
Abstract
This study introduces an innovative scheduling tool for dynamic identical parallel machine environments, leveraging a non-preemptive overlapping load adjustment methodology. Central to this tool is a dual-phase proactive-reactive dynamic scheduling mechanism. Initially, in the proactive phase, the tool utilizes an earliest loading strategy to map out a range of viable scheduling alternatives, capitalizing on job slack times without cementing any schedules prematurely. This is followed by a reactive phase, wherein the tool dynamically adjusts to real-time disturbances via a user-controlled module, thereby crafting adaptable schedules while ensuring continuous feasibility. Enhanced by real-time graphical displays, the tool offers end-users a holistic view of the scheduling process and the implications of unexpected disruptions, aiding in informed decision-making. Extensive computational experiments encompassing 600 instances of varying sizes - small, medium, and large - underscore the tool’s efficiency. These experiments reveal the generation of a wide spectrum of scheduling alternatives, ranging on average from 1676 for small-sized instances to as many as 298,210 for large-sized ones. Notably, the average maximum completion time (Cmax) closely mirrors the results obtained from the Cplex optimizer, with an average deviation of merely 1.07%, 0.48%, and 12.23% for small, medium, and large instances, respectively. Moreover, despite the creation of up to 300,000 potential scheduling solutions for larger instances, the tool consistently yields a low average number of tardy jobs; 1.28, 1.87, and 2.07 for the respective problem sizes, which clearly highlights its effectiveness. The outcomes conclusively demonstrate the tool’s flexibility and efficiency, offering end-users a multitude of superior scheduling options in the presence of unforeseen disruptions that characterize today’s operating environment.
Introduction
Scheduling, a pivotal operational practice, bears significant value in enhancing resource allocation and management across a wide spectrum of manufacturing and service industries alike. One prevalent scheduling scenario is the parallel machine scheduling problem, which arises frequently in various real-world settings, such as manufacturing systems, assembly lines, information services, and healthcare.1–4 In this context, the primary objective revolves around optimizing performance criteria, such as minimizing the makespan, tardy jobs, total tardiness, and total flow time, among many others. Beyond manufacturing, scheduling-related applications are encountered in various domains, including computer systems, transportation logistics, and healthcare operations. 5 Irrespective of the industry, the overarching goal remains consistent: to effectively assign tasks to resources over time to optimize performance metrics while meeting deadlines and adhering to technological and operational constraints. This dynamic and adaptable approach to resource management provides organizations with a competitive edge, particularly when confronted with high-cost resources and substantial workloads.
The dynamics of scheduling operations in today’s competitive markets are characterized by the inevitability of inherent and unanticipated disturbances. These disturbances fall into various broad categories, including job-related, machine-related, process-related, and other unforeseen disruptions. 6 Furthermore, the advent of the fourth industrial revolution has introduced a heightened level of automation and real-time communication within production processes, posing additional challenges to conventional scheduling methodologies. 7 As such, classical scheduling paradigms, rooted in the assumption of static and stable operating conditions, no longer align with the dynamic and uncertain nature of real-world operations. These approaches must now grapple with the unprecedented need to adapt to real-time disturbances without causing significant operational upheaval. Businesses are continuously on the lookout for scheduling solutions that possess rescheduling capabilities while effectively balancing flexibility, resilience, and stability. In essence, dynamic scheduling solutions have become essential in striking a harmonious balance between responsiveness and stability in today’s industrial landscape. The ability to swiftly react to unforeseen events and dynamically adjust schedules has transitioned from being a mere option to an imperative, underscoring its pivotal role in efficient scheduling.
