
Abstract
The financial applications of data technology have enabled the rise of Chinese fintech industries. As part of people's everyday lives, fintech apps have helped companies collect vast amounts of user data for business profit and social good. This paper takes an open-systems approach to study the constructs of this emerging idea of data governance, particularly its operational logic, involved stakeholders, and socio-cultural consequences in the context of fintech industries in China. It asserts that data governance at the company level has been realized through three types of tasks: standardization, configuration, and monetization of big data. These tasks are oriented by the imperative of business innovation which is considered pivotal for the company to survive the competition. An ensemble of internal and external actors joined the governing process, but internal actors hold the stake. The goal of innovation drives the companies to speedily collect data from a wider variety of sources, thus having to establish more sophisticated systems to manage and utilize those data. These complicated systems, however, have urged the government to strengthen regulatory controls alongside the general support of business innovation. This study unveils the performative aspects of big-data-based innovation at fintech firms. It also helps to understand the pathology of the innovation-governance paradox shared in the data economy in the global context.
This article is a part of special theme on Social Data Governance. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/socialdatagovernance
Introduction
The popular refrain of “data is the new oil” (The Economist, 2017) is usually underpinned by two contending logics. On the one hand, data algorithms have enabled new products and services that benefit users and profit startup businesses. Big data is thus considered the most valuable resource for business innovation. On the other hand, big data applications are considered threatening to the regulatory system when big techs monopolize data resources (Brevini and Pasquale, 2020; Campolo and Crawford, 2020). These beliefs lead to two contrasting attitudes toward the development of data technologies—one advocates marketization and liberalization, and the other advocates government control of data practices. While new resources are much needed to create business opportunities and boost the economy, particularly against the post-2008 economic downturn and the catastrophic impact of the pandemic, the question of how to deal with the innovation-regulation paradox has centered the debate between innovators and regulators.
Being one of the most data-driven industries, fintech companies in China well exemplify the values and challenges embedded in data governance. Leading companies, such as Ant Financial and Tencent Finance, are considered the most valuable companies in the 2020 investment market (Statista, 2020). They have also played a significant role in social governance projects, such as contact tracing for COVID-19 pandemic control (Huang et al., 2020) and social credit scoring (Liu, 2019). Their increasing capacity in data collection, processing, and computing undergirds the economic significance and social impact of these fintech companies. However, in March 2020, the State Council announced that big data is also a market factor as important as the other factors, such as land, labor, and capital; thus, it requires the plan and allocation by the government (Xinhua News, 2020). The announcement signifies the state's intervention in data governance work which used to be solely managed by companies. It was then followed by several regulative policies, including The Data Security Law (Xinhua News, 2021). Measures for Determining the Illegal Collection and Use of Personal Information by Apps (Cyberspace Administration of China, 2021), Personal Financial Information Protection Technical Specification (CFTSC, 2020), and the Amendment to The Anti-Trust Law (National People's Congress, 2022). These socio-technological changes have enriched the meanings of data governance, also known as shuju zhili 数据治理 by turning a market-oriented tech domain into a socio-political project that blurred the line between the state and market.
Data governance has been critically analyzed in various contexts, such as insurance (McFall et al., 2020), higher education (Whitman, 2020), municipal governance (e.g. Currie, 2020), and healthcare (e.g. Cruz, 2020). Despite the diversity of contexts, the research on data governance all focuses on how it affects the public interest. Theoretically, they speak to the study of citizenship, social classification, surveillance, and privacy protection. For companies, these issues fall in the category of corporate responsibilities which in practice often subordinate to business development imperative. As of implications, critical studies of big data have drawn more attention from the government than companies.
However, the private sector still plays the primary role in day-to-day data management and data governance at the company level. Taking the corporate perspective, as opposed to the public or governmental standpoint, this paper contributes to critical data studies (Iliadis and Russo, 2016) by connecting the studies of performativity economy (Berndt et al., 2020) in the context of data capitalism (Sadowski, 2019) with an open-systems approach to innovation. It reveals the performative nature of data-based innovation in China's fintech industries, a business domain widely considered to lead the global fashion in innovation. Based on interviews with the data governance managers and staff in fintech companies of various corporate structures, this research studies the data governance mechanisms—specifically, what does data governance mean to them, what has been done by whom, and for what purposes. This corporative perspective is chosen based on the belief that only when companies realize the problems embedded in their data-driven innovation can a responsible mode of data governance be developed and benefit sustainable economic growth and public interest.
Literature review
Taking data governance as part of the corporate governance work, this paper primarily speaks to the social studies of data management and monetization. It also relates to research in digital governance since corporate-owned data are increasingly used in social governance projects. This section briefly reviews the relevant literature in the two areas, with a focus on how behavior data and its value have been defined in various ways and the social consequences of these contrasting definitions.
