
Abstract
In recent years, both private and public organizations across contexts have begun implementing AI technologies in their recruitment processes. This transition is typically justified by improved efficiency as well as more objective, performance-based ranking, and inclusive selection of job candidates. However, this rapid development has also raised concerns that the use of these emerging technologies will instead increase discrimination or enhance the already existing inequality. In the present study, we first develop the concept of meta-algorithmic judgment to understand how recruiting managers may respond to automation of the hiring process. Second, we draw on this concept in the empirical assessment of the actual consequences of this type of transition by drawing on two large and unique datasets on employment records and job applications from one of Sweden's largest food retail companies. By comparing the outcomes of traditional and algorithmic job recruitment during this technological transition, we find that, contrary to the company's intentions, algorithmic recruitment decreases diversity. However, in contrast to what is often assumed, this is primarily not because the algorithms are biased, but because of what we identify as an unintended human–algorithmic interaction effect.
Introduction
One area in which the use of algorithm-based assessment systems has increased rapidly during the past few years is in hiring and human resources management (Jarrahi et al., 2021; Leicht-Deobald et al., 2019; Strohmeier, 2022). With new sophisticated recruitment technologies, working routines in this area have been fundamentally changed. Professionals who previously managed the entire evaluation and selection process by themselves today must handle recommendations generated by algorithms. A major driving force causing organizations to automate parts of the hiring process is that it saves a great deal of time and reduces costs (Köchling and Wehner, 2020; Raghavan et al., 2020). These systems are also generally assumed to enhance the objectivity and impartiality of the process by focusing only on measuring candidates’ actual skills and personality traits. The argument is that removing the potential impact of human biases and arbitrariness from the screening part of the process will also increase social inclusion and fairness (Lin et al., 2021). There are indeed great expectations that these new systems will support recruiting managers in identifying the most suitable and talented candidates, candidates they perhaps would have missed when only relying on their own professional judgments and “gut feelings” (Moss and Tilly, 2001; Pedulla, 2020; Rivera, 2015). This ongoing development is part of a more general trend, where important opportunities and life chances—including the ability to obtain loans, parole, housing, and insurance—are being automated (Ajunwa, 2020; Beer, 2022; Cevolini and Esposito, 2020; Citron and Pasquale, 2014; Gerdon et al., 2022; Kahneman et al., 2021; O’Neil, 2016; Zarsky, 2016).
The social impact of algorithmic assessment systems on hiring processes has thus far been given rather limited scholarly attention, and the contributions that have been made are primarily nonempirical in nature (Köchling and Wehner, 2020; Upadhyay and Khandelwal, 2018; van Esch et al., 2021; Vrontis et al., 2022). Given the potential effects of this development on labor markets characterized by social exclusion, inequality, and discrimination, studying the real consequences for organizations that have implemented algorithm-based hiring is of tremendous importance in promoting the common good.
Our study will contribute both empirically and theoretically to the latest research on automation and human–algorithm interaction effects. The primary empirical contribution concerns filling the above-mentioned knowledge gap by assessing the consequences the automation of hiring has for diversity, compared with traditional hiring processes. We do this by studying the socio-technological transformation of hiring at a large Swedish food retail company, here anonymized as “FoodMarket,” a multisite organization with hundreds of stores across the country. Accordingly, our first research question is: 1. Does automating the earlier phases of the hiring process at FoodMarket result in a more diverse set of employees, compared with the traditional, nonautomated process?
1
In analyzing the second research question, we introduce the intermediary concept of meta-algorithmic judgment in order to theorize the discretionary power of the recruiting managers when making use of the algorithmically generated outcomes to select candidates for job interviews. This notion is important, as it highlights a crucial moment in the automation process, that is, when the recruiting manager must choose among candidates after the algorithmic system has produced its shortlist. We use this concept to study the diversity outcomes of the algorithmic and human part of the algorithm-based hiring process at FoodMarket. We furthermore consider the issue of “algorithmic bias,” which can result in low diversity when a hiring technology screens out a disproportionate number of applicants of a specific gender, ethnicity, etc., because of systematic differences in test performance (Timmons, 2021). By following job applicants through the various steps in the assessment procedure, we ask: 2. Does the algorithm-based hiring process result in diversity bias? If so, when does bias emerge during the process?
We also relate meta-algorithmic judgment to the discussion on “algorithm aversion,” a phenomenon that has been recognized as a substantial challenge for organizations aiming to provide algorithm-driven support to augment decision-making processes (Burton et al., 2020; Dietvorst et al., 2015). In the present paper, we will study whether recruiting managers tend to under- or over-utilize algorithmically generated support when selecting candidates for a job interview, and how compliance and noncompliance relate to diversity parameters. Hence, we also ask: 3. Can differences in diversity outcomes at the different stages of the hiring process be linked to different degrees of compliance with the algorithms’ recommendations?
Diversity bias in the hiring processes
It is well known that employment discrimination systematically bars individuals identified with certain social categories of ethnicity/race, gender and age from employment (for a recent review, see Lippens et al. (2023); for Swedish evidence, see Bursell et al. (2021)). While it is not known how much of this discrimination results from traditional versus algorithm-based hiring processes, racial discrimination rates have remained rather constant over time, demonstrating the persistence of the problem (Quillian et al., 2017).
Traditional hiring
The processes we refer to here as “traditional” are those in which the entire evaluation process is conducted by humans, ranging from informal processes like the hiring of walk-ins and from social networks to formalized processes like merit- and competence-based selection.
Despite numerous efforts to reduce the influence of human bias in traditional hiring, even highly professional and well-intended recruiting managers have been shown to be susceptible to biases that influence their judgments when assessing job candidates (Rivera, 2015; see also Highhouse, 2008; Pedulla, 2020). The risk of bias influencing assessments is particularly high in the earlier phases of the hiring process, when a large number of job applications are processed and each application is, out of necessity, allotted very little time. Thus, if human biases that occur in the screening phase can be removed through automation, there is significant potential for discrimination to be decreased by using algorithmic assessment as a threshold mechanism.
Algorithm-based hiring
There is a wide range of algorithmic recruitment systems on the market, from rule-based to machine learning systems. The system that will be in focus in our study is presented by the systems provider as software based on the latest advances in psychometric research and state-of-the-art assessment techniques. The system is designed to evaluate applicants’ work-related competencies, social skills, and problem-solving behavior, assessed through psychometric lenses (“Big Five”) using tests that provide scores on how well the candidates respond to a series of tailor-made questions. While such tests have been used for decades as a screening mechanism (Barrick and Mount, 1991; Salgado and Andersson, 2002), the new recruitment technologies being used today have not only moved these selection tools online, but the algorithms employed to assess candidates have also become increasingly refined and sophisticated (Köchling and Wehner, 2020; Strohmeier, 2022). Most systems offer a general test that evaluates performance across occupations (e.g. service, leadership, sales), where personality traits and work-related competencies are weighted to predict a specific type of performance score. Unique profiles can also be designed on the request of customers. The algorithms are generally rule-based in this ethically sensitive type of decision-making context, but to maximize the predictive validity, many providers also integrate machine learning techniques such as natural language processing into the data analysis as well as the weighting procedures. As Kitchin (2017: 20) remarked, “algorithms are usually woven together with hundreds of other algorithms to create algorithmic systems. It is the workings of these algorithmic systems that we are mostly interested in, not specific algorithms.”
Rule-based algorithms are typically designed to follow predefined “if-then” coding statements in relation to a set of facts, which generally makes them more consistent than human judgment. They are also much less opaque than machine learning algorithms and cannot develop their own rules. By not using historical training data and data-mining techniques for the assessment procedures, the rule-based hiring technology may avoid reproducing already existing patterns of exclusion and discrimination in society. However, rule-based algorithms can also be systematically biased if certain groups that seem on average to be equally able to conduct certain work tasks (e.g. men and women) are being disproportionally weeded out by qualifying criteria or personality measures (Timmons, 2021), or when there are large differences in test performance between such groups. Because such differences have been shown to exist across several social categories (Cottrell et al., 2015; Risavy and Hausdorf, 2011; Soto et al., 2011; Weisberg et al., 2011), the concern for algorithmic bias is warranted (O’Neil, 2016). If such tests do predict work performance, itself a contested issue, this poses a dilemma for employers as regards balancing diversity and meritocracy.
