
Abstract
Background:
Hypoglycemia is a serious health concern in youth with type 1 diabetes (T1D). Real-time data from continuous glucose monitoring (CGM) can be used to predict hypoglycemic risk, allowing patients to take timely intervention measures.
Methods:
A machine learning model is developed for probabilistic prediction of hypoglycemia (<70 mg/dL) in 30- and 60-minute time horizons based on CGM datasets obtained from 112 patients over a range of 90 days consisting of over 1.6 million CGM values under normal living conditions. A comprehensive set of features relevant for hypoglycemia are developed and a parsimonious subset with most influence on predicting hypoglycemic risk is identified. Model performance is evaluated both with and without contextual information on insulin and carbohydrate intake.
Results:
The model predicted hypoglycemia with >91% sensitivity for 30- and 60-minute prediction horizons while maintaining specificity >90%. Inclusion of insulin and carbohydrate data yielded performance improvement for 60-minute but not for 30-minute predictions. Model performance was highest for nocturnal hypoglycemia (~95% sensitivity). Shortterm (less than one hour) and medium-term (one to four hours) features for good prediction performance are identified.
Conclusions:
Innovative feature identification facilitated high performance for hypoglycemia risk prediction in pediatric youth with T1D. Timely alerts of impending hypoglycemia may enable proactive measures to avoid severe hypoglycemia and achieve optimal glycemic control. The model will be deployed on a patient-facing smartphone application in an upcoming pilot study.
Keywords
Introduction
A prevalent and feared consequence of diabetes management is severe hypoglycemia, which can result in seizures, loss of consciousness, and death. Fear of hypoglycemia is prevalent in adults with diabetes 1 and in parents of children with diabetes. 2 This fear is greatest during high risk activities such as sleeping, exercising, and driving, 3 and often leads to more conservative glucose control, increasing the risks of hyperglycemia, which may lead to long-term micro- and macrovascular complications.4 -6
Continuous glucose monitoring (CGM) allows frequent, automated sensor glucose readings from inter-stitial fluid in the subcutaneous tissue space. CGM has been shown to improve glycemic control and reduce glycemic excursion—decreasing both hypoglycemia and hyperglycemia. 7 CGM can be used in combination with insulin pumps via sensor augmented pump therapy. 8 Real-time CGM devices provide real-time auditory alerts for glucose excursions above or below customized thresholds but do not yet predict impending hypoglycemic events (<70 mg/dL).
Bremer and Gough 9 first attempted to predict future glucose levels using past glucose values in 1999. Since then, many researchers have developed models for predicting hypoglycemia using statistical and machine learning methods. These studies can be broadly divided into classification-based approaches for predicting future hypoglycemic events and regression-based approaches for predicting future glucose values. Although some studies10,11 provide comparative analysis of various methodologies, detailed comparison is nontrivial due to differences in CGM sensors and sampling intervals, preprocessing steps for CGM data, variations in hypoglycemic event definition, and data collection (synthetically generated, controlled study, free-living conditions). 12 Because our work emphasizes feature extraction, the following review will focus on features used for prediction.
Studies have tried to include features from demographic data such as age, gender, body mass index, hemoglobin A1c (HbA1c), duration of diabetes as well as features extracted from CGM observations in the past 30 minutes to enhance predictive capabilities.12 -20 A 30-minute time window is often selected because autocorrelation was shown to dissipate beyond 30 minutes. 21 Some studies also use CGM values in the previous 30 minutes as input to time-series methods such as ARIMA-ARIMAX.16,22 -27 Owing to the ability of state-space models to better handle complex processes and have an interpretable structure, many works used methods based on state-space models to predict hypoglycemic events based on the CGM signal.11,28 -36 Recently, some researchers have relied on the use of sequence-based neural networks to automatically infer patterns from CGM data. However, it was shown that the neural networks resulted in only marginal improvements. 12
Cichosz et al 13 used variability-based features extracted from CGM readings in a 30-minute window along with heart rate data. As noted by the authors, the study was limited by small sample size (n = 10 and 903 sample points). Jensen et al 14 developed a model to predict nocturnal hypoglycemia using rates of glycemic change in the first, second, and third nights before the hypoglycemic event. The authors also included glycemic variability at specific intervals during the night as well as static contextual information.
Many studies have explored using meal information, insulin, and physical activity for the prediction of hypoglycemic events. Simple to highly sophisticated models have been developed to model insulin and carbohydrate absorption.37 -40 The results, in the context of hypoglycemia prediction, have been mixed with most reporting only marginal improvement.10,12,41 -43
Methods
Materials
The CGM datasets were obtained from 112 patients using Dexcom G6 CGM devices over a range of 90 days consisting of over 1 639 921 CGM values under normal living conditions. Corresponding insulin pump data for participants provided details on the amount of insulin administered, it’s time of delivery, and the associated carbohydrate count. Pump data was available only for 19 of the patients. Table 1 provides a profile of patients in the study.
Data Characteristics.
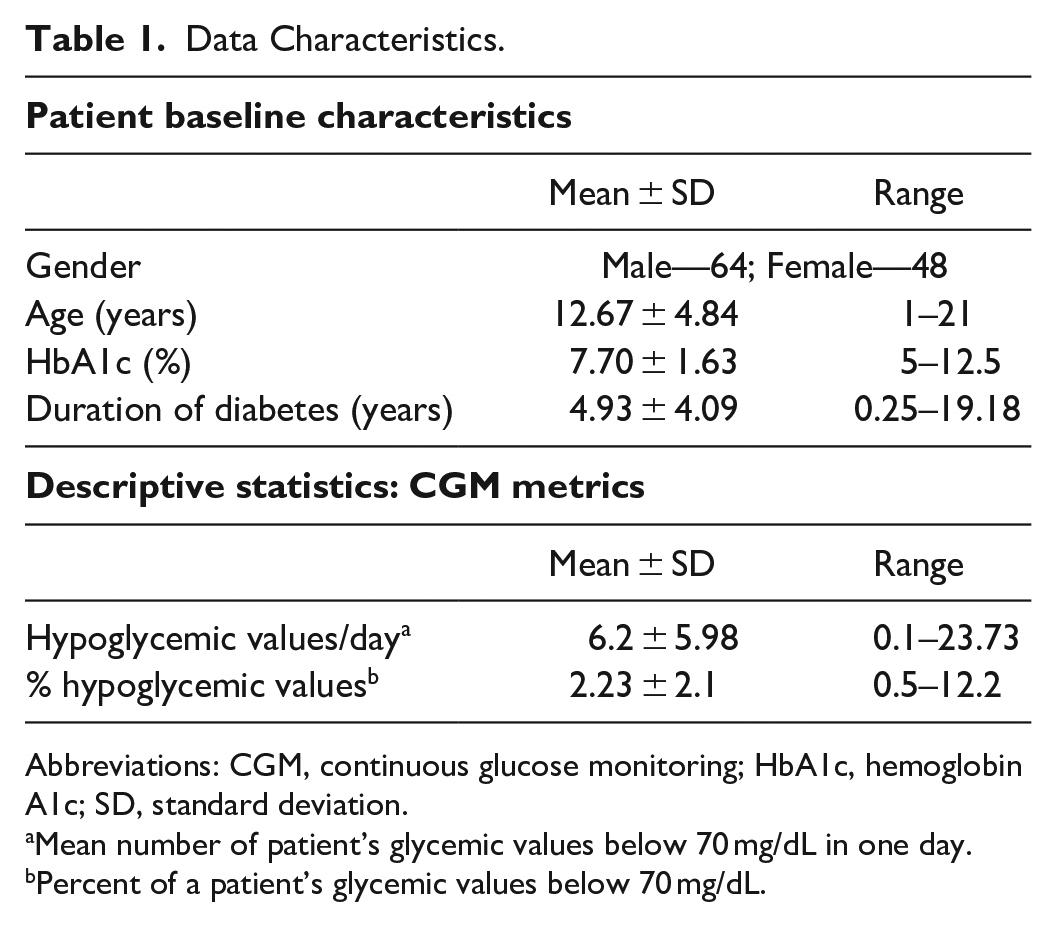
Abbreviations: CGM, continuous glucose monitoring; HbA1c, hemoglobin A1c; SD, standard deviation.
