
Abstract
This study provides a critical analysis of the efficacy of Multimodal Large Language Models (MLLM) in identifying visual hate speech on Instagram, such as image memes, specifically within the context of non-English and non-Western communities. By focusing on the unique dynamics of hate speech circulating among Chinese-speaking populations, particularly aimed at mainland Chinese individuals, this research illuminates the complexities and challenges associated with employing MLLMs for multi-modal hate speech detection through a zero-shot learning approach. Through a comparative evaluation of two cutting-edge MLLMs, Gemini-1.5 and GPT-4o-mini, measured against expert annotations and incorporating qualitative error analysis, the study reveals factors contributing to the complexity of the task. This includes hallucinations, tendencies toward over-labelling content as hate speech, and a notable absence of linguistic and cultural sensitivity. These findings highlight the needs for the development of culturally attuned models and methodologies that enhance the effectiveness of hate speech moderation in diverse cultural contexts.
Introduction
The proliferation of hate speech on social media platforms, including Instagram, has sparked widespread concern and academic inquiry. Despite the significant visibility and broad impact of hate speech in global contexts, relatively little attention has been given to understanding the dynamics of hate speech propagated within Chinese-speaking communities online. This research gap is particularly pronounced in the context of hate speech conveyed through visual content, such as image memes. As such, the exploration of multi-modal hate speech remains under-researched, especially within online non-Western linguistic and cultural contexts (Guan et al., 2024; Matamoros-Fernández and Farkas, 2021).
Recent advancements in technology have introduced large language models (LLMs) that present new avenues for identifying and moderating hate speech at scale and with minimal human oversight (Barbarestani et al., 2024; Hee et al., 2024; Huang et al., 2023;). However, significant uncertainties persist regarding the effectiveness of these emerging tools in recognizing hate speech in general, and particularly in images from diverse cultural and linguistic online settings. This article critically examines the potential and limitations of cutting-edge Multimodal Large Language Models (MLLMs) in addressing the challenges associated with hate speech detection on social media platforms.
More specifically, the research examines hate speech targeting mainland Chinese people/citizens represented in Chinese Instagram posts. Based on commonly used hate speech definitions in the literature (Paz et al., 2020), anti-mainland Chinese hate speech can be understood as deliberate, public expressions that denigrate individuals based on their national origin, often through dehumanizing, exclusionary or derogatory language. Examples of such type of hate speech include racial slurs such as ‘支那人’ (Zhina people), or dehumanizing terms like ‘蝗虫’ (locust) used in Hong Kong to describe people from mainland China in a derogatory way.
In essence, this study focuses on a form of intra-ethnic hate speech rooted in the cultural and political complexities among diverse Chinese ethnic communities. Developing a nuanced understanding of this phenomenon requires attention to the ongoing power dynamics between mainland Chinese people from the People's Republic of China (PRC) and ethnic Chinese communities in Taiwan, Hong Kong and the global diaspora. These dynamics have increasingly positioned mainland Chinese individuals as frequent targets of hostility and exclusion (Ip, 2015; Kádár et al., 2013). On the one hand, this discord originates from political and identity tensions stemming from PRC policies and immigrations; on the other, Chinese-speaking communities outside mainland China often exhibit a sense of superiority, rooted in their perceived political and economic advancements or their closer alignment with Western ideals and systems (Lowe and Tsang, 2017). As a result, mainland Chinese are not only scapegoated for resentment toward the Chinese government but also subjected to prejudice and discrimination by their Chinese-speaking counterparts in Taiwan, Hong Kong and other diasporic communities (Song et al., 2022; Sun and Chan, 2021; Wong, 2015). While hate speech is often entangled with political dynamics and power struggles, this study draws a clear distinction between hate speech targeting mainland Chinese individuals and political satire or criticism directed at the Chinese state. Our analysis focuses exclusively on the former. Satire or criticism aimed at political parties, institutions or policies – though potentially offensive – is not classified as hate speech within the scope of this study.
Social media platforms, including Instagram, are frequently used to disseminate toxic and harmful rhetoric targeting Chinese individuals (Zhu, 2020). However, such content often goes under-moderated due to a combination of limited platform resources, weak incentives and insufficient understanding of the cultural and ethnic dynamics within Chinese-speaking communities (Hong et al., 2023). It is a common practice for platforms to prioritize moderation efforts in markets that generate higher advertising revenue or face stronger regulatory pressure, which leads to unequal investment in content moderation for less economically strategic regions and languages. Since Instagram does not officially operate in mainland China, users from this region are both underrepresented and seen as less economically lucrative, reducing the likelihood that hate speech against them will be adequately detected or addressed.
