
Abstract
A recent innovation in the field of machine learning has been the creation of very large pre-trained models, also referred to as ‘foundation models’, that draw on much larger and broader sets of data than typical deep learning systems and can be applied to a wide variety of tasks. Underpinning text-based systems such as OpenAI's ChatGPT and image generators such as Midjourney, these models have received extraordinary amounts of public attention, in part due to their reliance on prompting as the main technique to direct and apply them. This paper thus uses prompting as an entry point into the critical study of foundation models and their implications. The paper proceeds as follows: In the first section, we introduce foundation models in more detail, outline some of the main critiques, and present our general approach. We then discuss prompting as an algorithmic technique, show how it makes foundation models programmable, and explain how it enables different audiences to use these models as (computational) platforms. In the third section, we link the material properties of the technologies under scrutiny to questions of political economy, discussing, in turn, deep user interactions, reordered cost structures, and centralization and lock-in. We conclude by arguing that foundation models and prompting further strengthen Big Tech's dominance over the field of computing and, through their broad applicability, many other economic sectors, challenging our capacities for critical appraisal and regulatory response.
Keywords
Introduction
Artificial intelligence (AI) can look back on a long and complex history. Initially developed in the 1950s, the field has gone through cycles of hype and disappointment, with ‘AI winters’ following announcements of new advancements. Although neural networks have existed for decades, the early 2010s saw the start of a new boom cycle centered around techniques known as ‘deep learning,’ which showed great aptitude for tasks like image classification, speech recognition, and machine translation (Cardon et al., 2018). While earlier innovations struggled to find their way into actual products and uses, deep learning has been adopted in various domains, particularly by a handful of Big Tech companies, both in their products and as providers of computational infrastructure and services. Thriving on massive amounts of training data and computational power, machine learning has become a core asset for these actors.
The rapid adoption and perceived potential of machine learning have led scholars from various disciplines, as well as regulators and critical commentators from civil society, to identify multiple concerns. The most intensely discussed issue is likely bias and ‘disparate impact’ regarding ethnicity, gender, and other variables, which occurs when data reflecting social prejudice is used to train classifiers that make decisions affecting human subjects (Barocas and Selbst, 2016). Other concerns include the opacity of complex algorithmic models, their role in radicalization and misinformation, potential effects on employment, and safety issues, for example, around self-driving cars. 1
Scholars studying the political economy of AI (e.g., Srnicek, 2018; Trajtenberg, 2018; Whittaker, 2021), that is, the relationship between economic conditions and power, have contended that machine learning may contribute to market concentration and monopolization. The central argument, here, is that a small set of companies equipped with technical knowledge, substantial amounts of data, vast compute resources, large userbases, and deep pockets are set to dominate AI and, through AI's ‘general-purpose’ character, some of the sectors where it can be applied productively.
A problem with (critical) assessments of social impacts is that AI is not a single technology, and even deep learning has diversified with the expansion of research funding and application domains. A recent innovation has been the creation of very large pre-trained models - also referred to as ‘foundation models’ (Bommasani et al., 2022) or ‘general purpose AI models’ - that draw on much more extensive sets of data than typical deep learning systems and can be applied to a wide variety of tasks. Underpinning text-based systems such as OpenAI's ChatGPT and image generators such as Midjourney, these models have received extraordinary amounts of public attention and prompted scholarly discussion concerning their construction, capabilities, and possible dangers (e.g., Bender et al., 2021).
While foundation models are remarkable in several ways, their swift uptake by internet users (Milmo, 2023) is (partly) explained by the reliance on prompting as the primary technique to direct and apply them. In the broadest sense, prompts are descriptive instructions for these systems to perform particular tasks. Depending on the model, this may result in the generation of text [poem about climate change] 2 , images [horse in a castle], computer code [website with feedback form], and other modalities. Although prompts do not necessarily have to be textual (Liu et al., 2021: 9) - an image can be used to generate another image, for example - natural language prompting has emerged as the dominant mode of interaction, allowing users to playfully experiment without requiring, at first glance, any previous knowledge.
This paper uses prompting as an entry point into the critical study of foundation models and their implications. Attentive to the materiality and ‘technicity’ of the underlying technologies, we scrutinize prompting as a gesture that combines characteristics of natural language, computer code, and probabilistic query, and we investigate possible repercussions for the larger political economy of AI, where foundation models risk amplifying already problematic tendencies. We understand prompting as a form of ‘programmability,’ even if its peculiar character challenges existing assumptions. Drawing on earlier formulations of platform studies, we aim to establish a ‘connection between technical specifics and culture’ (Bogost and Montfort, 2009: 4) and, following Helmond (2015), we are particularly interested in how the distinct ways foundation models allow others to interface with their capabilities reinforce trends toward platformization.
The paper proceeds as follows: In the first section, we introduce foundation models in more detail, outline the main critiques, and present our approach. We then discuss prompting as an algorithmic technique, explain how it makes foundation models programmable, and show how this enables different audiences to use these models as (computational) platforms. In the third section, we link the material properties of the technologies under scrutiny to questions of political economy, discussing, in turn, deep user interactions, reordered cost structures, and centralization. We conclude by arguing that foundation models and prompting further strengthen Big Tech's dominance over the field of computing and, through their broad applicability, other economic sectors, challenging our capacities for critical appraisal and regulatory response.
Scrutinizing foundation models
Foundation models
Concrete technical responses to the idea that machines could ‘learn’ have been around since the late 1950s, most famously through Rosenblatt's implementation of the perceptron, initially conceived by McCulloch and Pitts in 1943 (Cardon et al., 2018). Contemporary methods for machine learning typically apply statistical techniques to create models from training data, which can then be used to classify new data. While many of the ‘algorithmic techniques’ (Rieder, 2020) used to implement this idea are relatively simple, deep learning uses layered neural networks that can encode complex conditional relationships between inputs and outputs. These networks can show (much) better performance for specific tasks but require (much) larger amounts of data and computing power. The ‘deep learning revolution’ (Sejnowski, 2018) of the early 2010s only became possible because consumer-grade graphics cards designed for gaming could run these algorithms effectively. An emblematic application for deep learning is ‘supervised’ classification, where already labeled text messages or images are used to train a model that can apply these labels to previously unseen items. Since the system ‘learns’ the rules to apply from the examples shown, it is highly task-specific - it can only do what the training data implicitly instructs it to do.
