
Abstract
Diabetes is one of the top priorities in medical science and health care management, and an abundance of data and information is available on these patients. Whether data stem from statistical models or complex pattern recognition models, they may be fused into predictive models that combine patient information and prognostic outcome results. Such knowledge could be used in clinical decision support, disease surveillance, and public health management to improve patient care. Our aim was to review the literature and give an introduction to predictive models in screening for and the management of prevalent short- and long-term complications in diabetes. Predictive models have been developed for management of diabetes and its complications, and the number of publications on such models has been growing over the past decade. Often multiple logistic or a similar linear regression is used for prediction model development, possibly owing to its transparent functionality. Ultimately, for prediction models to prove useful, they must demonstrate impact, namely, their use must generate better patient outcomes. Although extensive effort has been put in to building these predictive models, there is a remarkable scarcity of impact studies.
With the arrival of electronic medical records, more information on physician-patient interactions is being captured and stored electronically. This era of “big health care data” provides rich opportunities for pooling data and for exploring aspects of health care management and for predicting therapeutic outcomes that would otherwise defy analysis. Combining numerous information from several health care providers about the patient would increase the level of information significantly.
Predictive models using various methods—from statistics to more complex pattern recognition—have the potential to fuse different kinds of patient information and output prognostic results in a clinical setting. 1 This could be used for clinical decision support, disease surveillance, and population health management to improve patient care. 2
Diabetes is one of the top priorities in medical science and health care management; and an abundance of data and information on these patients is therefore available. Diabetes is a very serious disease that can lead to a large number of very serious long-term complications such as blindness, amputation and heart disease if not treated properly in time.3-5 Also, early stages of type 2 diabetes are asymptomatic, so patients may go undiagnosed for years. 6 Treatment, especially with insulin, is not without adverse effects such as risk of hypoglycemia and weight gain.7,8 Predictive models could potentially inform the management of these diabetes-related problems. Fortunately, the past few decades have seen rapidly growing awareness of the possibilities in the field of using available information for predicting diabetes outcomes. The number of published articles has risen every year, from 5 publications in 1990 to about 300 in 2015, 9 as illustrated in Figure 1.