The research landscape in addressing the dynamic nature of parallel machine scheduling problems has garnered substantial interest, prompting the exploration of flexible and dynamic methodologies. Typically, two primary categories of approaches are employed to manage uncertainty in scheduling environments: reactive and proactive scheduling strategies. 8 A more detailed classification, proposed by Chaari et al. 9 and Davenport & Beck, 10 introduces four categories: purely reactive scheduling, predictive-reactive scheduling, proactive scheduling, and proactive-reactive scheduling. It is noted that reactive scheduling strategies are particularly well-suited for highly turbulent environments characterized by frequent and substantial uncertainties.8,9 These approaches rely on real-time information concerning the system’s current state and are crucial for making on-the-fly decisions when unexpected events occur. In such dynamic contexts, traditional offline scheduling quickly becomes infeasible, necessitating real-time decision-making. 10 Predictive-reactive approaches constitute a subcategory of strategies designed to manage risks effectively. They adopt a two-step structure: in the initial phase, a deterministic schedule is established offline without considering potential disruptions. In the subsequent phase, the schedule is implemented and continuously adapted on a real-time basis. During execution, scheduling decisions are made incrementally, with real-time adjustments to accommodate disturbances. Reactive algorithms are then employed to maintain schedule feasibility and, when possible, enhance performance. 11
Proactive scheduling, as a third category of scheduling approaches, finds its application in situations where uncertainty is acknowledged and quantifiable, as noted by Aloulou and Portmann. 12 These methods strive to instill resiliency and incorporate the potential for disruptions when constructing offline schedules. Their overarching objective is to craft robust schedules that can withstand unforeseen disturbances, even under assumed control policies). 9 The final category comprises proactive-reactive scheduling approaches, which also operate in a two-phase manner. In the initial phase, the focus lies in establishing a resilient baseline schedule, or a series of such schedules, which can withstand potential disruptions. Subsequently, in the second phase, these approaches employ reactive scheduling procedures to adapt and optimize the ongoing schedule as required, ensuring adaptability and efficiency in dynamic environments. 9
In principle, dynamic scheduling in identical parallel machine environments poses several significant challenges that the scheduling tool proposed in this work seeks to address. Traditional scheduling approaches often struggle with real-time disruptions such as machine breakdowns, variable job processing times, and unexpected order changes, which can lead to suboptimal schedules and increased operational costs. These challenges are exacerbated by the pressing need for continuous feasibility and adaptability in rapidly changing production environments. The proposed scheduling tool stands out from existing tools via incorporating a dual-phase proactive-reactive dynamic scheduling mechanism specifically designed for identical parallel machine settings. Unlike traditional scheduling tools that often rely on static scheduling or purely reactive adjustments, the tool begins with a proactive phase, utilizing an earliest loading strategy to explore a wide range of viable scheduling alternatives based on job slack times. This is followed by a reactive phase, where the tool dynamically adapts to real-time disturbances through a user-controlled module, ensuring ongoing feasibility and adaptability. Moreover, the integration of real-time graphical displays provides end-users with a comprehensive and an interactive view of the scheduling process that captures the impact of unexpected disruptions, which is a significant advancement over conventional static Gantt Charts. This combination of proactive planning, real-time adaptability, and user interactivity distinguishes the developed approach, making it more flexible, efficient, and effective in handling the dynamic and uncertain nature of modern manufacturing environments.
The literature review on dynamic scheduling approaches, emphasizing works related to parallel machines, is discussed initially. Subsequently, the overlapping load adjustment approach, which forms the basis for the proposed flexible scheduling tool, is outlined, with detailed descriptions of the tool itself. The setup and results of the extensive experimental study that evaluates the tool’s performance are then presented. This paper’s contributions and the advantages of the proposed tool over existing approaches are highlighted next. Concluding remarks and future research directions are provided in the final section. Appendices A, B and C offer the mathematical models and detailed real-life examples illustrating the tool’s dynamic schedule development capabilities upon implementation.
Relevant literature
The field of research addressing machine scheduling problems in uncertain environments is continuously expanding. This area encompasses a wide spectrum of scheduling strategies, including robust scheduling, dynamic scheduling, and rescheduling techniques. In this section, we provide a comprehensive review of the most noteworthy contributions in this field. The focus is primarily on studies tackling the scheduling of tasks on parallel machines, while exploring various performance metrics and problem settings.