While selection to an interview, and even final hiring decisions, could in principle be made by strictly following the algorithmically generated ranking of the candidates, most organizations assign these crucial tasks to HR professionals and/or recruiting managers. Hence, in practice, what we observe in algorithm-based hiring is partly automated recruitments, that is, processes in which algorithmic systems and human recruiters interact.
Meta-algorithmic judgment
By introducing the concept of meta-algorithmic judgment, our aim is to establish a general term for organizational decision-making processes that considers the relation between algorithmic assessments and human judgment. With the prefix meta- (μετά), which literary means “after” or “beyond” in Ancient Greek, we wish to highlight the procedural relationship in time between the evaluative output produced by algorithms and the judgment that must be made by a human user in the next step of the hiring decision-making process. We do indeed recognize the preparatory work that is being done by HR before the candidates can apply online. However, our concept focuses specifically on a crucial decision mechanism, namely the transition from the algorithmic assessment to the concrete judgments made by recruiting managers. Theoretically, we see this as a contribution to the ongoing discussions of the hybridization of AI and human intelligence (Jarrahi et al., 2022). In other organizational contexts, e.g. hospitals or insurance companies, the content of a professional's meta-algorithmic judgment will obviously change, but the general form is basically the same: the human user must consider the assessments produced by the algorithms to make a new decision. To illustrate, in the hiring context we are studying, the algorithmic system first scores candidates based on their test performances, resulting in shortlists of top-ranked candidates. This shortlist is thus the concrete product of the algorithms, and from there, the recruiting manager will typically move forward (after having received it from the HR department) by making their decision regarding which of the candidates on the shortlist will be invited for a personal interview.
The assessments the recruiting managers conduct at this point diverge in a crucial way from the assessments conducted in traditional recruitment processes (e.g. reading CVs and personal letters), where the recruiting manager usually does the ranking themselves and follows it precisely because it is based on their own judgment. Having conducted this process makes them more acquainted with the pool of candidates and gives them a basic overview of the possible alternatives, building on their professional insights from the work unit/group they are managing. The new algorithmic system, even if only rule-based, will inevitably make the process somewhat less transparent from the recruiting manager's point of view (see also Baykurt, 2022; Felzmann et al., 2019). Even in cases where a recruiting manager has delegated the screening and ranking to someone else, the rationale behind the shortlist can still be explained by the person who did the screening/ranking. The information delivered by the algorithms is quite sparse, often showing applicant name/contact information and score/ranking. This inevitably creates a somewhat obstructed view, although it has the potential of both promoting meritocracy and improving diversity within an organization.
While an algorithmic system can outperform human assessors in efficiency and impartiality, it is more mechanical, and its somewhat inflexible style can hardly make sensible exceptions or “look” beyond the given scores to see the larger picture in the way human assessors can (see, e.g., Newman et al., 2020). This is what makes the notion of meta-algorithmic judgment a new important socio-technical category in its own right. A shortlist produced by an algorithm may thus not always be perceived as the most ideal decision data for the person responsible for making the judgments in the next step of the hiring process. However, many companies therefore allow their managers some discretion to use their professional knowledge and sensibility to deviate from the algorithms’ ranking in an effort to identify the best candidates. This can be seen as a method to bridge the tacit knowledge or intuition of the recruiting manager with the “cold” rationality of the algorithmic system, thereby trying to avoid discontent within the organization (Burton et al., 2020).
To comply or not to comply, that is the question
The recruiting managers’ disposition regarding the work of the algorithm ultimately boils down to a question of compliance or noncompliance with the new hiring routine. To operationalize the concept of meta-algorithmic judgment on the empirical data we have been given access to, we place the issue of compliance/noncompliance at the center of our analytical method. The recruiting managers’ discretionary power may lead some of them to deviate from the ranking in ways unintended by top managers and the HR department. By leaning toward their own individual preferences and professional “gut feelings,” the meritocratic principles may be jeopardized. Recruiting managers may take this approach because they believe the algorithmic advice is a legitimate selection of eligible candidates, and thereby think they can choose freely any candidate from the shortlist. This type of meta-algorithmic judgment, thus, ignores the differences in scores and sidesteps the hierarchy between the candidates. Alternatively, this approach may also reflect a recruiting manager's protest against being deprived of control over the entire hiring process, a type of employee resistance to organizational change (Kellogg et al., 2020). This leads to a skewed coupling between the algorithmic assessment system and human judgment, as the original intention—to organize a competency-based, meritocratic, and inclusive recruitment process—is lost when the recruiting managers’ own preferences impact the selection of candidates to the interview phase. In short, recruiting managers’ meta-algorithmic judgments may calibrate the work of the algorithmic assessment, but also undermine it, distorting the ranking made by the algorithms by instead selecting candidates from the lower rank based on individual preferences and “gut feelings.”
In a systematic review on algorithmically augmented decision-making, Burton et al. (2020) underscored that a recurring challenge for organizations concerns the difficulty of effectively combining human judgment and algorithmically generated advice. To be sure, this issue “remains one of the most prominent and perplexing hurdles for the behavioral decision-making community” (Burton et al., 2020: 220). According to a growing body of research, the real crux of the matter is to make professionals feel comfortable with utilizing algorithmic recommendations when forming their own judgments. The human decision-maker plays a decisive role in how well a given algorithm-based technology works in practice. As Burton and colleagues explained: This means that a successful human-algorithm augmentation is one in which the human user is able to accurately discern both when and when not to integrate the algorithm's judgment into his or her own decision making. Neither blind neglect nor blind acceptance of algorithmic insights can be considered successful in this view because such decisions signal the absence or failure of interaction between the human and the algorithm. (Burton et al., 2020: 221)
If human users too easily accept algorithmic recommendations, a problem occurs if the algorithms (unintendedly) contain a diversity bias related to, for example, gender, ethnicity, or mental disabilities (Timmons, 2021). When recruiting managers follow biased recommendations, the result is a kind of automation bias. This “blind acceptance” could be explained by multitask overload, time constraints, or overreliance on the new technology (see, e.g., Aroyo et al., 2021; Parasuraman and Manzey, 2010; Wagner et al., 2018).
Alternatively, a common response among people who have witnessed or heard about algorithms making mistakes or delivering low quality output is that they develop algorithm aversion (Dietvorst et al., 2015; Prahl and Van Swol, 2017; Yeomans et al., 2019). Aversion may also be triggered by the way in which algorithms standardize assessments, stripping them of qualitative information included in CVs and personal letters. Newman and colleagues (2020) highlighted, for example, how the latest algorithmic management systems used for deciding about promotions have been perceived as too reductionistic. Algorithm-based decisions can simply make employees feel that important qualitative information and contextualization (about their productivity) are being disregarded, thus undermining their trust in procedural fairness within the organization. Similar attitudes and feelings may exist among recruiting managers, possibly affecting their meta-algorithmic judgments. Despite some of the obvious benefits of using algorithmic technologies, managers may still dismiss them as inadequate substitutes for real human judgments (Lauer, 2017). In the present study, we have no concrete knowledge about the hundreds of individual recruiting managers’ attitudes toward the algorithmic recommendations they received, but we can analyze and compare the consequences of their actual decisions at decisive stages in the hiring processes.