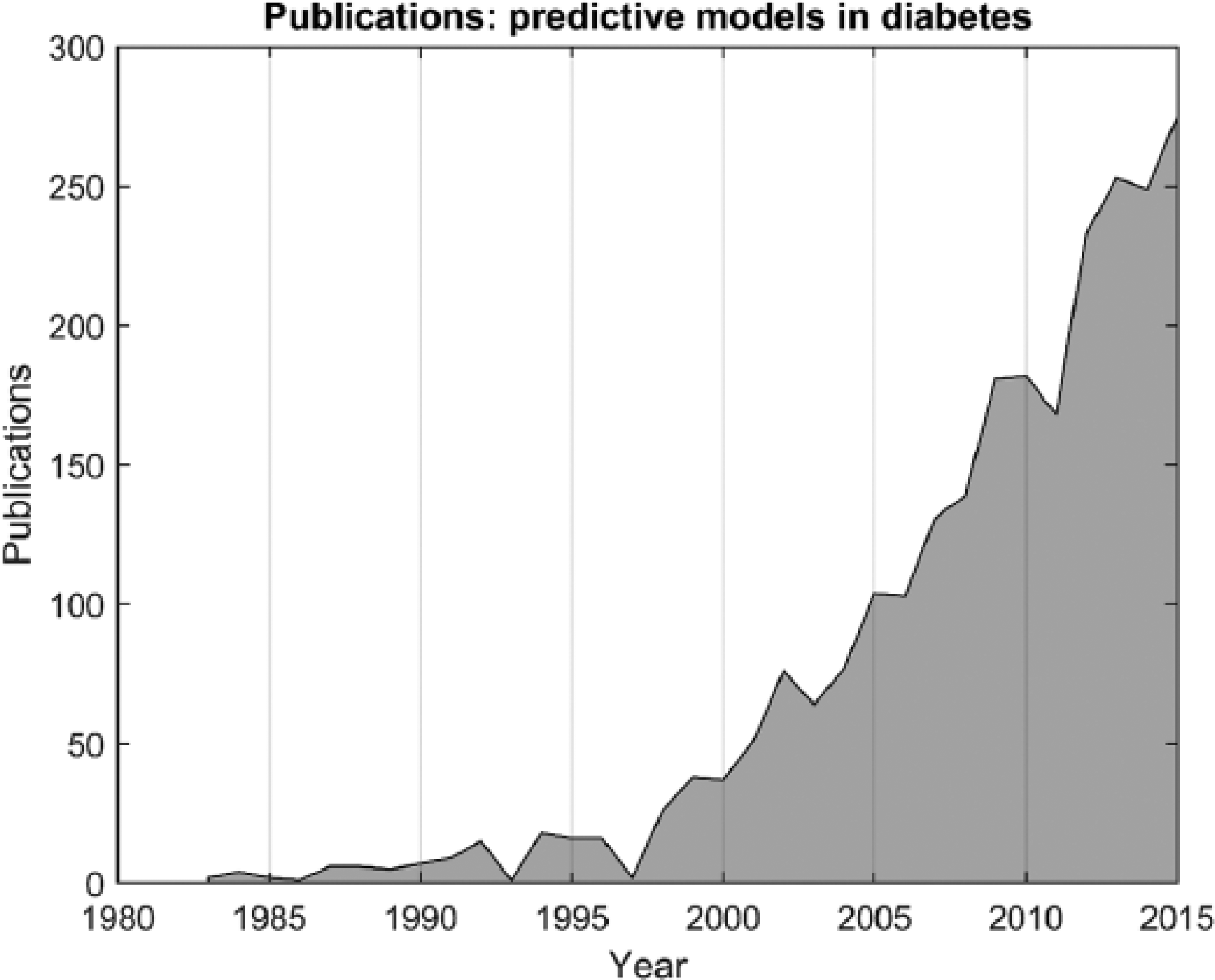
Number of publications index by PubMed with keywords “predictive AND model AND diabetes.” The 2015 count is extrapolated based on the number from May 27, 2015.
The aim of the present article is to narratively review the literature on predictive models in screening for and the management of prevalent short- and long-term complications in diabetes. This could help facilitate the importance of this scientific area and focus future research on what have been done and what should be the next step.
Predictive Models
Predictive models often include multiple predictors (covariates) to estimate the probability or risk of a certain outcome or to classify that a certain outcome is present/absent (diagnostic prediction model) or will happen within a specific timeframe (prognostic prediction model) in an individual. 10
Almost any statistical regression model can be used as a predictive model. Generally, there are 2 kinds of models: parametric and nonparametric. Parametric models make assumptions regarding the underlying data distribution, whereas nonparametric models (and semiparametric models) make fewer or no assumptions about the underlying distribution. The most common approach is to use a regression model for prediction. This often also involves the use of classic statistical methods to construct the mode based on level of statistical significance. 11 Other, less common model approaches resort to complex mathematical analytics of the data. These models often utilize a broad range of methods involving machine learning and pattern recognition, among others,12,13 and they are often, but not always, limited to classification tree, neural network, k-nearest neighbor. 13
The model is often trained on large number of individuals of the cohort and validated on a faction of the cohort data or on data from another study. Data could typically consist of single measurements or a time series. In either case, some kind of signal processing or mathematical transformation is needed to extract relevant predictors.
Whether simple parametric methods like linear regression or more sophisticated methods are deployed, c-statistics (receiver operating characteristic [ROC] curve) and sensitivity/specificity are often used to evaluate the performance of the prediction model. Furthermore, each approach has pros and cons; however, an in-depth discussion of these aspects falls outside the scope of the present review.
