
Abstract
Lung cancer is the second foremost cause of cancer due to which millions of deaths occur worldwide. Developing automated tools is still a challenging task to improve the prediction. This study is specifically conducted for detailed posterior probabilities analysis to unfold the network associations among the gray-level co-occurrence matrix (GLCM) features. We then ranked the features based on t-test. The Cluster Prominence is selected as target node. The association and arc analysis were determined based on mutual information. The occurrence and reliability of selected cluster states were computed. The Cluster Prominence at state ≤330.85 yielded ROC index of 100%, relative Gini index of 99.98%, and relative Gini index of 100%. The proposed method further unfolds the dynamics and to detailed analysis of computed features based on GLCM features for better understanding of the hidden dynamics for proper diagnosis and prognosis of lung cancer.
Keywords
Introduction
Lung cancer is the second leading cause of cancer and recent statistics of 2018 shows approximately 234,030 new cases of lung cancer are anticipated to be detected out of which 85% will be non-small cell lung cancer (NSCLC).1,2 The methods of ablation and stereotactic body radiotherapy and radiofrequency are used to detect NSCLC. Small cell lung carcinoma (SCLC) and NSCLC are two main types of lung cancer, which require more powerful tools to predict, properly diagnose, and different methods of treatment. NSCLC is more common and slowly grows. Where SCLC is produced due to smoking, grows very quickly, and forms tumor in the whole body. Cancer deaths are related to a total number of cigarettes smoked. 3 Lung cancer symptoms can be caused by a variety of reasons, one of which is smoking; therefore, active smokers are at a greater risk of acquiring lung cancer. Other variables that can influence the growth of lung cancer in the body include genes or a family history of lung cancer, working in an environment with dangerous compounds that can cause lung damage, and exposure to air pollution such as automobile and manufacturing fumes (Zakariya, 2014). Many distinct concepts and approaches have been proposed by various researchers. They also attempted to include image processing and machine learning techniques. Physicians are unlikely to recommend a biopsy for diagnosis unless there is clear evidence of lung cancer. Lung cancer can only be cured if earlier discovered. Lung cancer can be diagnosed using different technologies, including X-ray, magnetic resonance imaging (MRI), isotope, and computer tomography (CT). Chest X-ray (CXR) radiography and CT are two well-known anatomic imaging modalities commonly used to diagnose various lung illnesses. 4
Lung cancer can be diagnosed with radiographic projections such as the CXR. So far, reliable computer-assisted diagnosis and data-science-based diagnosis have been deemed crucial. However, more research is being conducted to improve accuracy and imaging. Computer tomography images are superior to X-rays for RCAD lung cancer identification. The researchers concluded that using CT images in computer-assisted diagnosis systems can improve the resilience of computer-aided diagnostic (CAD) systems because X-rays have a lot less features to take out and evaluate for further processing in the direction of lung cancer detection. 5 The CT scan is the best option for lung cancer patients because it provides detailed information on abnormal pulmonary tissues and tumors, including size, shape, and location. For a complete lung cross-section, CT scanners typically provide almost 300 scans in a short scan time. A new CAD method for the automatic detection of lung nodules in CT images is proposed in this work. The creation of a better diagnostic CAD system will enable clinicians to evaluate CT scan pictures more accurately and in less time. 6
In the past, researchers utilized traditional machine learning algorithms. However, a more comprehensive analysis to determine the associations and other Bayesian measures to further strengthen our analysis to unfold the hidden dynamics for further improving lung cancer prediction. The parametric information from the data in recent studies has been investigated using a probabilistic propagation algorithm (Bayes Rule) by applying Bayesian networks (BNs). The degree of uncertainty and associations of variables varies from different sources such as numerical data, empirical data, and expert opinion to capture the conditional dependencies of a variable upon others. 7 BNs have successfully been utilized in many studies by different researchers such as Kocian et al., 8 Amaral et al., 9 Laurila-Pant et al., 10 and Zhang et al. 11 The Bayesian inference (BI) approach utilizing the BayesiaLab has gained its popularity to investigate the causal relationships, dynamic profile analysis, target analysis, posterior probability analysis, etc. in variety of different applications including empirical analysis of brain tumor MRIs, 12 dynamic profile analysis of congestive heart failure, 13 environmental sustainability indicators to manufacture, 14 dynamical analysis of particulate matters future challenges monitoring and evaluations, 15 predicting childhood lead exposure risk from community water system using Bayesian approach, 16 etc. There are many applications of BI approach such as intrahepatic cholangiocarcinoma patients’ microvascular invasion, 17 human factor analysis for sustainable hazardous cargo port operations, 18 gallbladder polyps with malignant potential based on preoperative ultrasound Bayesian prediction analysis, 19 decision-making, 20 industries 4.0 technologies selection, 21 transport vulnerability, 22 etc.
