
Abstract
Argumentation is the process of creating arguments for and against competing claims. Computational argumentation involves different ways of analyzing and reasoning upon arguments and their relations. More precisely, Argument Mining is the research field aiming at automatically identifying and classifying argument structures in text. The research field is mainly focussed on the extraction of explicit argument structures (i.e., claims and premises connected by support and attack relations). However, an even more challenging task consists in extracting implicit argument structures in text (e.g., enthymemes). These structures are particularly valuable to then address argument reasoning, e.g., on incomplete and uncertain information, to finally compute the set of acceptable arguments, i.e., argument justification and skepticism. In this paper, we present and compare current approaches and available datasets for the novel task of Implicit Argument Mining. Future work perspectives are discussed to pave the way to further studies in this direction.
Keywords
Introduction
Rooted in people’s inherent ability and necessity to articulate opinions and thoughts, argumentation permeates everyday discourse, shaping discussions, justifying decisions, and fostering a sound exchange of ideas. At its core, argumentation involves constructing and articulating grounded reasoning through language. 1 It encompasses diverse ways in which individuals present claims, provide evidence, and engage in discourse to support their viewpoints.
In the last ten years, several works in Natural Language Processing (NLP) focussed on the computational modelling of human argumentation, exploring different tasks, such as Argument Mining,2,3 and its recent developments for automatic Argument Assessment 4 and Generation. 5 More precisely, Argument Mining (AM) stands out as the automatic identification and classification of explicit argument components and structures embedded in natural language text.3,6 Recent approaches in AM delve deeper into the comprehension of argument-based reasoning processes and the required knowledge, going beyond the explicit content to analyze hidden or implicit meanings. 7
While in general humans do not encounter significant difficulties in understanding an (even implicit) argument, this task is hard for computational approaches which often lack commonsense and background knowledge to reason on. Implicit inference refers to understated arguments, hidden assumptions and relations, that extend beyond the explicit context of an argument. To understand implicitness, computational models of argumentation consider different steps, among which the exploration of argumentation models to unveil argumentation structure, the study of enthymemes- i.e., incomplete arguments, where some components are left implicit 8 – to be able to identify and reconstruct this incompleteness, and the exploration of possible ways to restore implicit argument components.
The goal of this survey paper is to provide an overview of the existing approaches in the literature that explore the topic of implicitness in natural language argumentation, focussing in particular on the challenges that should be addressed by current methods to gain a complete understanding of an argument structure. Specifically, we begin by outlining our methodology for gathering a collection of research works focussed on enthymeme analysis (Section 2). Then, we provide a high-level roadmap of enthymeme analysis (Section 3), giving a clear understanding of the workflow before diving into the details of models, components, and methodologies. After that, we present the main argumentation models (Section 4) and highlight those used in implicitness studies in natural language argumentation. In particular, we emphasize the significant role played by argumentative schemes, 9 i.e., informal logic argument-based reasoning schemes, utilized in modelling implicit inferences within argumentation. Subsequently, we investigate argument components that may be left implicit (Section 5), playing, however, a key role for argument comprehension. After establishing the taxonomy of argument components that may be missing, in Section 6 we investigate how a natural language argument can be defined implicit and what makes it explicit (i.e., what kind of knowledge is required for argument explicitation), to obtain a full and sound understanding of the argument. 10 Also, we analyze computational methods for enthymeme analysis (Section 7) and we provide an exhaustive list of existing datasets for the implicit argument mining task (Section 8). We conclude the paper with the discussion of some new future research lines that can stimulate argument research communities to pursue new directions towards the achievement of fully automated argument mining and reasoning frameworks (Section 9), and we outline main points of the paper in the conclusion (Section 10).
Methodology
This section briefly discusses the methodology for collecting literature for the survey. Currently, resources on enthymeme studies that integrate computational approaches and argumentation theories are scarce, as implicitness remains a challenging phenomenon for automatic identification and modelling. Therefore, our primary goal was to include as many existing and relevant works on the topic as possible.
The search for relevant articles was conducted in three stages: (i) identifying key authors specializing in NLP, particularly in Argument Mining, implicitness in argumentation, hidden meanings, and figurative language, such as Lawrence, Reed, Walton, Boltužić, Šnajder, Stede etc.; (ii) searching by keywords relevant to the topic, including implicit argumentation, enthymeme, implicit premise, implicit warrant, implicit conclusion, enthymeme detection, and enthymeme reconstruction; (iii) using related papers found so far as benchmarks to discover additional relevant articles.
For the first stage, we referred to the programme committee members of the most recent workshop on AM (https://argmining-org.github.io/2024/index.html#committee) to retrieve author names and we conducted searches for their publications using platforms such as Google Scholar, ACL Anthology, and DBLP to find relevant works. At the second stage, we employed the same platforms, focussing on keyword searches to identify and evaluate titles, then, we reviewed the papers to select the most relevant ones. For the final stage, we utilized the Connected Papers resource (https://www.connectedpapers.com) which generates a graph of related works based on a selected paper or keyword. This graph visually represents the closeness between articles, highlights the most recent and most cited works, and provides metadata, such as authors, publication year, thus, it allows to select related and relevant articles.
The search was not restricted by time frame, as implicitness in argumentation is a relatively recent field within AM, with a limited number of publications. Similarly, no constraints were imposed on the type of publication. Our strategy aimed to include the majority of existing works on enthymemes and related topics, prioritizing their relevance to our research.
Enthymeme analysis pipeline
In this section we provide a high-level vision of the process of enthymeme exploration. To analyze and understand enthymemes, it is essential to follow key steps that allow to identify implicitness, to clarify reasons of omissions and to restore reasoning behind an incomplete argument. An overview of this process is represented in the pipeline (Figure 1). The process consists of two main steps or tasks: Enthymeme detection and enthymeme reconstruction.11,12 The goal of the first task is to identify incomplete arguments and define missing components in them. Given an argument with (a) missing component(s), the goal of the second task is then to reconstruct the component(s) that fill the gap. In general, enthymeme detection is perceived as a single-step task, where identifying missing argument components automatically determines the argument as an enthymeme.10,13 To effectively detect missing argument components, we need to apply a specific argumentation model to this step. However, we assume that identifying an argument as incomplete can be a distinct preliminary step, preceding the detection of its implicit components. This initial step involves evaluating argument quality, naturalness, and argumentativeness to determine incompleteness before analyzing the argumentative structure. 12 Such approach allows for a two-step process, (i) identifying incomplete arguments and (ii) detecting implicit argument components. While this flow is logical, it is still equally reasonable to detect missing components directly, since it allows to classify an argument as an enthymeme. At the same time, the second block of the pipeline, enthymeme reconstruction, nearly always requires extralinguistic information, such as commonsense knowledge 14 or domain-specific knowledge, as humans share background information for their reasoning. It is significant to note that some works address only the first module of the pipeline,11,15 because enthymeme detection is a complex and versatile process in itself, while other works tackle only the second step as they start reconstruction given an enthymeme.14,16 Addressing the complete pipeline, including both modules, is challenging, but some progress in this direction has also been made. 12 In the following, we will explore all the blocks of the presented pipeline, starting from the introduction of argumentation models employed for the other steps of enthymeme analysis.