This context presents an opportunity for research that focuses on testing the effectiveness of MLLMs – which are largely used by social media platforms for content moderation (AlDahoul et al., 2024; Kumar et al., 2024; Vargas Penagos, 2024) – to identify and moderate hate speech from the Chinese-speaking communities. Through doing so, this study underscores the importance of nuanced cultural and linguistic insights when investigating hate speech in non-English, non-Western contexts. Our research ultimately calls for the creation of a more just and inclusive online environment that protects the dignity and safety of all users, regardless of their linguistic or cultural background. The research design leverages the capabilities of two advanced MLLMs: Gemini-1.5 and GPT-4, to classify potential hate speech against Chinese nationals on Instagram.
The study has two primary objectives. First, by measuring the disparities in classification results between the MLLMs and the human annotators, the research aims to evaluate the extent to which the MLLMs are effective in identifying hate speech within the Chinese-speaking communities, especially hate speech conveyed through visuals such as image memes. Second, the study seeks to generate qualitative insights into the factors that contribute to the complexity of the task.
The findings from our mixed-methods analysis highlight several issues in using MLLMs to classify hate speech in Chinese social media content, particularly their tendency to over-estimate hate speech. These challenges include cross-modal misinterpretation, hallucination, and a lack of cultural and linguistic reflexivity in MLLM-based hate speech detection. It was reported that the reliance on large-scale biased pre-training significantly results in these detection challenges (Albladi et al., 2025). Our empirical findings contribute to the emerging methodological exploration of generative artificial intelligence (AI) in media and communication research while emphasizing the need for critical engagement with these tools. Additionally, with the growing adoption of LLMs in both harmful content moderation and academic research, our study provides empirical evidence that calls for caution. Prior research has illuminated the potential applicability of LLMs in facilitating content moderation on hate speech (Hee et al., 2024) and other forms of harmful content on social media (Barbarestani et al., 2024; Huang et al., 2023). However, our study shows that these technologies could fail to perform reliably in non-Anglo-American and culturally nuanced contexts. This limitation highlights the risks of embedding LLMs into platform governance without adequate cultural, linguistic, and geopolitical reflexivity—an issue that directly resonates with broader platformization debates on automated content moderation and the reproduction of systemic biases.
Literature review
Hate speech on social media and its moderation
A big challenge for content moderation on digital platforms is finding reliable and fair processes for understanding, identifying and potentially removing hate speech. One of the main difficulties of this task is the conceptual elasticity of ‘hate speech’ as a concept and the fact that the term itself is not explicitly covered in many countries’ laws (Benesch, 2020: 13). Platforms increasingly have to adjust their policies and processes to comply with national and supranational laws, particularly when they are under regulatory pressure to do so, as has been the case in Germany and Europe more broadly (Citron, 2018). But there is ample variety in the way different tech companies define ‘hate speech’ in their policies (Benesch, 2020: 9). While some digital platforms define ‘hate speech’ more expansively than many countries’ laws do (Brown, 2017), others offer narrow legal categories of speech prohibited under mainly US national legal rules. 1
Another difficulty of moderating hate speech is that historically, in their efforts to regulate speech, platforms’ policies have not distinguished between groups that have been historically marginalized from groups that have not (Bartolo, 2021; Siapera and Viejo-Otero, 2021). That is, hate speech policies follow, for example, a ‘race-blind approach that does not consider history and material differences’ and hence abuse directed at white people and Black people, for example, tend to receive equal treatment (Siapera and Viejo-Otero, 2021: 112). One especially valuable insight from critical race and feminist scholars has been detailed theorization of the ways in which the harms of speech not only connect with, but are inseparable from, broader contexts of structural social and political inequality and oppression (e.g. see McGowan, 2009). In Ethiopia, for example, the deep entanglement between politics and ethnicity has led scholars like Yared Legesse Mengistu (2012) to argue that labelling and regulating something as ‘ethnic hate speech’ risks veering into political censorship without a nuanced approach that is sensitive to power dynamics. The question of which groups should be covered by speech laws is not predetermined: indeed, protected categories vary across countries; for example, while various speech laws protect undifferentiated categories (e.g. ‘sexual orientation’ in the United Kingdom) there are also cases where protection is granted more specifically to a sub-group within that category (e.g. ‘homosexuality’ in New South Wales in Australia) (Brown, 2017: 41, 42). In an online platform context, these issues are just as pertinent. This is evidenced in controversies surrounding the removal of speech critiquing white supremacy and patriarchy under facially neutral ‘hate speech’ rules that assessed those critiques as attacks on the basis of race and gender (Bartolo, 2021).
These complexities in conceptualizing and understanding hate speech in different parts of the world has led platforms to perform high error rates in their identification and removal of hate speech, especially via its automated approaches to content moderation (Dias Oliva et al., 2021). In the context of content moderation, ‘machine learning (ML) techniques are (…) increasingly deployed as supposedly cheap and effective solutions’ to guarantee healthy participation (Rieder and Skop, 2021: 2) despite their obvious trade-offs, such as the over-removal of harmless speech (Dias Oliva et al., 2021), as we explain in the following section.