The causal relationships can be studied between variables that compute the probabilities of a variable when other variables in the model are known. Moreover, the Monte Carlo analysis can be used at a random sampling of probability distribution functions to denote the inputs of Bayesian model to produce hundreds or thousands of possible outcomes. 23 Recently, BNs have been utilized successfully in many applications ranging from predicting energy crop yield, 24 coffee rust disease prediction by employing BNs, 25 sustainable planning and management decision, 26 etc. The BNs computed the interrelation among variables that impact climate change scenarios in agriculture. 27 Moreover, recently, Lu et al. 28 utilized BNs to investigate the complex causal interactions between environments and plant diseases. Previous studies did not focus on the association among features to further unfold nonlinear dynamics in order to further diagnosis and prognosis of lung cancer.
In the present study, we aimed to apply the BI approach for comprehensive analysis to unfold the nonlinear and hidden dynamics present in the nonlinear and nonstationary lung cancer types. Lung cancer types have very severe health impact, so there is a dire need to unfold nonlinear hidden dynamics and associations among extracted features based on Bayesian artificial intelligence methods so that concerned health professional can take precautionary measures to reduce the mortality risks. We computed the associations and their strength among gray-level co-occurrence matrix (GLCM) features. The BI evaluates the posterior which can be yielded from a weighted combination of local estimates known as likelihood and estimates in surrounding spatial units. Researchers are developing intelligent methods based on machine learning algorithms that require the extraction of the most relevant features. Our research objective was multifold, first, we computed the multimodal features based on time domain, frequency domain, and entropy-based complexity measures. We then ranked the features based on t-test value. The higher the t-value indicates the more important the feature. Secondly, once we ranked the features, we then selected the high-ranked feature as our target node and then we further computed the detailed Bayesian analysis with other features to further unfold underlying hidden dynamics. We computed the relationship analysis among the extracted nodes using mutual information (MI), Kullback–Leibler (KL) divergence, and Pearson's correlation. The strength of relationship was computed using arc analysis with 3D mapping. We then computed the parent–child relationship and nodes force between the nodes. The association graph for segment profile analysis was computed for further analysis. Moreover, the network performance and significance of prominence were computed using tornado diagram. The flow of our work is presented in Figure 1. We first took lung cancer as an input signal. We then extracted the GLCM features. We then applied the features to BN and utilized different methods for detailed analysis. Finally, the network performance was evaluated using different metrics.

Schematic diagram to compute the Bayesian dynamics on gray-level co-occurrence matrix (GLCM)-based features.
The Bayesian approach recently gains its popularity and utilized in many medical, signal, and image processing problems. We first computed the features considering multiple aspects in order to capture the diverse dynamics of lung cancer MRIs. We then ranked the features based on t-test, which feature sets are more important. The Cluster Prominence was set as our target node for further detailed analysis. To unfold the deeper dynamics of computed features, we can further compute the strengths of correlations, associations, strengths of target nodes and its correlation with other nodes using target profiling, and associations of target node with other nodes. This study will be very helpful to understand the deeper insights to further investigate the hidden dynamics in the signals and can play a vital role in providing an improved diagnostic system.
Materials and methods
Dataset
A publicly available dataset from www.giveascan.org was taken which is detailed and recently used in Hussain et al. 29 These data contain 76 patients with SCLC subjects of 563 and NSCLC of 356.