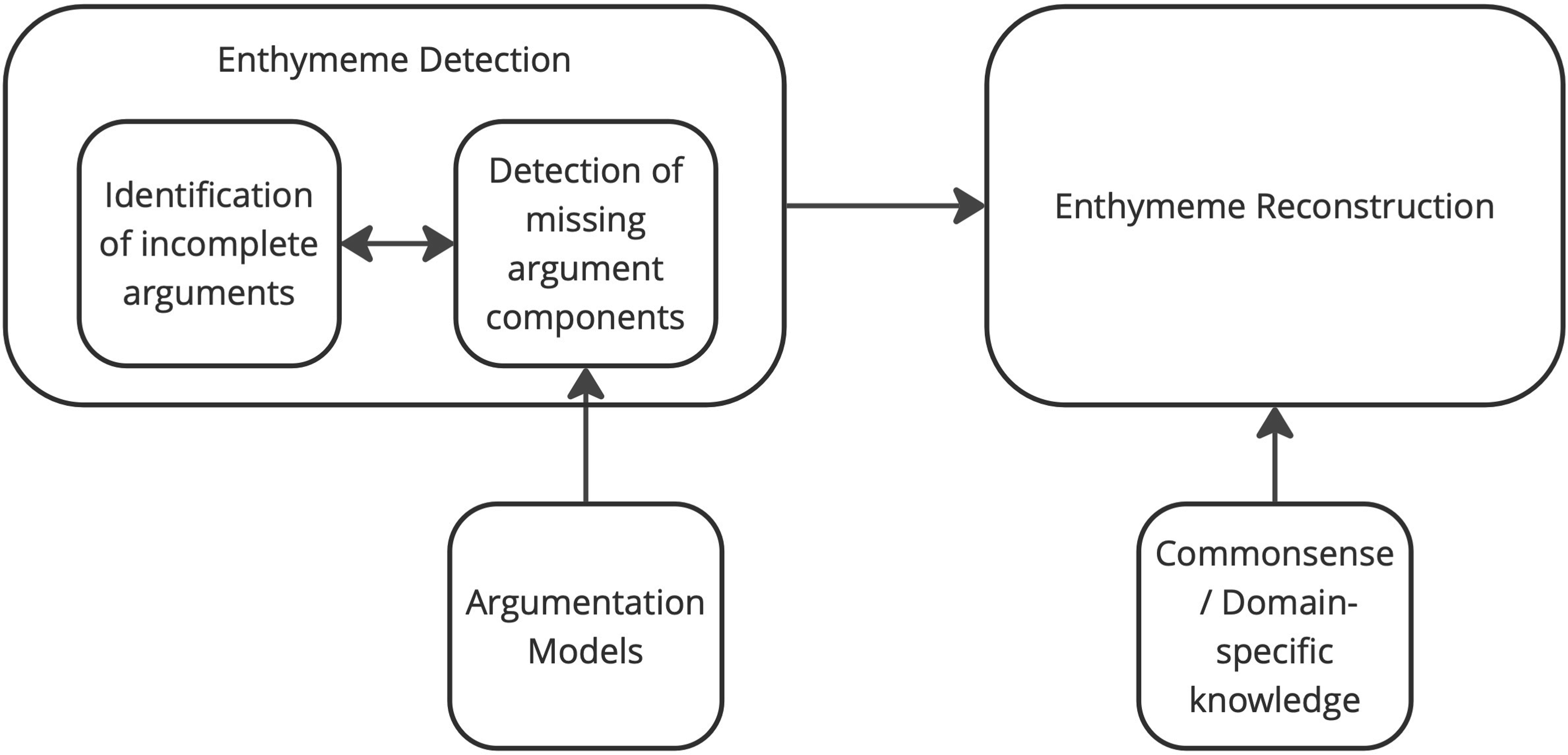
Enthymeme analysis pipeline.
As it has been mentioned in various works,3,10,17 understanding the argument structure first and foremost aids in enhancing comprehension and analysis of the underlying message in a natural language text. For example, decomposing argumentative units into distinct components allows us to attribute meanings to each component and trace the relations between them.18,19 Therefore, this decomposition enables a deeper grasp of the interlocutor’s reasoning that is nearly always hidden behind the text surface. As well as that, detection of argument components lets us better characterize arguments, for instance, to differentiate strong arguments from weak ones or complete arguments from incomplete ones. Moreover, argumentation schemes help us learn to construct various types of arguments in a proper way. Besides, employing argumentation schemes provides an undeniable advantage for argument mining. Unlike humans, computational models struggle to perceive the underlying reasoning in an argumentative text. By instructing them with prior knowledge of argument components and their relations, we address the challenge of automatically extracting arguments from free text, 3 thus, we take a step towards models that are able to understand human argumentation.
In the last years, a variety of AM approaches have been proposed, relying on different argumentation schemes and models. 3 Table 1 presents an extensive compilation of prominent Argumentation Models. It showcases contemporary argumentative approaches, beginning with those predominantly used in works exploring implicit argument components. The table provides insights into argument schemes and components, while strengths and drawbacks of each approach are discussed further in this chapter.
Argumentation models.
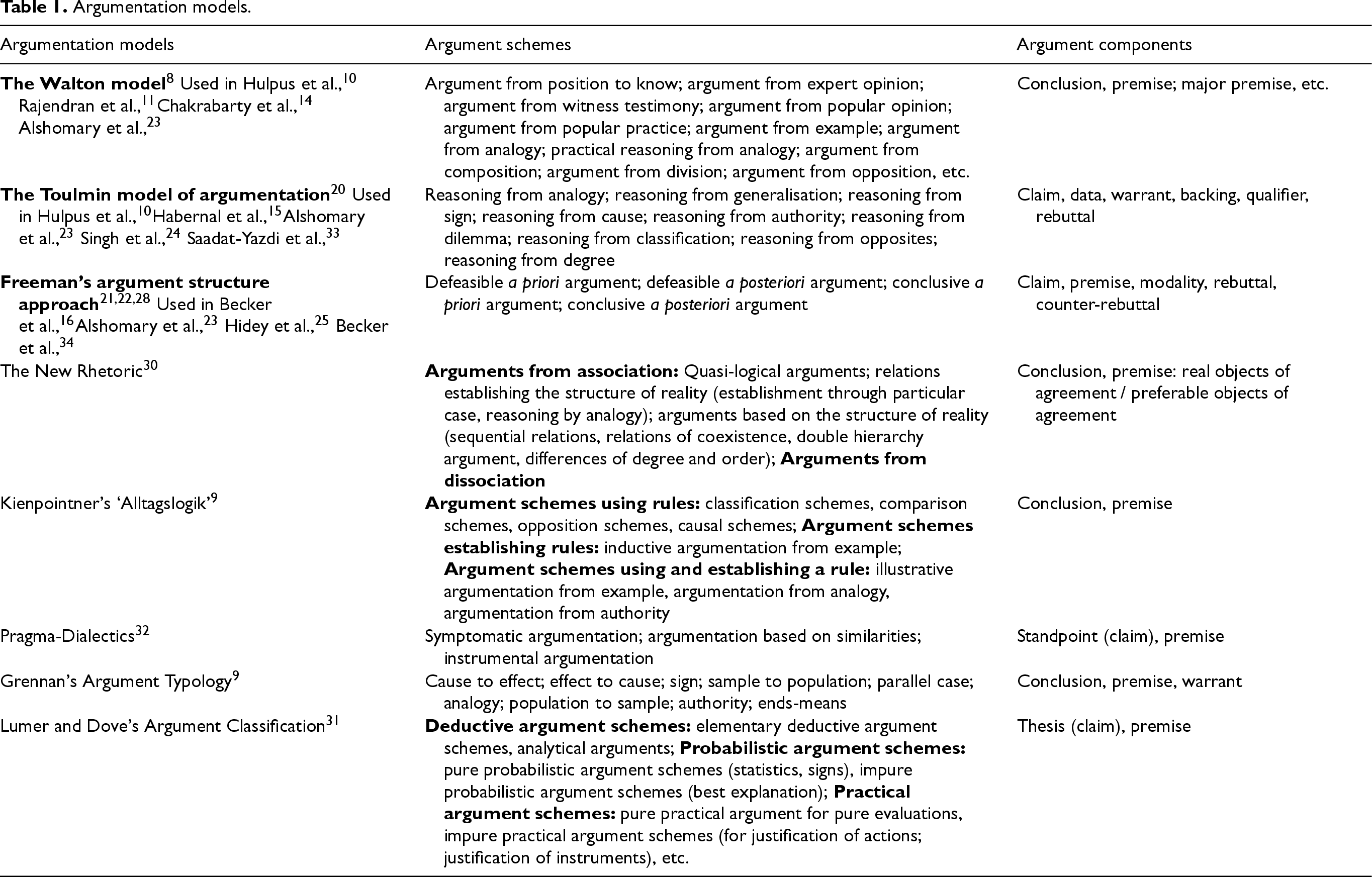
Argumentation models.