Potentials of LLMs for content moderation
Social media platforms increasingly rely on automated content moderation systems to address scalability challenges that human moderators struggle to overcome. While AI-based moderation is not new (Gillespie, 2020), the use of LLMs in this field has gained traction due to their potentially superior detection accuracy. This advantage stems from their technical structure and pre-training, which involve billions of parameters (Luo et al., 2024), enabling LLMs to understand complex contexts and adapt to changing circumstances (Huang, 2024; Touvron et al., 2023). GPT models, in particular, have been examined for annotating pre-labelled datasets, showing high accuracy in detection tasks for inappropriate language (Barbarestani et al., 2024), toxic content (Kumar et al., 2024, Li et al., 2024), violent speech in Incel 2 communities (Matter et al., 2024), and implicit hate speech in tweets (Huang et al., 2023). In undertaking personalized moderation tasks, GPT also outperforms traditional ML-based solutions (e.g. Perspective API and OpenAI Moderation API) when moderating Reddit comments based on sub-community policies (Franco et al., 2024).
It is worth noting that most of the aforementioned achievements have been made in applying LLMs to detect or moderate hate speech in monomodal text formats. Empirical studies on MLLM's ability to detect harmful visual content are still in their early stages. Mixed results are shown in prior research using MLLMs to detect harmful visual content. Some find MLLMs to be effective in detecting hateful memes (Van and Wu, 2023) and misleading visualization (Alexander et al., 2024), while others find MLLMs to underperform specialized neural network-based models in detecting violent videos (Nadeem et al., 2024).
Recent research has also explored the potential of LLMs to provide explicit reasoning for classification tasks (e.g. Taranukhin et al., 2024; Turpin et al., 2023). This line of inquiry has also been extended to generating harm-related explanations to justify the classification of problematic textual content (Franco et al., 2023; Li et al., 2024) as well as multi-modal content (Lin et al., 2024). While researchers caution that the explanations generated by LLMs should not be equated with human-like reasoning and may occasionally introduce erroneous information (Turpin et al., 2023; Li et al., 2024), these models can still provide clear and structured justifications that support the identification and resolution of classification errors (Franco et al., 2023) and aid moderators in making more informed decisions (Vargas Penagos, 2024). For instance, LLMs can enhance content moderation by offering high-quality explanations to help human reviewers gain contextual insights and improve user participation (Huang, 2024), exemplified by ChatGPT's ability to generate quality explanations on implicit hate speech comparable to human annotators by providing clearer illustrations to help users identify hatefulness (Huang et al., 2023).
Challenges and limitations of computational detection of harmful content
Despite potential, LLMs still face challenges in content moderation, with bias being a key concern. AI-based moderation has been shown to disproportionately affect marginalized groups (Haimson et al., 2021; Dias Oliva et al., 2021) and applying LLMs in content moderation is not immune to these biases. ChatGPT-3.5-Turbo and LLaMA-2 are found to be overly sensitive to certain topics (e.g. ‘vandalism’) and groups (e.g. ‘Black women’), leading to the misclassification of benign statements as hate speech (Zhang et al., 2024). In addition, their prediction consistency varies across social groups (Gomez et al., 2024). LLMs also exhibit uneven sensitivity to different types of problematic content. For instance, when comparing GPT-4's capacity to classify common tropes in Islamophobic hate speech, Mustafa et al. (2024) find that, while the model can detect narratives framing Islam as culturally incompatible with Western values, it fails to identify posts promoting the trope that Islam inherently oppresses women. Similarly, rule-based moderation in LLMs varies significantly across rules set by different Reddit subcommunities (Franco et al., 2024).
The advent of deep learning, and in particular LLMs, has catalysed progress in the field in the past decade (Kalloniatis and Adamidis, 2025; Ren et al., 2024). Nonetheless, even the most advanced of these models still struggle with things like context, which is crucial in recognizing and understanding humour (Dutta and Bhattacharyya, 2022; Salini and HariKiran, 2023). Detecting implicit hate speech – especially when conveyed through satire, humour, or irony – has long posed a challenge for deep learning models and remains a significant obstacle for LLMs as well (MacAvaney et al., 2019). Even with carefully engineered prompts, recent research shows that LLMs struggle to recognize implicit hate due to limitations in training data and vocabulary coverage (Ocampo et al., 2023; Yadav et al., 2024). Humour, in particular, presents a distinct challenge in computational research. Although substantial progress has been made in humour detection over the past two decades, accurately identifying and moderating harmful or aggressive humour remains far from resolved (Cowie, 2023; Kalloniatis and Adamidi, 2025; Matamoros-Fernández et al., 2023; Ren et al., 2024).