Mean number of patient’s glycemic values below 70 mg/dL in one day.
Percent of a patient’s glycemic values below 70 mg/dL.
Feature Extraction
A total of 26 features were extracted from the CGM signal based on exploratory data analysis and discussions with clinicians. Table 2 provides a description of each feature. These features are classified into seven categories:
(1) Short-term features: Short-term features capture glucose patterns within one hour before the current CGM observation.
(2) Medium-term features: Mid-term features capture glucose patterns from four hours to one hour before the current CGM observation and include features such as standard deviation and slope. Slope between two temporally ordered glucose values <X1, X2> is defined as (X2 − X1)/X1.
(3) Long-term features: Long-term features capture glucose patterns at times exceeding four hours before the current CGM observation. These features encapsulate the long-term ability of a patient to manage glucose levels. Innovative features extracted include number of rebound lows, rebound highs, near rebound highs, and near rebound lows. We define rebound lows as events when glucose is above 200 mg/dL and then falls to below 70 mg/dL within an hour and similarly a rebound high as an event when glucose levels rise from below 70 mg/dL to above 200 mg/dL within an hour. Near rebound lows and near rebound highs are similar patterns with 90 and 180 mg/dL thresholds.
(4) Demographic features: Demographic features such as age group, gender, duration of diabetes, and the last HbA1c value were included in the analysis.
(5) Snowball effect features: To capture the accruing effects of changes over time, positive and negative glucose changes accumulated over the last two hours are considered as features.
(6) Interaction and nonlinear features: For hypoglycemia, glucose falls at higher glucose levels are not as important as glucose falls at lower glucose levels. That is, a change of 10 mg/dL is more serious when glucose is at 70 mg/dL than when glucose is at 200 mg/dL. Thus, two variables were considered with interaction between: (i) current glucose value and overall standard deviation and (ii) current glucose value and difference in the last 10 minutes. Also, square of glucose was included as a feature to introduce nonlinearity in the model.
(7) Contextual variables: Hour of day and day of week were included in the analysis to capture “seasonal” types of patterns. Figure 1 provides boxplots of CGM variations by hour for a sample patient. Insulin on board and carbohydrates were also calculated and included in the analysis. (Day of week also appeared to have importance, but a figure is not included for brevity.) Insulin on board was calculated using a linear model, which assumed insulin effects wear off in four hours (Fig. 2). 44 Carbohydrates were modeled as being absorbed at a rate of 0.5 g/min after an initial lag of 15 minutes. 45
Features Extracted for Prediction.
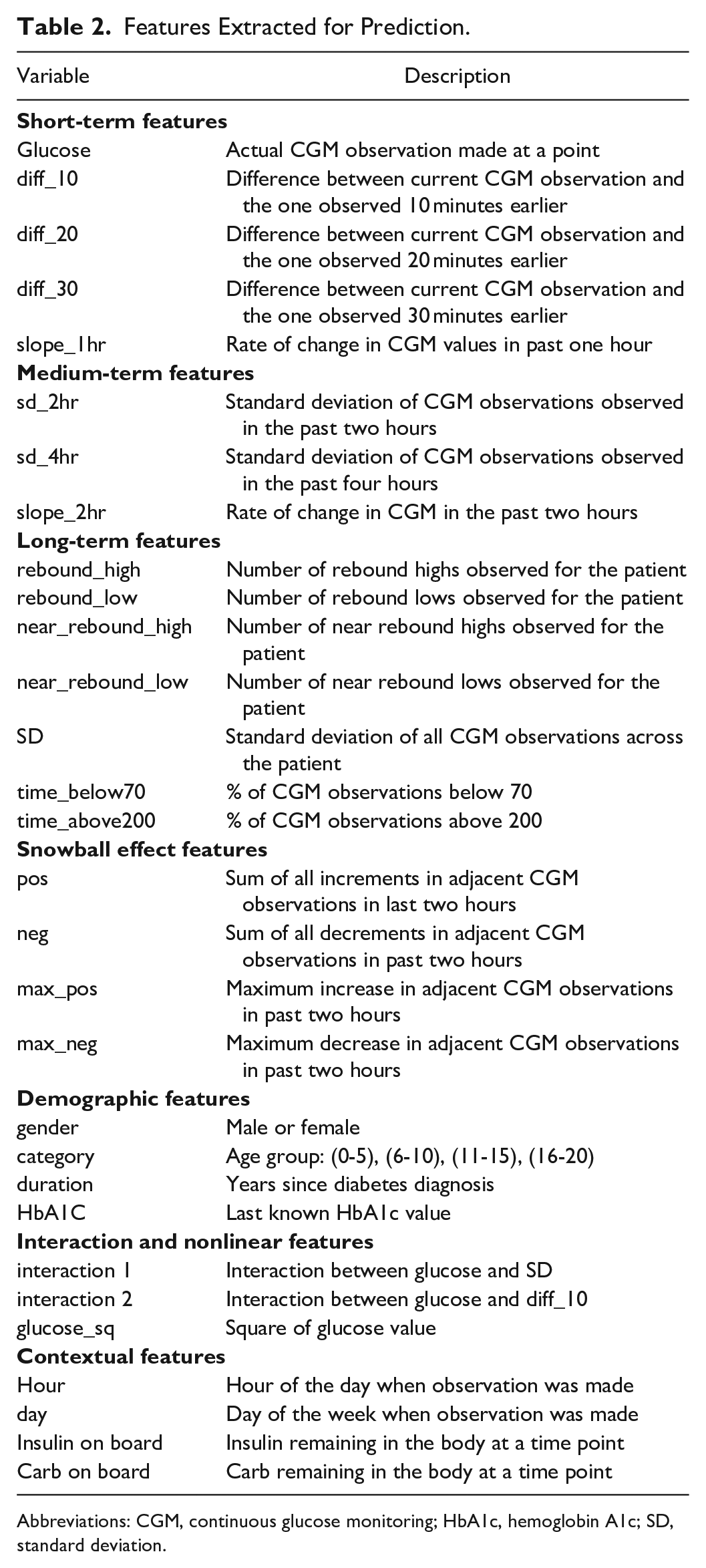
Abbreviations: CGM, continuous glucose monitoring; HbA1c, hemoglobin A1c; SD, standard deviation.