We will now explore specific details of the compilation. First, research on implicit inferences in argumentation mostly references the foundational models of Walton, 8 Toulmin, 20 and the argument structure approach of Freeman.21,22 Studies of implicitness in argumentation typically focus on the components and relations within arguments, aiming to identify omitted argumentative discourse units 18 that need reconstruction. Walton, Toulmin, and Freeman’s models are particularly valuable here, as they all centre on a core structure of argumentation – a conclusion (claim) supported or attacked by evidence (premises) – though each model circumstantiates these components in a distinct way. To illustrate the usability of these three models in enthymeme detection and reconstruction, we will explore some examples (full set of papers that refer to one or another argumentation model is presented in the first column of the Table 1). The Walton model, for instance, is addressed by Rajendran et al. 11 and Chakrabarty et al. 14 for the detection and reconstruction of implicit premises, while Alshomary et al. 23 exploit it for detection and further generation of implicit claims. Several authors15,24 use the model of Toulmin to explore implicit warrants. In this context, the Toulmin Model of argumentation serves the intended purpose due to its granularity. In the meantime, Becker et al. 16 resort to the argument structure approach of Freeman so as to annotate newly generated arguments with argument components and relations according to Freeman’s approach. Hidey et al. 25 reference Freeman’s approach as they apply semantic types of claims proposed in Freeman’s taxonomy 26 to their dataset. All in all, the research centred around implicitness in argumentation (i) utilizes only three major argumentation models, those of Walton, Toulmin and Freeman; (ii) exploits only argument components and relations, keeping aside argument schemes.
Although recent studies on enthymemes primarily focus on argument components of prominent argumentation models, argument schemes should not to be overlooked in this domain. They offer a pathway to easier detection of implicit components due to the fact that they classify arguments by their types and contexts and recognize their complete structure. Additionally, argument schemes may facilitate automatic reconstruction of incomplete arguments as they propose appropriate reasoning direction according to the specific type. 8 Therefore, we will discuss argument schemes from the Table 1 and we will elaborate on argument components characteristic of argumentation models where needed.
All in all, it is important to highlight that argument components from argumentation models play an essential role in unveiling the structure of an argument for argument mining and analysis, while being particularly useful for enthymeme studies. Since the first step in enthymeme detection is to determine which elements in an argument are missing, these models provide the foundation for identifying and classifying implicit components.
In this section, we define the argument components that may be left implicit and describe the associated challenges. The idea that premises are most often the implicit component in arguments can be traced back to early works on enthymemes, such as the paper of Rajendran et al., 11 which, influenced by Walton’s research, 8 defined enthymemes primarily as arguments with implicit premises. This early perspective introduced a bias in the literature, overlooking the fact that enthymemes may also define arguments with implicit claims, warrants, or other components. While it is true that premises are frequently left implicit, 14 as humans can infer and fill reasoning gaps using their background knowledge, the analysis of various types and genres of argumentative texts shows that other components can be left implicit to a similar extent. As such, some research works explore implicit warrants,15,24 while others state that conclusions that are self-evident may be left implicit. 23
Table 2 illustrates argument components that, although may be left implicit, are nevertheless essential for a comprehensive understanding of an argument. The identification of these implicit argument components is a challenging yet crucial task for automated systems. The table also outlines the NLP tasks that have been defined to tackle such challenge, as well as the benchmarks created to evaluate these tasks. Additionally, it includes details about the manual or automatic annotations proposed by the authors of the tasks. In the following, we describe each task, discuss the proposed annotations, and examine the similarities and differences in the approaches.
Implicit components of an argument.

Implicit components of an argument.
Note. (AC
To begin with, Fill-in-the-Gap Task or Claim Matching Task 35 is meant to develop methods able to fill the gap between two claims, specifically, a user’s claim on a certain topic and a major claim unifying all users’ claims on this topic. This task follows the assumption that arguments on a debatable topic discussed in social media share one main claim. However, in practice, real users’ claims do not correspond to this main claim. Consider an example: 35
Main Claim: Legalization of marijuana causes crime.
User Claim: It would be loads of empathy and joy for about 6 hours, then irrational, stimulant-induced paranoia. If we can expect the former to bring about peace on Earth, the latter would surely bring about WWIII.
The topic of this debate is Marijuana with a negative stance label (against marijuana). The main claim of the debate is clear; however, the user’s claim presented in the example is markedly different: while the main claim represents a general statement that calls things by their right names, the user’s claim describes a person’s specific condition after using drugs, defining neither an actor nor a reason of this state. The user’s claim remains figurative and understanding its link to the major claim requires a lot of background knowledge. Therefore, filling this gap between the main and the user’s claim is necessary for argument understanding and future reconstruction of the reasoning, especially for automatic argumentative analysis. The claim matching task 35 involves manually reconstructing fill-in-the-gap premises to link new users’ claims to existing ones. While this approach aids the matching process, the task presents several complexities that are currently difficult to address automatically. First, the size of the gap between the main claim and the user’s claim can vary significantly, making it challenging for language models (LMs) to handle larger gaps effectively. Second, while humans can easily reconstruct implicit premises between two claims, they often use entirely different premises for the same set of claims, posing a challenge for models to learn consistent patterns of reconstruction. Finally, the task itself is very specific, as it assumes the presence of main claims in the argumentation, which is not always the case unless the debate has a well-defined topic where opinions are explicitly related to that topic.
The tasks of Enthymeme Detection 11 and Enthymeme Reconstruction 14 focus on identifying and reconstructing implicit premises in arguments. Effective reconstruction of implicit elements first requires identifying missing elements. To do that, the ArguAna corpus 36 used by Rajendran et. al. 11 is manually annotated with the labels ‘explicit opinions’, ‘neutral opinions’ and ‘implicit opinions’ that allow to progress in automatic detection of enthymemes. The authors train a binary classifier on this annotated dataset to distinguish between implicit and explicit opinions automatically. This method demonstrates its utility and serves as an initial step toward enthymeme detection in natural language texts. On the other hand, Stahl et al. 12 take a step back to explore the creation of enthymematic dataset from scratch so as to automatically detect and reconstruct arguments with implicit components at a later stage. Their approach is based on the ICLEv3 corpus, 37 where they systematically remove argument components (claims or premises) to construct enthymematic arguments. This method ensures an extensive set of high-quality enthymemes, as the process of removal can be controlled at each step. The creation of such a dataset offers several advantages. First, the controlled removal ensures that enthymemes remain natural, sound, sufficient and maintain logical coherence. Second, it provides a diverse training resource for models, allowing exploration of different implicit argument components. Finally, this method facilitates evaluation of detection and reconstruction models, since the removed components serve as a gold standard for assessing performance. Following that, the authors propose baseline approaches for enthymeme detection and reconstruction that prove, on the one hand, the usability of the dataset, and the ability of computational approaches to learn from data and accomplish the task, on the other.
When comparing these two approaches of enthymeme detection, we observe that both have practical advantages, but some limitations are also present. The method proposed by Rajendran et al. 11 is grounded in real-world argumentative texts, ensuring that it reflects the authenticity and veracity of natural arguments. Additionally, the manual annotations provide high-quality metadata, offering a strong foundation for model training. In contrast, the corpus created by Stahl et al. 12 is more artificial, as its construction involves removing argument components to create enthymemes, which may not fully capture the natural occurrence of implicitness in real-world contexts. At the same time, controlled creation of the second (Stahl et al. 12 ) ensures higher data quality and offers the advantage of removed components serving as a gold standard for reconstruction – an opportunity that the approach of Rajendran et al. 11 does not provide. Furthermore, both methods demonstrate immediate applicability for the automatic detection of implicitness in argumentation, as they rely on training binary classifiers on their respective datasets. However, the applicability of these methods may be limited to specific domains. The first approach, using the ArguAna corpus, focuses on opinions, which may not encompass the full range of implicit argumentation phenomena. Meanwhile, the second approach, based on the ICLEv3 corpus, is better suited for applications like teaching students to write argumentative essays, which could restrict its broader applicability.