An open-systems approach to data governance
Data technologies have reshaped labor structure (e.g. Burrell and Fourcade, 2021) and means of production (e.g. Son, 2017) in the business arena. Companies increasingly rely on algorithms to make decisions regarding hiring, product design, and user insights. These shifts shed light on the open-systems approach to corporate governance (e.g. Aguilera et al., 2019; Scott, 2003) and the increasingly sophisticated environment for managers and executives in the context of globalization (Aguilera and Jackson, 2003) and digitalization (Filatotchev et al., 2020). Rooted in institutional theory in organizational sociology, the open-systems approach challenges the closed-systems assumption (Thompson, 2003) which takes the shareholder-manager relation within a company as key to successful management. In contrast, the open-systems approach believes that a good corporate governance case should consider a more comprehensive set of stakeholders and institutional settings.
In the 2010s, such a strategic turn in corporate governance ran into the rise of big data technologies and was followed by a shared belief in data assets—taking big data as a form of company property for sustainable development (Ciuriak, 2018; Short and Todd, 2017). The digital transformation invites a transition to long-term strategic plans to maintain and grow users, get support from internal stakeholders, external policymakers, and regulators, and assess the external risks, rather than only focusing on financial controls within the firm's governance mechanism. The conjuncture of the open-systems approach and the ideology of data assets demonstrates that the accumulation, collection, and valuation of a company's data assets is a social process driven by and serves the interests of a set of internal and external stakeholders.
In business practices, these stakeholders include but does not limit to investment banks, market research companies, corporate management, product managers, software users, and regulators (Birch et al., 2021). These key players have agreed upon the 3V vectors—volume, variety, and velocity (Laney, 2001), or later on 7V (McNulty, 2014)—adding variability, veracity, visualization, and value to the 3V metrics in gauging the value of data assets. Corresponding to the investment capital's expectations, corporate executives and product managers strive to increase the value of their data assets by expanding the scope of data sources and diversifying the data categories. Various types of data are sorted and processed by a broad spectrum of actors for multiple ends. In addition to the “personal data” or demographic attributes submitted by users, “behavior data” (Tanninen, 2020; Jeanningros, 2020) are also utilized to help capture the consumption habits and lifestyles of the consumers or users. Furthermore, product managers and software engineers have invented the “tech craft” strategies (Birch et al., 2021) to turn the users measurable and users’ engagement accessible. Similarly, behavior data are turned into “branded behaviors,” which help valorize and increase the data assets (Jeanningros, 2020). In recent years, data collection has been turning to social sources further to business and commercial settings. Also, social-behavior-based new analytical tools are used to process these data, including geospatial analysis, sentiment analysis, influence analysis, brand affinity text analytics, and so on (Krishnan and Rogers, 2015).
The open-systems approach helps to identify the stakeholders and how they define big data practices at the company level. It also helps to explain the shift from “data management” (Ladley, 2019) to data governance—the former is a set of administrative or instrumental work looked after by the data engineers and being part of a particular technical or business task. In contrast, the latter involves an ensemble of investment capital, management, and professionals who collectively define the design of data infrastructure, the scope of data collection, and the utilization of the collected data. Such a shift signifies that data practices at tech companies have become an integrated part of data marketization in the digital economy. Data as a device, together with the organizational and external stakeholders, has been constructing a new market in which the value of data could be extracted and accumulated for the companies’ sustainable development (Sadowski, 2019). Given the growing social and spatial complexity of production, distribution, and consumption in the digital age, the stakeholders have to opt for more indirect and flexible governance models for data work.
The involvement of a wider variety of stakeholders has transformed the tech-companies' data work into a socio-economic domain. Data governance at the company level is designed and operated to serve the formation and expansion of the “market”—the collective of investment capital, evaluation agencies, tech firms, and the data subjects. Such a market is not a free-standing entity organically growing from the deals between buyers and sellers. Rather, the stakeholders elaborately constructed it based on the performative valuation of data assets, and “data is now governed as an engine of growth” (Sadowski, 2019, 2020).
Data governance in financial industries
Algorithmic techniques took off in the 1980s when data technologies started being implemented in finance (MacKenzie, 2018). Specialists in big data joined the financial industries and became indispensable for financial companies’ evolvement. While data management has contributed to a more efficient and inclusive financial system (Kshetri, 2021), there are also critical voices pointing to the problems embedded in data-driven finance, particularly informational bias and inequality (Pasquale, 2015) and manipulated simplicity (Hansen, 2020). Literature on data and finance has focused on the sector of traditional finance, particularly banking industries. The fintech business, a confluence of big data technology and financial capital flows and a rich area for critical data studies, is yet much understudied.
