
Abstract
Questions regarding the quality of online platform data have gained significant attention and research focus in recent years. Inaccurate, incomplete, or inconsistent data are some of the many examples of data quality problems. At the same time, digital platforms have restricted access to their data in recent years. This strategy by digital platforms has now increasingly become the subject of political efforts of regulation, especially the Digital Services Act (DSA) of the European Union. Therefore, we argue that the quality of online platform data cannot solely be understood as a methodological, internal research construct but also as a contested concept in which various actors from politics, the tech industry, and academia negotiate and represent specific interests. To assess the role of data quality in and around the DSA, we analyze the content of the DSA itself, in particular Art. 40 and the respective Delegated Regulation (DR), as well as the feedback submitted to the European Commission's Call for Evidence and the Delegated Regulation draft. We then apply quantitative content analysis, multiple correspondence analysis, and thematic analysis. Results indicate that data quality plays little to no role in the official EU documents, namely, the DSA and the Delegated Regulation draft. In the public feedback, however, data quality concerns have been raised by various stakeholders in academia. Based on the results, we argue that data quality should play a more prominent role in the debate to fulfill the DSA aims of assessing systemic risks in the EU.
Keywords
Introduction
The Digital Services Act (DSA) of the European Union (EU) 1 grants researchers both the right and the opportunity to access public (Article 40(12)) and nonpublic (Article 40(4)) types of online platform data (European Union, 2022). For the first time, researchers can now refer to an established law that documents the right to request data from Very Large Online Platforms (VLOPs). 2 While the data use is restricted to enabling research specifically on “systemic risks” in the European Union and imposes strong regulatory settings around how to apply for data access, the DSA still offers a substantially different setting to previous cases. Here, researchers mainly used existing application programming interfaces (APIs) provided by the platforms or webscraping to collect those types of data that were accessible. This represents a significant shift that could fundamentally reshape interdisciplinary research on platforms, social media, and the Internet in general. Mimizuka et al. (2025) therefore already refer to the post-post-API age, which succeeds what Freelon (2018) termed the post-API age and Bruns (2019) described as the APIcalypse. While these concerns have primarily focused on the progressive closure of access points (e.g., CrowdTangle, Twitter Researcher API), the post-post-API age explicitly refers to new legal access mechanisms established under Article 40(4) of the DSA and new data access points emerging around it, such as the Meta Content Library 3 and the TikTok API. 4 The success of the DSA in ensuring reliable and sustainable research outcomes hinges critically on the quality of the data made available. In many respects, data quality problems have been documented in the access options previously provided by platforms, including researcher APIs and data download tools (Darius, 2024; Hase et al., 2024; Morstatter et al., 2013; Pearson et al., 2025; Rieder et al., 2025; Salvatore et al., 2021).
This raises two key questions: (1) What role does data quality play within the DSA, and (2) which discourses and actors have shaped this understanding, and how? Within the framework of the DSA, the latter question refers to the implementation process of the Delegated Regulation on data access provided for in the Digital Services Act (DR) (European Union, 2025), which involved several rounds of public consultation and feedback. To address these questions, this article (a) examines the role of data quality in Article 40 of the DSA and the associated Delegated Regulation (Chapter 3) and (b) analyzes the publicly available feedback submitted as part of the European Commission's Call for Evidence (Chapters 4 and 5). Before doing so, we provide an overview of the various understandings, interests, and motivations regarding data quality in online platform research (Chapter 2). This typology is based on the perspectives of the key stakeholders involved in this process: (a) researchers and their organizations, (b) platforms and their lobby groups, and (c) the European Commission and the Digital Services Coordinators. In doing so, we aim to contribute to the ongoing scholarly discourse by linking methodological considerations of data quality with critical reflections on platformization (Poell et al., 2019; Van Dijck et al., 2018) and platform governance (Gillespie, 2010; Gorwa, 2019; Hofmann et al., 2017).
Towards the quality of online platform data
Data quality is a multidimensional construct that has been applied in many disciplines, including the social sciences, economics/business, computer science, medicine, and biology (Batini et al., 2015; Birkenmaier et al., 2024; Chapman et al., 2020; Cichy and Rass, 2019; Davis et al., 1999; Kahn et al., 2015). In their reconstruction of the historical evolution of data quality as a concept, Keller et al. (2017: p. 85) highlight that data quality “transcend all boundaries of science, commerce, engineering, medicine, public health, and policy” and that these different disciplines contributed to the development of the concept. In the social sciences, so-called error frameworks (Groves and Lyberg, 2010) were developed within survey research, a field with a long tradition of addressing data quality issues, to systematize and identify potential sources of missing data quality. While error frameworks help researchers address data quality issues in advance, Blasius and Thiessen (2012: p. IX), on the user hand, conduct data quality assessment retrospectively as they emphasize the need to evaluate data using “screening procedures that should be conducted prior to assessing substantive relationships.” However, questions of data quality in the social sciences are no longer confined to survey data. While the early phase of communication and social science engagement with digital behavioral data has been described as a “wild west” (Puschmann, 2019: p. 1582), research on the quality of online platform data has received significantly more attention in recent years (Daikeler et al., 2025; Fröhling et al., 2023; Malthouse et al., 2024; Salvatore et al., 2021; Schmitz and Riebling, 2022; Weiß et al., 2025). A more general definition of data quality comes from Herzog et al. (2007) who conceptualize it as “the degree to which a set of inherent characteristics of data (ISO 8000-2:2020) fulfills intended operational decision-making and other specific roles.”
High data quality is generally considered essential for researchers to draw valid conclusions. In this paper, however, we confine our conceptualization of data quality to the debates surrounding the implementation of the data access provisions of the Digital Services Act –specifically, the two feedback periods associated with the EU's Call for Evidence. Consequently, it is necessary to consider the stakeholders’ perspectives, motivations, and interests on data quality that extend beyond the scientific domain. In this paper, we therefore argue that the quality of online platform data should not be understood solely as a methodological or internal research construct but rather as a contested concept in which various actors from politics, the technology industry, and academia negotiate and represent specific interests. In this regard, we consider data quality to be a discourse string within discourses of online platform regulation. We distinguish three main perspectives on data quality that are relevant to this discourse: (a) the perspective of researchers, who understand data quality as a research standard; (b) the perspective of platforms, which treat data quality as an economic good and a means to undermine critical research; and (c) the European-regulative perspective, which becomes visible in the implementation of data quality in the Delegated Regulation. While the first two perspectives are addressed in Chapter 2, the European regulatory perspective is discussed in Chapter 3.
