
Abstract
Objective:
Our aim is to analyze the identifiability of three commonly used control-oriented models for glucose control in patients with type 1 diabetes (T1D).
Methods:
Structural and practical identifiability analysis were performed on three published control-oriented models for glucose control in patients with type 1 diabetes (T1D): the subcutaneous oral glucose minimal model (SOGMM), the intensive control insulin-nutrition-glucose (ICING) model, and the minimal model control-oriented (MMC). Structural identifiability was addressed with a combination of the generating series (GS) approach and identifiability tableaus whereas practical identifiability was studied by means of (1) global ranking of parameters via sensitivity analysis together with the Latin hypercube sampling method (LHS) and (2) collinearity analysis among parameters. For practical identifiability and model identification, continuous glucose monitor (CGM), insulin pump, and meal records were selected from a set of patients (n = 5) on continuous subcutaneous insulin infusion (CSII) that underwent a clinical trial in an outpatient setting. The performance of the identified models was analyzed by means of the root mean square (RMS) criterion.
Results:
A reliable set of identifiable parameters was found for every studied model after analyzing the possible identifiability issues of the original parameter sets. According to an importance factor (
Conclusion:
This study shows that both structural and practical identifiability analysis need to be considered prior to the model identification/individualization in patients with T1D. It was shown that all the studied models are able to represent the CGM data, yet their usefulness in a hypothetical artificial pancreas could be a matter of debate. In spite that the three models do not capture all the dynamics and metabolic effects as a maximal model (ie, our FDA-accepted UVa/Padova simulator), SOGMM and ICING appear to be more appealing than MMC regarding both the performance and parameter variability after reidentification. Although the model predictions of ICING are comparable to the ones of the SOGMM model, the large parameter set makes the model prone to overfitting if all parameters are identified. Moreover, the existence of a high nonlinear function like
Keywords
Type 1 diabetes mellitus (T1DM) is an autoimmune condition resulting in absolute insulin deficiency and a life-long need for insulin replacement. 1 Glycemic control in T1D remains a challenge, despite the availability of modern insulin analogs, 2 and the improvement in insulin therapy by means of either multiple daily injections (MDI), the combined use of CGM 3 and continuous subcutaneous insulin infusion (CSII), and lately the use of automated insulin delivery systems, that is, the artificial pancreas (AP). 4
Regarding the design of control structures for AP, a large volume of available literature is specifically devoted to the design of model predictive control (MPC)-based schemes.5-13 However, in spite of the well-known advantages of this strategy, the lack of reliable control-oriented models of the glucose-insulin system limits the success of such approaches, for both physiology inspired models14-16 or black-box models.9,17,18 As stated in the literature, model individualization with “manageable” models (ie, minimal models) remains a challenge for two main reasons: (1) errors in CGM devices and (2) the complex and variable dynamics of the glucose homeostasis which is largely dependent on many uncontrolled factors like patient behavior, circadian rhythm, and other metabolic disturbances.14,17,19 Therefore, in spite of the large structural uncertainty, in order to obtain the best out of the available models for AP design, appropriate model identification (individualization) should be performed to minimize the overall model uncertainty.
Model identification consists in finding the model parameters’ numerical values such that the model describes the available data in predefined optimal way (e.g., deviation/cost minimization). However, nonlinear model identification is in general a very challenging task due to the lack of either practical or structural identifiability. 20
Model identification of control-oriented models in diabetes technology has been typically carried out in an informal way, giving most priority to insulin sensitivity (the gain of insulin action onto glucose uptake) for model individualization without assessing the role and impact of this and other parameters on the system output (measurements).14-17,21-31 For example, in Patek et al
14
the insulin sensitivity is the only parameter used for model individualization of SOGMM with the remaining parameters fixed at population values. In Lin et al,
15
the authors used an alternative representation of the minimal model for glucose control in patients at the intensive care unit (ICU). In this contribution, the authors identified the model in two steps: first on the glucose compartment and then on the insulin pharmacodynamics. The insulin sensitivity is considered as a critical parameter to be fitted every hour. The authors used parameter sensitivity analysis to assess the goodness of fit of the identified model. In Magdelaine et al,
16
a linear model of the glucose-insulin system is proposed. This model exhibits beneficial stability properties to correct non desired steady-state behaviors if compared with existing minimal models. After stating the structural identifiability property of the model, the model is directly identified using a least-square cost function. In this contribution, the authors claim that their model fits over two days of clinical data for a given patient with T1D. In Hann et al,