Leading the global innovative fashion, the fintech sector in China provides a large empirical ground for us to theorize the constructs of data governance and fill the gap. In China, datafication of financial businesses started in the early 2000s when the leading commercial banks, such as ICBC began to invest in their information management divisions heavily (Wang and Sinnreich, 2017). A decade later, endorsed by the government's marketization and modernization campaign in the finance sector, fintech companies started to lead the financial innovation until the mainstream banks began integrating data technologies into traditional financial services (Wang, 2018). In this process, data technology has been considered a game-changer in China's financial innovation. Data governance at fintech companies enables the provision of faster and more convenient financial services, including payment, loans, and investment, to a larger public. In the meantime, data governance has enabled the platform mechanisms through which tech companies strive to be evergreen amid the severe competition (Langley and Leyshon, 2021; Wang and Doan, 2018).
Data governance as statecraft
The refined and enlarging data governance by tech companies has raised the influence of big data in the public sector. Increasingly more governments believe in data's power in legislative, judicial, and executive functions (Thompson et al., 2015) and have started to adopt the “actuarial approach to governance” (Burrell and Fourcade, 2021). Algorithmic modes of thinking have been popular among the consortium of firms and governments (Bouk, 2015; Coletta and Kitchin, 2017; Lauer, 2020). Companies and governments collaborated to develop scoring systems to improve financial behavior and social morals (Ahmed, 2019; Liu, 2019). In these research works, data governance is not only a business project driven by corporate-dominated commercial dynamics but also utilizable for social governance.
In sum, the three groups of literature stress the role of data governance in enabling innovation both in business development and social governance. They unfold the essence of the tech companies’ big data practices from different perspectives but come together on the idea of performativity. Along with the advancement of data technologies, a wider variety of stakeholders have invented new management modes, novel products and services, and new institutions or policies under the banner of innovation. Nevertheless, innovation-oriented data governance is ubiquitous but highly performative. It reflects and reinforces the production logic and power relations constitutive of data capitalism and the embedded state-market relations.
Methods
Data governance is a relatively new idea in academic research and industry practices, not to mention its implications in emerging business categories, such as fintech. Thus, this research starts with case studies and takes a grounded approach to identify the relevant constructs. The grounded approach aligns with the goal of situating data governance as part of the open-systems corporate management. This approach also helps to identify a future research agenda. To avoid the homogeneity of big corporations, this research chose a commercial bank that the state holds the major shares. 1 (as BNK in below case analyses), a private fintech company headquartered in Shanghai and focused on digital/mobile payment 2 (FIN), and a fintech company founded by a state-controlled bank but operated as an independent market entity 3 (B-F). The three cases could be too limited to represent the whole map of data governance in fintech industries. However, they serve as a valuable start to ground further research generalizable in a larger context.
The three cases are chosen to reflect data governance practices in various types of fintech companies. Upon the company visits, the interviewees were categorized by three management levels: data governance (as DG in below case analyses) staff, DG managers, and company executives, and the questions asked accordingly are listed in Appendix 1. The interviews evaluated both their understandings and practices of data governance, focusing on what “data governance” means for a fintech business? How is data governance operationalized through development strategies, management rules, and everyday work? Upon each case, these inquiries have been translated into a set of practical questions (see Appendix 1). In the interviews, respondents were also asked about their awareness of the relevant policies and regulations. See Appendix 2 for the list of questions and how such awareness is measured broadly.
Understandings and mechanisms of data governance work
This section maps out the findings from the interviews and participatory observation at the three companies. It demonstrates how data governance has been considered and operated in various types of fintech businesses and also at different management levels. Underpinned by the open-systems approach which highlight the role of stakeholders, and critical data studies which take data as an emerging form of capital or assets for value extraction, the case studies in this section hinge on three foci: definitions of data governance work generated by the workers and executives at various management levels; mechanisms and techniques of data governance work; and the awareness of data-related policies by the workers and executives at various management levels.
The Data Management Center (DMC) in Case BNK was established in 2019, further to the Guidelines for Data Governance at Banking and Financial Institutions announced by the Chinese Banking and Insurance Regulatory Commission in May 2018. The Center has more than 120 staff against the total employees of around 90,000 at the Bank. In March 2020, the Center was merged into the Department of Financial Technologies, along with the Data Station, Software Development Center, and the Bank's Research Institute for Fintech Innovation. Most of the DMC's employees hold a graduate degree and a background in computer science, finance and business, or marketing. The Center has four major divisions: Data Infrastructure, Big Data Analyses, External Data Usage, Retail & Marketing Business, each focusing on one particular sector of data management work. The organizational structure of the data management work in Case FIN is very similar to that of Cast BNK but with some very meaningful variations. The company's Data Management Division has 30 plus Staff out of the around 1000 total employees. Most of the DG workers are experienced ETL engineers (extract-transform-load) and software development engineers who majored in statistics and computer science.
