
Abstract
Background
As a routine task, physicians spend substantial time and keystrokes on text entry. Documentation burden is increasingly associated with physician burnout. Predicting at top-1 with less keystrokes (TLKs) is a hot topic for smart text entry. In Western countries, contextual autocomplete is deployed to alleviate the burden. Chinese text entry is intercepted by input method engines (IMEs), which cut off suggestions from electronic health records (EHRs).
Objective
To explore a user-friendly approach to make text entry easier and faster for Chinese physicians.
Methods
Physicians were shadowed to uncover the real-word input behaviors. System logs were collected for behavior validation and then used for context-based learning. An in-line web-based popup layer was proposed to hold the best suggestion from EHRs. Keystrokes per character and TLK rate were evaluated quantitatively. Questionnaires were used for qualitative assessment. Nine hundred fifty-two physicians were enrolled in a field testing.
Results
14 facilitators and 17 barriers related to IMEs were identified after shadowing. With system logs, physicians tended to split long words into short units, which were 1–4 in length. 81.7% of these units were disyllables. Compared to the control group, the intervention group improved TLK rate by 40.3% (p < .0001), and reduced keystrokes per character by 48.3% (p < .0001). Survey results also promised positive feedback from physicians.
Conclusions
Keystroke burden and frequent choice reaction time challenge Chinese physicians for text entry. The proposed system demonstrates an approach to alleviate the burden. Contextual information is easily retrieved and it further helps improve the top-1 accuracy, with a smaller number of keystrokes. While positive feedback is received, it promises a benefit to protect patient privacy.
Introduction
Overloaded clinical documentation is a leading factor for physician burnout.1,2 Every day physicians click thousands of times especially on text entries in clinical notes. 3 The time spent on direct patient care is reduced by half.4,5 Physicians have to act as a skilled typist in order to spend more time with patients. 6 Scribe-based solutions are sought to alleviate the burden,7–10 implemented through either human or artificial intelligence. However, barriers persist such as extended labor and suboptimal accuracy. 8 Self-administered manual entry is still a preferred modality. 11
Physicians often used abbreviations for saving keystrokes in letter-by-letter input,12–14 but it leads to unstructured content, which hinders understandability for patients, other physicians, and machines.15–18 Recent improvements focus on using abbreviations transitorily through autocomplete.19–21 It involves several interactive steps: (1) physicians cognitively generate an acronym for a structured term, (2) physicians type it into notes, (3) a popup menu is displayed in-line with top-5 suggestions from electronic health records (EHRs), (4) physicians scan the list, and (5) physicians navigate and select a word. Suggestions would update for each entered letter. When the intended word is located at top-1, it can be selected by clicking Enter; otherwise, physicians have to navigate using the Up/Down and then press Enter.
Unlike direct input entered letter-by-letter, the suggestion-based input (SBI) uses an abbreviated input as a query parameter to fetch a list of normalized candidates. As shown in Figure 1, the suggestion list is updated for each letter entered into the parameter area. Normally, users will not stop to disambiguate each entered letter, as continuous typing within a single learned chunk is preferred by most typists. 22 When the intended word is not in the list, the parameter is then appended or modified. Before the wanted word is found out, it might need to go through several turns of trying. After that, making a selection from the list needs some reaction time. According to Fitts’ Law, 23 the reaction time spent on the top-1 item is the shortest. The top-1 candidate is popularly bound with a shortcut (e.g. the Enter), which makes the selection more touch-typing. Compared to direct input, SBI improves efficiency by using less keystrokes. A selection on the top-1 with less keystrokes (TLKs) seems a jackpot to the typist.
