
Abstract
Objective:
To evaluate the performance of three large language models in answering questions regarding pediatric developmental dysplasia of the hip.
Methods:
We formulated 18 open-ended clinical questions in both Chinese and English and established a gold standard set of answers to benchmark the responses of the large language models. These questions were presented to ChatGPT-4o, Gemini, and Claude 3.5 Sonnet. The responses were evaluated by two independent reviewers using a 5-point scale. The average score, rounded to the nearest whole number, was taken as the final score. A final score of 4 or 5 indicated an accurate response, whereas a final score of 1, 2, or 3 indicated an inaccurate response.
Results:
The raters demonstrated a high level of agreement in scoring the answers, with weighted Kappa coefficients of 0.865 for Chinese responses (p < 0.001) and 0.875 for English responses (p < 0.001). No significant differences were observed among the three large language models in terms of accuracy when answering questions, with rates of 83.3%, 77.8%, and 77.8% for Claude 3.5 Sonnet, ChatGPT-4o, and Gemini in the Chinese responses (p = 1), and 83.3%, 83.3%, and 72.2% for ChatGPT-4o, Claude 3.5 Sonnet, and Gemini in the English responses (p = 0.761). In addition, there was no significant difference in the performance of the same large language model between the Chinese and English settings.
Conclusions:
Large language models demonstrate high accuracy in delivering information on dysplasia of the hip, maintaining consistent performance across both Chinese and English, which suggests their potential utility as medical support tools.
Level of evidence:
Level II.
Keywords
Introduction
Large language models (LLMs) represent a major technological advancement in the fields of artificial intelligence and natural language processing. These sophisticated models employ advanced deep-learning algorithms and complex architectural frameworks to understand and process textual data. Trained on extensive and diverse datasets, LLMs develop the capability to comprehend and generate human-like language with impressive precision and fluency.1,2 They are considered as the models closest to achieving true mastery of human language. 3
Since the launch of OpenAI’s ChatGPT, LLMs have attracted considerable attention in the medical field. These models are being explored for their potential to assist in critical areas such as medical decision-making, where they can provide rapid and accurate insights. 4 In the realm of medical education, LLMs can function as interactive learning tools, offering personalized feedback and support to students. 5 Their utility extends to research, where they can aid in navigating vast medical literature, streamline research processes, and write impactful articles. 6 In documentation, LLMs can generate comprehensive patient summaries and articulate follow-up recommendations, producing discharge letters with both high quality and efficiency. 7
Another promising application of LLMs in medicine is intelligent question-answering. Research has demonstrated their efficacy in providing accurate responses to complex medical queries, as evidenced by their performance on questions related to cardiovascular disease prevention, 8 bariatric surgery, 9 and evidence-based dentistry. 10 Despite these successes, there remains a notable gap in exploring their effectiveness within the specialized domain of pediatric orthopedics.
Developmental dysplasia of the hip (DDH) is a prevalent pediatric orthopedic condition characterized by abnormalities in the morphology, position, and function of the femoral head and acetabulum.11,12 If not addressed early, DDH can lead to significant long-term mobility issues. It is a primary cause of total hip arthroplasty, 13 with studies indicating that 26% of patients under 40 undergoing this procedure have underlying DDH. 14 There is a clear need for accurate and reliable information to guide clinical decisions. However, the performance of LLMs in the context of DDH has not yet been evaluated. Furthermore, previous research has predominantly been conducted in English-language settings, leaving the performance in other languages largely unexamined.
This study aimed to compare the performance of three LLMs (ChatGPT-4o, Gemini, Claude 3.5 Sonnet) in answering questions related to pediatric DDH in both Chinese and English-language contexts. Our hypothesis was that ChatGPT-4o has a higher accuracy rate in answering questions than other models and that the accuracy rate of English answers is higher than that of Chinese answers.
Methods
Formulating questions and establishing gold standard answers
To evaluate the performance of LLMs in addressing pediatric DDH-related questions, we developed 18 open-ended clinical questions in both Chinese and English. These questions were formulated based on relevant clinical guidelines, expert consensus, and high-quality review articles indexed in PubMed, encompassing various aspects of DDH, including etiology, risk factors, pathological changes, clinical manifestations, diagnostic methods, differential diagnosis, classification, and treatment. To provide a benchmark for evaluating the responses generated by the LLMs, we established a gold standard set of answers. The answers to each question were strictly derived from the aforementioned clinical guidelines, expert consensus, and high-quality review articles, serving as the reference point for assessing the accuracy and quality of the LLMs’ responses.