Definition of data governance by various levels of actors
Data governance has been comprehended and executed differently by the actors at various levels. The comprehension and practices also vary over companies of different company sizes and shareholder structures. As shown in Table 1, bank-affiliated DG staff have to deal with vast amount of data collected from a large scope of businesses, and their daily work is mostly “cleaning the dirty data”—making sure those data are imported in the centralized platform in unified format. In contrast, the fintech company is relatively new, and the data format was defined and inherited almost from the founding moment. For those DG staff in fintech companies, their daily work is mainly to support the business development department—to ensure the database runs smoothly and stably. In addition, they need to promptly respond to their colleagues in business development departments when they ask for a particular set of data.
Definition of data governance by the actors at various levels.
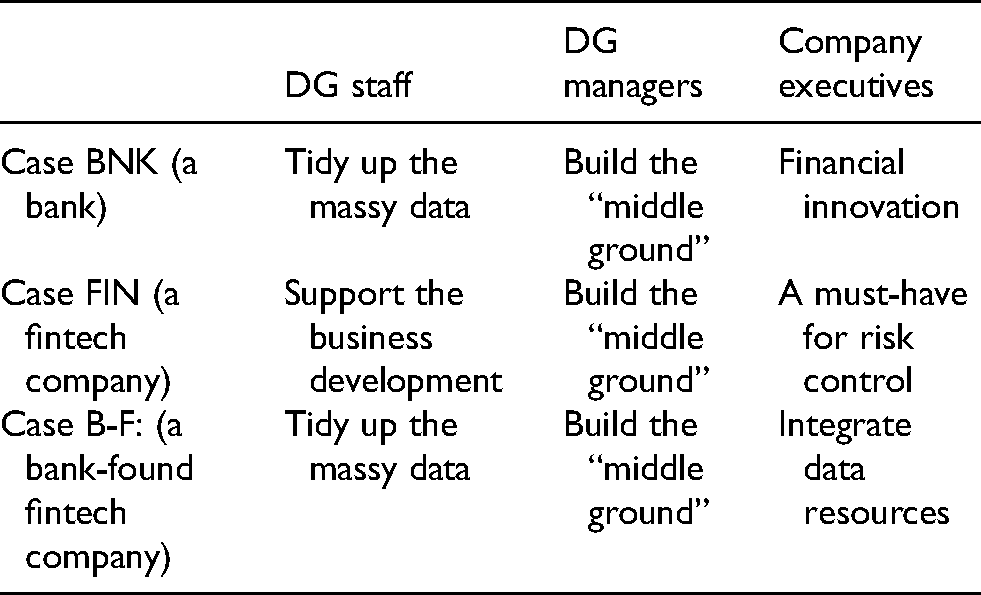
Surprisingly unanimous, the DG managers in three cases all consider the imperative of DG work is to build the “middle ground,” also known as zhongtai中台. In their understanding, the “middle ground” connects the “front end” (including the users’ interfaces, product designs, and service provisions) and the “back end” (the database, servers, and supporting software). The middle ground is also a channel run across various departments in which data can be collected and provided automatically, as opposed to counting on manual work to collect the patches department by department. If the personal power or inter-department relations used to affect whether the data are accessible, now the access to the middle ground is the key to get data.
At the executive level, the fintech company takes DG as instrumental and a must-have for risk control. As emerging financial service providers, fintech companies do not have as much data as the banks, thus have to ensure that data volume and quality can support the credit evaluation process, which often has a very high stake in a successful loan. In contrast, the interviewees at the bank and bank-subsidy did not show as much pressure as those in the fintech company. They consider DG a major dynamic for financial innovation and a motivation for the companies to integrate data from various resources.