The task of Enthymeme Reconstruction in its turn represents the process of generating an implicit premise (or claim, as discussed later in this section) for an incomplete argument. As previously mentioned, reconstruction cannot be accomplished without a preceding detection step, making these tasks complementary. For instance, the work of Stahl et al., 12 which we presented just before in the context of corpus creation and automatic enthymeme detection, naturally includes the reconstruction step. The authors frame enthymeme reconstruction as a generation task, where the model is provided with an enthymematic argument and a special mask token indicating the position of the implicit element. This approach demonstrates both the utility of the created corpus and the effectiveness of automatic generation, even at a baseline level. Meanwhile, Chakrabarty et al. 14 consider enthymeme reconstruction as a stand-alone task, assuming the argument to be incomplete. They also frame enthymeme reconstruction as a generation task but demonstrate that fine-tuning a baseline model on enthymematic data alone is insufficient for effective reconstruction of implicitness. To address this, they propose enhancing generation with commonsense knowledge, resulting in a more advanced reconstruction approach that achieves improved results. In general, the task of Enthymeme Reconstruction is inherently more complicated than that of Enthymeme Detection. Enthymeme detection is typically framed as a binary classification task (implicit vs. explicit), which is relatively straightforward for machine learning models. In contrast, reconstruction requires generating the missing component (a premise in our context). This involves creating meaningful, contextually appropriate, and logically coherent text, which is far more complex. Additionally, while detection often relies on surface-level linguistic cues or knowledge of argument structure, reconstruction demands a deeper understanding of the argument’s context and underlying reasoning. Furthermore, reconstruction frequently depends on integrating commonsense or domain-specific knowledge, adding an extra layer of complexity to the task. Despite these challenges, the necessity of enthymeme reconstruction is undeniable. Reconstructed premises provide valuable insights into deeper human reasoning behind arguments. Also, they enable experimentation with alternative methods for generating argument components of higher quality. 14
Argument Reasoning Comprehension Task15,40 is meant to fill in the gap between a premise and its claim in order to restore the reasoning. It is based on the assumption that to reach complete comprehension of an argument or to frame a new argument, humans apply common knowledge and reasoning skills that basically remain tacit. This common knowledge constitutes a warrant – an argument component between a claim and a premise that justifies the fact that the premise entails the claim, as in Example 2: 15
Premise: College students have the best chance of knowing history.
Claim: College students’ votes do matter in an election.
Warrant: Knowing history means that we won’t repeat it.
Here, the reconstructed warrant allows us to restore the reasoning behind the argument consisting of a premise and a claim: College students have the best chance of knowing history. Since knowing history means that we won’t repeat it, therefore, College students’ votes do matter in an election. Without this warrant humans are able to comprehend the relations between the premise and the claim, but their guesses may also vary according to their education, main values and even age. In this context, the Room for Debate dataset 15 has been annotated with manually reconstructed warrants and alternative warrants for opposite claims. The underlying intuition is that an alternative warrant reconstructed for an opposite claim (a claim of a twisted, opposite stance) can guide the reconstruction of the original claim by applying the same reasoning process with minimal modifications. Although this approach looks complex at the first glance, it provides valuable insights. Computational results indicate that current models used in argumentation, such as neural models, are not particularly effective for this task, often performing poorly when selecting the correct warrant from two options (the warrant for the original claim and the alternative warrant). This poor performance is likely due to the high lexical similarity between the original and alternative warrants. Since alternative warrants often differ only in negation, models struggle to distinguish them accurately. Nevertheless, this task proposes new challenges and a high-quality dataset for the future evolution of automatic generation of implicit warrants and argumentative analysis of incomplete arguments. SemEval-2018 Task 12 40 advances the automatic reconstruction of implicit warrants within the Argument Reasoning Comprehension Task. The datasets used in the task are enhanced with automatically selected correct warrants from available options — options that originally lead to contradicting claims. To identify the correct warrant, the authors leverage transfer learning from the Natural Language Inference task. This approach is valuable as it demonstrates the potential to address the challenge of distinguishing between two lexically similar stances (or lexically similar warrants, in this context). Moreover, the annotation and methodology provide a foundation for developing automatic systems to analyze implicit warrants. Both approaches to the Argument Reasoning Comprehension task15,40 point into the same direction: Advancing the automatic reconstruction of implicit warrants by first proposing the selection of a correct warrant from two possible options. Nevertheless, the approaches are elaborated differently: The former relies on manual annotations, which add complexity and presumably enhance the quality of the data, while the latter employs a transfer learning method that demonstrates better performance compared to other existing systems.
The task of Evidence Detection 24 has implicit warrants and premises in its focus of attention. The objective is to improve the detection of correct evidence (premise) for a claim by leveraging warrants. In order to explore the reasoning behind an argument, it is significant to restore both, warrants and premises. Thus, the authors of the task take a step back to shed light on both implicit components, assuming that reconstructed warrants may improve the identification of correct premises. Their approach involves first automatic extraction of implicit warrants given a claim and a premise from other existing corpora, to then verify that these warrants may help to correctly select a premise (now implicit) for a claim. This method resembles the previously described approaches to implicit warrant reconstruction, as it also relies on selecting a suitable component. In this specific case, extracting warrants from existing data ensures that the reasoning aligns with real-world arguments avoiding artificial noises that can arise during generation. Furthermore, by using data that reflects how humans naturally construct arguments, this approach enables LMs to learn reasoning patterns that are close to human logic. As a result, the approach holds significant potential for automatic reconstruction of arguments similar or identical to authentic human argumentation.
The last group of tasks concerns claims or conclusions that are left implicit in an argument. Target Inference task 23 proposes to reconstruct implicit conclusions with the help of restored targets of the conclusions. It is grounded in the assumption that targets explicitly stated in premises correspond to conclusion targets of the same argument. In this way, it is possible to infer conclusion targets from premise targets. Then, conclusion targets may be further leveraged in automatic generation of implicit conclusions, so that this generated conclusion is close to an authentic or a human-proposed conclusion. Considering an example: 23
Premise targets: Relocating to the best universities; Improving the pool of students; Online courses; Stanford University’s online course on Artificial Intelligence
Conclusion target inferences: Online courses; Distance-learning
Conclusion target ground-truth: Online courses
Example 3 represents premise targets automatically extracted from the dataset with conclusion targets automatically inferred from them. As can be seen, one inferred conclusion target perfectly matches with the ground truth, while the second one is semantically close to the ground truth. 23 This novel approach to implicit conclusion reconstruction is valuable and practical due to several reasons. First it ensures that generated conclusions remain consistent with the argument’s actual content, reducing the likelihood of irrelevant outputs. Second, using inferred targets aligns conclusions with premises, therefore enhancing the coherence of argumentation. Additionally, exploiting explicit information within an argument may avoid the need for external knowledge, while also limiting risks associated with purely generative techniques, such as hallucinations and biases. Overall, the authors propose a self-contained methodology that successfully generates meaningful conclusion targets. This approach has the potential to produce coherent conclusions and can also be combined with other methods to further enhance generation.
Modelling Implicit Argumentation by Explicit Stances task 47 proposes to leverage an explicit stance of an argument and overall explicit debate stances to reconstruct implicit claims. The authors hypothesize that humans can infer an argument given a stance, which represents a standpoint supporting or contradicting a target. Consequently, using explicit stances to model complete arguments is a reasonable approach. To support this hypothesis, the authors first semi-automatically select debate targets that define positions on the debate topic. Next, stances toward these targets are manually annotated. In a subsequent step, the authors verify whether targets and stances can be assigned automatically, demonstrating the potential for automatic detection of debate stances. This approach is promising not only for detecting stances but also for improving the reconstruction of implicit conclusions, and it shares similarities with the previously discussed Target Inference task. As in the previous task, here the authors explore how to exploit information contained within arguments, avoiding the need for external resources and maximizing the use of the information already available. Therefore, the advantages of this methods, if further used for implicit claim reconstruction, are clear: It ensures the relevance and coherence of reconstructed claims, it minimizes the risk of generative errors and biases, and it offers broad applicability across various domains of argumentation.
The last task addressing implicit claims, Enthymeme Detection and Reconstruction, 12 has been extensively discussed as a task that deals with implicit premises in argumentation. However, the authors of this approach focus on both argument components – premises and claims – by creating a corpus of enthymematic arguments containing either implicit premises or implicit claims. The main advantage of this approach to implicit claim detection and reconstruction is that the task is divided into two blocks (detection and reconstruction), allowing each block to be used independently or improved separately. In comparison, the Target Inference 23 and Modelling Implicit Argumentation by Explicit Stances 47 tasks presuppose that claims are left implicit, focussing exclusively on reconstructing the missing claims. As a result, these tasks have to be specifically adapted for datasets where the first step involves detecting whether implicit claims are present in the argument at all. Another advantage of the Enthymeme Detection and Reconstruction approach by Stahl et al. 12 is that it accounts for the interplay between claims and premises. In contrast, all the other tasks presented focus on a single argument component that may be left implicit. Therefore, this approach represents a significant step forward in the detection and reconstruction of enthymemes.