While classification remains a common application, machine learning is also increasingly used to generate content. For example, a prominent technique for producing images is generative adversarial networks (GANs), which can create ‘convincing’ outputs when trained on large datasets. But their focus is again narrow as these models typically only capture one particular concept, such as ‘face’ or ‘dog.’
Over recent years, however, a new class of machine learning models has been lauded as a ‘paradigm shift’ (Bommasani et al., 2022). These models are both task-agnostic and particularly apt at generation while remaining useful for classification. Although not limited to image and text, these two domains have been the most visible. Text-to-image models like Midjourney, Stable Diffusion (Rombach et al., 2022), and OpenAI's DALL·E (Ramesh et al., 2021a) have made a splash as powerful tools for generating images with a wide variety of subject matters and styles, much less specialized than GANs. OpenAI's GPT-3 (Brown et al., 2020) and derivatives like ChatGPT and Bing's new ‘chat’ feature have received similar levels of attention for their capacity to generate ‘human-like’ output and engage in ‘deep’ conversations.
In both cases, the seeming prowess of these systems comes from the use of much larger and broader sets of training data compared to the more focused models preceding them. This was made possible by continuous growth in available compute power and, crucially, by innovations in algorithmic techniques. Google's transformer architecture (Vaswani et al., 2017) has been particularly important. Relying on a mechanism called ‘attention,’ transformers learn more selectively and, compared to techniques like long short-term memory (LSTM), allow for greater parallelization, making them ideally suited for large data centers (Luitse and Denkena, 2021). Computer scientists indeed noted a continuous increase in performance on standard benchmarks as models grew (e.g., Brown et al., 2020), driving a logic of ‘bigger is better,’ where always larger pools of training data are collected almost indiscriminately from the (anglophone) web (Bender et al., 2021).
What makes these new models stand out is the perceived 3 quality of their outputs and their capacity to produce very different kinds of images, texts, and so forth. As the ‘P’ in OpenAI's GPT (Generative Pre-trained Transformer) line of models indicates, they are only ‘pre-trained’ and thus require some kind of ‘task specification,’ for example, a prompt (Liu et al., 2021). While the term ‘foundation model’ has not received universal endorsement, it captures the ‘unfinished character’ (Bommasani et al., 2022: 6) of these systems, highlights their role as base infrastructures for various uses and applications, and - unlike ‘large language model’ (LLM) - allows addressing models for different media types conjointly. However, to avoid distancing the ‘legacy of criticism’ (Whittaker, 2021: 52) LLMs have received, we read the term ‘foundation’ through the lens of platform theory, putting questions of power and market dominance at the heart of our inquiry.
Critiques of foundation models and our contribution
Although foundation models are still relatively new and many open questions about their technical capabilities and limitations remain, they have already received critical scrutiny. The extensive report by Bommasani et al. (2022) underscores their potentially homogenizing impact when applied across broad application domains. Other scholars have called attention to environmental harms (Bender et al., 2021), inherent biases (Lucy and Bamman, 2021), the capacity to generate harmful and misleading content (Goldstein et al., 2023), the underlying greedy and unregulated data-harvesting practices (Jo and Gebru, 2020), and the proliferation of mass-produced digital artifacts (Floridi and Chiriatti, 2020). But so far, prompting has yet to figure prominently in these critiques, and social research has mostly been limited to studies on online communities and practices around text-to-image models (Oppenlaender, 2022a, 2022b). However, because prompting fundamentally changes how machine learning models can become part of application domains and products, our inquiry seeks to investigate how this specific technique may affect the larger political economy of AI.
Scholars like Srnicek (2018) have situated AI within platform capitalism, arguing that the concentration of data, expertise, and compute power in a handful of Big Tech companies also sets them up to control the AI industry. These companies are remarkable in terms of market dominance, capitalization, and global imprint, and they have been able to extend and leverage their capabilities and assets across various technological and economic sectors. In the context of AI, this trend is most clearly visible around cloud infrastructures, where Amazon, Microsoft, and Google play dominant roles (Luitse and Denkena, 2021). It also applies to control over (training) data (Edwards, 2023a), software frameworks, environments for experimentation and teaching (Luchs et al., 2023; Oppenlaender, 2022a), and AI research more broadly (Ahmed and Wahed, 2020). Unsurprisingly, their dominance extends to developing and deploying foundation models, as Microsoft (in close partnership with OpenAI) and Google, most notably, try to rapidly integrate them into products and make them available to third-party customers. This connects foundation models to the overall trend toward ‘AI-as-a-Service’ and the ‘global restructuring in the composition, organization, and consumption of computing assets’ (Narayan, 2022) around cloud providers. As Luitse and Denkena (2021) have argued, the hardware voraciousness of the transformer architecture risks extending the monopoly power of these companies. Since AI is often considered a ‘general-purpose technology’ (e.g., Trajtenberg, 2018) affecting many different industries, the power of these companies may also spread further into the industrial fabrics of other economic sectors.
To add to existing scholarship, we seek to pinpoint the role of prompting within this techno-economic configuration by addressing the technological materialities involved. Speaking about architecture, Blanchette notes that differences in strength, durability, and density between construction materials register ‘on the entire ecology of the field, from construction methods to economics, design traditions, professional training, cultural symbolism, etc.’ (2011: 1055) and argues that the opportunities and constraints afforded by digital technologies have comparable effects. Attentive to similar differences between approaches within computing, we have reservations about the analytical utility of broad categories such as ‘AI’ or ‘algorithms’ and focus instead on the specific properties of foundation models and their possible repercussions. Our question, however, is not whether these models showcase ‘real’ intelligence but how they (can) serve as means of production within larger assemblages and ecosystems. How do the specific ways foundation models can be ‘built upon’ (Bogost and Montfort, 2009) constitute a novel chapter in the larger story of ‘platformization’ (Helmond, 2015)?
