
Abstract
Purpose:
Developmental dysplasia of the hip (DDH) requires timely, guideline-concordant decisions to prevent long-term morbidity. ChatGPT-5.0 may support clinicians—especially where pediatric orthopedic expertise is limited, but their reliability across typical and discordant presentations is uncertain. This scenario-based validation study evaluated the accuracy of ChatGPT-5.0’s management recommendations for DDH using 30 structured clinical cases and compared these outputs against AAOS (2022) and AAP (2016) guidelines.
Methods:
Scenario-based validation using 30 unique cases: 20 concordant (aligned clinical and imaging findings) spanning Graf and acetabular index-based ages, and 10 mismatch scenarios with correct examinations but intentionally erroneous radiology. The primary outcome was guideline-concordant accuracy, categorized as correct, partially correct, undertreatment, overtreatment, or incorrect. Secondary outcomes included the effect of error-aware prompts and multilingual consistency.
Results:
In concordant scenarios, guided ChatGPT achieved 100% correct, while non-logged-in ChatGPT achieved 95% with one overtreatment. In mismatch scenarios, guided ChatGPT frequently tends toward overtreatment and failing to recommend repeat ultrasound or urgent pediatric orthopedic consultation. Non-logged-in ChatGPT performed better in mismatch cases but similarly under-emphasized remeasurement/consultation. Error-aware prompts did not materially alter recommendations in either environment. Swahili queries produced outputs clinically identical to English responses.
Conclusions:
ChatGPT-5.0 provides reliable, guideline-concordant guidance for DDH when clinical and radiologic data are concordant, supporting potential use as a decision aid in settings without immediate pediatric orthopedic access. Safe clinical implementation requires human oversight and integration of guideline-based safety checks to prevent mismanagement in ambiguous cases.
Introduction
Developmental dysplasia of the hip (DDH) is a prevalent condition in pediatric orthopedics, affecting approximately 1–2 per 1000 live births, and up to 1.5% of infants within the first year of life in some populations, especially females.1,2 DDH encompasses a spectrum of abnormalities ranging from mild acetabular dysplasia to frank dislocation, arising from a combination of genetic predisposition, mechanical factors, and intrauterine positioning. Early diagnosis relies on clinical screening (Ortolani and Barlow maneuvers) and age-appropriate imaging, such as ultrasonography in infants and radiographs after ossification begins. Management principles emphasize early conservative treatment—including dynamic bracing with a Pavlik harness or static abduction braces—to promote acetabular remodeling and prevent long-term complications. 3 Conservative management remains the cornerstone of early DDH treatment, with the Pavlik harness being the preferred first-line modality in infants under 6 months due to its dynamic positioning and high success rates. When instability persists, or in slightly older infants, static abduction bracing may be used to maintain concentric reduction and promote acetabular development. These approaches are strongly supported in the literature and remain central to contemporary DDH care pathways. 4
Early recognition and appropriate intervention are crucial to prevent gait disturbances, pain, premature osteoarthritis, and the need for complex surgeries. The American Academy of Orthopaedic Surgeons (AAOS) published clinical practice guidelines in 2022 that provide evidence-based recommendations for early detection and nonoperative management of DDH. 5 The American Academy of Pediatrics (AAP) earlier released a clinical report in 2016 outlining referral and follow-up strategies for suspected DDH cases. 6 Despite these frameworks, variability among practitioners, especially non-specialists in remote or resource-limited settings, poses a risk for delayed diagnosis or suboptimal treatment. In settings where pediatric orthopedic expertise is not readily available, such as rural clinics or developing regions, generalized orthopedists may be required to assess and manage DDH cases. In such contexts, access to decision-support tools that encapsulate guideline-driven logic could help mitigate diagnostic errors and guide appropriate management pathways. Artificial intelligence (AI)-based language models, such as ChatGPT, have rapidly evolved to assist in medical decision-making. In orthopedic disciplines, AI has demonstrated utility in areas such as diagnostic accuracy, surgical planning, and educational facilitation.7,8 Recent narrative reviews underline ChatGPT’s capacity to support differential diagnoses, suggest imaging modalities, and propose evidence-based treatment recommendations. 