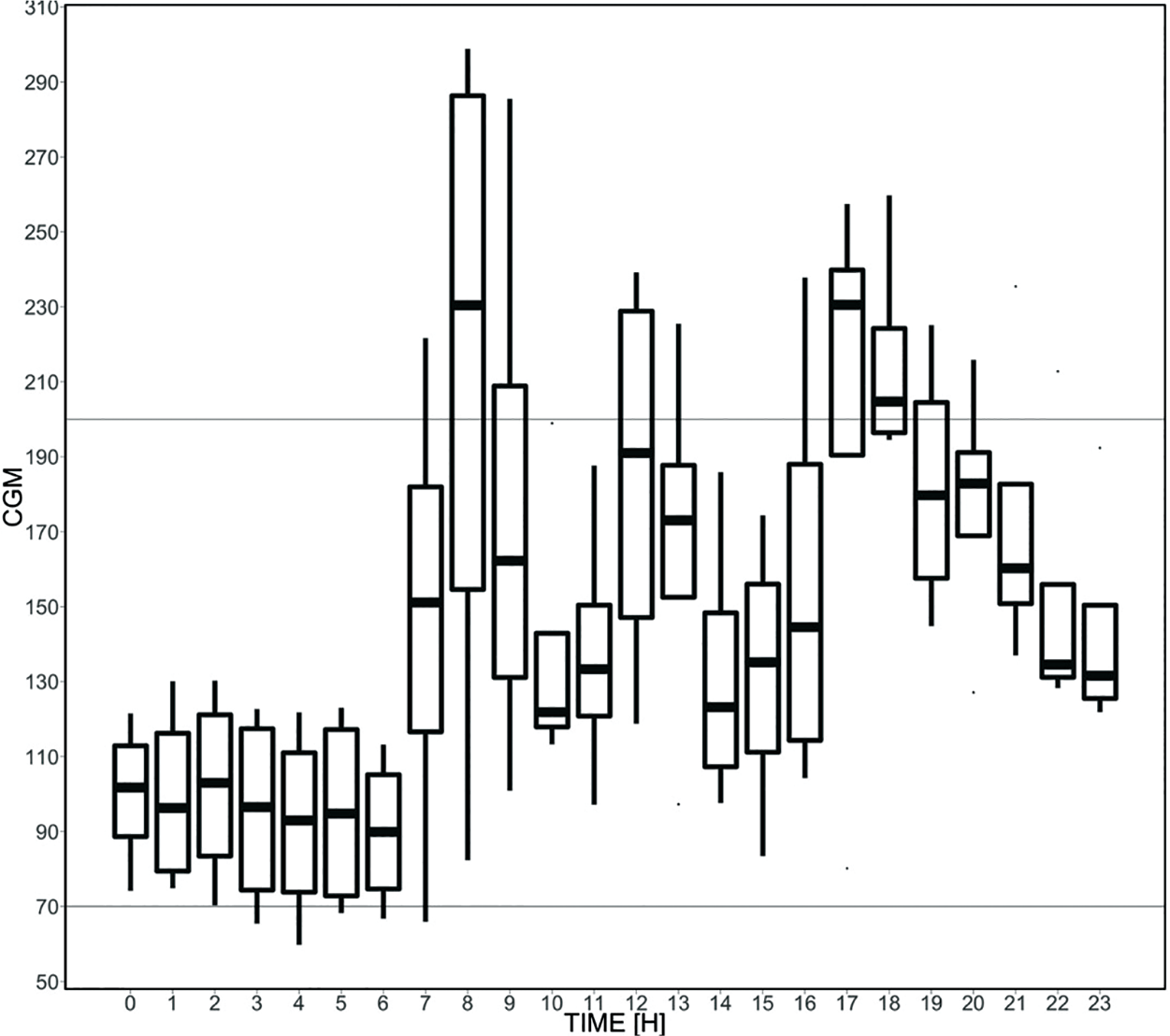
Boxplot of CGM variations by hour for a sample patient.
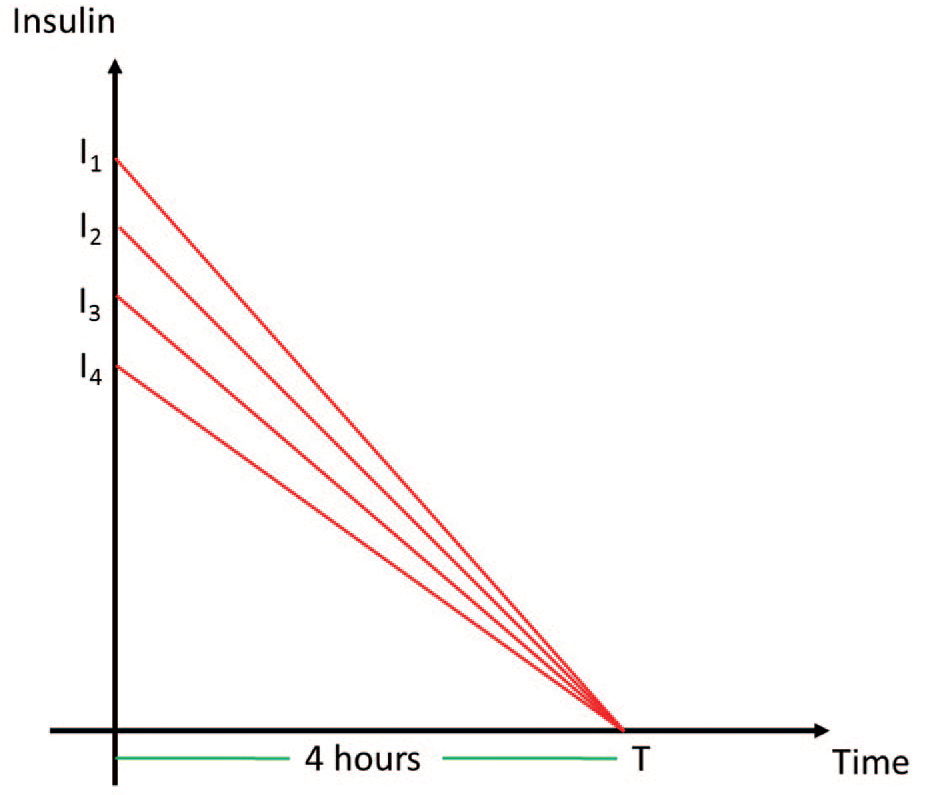
Insulin on board over time for different insulin boluses.
Machine Learning Algorithms/Methodologies
A threshold of 70 mg/dL was used to identify a hypoglycemic event (positive hypoglycemic class—class 1).46,47 Two approaches were considered for prediction: (i) Logistic Regression (LR) and (ii) Random Forests (RF). 38 These two methods were selected based on their predictive capabilities in similar settings48,49 and their ability to rate feature importance. Classifiers based on Decision Trees, Gradient Boosting, and Support Vector Machines 50 were developed, but the results obtained were at best similar to the methods short-listed.
Hypoglycemic Prediction Window
Existing studies focus prediction of hypo- and hyperglycemic events at a specific time point in the future. For example, they predict the risk of hypoglycemic events at 30 or 60 minutes from the reference time. CGM values are highly dynamic and will go through significant pattern changes in a 30-minute window. Some of these might be due to interventions such as consuming fast-acting carbohydrates and others due to normal pattern changes. Focusing on events at exactly 30 minutes in the future (34 225 hypoglycemic events) will result in ignoring clinically significant events happening “within” that 30-minute window (45 506 hypoglycemic events). It makes sense that a patient’s hypoglycemia risk within the next X minutes would have more clinical significance as a patient’s hypoglycemia risk at exactly X minutes in the future.
To accommodate this important observation and to facilitate more clinically and patient relevant predictions, we predicted the hypoglycemic risk within an interval of time into the future (0-15, 15-30, 30-45, and 45-60 minutes) (Table 3). Results for predicting at exactly 15, 30, 45, and 60 minutes were also evaluated and are presented in Table 4 for comparison.
Model Performance Metrics.
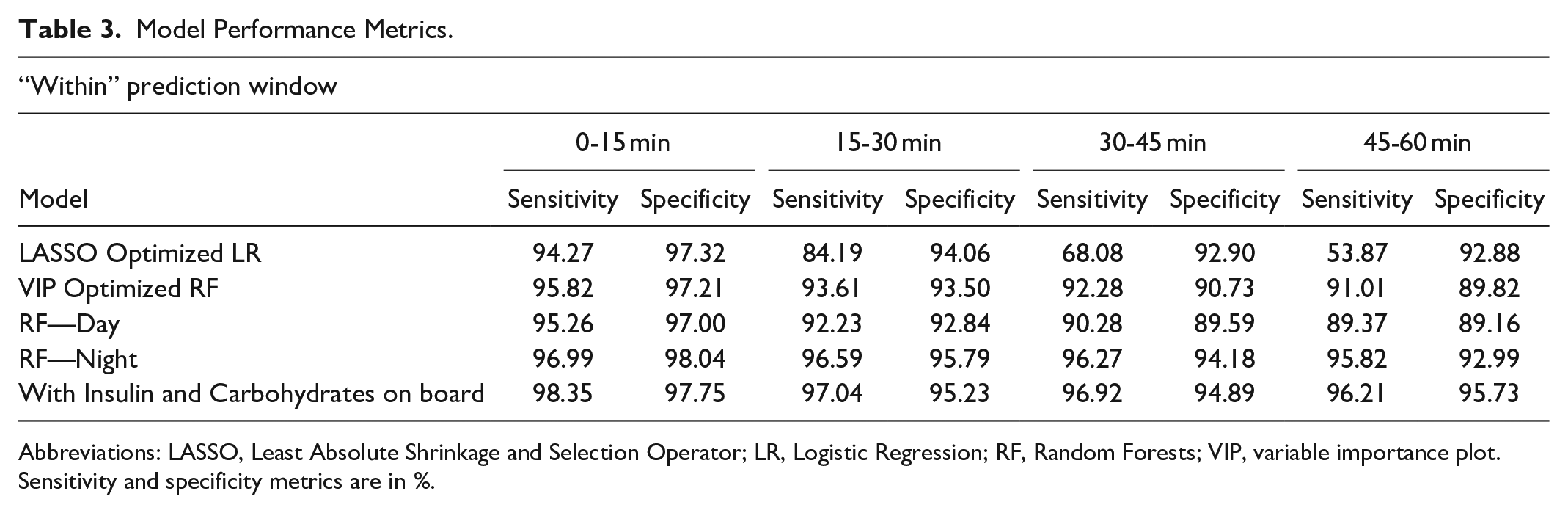
Abbreviations: LASSO, Least Absolute Shrinkage and Selection Operator; LR, Logistic Regression; RF, Random Forests; VIP, variable importance plot.
