
Abstract
Archival versions of apps present a unique opportunity to study how apps functioned at different points in time, how they evolved individually, and how their roles in wider digital ecosystems can be useful to understand the increasing dominance of platforms as organizers of the internet. In this paper, we propose a novel approach to studying apps’ histories by analysing the URLs embedded in their code, and a tool, Janus, to automate the collection and analysis of apps, and output visualisations of their hard-coded links. By pruning these URLs at different levels, these visualisations can show an app’s map of connectivity at various levels of detail (domain, subdomain and full URL) across time. We propose Janus as a locus of multidisciplinary research, to triangulate findings especially from qualitative researchers, but also to identify new lines of inquiry for different disciplines. We test Janus and its potential for multidisciplinary research on historical versions of the Kazakhstani ‘super-app’ Kaspi and of other local financial apps.
Introduction
Is the internet becoming more Chinese? This question has increasingly been asked in Western academic and policy circles to examine the rise of Chinese platforms and digital infrastructures. Alongside this question arise fears that the purportedly democratic character of the internet might be compromised, and that the internet might lose its connective character as it comes to be defined by restrictions within national borders. Since 2018, and in the context of the so-called US–China technological decoupling (Bateman, 2022), there has been much discussion of splinternets on the one hand, and platform dominance on the other. Splinternet originally referred to the worry that the internet might fragment into a subset of non-compatible and non-communicating networks (Mueller, 2017; Perarnaud et al., 2022), but lately it has been used to describe the possible effects of the expansion of Chinese internet technologies, standards, and ideas about digital sovereignty in the global arena (Hoffmann et al., 2020). Platform dominance looks at the increasingly powerful role that a handful of platforms play in directing traffic, hosting services and shaping how we use the internet (Dijck et al., 2018). Against this background, we set out to examine how it might be possible to track whether Chinese platforms have indeed been expanding outside of China, and whether it is possible to document a move towards a ‘Chinese digital ecosystem’ in third countries that would justify fears of a splinternet, or an increased dominance of Chinese actors in different countries.
In this article, we present the approach we developed to address these questions by uncovering the data flows behind what is perhaps the dominant mode of digital interaction for most people: the apps on our phones. Apps at once reflect and shape the environment where they are deployed, as their code changes constantly to reflect changes in technology, business priorities, and society. In particular, we are concerned with analysing changes in back-end connectivity of apps to examine the corporate and state entities to which their data goes. Our approach is premised upon the argument that the evolution of the code of apps (and especially their back-end connectivity) through time is symptomatic of wider socio-technical and geopolitical changes – and thus if there is an emerging ‘Chinese internet’ at the level of connectivity, we should be able to see when and how that happened. To facilitate our analysis, we take advantage of the historical versions of apps maintained in mobile phone app stores. App stores maintain copies of the latest app releases, but many also preserve older versions for users who want to install an application unavailable in their region, or who are not registered with mainstream app stores, or have older phones that cannot support the latest operating systems or latest versions of apps. These archival versions present a unique opportunity: they are not necessarily usable, but when systematically aggregated and analysed, they can provide insights into the behaviour and functioning of apps at different points in time.
Prior work studying changes to software code has typically been event-driven, comparing versions of code before and after a specific event, e.g. to look for changes in data flows after the introduction of the European Union's General Data Protection Regulation (GDPR) (Ou et al., 2022; Rahat et al., 2022). Expanding on this approach, we ask: how can we study the evolution of code through a longer span of time to see traces of wider socio-technical or geopolitical changes? How can the analysis of code be more inductive, rather than event-driven, and provide a way to triangulate findings from other research methods?
We show how changes in the back-end connectivity of apps apparent across historical versions of their code can be indicative of wider socio-technical and geopolitical changes. We present a method to extract and analyse hard-coded URLs from archival versions of apps to visualise and map their back-end connectivity across versions. We focus on domains in hard-coded URLs, as these represent online back-end services that apps access to enable networked functionality. URLs are a rich metric that can provide semantic indications of their behaviour/purpose and associated organisation, and that can be used to learn about physical and logical infrastructure. They can indicate the presence of internal/external APIs, SDKs, third-party services and dependencies, servers and infrastructure. By proxy, they can indicate the presence of specific companies, relationships between organisations and countries, and wider financial/business dependencies. As there can be a high number of these URLs, we map them at different levels: domain (e.g. google.com), subdomain (e.g. mail.google.com), and full URL (e.g. mail.google.com/inbox), to enable different types of analysis. By examining how connectivity changes over time across progressive releases of an app, we can show how cross-organisational and cross-national dependencies evolve, as organisational and national affiliations can be inferred from domains.
We begin with a literature review, followed by our research questions. We situate them in the context of a larger, multidisciplinary research on the emergence of digital ecosystems in non-Western countries – ecosystems which we define, following (Van Dijck et al., 2018), as ‘an assemblage of networked platforms’ that are in constant evolution, but that also concentrate power in the hands of few actors, and, following (Helmond, 2017) as ‘environment(s)… inhabited and shaped by third parties’ that embed them in diverse socio-technical systems. We then describe the logic and steps of our process and the creation of Janus, a tool that automates the process. We show how it works in practice with a deep dive into the Kazakhstani ‘super-app’ Kaspi and other banking and financial apps popular in Kazakhstan. We conclude with a discussion on the limitations of our approach and on how our findings and methods speak to existing research.
Our study contributes to methodological approaches to data traffic analysis, which seek to understand how politics are actualised (or not) in code from computer science and social science perspectives (Degeling et al., 2019; Nouwens et al., 2020; Urban et al., 2020); and to research on historical studies of websites and platforms, that analyse legacies from archival versions of digital objects from a social science and humanities perspective (Helmond and van der Vlist, 2021; van der Vlist et al., 2022). We aim to combine these two perspectives, leveraging code as both an object and a tool of multidisciplinary research. With Janus, we offer a software tool which facilitates the historical study of the evolution of apps back-end data connectivity and a methodological approach which demonstrates how the insights gained from this tool can aid in understanding broader geopolitical and socio-technical changes.