Data quality as a research standard: The researcher's perspective
High-quality research needs high-quality data
Although conceptions of data quality and its indicators vary by research field and data type, the foregoing sentence encapsulates the core of researchers’ perspectives on data quality (Birkenmaier et al., 2024). Here, data quality functions as a research standard, which is very necessary to deliver correct and thus meaningful research results. However, because data quality is multidimensional, a variety of data quality frameworks and indicators exist, each emphasizing different features and aspects. To adopt a representative understanding of data quality, we draw on the systematic review of data quality and error frameworks in social science research by Daikeler et al. (2025). Against this backdrop, we also distinguish between an intrinsic perspective on data quality, which focuses on characteristics such as accuracy, relevance, consistency, and completeness, and an extrinsic perspective, which places greater emphasis on infrastructural access and the subsequent processing of data (Daikeler et al., 2025). In their systematic review, Daikeler et al. (2025) demonstrate that these two perspectives are reflected across a range of error frameworks. An example of extrinsic data quality is provided by the so-called FAIR principles, which state that data should be findable, accessible, interoperable, and reusable (Wilkinson et al., 2016). This latter view corresponds more closely to the perspective of data users and addresses the question of whether data are “fit for use” (Herzog et al., 2007: p. 7). In the past, there have been numerous cases in which data provided by platforms via APIs or data donations has proven to be inaccurate or incomplete. For example, Valkenburg et al. (2024) found in a survey of 51 data donation researchers that 63% of respondents considered the data incomplete due to missing information, while 48% mentioned limited time ranges as a source of incompleteness. Furthermore, 51% of respondents judged the data to be inaccurate. Hase et al. (2024) identify the incompleteness of data downloading packages of users as a significant issue in accessing platform data. In their error framework for Twitter data, Salvatore et al. (2021) highlight query-based errors as a source of inaccuracy and data changes as related to consistency problems. Morstatter et al. (2013), in contrast, compared different API versions to demonstrate the lack of representativeness and generalizability of the then freely available Twitter API. More recently, Pearson et al. (2025) and Darius (2024) showed that the TikTok API suffers from insufficient accuracy, with values collected via the API failing to match those displayed in the app or browser. Finally, the YouTube API also exhibits deficiencies in completeness, representativeness, and consistency (Rieder et al., 2025). Against this backdrop, it is reasonable to ask whether the quality of data collections enabled under the DSA is sufficient, reliable, and, ideally, high.
Data quality as an economic good: The platform's perspective
The higher the quality of data, the higher its economic value
This perspective of data quality, highlighting its economic value, is visible in research papers in the field of business and economics, for example, when Cichy and Rass (2019: p. 24634) write that “based on its impact on businesses, the quality of data is commonly viewed as a valuable asset.” In general, low data quality is considered not profitable as it results in “poor decision-making and missed business opportunities, since the data might not provide a clear picture of the circumstances” (Cichy and Rass, 2019: p. 24634). In the context of online platforms, this aspect is even more important as it relates to one of their core business principles, which involves the datafication of user activities and the subsequent commodification of the data thus obtained (Van Dijck et al., 2018). In recent years, digital platforms have significantly restricted access to their data (Bruns, 2019; Freelon, 2018). Previously, business models had been established that enabled researchers to use free API versions that provided only limited data access or to buy access to additional data. For instance, Twitter's free Streaming API allowed researchers to collect merely a 1% sample of all tweets, while the free REST API permitted access only to data from the previous 6 to 9 days (Pfaffenberger, 2016: p. 45, 55). Higher data quality could be obtained solely through monetized API access (Salvatore et al., 2021). Following a brief phase, from 2021 to 2023, of comparatively extensive data access via the Twitter Researcher API, this opportunity was abolished after Elon Musk's takeover of the platform. To increase efficiency and profitability as part of Elon Musk's rebranding of the platform as X, access to platform data was once again monetized (Peters and Thimm, 2025). Table 1 provides an overview of X's four current API tiers.
Overview of X API tiers in October 2025.

The Enterprise data access version does not contain public information on prices and scopes, as this is not standardized.
Data quality functions as a determinant of price: the higher the data quality, the higher the cost. In terms of completeness, the Pro version – priced at $5000 per month – offers up to 10,000 times as many posts per month (reads) as the free version. This represents a substantial disparity in data completeness, to the extent that the free version is insufficient for academic purposes – at least for quantitative research. Moreover, only the Pro and Enterprise versions provide access to the filtered stream and full-archive APIs, which enable the collection of real-time and historical platform data. In this respect, the timeliness and granularity of the data are also monetized. Overall, X appears to use data quality primarily for profit maximization, following the principle: if you do not pay much, you will not receive good data. The monetization of data quality is not only relevant for researchers but also for third-party companies across the data value chain as they also function as “data reusers (access seekers)” (Trampusch, 2024). In this regard, for scientific access, however, it has a further consequence: it diminishes or even precludes researchers’ ability to obtain the data. This matters to platforms that seek to cultivate the most favorable public image. Especially in their early development, platforms deliberately promoted a narrative of neutral meeting places that fostered public discourse and democracy. Instead of “social media,” van Dijck (2013: p. 13) therefore first favored the term connective media; later the term platforms was established (Poell et al., 2019; Van Dijck et al., 2018). Against this backdrop, critical, empirical, and independent high-quality research is not in platforms’ interests, because issues such as misinformation, political polarization, hate speech, and the algorithmic influences on the formation of public opinion question platforms’ legitimacy and position in democratic societies. Overall, most online platforms, especially social media, have an interest in strategically preventing the establishment of data quality standards for their data.
Data quality in the Digital Services Act: The European-regulative perspective
After briefly reflecting on the perspectives on data quality of researchers and platforms – the two parties involved in what Goanta et al. (2025) describe as the “great standoff” –one important actor remains to be addressed: the European regulatory perspective, represented by the European Commission and the Digital Services Coordinators (DSCs). The strategies employed by digital platforms have increasingly become the focus of political regulation, particularly within the European Union (EU). The EU occupies a distinctive position in this regard, as it does not possess its own major platform ecosystem but instead relies primarily on platforms provided by American companies (e.g., Meta, Microsoft, Amazon, Google, and X) and, to a lesser extent, Chinese ones (e.g., Baidu, Alibaba, Tencent, and ByteDance). Consequently, the European approach has largely centered on the regulation of digital platforms, ideally in accordance with European public values (Van Dijck, 2020). In this context, a political and academic discourse on the EU's digital sovereignty has emerged that is considered a driver of platform regulation (Bendiek and Stürzer, 2022; Herrmann, 2023; Kreutzer et al., 2022; Pohle and Thiel, 2020). The EU's most significant recent regulatory frameworks for digital platforms include the Digital Services Act (DSA), the Digital Markets Act (DMA), and the AI Act. For example, under the DSA the European Commission and member states gain access to large platforms’ algorithms, and platforms will be required to identify, report, and, where necessary, remove illegal content. Herrmann (2023) attributes this new phase of online platform regulation largely to the “strategic use in the policy-making process” of the concept of digital sovereignty by different stakeholders. Rhetorically, the EU has also adopted a tougher stance toward platforms: for example, former European Commissioner for the Internal Market Thierry Breton has repeatedly invoked the DSA when discussing the possibility of banning platforms such as Twitter or TikTok in Europe if they do not comply with its rules (Milmo and Rankin, 2022).