Querying the models
From August 15 to 16, 2024, one author posed 18 questions to the three LLMs in Chinese. From August 17 to 18, 2024, the same author posed the same questions to the models in English. The models tested included OpenAI’s ChatGPT-4o, Google’s Gemini, and Anthropic’s Claude 3.5 Sonnet. Each question was posed in a new chat window without additional explanations or prompts, ensuring that the models were not influenced by previous interactions or any other information. The responses provided by the LLMs were recorded in two separate Excel spreadsheets: one for Chinese answers and another for English answers. Each model’s responses were assigned to a distinct column to facilitate scoring by reviewers. There were two reviewers who held senior titles in pediatric orthopedics and had over 13 years of experience with DDH.
Scoring the LLMs
Duplicate spreadsheets were created, with the LLM names removed to ensure the anonymity of the models for the reviewers. Reviewers, who had previously familiarized themselves with the gold standard answers, scored the responses on a scale of 1 to 5, where 1 indicated an inappropriate answer that was severely incorrect, harmful, or clearly contradictory to the gold standard. A score of 2 was assigned for answers that were mostly inappropriate due to significant inaccuracies, omissions of key details, or inconsistencies with the gold standard. A score of 3 indicated answers that were partially appropriate, providing reasonably accurate information but necessitating improvement in completeness, depth, or consistency with the gold standard. A score of 4 was assigned to answers that were mostly appropriate, essentially accurate, covered the most critical information, and aligned with the gold standard, albeit with minor omissions or the need for clarifications. A score of 5 indicated answers that were fully appropriate, comprehensive, aligned with the gold standard, and addressed all key aspects of the clinical question 9 . The average score from the two reviewers was rounded to the nearest whole number to determine the final score for each answer, with scores of 4 and 5 considered accurate, and scores of 1, 2, or 3 deemed inaccurate.
Statistical analysis
The consistency of the scores assigned by the two reviewers was assessed using weighted Kappa testing. For each model’s scores from each reviewer, the distribution was described using the lowest, highest, and median scores. The accuracy rate of each LLM in answering questions was calculated and expressed as a percentage, with categorical data comparisons performed using Fisher’s exact test. All statistical analyses were conducted with two-tailed tests, using a significance threshold of p < 0.05. Statistical analyses were performed using SPSS 27.0 (IBM Corporation, Armonk, NY, USA).
Results
The weighted Kappa coefficient for the scores given by the two reviewers for the Chinese answers was 0.865 (p < 0.001), and for the English version, it was 0.875 (p < 0.001), indicating a high level of inter-rater reliability in both cases. Queried questions are shown in Table 1. Table 2 presents the distribution of scores for the three LLMs in responding to both Chinese and English questions. Irrespective of language, all models received the same minimum score of 1 and the same maximum score of 5. In the Chinese responses, Claude 3.5 Sonnet achieved the highest median score of 5, whereas ChatGPT-4o and Gemini shared the same median score of 4. In the English responses, both ChatGPT-4o and Claude 3.5 Sonnet achieved the same median score of 5, while Gemini had a median score of 4.
List of queried English and Chinese questions.
