
Abstract
Objective:
To establish and validate a deep learning model that simultaneously segments pediatric burn wounds and grades burn depth under complex, real-world imaging conditions.
Methods:
We retrospectively collected 4785 smartphone or camera photographs from hospitalized children over 5 years and annotated 14,355 burn regions as superficial second-degree, deep second-degree, or third-degree. Images were resized to 256 × 256 pixels and augmented by flipping and random rotation. A DeepLabv3 network with a ResNet101 backbone was enhanced with channel- and spatial attention modules, dropout-reinforced Atrous Spatial Pyramid Pooling, and a weighted cross-entropy loss to counter class imbalance. Ten-fold cross-validation (60 epochs, batch size 8) was performed using the Adam optimizer (learning rate 1 × 10⁻⁴).
Results:
The proposed Deep Fusion Network (attention-enhanced DeepLabv3-ResNet101, Dfusion) model achieved a mean segmentation Dice coefficient of 0.8766 ± 0.012 and an intersection-over-union of 0.8052 ± 0.015. Classification results demonstrated an accuracy of 97.65%, precision of 88.26%, recall of 86.76%, and an F1-score of 85.33%. Receiver operating characteristic curve analysis yielded area under the curve values of 0.82 for superficial second-degree, 0.76 for deep second-degree, and 0.78 for third-degree burns. Compared with baseline DeepLabv3, FCN-ResNet101, U-Net-ResNet101, and MobileNet models, Dfusion improved Dice by 15.2%–19.7% and intersection-over-union by 14.9%–23.5% (all p < 0.01). Inference speed was 0.38 ± 0.03 s per image on an NVIDIA GTX 1060 GPU, highlighting the modest computational demands suitable for mobile deployment.
Conclusion:
Dfusion provides accurate, end-to-end segmentation and depth grading of pediatric burn wounds captured in uncontrolled environments. Its robust performance and modest computational demand support deployment on mobile devices, offering rapid, objective assistance for clinicians in resource-limited settings and enabling more precise triage and treatment planning for pediatric burn care.
Keywords
Introduction
Burns are one of the leading causes of fatal injuries in children. Compared to adults, children are more vulnerable to burns due to their lower awareness of danger and inability to react promptly and appropriately. 1 Additionally, children have a relatively larger body surface area, which results in greater fluid loss and rapid onset of systemic symptoms in case of burns. Children have thinner skin than adults, making them more susceptible to deeper burns at lower temperatures and shorter exposure times. 2 Furthermore, distinguishing the severity of burns in children is challenging due to their thinner skin. Improper early management can easily lead to deeper wounds. Therefore, early professional identification of pediatric burn wounds is crucial. 3 However, current epidemiological studies on burns indicate that burns are more common in economically underdeveloped areas where medical resources are limited, and there is a lack of specialized pediatric burn doctors. 1 Thus, deep learning models for pediatric burn wound recognition hold significant value for guidance.
Related work
Most existing models for burn wound recognition use convolutional neural networks (CNN) and their variants, such as U-Net, MobileNet, and Mask R-CNN. 4 These models can automatically extract image features without manual parameter adjustment, greatly improving the efficiency of image processing tasks. However, most models for burn wounds either achieve wound segmentation or burn severity recognition but rarely accomplish both tasks simultaneously.5,6 Current deep learning models for medical image segmentation and classification, such as U-Net and MobileNet, have shown success in controlled environments, but they often lack robustness under complex, real-world imaging conditions, as indicated by recent studies addressing robust segmentation in challenging domains like autonomous vehicle control.7,8 Additionally, the datasets for burn wound recognition are limited and often consist of images taken under the same conditions, which differ significantly from real medical environments. In real life, burn wound images are taken under various conditions with different brands of mobile phone cameras, often with complex backgrounds, posing challenges for image recognition. Moreover, distinguishing burn depth in children is more difficult than in adults due to their thinner skin.2,9,10 There is also a lack of pediatric burn wound datasets, leading to limited research on image recognition models for pediatric burns. As a national pediatric hospital, our institution has long been receiving and treating pediatric burn patients, accumulating a considerable number of pediatric burn wound images. By analyzing these images, we aim to develop a deep learning model capable of both image segmentation and burn severity recognition.
