
Abstract
The notice-and-comment period in US federal rulemaking fosters civic engagement but has long been dominated by well-resourced actors with specialized knowledge, creating an “accessibility gap.” Large language models (LLMs) may help bridge this divide by assisting citizens in understanding dense policy documents and drafting effective comments. However, these tools could also exacerbate existing disparities, as those actors already well-represented in the rulemaking process may be better positioned to use LLMs effectively. We employ two empirical tests to assess whether LLMs bridge or reinforce these disparities. First, we conducted a survey experiment where participants submitted mock comments on a policy proposal, with the treatment group using an LLM to assist their responses and the control group completing the task unaided. The LLM made comment-writing easier, as self-reported by participants across education levels, suggesting a potential to expand accessibility. However, it did not improve participants’ self-reported policy comprehension, indicating that LLMs are not a solution to knowledge gaps. Second, reviewers evaluated the quality of comments written with and without assistance. Comments written with LLM assistance consistently received higher ratings regardless of the commenter's education level. While assistance did not disproportionately benefit any particular educational group, the quality improvement may be especially meaningful for less-educated citizens, helping their submissions reach the threshold of serious consideration by policymakers. LLMs could therefore serve as an entry point for those who have traditionally been underrepresented in the rulemaking process.
Keywords
Introduction
The United States’ Administrative Procedure Act (APA) of 1946 requires federal agencies to solicit public feedback on proposed regulations through the submission of written comments. Known as the “notice-and-comment period,” the process is often described as a hallmark of modern governance; it promises transparency, accountability, and an avenue for citizen input in otherwise expert-driven policymaking (Rochvarg, 1981: 1). At the same time, scholars and policymakers have long debated whether the process meaningfully enables broad participation or instead privileges well-resourced actors with the expertise to navigate its demands.
Recent advances in artificial intelligence (AI) raise new questions about this long-standing accessibility gap. Large language models (LLMs), a subset of generative AI that includes commercial systems such as ChatGPT, Claude, and Gemini, leverage massive datasets, machine learning, and transformer-based architectures to recognize, predict, and mimic patterns in human language. For brevity, we sometimes refer to this as “AI assistance,” but throughout this paper all uses of “AI” refer specifically to LLM-based tools. Capable of analyzing complex prompts and generating seemingly credible responses, LLMs may expand access to a deliberative process, empowering a more diverse audience to participate in rulemaking. Generative AI models could be used to summarize policy documents, simplify information about the notice-and-comment process itself (Johnson, 2024), and expand the range of lived experiences expressed in comments, ultimately generating more meaningful and actionable commentary.
At the same time, LLMs could exacerbate the accessibility gap, deepening the very social and political inequalities that have long hindered inclusivity in the rulemaking process. Generating meaningful comments may require familiarity with generative AI that is unevenly distributed across citizens. Some scholars argue that prompt engineering remains essential for effective AI use, especially in specialized or high-stakes contexts (Li et al., 2024; Zamfirescu-Pereira et al., 2023). However, recent studies have challenged this argument, finding that elaborate prompting yields few benefits—or even negative impacts—compared to simpler approaches (Wang et al., 2024). Either way, achieving the best outcomes typically involves skill and domain knowledge, which may track with education and thus risk amplifying the representation gap.
In an effort to move beyond theoretical speculation about the relationship between LLMs, accessibility, and the notice-and-comment period, we ask: How might LLMs close the representation gap between groups that have typically been well-represented in the public comment process and those who are typically on the sidelines? Alternatively, do they widen the gap if the groups best equipped to leverage the technology are well-educated individuals already represented in this process?
Our study adopts a variety of empirical methods to explore these questions. We developed a survey experiment that tasked participants from a range of educational backgrounds to read about a proposed environmental rule and write a mock comment in response. Half of our sample used an LLM to understand the policy and write a comment in response, while the other half completed the same task without the aid of LLMs. In the second phase of our project, we randomly assigned a set of mock comments to both human respondents and an LLM, asking them to rank the comments based on a standard rubric. We then compared rankings, paying particular attention to participants’ educational backgrounds, to assess whether LLMs may narrow or exacerbate disparities in the inclusion of underrepresented voices in the public comment process.
This study finds that LLMs may improve the accessibility of the notice-and-comment period, but do not necessarily increase policy comprehension. While access to an LLM made drafting mock comments easier for participants regardless of education level, it did not have a significant effect on participants’ self-reported comprehension of policy documents. Instead, higher-educational levels remained the strongest predictor of self-reported understanding, suggesting that while LLMs help with articulation, they do not eliminate knowledge gaps and civic illiteracy.
Our findings also suggest that LLMs may help level the playing field by enabling participants with less formal education to write higher-quality comments. Our results show that comments written with the help of an LLM were rated higher in quality by both human and AI evaluators, regardless of the commenter's education level. That is, access to LLMs did not disproportionately benefit any educational group. However, because the notice-and-comment period has historically favored highly educated individuals with specialized knowledge and resources, the quality boost from LLM assistance may be more meaningful for those with less formal education. By helping these participants reach an implicit threshold for being taken seriously by policymakers, LLMs could provide a crucial entry point for those who have traditionally been underrepresented in the rulemaking process.
These findings contribute to ongoing debates about the role of AI in democratic governance and highlight questions about whether LLMs mitigate or reinforce disparities in civic participation (Engstrom and Ho, 2021; Kreps and Kriner, 2024; Li et al., 2024; Zamfirescu-Pereira et al., 2023). While we find that AI-assisted public commenting may help democratize access to rulemaking, it also raises regulatory challenges, particularly in distinguishing between authentic, meaningful citizen input and mass, AI-generated comment campaigns. These findings connect to long-standing concerns about the possibilities and limits of citizen voice in governance that we discuss in the next section.
Background and related work
To situate our study, we approach the US public commenting process from three perspectives. First, we review ongoing theoretical debates about the role of public participation in democratic governance. Second, we turn to empirical evidence showing the practical limits of participation and the barriers that make it difficult for ordinary citizens to contribute effectively. Finally, we consider how new technologies, particularly LLMs, could alter this dynamic, either by lowering participation costs or by reinforcing existing inequalities and creating new challenges for agencies.