The hiring processes at FoodMarket
We analyze employment and hiring records from a large food retail group in Sweden, anonymized as “FoodMarket.” The company has ambitious diversity goals and has recently begun the work of automating the initial phases of its hiring processes by incorporating an algorithmic hiring platform. Implementation of the new technology began in 2019. In parallel with the algorithm-based process, traditional hiring has continued, i.e. some positions have been filled through the traditional process and some through the algorithm-based process. Thus, the two processes have run in parallel, enabling a comparison. We have acquired an in-depth understanding of how hiring processes are conducted at FoodMarket through meetings, conversations, and e-mail correspondences with key informants at the company's central HR department, as well as by reading formal documents provided by the company.
The algorithm-based process: Applicants apply for vacancies through FoodMarket's website. From this website, applicants are redirected to the digital platform where they answer questions on qualifying criteria such as previous work experience, education, etc. Eligible candidates automatically receive an invitation to take a work test, which scores the applicants on how well they match the profile that the employer believes will perform the job in question well. Performance is measured using competency-based scoring algorithms built on the five-factor model (“Big Five”), accounting for personality traits along the dimensions: Openness, Conscientiousness, Extraversion, Agreeableness and Neuroticism. The assessment system thus scores and ranks candidates by their answers to several work-related questions to evaluate their social skills and predict their future potential. For high-skilled jobs, the work test results are combined with an aptitude test, assessing problem-solving capacity and logical skills. The company providing the algorithmic hiring system claims that the relationship between predictive scores and position/organizational fit is linear—the higher the score, the better the match—explicitly stressing that the output should be interpreted in this way. 2 In correspondence with HR, we learned that their original intention was in line with this—a completely automated shortlist selection, and that the recruiting managers should put much weight on test scores in the selection of candidates to the interview stage.
Throughout the test stages, the process is completely automated, but the shortlists are generated by HR manually “moving” candidates from the test phase to the shortlist. The policy is that the shortlist should be composed of the highest scoring candidates, and that applicants scoring below 70 should not be considered at all. But HR has the discretion to make exceptions, so in this sense, it is HR, not the algorithms, that “makes the cut” (Pedulla, 2020). However, according to our informants, exceptions to the general rule are typically made based on the recruiting managers’ requests. The recruiting managers do not have access to the candidates who are not shortlisted; if they are not happy with the shortlist, they need to contact HR and ask them to include more or specific candidates. Thus, we interpret this kind of action to be part of the recruiting managers’ meta-algorithmic judgment, as it concerns their responses to assessments of the algorithmic advice. Common requests from recruiting managers include shortlisting low-scorers who are already/have been employed by the organization (i.e. the applicant's strengths and weaknesses are already known), owing to a shortage of high-scoring applicants, or to increase the size of the shortlist. This means that human bias can influence the process at this stage, contrary to FoodMarket's initial intention.
Once a shortlist has been agreed upon, the recruiting managers select candidates to interview (about one in ten is selected to interview); this selection represents the crucial part of their meta-algorithmic judgment process. Thereafter, they conduct the interviews, check references, and make the formal hiring decisions. The information available to managers when selecting to interviews includes, according to the HR department, the applicant's name, information related to the basic qualifying criteria (education, work experience, information on willingness to work fulltime, etc.) and the applicant's test results. The process is summarized in Figure 1 below.

Illustration of the automated recruitment process at FoodMarket. The automated phase in dark grey, nonautomated in light grey, recruiting manager abbreviated as “RM”.
The traditional process: In traditional hiring, the recruiting managers handle the entire process. This process is not centralized—and is thus not registered in the online job application system. Essentially, HR does not know the nature of these processes—they may be formalized or nonformalized (as discussed above). Thus, the HR department has no data, neither on these processes nor on the job applicants. The candidates who are employed through the traditional hiring process are only visible to the HR department when new employees are to be registered in the centralized employment records.
Data, methods, and analytical strategy
Analytical strategy
We analyzed two datasets from FoodMarket: one including information on new employees/employments, the other containing information on job applicants/job application processes. Drawing on the employment data, we will be able to answer our first research question, concerning whether the automation of hiring has an impact on diversity. We do this by comparing the diversity resulting from traditional versus algorithm-based hiring. We will address our second research question, concerning whether biases occur in the algorithm-based process, by analyzing the hiring process data and establishing how different groups fare at different stages of the algorithm-based hiring process. If the process gives rise to bias, we will identify where in the process this bias occurs, i.e. whether bias is driven by the algorithm, the negotiations between HR and recruiting managers about the shortlist, or at the interview or hiring stage. Thus, we will be able to answer our second research question by isolating any potential bias that emerges in the algorithmic phase from potential bias that may emerge in the meta-algorithmic phase. To address our third question, concerning the relationship between compliance and diversity, we study to what extent test scores explain the probability of being shortlisted and invited to an interview.
Table 1 below illustrates the type of data available for analysis. The lack of data on the traditional hiring process leaves the door open to several explanations for a possible difference in diversity outcomes between the two hiring processes. To exemplify, assume that the analysis of the employment records shows that fewer women are employed with the algorithm-based process. This difference could be caused by a bias in the process, but it could also be caused by an unobserved gender preference for applying for jobs that use different hiring processes. Thus, while showing that there is a difference, we would be unsure as to why we observe such patterns. However, this limitation is compensated for to a significant extent by the availability of job applications data from the algorithm-based hiring process. In this analysis, we will be able to identify whether there are signs of bias in the algorithm-based process. If there is no sign of bias in this process, there is little reason to assume that it is this process that generates decreased diversity relative to the traditional process. In this case, it would be more likely that it is applicant sorting that explains the diversity difference between the two processes. Thus, by combining insights from the analysis of these two datasets, we will be able to rule out most, though perhaps not all, competing explanations for the findings. We will discuss this issue in relation to the results in the “Study limitations” section.
Data availability at FoodMarket.

As in most studies of register data, it is difficult to fully establish causal relationships. We will interpret unexplained systematic group differentials (gender and geographical background) in test scores as a sign of algorithmic bias. Unexplained group differentials at the interview or hiring decision stages will be interpreted as signs of human bias. Clearly, this interpretation concerns diversity bias alone; we are in no position to assess whether the algorithmic system or the recruiting managers are selecting the right candidates from a meritocratic perspective.
Data and methods
The employment data include all new employees recruited in 2019–2020, in total 12,336 individuals, and the recruitment data include job applications sent to FoodMarket for the same years. This dataset only includes applications for positions recruited using the algorithm-based process, because the traditional hiring process, as mentioned earlier, is decentralized. The job applications have been stored by FoodMarket in the event of questions or complaints about the hiring process; they have never been used for analysis. In dialogue with FoodMarket, we have converted these raw data into a coherent, analyzable dataset consisting of 187,880 analyzable observations. 3 See Appendix B in the Supplementary Material for more information.
Variables
Outcome variables. In the analyses of employment records, the primary outcome variable is type of hiring process: algorithm-based or traditional. In the analysis of job applications, the outcome variable is also dichotomous, comparing those who reached at least the shortlist, and at least the interview stage, with those who did not reach these stages.
Explanatory variables
Employees’ (juridical) sex is registered in employment records as a dichotomous variable. Age is coded as above or below 40. This cut-off point has been chosen because previous field experiments have shown that, in Sweden, employment discrimination takes off at the age of 40 (Carlsson and Eriksson, 2019).
Given that individuals’ self-ascribed ethnicity or actual country of birth is not registered in employment or job applicant records in Sweden, we have, as an alternative, created a proxy for perceived geographical background based on surnames. This variable is used in both datasets. While surnames are passed on over generations and may in some cases not reflect the self-ascribed ethnicity of the name-bearer at all, it is the ethnic signal picked up by the recruiter that influences the chances of being invited to a job interview, not actual ethnicity. Most recruiters will (with varying precision) automatically perceive signals of ethnicity, culture, or geographical region in surnames. These perceived backgrounds may in turn trigger implicit or explicit attitudes or stereotypes (Bursell and Olsson, 2020), regardless of whether the applicants identify with this perceived category. In this way, perceived ethnicity or region of origin may be even better predictors of employment discrimination than actual ethnicity or region of birth. In the employment process, at least prior to the interview stage, the name is all the employer sees (except in cases where a photograph is attached, but this is not standard practice in Sweden).