Mechanisms and techniques of the data governance work
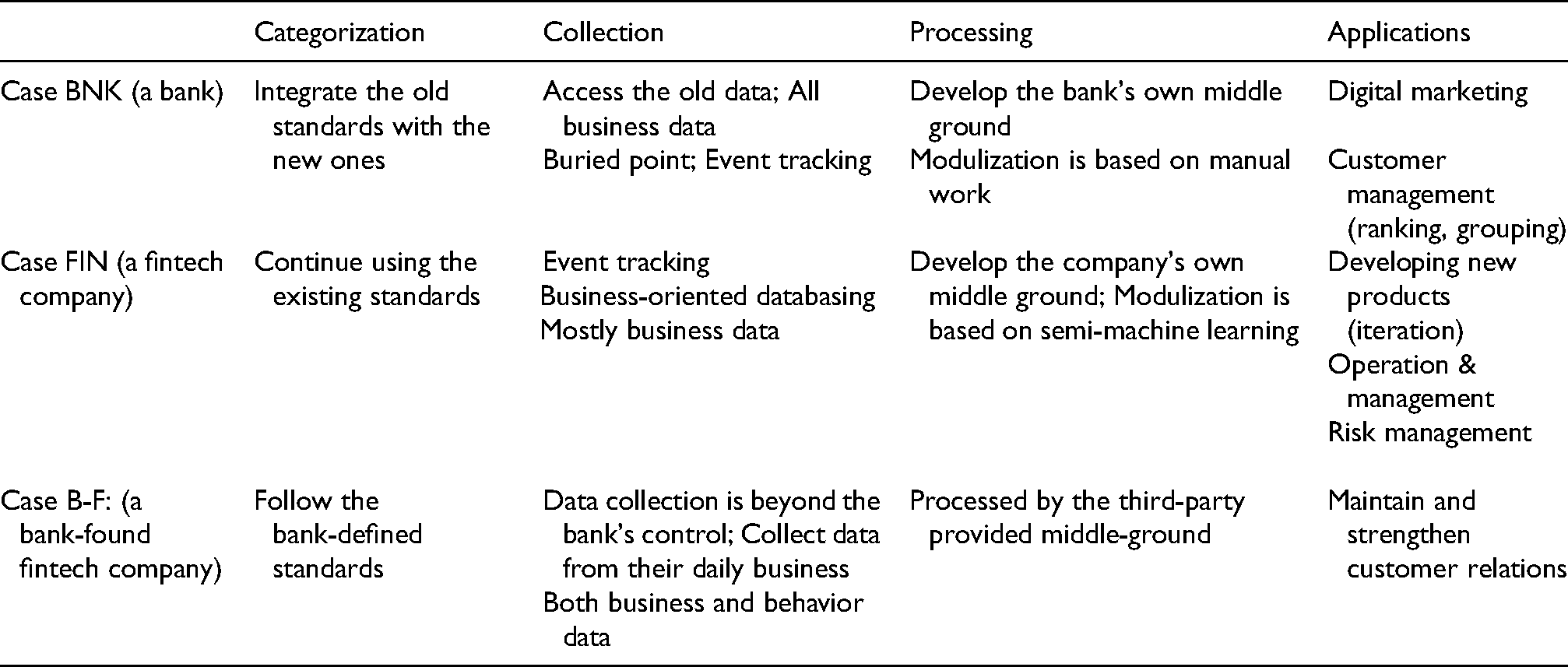
When it comes to the specific workflows, the data governance work is usually into four stages: categorization, collection, processing, and application. The three companies have many shared features but are also distinct for various purposes. Specifically, the three cases have some common technics and technologies, such as using buried point (aka, maidian 埋点) and event tracking for data collection. In the meantime, each of them has unique rationales in their DG work. DG workers in Case BNK needed to spend lots of time integrating the old data categories with the new ones. For example, the customers’ Income Segments have changed compared to the divisions that the bank defined five years ago (e.g. 5000–7500 RMB versus 6000–10K RMB). In order to merge the old data into the middle ground, the two sets of data have to be re-arranged. This kind of challenge doesn’t apply to the Case FIN. The fintech companies have been using the same set of labels since they started building the middle ground. In Case B-F, their data labels need to be consistent with the parent company's, but they don’t have the hassle of merging the old into the new. In this vein, the company with a longer history has to deal with much more work in order to make their data label consistent and get the value of old data realized.
The data processing at three companies are based on different mechanisms. In the Case BNK, the company develops its own middle ground using the software provided by the third party and heavily relies on manual work to develop tailored algorithmic models. The investment was high but has given the company more autonomy and flexibility. For example, on the self-owned risk management platform, the Bank could change the algorithm and customize credit evaluation metrics for investment products of different risk levels. Case FIN shows the highest level of intelligence since the middle ground is self-owned and more than half of the risk management modules are engendered by machine learning mechanisms. The interviewees stressed that they could largely rely on the machine because they were quite confident in the quality of the data. In the Case B-F, the data processing work is highly mechanical, though. The DG staffs have been using the third-party-provided software, DataStack, to import, run, and export data through intensive labor work.
When it comes to the applications, the Case FIN emphasized that data governance is crucial for many of their business divisions, including the design and development of new products, management of daily operations, as well as risk management. Yet, for Case BNK, data governance work mainly was for digital marketing—sending emails and messages based on the database of customers’ information, and customer management—data governance work helps to rank and group the customers so the business development managers have a better idea of the priorities of sales work, as well as which group of customer needs extra attention to hedge risks of default. The interviewees stressed that they had been “doing the same thing” (marketing and customer management) as before the Data Governance Division was established, but the information produced from the DG work had been a great add-on helping them sort the customer information.