Sensitivity and specificity metrics are in %.
Model Performance Metrics.
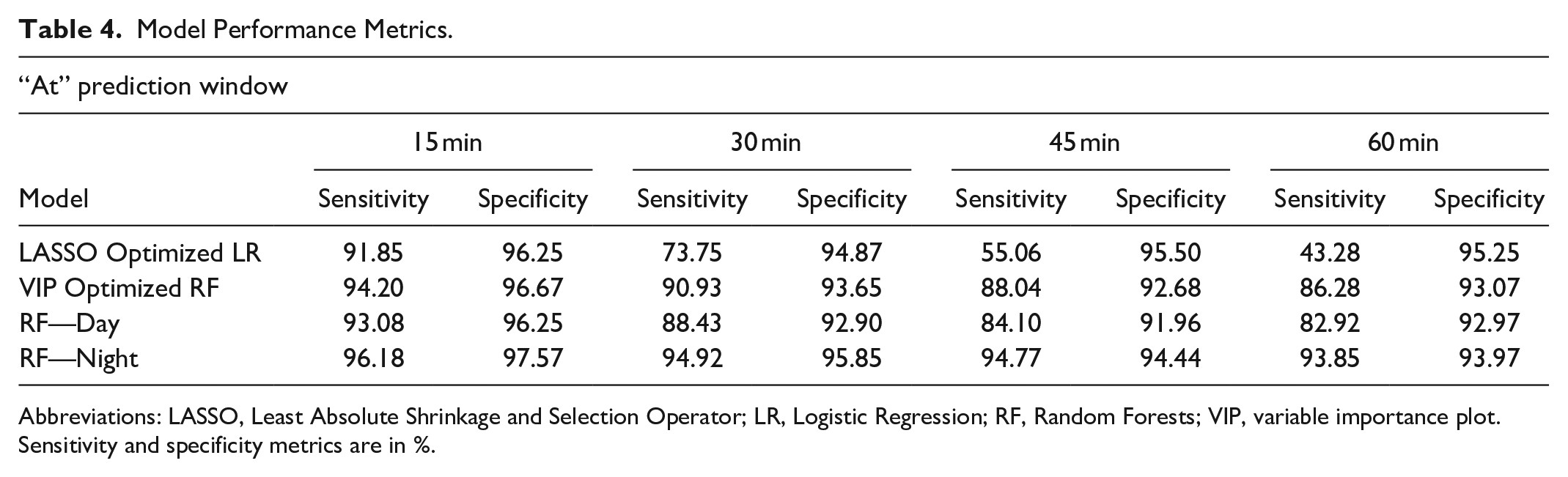
Abbreviations: LASSO, Least Absolute Shrinkage and Selection Operator; LR, Logistic Regression; RF, Random Forests; VIP, variable importance plot.
Sensitivity and specificity metrics are in %.
Feature Selection and Classifier Evaluation
Feature selection for LR was performed by adding a Least Absolute Shrinkage and Selection Operator (LASSO) penalty. Compared to the conventional LR problem, which minimizes the loss function, LASSO adds an extra tuning parameter to the LR equation which puts a penalty for each variable included in the model. Thus, a variable is only incorporated in the model if the value of the modified loss function decreases. The coefficient for an unimportant variable is shrunk toward 0, minimizing its impact on the model. The optimal value of the tuning parameter is determined by iteratively considering different penalty values and selecting the value that minimizes misclassification.
RF is an ensemble classifier consisting of multiple randomized decision trees. Feature selection was performed using the variable importance plot (VIP), which captures average improvement in class purity for splits involving a feature across all the ensemble trees. 51 VIP is used to order features based on their misclassification impact, and features with marginal impact can be excluded. Figure 3 illustrates this for our dataset. In order to evaluate hypoglycemic risk based on time, different models for daytime and nighttime risk were developed. CGM observations between 11:00 PM and 6:00 AM were considered as nighttime. Lastly, effects of insulin and carbohydrate intake were measured by including them as additional variables.
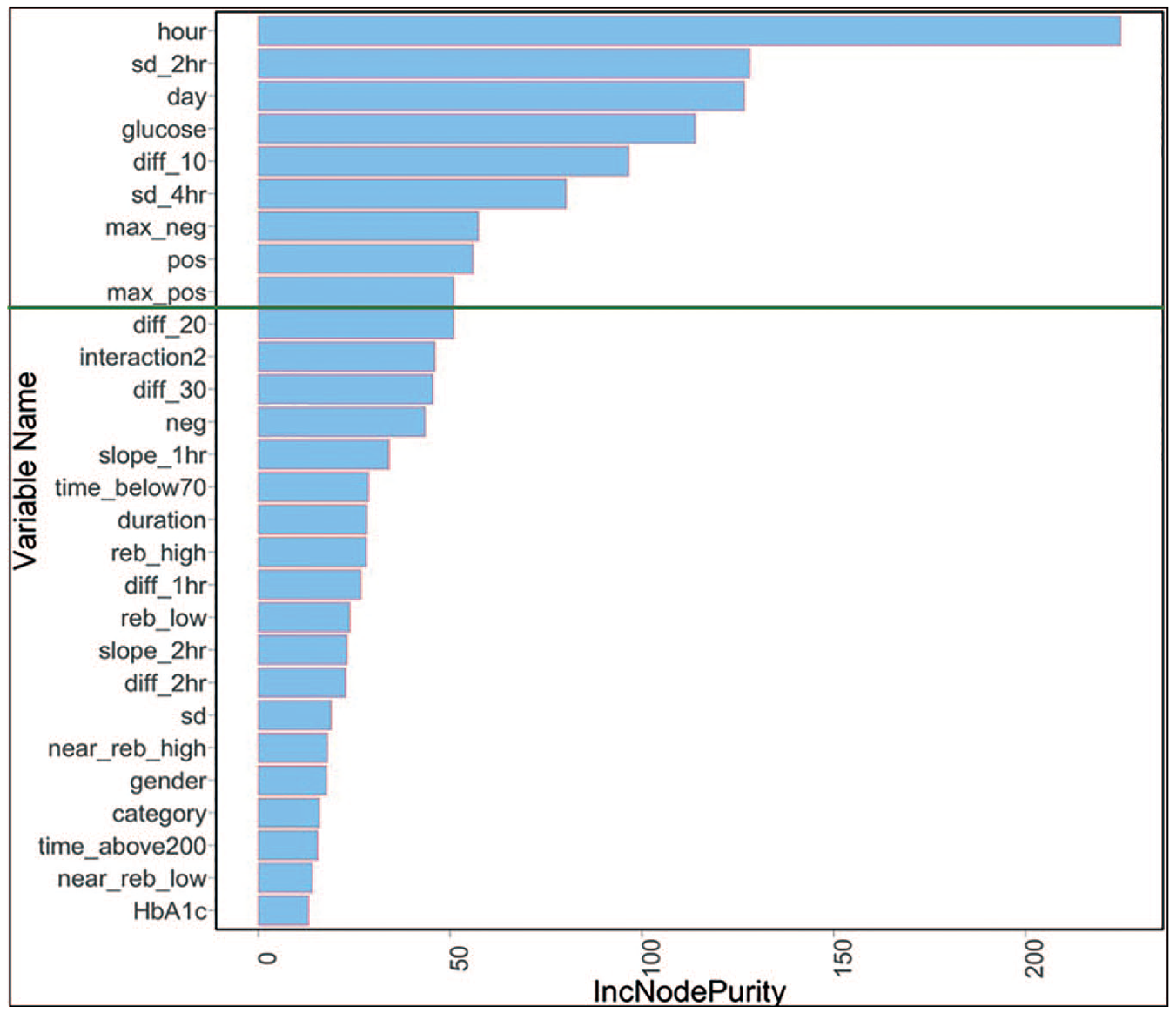
Variable importance plot for random forests.