Research on toxic memes has showcased the difficulty AI tools face in detecting hate speech implicitly conveyed through visual elements (Cao et al., 2023). Cross-modal interpretation and evaluation of hate speech remain significant technological challenges. In multi-modal contexts such as memes, hate can be manifested across modalities – becoming apparent only when text and image are interpreted together. In such cases, toxic content may be undetectable when each element is viewed in isolation (Lu et al., 2024). For example, a hateful message embedded in a seemingly benign image (e.g. a cute animal) may only emerge when paired with dehumanizing language in the accompanying text. While fusion-based machine learning models have made some progress, MLLMs show greater potential in jointly interpreting textual and visual content, thereby improving moderation efficacy (Huang et al., 2024; Ji et al., 2023). In addition to cross-modal toxicity, existing research on toxic visual content underscores how interpreting hate-related symbols, memes, and visual cues requires nuanced cultural and contextual understanding (Hee et al., 2024). This issue further underscores the need to critically reflect on current MLLM research, which remains largely shaped by technological logics, value systems, and training data rooted in Western and English-language contexts (Kalloniatis and Adamidi, 2025; Ren et al., 2024). Such Western-centric bias limits the applicability of existing models in diverse cultural settings, increasing the risk of mislabelling or overlooking harmful content in non-Western contexts. What constitutes hate or harm is often culturally specific, and models that lack contextual sensitivity may fail to recognize or accurately interpret regionally embedded expressions of toxicity (Jahan and Oussalah, 2023; Sheth et al., 2022).
Meanwhile, LLMs used for content moderation can be highly brittle, as subtle changes in prompt structure can lead to substantial variations in models’ performance (Wei et al., 2022; Savelka et al., 2023). Masud et al. (2024) found that LLMs are sensitive to geographical signals, pseudo-voting values and persona cues. Similar to findings from prior research on automated content moderation (Dias Oliva et al., 2021), as discussed in the previous section, studies on the application of LLMs in content moderation suggest that these models can have the tendency to over-label content as problematic or recommend its removal (Li et al., 2024; Vargas Penagos, 2024). One important factor contributing to LLMs’ over-blocking behaviour, as shown in prior research, is their inability to accurately interpret triggering language (e.g. profanity and slurs) and stereotypes when such language appears in neutral or positive contexts (Kumar et al., 2024).
Research gaps and research questions
The current research on hate speech moderation on social media platforms reveals several significant gaps that need to be addressed. First, the existing body of scholarship primarily focuses on English-speaking and Western cultural contexts, creating a pressing need for studies that explore new opportunities and challenges associated with automated hate speech detection technologies in diverse linguistic and cultural settings. Second, the complexity of this task is further exacerbated by the multi-modality of contemporary communication on social media. While existing research on hate speech detection has predominantly concentrated on textual content, research concerning multi-modal content such as image memes, especially on platforms like Instagram that integrate both visual and textual elements, remains largely understudied. Third, from a methodological viewpoint, the latest advances in LLMs show potential in handling multilingual and multi-modal hate speech but also urge new critical research. For instance, the critical scholarship of content moderation needs to be expanded to interrogate new opportunities and risks associated with LLM-based methods.
To address these gaps and broaden the scope of existing scholarship, the current study focuses on multi-modal hate speech content circulated within Chinese-speaking communities on Instagram. The research critically examines the potential of applying cutting-edge MLLMs by asking: RQ1: How effective are MLLMs in detecting multi-modal hate speech content directed against mainland Chinese individuals in the Chinese language? RQ2: What factors contribute to the complexity of this task?
Methods
Data collection
This study focuses on intra-ethnic hate speech targeting Chinese nationals from mainland China on Instagram. To retrieve related data from Instagram, we employed a multi-step procedure. We conducted our data collection using a keyword-based hashtag approach, following a two-step snowballing methodology. In the initial step, the process began with a commonly used Sinophobic slur, #ZhinaPeople(#支那人). The derogatory and racist term ‘Zhina’ has historically been used to refer to ethnic Chinese people and has been specifically repurposed online to target mainland Chinese individuals (Huang, 2000). By examining co-occurring hashtags in Instagram posts featuring #ZhinaPeople, a list of 10 additional 3 candidate hashtags was identified. A total of 21,528 posts associated with these hashtags were collected using Zeeschuimer (Peeters, 2024). All of our data were collected on 25 October 2024.
In the second step, we conducted an audit to assess the suitability of the candidate hashtags and their associated posts. Exclusion criteria included: (1) false positives, where the content was unrelated to hate speech, (2) hashtags that introduced a significant amount of non-Chinese content and (3) hashtags associated with spam, such as posts advertising VPN services. Following this process, we selected five hashtags for our analysis: #ZhinaPeople (#支那人), #InsultingChina (traditional Chinese: #辱華), #InsultingChina (homophone: #乳滑), #InsultingChina (simplified Chinese: #辱华) and #StrongCountryPeople (a sarcastic term referring to Chinese nationals: #強國人). Subsequently, all video content was excluded, resulting in a dataset of 2863 images (see Table 1 for the distribution of data across hashtags). In the final step, non-Chinese posts were removed to refine the dataset further. Figure 1 illustrates the dataset preparation process.