Robust scheduling
Recognizing the vital importance of offering adaptable scheduling solutions, especially within the framework of unpredictable and incomplete data that characterize rapidly evolving environments, it is essential to explore various facets of flexibility. According to a study by Chang et al., 13 flexibility can be construed in diverse ways, with the primary metrics for evaluating manufacturing flexibility being versatility and efficiency. Versatility pertains to a system’s capability to perform a wide range of tasks and transition between them seamlessly, while efficiency gauges the speed at which a manufacturing system carries out these tasks. 14 The integration of flexibility into a scheduling solution implies the presence of a substantial degree of freedom during the operational phase, often achieved by presenting a multitude of alternative schedules to the decision maker. 1 Numerous researchers have proposed methods for infusing flexibility into manufacturing systems. For an in-depth exploration and comprehensive reviews of these approaches, interested readers can refer to the works of Seebacher & Winkler 15 and Teich & Claus. 16
Robust scheduling is a scheduling approach that accounts for uncertainties within a system, providing the possibility to craft schedules capable of accommodating unforeseen events or alterations, such as delays, machine malfunctions, or shifts in demand, all while upholding the overarching objectives of the system. In principle, the core objective of robust scheduling is to yield schedules that exhibit resilience in adapting to uncertain environments while preserving system-wide stability. Notably, robustness and flexibility are intricately linked, with schedules characterized by robustness often displaying a degree of flexibility as well. 17 It is important to note that there is no universally agreed upon definition for robustness, as its precise definition hinges on the specific problem in question and the context in which robustness is being applied or evaluated. 1
Numerous researchers have delved into robust scheduling for parallel machines. De La Vega et al. 18 introduced a proactive strategy to minimize production makespan under uncertain processing and setup times, using a mixed integer linear program (MILP) in a deterministic framework. Their findings highlighted the model’s efficacy in integrating uncertainties in the context of parallel machine scheduling, but also its limited applicability to larger instances. Yanıkoğlu & Yavuz 19 developed a model for realistic size instances in unrelated parallel machines, aiming to minimize total tardiness. Their approach, utilizing a branch-and-bound algorithm, proved effective in handling uncertainty and improving objective function values compared to solutions not accounting for uncertainty.
In the same context, Cohen et al. 20 presented an adaptive proactive-reactive approach that accounted for tasks’ duration uncertainties. The model’s primary objective was to minimize the worst-case makespan, and it achieved this through a MILP within a deterministic context. Their mathematical model highlighted the superiority of adaptive scheduling over static approaches, yielding results with more robust and improved makespan realizations. Furthermore, in a similar vein, Novak et al. 21 introduced a proactive scheduling strategy for parallel machines with the aim of minimizing the total flow time. This model took into consideration the uncertainty associated with processing times, employing a polynomial-time algorithm within a deterministic framework. The results obtained underscored the competitive performance of the proposed algorithms, offering results of similar quality to existing methods while exhibiting superior computational efficiency. In a distinct approach, Li et al. 22 advocated proactive scheduling for parallel machines to minimize the total weighted completion time. They addressed the challenge of uncertainty in processing times through a hybrid algorithm, operating in a stochastic environment. The outcomes and sensitivity analysis demonstrated the effectiveness and efficiency of the distributionally robust optimization model across various scenarios, including different problem sizes, processing time variations, and information misalignment.
Seo & Chung 23 and Hu et al. 24 both developed proactive scheduling strategies to minimize makespan on identical parallel machines using MILPs. Seo & Chung 23 devised a deterministic MILP to handle uncertainties, finding that their robust counterpart performed better in terms of mean and standard deviation. Hu et al. 24 considered uncertain processing and arrival times in their MILP and introduced a modified artificial bee colony algorithm for large-scale problems. Their results showed the algorithm’s efficiency over exact methods in achieving near-optimal solutions quickly.
