
Abstract
Amazon’s Mechanical Turk (MTurk) platform is a popular tool for scholars seeking a reasonably representative population to recruit subjects for academic research that is cheaper than contract work via survey research firms. Numerous scholarly inquiries affirm that the MTurk pool is at least as representative as college student samples; however, questions about the validity of MTurk data persist. Amazon classifies all MTurk Workers into two types: (1) “regular” Workers, and (2) more qualified (and expensive) “master” Workers. In this paper, we evaluate how choice in Worker type impacts the nature of research samples in terms of characteristics/features and performance. Our results identify few meaningful differences between master and regular Workers. However, we do find that master Workers are more likely to be female, older, and Republican, than regular Workers. Additionally, master Workers have far more experience, having spent twice as much time working on MTurk and having completed over seven times the number of assignments. Based on these findings, we recommend that researchers ask for Worker status and number of assignments completed to control for effects related to experience. However, the results imply that budget-conscious scholars will not compromise project integrity by using the wider pool of regular Workers in academic studies.
Introduction
Amazon’s Mechanical Turk (MTurk) program enables individuals (“Workers”) to complete a variety of “human intelligence tasks” (HITs) posted by “Requesters,” including academic researchers. Scholars utilize the platform for survey recruitment because it improves sample quality over conventional student pools while minimizing costs (Mason and Suri, 2012; Paolacci, Chandler, and Ipeirotis, 2010). However, validity concerns typically motivate researchers to mandate that Workers meet basic qualifications, such as having strong reputations for submitting satisfactory work (Peer, Vosgerau, and Aquisti, 2014). Yet another option exists that has received less attention in the MTurk literature: Amazon grants its highest-quality Workers a “Master Qualification.” In this project, we evaluate data generated by both “regular” and master Workers in order to identify potential advantages of using master Workers in social scientific research. While we find that master Workers are more representative in some key respects, their use only modestly affects research outcomes.
The MTurk pool: valid but increasingly professionalized
Audits of MTurk affirm that: (1) its population is as representative as other methods for recruiting subjects for political studies (e.g., Clifford, Jewell, and Waggoner, 2015), and (2) treatment effects obtained through experiments conducted using MTurk are extremely similar to effects obtained from population-based samples (Mullinix et al., 2015). However, MTurk is not immune to criticism concerning data quality. Some challenges stem from the utilization of novice Workers. Amateurs may be more easily distracted in their work (e.g., Peer, Vosgerau, and Aquisti, 2014), and are more likely to fail attention-check questions (ACQs) designed to identify if survey takers are focused on the task at hand (Peer, Vosgerau, and Acquisti, 2014). Not surprisingly, scholars often desire more experienced Workers to take their surveys.
However, experience may also provoke several research hazards: first, experienced Workers may develop an understanding of the social science research process that can compromise the naiveté that valid research assumes and requires. For example, many veteran Workers report familiarity with common experimental paradigms such as the Prisoner’s Dilemma (Chandler, Mueller, and Paolacci, 2014). Not surprisingly, there is also evidence of “practice effects” among frequent research participants that can affect downstream studies (e.g., Basso, Bomstein, and Lang, 1999). For instance, cooperation in social games conducted on MTurk has declined in recent years, possibly due to more prolific Workers learning from past experiences (e.g., Mason, Suri, and Watts, 2014).
Veteran Workers are also more apt to foil procedures set to track attentiveness (e.g., Hauser and Swarz, 2016). Moreover, while more experienced Workers tend to pass ACQs at higher rates (Peer, Vosgerau, and Aquisti, 2014), there may be adverse effects as a result of integrating them heavily into research protocols. High levels of ACQ exposure tend to produce suspicion, which can affect future responses (Mayo, Alfasi, and Schwarz, 2014). Finally, experienced Workers often identify preferred Requesters and seek out multiple tasks within the same laboratory, potentially compromising the independence of samples over multiple projects (e.g., Harms and DeSimone, 2015). If a particular survey is part of a series of related projects, some Workers may undertake a task while possessing some knowledge of the study that could influence their responses (e.g., Stewart et al., 2015). Thus, while more professional Workers are desirable in many respects, their experience may also be detrimental.