The DSA introduces provisions for researcher access to platform data, which cover both public data and nonpublic data generated by platforms 5 (Keller, 2025). These two types of access are specified in Articles 40(4) and 40(12) of the Digital Services Act. Under DSA Article 40(4), vetted researchers can request access to nonpublic data from very large online platforms. Under DSA Article 40(12), those providers must also give researchers data that is publicly accessible in their online interface, including real-time data where technically possible. Beyond data protection and security requirements, the primary criterion that research proposals must satisfy is the “detection, identification and understanding of systemic risks in the Union” (Articles 40(4) and 40(12)) or, in the case of Article 40(4), the assessment of the “adequacy, efficiency and impacts of the risk mitigation measures” that platforms are required to implement. According to Recital 97 of the DSA, very large online platforms must grant “access to data […] to vetted researchers affiliated with a research organization.” The DSA explicitly justifies this provision by referring to the goal of “supporting [research organizations’] public interest mission.” In this sense, data access is considered to identify and understand systemic risks in the EU, serving the public interest and even public values.
Although data access represents an essential component of external data quality – captured by the “A” in the FAIR principles (Wilkinson et al., 2016), which promote better research data management practices – other dimensions of data quality remain underrepresented in both the DSA and its Delegated Regulation. Figure 1 provides an overview of selected data quality indicators across all relevant documents, illustrating the DSA's predominant focus on data access. In addition to the DSA and Article 40, we included both the draft and the final versions of the Delegated Regulation. The Delegated Regulation was developed by the European Commission against the backdrop of two public feedback periods, referred to as a Call for Evidence. The Call for Evidence is a means of stakeholder engagement under the EU's Better Regulation framework and typically consists of two stages: an initial call for evidence (in this case, open for 4 weeks and referring to Article 40 of the DSA), followed by a 12-week public consultation on the draft Delegated Regulation.
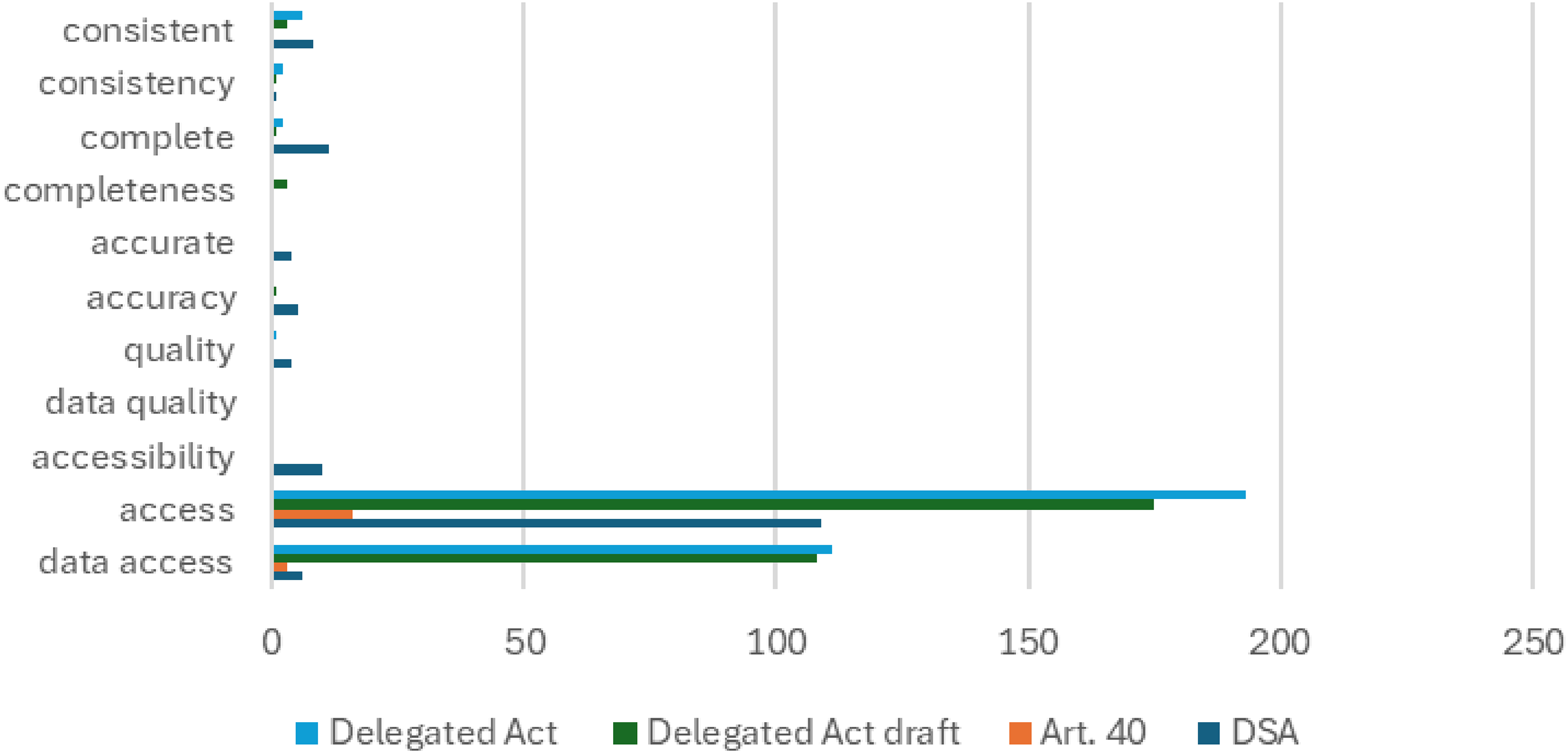
Word frequency of data quality indicators in relevant EU legislation documents.
Terms related to data quality – such as accuracy, completeness, or consistency – are rarely mentioned across the relevant documents. This indicates that data quality was not a central concept to the European Commission. While these terms appear most frequently in the DSA itself, they are often not explicitly discussed in connection with data quality. One example in which data quality is actually addressed in the DSA is Article 39(1), which provides that platforms “shall make reasonable efforts to ensure that the information is accurate and complete.” However, this obligation is limited to the context of additional online advertising transparency and does not extend to Article 40. Ironically, in the few instances where accuracy and completeness are referenced in the draft version of the Delegated Regulation, they do not pertain to data quality either. Instead, researchers are described as being responsible for ensuring “the completeness and accuracy of the information in and the supporting documentation of a data access application” (Delegated Regulation draft). Notably, this provision was removed from the final version of the Delegated Regulation. In addition, the first explicit references to data quality appear in the Delegated Regulation: “Where the requested data are also available through other sources, the Digital Services Coordinator of establishment should assess whether the request for such data in the data access application is duly justified, having regard to the information in the data access application. Possible justifications may include evidence of poor quality or unreliability of such data deriving from other sources or the unsuitability of the format in which such data may be retrieved from other sources for the purposes of the research project, which would hinder the performance of the research project” (DR, Recital 13).