21
the minimal model is rewritten in integro-differential form. In a first attempt, almost all parameters were fixed with population values and only the insulin sensitivity
Alternative methods have also been presented.29,30 In Herrero et al, 29 the minimal model is reparametrized to render globally structural identifiable. The parameter identification is performed through the set inversion via interval analysis (SIVIA) assuming a set of acceptable errors (intervals) from standard intravenous glucose tolerance test (IVGTT) data. The authors claimed the use of a computationally efficient implementation to overcome the extensive computational complexity derived from the method. In Laguna et al, 30 the authors used the Cambridge model 12 (Hovorka’s model) together with interval analysis, tackling the model uncertainties with interval models. Unlike the above methods, interval analysis provides an envelope of glucose covering all the possible glucose trajectories given an allowed parameter variability.
As it was evidenced, model individualization in diabetes technology has been typically addressed without a formal procedure or method, that is, direct identification is made without exploring possible problems in the model structure or in the amount and quality of the available data. A possible hypothesis explaining why identifiability analysis is usually overlooked by some researchers is perhaps due to the availability of powerful software suits able to solve complex numerical optimization problems. 26 However, disregarding possible identifiability issues will probably produce ill-posed problems, and with this, multiple solutions for a given parameter set. In some cases, structural identifiability is studied under different conditions and using different model structures; only few contributions addresses possible practical identifiability issues.
Analyzing both structural and practical identifiability give a clear path to obtain unique representations for a given experimental dataset. In this regard, this manuscript presents a complete identifiability analysis of three commonly used models for AP design. The models are selected according to (1) the number of equations and (2) different model structures, that is, models are control-oriented models with similar number of equations but with alternative descriptions of the main variables in the glucose metabolism. Our study differs from the existing ones as possible structural and practical (related to the amount and quality of data) limitations of the analyzed models are carefully addressed to guarantee a reliable model identification/individualization.
Methods
Participants and Data Selection
CGM (Dexcom G5, San Diego, CA) and insulin pump data (Tandem Diabetes Care, Inc, San Diego, CA) together with meal information (timing and carbohydrate counting) and physical activity data (fitbit, San Francisco, CA) were collected during an IRB-approved clinical trial (clinicaltrials.org NCT02558491) at the University of Virginia (Charlottesville, VA, USA) for 15 study subjects on continuous subcutaneous insulin infusion (CSII) and 10 study subjects on multiple daily injections (MDI), all having been diagnosed with type 1 diabetes for at least six months. Each patient experienced two identical outpatient admissions of 48 hours (separated by four weeks or more), experiencing both meal and exercise challenges designed to induce glucose variability. In the time in between the admissions, the patients were asked to perform at least three exercise bouts every week. In order to go through the details of the role of identifiability on model individualization, 7-day data in between the admission periods was selected from five subjects (group CSII) in rest periods, that is, data from 1h before to 3h after exercise periods were excluded. For analysis purposes, the data is divided into 6h intervals, every 6h interval corresponding to an experiment.
Models Under Study
In all the models, it is assumed that the only measurement comes from the CGM. Therefore,
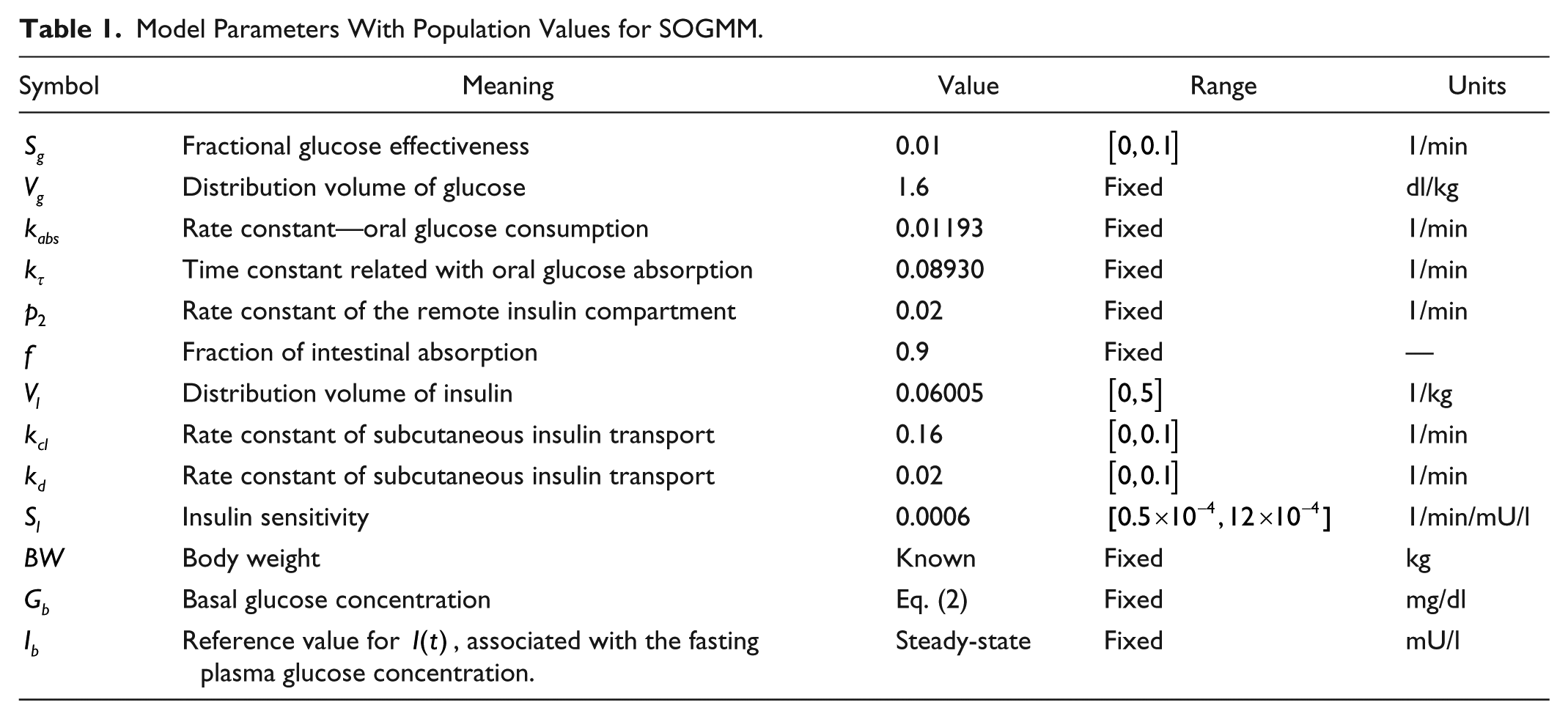
The Subcutaneous Oral Glucose Minimal Model—SOGMM
Consider an extended version of the minimal model, known as the subcutaneous oral glucose minimal model (SOGMM) 14
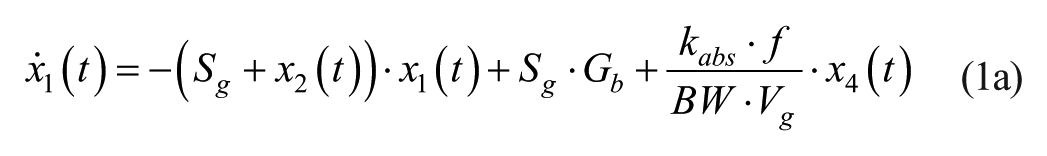
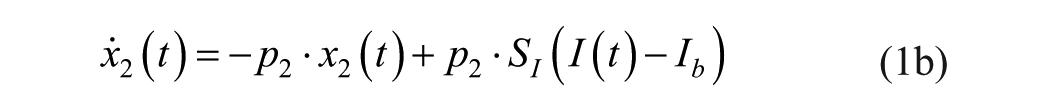
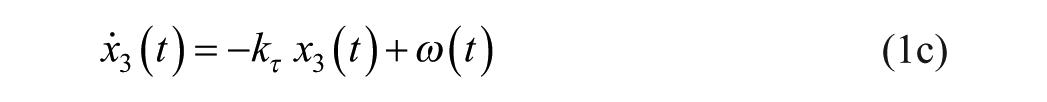
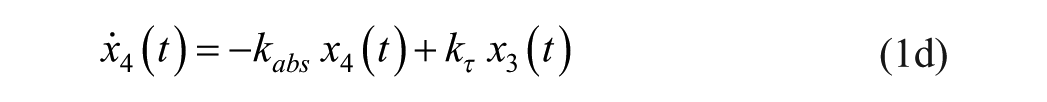
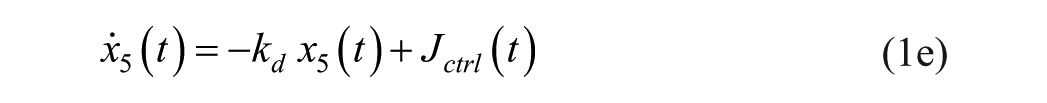
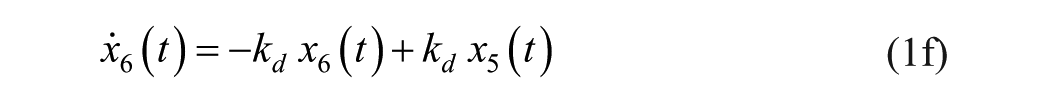
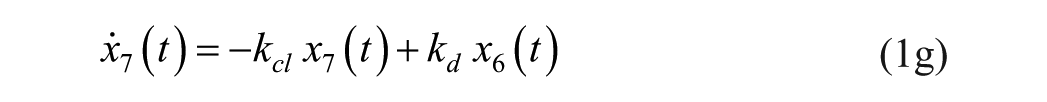
with
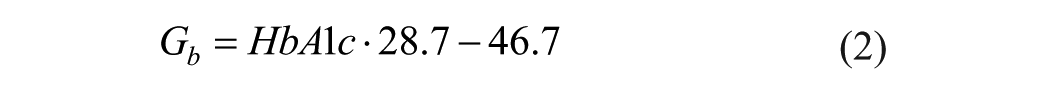
where HbA1c is the patient’s most recent glycated hemoglobin.
Model Parameters With Population Values for SOGMM.
The Intensive Control Insulin-Nutrition-Glucose (ICING) Model
Consider an extended version of the Bergman’s minimal model, known as the intensive control insulin-nutrition-glucose model (ICING) presented elsewhere. 15 Although this model is originally used for tight glycemic control at the intensive care unit (ICU), it was found to be suited for patients with T1D after some modifications: the terms for parenteral feeding and endogenous insulin production are neglected to represent the glucose-insulin dynamics for a patient with T1D in an outpatient setting.
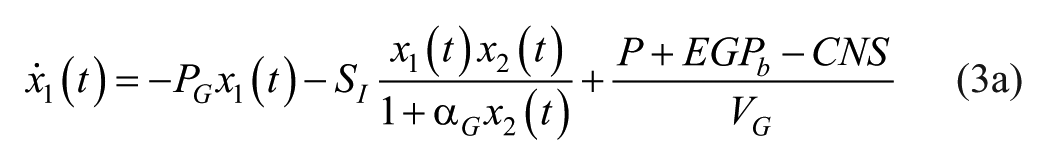
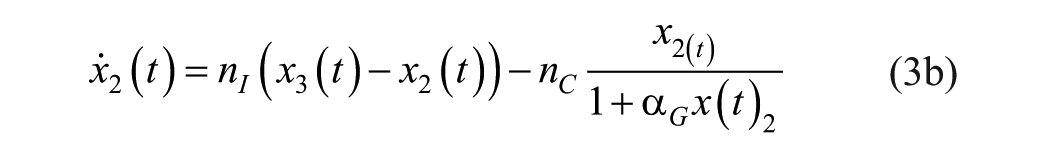
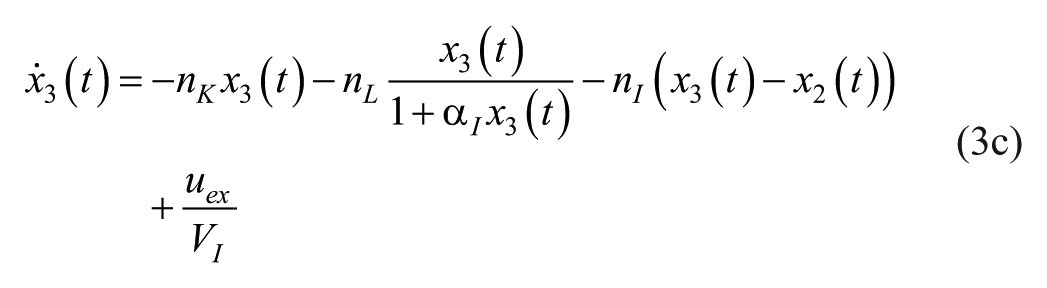
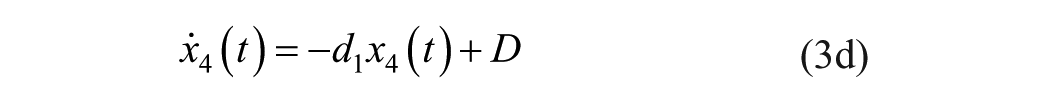
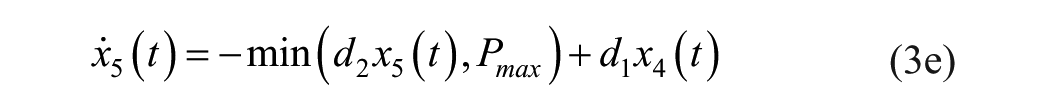
where
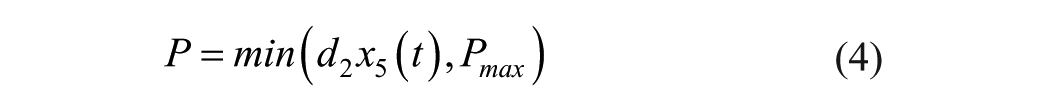
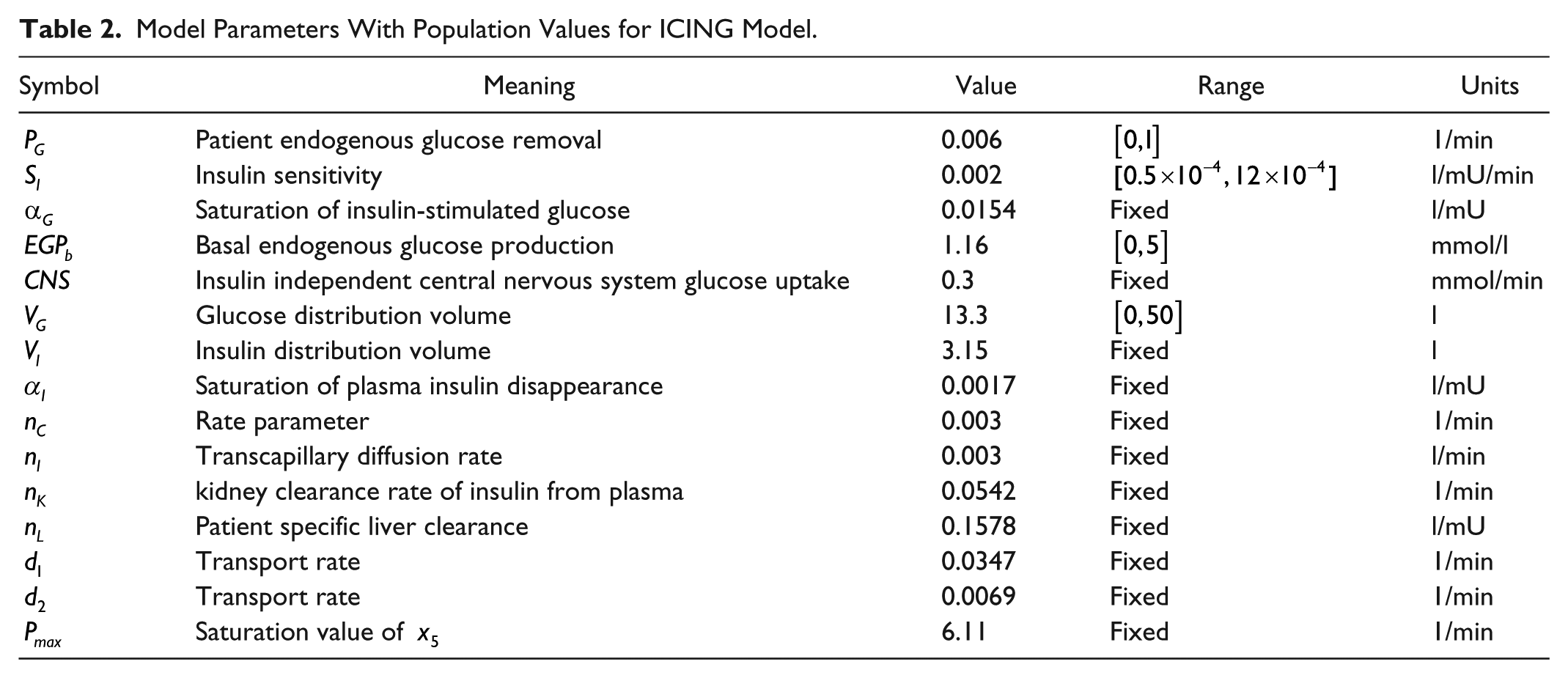
The description of the model parameters together with its units and numerical values (seed or population values) are presented in Table 2.