9 In pediatric orthopedics, specific applications of AI include the evaluation of limb deformities and developmental conditions, with AI chatbots facilitating parent education and triage discussions.10,11 Despite potential benefits, evidence on the reliability of AI tools in clinical decision support for pediatric orthopedics remains limited. A recent study comparing ChatGPT, Gemini, and Copilot in handling parental queries about pediatric knee deformities found that ChatGPT provided relatively more accurate and comprehensive responses, yet emphasized that human oversight remains essential. 12 Moreover, emerging AI tools beyond language models—such as deep learning systems are being developed for DDH detection from imaging, showing promise in measurement precision and classification agreement levels that outperform human raters. 13 AI can also assist with bone age determination, radiographic analysis, and growth trajectory predictions in pediatric populations. 14 Taken together, these trends suggest that AI, and specifically language models like ChatGPT, may have a role in guiding both experienced and less-experienced clinicians in DDH management. Yet, rigorous validation against established guidelines is essential to demonstrate safety and effectiveness, particularly when applied across different care settings and languages. The objective of this study is to evaluate the accuracy of ChatGPT-5.0’s treatment recommendations in DDH scenarios compared against current clinical practice guidelines.
Materials and methods
This was a scenario-based validation study designed to assess the accuracy of ChatGPT-5.0 in providing clinical recommendations for DDH.
Scenario development
Two pediatric orthopedist constructed 30 unique clinical scenarios representing a spectrum of DDH cases across age groups (0–46 months). All scenarios will be considered as initial applications unless additional information is provided. These scenarios were systematically derived from:
Graf classification (0–6 months)
Acetabular index (AI) criteria (6–24 months)
Walking-age presentations (>12 months)
Complex and late-presenting cases (>24 months)
Mismatch scenarios where clinical and radiological findings were discordant.
Each scenario incorporated:
Age (in months)
Clinical examination findings (Ortolani/Barlow or hip abduction limitation or unstable/stable)
Ultrasound parameters (α, β angles, or Graf classification)
Radiographic findings (AI values or femoral head development)
Inclusion criteria for scenarios:
Age-specific DDH presentations spanning 0–46 months
Scenarios containing complete clinical examination findings (e.g. Ortolani/Barlow, abduction limitation).
Imaging parameters appropriate to age (Graf ultrasound findings for <6 months; acetabular index values or radiographic features for ≥6 months).
Both concordant presentations (aligned clinical and imaging findings) and intentionally discordant (mismatch) presentations.
Exclusion criteria for scenarios:
Scenarios with incomplete clinical or imaging data.
Cases representing conditions other than DDH (e.g. septic hip, neuromuscular dislocation).
Scenarios requiring advanced surgical decision-making beyond the scope of AAOS/AAP nonoperative DDH guidelines.
Any real patient data (the study used no identifiable clinical records).
These scenarios did not include diagnostic timing or real patient age at diagnosis; instead, they presented age-appropriate clinical and imaging findings without anamnesis, allowing ChatGPT to be evaluated solely on guideline-based interpretation rather than disease timing.
ChatGPT application protocol
Two testing environments were used:
Non-logged in
Each scenario was entered into ChatGPT-5.0 without prior training or a user account.
This minimized recall bias and reduced the risk of false-positive reinforcement.
The responses any person would receive with these scenarios were simulated.
Guided session (trained, membership-based)
The same scenarios were presented in a guided ChatGPT-5.0 environment.
This allowed comparison of raw versus trained responses.
Before presenting the scenarios, ChatGPT was instructed to base its recommendations on two established guidelines: the 2022 AAOS Clinical Practice Guideline for early detection and nonoperative management of DDH, and the 2016 AAP Clinical Report outlining referral and follow-up strategies for suspected DDH.”