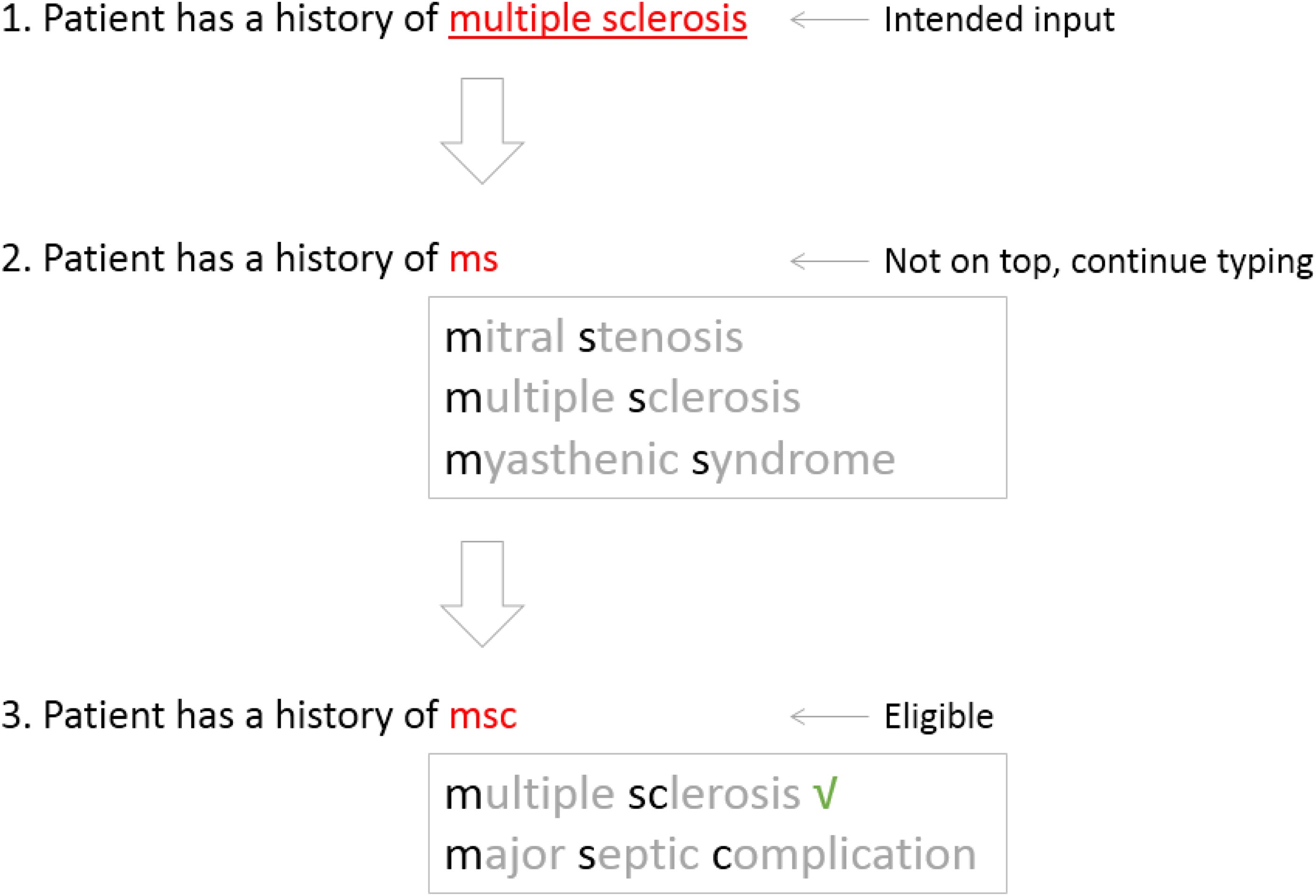
Suggest a word at the top position with less keystrokes.
Chinese text entry is born to be a SBI, with the help of input method engines (IMEs). 24 Pinyin is the official romanization system, commonly used as a phonetic system for writing. 25 Like autocomplete, IMEs consume Pinyin and output a list of Chinese candidates. Averagely, each character's Pinyin has 4.2 Latin letters, 26 which is either a vowel or a consonant–vowel combination. Mandarin Chinese uses only around 410 distinct syllables to encode more than 6000 characters. 27 Thus, using Pinyin causes ambiguities. Multiple characters form a linguistic word, and 64% of words have only two characters. 27 For efficiency, word-based input is widely used.28,29 Pinyin could also be abbreviated. For example, the full Pinyin for the Chinese word of “asthma” is “qi chuan.” It can be shortened to “qc,” “qch,” “qic,” “qich,” or “qchuan.” Basically, the shorter the sequence is, the more ambiguities it has.