This article is structured as follows: Section “Materials and methods” presents our data collection methods, annotation protocol, model architecture, and validation procedures. Section “Results” outlines detailed performance metrics and comparisons with classical CNN methods. Section “Discussion” discusses clinical implications, model robustness under real-world conditions, potential clinical impact of misclassification, and study limitations. Section “Conclusion” summarizes our conclusions and suggests future research directions.
Materials and methods
The overall workflow of our methodology is illustrated in Figure 1. This flowchart summarizes the main steps, including image acquisition, preprocessing and annotation, data augmentation, model construction, model training, and performance evaluation.
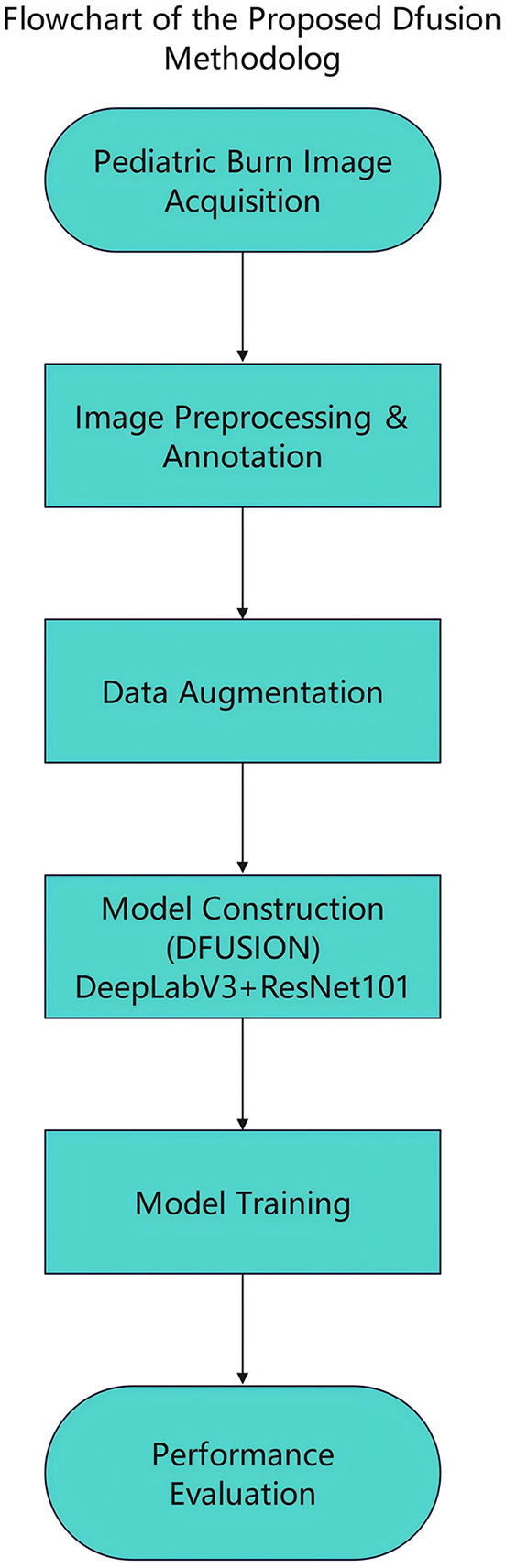
Flowchart of the proposed Dfusion methodology. The diagram provides a concise summary of the main methodological stages: (1) pediatric burn image acquisition from smartphones and digital cameras; (2) image preprocessing and annotation by physicians; (3) data augmentation using flipping, rotation, brightness adjustment, and Gaussian noise addition; (4) model construction based on DeepLabv3 and ResNet101 with custom attention mechanisms; (5) model training utilizing 10-fold cross-validation and weighted loss functions; (6) performance evaluation using segmentation and classification metrics. Specific details on annotation methods, augmentation strategies, model architecture, training parameters, and performance evaluation metrics are elaborated upon within the section “Materials and methods” of the article.