For each case, ChatGPT recommendations were recorded verbatim.
Global applicability: Swahili testing
To assess cross-linguistic reliability, all scenarios were presented to ChatGPT in Swahili, a widely spoken language in East Africa. The responses were translated back into English by the platform, and their clinical content was compared to English outputs. Identical recommendations across languages confirmed cross-linguistic consistency.
Error-aware analysis
Recognizing the risk of measurement variability in clinical practice (e.g. inconsistent hip positioning during ultrasound, interobserver differences in AI measurement), we incorporated an error-aware column into mismatch scenario evaluation. This adjustment:
Highlighted where repeat imaging or urgent referral was warranted
Simulated real-world variability
Assessed whether management recommendations would change when accounting for such errors.
Scenario numbers were based on clinical relevance rather than statistical pairing, as each scenario functioned as an independent test case.
Evaluation criteria
ChatGPT responses were compared against the AAOS 2022 Clinical Practice Guideline and AAP 2016 Clinical Report.5,6 Each response was classified as:
Correct—fully aligned with guidelines
Partially correct—contained valid elements but lacked key details
Undertreatment—less than the guideline-recommended management
Overtreatment—excessive intervention beyond recommendations
Incorrect—not in line with guideline recommendations.
Two pediatric orthopedic specialists independently reviewed all responses for classification, with discrepancies resolved by consensus.
Results
As shown in Table 1, both guided and Non-logged-in ChatGPT produced largely guideline-concordant recommendations across concordant scenarios, with a minor difference in the 5-month case.
Guideline-based treatment recommendations for DDH, comparing guided ChatGPT and non-logged-in ChatGPT output.
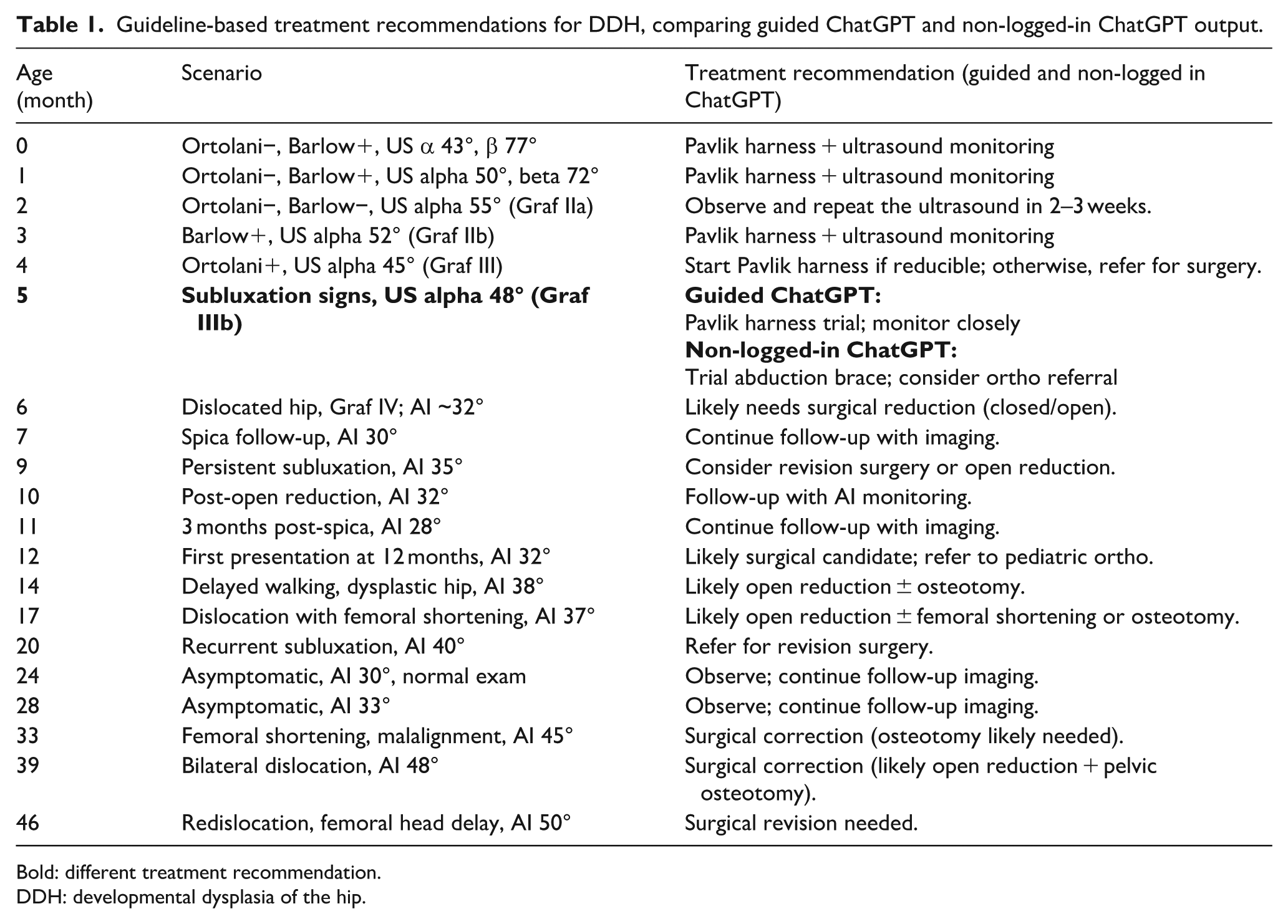
Bold: different treatment recommendation.
DDH: developmental dysplasia of the hip.
Mismatch scenarios
As shown in Table 2, both guided and non-logged-in ChatGPT frequently failed to provide guideline-concordant recommendations in mismatch scenarios, highlighting the model’s limitations when clinical and radiological findings were discordant.
Guideline-based treatment recommendations for DDH in mismatch scenarios, comparing guided ChatGPT and non-logged-in ChatGPT outputs.
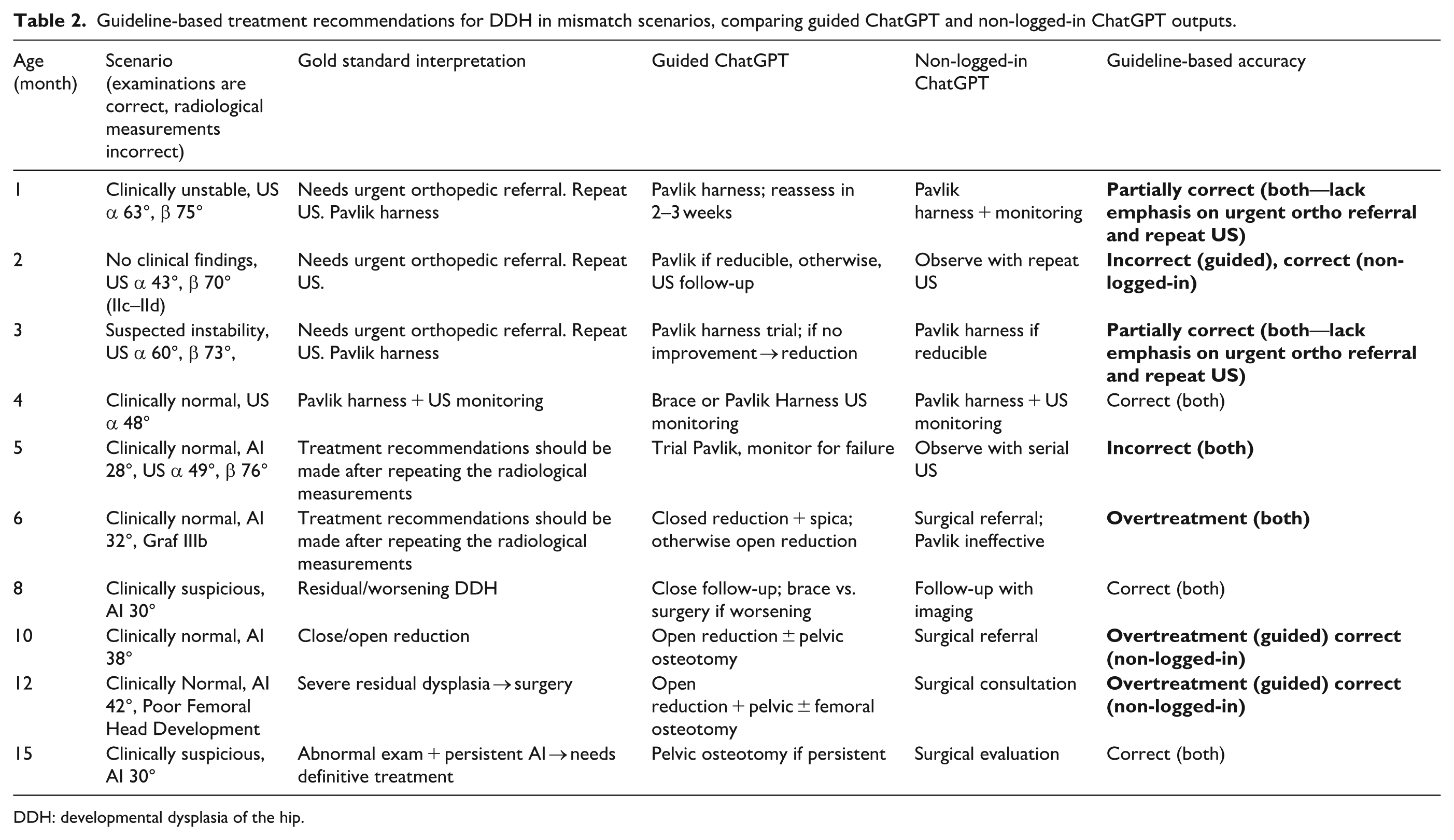
DDH: developmental dysplasia of the hip.
Error-aware evaluation
Even after being explicitly cautioned about possible examiner or measurement error, ChatGPT continued to recommend the same treatment strategies, failing to redirect toward repeat imaging or urgent consultation.
Global applicability: Swahili testing
For cross-linguistic validation, all scenarios were also tested in Swahili. The translated outputs were clinically identical to the English versions across both concordant and mismatch cases, confirming language-independent consistency.
Discussion