Model Parameters With Population Values for ICING Model.
The Minimal Model Control-Oriented
Consider a control-oriented model of the glucose-insulin system, presented elsewhere in Magdelaine et al. 16
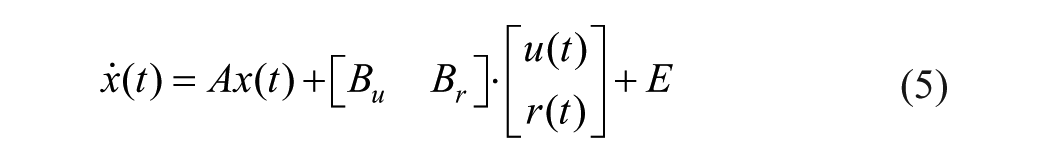
with
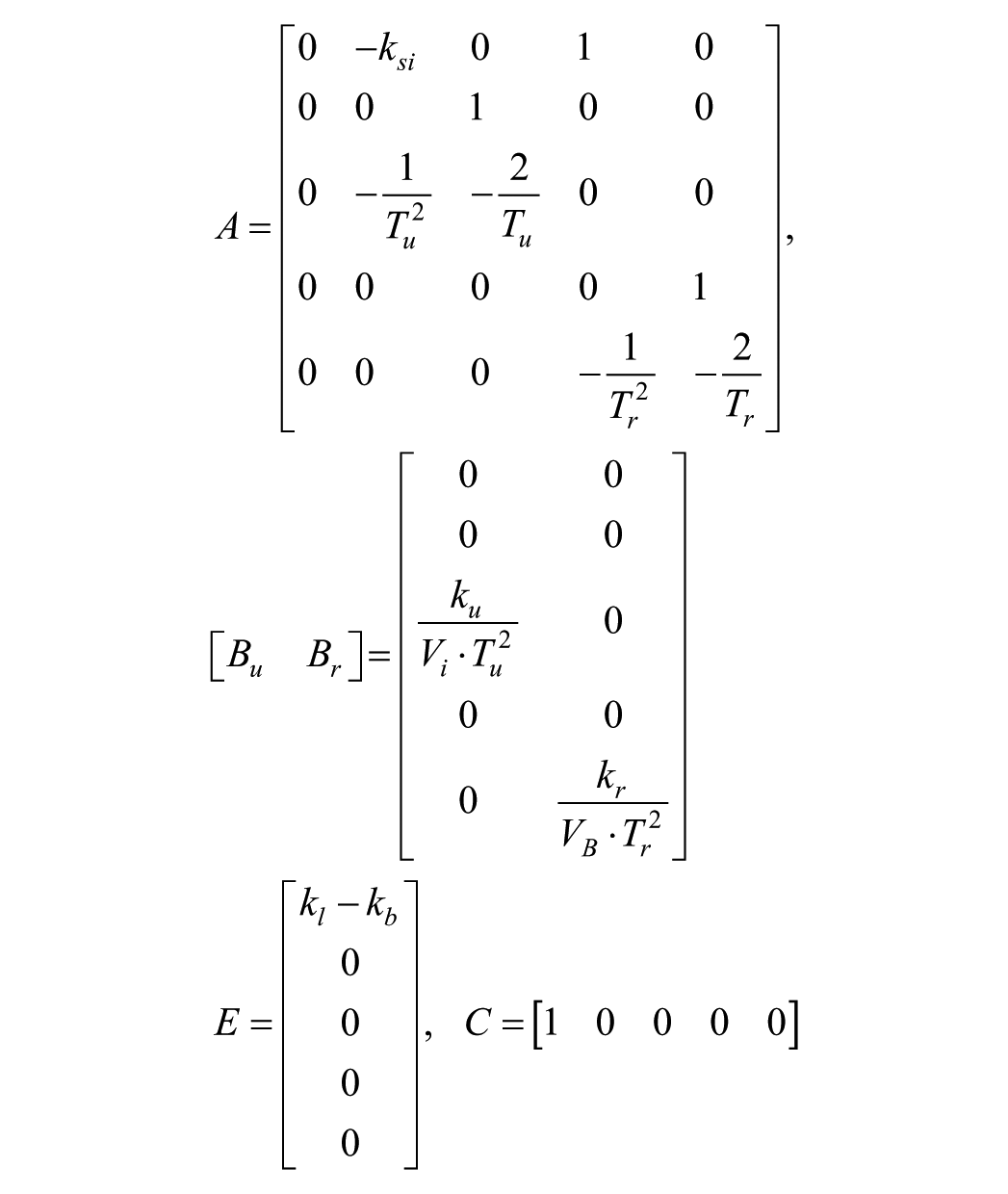
where
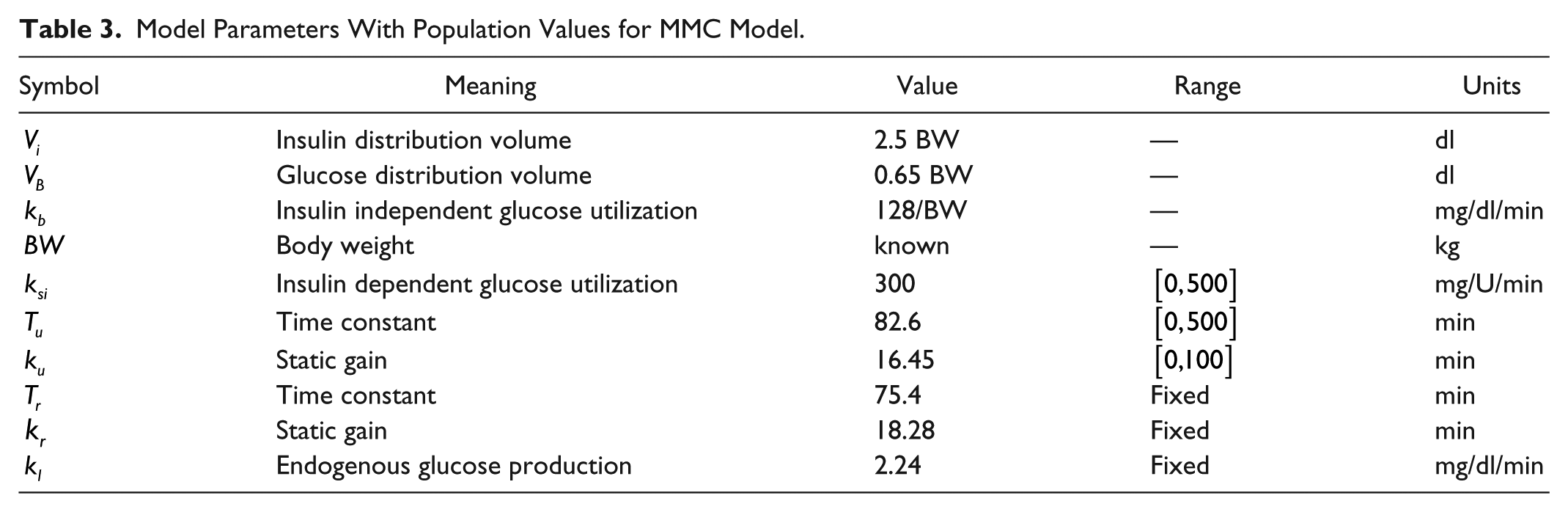
Model Parameters With Population Values for MMC Model.
Identification Methodology
In the present study, it is considered that the only available source of information (measurement) comes from the plasma glucose concentration (CGM). We follow the procedure in Figure 1. The arrows indicate the (possible) existence of an iterative process where a subprocedure can be revisited once preliminary results from the following/preceding subprocedure is obtained. At the end, model identification is performed by the minimization of the mean square error (MSE) through the defined dataset.
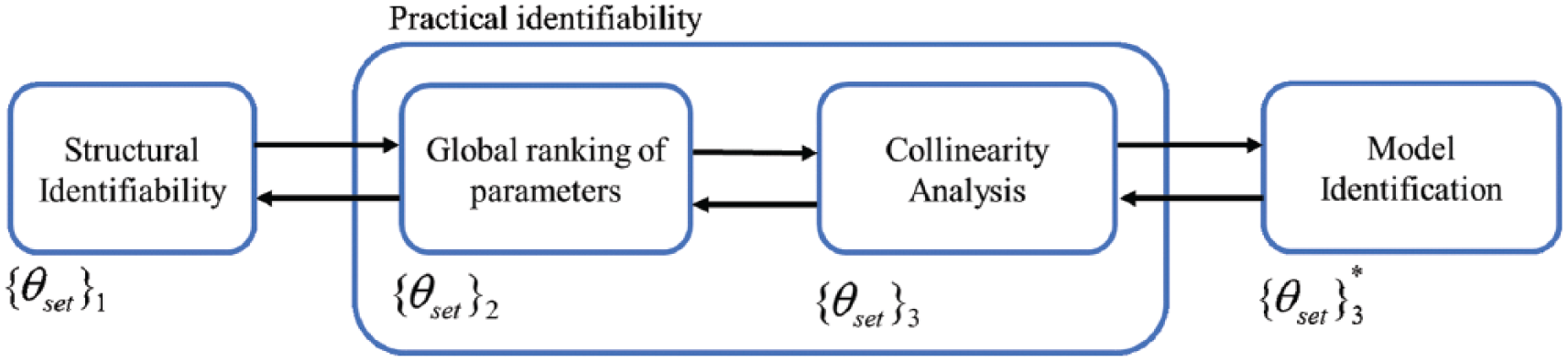
Identification procedure.