Feature extraction
The most important step in machine learning is the extraction of the relevant hand-crafted features. The features can help to improve the classification performance. In the past, researchers computed features based on different variations including texture, shape-based, geometric, and complex dynamics.29–34 In this study, we computed GLCM-based features. GLCM features proposed by Haralick and Shanmugam 35 in 1973 based on texture properties. We extracted the GLCM texture features from lung MRIs developed in MATLAB and utilized them in many recent renowned studies for texture analysis.36–39 We extracted 22 GLCM features from lung MRIs. There are various GLCM features that can be calculated, such as contrast, correlation, energy, homogeneity, and entropy. However, not all features are equally informative, and some of them may be redundant or highly correlated with others. Therefore, it is often useful to select a subset of features that are most relevant for a particular task, such as classification or segmentation.
In the context of feature selection, BayesiaLab is used to identify the most informative and relevant features for a given task. This is typically done by constructing a BN model that captures the conditional dependencies between the features and the target variable, and then using probabilistic inference techniques to estimate the marginal and conditional probabilities of the features. The final most relevant selected features were 10 returned by the BayesiaLab.
Feature importance ranking algorithms
The feature importance ranking (FIR) is used to rank the importance of features using supervised ranking algorithms. 40 The FIR algorithms developed in MATLAB were utilized. 41 The importance of the extracted features was computed based on the entropy values. Entropy is used in many applications of medical systems to compute the nonlinear dynamical measures present in these systems. The higher the entropy values indicate the more complex systems with interacting components. Multiple interacting modules of biological systems produce biological signals, which show different arrangements in a complex rhythm. Due to structural part malfunctions and decreased interactions in coupling functions, these rhythms and patterns are disrupted.
T-test method for feature ranking
The t-test is a statistical hypothesis test that is used to determine whether the means of two groups of data are significantly different from each other. In the context of feature ranking, the t-test can be used to compare the means of a particular feature across groups of data and to determine whether the feature is significantly associated with the target variable. MATLAB has developed a diagnosticFeatureDesigner by providing 30 FIR methods. Based on the present data, we utilized the t-test method which is built-in in fir_mat_ttest () method which sorts the features based on the class separability criteria of two-sample t-test. 42 The t-test method is used to rank features based on their ability to discriminate between different groups and classes of data.
The procedure for the t-test in the Diagnostic Feature Ranking Tool may involve the following steps:
Partition the dataset into two or more groups based on the target variable or class labels; Calculate the mean and standard deviation of each feature for each group; Calculate the t-value for each feature, which measures the difference between the means of the groups relative to the standard deviation and sample size; Calculate the p-value for each feature, which measures the probability of obtaining the observed t-value or a more extreme value if the null hypothesis (i.e., no difference between the means) is true; Rank the features based on their t-values or p-values, with higher values indicating greater discriminatory power.
By ranking the features based on their t-test results, the Diagnostic Feature Ranking Tool can identify the most relevant and informative features for a given classification problem.
Bayesian network analysis
Our main focus is to compute the association and relationship strength between extracted GLCM features using BI approach which is a directed acyclic graph (DAG).
43
Consider X = {X1, X2, X3, ……Xn} a set of m dimensional variables, the couplet





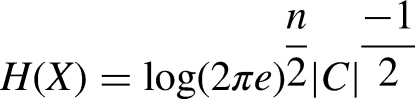
The MI and CMI2 after mathematical transformation is:

Statistical analysis
We computed the GLCM features from lung cancer NSCLC and SCLC MRIs using MATLAB. We then provided the feature matrix to BayesiaLab for further detailed analysis. We conducted the analysis using BayesiaLab 11.0. We used the BayesiaLab available at (https://www.bayesia.com/home/en-us/) with minimum description length (MDL) of the candidate network in its score-based algorithm to compare the BN structure. 48 The statistical independence test (GKL-test; p > 0.05) was used to validate the connections among the descriptors which were identified by the learning algorithm. The p-values or independence probabilities were utilized to check the significance of each individual relationship between the nodes or between nodes and the target node.49,50
Exploratory analysis of the unsupervised network
The exploratory analysis can be utilized to determine the potential relationship between variables of interest. 51 We can further explore the global analysis of problem of interest by computing the influence between nodes and the influence of nodes under investigation. We build our model by learning an unsupervised learning algorithm utilizing maximum spanning tree (MWST) algorithm approach developed in BayesiaLab V10. 52 We also computed MWST. The lowest value of MDL denotes the best trade-off between complexity and data representation.