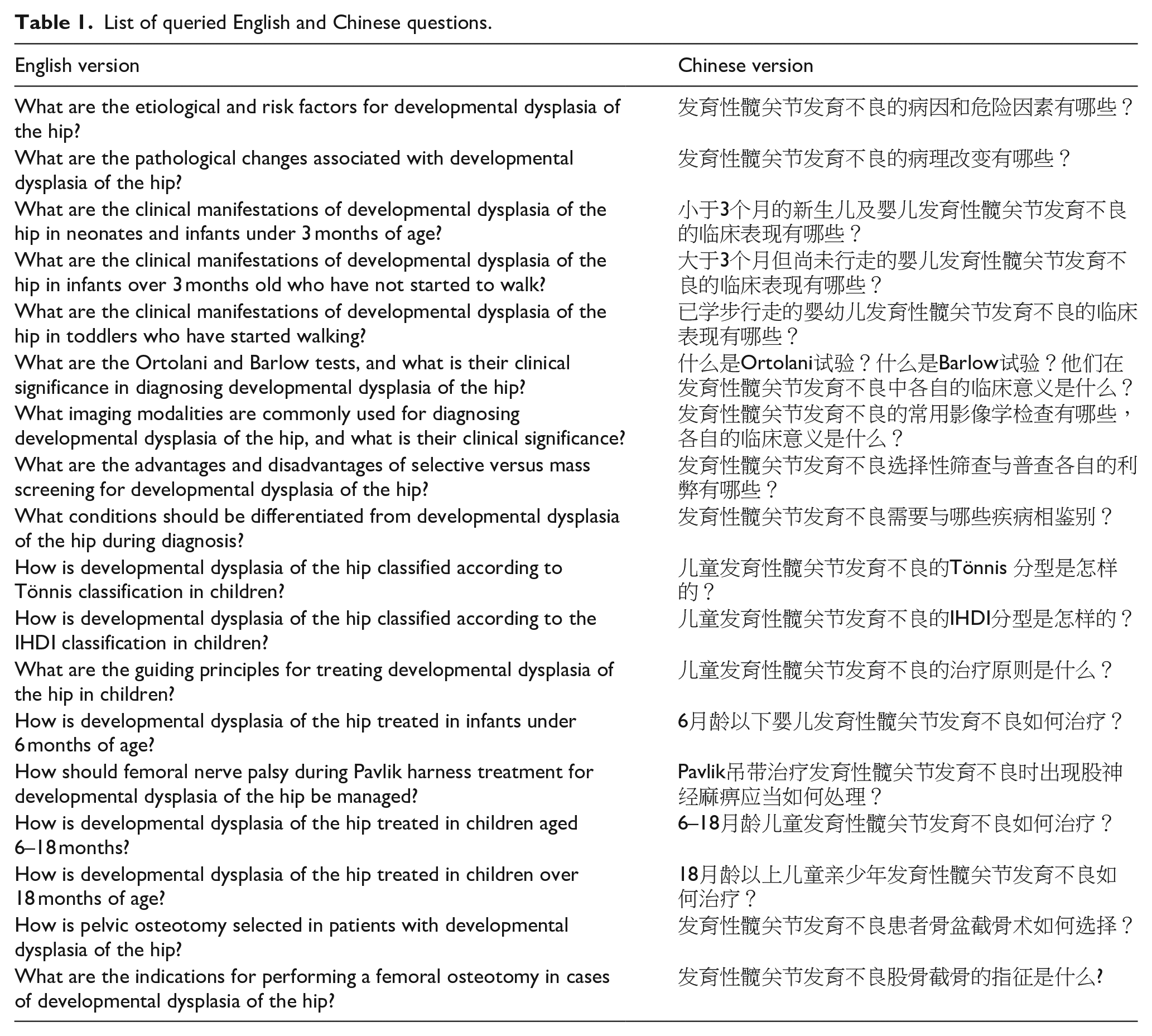
Statistical description of the scores given by the two evaluators for the answers provided by the three LLMs.
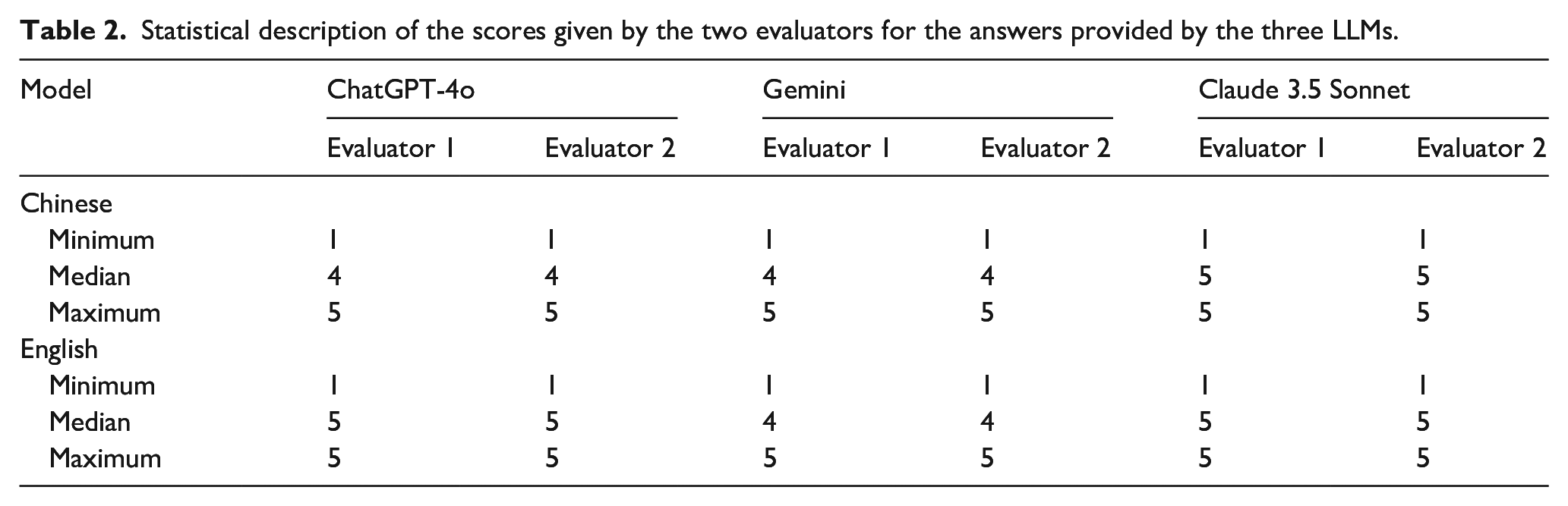
In the Chinese responses, Claude 3.5 Sonnet achieved the highest accuracy rate of 83.3%, whereas ChatGPT-4o and Gemini both had accuracy rates of 77.8%, with no statistically significant differences among the groups (p = 1). In the English responses, both ChatGPT-4o and Claude 3.5 Sonnet achieved accuracy rates of 83.3%, while Gemini had an accuracy rate of 72.2%, with no statistically significant differences among the groups (p = 0.761). The accuracy rate of ChatGPT-4 in English was higher than in Chinese, and Gemini’s accuracy rate in Chinese was higher than in English; however, these differences were not statistically significant (p = 1). Regardless of language, Claude 3.5 Sonnet maintained an accuracy rate of 83.3% (Table 3).
Number and proportion of accurate answers from the three LLMs.

Discussion
Following extensive training in medical literature, LLMs have demonstrated the ability to understand and generate medically relevant information. This is particularly evident with OpenAI’s ChatGPT, which has been a subject of comparison studies with other LLMs in the context of medical intelligent question-answering. ChatGPT-4 outperformed Bard in answering questions related to hematopoietic stem cell transplantation. 15 ChatGPT-4 outperformed Bing Chat and Bard in answering questions related to evidence-based dentistry and bariatric surgery.9,10 In pediatric orthopedics, research regarding the application of LLMs remains limited. A recent study evaluated ChatGPT 3.5’s performance in responding to questions about pediatric in-toeing, finding that 46% of the responses were rated as excellent and 44% as satisfactory. 16