Data processing mainly focuses on enabling two types of modules: the risk management model and the sales monitoring model. In the first set of modeling practices, data and algorithms are utilized to determine the risk levels of a new loan product/service. The models will also be used in underwriting processes, as well as in fraud detection. See Appendix 3 for the algorithmic mechanisms in risk management models.
One of the primary functions of the Data Infrastructure Division is to standardize the data collected and accumulated from various sources. A two-fold “caisson” logic is embedded in the standardizing process. First, it is a top-down order that all the bank branches and business units need to collect and label the data according to the same set of standards. Second, a database is constructed for a very specific purpose defined by a particular department, and irrelevant data won’t get collected in the database. This kind of logic, also known as the “silo system” in data science, makes data management neat and easy but also leads to the isolation between individual databases. The second set of models reflects whether sales (of loans) status, particularly on the information of what has been sold to whom, when, and through what platforms (is it online, over-the-counter, or through the agent). The algorithmic modeling ultimately serves risk management, digital marketing, and customer management. In recent years, algorithms are shifting from making decisions based on single-factor analyses to dual or even multiple factor analyses.
While more than half of the data are processed using machine-learning technologies, the data department is assigned to (1) construct a closed-loop for data collection; (2) clean data manually when machine cleaning does not suffice; (3) label and document semi-structured data. The company will purchase data from external sources when its database cannot provide information that is needed for hedging risks. For example, upon peer-to-peer lending businesses, the company will purchase social credit data from banks or credit scoring agencies. Yet, the entire p2p sector was shut down in October 2020 by the central bank and the police. Social credit data is no longer needed. Since then, the company has seldom turned to external data sources. Instead, it focuses on constructing the loop and collecting more data from the existing users.
Policy awareness at various levels
When it comes to regulatory adherence, all three companies mentioned that they’re kept updated with the policy changes, but mostly at the executive level. The interviewees answered a set of questions and got measured on their regulation and policy awareness. Several policies were brought up upon the interview, including Illicit Collection of Personal Information defined by the Cyberspace Administration of China (2021) and the Guideline for Financial Institutions’ Data Governance Work by the China Banking Regulatory Commission (2018) (see Appendix 2 for the specific questions and measurements). As demonstrated in Table 2, the executives at the three companies all showed a very strong sense of awareness of the latest regulations. Most of them met regulators very often and would participate in the conferences organized by the China Banking Regulatory Commission. DG managers in Case B and Case BF were aware of the relevant policies and regulations but did not take the responsibilities. They depended on the legal work department or the executives to ensure that the companies’ DG work abide by the new policies and regulations. In contrast, DG managers know very little about the relevant law and policies that fintech businesses are subject to. At the staff level, the bank sector seemed to have slight policy awareness, although they could not point out what specific policies their everyday work has to stick to. For DG staff in Case F and Case BF, DG work seemed purely technical and they assumed the “high management” or so-called gaoguan 高管 would take care of the regulatory or legal issues.
Regulation and policy awareness at various levels.

Discussion
The cases analyzed in this paper unfold three rationales embedded in the data governance work in fintech industries, including standardization, configuration, and monetization. This logic set is formed, recognized, and shared by the fintech managers, data professionals, and regulators in distinctive ways.
Standardization
Data governance is part of the standardizing work inherited from the era of enterprise information management (EIM). EIM in practice, is usually called data management, which refers to a disciplined, formal process to collect and manage data (Ladley, 2019). Data could be collected between teams, within companies, but also from the external. Regardless of the externality of data sources, the goal of data management is to form an integrated internal system that assures the various divisions in a company to work on the same set of standards for the collection and applications of information relevant to business growth. This legacy of standardization has been reinforced in the age of big data, especially in the collection and processing of non-structured or semi-structured data. Due to the high level of professionality, data governance work has been quite technical and mostly lead by IT professionals and specialists. This group of people are very capable in the execution of the top-down orders but lacks of critical thinking towards data governance. Some of the interviewees said, “my boss told me to do this; I then go ahead doing this.” When they were asked what would drive data governance as their daily work, many of them could not relate to the long-term vision but only focused on the designated assignment.