Our study evaluated the performance of ChatGPT-5.0 in DDH using 30 structured clinical scenarios covering a wide spectrum of patient ages and presentations. The most important finding is that ChatGPT performed with very high accuracy in concordant cases, where clinical examination and radiological measurements were aligned. In these scenarios, both guided and non-logged-in versions of ChatGPT produced guideline-based recommendations consistent with the AAOS 2022 Clinical Practice Guideline and the AAP 2016 Clinical Report.5,6 This indicates that ChatGPT can serve as a reliable adjunct to non-specialist physicians, especially in settings where pediatric orthopedic expertise is unavailable.
However, our analysis of mismatch scenarios revealed important limitations. When clinical examinations were accurate but radiological values were deliberately erroneous, ChatGPT frequently provided inappropriate recommendations. The guided model achieved only 30% strict accuracy in these cases, often suggesting overtreatment such as early surgical intervention, while failing to recommend repeat ultrasound, second-reader confirmation, or urgent referral to a pediatric orthopedist. The non-logged-in version performed somewhat better (60% strict accuracy), but still neglected to emphasize re-measurement or consultation. Even when specifically prompted with an error-aware adjustment, the model continued to recommend treatment without re-evaluation. This shows that while ChatGPT is highly effective in straightforward cases, it lacks the clinical “safety nets” that human specialists apply in the face of discordant findings.
