
Abstract
Google results have been scrutinized over the years for what they privilege, be it the surface web, the powerful, optimized webpages, the personalized and/or their own properties. For some time now, another type of Google returns also has been the source of attention: the offensive result. The following revisits a selection of offensive and other problematic results found by journalists and researchers alike. In a technique termed ‘algorithmic probing’, the prompting queries are re-run to study what has come of these results in Google Web and Image Search but mainly in Google Autocompletion. The question concerns a different kind of privileging – Google's hierarchy of concerns – or the extent to which certain categories as well as languages are moderated and others less so. In all, it was found that Google heavily moderates religion, ethnicities and sexualities (albeit with gaps) but leaves alone stereotypes of gendered professions as well as ageism. It also moderates to a greater degree in English compared to southern European and Balkan languages. The article concludes with a discussion of the stakes of Google's moderation, including its uneven coverage.
Keywords
This article is a part of special theme on The State of Google Critique and Intervention. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/thestateofgooglecritiqueandIntervention
Introduction: Studying ‘privileging’ and problematic results in Google returns
In the early 2000s, search engines began to overtake web directories (and their alphabetical lists) as the main sources of information online. Since then, they have been scrutinized for their privileging mechanisms, or what is behind the hierarchies of sources they return. Do they privilege the surface web, the powerful, optimized webpages, the personalized and/or their own properties (Hindman et al., 2003; Lawrence and Giles, 1998; Lewandowski et al., 2021; Pariser, 2011)? In the mid- to late 2000s, however, another type of result gained the attention of journalists and scholars alike: offensive returns.
First, in a comparatively early discovery, there was the question of why a query for ‘Jew’ in Google Web Search had an antisemitic website among the top returns (Brandon, 2004; Sullivan, 2004) (see Figure 1). Subsequently, over the next decade and a half, Google products such as Google Ads, Google Web Search, Google Images and Google Autocompletion have been found to have results, at or towards the top of returns, that are problematic for their stereotypical, discriminatory and even racist orientations (Baker and Potts, 2013; Noble, 2018; Sweeney, 2013). Google Maps and Google Vision also have been scrutinized in this regard (Gibbs, 2015; Hern, 2018; Kasperkevic, 2015).