The evolving field of app studies
As Gerlitz et al. (2019) note, apps can be studied as stand-alone objects, but their existence and functionality is embedded in socio-technical systems. They identify three approaches to the study of apps. The first focuses on mobility as the key characteristic of apps, and comes mostly from a social perspective. The second, popular in business studies, looks at the political economy of apps monetisation. The third is an infrastructural approach, which we are most concerned with in our work: apps have infrastructural characteristics, and are part of a continuum of software and social practices. App functionality often depends on connections to remote services and systems. Banking, e-commerce, e-government, and social media apps in particular depend on back-end infrastructures to provide real-time data, transaction capabilities and general connectivity. 1 Their modularity and data flows are hidden, and yet necessary to understand the environment in which they operate and the relationships within which they exist. In outlining a research agenda for apps that takes seriously their socio-technical embeddedness, one of the areas Gerlitz et al. highlight is the exploration of apps’ connectivity at the network level, to analyse data traffic flows and services that are connected through those flows. In their view, this matters especially for users’ privacy and data protection, which is indeed an area that has seen significant work in recent years. The EU's 2016 GDPR has been a particular catalyst for exploring whether back-end systems changed to comply with the new rules on privacy. Several researchers have tracked compliance through automated privacy policy analysis (Ou et al., 2022; Rahat et al., 2022), by looking at third-party trackers and whether they decline or not (Hu and Sastry, 2019; Kollnig et al., 2022; Sørensen and Kosta, 2019). The importance of this kind of longitudinal approach has been highlighted by a series of studies that leverage the Android app repository Androzoo, which crawls a variety of sources to collect all available versions of apps across multiple app stores (Allix et al., 2016). In a recent article on Androzoo's statistics and usage, Alecci et al. discuss research based on the repository, highlighting in particular work on security, malware, and privacy, and how the robustness of such studies is improved by the evolutionary approaches facilitated by Androzoo (Alecci et al., 2024). Many of these studies are centred on malware and vulnerabilities (Cai, 2020; Cai and Ryder, 2021; Gao et al., 2021), and are an important corrective to static views of apps that emphasise what happens at specific points in time. In practice, apps are constantly evolving through their own code and the links to other services embedded in it, via Software Development Kits (SDKs), which are freely available to software developers to integrate specific functions into their code. An emerging and significant body of work has focused on traffic from/to apps to understand specific digital ecosystems (e.g. trackers) from a privacy and user awareness perspective. These have their origins in studies of website trackers (Acar et al., 2014), email (Englehardt et al., 2018; Kalantari et al., 2021) and apps (Blanke et al., 2014; Pybus and Coté, 2022), and link the technical features of apps with the social worlds where they are situated. They are often focused on end-users and on opening the black-box of technical features that are otherwise inaccessible (Pybus and Coté, 2022), and on the importance of SDKs in expanding the reach of tech corporations into apps of all kinds. Blanke and Pybus (2020) show that the tendency of platforms such as Google and Facebook towards an oligopolistic dominance of digital markets is extended by the fact that they embed themselves into the wider ecosystem of apps by providing services for their development, such as analytics, advertising and social sharing. They argue that the technical integration of platforms within apps further concentrates power in the hands of a few players – specifically, Google and Facebook – which are also highly technically integrated between themselves. This integration is mostly geared towards monetisation.
Pybus and Coté (2024) take the work on SDKs further by categorising them into three main categories: AdTech for monetisation, App Development for AI features, and App Extension to embed maps, payment services, etc. They single out Facebook and Google as Super SDKs, as they provide services across the categories and thus have a disproportionate influence on the technical and economic organisation of most apps. The rise of super-apps is also analysed by Van der Vlist et al. (2024), with a focus on the front-end, and they draw explicit attention to the pliability of the term and the different contexts in which it is deployed. Their definition of super-apps refers to those apps that combine a multitude of services across different fields, while providing a unified experience. Expanding their view to the political economy of apps, rather than focusing on code, they include under the ‘Swiss-Army Knife’ category a wider range of apps that are often very significant in a specific context, but unknown elsewhere, and that integrate different services into a single app – such as the Kazakhstani app Kaspi, which we will discuss later in this article. The political economy approach is also deployed by (Jia et al., 2022), who go beyond Western-centric perspectives by looking at the dominant position of Tencent in the Chinese app market, and its gatekeeper role through its app WeChat. They argue that the mechanisms of conglomeration, financialisation, platformisation, and infrastructuralisation allow the company to play such a dominant role, despite the fact that Tencent is neither a hardware manufacturer nor a vertically integrated tech conglomerate that controls mobile operating systems.
Developing a method for the historical analysis of APKs
The approaches surveyed in the previous section are all aimed at ‘theorising power’ (Jia et al., 2022) from a technical, economic and political perspective. Our research is in dialogue with this body of work, and contributes a method and a software to analyse apps back-end connectivity, and to integrate geopolitical perspectives into the discussions of capitalistic monopoly in back-end infrastructures. As part of a larger project investigating the expansion of Chinese tech in neighbouring countries, we discovered multiple layers of digital infrastructures, which raised questions difficult to answer through qualitative research alone, e.g. how dependent local apps are on which foreign back-end services, who the dominant players were at any given moment, and so on. We wondered if we could develop a way to track the historical evolution of back-end connectivity, map its changes over time, and bring these findings into dialogue with what we were discovering through qualitative research. While the method and tool we developed are context agnostic and can answer different research questions, in our project we were focusing on Chinese companies, to see if and how they were appearing in back-end links from third countries and whether they were achieving dominant positions in specific fields and/or countries,
2
as some of the literature cited above suggested. We ask the following questions:
Can an analysis of hard-coded URLs that appear in Android Package Kits (APKs) of apps popular in specific countries provide evidence of the emergence of new dominant players (whether specific companies or countries), and more specifically of a Chinese-led digital ecosystem? Can these findings provide a way to triangulate findings from other methods, or offer new venues of enquiry?