Seventy percent training and 30% testing partition were randomly repeated 10 times and performance results averaged across these 10 replications to generate robust estimates for sensitivity and specificity. VIP optimized model was used for developing different models for daytime and nighttime risk as well as for evaluating effects of insulin and carbohydrate.
Results
Feature Selection
Figure 4 provides misclassification error curve for the number of variables used in the LR model. The two vertical dashed lines represent λmin (that corresponds to minimal cross-validation misclassification rate) and λ1se (that corresponds to model with error falling within one standard deviation of the minimum). The upper x-axis represents the number of features in model for the corresponding λ, with λ1se being used to select 21 significant features for the final LR model.
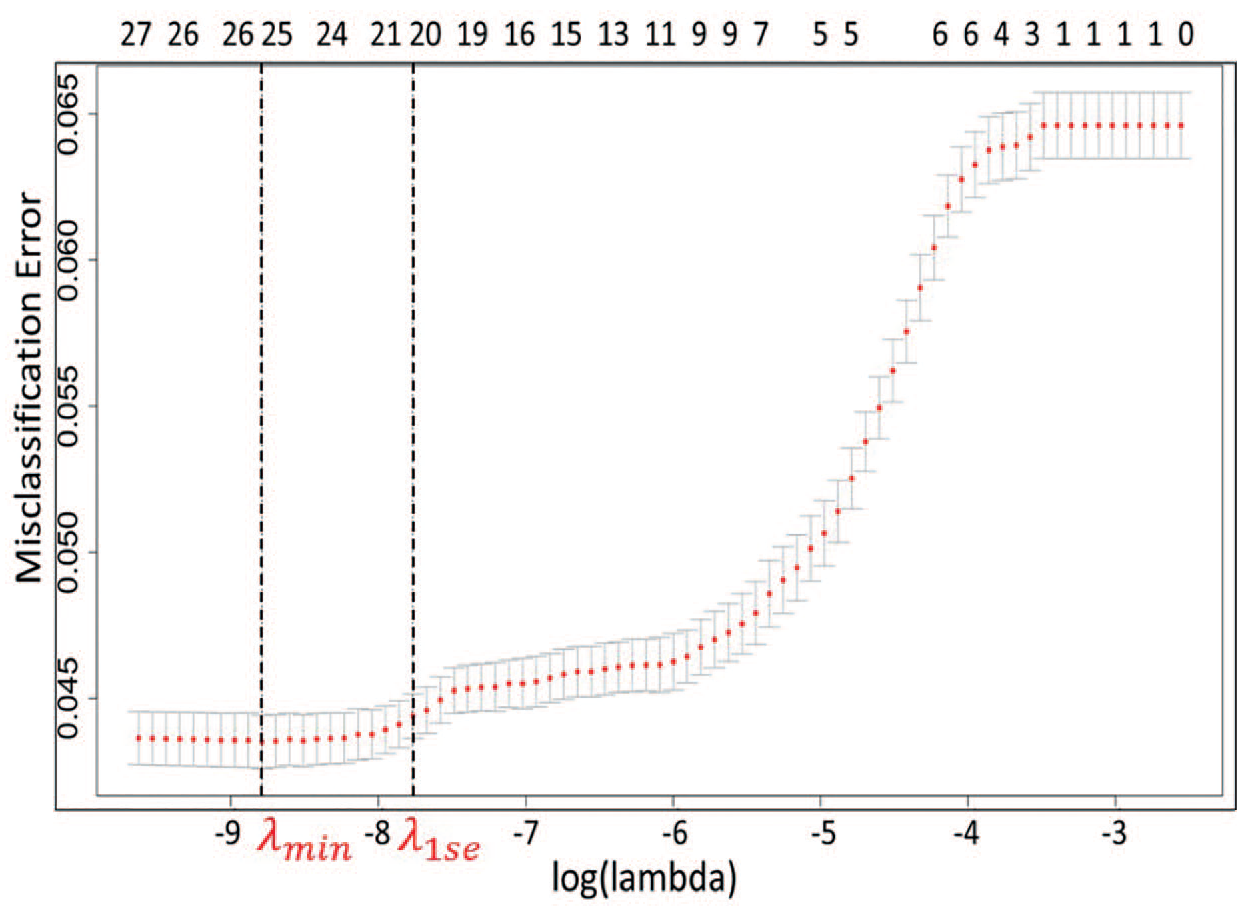
Cross-validation error rate in LASSO.
For RF, as shown in Fig. 5, the misclassification rate increases significantly when the number of variables is less than nine important features. Thus, the top nine significant variables from the VIP are selected for the final RF model (Fig. 3). Table 5 provides a summary of features selected for LR and RF models.
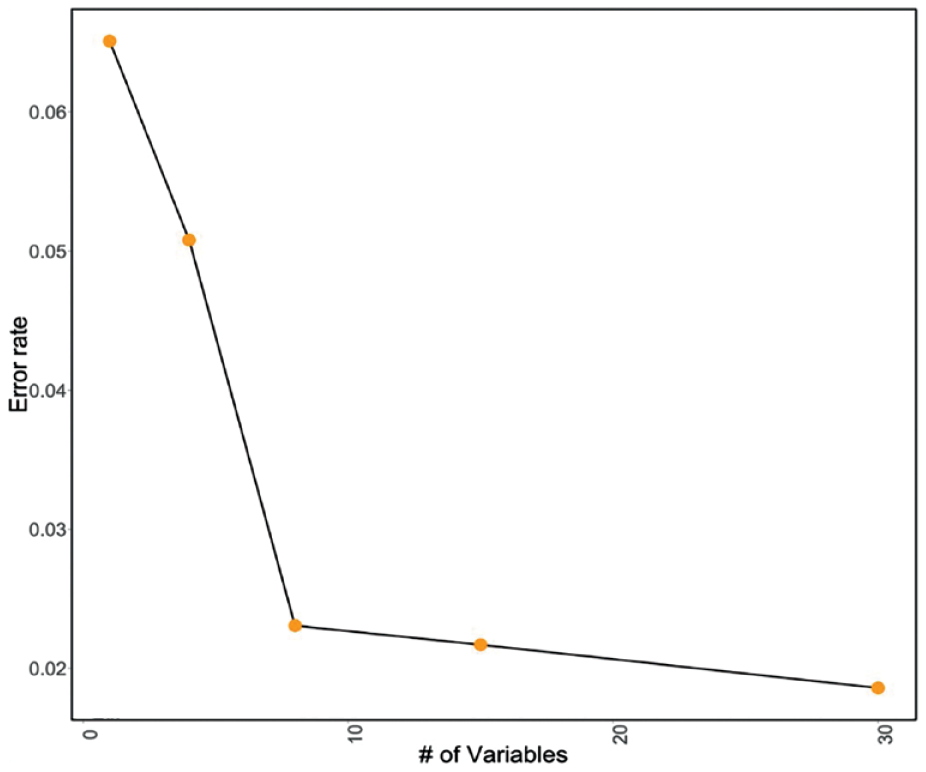
RF out-of-bag misclassification rates.
Model Configurations.

Abbreviations: LASSO, Least Absolute Shrinkage and Selection Operator; LR, Logistic Regression; RF, Random Forests; VIP, variable importance plot.