‘Offensive search results’, marked by Google, for the query, Jew, Google Web Search, 2004.
In the following, I revisit publicized, offensive results found by journalists and scholars alike through the technique called algorithmic probing, which entails re-running a selection of the queries (‘probing’) that previously turned up problematic results. The overall purpose is to evaluate the current outputs in terms of what they imply for engine result moderation, where the focus appears to be more on certain categories (religions, ethnicities and sexualities) rather than on others (gendered professions and ageism).
One principal question is asked of the fate of once problematic results. How to interpret what has been removed or otherwise moderated? In line with previous research, touched on above, as a tentative answer, I put forward a new privileging mechanism that is the result of the probing: a hierarchy of moderated concern, as seen through patches made to Google Web and Image Searches as well as what is still displayed, primarily through Google Autocompletion.
I also revisit how Google characterizes these results (among other terms) as offensive, inappropriate, unpleasant, unwanted and shocking (Gibbs, 2015; Sullivan, 2018, 2020), in light of how the journalists and researchers regard them as stereotypical, discriminatory and racist (Baker and Potts, 2013; Kay et al., 2015; Noble, 2018). Google's deflective language is discussed alongside established critique concerning how the engine is testing its products in society (rather than exclusively in the lab), while journalists, researchers and everyday users (with Google's flagging tool) suggest patches and make other training inputs from which the automated systems learn. In the concluding sections outlining Google's hierarchy of concerns and linguistic coverage, I also discuss the stakes at play in Google's uneven moderation.
Research context: Search engine results critique
Broadly speaking, the research reported here may be situated in the context of the critique of search engine output (Introna and Nissenbaum, 2000), referred to above as ‘privileging’ mechanisms, and could be linked to more recent work on content moderation, albeit for search engines as Google rather than social media platforms as Facebook (Gillespie, 2018). More specifically, the research may be situated in approaches that seek to glean the extent to which search engines output problematic returns, variously called offensive, inappropriate, unpleasant, unwanted, shocking, stereotypical, discriminatory and/or racist.
Some of the earliest critical work on search engine output focused on how engines were indexing low percentages of web pages available online, or what was referred to as the surface web, compared to the deep web (Lawrence and Giles, 1998). The coverage of engines was particularly low for those websites with fewer inlinks (Lawrence and Giles, 2000); especially orphan sites (without inlinks) were neglected by crawlers, as web archivers found (Gomes and Silva, 2005). The well-linked also had another advantage, apart from being indexed. They comparatively would land higher in the rankings, leading to the notion of a ‘Googlearchy’ (Hindman et al., 2003; Hindman, 2008), or the ‘rule of the most heavily linked’ (Van Dijk, 2011: 28).
The year 2010 marked a turning point in which Google Web Search directed the majority of user traffic to websites, compared to that driven by links from other websites. Combined with findings on how searchers honed their sights on the first page of results (Jansen and Spink, 2006), it made Google's ‘front page real estate’ more valuable, both for advertisers and for website owners (Battelle, 2011). Already a burgeoning practice (Evans, 2007; Kent, 2008), optimizing a website to boost its standing (and value) in search came to public attention after a series of notorious ‘black-hat’ scandals involving major brand names (Cutts, 2006; Segal, 2011). They had manufactured top rankings. It also led to questions of whether a website's content could earn (rather than have to engineer) its placement at the top of query returns. Through which ‘evaluative metrics’ was the ‘relevance’ of a website determined (Rieder, 2012; van Couvering, 2007)? Indeed, Google's understanding evolved from the Googlearchy approach of earlier years with the introduction of personalization, which replaced universal results (Bozdag, 2013; Pariser, 2011). Personalization coupled individual users with results in their own language, locality and other preferences (derived for example from one's search history), and, significantly, advertisers also were offered those features (Halavais, 2017). The further commercialization of search also could be viewed through the prism of self-privileging (or even self-dealing), whereby search engines such as Google would return its own ‘properties’ at the top of results, driving traffic (and advertising) to itself (Jeffries and Yin, 2020). In the event, Google has faced large fines for privileging, in the results for consumer product queries, its own shopping site over competitors (General Court of the European Union, 2021).
The privileging critiques are results of a variety of approaches to tease out and evaluate algorithmic output. The probing method reported here could be situated alongside algorithmic auditing (Sandvig et al., 2014), platform observability (Rieder and Hofmann, 2020), ethical hacking for vulnerabilities and (commercial) content moderation critique (Gillespie, 2018; Roberts, 2019), though each of these approaches has a somewhat different emphasis. Algorithmic auditing is a method in the social scientific study of discrimination by software (Sandvig et al., 2014). It derives from the audit, where fictitious applications (for housing or a loan, for example) are submitted with varied names signalling different people to uncover discrimination (Pager, 2007). Indeed, the queries discussed here are also seeking (the perpetuation of) discrimination, albeit not explicitly in the context of evaluating consumer protection.
Platform observability has commonalities with algorithmic auditing, though it is a broader proposal for a form of platform regulation that would allow social media empiricism through the continuous monitoring of outputs, distinct from connecting to existing company application programming interfaces that control data flows. The research also discovers vulnerabilities and reports them either to the service or via publication, providing both the queries and the results. Vulnerability seeking is, however, not the only aim, for I am interested in gaining insight into the distribution of attention by the engine to the different offences, asking which ones are addressed (and how) and which ones are less so. Finally, there is a growing, critical literature on (commercial) content moderation. Much of it focuses on the working conditions of those who screen social media content. The emphasis here is less on the workers than on moderation overall. It relates more closely to work on ‘hard’ content moderation, which has been defined (largely in the study of social media platforms) as ‘systems that classify user-generated content based on either matching or prediction, leading to a decision and governance outcome (e.g., removal, geo-blocking, account takedown)’ (Gorwa et al., 2020).
As remarked, the approach here is termed ‘algorithmic probing’, which is a variation on algorithmic auditing as well as an ethical hacking practice that searches for vulnerabilities in order to report them via publication to the software makers. The reporting comes in the form of documenting results, including autocompletions. The term probing is preferred, rather than a more formal idea of auditing, because the research approach involves taking snapshots (or screenshots).
Over the past decade or so, scholars and journalists have made probing queries that have prompted engines to output what are referred to as stereotypical, discriminatory and/or racist results. High-profile examples of these are Baker and Potts’ (2013) scholarly work on stereotypes including ‘why do white people have thin lips’, where, following Hall (1997), they show how in Google Autocompletion people are ‘reduced to a few essentialising and naturalising characteristics’ (Baker and Potts, 2013: 190). Alexander's (2016) work on discriminatory outputs of ‘unprofessional hair’ in contrast to ‘professional hair’ and Hunt's (2016) results for ‘three black teenagers’ compared to ‘three white teenagers’ are also taken up. To the journalist reporting the query results for hairstyles, the results exclude many people of colour from the ‘professional’ workplace; in the other case, one group of teens is pictured as hale and sporty, and in the other as in police custody. Subsequent work found similar profiling for queries of ‘unwanted pregnancy’ in contrast to ‘pregnancy’ (Bogers et al., 2020).
Noble's (2018) research on Algorithms of Oppression, through queries of ‘black girls’, ‘beauty’, ‘Michelle Obama’ and others, demonstrates ‘how Google reinforces racism’ for the manner in which the outputs offer painful slurs or antagonizing mockery. The nadir could be The Guardian and Observer journalist Cadwalladr's (2016) infamous ‘are Jews [evil]’ in Google Autocompletion, where the completion is in the brackets, which she discusses in terms of uncovering a ‘constellation of websites’ promoting hate online. Having made the finding, she also queried women as well as Muslims, finding more.
Approach: Prompting problematic results through algorithmic probing
The research reported below revisits the queries made by Cadwalladr, Noble, Alexander and Hunt, together with a sampling of those of other journalists and scholars over the past decade. In all, I revisit some 25 sets of (English-language) queries across three Google products: Web Search, Image Search and Autocompletion, with an emphasis on the last service. The selection of queries, or probes, is made on the basis of celebrated or infamous journalistic and academic findings, presented here in chronological order.
I also redo some recent queries (by journalists and scholars) concerning the Covid-19 global pandemic, pressing social issues as well as a ‘data void’, discussed below. The queries concerning Covid-19 follow on the work by Houli et al. (2021), who captured Google Autocompletions with the prompts, ‘coronavirus is’ and ‘COVID-19 is’, across some 76 countries (or Google regions), albeit all in the English language. The Covid-19 and coronavirus-related queries are in English-language Google regions as well as in European and Balkan regions and languages, a subset of the regions queried by Houli et al. (2021). These queries are in Albanian, Croatian, Dutch, French, German, Greek and Slovenian, where among the questions are whether Covid-19 queries would result in conspiracy-related results, as they found, and whether there is a linguistic or geographical distribution of Google moderation.
Poignant social issues also are queried. Apart from Covid-19 and related queries which have been heralded by engines and platforms as highly moderated spaces, social issues more generally have not often come under autocompletion critique. Journalists have queried and taken screenshots of the results for ‘climate change’ and ‘abortion’, finding such results as ‘climate change is a hoax’ and ‘abortion is a sin’ and discussing them in terms of the likelihood of negative autocompletions receiving more clicks and how, at a time when ‘fake news’ is receiving attention, ‘rightwing groups’ are influencing the results, ‘us[ing] a variety of techniques to trick the algorithm and push propaganda and misinformation’ (Solon and Levin, 2016). They also queried ‘homosexuality is’, finding, among the top returns, ‘a disorder’. A Wired journalist, following up on Cadwalladr's work and making queries for such terms as ‘Islamists’, ‘white supremacy’ and ‘Hitler’, also searched for ‘climate change’, finding what she called ‘a wide range of options for climate change deniers’ (Lapowsky, 2018). A selection of social issue queries is repeated and reported below.
On top of the queries discussed above, there is also another contemporary category designed to tease out Google's moderation concerns. Google outputs may contain misinformation or pranks that have come into being by ‘gaming’ or manipulating results, once referred to as ‘Google bombs’ and more recently considered ‘trolling’ as well as filling ‘data voids’. A notorious case concerned how troll accounts from 4chan conjured a ‘leftist and democratic supporter’ atop Google Web Search results for a query related to the Las Vegas shooting in 2017 (Guynn, 2017). Such queries display what Golebiewski and Boyd (2018) have called ‘data voids’, which occur when quality information is not associated with ‘strategic new terms’, ‘breaking events’ and other such keywords and are populated by those gaming (or hijacking) the engine for trolling, political, commercial or other purposes. Recent examples pertain to the former US President Trump's election defeat and the US Capitol riots of January 2021 as portending an upcoming revolution. In Google Autocompletion, a researcher found ‘civil war [is coming]’ and ‘civil war [is brewing]’; ‘we’re hea’ suggested ‘we’re hea[ding for civil war]’ (Chaslot, 2021). Certain of these searches are re-run.
The queries are made in fit-for-purpose research browsers, which are cleanly installed browser instances not logged into Google. They repeat the wording as well as the original circumstances of the journalistic and scholarly inquiries. The queries are made using the Google region where the original ones were undertaken, together with a VPN set to that place. Thus, for Noble's, we apply the US region, for Cadwalladr's the UK and so forth, together with a VPN working from the country in question. As they did, I furnish screenshots of the queries together with the results.
The general display technique in reporting our findings is to compare ‘then’ and ‘now’, reusing either the original screenshots provided in the scholarly work or in the news stories and putting them side by side with the recent results. For example, a screenshot taken of the results for the Google Images query, ‘professor’, once showing only images of males, is placed next to a recent screenshot of the results for the same query (which continues to show only males).
With this technique, I display how abiding the ‘patches’ or suppressions have been on stereotypical, discriminatory and racist returns or in some cases how the findings about stereotypes, such as with ageism and certain professions, have not been addressed. While I am discussing moderation throughout, it should be noted that it is a broad notion that extends beyond patching and suppressing and includes algorithmic updates that impinge upon results hierarchies as well as the introduction of what Google terms ‘automated systems’, which I discuss particularly in relation to Autocompletion.
For the cross-lingual moderation comparison, both queries are made for the same timeframe, displaying contemporaneous English-language results next to those of the other languages. In the research browser, for the cross-lingual analyses, the region is set to the country in question, a VPN operating from that country is used, and the queries are in the local languages.
Before discussing the findings and their implications, I would like to turn briefly to Google's moderation of Autocompletion. The purpose of the next section is to situate further the study of moderation categories as a privileging critique before turning to a display of Google's hierarchy of concerns and the stakes at play in its moderation strategies.
Unpacking Google's and other commentaries on Autocompletion
In April 2018, Danny Sullivan (2018), formerly of the leading industry publications – Search Engine Watch and Search Engine Land – and more recently working as Google's Public Liaison for Search, wrote a long blog post about ‘how autocomplete works in Search’. He relates how the company prefers the term ‘prediction’ over ‘suggestion’ and that these predictions shown are ‘common and trending ones related to what someone begins to type’. Scholars have described them as primarily sourced from search engine query logs (Cai and de Rijke, 2016), are oriented to a user's geographical location and are aimed to be timely.
Subsequent work has demonstrated how autocompletions are the product of a switch in how Google prepares them, from an approach based on probability to one on machine learning and the implementation of RankBrain (Graham, 2022). Graham in fact argues that Google has obscured the origins of autocompletions to leave it inculpable for the stereotypes and other problematic outputs. It does so by demonstrating how people actually make problematic queries, but they are often more innocent than one would imagine.
Indeed, in Sullivan's blog post and a series of tweets that preceded it, he discusses the common reaction, ‘Who would search for that?’, in reaction to distasteful autocompletions such as ‘school shootings [are funny]’, breaking down how users are really searching for such because the phraseology appeared in a magazine article or similar. These problematic outputs, when seen in the context of actual searches, can be explained.
Sullivan (2018) is also quick to point out that Google actively removes ‘sexually explicit predictions that are not related to medical, scientific, or sex education topics’; ‘hateful predictions against groups and individuals on the basis of race, religion or several other demographics’; ‘violent predictions’; and ‘dangerous and harmful activity in predictions’. There is also a reporting feature, available since 2017, that allows users to flag such content for Google to investigate (as can be seen in Figures 2 and 3).