Our approach is systematic and holistic. By systematic, we mean that we look at the natural evolution of back-end connectivity over time, rather than at event-driven changes. In this, we are inspired by Helmond and van der Vlist's discussion of the opportunities offered by studying apps and software from a historical viewpoint, and highlighting how the constant software updates that make any one form of digital object transitory represent an opportunity to study change itself (Helmond and Van der Vlist, 2021). By holistic, we mean that we study apps connectivity without relying on predetermined categories – such as SDKs – to see what matters and what does not. Unlike work that focuses on SDKs, which tends to rely on a priori definitions of SDKs based on existing lists, to then look for them within the code of the apps, we take a ground-up approach that focuses on code in its entirety and looks for any type of back-end hard-coded connections, not only at links to known SDKs. This allows us to find connections that exist outside well-known SDKs, to see emerging actors, but also to account for different styles of programming that might not rely so much on SDKs. We focus on APKs, which are the actual technical implementation of an app, containing the compiled code (DEX files), metadata, resources, native libraries, assets, and manifest file required for an app to function, as Figure 1 shows.
When users add a new app to an Android device or update an existing one, they download and install the latest app's APK. There are several repositories that maintain historical sets of APKs, including Androzoo, which we discussed above. Even if older APKs cannot run, it is possible to examine their code to extract the hard-coded URLs that remain as part of their historical record. By doing so, we can understand the evolution of the context, strategy, and technical solutions that apps have adapted through their lifetime. By triangulating such findings with other methods – in our case, qualitative research – we can leverage the role that apps can have as an ‘entry point, or strategic node in a larger system and assemblage’ as such system changes over time (Goggin, 2021:5).
Rationale for hard-coded URLs
Within APKs, we focus on hard-coded URLs as aspects of code which reveal changes over successive releases of an app, representing dependencies on networked services that can signal the presence of a meaningful relationship between the app and the third-party services they link to. We consider hard-coded URLs analogous to a phone number that a person adds, removes, or updates in their phone book: even though someone looking through the person's contacts would not necessarily be able to discern much about the relationship between the person and their contacts, the fact that they have been saved suggests that they matter in a way that numbers that are not saved do not. We can look at the code in which URLs are embedded to find more information about their function and purpose, and examine the components of individual URLs to gain more information about them. Additionally, since hard-coded URLs are detected across the entire codebase of the app, they can signal the presence of SDKs and libraries (which are integrated into the codebase). Looking at the hard-coded URLs enables an assessment of connectivity for an app as a whole, including its SDKs, third-party libraries, internal or undocumented APIs.
The structure of a URL allows multiple levels of analysis, across the full URL, and the domain and subdomain included in the URL, as shown in Figure 2:
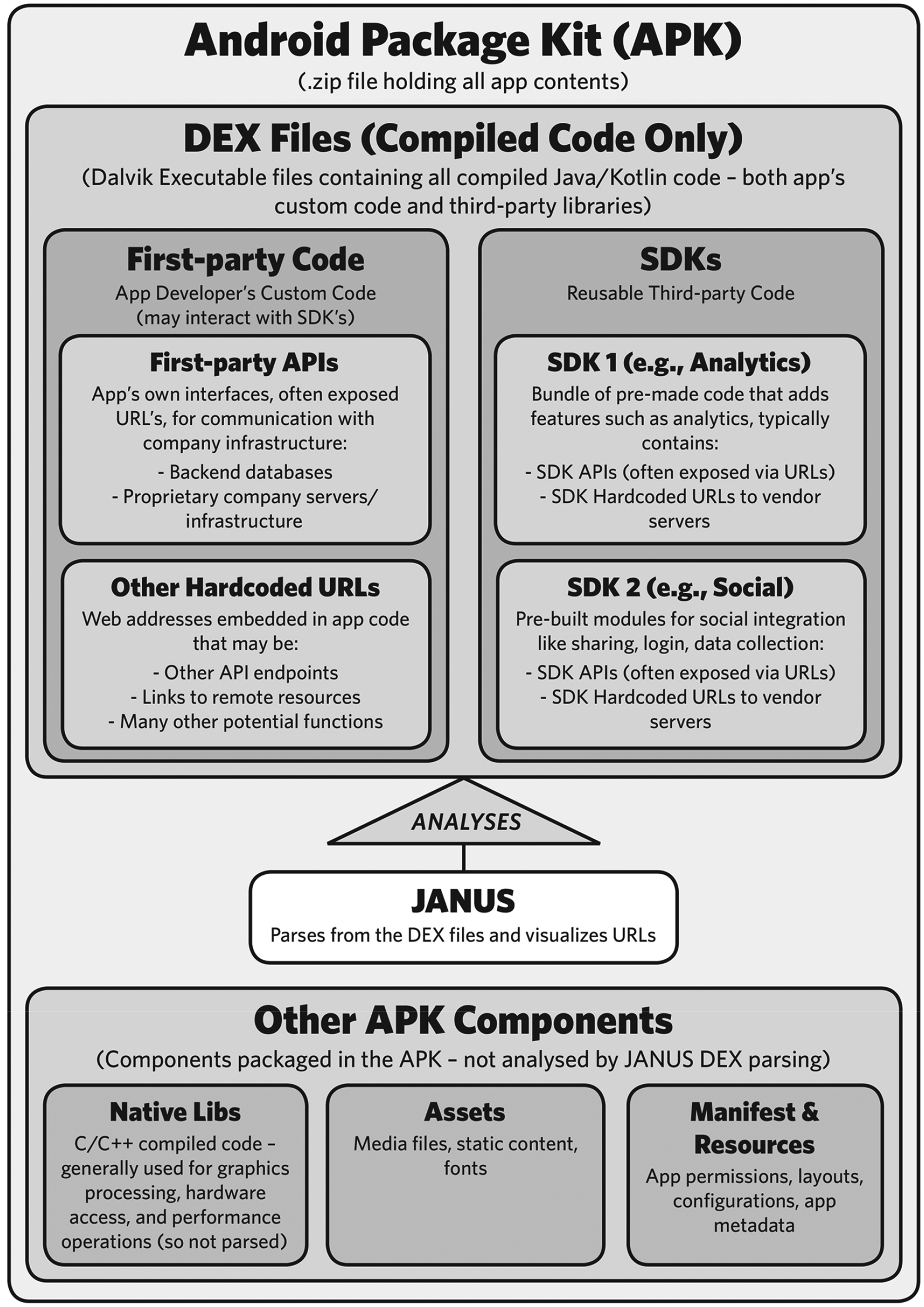
APKs as containers of SDKs and other components.