Sensitivity analysis
A detailed sensitivity analysis was performed to check the relationship among the nodes in the selected network. To understand the relationship between the nodes, we computed the highest and lowest values PM, MI, and KL, and node force between the nodes was examined globally on the network. The probabilistic dependencies were computed using MI between the nodes in the network. The tornado plots are used to display the influential knowledge of each node using sensitivity analysis on the probability of each descriptor and maximum strength of the individual relationship between the nodes and descriptors was computed. The lowest and highest probability values are displayed from the tornado plots to achieve the each node from hard evidence placed on the corresponding descriptor state. The confidence and consistency level of the sensitivity analysis using the BN model are verified by validating the model53–55 to verify different conditions.
Segment profile analysis of energy
The analysis was also done using segment profile analysis using Radar chart for normalized mean values conditionally to Cluster Prominence for all other GLCM features. The significance was tested using Bayesian test (Best) and NHST t-test (a frequentist test). Using NHST t-test, the two-tailed t-test is utilized for null hypothesis significance testing. The Bayesian (Best test) is detailed by Kruschke 56 which follows the student's t-distribution. Moreover, 95% confidence interval is utilized. When the mean values are estimated as significant, a square is added next to the Label.
Results
In this study, we first extracted the GLCM features from lung cancer NSCLC and SCLC MRIs. The features were ranked using t-test. The highest t-test values were yielded using Cluster Prominence, and we kept it as our target node. The rest of the analysis is performance with Cluster Prominence.
Figure 2 shows the ranking of GLCM features ranked using t-test. The features are ranked without utilizing any unsupervised or supervised machine learning algorithm. A specific method that ranks the features is based on the assigned score values. 40 Finally, based on these scores, the features are ranked and the features with redundant information are further eliminated for classification. In this study, we ranked the features developed in MATLAB diagnostic tool.
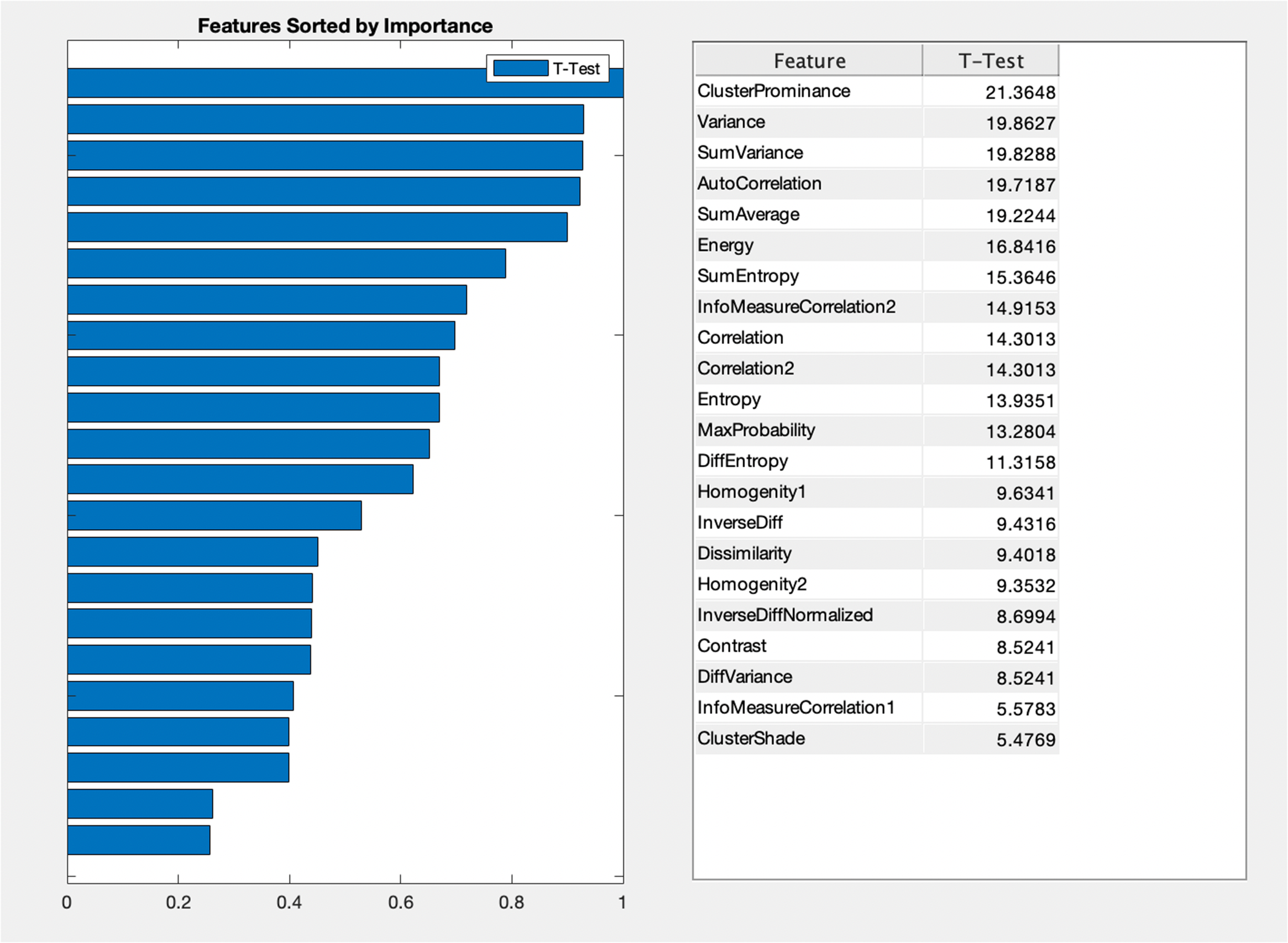
Feature ranking based on T-test values.
Figure 3 depicts the relationship analysis using BI methods including the MI, KL, and PC. The bold lines represent the stronger relationship, and the lighter lines indicate the smaller relationship. The blue color indicates the positive relationship, whereas the red color indicates the negative relationship. Moreover, the arrows indicate the