So far, we have primarily explored argument components that may be left implicit, as they represent a challenge for computational approaches. Nevertheless, the ability to properly recognize relations connecting different arguments plays a major role in understanding the argumentation. Relations of support or attack can hold between argument components, such as premise–claim, premise–premise, claim–claim. The difficulty of their automatic detection lies in their implicit nature: Quite often argument components are connected to each other via implicit inferences that may be retrieved only with the help of external knowledge. 49 However, the literature on implicit argumentative relations identification is sparse. Argumentative Relation Classification task 49 demonstrates how injected commonsense knowledge improves argumentative relations detection on two datasets: Student Essays version 2 46 and a dataset from Debatepedia. 49 Saadat-Yazdi et al. 33 also assume that the majority of argumentative relations are implicit and the detection of implicit argumentative relations is highly dependent on commonsense knowledge. In particular, authors highlight that commonsense knowledge in an argumentative unit is expressed in warrants that are often left implicit. Therefore, it is necessary to explore and reconstruct implicit warrants. Authors use Student Essays corpus, 50 Debatepedia 49 and M-Arg Presidential Debate corpus. 51 All in all, implicit argumentative relations still require extensive and thorough exploration, particularly in understanding the role of external information and the importance of human reasoning for the complete comprehension of argumentative flow.
Although main argument components that can be left implicit are already addressed in various studies, many gaps still persist and the defined tasks remain challenging for automatic analysis. First, almost all the research works described here represent either initial or preliminary studies of enthymeme detection and/or reconstruction, meaning that future works are indispensable. Some of these primary studies already set further goals, while proposing first and necessary steps to approach them,11,23 others create valuable datasets that will facilitate detection and reconstruction tasks and improve evaluation. 12 Majorly, they test baselines so as to set an initial threshold for the tasks. Therefore, we can claim that there is still an open perspective of in-depth approaches addressing different implicit argument components. Beyond that, some of the methods of enthymeme reconstruction take a step towards employing extralinguistic knowledge to improve generation quality and versatility, 14 but such strategies are underexplored. It is essential to push the research in this direction in order to explore how various linguistic characteristics, sociological features or external knowledge may aid not only in enthymeme reconstruction, but in the detection phase as well, and not only for premises, but for all argument components. Additionally, the studies discussed in this section explore implicitness in argumentation across various fields of application, such as debates, social media posts, essays, and learners’ argumentation etc., however, none address the generalizability of the proposed techniques. It might be practical to apply each method to different fields to determine whether argument components vary significantly between domains or if the same approaches can be effectively utilized across multiple domains. Such a study would reveal if it is mandatory to elaborate different strategies for each domain or it is possible to find and enhance the only one applicable to all fields. Furthermore, this investigation could identify the most challenging domains for enthymeme analysis, opening new directions for scientific exploration.
Argument explicitation
This section focuses on the examination of established methodologies for restoring implicit elements, a process referred to as argument explicitation. 10 This investigation will entail an exploration of the knowledge sources employed in argument reconstruction, as well as a detailed examination of the existing techniques facilitating the transition of an argument from an implicit to an explicit state.
Required knowledge and proposed methods
The exploration of argument explicitation unfolds along two research directions: (i) Some works assert that the contextual information surrounding an argument may be sufficient to restore its implicit components, facilitating argument understanding; (ii) in contrast, alternative studies emphasize the necessity of additional knowledge beyond the argument context. This additional knowledge encompasses both universally shared commonsense knowledge and domain-specific knowledge inherent to a particular field. As mentioned by Lauscher et al., 7 argument reasoning is highly dependent on commonsense and domain-specific knowledge, therefore, this approach seems sound. While these two directions are shortly described by Becker et al., 34 we propose a thorough analysis in the following (see Table 3).
Argument explicitation knowledge and methodologies.

Argument explicitation knowledge and methodologies.
Works pertaining to the first group consider local context of an argument as sufficient for implicit components identification and reconstruction. More precisely, it is possible to reconstruct an enthymeme using information within the argument to detect missing components and filling these gaps with the help of similar or related arguments. For example, Rajendran et al. 11 propose analyzing opinions from an online hotel reviews dataset to facilitate the detection and reconstruction of implicit argument components within the dataset, using opinion analysis as a foundation. The authors hypothesize that opinions about a hotel or its specific aspects, classified as implicit or explicit, indicate whether an argument is complete or enthymematic. To test this hypothesis, they annotate the stances of opinions as either implicit or explicit. In addition to classifying opinions, they suggest extracting sentiments from these opinions to further support the reconstruction of incomplete arguments. Retrieved sentiments (positive or negative) are then used to reconstruct predefined conclusions for the reviews. Thus, the authors already address cases where the implicit component of an enthymeme is a conclusion. This approach utilizes both metadata and the dataset itself as sources of essential knowledge, aiding in the detection and reconstruction of enthymemes. Following the same direction, Alshomary et al. 23 propose using the target of an implicit conclusion as a basis for its reconstruction. To identify the target of the conclusion, they first determine the target of an explicit premise within the same argument. The authors hypothesize that the target of the premise typically corresponds to the target of the conclusion, as all components of an argument collectively work toward addressing a single subject. Consequently, they reconstruct the target of the conclusion based on the identified premise target, which then serves as a foundation for reconstructing the conclusion itself. Once again, this method emphasizes leveraging the inherent knowledge and relationships present within the dataset under study. A work of Wojatzki and Zesch 47 is grounded in the correlation between the explicit overall stance of a debate and an argument within that debate that contains implicit components. Specifically, they assert that it is possible to infer an implicit claim of an argument by considering the explicit stance of that argument and the explicit overall stance of the debate. Consider Example 4:
Premise: As the Bible says that infidels are going to hell!
Debate stance: being against atheism
Argument stances: being in favour of Christianity; being in favour of existence of hell
Having as explicit premise ‘As the Bible says that infidels are going to hell!’ we are unable to restore a claim. However, taking into consideration the stances of this incomplete argument, that are ‘being in favor of Christianity’ and ‘being in favor of existence of hell’, and the overall explicit stance of the debate, we can reconstruct the claim ‘I am against atheism’. The complete argument will be: ‘As the Bible says that infidels are going to hell! I am against atheism’.
The second facet of argument explicitation presented in Table 3 pertains to knowledge enhancement. It encompasses harnessing shared knowledge or employing domain-specific knowledge for the purpose of enthymeme reconstruction and implicit argumentative relations detection. Shared knowledge utilization is based on the assumption that in order to restore an enthymeme or implicit argumentative relations, it is necessary to apply shared knowledge outside the scope of the argument. Reconstructing implicit elements often requires understanding unstated assumptions or connections that are commonly accepted or understood within a broader context. Shared knowledge bridges this gap, providing the necessary context to make sense of implicit components that are not explicitly stated in the argument itself. There are several explored methodologies of introducing common knowledge to facilitate the reconstruction of incomplete arguments. Primarily, such knowledge may be incorporated in the form of commonsense knowledge relations. In this context, ConceptNet
16
serves as a graph repository of commonsense facts about the world interconnected by relations. According to this method, commonsense knowledge is universally shared, thus, humans do not include it in the discourse. Intuitively, we need to apply to commonsense knowledge, so as to restore implicit argument components. Additionally, authors claim that the inclusion of semantic clause types proves beneficial in the process of enthymeme reconstruction. Being supplementary information about an argumentative text, semantic clause types potentially facilitate argument explicitation.16,34 Another method of incorporating commonsense knowledge introduced by Chakrabarty et al.