Reference is also made to data quality indicators in relation to the data catalogues outlined in the Delegated Regulation, which require platforms to publish sample datasets: “To ensure the relevance and timeliness of the DSA data catalogues, those catalogues should be updated regularly with due consideration to newly identified systemic risks and the evolution of systemic risks” (Delegated Regulation, Recital 7). In this regard, it becomes evident that changes
6
concerning data quality occurred between the draft and the final version of the Delegated Regulation. This suggests that the public consultation processes – in which platforms, scientific organizations, and NGOs participated – had an impact on the design of the Delegated Regulation. Specifically, this pertains to the two feedback periods conducted by the European Commission on this topic. The first feedback period, which took place from April 25 to May 31, 2023, was particularly influential for the initial drafting of the Delegated Regulation. In its Call for Evidence, the European Commission outlined eleven questions across four main categories: (a) data access needs, (b) data access application and procedure, (c) data access formats and the involvement of researchers, and (d) access to publicly available data. Respondents were encouraged to address each of these categories, which likely contributed to the standardization of the responses. A total of 133 responses were submitted during the first period. The second feedback period took place from 29 October to 10 December 2024, following the publication of the draft of the Delegated Regulation. Unlike the first period, this second one focused directly on the draft of the Delegated Regulation itself, which was published for this specific purpose. Also, the second period was not guided by pre-specified questions. A total of 109 responses were submitted during this second period. The official Delegated Regulation (sometimes also referred to as Delegated Act) was published in July 2025. The changes observed across the two versions suggest that these public consultation processes were influential and that various stakeholders sought to advance their respective interests. Accordingly, we consider these feedback periods to be an ideal source of data for examining the discursive negotiation processes that shaped the role and significance of data quality in the DSA and particularly in the Delegated Regulation. Against this background, we formulate the following guiding research questions which aim to reveal the structure of the data quality discourses within the feedback periods:
RQ1: How prevalent were considerations of data quality in the feedback periods on the Delegated Regulation? RQ2: To what extent did the various stakeholder groups differ in this regard? RQ3: How did the stakeholders employ the concept of data quality in their argumentation?
By emphasizing the diverse perspectives on data quality and its multidimensional nature, this paper adopts an exploratory empirical approach to assessing data quality. Specifically, we examine how various actors invoke and reference data quality and its indicators during the feedback periods. Because the documents are policy papers in which data quality was not explicitly predefined or requested, we find that a more open, interpretive understanding of data quality is most appropriate for this use case. This is particularly important because different actors may have heterogeneous understandings of data quality, as highlighted in the theory section.
Data and methods
To investigate the research questions outlined above, we collected all available data from the publicly accessible feedback on the Delegated Regulation drafts. This resulted in a total of N = 242 feedback entries – 133 from the first period and 109 from the second. These 242 entries were submitted by 214 unique actors, indicating substantial inconsistency in participation across the two periods. We therefore transformed the dataset so that the unit of analysis was the submitting organization rather than individual entries. Consequently, each organization could contribute up to two entries; 190 submitted only one, while 24 submitted two. The dataset contains the submitter's name, submitter's type, submission date, country of origin, the message provided in the open-text field, and any attached PDF documents. The (self-descriptive) types of submitters included academic/research institution, EU citizen, non-governmental organization (NGO), non-EU citizen, companies/business, business association, public authority, and others. While all submissions contained a message in an open-text field, not all respondents provided an accompanying PDF document in which the key questions could be addressed in greater detail. A total of 26.4% of all submissions did not include any PDF attachments. We included both the open-text messages and the available attachments in the analysis to ensure completeness. The exploratory analysis was conducted as a multistage process employing a mixed-methods approach. First, a quantitative content analysis of all actors’ feedback entries was performed to identify and extract all text passages that referred to data quality. The quantitative content analysis primarily examined whether each message or document (a) addressed data quality in general and (b) mentioned specific indicators such as consistency, completeness, or accuracy. Accordingly, four variables (two variables for the two feedback periods and two data quality variables for mentioning data quality in general and specific data quality indicators) were added to the raw dataset, which were annotated binary (0–1). As data quality was not designated as a discrete topic in the two feedback periods, many actors mentioned it only briefly. Consequently, we limited the quantitative content analysis to those few variables and conducted an additional qualitative analysis of all passages that referred to data quality (see Chapter 5.3).
To be classified as referring to data quality, a response could, for instance, explicitly use the term, provide concrete examples or use cases, or mention specific indicators. When such indicators were present, they were coded separately, but the overall reference to data quality was also noted. This created a one-sided dependency between the variables: while the mentioning of indicators implied a reference to data quality, the reverse was not necessarily the case. In other words, data quality could be discussed in general terms without mentioning any indicators. Care was taken to ensure that comments on quality or indicators referred to the data itself and not, for example, to data access. Although these dimensions are closely related, we applied a conservative coding approach in this regard. It is particularly important to note that only intrinsic data quality was considered in the coding – that is, only intrinsic indicators like accuracy, completeness, or consistency were included. This decision was made because the European Commission's guiding questions inherently emphasized aspects of extrinsic data quality in four respects – for example, through their focus on data access, interoperability, metadata, and documentation (even reflecting the accessibility and interoperability dimensions of the FAIR principles). This meant that virtually all feedback displayed some form of extrinsic data quality. However, to capture the relevant differences between stakeholders, it was therefore necessary to restrict the analysis to intrinsic indicators and overall references to data quality. The coding was primarily conducted by an expert coder, with a randomly selected 10% of the dataset 7 independently annotated by a second coder to assess inter-coder reliability. Across all double-coded variables, a Krippendorff's alpha of 0.92 and a Holsti's coefficient of 0.95 were achieved, indicating a high level of agreement.
Multiple correspondence analysis (MCA) (Blasius and Greenacre, 2014; Greenacre and Blasius, 2006; Greenacre, 1991), notably applied by the French sociologist Pierre Bourdieu (1987), was selected for the quantitative analysis of the data. Because it functions as a structure-discovering method and requires categorical variables as input, it is well-suited to our exploratory research design. MCA is therefore also referred to as “the analogue of principal component analysis (PCA) for multivariate categorical data” (Greenacre, 2019: p. 4). In addition to the formal arguments in favor of MCA, there are also substantive reasons that support its use. As a method of geometric data analysis, MCA allows the discourse surrounding data quality in the feedback periods to be visualized and represented as a statistically constructed space. In doing so, it explicitly accounts for the relational character of discursive positions and the dependencies between them across multiple categorical variables. These relational structures cannot be adequately captured through simple cross-tabulations, which are limited to pairwise associations and therefore fail to represent the multidimensional organization of discourse. In addition, individual actors can be located within this space, making it possible to relate discursive positions to actor characteristics. For this study, the four variables related to data quality (general reference of data quality in feedback period 1, mentioning of data quality indicators in feedback period 1, general reference of data quality feedback period 2, and mentioning of data quality indicators feedback period 2) were used as active variables in the MCA. This space is defined by the two dimensions that account for the greatest proportion of total inertia, which serve as orthogonal axes spanning the space. To highlight differences between the various stakeholders, these factors were included as passive or supplementary variables in the correspondence space. Passive variables do not influence the spatial configuration themselves, but their positions within the constructed space can be determined. This approach is particularly useful for examining the relationships between stakeholders and active data quality variables. In addition to the stakeholder type, we clustered all individual actors in the correspondence space using Hierarchical Clustering on Principal Components (HCPC) to determine the clustering between individual actors (Husson et al., 2010). Although our MCA provides information on which actors refer to data quality (indicators) and the relationships among them, it does not reveal how these references are employed – for example, how data quality is discussed and used in argumentation. All data quality-related text passages were qualitatively analyzed and coded following the five phases of thematic analysis (Braun and Clarke, 2006). In addition to identifying categories and subtopics, we aimed to capture the role of data quality within stakeholder arguments. This exploratory mixed-methods approach enables both the statistical quantification and qualitative interpretation of the discourse on data quality across the two feedback periods.