Data collection
We collected clinical photographs of pediatric burn patients, including both inpatients and outpatients, treated at our institution over the past 5 years (2020–2024). To ensure the photos are representative of real medical scenarios, they were taken by family members or medical staff using personal mobile phones or digital cameras, ensuring data authenticity and diversity. Photos were acquired from diverse devices (Apple, Huawei, Samsung, digital cameras) to reflect real-world variability. Before using these photos, we confirmed that each image contained burn wounds. Additionally, we obtained explicit authorization from the patients’ families for the use of these photos, respecting and protecting patient privacy and rights.
Image data processing
The burn wounds were categorized into first-degree, superficial second-degree, deep second-degree, and third-degree burns. Ground truth annotations for burn depth and area were determined by a panel of six physicians: three senior physicians and three intermediate-level physicians. To ensure annotation reliability, inter-rater agreement among the six annotating physicians was evaluated, resulting in a Cohen’s kappa coefficient of 0.86, indicating substantial consistency. The annotations were based on their consensus judgment following detailed clinical assessments, including visual inspection, patient history, and physical examination.
Histological evaluation or healing outcomes were not routinely used as ground truth due to the logistical constraints of retrospective data collection and ethical considerations in obtaining biopsy samples from pediatric patients. Instead, the annotations reflect expert clinical evaluations, which align with real-world diagnostic practices in pediatric burn care.
The annotation process was conducted using Labelme, an open-source annotation tool.
Model architecture
We employed a DeepLabv3 model with a ResNet101 backbone for burn wound segmentation. The DeepLabv3 architecture is well-regarded for its ability to perform semantic segmentation tasks, particularly due to its integration of the Atrous Spatial Pyramid Pooling (ASPP) module. 11 The ASPP module uses parallel atrous convolution layers with varying dilation rates, effectively capturing multi-scale contextual information. This capability enhances the model’s adaptability to objects of different sizes within an image, an essential feature for handling the variability in pediatric burn wound images. To improve its robustness and generalization in our task, we incorporated a Dropout layer into the ASPP module. This addition minimizes overfitting, particularly in scenarios with limited and diverse datasets, as is the case in our study.
Custom attention mechanism: rationale and justification
Burn wound images often feature complex backgrounds, variable lighting conditions, and subtle differences in burn severity. Conventional convolutional layers may not sufficiently focus on the most relevant features in such challenging conditions, leading to potential misclassification or segmentation errors. The Custom Attention Mechanism was introduced to address these challenges by adaptively enhancing important spatial and channel-specific features during training. This approach ensures that the model focuses on clinically relevant regions (e.g., burn-affected areas) while suppressing noise or irrelevant information (e.g., background artifacts).
Key objectives
Channel attention: Improves the model’s ability to prioritize channels that contribute most significantly to feature extraction, enabling enhanced identification of subtle variations in burn depth and severity.
Spatial attention: Focuses the model on spatial regions of interest (ROI), ensuring more accurate segmentation and boundary delineation between healthy and burn-affected skin.
Mechanistic implementation
The Custom Attention Mechanism was implemented as follows:
1. Channel attention:
● For each feature map produced by a convolutional layer, global average pooling and global max pooling were applied to generate two descriptors. These descriptors summarize the importance of each channel globally.
● A shared multi-layer perceptron was then applied to these descriptors, followed by a sigmoid activation to produce attention weights for each channel.
● The attention weights were multiplied by the original feature map to emphasize the most relevant channels.
Mathematically:

where Mc represents channel-wise attention weights, F is the feature map, σ is the sigmoid function, and global average pooling (GAP)/global max pooling (GMP) are global average/max-pooling functions.
2. Spatial attention:
● For spatial attention, the feature map was pooled along the channel axis using both max-pooling and average-pooling operations, resulting in two 2D descriptors.
● These descriptors were concatenated and passed through a convolutional layer followed by a sigmoid activation to generate a spatial attention map.
● The spatial attention map was then element-wise multiplied with the input feature map to enhance spatially significant regions.
Mathematically:

where Ms is the spatial attention map, F is the input feature map, and Conv represents the convolutional operation.
Impact on the model
The addition of channel and spatial attention mechanisms improved the model’s ability to
Distinguish between burn areas of varying severities, even under complex backgrounds or poor image quality.