URL pruning and hierarchy (for illustrative purposes only, not necessarily actual endpoints).
To gather and visualise hard-coded URLs, we developed the following process:
Build a corpus of an app's APKs; Extract hard-coded URLs from each APK; Prune/process the URLs to the desired level of precision (full URL, subdomain or domain level). Depending on the individual app and its level of connectivity, and on the specific research question, it may be useful to move between these levels to balance a detailed view versus information overload; Visualise the results by presence across versions and frequency of pruned URLs if viewing at the domain/subdomain level (i.e. the number of URLs that are under that domain/subdomain).
Each of these seemingly straightforward steps masks significant challenges, which we detail below, before providing an overview of Janus, the tool we created to automate this workflow. By documenting our experience, we want to show the kinds of challenges that arise when approaching the analysis of APKs as an interdisciplinary problem.
Early challenges
Releases versus dates
All APKs contain a unique version number that identifies the release of the app with which they are associated. By ordering these version numbers, it is trivial to assemble the sequence of an app's APKs from its initial to its latest release. However, an increment in version numbers often will not correlate linearly to any specific unit of time, so there might be several releases in a few months, and nothing new for several more. Determining the specific dates when particular versions were released is a critical problem, as versions are not sufficient for social science research that aims to correlate changes in versions against external events. APK metadata does not necessarily contain reliable dates, and sometimes lacks a date altogether. Google Play Store doesn’t support download of older versions of apps, but as Android generally allows users to install apps from unofficial sources, there are many websites that provide current and past versions of apps. 3 However, it can be hard to find complete collections of all releases in one place – and different APK repositories might disagree on the date of release of the same version. 4 We first addressed this issue by collecting historical versions of APKs across several online archives, which involved finding repositories, checking their legitimacy, and cobbling together a complete set, which would then have to be checked manually. For common apps such as Facebook it is easy enough to find accurate dates and even automate the matching of dates to APK versions for visualisation, because of the availability of complete archives and accurate metadata. Less mainstream apps, or apps that might be very popular but only in a specific place, are more complicated. In this case, there might be the need for human intervention to match releases to dates, especially if looking for not only the year, but the exact month and day (which might be important if looking at specific offline events and trying to match them to changes in code). This step is difficult to automate, which would be a significant hurdle to create a robust tool that handles a significant volume of apps.
We ultimately found a workaround in AndroZoo, 5 which features APKs gathered since 2011 from multiple websites, and runs most of them through malware checks. Particularly important for our research questions, AndroZoo indexes Chinese app markets that feature apps for Chinese versions of Android (different from the international version). Recently, AndroZoo made available scrape dates, which often correlate with the actual release date of the APK. They are not always reliable: AndroZoo crawlers might go offline for technical reasons, might miss versions, scrape them later than their release date, or encounter the issues related to release dates we highlight above (Li et al., 2018). Dates for APKs released before AndroZoo started are obviously not included. We considered these issues worthwhile trade-offs to automate the process as much as possible, but whether the margin of error built into this process is acceptable depends ultimately on the research question. 6 For Janus, AndroZoo is the solution that provides the easiest and widest range of apps; however, we also developed a function to allow users to upload their own collections of APKs.
Obfuscated and packed code
Obfuscation involves converting the source code (or elements of it) into a format that is difficult for humans to understand, while maintaining its functionality. We were concerned with string obfuscation, which involves hiding sensitive data (such as URLs, API keys, or other hard-coded string values) by encoding, encrypting, or splitting strings into multiple parts and scattering them across the code base, and reconstructing them at runtime. Strings may also be dynamically constructed at runtime (with string formatting) for code flexibility. These are techniques used to prevent unauthorised access, usage and analysis of code, and they can present a challenge to extracting hard-coded URLs from APK files. Similar challenges arise from the use of packing, which involves compressing or encrypting the code in an application, and then wrapping it with a loader that decompresses or decrypts the code at run time. This can be used to prevent static analysis of the code (and hard-coded strings), because the code is not available in its executable form until it is run. Packing is often associated with malware in cyber security contexts, to conceal malicious code and hinder analysis. However, aligned with the findings of Wermke and colleagues (Wermke et al., 2018), in the course of analysing dozens of apps, we have found that obfuscation and packed code are much less common than we anticipated, and did not materially impact the detection of hard-coded URLs.
Dynamic code loading
Although Google Play has policies against it, some apps can download and run additional code during execution. This is known as Dynamic Code Loading (DCL). It can create issues when trying to analyse apps because some parts of the app, including hard-coded URLs, are not included in the original APK. As a result, if we try to extract URLs just by looking at the APK, we may miss out on analysing segments of code that are downloaded and incorporated only when the app is actually running on an Android device. This is a potential limitation of our approach, which is unfortunately necessary as we focus on examining code in archives of APKs without going through the difficult process of running each of them.
Creating Janus
We used a combination of existing APK archives and libraries to automate the workflow into Janus, available to be downloaded and run locally at https://github.com/digisilk. The Janus workflow proceeds as follows:
To construct a corpus of an app's APKs, Janus users need to obtain an API key from AndroZoo
7
and abide by their access conditions. For users who do not want to do this or have specific requirements in terms of APKs, there is also the option to directly upload their own corpus of APKs. Janus extracts strings from the DEX files contained within the APKs to detect hard-coded URLs. To carry out high-throughput analysis across this large corpus, we implemented a lightweight binary parser that reads DEX files directly, following the official DEX file format specification. The strings are filtered through regular expressions to obtain the hard-coded URLs. We also attempt to detect dynamically constructed URLs, which are not hard-coded, but rather built by code when it executes to pass data to back-end services or even change which back-end service is being evoked. While these are valid endpoints containing important information, they are essentially fragments of code and can often be identified by the presence of characters like square brackets, which are not typically found in standard URLs. The identified URLs are processed with tldextract to prune them.
