
Abstract
Machine learning offers the potential to enable probabilistic-based approaches to engineering design and risk mitigation. Application of such approaches in the field of blast protection engineering would allow for holistic and efficient strategies to protect people and structures subjected to the effects of an explosion. To achieve this, fast-running engineering models that provide accurate predictions of blast loading are required. This paper presents a novel application of a physics-guided regularisation procedure that enhances the generalisation ability of a neural network (PGNN) by implementing monotonic loss constraints to the objective function due to specialist prior knowledge of the problem domain. The PGNN is developed for prediction of specific impulse loading distributions on a rigid target following close-in detonation of a spherical mass of high explosive. The results are compared to those from a traditional neural network (NN) architecture and stress-tested through various data holdout approaches to evaluate its generalisation ability. In total the results show five statistically significant performance premiums, with four of these being achieved by the PGNN. This indicates that the proposed methodology can be used to improve the accuracy and physical consistency of machine learning approaches for blast load prediction.
Keywords
Introduction
Initiation of an explosive charge rapidly converts the material into high-energy gaseous products of detonation. This gas initially occupies the same volume as the explosive but at pressures, densities and temperatures orders of magnitude larger than ambient conditions. This causes the detonation product cloud to rapidly expand, displacing the surrounding medium (typically air) at supersonic velocities and forming a blast wave (Baker, 1973). This blast wave is characterised by a near-discontinuous rise to peak pressure followed by a temporal decay back to ambient conditions. Impingement of this shock wave on a structure results in a transfer of momentum, equivalent in magnitude to the impulse of the blast load (Rigby et al., 2019a), that is, the integral of applied force with respect to time. Integrating pressure histories with respect to time at various locations across a target surface yields a distribution of specific impulse, that is, momentum per unit area. Specific impulse distribution is a key metric when assessing the response of structures subject to extreme blast loading over very short durations (Rigby et al., 2019b). Therefore, knowledge of how specific impulse distribution is influenced by key parameters such as charge size and location with respect to the target surface will facilitate comprehensive vulnerability assessment of protective structures, vehicles, critical infrastructure and human injury.
In so-called ‘far-field’ scenarios, where the blast wave is freely expanding and is no longer being driven by the explosive fireball (i.e. the fireball is said to be ‘detached’), well-established and highly accurate semi-empirical methods exist to predict pressure and impulse, for example, Kingery and Bulmash (1984). Conversely, in scenarios where the blast wave has not detached from the explosive fireball, in the so-called ‘near-field’, loading distributions are much more complex, considerably higher in magnitude and shorter in duration (pressures in the region of MPa, with sub-millisecond durations (Rigby et al., 2015a)). Alongside the momentum transfer from the shock wave, there is additional momentum transfer from the high pressure cloud of detonation products. Because of this challenging environment, very few experimental studies exist on near-field loading, with the exception of Esparza (1986), Edwards et al. (1992), Piehler et al. (2009), Rigby et al. (2015a), Cloete and Nurick (2016) and Tyas et al. (2016). The lack of available experimental data has, to date, prevented critical insights and key contributions being made from numerical modelling studies owing to unproven validity of such approaches.
Obtaining data in the field of blast protection engineering is considerably expensive in both time and cost, yet accurate appraisal of the viability of structures following close-in detonation of a high explosive is only possible with the availability of accurate models detailing both the distribution and magnitude of the imparted load. It has been shown that localised variations in specific impulse lead to localised variations in target displacement (Rigby et al., 2019a). In order to provide accurate appraisals of the viability of protective structures following close-in detonations, it is not only necessary to have accurate fast-running models, but also to adopt a probabilistic rather than deterministic approach when modelling blast scenarios. Such approaches (Alterman et al., 2019; Campidelli et al., 2015; Netherton & Stewart 2016) allow for the uncertainties related to the blast event to be modelled which accurately support a quantitative calculation of risk relating to blast events. In order to adopt probabilistic approaches, it is necessary to provide loading information for a large range of potential loading scenarios in a reasonable time-frame. Existing empirical and semi-empirical models are fast and can be accurate, but lack flexibility to consider anything other than scenarios with few variables and simple geometries, and typically only focus on far-field scenarios. Conversely, artificial neural networks (ANNs or NNs) can accommodate more variables when acting as a vector mapping model and provide the additional flexibility required to handle highly non-linear behaviour, as expected in extreme near-field blast events. They have been shown to accurately predict explosive loading in confined internal environments (Dennis et al., 2020), on a building behind a blast wall (Flood et al., 2009; Remennikov & Rose 2007) or along simple city streets (Remennikov & Mendis 2006).
An appropriate technique is to use validated computational fluid dynamics (CFD) analyses as a model to generate data from which predictive models can be built and surrogate models can be constructed. Such physics-based numerical models solve equations governing fluid flow by discretisation in space and time, leading to accurate solutions though often at high computational cost. Surrogate models built from this approach have been shown to produce accurate near-field predictions with an order of magnitude improvements over the traditional CFD approaches (Pannell et al., 2019, 2021). However, there exist limitations in these ‘black-box’ approaches (such as NNs) in that they are independent to the underlying scientific principles that drive real-world physical phenomena and therefore do not provide interpretable characteristics. Due to this nature, they often show poor generalisability when extrapolating beyond the realms of the training data, or indeed interpolating between gaps within it as they possess no knowledge of the underlying physics. This issue can be exacerbated in supervised learning problems when the sample training sets may be small as the model is more likely to learn spurious, non-physical relationships.
A fundamental challenge in machine learning (ML) is for the trained algorithm to perform well on new, unseen data, referred to as ‘test’ data. The ability for a model to accurately predict previously unobserved inputs is called generalisation. The main factors that determine how well a ML algorithm will perform are its ability to: (a) make the training error small and (b) make the gap between training and test error small (Goodfellow et al., 2016). These two factors also refer to two fundamental challenges in ML, preventing overfitting and underfitting. The former occurs when the gap between the training error and test error is too large, whilst the latter occurs when the model does not achieve a low enough error on the training dataset. The likelihood of a model overfitting or underfitting can be controlled to some extent by changing its capacity (or also known as complexity). A model’s capacity refers to its ability to fit a wide variety of functions. A useful analogy to demonstrate model capacity is imagining a linear, quadratic and fifth order predictive model attempting to fit to data that is sampled from a quadratic function. In this instance, the linear model’s capacity will be too low and will not capture the curvature in the underlying data (underfitting). The fifth order model will be able to represent the correct function and many more in between (overfitting), whilst the quadratic predictor will have the optimum capacity. The relationship between model capacity and error is summarised in Figure 1, where the underfitting and overfitting zones can be seen either side of the ‘optimal capacity’ region. Typical relationship between model capacity and error. Training error and test error show different behaviour. Once a model reaches the ‘optimal’ capacity, its performance on unseen test data decreases, whereas its performance on the training dataset increases, this is the overfitting zone and this gap in performance is known as the generalization gap. Conversely the underfitting zone is where the model does not have sufficient capacity to accurately model the training set. Figure adapted from Goodfellow et al. (2016).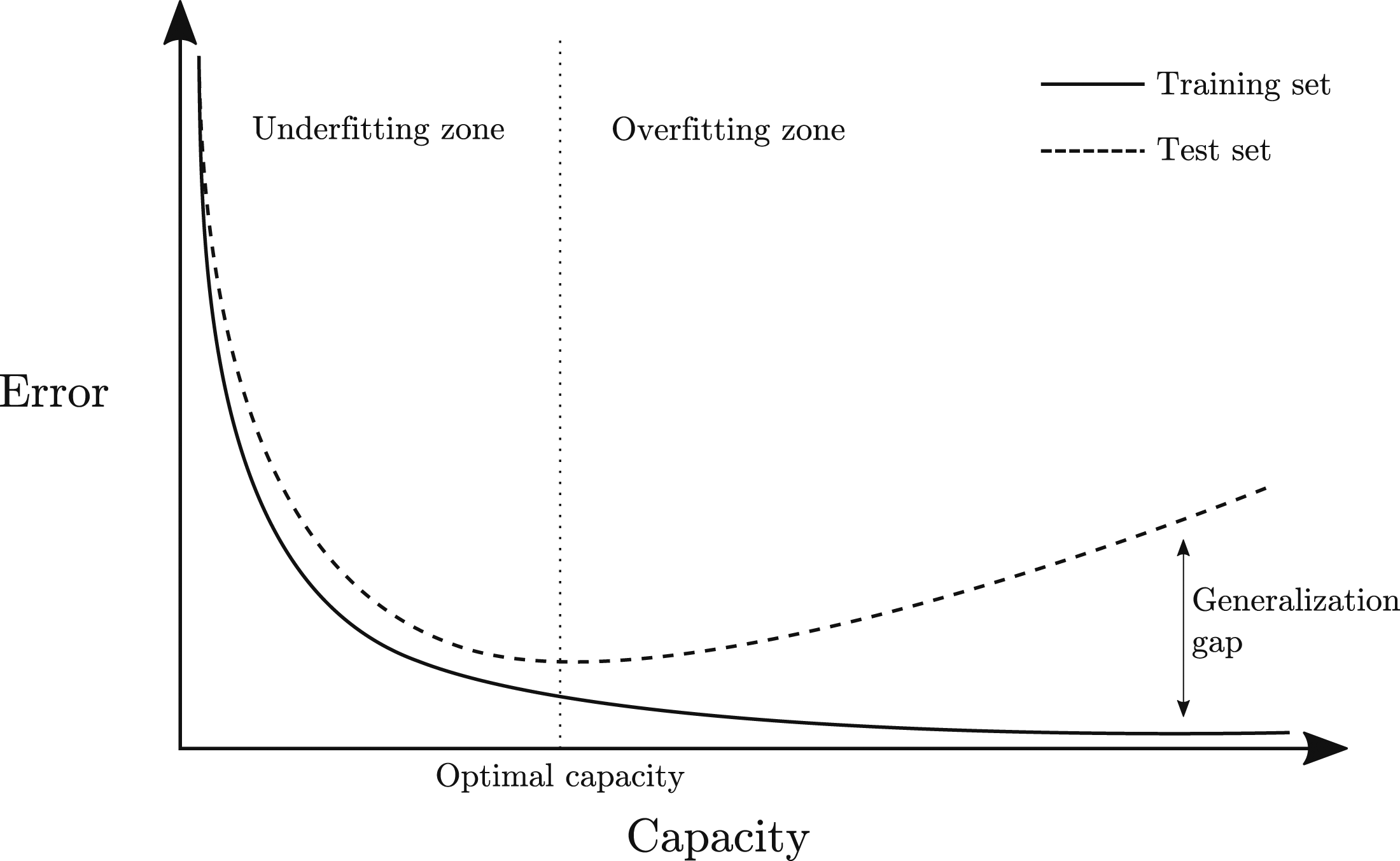
Enhancing the model’s capacity can be achieved in several different ways. One way is by restricting the set of functions an algorithm can choose as its solution through selection of its hypothesis space. In the context of the previous example, this would be allowing higher order polynomials rather than just linear functions for the quadratic and fifth order predictors. Once a family of representative functions has been chosen, there is the issue of finding the optimum function within this, termed the representational capacity of the model. In many cases, finding the optimum function proves to be a difficult optimisation problem.