This approach responds to Matzner's (2022) critique that research on algorithms and power typically treats algorithms either as abstract ideas or as flat technical assemblages without political depth. By centering foundation models’ technical properties and prompting's specific character as task specification technique, we seek to explore and reflect on their potential to alter relations within environments of production, and thus to ‘connect detailed analyses of specific information technologies with general political concerns’ (Matzner, 2022). How are foundation models reconfiguring AI, and what does this mean for the role computing plays in contemporary societies?
What is prompting?
Prompting as algorithmic technique
When the first transformer-based models were introduced, prompting was not a priority but only came into view later as an unexpectedly useful ‘by-product’ (Bommasani et al., 2022). BERT (Bidirectional Encoder Representations from Transformers), Google's first and widely adopted LLM, was initially designed and pre-trained - using the BookCorpus and English Wikipedia datasets - for two kinds of ‘downstream’ uses (Devlin et al., 2019). On the one hand, for language representation in traditional task-specific pipelines to improve performance; on the other hand, after adaption through fine-tuning, for language processing tasks such as question-answering. Like prompting, fine-tuning is a ‘transfer learning’ technique (Torrey and Shavlik, 2010) that aims to apply learned skills to unfamiliar but related problems. Unlike prompting, however, fine-tuning ‘re-trains’ and thereby alters the parameters - the weighted relations between neurons that encode what a model ‘knows’ - of pre-trained ‘generalist’ models like BERT using small, task-specific datasets with typically thousands or tens of thousands of examples (Brown et al., 2020; Liu et al., 2021). Conversely, ‘in-context’ learning techniques like prompting leave model parameters untouched and use only a handful of examples (‘few-shot’) - or no examples at all (‘zero-shot’) - to apply a model to an unfamiliar task. Compared to fine-tuning, where at least some part of the underlying system is modified, prompting thus allows different external actors to access a model simultaneously, each using their own task description to express their specific wants and needs.
Prompting moved to the center of attention when OpenAI's GPT-2 and, in particular, GPT-3 (Brown et al., 2020), two autoregressive decoder models trained for finishing text sequences, became competitive with task-specific and more data-intensive training methods (Wang et al., 2021). Fine-tuning and prompting are not mutually exclusive: OpenAI's ChatGPT is a version of GPT-3.5 and GPT-4 (Figure 1), fine-tuned for conversational interaction and further adaptable through prompting.

The evolution of large language models (Yang et al., 2023).
Prompting can be understood as a probabilistic technique for accessing and (re-)programming the internal ‘knowledge space’ of a foundation model without modifying the model itself (Jiang et al., 2020). Whereas traditional machine learning represents tasks indirectly through sometimes billions of labeled data examples, prompts describe them directly and intelligibly, using the capabilities of the underlying ‘generalist’ (Sejnowski, 2023) yet ‘unfinished’ (Bommasani et al., 2022) general-purpose model as semantic embedding or, indeed, as foundation. In a sense, a prompt (temporarily) activates a latent but underspecified capability already present in the pre-trained model. The reason why systems like ChatGPT can produce text about many different subjects and answer factual questions, often correctly, is that the term ‘language’ in LLM should not be seen as referring to Saussure's (1916) langue, the abstract rules of a specific language, but to parole (‘speech’), that is, language as used in everyday practice, including all of the actual utterances made, which are always about something. Foundation models are not grammatical generators and more than ‘stochastic parrots’ (Bender et al., 2021) since learning involves forms of aggregation, interpolation, and generalization - outputs are not simply lookups or search queries over the training data. The fact that different prompt formulations often produce different answers, even to factual questions, also shows that the plurality of ‘knowledges’ present in the underlying training corpora remains - to a degree - intact, even if imbalances in the training data and various kinds of processing create hierarchies of meaning: some parts of the model are more accessible than others. Prompting activates and funnels these knowledge reservoirs to ‘innovate’ within the latent space defined by the learned representation of the training data.
This has been described as a ‘sea change’ that extends beyond the hype around conversational interfaces such as ChatGPT: as task-specific training is replaced first by ‘pre-train and fine-tune’ and then by ‘pre-train, prompt, and predict’ procedures (Liu et al., 2021), even systems performing standard classification tasks increasingly rely on foundation models, particularly in situations of data scarcity (Le Scao and Rush, 2021). New algorithmic techniques may again change the equation, but there is a distinct possibility that cutting-edge performance in many applications will only be achievable with the help of ‘generalist’ models, impacting the entire field of AI.
While these repercussions for the ‘backend’ of AI are important, the models reaching furthest into public environments are those with strong generative capabilities for tasks that are performed by people in everyday settings, such as GPT-4 for text, DALL·E for images, Codex for code, or ChatGPT for conversations. In all of these cases, the underlying architectures are similar. As OpenAI states in its DALL·E documentation, ‘just as a large transformer model trained on language can generate coherent text, the same exact model trained on pixel sequences can generate coherent image completions and samples’ (Chen et al., 2020). Again, the ‘secret’ is the sheer size of the training data. For example, the multi-modal model CLIP (Radford et al., 2021) was trained on 400 million text-image pairs to achieve ‘general purpose’ image processing capabilities.
The ongoing development and exploration of prompting techniques can be subsumed under the term ‘prompt engineering,’ which has become both a user practice (Oppenlaender, 2022a) and a ‘rapidly developing field’ (Liu et al., 2021: 3) in AI research. Computer scientists develop sophisticated frameworks to optimize and automate prompting (Wei et al., 2022), leading to approaches where prompts are not intelligible text but ‘described directly in the embedding space of the underlying LM’ (Liu et al., 2021: 12). Prompting is thus not limited to chatbots and direct input interfaces but also establishes a novel paradigm for building AI applications where generalist systems are oriented toward specific tasks, suggesting that prompting should be understood as a particular form of programming.
Prompting as programming
While early literature in platform studies (Bogost and Montfort, 2009) identified programmability as the central characteristic of (computing) platforms, recent thinking often follows Gillespie's broader definition as online services that ‘afford an opportunity to communicate, interact, or sell’ (2010: 351), de-emphasizing their role as infrastructures for writing and running code. But through prompting, a foundation model indeed operates as ‘a computing system […] upon which further computing development can be done’ (Bogost and Montfort, 2009: 2), albeit in specific ways.