Transgender query as an example of single result for Google Autocompletion.
Older men query results in Google Autocompletion.
That Google discusses such autocompletion moderation in those terms could be considered a policy change, or at least a new emphasis on active monitoring rather than on defending ‘organic’ content. Indeed, in 2016, in response to Cadwalladr's infamous findings for ‘are Jews [evil]’ in Google Autocompletion, Google put the onus on the users who search, calling the returns a ‘reflection’ of what is happening on the web: ‘Our search results are a reflection of the content across the web. This means that sometimes unpleasant portrayals of sensitive subject matter online can affect what search results appear for a given query’ (2016). ‘Unpleasant’ is one description of the outputs; for the most egregious results, Google has called them ‘offensive’ (beginning in 2004) and more recently ‘shocking’, largely avoiding the language used by scholars and journalists such as stereotypical, discriminatory or racist results (Sullivan, 2018, 2020), a point to which I return below.
As mentioned above, Google's policy (in Web Search as well as Autocompletion) had been to leave alone the returns such as for ‘Jew’, despite the presence of the antisemitic website at or near the top. In a banner inserted above the return, Google offered a disclaimer that it is an ‘offensive result’, which they prefer to retain in the results so as not to be accused of ‘hand manipulation’ (Sullivan, 2004). From Sullivan's 2018 blog post, however, it becomes evident that Google has shifted to removing and otherwise moderating certain offensive content (in Autocompletion) and, as I relate below, to suppressing and seemingly editing it in other Google products, including Web Search and Image Search.
There is still in-house consternation about giving the impression of ‘hand manipulation’ or more broadly an editorial voice. As Sullivan writes, while Google moderates ‘violent, sexually-explicit, hateful, disparaging or dangerous content, [p]eople can still search for such topics (…), of course. Nothing prevents that. We’re simply not wanting to unintentionally shock or surprise people with predictions they might not have expected’ (Sullivan, 2020).
Significantly, for the research reported here, Sullivan (2018) discusses the Google Autocompletion removal policy of text that targets individuals or groups based on ‘race, ethnic origin, religion, disability, age, nationality, veteran status, sexual orientation, gender, gender identity, or any other characteristic that's associated with systemic discrimination or marginalization’. There is also mention of an ‘expanded policy’ whereby Google would additionally remove content that is ‘reasonably perceived as hateful or prejudiced toward individuals and groups, without particular demographic’ (2018).
It is a flat list suggesting attention paid to each type, and it has a further catch-all category (‘without demographic’). Both are of interest in the sense that it is worthwhile to explore whether there are emphases as well as any under-emphasis. Are there categories that appear to be given greater attention than others when judged by comparing the results of queries about each? That is another way to phrase the question at hand concerning the hierarchy of problematic results.
In 2020, in a second blog post elaborating upon Google Autocomplete, Sullivan (2020) emphasized the content moderation taking place by ‘automated systems’ (which may refer to RankBrain and others) and ‘enforcement teams’ that remove ‘violent, sexually explicit, hateful, disparaging or dangerous’ content and act upon user reporting. He also added breaking events as a new category for moderation where in the emerging news environment, the quality of information may be low. In other words, Google moderates ‘data voids’.
Findings: Results of the algorithmic probing
The research overall is about interpreting what has been removed or otherwise moderated, and the approach revisits notoriously problematic autocompletions and other Google results as found or reported by such journalists and scholars as Cadwalladr, Noble, Alexander and Hunt, together with a sampling of others. Can we distil a hierarchy of concern and a geographical distribution of attention to moderation? How to characterize what is at stake?
There is such a hierarchy as well as distribution. For particular keywords, there are blocks and related suppressions of discriminatory and racist results as well as the persistence of certain stereotypes both in English and in other languages. Here, I detail the main findings before concluding with a discussion of the consequences of uneven moderation.
It is important to point out at the outset that many of the previously reported, problematic results from Google Web Search, Google Image Search and Autocompletion are remarkably patched or otherwise moderated – at least in English. Cadwalladr's notorious result emanating from ‘are Jews [evil]’, where the autocompletion part is in brackets, is no longer in evidence. The prompt does not autocomplete. The same can be said for other religions, indicating a suppression strategy across faiths (Figure 4).
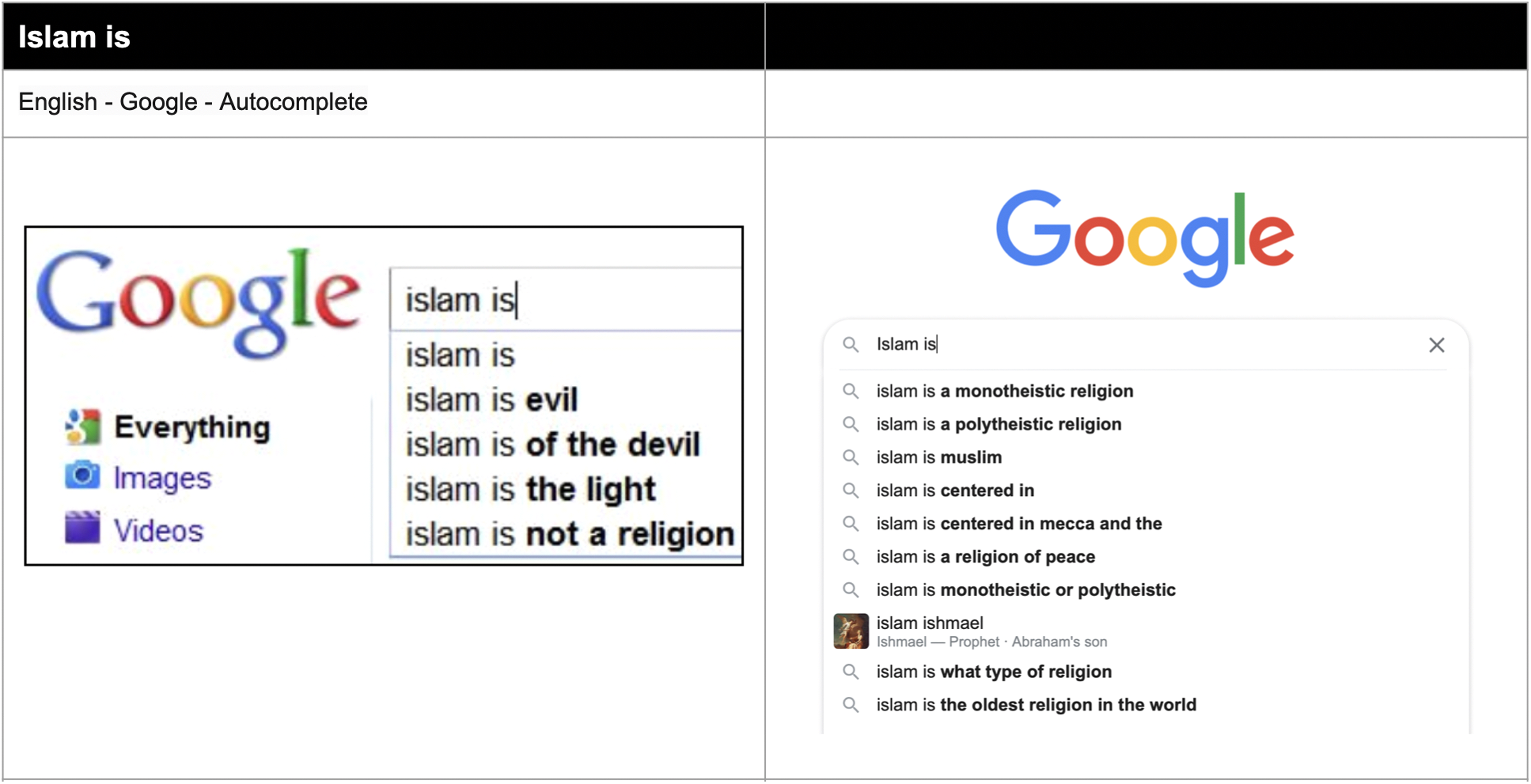
‘Islam is’ query 2011 (Sullivan, 2011) versus 2022 (author).
The picture is not as perfect where Noble's discriminatory and racist findings are concerned. In 2011, Noble found that queries for ‘Black girls’, ‘Asian girls’ and ‘American Indian girls’ (among others) often resulted in pornographic and otherwise prurient material (Figure 5; see also Figure 6). Comparing Noble's screenshots to those nowadays, that kind of content has been removed, but at least for ‘Asian girls’, the results are still associated with dating (Figure 7). There are stereotypical results: ‘American Indian girls’ are in costume (Figure 8). For the query ‘beautiful’, another of Noble's, comparing the results in Google Image Search from 2016 and 2022, we see some diversity, but images of white women still predominate (Figure 9). The query was also made in a variety of Google regions, and the results showed some consistency. For Nigeria, for example, most images returned for the query ‘beautiful woman’ are of white women (Figure 10).

‘Black girls’ query 2011 (Noble, 2018) versus 2022 (author).

‘Black girls’ image query 2014 (Noble, 2018) versus 2022 (author).

‘Asian girls’ query 2011 (Noble, 2018) versus 2022 (author).