Recent advancements in improving generalisability suggest that, amongst competing hypotheses that explain the data equally well, the ‘simplest’ should be chosen (Blumer et al., 1989; Goodfellow et al., 2016; Vapnik & Chervonenkis, 1971; Vapnik, 2006, 2013). From the ‘no free lunch’ theorem (Wolpert, 1996), it is impossible to discover the overall optimum ML algorithm but that instead, ML algorithms should be designed to perform well on a specific task by building preferences into the learning algorithm (Goodfellow et al., 2016). Previously mentioned methods of modifying the model’s representational capacity have focused on controlling the hypothesis space of possible solutions; however, there are other ways of controlling a preference for certain solutions, known generally as regularisation. Regularisation is ‘any modification we make to a learning algorithm that is intended to reduce its generalisation error but not its training error’ (Goodfellow et al., 2016). In other words, the chosen learning algorithm can be forced to express a preference for certain solutions in the hypothesis space. Alternative approaches to regularisation which make use of data transformation procedures are particularly useful if the data is well understood. These approaches transform the data to a space where it is well-defined and then train on this new transformed distribution (Notley et al., 2021).
Integrating deep learning approaches (which are data intensive) and scientific theory is considered to be a crucial step to improve model predictive performance whilst respecting natural laws (Reichstein et al., 2019). A promising avenue of research involves guiding the learning of a ML model though introducing a physical consistency penalty as a regularisation procedure (Daw et al., 2020; Jia et al., 2019; Karpatne et al., 2017; Stewart & Ermon, 2017). This framework aims to combine the use of scientific theory and leveraging the power of data-intensive approaches to develop a hybrid approach (as shown in Figure 2) that improves generalisability by guiding the learning process to bias physically valid solutions. Physics-based approaches such as these have been used effectively in a variety of domains such as the geo-sciences community (Karpatne et al., 2017; Muralidhar et al., 2018), power-flow research (Hu et al., 2020) and seismic response modelling (Zhang et al., 2020). Schematic representation of physics-guided neural networks in the context of other knowledge discovery approaches. Adapted from Karpatne et al. (2017).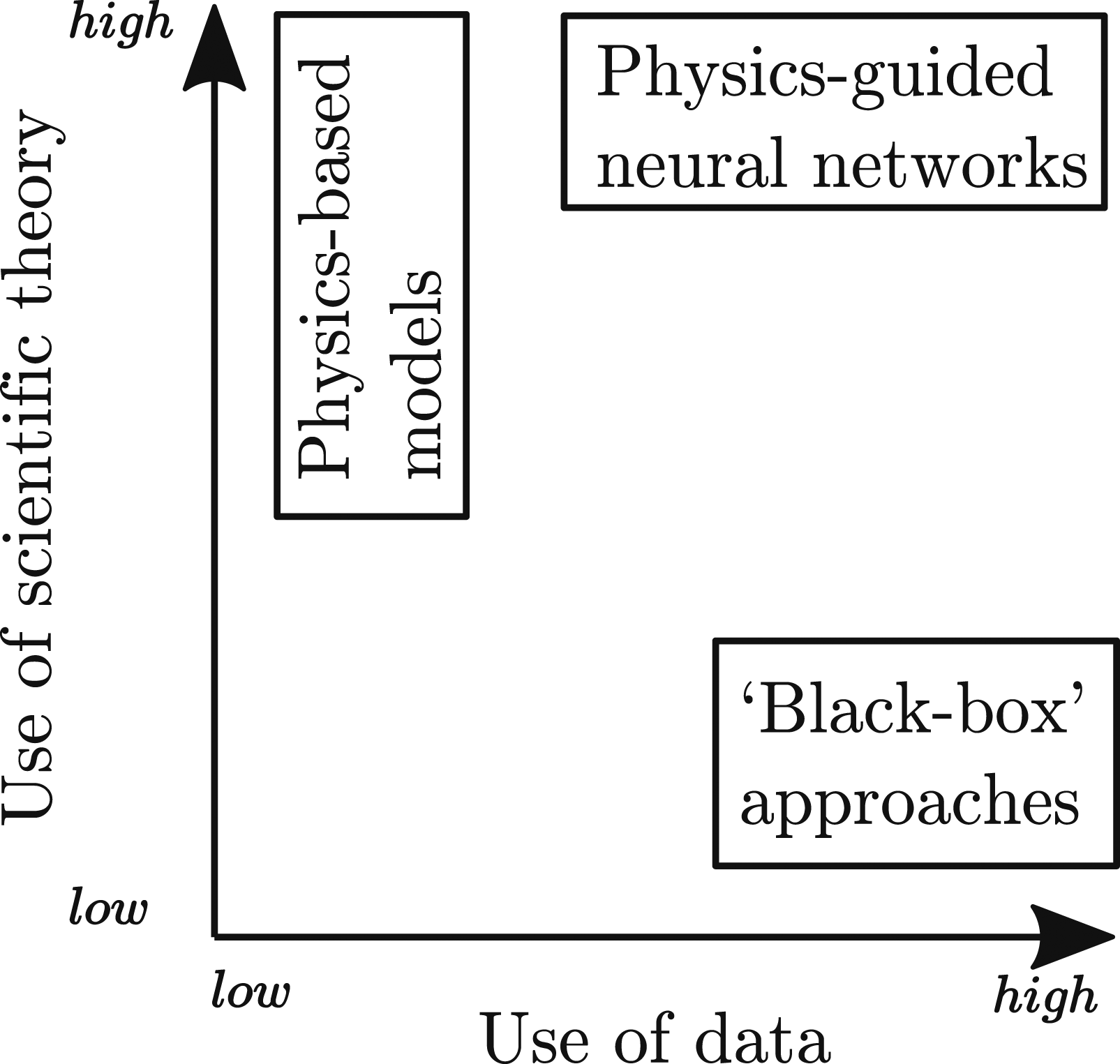
This paper presents a novel use case of this framework in modelling peak specific impulse distributions of near-field blast loading distributions with a comparison against a standard neural network. Firstly, generation of the dataset is discussed. Next, the neural network architecture is developed through a sensitivity study of the network parameters, which is followed by the implementation of a physics-based regularisation. Then the generalisation ability of two neural network architectures (PGNN vs NN) is evaluated by stress-testing the models through withholding specific fractions of the variable distribution. A discussion and concluding remarks are then provided where results show that of the seven stress tests performed, four of the five statistically significant performance premiums were shown by the PGNN. These results indicate that physics-based regularisation procedures should be implemented when specialist knowledge of the problem domain is available.
Surrogate modelling and reduced order models
Data-driven modelling
A surrogate model is an engineering method when an output of interest cannot be directly measured with relative ease. Particularly in engineering, most practical problems require extensive experimental or numerical data to evaluate design decisions. For instance, in aerospace engineering the design of an optimal aerofoil shape for an aircraft wing requires knowledge of airflow parameters for a variety of variables (length, material, angle, etc.), typically determined through simulation (Mack et al., 2007). However, due to the computational expense of running an accurate numerical simulation, obtaining complete information for the design space would carry a considerable time cost and be unsuitable in practice, so a surrogate model is constructed that can evaluate points in the design space that may not necessarily have been explicitly sampled. Surrogate models are constructed using a data-driven, bottom-up approach whereby data sampled from particular simulations or experiments is used to inform a surrogate model (also known as a metamodel or response surface model). The surrogate model then essentially becomes a tool to interpolate in the input–output space of the different design variables.
The data-driven, bottom-up nature of building a surrogate model therefore requires large amounts of data. However, a particular issue in blast engineering is that experimental data can be prohibitively expensive or difficult to obtain due to the high loading magnitudes and sub-millisecond durations of blast events, as mentioned previously. Computational fluid dynamics software provides engineers with the ability to generate the data required to inform an input–output space by solving the physical equations governing fluid flow through discretisation in space and time, and can be validated against known experimental data. The CFD models provide a response for a given set of input parameters, and these are used to fill a parameter space, requiring next the choice of surrogate model to interpolate within this parameter space. A detailed discussion on different types of surrogate model is given in Jin (2005). One such surrogate model is an artificial neural network (ANN) and has been used extensively for this purpose in a variety of disciplines (Ahmadi, 2015; Kim et al., 2015; Papadopoulos et al., 2018; White et al., 2019) and in specific blast engineering applications (Dennis et al., 2020; Flood et al., 2009; Remennikov & Mendis, 2006; Remennikov & Rose, 2007).
ANNs as a surrogate model
Artificial neural networks (ANNs) are collections of connected nodes (also called neurons), inspired by a simplification of neurons in a brain (as per the example shown in Figure 3). They have been used extensively in a wide variety of disciplines due to their ability to act as universal approximators for complex functions. A linear model, which would map inputs to outputs through matrix multiplication, can only represent linear functions, or summations thereof. The universal approximation theorem (Cybenko, 1989; Hornik et al., 1989) states that any feed-forward network with a linear output layer and at least one hidden layer with any ‘squashing’ activation function can approximate any Borel measurable function from one finite-dimensional space to another with any desired non-zero amount of error, provided the network is given enough hidden units (Goodfellow et al., 2016). Similarly, an ANN can approximate any function mapping from any finite dimensional discrete space to another. This ability to approximate non-linear functions makes ANNs a suitable choice for a wide variety of procedures, and particularly for recreating the non-linear physical phenomena seen in near-field explosive events. Example neural network architecture with two input nodes, three nodes in a hidden layer and one output node.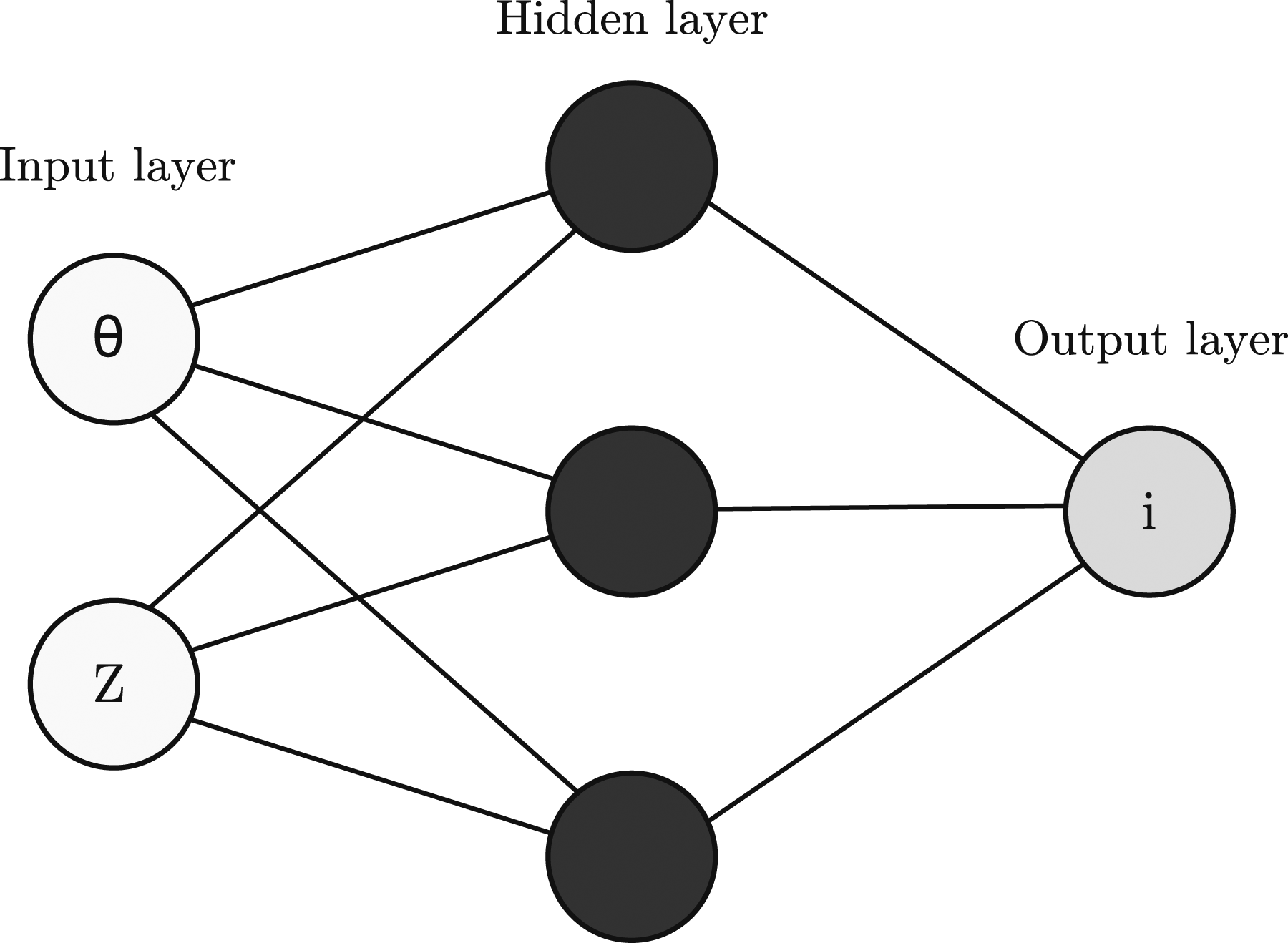
The hidden layers in an ANN consist of interconnected neurons. Information is conveyed through these neurons with a series of weights and biases, transmitted with non-linear activation functions. To train an ANN, the optimal values for weights and biases must be found, which typically involves two stages: ‘feedforward propagation’ and ‘error backpropagation’. Considering equation (1)

As shown previously in Figure 1, as the capacity of an ML model increases, as does the chance of overfitting. Specific to an ANN, there are several variables that can be changed in order to find the ‘optimal capacity’. Firstly, considering the structure of the network itself, the capacity of the model can be altered by increasing the number of layers, the nature of these layers, number of neurons in each layer and the connectivity of these neurons. If every neuron in each layer is connected to every other neuron in adjacent layers, this is known as ‘fully connected’ or ‘dense’. This is the structure of traditional multi-layer perceptrons. An alternative class of neural networks are convolutional neural networks (CNNs), which also consist of input layers, hidden layers, and output layers, but the hidden layers perform convolutions on input data. CNNs have been shown to be useful in many image analysis tasks (Albawi et al., 2017), with some applications in blast analysis (Xu et al., 2021). Finding the optimal structural configuration of an artificial/convolutional neural network is a challenging task and has been shown to be case-dependent and largely data-driven in nature (Dsouza et al., 2020).