8
The results are visualised using Plotly.
9
This visualisation associates each extracted URL with the APK version it was discovered in, and the scrape date of that version from the AndroZoo dataset. The domains/subdomains/URLs are sorted by their introduction and removal across different versions, with features introduced in earlier versions appearing higher on the y-axis. Once a feature appears, it is locked into place in the visualisation. If a previously removed feature is reintroduced, it is indicated at the point of reappearance in the chronological sequence. This approach creates a ‘staircase effect’, showing the evolution of the app, with each ‘step’ showing the introduction/removal of features from version to version. This is output as an interactive HTML file that users can zoom in or out of, which provides more details on the visualised URLs. This pipeline is integrated into a Python web application, so that it can be operated through a user interface.
Janus can be downloaded and run locally. Users input the API key from AndroZoo to connect to its archive. When combined with the Package ID (that is, the name of the app package 10 ), it allows Janus to retrieve the specific APK corpus needed. Retrieving and processing the APKs might take a while, depending on the size of the corpus. Some apps have been available for several years and can have a very high number of versions, which can require significant time and computational power to be processed. Users can select any number of versions to analyse, as well as start and end dates of the period they want to cover. With more versions, the visual complexity of the output increases. We found that in many cases, selecting around 10 versions provides a good balance between detail, processing time, and interpretable visualisation. 11 Janus outputs a downloadable file with visualisations by URL, subdomain, and domain. These are listed on the Y axis and associated with the specific version of the APKs where they were found through the dates of release on the X axis. With some practice, it is easy to quickly gain an impression of the analytics, trackers, APIs, and services an app is integrating, and how these have evolved over time.
Janus can also support queuing multiple packages and parallel processing to analyse several apps at once, and regular expressions to pattern match particular elements and flag their presence with specific colours. This latter function is useful to highlight links to companies that belong to the same entity even if they use different domain names, or links to specific countries. Finally, users can select specific domains from the visualisations, and run them directly from Janus through services such as WHOIS, a website to check registration data for domain names, and AlienVault, to look for malware and cyberthreats.
Case study: Kazakhstan's Kaspi
We tested Janus on apps from Kazakhstan, one of the field sites for our wider project, and a country that has been building strong relationships with the West since its independence in 1991, but that also has extended borders and commercial ties with Russia and China. Kazakhstan provided an interesting app for our project: Kaspi. Originally a bank, with a simple website featuring e-wallets and banking-related services, in 2017 it launched an app which included financial services, maps, and later QR codes for payments, a market place, and e-government services such as paying taxes and fines, and getting COVID relief (Dawkins, 2020). Because of its history, evolution and geographical focus, Kaspi represents an interesting socio-technical system that includes software, business and political processes (especially through its role as a proxy for the Kazakhstani state) and potentially geopolitics (de Reuver et al., 2018). Its rapid evolution and prominence in the Kazakhstani digital world made it a good test case to see if we could map the presence and evolution of Chinese, but also US/Western and Russian connections. AndroZoo includes Kaspi APKs from 2018 to 2024. After running them through Janus, we output visualisations at the three levels outlined above: domain, subdomain and full URL.
Domain-level visualisation
This visualisation prunes hard-coded URLs to domains, giving a bird's eye view of links to specific countries and companies/services. It is useful to get a sense of general connectivity before taking a deep dive into the specific subdomains/URLs.
Domains are sorted by their introduction and removal between versions. The ‘staircase’ effect emphasises changes in connectivity between each version (each ‘step’ of the staircase). Moving across left to right, we can see which groups of domains have been added and removed in each version, maximising contiguous blocks and showing how changes often do not occur in isolation. A good example is the mass addition of US social media and email services in version 2140133 of 2019. We cannot tell what kind of change that represents, but it is an entry point to look further into the code, or to investigate with other methods.
In this view, all the URLs that belong to a domain are folded into it, e.g. the domain kaspi.kz contains subdomains (e.g. events.kaspi.kz) and full URLs (e.g. auth.kaspi.kz/phv/api/v3/checkservice/verifyPhoto). The visualisation shows the number of full URLs folded into domains by shading the cells in a heatmap: the more URLs under a domain, the darker the cell is (in both greyscale and in colour). In the HTML version of Figure 3, it is possible to hover over a cell to see the exact number of URLs.

Visualisation of domain presence sorted by their introduction and removal across versions. Kazakhstan ‘.kz’ TLD are highlighted in blue/green and Chinese companies in purple.
Domains also contain a top-level domain (TLD) as their final element, which reveals additional information, including, in certain cases, country affiliation. Importantly for our analysis, countries manage their own TLDs, identified by two-letter country codes. In kaspi.kz, the last element (‘.kz’) is the TLD, which indicates that this is a service maintained in the Kazakhstani domain name registry. 12 In Kaspi's APKs, links to Kazakhstan (.kz) appear in 2019, and there are no domains with TLD ‘.ru’ and ‘.cn’ for Russia and China, respectively. Considering only the TLD is not a reliable way to identify the countries where companies are headquartered, as many companies use the generic ‘.com’ suffix. We then looked for specific Chinese and Russian tech companies that have been rapidly expanding and that might appear with a .com suffix: Alibaba (and its subsidiary Alipay), Tencent, and Huawei for China, Yandex for Russia. In 2024, we began to see connectivity to a Chinese company, Alipay, in version 2160547, released on 18 January 2024. We asked our colleague working in Kazakhstan whether Kaspi had integrated Alipay in the app. They did not find any trace of it, until at the end of April it was publicly announced that Kaspi's users travelling to China could now use the app there to pay via QR code (Tengri News Kazakhstan Главные новости Казахстана, 2024). More information about domains can be found by looking them up using public WHOIS services, as mentioned above. Sometimes their function can be inferred from the domain name (e.g. google-analytics.com), or becomes clearer in subdomain and URL visualisations. Domain-level view, however, can already tell us a lot about Kaspi: that it tested several analytics services, that it started by connecting to US social media at once, that initially it did not have any links to Russian or Chinese services, and that it has integrated Alipay services, which appeared in the APK before their official launch.