We created Perceived geographical background by categorizing the employees’/applicants’ surnames dichotomously as either European or non-European. For reasons of anonymity, we did not have access to applicant/employee first and last names combined when working with this classification. We have used a machine-learning classifier algorithm to code our large datasets. Lacking data on how surnames are perceived, the model used for the classification of geographical background is a neural network consisting of three stacked bidirectional LSTM layers. The classifier model was trained on data from biographical articles of living people on the English-language Wikipedia. The names of the subjects were matched to a country of origin based on the article's belongingness to different geographical categories (categories like, e.g., “People from Stockholm, Sweden”). Countries around the world were thereafter placed in two sub-categories: “European” and “non-European.” For more details, see Appendix A.
To achieve a proxy for gender in the job applications data, we have built a gender probability estimator based on Statistics Sweden's onomastic database (“SCB namnstatistik”) table of first names (tilltalsnamn), which contains all given names in Sweden that have at least two bearers and provides numbers for how many women and men (based on legally registered sex), respectively, have that given name. We have used these data to calculate, for each given name, the probability that the person is a woman using the formula p(woman|name = x) = number of women with name x/total number of people with name x. For more details, see Appendix A. While there may be generational trends in first names, these are not distinct enough to construct a meaningful proxy for age; we have thus made no attempt to create such a proxy.
The continuous Test score variable is used in the job applications data to assess the extent to which the HR department and recruiting managers comply with the algorithm's recommendations in the selection-to-shortlist and selection-to-interview phases, respectively.
Control variables. In the employment records, we control for 179 geographical locations to which the employees have been recruited. Because locations in larger cities are in most cases presented with suburb names, location often represents a specific store, i.e. work unit. As evident in the data presented in Appendix C (Figure C1 and Table C1), there has been an even take-up of the algorithmic process across location and occupation, an important feature in the comparison of the two processes. If this had not been the case, differences identified in the analyses could have been driven by differences between the work units, related to uptake of the new process. We also control for position using an occupational dummy variable. The employment record contains 203 distinct types of positions, ranging from low- to high-skilled, but the vast majority of positions are low-skilled. As many as 81% of new employees are employed as store employees. Thus, the remaining 202 occupational positions are distributed over only 19% of employees. For this reason, we have decided to code the occupational dummy with separate codes for store employees, thereafter categories for: other low-skilled positions, vocational positions, low-skilled managers, and high-skilled positions. We also control for year of employment in the employee data, and for year of application in the recruitment data. In the recruitment data, each vacancy is assigned a unique identification number, a “job ID.” In the analyses, we use job ID to control for within-job competition.
Statistical models
We analyze the data using linear probability models (LPMs) using STATA 14 (StataCorp 15). LPM coefficients show the average, absolute (percentage points) difference in the outcome variables (reaching the shortlist and the interview stage) associated with a one-unit difference in the explanatory variables. The LPM is a reliable estimator also for binary outcomes when used with heteroskedasticity robust standard errors, which mitigates the potential inference problem due to heteroskedastic residuals in LPMs (Angrist and Pischke, 2009; Breen et al., 2018).
We have chosen LPM over logistic regression (NLPM) since problems have been identified concerning the NLPMs error term assumptions (it fixes the error variance at an arbitrary constant). As a consequence of this problem, it is argued that NLPMs do not allow for direct comparison of coefficients across within-sample models and groups (e.g. Allison, 1999; Breen et al., 2018; Mood, 2010). Since such comparisons are a key feature of the empirical analyses, the LPM is more suitable.
Results
Descriptive statistics on employment data
Table 2 summarizes descriptive statistics on the new employees by hiring process. Among the newly employed, 90% are below forty years of age, 58% are women, and 79% have a European-sounding surname (henceforth abbreviated as “European surnames”). Compared with Sweden's population of working age, the new employees at FoodMarket are thus fairly diverse when it comes to gender and geographical background, but less so regarding age. In the year 2020, 53% were recruited through the traditional process and 47% through the algorithm-based process. Comparing the two selection processes in relation to diversity, we observe that employees recruited through the algorithm-based process are more likely to be younger, women, and have European surnames, compared with employees selected through the traditional process. In the algorithm-based process, where there is documentation on test scores, we observe that women and younger employees have higher scores than new employees who are men and above 40 years of age.
Descriptives by the type of recruitment process (upper panel) and test scores by the demographic category (lower panel), new employments.

Analyses of the employment data
In Table 3, we estimate, using LPMs, the probability of new employees being women, having European surnames, and being below 40 in algorithm-based compared with traditional hiring. In Model 3-6, we introduce interaction effects for European surname, Women and Below 40 with position, and in Model 6, we include year of employment and random effects at the level of work units. Because the coefficients are stable across the models, we focus our attention on Model 6. Algorithm-based hiring is associated with 7-percentage-point (rounded up) higher probability of new employees having European surnames, 6-percentage-point higher probability of being women, and 10-percentage-point higher probability of being below the age of 40, compared with employees selected through the traditional process. While there are no statistically significant interactions between gender or age and position, the algorithm-based process is associated with an additional 17-percentage-point higher probability of new employees in high-skill positions having European surnames. Because we control for employment year and work unit location in Model 6, the results cannot be driven by an uneven uptake of the algorithm-based process. The difference is illustrated in Figure 2, in which non-European surnames, men, and employees above 40 represent the baseline.

Probability differences with 95% confidence intervals of new employees being women (0 = men), below 40 (0 = above 40) or having European surnames (0 = non-European surnames) in the algorithm-based process compared with the traditional process (Model 6, Table 3).
LPM estimates of being employed by the algorithmic recruitment process (traditional process = ref. category) among the newly employed. Unstandardized coefficients and robust standard errors in parentheses.
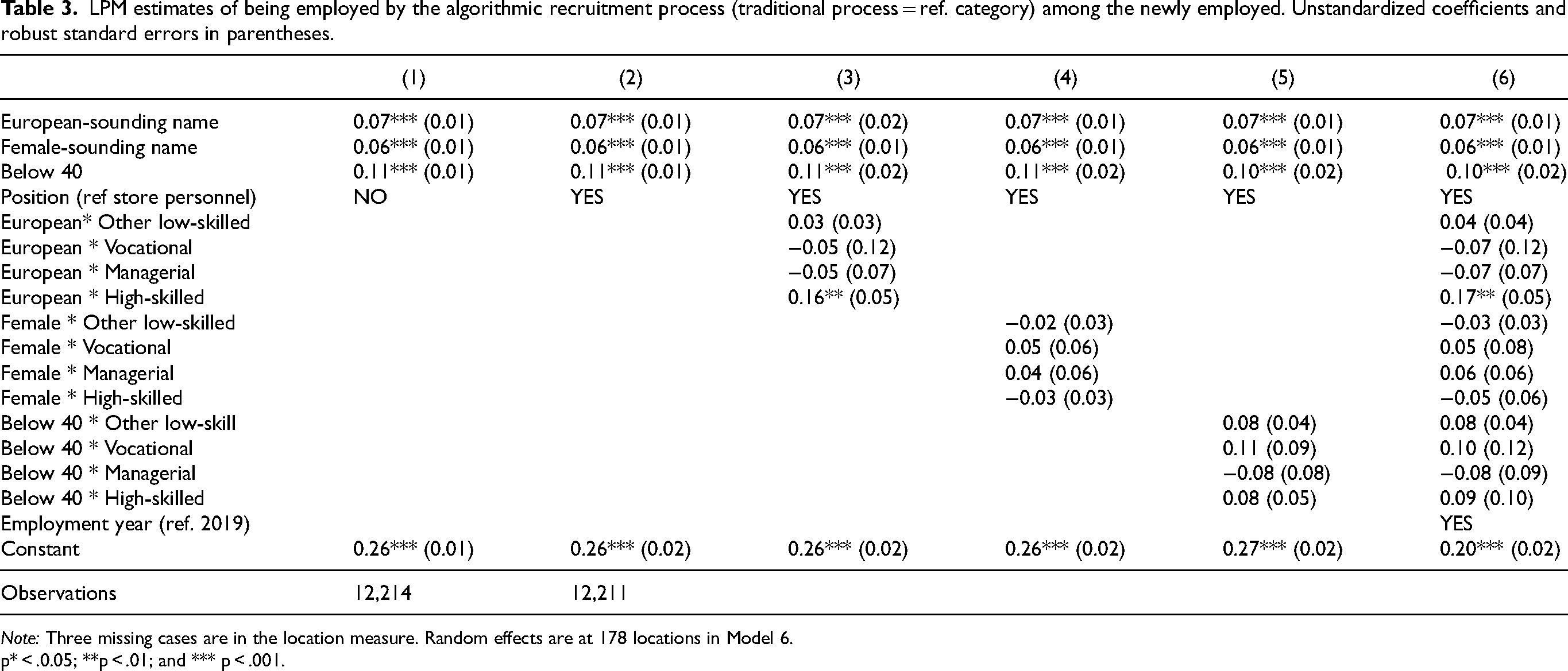
Note: Three missing cases are in the location measure. Random effects are at 178 locations in Model 6.