Theorists of deliberative democracy emphasize the importance of discourse and civic engagement in amplifying citizens’ voices, legitimizing political authority, and constraining governmental discretion. For decades, scholars have debated the extent to which participation in democratic deliberation can contribute to legitimacy and policy effectiveness. As Habermas (1996) argues, the legitimacy of law depends on discursive processes that enable broad and equal participation. Notice-and-comment rulemaking aspires to this ideal, but in practice is skewed toward organized interests. Mansbridge (1983) underscores that participation is often partial and shaped by context, while Fung (2006) points to institutional designs that can expand opportunities for citizen voice.
Tocqueville, writing in Democracy in America (1835/2000), saw participation in local associations and town meetings as a school of democracy. These practices did more than just solve immediate political questions; they trained citizens in habits of deliberation, cooperation, and self-restraint. For Tocqueville, the legitimacy of American democracy was not only procedural but also moral and cultural, rooted in the daily exercise of civic responsibility. This anticipates later theories of deliberative democracy by emphasizing how discourse and shared decision-making cultivate the very virtues needed for self-government. Skocpol and Fiorina (1999) similarly contend that democratic strength depends on broad citizen involvement in civic life, but later work shows how civic engagement in the United States has shifted from grassroots membership associations to professionalized organizations, reducing opportunities for ordinary citizens to exercise influence (Skocpol, 2003).
At the same time, scholars have also expressed skepticism about the values of deliberative democracy. Plato warned of democracy's vulnerability toward majority tyranny, while modern critics have argued that expansive participation risks incoherence, demagoguery, or symbolic rather than substantive input (Lippmann, 1922; Schattschneider, 1960). Contemporary institutionalists extend this critique by emphasizing that democracy also depends on mechanisms that channel expertise, promote efficiency, and hold decision makers accountable through legal and procedural checks (Mashaw, 1997; McCubbins et al., 1987). These perspectives maintain that not all democratic deliberation is equal, nor is more public participation inherently beneficial.
The APA of 1946 embodies this dual commitment: notice-and-comment creates a formal channel for public participation, while embedded requirements for reasoned decision-making and judicial review reflect a commitment to rationality, expertise, and legal accountability. By requiring agencies to solicit and respond to public comments, the APA provides a venue through which citizens and stakeholders can register concerns, supply information, and contest agency reasoning. Some view this as a potential source of democratic responsiveness in an otherwise technocratic process (Mendelson, 2011, 2021).
Others, however, question how far the process delivers on that promise. Agencies are legally obligated to respond only to “substantive” comments that raise new evidence or highlight overlooked issues (Savitz, 2021: 761), meaning general expressions of personal opinion carry little weight. This institutional threshold privileges well-organized actors who can marshal the necessary technical, legal, and bureaucratic expertise that ordinary citizens rarely possess (Balla, 1998; Furlong and Kerwin, 2005). As such, the most impactful comments typically come from organized groups or elite actors who can afford the time, training, and resources to justify their positions with regulatory precedents, economic analyses, or novel data (Ahmed et al., 2018; Golden, 1998; Johnson, 2024: 1028; Mendelson, 2012; Yackee, 2006). Indeed, empirical studies suggest that in many rulemaking processes, only a small fraction of the public participate—with most submissions coming from business groups, lawyers, or lobbyists (Coglianese, 2006; Golden, 1998; Kim, 2011; West, 2004).
Consider, for example, this citizen's comment to the Environmental Protection Agency's (EPA) proposed Safe Drinking Water Act read, “Get the lead out of the water by any means possible…now!!!” (United States Environmental Protection Agency, 2024: 1–43). While heartfelt, it lacked the legal reasoning, empirical evidence, or detail that characterize influential submissions. The difficulty for ordinary citizens therefore lies not only in showing up but also in producing the type of input that agencies consider (Farina et al., 2012).
Our small-N exploratory study, conducted prior to our survey experiments, revealed significant knowledge gaps that may further explain the accessibility barriers in rulemaking. 1 When participants were asked to diagram their understanding of the rulemaking process, none included a role for themselves or for the public. While limited in scope, this absence illustrates both the low visibility of the notice-and-comment process and the broader challenges of civic and policy literacy that deter participation, even before citizens face the technical difficulty of drafting substantive comments.
The digital divide and democratic participation
These difficulties do not occur in isolation but reflect a broader digital divide. Unequal access to technology and the skills to use it increasingly shape who can take part in political life. A large body of research shows that disparities in connectivity and digital literacy track with socioeconomic status, race, geography, and age, producing unequal opportunities to engage with legislators, access information, or benefit from online services (Norris, 2001; Robinson et al., 2020; van Dijk, 2006). From a democratic perspective, these inequalities raise concerns about civic inclusion and legitimacy: if only some citizens can effectively use available channels to make their voices heard, the representative character of legislative processes may be diminished (Dahl, 1989; Fung, 2006; Mansbridge, 1983). We therefore treat the digital divide not simply as a descriptive phenomenon but as a normative problem that undermines equality of participation and the quality of democratic governance.
As new tools such as LLMs emerge, the question is whether they can help narrow these divides by lowering barriers to participation, or instead risk reinforcing the same structural inequalities that already limit who takes part in rulemaking. Early work points to both opportunities and risks, particularly in two areas most relevant to our study: how citizens use these tools to participate in the policy process and how policymakers evaluate the resulting comments.
LLMs have the potential to make the commenting process more accessible by helping individuals with less education or experience articulate their concerns in clear, formal language. They can simplify dense regulatory text, translate jargon, and provide context that helps nonspecialists engage substantively with proposals (Chenok and Huth, 2023; Dooling and Febrizio, 2023; Johnson, 2024). While scholars have advocated for the use of plain language in regulatory documents (Sant’Ambrogio and Staszewski, 2018), Farina et al. (2012) point out the linguistic differences between policy “insiders,” who have developed a “highly characteristic and esoteric set of practices around writing, justifying, commenting upon, attacking, and defending new regulations” that is largely inaccessible to outsiders (Farina et al., 2012: 108). Because LLMs can be prompted to generate text in diverse tones and styles, they may enable users to adopt the professional language or jargon of the type commonly used in regulatory documents, potentially enhancing the perceived credibility of citizens’ comments (Bai et al., 2025; Johnson, 2024). These capabilities suggest a pathway for broadening participation and amplifying underrepresented voices.