A central problem in ML is improving the ability of a model to generalise to unseen data. One such approach that focuses on reducing the test error (typically at the cost of an increased training error) is regularisation, as mentioned previously. There are several approaches to regularisation; some target the parameters of the model by restricting or constraining their values in some way or including additional penalties, thereby encoding some prior knowledge into the model. One common example of a regularisation procedure is ‘weight decay’, where a sum is minimised that involves an additional criterion that adds a preference for model parameter weights to have a smaller L2 norm, as shown in equation (2) (Goodfellow et al., 2016)

Further regularisation techniques rely on combining several different trained models, in the hope that their average, aggregate performance shows better generalisability, known as bagging (Breiman, 1996). This general strategy is known as model averaging and similar methods are known as ensemble methods. Neural networks often benefit from model averaging of some kind due to the differences in parameter initialisation or other hyper-parameters (Goodfellow et al., 2016). On a similar theme, another particularly useful form of regularising ANNs is known as ‘dropout’ (Srivastava et al., 2014). When a fully connected layer has a large number of neurons, there is likely to be some co-adaption. Co-adaption refers to the scenario where multiple neurons extract the same information or features from a set of input data, the detriment of this is an inefficient use of computational resources and an increased risk of overfitting by adding more significance to certain model features. In dropout, the ensemble of all the model subnetworks that can be formed by removing units from a base network are trained. For an extensive overview of further regularisation procedures, see Goodfellow et al. (2016).
Dataset overview
The dataset was generated from CFD simulations using APOLLO Blastsimulator, an explicit CFD software which solves the conservation equations for transient flows of compressible fluid mixtures (inviscid and/or non-heat conducting, inert and/or chemically reacting). APOLLO uses a HLL-type Reimann solver, particularly suited for problems involving rapid changes in pressure and density, and high speed flows, and is second order accurate owing to the tri-linear reconstruction of cell-centred conservative variables (Fraunhofer EMI, 2018).
Analyses were performed in quarter symmetry. In order to prevent spurious expansion waves from the edge of the domain corrupting the results (Rigby et al., 2014b), the domain side lengths were set to the minimum of either 1.5 m or 1.3 times the distance from the centre of the target to the most remote gauge (Pannell et al., 2021). The mesh size was set at 100 mm zone length and resolution level 5 (minimum element size of 100/25 = 3.125 mm).
The dataset consists of peak specific impulse distributions from 100 g spheres of PE4 located between 0.05 m and 0.26 m normal distance from the centre of the charge to the surface of the target, termed ‘stand-off’ distance. This is equivalent to a scaled distance range of 0.11–0.55 m/kg1/3 according to cube-root or Hopkinson–Cranz scaling (Cranz, 1926; Hopkinson, 1915), where scaled distance, Z, is given by S/W1/3, where S is stand-off distance and W is the mass of explosive. The explosives were modelled using Apollo’s in-built model for C4 explosive, with Klomfass Afterburning Model and Chapman–Jouguet detonation model both used.
For each analysis, 150 gauges are linearly spaced along the target surface at angles of incidence between 0 and 60°, where angle of incidence is defined as the angle between the outward normal of the surface and the direct vector from the explosive charge to that point (Rigby et al., 2015b). Each gauge outputs pressure-time histories at that location, which are numerically integrated (with respect to time) in postprocessing to yield specific impulse-time histories. The maximum of each of these is taken to provide the distribution of peak specific impulse.
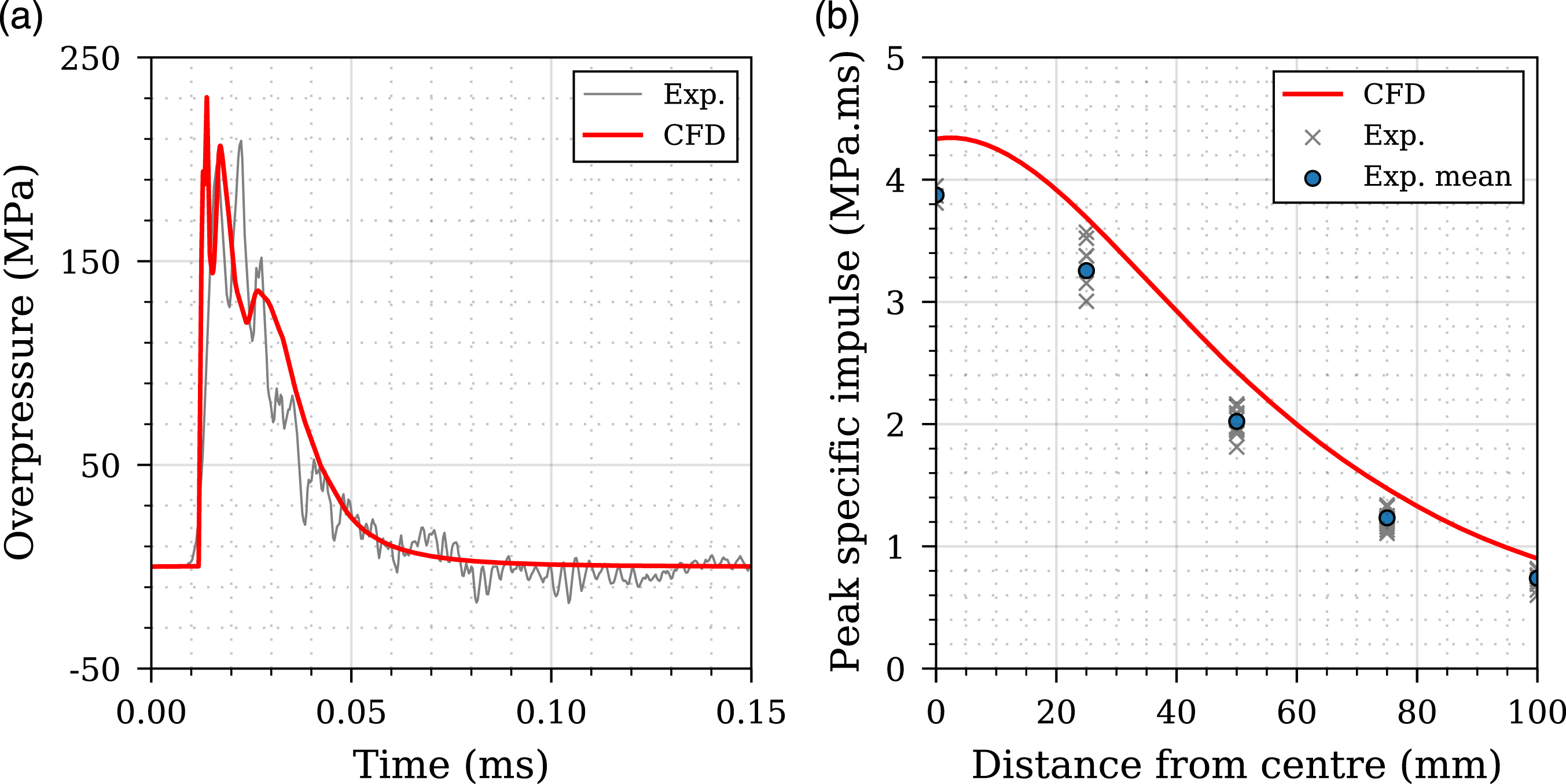
In summary, there are 18 CFD experiments with 150 values of peak specific impulse for each, resulting in a dataset of 2700 data points. An overview of this dataset is given in Figure 4b, with a schematic detailing the generation of this dataset shown in 5a. Mesh sensitivity and experimental validation for APOLLO has previously been conducted in Pannell et al. (2021). Here, numerical results were compared to experimental data of Rigby et al. (2019a), measured using the Characterisation of blast loading apparatus (Clarke et al., 2015). The apparatus consists of arrays of Hopkinson (1914) pressure bars mounted flush with the surface of a nominally rigid target plate, and provides spatial and temporal distributions of loading, that is, pressure-time and impulse-time histories, and peak pressure and peak specific impulse distributions. In this validation exercise, the loading from 100 g PE4 spheres at 80 mm perpendicular stand-off distance (to the charge centre) was measured out to 100 mm from the centre of the target plate. An example of the validation of APOLLO is given in Figure 5. (a) Experimental schematic for the dataset generation: S is perpendicular stand-off distance between spherical charge and reflecting surface, gauges were placed along the perpendicular length r. (b) computational fluid dynamics dataset: filled contours of scaled peak specific impulse for full dataset, 0.11–0.55 m/kg1/3. Validation of Apollo using experimental data (Rigby et al., 2019a) from 100 g PE4 sphere at 80 mm (to charge centre) stand-off distance: (a) overpressure history at 25 mm from the plate centre (θ = 17°); (b) peak specific impulse distributions at 0–100 mm distance from the plate centre. Figure adapted from Pannell et al. (2021).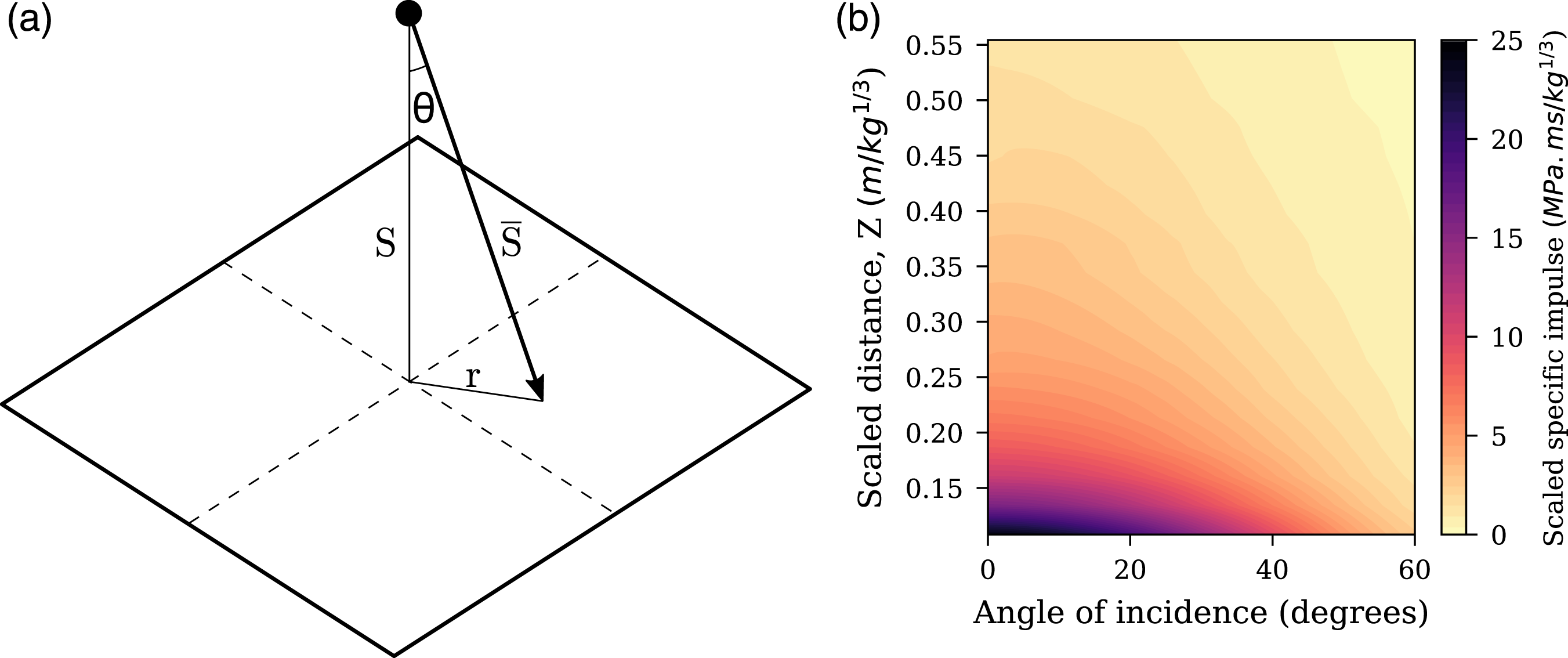
Example dataset information.