Relationship analysis using different Bayesian inference approaches such as (a) Mutual information (MI), (b) Kullback–Leibler (KL) divergence, and (c) Pearson's correlation by applying the unsupervised learning using maximum spanning tree and selecting Cluster Prominence as our target node.
Figure 4 represents the 3D mapping arc analysis to show the relationship among the multimodal extracted features. The nodes represent the features and lines represent the relationship between the nodes. The strength of relationship is denoted by the width of line. The blue color represents the positive relationship, whereas the red color denotes the negative relationship. Using the MI, the highest association was obtained between the nodes between the nodes

Arc analysis 3D mapping to determine the relationship among the nodes (a) Mutual information, (b) Kullback–Leibler (KL) divergence, and (c) Pearson's correlation.
Parent–child relationship on extracted multimodal features to distinguish the NSCLC from SCLC using mutual information (MI), Kullback–Leibler (KL) divergence and Pearson's correlation.

Table 2 reflects the incoming, outgoing and total force of GLCM features from lung cancer MRIs. The correlation2 node has outgoing force (1.3409), incoming force (1.6997), and total force (3.0406); the AutoCorrelation node has outgoing force (1.4760), incoming (0.7872), total force (2.2632), and so on. The highest outgoing and total force was yielded by the node Correlation2. The highest incoming force was yielded by the node WE-Th (1.6997).
Node force of extracted multimodal features from lung cancer MRIs.

We first extracted the GLCM features from NSCLC and SCLC. We then ranked the features before applying the BI approach. The cluster Prominence was highly ranked features measured using t-test, which was selected as our target for further Bayesian analysis. We computed the association of top-ranked Cluster Prominence feature with other features to further unfold the association among the features. There were four states represented by ≤330.885, ≤714.925, ≤1004.873, and >1004.873 with highest data points to lowest data points in ascending order, respectively, as represented in the Mosaic association graph in Figure 5 and Table 2.

Analysis of target node Cluster Prominence with other extracted nodes using Mosaic graph and predictions of occurrence made against each state ≤330.885, ≤0.714.925, ≤1004.873, and >1004.873.
In a BN, the prior probabilities represent the probability distribution of each variable before any evidence is observed. These prior probabilities are used as inputs to calculate the posterior probabilities, which represent the probability distribution of the variables after the evidence is observed.