‘American Indian girls’ query 2011 (Noble, 2018) versus 2022 (author).
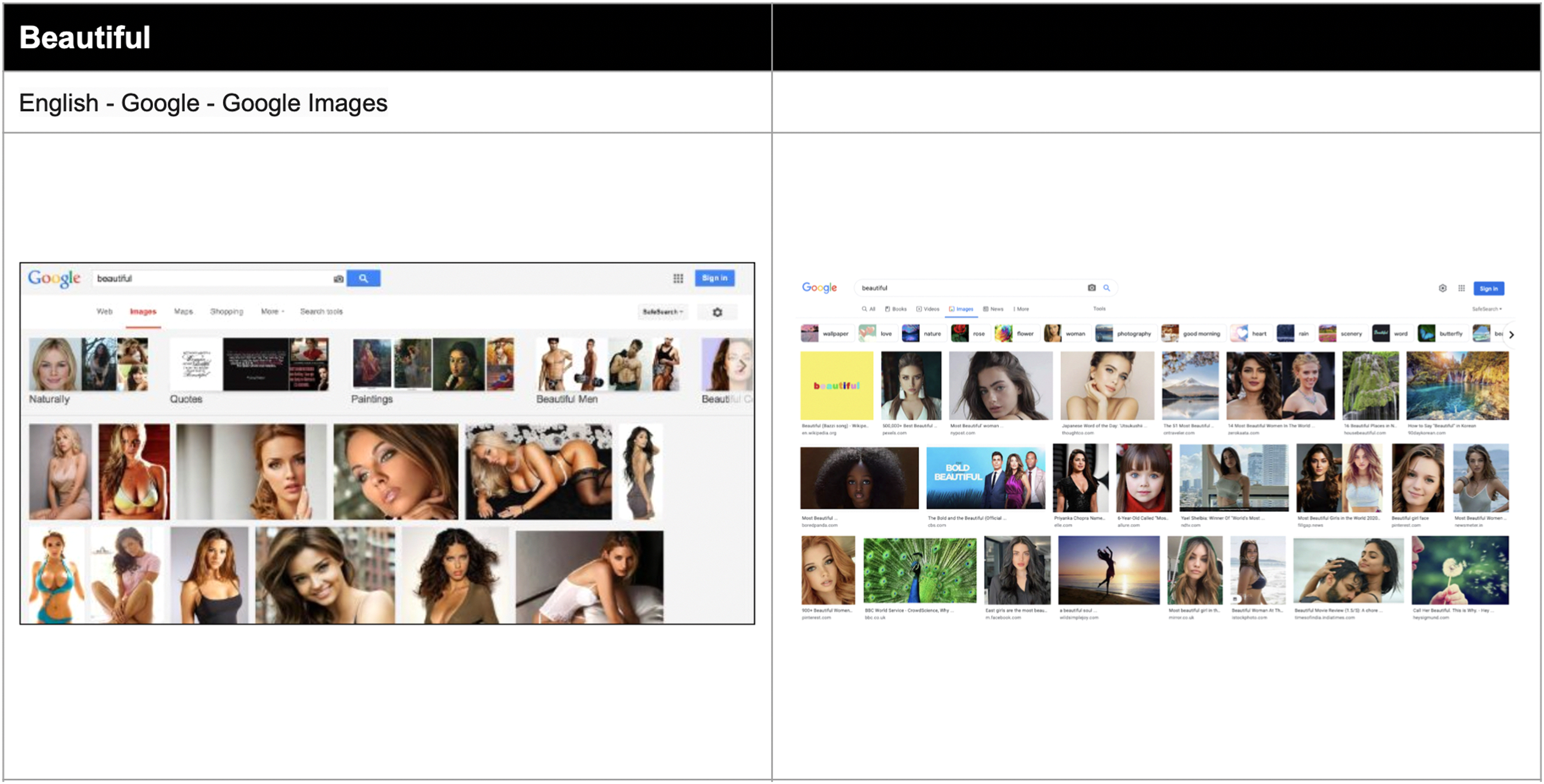
‘Beautiful’ query 2014 (Noble, 2018) versus 2022 (author).

‘Beautiful woman’ query in Nigeria Google region 2022 (author).
Moving to Alexander's and Hunt's queries, the Google Image returns for the query, ‘three black teenagers’, once showing mugshots, in contrast with ‘three white teenagers’ (the smiling youngsters), have been remedied in the sense that ‘three black teenagers’ are no longer criminal mugshots (Figures 11 and 12). As with other examples, the original media coverage with the offending results is also in the results set. With respect to Hunt's queries, while there is some diversity compared to the originals, image results for ‘professional hair’ are predominantly of white women and ‘unprofessional hair’ continue to show women of colour in the majority (Figures 13 and 14).

‘Three black teenagers’ image query 2016 (Hunt, 2016) versus 2022 (author).

‘Three white teenagers’ image query 2016 (Hunt, 2016) versus 2022 (author).
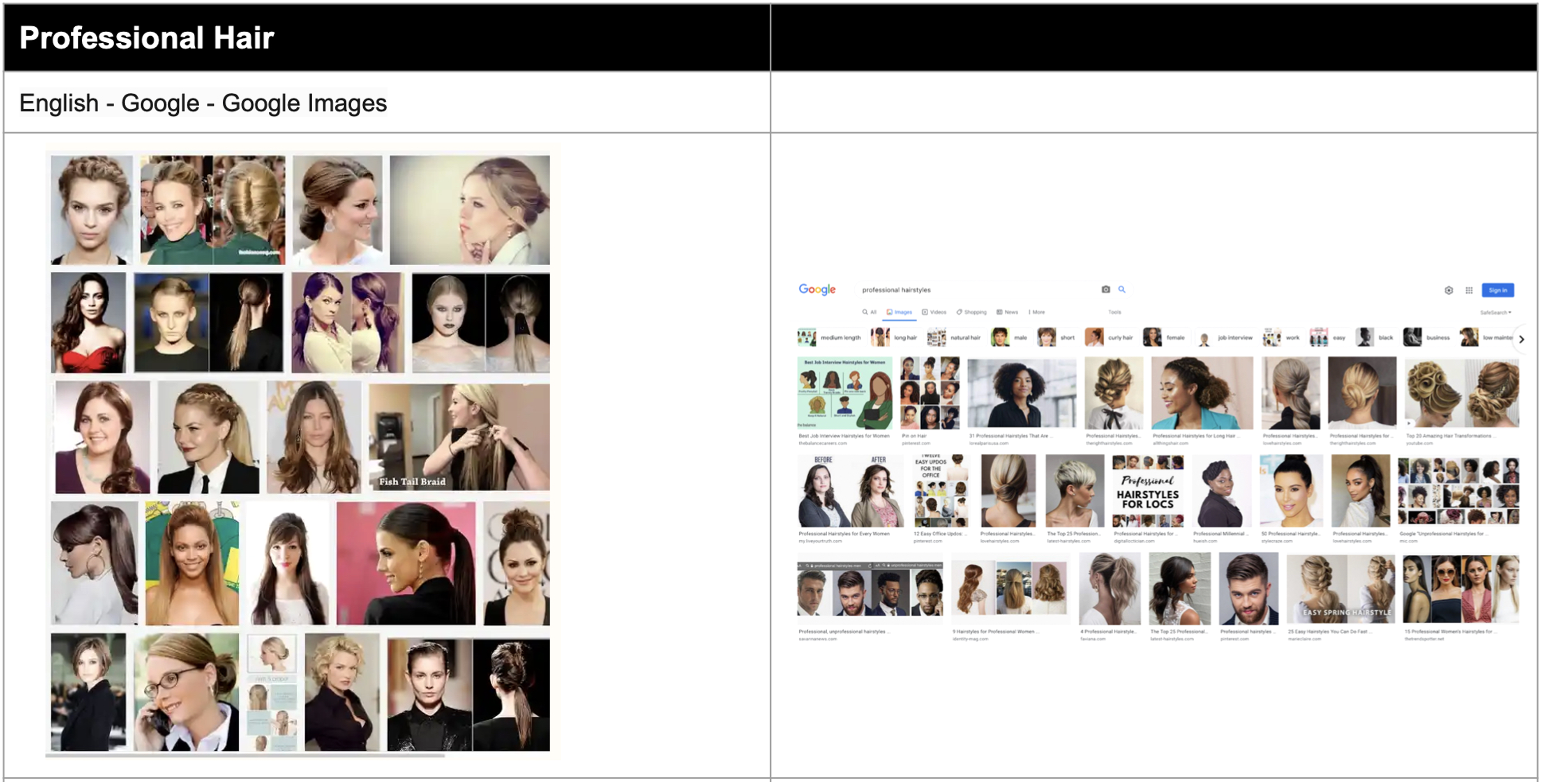
‘Professional hair’ query 2016 (Alexander, 2016) versus 2022 (author).
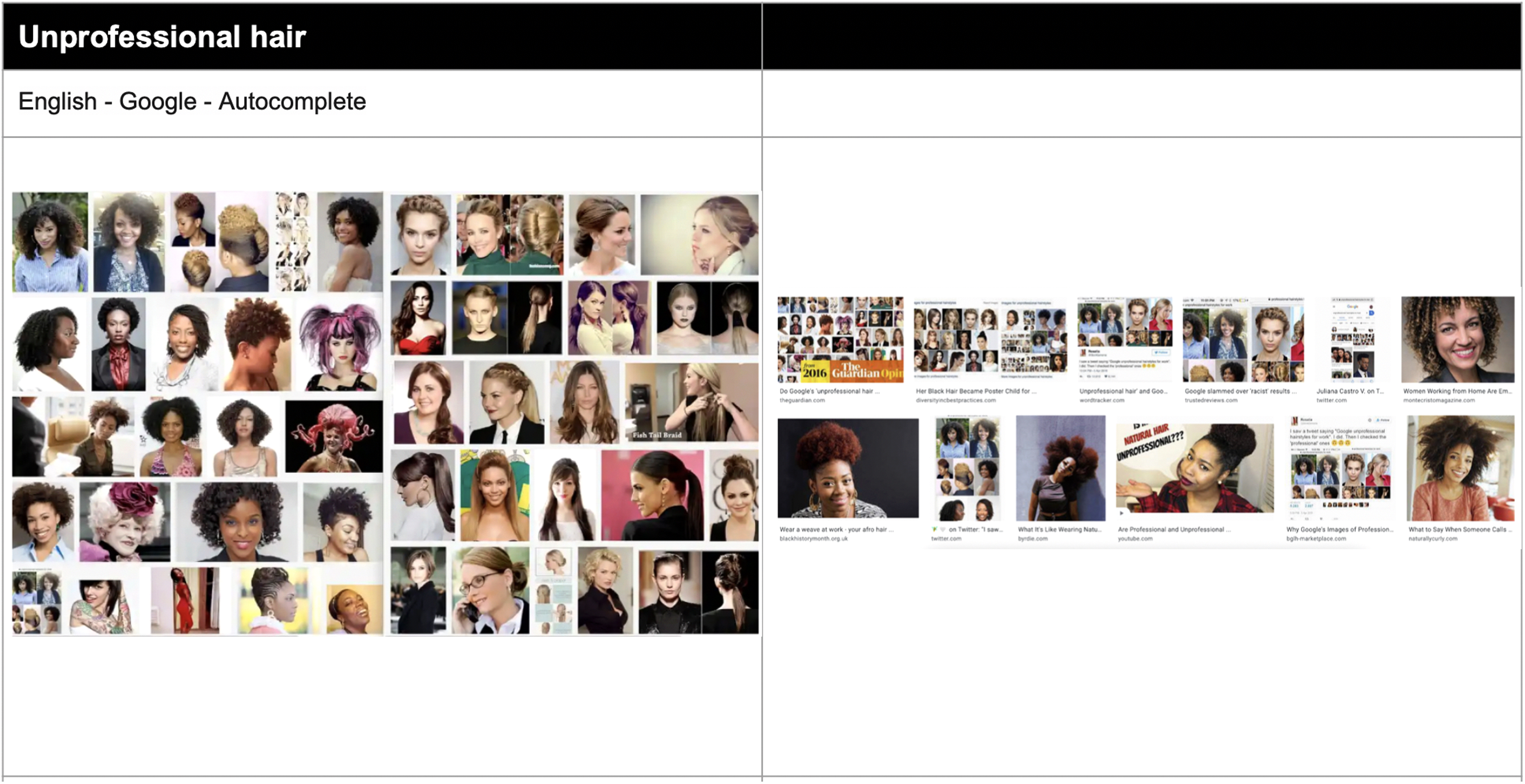
‘Unprofessional hair’ image query 2016 (Alexander, 2016) versus 2022 (author).
Sexual orientation also receives moderation, as in the case of the single result for ‘transgender’, though there are gaps. One noteworthy result is encountered when typing ‘is homosexuality’, in a repeat of the findings made in 2016 (Solon and Levin, 2016). In one completion, it reads ‘is homosexuality [a disorder]’ (Figure 15).