At first glance, likening prompting to programming may seem counterintuitive, as [the pope in Balenciaga] hardly resembles computer code. But looking at more complex examples (Figure 2) reveals prompting's dual character as both ‘natural’ and ‘formal’ language, or rather a combination or spectrum of both, blurring the line between conversational interaction and formal instruction. If programming is understood as a specification process for how certain inputs should be transformed into certain outputs, prompting serves similar ends and often also requires highly specific formulations to produce desired behaviors. But if we argue that ‘traditional’ machine learning systems are already programmed indirectly through data selection and preparation, prompting can also be seen as a form of data manipulation, as input data is not created to have it processed in a certain way but to cause a specific processing to happen. Through all these lenses, prompting appears as an ‘in-between’ that does not easily map onto existing practices.

An image generated with Microsoft Bing.
Prompting is (most often) probabilistic rather than deterministic, yielding different outputs for the same input; it can be unpredictable, and behavior strongly depends on the underlying training data. Indeed, the ‘semantic space’ addressed by a prompt is neither a microchip that implements the fundamentals of mechanical computation nor a search engine that matches queries to indexed site content but a distinctive algorithmic compression, projection, and operationalization of human language and knowledge. Prompting introduces a ‘command style’ that is neither the anthropomorphized conversational interaction we know from science-fiction movies nor the specialized logic of programming languages, but an amalgam of both that reflects the specific ‘transformer intelligence’ foundation models instantiate.
Indeed, as the term ‘prompt engineering’ suggests, structured knowledge is necessary to get the most out of generative AI systems. Additionally, since different foundation models use different training data and optimize for different objectives, their capabilities and ‘character’ vary, requiring model-specific prompting expertise. For example, Midjourney affords a variety of prompt manipulations, such as ‘multi-prompts,’ where a formatted prompt like [lonely::dog] treats both words as separate concepts instead of inferring their meaning together. Adding [tl;dr] at the end of a phrase instructs OpenAI's language models to perform text summarization. Because the training data of foundation models is scraped from the web, they can typically emulate various forms and styles, such as HTML tags or community vernaculars. However, users must adapt their language to optimize outputs. For example, the Very Unofficial Midjourney Manual 4 suggests that using the name of a camera or lens yields better results than words like ‘photorealistic’ and broadly recommends ‘to think less like yourself and more like a silly machine that has never once inhabited the physical world.’ Still, a single model can support various prompting styles and thus accommodate different audiences. Beginners can quickly produce results, and expert users can use their knowledge to extend control over outputs.
How prompting works for a specific model is governed by the training data and through fine-tuning, but also through guardrails and other ‘base prompts’ that orient and limit user queries without having to adapt the model itself. This is also how third parties can build applications on top of (closed) foundation models: using base prompts, they orient the generalist system to targeted application spaces, e.g., office work or poetry generation, which can both reduce possibilities and improve task-specific performance. This flexibility undergirds foundation models’ role as platforms.
Prompting as practice
Although many programmable computational artifacts could technically be considered platforms, a critical material inquiry becomes particularly important when their specific ‘computational expression’ operates beyond niche audiences and broadly transforms cultural practices. In the case of foundation models, prompting drives both novel end-user practices through direct interaction via text forms and product development through APIs (application programming interfaces). In this section, we discuss these modalities in turn.
The uptake of foundation models has been impressively quick despite many systems not being available globally. According to analysts (Milmo, 2023), ChatGPT may be ‘the fastest-growing consumer internet app ever,’ reaching 100 million users two months after launch. Similarly, Stable Diffusion reportedly gained ‘more than ten million daily active users’ shortly after its release (Kemper, 2023). Midjourney claims that approximately 1.1 million users are ‘online and active at any given time’
5
. These numbers have led scholars like Lev Manovich to speak of a ‘cultural revolution’: First iPhone and Instagram created billions of photographers. And now, #MidjourneyAI and #dalle2 are creating billions of artists. It's the ultimate democratization of something that until now required lots of training or money.. a real cultural revolution! (Manovich, 2022)
While user numbers may level off as novelty fades, active communities of practice have formed around creation- and prompt-sharing. Generated text and images are posted on social media, where millions of messages are tagged with #midjourney, #aiart, or #aiartcommunity. Users exchange and collect ideas, experiences, and best practices, e.g., on Discord servers, creating rich and systematic knowledge repositories around specific models and their peculiarities. Next to helping practitioners, knowledge sharing also provides valuable insights to computer scientists working on prompt engineering or human-computer interaction (Oppenlaender, 2022b) and to the companies running these models. The potential economic value of prompting becomes visible around marketplaces like The AI Prompt Shop 6 or PromptBase 7 . The former sells Midjourney prompts, usually for around $3, to produce game assets, storybook illustrations, character art, or cartoons in particular styles. The latter allows users to sell prompts for different models.
The professional uptake of prompting builds mainly on its capacity to instantly translate ideas into digital media forms, particularly in fields like journalism, marketing, design, or software development. Here, prompting enables less tech-savvy audiences to use generative models manually but also API-based automated content production for websites, a quickly growing practice (Hanley and Durumeric, 2023). Consequently, various application domains are experiencing intense debates about AI's current and future potential to replace or ‘augment’ workers, transforming modes of operation and compensation with potentially significant effects on labor markets (Verma and Vynck, 2023). While threats of worker replacement are, at least in part, means to exert pressure on employees, the ‘industrialisation of automatic and cheap production of good, semantic artefacts’ (Floridi and Chiriatti, 2020: 681) will have wide-ranging consequences.