Those same tools may also help agencies process and respond to public input. Scholars note that LLMs could sort comments, identify themes, and highlight substantive issues more efficiently than existing methods. For example, Corcoran (2023) explores how AI tools could be deployed in judicial review to help categorize and prioritize comments, while Balla et al. (2022), writing before the advent of modern LLMs, discuss how computational tools such as de-duplication filters, metadata checks, and text analysis can help agencies manage mass submissions, identify discursive patterns, and flag substantive content. Beyond efficiency in processing large volumes of input, LLM-generated comments could also affect the substance of policymaking. If these comments are more structured, evidence-based, and reflective of a broader range of concerns, they may improve the quality of the feedback policymakers receive, allowing agencies to craft more responsive rules (Kreps and Jakesch, 2023; Levin, 2024).
However, LLMs also introduce risks that include exacerbating existing disparities in participation and creating new vulnerabilities to manipulation. Effective use often requires familiarity with prompt engineering or domain knowledge that tracks closely with education and socioeconomic status (Bartels, 2008; Hacker and Pierson, 2014; Zamfirescu-Pereira et al., 2023). Individuals who already hold political advantages may therefore be best positioned to benefit, while marginalized groups risk falling further behind (Jacobs and Skocpol, 2005; Kreps and Kriner, 2024).
Other scholars highlight more systemic threats, such as the possibility that malicious actors could exploit LLMs to generate mass comments at scale, overwhelming agencies and distorting perceptions of public opinion (Kreps et al., 2022; Weiss, 2019). While “mass comment campaigns” involving large numbers of identical or near-identical submissions are not a new phenomenon (Savitz, 2021: 765) and only substantive input is legally relevant, agencies must still process these comments. AI-generated comments may therefore drain agencies’ resources. Recent work also shows that generative AI tools could be used to simulate citizen voices in legislative or agenda-setting contexts, raising concerns about astroturfing, the practice of manufacturing the appearance of grassroots participation (Kreps and Jakesch, 2023; Kreps and Kriner, 2024).
While our study does not evaluate automated manipulation directly, these concerns illustrate the broader uncertainty surrounding how AI will reshape the rulemaking process. To date, research on LLMs and rulemaking has been largely conceptual or exploratory. Scholars have examined potential agency-side uses of computational tools for sorting and clustering comments (Balla et al., 2022; Corcoran, 2023), and policymakers have begun experimenting with generative AI in legislative and local-government contexts. Yet, no study systematically evaluates how citizens use LLMs to participate in notice-and-comment or how policymakers assess AI-assisted submissions. To address these research gaps, we focus on two questions: How may LLMs mitigate or exacerbate the participatory gap in the public commenting process? Further, do policymakers interpret AI-assisted comments differently from those drafted without such tools?
Methodology
To understand whether LLMs could help bridge the digital and participatory gap in the notice-and-comment period, we conducted a two-part study. The first phase consisted of a survey experiment that asked individuals to read and comment on a federal policy. Participants in the treatment group were instructed to use ChatGPT, a popular and publicly available LLM developed by OpenAI, to support the reading and writing process, while the control group was asked to submit a comment without the help of generative AI. We selected ChatGPT 3.5 because it is free, well-known, and accessible without requiring that users create an account. Indeed, recent surveys suggest that ChatGPT accounts for roughly 70% of consumer use of LLMs (Muhammad, 2025). Employing this platform therefore approximates real-world adoption patterns, even if broader generalizability across models remains a question for future research.
In the second phase of this study, we randomly assigned six mock comments submitted in the first phase to a sample of individuals approximating policy elites. Participants were provided with a standard rubric and asked to evaluate the comments, allowing us to explore how access to LLMs influenced the quality of comments across participants from a variety of socioeconomic and educational backgrounds.
Study 1
In the first part of the study, 386 participants engaged with a real policy submitted for public comment in 2019, with half of the participants (N = 193) having access to ChatGPT, and the other half (N = 193) completing the same task without access to AI tools. We recruited our participants online, using Prolific. 2
We also needed to decide how to conceptualize “underrepresentation” in the context of the notice-and-comment process and policymaking more broadly. Operationalizations of “underrepresentation” vary across literatures, with many studies emphasizing demographic or socioeconomic disparities (e.g. Balla, 1998; Feinstein, 2022; Rossi and Stack, 2023; Yackee and Yackee, 2006). In this paper, we focus on education level as a proxy for representation, given the arcane knowledge required to parse complex regulatory proposals. Our sample had a nearly 50/50 split in terms of participants who had completed a high school education or less (i.e. no formal education, secondary education, N = 201 or 52%) and those who had completed additional schooling beyond high school (i.e. technical/community college, undergraduate degree, graduate degree, and PhD or equivalent, N = 185 or 48%). 3
Of the 386 participants in Study 1, 185 identified as women (47.9%), 188 as men (48.7%), 11 as nonbinary or third gender (2.9%), and 2 preferred not to indicate their gender (0.5%). Participants’ ages also varied; 118 (30.5%) were 18–29 years old, 173 (44.8%) were 30–44 years old, 73 (18.9%) were 45–60 years old, and 16 (4.14%) were 61 years or older. Participants also varied in their prior experience with LLMs. Sixty-four participants (16.5%) reported not having used LLMs before, 317 (82.1%) had previously used these tools, and 5 (1.29%) reported not knowing. Among the 317 participants with previous experience working with LLMs, 304 answered a follow-up question about whether they had used these models for reading comprehension or writing. In total, 213 (70.1%) reported having used LLMs for these purposes, while 91 (29.9%) did not.
In the first phase of this study, we probed how generative AI can assist citizens, especially those from underrepresented backgrounds, in discerning complex proposals and drafting comments in response. As our test case, we used the 2019 Repeal of the Clean Power Plan. In 2015, the EPA proposed new greenhouse gas emissions guidelines for existing power plants and subjected the new regulations to public comment. In 2019, the EPA then proposed repealing that plan. While we considered using the original proposal, we ultimately used the repeal for practical reasons. The original proposal was 302 pages long and even the Executive Summary was 16 single-spaced pages (United States Environmental Protection Agency, 2015). By contrast, the repeal proposal was just 64 pages and the Executive Summary was one page (United States Environmental Protection Agency, 2019). We used the latter and advised individuals that the Executive Summary could be found on page 2 of the document.