Skutella & Verschae 25 and Xu et al. 26 each proposed reactive scheduling strategies for parallel machine scheduling aimed at minimizing makespan. Skutella & Verschae’s study utilized a polynomial-time approximation model to handle uncertainties in job timings, identifying lexicographically optimal solutions as key to robustness. Though focused on machine packing and covering problems, their methods have wider applicability. Conversely, Xu et al. 26 tackled uncertainties in processing times, introducing a general iterative relaxation procedure within in a deterministic context. This method effectively manages uncertainties in manufacturing, providing a foundation for addressing other parallel machine scheduling challenges involving interval data. In a recent study, Wang et al. 27 tackled uncertainties in processing times with a multi-start decomposition-based heuristic algorithm and an enhanced regret evaluation method, significantly improving scenario assessment and process efficiency. This algorithm demonstrated its effectiveness over other existing methods, showcasing robust performance in various conditions. Rambod & Rezaeian 28 developed a model focusing on reworking uncertainty, using genetic algorithms and bee algorithms. By testing parameters across different problem sizes, they found that these algorithms provided competitive solutions to exact methods with reduced computational effort. Their study opens avenues for future exploration in estimating uncertain parameters using probability distributions.
Liu et al. 29 advocated a proactive approach for parallel machines, utilizing a mixed-integer second-order cone programming model to manage variable processing times in a stochastic setting, with numerical tests validating its efficacy. Chang et al. 30 proposed a proactive scheduling strategy to minimize the worst-case expected total flow time, incorporating uncertainties in their model. Alimoradi et al. 31 focused on maximizing the probability of not exceeding a total flow time limit for identical parallel machines, applying a branch-and-bound algorithm for uncertain processing times. Branda 32 introduced a robust scheduling strategy for parallel machines, aiming to minimize the number of required machines, using a decomposition algorithm in a stochastic environment.
Dynamic scheduling
Numerous researchers have delved into the dynamic parallel machine scheduling problem, a scenario where jobs have staggered release dates, meaning that jobs arrive gradually over time. Dynamic scheduling, in this context, revolves around the use of intelligent approaches that take into account various critical factors such as business objectives, staff availability, skill sets, and unexpected events that can potentially disrupt daily operations. This approach requires real-time decision-making and typically aims to optimize machine utilization, enhance overall system performance, and bolster adaptability in response to evolving circumstances. In the specific context of dynamic scheduling, Baykasoğlu & Ozsoydan 33 developed a predictive-reactive scheduling approach using a Greedy Randomized Adaptive Search Procedure (GRASP) for managing parallel heat treatment furnaces, while factoring in various uncertainties like order changes and machine breakdowns. Juarez et al. 34 focused on dual objectives of reducing energy consumption and makespan in a dynamic environment, employing a multi-heuristic resource allocation strategy. This approach took into account complex factors such as setup times and energy profiles, balancing energy efficiency with potential impacts on completion times. Zhang et al. 35 adopted a differential evolution algorithm for dynamic parallel machine scheduling to achieve synchronous optimization, showing promising results in simulations, especially for large-scale problems. These studies reflect the growing focus on adaptive, efficient scheduling strategies in dynamic and uncertain manufacturing environments.
Wang et al. 36 utilized metaheuristics and a MILP for dynamic scheduling in parallel machines, focusing on makespan reduction and managing uncertainties in resource and job scheduling. Their model showed satisfactory performance, though there is potential for improvement, particularly in multi-objective handling and efficiency in complex scenarios. Mauergauz 37 devised a dynamic Pareto-optimal method specifically for parallel machine scheduling. This method uniquely considers both relative manufacturing costs and the utility of average orders, generating a variety of non-dominant schedules for users, particularly effective in moderate ‘make-to-order’ and ‘make-to-stock’ job scenarios. Yuan et al. 38 introduced a solution to address dynamic scheduling in parallel machines with possible random breakdowns, incorporating a reactive strategy with simulation and a learning agent adhering to various dispatching rules. Ding et al. 39 focused on dynamic parallel task scheduling for cloud computing resources, emphasizing workload-based scheduling. Ghamami & Ward 40 proposed a reactive scheduling approach to minimize expected infinite horizon discounted costs in environments with random service times, applying an asymptotic regime in heavy traffic and resource pooling conditions. This comprehensive array of methodologies highlights the evolving strategies in parallel machine scheduling, addressing various complexities and uncertainties inherent in dynamic manufacturing environments.