Like autocomplete, IMEs also used the Up/Down for candidate navigation. However, IMEs use the Spacebar for selection. The Enter is reserved for direct input of Western words. Besides, IMEs use numeric keys for direct selection, although it is not friendly to touch-typing. 26 Unless the target word is located at top-1, about 52% of the input time is used for choice reaction and candidate selection. 26 Apparently, TLK is also important for Chinese physicians. However, as a standalone third-party tool, IMEs rank candidates, ignoring the possible suggestions from EHRs.
There are several popular IMEs on the market, such as Sogou Pinyin, 30 Baidu IME, 31 and Google Pinyin. 32 In September 2018, the vendor of Sogou Pinyin 30 launched a specific version for Chinese physicians, 33 shipped with 90,047 medical terms. The commercial tools are all free of charge, and physicians are allowed to use their favorite ones. 34 In 2019, Yang et al. developed a tool to evaluate the domain-specific version against other general IMEs for medical writing. 34 Surprisingly, it failed to outperform the others. Although the evaluation is limited to full Pinyin in a lab, it suggests that commercial IMEs are converging in terms of input performance. For years, vendors’ endeavors are limited to the kernel including a built-in vocabulary.35–38 Increasing the underlying word length seems friendly to TLK. However, to our knowledge, it receives limited attention in the clinical setting.
As an initial step to improving text entry for medical records, we shadowed physicians in the clinical setting to understand their input behaviors in the time-intensive environment. We designed a context model for note-taking and used system logs to collect contextual entries. With the learned knowledge from logs, we developed and evaluated a tool to promote TLK for Chinese note-taking. Our overall goal was to explore a user-friendly approach to make text entry easier and faster for Chinese physicians. It is the first study to use server-based rules to enhance client input in an IME-based setting, to our knowledge.
Methods
Study setting
This study was approved by the institutional review board of Shanghai Sixth People's Hospital. It was completed in three steps. First, shadowing was used to collect barriers and input behaviors associated with IME-based clinical documentation from the frontline. Second, a web-based tool was developed to enhance input behavior. Finally, a controlled study was conducted for quantitative and qualitative assessment.
Workspace shadowing
To mitigate disparity between self-reported input behavior and the actual observable patterns, the team conducted workspace shadowing, 39 which is a qualitative research technique conducted on a small scale based on real-time observations. The team spent more than 80 hours with physicians, taking notes about barriers or behaviors associated with text entries to clinical notes. Their writing process was not interrupted during the shadowing phase. One of us (T.L.) collected the notes and then coded them using NVivo (Version 11).
System design
The hospital adopted an EHR platform, provided by Winning. 40 In March 2020, the vendor upgraded the platform from the Windows-based client to a thin client, implemented via the framework of Electron. 41 The tech stack of the client was mainly based on JavaScript.
As most of desktop computers are on Windows operating system, Microsoft's Text Services Framework was a popular foundation for the architecture of IMEs. 42 As standalone tools, they are easy to install. But it was challenging for them to log entries within an EHR-driven context. With the help of “CompositionEvent,” 43 server-based logging was developed. The composition session for an IME entry was comprised of three phases, such as start, update, and end. 43 When a composition session starts, the event of “compositionstart” is fired. Each letter entered as query parameters would trigger a “compositionupdate.” After a candidate is selected, “compositionend” is emitted. Then, client input behaviors were exposed to JavaScript. Some webhooks were developed for server-based collection. When the logging function was shifted from client to server, the context could be retrieved. Server-based logging was easy to configure, and it can be turned on or off centrally. The logging went alive after approval. After that, based on the architecture, the team worked on a prediction module. It was implemented as a visual intervention (Figure 4) at the front end. The detailed information was covered as a result in the section of “Suggestion Tool.” It took six months for the development and testing. After that, the review board approved field-deployment.
Assessment methods
For evaluation, a parameter was designed to let each participant complete a testing using both approaches. After that, the parameter was automatically turned off for the participant. A training schedule was sent to physicians electronically. Nine hundred sixty-three physicians enrolled in an online workshop. The evaluation started after the training, by turning on the parameter for them. In the end, 952 physicians completed the trial within the four-week testing period.