Prediction Models for Screening
In the United States alone, an estimated 7 million people have undiagnosed diabetes; 14 and when they are finally diagnosed, up to 30% show clinical manifestations of complications of diabetes. Early diagnosis of patients with type 2 diabetes is thus very important, not least because intensive diabetes management can considerably reduce long-term complications.15-17
Screening entire populations is not cost-effective, and screening should therefore be restricted to groups that are at high risk for diabetes.18,19 Models predicting who are at risk for diabetes (prevalence)20-29 or for developing diabetes in the near future (incidence)24,30-42 have therefore attracted much interest in the medical literature. Most models are variants of multivariable linear regression models; and most use anthropometric, anamnestic, and demographic information as predictors. The most common predictors included in these models are body mass index (BMI), age, and family history of diabetes and hypertension. 11 However, although the number of prediction models developed is large, only very few end up being used in clinical practice. The reasons for this are numerous and mainly involve methodological shortcomings and a generally insufficient level of reporting in the studies in which the screening prediction models were developed. More specifically, the problematic issues typically encompass which predictors were included, how continuous variables were dichotomized, how missing values were dealt with, how adequate statistical measures were reported, or which procedures were used for validating the results. 11 Furthermore, poor design and reporting could entail skepticism regarding the reliability and the clinical usefulness of a model. Debatably, regardless of how the model is developed, all that in the end matters is that the model works in a clinical setting. A typical problem in this respect is that when a model is externally validated in another sample, its accuracy often declines. This is, for example, the case with the model by Bang and Edwards, 21 where the sensitivity/specificity dropped from 79/67% to 72/62% in the external validation. Moreover, temporal validation (assessed the performance of a predictive model using data collected from the same population after the model was developed) also showed a drop (63/72%) in this model. 27 In addition, some models like the FINDRISC (link) and Framingham Diabetes risk scores (link) have been validated in several cohorts and have been developed with a strong methodological approach.43,44
Prediction Models for Long-Term Complications
Retinopathy
Diabetic retinopathy is a primary cause of blindness worldwide, 45 and this serious complication of diabetes is already present at the time of clinical diagnosis of type 2 diabetes in some patients. 46 In the Wisconsin Epidemiologic Study of Diabetic Retinopathy, 3.6% of patients with type 1 diabetes and 1.6% of patients with type 2 diabetes were blind. 47 It is recommended that patients with type 2 diabetes should have an initial comprehensive eye examination by an ophthalmologist or optometrist shortly after being diagnosed with diabetes. 3 Subsequently, the patient should be included in a screening program. 48 The optimal interval for screening of this group of patients with diabetes is not certain; yet, in Denmark, patients are typically seen once a year depending on the progression of the disease. 49 There is a long latent period before visual loss, and progression of this disease is to a large extent preventable and treatable.
Several studies have focused on individualizing the screening interval based on risk factors for retinopathy progression.50-52 Looker et al 52 used hidden Markov models to calculate the probabilities of extending the interval for people with no visible retinopathy. The results showed that extending the interval involved only a small risk. Mehlsen et al 53 constructed a multiple logistic regression model to adjust the screening interval in low-risk patients. The model on average prolonged the screening interval 2.9 times for type 1 diabetes patients and 1.2 times for type 2 diabetes patients. Predictors included in the model were HbA1c, number of retinal hemorrhages and exudates, longer diabetes duration and blood pressure. Cichosz et al have published a model usable for selecting a high-risk group among newly diagnosed patients with diabetes. This model was suitable for remote areas of the world and for developing countries with limited resources. 54 Convincing evidence for using predictive models for treatment and prevention of retinopathy are yet to be seen. Retinopathy is a feared complication among patients and, in general, the costs of offering frequent screening to all patients are small.
Neuropathy
Diabetic peripheral neuropathy is frequent, and 50% of people with type 2 diabetes have neuropathy and therefore feet at risk of developing diabetic foot ulcer. 55 Diabetic neuropathy is known by the American Diabetes Association as “the presence of symptoms and/or signs of peripheral nerve dysfunction in people with diabetes after the exclusion of other causes.” Food ulcer is one of the major complications in patients with diabetes, with a 15% lifetime risk of amputation. The risk of having a lower extremity amputation is up to 40 times higher among patients with diabetic than among the background population without diabetes. 56
It has been reported that with early detection and proper multidisciplinary treatment, the amputation rate can be reduced by up to 60-85%.55,57 Many potential risk factors have been investigated over the years. 58 However, much less attention has been devoted to developing and validating multivariate prediction models.59-62 In 2006, Boyko et al 59 followed 1285 diabetic veterans and published a prediction model based on 7 commonly available clinical variables for development of foot ulcers. Later Monteiro-Soares and Dinis-Ribeiro 62 validated and updated Boyko et al’s model in different settings. Monteiro-Soares and Dinis-Ribeiro included information about patients’ footwear and increased the prediction capabilities from an ROC area under the curve (AUC) of 0.83 to 0.88. Yet, no fixed system has eventually been adopted, and the implementation of validation models in clinical practice remains limited. 60 The potential of foot ulcer prediction models is large, but more studies are needed.