Results
Descriptives
An examination of the descriptive distribution of feedback responses shows that, by sender type, academic and research institutions (35.98%) and NGOs (21.02%) submitted feedback most frequently (see Table 2). In contrast, EU citizens (16.82%) and non-EU citizens (05.61%) were less represented, as were companies/businesses (07.48%) and business associations (04.67%). With regard to country distribution, it is noteworthy that the largest share of submitters originates from the USA (20.56%, see Table 3). This illustrates the transnational nature of the debate, which – although centered on European legislation – is by no means confined to Europe. Central to this is the provision that non-European institutions may also obtain data under the DSA, provided their research serves the objectives of Art. 40(4) or 40(12) (e.g., the study of systemic risks in the European Union). Overall, 9 of the 28 countries in which the submitters of responses are based are non-EU member states.
Overview organization type in public feedback periods.

Overview country in public feedback periods.

Overall, intrinsic data quality was mentioned at least once by 38.79% of the submitters across both feedback periods, while 61.21% made no reference to it at all. This indicates that, generally, data quality was a notable theme in the debate. Figure 2 shows that data quality was mentioned more frequently in the second feedback. In the first period, data quality was mentioned by 19.6% of all submitters, while intrinsic indicators appeared in 13.1%. In feedback period 2, 24.3% discussed data quality in general – nearly as often as it was not discussed – while specific indicators were mentioned somewhat less frequently (19.2%). And 38.3% of submitters did not submit in period 1, while 48.6% of all actors did not submit in feedback period 2. They were therefore coded as missing (NA) for both variables. We still included the NA values in the following multiple correspondence analysis, because we consider them meaningful for the general structure and consistency of the debate.

Distribution of data quality variables: do responses mention data quality (indicator) in the feedback period 1 (left columns) or feedback period 2 (right columns)? NA indicates that the submitter did not participate in the respective feedback period.
The empirical construction of a data quality space
Figure 3 presents the results of the multiple correspondence analysis (MCA), representing a data quality space constructed from the four active, data quality-related variables. The first two dimensions account for 69.2% of the total inertia, indicating that they capture the majority of the variance in the data. However, since the third dimension still explains 19.93% of the inertia, a three-dimensional solution can also be justified to capture additional structure within the data.

Active data quality (indicator) variables and supplementary sender type variable in multiple correspondence space (biplot), N = 214.
Figure 3 depicts a clearly structured discursive space of data quality. Dimension 1 (x-axis) primarily distinguishes whether feedback was given in period 1 or period 2 of the Call for Evidence, as indicated by the spatial proximity of the NA categories to the x-axis. Specifically, the NA category for feedback period 2 and the four data-quality-related categories from feedback period 1 are positioned on the negative side of the x-axis, whereas the NA category for feedback period 1 and the data-quality categories for feedback period 2 occupy the positive side. Dimension 1 explains 44.3% of the variance and is therefore the dominant axis structuring this discursive space, reflecting submitters’ inconsistent participation across the two periods. The y-axis, in contrast, differentiates whether submitters mentioned data quality and explains 24.8% of the variance. The mention categories for periods 1 and 2 occupy the positive range of the y-axis, whereas the non-mention categories appear in the negative range.
Figure 3 also includes the passive (supplementary) variable (shown in yellow), which helps illustrate differences between sender types. Variation occurs along both the x- and y-axes indicating that sender types differed not only in whether they mentioned data quality but also in their participation across the two periods. Academic research institutions and NGOs are the only sender types located in the upper-right quadrant of the biplot. NGOs appear to mention data quality more frequently than every other actor type. Academic research institutions are closest to the origin (except for the Others category), reflecting the center of the distribution. Both lie only slightly on the positive side of the x-axis, suggesting that submissions from these two groups were relatively balanced between the two periods. Companies/businesses, business associations, and public authorities, in contrast, are located in the lower-right quadrant (positive x, negative y). This indicates greater participation in the second feedback period and that they were less likely to mention data quality. Finally, the EU and non-EU citizen categories are positioned in the lower-left quadrant of the biplot (negative x, negative y). Both groups rather tended not to mention data quality and to submit primarily in the first feedback period. One reason for this may be that the open Call for Evidence in period 1 was easier to respond to than a detailed policy document such as the Delegated Regulation in period 2, which requires more in-depth knowledge. In practice, EU citizens in particular often did not even attach supporting documents and submitted only very brief comments in the open-text field.
Using the MCA coordinates of all actors, we performed hierarchical clustering on principal components (HCPC) to map actor clusters in the correspondence space. The HCPC produced a four-cluster solution, shown in Figure 4. Each point in the figure represents a distinct annotation profile, and point size indicates how often that profile occurs in the annotated dataset. Because the analysis involved relatively few variables with internal dependencies, there are substantially fewer distinct profiles than actors. The four clusters reveal different reply profiles. Cluster 1 (n = 97) is the largest and lies primarily in the negative ranges of both axes, although it extends into the positive range of both dimensions; members of this cluster mostly submitted feedback only in period 1 and generally did not mention data quality. Cluster 2 (n = 28), the smallest cluster, is located mainly in the second quadrant and comprises actors who submitted in period 1 or in both periods and who mentioned data quality. Cluster 3 (n = 36) is found in the first quadrant (positive x, positive y), slightly overlapping cluster 2, and largely consists of actors mentioning data quality in period 2 or in both periods. Finally, cluster 4 (n = 53) occupies the fourth quadrant (positive x, negative y) and primarily includes actors who did not mention data quality in the second period.