For each participant, when an encounter was completed for note-taking using the intervention (Figure 4), the next encounter had to be completed with the traditional approach. With that said, each participant had to complete 100 notes for each approach during the evaluation. Entries collected with the traditional approach were classified as the control group, and the rest data was marked as the intervention group. All the participated physicians and patients were provided verbal informed consent.
For quantitative assessment, as shown in Table 1, Four metrics were designed for both of groups. For qualitative assessment of physician perceptions in terms of usefulness and trust, a questionnaire was designed, which contained an adapted version of the System Usability Scale 44 and a feature-level Likert-scale assessment. It was placed right after each participant completed testing. At last, 837 participants responded.
Quantitative assessment metrics.

TLK, top-1 with less keystroke.
Results
Workspace findings
After the coding was completed, the team (P.W. and L.Y.) reviewed and some emergent codes were incorporated after a discussion. Qualitative analysis of the shadowing notes resulted in 14 facilitators and 17 barriers. They are sorted and displayed in Table 2.
Facilitators and barriers.

TLK, top-1 with less keystroke.
Word distribution
As shown in Figure 2, most of medical terms provided by Sougo IME dictionary have more than four characters. Based on logging, 81.7% of entries were completed in disyllable, 7.2% in monosyllable, 8.3% in three-syllable, and 2.7% in four-syllable. The shadowing results also suggested that physicians tended to split a longer input into multiple short semantic input units (SIUs). It suggested that the frequency was created on SIUs rather than the actual entity.

The distribution of medical terms provided by the Sogou IME.
Context model
Although clinical notes promised expressivity for physicians,
45
the narrative often went through a semi-structured template with a couple of sections, such as subjective, objective, assessment, and plan.
46
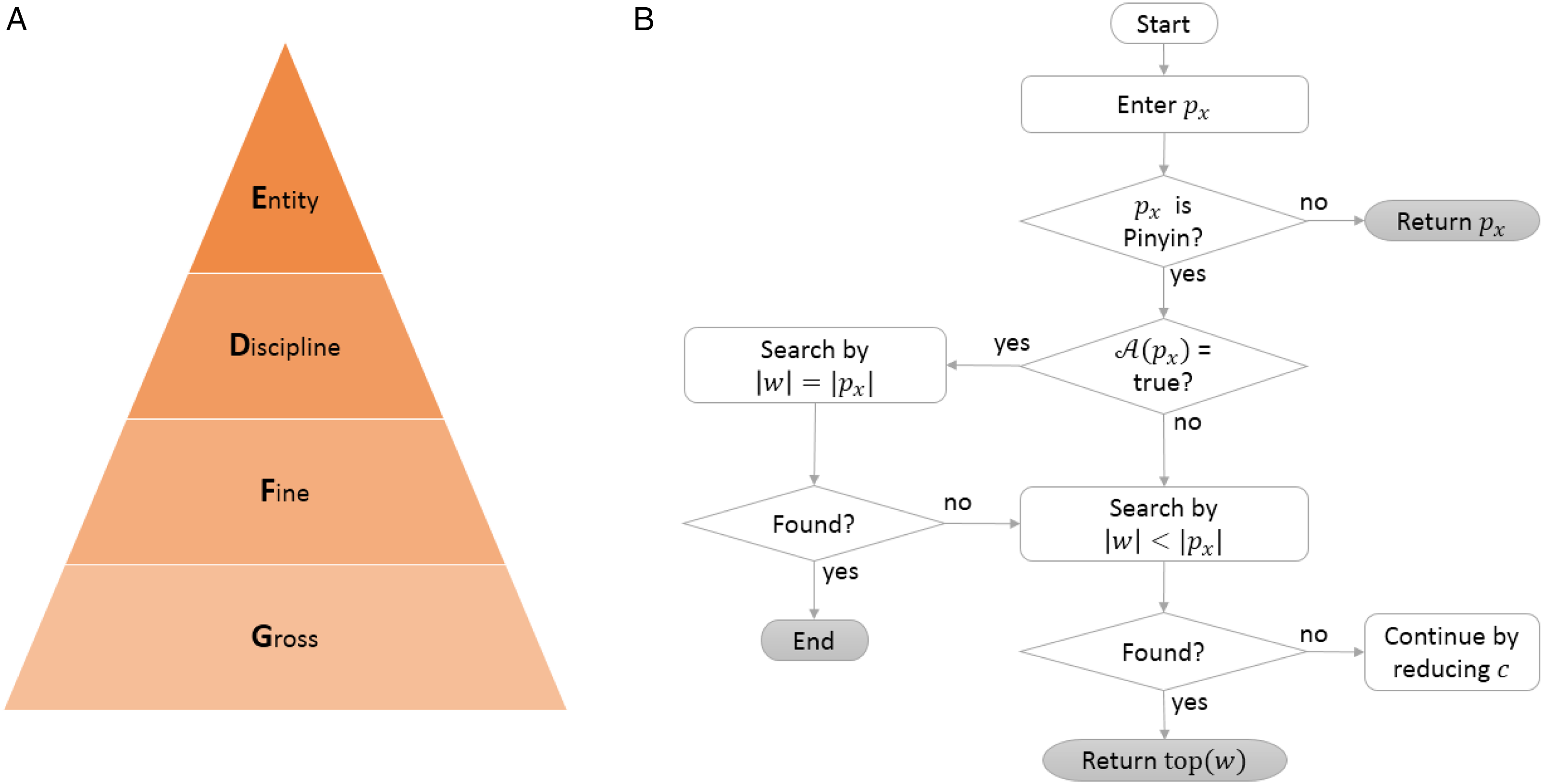
Proposed models. (A) Context model. (B) Suggestion generation.
Normalizations of the preceding component.

SIU, semantic input units.
For a given c, a word w was pending for documentation, physicians chose a specific form of Pinyin, denoted by
Suggestion generation
Workspace shadowing suggested that Pinyin length was gradually increased in the process of pursuing TLK. The index of the desired form was denoted by x. All of the suggestions were ranked by frequency.