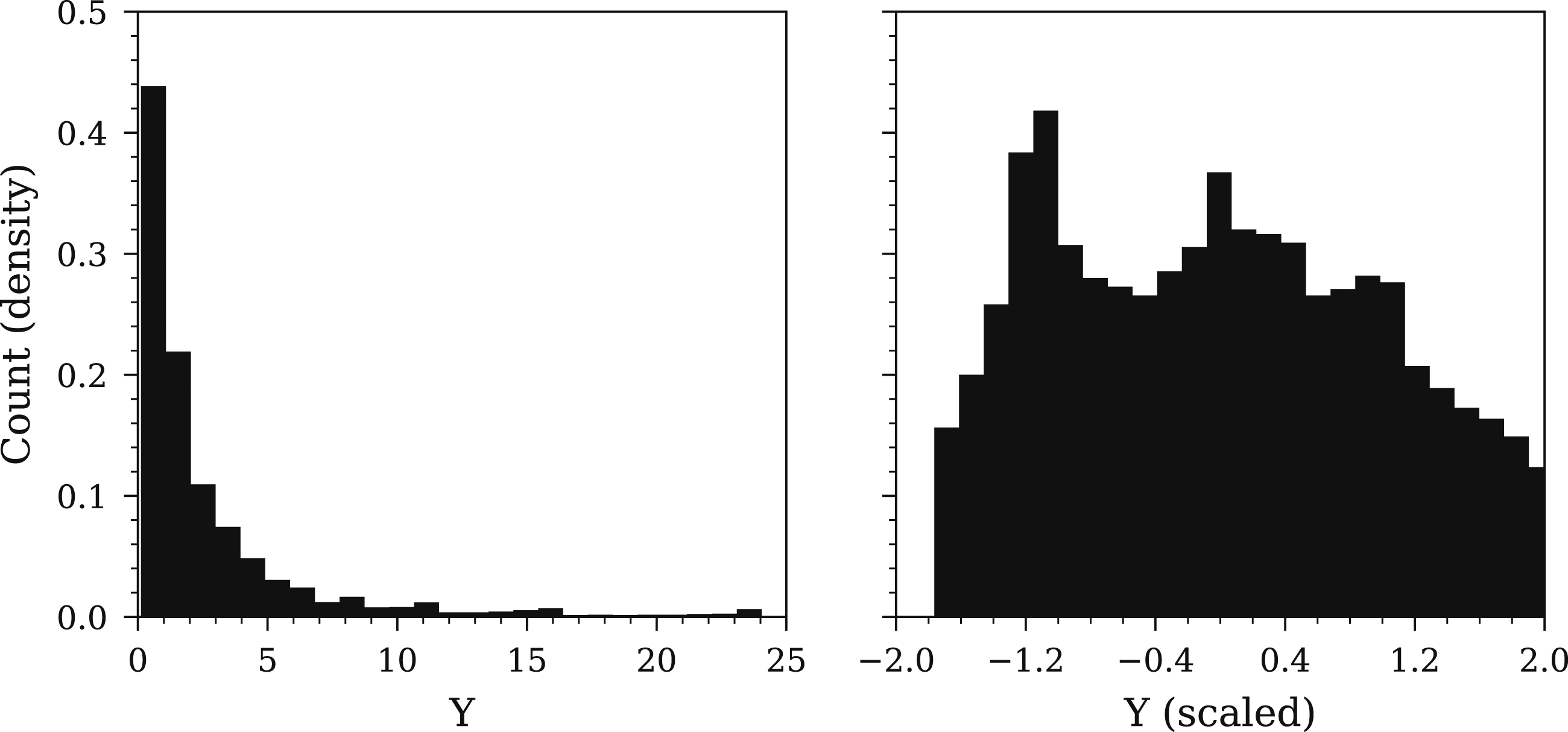
Unscaled Y dataset showing a log-normal distribution (left) and the resulting power transformation (right).
Training and network architecture
To create and train the networks, the Keras package with tensorflow backend (Chollet et al., 2015) was used. The Adadelta (Zeiler, 2012) gradient descent algorithm was chosen which has the added benefit of not requiring a default learning rate. 10 000 epochs with early stopping set at 500 epochs was implemented to prevent over-fitting, with a batch size of 32. Activation functions for the hidden units were set as hyperbolic tangent, and layer weights initialised with the Glorot normal initialiser (Glorot & Bengio, 2010). K-fold cross-validation was implemented with five splits, following an initial data split of 25% data randomly removed, this data splitting schematic is summarised in Figure 7. The networks to be examined all had one hidden layer, and are fully connected. Example schematic of splitting the dataset prior to and during training and the subsequent k-fold cross-validation. The initial 25% of test data removed is never seen by the model during training.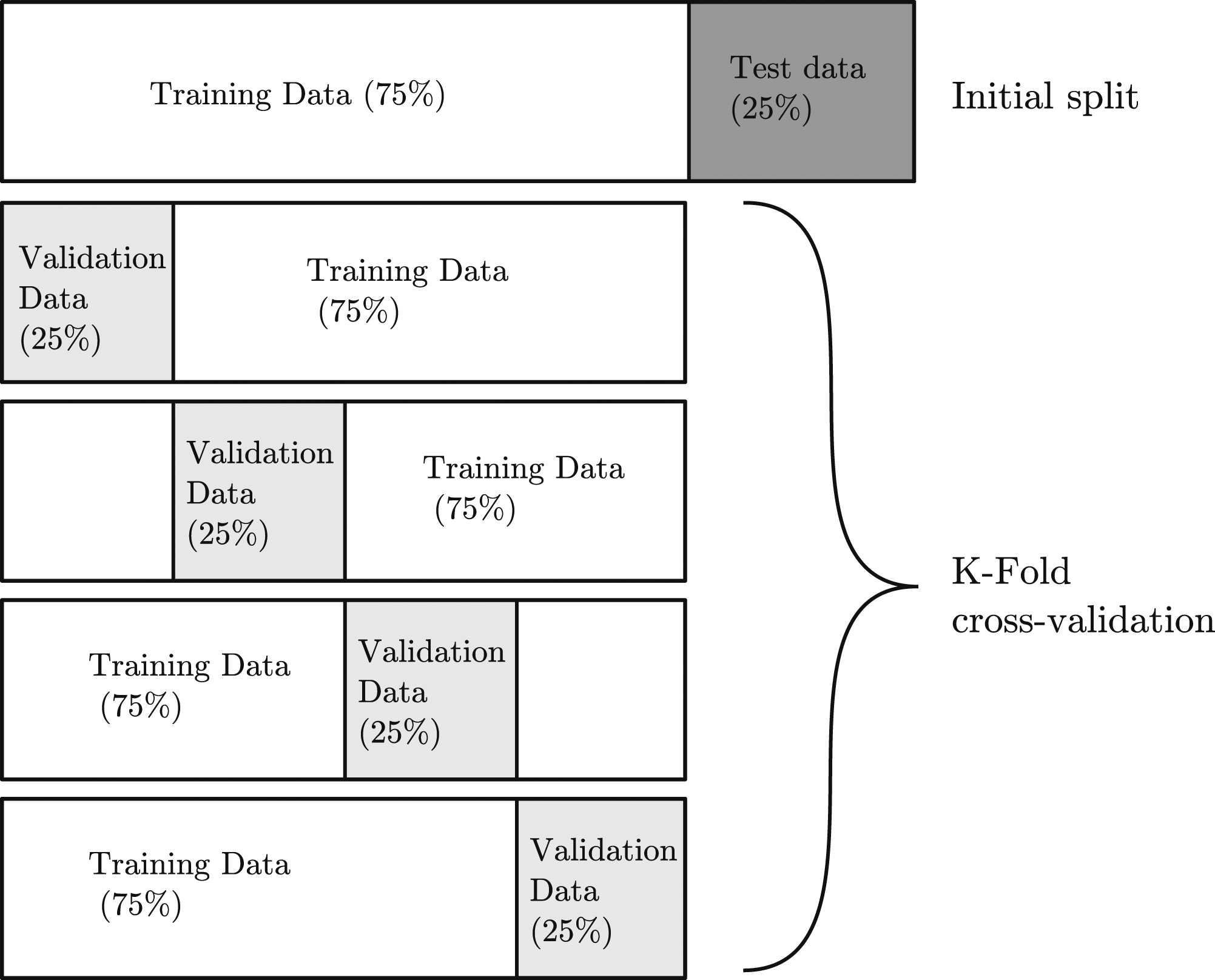
Initially, a varying number of hidden units were examined, from 1 to 8. The results of these analyses are presented in Figure 8. Ideally, the structural optimisation of the network would be performed in parallel to the parametric optimisation via an overarching, many-objective process (Jin & Sendhoff, 2009; Loghmanian et al., 2012), though this is considered to be beyond the scope of this paper. Three separate sub-figures provide different metrics: mean squared error (Figure 8(a)), mean absolute error (Figure 8(b)) and coefficient of determination (Figure 8(c)). For all analyses, the metrics are assessed for the three separate data portions: test, train and validation as previously summarised in Figure 7. If large discrepancies occur between the different data types, this can be indicative of over-fitting issues, as the models may perform far better on ‘seen’ data rather than ‘unseen’ data. As shown, there is a general trend of error reducing as the number of neurons increases, though this plateaus after four neurons, suggesting that four neurons provide sufficient predictive capability. Furthermore, from two neurons and upwards, there are no significant discrepancies between the different data types, suggesting that the model is not over-fitting. For later analyses, a network with four hidden units was chosen to take forward. Hyper-parameter configuration with various performance metrics shown on the unseen test data. Error bars are standard deviation: (a) Mean squared error of model predictions for varying number of neurons in hidden layer (b) Mean absolute error of model predictions for varying number of neurons in hidden layer (c) Coefficient of determination of model predictions for varying number of neurons in hidden layer.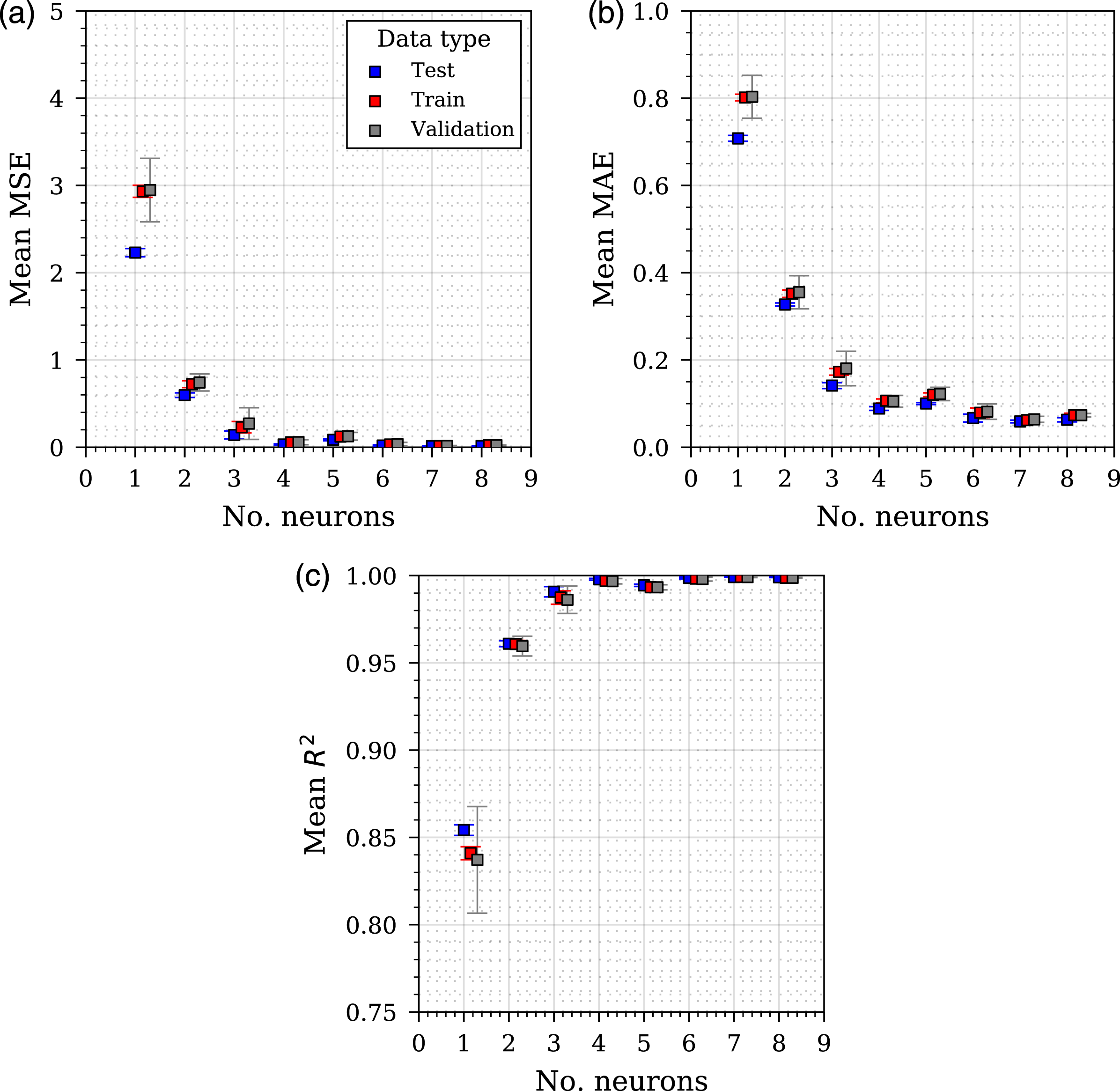