Nephropathy
Diabetic nephropathy is the leading cause of renal failure in the United States. 63 The kidneys begin to leak, and albumin passes into the urine. This can be preceded by lower degrees of proteinuria, or micro albuminuria and can proceed to renal failure in the worst case. 63 Identification of people at high risk of rapid decline in renal function is important, and evidence-based interventions have been shown to prevent or slow the development toward advanced stages of nephropathy. 64
Most models developed to predict the progression of kidney disease have been tested in a general context, but often with diabetes as an important factor.65-70 Others have been targeting people with diabetes.71-74 The factors most commonly used in these models are gender, age, BMI, diabetes status, blood pressure, serum creatinine, protein in the urine, and serum albumin/total protein. Often the Cox model is used to construct the predictor model—but decision tree and logistic regression have also been used for modeling. C-statistics for these models are generally high and range from 0.56 to 0.94. In a systematic review, Echouffo-Tcheugui and Kengne 64 concluded that the use of risk models still needs to be better calibrated and validated in external populations. 75 Furthermore, the clinical impact of using such models also needs to be evaluated.
Heart Disease
Diabetes is a well-known risk factor for coronary heart disease. Diabetes adds an about 2-fold risk for a wide range of vascular diseases, independently of other conventional risk factors. 76
Much research has been conducted in the field of developing predictive models or risk scores for at-risk individuals from the general population. 77 One of the best models is the Framingham score (link), 78 which has been widely accepted and includes diabetes as a predictor. Several scores have been developed specifically to predict heart disease in patients with diabetes.78-90 The AUC of these models ranges from 0.59 to 0.80. Typically, a Cox regression model or a logistic regression is used for prediction. The most frequently included predictors are sex, age, systolic blood pressure, cholesterol, and smoking. Despite much effort within this field, most models still need to be proven valuable in daily care. According to the International Diabetes Federation, these models fall short of adequacy or are limited because they have not been proven useful in populations older than 65 years and because they have been applied in people in whom treatment to prevent heart disease had already been initiated. 48 Future research should focus on the impact of using coronary heart disease prediction models in the daily care of diabetes patients. 77
Prediction Models for Short-Term Complications
Hypoglycemia
People with type 1 diabetes often experience episodes of hypoglycemia because they need to reduce the level of blood sugar by using insulin. 8 Also patients with type 2 diabetes may experience episodes of hypoglycemia because of the increasing use of insulin in this group. The fear induced by hypoglycemia is pronounced, and the clinical results of this condition are serious. The literature suggests that the incidence of hypoglycemia requiring emergency assistance reaches 7.1% per year among patients with diabetes 91 and that as many as 6% of all deaths in patients with type 1 diabetes are due to hypoglycemia.92-94
The arrival of the continuous glucose monitoring (CGM) system made it possible to frequently measure interstitial blood glucose, and many scientists have since investigated the opportunities offered by this new technology. However, using CGM for prediction of hypoglycemia involves accepting a certain proportion of false positive alarms.95-98 Hypoglycemia affects the entire autonomic nervous system, including the heart, the brain, and perspiration.99,100 This has led to development of prediction systems that include information from EEG, skin impedance measurements, and electrocardiograms.96,101-103 Some have attempted to use the glucose content in perspiration to predict blood glucose levels.104,105 Moreover, the use of signal processing to make the CGM signal more accurate has also been investigated. 106 Many methodologies have been explored in pursuit of finding the holy grail in reducing hypoglycemia using a predictive alarm system. However, the differences in styles of reporting and uses of data essentially make these systems incomparable.
