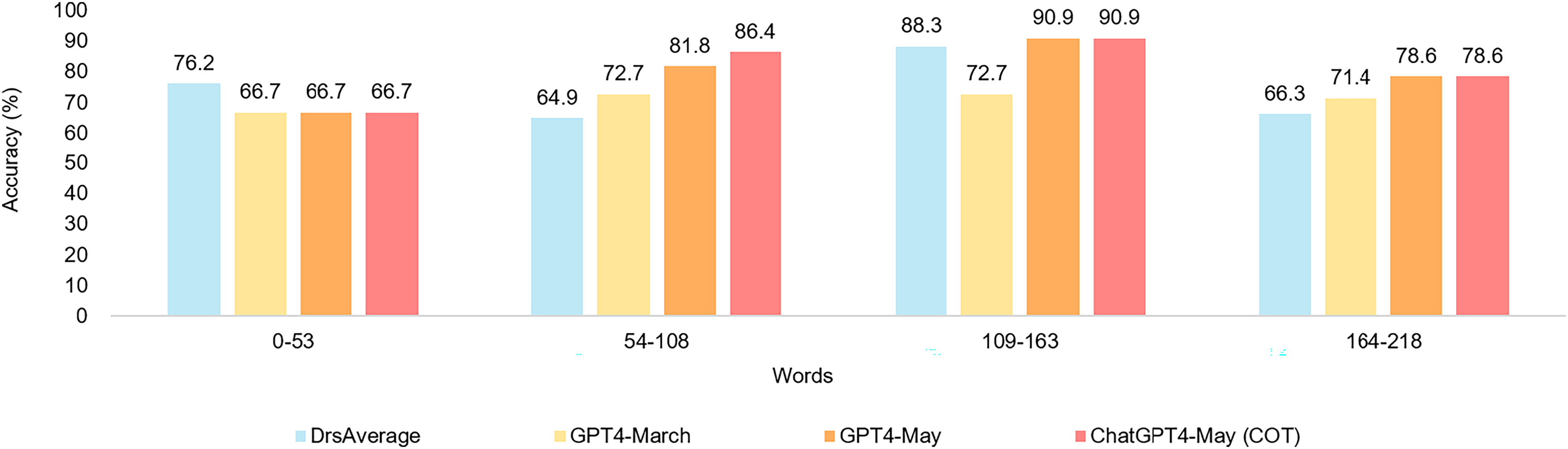
Performance results for different word counts.
Further, our team has conducted an in-depth examination of factors that may influence the accuracy of nuclear medicine physician candidates and AI, among which includes consideration of the language ratio in the questions. Our primary focus in this research has been to determine whether the ratio of Chinese to English in the questions would have any impact on their accuracy. In this segment of the study, we adopted a methodology that involved directly calculating the proportion of English words in the questions. We categorized the ratio of English words in the questions into four segments: less than 10%, 10%–19%, 20%–29%, and above 29%. Across these four segments, we discovered a trend wherein the accuracy of both physician candidates and AI would increase correspondingly with a higher ratio of English words. To be more specific, when the ratio of English words exceeds 29%, the accuracy of both nuclear medicine physician candidates and AI surpasses 80%, as shown in Figure 6.

The performance results of different English scales.
Discussion
The results of this specialized nuclear medicine test study reveal that our AI model, ChatGPT, stands out in multi-language environments and professional knowledge challenges. This research provides important insights into the potential applications of AI in the medical field and highlights how the model has improved over time.
Firstly, we noted that in the fundamental theory questions section, AI demonstrated abilities surpassing the average doctor level. This can be explained by the AI model's capacity to quickly and accurately access vast amounts of medical theoretical knowledge, while doctors may encounter difficulties recalling these details. However, we saw in the medical regulatory questions section, AI performance was zero. This is possibly because regulations often require specific understanding and judgment, which current AI struggles to achieve. This also unveils the challenges that AI needs to overcome in future development, that is, to improve in understanding and applying knowledge of depth and complexity.
One reason for the suboptimal performance in medical regulatory questions is the unique challenge posed by the variance in medical legal oversight among different nations. Specifically, since GPT-4 training data is sourced predominantly from English-speaking countries, it does not align with Taiwanese laws, resulting in less-than-ideal performance.
In the clinical medicine questions section, we saw AI performing comparable to doctors and significantly improved in the version with COT technology implemented. This suggests AI is capable of understanding and applying complex clinical medical knowledge, an important milestone for AI applications in the medical field. On the other hand, we also noticed in the integrated question types section, AI performed as well as doctors, reaching a 100% accuracy rate, indicating AI can effectively integrate and apply across different medical domains.
Next, we focused on how the complexity length of questions affected AI and doctors’ performance. Results showed that within the 109- to 163-word range, both doctors and AI performed best. This might be because questions of this length provide enough detail, yet are not overly long or confusing, posing challenges to comprehension.