Enhance segmentation accuracy by focusing on relevant regions while ignoring irrelevant information.
Performance comparisons with and without attention mechanisms demonstrated measurable improvements in segmentation metrics, including Dice coefficient and intersection-over-union (IoU). These enhancements validate the necessity and effectiveness of the attention mechanisms in addressing the challenges of pediatric burn wound image analysis.
Mitigating model bias
To ensure protection against model bias:
Data diversity: Training data was carefully curated to include diverse imaging conditions, camera types, and patient demographics.
Objective implementation: The attention mechanisms were applied uniformly across all images, with no subjective selection or manipulation of data during training or testing.
Evaluation: The model was rigorously evaluated on an independent test set using multiple performance metrics to ensure generalization and robustness.
Training configuration
The dataset was split using 10-fold cross-validation. In each fold, 90% of the data was used for training and 10% for testing. A weighted cross-entropy loss function was used to address class imbalance. Hyperparameters, including learning rate (1e-4) and dropout rate (0.3), were selected empirically through initial tests, balancing model convergence and avoiding overfitting, consistent with standard CNN optimization practices. 8 The model was optimized using the Adam optimizer with a learning rate of 1e-4. Training was carried out for 60 epochs with a batch size of 8. The model was trained on an NVIDIA CUDA-compatible GPU to accelerate the computation process.
Performance evaluation
The model’s performance was evaluated using a comprehensive suite of metrics: accuracy, precision, recall, F1-score, Dice coefficient, and IoU. These metrics were calculated to assess two specific outcomes 12 :
Segmentation accuracy: The ability of the model to delineate the boundaries of burn wounds, distinguishing affected areas from healthy skin.
Burn depth classification: The ability of the model to classify burn wounds into predefined categories (superficial second-degree, deep second-degree, and third-degree burns).
Receiver operating characteristic curve analysis
To further evaluate the model’s performance in classifying burn wounds, receiver operating characteristic (ROC) curve analysis was conducted for each burn severity category. This analysis provides a comprehensive evaluation of the model’s sensitivity (true positive rate) and specificity (1—False Positive Rate) across various classification thresholds. For this study, ROC curves were computed for each burn severity class (superficial second-degree, deep second-degree, and third-degree burns) using the predicted probabilities output by the model.
Ground truth or reference
For segmentation, the ground truth was derived from the annotated regions provided by the physician panel. For classification of burn depths, the labels were based on consensus among three senior and three intermediate-level physicians, following detailed clinical evaluation (e.g., visual inspection, patient history, and physical examination).
The model’s predictions were compared to these annotated ground truths to compute the performance metrics. Specifically:
Accuracy: Assessed the proportion of correctly predicted burn wound areas and burn depth classifications relative to the total annotated dataset.
Precision and recall: Evaluated the model’s ability to correctly identify burn regions and their corresponding depths, with precision focusing on minimizing false positives and recall emphasizing the identification of all true positives.
F1-score: Provided a balanced measure of precision and recall.
Dice score and IoU: Quantified the overlap between predicted segmentation maps and ground truth annotations, reflecting spatial accuracy in burn wound delineation and the distinction between different burn severity levels and healthy skin.
Handling pixel-level and boundary mislabeling
The evaluation was conducted at the pixel level, where each pixel in the test samples was compared against the corresponding pixel in the ground truth annotations. This pixel-level approach ensured that boundary errors were directly reflected in metrics such as Dice coefficient and IoU, which are sensitive to spatial mismatches.
To account for the potential impact of boundary errors, the evaluation also considered the following aspects:
Boundary mislabeling: Boundary regions between burn areas of different severities or between burn wounds and healthy skin were occasionally mislabeled. These errors were factored into the metrics, particularly Dice coefficient and IoU, which penalize discrepancies in overlap.
ROI: Burn wounds in each image were segmented into defined ROIs during annotation. These ROIs helped refine the evaluation by localizing analysis within specific regions of the image.
Per-image evaluation for classification: For burn depth classification, each burn wound within an image was treated as a discrete region. Labels were assigned to the entire ROI, and predictions were compared to the ground truth for classification metrics.