The performance of the models after identification will be assessed by means of the root mean square (RMS) criterion
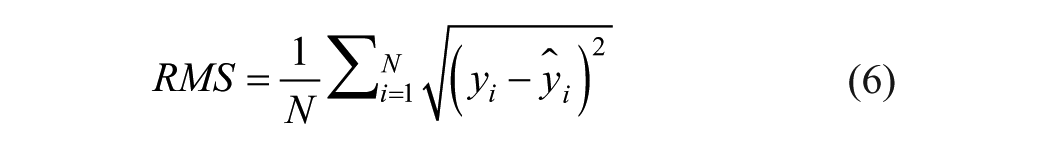
where
Identifiability Analysis
Let’s consider the following nonlinear ODE model representing the system dynamics of the phenomena of interest
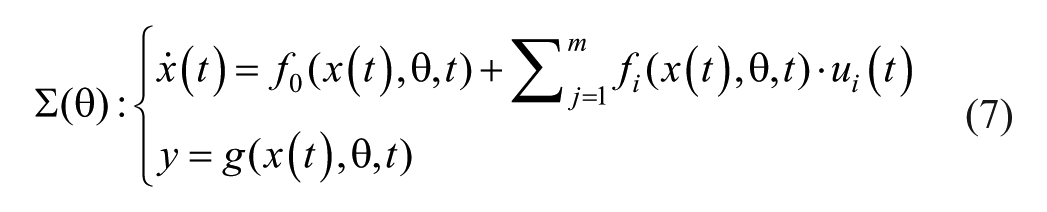
where
Structural Identifiability
Structural identifiability is a theoretical property of the model structure depending only on the system dynamics, the observation and the stimuli functions.
32
Formally, this property is defined as the possibility of assigning unique values to model parameters from the observables (system outputs) but assuming noise-free and continuous-time data.
32
In this regard, a parameter
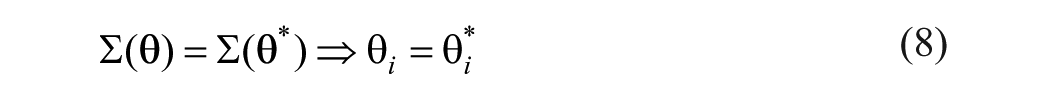
This property means that if a parameter or set of parameters under study are found to be structurally globally identifiable, it is possible to obtain a unique numerical value for every parameter under the stated conditions (noise-free and continuous-time data). Global structural identifiability can be hard to characterize, therefore, as an alternative, a parameter
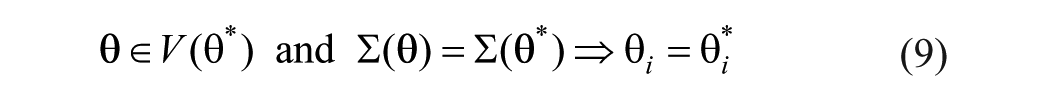
Methods assessing structural identifiability can be found in the literature, and the reader is directed to the review from Chis et al.
33
Here, we chose the method of the generating series approach (GS).
34
The method relies on the fact that the system outputs can be expanded in series with respect to time and inputs, using as coefficients the function
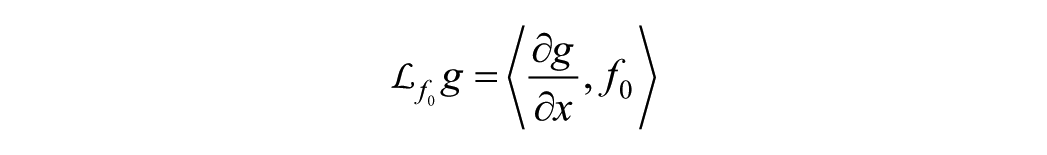
where 〈⋅,⋅〉 denotes the scalar product between two vectors. It is important to emphasize that the GS approach does not specify an upper bound for the order of the derivatives to be taken to prove/disprove the property. Therefore, either the Lie derivatives are taken until a solvable set of algebraic equations in the parameters is found or until, after some coefficient, all subsequent coefficients become zero. The advantage of this method over the Taylor series approach is that the obtained mathematical expressions are easier to handle. 33 Since the amount of Lie derivatives can be overwhelming, Balsa-Canto et al introduced the concept of the identifiability tableaus 33 to (1) organize the Lie derivatives, (2) systematize the resulting algebraic equations, and (3) handle possible structural identification issues. The tableau depicts the nonzero elements of the Jacobian of the series coefficients with respect to the parameters. In this sense, the tableau is an array with as many columns as parameters and as many rows as nonzero computed coefficients. Once enough nonzero coefficients guarantee the full-rank condition of this array, at least the local identifiability of the parameters can be stated. Structural identifiability of the models is studied by a combination of the GS approach 34 and identifiability tableaus 35 by means of the GenSSI tool. 36
Practical Identifiability
Structurally identifiable parameters may not though be identifiable in practice. Practical identifiability deals with whether the parameters can be estimated with sufficient precision using experimental data. 37 Lack of practical identifiability can result from (i) parameters without influence on the system outputs and (ii) correlated parameters, that is, the effect of some parameter is affected or overshadowed by the effect of some other parameter or parameters.
Global Parameter Ranking
Global parameter ranking proposes to sort the model parameters with respect to their impact on the system outputs. In this sense, the parameters impacting the outputs the most can be either selected for a further structural identifiability analysis or for model identification. The most common approach for parameter ranking involves the use of parametric sensitivities 38 like
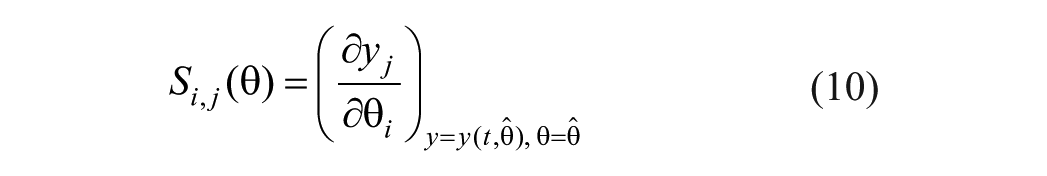
where
Once the sensitivities are computed for every sample, the importance factor for parameter
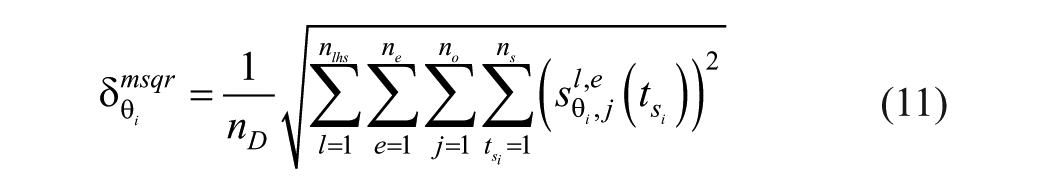
where
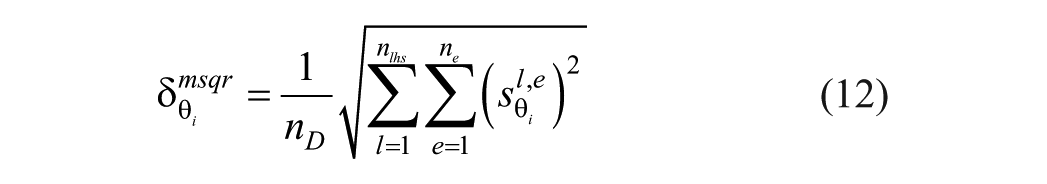
since there is only one observable (CGM trace) and in every experiment the same sampling time is used. Note that (12) depends on the number of samples in the LHS method as well as the number of experiments. Our findings show similar results using
Correlation Among Parameters
As stated before, even the effect of most significant parameter(s) might be overshadowed by the effect of others.35,41 Analysis of the correlation between parameters can indicate such deficiency.35,37 To avoid a pair-by-pair analysis of parameters, a collinearity analysis of the entire subgroup can be performed instead.41,42 The collinearity analysis is based on the linear dependence definition: the parameters are linearly dependent (collinear) if there exist
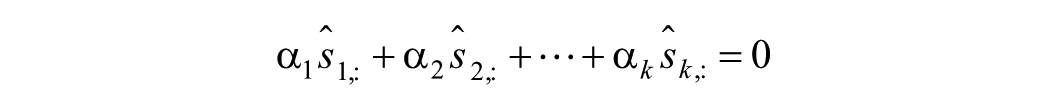
where
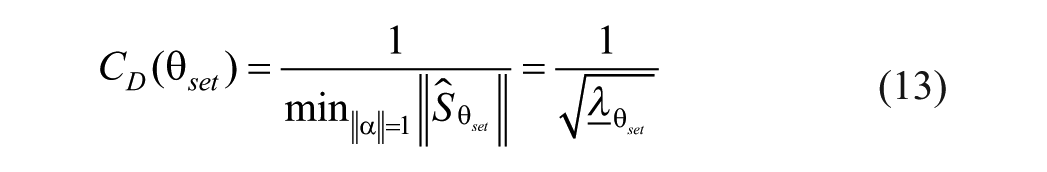
where
Results
Structural Identifiability Analysis
It is important to note that none of the three models considered in this analysis is either locally or globally structurally identifiable considering the original parameter set, that is,
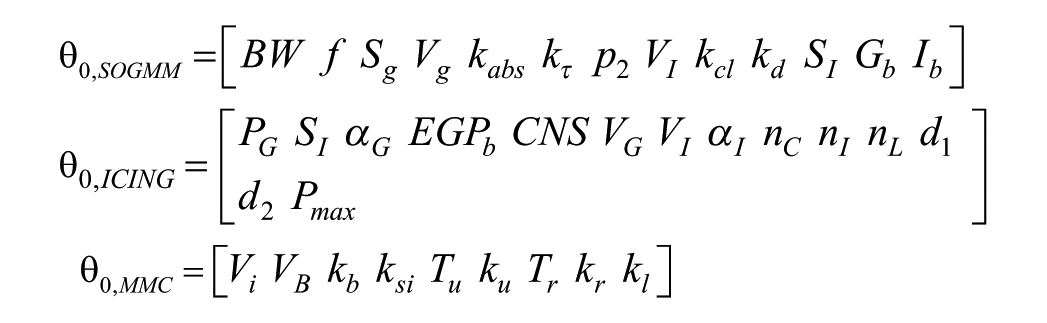
In the case of SOGMM and MMC models, the authors indicated a reduction of the parameter sets to
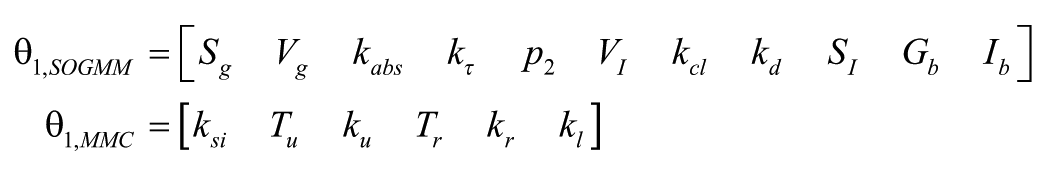
since both
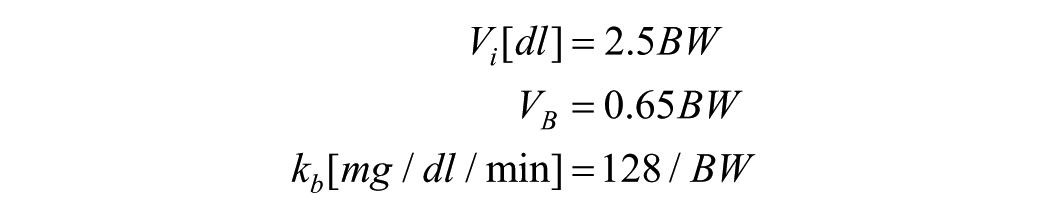
which lead again to nonidentifiable models (from the structure). With the above scenario, there exist many combinations of parameters to be analyzed from every model in order to obtain a subset of structurally identifiable parameters, making the procedure cumbersome. Therefore, a method helping in that selection is of paramount importance. In this case, we circumvented the above issue by means of the global ranking of the parameters in terms of the parameter sensitivity, that is, what are the parameters impacting the output the most.