With the network architecture chosen, it is useful to gain an insight into the model learning performance of this network to check further for over-fitting and to confirm that the model is learning as expected. Training histories from the cross-validation are provided in Figure 9, which shows the loss from validation and training data during training. As demonstrated, the performance consistently improves as the number of epochs increases, and also improves for each fold of the cross-validation, suggesting that the network is learning effectively. The generalisation gap between the training and validation set is small and remains fairly constant throughout which is demonstrative of a good fit. On initial inspection there appears to be some stochastic behaviour in the later folds, however considering the magnitude of the losses here these are not considered to be a cause for concern and it can be concluded that the model shows a good fit. Training loss histories for each of the 5-fold cross-validation. Analyses represent the chosen network with four hidden units: (a) First fold (b) Second fold (c) Third fold (d) Fourth fold (e) Fifth fold.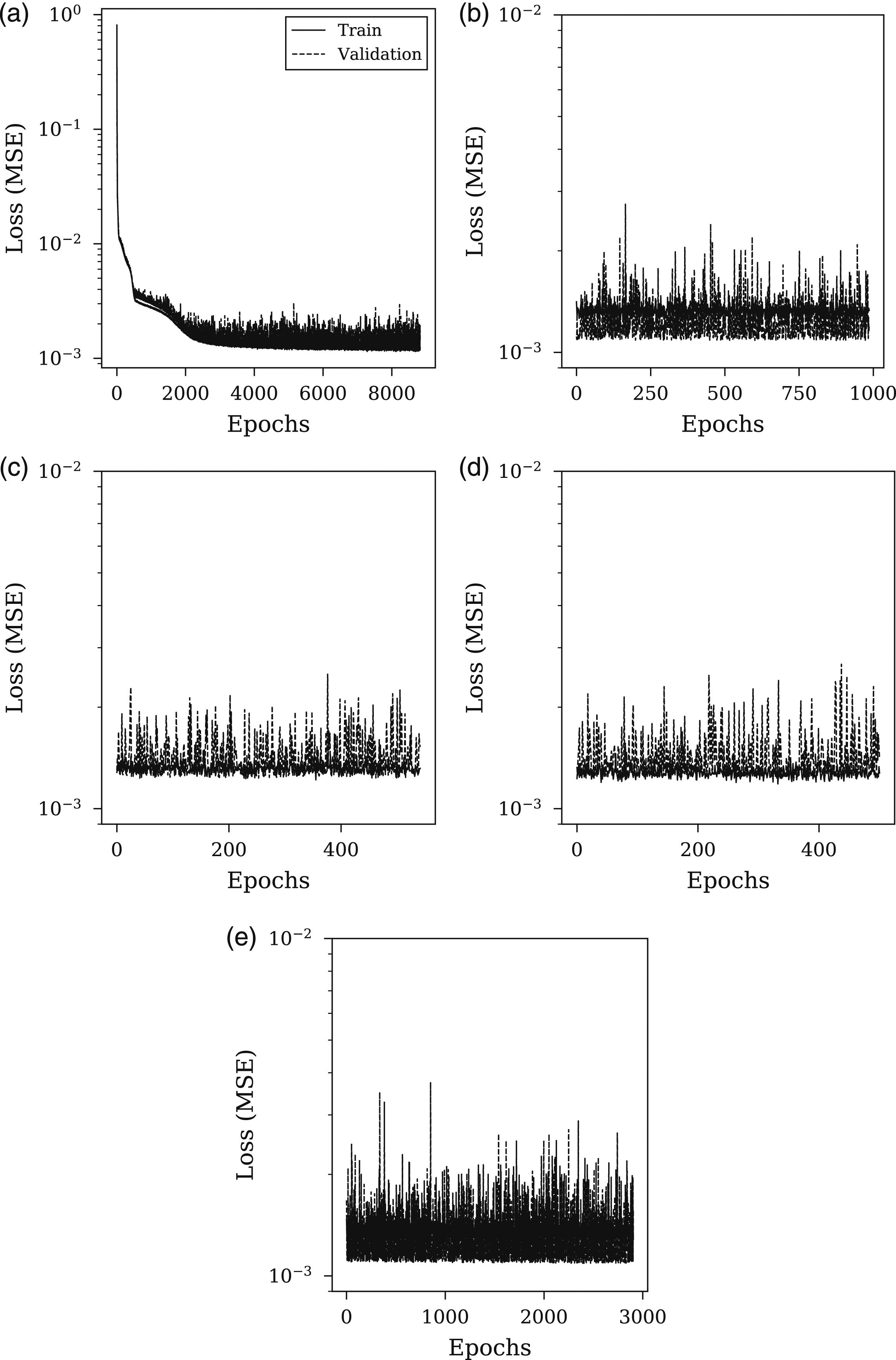
A physics-based regularisation procedure
All regularisation methods are attempting to improve the generalisability of a ML model. That is, how it performs on unseen data. Regularisation would not be required if the optimum structure, learning algorithm, and data transformation for a given NN were known a priori. Typical approaches for training models without physical constraints involve minimising empirical loss (mean square error, MSE) of model predictions 
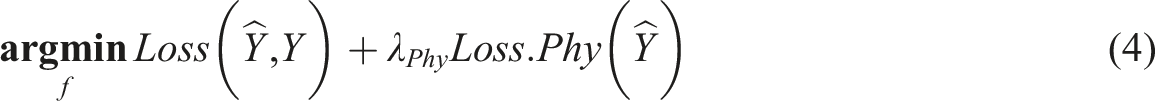
In this research, we present an implementation of a physics-based regularisation procedure based on each of the input features. Firstly, we make use of prior knowledge that peak specific impulse decays monotonically with scaled distance for a given angle of incidence (Pannell et al., 2021), which allows the implementation of a monotonic loss constraint. This monotonic loss constraint is in place to only penalise values that do not satisfy the requirement, implemented through the use of a rectified linear unit activation function (ReLU). The ReLU function is represented mathematically as f(x) = max(0, x). Then the physical loss function returns the following, adapted from Karpatne et al. (2017)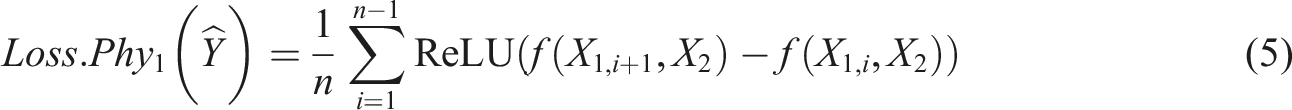
Similarly, prior knowledge (Pannell et al., 2021) that peak specific impulse decays monotonically with angle of incidence for a given scaled distance (where scaled distance is calculated from the hypotenuse distance between the charge centre and the measurement location) allows the implementation of a second monotonic loss constraint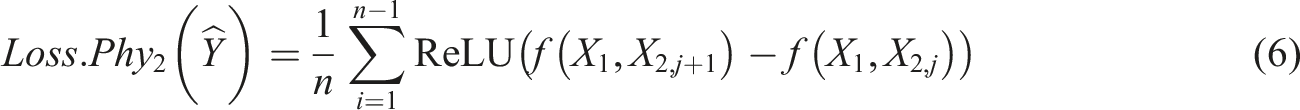
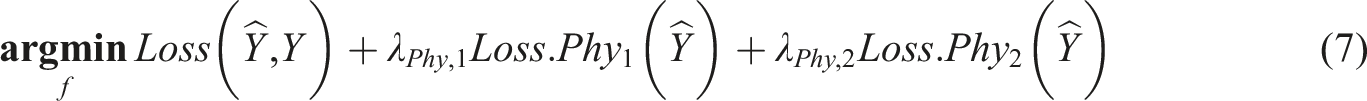
Implementation of the physical loss function requires values for the hyper-parameters to be found. A sensitivity study was conducted and with the performance metric set as root mean square error (RMSE) on unseen, test data. The sensitivity study for these hyper-parameters (λPhy,1 and λPhy,2) assessed six logarithmically spaced values varying between 100 and 105. The results from this sensitivity study are given in Figure 10, with λPhy,2 shown on the x-axis and λPhy,1 on the y-axis, with the colour presenting the mean value for test RMSE (from the five folds of the cross-validation). The global optimum hyper-parameter values from this exercise were seen to be λPhy,1 = 105 and λPhy,2 = 102. The values taken forward however were λPhy,1 = 104 and λPhy,2 = 104; although not the global optimum for each, these values were in the top 20% of recorded RMSE values and were the top hyper-parameter set under the constraint λPhy,1 = λPhy,2. This constraint was considered to be suitable to provide no bias towards the features X1 or X2, and on inspection the training history for this hyper-parameter set demonstrated the penalty was working effectively and therefore was a suitable choice to take forward. Grid search of λPhy,1 and λPhy,2.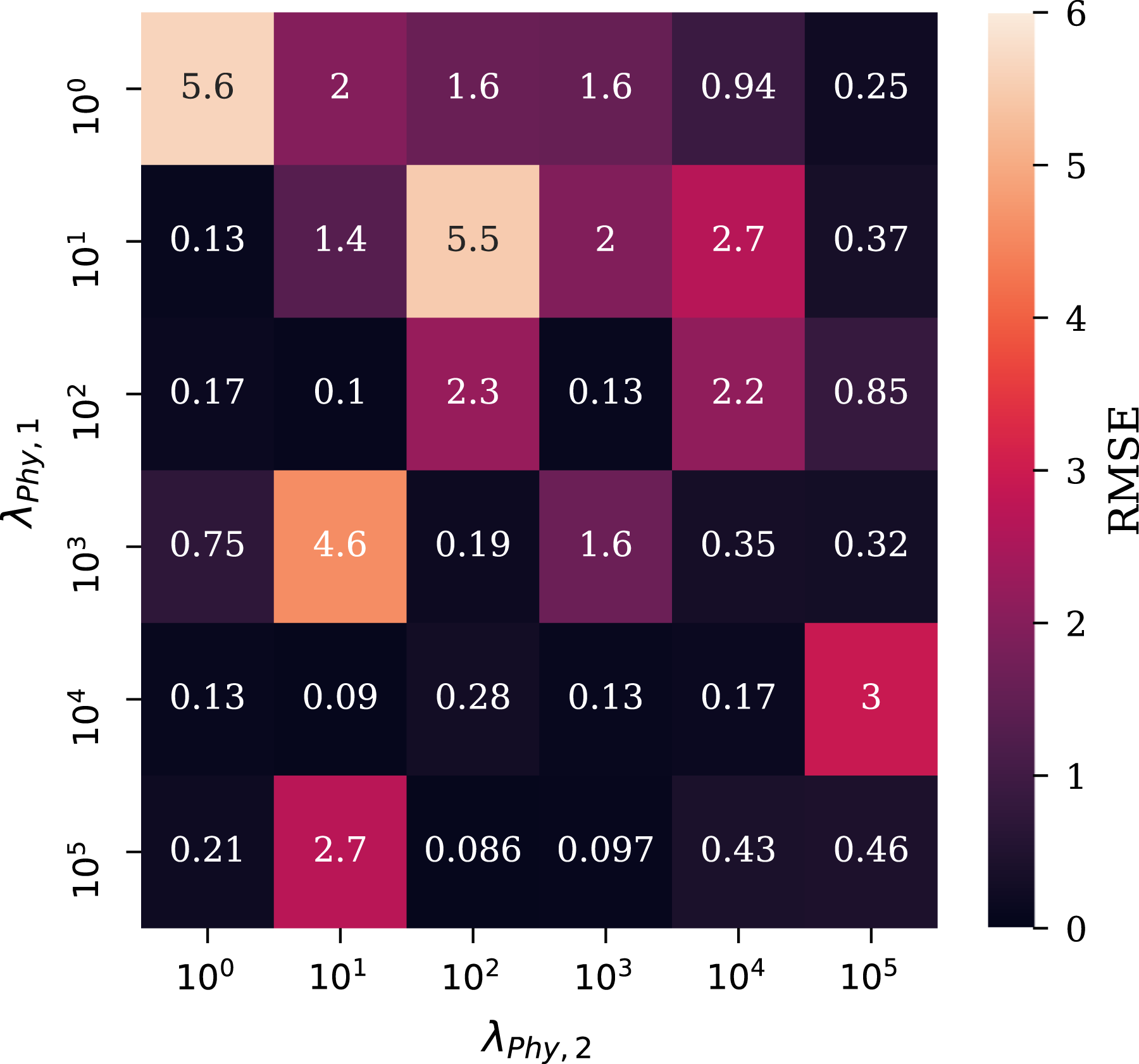