We randomly assigned half of the participants to the treatment group, provided access to ChatGPT, and asked them to complete the following: Copy and paste portions of the executive summary (page 2) into the “Message ChatGPT” box and ask it to provide you with a summary. In addition to summarizing the document, you may also use the ChatGPT tool to ask follow-up questions about the policy and help you draft a comment. An introduction that explains your interest in the regulation Constructive argumentation in favor or opposed to the proposed policy Justification on the basis of sound reasoning, evidence, and/or insight into how you would be impacted by the proposed policy Consideration of potential trade-offs and opposing views that counter your position Conclusion that summarizes position
Individuals were told that there were no formatting requirements, allowing for complete freedom regarding the number and length of comments. While participants received basic information on how LLMs generate text, they were not trained on how to use ChatGPT, nor did they receive guidance on what portions of the executive summary to input.
As previously mentioned, the quality of an LLM's output largely depends on the user's ability to craft effective prompts. If individuals with more formal education are more likely to have prior experience with LLMs compared to those with less education, these tools may enable higher-educated participants to generate more persuasive, effective comments, potentially exacerbating accessibility gaps in the rulemaking process. To test this hypothesis while avoiding priming effects, we deliberately refrained from providing training on LLM usage or specific guidance on prompt engineering. This methodological approach ensured that our experiment accurately reflected how citizens from varying educational backgrounds would engage with these tools in real-world settings.
Once participants had submitted their comments, we asked how well they understood the policy document, what they identified as the main policies being proposed, what challenges they faced in reading the policy and writing the comment, and the ease with which they wrote the comment. 4 Participants in the treatment group were asked additional questions about how they used the LLM to support them in the reading and writing process.
Study 2
For the second study, we recruited 43 evaluators from a top 20 Northeast US university to serve as proxies for the policymakers responsible for reading and evaluating public comments. We targeted recruitment efforts toward individuals with academic backgrounds in law, public policy, or political science, as these fields provide training in the analytical skills required to evaluate comments. In terms of educational attainment of the evaluators, 5 participants (11.6%) are currently enrolled in an undergraduate program, 15 (34.9%) have completed an undergraduate degree, 16 (37.2%) had completed some type of graduate degree (e.g. MA, MSc, MPhil, MBA), and 5 (11.6%) had received a doctoral degree.
We acknowledge that relying on students and faculty, rather than policymaking professionals, is a limitation of our methodological approach. However, recruiting professionals at administrative agencies poses significant feasibility constraints, including inflexible schedules, limited time, and institutional barriers that restrict participation. Instead, our participants were selected on the basis of their training in critical thinking and analytical reasoning, skills required by competent policymakers that make them appropriate proxies for policymakers.
Individuals were randomly assigned to a set of six comments submitted by participants in the previous phase of the study—three written with the aid of ChatGPT and three written without AI. Using the same rubric that was provided to comment-writers in Study 1, we asked our “elite” participants to rate the overall quality of the comments on a 1–4 scale. Participants were also asked to score each comment on five qualities of a strong comment, as identified in the rubric that was provided to both commenters in Study 1 and evaluators. Using a Likert scale from 1 to 5, these questions asked participants to what degree they agreed or disagreed that the comment's introduction, argumentation, reasoning based on evidence, acknowledgment of trade-offs, and conclusion met the rubrics standard of a “strong” comment. 5 They were also given the opportunity to highlight the comment's limitations and strengths in an open-ended question. 6
By way of comparison, we also tasked ChatGPT with reviewing the comments, giving it the same rubric that we had given the human evaluators. Here, we aimed to understand whether the LLM could also conduct a subset or summary of the reviews to alleviate the review burden of administrative officials.
Ethics
The institution's IRB reviewed our experimental research design and considered it exempt. 7 Our consent form provided a brief explanation of how LLMs and ChatGPT generate outputs and notified participants that they could be asked to use ChatGPT as part of the survey, allowing them to opt out if they were not comfortable using generative AI. Participants also received a disclosure notice about the limitations and risks associated with LLMs like ChatGPT, which include generating false or incomplete information. To preserve our participant's privacy, they were cautioned not to provide the model with “proprietary, sensitive, and confidential information.” To protect the anonymity of participants in Study 1, we ensured that no personal or identifiable information was included in the comments.
Study 1
First, we compare the results of individuals who read and responded to the policy proposal with ChatGPT (N = 193) and without the aid of LLMs (N = 193). In this sample, we compared responses to the question “How well did you understand the policy document you read?” Both groups felt that they understood the policy “slightly well,” with participants in the treatment group (with access to ChatGPT) reporting an average score of 2.61 (SD = 1.01, N = 193), compared to 2.46 (SD = 1.02, N = 193) for those in the control group (without ChatGPT). While the treatment group reported slightly higher levels of understanding compared to the control group, this difference was not statistically significant; a Wilcoxon rank-sum test revealed a p-value of 0.092. 8 Similarly, a bivariate regression model assessing the relationship between LLM access and self-reported understanding produced a coefficient of 0.155 (p = 0.135), further indicating that the treatment had no statistically significant effect on participants’ self-reported comprehension. 9
However, participants’ level of education emerged as a significant predictor of self-reported understanding. When education was included as a control, it had a measurable and positive effect on participants’ reported comprehension (p = 0.0134*), indicating that participants with higher levels of education were more likely to report a better ability to understand the document. This finding is consistent regardless of whether education is measured as an ordinal variable (1–7, with lower numbers indicating less education) or as a binary variable (e.g. completed education beyond high school versus high school or less). 10
High-educated participants who used AI reported slightly higher comprehension scores relative to those with the same educational background who did not have access to ChatGPT, with average comprehension scores of 2.79 (SD = 0.97, N = 92) and 2.51 (SD = 0.97, N = 93) out of 5, respectively. Similarly, low-educated participants with access to ChatGPT also saw marginal increases in reported comprehension scores compared to participants without access, from 2.41 (SD = 1.06, N = 100) to 2.45 (SD = 1.03, N = 101). While these descriptive findings suggest that AI access may have assisted comprehension for both experimental groups, there was no statistically significant interaction between education and ChatGPT access. 11 Thus, the effect of educational attainment on understanding was consistent across treatment groups and access to ChatGPT did not provide a disproportionately greater benefit to participants with either low- or high-educational attainment. Moreover, the main treatment effect remained nonsignificant in these models. Participants’ prior experience with ChatGPT, measured by the questions “Prior to today, have you ever used a Large Language Model (i.e. ChatGPT, Gemini/Bard, Claude, etc.)?” and “Prior to today, have you ever used a Large Language Model for reading comprehension and/or writing?” had no effect on self-reported comprehension.