Procedures for dataset creation.
Data distribution across five hashtags.
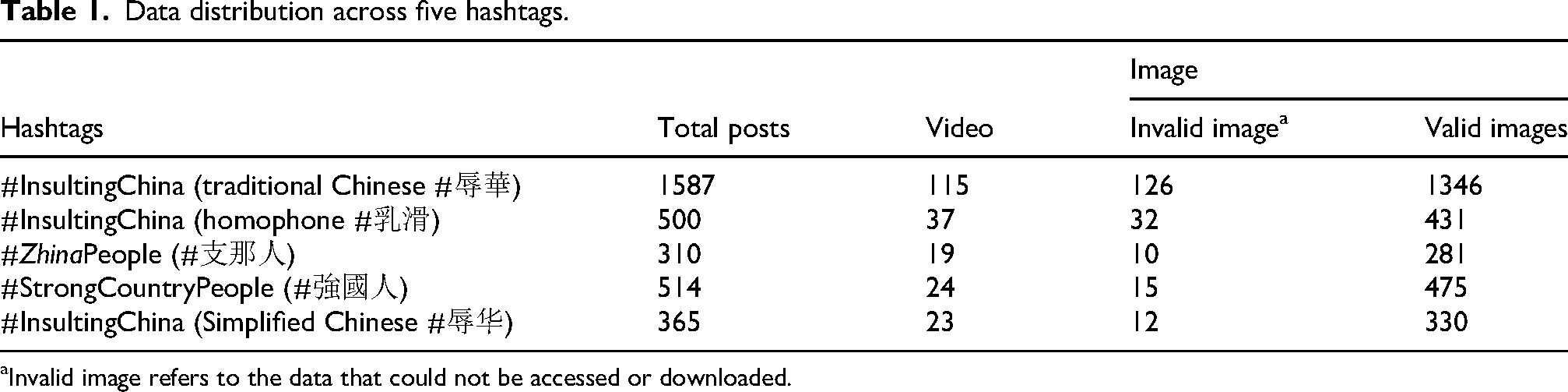
Invalid image refers to the data that could not be accessed or downloaded.
Expert annotation
The expert annotation process for hate speech classification involved two trained graduate students with expertise in social science and Chinese languages. To prepare, and calibrate the expert ratings, the annotation was conducted in three iterative rounds. In the piloting stage, both annotators thoroughly reviewed the hate speech descriptions provided in Meta's hate speech documentation 4 and a codebook prepared by the senior authors. 5 They subsequently annotated a randomly selected set of 200 images from the dataset using the labels: ‘hate speech’, ‘not hate speech’ and ‘hard to say’. This exercise allowed them to familiarize themselves with the annotation task and identify potential disparities in interpretation. During the calibration phase, the annotators engaged in discussions and reconciliations with the senior authors to address inconsistencies and refine the annotation guidelines (McDonald et al., 2019). In the second phase, following calibration, the annotators independently classified all 2863 posts. When selecting the label ‘hate speech’, they also provided rationales for their classifications. A Krippendorff's alpha of 0.78 (Hayes and Krippendorff, 2007) was achieved, indicating a high level of consistency between the two expert annotators. In the final phase, any remaining disparities in labelling were discussed and resolved, resulting in a final dataset used as the gold standard. This iterative and collaborative coding process ensures consistency and reliability in hate speech annotation.
Models and prompt
The present research selected GPT-4o-mini (OpenAI et al., 2024) and Gemini-1.5-flash (Gemini Team et al., 2024) as the MLLMs because of their distinct features and state-of-the-art capabilities. GPT-4o is renowned for its advanced complex text processing ability (Thelwall, 2024). Gemini-1.5, a leading model in multi-modal integration, is designed to handle complex tasks involving both text and visual inputs (Islam and Ahmed, 2024). These models can provide a balanced comparison of linguistic and multi-modal capabilities in hate speech detection, especially in a cross-cultural context. Hereafter, we refer to these models as GPT and Gemini for simplicity.
We also tested two open-source models from Meta and the Chinese company Alibaba, but we found them unsuitable due to their limitations in handling Chinese language and the sensitive nature of the research topic. 6 One important parameter to configure for both MLLMs is temperature, which controls the level of randomness in the model's output. Lower temperature values produce more deterministic responses, while higher values result in more creative and unpredictable text. We set the temperature of both GPT and Gemini to 0 to ensure output stability and minimize variability in the generated responses. 7
Prompt engineering is a critical component in the effective use of LLMs. To construct our prompts, we adopted a structured format based on the approach proposed by Marvin et al. (2024). As shown in Figure 2, the system prompt included a definition of hate speech derived from Meta's official content moderation guidelines and instructed the models to consider both image and text inputs during the annotation process. The instructions provided to the MLLMs were equivalent in content to those given to human annotators, ensuring consistency across both human and machine evaluation. Image inputs were formatted and processed according to the specifications outlined in the model documentation (Google, 2025; OpenAI, 2025). Additionally, we specified the desired output structure (i.e. json) to ensure consistency and clarity in the results. Finally, we prohibit LLMs from generating uninformative responses, such as ‘none’ or similar placeholders (Zheng et al., 2024), to prevent invalid answers that are difficult to evaluate.