Classification Performance
Table 3 summarizes model performance. Sensitivity dropped only about 1% point for both the LASSO and VIP selected features when compared with the full model. This is even more significant for RF models as only 9 out of the total 26 features are used in the final model. Our predictions uniformly remained above the 90% mark in identifying hypoglycemic events while only reporting 8%-10% false positives, be it for 0-15-minute or 45-60-minute prediction intervals. The sensitivity drops from 91% for RF to 58% for LR in 45-60-minute window, giving RF models a significant advantage for longer prediction horizons. RF models seem to capture the complex nonlinear relationships influencing hypoglycemia risk much better for different prediction horizons. Figure 6 gives summary of the confusion matrices of VIP Optimized RF for all the prediction horizons. Since this is a rare event classification problem, we set an appropriate threshold level for optimizing the trade-off between sensitivity and specificity through the Receiver Operating Characteristic curves (Fig. 7).
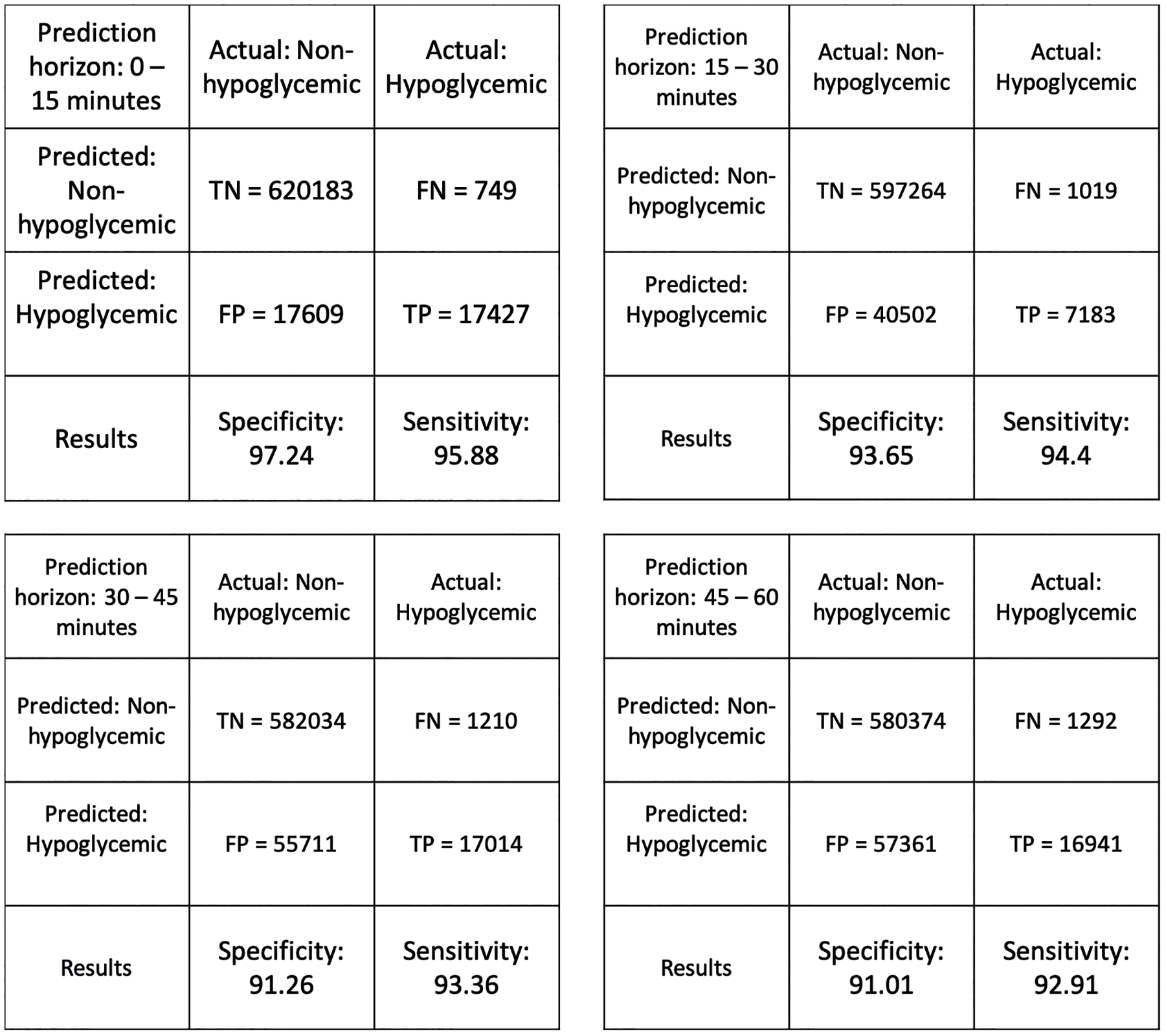
Confusion matrices for prediction horizons: (a) 0-15 minutes, (b) 15-30 minutes, (c) 30-45 minutes, and (d) 45-60 minutes.
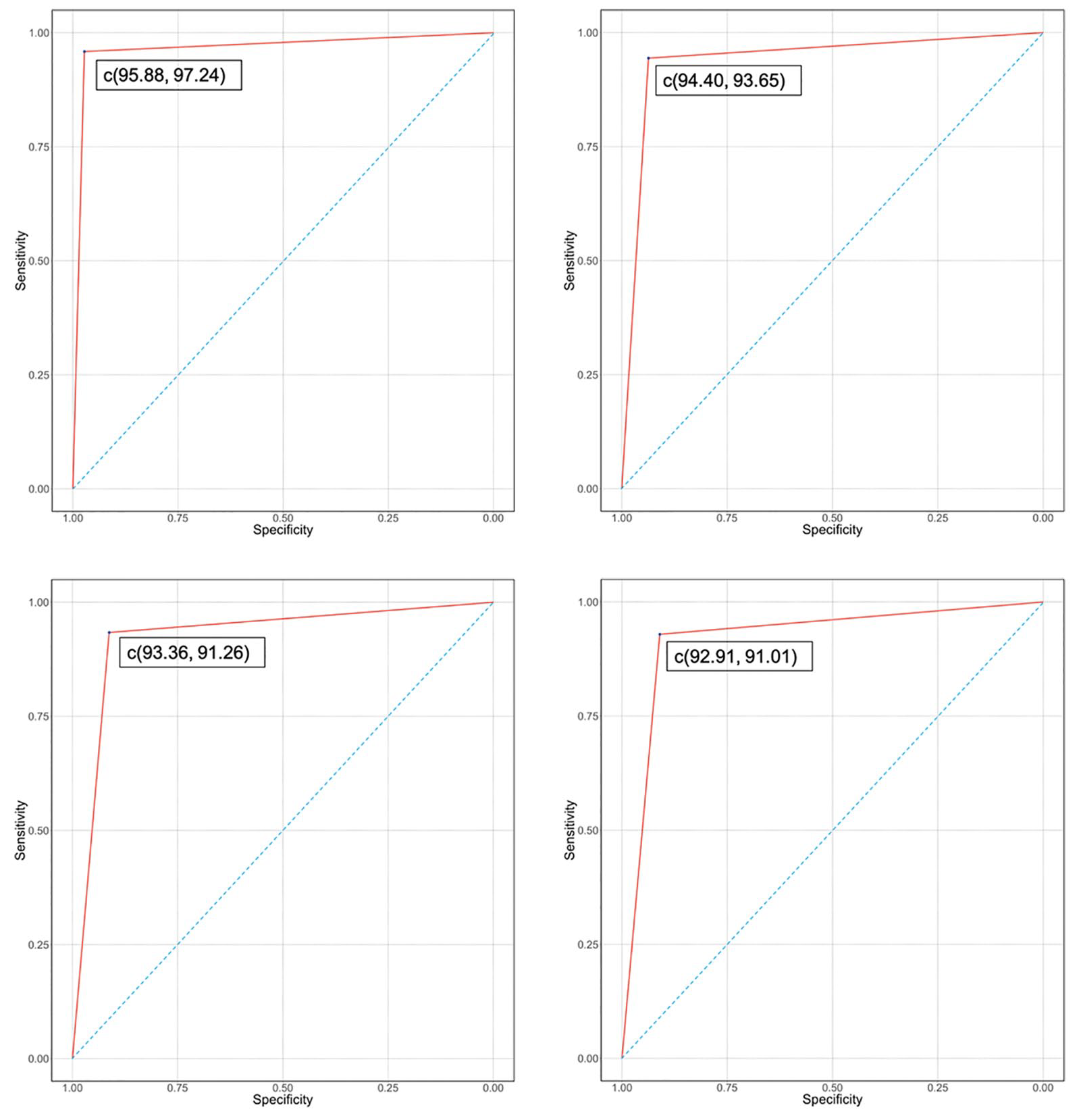
ROC curves for prediction horizons: (Upper left) 0-15 minutes, (Upper right) 15-30 minutes, (Lower left) 30-45 minutes, and (Lower right) 45-60 minutes.