Our study provides the first comparative evaluation of ChatGPT-4o, an advanced version of ChatGPT-4 model, 17 alongside Gemini and Claude 3.5 Sonnet, in terms of their performance in answering questions related to pediatric DDH. This represents our preliminary exploration into applying LLMs to pediatric orthopedics, with the potential to spark interest and stimulate discussions among the pediatric orthopedic community. It may also encourage more extensive applications and in-depth research of LLMs within the field of pediatric orthopedics in the future.
The questions used to assess the models’ performance, as well as the gold standard answers, were developed based on guidelines, expert consensus, and high-quality review articles, ensuring clinical relevance and alignment with current best clinical practices. The establishment of a gold standard was crucial for producing reliable and valid results, providing an objective measure of the models’ performance. It ensured that the evaluation was grounded in established medical knowledge and practices, rather than being influenced by subjective interpretations or individual biases.
The results of our study demonstrated that LLMs exhibited a high accuracy rate in answering questions in this specific field of DDH, indicating their potential utility as auxiliary tools for healthcare professionals. In contrast to findings from other domains, this study found that the performance of other LLMs was comparable to that of ChatGPT-4o, with all models achieving high accuracy rates. This outcome may be due to the intense competition within the LLM domain, prompting continuous optimization and enhancements of various models, and to the similar quality of the training data, which is a critical factor affecting model performance.