Metric calculation and interpretation
Each metric’s calculation was grounded in the detection outcomes: true positives, false positives, true negatives, and false negatives. By running the model on the test set without gradient calculation, the predictions and true labels were collected for further analysis. These outcomes allowed the model’s performance to be assessed under varied operational conditions, providing insights into its robustness and accuracy for real-world applications.
This evaluation methodology ensures a balanced consideration of pixel-level precision, region-level accuracy, and the ability to generalize across diverse images, making it reflective of practical clinical scenarios.
Results
Dataset
A total of 694 pediatric patients were included in this study, with a mean age of 5.2 ± 1.3 years. The male-to-female ratio was 1.28:1. Scald injuries accounted for 92% of cases, while the remaining cases were due to flame burns. The mean total body surface area affected was 12.3% ± 2.5%. In 83.2% of patients, burns were located on the trunk and extremities, whereas the remaining cases involved facial burns.
Through photo collection, a total of 4785 images were selected. These photos were sourced from hospitalized children receiving treatment at our hospital. Many of these children had extensive burn areas and possibly multiple burn sites with varying degrees of severity. All the photos were taken by family members or medical staff using personal phones or digital cameras, resulting in varying shooting environments and conditions (Figure 2). Through the annotation of burn wounds, a total of 14,355 pediatric burn wounds were identified, including 4307 superficial second-degree burns, 8613 deep second-degree burns, and 1435 third-degree burns. For convenience in training, all the photos were resized to 256 × 256 pixels (Figure 3).

Images of burn wounds under varying conditions, including different imaging equipment, backgrounds, and environmental settings. The dataset predominantly consists of such photographs. In this figure, (a, b) represent superficial partial-thickness burns, (c, d) depict deep partial-thickness burns, and (e, f) illustrate full-thickness burns.

Images of pediatric burn wounds with annotations. (a, b) Represent superficial partial-thickness burns, while (c, d) depict deep partial-thickness burns. (e, f) Illustrate full-thickness burns. The original images of these annotated examples are as shown in Figure 2.
Due to the difficulty in data collection and the lack of sufficient data, we employed data augmentation methods, including flipping and random rotation, as effective strategies to mitigate data scarcity, enhance performance, and minimize prediction errors.
To further enhance the model’s robustness against real-world imaging uncertainties, we implemented additional data augmentation techniques beyond flipping and rotation. Specifically, we applied random brightness adjustment to simulate varying lighting conditions and introduced Gaussian noise to mimic sensor and environmental noise. These augmentations aimed to improve the model’s generalization ability under diverse and unpredictable imaging scenarios. Such strategies have been shown effective in previous robust validation studies of medical image analysis. 13 All the augmented images were included in the training set to maximize model exposure to a broad spectrum of imaging conditions. To ensure the reliability of the experiments, all the experiments in this study were conducted using 10-fold cross-validation. Specifically, the dataset was divided into 10 equal parts, each serving as a test set once, while the remaining 9 parts served as the training set. The model was trained for 60 epochs each time, and validation was performed on the test set. The average of the 10 training and validation runs was calculated as the final result. This method provides robust validation for small datasets, enhancing the model’s generalization and accuracy.
Model adjustments
In this study, we used the pre-trained DeepLabv3 model (based on ResNet101) as the baseline model. DeepLabv3 is a deep learning model widely used for image semantic segmentation, effectively capturing multi-scale information through the introduction of the ASPP module. However, traditional DeepLabv3 models have some limitations in dealing with burn wound images in complex backgrounds. Therefore, we implemented several improvements.
Custom attention mechanism
To enhance the model’s ability to handle different channel features and spatial dimensions, we introduced custom attention mechanisms, including Channel Attention and Spatial Attention. The Channel Attention mechanism adjusts the importance of each channel adaptively, enhancing the model’s response to significant channels during feature extraction. The Spatial Attention mechanism emphasizes important spatial areas in the image, improving the model’s feature extraction capabilities in the spatial dimension.
Improvements to the ASPP module
We added a Dropout layer to the original ASPP module. The Dropout layer is an effective regularization technique that prevents the model from overfitting, especially in training with small datasets, significantly enhancing the model’s generalization ability and robustness.