14
is using a discourse-aware commonsense knowledge model. PARA-COMET is a knowledge model that is able to generate commonsense inferences and relations on the basis of its own knowledge graph (KG) of commonsense relations and given texts from the dataset. As commonsense knowledge forms the foundation for implicit argument components, leveraging generated knowledge has the potential to enhance the reconstruction of these components. As an auxiliary approach, authors propose to appeal to abductive reasoning implying that humans reach out to this kind of reasoning to comprehend incomplete arguments. Consider an example:
Reason: Vaccinations save lives.
Claim: Vaccination should be mandatory for all children.
Reconstructed premise: Vaccinations are the best way to prevent childhood diseases.
In Example 5, the implicit premise generated by the model with PARA-COMET commonsense knowledge serves as an inference between the stated claim and its reason. Without this connection, it is not clear why the author mentions only children in the claim, as the reason acknowledges the benefit of vaccination in general. Yet another methodology to incorporate common knowledge is to use similar corpus that may provide missing information and relations. Transferring knowledge from other datasets has the potential to improve the reconstruction of implicit argument components. 40 This claim is based on the assumption that other large datasets can fulfil unstated essential knowledge by providing numerous texts. Therefore, the authors use this knowledge to address argument reasoning comprehension task, in particular, to select a correct warrant out of two possibilities automatically. Last but not least, recent papers consider that implicit argumentative relations are also highly dependent on commonsense knowledge.33,49 Authors of these researches propose incorporating ConceptNet commonsense knowledge relations 49 and generating missing knowledge with the Commonsense Transformer (COMET) that is able to produce necessary warrants in a form of chains of inferences. 33 The second approach has better performances on the same data, presumably due to the fact that COMET varies according to cultures and beliefs while ConceptNet is a static KG providing universal knowledge.
Despite the diversity in methods for integrating commonsense or shared knowledge into argument explicitation, there remains an underrepresentation of both commonsense and domain-specific knowledge. For instance, in a comprehensive survey of knowledge use in computational argumentation, researchers join both categories of knowledge, underlining the persistent challenge of harnessing this extensive domain of knowledge.
7
Moreover, state-of-the-art works focus mostly on exploiting commonsense knowledge while domain-specific knowledge remains unexplored. It is clear that domain-specific focus narrows the generalizability and practical application, however, it might be needed for specific tasks in specific spheres. In this regards, we would like to highlight that using domain-specific knowledge for enthymeme reconstruction in such spheres as medical or legal domain is significant for improvement of manual annotations and development of automatic identification with further reconstruction of incomplete arguments. In the medical domain, casiMedicos
52
is a publicly available dataset of medical questions with possible answers to the questions and explanations of a correct answer which constitute an argument. Analyzing it, we noticed that clinicians tend to omit pieces of evidence that are clear to medical community or replace medical terms with jargon producing miscomprehension by general public. Considering an example:
Premises: A 6 months-old infant presenting to the emergency with axillary temperature 37.2°C, respiratory rate 40 rpm, heart rate 160 bpm, blood pressure 90/45 mmHg, SatO2 95% on room air. He shows moderate respiratory distress with intercostal and subcostal retraction. Pulmonary auscultation: scattered expiratory rhonchi, elongated expiration and slight decrease in air entry in both lung fields. Cardiac auscultation: no murmurs.
Claim: The patient probably presents with bronchiolitis.
In Example 6, in order to claim the diagnosis, it is necessary to know which symptoms should be taken into account as relevant. Here the reasoning behind the choice of the disease is unstated: It is not clear even for a human which information provided in the premise leads to the conclusion. Manual analysis of such implicit elements reveals that commonsense knowledge is not sufficient for their reconstruction. Therefore, it might be beneficial to incorporate domain-specific knowledge from biomedical ontologies (e.g., Human Phenotype Ontology 53 ) and biomedical vocabulary (e.g., Unified Medical Language System (UMLS) 54 ) to be able to identify and reconstruct enthymemes in medical domain.
In our exploration of argument explicitation methodologies, we observed an interesting trend. A subset of studies adopt an argumentation model as the foundational framework for further research. This argumentation model serves as a cornerstone for identifying implicit argument components. Subsequently, researchers employ diverse knowledge and apply various techniques within the framework of this model to reconstruct implicit argument components. As a result, the entire process of exploring and reconstructing argument reasoning is centralized around the major role of the argumentation model and its components.11,14,15,23,24,35,40,47 These approaches can be referred to as Model-based Explicitation or Explicitation Based on Enthymeme Reconstruction, depending on whether the emphasis is placed on the reconstruction of enthymemes or on the fact that the arguments under study represent a certain argumentative model. 10
Another group of studies highlights that the argument reasoning comprehension relies on background commonsense knowledge, universally shared among humans, along with reasoning skills. As shared knowledge is generally evident to most individuals, it needs not be explicitly articulated. Human reasoning skills, a component hidden between the lines, also requires deeper study. With these integral elements, humans effortlessly achieve a comprehensive understanding of arguments. However, computational models meant to analyze natural language are equipped with neither background knowledge nor with reasoning skills. Thus, research within this direction brings forward the necessity to reconstruct commonsense knowledge that is majorly left implicit.16,33,34,49 This approach can be referred as Knowledge Enhancement-based Explicitation of enthymemes. 10
The above mentioned directions, however, are not mutually exclusive. In Model-based Explicitation, authors underline the importance of argumentative structure for the exploration of implicitness. Nevertheless, they do not obviate methods to incorporate commonsense knowledge to improve enthymemes detection/reconstruction. Similarly, Knowledge Enhancement-based Explicitation methods do not dismiss the presence of model-based representation of arguments, they rather accentuate the imperative of having commonsense knowledge integrated in automatic analysis of argumentation.
It is also noteworthy to mention that the identification of the best argument explicitation method is currently challenging due to several reasons. First, the scope of existing research is still limited to allow for meaningful comparisons of different approaches on the same task. For example, it is unreasonable to compare and rate approaches for explicitation of different components (e.g., implicit claims reconstruction and implicit premise reconstruction) as the detalization and depth vary, while different components presumably require distinct knowledge for reconstruction. Therefore, it is needed to have more studies on each component, which is not yet the case. Second, factors such as limited resources and privacy concerns (e.g., clinical data), restrict the range of methods that researchers can test on certain enthymematic datasets. Additionally, the diversity of datasets and domains further complicates the identification of a universal approach, as different methods may perform variably depending on the type of data or the nature of the implicit components. For instance, approaches that work well for reconstructing implicit premises in short argumentative texts may not generalize effectively to long, domain-specific discourses. Moreover, the absence of standard evaluation metrics for enthymeme reconstruction adds another layer of complexity, making it difficult to directly compare the effectiveness of various techniques.
Computational approaches towards enthymeme detection and reconstruction
So far, we have discussed the steps involved in enthymeme analysis, introduced argumentation models that support this process, explored tasks designed to detect and reconstruct implicit argument components and analyzed key techniques for argument explicitation. In this section, we will describe computational approaches predominantly used for enthymeme detection and reconstruction, taking into account main ways to introduce universally shared knowledge into automatic enthymeme analysis.
The foundation for developing robust computational approaches to study implicitness in argumentation begins with manual annotations. Early research in enthymeme analysis relied heavily on manual annotation of argument components,25,35 stances in opinions, 11 stances towards targets, 47 reasons, 15 and commonsense relations. 16 Also, before the adoption of automatic techniques, researchers focussed on preliminary manual approaches to simulate automatic analysis. These included manual classification of argument components into semantic types, 25 manual reconstruction of implicit knowledge, 16 manual reconstruction of argument components such as warrants and alternative warrants, 15 human similarity judgment (e.g., semantic similarity between a claim and a major claim). 35 Such foundational steps are crucial for several reasons. First, human-annotated data enables researchers to explore the nature of implicitness, uncovering patterns and features that characterize implicit premises, claims, and warrants, while also providing valuable insights into human reasoning. Additionally, manual analysis serves as the ground truth for evaluating automatic approaches. Finally, it demonstrates the feasibility of tasks related to implicitness and helps identify potential challenges and pitfalls for future automatic analysis.
With the foundational groundwork established, we now turn to the computational approaches used for enthymeme analysis. The two core tasks – enthymeme detection and reconstruction – shape two distinct groups of approaches, which in turn define two categories of computational models.