‘Is homosexuality’ query 2016 (Solon and Levin, 2016) versus 2022 (author).
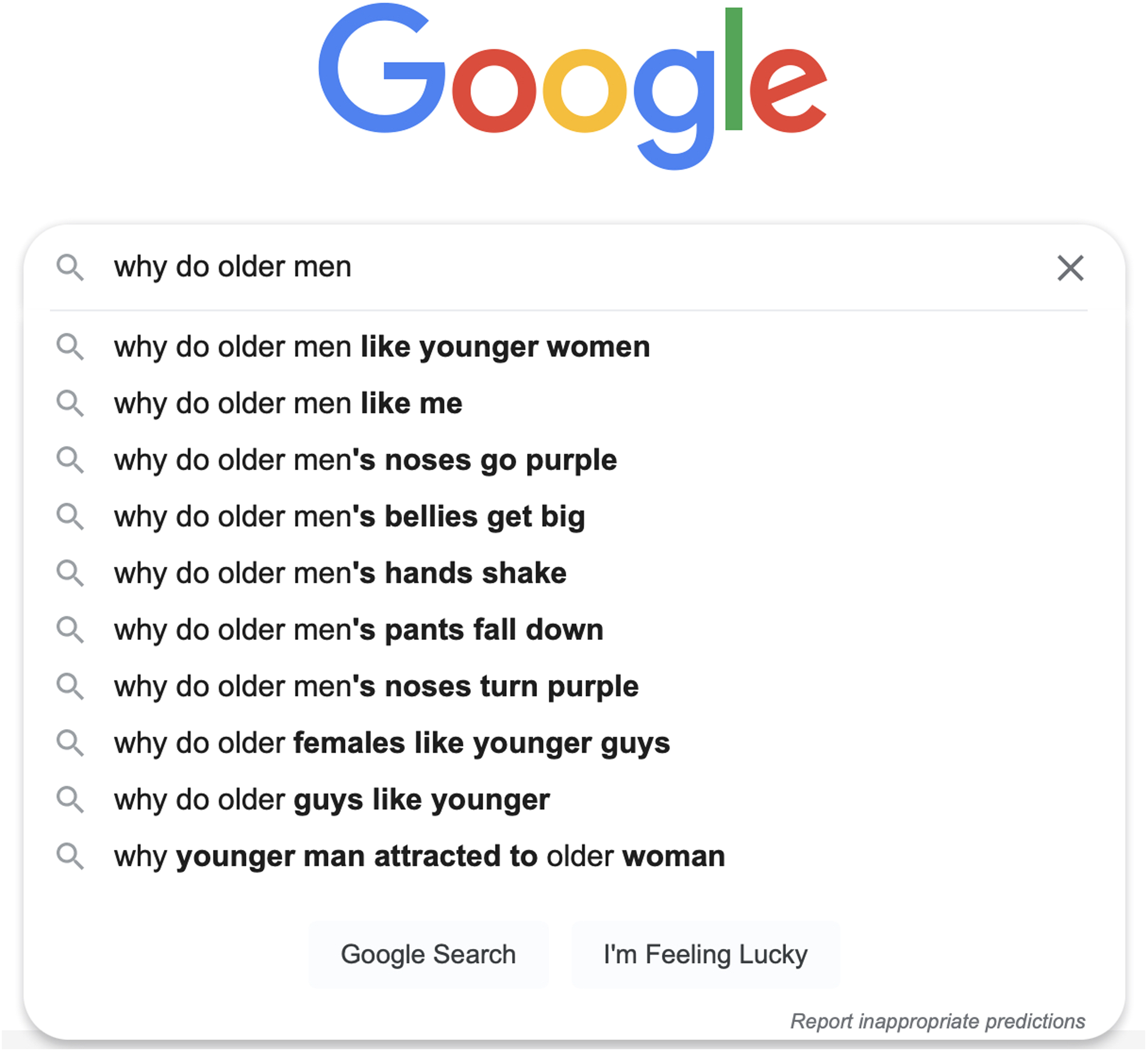
Extending the work of Baker and Potts on stereotypes, additional queries were re-rerun concerning gendered professions as well as age. Professors are still male; nurses are still overwhelmingly female (Cohn, 2015) (Figures 16 and 17). Queries for ‘older men’ do not return particularly tactful results, suggesting that ageism is still not a category that is actively moderated (Roy and Ayalon, 2020) (Figure 18).
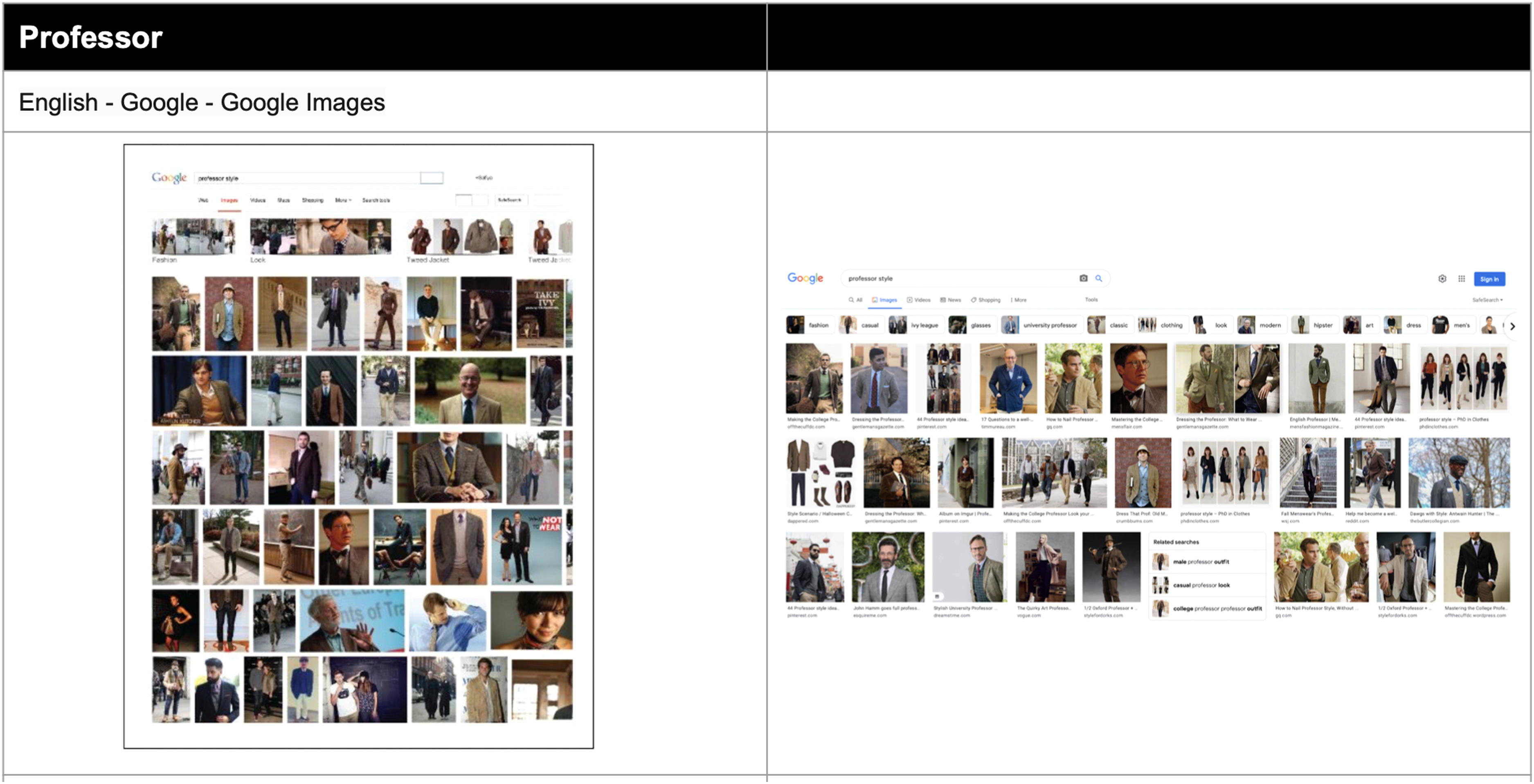
‘Professor’ image query 2015 (Noble, 2018) versus 2022 (author).