One of the main challenges in predicting or detecting an early onset of a hypoglycemic event is the lack of high-quality data for validating predictive models—these studies are often expensive and complex to conduct. It is known that CGM has a physiological lag time and, moreover, less precision in the lower glucose concentration range.107-109 Knowing the underlying blood glucose level is therefore necessary. One way to obtain such knowledge could be by establishing access to a large, open database, as seen in other fields such as the MIT-BIH Arrhythmia Database. 110 This would make validation and comparison between the proposed models much more transparent and easy.
Insulin-Associated Weight Gain
In most patients with type 2 diabetes, it will eventually be necessary to begin insulin treatment to achieve the therapeutic goal of HbA1c < 7 mmol/l (126 mg/dl). 7 The problem of weight gain induced by insulin has long been documented as an issue in diabetes treatment.111,112 In the Diabetes Control and Complications Trial (DCCT), the average weight gain of patients with type 1 diabetes undergoing intensive treatment was 5.1 kg compared with 2.4 kg in standard treatment arm, 113 and similar results are seen for type 2 diabetes. 114 This increase in weight can negatively affect the cardiovascular risk profile and increase morbidity and mortality when intensive treatment is postponed due to the patient’s fear of gaining weight. 111 Prediction of insulin-associated weight gain has attracted only little attention in the literature115-117 compared with other complication of diabetes. It is known that insulin dosage is a strong predictor of weight gain. 118 Jansen et al 115 followed 65 patients with diabetes during insulin treatment, and they proposed a regression model for “prediction” of weight gain. However, the model is not suitable for prospective usage as it requires data on 0-12 months of insulin dosage and any changes in insulin dosage. In addition, common performance measures are not reported in this study. Balkau et al 116 reported data on factors associated with insulin-associated weight gain in 2179 patients with type 2 diabetes. They also proposed a model that could explain part of the weight gain, but their model was not operational for prospective usage in the clinic. Factors included in this model were HbA1c, BMI at baseline, and information about insulin. Cichosz et al 117 developed a model to predict if patients in insulin treatment are excessive weight gainers 1.5 year from baseline. This model had a ROC AUC of 0.80. Baseline information was incorporated into a multilogistic regression model combined with weight gain the first 3 months. In future, more studies within this field are needed, and the model by Cichosz et al may be used in clinical practice to identify people a risk of large weight gains, but a validation study is desirable.
Discussion
Predictive models drawing on and analyzing “big data” are being used for the handling of many daily-task applications. Much sparser use has been made of predictive models in clinical practice, however.48,119 There are many reasons why this is so. First, a prediction model must provide valid and accurate estimates, and these estimates should be able to inform management and clinical decision-making and subsequently improve outcome and cost-effectiveness of care. A study have indicated that only ~50% of studies are externally validated and ~25% are internally validated. 11 Second, a prediction model must be accepted and understood by clinicians for the model to be adopted on a wider scale. These requirements often imply that the models become oversimplified, which could weaken their accuracy. This trend of focusing on simplification rather than performance have been observed in many studies. Convincing documentation and evidence for all relevant aspects must be provided, which is not always possible in a pragmatic context. Prediction models are therefore often based simply on multiple logistics or similar linear regression. The advantage of this approach lies in the transparency of its functionality; however, this advantage comes at the cost of not taking into account that predictors are rarely independent. In future work, it would be interesting to further explore the potential of other methods taking predictor dependencies into account.
Ultimately, prediction models have to prove useful in terms of impact, that is, better patient outcomes.10,120 Such studies are time-consuming and expensive, and these impediments will have to be fought to reap the full benefit of the “big clinical data” available.
Conclusion
Much effort have been put into developing predictive models for use in the management of diabetes and its complications. However, in general, most of these models have not been implemented and the clinical impact has not been investigated. Although evidence from implementation is lacking, it is argued that predictive models do have the potential to transform the way health care providers use sophisticated technologies; and much insight may be gained and more informed decisions made by drawing on the large amount of electronically stored clinical data.
Footnotes
Abbreviations
AUC, area under the curve; BMI, body mass index; CGM, continuous glucose monitoring; DCCT, Diabetes Control and Complications Trial; EEG, electroencephalography; hemoglobin A1c (HbA1c); ROC, receiver operating characteristic.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.