We also compared responses to the question, “How easy was it for you to write a comment in response to the policy document?” Participants in the treatment group reported an average response of 3.13 (SD = 1.3, N = 193) compared to 2.60 (SD = 1.16, N = 193) in the control group, and a Wilcoxon rank-sum test yielded a p-value of 4.77 × 10−5***. 12 A bivariate linear regression with self-reported ease of writing a comment as the dependent variable and treatment group assignment as the independent variable generated a coefficient of 0.53 (p = 2.79 × 10−5***), further demonstrating that ChatGPT access had a highly significant positive effect on participants’ perceived ability to write comments.
Broken down by education, we found that high-educated participants’ self-ranked ease of writing increased from 2.62 (SD = 1.11, N = 93) to 3.25 (SD = 1.27, N = 92) with AI, while low-educated participants also experienced a notable boost from 2.58 (SD = 1.21, N = 100) to 3.02 (SD = 1.33, N = 101). This indicates that AI assistance significantly improves perceived ease of writing. Adding educational achievement as a control yielded a coefficient of 0.53 (p-value = 2.3 × 10−5***) for the treatment variable and a coefficient of 0.049 (p = 0.153) for education, indicating that while LLM access strongly influenced participants’ self-reported ease of writing, educational attainment did not have a significant effect. The treatment effect remains highly statistically significant (p < 0.001) when education, gender, race, income, and political ideology were included as control variables in the model, and these results were consistent when education was measured as a binary variable. 13 These results suggest that ChatGPT may weaken the advantage that higher education might provide in producing written responses. Participants’ prior experience with ChatGPT had no effect on self-reported ease of comment-writing. Figure 1 summarizes the main findings from Study 1, highlighting participants’ scores for comprehension and ease of writing by education and treatment group.

Impact of AI on self-reported comprehension and ease of writing. Note. Based on Likert scale: 1 = Not well at all, 2 = Slightly well, 3 = Moderately well, 4 = Very well, 5 = Extremely well..
It should be noted that the statistical findings discussed above are based on self-reported evaluations of participants’ understanding of the policy document and their ease in drafting comments. As such, it is possible that participants with higher levels of education may be more confident in their ability to understand the policy document, while those with lower-educational attainment might be less inclined to report a high level of comprehension. Indeed, there is scholarly literature linking educational attainment to greater self-confidence in one's academic and analytic skills. Yamashita et al. (2022) find that individuals with higher-educational attainment enjoy “more positive self-evaluation” and self-efficacy, resulting in greater motivation to learn later in life (14). Similarly, a survey conducted by Smart and Pascarella (1986) found that individuals with higher-educational attainment reported a more positive academic self-concept, defined as “self-ratings of intellectual self-confidence, academic ability, and mathematical ability,” relative to those with lower levels of educational attainment (7). Access to LLMs could also boost participants’ confidence, leading them to view the writing process as easier compared to those without access to these tools. To move beyond self-assessment, the following sections use both qualitative and quantitative methods to evaluate the quality of participants’ comments.
Our survey also included open-ended questions, enabling a deeper examination of participants’ experiences with reading proposed policies and writing comments, both with and without LLMs. We compared participants’ answers to the question, “What were the main policies proposed in the document?” We coded responses that were confused (“idk”), vague (“clean power plan” or “policy draft”) or incorrect (“Air Heater and Duct Leakage Control”), finding that 31.6% of comments submitted by the control group (N = 61) and 21.2% of those submitted by participants in the treatment group (N = 41) could not accurately summarize the proposed policy they had read. 14 Approximately 10% more participants in the control group provided inaccurate responses compared to the treatment group, suggesting that access to LLMs may have enhanced participant understanding or, at the very least, increased confidence in comprehending the assigned policy.
Next, we asked participants, “What challenges, if any, did you face while reading the policy?,” classifying responses by theme and counting them as shown in Table 1.
Comprehension challenges reported by treatment and control group participants.

As these numbers suggest, ChatGPT did not eliminate policy fog, the dense mix of technical jargon, bureaucratic language, and document length that makes regulatory proposals difficult for nonspecialists to understand, although it greatly reduced the perception of unclear acronyms and information overload. Open-ended responses corroborate this point. A participant in the treatment group said, “I feel like a lot of it was difficult to navigate. Given that I am basically completely unaware of this document and what it was about, I found that even some of ChatGPT's summaries were sort of difficult to read through.” Another said that “It was way too long. To [sic] much legaleze. It is ridiculous that these laws aren't written so the common person can read and understand them without difficulty.” Participants in the control group experienced similar challenges with policy complexity and jargon, with one writing, “The subject matter is extremely unfamiliar. The jargon and abbreviations are excessive. I wished the writing style could have been more clear and direct. The document is extremely long. It was difficult to stay focused due to the aforementioned reasons.” Another participant in the control group described the policy as “dense, complex, and not written in an easily understandable or consumable way for most Americans.”
Many participants in the treatment group felt that ChatGPT was helpful in understanding the policy document. Importantly, we did not independently review the summaries generated by ChatGPT for accuracy; it is therefore possible that the model provided information that was easy to comprehend, but ultimately incorrect or misleading. Further, authority and automation bias, whereby individuals trust LLM outputs to be inherently reliable without independent verification or critical reflection (Romeo and Conti, 2025), could result in inflated self-reported comprehension scores. To assess comprehension, we instead rely on participants’ responses to open-ended questions asking them to summarize the main policies proposed in the document, as well as their self-reported comprehension scores.
The average response to the question, “How helpful was ChatGPT 3.5 in understanding the policy document?” was 4.09 (SD = 1.04, N = 193) out of 5.0, indicating that most participants found ChatGPT to be “very helpful.” 15 Again, this finding is corroborated by the qualitative responses to open-ended questions. For example, one individual reported that, “when first opening the document, the amount of information was perplexing! I was able to see just how ChatGPT can be helpful. I do not use AI at all, so this was an interesting experience. It was able to summarize all the information for me, in a matter of seconds. I was able to understand and digest the policy and/or policy changes.” Another said, “The policy was way too long and did not use common language, I read the summary a few times but did not have a clear understanding until I asked ChatGPT to summarize.”
When it came to writing the mock comments, answers to the question “What challenges, if any, did you face while writing your comment?” also revealed common themes and patterns, as illustrated in Table 2.
Writing challenges reported by treatment and control group participants.