Master workers
Scholars recommend that MTurk researchers only recruit individuals whose work is accepted at a high rate (e.g., Peer, Vosgerau, and Aquisti, 2014), or who meet certain qualifications (e.g., Thomas and Clifford, 2017). Yet Amazon offers its own in-house method for identifying top talent: the “Master Worker” qualification. This designation is awarded to individuals that have “consistently demonstrated a high degree of success in performing a wide range of HITs across a large number of Requesters.” 1 Individuals cannot apply for it. Amazon determines which Workers earn master status through a proprietary algorithm, but indicates that some factors include “the Worker’s ability to consistently submit high-quality results, [. . .] marketplace tenure, and variety of work performed.” 2 Given that scholars tend to focus principally on the rate of work acceptance as a measure of Worker quality—a measure that ignores the deleterious effects stemming from Workers specializing in particular types of tasks (Harms and DeSimone, 2015)—Amazon’s Master Qualification may represent a more robust gauge of overall worker quality.
In this paper, we seek to answer two key questions. First: do master Workers generate significantly different research results than regular Workers? Second: are they worth the higher costs required to utilize their services? 3 To identify whether and to what degree such differences exist, we designed a comprehensive survey containing a variety of measures, tests, and experiments. Our goal is to assess whether the two types of Workers generate meaningfully different data when assessed in isolation. 4
Study design
To identify similarities and differences across regular and master Worker populations, we developed a series of experiments that generated several types of data for comparison. The five experiments were selected to vary in their cognitive complexity, as well as to be representative of common experimental paradigms employed in survey research. 5 The first two test the effects of source cues. One is a simple candidate evaluation experiment based on Rahn’s seminal (1993) study whereby the partisan affiliation of a candidate for office differs between conditions (Democratic, Republican, or unspecified). We expect partisan source cues will significantly affect individuals’ perceptions of candidate ideology. The second experiment is a new study testing the effects of a more subtle cue—marital status—on candidates’ appeal to voters. We expect individuals will perceive married politicians to be more appealing than divorced politicians.
The second set of experiments tests framing effects. Experiment 3 replicates a classic framing paradigm developed by Nelson, Clawson, and Oxley (1997). Participants were randomly assigned to read one of two versions of a newspaper story about a proposed Ku Klux Klan rally: one with a free speech emphasis, and the other with a public safety emphasis. After reading the story, respondents were asked to decide if they would support or oppose issuing the KKK a rally permit.
Experiment 4 replicates the risk aversion scenario developed by Kahneman and Tversky (1984). Participants evaluated one of two scenarios in which they had to make a life or death choice. In the first condition, outcomes were framed in terms of potential losses: Program A would guarantee that 400 of 600 people would die, while Program B would provide a 1-in-3 probability that none of the 600 would die, and a 2-in-3 probability that all 600 would die. In the second (mathematically equivalent) condition, the programs were framed in terms of the number of people saved: Program A guaranteed that 200 of 600 people would live, while Program B produced a 1-in-3 probability that all 600 would live, and a 2-in-3 probability that no one would live. Respondents then selected their preferred program: A or B.
The fifth experiment varies the version of the cognitive reflection test (CRT). Participants were randomly assigned to receive either the original (Frederick, 2005) or new (Finucane and Gullion, 2010) version of the CRT. The goal is to identify non-naiveté using a strategy developed by Chandler, Mueller, and Paolacci (2014). These scales consist of three related problems that are at once simple to solve, but also easy to miss if the question is not considered carefully. For example: “A bat and a ball cost $1.10 in total. The bat costs $1.00 more than the ball. How much does the ball cost?” It may be tempting to say the ball costs $0.10, but this would make the bat cost $1.10, leading to a grand total of $1.20 for the pair of items. We expect that master Workers are more likely to have seen the old (original) version more often and therefore would score higher through experience. However, this is less likely to be the case for the new version of the scale. A summary of these five experiments is shown in Table 1.
Summary of experiments.

Several sets of measures complete the study. These include the modern racism scale (McConahay, 1986), a political knowledge inventory, 6 as well as a set of questions related to respondents’ MTurk activity, such as how many HITs Workers have completed in their lifetimes. We also include standard demographic measures and an ACQ as the final item. 7 The directions instruct participants to select the last option (“lotteries”) while the question text asks participants to select the topic of the survey from several choices. Careless respondents are much more likely to pick a seemingly relevant option like “politics.” Finally, we capture Worker IP addresses in order to examine if the probability that respondents are using a proxy or VPN to mask their true IP address and geolocation, which could be used to circumvent restrictions on location and/or complete the survey multiple times.
Recruitment method and sample
We recruited 600 MTurk Workers across two 300-person waves to participate in the study. 8 During both periods, we initially only permitted Workers with the master qualification to participate. After master Workers completed the survey, the survey was immediately posted again but this time regular workers were able to participate. 9 In both phases, we restricted eligibility to Workers with a 90 percent or higher work approval rating and with a work history comprising at least 100 HITs. Such restrictions are common in research using MTurk in order to help ensure quality data.