Subdomain-level visualisation
Switching to the subdomain view shows more information on what different domains do, as subdomains typically include semantic elements that indicate their function, as shown in Figure 4.
We can see at a glance that functions primarily fall into the categories of analytics, tracking, external functionality (i.e. APIs from other entities for machine learning, cloud, etc.), internal functionality, and integration with other services (i.e. Yahoo login). Digital marketing and ad services change through time: earlier versions connected with adjust.com, a Berlin-based mobile analytics platform, which disappeared in 2020.
The frequency of URLs is more distributed than in the domain view, as full URLs are still folded within the subdomain. This visualisation still shows lighter and darker blocks, with details visible when hovering on the cell in the HTML version. For example, in the domain visualisation in Figure 3, there are two domains related to Kaspi.kz (kaspi.kz and cdn-kaspi.kz), while in Figure 4, we see the evolution of in-house functions, with the addition of services (e.g. pay) and new areas of business (e.g. travel). Once again, we asked our colleague, who confirmed from their fieldwork that with the success of the banking app that followed the introduction of QR codes in 2018, Kaspi was becoming a super app expanding in different markets, with many new features added rapidly, each requiring its own subdomain. Seeing evidence in the app's code provided further validation.

Visualisation of sub-domains’ presence, sorted by their introduction and removal across versions.
Going back to our original question of whether we could see an expansion of Chinese tech companies or other emerging actors, what we see instead is how prominent US companies are, especially Google, as shown in Figure 5.
From a back-end connectivity perspective, Figure 5 shows how Kaspi features an increasingly diverse set of linkages, with localised .kz connectivity becoming critical to the functioning of the app.

Visualisation of sub-domains related to Google, highlighted in green.
Full URL visualisation
The most detailed view of functionality is provided by URLs, which typically show the purpose of the endpoint, e.g. u.kaspi.kz/photoprofile/api/v1/photoprofile/photo/delete
Figure 6 shows all the hard-coded URLs in the APKs. Cells are not shaded because no pruning is applied: each cell represents an individual URL.
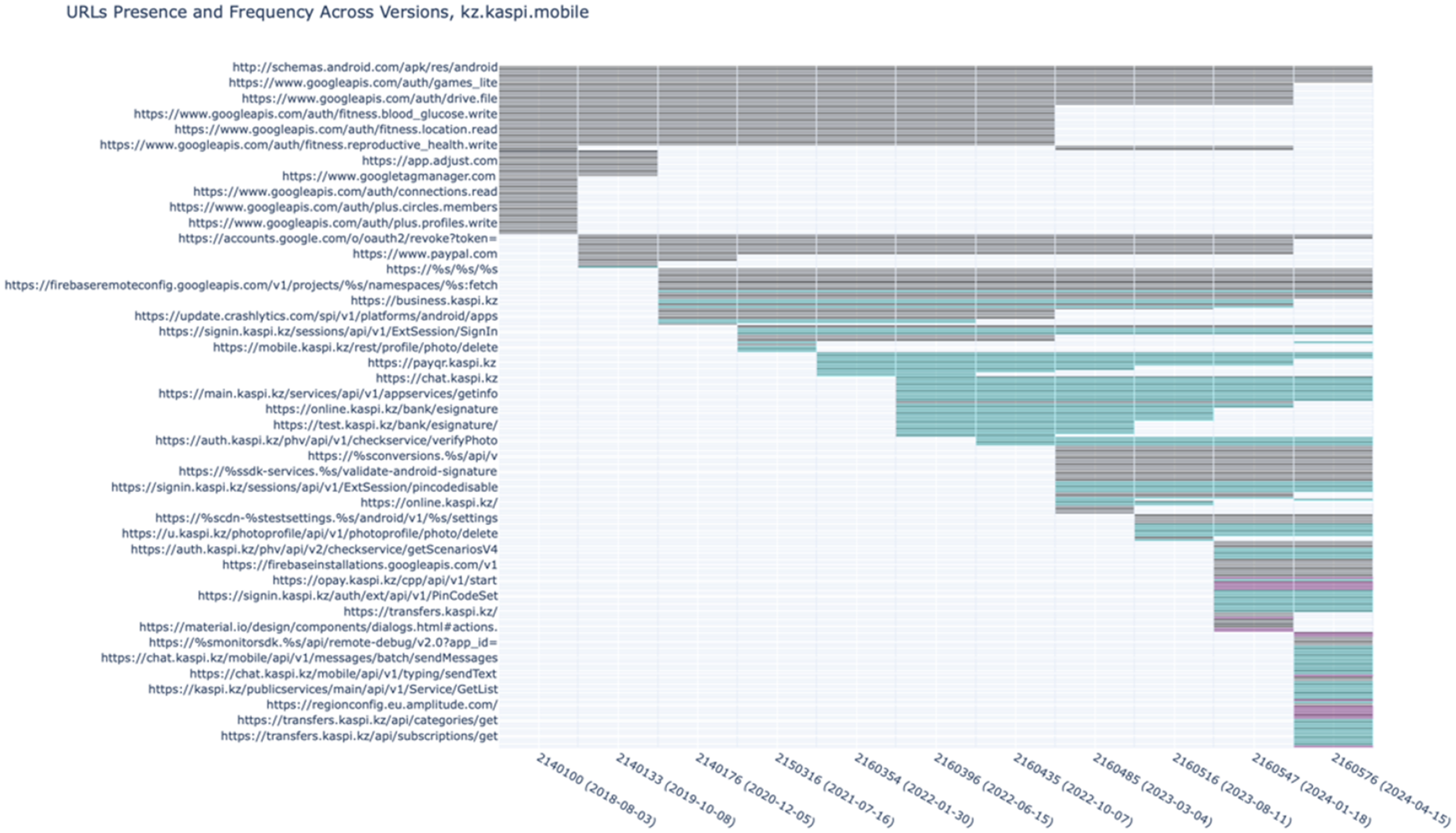
Visualisation of full hard-coded URLs.