Weighted loss function
Due to the imbalance in the distribution of different categories of burn wounds in the dataset, we employed a weighted cross-entropy loss function. By assigning different weights to different categories, the model can better balance the importance of each category during training, thereby improving performance on less frequent categories (Figure 4).

Training duration and iteration convergence curves for the Deep FusionNet model. The x-axis represents the number of iterations, and the y-axis shows the changes in training metrics.
Recognition experiment results
We compared the improved model with commonly used image recognition models. The recognition experiment results are shown in Table 1. The Dfusion model achieved an average accuracy of 97.65%, an average precision of 88.26%, an average recall of 86.76%, an F1-score of 85.33%, a Dice coefficient of 87.66%, and an IoU of 80.52%.
Performance of pediatric burn wound recognition models.
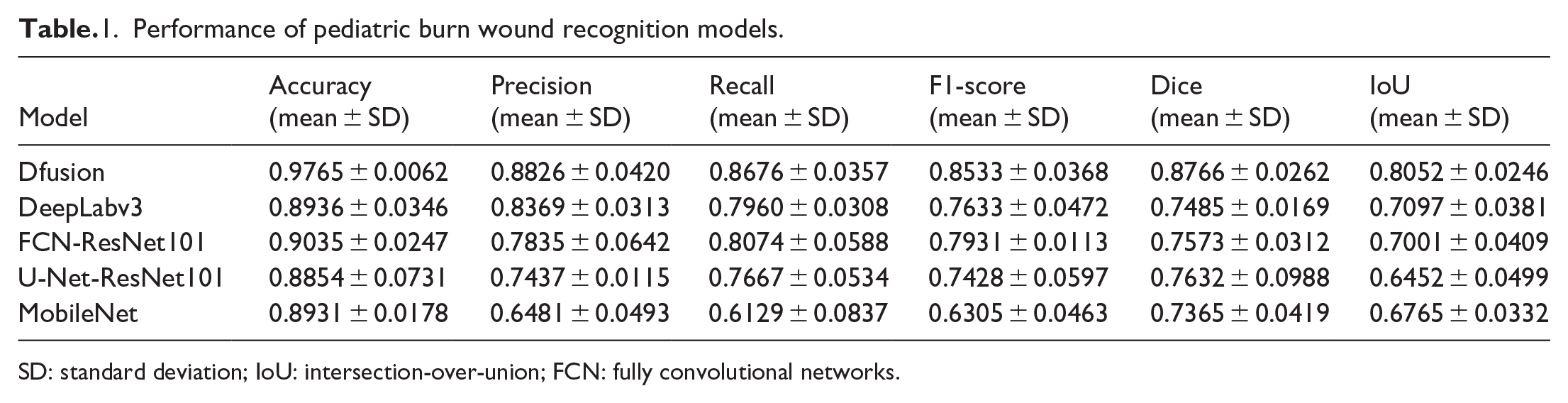
SD: standard deviation; IoU: intersection-over-union; FCN: fully convolutional networks.
Compared with baseline DeepLabv3, FCN-ResNet101, U-Net-ResNet101, and MobileNet models, Dfusion improved Dice by 15.2%–19.7% and IoU by 14.9%–23.5% (all p < 0.01).
Inference speed was measured at 0.38 ± 0.03 s per image on an NVIDIA GTX 1060 GPU, highlighting the modest computational demands suitable for potential deployment on mobile devices.
These metrics indicate superior performance in accurately segmenting and identifying superficial second-degree, deep second-degree, and third-degree burns in children, compared to other models such as DeepLabv3, FCN-ResNet101, MobileNet, and U-Net-ResNet101 (Table 1). This result verifies that the introduction of attention mechanisms, improvements to the ASPP module, application of data augmentation strategies, and use of a weighted loss function significantly enhanced the model’s performance in burn wound image recognition tasks under complex backgrounds. Unlike previous binary classification experiments, we found that not only Dfusion but also structures such as U-Net and fully convolutional networks (FCN), when combined with ResNet101, could simultaneously achieve segmentation and recognition of multiple burn categories (Figure 5). Furthermore, the model effectively performed burn wound segmentation and recognition under different backgrounds and shooting conditions.