Table 3 also includes performance metrics when separate models were considered for day and night hypoglycemia risk (RF-Day and RF-Night). Night models had a consistent 5% advantage over to daytime predictions, or when considering single model for day or night. We also present a visual comparison of performance of different classifiers (Fig. 8A, B).
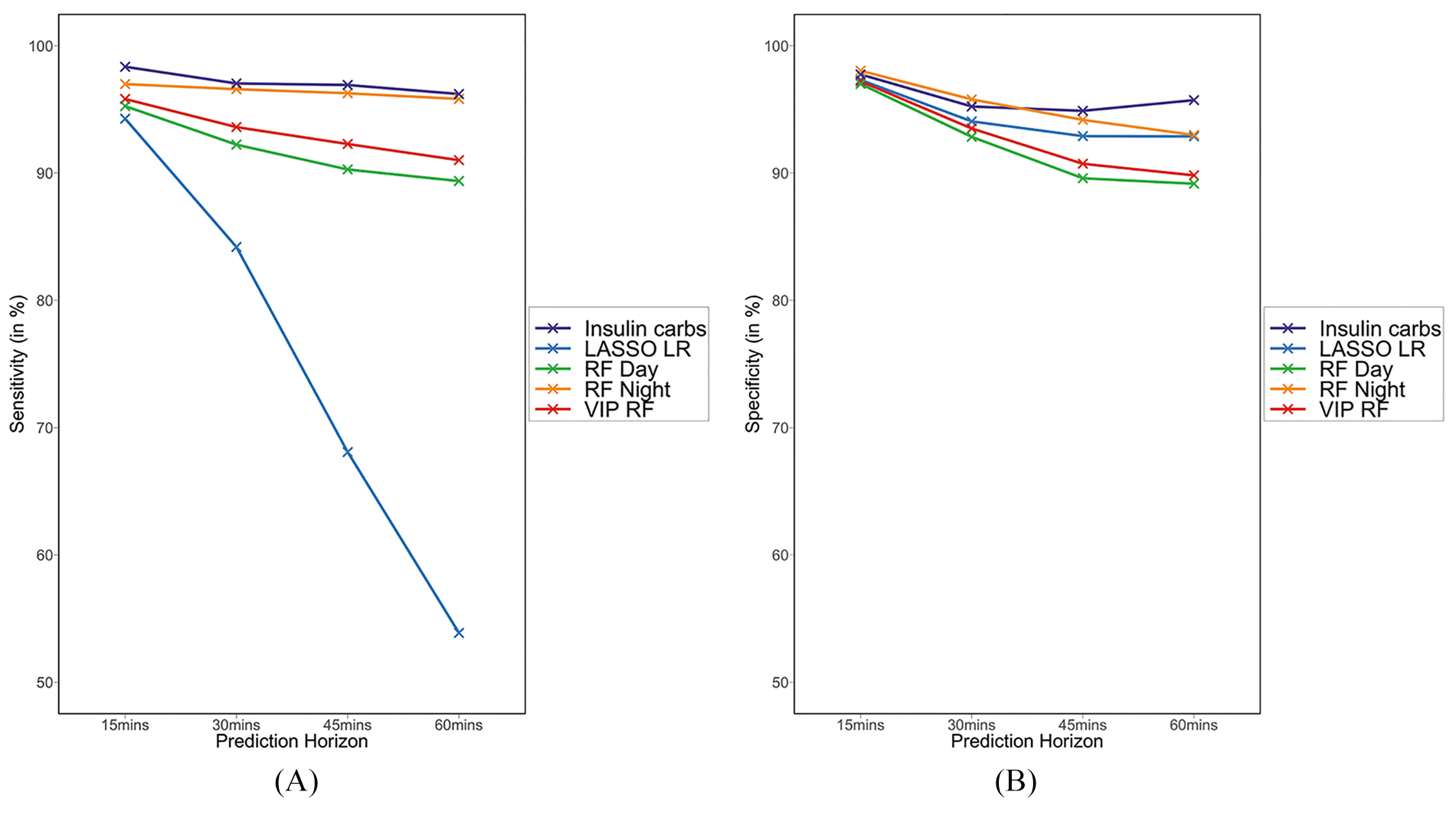
(A) Comparison of sensitivity for various models at different prediction horizons. (B) Comparison of specificity for various models at different prediction horizons.
Discussion
The main contributions of our work to address the challenge of hypoglycemic risk prediction are:
(1) A comprehensive feature-engineering process to identify the features influencing future hypoglycemia risk. We extracted short-term (less than one hour), medium-term (one to four hours), and long-term (more than four hours) patterns from the CGM signal, as well as demographic, contextual, interaction, and nonlinear features and use these features to improve the performance of prediction model.
(2) Ideal set of features for prediction performance and ease of deployment were identified.
(3) Hypoglycemic risk prediction within an interval (0-15, 15-30, 30-45, and 45-60 minutes). In contrast, existing approaches focus on prediction at a discrete point in time (30 and 60 minutes).
(4) Significant improvement in sensitivity and specificity of predictions (Table 6).
Literature Comparison.
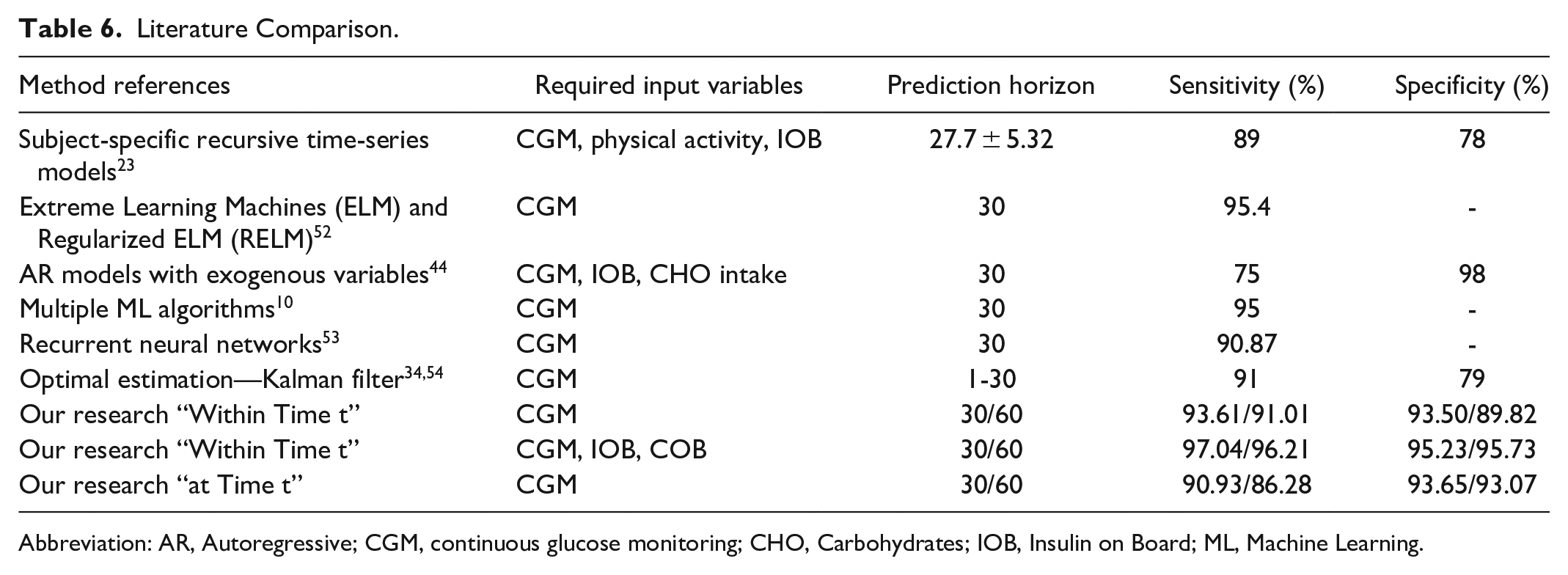
Abbreviation: AR, Autoregressive; CGM, continuous glucose monitoring; CHO, Carbohydrates; IOB, Insulin on Board; ML, Machine Learning.