The prior probabilities in BayesiaLab represent the probabilities of each variable before any evidence is observed, and the rules for calculating posterior probabilities are based on Bayes’ theorem. To set different states for prior probabilities in BayesiaLab, we used a prior probability distribution. The prior probability distribution can be chosen from a set of predefined distributions, such as uniform, normal, beta, and gamma, and we used the normal distribution as reflected in Figure 5. Once the prior probabilities are set, BayesiaLab uses the rules of BI to calculate the posterior probabilities.
Figure 6 depicts the analysis of the association graph for segment profile analysis of top-ranked target node with other extracted Multimodal features using the Radar chart which reflects the distributions based on 1–12 clock hours. Figure 6 (a) reflects the overall probability and we used the NHST t-test and Bayesian test to find the significance to distinguish with other different states such as (a) overall, with selected states, (b) ≤330.885, (c) ≤0.714.925, (d) ≤1004.873, and (e) ><=1004.873 as reflected in Figure 6 (b-e). The highest significance using both tests is reflected by double boxes blue and light blue. Where the significance of any one test is reflected by single box. The node with no box shows no significance at all with any test.

Association graph of segment profile analysis of SDAPM node with other extracted multimodal features using radar chart graph at different selected states (a) overall, with selected states (b) ≤330.885, (c) ≤0.714.925, (d) ≤1004.873, e) ><=1004.873.
The network performance of selected target node Cluster Prominence with other selected nodes yielded the highest predictions with 100% reliability and precision for all selected states as Figure 7 (a-d). A relative Gini index of 99.98%, ROC index of 100% was obtained as reflected in Figure 7 (b-c) and lift index of 99.95%.
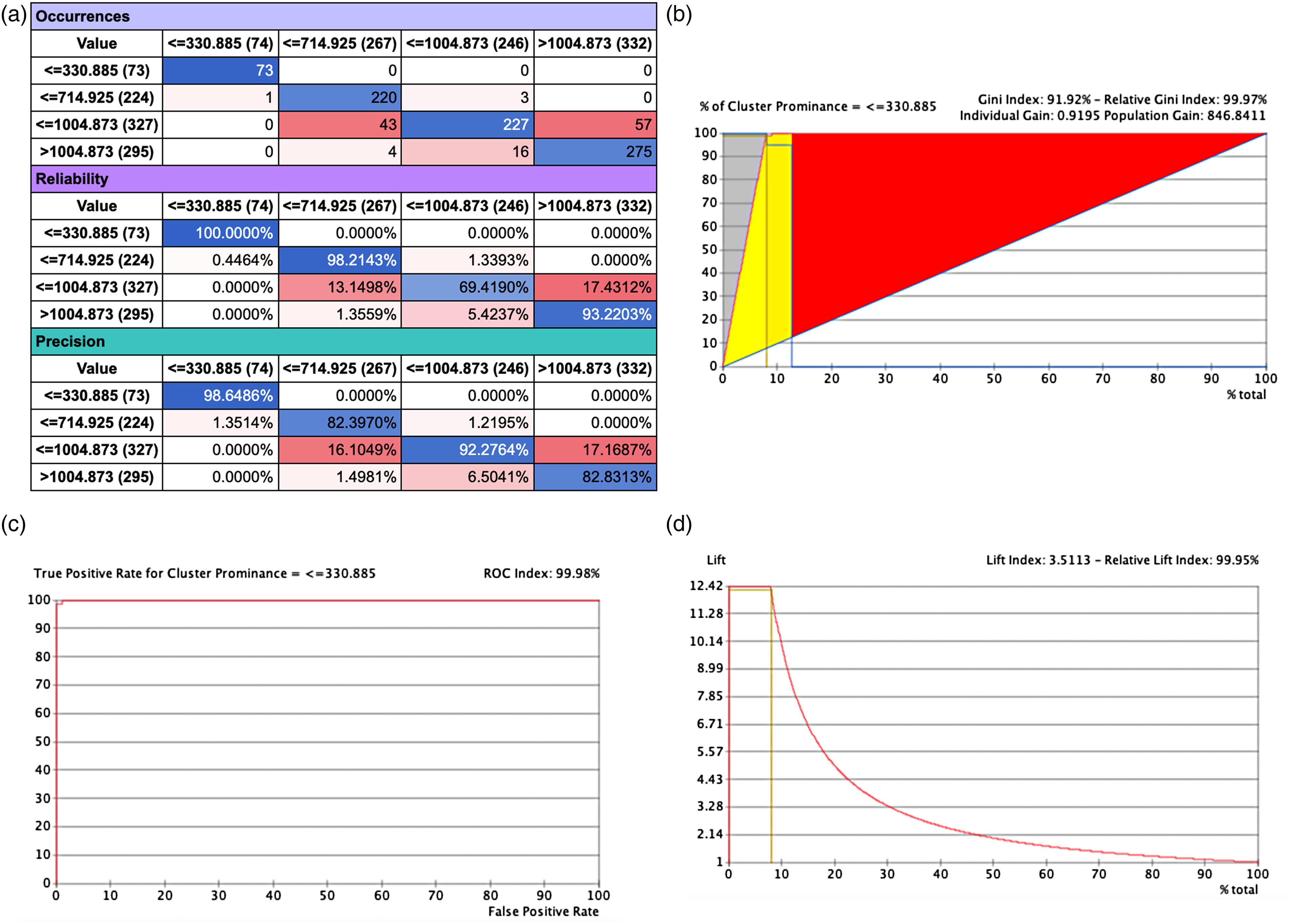
Network performance target evaluation Cluster Prominence node with other selected nodes (a) Occurrence, reliability and precision report; (b) Gain report of state ≤330.887, (c) ROC index of state ≤330.887, and (d) Lift index of state ≤330.887.
Figure 8 reflects the Tornado diagram of posterior probabilities to compute the significance of Cluster Prominence node with all nodes at different selected states. Table 3 shows the local analysis of the target state Cluster Prominence with state ≤330.887. The highest association was achieved with node Cluster shade with binary MI (0.19710), relative BMI (54.24%), binary relative significance (1.00), posterior mean value (1.540), and max Bayes factor (state ≤25.48 (1/4) with occurrence 93.93% and contribution of 7.33) followed by contrast with binary MI (0.1146), relative BMI (31.54%), binary relative significance (0.581), posterior mean (0.324), Max Bayes factor (state 0.397 (1/4) with occurrence 97.40% and contribution 5.11), and so on.