Open-ended responses from participants in the treatment group shed light on both the limits and utility of ChatGPT for writing comments. Some participants thought using ChatGPT posed a challenge, rather than being helpful in writing a comment. For example, a participant in the treatment group referenced, “being overly reliant on ChatGPT instead of providing my own opinion” as a challenge. In general, however, participants reported that ChatGPT was helpful in the writing process, with the question, “How helpful was ChatGPT 3.5 in drafting the comment(s)?),” receiving an average score of 4.15 (SD = 1.18, N = 193) out of 5.0, with 5 indicating “extremely helpful.” Respondents articulated that it assisted their writing in the following ways:
“With the support of ChatGPT I found it extremely easy to generate a comment that reflected my view and concerns.” “I didn't really understand the document on its own but could use AI to summarize and help me understand the consequences.” “I did not really understand the topic I was writing about which made it difficult. Once I used ChatGPT it became much easier as I had the resources to understand what I was doing.”
Conversely, those in the control group expressed challenges drafting responses to the policy proposal, with one participant saying, “I felt like I was not writing a technical enough argument and that my position would therefore not be taken seriously.” Another was less focused on writing than on outcomes, writing “Its [sic] hard to be passionate or even care about making a comment when its [sic] probably just going to get ignored.”
Study 2
In Study 1, we explored individuals’ self-reported experiences reading a complex policy document and writing a mock comment in response. Moving beyond participants’ self-reported experiences, which may be biased by education levels, Study 2 measures how comments generated in Study 1 were evaluated by both human and AI judges.
Comments were evaluated by individuals with backgrounds in law, policy, or political science—fields that align with decision makers in agencies reviewing public comments. Both human evaluators and ChatGPT assessed the comments using identical guidelines for writing a “strong” comment, which were provided to participants in Study 1.
The statistical analysis employs a bivariate cumulative link mixed model to account for evaluator mixed effects, controlling for variations in scoring due to individual evaluators. Unlike a simple comparison of averages, this model provides a more precise estimate of ChatGPT's impact, showing that access to the tool increases overall comment quality scores by approximately 1.37 units or 45.83% on average. 16 This suggests a substantial impact of ChatGPT on the quality of submitted comments, suggesting that the improvement in comment quality is not merely a product of random variation or evaluator bias. Further, participants with access to ChatGPT also received higher scores for all five qualities associated with a strong comment. On average, participants with access to ChatGPT received higher scores for their comments’ introduction, argumentation, use of evidence, assessment of trade-offs, and conclusions by approximately 1.12, 1.25, 1.21, 1.44, and 1.34 units (p < 0.001), respectively. 17
We also evaluated the relationship between a commenter's education levels, access to ChatGPT, and the evaluator's assessment of the overall quality of their comments, finding that ChatGPT use is associated with higher-quality comments across all education levels. Participants with more than a high school education who did not use ChatGPT received an average score of 2.00 (SD = 1.17, N = 53), while those who did use ChatGPT scored significantly higher at 2.88 (SD = 1.08, N = 53). Similarly, participants with less than a high school education without access to ChatGPT scored an average of 1.90 (SD = 1.09, N = 66), whereas those who did scored 2.69 (SD = 1.12, N = 69). These results suggest that AI assistance leads to improvements in writing quality, as judged by external evaluators.
When educational attainment is added to a multivariate mixed-effects regression, access to ChatGPT continues to have a significant and positive effect on overall quality ratings, but education level does not significantly affect how their comment is evaluated. We also tested this relationship by interacting the educational attainment and treatment variables, finding that the effect of access to ChatGPT does not vary based on educational attainment—instead, access to ChatGPT improves quality of comments regardless of educational level. These results hold when educational attainment is measured with a binary variable indicating whether the participant has more than a high school education. The main treatment effect remains robust after controlling for education level, use of public transportation (a proxy for commitment to environmental issues), prior experience using LLMs for writing and comprehension, race, gender, age, income, and political preference. Figure 2 summarizes the main findings from Study 2, illustrating the evaluator scores for overall quality by education and treatment group.
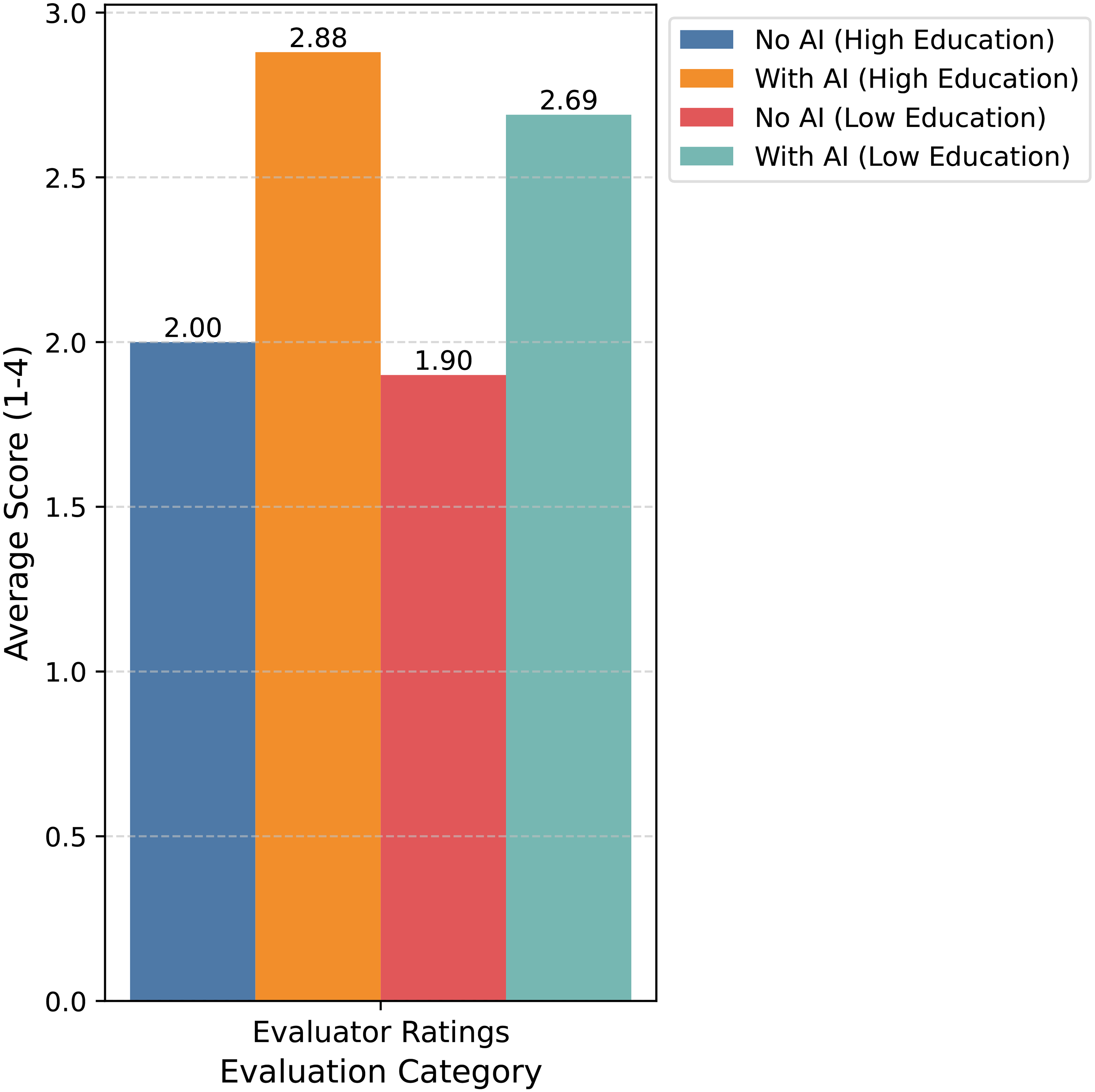
Impact of AI on evaluator ratings. Note. Based on Likert scale: 1 = Poor, 2 = Fair, 3 = Good, and 4 = Excellent.