Stress-testing evaluation
Overview of stress-testing procedure
It is useful for predictive models in blast loading to be able to generalise both beyond the limits of the dataset and between points within the dataset. A model which is able to generalise in this way would be particularly beneficial to bypass practical/physical constraints relating to availability of equipment, placement of gauges and limitations of the recording equipment. For example, there may be practical limitations which prevent tests from being performed at certain scaled distances (limitations on robustness and survivability of recording equipment at smaller scaled distances, excessive signal to noise ratios at larger scaled distances) as well as potential issues relating to limited availability of diagnostics which may result in a sparse dataset. Understanding how accurately a model can extrapolate and interpolate has significant implications for the design of future experiments: such knowledge will provide experimentalists with a clear steer on typical areas of high sensitivity and therefore those with significant contributions to the overall accuracy of ML approaches, as well as areas where detailed measurements may not be required.
The stress-testing evaluation procedure therefore aims to investigate two themes of estimation ability: interpolation and extrapolation, as well as their dependencies on the availability of data to make accurate predictions. Herein, the dataset comprises three variables: X1 (Z, scaled distance), X2 (θ, angle of incidence) and Y (peak specific impulse). By restricting the availability of certain regions of each variable distribution, the ability of the model to generalise can be assessed for each given variable. Seven types of stress-test were performed, assessing either extrapolation or interpolation ability with 25% of the dataset removed. For each stress-test, each network was trained to 100 epochs, and this procedure repeated 25 times. Early stopping was used in all cases with a patience value set to 5 epochs. The information for each type of stress-test is summarised below: 1. Interpolation (a) Mean X1 values removed (b) Mean X2 values removed (c) Random data removed 2. Extrapolation (a) Maximum X1 values removed (b) Minimum X1 values removed (c) Maximum X2 values removed (d) Minimum X2 values removed
The architecture of the neural networks (NN and PGNN) follows that summarised previously, with the two additional hyper-parameters λPhy,1 = 104 and λPhy,2 = 104 included for the PGNN. Before the training process, various proportions of the data were removed, dependent on the mode of stress-testing, and the model performance was evaluated in each case by recording the RMSE on the removed, unseen test data. By also analysing the training history in each simulation, a physical inconsistency term can be quantified as the proportion of total epochs where physically invalid predictions are made (Karpatne et al., 2017), this will provide an insight into how ‘physically valid’ each network is. For clarity, if physically inconsistent predictions are made in 4 of the 100 epochs, then the physical inconsistency measure will be 0.04, where a physically inconsistent prediction is defined as a positive result from equations (5) or (6).