p* < .0.05; **p < .01; and *** p < .001.
As a sensitivity test, we have run the models in Table 3 with below 30 and below 50 years as cut-off points. Exemplifying with Model 1, the effect is somewhat weaker using the former (0.07) and somewhat stronger using the latter (0.12) (results available upon request) than when using Below 40.
The answer to our first research question—asking whether automating the initial phases of the hiring process results in a more diverse set of employees compared with the traditional process—is thus no. On the contrary, it results in a more pronounced dominance of employees who are younger, female, and have European surnames compared with employees from the traditional recruitment process. However, it would be premature, based on the above analyses, to conclude that it is the algorithm-based process itself that is generating decreased diversity. At this point, we cannot discern applicant reactions to the two processes from different evaluative outcomes emanating from these processes. This leads us to our second and third research questions, which we address below.
Descriptive statistics of the hiring process data
A closer look at the algorithm-based process and when applicants are rejected may provide a clue as to why this process generates lower diversity than traditional recruitment. Does the algorithm-based process generate diversity bias (in terms of over-/underrepresentation), and if so, is it driven by algorithmic or meta-algorithmic bias? In Table 4, we report the share of job applicants with European surnames and female-sounding first names (henceforth abbreviated as “female names”) who have reached the different stages of the job application process, average test scores, and the share of job applicants across the years. As mentioned earlier, we do not have information on job applicants’ age. “Rejected before assessment” means the applicants did not fulfill the basic criteria for the position. “Rejected in assessment” means the applicants met the basic criteria but had scores too low to be put on the shortlist. “Rejected in shortlist” means the applicants were on the shortlist but were not invited to interview. “Rejected after interview” means the applicants were invited to an interview but were not hired. “Hired” means the applicants passed the interview and received a job offer.
Distribution of applicants across occupational categories (first panel), mean shares of European surnames and female names by application progress (second panel), application year (third panel), and the mean test scores by the perceived geographical background and gender (fourth panel).

Job applications with female names make up 58% of all applications. Female names are somewhat underrepresented among those who are rejected at the earlier stages of the hiring process, and somewhat overrepresented at the later stages, indicating that women advance farther than men in the algorithm-based process. This is consistent with women having 4 points higher average test scores than men. Seventy-three percent of the job applications have been submitted by individuals with European surnames. They are proportionally represented among those rejected during the early stages of the selection process, in “Rejected before assessment” and “Rejected in assessment,” and in “Rejected in shortlist.” However, when the recruiting manager takes over the process (i.e. in “Rejected in interview” and “Hired”), applicants with European surnames are overrepresented. Among those who are interviewed but rejected at this stage, 81% have European surnames, and among those who are recruited, as many as 84% have European surnames. Thus, it seems as though it is the recruiting managers who are responsible for job applicants with European surnames being hired more often, not the selection in the automated phases. Note also that the difference in test scores between candidates with European and non-European names is very small. The pattern is illustrated in Figure 3, with the dashed line demarcating where the recruiting managers take over the process.
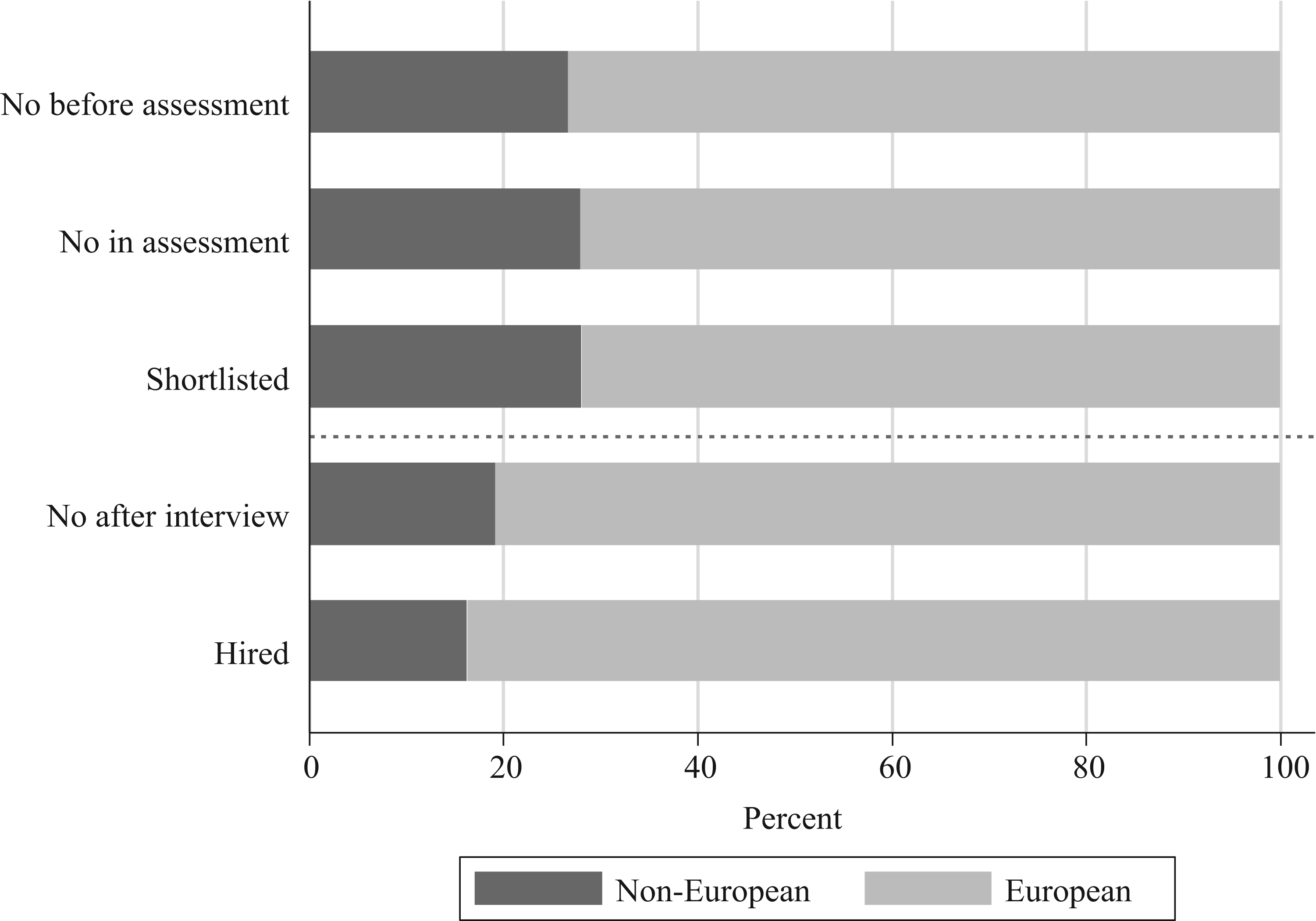
Application process ladder. By European- and non-European surnames.