SOGMM
Consider the parameter set
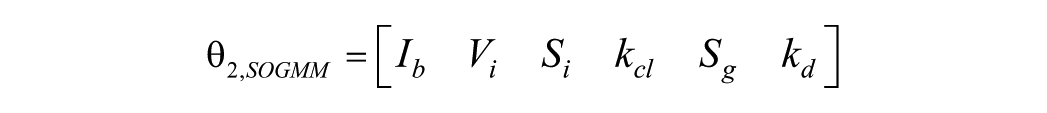
However, as it will be confirmed later,
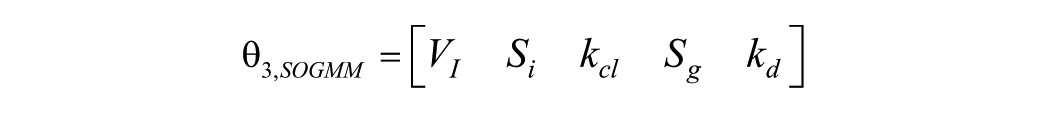
where is found, by means of GS method and the identifiability tableaus, that all the parameters are locally structurally identifiable as shown in Figure 2. Note that 120 coefficients are generated by means of the Lie derivatives (left) from which 5 coefficients are found to fulfill the rank condition (right).
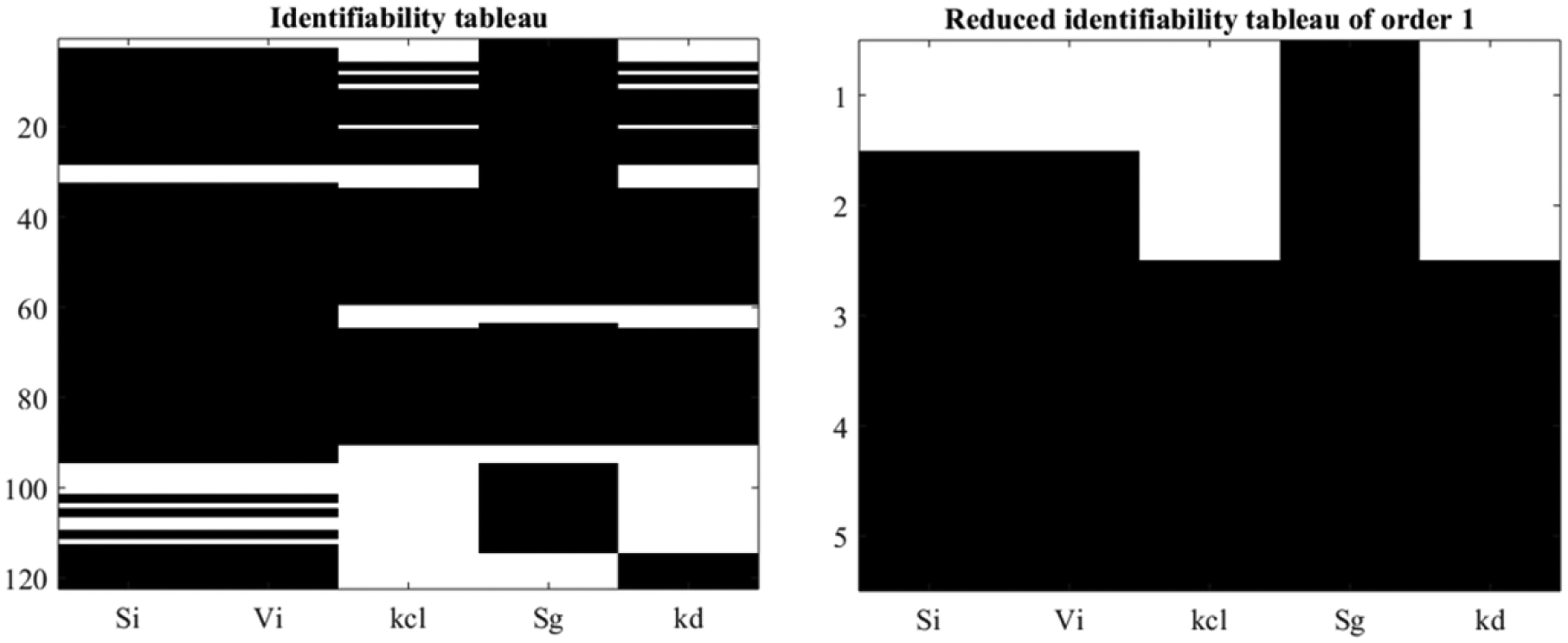
Identifiability tableaus for SOGMM.
ICING Model
Using the global ranking of parameters and a similar analysis as before we found that the set
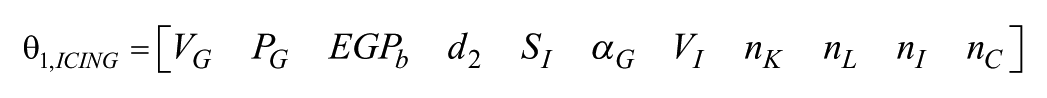
is globally structurally identifiable. Figure 3 show the identifiability tableaus with more than 700 coefficients of the series (left) and 11 relations fulfilling the rank condition. Moreover,
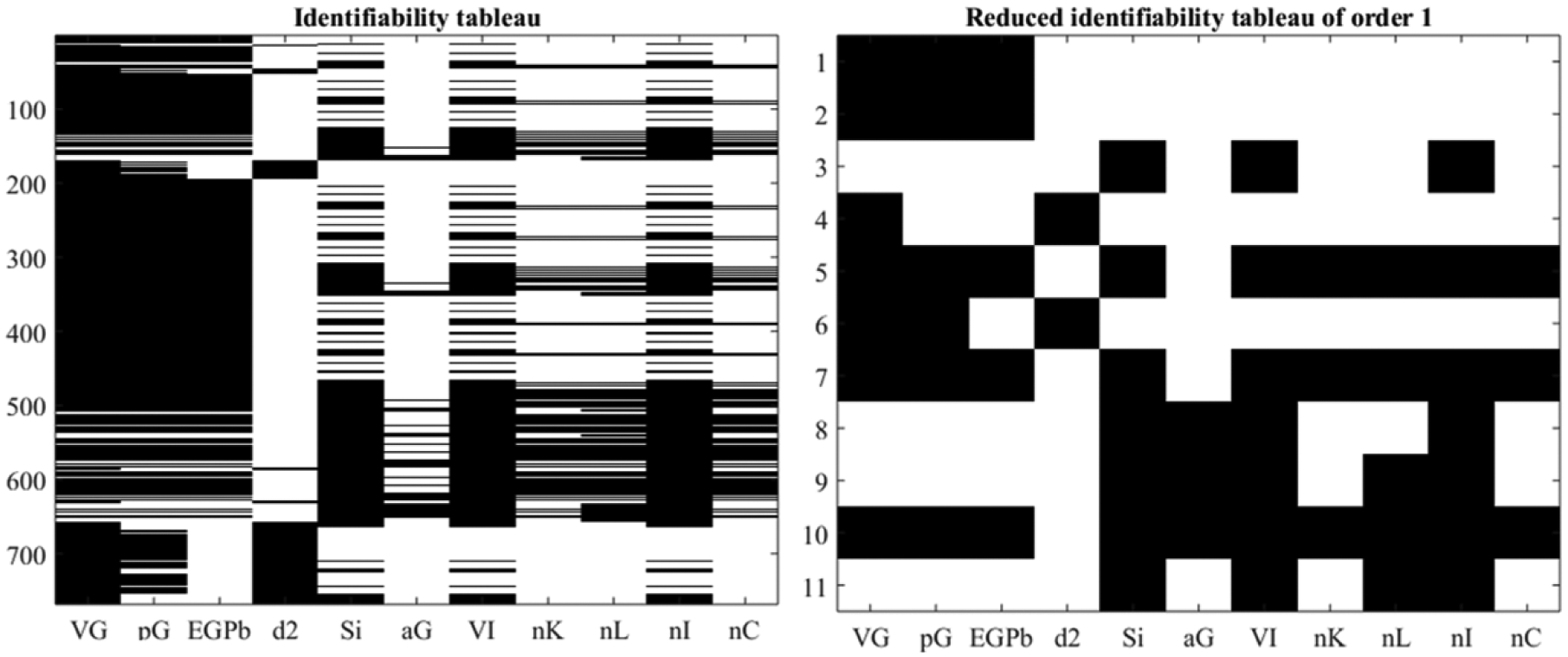
Identifiability tableaus for ICING model.
MMC
Using the global ranking of parameters and a similar analysis as before we found that
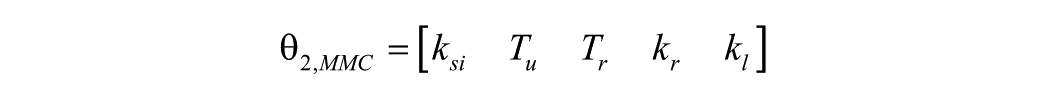
is globally structurally identifiable. Figure 4 show the identifiability tableaus with around 22 coefficients of the series (left) and reduced tableaus indicating the fulfillment of the rank condition (and the uniqueness in the solution).