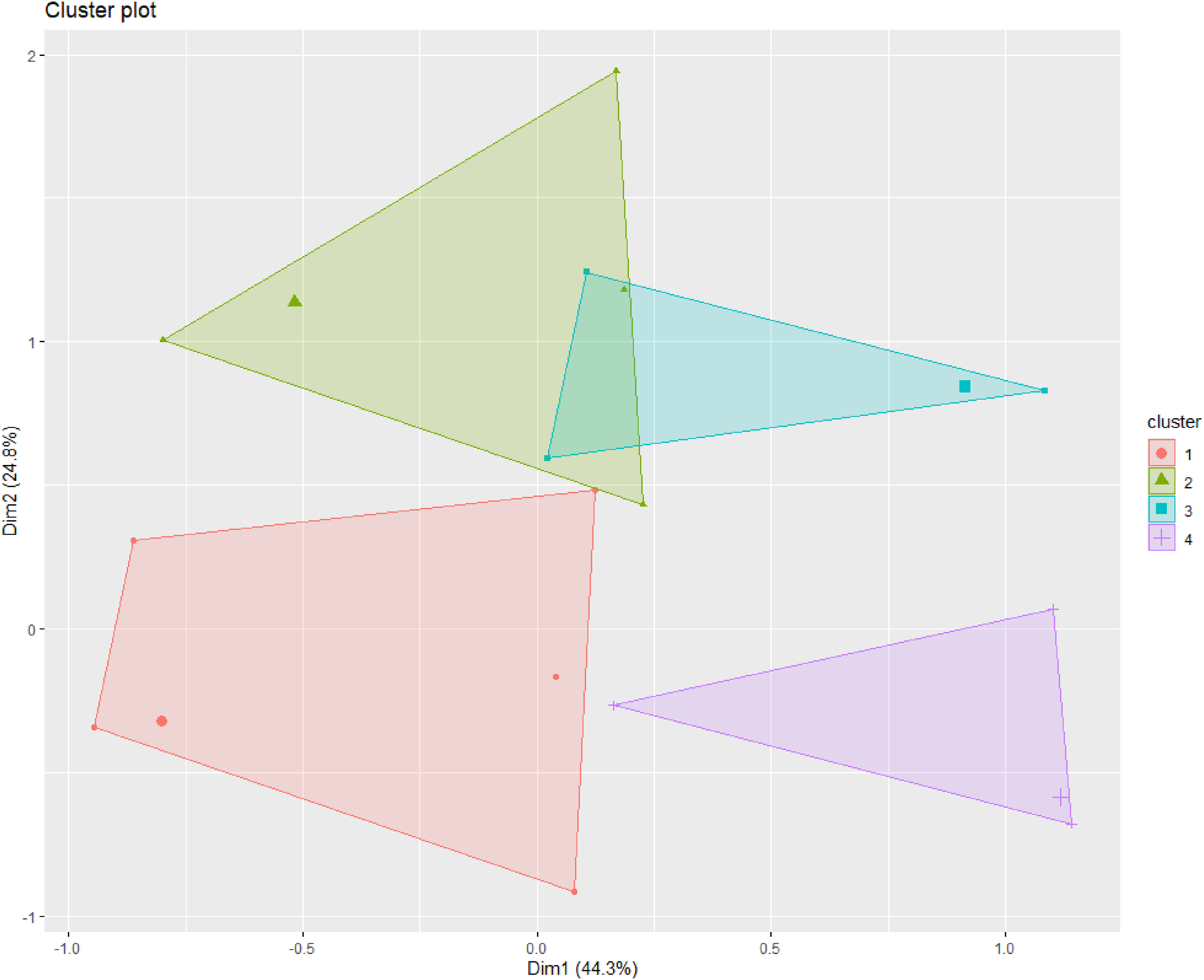
Actor clusters in correspondence space.
Table 4 provides an overview of cluster membership by actor category. Because academic research institutions constitute a large share of the overall sample, they appear in all clusters but are particularly prevalent in clusters 2 and 3. NGOs are concentrated in cluster 2, EU citizens in cluster 1, and companies and business associations in cluster 4.
Distribution of cluster by submitter type, in percent, N = 214.

Figure 5 plots each platform as an individual point in the data quality space. The majority of platforms do not refer to data quality – neither in general terms nor with respect to specific indicators. This is true for TikTok, Booking.com, Google, Pinterest, Wikimedia, Zalando, X, and Amazon. Only Meta and Snapchat explicitly mention data quality in their submissions.
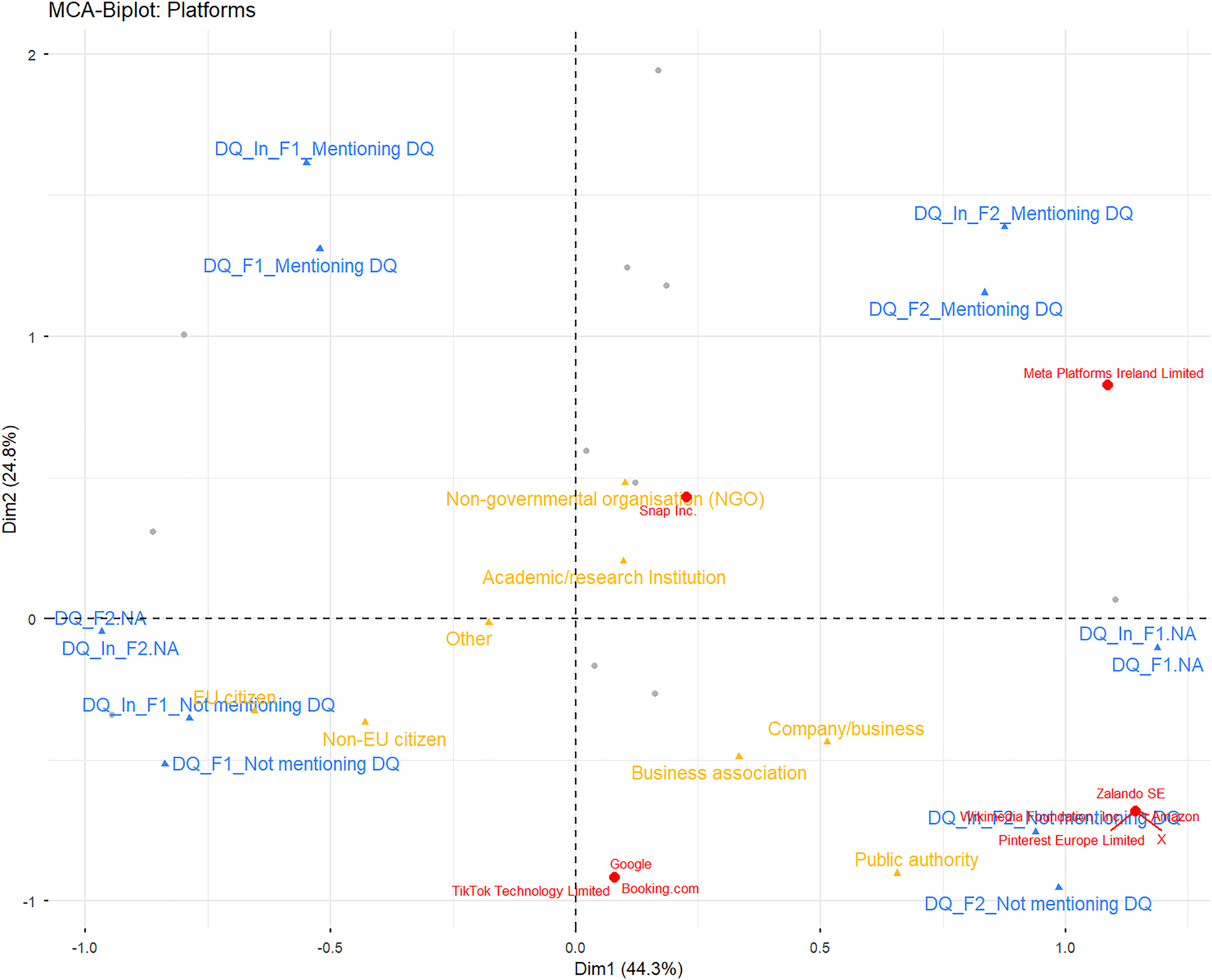
Platforms in correspondence space.
To this point, multiple correspondence analysis has been used to empirically construct a discursive space of data quality. Because our quantitative content analysis was limited to the mentioning of data quality, we still needed to examine how actors incorporated the concept into their argumentation. To do so, we re-evaluated the public feedback using a thematic analysis approach.