Analyses of the algorithmic hiring process
As described in “The Hiring process at FoodMarket” section, the original intention underlying automation was that the test score should completely determine shortlist selection. In practice, however, shortlist selection results from test score performance and at times also manager requests (e.g. to include more or specific candidates). If neither the test nor the managers’ requests contain diversity bias, then neither gender nor geographical background should be significantly correlated with shortlist selection.
In Table 5, we estimate the probability of being shortlisted using LPMs. European surnames are associated with a small but statistically significant negative effect of 1 percentage point in Model 1. Thus, if anything, European names are slightly disfavored at this stage. However, when interacting European with position, a few nuances appear. In Model 3, European surnames are associated with a 5-percentage-point higher probability of shortlist inclusion in low-skilled work, and a 6-percentage-point higher probability in managerial positions. However, the latter is not statistically significant in Model 5, when also interacting position with gender and controlling for job ID and application year.
LPM estimates of reaching the shortlist stage (not shortlisted = ref category) For all job applicants. Unstandardized coefficients, robust standard errors in parentheses.
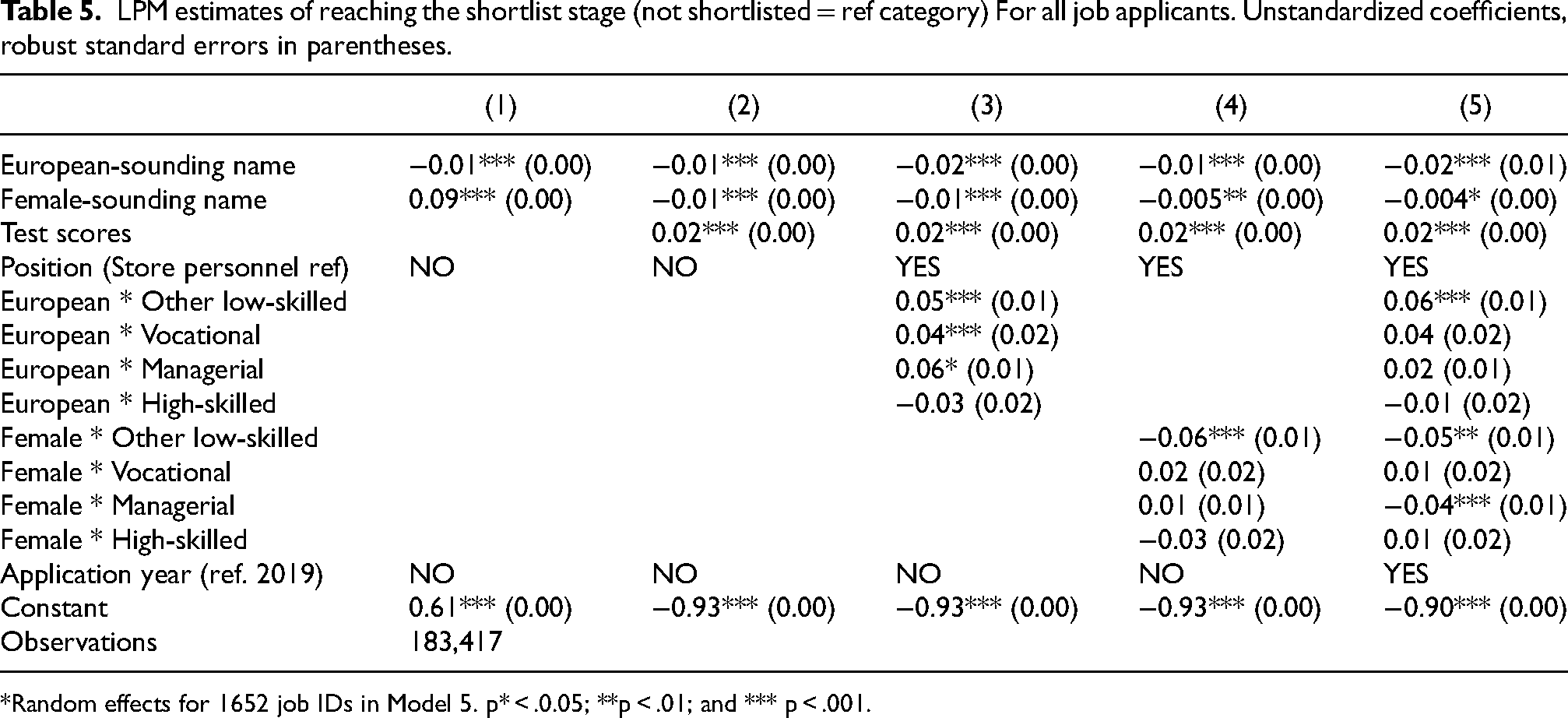
*Random effects for 1652 job IDs in Model 5. p* < .0.05; **p < .01; and *** p < .001.
In line with FoodMarket's intentions, test score is the strongest predictor of shortlist selection, such that each 1-unit increase in test score is associated with a 2-percentage-point higher probability of being selected to the shortlist. Controlling for test scores does not impact the European coefficient. Thus, the probability differences identified for the European coefficient are not driven by algorithmic bias.
Female names are associated with a notable 9-percentage-point higher probability of inclusion in Model 1. As evident from Model 2–5, this effect is entirely explained by test score, i.e. women score higher than men. We also find negligible differences between the genders in shortlist inclusion for the largest occupational category: store personnel. However, this pattern does not apply to the categories other low-skill work and managerial positions, where female names have a 5- and 4-percentage-point lower probability of shortlist inclusion, respectively in Model 5. Figures 4 and 5 below illustrate the “rewards/penalties” for having a European surname and a female name by position (with non-European and male names represented by the dashed line). The varying widths of the confidence intervals reflect the positions’ share of the sample (see Table 4).

Probability difference with 95% confidence intervals of reaching shortlist for European surname (0 = non-European) by position (Model 5, Table 5).

Probability difference with 95% confidence intervals of reaching shortlist for female name (0 = male) by position (Model 5, Table 5).
In Table 6, we assess the probability of reaching at least the interview stage for applicants who were shortlisted. In other words, we focus our analyses on the effect of the recruiting managers’ meta-algorithmic judgment. We observe a notable difference compared with the results of Table 5. In Model 1–5, the European coefficient is associated with a statistically significant 3- to 4-percentage-point higher probability and the Female coefficient with a 1-percentage-point higher probability of reaching the interview stage. In addition, having a European surname comes with an additional 4-percentage-point higher probability of being invited to an interview for managerial positions, and 6-percentage-point higher probability for high-skilled positions. Thus, applicants with European surnames are especially advantaged regarding the more attractive positions.
LPM estimates of reaching the interview stage (no interview = ref. category) for job applicants in the shortlist. Unstandardized coefficients, robust standard errors in parentheses.

Note: Random effects for 1652 job IDs in Model 5.
p* < .0.05; **p < .01; and *** p < .001.
Applicants with female names have an additional 7-percentage-point higher probability of reaching the interview stage for vocational positions. In Model 4, there is a 4-percentage-point lower probability of women being invited to interviews for managerial positions, but this effect disappears in Model 5, where we control for other interactions, application year and within-job-posting competition. Figure 6 and 7 illustrate the patterns of ‘rewards’ for having a European surname and a female name by position in selection to interview.