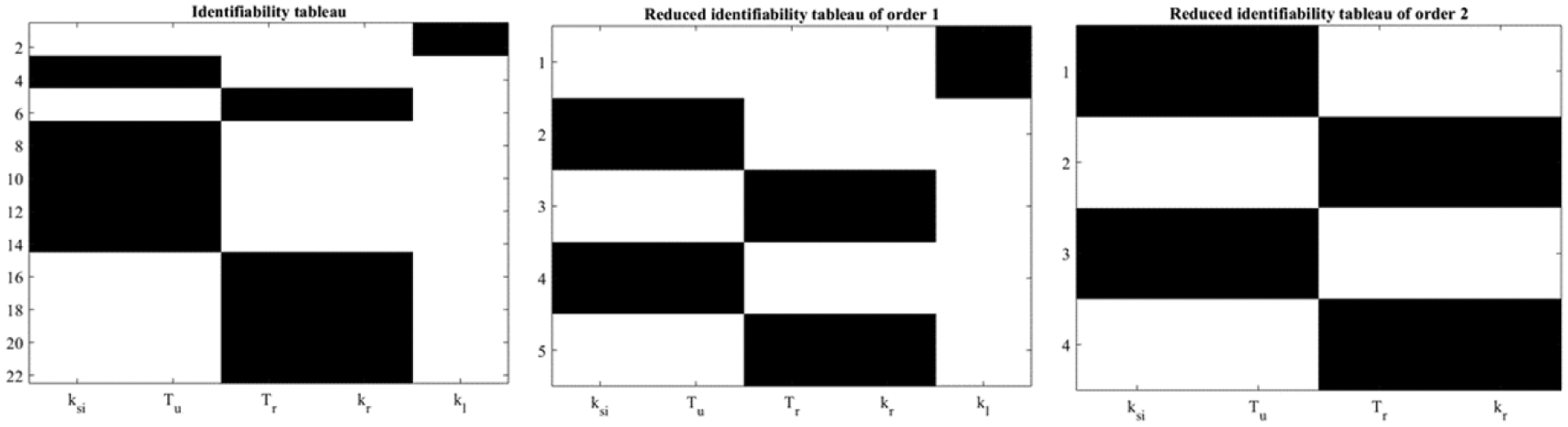
Identifiability tableaus for MMC.
Practical Identifiability Analysis
The parameters of every model are ranked with respect to
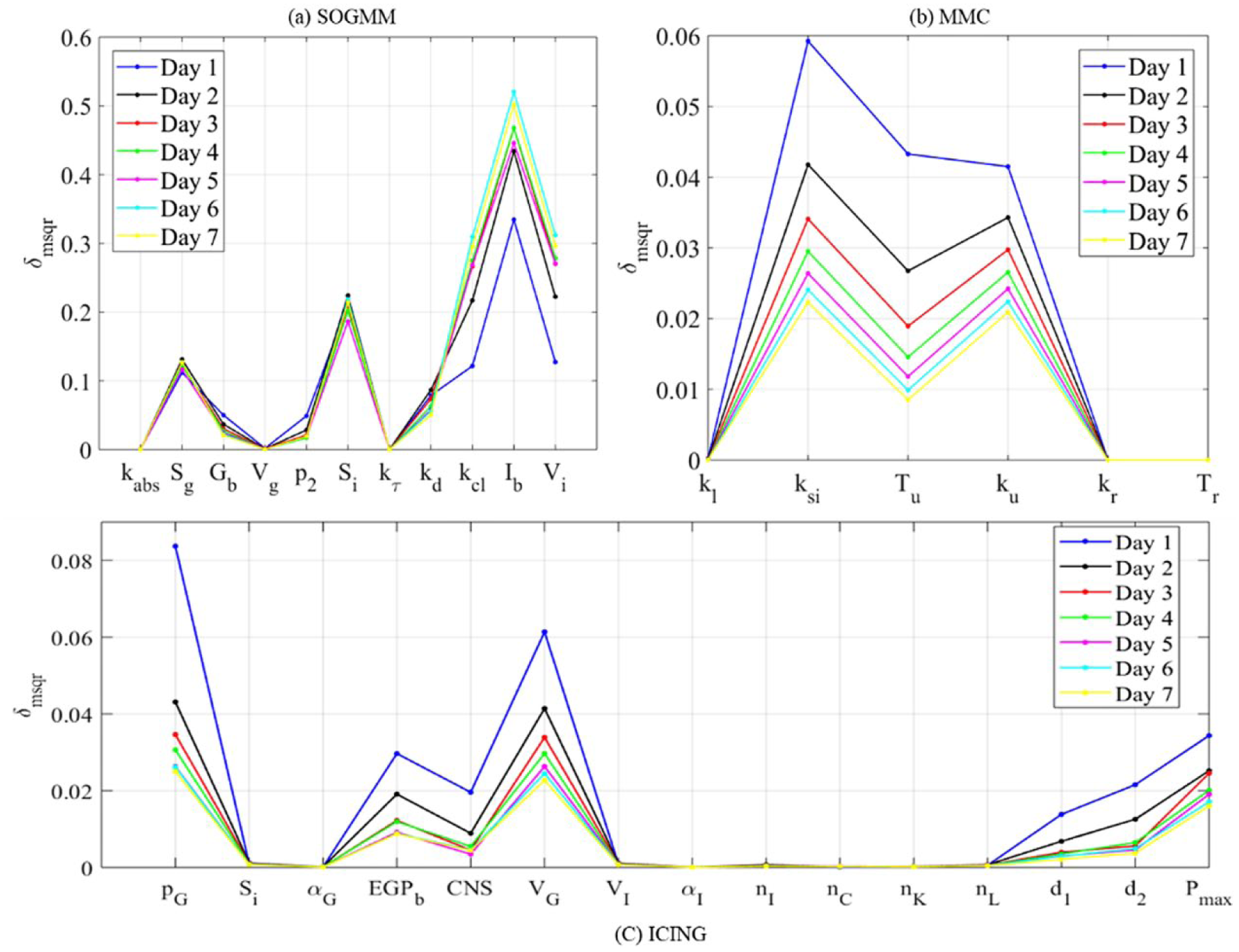
Global ranking of parameters for patient 1 in seven days using the three models.
Figure 6 shows the global ranking of the parameters for all the selected patients during the last dataset. In spite of the numerical differences, the relations among parameters within a subject are maintained, therefore the rank remains with no change. Table 4 summarizes the different effects of the parameters on the system output (plasma glucose concentration). Sensitive parameters sum the 97%, 99%, and 85% of total
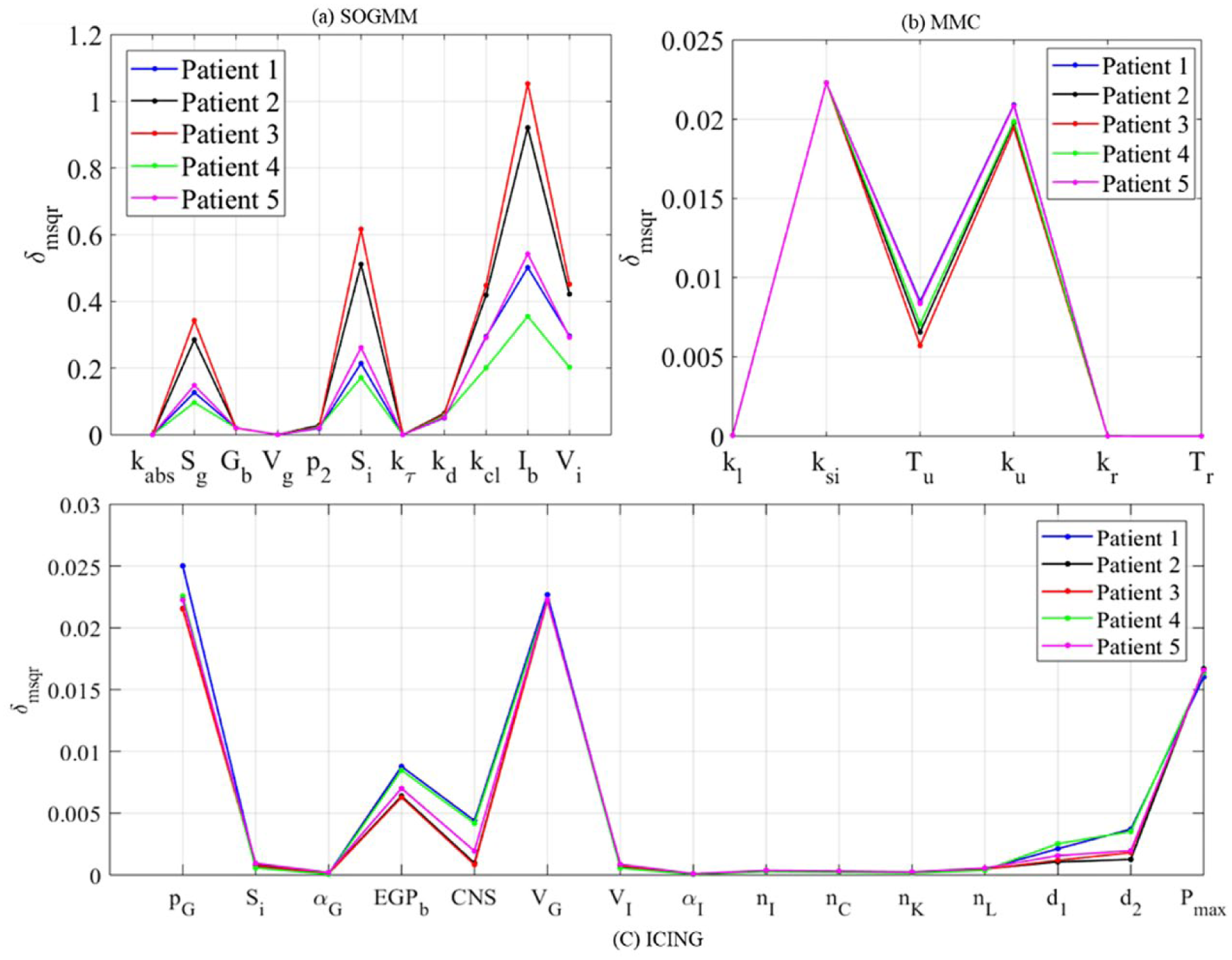
Global ranking of parameters for patients 1-5 during day seven using the three models.
Parameter Clustering in the Studied Models.