Additionally, several approaches to enthymeme detection and reconstruction focus on incorporating commonsense knowledge into the classification or generation process. These techniques typically involve either using a static structured KG 49 or leveraging a specialized knowledge model capable of generating commonsense knowledge based on a KG and the given discourse.14,33 In the first approach, encoded commonsense relations from the KG can be directly injected into a neural model to define relations between arguments or into a transformer model to generate missing information, such as implicit argument components. In the second approach, the transformer-based knowledge model COMET dynamically generates novel knowledge by combining the commonsense relations of the KG it was trained on with the current discourse. This newly generated knowledge can then be injected into a transformer model to generate implicit argument components or identify the relations between them. According to the performances presented in Chakrabarty et al., 14 Paul et al., 49 Saadat-Yazdi et al., 33 dynamic generation of knowledge proves to be more meaningful and coherent, as it considers specific arguments it is applied to, ensuring consistency with the context. In contrast, the static approach lacks this adaptability.
For all the approaches discussed, computational models can be provided with either pairs of sentences (e.g., a premise and a claim) or individual sentences, with or without accompanying metadata. While LLMs are capable of processing longer text sequences with reasonable performance, research on enthymemes has not yet fully explored this direction. This hesitation stems from the challenges of the task: Within a pair of sentences, it is difficult enough to detect missing information, and it is even more complicated to generate meaningful argument components that fit the overall context without duplicating explicit parts. Additionally, processing larger texts, whether annotated or not, reduces control over the reconstruction process. As a result, biases and inconsistencies in generated components are harder to trace back to their source, making it difficult to identify and reduce potential quality issues. Lastly, detecting exact locations of missing information, maintaining logical consistency throughout a full-text argument, and aligning generated components with the nuances of the argument’s domain require advanced modelling techniques and fine-tuning. Therefore, addressing these challenges will be critical for the future advancement of automatic systems.
Evaluating and comparing computational approaches to enthymeme analysis is challenging for several reasons. First and foremost, the field of enthymeme studies is not yet extensive enough to allow for meaningful comparisons between approaches addressing the same task. Instead, most approaches explore unique directions, making it difficult to identify a single best method. Moreover, it is not reasonable to directly compare early approaches with more recent ones, as the former were appropriate and innovative for their time, while the latter benefit from advancements in technology and methodologies. Furthermore, certain areas of research within implicit argumentation remain underexplored, which limits our ability to fully evaluate the best technologies. Nevertheless, it has to be noted that both neural networks and transformer-based LMs are predominantly used and have demonstrated success in the tasks discussed. Transformer-based models, in particular, are gaining preference due to their scalability and consistently strong performance across various domains and tasks in implicit argumentation.
Data for argument reasoning studies
This section presents a compilation of datasets used in implicit argumentation studies (see Table 4), selected for their relevance to AM and reasoning. The table provides details about each dataset’s size, source, original annotations (whether argument components and/or relations are labelled), and additional annotations introduced in subsequent works, highlighting the methodology used for annotation collection (manual or automatic). As well as that, the datasets are grouped according to their application domains: education, web-based discussions, public opinions.
Datasets in implicit argumentation studies grouped by their application domain.
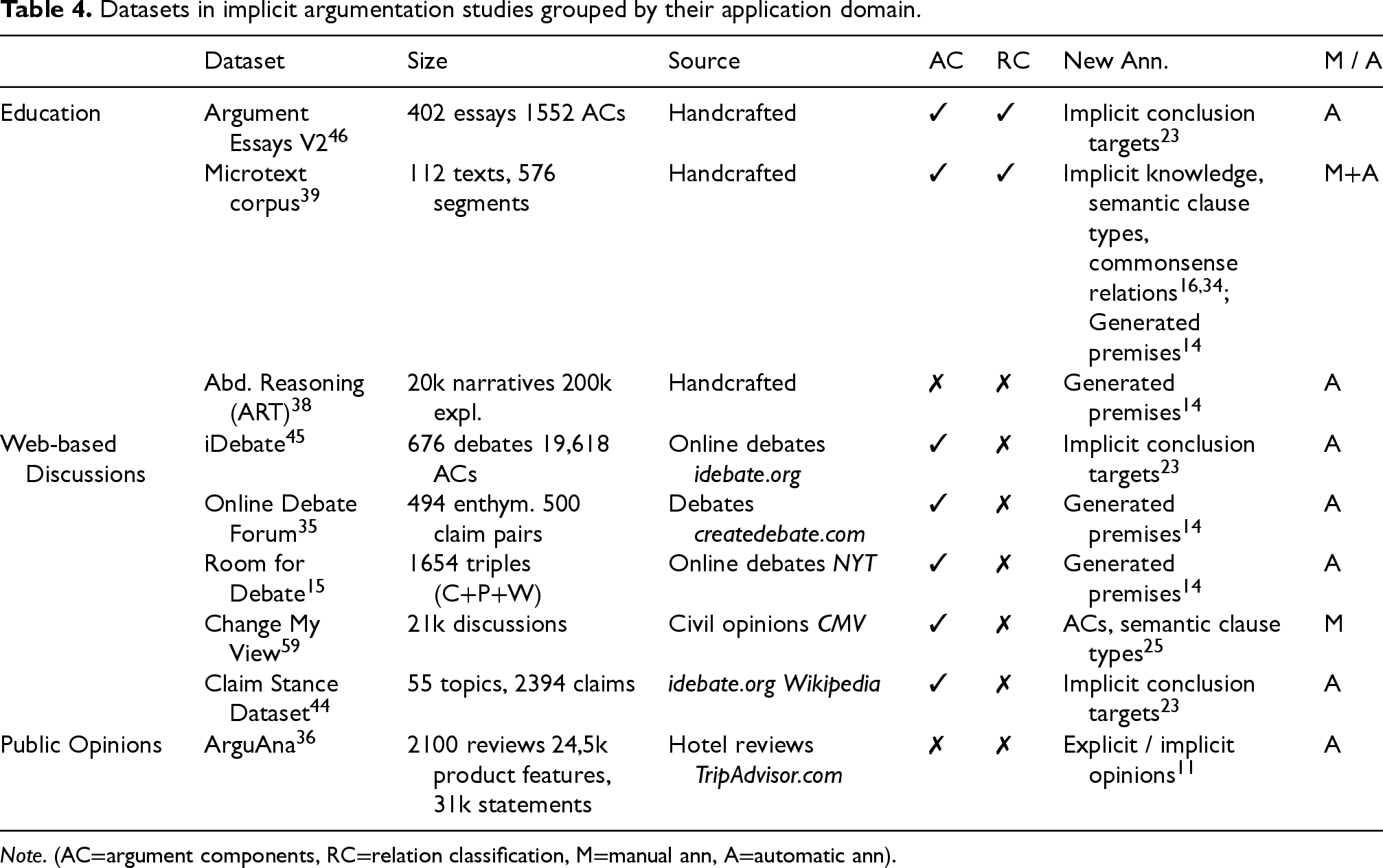
Datasets in implicit argumentation studies grouped by their application domain.
Note. (AC
Handcrafted educational datasets have been created to teach students to improve their reasoning39,46 and persuasiveness of their arguments, 46 and to explore abductive reasoning in natural language texts. 38 Argument Essays V2 46 and Microtext corpus 39 consist of high-quality argumentative texts in monologue form, containing up to 40 and 5 sentences per text, respectively. These datasets have several advantages: each document has a predefined topic, thus, the documents can be analyzed and compared more effectively, each document has a homogeneous reasoning flow due to single authorship, and they all have self-contained arguments as they are manually written answers to specific themes. Both datasets were originally annotated manually with argument components and their relations. They are well-suited for implicitness detection and subsequent generation tasks, as humans often omit evident information or weak arguments. Moreover, provided annotations enable researchers to intentionally remove specific components for automatic generation experiments.