System prompt designed.
Qualitative error analysis
Using expert annotations as the gold standard, we assessed the performance of the GPT and Gemini models and identified two types of common errors for qualitative analysis: over-estimation of hate speech and under-estimation of hate speech. These errors are categorized in the confusion matrix shown below (Giorgi et al., 2024). As shown in Figure 3, the confusion matrix compares the classifications made by the model against those provided by experts. The rows represent the expert labels, which are divided into three categories: ‘not hate-speech’, ‘hard to say’ and ‘hate-speech’. The columns correspond to the model's predictions, which are categorized in the same way. Each cell in the matrix represents a specific combination of expert labels and model predictions. For instance, red cells labelled as ‘over-estimate’ indicate instances where the model shows higher tendency to label content as hate speech (i.e., predicting hate-speech when the expert labelled it as ‘not hate-speech’ or ‘hard to say’) in comparison to our golden standard. Conversely, green cells labelled as ‘under-estimate’ represent cases where the model shows a tendency to overlook hate speech (i.e. predicting ‘not hate-speech’ when the expert labelled it as ‘hate-speech’ or ‘hard to say’).

Error categorization for qualitative analysis.
Based on the matrix, four groups of sub samples were extracted: GPT over-estimation, GPT under-estimation, Gemini over-estimation, and Gemini under-estimation. For categories containing over 300 instances, a saturation sampling strategy (Saunders et al., 2018) was applied to ensure a representative subsample was selected for qualitative analysis while avoiding redundancy. The qualitative analysis followed an inductive grounded-theory approach and was conducted collaboratively by two senior authors who were not directly involved in the annotation process to maintain impartiality. This process involved a detailed review of the annotation explanations provided by both expert annotators and the models, with a focus on the rationale for the assigned labels. Ambiguities or inconsistencies in the explanations were further clarified through interviews with the expert annotators (Ljubešić et al., 2023). This systematic approach allowed us to identify recurring patterns and contextual factors contributing to model errors, such as ambiguous language, cultural nuances and missing contextual information. Figure 4 illustrates the complete workflow for this research.

Workflow of data preparation and analysis.
Findings
Quantitative results
To evaluate the performance of Gemini and GPT in detecting hate speech against mainland Chinese individuals, the models’ classification results were compared with expert annotations. Overall, both GPT and Gemini exhibit substantial limitations in distinguishing hate speech from non-hate speech, characterized by a pronounced tendency towards over-estimation. Figure 5 illustrates the normalized confusion matrices for both models. GPT, in particular, demonstrates a high over-estimation rate, with 61% of instances incorrectly labelled as ‘hate speech’ despite being classified as ‘not hate speech’ by expert annotators. Similarly, Gemini misclassified 49% of ‘not hate speech’ instances as ‘hate speech’, although it displays slightly better balance compared to GPT. While both achieve limited success in correctly identifying ‘hate speech’ (5% for GPT and 3% for Gemini), their over-estimation tendencies and inability to accurately address nuanced or borderline cases highlight significant weaknesses in their contextual understanding and multi-modal assessment of hate speech.

Comparison of GPT and Gemini predictions against expert annotations.
In our analysis of each hashtag sub-dataset, as illustrated in Figure 6, both models consistently over-estimated instances of hate speech compared to expert annotations. This over-estimation tendency was especially pronounced in three hashtags associated with the phrase ‘insulting China’. Statistical tests further confirmed significant variations in the models’ over-estimation tendencies across different hashtags. The Chi-square results revealed that Gemini's over-estimation rates (χ2 = 251.92, p < 0.0001) and GPT's over-estimation rates (χ2 = 157.25, p < 0.0001) were substantially influenced by the specific contexts of the hashtags. Furthermore, when comparing the two models, GPT exhibited a greater overall propensity for over-estimation than Gemini across all five hashtags analysed.

Distribution of three labels across five subsets.
Qualitative results
Qualitative analysis was conducted to examine two types of errors in model predictions: over-estimating hate speech and under-estimating hate speech. The distribution of observations across these categories is visualized in the confusion matrix shown in Figure 2 (Giorgi et al., 2024). The confusion matrix illustrates the performance of GPT- and Gemini-based models in classifying text as ‘not hate-speech’, ‘hard to say’ or ‘hate-speech’, with rows representing expert labels and columns representing model predictions. Colour coding highlights model performance: green cells represent agreement between the model and expert labels, red cells indicate models’ over-estimation (e.g. predicting ‘hate-speech’ for instances labelled as ‘not hate-speech’), and purple cells indicate models’ under-estimation (e.g. predicting ‘hard to say’ for instances labelled as ‘hate-speech’) (Figure 7).