Foundation models also support the creation of third-party applications and services, many of which are still ‘in the making’ or available as limited beta-versions. Following the AI-as-a-Service principle, these applications integrate the generalist capabilities of foundation models into specific application logics. For example, AI Dungeon 8 uses GPT-3 to create ‘a text-based, AI-generated fantasy simulation with infinite possibilities,’ Forever Voices AI 9 uses foundation models and text-to-speech technologies to make virtual facsimiles of celebrities, and AutoGPT 10 leverages GPT-4 as an ‘autonomous AI agent’ that can execute iterative web actions in the browser. Many of these products are financed through premium subscription models. However, which applications and business models will prove viable in the long run is hard to anticipate in this quickly evolving landscape. For example, as we were putting the finishing touches on this paper, OpenAI introduced the ability for developers to create custom versions of ChatGPT that run on the company's infrastructure, are shared through a ‘GPT Store,’ and come with a revenue-sharing program, echoing the two-sided market setup we know from mobile app stores and other sales platforms.
Third parties can also provide endpoints for models to interface with. OpenAI has launched a plugin feature that allows ChatGPT to connect with external services, for example, to create Spotify playlists, shop for groceries via Shopify, or deploy generated code directly via DeployScript. Google's Bard provides a similar plugin system to enhance capabilities, creating complex service ecosystems that cannot be easily replicated.
Finally, stakeholder companies like Google or Microsoft rapidly integrate prompting into their existing products and seek to drive their large userbases to these AI services. Both companies have added direct interaction with foundation models to their search offerings and Microsoft, in particular, sees its partnership with OpenAI as a way to compete for this ‘most profitable, large software business’ (Fortt Knox, 2023). The company has also begun to add ‘co-pilot’ features to products for software development (GitHub, VS Code) and to Office, for example, to enable Teams ‘to simplify meetings, including automating notes and recommending tasks based on conversations had during the call’ (Morrison, 2023). Google is following suit in its Cloud and Workspace environments (Saran, 2023). The well-known synergies between internal and external use of technological assets and the benefit of having popular services that function as springboards for new products already indicate Big Tech's fundamental advantages when it comes to AI.
The political economy of prompting
Foundation models are based on deep learning and, therefore, susceptible to similar critiques regarding, for example, data voracity, energy costs, opacity, and potential biases (Bender et al., 2021). But they also introduce new concerns and exacerbate and reconfigure existing ones, as their specific properties and capabilities exert pressures that cannot be dissolved with appeals to human agency. They transform incentives, shift cost structures, alter social relations, and produce new marketable functionalities. Attending to these model-specific factors is not succumbing to ‘technological determinism’ but accounting for the influence of material conditions on human life and decision-making (Blanchette, 2011).
In this section, we examine foundation models - again with an emphasis on prompting - from a ‘material-technical perspective’ (Helmond, 2015) on ‘platformization,’ that is, ‘the penetration of infrastructures, economic processes and governmental frameworks of digital platforms in different economic sectors and spheres of life, as well as the reorganization of cultural practices and imaginations around these platforms’ (Poell et al., 2019: 1). Our goal, however, is not simply to apply the familiar blueprints of platform theory to foundation models but to proceed inductively, from the objects themselves, to understand how they may reconfigure the political economy of AI.
We propose three interrelated analytical directions: deep user interactions tackles the heavy dependence of foundation models’ value on user input; reordered cost structures thematizes the changes in resource requirements; centralization and lock-in, finally, discusses some of the broader effects of foundation models on the AI landscape.
Deep user interactions
The idea that user feedback is central to improving (software) products has been frequently put forward, for example, when O’Reilly (2005) suggested that Web 2.0 services should embrace the ‘perpetual beta’ principle and treat users as ‘co-developers.’ Users, including developers connecting to models via APIs, function as testing and innovation departments that provide various kinds of knowledge and creativity to companies. For example, mashups and applications built on top of ‘infrastructural’ systems relieve tech companies from running costly and potentially risky experiments themselves, and they can later copy products and functionalities that have proven viable. Since foundation models’ size, opacity, and often unforeseeable behavior make them hard to engineer in line with precise functional specifications, user interaction via prompting is even more fundamental, particularly when developing marketable products. Companies that can leverage the network effects from large userbases have clear advantages. As Google CEO Sundar Pichai conceded (Roose et al., 2023), bringing Bard to market quickly was critical to starting the user feedback cycle early, even if first versions still had to rely on the older LaMDA model.
On the one hand, user input helps identify ‘problems,’ for example, with veracity, bias, security, or offensiveness. Systems trained on vast and only thinly vetted troves of data cannot be ‘fixed’ without armies of users probing and derailing them, as traditional evaluation and debiasing techniques are not easily applied to foundation models. 11 The quick update cycles to ChatGPT and Bing Chat, which regularly add new guardrails and limitations, often respond to users finding new ways to ‘trick’ models into producing all kinds of problematic outputs. OpenAI's emphasis on outreach 12 can undoubtedly be seen as an effort to present the company as responsible and virtuous. However, user engagement is essential when adapting models with far-reaching capabilities to ambiguous ethical requirements.
On the other hand, since prompting is not a trivial lookup technique or a deterministic query, foundation models thrive on deep experimentation through rich semantic and contextual layers, both to discover and optimize capabilities and to understand what renders a particular outcome satisfying or ‘authentic.’ This can be seen as a process of alignment, that is, as the coordination between system behavior and intended goals (Ouyang et al., 2022), or as a form of ‘contextual grounding’ within actual use practices to improve model performance and ‘acceptability’ in downstream applications. When users prompt a model, they create input-output pairs with information about optimal task-specific behavior. Until the model performs as desired, iterative updates to prompts launch sequences of task description, output evaluation, task reformulation, and so forth, producing nuanced semantic interactions. The grassroots efforts mentioned in the last section thus give model providers systematized insights into how the emergent ‘mysterious’ AI system can perform as its users desire. More than ever, use produces knowledge that can be exploited directly through automated optimization based on, for example, reinforcement learning or indirectly in dedicated evaluation cycles.