To summarize, AI usage appears to increase average scores in all categories, although the difference is only statistically significant for self-reported writing ease and overall quality, as reported by independent evaluators. While AI use improved self-reported comprehension for all participants, educational attainment was the strongest predictor with participants with higher-educational levels reporting greater understanding. Access to ChatGPT had a highly significant impact on participants’ perceived ease of writing regardless of educational background, suggesting that LLM access may reduce the advantage that highly educated citizens have enjoyed in the public comment period. However, generative AI's most substantial impact was observed in evaluator ratings, which reflect external assessments of comment quality. Both groups saw their scores increase when using ChatGPT, suggesting that AI results in higher-quality output regardless of the commenter's education level.
We also examined how government agencies might use LLMs such as ChatGPT to process and respond to public submissions to the notice-and-comment period. To do so, we asked ChatGPT to evaluate the comments submitted in Study 1, using the same rubric and instructions that were provided to human reviewers. Notably, the evaluations produced by ChatGPT were generally consistent with those of human evaluators. Comments written without AI assistance received an average score of 2.40 (SD = 0.48, N = 119) while those written with ChatGPT scored an average of 2.83 (SD = 0.65, N = 122). As with the human evaluations, access to ChatGPT was a significant predictor of overall quality (p = 2.53 × 10−7***) whereas participant education had no significant effect. 18 Additionally, interacting our treatment variable with an ordinal measure of commenter education yielded a coefficient of −0.304 (p = 0.018*), suggesting that the positive effect of ChatGPT access on comment quality is significantly larger for participants with lower levels of education. It is important to note, however, that these results only hold when ChatGPT is acting as the evaluator—when the same comments were assigned to human evaluators, education did not moderate the relationship between access to LLMs and overall quality of comments.
Discussion
Our findings suggest that LLMs can lower barriers to participation in notice-and-comment rulemaking, particularly on the writing side. Access to ChatGPT made drafting easier and consistently raised external quality ratings across education levels. Gains in perceived understanding were smaller, and education continued to track most closely with comprehension. LLMs may therefore help citizens express themselves in a policy-relevant form but do less to close underlying knowledge gaps.
Study 1 showed that ChatGPT had no statistically significant effect on participants’ self-reported comprehension of a complex policy proposal. Education, by contrast, was a consistent predictor of perceived understanding. This suggests that policy literacy rather than AI access remains the strongest determinant of comprehension. Participants frequently cited document length, jargon, and acronyms as barriers, and ChatGPT did little to remove those obstacles. Because comprehension was self-reported, these results may reflect confidence as much as understanding, but the pattern helps explain why highly educated citizens remain overrepresented in policymaking: they are more likely to feel capable of interpreting and responding to complex rules.
Study 2 revealed a different story on the writing side. Comments written with ChatGPT were consistently rated higher in quality across a variety of criteria, regardless of the writer's education level. The quality boost may matter most for individuals who face the steepest barriers to participation, including limited education and challenges digesting complex regulatory texts. By lowering the difficulty of drafting and raising the quality of output, LLMs can help more citizens reach the implicit threshold for a “serious” comment that agencies must consider. Because well-resourced actors already meet that bar more often, the same absolute boost may carry greater value for underrepresented participants. This finding points at a “leveling” effect: equal marginal gains can narrow the gap that matters most for whether a comment is taken seriously.
These results speak to three literatures. First, they suggest that AI-assisted commenting can modestly broaden access by helping citizens structure and phrase their submissions in more professional language. In democratic theory, this resonates with Habermas' claim that legal legitimacy depends on inclusive discursive processes (1996) and Mansbridge's observation that participation is partial and context-dependent (1983). LLMs help some citizens overcome linguistic and stylistic hurdles, but they do not resolve deeper concerns about equality, reciprocity, or the deliberative quality of input. Second, in political science and public administration, the results align with evidence that participation is shaped less by apathy than by information costs, which restrict both who takes part and the weight agencies can reasonably assign to submissions (Coglianese, 2006; West, 2004; Yackee, 2006). Finally, in administrative law and practice, they underscore a division of labor. LLMs assist with articulation and tone, while comprehension continues to depend on citizens’ policy literacy and on the clarity of agency design (Ahmed et al., 2018; Johnson, 2024).
While these connections highlight the promise of LLMs for broadening access, they also frame the risks of misuse and distortion that accompany their adoption. First, polished language can mask thin evidence. Overreliance on model output may produce confident but incorrect claims that inexperienced users cannot easily detect. Second, synthetic volume can distort perceptions of public opinion. Mass comment campaigns predate LLMs and already strain review capacity (Savitz, 2021; Weiss, 2019). Generative tools may accelerate this by enabling astroturfing, the manufacture of fake grassroots input (Kreps and Jakesch, 2023; Kreps and Kriner, 2024). Expanding public participation in policymaking is beneficial only insofar as it is meaningful. Although our design did not test the use of LLMs for informational manipulation, the potential for such misuse warrants oversight.