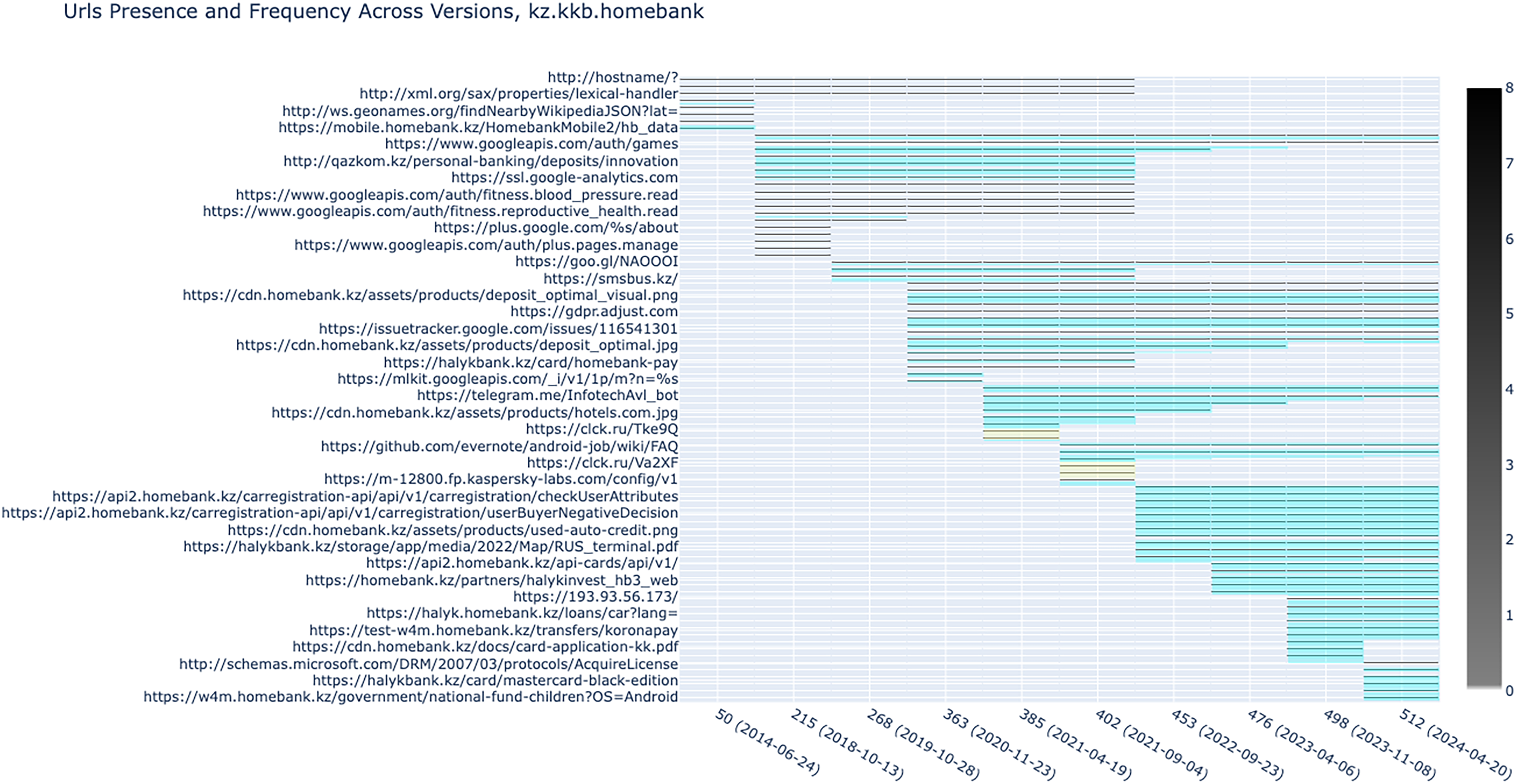
Subdomain view of Halyk Bank's APKs (the APK ID is kz.kbb.homebank).

Subdomain view of FFIN Bank Kazakhstan's APKs (APK ID is com.bpc.internetBanking).

Tabys investment app (APK ID is kz.aix.tabys).
Expanding the field of enquiry
Kaspi did not show any evidence of new dominant players, nor of a Chinese-led digital ecosystem, which was the focus of our first research question. However, the integration of Alipay might indicate some interesting developments in international payments. Kaspi featured several integrations with US back-end services, but also a steady growth in services that are hosted internally. As discussed by Blanke and Pybus (2020), US back-end connectivity is commonly found across many apps for services such as analytics and advertising, and is not necessarily essential to their core functioning. The latest versions of Kaspi, on the other hand, showed that critical infrastructure had become localised and under Kazakhstan's domains, which suggests a decreasing dependence on external services.
The scarcity of links to Chinese companies provided an interesting counter-narrative to the worries about the Chinese presence in the Kazakhstani market that our colleague was hearing in her field interviews, but it was also a single data point in a rather crowded app market. To see whether Kaspi was an outlier in this sense, we compiled a list of the main Kazakhstani banking, financial and marketplace apps that could be considered competitors of Kaspi, and we ran their APKs through Janus: Halyk (bank and marketplace), FFIN Bank Kazakhstan (bank), and Tabys (retail investment). We use the subdomain view to display the results, as it provides the best balance for an initial analysis when the research question (do we see links to China and Russia, or other emerging actors?) is clear.
Halyk Bank is a large commercial bank with branches across Central Asia and Russia. Its subdomains show that Google services appear frequently (see Figure 7), as in Kaspi. It also shows many links to domains hosted in Kazakhstan, some of which are internal to the bank, again, like Kaspi, alongside connections to other Kazakh companies. We also see a link to a Russian domain, ‘clck.ru’. A quick search on WHOIS shows it is registered by Yandex, a Russian tech company that offers a variety of internet services, from search to widely used apps, and is a URL shortening service that redirects to .kz resources on Halyk.