Prompts thus serve as an attentive medium to capture user needs, wants, and critiques. If search engine queries feed into a ‘database of intentions’ (Battelle, 2011), the prompts submitted to foundation models constitute even richer and more detailed cultural repositories that reach beyond the more utilitarian aspects of search and include, for example, affective relationships with conversational agents. AI providers offer free usage while harvesting and leveraging these interactions, sticking to the same behaviorist logic as search engines and social media. It thus comes as no surprise that advertising is seen as a central opportunity to generate economic value: Microsoft's ability to understand complex queries in greater depth and precision, as well as the rich insight we will gain into user intent through deep conversational engagement, will deliver smarter and more actionable opportunities for advertisers to engage with customers. (Wilk, 2023)
These processes resemble what Terranova (2004) describes as the capturing, absorption, and exploitation of ‘collective intelligence’ or of what Marx called the ‘general intellect,’ the diffuse ensembles of knowledge running through societies. The production of knowledge, Terranova argues, is always a collective process, and ‘[c]apital's problem is how to extract as much value as possible […] out of this abundant, and yet slightly untractable terrain’ (88). If social media platforms’ pervasive behavioral data collection is one way to extract value from the ‘society-factory’ (74), foundation models constitute an even more comprehensive pathway. On the one hand, training data representing the work of innumerable individuals is taken almost indiscriminately from public sources. On the other hand, deep user interactions align, orient, and activate the latent knowledge in these reservoirs, increasing their economic potential by making them ready for deployment as commercial products.
Reordered cost structures
As prompting reduces the need for ‘traditional’ task-specific training data, architecture design, and access to model parameters, it gives rise to new scenarios, workflows, and types of engineering (Liu et al., 2021). This may have profound consequences for how AI is typically provisioned, including how costs are distributed along the production chain.
While Srnicek (2019) has argued that data plays an increasingly smaller role in the political economy of AI as free datasets and synthetic data proliferate, foundation models suggest a significant reshuffling. The central factor is the split between the initial pre-training, where vast amounts of task-agnostic data is ingested, and the adaptation to an application space, where requirements for task-specific examples are dramatically reduced (Figure 3). Software frameworks like TensorFlow and cloud infrastructures have already ‘platformized’ fundamental research and compute power, and prompt-based learning operates a similar transformation for data. This again means that investments are shifted to the platform side, with the promise that increased efficiency will lower costs for clients (Narayan, 2022). Even if recent discussions have suggested that open-source foundation models could outcompete proprietary solutions in technical terms, the cost of assembling, curating, securing, and sanitizing the underlying data should not be underestimated. Attenuating looming issues with bias, veracity, privacy, and copyright will likely require this data to be handled much more proactively than the indiscriminate collection schemes we see now. For example, OpenAI licensed Shutterstock's image collection, which not only includes well-tagged, high-quality images of human beings in various settings, but also responds to increasing pressures concerning data providence. Microsoft is going as far as providing legal protection for copyright infringement to its clients (Edwards, 2023b).
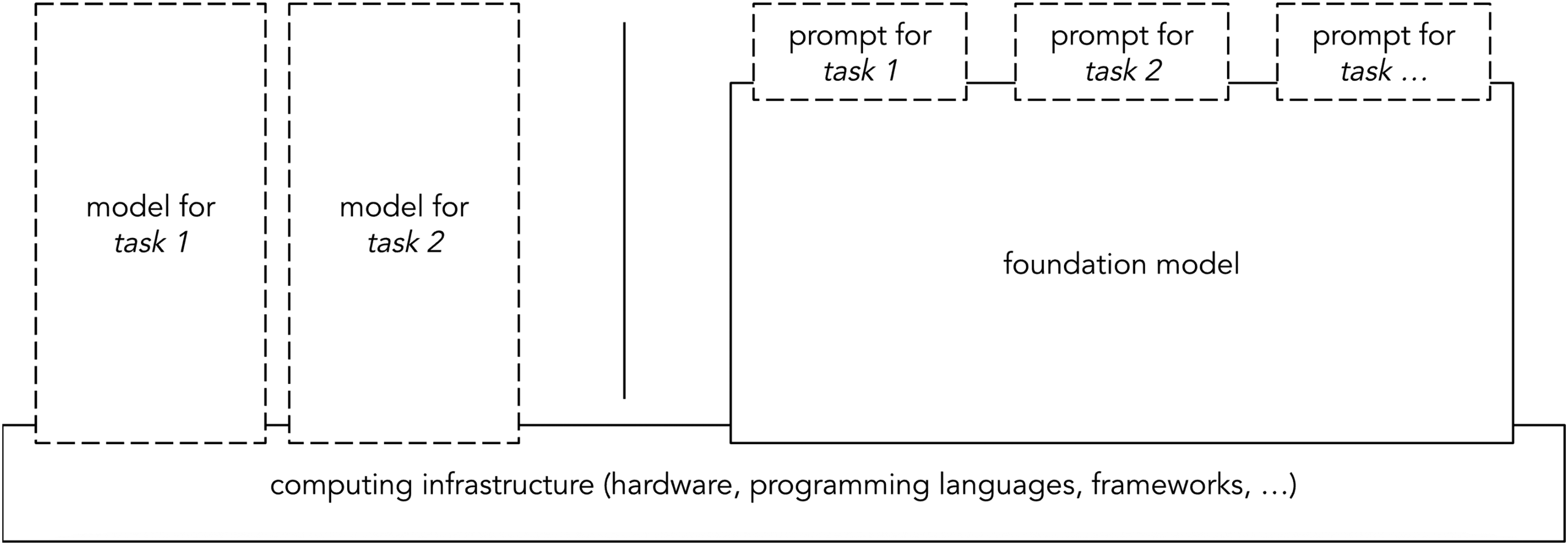
Schematic comparison between ‘traditional’ machine learning and foundation models.
Similarly, attempts to de-bias foundation models will have to draw on well-curated and regularly updated datasets. In addition, reports on low-paid and psychologically harmful tagging work (Perrigo, 2023) feeding into reinforcement learning from human feedback (RLHF), a fine-tuning technique that allows for the purpose-driven alignment and ‘securing’ of foundation models, suggest that these tasks cannot be fully delegated to users. Big Tech companies have the deep pockets to finance these operations and, crucially, can draw on vast amounts of high-quality data already collected for other purposes. Meta, for example, used 1.1B public images from Facebook and Instagram to train its new image generator, side-stepping legal issues through shrewd terms of service assuring the right to mine the outputs of its huge userbase (Edwards, 2023a). And constructs like Google's Knowledge Graph, a formal representation of curated and expanded Wikipedia data, may be necessary to deal with the factual errors and ‘generative exuberance’ current foundation models are prone to. There are thus good reasons to believe that data-related costs on the platform side will remain significant, constituting a ‘moat’ to protect against competitors and creating incentives to spread investments over many internal products and external clients.