Results: worker characteristics
The demographic characteristics of the sample are presented in Table 2. Our principal interest is to diagnose differences across Worker types. Significant differences between regular and master Workers are bolded in the rightmost column. The master Worker group: (1) contained more women, (2) was slightly older, and (3) comprised more Republicans and fewer independents. Given MTurk’s well-documented overrepresentation of younger and more Democratic individuals within its ranks, these differences render the master Worker group somewhat more representative of the U.S. population. We also examine several characteristics of Workers. Two findings stand out: first, there is a marginally significant difference in political knowledge between Worker types (p=0.06); second, master Workers score significantly higher on the modern racism scale (p<0.05).
Sample demographics and characteristics by Worker type.

Standard errors in parentheses.
Significant differences (p<0.10) indicated in bold typeface.
Education was measured on the following seven-point scale: less than high school (1), high school/GED (2), some college (3), 2-year college degree (4), 4-year college degree (5), Masters degree (6), doctoral or professional degree (JD, MD) (7).
Income was measured on the following fifteen-point scale: <20,000 (1), 20,000–29,999 (2), 30,000–39,999 (3) . . . 140,000–149,999 (14), 150,000+ (15).
Ideology was measured on a 1 (very liberal) to 7 (very conservative) scale.
While the actual mean number of HITs is reported in the table, the t-test was conducted using the natural log of the total number of HITs.
This was measured using the following six-point scale: a few times per year (1), once or twice a month (2), once a week (3), 2–3 times a week (4), 4–6 times a week (5), daily (6).
Next, we analyzed measures related to MTurk usage. Master Workers report being on the platform an average of three years longer than regular Workers—or roughly twice the tenure of regular Workers (p<0.01). Unsurprisingly, this difference manifests itself in overall productivity: master Workers self-report an average of 195,026 HITs completed, which is roughly ten times the 19,791 (on average) tasks reported by non-master Workers (p<0.01). Yet there does not appear to be much difference in reported performance. Both groups indicate an HIT acceptance rate of approximately 97 percent (p=0.47) and high levels of self-reported attentiveness when completing surveys (p=0.68). However, there is a significant difference in ACQ failure rate: 0.63 percent for master Workers and 3.52 percent for regular Workers. Master Workers do appear to be more attentive, or at least better able to spot an ACQ due to experience (p=0.01).
Finally, following Kennedy et al. (2018), we examined the likelihood that respondent IP addresses were proxies, which would indicate a higher likelihood of respondents taking the survey multiple times, or being located outside of the United States. We used IP Intel to generate scores ranging from 0 to 1, corresponding with the probability that an IP address is a proxy or VPN. We flagged addresses as likely proxies at two thresholds recommended by IP Intel: 0.9 and 0.95 (indicating a >90 percent or >95 percent chance that the address is generated through a proxy or VPN). While fewer than 5 percent of all IP addresses cross either threshold, those that did were more frequently associated with regular Workers compared to master Workers (p=0.05 and p=0.02, respectively). This is consistent with the expectation that data generated by master Workers are less likely to be fraudulent.
Source cue effects (Experiments 1 and 2)
Experiment 1 varied the stated partisanship of a political candidate. Figure 1 (Panel A) presents the findings. Using analysis of variance (ANOVA) tests for both Worker groups, we found that among both regular Workers, F(2, 281)=55.24, p<0.01, and master Workers, F(2, 313)=117.24, p<0.01, the Republican (Democratic) candidate was seen as most conservative (liberal), with the unspecified candidate rated in between. We also conducted a three (source cue) × two (Worker type) factorial ANOVA to examine potential interactive effects. There was no main effect, F(1, 594)=0.1.85, p=0.26, nor interaction effect, F(2, 594)=2.71, p=0.16, for master status. In addition, while the model explained 35.7 percent of the total variance, the source cue condition accounted for nearly all of it (η2=0.35). Neither master status (η2=0.002) nor the interaction (η2=0.006) explained a meaningful amount of variation in perceptions of candidate ideology.