Suggestion tool
The visual intervention was shown in Figure 4. When physicians entered

A screenshot of the suggestion tool.
Basically, both IMEs and the system provided conversions for pure lowercase letters. As aforementioned, when the input sequence contained at least one uppercase, when the Enter was clicked, the system would skip suggesting and use the literal value of
Assessment results
The quantitative analysis results were shown in Table 4. In terms of keystrokes per character, compared to the control group, the intervention group received significant improvement (p < .0001). The average TLK rate was 0.62 for the control group. As observed in the shadowing phase, before the intervention, physicians tended to use full Pinyin and only used abbreviated Pinyin when they felt confident to bring the expected word to the top. The average rate was improved by 40.3% (p < .0001) in the intervention group. The overall word per minute was improved by 28.4%. After randomly selecting 100 records from each group, five typo errors were found in the control group and none was found in the intervention group. The qualitative analysis results were demonstrated in Figure 5. Overall, the team received positive feedback that the system was useful, though some physicians were not determined to use abbreviated Pinyin on infrequent terms.

Usability evaluation results. (A) System usability scale assessment results. (B) Feature-level Likert-scale assessment results.
Quantitative improvement.

TLK, top-1 with less keystroke; KPC, keystrokes per character; WPM, word per minute.
We broke down the improvement in terms of KPC by note section. In descending order, they were review of systems (58.2%), diagnosis (58.1%), social history (58.0%), family history (57.8%), physical exam (57.7%), past medical history (57.3%), chief complaint (56.3%), medications (52.6%), history of present illness (42.8%), and medical decision making (42.0%).
Discussion
Documentation burden is a leading factor for physician burnout, as too many keystrokes and time are spent on clinical text entry.3,4 For Chinese physicians, IMEs serve as an essential component for note-taking. Most of the IME-related time is spent on choice reaction and candidate selection. 26 Although abbreviated Pinyin saves keystrokes, full Pinyin is dominant as it helps reduce the time for choice reaction. 34 This study suggests an approach to alleviate the burden on both sides.