‘Nurse’ image query 2015 (Cohn, 2015) versus 2022 (author).
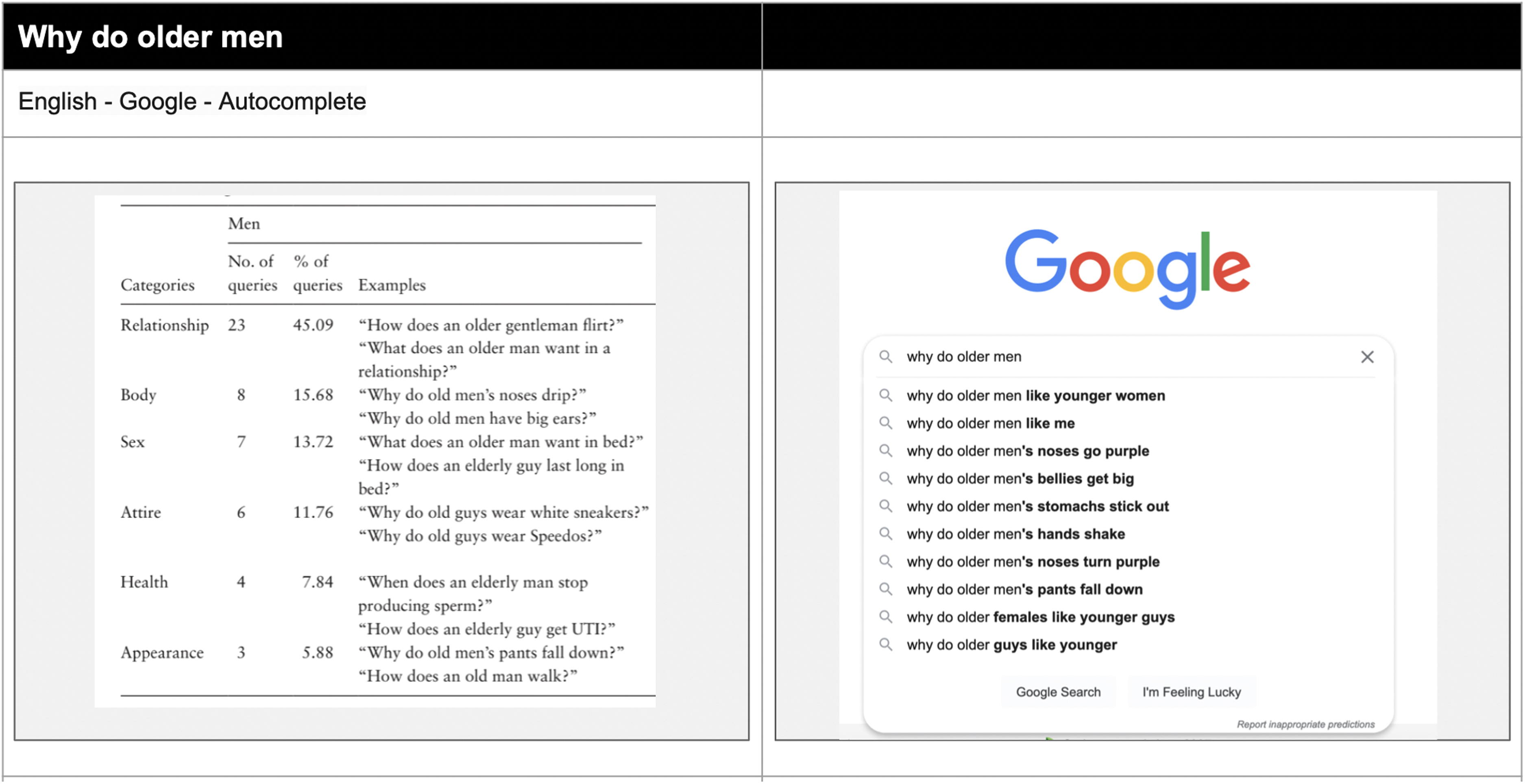
‘Why do older men’ query 2020 (Roy and Ayalon, 2020) versus 2022 (author).
These findings indicate a hierarchy of concerns, whereby religions, ethnicities and, to an extent, sexualities are more moderated categories, while gendered professions and ageism are less so or un-moderated, at least for the examples given.
With respect to social issue queries, remarkably, certain Google Autocompletions, viewed via the US region and VPN, have gone from a conservative political orientation to one that is more progressive (e.g. for the queries ‘abortion’ and ‘climate change’) (Figures 19 and 20). As related above, there are certain current events politicized in autocompletion (e.g. ‘civil war is coming’) that appear to be the result of ‘data voids’, populated by those seeking to game the engine. They appear to have been ‘patched’, as the researcher also reported after tweeting his findings (Chaslot, 2021); it also could be that the time period of actively gaming the engine for those terms has passed (Figures 21 and 22).

‘Abortion is’ query 2016 (Solon and Levin, 2016) versus 2022 (author).

‘Climate change is’ query 2018 (Lapowsky, 2018) versus 2022 (author).