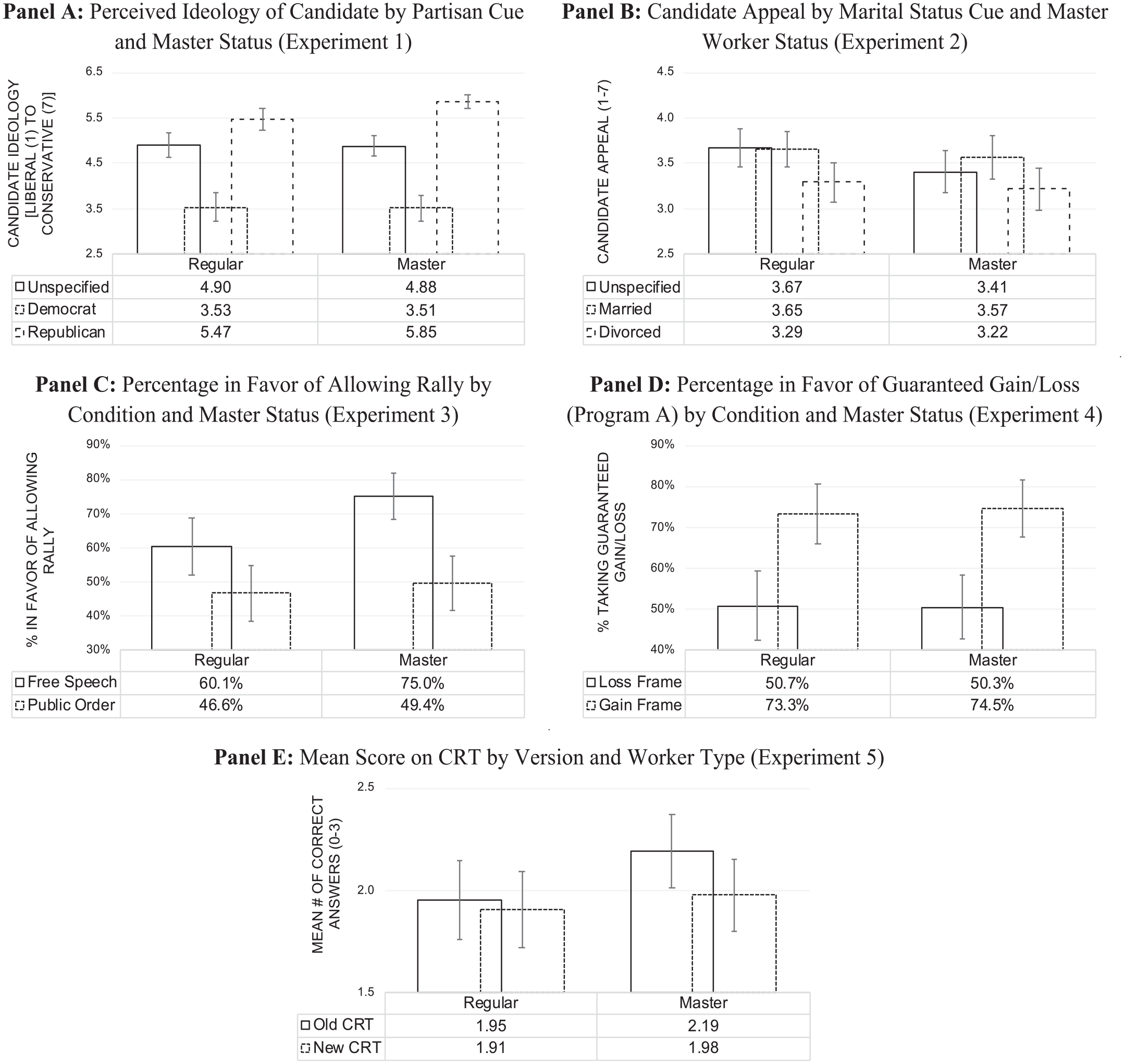
Experimental results by worker status.
Experiment 2 varied a more subtle cue: marital status (married, divorced, unspecified). The dependent variable is candidate appeal using a seven-point scale, where higher values indicate more appeal. The results are shown in Figure 1 (Panel B). Here we do observe modestly different patterns of behavior across Worker types. There are significant differences in candidate appeal among regular Workers, F(2, 281)=4.17, p=0.02, who perceived the divorced candidate as significantly less appealing than the married (p=0.04) and unspecified (p=0.04) candidates. Meanwhile, master Workers F(2, 313)=2.20, p=0.11, viewed all candidates as equally appealing. However, in a three (source cue condition) × two (Worker type) factorial ANOVA, there is neither a main effect of master status, F(1, 594)=2.96, p=0.12, nor an interactive effect between master status and source cue condition, F(2, 594)=0.55, p=0.64. Master Workers simply rated all candidates to be of roughly equal appeal, while regular Workers indicated a preference for the unspecified and married candidates relative to the divorced candidate. In short, save for some minor distinctions, both worker groups produce similar results in source cue experiments.