Insights and Observations
RF seem to be able to capture the complex, nonlinear patterns affecting hypoglycemia better than LR. As evident from the results, we were able to accurately predict true hypoglycemic instances not only for shorter durations but also for longer prediction horizons up to 60 minutes with more than 90% accuracy. This has clinical significance because the additional time may provide more flexibility for the patient to respond. The VIP optimized RF model was able to achieve high performance with only 9 features compared to 21 needed for LR (Table 5). A majority (seven out of nine) of the features used in the VIP optimized RF model are short (less than one hour) and medium (one to four hours) time range, while the other two were contextual features representing day of the week and hour of the day. This is important since it implies that the prediction model can be implemented for new patients without having to collect large amount of data. Based on this insight, the RF-based prediction model will be deployed in the pilot.
We extended the VIP optimized RF model to develop separate models for daytime and nighttime risk with the selected set of nine features. The VIP optimized RF is trained independently on daytime and nighttime data. Developing a separate prediction model for night resulted in significant performance improvement in detecting nocturnal hypoglycemia. While this may not be surprising, due to reduced influences of physical activity and food intake at night, the result is clinically relevant to address the serious consequences of nocturnal hypoglycemia. 14 While the relative ranking of the important features are changed, the list of the important features for the nighttime prediction model are mostly same as whole day model, except that diff-20, time-below-70, and diff-30 replaced sd-4hr, pos, max-pos in the shortlist.
Finally, insulin and carbohydrate data resulted in performance improvement for 30- to 60-minute predictions. Currently, insulin and carbohydrate data are not available in real time from insulin pumps. This study highlights the need to have these data available in real time for facilitating longer horizon hypoglycemic predictions.
Performance Comparison
Most approaches in the literature use raw CGM and supplemental data streams and rely on the algorithm for achieving good model performance. Classical time-series-based approaches as well as optimal estimation theory models like Kalman filter offer the advantages of having a simplistic structure and are more interpretable. However, these methods have significant prediction errors and a very limited forecasting window. 55 On the other hand, sequence-based neural networks dynamically capture complex patterns from the signal and provide more predictive power, but it comes at the cost of model complexity and require large amounts of processed data. In contrast, our approach relies on a rich set of features that capture the patterns and events influencing the hypoglycemia risk. We were able to achieve exceptional predictive performance using only nine features for RF. These nine features are derived from CGM observations in a four-hour window and are computationally simple. Therefore, our approach provides a simplistic structure of classical parameter-based models while deriving the predictive strength of dynamic models by capturing complex patterns through easy-to-calculate features. In this way, we derive the advantages of both the approaches while implementing the trained model in a device. The implemented model continuously monitors for hypoglycemia risk by just updating the latest CGM value.
We compare our performance results with literature in Table 6, which summarizes our results for both “at time t” as well as “within time t” approaches for t = 30 and 60 minutes in the last two rows. It can be observed that “at time t” predictions accuracies, especially specificity, are a little lower than “within time t” predictions, but are still good performance results. Comparison of performance results across different studies is complicated due to the differences in the definition of hypoglycemic event.18,56 -58 We use a threshold of 70 mg/dL to define a hypoglycemic event. Most studies report predictions at a specific time in the future. Predictions within an interval is a contribution of this study. We report results for both interval and specific time-based predictions.
Some studies12,59 -63 have relied on simulated data or data that have been collected through a controlled study. Such data might not truly capture the variations in glucose levels that a person might experience in normal living conditions. Some studies are based on very limited sample size.13,64 Use of a large sample size under normal living conditions will ensure generalizability of the results. To our knowledge, the sample size used in this study is one of the most comprehensive datasets used in hypoglycemia prediction studies.
On the statistical aspect, in rare event classification problems, such as hypoglycemia prediction, it is important to evaluate model performance on specificity as well as sensitivity, since false alarms can be a major drawback. Some studies do not report specificity or report performance metrics using statements that are difficult to compare across studies such as “low false alarm rates of only 1 or 2 per week.” 60 These metrics are highly dependent on the frequency of hypoglycemic events in the study dataset and make it difficult to compare performance across different datasets.
Differential Effect of Inclusion of Insulin and Carb on Board
The inclusion of insulin and carbohydrate data resulted in incremental performance improvement especially for 30-60-minute predictions, which is consistent with the findings of Zecchin et al. 41
Limitations and Future Work
The insulin and carbohydrate analysis was based on only 19 patients, compared to CGM data on 112 patients. Although the insulin data coverage was stratified by gender and age group to be representative of the overall study population, a larger sample size would have facilitated more generalizable results. The carbohydrates on board in this study is based on patient-estimated carbohydrate intake which can be an unreliable estimate. We only consider insulin data related to food bolus and ignored basal insulin in this study. In the future, we plan to explore analysis of basal insulin as well as timing of bolus insulin relative to carbohydrate intake and exercise. Finally, we plan to build more individualized prediction model where a personalized model complements a generalized prediction algorithm. This will help leverage glucose patterns unique to a specific individual.
Comparison to Currently Available Systems
Basal IQ is a predictive low glucose suspend system that uses a simple algebraic approach to predict glucose levels 30 minutes ahead and suspend basal insulin in the t-slim:X2 pump if glucose values are expected to drop below 80 mg/dL. 65 The more recently Food and Drug Administration approved Control IQ automated insulin delivery system uses a complex algorithm to project 30-minute glucose values based on the last four readings to modulate insulin pump basal rates.66,67
The current Dexcom G6 CGM device provides alerts based on user-specified threshold settings. In examining the accuracy of the Dexcom G6 system at a hypoglycemia threshold of 70 mg/dL, the sensitivity and specificity were found to be ~84% and ~85%, respectively, in the 30-minute prediction horizon. 68 In contrast, our approach is able to achieve much higher sensitivities (~95% and 94%) and specificities (~97% and 95%) for prediction horizons of 0-15 and 15-30 minutes.
Our machine learning-based hypoglycemia prediction model is novel as it relies on a comprehensive feature extraction process to infer glucose patterns and achieve exceptional performance results, which are superior to existing data published in the literature. Also, our model preserves a simplistic structure with an ideal set of features for ease of deployment in a patient-facing mobile application regardless of insulin modality (ie, injections, insulin pump, or even oral agents in the case of type 2 diabetes).
Conclusion
We present an optimized RF model for probabilistic prediction of hypoglycemic risk in type 1 diabetes patients. The final model was derived after careful consideration of linear and nonlinear models using a rich combination of extracted features. An important contribution of this study is the identification of short (less than one hour) and medium (one to four hours) time range features that are ideal for hypoglycemic risk predictions. The VIP optimized model had sensitivity of 94% and 91% for 30 and 60 minutes, respectively. Specificity was 93% for 30 minutes and 90% for 60 minutes prediction horizons. Incremental benefits of including insulin and carbohydrates data were analyzed and found to be useful for 60-minute predictions as a 4%-point increase in prediction performance was observed. Isolating model for nighttime predictions was found to be beneficial to address nocturnal hypoglycemia. The analytical models presented in this article will be implemented in a smartphone application in an upcoming pilot study.
Footnotes
Acknowledgements
This study involves the use of secondary analysis of de-identified data that was not collected specifically for this project and is not human subject research (Texas A&M IRB number 2019-0710).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article. TAMU and BCM have applied for provisional patent of this technology.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Real-World Evidence project of FDA grant P50FD006428.