This feature is particularly relevant for resource-limited regions, where healthcare providers may not be fluent in English or may rely on translations in daily practice. By ensuring that outputs remain stable across languages, ChatGPT could help standardize DDH management worldwide.
These results are consistent with prior observations on the potential of AI in orthopedics. Song 7 highlighted that artificial intelligence has broad applications in diagnostics, imaging interpretation, and predictive analytics, offering significant benefits where structured tasks are involved. Burns 8 also noted that decision-support systems are among the most impactful AI domains for orthopedics, capable of embedding guideline-based reasoning directly into clinical workflows. Our study supports these conclusions in concordant cases but shows that in ambiguous conditions, ChatGPT’s limitations become evident.
The severe physician shortages documented by the World Health Organization in East Africa further contextualize our findings. According to WHO workforce reports, physician densities in this region range from 0.02 to 0.15 per 1000 population—levels more than 20–100 times lower than the WHO-recommended threshold of 4.45 needed to provide essential surgical and pediatric care. 15 Such extreme workforce deficits imply that access to subspecialty services, including pediatric orthopedics, is profoundly limited. Under these conditions, early detection and consistent follow-up of DDH become particularly challenging. For this reason, we intentionally included Swahili, the most widely used lingua franca in East Africa, in our multilingual testing. Demonstrating that ChatGPT provides identical, guideline-based recommendations in Swahili was important to simulate real-world use in regions where pediatric orthopedic expertise is scarce and where AI-assisted decision support may have the greatest impact.
Although our scenarios focused on management after clinical and imaging findings were available, effective DDH screening remains essential—particularly in underserved regions where delayed diagnosis is common. Future AI-based evaluations may incorporate screening-focused scenarios to assess ChatGPT’s potential role in supporting early detection pathways.
Several comparative chatbot studies echo these results. Giorgino et al. 9 compared Bard and ChatGPT in orthopedics and found that ChatGPT gave more clinically relevant responses, but both models still exhibited important gaps. Kamal et al. 10 examined parental queries regarding pediatric knee deformities and found ChatGPT superior to competitors, yet noted oversimplified recommendations that sometimes lacked context. We also thought that ChatGPT 5.0 was superior to its counterparts, so we used it in our study. Similarly, Alomran et al. 11 surveyed pediatric orthopedic surgeons and revealed both optimism and skepticism: while AI was seen as potentially transformative, concerns centered on diagnostic reliability, ethics, and medico-legal liability. These concerns are validated by our mismatch analysis, where ChatGPT’s tendency toward overtreatment in ambiguous cases underscores the necessity of human oversight.
By contrast, computer vision approaches in DDH have shown strong results in quantitative tasks. Li et al. 13 used Dense U-Net for automated measurement of lateral center-edge angle and achieved excellent agreement with manual raters (intra-class correlation (ICC) > 0.90). Another study by the same group automated Sharp, Tönnis, and CE angle measurements with high repeatability (ICC > 0.75) and faster results than humans. 16 Darilmaz et al. 17 developed AI-SPS, a deep learning software for real-time ultrasound standard plane detection in DDH screening, which achieved 86.3% accuracy, improving reproducibility in Graf-based evaluation. Den et al. 18 applied YOLOv5 to hip radiographs in infants <12 months, reaching 94% sensitivity and 96% specificity. Finally, Chen et al. 19 conducted a meta-analysis of 13 studies (28 AI models) and reported a pooled sensitivity of 99% and a specificity of 94% for AI-assisted DDH detection. These imaging-focused tools demonstrate the strength of AI when ground truth is objective and measurable, in contrast to ChatGPT’s difficulty with integrating conflicting clinical and imaging findings.
Recent studies directly testing large language models (LLMs) in pediatric orthopedics parallel our findings. Li showed that while ChatGPT 4.0 outperformed other LLMs in pediatric orthopedics, accuracy declined when guideline-specific detail was required. 12 Nian et al. 20 tested ChatGPT 4.0 and Google Gemini against AAOS guidelines for DDH and concluded that both were inadequate, often providing incomplete or clinically unsafe recommendations. In these studies, questions were asked based on general information, not scenarios. And we used a higher version, ChatGPT 5.0. Our scenario-based design extends these findings by quantifying performance across concordant versus discordant cases, demonstrating that the problem is not baseline performance but failure under uncertainty.