Tornado diagram of posterior probabilities to compute the significance of Cluster Prominence node with all nodes at selected cluster states (≤330.887, ≤714.925, ≤1004.873, and > 1004.873).
Local analysis of target state cluster prominence with state ≤330.887.

Figure 9 reflects the structural coefficient analysis to reflect the strength of the association of arc frequency and v-structure frequency among GLCM extracted features. The highest 100% arc frequency was yielded between nodes

Structural coefficient analysis based on learning of taboo algorithm.
Discussions and conclusions
The process segment discusses the machine learning advantages, hypotheses, and conditions for the following machine algorithms: Naive Bayes, decision tree, KNN, Neural Network, Support Vector Machine, and Genetic Algorithm. CAD operations are dynamic schemes built in the range of lung cancer diagnosis to identify and classify several lesions. A conventional CAD system involves processing multiple images, performing different tasks, and then classifying these into tumors or benign lesions. 57 The CAD device is used specifically to detect lung cancer. This method addresses the issue of designing a computer-based system to obtain the highest features from the differentiated unusual region of the lung CT image. Those features could be utilized to specifically identify lung tumors from the CT as favorable or destructive. A recent study achieved a sensitivity of 80% for detecting nodules with malignant potential and resulted in 0.85 false positive readings per section. In short, computer-aided diagnosis of lung nodules is likely to have an important role in CT-based screening tests in the near future. 58 The present research is consistent with similar studies investigated by utilizing BayesiaLab to determine the strength of relationship, causality among the features, node force, dynamic profile analysis, sensitivity analysis to further unfold the nonlinear hidden dynamics to further improve the diagnostic and prognostic such as brain tumor MRIs, 12 congestive heart failure, 13 prostate cancer, 59 and lungs infection due to particulate matters. 15 The results reveal that the proposed approach can be better utilized for early decision-making and improving the better diagnostic and prognostic system for patients suffering from lung pathologies.