Framing effects (Experiments 3 and 4)
The third experiment frames a Ku Klux Klan rally in terms of free speech or public safety. Figure 1 (Panel C) indicates the percentage in favor of allowing the Ku Klux Klan rally, contrasting results by master status and framing condition. Using logistic regression, we successfully replicate the original study: respondents in the free speech condition were significantly less likely to favor the rally (p=0.02). 10 We also find a main effect of Worker type, with master Workers more likely to favor allowing the rally (p<0.01). There is a significant difference in proportions in the free speech (χ2=7.53, p<0.01), though not the public safety (χ2=0.24, p=0.63) condition, resulting in a marginally significant interaction between Worker type and condition (p=0.09).
Experiment 4 successfully replicates Kahneman and Tversky’s (1984) classic framing study. Employing logistic regression, we find respondents are more likely to choose a guaranteed outcome if it is framed in terms of a gain rather than a loss (p<0.01), as shown in Figure 1 (Panel D). There is no main effect of Worker type (p=0.94) nor a significant interaction between Worker type and condition (p=0.82). In short, both framing studies indicate Worker type has only minor effects on experimental outcomes, with the same pattern of results observed across worker types.
The CRT (Experiment 5)
In Experiment 5, participants were randomly assigned to either the old or new version of the CRT. Figure 1 (Panel E) presents the comparisons of Worker types across the two inventories. We expected that master Workers may score higher on the (more common) old version but not the (less common) new version. There is little variation in performance across either CRT version, t(1, 598)=1.41, p=0.16. However, there is a marginally significant difference by Worker type on the old version, t(1, 297)=1.81, p=0.07, but not on the new version, t(1, 299)=0.54, p=0.59, consistent with the expectation of master Workers being more experienced with the old version of the CRT.
We next employ OLS regression to predict the CRT score by Worker type, experience, and CRT version. Table 3 presents the results, which indicate an effect for Worker experience, as measured by the natural log of HITs completed. Workers who have completed a greater number of HITs score significantly higher on the CRT. However, we find no evidence that master status or CRT version affects performance; all interaction terms are statistically insignificant. Rather, more experienced Workers appear to be better at answering these questions—a pattern consistent with concerns about expertise compromising non-naiveté. Interestingly, while master Workers have completed a high number of HITs in order to get their master qualification, these individuals do not score higher on the CRT scale overall. This suggests that the Master Qualification itself is not as strong an indicator of non-naiveté as overall experience completing HITs.
Predicting CRT score by version and Worker type/experience.

p<0.10; **p<0.05; ***p<0.01.
Standard errors in parentheses.
Conclusion
This project yields important insights concerning differences in composition and performance across MTurk Worker types. First, both groups generated similar replications across multiple experiments. Second, master status did not predict any significant differences on the CRT, including the newer version. Critically, master status in and of itself does not appear to indicate greater non-naiveté. However, the groups do differ in some important respects: the master Worker pool is older, more Republican, and contains more women. These individuals also have far greater experience using MTurk. Those with more experience tend to score higher on the CRT, suggesting that experience may indeed condition responses to commonly used psychometric measures.
What do these findings suggest about how researchers should use MTurk workers in the future? First, scholars need not worry that including (omitting) particular Worker categories will dramatically affect their results. However, using master Workers does provide some quality assurances. Common concerns about using MTurk, such as using proxies or VPNs that allow non-U.S. Workers or repeat participants to complete HITs multiple times using different IP addresses, appear to be less likely among master Workers. Additionally, master Workers can improve sample representativeness by boosting the presence of groups that tend to be underrepresented in the MTurk pool. The differences we uncover also suggest that, at a minimum, scholars consider including variables in their models to account for Worker type and experience. Ultimately, while we are encouraged to report that research findings are only minimally impacted by Worker type, utilizing master Workers may help assuage concerns about MTurk sample quality overall.
Supplemental Material
ONLINE_APPENDIX – Supplemental material for Distinction without a difference? An assessment of MTurk Worker types
Supplemental material, ONLINE_APPENDIX for Distinction without a difference? An assessment of MTurk Worker types by Eric Loepp and Jarrod T. Kelly in Research & Politics
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental materials
The replication files are available at https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/VX6ST9&version=DRAFT
Notes
Carnegie Corporation of New York Grant
This publication was made possible (in part) by a grant from the Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the author.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.