‘Civil war is’ query 2021 (Chaslot, 2021) versus 2022 (author).
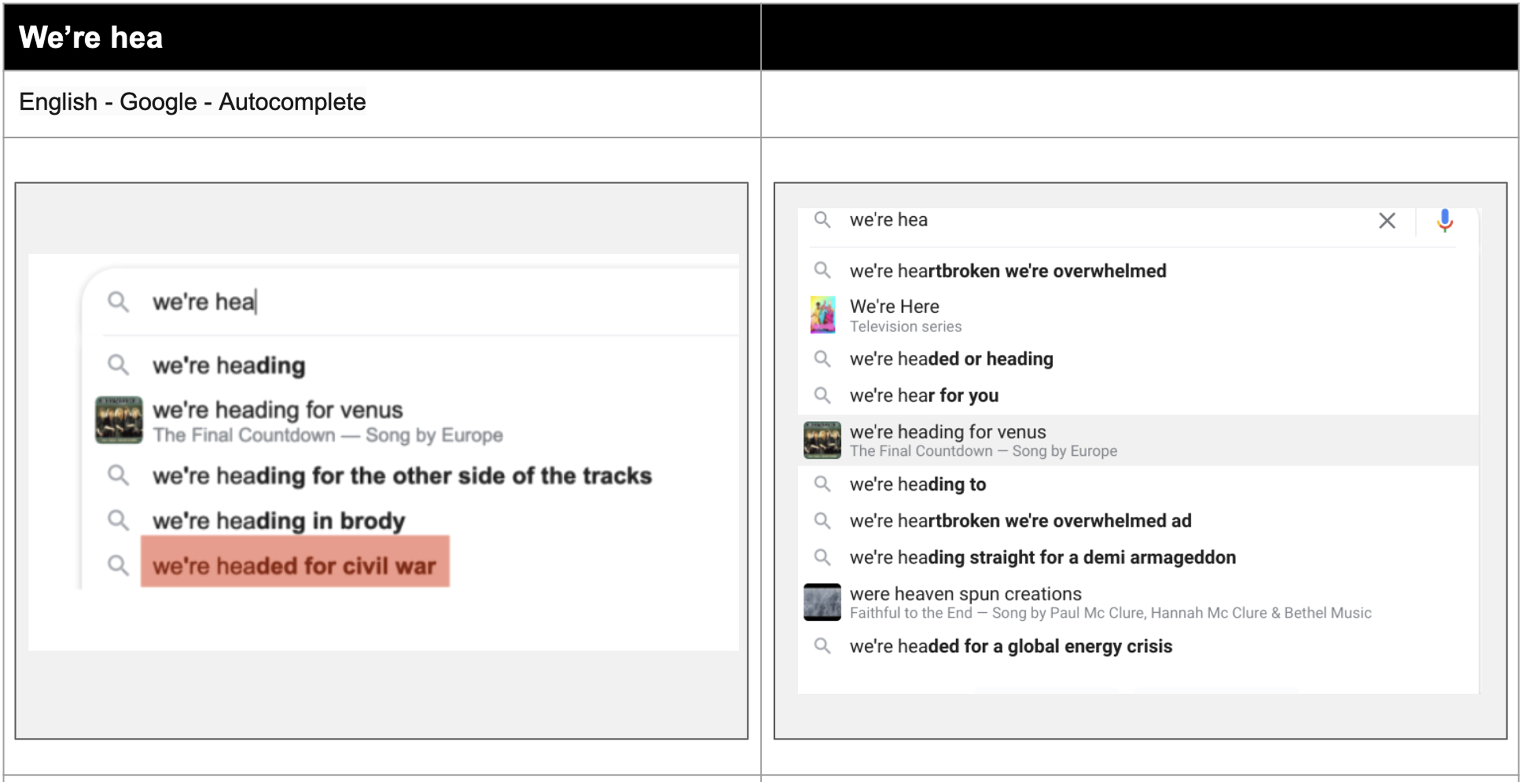
‘We’re hea’ query 2021 (Chaslot, 2021) versus 2022 (author).
For Covid-19 keywords in English (US region), we found most results to be unproblematic compared to those from 2021 in the sense that Autocompletion suggestions are mostly in line with official viewpoints, except for one phrase downplaying the impact of the virus; (Figure 23) the same holds for the UK Google region as well as those from India and South Africa (not pictured).

‘Coronavirus is’ query 2021 (Houli et al., 2021) versus 2022 (author).
When examining the local language results, moving from northern to southern Europe and the Balkans, the results gradually deteriorate. In the German language, the Covid-19 autocompletions are partially problematic. The suggestions in parts promote scepticism, suggesting Covid-19 is a farce, which are absent in the English-language predictions (Figure 24). Something similar can be said for the other language queries, though to a greater degree. Albanian Autocomplete on Google suggests that Covid-19 is a fraud (Figure 25), Greek Autocomplete suggests Covid-19 to be a scam (Figure 26), and conspiracies populate the Slovenian autocompletions (Figure 27). For Croatia, we found the query returned completions about how the virus is made up and is a biological weapon (Figure 28). Exceptionally, these results appeared after moving the cursor between ‘corona’ and ‘is’, suggesting that autocomplete is sensitive to tiny variations in how one types or corrects a typo. In all, the Covid-19 autocompletions in languages other than English (e.g. Slovenian and other Balkan languages) often teem with conspiracy theory. The English language appears to be given more scrutiny in the overall moderation efforts.

‘Coronavirus is’ query in English versus German 2022 (author).

‘Coronavirus is’ query in English versus Albanian 2022 (author).

‘Coronavirus is’ query in English versus Greek 2022 (author).

‘Coronavirus is’ query in English versus Slovenian 2022 (author).

‘Coronavirus is’ query in English versus Croatian 2022 (author).
When considering these findings across the various Google products, there are two hierarchies of concern encountered. The first is that there is a particular sensitivity for religion (where terms do not autocomplete), ethnic diversity (where Image Search has been re-populated) and sexuality (where results are trimmed). Gender diversity in professions and ageism, however, do not appear to be of great concern. There is also a distinctive geographical distribution of moderation attention, where English receives the most, followed by Western European languages. From a results moderation standpoint, at least for the queries made in our study, southern European and Balkan languages languish.
Discussion: Google's ‘quiet patching’ and technical moderation of problematic query results
In their piece concerning data voids, Golebiewski and Boyd (2018) argue that there is no wholesale, moderation ‘fix’ to be made to results. Rather, providing quality information is a calling, as in journalism, but also a continually recursive effort for platforms and their users. I would like to discuss what we have learned of such recursive efforts, especially since Google started to discuss its moderation practices. I would like to make four points concerning what could be termed Google's ‘technical moderation’ strategies. They concern Google's status as intermediary, its routine ‘quiet patching’ (and the potential for it to be politicized), its deflective descriptions of problematic results and the larger stakes in moderating or under-moderating.
As those who have studied commercial content moderation have found, in the early years, content removal was undertaken behind the scenes, unpublicized, drawing little to no attention (Roberts, 2019). Perhaps the lack of acknowledgement owed the status of engines (and platforms) as intermediaries rather than publishers. In the USA, where Google (or Alphabet) is headquartered, the key piece of legislation, the Communications Decency Act of 1996, also referred to as the ‘twenty-six words that created the internet’, states that ‘[n]o provider or user of an interactive computer service shall be treated as the publisher or speaker of any information provided by another information content provider’ (Kosseef, 2019). In posts about how Autocompletion works, especially the sections about moderation, Sullivan (2020) quashes any idea that Google is editing, or removing content, writing that people ‘of course’ can still search for problematic content.
Accusations of editing, in the form of autocompletion moderation, are raised on occasion. One publicized case involved the former US President Donald Trump, who politicized Google's moderation efforts, accusing the company of cleaning up autocompletions related to Hillary Clinton, his political opponent, saying that Google should just let the keyword completions flow (Lima, 2016). The remarks came on the heels of a Fox News investigation into Google autocompletions of Hillary Clinton related to criminal conduct. It was claimed that, when searching for her name, ‘“crime,” “criminal activity,” “indictment,” [and similar terms] have been filtered out by Google in favor of Hillary Clinton’ (Graves, 2016). Here, the moderation of individual names, which is part of Google's policy, is at work, as fact-checkers at PolitiFact ascertained, when re-running those autocompletions and interviewing company spokespersons (Graves, 2016).
Such an acknowledgement of filtering, however, is a course change. For many years, Google preferred to insist that the results are ‘organic’, as discussed above. In the higher profile cases of particularly offensive returns, Google spokespeople responded either by interview or through a posting on its website, discussing how autocompletions are organic content, reflecting what is happening on the web.
One such high-profile case was the UN Women's campaign concerning misogynistic autocompletions such as ‘women should stay in the kitchen’ (UN Women, 2013) (Figures 29 and 30). Another was ‘are Jews [evil]’, as discussed, but there have been numerous cases, reported in the press and industry publications and published in the scholarly literature.

‘Women need’ query 2013 (Mahdawi, 2013) versus 2022 (author).