Unlike linguistic words, during the phase of input, words are segmented naturally by IMEs. 49 Based on the findings via system logs and workspace shadowing, this phenomenon is confirmed in the medical domain. Each IME word has 1–4 characters and has its own semantic meaning. Surprisingly, 81.7% of text entries are completed using disyllables. The first reason is that 64% of the popular terms are two-character words. 27 The second reason is that disyllables are so elastic that they can be easily truncated to become a monosyllable or combined with the next entry to become a multisyllable. As observed from shadowing, the last reason might be related to the typo rate of Pinyin input. 51 Typo rate grows with the length of the input sequence for Pinyin. When an error happens, it takes time and patience for finding out and correction. The splitting strategy forms the fundamental of the input language. A linguistic word with a lower term frequency is divided into multiple high frequently used IME words. This helps explaining why an extended medical dictionary would not boost the input performance as expected. 34
As short frequent IME words become the major part of typewriting, homophone disambiguation 52 turns prominent. For both autocomplete and IMEs, as the triggering input sequence shrinks, the uncertainty of suggestions grows. To improve top-1 accuracy while sticking to least effort of keystrokes, autocomplete tries to get more contextual information for help.19,20 On the other hand, autocomplete enhances accuracy based on a learned corpus coming from EHRs rather than an individual machine or physician. Fundamentally, the IME is a standalone tool, tethered to an individual machine. As a commercial product, it is not open-source to EHRs, even for the domain-specific IME. 33 As per the current IME architecture, EHRs are excluded for disambiguation. For security reasons, as a third-party tool, the IME has limited access to the context. As IMEs are used for daily input on all kinds of occasions, the number, sequence, and frequency distribution of the homophonic characters for each syllable are affected significantly, 26 especially on short frequent words. Consequently, 52% of entry time is reported to be an overhead, 26 used for choice reaction and locating selection keys. However, the disambiguation time is minimized if the intended word is found at top-1, and selection is also touch-typing on the Spacebar key. It serves as the only entrance for TLK. Our study provides another entrance by unleashing the power of the Enter key. The dual entrance reserves two top positions for TLK from top to bottom. Besides, the popup layer is sensitive to the context. Compared to the control group, the intervention improves TLK rate by 40.3% (p < .0001). Meantime, keystrokes per character are reduced by 48.3% (p < .0001). Physicians also show great interest. The qualitative results suggest that a positive impact is happening to physician input behaviors. Being borrowed from autocomplete, the popup layer demonstrated the potential of bridging IMEs with EHRs. With that said, entries completed out of the IME menu are not tracked by the IME vendor. It helps protecting patient privacy.
Limitations
This study has some limitations. First, for simplicity and latency, rule-based prediction is used only by the proposed tool. Incorporating more contextual information (e.g. patient demographic and medical history) and deep learning could boost the top-1 accuracy. Second, the prediction is pragmatic based on collected system logs rather than a standard corpus. The results might vary in different settings. Third, the Spacebar is superior to the Enter in terms of touch-typing. However, being fixed by IMEs, the Spacebar cannot swap with the Enter, at least during text entry. But it suggests a direction for IMEs for future optimization. Fourth, the typo rate is evaluated qualitatively. A quantitative assessment is warranted in the future. Last, the project is being developed as a pragmatic improvement for a web-based EHR. The software is proprietary to the in-house platform.
Conclusions
Keystroke burden and frequent reaction time used for disambiguation challenge Chinese physicians in the process of routine text entry. Contextual autocomplete helps alleviating the burden in Western countries. For Chinese, IMEs are generally used for text entry, being separated from EHRs. This study suggests an approach to connect EHRs with IMEs. The bridge helps increasing the top-1 accuracy using keystrokes as few as possible. It is friendly to patient privacy and receives positive feedback from physicians.
Footnotes
Authors Note
Tao Li and Lei Yu are equally important as first authors for contribution.
Conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Shanghai Sixth People's Hospital, (grant number DY2019015)
Ethical approval
Not applicable.
Guarantor
P.W.
Contributorship
P.W., T.L., and L.Y. designed the study. P.W. developed the model and prepared figures. T.L. and L.Z. performed the evaluation and assembled the data. P.W., T.L., and L.Y. wrote the article. All authors contributed to the final approval of the article.