FFIN Bank shows a similar profile to Halyk in terms of links to Google and to Kazakhstani domains, and a link to a Russian domain, bpcbt.ru, a software company that specialises in software for financial operations (see Figure 8). BPC also appears in the package name, so the development of the app might have been contracted to this company – not something we can find out from our analysis, but something that could be followed up with other methods.
Finally, Tabys does not show any link to either Kazakhstan-hosted domains, Russian domains, or Chinese companies (see Figure 9).
Analysing Kaspi and its competitors from the perspective of back-end connectivity, but in dialogue with qualitative approaches, has shown us a more complex picture than what we could achieve with either method on its own. Qualitative research identified where to focus first (Kaspi, a list of Chinese and Russian companies to look for, a list of competitors), and provided context and follow-ups on what we were seeing in terms of URLs. URLs, on their part, showed us features that were launched to the public only a few months later, new domains to look out for, and how apps in the same sector share some similarities in connectivity (links to Google and other US companies), but also some differences in how they are evolving.
Limitations
Technological limitations
The easiest way to access a significant historical corpus of APKs is through third-party repositories like AndroZoo, and AndroZoo's limitations can become Janus's limitations. As we have already noted, issues with downtime, scrape dates, and reliance on third-party services (Allix et al., 2016) impact its functioning. To bypass, at least in part, such problems, Janus allows users to upload their own collection of APKs. Rather than limitations, we see these as trade-offs: for people new to the process and APKs, AndroZoo is a convenient way to test whether this method can be useful for their research question without investing too much time figuring out the ins and outs of APK repositories, dates versus releases, and so on.
Methodological limitations
As useful as Janus has been for our research, it has been essential to understand the limitations of our methodological approach, allowing us to understand more clearly the uncertainties inherent in findings derived from Janus alone:
1. URLs embedded within source code are heuristics to start mapping a network, rather than an end point of research. Our method might underestimate the true number of URLs, because apps may be designed to download executable code at runtime, which is not present in the original APK file, or they may be obfuscated, although this is not a frequent occurrence, as discussed earlier and confirmed by others (Wermke et al., 2018). This is a conscious trade-off on our part, as it is what allows us to analyse apps while they are not running, and thus to look at their historical versions. Traffic analysis is obviously not an option for historical versions of APKs, as they may not run, so accessing URLs is the best option to glimpse how things worked in past versions.
2. URLs can help us determine where data is going to and coming from, but we cannot tell the exact size or type of data flowing, even though the full URL can often tell us something about the nature of the communication. Even if we were to examine the actual data flows, the volume of data alone does not tell the whole story. Extremely impactful data could be shared in a whisper, easily lost like a needle in a haystack of connections.
3. Through Janus, we see communication channels from the app to services defined by URLs, but these services aren’t necessarily the final destination. Data can be moved between cloud services, duplicated, or sold on, with much of this activity happening behind the scenes. Movements of data are ruled by complex norms and political-economic incentives that cannot be seen from APK code. The fact that we see only occasional Russian or Chinese URLs in Kazakhstani banking apps doesn’t mean that these countries’ infrastructure is not used by them, e.g. in back-up servers. This infrastructure may well be hidden behind the URLs that are visible to us in the APK, appearing just one step away from what we can access and analyse.
4. Our research focuses on extracting hard-coded URLs within APKs from DEX files, that is the components contained within APKs with the compiled code responsible for driving an Android app's primary functionality. It is within these DEX files that we anticipate finding a significant number of URLs related to the app's back-end infrastructure, including connections to back-end services, API endpoints, and other critical resources. However, we acknowledge the possibility of URLs being present in other APK components, such as native libraries or resource files, which may require further investigation based on the specific research objectives.
In spite of these limitations, Janus sheds light on otherwise invisible histories of data flows: the signals we extract from URLs can be indicative of socio-technical and geopolitical changes, and although they are of course not determinative, they can be very powerful, especially when used in combination with other research methods.
Conclusions
Looking at the evolution of apps back-end connectivity can be an entry point to more extensive analyses, which can be directed inward to further study other aspects of the code, or outward, towards the wider internet ecosystem. Once a baseline is established, research can evolve just as the ecosystem evolves, and observe changes as they happen. Janus is our contribution to the growing body of work that uses technical tools to trace data flows as a way to analyse broader socio-technical phenomena. In combination with other research methods, it can be used to understand not only individual apps, but also ecosystems of apps within a country or a sector, contributing to bringing to light hidden data flows and their historical development, as suggested by Gerlitz, but also reconstructing the specific environment in which they lived at given moments in time. The backend connectivity of apps in this sample does not appear to have become more Chinese, as we wondered in the introduction, but Janus offers a new perspective on how to investigate this question.
Calls to better consider the materiality of software and the digital world have been common for some time now (Geiger, 2014; Kitchin and Dodge, 2011; Takhteyev, 2012), yet approaches remain siloed by discipline and methodological expertise. Even popular metaphors that take into consideration the complexity of the digital, such as Van Dijck's ‘platformization tree’ (2021), ultimately rely on abstractions that do not account for the complexity of connectivity and code behind the scenes, which can make even identifying the main ‘platform tree’ quite difficult. As Helmond writes of historical approaches to studying websites, The website can be seen as an assemblage of modular elements that on the one hand enable interactions with other actors on the web and on the other permeate or redraw the boundaries of the website by setting up data channels for the exchange of content and data stored in external databases. (Helmond and van der Vlist, 2021, p.144)
This is also true for apps: examining the evolution of their networked interactions and their modularity allows us to better understand not only the digital environment in which they evolve, but also the greater changes in the economic and political landscape in which they are deployed. We hope that our work can contribute to access more easily the ‘behind the scenes’ and inform future theoretical as well as methodological developments.
Footnotes
Acknowledgements
This article is part of a project that has received funding from the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme, Grant agreement No. 850891. The authors would like to thank DIGISILK team members Oyuna Baldakova for her help on Kazakhstan and in understanding data from the country, Thais Lobo and Thant Sin Oo.
Ethical considerations
There are no human participants in this article, and informed consent is not required.
Funding
This article is part of a project that has received funding from the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme, Grant agreement No. 850891.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.