The extraction of the most relevant features is a tedious task that requires specialist knowledge to compute the most relevant feature based on the choice of the problem. Previously, the researchers computed features based on texture, morphological, scale-invariant Feature transform, elliptic Fourier descriptors, and entropy features to detect the different pathologies in breast cancer and lung cancer. However, the extensions in texture features based on GLCM are further strengthening to improve lung cancer prediction which is proposed in this study. The GLCM features are widely used in medical image analysis, including lung cancer detection and diagnosis. GLCM features are extracted from the co-occurrence matrix that describes the distribution of gray-level pairs in an image. The GLCM features capture texture information and provide quantitative measures of the image's texture properties. Contrast measures the difference in intensity between neighboring pixels and is useful in distinguishing between regions with varying intensity levels. Correlation measures the linear relationship between pixel intensities and is useful in identifying patterns in the image. Energy measures the uniformity of gray-level values and is useful in identifying areas with homogeneous texture. Homogeneity measures the similarity between neighboring pixels and is useful in identifying areas with consistent texture. Entropy measures the randomness of gray-level values and is useful in identifying areas with complex texture.
In terms of ranking, if the goal is to identify differences between groups or features based on means, a t-test may be more appropriate. However, if the goal is to identify complex patterns and features based on their randomness or entropy, an entropy test may be more appropriate. In other cases, entropy-based methods may be more appropriate, such as when the data are nonparametric, or the goal is to identify informative features regardless of their relationship to the target variable.
To use BayesiaLab for lung cancer detection based on GLCM features, we constructed a BN. A BN is a graphical representation of the probabilistic relationships between variables. In this case, the variables computed were GLCM features and the presence or absence of lung cancer. The first step in building a BN is to define the variables and their relationships. We defined the GLCM features as the input variables and ranked these features based on t-test. We then kept the high-ranked features Cluster Prominence as our target variable. We then defined the conditional probabilities between these variables based on prior knowledge and available data. Once the BN was constructed, we used to make predictions about the presence or absence of lung cancer based on the GLCM features. To do this, we input the GLCM features into the network and calculated the probability of lung cancer given those features. A detailed analysis was then performed with the target variable such as exploratory analysis, relationship analysis, target optimization, segment profile analysis, network temporization analysis, dynamic profile analysis, and structural coefficient analysis. This approach can be more helpful to unfold the complete picture of the extracted nodes and their strengths and associations can help us to further investigate to build a better diagnostic system. The proposed approach will be very helpful to investigate the hidden complex and nonlinear dynamics and associations among the extracted GLCM features which can be further utilized to improve the prognosis and diagnosis of lung cancer and can assist healthcare practitioners to provide better disease decision-making system. The proposed approach will further help to decrease the mortality rate.
There are few limitations of the study, as currently, the dataset is single centric study and lacks of clinical information of the patients, thus need more computational methods with hyperparameters optimization to manage the multicenter studies. In the future, the proposed approach can be utilized on depository dataset from different facility to authenticate the results for larger and multicentric study. Multicentric studies have several advantages over single-center study and are commonly used in medical research, where they may involve several hospitals, clinics, or research centers collaborating on a common research question.
For example, a multicentric study might investigate the effectiveness of a new cancer treatment by collecting data from patients treated at different hospitals across the country or the world. The advantages of multicentric studies include the ability to recruit a large and diverse sample, which can increase the generalizability of the results, and the ability to combine resources and expertise from multiple sites. We will apply the proposed methods on a larger dataset with more clinical information of the patients.
Footnotes
Acknowledgments
This work was supported by the King Khalid University, Abha, Saudi Arabia. The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Larg Groups Project under grant number (R.G.P. 2/43/44). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R192), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Shaqra University for supporting. This study is supported via funding from Prince Sattam Bin Abdulaziz University project number PSAU/2023/R/1444
Consent statement
A publicly available dataset from ![]() was taken which is detailed and recently used in Hussain et al,
29
so the patient consent is not necessary.
was taken which is detailed and recently used in Hussain et al,
29
so the patient consent is not necessary.
Declaration of conflicting interests
The author(s) declares that they do not have any conflict of interest.
Ethical approval
A publicly available dataset from ![]() was taken which is detailed and recently used in Hussain et al.
29
was taken which is detailed and recently used in Hussain et al.
29
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Guarantor
N/A