‘Women should’ query 2013 (Mahdawi, 2013) versus 2022 (author).
In the trade press and elsewhere, one may read how certain discoveries, including the UN Women's campaign, prompt attention within Google to address it in short order. Phrases from the campaign (‘women need…’; ‘women should…’) would be blocked so that they would not autocomplete all together. These are examples of what Sullivan (2011), writing in an industry publication, described as instances that were ‘escalated’ within Google owing to the press coverage. As related above, journalists often follow up on their initial discoveries of offensive outputs and confirm the individual and related takedowns.
These are ‘quiet patches’, or examples of suppressions; they also could be called ‘hard moderation’, as mentioned above (Gorwa et al., 2020). The blocks are implemented for infamous autocompletion queries (such as ‘are Jews…’) but also related ones as ‘Jews have’ and ‘Jews were’ (Gibbs, 2016). Suppressions are implemented across categories such as religion, ethnicity, sexual orientation and others, including more recent additions. Indeed, as mentioned, Google addressed the autocompletions concerning a ‘coming civil war’, filling the so-called data void, after a researcher (and former Google employee) tweeted about it (Chaslot, 2021).
In a sense, the research reported here concerns the extent and the staying power of the patchwork, or how Google through its moderation has responded to problematic query results. Indeed, the analysis found blocking practices and the implementation of related blocking to be the most egregious results that have been found by journalists and scholars. Platform ‘suppression’ strategies are of interest in this regard. There are such practices as maintaining block lists which are lists of highly offensive terms that will return no result as well as the so-called n-strike rule which extends the working of the lists to phrases (Hazen et al., 2020). Indeed, rather than ‘fixes’, the work is in the realm of patching and maintenance. The ever-evolving automated semantic infrastructure, using machine learning and language models, also appears to require list-makers and other more mundane moderators and maintenance workers.
Google Autocompletion appears to be a patchwork of blocks and related suppressions, found by journalists, researchers and presumably everyday users, using Google's crowdsourcing or crowd-flagging tool, but the research also found other moderation practices. Where there could be up to 10 returns, for common, albeit sensitive, keywords, there are occasionally single results (recall the ‘transgender’ autocompletion in Figure 2). In another case, there is just one line that is infused with a measure of positivity or inquisitiveness. In both cases, it is as if the results have been pruned. For social issue queries, there also appear to be result set makeovers, where the whole gives a positive or even progressive impression (in the US Google region) when in the past the returns were quite the opposite. There are also results that are cultural products from Google's Knowledge Graph such as ‘civil war is [an Avengers movie]’ as well as other automated outcomes that are the result of what Sullivan (2018) has called ‘word patterns’.
When one switches languages, however, the autocompletion engine goes haywire, so to speak, with their quality deteriorating, at least for Covid-19 queries. Seemingly, without much patchwork or other work done for Albanian, Greek and other southern European and Balkan languages, here the technical moderation weakens.
It is noteworthy that Google Autocompletion is not a service that can be disabled, at least at the time of writing, meaning that the user is not opting in to being exposed to stereotypes and other problematic results. Indeed, the journalist who discovered the autocompletion ‘are Jews [evil]’ wrote that she stumbled upon the antisemitic suggestion, rather than seeking it (Cadwalladr, 2016). Other journalists and scholars explicitly seek them, casting about for problematic autocompletions by running critical experiments and investigative queries, prompting the engine to divulge stereotypical, discriminatory and/or racist autocompletions in a variety of categories. Certain experiments take a broad scoping approach, creating prompts in categories from religion and sexual orientation to politics and nationalities. Others are more in-depth case studies, such as on ageism (Roy and Ayalon, 2020).
These are all tests that seek to discover the efficacy of Google's moderation, generally, and the consequences of the form that moderation assumes. Google is moderating through a variety of patchwork and other technical means, but often discusses what researchers have called stereotypical, discriminatory and/or racist results in a deflective manner, using terms such as offensive, inappropriate, unpleasant, unwanted and shocking. There is a well-established critique of companies such as Google performing live beta-testing, where the users are proverbially ‘living within [Google's] lab’ (Davies, 2015). The deflective language arguably allows for carrying on with this ‘testing in society’, despite ‘what tests generate’ in the form of problematic outputs (Marres and Stark, 2020).
The stakes involved in removing and managing such results and autocompletions have been discussed in the scholarly literature and in the journalistic pieces in terms of the harm done in allowing the perpetuation (or reintroduction) of stereotypical, discriminatory or racist results and the credence they gain as suggestions. There is the infamous case of problematic Google Ads, when a researcher found when searching for names ‘assigned at birth to more black babies’ than white a disproportionate number of ads that asked, ‘have you been arrested’, offering a link to a site providing criminal background checks (Sweeney, 2013). Such associations can have deleterious effects on job, housing, loan and other applications and pursuits. In the case of a mass shooting in Las Vegas, when a so-called data void was plugged with misinformation appearing at the top of Google's stories, it was a case of mistaken identity (Madrigal, 2017). For other scholars and journalists, problematic search results reinforce ‘oppressive social relationships’ (Noble, 2018); they can ‘influence people's views and opinions’ (Cadwalladr, 2016). In practical terms, researchers have reported a decline in such queries after the removal of the suggestions, for example, after Google removed the autocompletion, ‘are Jews [evil]’ (Stephens-Davidowitz, 2019).
Conclusions: Hierarchies in Google Autocompletion
As related in the opening, since its inception, Google (like other search engines) has been scrutinized for its privileging mechanisms. To what extent does it boost the surface web, the powerful, optimized webpages, the personalized and/or its own properties? The research reported here adds to the study of Google privileging mechanisms by examining another type of Google output: problematic results, including stereotypical, discriminatory or even racist.
The study re-runs a selection of these results previously found by journalists as well as researchers in a method described as algorithmic probing. The results from Google Web Search, Images and Autocompletion are displayed in the side-by-side style of ‘then’ and ‘now’ to enable an examination of how they have been handled, if at all. More recent problematic results, largely related to the global pandemic, are also queried anew in a variety of Google regions (and also languages), in order to gain an additional sense of any geographical or linguistic distribution of concern present in Google Autocomplete, the service that constitutes the bulk of this study.
The overall question is which of the results have been addressed and in what manner, and how can an accounting be made of Google's hierarchies of concern and geographical distribution of moderation. Moderation is broadly defined beyond patching and suppression to include algorithmic updates (that may have had impact on the results) as well as what Google refers to as ‘automated systems’ that include RankBrain and others. The algorithmic updates and automated systems could be construed as softer moderation whereas the patching and suppression harder moderation, defined, as discussed above, as content classification that results in a ‘governance outcome’ such as removal (Gorwa et al., 2020).
Compared to results from 5 to 10 years ago, Google Images (and Google Web Search) have removed a series of offensive results, having diversified and desexualized results for people and ethnicities, albeit with some gaps. Specific queries that once resulted in offensive or shocking results (‘unprofessional hair’) have been somewhat remedied. Gendered and ageist stereotypes persist, however. Professors are men; nurses are women, though a modicum of diversity is in evidence compared to searches some years ago. Autocompletions concerning older men would not be regarded as tactful (recall Figure 18).
Overall, there is a sensitivity scale built into the moderation, with particular concerns receiving more attention than others. Religion, ethnicities and sexualities are blocked or curated (though with some inconsistency) while professions and ages are mainly left to their own devices.
There is additionally a category of result changes that have other signs of ‘hard moderation’. One example is the single result (such as for the autocompletion of ‘transgender’) which seems to be one prediction that has been selected and highlighted, so to speak (see Figure 2). Other result sets concerning social issues appear to have become more progressive (in the US Google region). Autocompletions for abortion and climate change, for example, no longer output conservative positions (in the US region). Covid-19 could be described in a similar fashion, as there are hardly any results (in English) that question its seriousness. Finally, automated associations include associative linkages between keywords and cultural products or other tags. Instead of ‘civil war [is coming]’, Google predicts that ‘civil war [is an Avengers movie]’. Whether hard or softer strategies, these elements together could be described as technical content moderation.
The above observations relate to moderation of the English-language version of Google. As one begins to query other languages, the semantic situation changes. In the probes, particularly Covid-19-related queries were run. It is heralded as a highly moderated space, given the efforts made by Google to populate the search engine results page with official sources and otherwise moderate the content returned. The results are surprising in the sense that, unlike in English, there remain a few questionable results in German, Dutch and French. As one moves to languages from southern Europe and the Balkan Peninsula, however, the moderation falls apart, with serious Covid-19 accounts competing with conspiracy theories and other questionable associations.
Google's moderation of Web Search, Images and particularly Autocompletion displays certain hierarchies of concern, as related above. In Autocompletion (for queries of contemporary issues), it is also linguistically or geographically uneven.
Discussing these findings, I put forward several points concerning the stakes at hand. One is the sensitivity involved in any perception of ‘editing’ results, given that it would become associated ‘hand manipulation’ and perhaps the work of a publisher rather than an intermediary. In the event, Google quietly ‘patches’ outputs after journalistic revelations about stereotypical, offensive or even racist results, while at the same time discussing its moderation as performed largely through automated systems, aided by user reporting (and interaction).
Another observation concerns how autocompletion cannot be switched off, at least at the time of writing. The feature could be viewed in the context of Google as a continuous testbed. It is perpetually under development, learning from user interaction with the returns, including from its autosuggestions or predictions. Having users switch it off would lead to fewer opportunities for optimization.
When a stereotypical or other problematic result appears, Google has described them with terms such as ‘unwanted’ or ‘shocking’ returns. Such deflection is part of the model of improvement of the underlying systems, giving grounds for their continued use, despite reinforcing (or reintroducing) stereotypical and other problematic associations, such as Covid-19 with conspiracy theories, as noted in one of the result sets.
Indeed, the larger stakes in moderating or under-moderating concern the persistence of stereotypical, offensive, racist or other problematic outputs, many of which, as we found, have been remedied in English-language Google outputs, albeit with gaps and a hierarchy of concerns that could be addressed. In other languages in Europe, we found larger holes in the moderation, giving rise to the potential for greater exposure to problematic associations.
Footnotes
Acknowledgements
The article benefited from the analyses conducted by Zoe Chan, Sarah Gralla, Alistair Keepe, Natalie Kerby, Goran Kusic, Barbara Matijasic, Leah Nann, Olga Parai, Piet van den Reek, Miazia Schueler, Tatiana Smirnova and Liam van de Ven at the Digital Methods Winter School, Media Studies, University of Amsterdam, January 2022.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.
Correction (June 2023):
Since the original online publication, this article has been updated for sequence of figures.