Moreover, we found that changes in the proportion of English words in the questions also affected the accuracy of AI and doctors. With the increase of English word ratio, the accuracy of both improved. This might be due to the more widespread use of English in the medical field, particularly in professional terminologies and theories. However, it also highlights AI adaptability in a Chinese-English bilingual environment and hints at AI potential advantages when handling multilingual issues.
Lastly, the current AI model may serve as a pre-evaluation method that can be used as an approach to assess whether the exam questions of the year are in line with the usual standards, in order to avoid an excessive number of overly difficult or too easy questions. This would prevent unfair situations in the examination, preserving the rights of candidates who have only one opportunity to take the exam per year. Similar applications have been used for diversities of educational purposes, not limited to certification exams of medical professionals as discussed here. ChatGPT may serve as a valuable tool for teachers in preparation of presentation slide, formulating essay-type, multiple-choice, and viva questions, answering students’ queries, making customized content for students according to comprehension capability, evaluation of answers, creating case vignette, plan a lesson, or create contents for blended learning.12,13
Utilizing ChatGPT for preparation or participation in medicine exams comes with its inherent limitations. One significant constraint is the lack of updated information. Medicine is a rapidly evolving field, with new studies and clinical guidelines emerging frequently. Since ChatGPT's training data is cut off at a specific point in time (up until 2021), it may not be aware of the latest research or the most recent clinical practice guidelines published after that period. This gap can limit the tool usefulness in providing the most current medical guidance or information for exam preparation.
GPT-4 Versions are regularly updated due to performance optimizations. Through user feedback and performance testing, developers can identify areas that require improvements. These enhancements may include increasing the accuracy in answering questions, improving natural language processing capabilities, and reducing errors. Additionally, security and privacy considerations are crucial. With a heightened awareness of these issues, updates can address security vulnerabilities present in previous versions and reinforce data protection measures to comply with emerging regulations or standards.
While we attempt to compare the performance of AI and medical experts in specialty exams, limitations due to confidentiality issues prevent us from effectively utilizing statistical methods to make a more robust result. However, considering the results from an uncommon subject with limited access to exam information, AI has demonstrated an impressive ability for reasoning and generation. In the future, assessing more comprehensive test results in a similar manner may provide a better representation of the actual capabilities of AI compared to humans.
In summary, this study provides insights into the practical applications and potential challenges of AI in the medical field. In the future, AI may need to improve in understanding and applying complex knowledge, such as regulations. Simultaneously, this research emphasizes AI ability to handle medical theoretical and clinical knowledge questions, as well as its performance in multi-language environments. With the continuous advancement of AI technology, we can anticipate seeing more AI applications in the future medical field.
Conclusion
This research offers an in-depth understanding of the Taiwanese Nuclear Medicine Specialty Exam, and how AI performs in such a challenging medical specialty environment. From theory to practice, from professional knowledge to language use, AI demonstrates excellent capabilities in many aspects, particularly in the version incorporating COT technology.
The study results reveal that AI grasp of theoretical knowledge and understanding of clinical medical problems is on par with, and even exceeds, the average performance of actual doctors. This underscores AI capabilities and offers valuable insights into AI applications in the medical field. However, AI scored 0% on medical legal regulation questions, indicating that there is room for improvement in understanding and applying professional regulations.
Additionally, question length and language proportion also affected the accuracy of both doctors and AI. The results indicate that the highest accuracy for both doctors and AI occurs when the question length is between 109 and 163 words, and when the English word ratio exceeds 29%. This might be because questions of this length provide sufficiently detailed information without being overly long or confusing.
In summary, AI holds tremendous potential for applications in the medical field. Despite challenges like understanding and applying medical regulations, AI has proven its grasp of theoretical and clinical knowledge and adaptability in handling multilingual questions. This study not only reveals the possibilities of AI in the medical field, but also provides valuable insights for AI future development and improvement.
Footnotes
Author contributions
These authors’ individual contributions were as follows. Yu-Ting Ting, Te-Chun Hsieh, Yuh-Feng Wang, Chia-Hung Kao were responsible for the study design. Yu-Chieh Kuo, Yi-Jin Chen, Pak-Ki Chan collected the data. Yu-Ting Ting, Te-Chun Hsieh, Yuh-Feng Wang, Yu-Chieh Kuo, Yi-Jin Chen, Pak-Ki Chan, Chia-Hung Kao performed statistical analyses, interpreted data, and drafted the article. All authors provided some intellectual content. Yu-Ting Ting, Te-Chun Hsieh, Yuh-Feng Wang, Yu-Chieh Kuo, Yi-Jin Chen, Pak-Ki Chan, Chia-Hung Kao approved the version to be submitted. All authors read and approved the final manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported in part by China Medical University Hospital (DMR-113-048, DMR-113-060, DMR-113-061).