Probability difference with 95% confidence intervals of reaching interview for European surname (0 = non-European) by position (Model 5, Table 6).
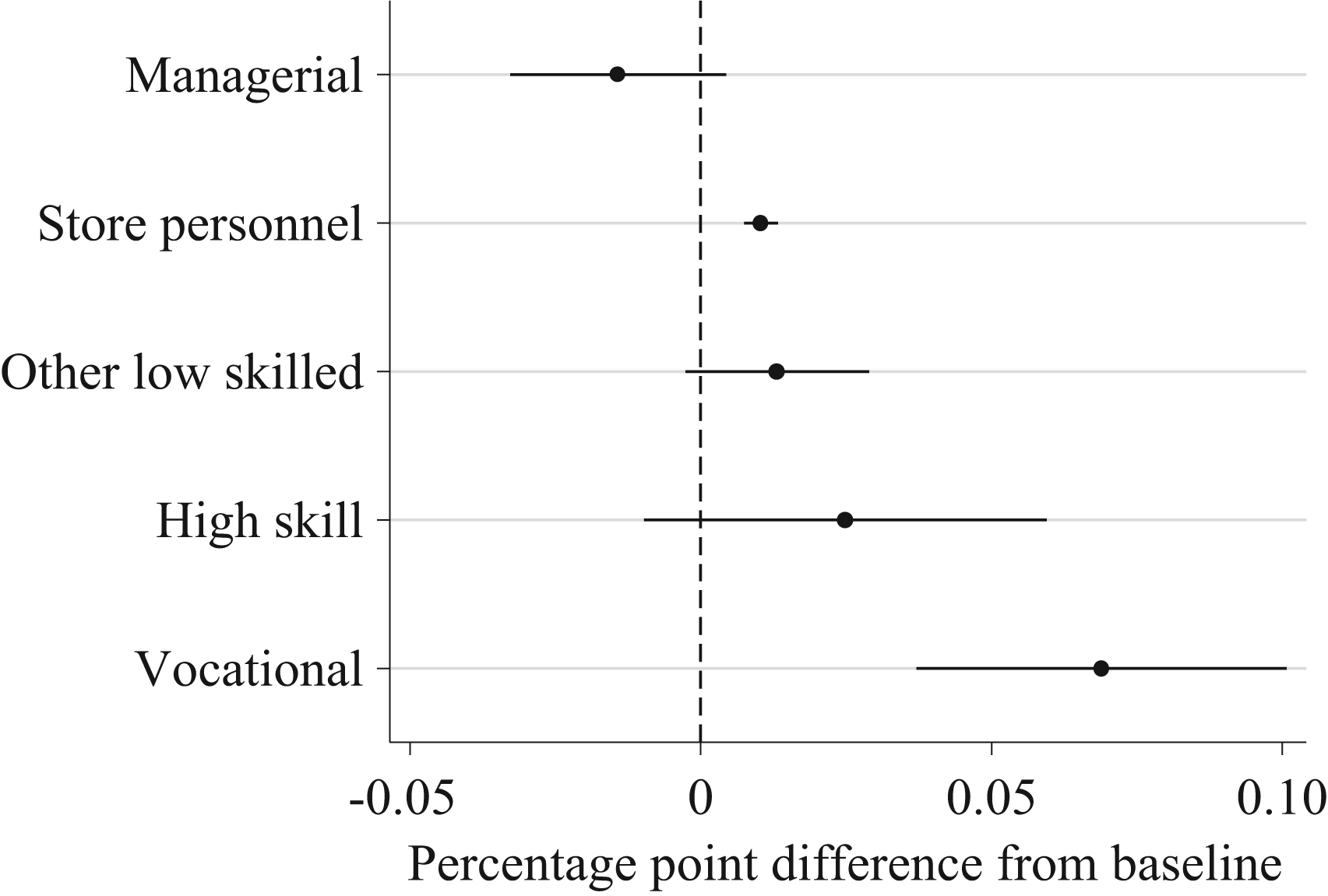
Probability difference with 95% confidence intervals of reaching interview for female name (0 = male) by position (Model 5, Table 6).
Notably, while the effect for test score was strong in selection to the shortlist, it is close to zero in selection to an interview. Thus, recruiting managers seem to pay virtually no attention to test scores—a remarkably clear sign of noncompliance.
As a sensitivity test, we have rerun the same models as those presented in Table 6 assessing the probability of actually being hired among applicants who were invited to an interview. This sample is of course much smaller, and there are too few observations for drawing conclusions concerning the interaction effects, but the main effects are similar to those presented above (see Table D1 in the Appendix).
While there are problems with comparing NLPM coefficients across models and groups (as described in the Statistical models’ section), it is possible to compare NLPM coefficients’ direction and statistical significance (Breen et al., 2018). We have estimated the models in Tables 3–6 with NLPMs (logit and probit) with this focus (available upon request), resulting in similar outcomes for the main effects gender and geographical background and for test score, but there are some discrepancies for the interaction effects. Thus, the interaction effects in the applications data may not be as robust as the main effects for gender and geographical background.
The answer to our second research question is thus that there is diversity bias in the algorithm-based process. In selection to the shortlist, we observe primarily a gender bias, since women have higher test scores than men. Due to the high compliance in this phase of the process (test score has a high impact), the algorithmic bias is influential at this stage. It is to some extent counterbalanced by a meta-algorithmic bias (manager-HR negotiations) benefiting men. Notably, there is not a clear bias in relation to geographical background. There is even a weak preference for non-Europeans at this stage in the largest occupational category, but there is also a preference for Europeans in some of the smaller categories. In selection to an interview, a phase that the recruiting managers control themselves, clearer patterns of diversity bias appear: a preference for Europeans and for women.
The answer to our third question—concerning whether diversity bias can be linked to different meta-algorithmic responses to the algorithm's recommendations—we observe (by design) high compliance in the shortlist phase but virtually no compliance at the later stages of the recruitment process. Thus, when it is just up to recruiting managers to decide, they ignore the algorithms’ rankings.
Discussion of the results
One striking finding in the analyses presented in Table 5 was that the test score algorithm generated a gendered diversity bias, benefiting women. We also saw in the descriptive statistics for new employees (Table 2) that employees below 40 years of age had higher average scores, indicating that there may also be an algorithmic age bias. Because age is not included in the job applications data, we could not study this issue further.
It is beyond the scope of the present study to evaluate the meritocratic properties of these tests; the gender bias generated at this stage may indeed result from women being a better match for these positions, but it may also result from a gender bias unrelated to competence, i.e. indirect discrimination. This would be the case, for instance, if the personality test assigns exaggerated significance to traits on which women score higher on average, such as Agreeableness, or if it assigns lower significance to Neuroticism, where men on average score lower (e.g. Weisberg et al., 2011) than is warranted from a meritocratic perspective. As we discuss below, the risk of bias in the algorithmic assessment deserves more attention from researchers.
Earlier in the paper, we argued that humans make different kinds of judgments when their judgments are based on the recommendations of algorithms, compared with their own assessments or those of human colleagues. Algorithm-based evaluative processes generate outcomes in which the possible biases of algorithms and humans play out differently depending on the degree to which humans comply with the algorithm's recommendations. We found that once it was only up to the recruiting managers to decide, they ignored the algorithms’ recommendations, resulting in a disproportionate number of European-named applicants (relative to their share of the shortlist). What is striking about this is that we observed a different pattern in the new employee data. The traditional process, where the recruiting managers control the entire process, generated more diversity than the algorithm-based process, where they only control the later stages. We argue that this discrepancy illustrates the relevance of the notion of meta-algorithmic judgment; people make different judgments when faced with algorithmic recommendations than when their judgments are based on their own assessments. But why would the recruiting managers’ meta-algorithmic judgments result in less diversity compared with the traditional process?