Results
Interpolation
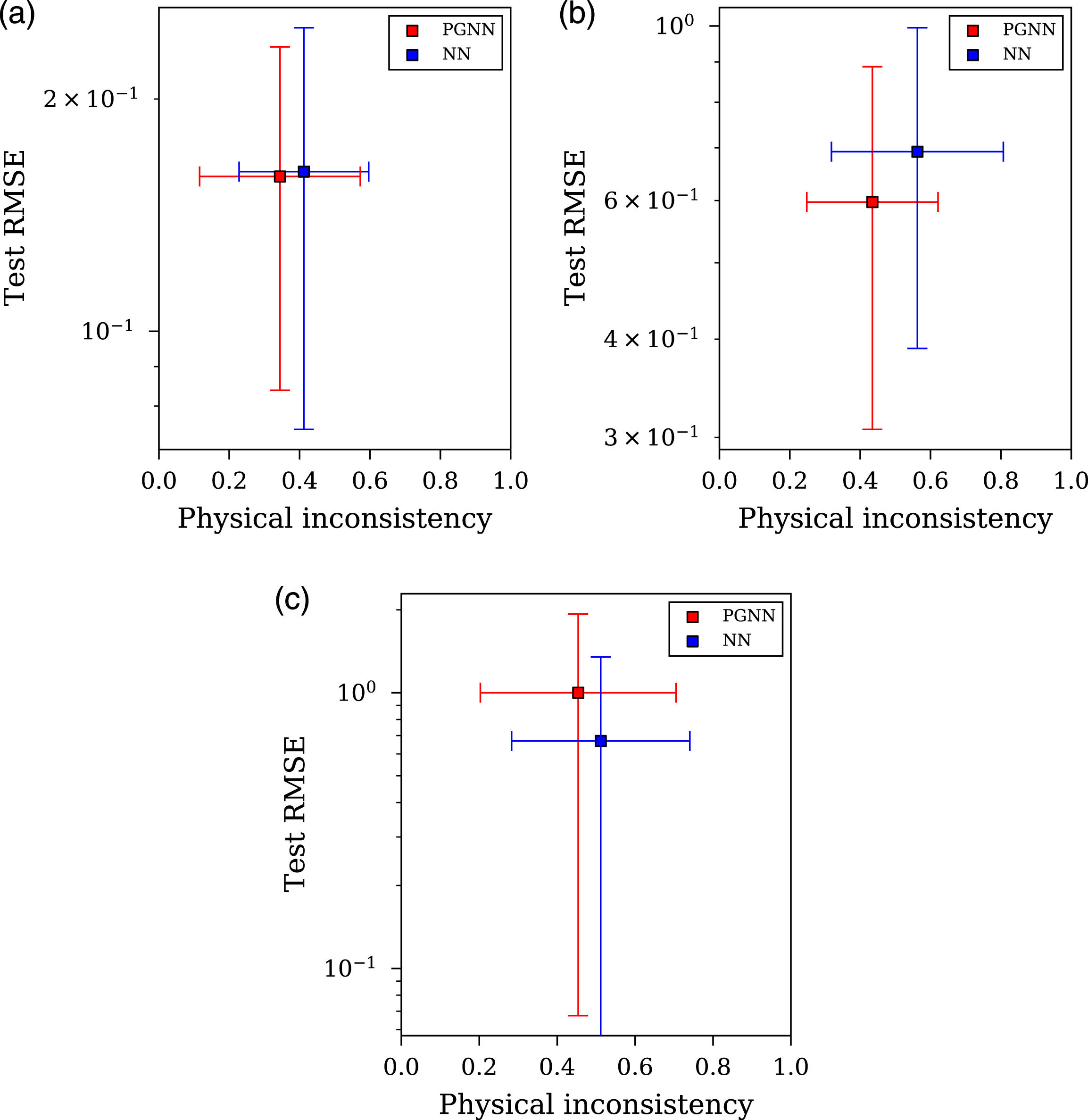
The first theme of stress-testing aims to assess the estimation ability of the models to interpolate between the upper and lower limits of the dataset. Firstly, removing the region of the variable distribution around the mean of scaled distance (X1), and angle of incidence (X2), and finally removing data randomly across the distribution space. For each analysis, the distribution of the dataset with 25% of the variable removed is presented in Figure 11, with the RMSE on unseen test data and physical inconsistency values presented in Figure 12. Due to the cross-validation procedure and the simulation repeats, more than one value for RMSE, and physical inconsistency, is provided for each NN architecture; therefore, the standard deviation of these values are plotted as error bars whilst the mean indicated as the scatter point for each architecture. Also shown in Figure 11 are a representation of the data remaining for the training process after removal according to the stress test. Here, a black pixel denotes the presence of labelled data for that combination of X1 and X2, whereas a white pixel denotes the absence of data. Interpolation stress tests, effects of data removal on the data distributions. Distribution of Y (peak specific impulse) before and after data removal (left); distribution of X1 (scaled distance) and X2 (angle of incidence) after data removal (right): (a) Removing 25% of data around the mean X1 value (b) Removing 25% of data around the mean X2 value (c) Removing the 25% of X values randomly. Results showing root mean square error of removed test data and physical inconsistency for various interpolation stress-test procedures: (a) Removing 25% of data around the mean of X1 (scaled distance) (b) Removing 25% of data around the mean of X2 (angle of incidence) data (c) Removing the 25% of X data randomly.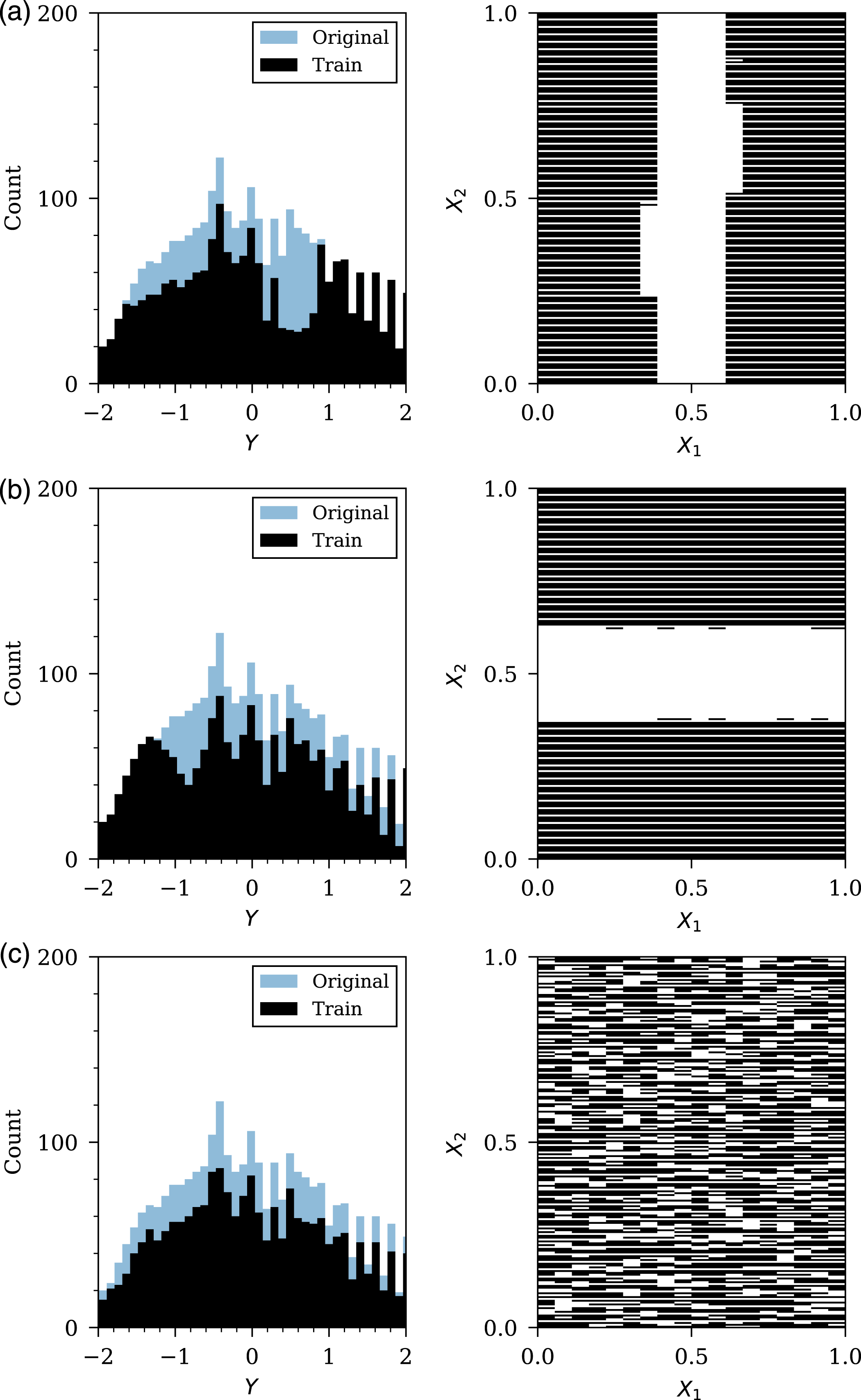
Extrapolation
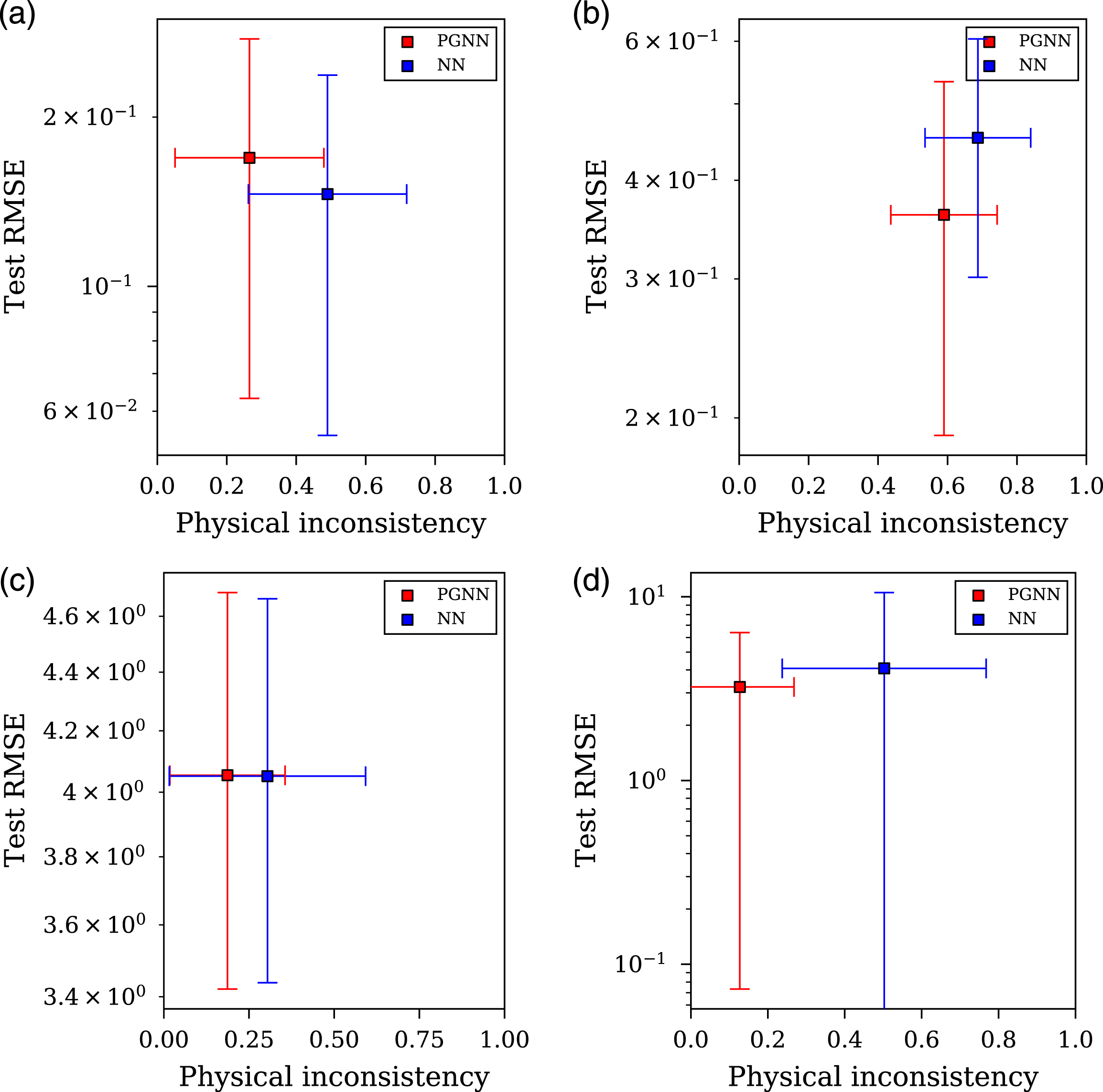
The second theme of stress-testing aims to assess the estimation ability of the models to extrapolate beyond the upper and lower limits of the dataset. Firstly, removing the maximum values of scaled distance (X1) and maximum values of angle of incidence (X2). It is important to note here that the minimum values of peak specific impulse correspond to the maximum values in scaled distance and angle of incidence (due to the monotonic decrease of specific impulse with an increase in these variables). For each analysis, the distribution of the dataset with 25% of the variable removal is presented in Figure 13, with the RMSE on unseen test data and physical inconsistency values presented in Figure 14. As mentioned previously, due to the cross-validation procedure and the simulation repeats, more than one value for RMSE, and physical inconsistency, is provided for each neural network architecture. The standard deviation of these values are plotted as error bars whilst the mean is given by the scatter point for each architecture. Extrapolation stress tests, effects of data removal on the data distributions. Distribution of Y (peak specific impulse) before and after data removal (left); distribution of X1 (scaled distance) and X2 (angle of incidence) after data removal (right): (a) Removing the maximum 25% of X1 values (b) Removing the maximum 25% of X2 values (c) Removing the minimum 25% of X1 values (d) Removing the minimum 25% of X2 values. Results showing root mean square error of removed test data and physical inconsistency for various extrapolation stress-test procedures: (a) Removing the maximum 25% of X2 (scaled dis- tance) data (b) Removing the maximum 25% of X2 (angle of incidence) data (c) Removing the minimum 25% of X2 (scaled dis- tance) data (d) Removing the minimum 25% of X2 (angle of incidence) data.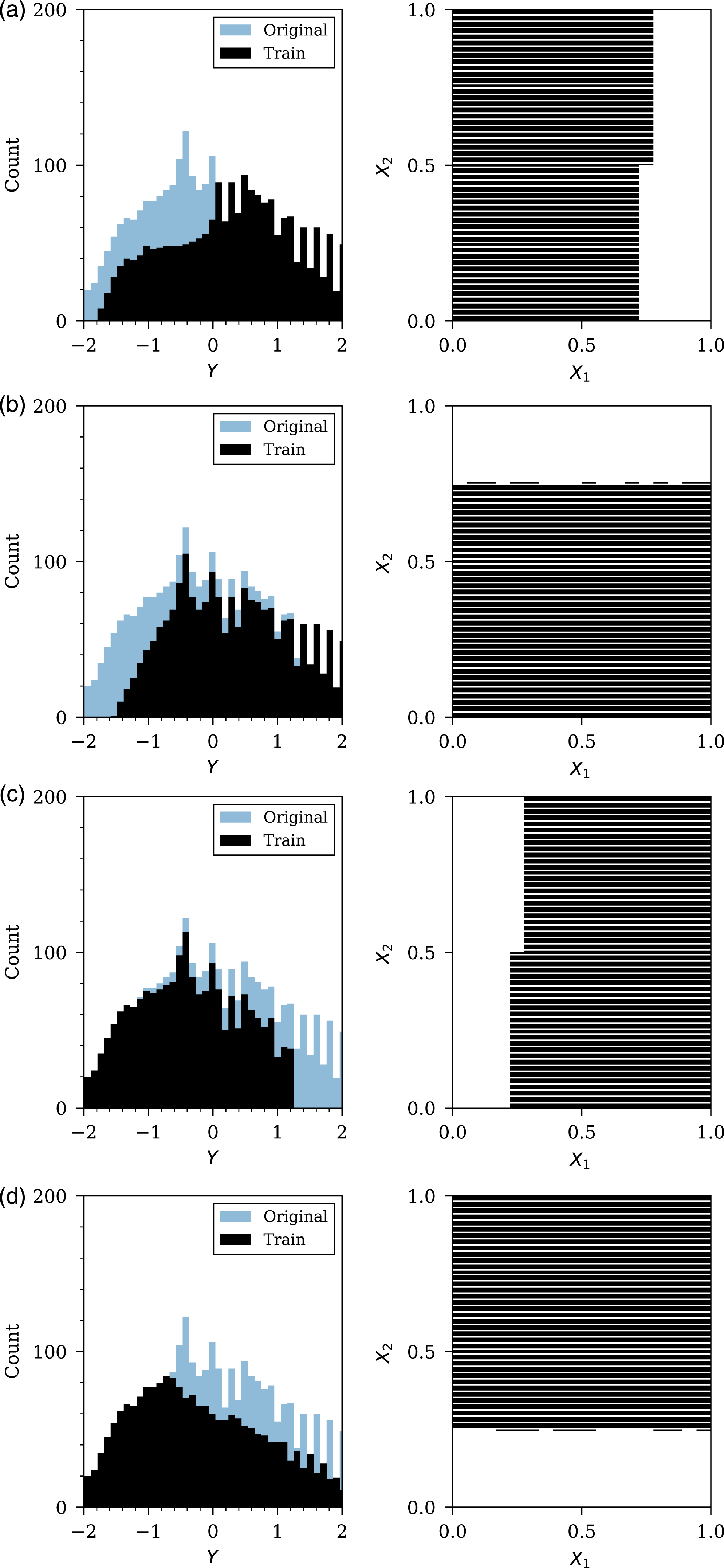
Discussion
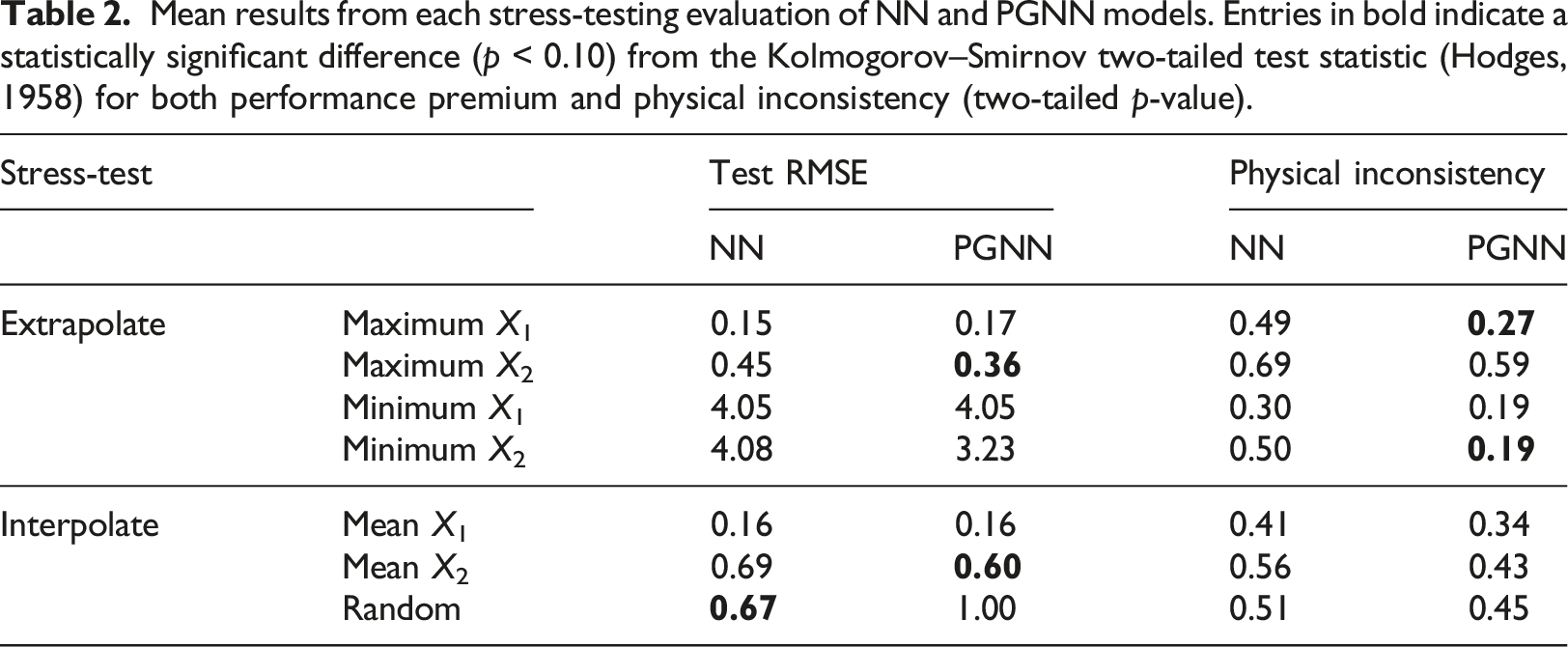
Mean results from each stress-testing evaluation of NN and PGNN models. Entries in bold indicate a statistically significant difference (p < 0.10) from the Kolmogorov–Smirnov two-tailed test statistic (Hodges, 1958) for both performance premium and physical inconsistency (two-tailed p-value).
It is clear that the PGNN outperforms the NN when extrapolating and interpolating with respect to X2, whilst extrapolation and interpolation with respect to X1 appears insensitive to network type. This could suggest that the hyper-parameter λPhy,1 is not set at an optimum level and could be adapted to further improve the method presented in this paper. There were three statistically significant findings with respect to test RMSE values: the results show that the PGNN significantly outperformed the NN when extrapolating beyond the maximum of X2, and removing data around the mean of X2, whereas the NN outperformed the PGNN when data was removed randomly.