Configuration
In these analyzed cases, data governance has been part of the institutional configurations. Technically, data governance was also promoted to build a solid tech infrastructure, namely the “middle ground.” If data is relatively intangible, middle ground is much more concrete in terms of defining how data will be arranged and further utilized. For this reason, the mechanisms and technics (summarized in Table 3) have often been formalized as part of the companies’ institutions. Nevertheless, data governance has unique meanings for fintech companies of various natures. The distinctive essences of data governance are determined by what kind of data would be put in the middle ground—the central and sole data infrastructure of a company. Those companies who plan to build a giant apparatus would invest much more than those who are dealing with a limited amount of data. In particular, banks face more challenges than fintech companies. They need to invest in integrating old data collected before there is a middle ground with the new data.
Mechanisms and technics in data governance.
On the regulatory dimension, this research does not exhaust the data policies applied in China's fintech sector. Instead, it uses the above three cases to map out what kind of policies influence the data governance practices at fintech companies and how. In general, the fintech sector in China is subject to three types of overlapping legal or political orders: financial regulation, information law, and Internet regulations. Fintech businesses are more constrained nowadays by the regulations than in its infant stage around the 2010s (Wang, 2021). In practice, regulatory agencies would notify the fintech companies and call for a meeting at least once a month. In these meetings, the fintech executives are organized to study the latest announcement from CBIRC or the State Council that are pertinent to the fintech development. In the meantime, fintech executives have actively participated in such conferences to show the companies’ regulatory alignment.
Although the three companies are equally diligent to show up upon the compliance meetings, their data governance work weighs differently in the government's overall regulatory regime. The Case BNK and B-F are convenient venues for digital governance. Commercial data collected by these companies are also available to the central bank, thus the State Council. In this case, fintech data are ready to be turned into instruments for social governance. In contrast, the fintech company had better control of its middle ground. This kind of autonomy has also been found in some of the fintech giants, such as Ant Financial (Yang and Liu, 2019).
Monetization
All the interviewees believe in the monetary value of big data that they collect and process. Yet, the specific understandings of such values vary across the types of the company, also by the different department or roles in the data work. Both the Case BNK and Case B-F recognize the commercial value of big data which mostly focus on targeted marketing and customer relations, or in the interviewees’ language, “traditional way of utilizing data” for business development.
The Case FIN's data work covers the “traditional” approach to valorizing big data but emphasizes another two dimensions of data valuation: developing new products and services based on data algorithms, and optimizing revenues through data-based risk management. As explained by the Manager of the Data Center, data governance work had assured the company to design and launch new apps and software rapidly, which is crucial for them to standout among the competitors. Also, clean and well-organized data helps the company to evaluate the risk levels. One of the Business Development Directors mentioned this when we talked about the design of digital loan products, “in financial businesses, high risks mean high returns. We want to optimize the return to the extent that corresponds to the level of risks that we could afford. In this scenario, quality data is crucial, and it is worthy of investing time and human resources on it.” In addition, the Vice President of the Case FIN also mentioned that how they deal with data also matters for their market value, and boosting the market value had been an imperative for them as a pre-listing company. 4
Conclusion
The rise of fintech industries in China started around year 2011 and was termed as “Internet finance” (also known as hulianwang jinrong) back then (Wang, 2017). The idea is to utilize the internet to make finance more accessible and efficient. The peer-to-peer lending sector grew the most rapidly among all the internet finance services. At this time, the role of big data had not been highlighted yet. The internet was mostly a medium connecting the borrowers and lenders who were locked out of the formal banking system due to the lack of credit records. In around five years, tech giants such as Tencent Finance, Ant Financial, and Jingdong Finance really turned big data the primary drive of the fintech development. For instance, based on the user data collected from WeChat the social media, or the consumer data aggregated from the e-commerce website, Taobao, Tencent and Alibaba was able to roll out the payment apps (i.e. WeChat Wallet and Alipay), consumer loans (i.e. Huabei), cash loans (i.e. Jiebei) or even credit record (i.e. Zhima credit) and credit-based convenience such (i.e. getting the deposit waived when rent the sharing bikes). As fintech services become the infrastructure of everyday life, these platforms have developed more capacity to collect data. The companies then invested more on data governance in order to deal with the increasingly versatile and growing databases. In the meantime, the fintech platforms’ data-based virtual cycle for business growth has attracted other companies in and beyond financial industries to develop their data governance department, hoping to boost the data capabilities and survive the competition. Data governance, at this point, is considered an imperative for the transformation of business models and ultimately for the companies’ sustainable development.