Regarding compute power, scholars have argued that memory requirements and parallel execution make transformer-based models ideally suited for large data centers (Luitse and Denkena, 2021). Microsoft is reported to have invested $13B into OpenAI (Kahn, 2023), much of that in the form of compute credits for Azure, and the startup is still said to have lost $540 M in 2022 (Woo and Efrati, 2023), mostly due to the enormous costs of training and running their systems. The demand for compute power has pushed Nvidia's stock price to stratospheric levels and prompted cloud companies to design hardware themselves; Google indeed claims that the fourth version of its Tensor Processing Unit ‘is faster and more efficient than competing Nvidia systems’ (Leswing, 2023). Companies running massive data centers for both internal products and external clients can mobilize the necessary processing power and optimize resource usage by scheduling compute-intensive operations like training during periods of lower utilization, increasing the ‘load factor’ (Hughes, 1983) of expensive equipment that would otherwise sit idle. There are certainly many smaller and larger innovations that can reduce these costs. For example, after the weights for Meta's LLaMA model were ‘leaked’ - only the code was open-sourced - researchers and enthusiasts quickly found ways to shrink model size and compute requirements to the point where a consumer laptop can fine-tune and run an LLM similar in performance to GPT-3 (Hu et al., 2021). However, running millions of queries from global audiences differs greatly from tinkering on local machines, and the initial training of the many LLaMA-derived models floating around the web was still performed on Meta's massive server farms.
Both data and compute requirements point toward the fundamental difference between (academic) experiments and products that can provide high safety levels, scale to billions of users, withstand public scrutiny, and generate income. While open-source approaches will find their niches, we argue that foundation models will likely strengthen AI-as-a-Service provision, which makes it easier to spread high initial investments over many income-generating endeavors. Prompting plays a unique role in this development, as it greatly facilitates creating AI-based applications and potentially attracts many more clients to the dominant cloud infrastructures, which can offer the most ‘application-ready’ models and the hardware to run them. Much like in other capital-intensive industries, where entry barriers are high, and economies of scale favor winner-takes-all outcomes, the reconfigured cost structures of foundation models point toward monopoly. And the enormous investments made will have to generate returns further down the line. As Morozov (2023) insists, ‘the charm offensive of heavily subsidized services’ will be followed by an ‘ugly retrenchment, with the overdependent users and agencies shouldering the costs of making them profitable.’
Centralization
While separating off-site pre-training and local adaptation through prompting makes accessing AI capabilities easier for broad audiences, there are important repercussions for power relations. As external actors explore and adapt the capabilities present in the latent space of foundation models, they interact with opaque systems that are ‘open-yet-sealed,’ delegating essential decisions to service providers. The applicability ‘to countless needs and niches that the platform's original developers could not have possibly contemplated, much less had time to accommodate’ (Andreessen cited in Bogost and Montfort, 2009) and the overall trend toward cloud-based provision make foundation models formidable centers of control that profit from the inputs of potentially billions of users, ranging from lay people to corporate clients.
Economists have variably described AI (Trajtenberg, 2018), machine learning (Goldfarb et al., 2023), and now foundation models (Eloundou et al., 2023) as ‘general-purpose technologies’ that, like electricity and the steam engine, can be applied across different industries and therefore wield outsized influence on economic development. While many questions remain about the actual penetration into application spaces, we already see tasks that were emblematic examples of traditional machine learning, for example, content moderation (Lees et al., 2022), transitioning toward foundation models. If a few companies come to dominate the design and deployment of task-agnostic - or at least widely applicable - technologies, prompting-based deployment fuels a central component of platformization, namely the tendency ‘to decentralize data production and recentralize data collection’ (Helmond, 2015: 5), further exacerbating network effects.
For cloud computing providers, this is a tremendous opportunity, not only due to the already mentioned economies of scale and synergies between internal and external use but also due to the possibility of moving further up the value chain, from ‘mere’ hardware provision to more sophisticated service products, a path these companies have already been pursuing diligently. Prompting-driven foundation models, which are easy-to-use for clients but require elaborate and costly background work, represent another step in this endeavor. The combination of broad applicability, increasing sophistication, and ‘platform-based organizational forms and business models’ (Narayan, 2022: 925) creates new opportunities for lock-in. On the one hand, bringing pipelines based on foundation models from the cloud in-house will be impossible for all but the most capable actors. Many companies may desist or divest from building models altogether. On the other hand, moving operations to a competing foundation model will also not be easy due to differences in capabilities and prompting practices (Oppenlaender, 2022a). As cloud companies provide fine-tuned ‘heads’ for specific application domains, for example, versions of a larger model optimized for specific domains, switching costs will increase further. Since the main cloud computing providers already have millions of users who rely on their increasingly sophisticated products, they are well-positioned to lock them deeper into their service offerings. And what happens if a company decides to modify, restrict, or discontinue a model, leaving the applications and businesses built on top of it scrambling to adapt? What if AI providers copy successful third-party products and raise prices for their competitors? These entanglements are already prominent in the larger platform economy, and AI is set to exacerbate them even further.
These questions raise concerns about monopolization at the economic level but also concerning knowledge technologies that wield (subtle) semantic control over societies. While Bommasani et al. (2022) highlight the potential for homogenization and the proliferation of ‘defects’ as downstream adaptations of foundation models inherit biases, security flaws, and so forth, there are potentially broader practical and ideological effects that are not captured by the opposition between presumed neutrality and problematic deviations. If foundation models become the dominant way to design and deploy AI, through sealed cloud-based offerings or as equally opaque components in more distributed pipelines, the question of how AI develops as a technology and what role it can play in society come under even greater influence of companies that primarily serve their economic interests (Whittaker, 2021). At stake is not only the centralization of control over powerful means of production but also over technologies promising to process meaning and, when given access to other systems, to orient action in ways that far exceed the already important influence of algorithmic systems, yet are even harder to track, scrutinize, and critique.