The PGNN showed a statistically significant performance premium when extrapolating beyond the maximum of X1, and beyond the minimum of X2 with respect to physical inconsistency. When considering performance with respect to physical inconsistency on aggregate, however, it is shown that the PGNN outperforms the NN across all seven stress tests (even those not deemed statistically significant). If the null hypothesis of equal mean performance between the PGNN and NN with respect to physical inconsistency is considered, the observed outperformance in all seven modes of testing has a probability of 0.007 (p < 0.05); a clear performance premium.
These results are highly promising from an engineering perspective. The PGNN model is constructed so that it is far less likely than the NN to under-predict when extrapolating. Essentially, the PGNN contains inbuilt conservatism in model predictions. This ensures that when analysing structures subjected to blast loading following close-in detonation of a high explosive, solutions informed by PGNNs are more likely to be conservative; an approach that whilst not maximising efficiency will ensure safety. Extrapolating beyond data limits should always be handled with caution in predictive models, however the PGNN approach explored in this article provides additional conservatism and maintains physical consistency if extrapolation is ever required.
Summary
This paper presents a novel application of a physics-based regularisation framework for neural networks in the application of predicting blast loading following detonation of an explosive charge. The physics-based regularisation is shown to provide statistically significant performance improvements over traditional neural network procedures when generalising beyond the dataset through extrapolation and interpolation with regards to accuracy (shown via test RMSE) and physical validity (via a physical inconsistency metric). This finding provides positive evidence towards using physics-based regularisation when training ML models, and the use of ML models generally, especially in applications involving the prediction of blast loads resulting from the detonation of high explosives.
An initial parameter search study was completed for a traditional neural network (NN), with the chosen parameters also used in the physics-guided neural network (PGNN). Both models were stress-tested through various data holdout approaches, and their ability to predict high explosive blast loading were comprehensively evaluated and compared. It is found that the PGNN out-performed the NN in 57% (4/7) of the stress tests (lower RMSE), and exhibited lower physical inconsistency in the training process in 100% (7/7) of the stress tests (p < 0.05). With respect to the specific mode of stress-testing, of the PGNN’s 11 performance premiums, 4 were found to be statistically significant: RMSE when extrapolating with respect to maximum X2 and interpolating with respect to mean X2, and physical inconsistency when extrapolating with respect to maximum X1 and minimum X2 (where X1 is scaled distance and X2 is angle of incidence).
Additionally, this research has considered the importance of careful consideration of the parameters which govern a network’s ability to generalise, and subsequent implications for experimental design. The results demonstrate the feasibility and enhanced accuracy achievable when developing ML models to predict near-field blast loading. As a continuation of this research, future work will involve incorporating different charge types (Grisaro et al., 2021), shape effects (Rigby et al., 2021) and blast wave clearing (Rigby et al., 2013) as features in the model. Further, incorporating more complex physics (through implementing a non-linear loss constraint instead of the monotonic loss constraint) will enable the possibility of improved PGNN performance through transfer learning. Developments in this area will facilitate more accurate probabilistic-based approaches to engineering design and risk mitigation that encompass a more complex suite of scenarios than is capable presently.
Footnotes
Acknowledgements
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Jordan J Pannell gratefully acknowledges the financial support from the Engineering and Physical Sciences Research Council (EPSRC) Doctoral Training Partnership.