Confusion matrices of under- and over-estimation in GPT and Gemini predictions.
As mentioned in the previous section as well as shown in Figure 7, for both models’ over-estimation of hate speech (GPT: 1980; Gemini: 1746) is far more common than under-estimation (GPT: 9, Gemini 98). Following the methods described in the Qualitative error analysis section, key factors contributing to the over-estimation of hate speech by the MML include: (1) failure to triangulate imagery and textual content to contextualize the post accurately; (2) an overemphasis on textual elements; (3) hallucination or far-fetched interpretations and (4) an inability to understand humour, particularly when sarcasm or satire is present.
Over-estimation
First, the MMLs often struggle to effectively integrate visual and textual information, resulting in difficulties in contextualizing content. For instance, posts featuring neutral or non-hostile imagery paired with text that appears aggressive when taken out of context are frequently flagged as hate speech. Conversely, an image may be misinterpreted outside the context of its accompanying caption, leading to its mislabelling as hate speech due to potentially provocative visuals. Examples of this issue can be observed in GPT and Gemini's annotations in example A, as well as GPT's annotation in example C, in Figure 8. In both cases, the models mislabelled non-hate speech political satire as hate speech. In example A, Gemini classified a meme as hate speech solely due to the presence of the phrase ‘insulting China’, without considering the broader visual context. Similarly, in example C, GPT misclassified a cartoon mocking political brainwashing by the Communist Party of China as hate speech due to the presence of the derogatory slang NMSL. 8 These cases demonstrate that the models overlooked the visual context of the Instagram posts and instead relied solely on the textual caption, leading to misclassification.

Examples of ‘over-moderated’ category.
Second, hallucination, or far-fetched interpretation, is another factor contributing to the over-estimation of hate speech. The model can assign unwarranted meanings to posts, falsely attributing hate intent. This issue arises from an over-interpretation of the content, where the model extrapolates meanings to align with the provided definition of hate speech. For instance, Gemini's explanations in examples B and C (Figure 8) illustrate clear cases of hallucination. In example B, a meme template featuring a couple in a counselling session is repurposed as political satire commenting on freedom of speech in China. However, the Gemini model hallucinates an incorrect interpretation, falsely classifying it as hate speech for supposedly promoting the stereotype that Chinese women are victims of state control – an inference not supported by the image or text.
Under-estimation
Mislabelling hate speech content as ‘non-hate speech’ or ‘hard to say’ was relatively rare in the two models we tested. However, despite its lower frequency, the qualitative analysis of factors contributing to Gemini and GPT's failure to recognize hate speech provides valuable insights into the models’ limitations, particularly in detecting subtle contextual and cultural cues.
An important factor contributing to the under-estimation of hate speech is the lack of linguistic and cultural insights. For example, in Figure 9, a post-dehumanizing mainland Chinese people by visually and textually referring to them as ‘locusts’ – a term commonly used in Hong Kong as a derogatory slur for mainlanders – was misclassified. Both models failed to recognize the harmful intent of this slur. It is worth mentioning that although Gemini classified this post as hate speech, the reasoning provided was based on hallucination and misinterpretation of the image, rather than an accurate understanding of the language and visuals used.

Examples of ‘under-moderated’ by GPT (original post in Chinese).
Another issue revealed by the qualitative analysis is Gemini's inconsistency in incorporating text input into its judgements. Figure 10 illustrates three instances where Gemini misclassified hate speech as non-hate speech. In all three cases, the posts contained hate speech-related language explicitly targeting mainland Chinese people, such as characterizing them as an inferior race or making generalized derogatory claims about their intelligence. However, Gemini based its judgement solely on the benign visual content of the posts, disregarding the accompanying textual input. This oversight highlights a critical limitation in Gemini's ability to produce consistent performance in making judgement when reading images in combination with their associated posts.

Examples of Gemini under-moderate.
Discussion and conclusion
The investigation into GPT's and Gemini's effectiveness in detecting multi-modal hate speech targeting mainland Chinese individuals (RQ1) highlights the limitations of state-of-the-art LLMs, despite the strong benchmark performance reported in prior research. Van and Wu (2023) demonstrated that a 13B-parameter LLaVA model with zero-shot prompting achieved 62.5% accuracy on the Hateful Memes Challenge (Kiela et al., 2020) seen test set, outperforming ViLBERT (62.3%) and substantially surpassing ResNet-based baselines (52%). In addition, Lin et al. (2024) employed an LLM-based approach that improved upon the best non-LLM baselines by 3.24%, 2.46% and 3.71% in Macro-F1 score on the Harm-C (Pramanick et al., 2021a), Harm-P (Pramanick et al., 2021b) and Hateful Memes Challenge datasets, respectively. However, it is important to note that these benchmarks are all based on English data and predominantly reflect Western cultural contexts. Taken together, advances reported in earlier work on LLM-based hate speech detection should be scrutinized across diverse linguistic and cultural contexts.