The strengths of our study include the construction of 30 unique scenarios covering the full clinical spectrum of DDH, systematic comparison of guided and non-logged-in ChatGPT sessions, incorporation of multilingual testing (Swahili), and evaluation under error-aware conditions to simulate real-world diagnostic variability. Limitations include the use of simulated cases rather than real patient data, analysis of a single LLM (ChatGPT-5.0), and a lack of prospective validation in clinical settings. In addition, while mismatch scenarios are valuable stress tests, they may not fully replicate the complexity of real-life ambiguity.
This suggests that in real-world clinical environments, where measurement variability is frequent, ChatGPT should not be used without human oversight. It highlights the necessity of integrating explicit guideline-based safety nets (e.g. mandatory repeat imaging in borderline or inconsistent cases) if such AI models are to be applied in pediatric orthopedic practice. This study demonstrates that ChatGPT-5.0 provides highly accurate, guideline-concordant recommendations for DDH in concordant clinical and radiological scenarios, suggesting its potential as a supportive tool for non-specialist clinicians, particularly in resource-limited settings. However, its reduced reliability in mismatch cases, where erroneous measurements led to overtreatment or inappropriate management without prompting for repeat imaging or consultation, underscores the necessity of human oversight and the integration of explicit safety safeguards before clinical implementation. This recommendation arises directly from the overtreatment tendencies we observed in discordant scenarios, even though such safeguards were not implemented in our study.
Although our scenarios focused on management after clinical and imaging findings were available, effective DDH screening remains essential—particularly in underserved regions where delayed diagnosis is common. Future AI-based evaluations may incorporate screening-focused scenarios to assess ChatGPT’s potential role in supporting early detection pathways. Future work should evaluate ChatGPT prospectively in clinical care, integrate mandatory safeguards (e.g. prompts for repeat imaging in ambiguous findings), and explore hybrid systems combining computer vision accuracy with LLM contextual reasoning. Incorporating these systems into telemedicine platforms may expand access in underserved areas. Ultimately, ChatGPT should be considered not a replacement but an adjunctive decision-support tool, with human oversight essential to mitigate risks.
Supplemental Material
sj-pdf-1-cho-10.1177_18632521261419320 – Supplemental material for Evaluating ChatGPT-5.0 in developmental dysplasia of the hip: A scenario-based validation study against AAOS and AAP guidelines
Supplemental material, sj-pdf-1-cho-10.1177_18632521261419320 for Evaluating ChatGPT-5.0 in developmental dysplasia of the hip: A scenario-based validation study against AAOS and AAP guidelines by Süleyman Kozlu, Barış Görgün and Süleyman Kaan Öner in Journal of Children's Orthopaedics
Footnotes
Acknowledgements
During the preparation of this manuscript, the authors used ChatGPT-5.0 (OpenAI, San Francisco, CA, USA) for the purposes of scenario generation, guideline-based comparison, and assistance in drafting text. The authors have reviewed, revised, and edited all AI-assisted content and take full responsibility for the integrity and accuracy of this publication.
Author contributions
Conceptualization: SK, BG. Methodology: SK. Validation: SKÖ, BG, SK. Formal analysis: SK. Investigation: SK. Resources: SK. Data curation: SK. Writing—Original draft preparation: SK. Writing—Review & editing: SKÖ, BG. Visualization: SK. Supervision: SK. Project Administration: SK. Funding Acquisition: Not applicable.
Data availability statement
All data generated or analyzed during this study are included in this published article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical statement
This study did not involve human participants or animals. Ethical approval and informed consent were not required, as the study consisted of simulated clinical scenarios without patient data.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.