Another handcrafted dataset ART 38 consists of manually created 5-sentence commonsense narratives and their explanations based on abductive reasoning. Therefore, it represents a set of short argumentative texts that are also suitable for enthymeme detection and reconstruction tasks, since gaps in human reasoning are quite probable. The original version of this dataset includes neither argument component annotations nor relation classifications; however, it was later enriched with automatically generated premises. 14
Datasets based on web discussions include debates on various topics (politics, abortions, human and minority rights etc.), comments on controversial issues and persuasive arguments in monologue and dialogue forms. iDebate dataset 45 includes 676 short argumentative texts on controversial topics from an online debate platform idebate.org. Each discussion consists of a central claim that represents a positive or negative position towards the topic and arguments (premises) that support this position. In total, there are 2,259 claims and 17,359 premises. Although this dataset was initially created to develop methods for concise and informative summarization of argumentative texts, it is also well-suited for elaborating techniques for implicitness detection and reconstruction. For instance, the clear and well-defined conclusions of each argument in the dataset can be omitted to test the feasibility of reconstructing them based on the premises. 23 The evaluation of these reconstructed conclusions is straightforward, since the original conclusions serve as gold-standard references for the debate topics.
The Online Debate Forum dataset, 35 extracted from createdebate.com, contains arguments on four topics: Marijuana, Gay Rights, Abortion, and Obama. Each text’s main position (for or against the topic) is labelled, and every sentence is manually matched to a single major claim corresponding to the topic. Originally, this dataset was designed for ‘fill-the-gap’ task, where a gap between a user claim and a manually matched major claim represents reasoning that humans can infer. Therefore, the idea was to bridge this gap by manually annotated premises. In total, after the annotations the dataset contains 500 claim pairs (user claim + major claim) and 3977 fill-the-gap premises, meaning that each argumentative text has 8 premises in average. Subsequently, the dataset was updated with automatically generated premises, not to bridge the gap between two claims, but to enable the correct inference of conclusions and to complete enthymemes. This means that the dataset is suitable for both, specific tasks, such as detecting or reconstructing components in a specific position (e.g., a premise between two claims), and more general tasks, such as fully reconstructing an enthymeme, regardless of the specific position of implicit components.
Another debate dataset, created from scratch and claiming higher quality argumentative texts compared to those extracted from debate platforms, is Room for Debate. 15 This dataset comprises a collection of arguments from The New York Times, which, due to editorial oversight and moderation, can be considered more credible. The dataset consists of 1,654 argumentative triples, each containing a claim, a premise, and a warrant. It is well-suited for the detection and reconstruction of implicit warrants, premises, or claims; however, its strict triplet structure could be a potential limitation. Real-world argumentation is often more complex, as arguments frequently involve more than three components. For example, a single claim might be supported by several premises or warrants, thus, the triplet structure oversimplifies these dynamics, potentially excluding valuable information and overlooking multi-level relations between argument components. As well as that, such structure may restrict flexibility of the analysis, meaning that arguments with a different set of components may be poorly represented.
Change My View (CMV) dataset 59 comprises 21,000 civil discourse texts. The dataset is structured as follows: The initiator of a discussion creates a title for their post, which represents the major claim of their argument, and then describes the reasons for their belief. These reasons can include both claims and premises. Other participants respond in an attempt to change the initiator’s view. Their argumentative speech also includes claims and premises. If successful, the initiator indicates that their perspective has shifted. Furthermore, each discussion tree in this dataset is divided into separate dialogues, with each argumentative text featuring one initiator and one respondent attempting to challenge the initiator’s opinion. Such update allows to trace the reasoning flow and consistency of arguments, making it easier to analyze how the initiator’s opinion evolves in response to challenges. It also enables a focussed examination of one-to-one argumentative interactions, providing insights into persuasive strategies. Additionally, this structure facilitates the identification of implicit components within a single dialogue, improving the dataset’s utility for tasks like argument reconstruction and implicitness detection. Compared to the other datasets discussed in this section, the CMV dataset offers the richest arguments in terms of both, quantity and quality of data. Each argumentative text represents a complete discussion, featuring dynamic exchanges between the initiator and the respondent. Also, as stated in the table, the CMV dataset is annotated with argument components.
Claim Stance Dataset 44 introduces arguments addressing 55 topics randomly chosen from idebate.org. Each argument includes claims and premises that were manually extracted from Wikipedia articles. Furthermore, each argumentative text is enhanced with manually annotated stances for the claims, indicating whether they take a pro or contra position on the topic. The targets of claims are also highlighted. This labelling is particularly useful for implicit claim reconstruction, as the target of an argument helps define the context of the claim. 23 However, this dataset has a characteristic that may be a limitation for certain studies. Since each argument follows a strict structure, containing only one claim and its associated set of premises, this may limit the depth of analysis by restricting the exploration of more complex argumentative relationships.
The last group of datasets is based on public opinions and includes ArguAna dataset. 36 This dataset is a collection of hotel reviews extracted from TripAdvisor.com platform. The dataset consists of 2100 review texts with ratings of 1850 hotels across over 60 locations. In addition to ratings, each review includes metadata, sentiment scores about various aspects of the hotels (e.g., cleanliness or service), and manual annotations of hotel features and amenities. These specific annotations enable fine-grained analysis of argumentation, allowing researchers to examine how sentiment and specific hotel attributes influence the reasoning behind user ratings. Moreover, subsequent work on this dataset 11 demonstrates that users’ opinions about hotels and their amenities are expressed both implicitly and explicitly, making this dataset particularly valuable for enthymeme studies. Thus, the dataset was further utilized for the automatic classification of implicit and explicit opinions, facilitating enthymeme analysis. However, it is important to note that the dataset is not labelled with argument components at any stage, which could be seen as both a limitation and an opportunity for future work.
In advancing the areas of argument reasoning and AM, several ambitious directions emerge, each offering unique opportunities for further development of implicit inferences exploration. These directions, when integrated and expanded upon, hold the potential to significantly contribute to the advancement of computational argumentation.
These four perspectives comprise a significant step forward in the maturation of advanced reasoning methods.
Conclusion
In this survey paper, we explored the process of enthymeme analysis, from the initial steps of identifying incompleteness in arguments to the advanced stages of restoring implicit elements. We began by defining the pipeline for enthymeme analysis, outlining its key steps, and conducting an in-depth exploration of the argumentation models used in enthymeme studies. Our findings revealed that only three argumentation models are commonly employed in this field, and current studies focus exclusively on argument components from these models. Despite their potential value, argument schemes remain overlooked due to the probable complexity of their integration in the process of implicitness analysis. To address this gap, we provided detailed descriptions of argument schemes within argumentation models to encourage further research and facilitate informed selection.
Next, we introduced argument components that are frequently left implicit, based on the current state of research. As argumentation model selection for enthymeme analysis may be considered as a preliminary or even an optional step (Section 6), identifying missing argument components remains a critical and indispensable part of the two-step pipeline for analyzing implicitness in argumentation. Our representation of implicit argument components includes the associated tasks designed to address implicitness detection and/or reconstruction. Additionally, we expanded on the annotations proposed by task authors to tackle these tasks, highlighting the strengths and limitations of their approaches.
We then examined which additional knowledge (if any) is needed for the successful explicitation of arguments with implicit components. Our analysis focussed on two primary approaches to enthymeme explicitation: Relying solely on the local context and the information within the arguments themselves, and incorporating external knowledge to aid in reconstruction. For the latter, we discussed the integration of universally shared knowledge and domain-specific knowledge, tailored to the type and subject of the discourse. We also highlighted that neither approach to knowledge integration is sufficiently explored, with only a few studies addressing the use of universally shared knowledge and no research yet delving into the application of domain-specific knowledge for enthymeme explicitation.
Furthermore, we reviewed computational approaches to enthymeme detection and reconstruction, presenting the tasks as they are formulated for automatic methods. We described the development of models for automatic enthymeme analysis and attempted to evaluate their relative performance.
Subsequently, we examined the most representative and utilized datasets for exploring implicitness in argumentation. We categorized these datasets into three groups to facilitate their selection, visualized their annotations and types in a table, and discussed their respective advantages.
Finally, we discussed the future perspectives of implicitness studies in argumentation, particularly within the context of Argument Mining. Our findings emphasize the need for more extensive research into integrating diverse knowledge sources, utilizing advanced computational models tailored to the complexities of enthymeme analysis, and adopting versatile datasets to encompass the diverse domains where enthymemes may occur.
Footnotes
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the French government, through the 3IA Cote d’Azur Investments in the project managed by the National Research Agency (ANR) with the reference number ANR-23-IACL-0001.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.