Using the above results, the parameters labeled as “almost insensitive” are fixed with population values. Then, considering the results from the structural identifiability analysis, we update the sets of parameters to be identified as
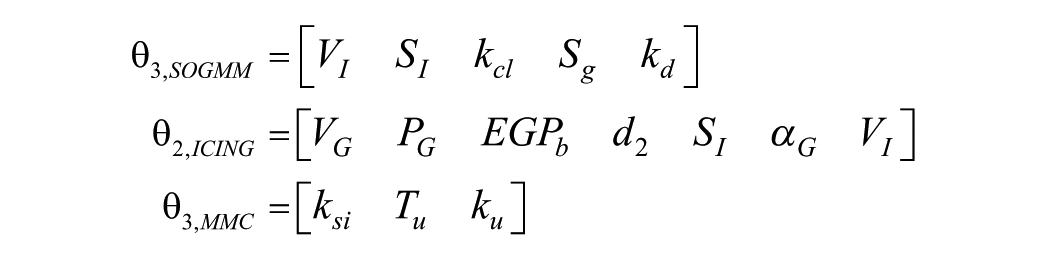
From the above parameter sets, the collinearity of the parametric sensitivities is investigated for every patient in different time windows. As stated before, datasets with 6h data each are used in this analysis to account for the intrapatient variability and dynamic changes contained in the CGM traces. Moreover, this short-term analysis will also allow further investigation of the data reliability for model identification at different times of the day. After evaluating the collinearity of the parametric sensitivities for the different combinations of parameters, the following sets were found to be the best conditioned in most of the evaluated time windows
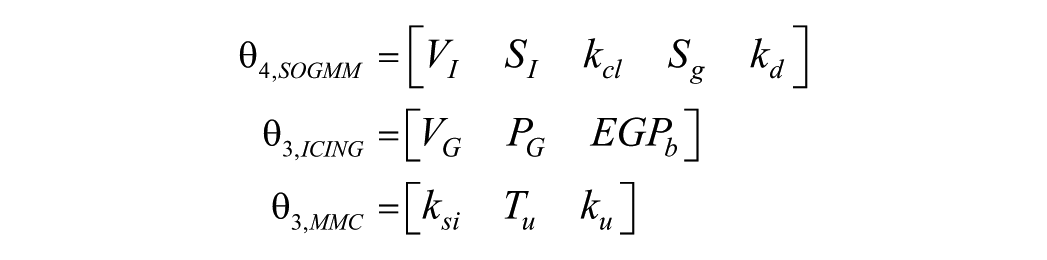
Tables 5-7 show the evaluation of the condition
Collinearity Test for
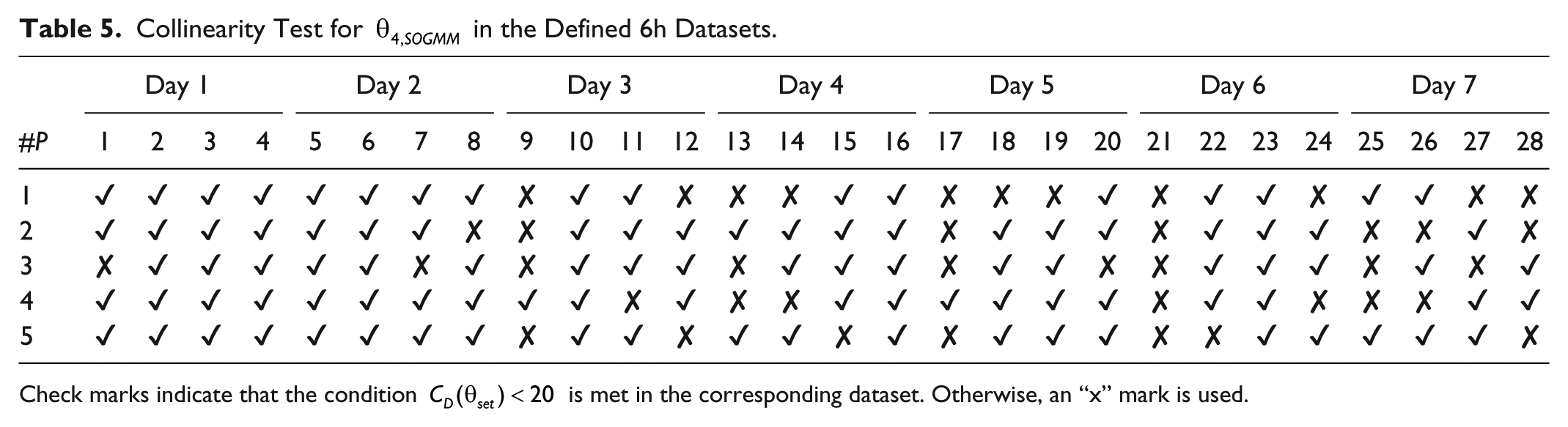
Check marks indicate that the condition
Collinearity Test for
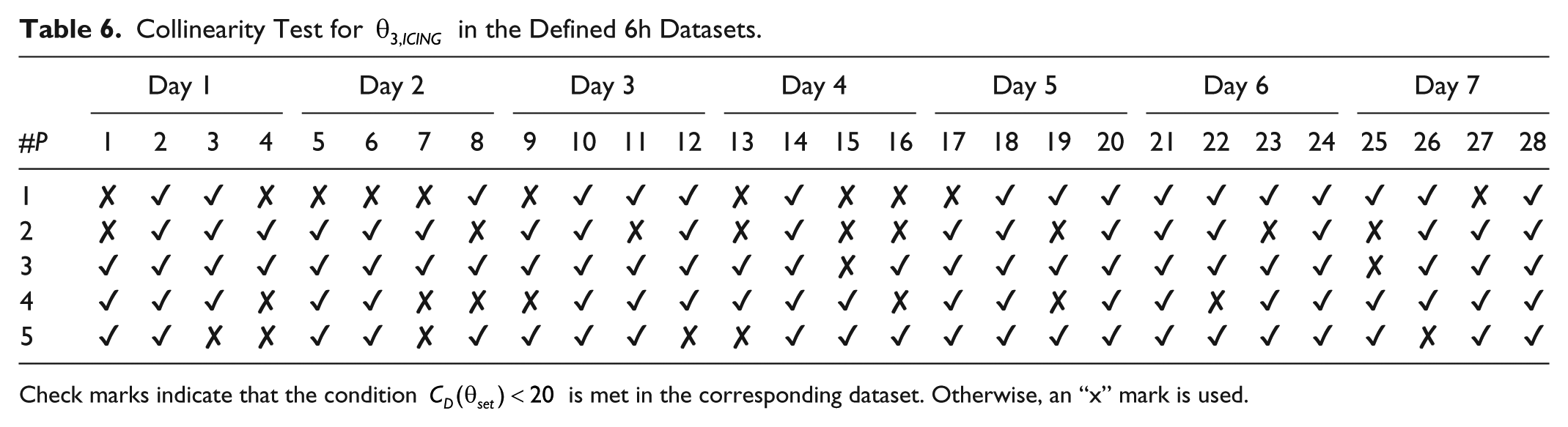
Check marks indicate that the condition
Collinearity Test for
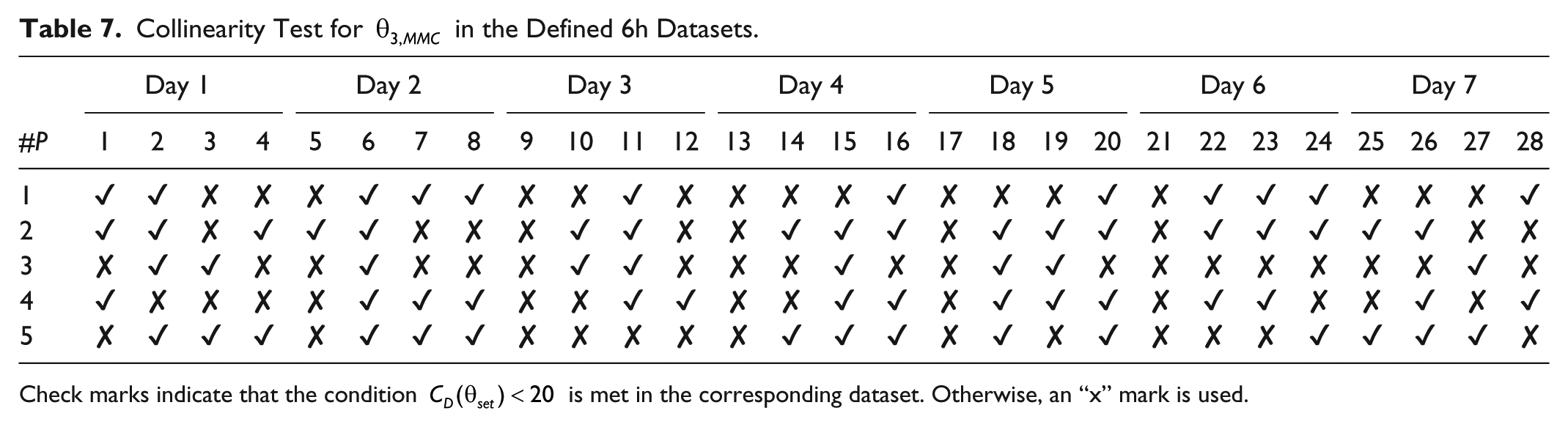
Check marks indicate that the condition
Model Identification
The three models are identified with the parameter sets defined above and with the suitable datasets for identification as presented in Tables 5-7. The variation intervals of the parameters to be identified are presented in Tables 1-3. Figure 7 shows the model identification for patient 1 using the three models. The parameter variability of the models after every 6h identification is presented in Figure 8. The RMS index is presented in Table 8 for all patients. Note that MMC model was not able to provide results for patient 4, possibly for limitations in the model structure.
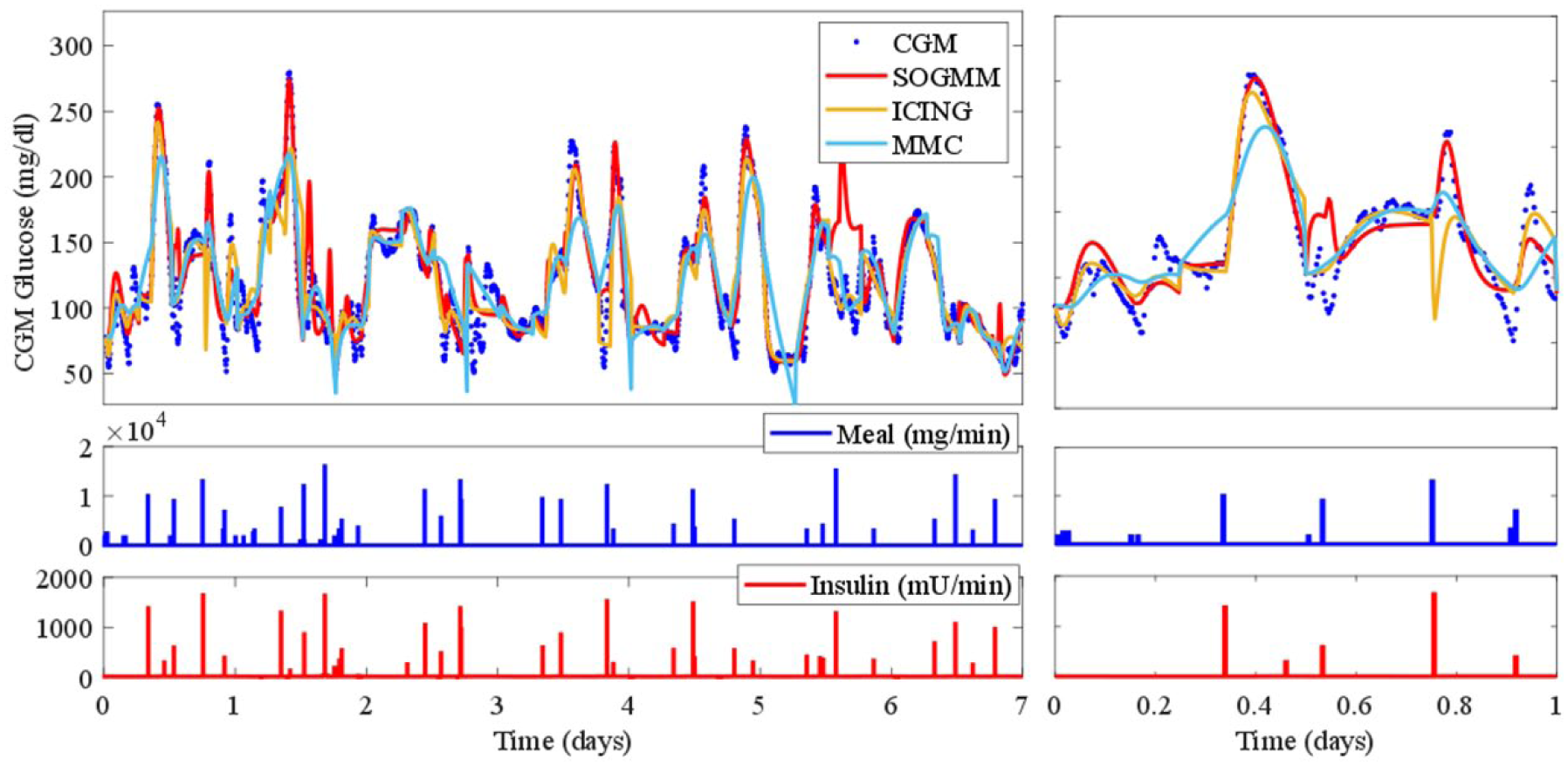
Model calibration of the three analyzed models for patient 1. The rightmost figure shows a zoom of the first day.