Performance of various image recognition models on the pediatric burn wound dataset. “SII” denotes superficial partial-thickness burns, “DII” represents deep partial-thickness burns, and “III” indicates full-thickness burns.
ROC curve results
ROC curve analysis indicated differences in area under the curve values (superficial second-degree: 0.82; deep second-degree: 0.76; third-degree: 0.78), primarily due to inherent class imbalance and subtle visual differentiation between burn severity classes. These results confirm the model’s high discriminatory power for burn severity classification, providing reliable support for clinical decision-making.
Computational complexity and training time
The computational complexity of the proposed Dfusion model was evaluated on an NVIDIA GTX 1060 GPU (6GB VRAM). The average inference time per image was approximately 0.38 ± 0.03 s, indicating the modest computational requirements suitable for clinical and mobile-device applications. For the training phase, each fold of the 10-fold cross-validation involved approximately 4300 training images, batch size of 8, and a total of 60 epochs. Under these conditions, the average training time per fold was approximately 6.3 h (378 min), highlighting the practical feasibility of training this deep learning model in a clinical or research setting without requiring high-end computational resources.
Discussion
DeepLabv3 is an advanced semantic segmentation network that enhances the model’s ability to capture multi-scale features of images using atrous convolutions and ASPP. Specifically, one of the key innovations of DeepLabv3 is the introduction of atrous convolution into traditional convolutional layers, allowing the convolutional kernels to expand their receptive fields without increasing the number of parameters.14,15 This strategy is particularly important for understanding large-scale structures in images.
The ASPP module is another core component of DeepLabv3, capturing multi-scale information by using different dilation rates in multiple parallel atrous convolution layers, thereby improving adaptability to objects of varying scales. This design allows DeepLabv3 to effectively handle image features of various sizes, enhancing segmentation accuracy in complex scenes. 16
In comparison to other models like FCN, U-Net, and MobileNet, DeepLabv3 offers several advantages:
FCN: While FCN is efficient and can handle images of varying sizes, it lacks the multi-scale feature extraction capabilities provided by the ASPP module in DeepLabv3. 17 This makes DeepLabv3 better suited for segmenting objects at different scales within the same image.
U-Net: U-Net excels in medical image segmentation due to its encoder-decoder structure, but it often struggles with large-scale variations within images. The atrous convolutions in DeepLabv3 allow for better handling of such variations, improving segmentation accuracy in complex scenes. 18
MobileNet: MobileNet is designed for efficiency and deployment on mobile devices. While it is lightweight and fast, it does not offer the same level of accuracy and detail in segmentation as DeepLabv3, which benefits from deeper networks and advanced feature extraction modules like ASPP. 19
ResNet101, part of the residual network (ResNet) family, addresses the vanishing gradient problem in deep networks through residual learning. ResNet101 has a depth of 101 layers, with each residual block consisting of several convolutional layers with batch normalization and ReLU activation functions, and each block’s output is added to its input via a skip connection. This design allows direct signal transmission and increases network depth without additional computational burden, enabling deeper feature extraction.20,21
Using ResNet101 as the backbone network for DeepLabv3 provides a strong feature extraction foundation. The deep and complex feature extraction capabilities of ResNet101, combined with the atrous convolutions and ASPP of DeepLabv3, offer superior performance for complex segmentation tasks. This combination optimizes the feature representation of DeepLabv3, particularly in handling high-resolution images, allowing more precise localization and segmentation of various objects in images. 22
In the field of image segmentation, ResNet101 can be used not only with DeepLabv3 but also with U-Net or FCN. The deep feature extraction capabilities provided by ResNet101, when used as the encoder for U-Net or the feature extraction network for FCN, can significantly enhance the performance of these models. The encoder-decoder structure of U-Net is particularly suitable for precise medical image segmentation, while the fully convolutional network of FCN is convenient for learning images of any size. Combined with ResNet101, these models can more effectively handle image details, providing higher segmentation accuracy and better generalization.