Several limitations qualify our conclusions. Measures of comprehension rely on self-reports, which may not capture actual understanding. Some control participants may have used AI despite instructions, though strong treatment effects on evaluator scores suggest limited data contamination. Our policy case also centers on one domain and one family of documents; future work should examine other areas such as healthcare, financial regulation, or civil rights, and vary document length and complexity. Finally, we relied exclusively on ChatGPT. Model-specific behavior may shape outcomes in subtle ways: Claude, for example, is often more cautious and verbose, while ChatGPT is more direct and prone to “fill in gaps.” Such differences could affect measures of correctness, style, or confidence. Future research should test identical prompts across multiple models to assess cross-model robustness.
Despite these limits, the results carry implications for practice. For agencies and civic groups seeking broader public participation, LLMs can serve as scaffolding for expression, helping more citizens produce comments that meet the substantive bar for consideration. Yet, comprehension remains the ceiling; plain-language policies, shorter executive summaries, and expansive glossaries are likely to yield larger dividends than writing aids alone. AI tools can complement but not substitute for these reforms.
Finally, just as policy literacy shapes who can engage effectively in rulemaking, AI literacy will determine how helpful or how risky these tools become. Citizens with the skills to prompt, evaluate, and edit AI output may benefit most, while those without such knowledge risk errors or overreliance. Unless paired with civic and digital education, AI literacy could itself become a new axis of inequality.
The broader question is both normative and practical. Notice-and-comment has always been a hybrid institution, blending participation with expertise and accountability. LLMs can widen access on the writing side, but they will not by themselves close gaps in knowledge or trust. A sound approach pairs AI-enabled drafting support with reforms in rule design, civic and AI literacy initiatives, and transparent review procedures. That mix offers the best chance to broaden who speaks while keeping agency attention on evidence rather than volume.
Conclusion
This study suggests that LLMs can lower barriers to participation in notice-and-comment rulemaking by making drafting easier and producing higher-quality comments across education levels, yet they do little to resolve the deeper knowledge gaps that limit comprehension. The effect is therefore asymmetrical: AI assistance expands expression but does not substitute for policy literacy.
Placed in a broader context, these findings illuminate a tension at the heart of democratic governance. Public participation remains a central aspiration of modern regulatory systems, but information costs and technical complexity have long limited who can meaningfully take part. LLMs offer a partial remedy by helping underrepresented citizens meet the threshold for serious consideration, but they also risk creating new inequalities tied to AI literacy and new vulnerabilities to manipulation.
The challenge for governments is to integrate these tools in ways that foster inclusion while safeguarding legitimacy. Agencies will need disclosure and review mechanisms that protect against synthetic volume without sidelining authentic citizen input. Equally important are reforms in rule design, civic and AI literacy, and transparent intake processes that make participation both accessible and meaningful.
Democracies worldwide face similar pressures as digital tools reshape channels for voice and accountability. By clarifying both the promise and the limits of LLMs in US rulemaking, this study contributes to a growing debate over how AI will intersect with democratic institutions. The future of participation will depend not only on technological capability but also on the institutional choices that determine whether these tools broaden citizen voice or entrench existing divides.
Supplemental Material
sj-pdf-1-bds-10.1177_20539517261419341 - Supplemental material for Whose voice counts? The role of large language models in public commenting
Supplemental material, sj-pdf-1-bds-10.1177_20539517261419341 for Whose voice counts? The role of large language models in public commenting by Amelia C Arsenault and Sarah Kreps in Big Data & Society
Supplemental Material
sj-pdf-2-bds-10.1177_20539517261419341 - Supplemental material for Whose voice counts? The role of large language models in public commenting
Supplemental material, sj-pdf-2-bds-10.1177_20539517261419341 for Whose voice counts? The role of large language models in public commenting by Amelia C Arsenault and Sarah Kreps in Big Data & Society
Supplemental Material
sj-Rmd-3-bds-10.1177_20539517261419341 - Supplemental material for Whose voice counts? The role of large language models in public commenting
Supplemental material, sj-Rmd-3-bds-10.1177_20539517261419341 for Whose voice counts? The role of large language models in public commenting by Amelia C Arsenault and Sarah Kreps in Big Data & Society
Supplemental Material
sj-Rmd-4-bds-10.1177_20539517261419341 - Supplemental material for Whose voice counts? The role of large language models in public commenting
Supplemental material, sj-Rmd-4-bds-10.1177_20539517261419341 for Whose voice counts? The role of large language models in public commenting by Amelia C Arsenault and Sarah Kreps in Big Data & Society
Supplemental Material
sj-csv-5-bds-10.1177_20539517261419341 - Supplemental material for Whose voice counts? The role of large language models in public commenting
Supplemental material, sj-csv-5-bds-10.1177_20539517261419341 for Whose voice counts? The role of large language models in public commenting by Amelia C Arsenault and Sarah Kreps in Big Data & Society
Supplemental Material
sj-csv-6-bds-10.1177_20539517261419341 - Supplemental material for Whose voice counts? The role of large language models in public commenting
Supplemental material, sj-csv-6-bds-10.1177_20539517261419341 for Whose voice counts? The role of large language models in public commenting by Amelia C Arsenault and Sarah Kreps in Big Data & Society
Footnotes
Acknowledgments
This research benefited greatly from feedback offered at the Cornell Law Faculty workshop in March 2025 as well as the 2024 Asian Law and Economics Association meeting in Tainan, Taiwan. The authors wish to thank Qian Yang and Yeon Ju Jang (Cornell University, Department of Information Science) for their helpful advice in the conceptualization stage of this project, as well as Avishai Melamed (Cornell University, Government Department) and Yun-Chien Chang (Cornell Law) for their constructive feedback. The authors would also like to thank Matt Thomas from the Cornell Statistical Consulting Unit for coding advice, as well as all article reviewers and editors at Big Data & Society.
Ethical approval
This research project was considered exempt by Cornell University’s Institutional Research Board (IRB0148837). All participants provided informed consent and all information was confidential.
Author contributions
Coauthors Amelia C. Arsenault and Sarah Kreps conceptualized the research questions, and methodological approach. Kreps conducted the “mapping” exercise, while Arsenault conducted the experiments performed in Studies 1 and 2. Arsenault performed the quantitative statistics, and Kreps supervised the findings. Both authors discussed the results and coauthored the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.