Data quality in stakeholders’ argumentation
The thematic analysis yielded numerous inductively derived categories related to data quality. These include specific indicators – (a) accuracy, (b) completeness, (c) consistency, and (d) representativeness/generalizability – as well as links between data quality and collection methods (e.g., APIs, data donations, and scraping). Within the MCA (biplot), this thematic analysis dives deeper into what is located in the upper half of the correspondence space (the positive range on the y-axis). We first explore how different stakeholders discussed these dimensions in the first feedback period (second quadrant, upper left) and then in the second period (first quadrant, upper right). We will focus specifically on the differences between companies/businesses and business associations on one hand, and academic/research institutions and NGOs on the other.
In the first feedback period, data quality was rarely mentioned by platforms or business associations at all. The only platform that explicitly calls for accurate information from platforms in either feedback period is Snapchat – and even this occurs only in the first one. As Snapchat notes, “In other words, regardless of the platform policies, all platforms may consider implementing some version of data governance controls that ensure the final metrics seen in their transparency reports are properly controlled, stable, and accurately calculated.” However, it should be emphasized that this statement refers to metrics within transparency reports, rather than to the platform data itself made available to researchers under the DSA framework. In general, platforms focused mainly on the vetting process and data security, emphasizing the requirements on the researcher's side. When data quality was referenced by business organizations, however, it was primarily used to justify extended time periods for processing requests and delivering data, for example, by DOT Europe or the European Tech Alliance: “Also, the VLOP/VLOSE should be allowed under article 40 (5) to request longer deadlines where this is proportionate/necessary because of special circumstances and when giving access within the proposed deadline is not reasonable. This also reflects that time may be required to ensure that the data is of the required quality and adequately verified” (DOT Europe). At this stage, it appears that platforms have little incentive to provide high-quality data because (a) such data can enable critical research into platform practices and (b) under the DSA data are not easily commodified. Consequently, platforms (and some other actors) may avoid mentioning data quality altogether. When data quality is invoked, it is generally used instrumentally to secure favorable terms or advantages in the data-transfer process.
In contrast, the research institutions and NGOs mentioning data quality behaved quite differently in the first period of feedback as they frequently highlighted well-known data quality requirements. With regard to data quality indicators, the most frequently cited were (a) completeness and (b) accuracy. These two categories were often mentioned together, for example, by the Mozilla Foundation: “Often, shared public data proves incomplete or inaccurate […].” Less often, although still in multiple cases, consistency and representativeness/generalizability were listed as necessary data quality standards. In addition to these categories, data quality was described by numerous other attributes and descriptors. Among others, online platform data should also be reliable, verifiable, timely, error-free, adequate, integer, unbiased, transparent, stable, diverse, and reproducible. These standards were also associated with specific data-collection methods, particularly APIs. Less common methods, such as data donations, were likewise linked to data quality; for example, respondents noted that they can suffer from missing information and inconsistency (Stiftung Neue Verantwortung). With regard to scraping, data quality is used in argumentation as a reason for not restricting scraping as a data collection method: “Scraping is a rare form of transparency that does not depend on the very platforms who are being studied to generate information or act as gatekeepers. As such, it is uniquely resistant to problems caused by platforms’ own errors and inadvertent or deliberate manipulation of data. Scraping allows researchers to see the world, or at least the very important world of content made publicly available by platforms, as it actually exists” (D. Keller). In this regard, triangulating data from multiple sources is recommended as a method for assessing data quality. Moreover, data quality was described as a prerequisite for researching systemic risks, and it was suggested that assessment of data quality should be incorporated into the DSA request process via independent audits: “In our report, we suggest that this independent institution (or institutions) be regarded as a ‘transparency facilitator’ and empowered to serve a variety of important functions, such as reviewing the quality of reported data by periodically auditing disclosing parties, pre-processing and pseudonymizing data (in a transparent way) before making it accessible to researchers[….]” (AlgorithmWatch). It was also linked to the legal and ethical dimensions of data protection and online privacy, where an inherent trade-off was assumed: “Yet setting the ‘privacy cursor’ higher (by adding noise to data or removing outliers) could reduce the quality of data in unknown but potentially harmful ways” (Non-EU citizen). While the term “data quality” was frequently used and specific indicators were repeatedly listed, no clear systematization or in-depth conceptualization was evident. This is, of course, partly because data quality was not explicitly requested in the Call for Evidence. There are also selected examples of organizations that incorporated data quality-related aspects from earlier feedback entries. For instance, Avaaz adopted a sentence on completeness and accuracy almost verbatim from the Mozilla Foundation, which had submitted its feedback 1 day earlier.
In the second period of feedback, the role of data quality shifts once again. While research institutions and NGOs even increased to refer to data quality, Meta also directly addresses the issue. However, Meta inverts the researchers’ argument and their call for high-quality data by turning it on its head: the company argues that, given the inherently poor quality of platform data, providing such data to researchers would be futile, as it would not enable them to produce meaningful scientific results: “Moreover, providers should not be required to provide data of low accuracy. This generally means that data should a) be complete, such that researchers do not draw conclusions based on a small sample of available, i.e. non-null data; and b) inspire confidence in its accuracy, in order to prevent uncertainties from compounding in downstream analysis. It bears emphasizing that ‘existence’ and ‘accuracy’ are distinct criteria; data artifacts constructed in the service of low-level analyses should not be misconstrued as valid, or useful, for researchers’ needs” (Meta).
In the second period of feedback, academic institutions and NGOs still refer to data quality indicators in a similar manner, for example, the researchers from the Oxford Internet Institute highlighting the relevance of data quality for meaningful research: “Previous research has documented instances where platform-provided data or research tools proved inconsistent or misleading. To address these concerns, the Draft Act should require data completeness and quality assurances from the data providers. Without these additional safeguards and specific requirements, the risk of ‘transparency theatre’ – where platforms provide data that satisfy technical requirements without enabling meaningful oversight – remains significant.” In addition, researchers have proposed concrete methods to ensure data quality for DSA data, such as blinding during data preparation, so that platform staff compiling the data are unaware of the research purpose and thus avoid introducing bias (Karlsruhe Institute of Technology). Also, experiences with requests from public data access with Art. 40(12) were used to argue for higher data quality standards: “It will be important to outline how the accuracy of data (and statements about availability of data) can be verified. There has already been evidence of inaccuracy about data provided under 40(12), and the non-public nature of data under 40(4) will be even harder to verify” (AlgorithmWatch). In general, in feedback period 2, researchers are now additionally able to argue for data quality in a more concrete and targeted manner, as they now have the draft of the Delegated Regulation – which, as previously noted, does not explicitly address data quality – as a reference point. This reflects the absence of the term in any relevant policy document by the EU Commission before. In addition to invoking data quality in the same way as in the first feedback period, it is now used more specifically in connection with three central aspects: (1) Article 13 of the DR draft grants platforms, as data providers, the right to contest decisions made by the DSC and to initiate mediation proceedings. However, this right exists solely in favor of the platforms. In this context, poor data quality is cited by multiple stakeholder as an example illustrating why scientists and NGOs should likewise be granted the right to initiate mediation proceedings: “The Draft does not seem to include a mechanism that would allow researchers to issue a complaint if they find that the data that they received is insufficient in terms of quality (for example, regarding the granularity or the completeness of the data) or otherwise does not enable the research for which the request was made” (University of East Anglia). (2) Furthermore, academic institutions and NGOs expressed concern that platforms might argue that the relevant data are already available through other sources, thereby justifying the refusal to provide them again. In response, academics and NGOs contend that if the quality of such alternative data sources is insufficient, platforms should nonetheless be required to provide the data directly. (3) Data quality standards were also demanded for overviews of companies’ own data inventories 8 including the provision of sample data sets. Here, emphasis was placed on ensuring that these inventories are regularly updated to maintain their relevance and timeliness.