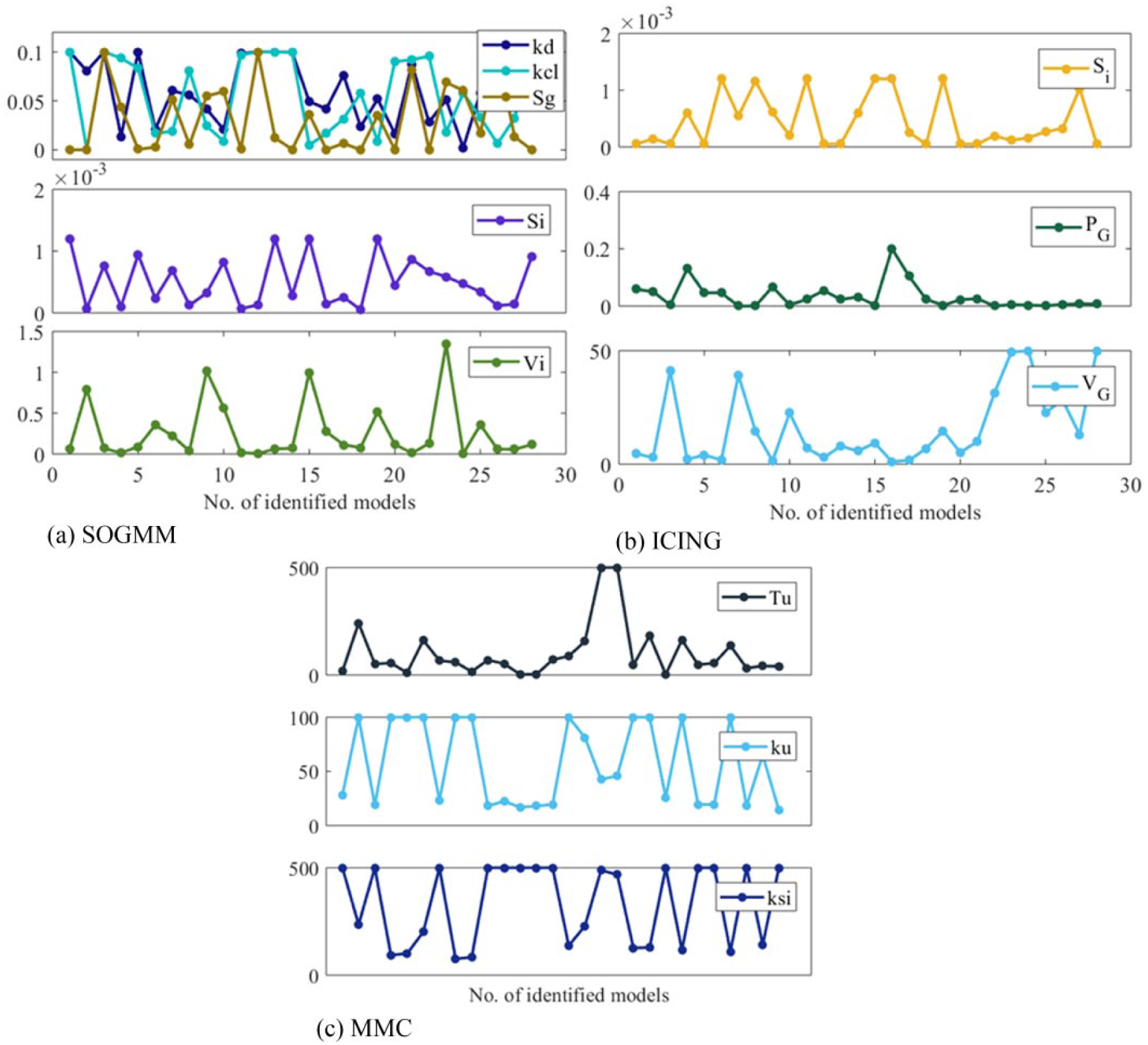
Parameter variation (after identification) in all the used data batches.
Model Performance Using the RMS (mg/dl) in All Patients (#).

Several runs were performed by comparing
Discussion
In this study, three commonly used control-oriented models for artificial pancreas systems are investigated in terms of their properties to be individualized (identified) to field collected data. While previous contributions gave a big role to the insulin sensitivity, likely due to its role in the evolution of mathematical models of glucose metabolism,44,45 the presented results indicate that insulin sensitivity is not the parameter impacting the model output the most in the three studied models.
While structural identifiability16,22-26 has been significantly more studied than practical identifiability24,31 in control-oriented models for artificial pancreas design, it appears that direct identification is typically performed disregarding the potential pitfalls from the misestimation of model parameters. However, as it has been widely shown in diverse contributions,20,35,41 both properties are necessary to guarantee the uniqueness of the identified parameters and hence the model usefulness.
In this contribution, we showed a straightforward identification/individualization methodology for control-oriented models in diabetes technology capable of reproducing outpatient data from patients with T1D. Our methodology uses existing procedures and tools such as the generating series approach, identifiability tableaus, global parameter ranking, and collinearity analysis to investigate possible structural or practical issues before performing parameter identification. When compared to direct identification of the whole parameter set, our approach gives a subset of identifiable parameters which in turn reduces the computational load from the solution of the identification problem while guaranteeing the uniqueness of the solution.
Results from the present study showed that the studied models are able to reproduce the experimental data in 6h intervals or less in spite of their different model structure. This may be explained by the structural uncertainty of minimal models when compared to maximal models which are able to reproduce experimental data for longer periods of time. 46 This fact and high intrapatient and interpatient variability makes online identification a desired feature for use of these models in dosing strategies.
As it was evidenced, structural identifiability analysis needs to be revisited once the global ranking of parameters is performed. Therefore, a good idea is to start with the global parameter ranking and propose a candidate parameter set for structural identifiability. If the structural identifiability test rejects a sensitive parameter then this parameter should be dropped (as with
Global parameter ranking reveals possible insensitivity of the observables to some parameters. Moreover, using the global ranking, we may define the parameter set with most influence on the system output. In our case, we obtained parameter sets summing the 97%, 99%, and 85% of total
The collinearity test shows possible linear dependence among candidate parameters as a whole for a given dataset instead of examining the correlation for every pair of parameters. In this way, ill-conditioned data (sometimes referred as weak data) need to be avoided or replaced if possible. As shown in Tables 5-7, not every dataset was conditioned for identification for the given sets of parameter candidates
While a good model fitting is shown in Figure 7 for the three models in almost all the scenarios, what is important to highlight is the uniqueness of the identified parameters (since similar performances may be obtained with the full parameter sets). However, we found that the optimization did not converge for MMC (patient 4) as the linear model might be found limited to represent such complex data.
From the three studied models, ICING is perhaps more prone to overfitting if all parameters are used for identification since it has more parameters (degrees of freedom) and almost the same number of equations if compared with SOGMM and MMC. Although MMC is found to be the simplest model, the lack of parameter interpretability hampers the definition of practical parameter ranges. Moreover, our analysis indicates larger variability over the parameters of this model, inferior accuracy, and high correlation.
Conclusion
Model individualization in diabetes technology has typically been carried directly, that is, given a parameter set determined in an arbitrary way, the parameters are identified from the optimization of a certain cost function. In this contribution, we presented a thorough and easy-to-follow identification procedure based on the structural and practical identifiability properties. In this sense, it was found that structural identifiability, global parameter rank, and correlation analysis of the parameters give a complete picture for parameter selection in terms of model individualization (patient-adjusted models). Identification results show acceptable fitting with the studied models with respect to real CGM and insulin pump data from patients with T1D in an outpatient setting while guaranteeing the uniqueness of the parameter selection. As far as we are aware, this is the first time that a thorough identifiability analysis is performed on control-oriented models for artificial pancreas systems.
Footnotes
Abbreviations
AP, artificial pancreas; CGM, continuous glucose monitor; CSII, continuous subcutaneous insulin infusion; FDA, US Food and Drug Administration; GS, generating series approach; ICING, intensive control insulin-nutrition-glucose model; ICU, intensive care unit; IVGTT, intravenous glucose tolerance test; LHS, Latin hypercube sampling; MDI, multiple daily injections; MGTT, meal glucose tolerance test; MMC, minimal model control-oriented; MPC, model predictive control; MSE, mean square error; ODE, ordinary differential equation; PADOVA, University of Padova; RMS, root mean square; SIVIA, set inversion via interval analysis; SOGMM, subcutaneous oral glucose minimal model; T1D, type 1 diabetes; UVa, University of Virginia.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: JGT and CZB have nothing to declare. MDB consults for Roche Diagnostics, Sanofi-Aventis, and Ascensia Diabetes Care; receives research support from Dexcom, Senseonics, Tandem, Roche Diagnostics, Sanofi-Aventis, and Ascensia Diabetes Care; and holds equity in TypeZero Technologies.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.