However, the regulatory backlash since 2018 has reshaped the data governance arena. Prior to the government's policy intervention, data governance has been part of the fintech companies’ daily operations and business strategies. The central bank had voices out which were essentially pro-innovation (e.g. Xinhua News, 2019) and focused on how data governance at the company level could lead to the innovative design and delivery of new financial services, thus would enhance capital liquidity and contribute to economic growth. Nevertheless, the central bank started to be stringent on data policies after the state council issued several laws and policies on data security, privacy protection, and even monopoly issues embedded in those fintech platforms. After a decade of rampant growth, the fintech industries in China started to slow down for self-adjustment and to adapt to the shifting policy environment. Companies have been looking for new models of business growth while the regulators tighten the control. In this context, fintech companies and the banks’ fintech divisions have considered data governance one of the top agendas. As an emerging set of techno-commercial practices, data governance marks a higher level of corporate governance. It has enriched the meaning of corporate assets in which big data becomes a form of companies’ properties. The companies have a new way to increase the market value which is to manage and maintain quality data. As part of the financial capitalist economy, the investment market believes quality data is the foundation for innovative products and services since it provides more chances to access users and user engagement (Birch et al., 2021). Hence, data governance is considered crucial for the companies’ sustainable development. In the same vein, the Chinese government also considers data governance the pinpoint of data economy (ascended from the Internet economy), thus pivotal for continuous economic growth.
While the idea of data governance is coined and promoted to propel innovation, the practices in the real world are highly performative and drift from the original intention. Although data governance has been considered a public project in which civic society and regulators are key actors (Micheli, et al., 2020), in reality, the corporate actors often hold a much higher stake in specific practices such as data collection and utilization. As shown in the above cases, the idea of middle-ground has been fetishized and oftentimes considered an equivalent of data governance. Underpinned by the technocracy mindset, many fintech businesses fashion the goal of building the middle-ground. In daily operations, it is believed that a company has to construct its own data infrastructure to connect the business front with the operations in the back-end. Consequentially, data governance work is largely mechanical than managerial. The understanding of data governance works is often limited to purchasing hardware and maintaining datasets rather than realizing the value of that equipment and information.
Also, the above case studies unveil an ideological gap between the corporate management's vision toward data governance and the understanding of those employees. The latter, however, are supposed to actualize the idea of data governance through their daily work. Many data analysts do not fully understand the long-term goal of data governance defined by the management. The foundational work, such as labeling and categorizing new data, or converging the old and new data, only focuses on the idea of standardization without knowing the rationales undergirding the standards. Also, many data analysts take such standards as a set of static rules and fail to understand they could be fluid as the market and policy environment are changing. Furthermore, in the above cases, very few data governance workers demonstrated their policy or legal awareness. They do what their managers ask them to do, and the managers’ responsibility in abiding by the law and policies is taken for granted.
Furthermore, for most of the giant banks in China, data-governance-based innovation is more performative than being practical. Since the 2010s, the IT corporations such as Huawei have fueled up a trend of building the middle-ground, followed by the fintech startups. Threatened by the fintech competitors, Chinese banks all embarked on data governance but encountered much more significant challenges—they have so much data scattered in a variety of business divisions but need to be integrated. Thus, most banks have been promoting data governance under the banner of innovation, but the practical consideration is to get prepared for the competition.
Another problem that reflects more at the management level is that data governance has been promoted for the sake of data governance. The pragmatic goal of turning data into assets and monetizing these assets has overridden the vision of using big data to better understand the users, thus enabling innovation. Many product managers focus more on data itself and the data-based moduling work rather than understanding the fintech market and app users via critically thinking through what the data could possibly reflect or represent. Although increasingly more attention has been paid to the power of big data in portraiting the users, the data-based KYC model could be performative than being of real value because of such a gap.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article
Notes
Appendix
Interview questions on the self-definition of data governance.

| DG actors at various levels | Questions |
|---|---|
| DG staff |
Your work is part of the "data governance" in your company. How do you define data governance? Is there any difference between "data governance" and "data management"? What are your daily work routines? Which departments/divisions do you co-ordinate/collaborate with? Can you draw a workflow chart to demonstrate the company structure underpinning the data governance work? what are the policy and regulations that your work might cross paths with? |
| DG managers | Same as the above, plus, 6) what drives the DG work in your company? |
| Company executives | 1), 4), 6) |
Interview questions and measurements on the awareness of regulation and policies.

| DG actors at various levels | Questions |
|---|---|
| DG staff |
Does your work cross paths with data policies and regulations? If so, how? Do you need to collaborate with the department of legal work very often? |
| DG managers | Same as the above, plus, 3) for the company's data governance work, will you get yourself updated with the new policies or regulations? If so, how? |
| Company executives | 1), 2), 3) |
Algorithmic mechanisms in risk management models.

| Levels | Measurement |
|---|---|
| None | Answer “no” to all the above questions |
| Little | Answer “yes” to one of the above questions but cannot articulate any further details |
| Strong | Answer “yes” to at least two of the above questions and can articulate details of at least one of the questions |
| Very strong | Answer “yes” to all the above questions and can articulate details of all. |