Based on the literature on how bias in recruitment occurs, and the knowledge we have acquired about the recruitment process at FoodMarket (see “The hiring process at FoodMarket” section), we identify two possible explanations. First, we saw that the managers did not follow the algorithmic ranking in their selection to the interview stage (Table 6). The problem with the algorithm-based process is that, if managers do not see test scores as a reliable assessment of candidates’ suitability and competence, there is little left for them to base selection on, other than the basic information on qualifying criteria and the perceived ethnicity and gender signals discernable from applicants’ names. Thus, in this situation, information has become quite scarce, a fact that might explain why diversity bias is generated at FoodMarket. To be sure, previous research has repeatedly shown that people tend to be more prejudiced against out-groups (e.g. Eagly and Karau, 1991; Turper et al., 2015), and to discriminate more (e.g. Laouénan and Rathelot, 2022; Singletary and Hebl, 2009), when they lack proper information about the people they are evaluating. Thus, recruiting managers may be less inclusive in the algorithm-based process than in the traditional process due to the lack of individuating information in the former.
Relatedly, it is also possible that the different types of information available in algorithm-based and traditional hiring do not enable expression of the same preferences. For example, when controlling the entire hiring process, recruiting managers may single out a certain type of candidate from otherwise nonpreferred social categories. They might, for instance, prefer non-European applicants who signal “Swedishness,” secular values, or assimilation in their personal letters (Bursell, 2012). Thus, the recruiting managers may, in traditional recruitment, take the organization's diversity goals into account in their own (biased) manner. When this possibility is removed through automation, i.e. when the application process is stripped of individuating features, recruiting managers may settle, to a greater extent, for in-group candidates. In either case, noncompliance brings human biases and “gut feelings” (Moss and Tilly, 2001; Pedulla, 2020; Rivera, 2015) back into the process. This explanation is also consistent with accounts from informants at the FoodMarket HR department, who have confirmed that several recruiting managers have expressed discontent with the applicants included in the algorithms’ shortlists, without explicitly explaining what is “wrong” with these applicants.
Study limitations
As highlighted in the “Analytical strategy” section, due to the decentralized organization of the traditional hiring process at FoodMarket (Table 1), we lack the job applications data from this process. This puts some limitations on the conclusions that can be drawn based on the present results; we do not know at what stages women and applicants with European-sounding names are over- or underrepresented in traditional hiring. However, with only one piece of a jigsaw puzzle missing, you can still see the greater picture. Combining the results of the analyses of the new employee data on both the traditional and the algorithm-based process with the analysis of the algorithm-based recruitment process, we believe the evidence points rather convincingly toward meta-algorithmic judgment decreasing geographical background diversity and algorithmic bias decreasing gender diversity. Nevertheless, if future research based on data that captures both traditional and algorithmic application processes could test this conclusion, it would further strengthen the present findings.
Another obvious limitation of the study concerns the lack of deeper qualitative knowledge regarding recruiting managers’ real experiences of making decisions based on the recommendations produced by an algorithmic system. Our main source of information has been the conversations we had with people in key positions at the HR department at the company's headquarters. In the future, an extensive interview study with recruiting managers could help to further develop the conceptual framework we have initiated in the present study. Qualitative knowledge would facilitate a better understanding of the motivations and attitudes underlying the hiring decision-making processes at FoodMarket.
Theoretical conclusions and future research
To pinpoint the bounded interplay between algorithms and human decision-makers, we introduced the notion of meta-algorithmic judgment to emphasize the situation recruiting managers face after the algorithm has delivered its recommendations. The notion includes both discretion and responsibility attribution. Given the exponential growth of human–algorithm interactions currently taking place in social life, the concept of meta-algorithmic judgment can thus function as a crucial factor for analyzing the socio-ethical implications of these interactions in different organizational contexts (cf. Gerdon et al., 2022; Mittelstadt et al., 2016). Meanwhile, the concept can also be used to further theorize the issue of human decision control and the problem of “algorithm aversion” (Burton et al., 2020; Dietvorst et al., 2015). It is also important to underscore the potential problem of automation-related complacency that may arise if human decision-makers feel pressured to accept algorithmic advice (e.g. lack of time, multiple-task load), because that could generate new unintended forms of “automation bias” (see, e.g., Parasuraman and Manzey, 2010). In the present study, we took the opportunity to shed light on these aspects as parts of our operationalization of meta-algorithmic judgment, focusing more specifically on compliance and noncompliance. For the purpose of our study, this dichotomy helped us make sense of how recruiting managers may have approached the algorithmically generated shortlists.
The empirical results showed that the algorithms and the recruiters brought different types of bias into the hiring process: the algorithmic assessment disproportionately favored women, and the recruiting managers, who controlled the later stages of the process, favored European names. Previous studies (e.g. Burton et al., 2020) have mentioned the fact that different problems may evolve when organizations try to bridge human intuition and the “cold” rationality of the algorithmic system (“human-in-the-loop”). Our study sheds new light on the increasing challenges concerning how to support well-calibrated meta-algorithmic judgments in organizations. Organizations can to some extent mitigate these problems by increased dialogue between HR and recruiting managers, the goal being to improve the outcomes of the new hiring technology, and by educating managers in how the algorithmic system works and how to approach its recommendations. Finally, organizations can on a regular basis conduct analysis, similar to the one presented here, to assess whether the hiring processes are working as intended.
The problem of algorithm aversion will probably not disappear in the near future, and organizations will have to discover the best practice of dealing with all the conflicting values at stake in the processes. However, the concept of meta-algorithmic judgment needs to be further developed, particularly in relation to qualitative data. A more refined typology of meta-algorithmic judgment may contribute to a better understanding of the future development of human–AI interactions, where new autonomous deep-learning algorithms and neural networks have been implemented in the hiring industries.
Regardless of why men and older applicants scored lower, or why recruiting managers employed fewer candidates with non-European-sounding names when supported by an algorithmic assessment system, we have shown that this technological shift has the potential to decrease diversity in hiring. Rule-based algorithmic recruitment systems are widely employed in recruitment across contexts, increasing the relevance of our findings. From a societal perspective, it is especially important that large organizations monitor the effects of automating their hiring processes. With a yearly staff turnover of around 13% (a common rate in this industry), FoodMarket will change the demographic composition of its employees in line with patterns identified in the analyses of the new employee data in only a few years if it continues to recruit using the current algorithm-based process. Decreasing diversity may also trigger mechanisms unrelated to hiring, if tipping points are reached where preferences for social homophily (McPherson et al., 2001) are not satisfied, decreasing diversity even more. This concern is not unwarranted: previous research has shown that employees from underrepresented categories do have higher turnover rates (Bygren, 2010). To conclude, automation of the assessment of human competence and potential should be continuously scrutinized, as organizations are increasing the number of crucial decisions being made based on the selections and recommendations of algorithms. These decisions influence people's life chances, which is reason enough for us to maintain a sharp focus on this sociotechnological development in the future.
Supplemental Material
sj-docx-1-bds-10.1177_20539517231221758 - Supplemental material for After the algorithms: A study of meta-algorithmic judgments and diversity in the hiring process at a large multisite company
Supplemental material, sj-docx-1-bds-10.1177_20539517231221758 for After the algorithms: A study of meta-algorithmic judgments and diversity in the hiring process at a large multisite company by Moa Bursell and Lambros Roumbanis in Big Data & Society
Footnotes
Acknowledgments
First and foremost, we would like to thank Rojan Karakaya for designing and training the ML classifier algorithms that were used in this study. We also thank our key informants at “FoodMarket” for sharing their knowledge with us. Finally, we are also very grateful to the Editor-in-Chief Matt Zook and the three anonymous reviewers for their valuable comments on previous versions of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study has received funding from the Swedish Research Council (Vetenskapsrådet) grant number 2019-02550, and Forte (Forskningsrådet för hälsa, arbetsliv och välfärd) grant number 2022-00625.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.