As shown in the quantitative results, both state-of-the-art models, from OpenAI and Google, exhibit a persistent tendency toward over-estimation, consistent with prior research documenting algorithmic limitations in hate speech detection (Zhang et al. 2024; Dias Oliva et al., 2021). This over-estimation poses risks of over-moderation when integrated into platform content moderation pipelines, potentially exacerbating inequality and marginalization of non-dominant language users on social media (Franco et al., 2024). While zero-shot classification has shown promise in detecting problematic content in earlier studies, our findings reveal its inadequacies in non-English and multi-modal contexts. Without cultural and contextual adaptations, zero-shot approaches fail to address the nuanced demands of hate speech detection in diverse linguistic and cultural settings.
To answer RQ2, we conducted a qualitative error analysis to uncover key factors contributing to discrepancies between models’ and expert’ annotation. Our study highlights challenges in detecting hate speech embedded in culturally specific derogatory language, such as slurs targeting mainland Chinese individuals. Consistent with prior studies on harmful Chinese meme content (Lu et al., 2024), our findings show that textual toxicity in Chinese often relies on slang, homophony and linguistic wordplay. Despite their advanced linguistic capabilities, MLLMs struggle with cultural adaptability, limiting their ability to interpret complex harmful linguistic practices. This aligns with multilingual hate speech research emphasizing the need for culturally aligned training data (Masud et al., 2024).
Another prominent issue is the models’ intrinsic susceptibility to hallucination – generating erroneous outputs by extrapolating unwarranted meanings from content. This not only undermines accurate hate speech detection but also exposes the models’ limited grounding in factual and contextual understanding. Humour, particularly in the form of sarcasm and satire, further complicates this task. Such expressions often rely on subtle cues, linguistic nuances, and shared cultural or political knowledge (Godioli et al., 2022). As previously discussed, AI-driven content moderation systems frequently struggle to interpret these complexities (Dias Oliva et al., 2021), leading to the misclassification of ironic or satirical content as hate speech. Our own findings confirm this tendency: models often failed to detect the humorous or satirical intent of posts aimed at politics. Instead, they hallucinated hostile meaning and incorrectly labelled the content based solely on surface-level textual features.
Furthermore, both models often fail to effectively integrate textual and visual cues. These shortcomings are consistent with existing literature on multi-modal machine learning, which emphasizes that inadequate contextual awareness often leads to misinterpretation of complex multi-modal signals (Dutta and Bhattacharyya, 2022; Salini an HariKiran, 2023). In visual social media content, including image memes, humour and sarcasm are conveyed through the integration of dual modalities – visual and textual. Detecting the cross-modal contextualization of online content is therefore crucial for MLLMs in recognizing nuanced communicative forms such as sarcasm and humour. However, as demonstrated in this study and prior research (Lu et al., 2024), MLLMs often struggle to balance and align the meaning of textual and visual elements, leading to misinterpretations. Given that leading LLMs struggle to detect humour, sarcasm or irony in text alone (Yadav et al., 2024), MLLMs still have a long way to go in understanding nuanced meaning that arises only through the interplay of text and visuals in cross-modal or multi-modal contexts.
Future research should prioritize more effective multi-modal integration to better analyse cross-modal intertextuality between text and visuals. There is also a pressing need to develop culturally attuned moderation models that move beyond surface-level linguistic coverage and incorporate deeper contextual and sociopolitical awareness. This includes not only training on more culturally diverse and representative datasets – featuring varied linguistic practices and visual grammars – but also aligning model values with non-Western cultural norms.
Finally, this study sheds light on systemic inequities within content moderation practices on social media platforms. As mentioned earlier, the limited moderation of hate speech targeting mainland Chinese individuals can partially be attributed to market considerations, as platforms like Instagram do not officially operate in mainland China. This neglect not only fosters polarization and toxicity within Chinese-language content but also alienates diaspora mainland Chinese communities by perpetuating exclusion and hostility. More broadly, our findings underscore that platform's decision about which markets to prioritize, which languages to resource, and which communities to safeguard are not merely technical questions, but reflect platforms’ political economies. By foregrounding how uses of LLMs in moderation risks reproducing or intensifying inequities, our study provides important empirical evidence that advances platform studies debates on automated governance and its consequences for fairness and justice.
Footnotes
Funding
The authors received financial support for the research, authorship, and/or publication of this article. Ariadna Matamoros-Fernández received funding from the Australian Research Council under the DECRA scheme (grant: DE230101558) to participate in this research.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.