Overall, researchers and NGOs were partially successful in their efforts. However, regarding the mediation process, they were ultimately unsuccessful, as Article 13 still does not allow researchers to initiate such measures or processes. Regarding the second use case, however, data quality was explicitly incorporated into the DR for this very purpose. Accordingly, “evidence of poor quality or unreliability of such data deriving from other sources, or the unsuitability of the format in which such data may be retrieved from other sources for the purposes of the research project” (Recital 13) is now recognized as a legitimate ground for granting data access. The same applies to the data catalogues, as the DR emphasizes that “to ensure the relevance and timeliness of the DSA data catalogues, those catalogues should be updated regularly” (Recital 7). Research institutions also directly addressed the platforms’ attempts to reinterpret the role of data quality, as exemplified by the Amsterdam School of Communication Research: “It is important that “low quality data” should not be used by platforms as a reason not to provide a dataset, but rather potential limitations with the data must always be communicated clearly so researchers can correct for potential errors or biases in their analyses” (ASCoR). Also, Trilateral Research Limited frames “metrics of data quality, accuracy, consistency and completeness” as “internal standards” of platforms, not as something platforms could not assess. All in all, this shows how versatile data quality is used in the context of the DSA. While our exploratory study cannot “prove” any causal relationship, there is a clear chronological order between the frequency and volume of second period feedback and its inclusion in the Delegated Regulation.
Limitations of the analysis
Our analysis has several limitations. The Call for Evidence is a specific format within European regulatory processes: under the Better Regulation Framework (European Commission, 2026), “simplification and implementation” are key criteria of success. This implies that the Call for Evidence, as a data source, has inherent limitations that must be acknowledged. First, the specific goals of each Call for Evidence must be understood by all stakeholders; in several cases of our study, submitters seem not to follow the instructions for the respective feedback periods. Also, most actors submitted in only one of the two feedback periods, highlighting the inconsistency between them. Second, although we identified patterns in how actors used data quality (and its indicators), we cannot assume that all actors understand the term “data quality” in exactly the same way. The analysis suggests that, for many respondents, data quality functioned as a broad concept: actors typically linked data access and data quality in general terms and via indicators but rarely defined it or referred to a definition. Third, participation in the Call for Evidence is not representative of the broader interdisciplinary discourse on data quality. Fourth, our main finding – that data quality was often mentioned (or not) by specific stakeholders – should be regarded as indicative rather than definitive. Because data quality was not a predefined category, mentioning it is an indicator of concern; however, the motives for mentioning it vary and do not necessarily reflect a commitment to improving data quality (the case of Meta illustrates this). Conversely, failure to mention data quality does not necessarily indicate avoidance; it may simply reflect that data quality was not a pre-mentioned construct by the EU commission. For example, Wikimedia was classified as a company in some submissions and did not explicitly mention data quality, yet the organization places a high priority on information accuracy – a context that differentiates it from typical social media platforms. To address these flattening in the quantitative analysis, we highlight the importance of the qualitative analysis that preserves organization-specific detail. Finally, another limitation is that we could not include extrinsic data quality indicators in the analysis because they were not solicited in the Call for Evidence. Nevertheless, researchers and NGOs highlighted the importance of data documentation, metadata, and reproducibility; these aspects should be regarded as contextual limitations of our study. Future research could (a) extend the analysis to extrinsic aspects of data quality, (b) employ alternative data sources (e.g., interviews), and (c) investigate additional topics addressed in the Call for Evidence.
Conclusion
With 38.79% of the submitters across both periods referencing data quality – either in general or via specific indicators – it is evident that data quality constituted a significant thread in the discourse surrounding the feedback periods and the public negotiation of the DSA and Delegated Regulation. Here, the role of data quality is highly politicized. First, it was not part of the draft of the Delegated Regulation. The lack of attention to data quality in the DSA as well as the documents of the first period may partly reflect limited familiarity with the concept among EU actors, who primarily focused on data access. Another interpretation is that policymakers sought to preserve flexibility for platforms in how they provide data. In the second period, however, academic institutions and NGOs employed more concrete arguments regarding the significance of data quality and achieved partial success, as certain provisions were ultimately included in the Delegated Regulation. This refers primarily to the incorporation of data quality as a term, as well as specific indicators for the platforms’ data catalogs. However, in the absence of an agreed framework for data quality across research organizations and NGOs, it was unlikely to be operationalized more comprehensively or concretely than by merely including the term in the Delegated Regulation. This is also reflected by the fact that, although frequently mentioned in the feedback periods, data quality is not regarded as a core element of the procedure. For instance, neither Leerssen (2023)’s summary of the first feedback period nor the newly published Better Access Framework (Abdo et al., 2025) reference to data quality.
Despite the lack of detailed conceptualization beyond brief mentions of data quality and its indicators, we still find presumed patterns by different stakeholders. Researchers frequently emphasized the importance of data quality and data quality indicators, such as completeness and accuracy, for online platform data, linking these concerns to subtopics including diverse data collection methods, independent audits, mediation processes, and online privacy. Platforms and business associations, on the other hand, rarely mentioned data quality and, when they did, partially sought to invert or undermine the researchers’ arguments. Providing data quality would not only create a burden and would not be economically profitable for them but could also facilitate critical research on the platforms and their algorithms – an outcome contrary to their interests.
That data quality has still become prominent in the debate, despite its limited emphasis by the European Commission, underscores not only the success of the agenda-setting processes but also their general significance. Therefore, this case study suggests that academia needs to advance its conceptualization and systematization of online platform data quality. There also seems to be a need for new, independent actors to assess platform data quality and to provide long-term accountability and sustainable infrastructures for data-quality assessment. This independent assessment of data quality has been repeatedly called for by researchers and NGOs in their feedback on the DSA. Such institutions could, first, serve extrinsic data quality by establishing long-term archival structures that secure continued data access. Second, they could foster communication about intrinsic data quality by developing and promoting standardized approaches to data documentation. Third, these actors could create and provide benchmark datasets and data quality indicators, enabling systematic comparisons across platforms and over time. Fourth, they could establish auditing mechanisms for APIs and other data access modes to ensure transparency and reliability. Finally, they could assume a mediating role between research communities and platform providers by coordinating data needs within the research community and facilitating dialogue.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was conducted within KODAQS, a competence center for data quality in the social sciences. KODAQS is funded by the BMFTR (German Federal Ministry of Research, Technology and Space) and Next Generation EU.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
All raw data are publicly available via https://ec.europa.eu/info/law/better-regulation/have-your-say/initiatives/13817-Delegated-Regulation-on-data-access-provided-for-in-the-Digital-Services-Act_en. The annotated data set and code is publicly accessible via the linked ![]() .
.
Any other identifying information related to the authors
GESIS itself provided feedback in the second feedback round on the Delegated Regulation, the main object of study.