Currently, research on burn wound recognition primarily focuses on adult burn wounds, with most studies targeting either segmentation or recognition individually rather than simultaneously. For instance, Khan et al. 23 utilized a deep CNN architecture specifically for burn wound segmentation, achieving promising results, yet did not concurrently classify burn severity. Similarly, Zhang et al. 4 developed an integrated Mask R-CNN neural network for wound area segmentation but lacked direct severity grading. For burn severity classification, most studies adopt residual networks; for instance, Goyal and Abubakar employed ResNet50 for burn severity prediction but conducted their experiments under simplified imaging conditions. 24 These existing studies often employed datasets captured under controlled, uniform conditions with relatively simple backgrounds. In contrast, our study significantly extends these prior works by introducing a comprehensive pediatric dataset captured under highly variable real-world imaging conditions, explicitly addressing complex backgrounds and diverse camera devices. Moreover, the proposed Dfusion model uniquely integrates simultaneous segmentation and severity grading tasks, demonstrating superior performance and robustness under practical clinical scenarios.
Our study collected wound datasets from hospitalized pediatric burn patients and outpatient pediatric burn cases. at our center, with varying shooting conditions and complex backgrounds, closer to real medical environments. This dataset is currently the largest known pediatric burn wound dataset in China. Moreover, most current studies only classify burns into I, II, and III degrees, lacking differentiation between superficial and deep second-degree burns. 4 Especially in pediatric burn wounds, distinguishing between superficial and deep second-degree burns is more challenging. Through transfer learning with the DeepLabv3 architecture, we found it achieved good results in distinguishing superficial, deep second-degree, and third-degree burns in children.
This study had certain limitations. Although recent robust CNN approaches 8 have demonstrated effectiveness in similar challenging imaging tasks (e.g., vehicle control), direct comparative analysis was not feasible due to the lack of accessible implementations or detailed methodological disclosures in these studies. Future research should aim to validate the Dfusion model against such cutting-edge approaches, as this will further confirm its robustness and efficacy.
The collected dataset exclusively comprised hospitalized pediatric burn patients from a single center, potentially limiting generalizability to outpatient settings or different ethnic populations. Although data augmentation was employed, the potential for overfitting cannot be fully excluded. Further validation using external datasets from multiple institutions is recommended.
Conclusion
This study demonstrates that combining ResNet101 with current mainstream image recognition architectures enables effective segmentation and recognition of pediatric burn wounds captured under varying conditions. The model adjustments and transfer learning with the DeepLabv3 backbone, leading to the development of the Dfusion model, significantly enhance the segmentation of pediatric burn wounds. Moreover, this model achieves precise identification of superficial second-degree, deep second-degree, and third-degree burns in children. The introduction of custom attention mechanisms, improvements to the ASPP module, and the use of data augmentation and weighted loss functions contribute to the model’s superior performance in handling complex backgrounds and diverse shooting conditions. This research underscores the potential of advanced deep learning techniques in improving the accuracy and robustness of burn wound assessment in clinical settings. However, the current study was limited by its single-center dataset and potential class imbalance. Further research with multicenter datasets, inclusion of first-degree burns, and additional robust validation techniques are warranted to expand model applicability and reliability in diverse clinical scenarios.
Footnotes
Ethical considerations
This study was approved by the Beijing Children’s Hospital Ethics Committee (Ethical Clearance Reference Number: 2019-k-155).
Author contributions
X. L.: Conceptualized, designed, raised funding for the study, performed data analysis, interpreted results, and drafted the article.
Z. L.: Designed, supervised, and revised the article, computerized image processing and revised the article.
L. L.: Conceptualized, designed, supervised, performed data analysis, interpreted results, and made a major contribution to the article.
All authors contributed to the interpretation and discussion of the results, read, and approved the final article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Due to ethical considerations and patient confidentiality, the datasets for this study are not publicly available. They can be requested from the corresponding author, provided there is an appropriate reason and approval from the relevant ethics committee.
Informed consent/patient consent
Written informed consent was obtained from all subjects (and their guardians, where applicable) before the study.
Explicitly confirmed obtaining consent from legally authorized representatives.
Trial registration
Not applicable.