Conclusion
In this paper, we have discussed foundation models and some of their (potential) repercussions through the lens of prompting, the most visible mode of interacting with and ‘programming’ these general-purpose systems. While many questions about their future remain, including the question whether regulation and legal troubles will stall their diffusion, we have argued that they operate as platforms in at least three different ways: as components in machine learning pipelines that draw on language and image understanding to improve the performance of task-specific systems, potentially reducing the need for specially labeled datasets; as direct-to-consumer interfaces that allow for generating wide ranges of texts and images as responses to prompts, enabling both beginners and expert users to replace previous modes of production with generation; and as AI infrastructures for systems that use APIs to interact with foundation models, integrating their generative capacities into specific application spaces, sometimes in ways that the underlying model remains visible, sometimes hiding its contributions. Each of these three layers constitutes a vector of infiltration into everyday practices. This concerns quantitative elements, such as revenue numbers, percentages of circulating content, and shifts in labor markets, as well as more qualitative aspects that are hard to measure, such as transformations in how things are done, what kinds of content are produced, and, in the long run, how thinking patterns and human subjectivity are affected. How far this will eventually reach is hard to estimate, but what stands out is both the breadth of possible applications and the enormous sums companies are willing to invest. Considerable amounts of critical conceptual and empirical research will be needed to provide answers.
While foundation models have been in the news for their sometimes striking capabilities, which may indeed affect professions and labor markets in the (near) future, their (potential) influence on the larger field of AI goes beyond these visible engagements. This is why the architectural connotation of the term ‘foundation’ requires, as a supplement or corrective, the sensitivity for questions of power that ‘platform’ suggests. Yes, foundation models can do things that were hardly possible without them, but they also change how and which audiences can interact with, make use of, and build on AI; they transform how AI systems are organized and constructed; they direct local efforts toward ‘production series’ of massive models developed and controlled by a handful of companies; they orient research from domain-specific approaches and techniques toward singular methods that reach across domains; in short, they reshuffle the industrial basis for AI development and provision, reshaping the entire ecosystem of AI and, by extension, of contemporary computing.
In economics, ecosystems are groups of firms that interact with and depend on each other; to no surprise, researchers investigating AI ecosystems have found that ‘AI provision is characterized by the dominance of a small number of Big Tech firms’ (Jacobides et al., 2021: 412). Given the enormous capital expenditures we have already seen, these companies are clearly aware that foundation models present extraordinary opportunities to enhance existing products, create new ones, and extend their lead as providers of essential infrastructure for armies of third-party actors. As techniques like prompting and fine-tuning shift AI development on top of foundation models, how many actors will be able to invest in data collection and administration, data centers and custom hardware, testing and ‘safety engineering,’ continuous research, and large-scale user engagement environments? Even if optimized algorithmic techniques promise to reduce costs, there is little reason to believe that creating and running foundation models will not be extraordinarily capital-intensive. The likely outcome, as so often, is further monopolization.
If foundation models prove to be the most performant and effective way to organize AI provision, those who control them will have extraordinary power over AI in general, including both current applications and future developments. As Hooker (2020: 1) has argued for what she calls the ‘hardware lottery,’ that is, the situation where ‘a research idea wins because it is suited to the available software and hardware and not because the idea is superior to alternative research directions,’ the companies in charge of foundation models will assure that AI development proceeds in ways that conform to their interests and play to their strengths. This risks reinforcing the focus on techniques and methods that are well-suited for cloud-based provisioning, with resources being allocated toward the exploration and exploitation of series of large models instead of developing alternatives that are less geared toward AI-as-a-Service and thus less susceptible to monopolization dynamics. But even if the movement toward further centralization seems to be a foregone conclusion, what does this mean beyond the question of how many and which companies are left standing?
As Bommasani et al. (2022) argue, the widespread use of a limited set of foundation model series risks homogenization and the spread of inevitable biases across application domains. However, if these models are specific projections of the ‘general intellect,’ they imply not only differential treatment but also all kinds of subtle forms of aggregation, normalization, and generalization: even if they can contain a variety of ‘knowledges,’ some will be closer to the surface than others, constituting the default rather than having to be ‘teased out’ through creative prompting. Since the work to debias, align, and, in fine, semantically engineer foundation models will hardly happen in the public domain - free labor is not democratic participation - another layer of centralized opacity is in the making. This opacity concerns not only the ‘explainability’ of models and algorithms but, more broadly, the logistical and semantic power spreading through the full assemblage from research to application, including data curation, design, provision modalities, contractual arrangements, and billions of instances where these models are generating, classifying, summarizing, and so forth.
What can be done about this? Halt the development of foundation models for six months as an open letter signed by many researchers, critics, practitioners, and tech moguls has recently proposed? 13 Create purpose-built regulations focusing on safety and transparency rules? (Bertuzzi, 2023) Extend and apply copyright laws more strictly? Foster the open-source movements already seen by some as powerful alternatives to Big Tech companies? Unbundle services and break up companies that have become too large? We do not have any clear answers to these questions as the technologies at hand are still at early stages of (commercial) deployment and may or may not have the far-reaching effects we and other commentators anticipate. As Lina Khan (2023), the current chair of the US Federal Trade Commission, remarked in a recent call to avoid previous mistakes, ‘[w]hat began as a revolutionary set of technologies ended up concentrating enormous private power over key services and locking in business models that come at extraordinary cost to our privacy and security.’ The key question, then, is whether we can develop the intellectual, institutional, and practical resources to conceptualize and implement forms of democratic control over technologies that are challenging our societies through the promise to automate sense-making at levels that are genuinely new.
Footnotes
Acknowledgements
The authors would like to thank Antal van den Bosch, Fabian Ferrari, the members of the UvA Social Tech Club and Machine Learning Reading Group, and three anonymous reviewers for their very helpful comments and suggestions.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Platform Digitale Infrastructuur Social Science and Humanities (PDI-SSH) (Call Digital Infrastructure SSH 2020, Twi-XL project).