In the domain of natural language processing, the availability and richness of language resources significantly affect model performance. English, classified as a high-resource language, is often contrasted with other languages that are considered low resource. 18 A study comparing ChatGPT’s responses to questions regarding total hip arthroplasty reported a satisfaction rate of 90% for English responses, whereas only 10% for responses in Urdu. 19 In this study, we not only compared the performance of different LLMs in Chinese question-answering but also evaluated the same models in both Chinese and English contexts. The results indicated that the three tested LLMs exhibited comparable performance in Chinese question-answering, and each model showed similar performance across both English and Chinese contexts, with high accuracy rates.
The Chinese answers were not simply translations of the English answers. For specific questions, the Chinese answers were completely different from the English ones. For example, regarding the Tönnis classification of DDH, the English answer provided by Claude 3.5 sonnet was fully appropriate, hence both evaluators awarded 5 points. However, the Chinese answer provided by Claude 3.5 sonnet was inappropriate; instead of connecting the superior margins of the bilateral acetabulum, it connects the centers of the bilateral acetabular Y-shaped cartilage, resulting in both evaluators only awarding 1 point. Besides, even when the scores for the Chinese and English answers were the same, their logic, order, details, and reasons for deducting points also differed. For instance, in the differential diagnosis of DDH, both evaluators gave 4 points to Gemini’s answers in both languages. The Chinese answer did not differentiate from spastic hip dislocation, while the English answer did not differentiate from pathological hip dislocation.
To avoid simple translations and learning during the questions and answering process, we took some control measures in advance. First, Chinese and English questions were asked at different times. The Chinese questions were asked between August 15th and 16th, 2024, and the English questions were asked between August 17th and 18th, 2024. Second, a new dialogue window was created for each question. Although the accuracy of the Chinese and English answers from the same model was similar, we found the Chinese answers were not a simple translation of the English answers. This indicates that Chinese resources are already quite rich and reliable, and models trained with Chinese resources can achieve performance equivalent to those trained with English resources. These findings suggest that these LLMs have the potential to serve as valuable auxiliary tools in medical consultations within Chinese-speaking regions, offering informational support to healthcare professionals in China.
Prior research has emphasized the inherent risks of employing LLMs in medical consultations, particularly the risk of hallucinations, where models might produce responses that conflict with accepted medical knowledge, which could mislead or harm patients.9,20 In this study, while the models largely provided accurate information, there were cases where they offered incorrect responses to certain queries, including DDH grading. Accurate DDH grading is crucial for guiding clinical treatment decisions; inaccurate grading could lead to misguided treatment plans, thereby negatively affecting patient outcomes. Consequently, the use of LLMs in medical intelligent question-answering systems must be approached with caution, viewing them as adjuncts rather than replacements for professional medical decision-making. All responses generated by LLMs must be subject to rigorous review and validation by qualified medical professionals. Furthermore, to enhance LLM accuracy in the medical domain, future research should concentrate on refining algorithms, improving the quality of training datasets, and adopting more nuanced fine-tuning strategies.21,22
Our study has several limitations, which include the following: The sample size of questions was limited to 18, potentially not providing a comprehensive reflection of the LLMs’ performance. Besides, only two reviewers might affect the objectivity of our quality assessment of the answers. Furthermore, the study captures the performance of LLMs at a single point in time. Considering the rapid pace of technological advancements, the performance of LLMs is likely to evolve, necessitating continuous reassessment to maintain accuracy.
This study provides a preliminary assessment of the potential applications of LLMs within the DDH domain. Despite its limitations, the study demonstrated that LLMs have a high accuracy rate in delivering medical information, and their performance remained consistent across different languages, indicating their potential to serve as valuable adjuncts in the medical field.
Supplemental Material
sj-pdf-1-cho-10.1177_18632521251331772 – Supplemental material for Preliminary assessment of large language models’ performance in answering questions on developmental dysplasia of the hip
Supplemental material, sj-pdf-1-cho-10.1177_18632521251331772 for Preliminary assessment of large language models’ performance in answering questions on developmental dysplasia of the hip by Shiwei Li, Jun Jiang and Xiaodong Yang in Journal of Children’s Orthopaedics
Footnotes
Acknowledgements
We express our gratitude to statistical expert Ting Wang from the Clinical Research Management Department of West China Hospital, Sichuan University, for providing us with professional statistical advice.
Author contributions
Shiwei Li: Investigation, data curation, formal analysis, and writing—original draft; Jun Jiang: Investigation and data curation; Xiaodong Yang: Investigation, conceptualization, methodology, writing—review & editing, and supervision.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.