Rescheduling approaches
In addition to the robust and dynamic scheduling methods, rescheduling techniques offer a practical alternative for incorporating adaptability into scheduling solutions. These techniques involve periodically revising schedules, initially established as a baseline, to enhance the system’s ability to respond to unexpected disruptions as time advances. However, the frequent adjustments to schedules can introduce instability or what is often referred to as “nervousness.” Thus, it becomes crucial to strike a balance between the frequency of rescheduling and the system’s stability. In the existing body of literature, three primary rescheduling approaches have been developed: event-triggered rescheduling, interval-based rescheduling, or a hybrid fusion of these two methods. Event-triggered rescheduling, originally proposed by Yamamoto & Nof, 41 revolves around generating new schedules in reaction to specific events, such as the arrival of new jobs. The second approach, interval-based rescheduling, confines the creation of fresh schedules to predefined time intervals.
Tighazoui et al. 42 concentrated on identical parallel machines and developed a predictive-reactive rescheduling strategy using a MILP in a stochastic environment. The objective was to minimize total weighted waiting times while accommodating new job arrivals. Similarly, Wang et al. 43 introduced an event-based rescheduling approach for identical parallel machines, aiming to minimize total completion time. They utilized a pseudo-polynomial time dynamic programming algorithm for creating reactive schedules in deterministic settings. Their research focused on balancing schedule adjustment and disruption mitigation, highlighting the challenge of this NP-hard problem in scenarios with a fixed or variable number of machines. Yin et al. 44 and Liu & Zhou 45 proposed event-based rescheduling strategies for identical parallel machines, focusing on minimizing total completion time. Yin et al. 44 developed a model using a pseudo-polynomial time algorithm that addresses machine disruptions uncertainty, creating a reactive schedule in a deterministic setting. Their work demonstrates the feasibility of a fully polynomial-time approximation scheme for handling schedule and machine disruptions. Conversely, Liu & Zhou 45 concentrated on job rework disruptions, employing two polynomial-time algorithms in a deterministic environment. They formulated the rescheduling issue as three bicriteria scheduling problems, applying both lexicographical and simultaneous optimization methods.
In two related works, Hamzadayi and Yildiz explored reactive rescheduling in dynamic parallel machine environments using simulation techniques. In the first study Hamzadayi & Yildiz, 46 they focused on minimizing makespan for identical parallel machines, proposing a strategy that combines simulated annealing with dispatching rules. This approach considered uncertainties like physical work-in-process in stochastic settings, with simulations showing its effectiveness over other methods. In the second study Hamzadayi & Yildiz, 47 they aimed to minimize the number of tardy jobs by developing a model that addresses uncertainties due to machine breakdowns and repairs. Their findings suggest that the simulated annealing-based rescheduling method generally outperforms dispatching rule-based methods.
In the context of unrelated parallel machines, Kim & Kim 48 developed a predictive-reactive rescheduling strategy using a simulated annealing algorithm enhanced with a fuzzy logic controller. This approach aimed to minimize makespan, considering machine breakdown uncertainties and balancing stability and penalty costs. The algorithm showed high effectiveness in scenarios with predictable machine breakdowns. Additionally, Arnaout 49 proposed an event-based approach for unrelated parallel machines, focusing on minimizing the Minimum Weighted Cmax Difference (MWCD). Employing discrete event simulation for reactive scheduling, the model factored in uncertainties like machine disruptions and new job arrivals, with results indicating MWCD’s superiority across various processing and setup time scenarios.
A summary table of the relevant literature.
While existing methods in robust and dynamic scheduling have made significant strides, they exhibit several critical limitations necessitating the development of the proposed tool. One major shortcoming is the lack of real-time adaptability. Many traditional robust scheduling approaches, such as those using MILP techniques, are designed for static environments and fail to adjust effectively to real-time disruptions, leading to suboptimal performance when unexpected events occur. Furthermore, the computational complexity of these methods, particularly in handling large-scale problems, can be prohibitively high. Additionally, existing dynamic scheduling solutions often do not adequately address the inevitable need for user interactivity and engagement, which is crucial for effective decision-making in dynamic environments. Methods that rely heavily on static visualizations, such as Gantt charts, would typically lack the flexibility and intuitiveness required for real-time schedule adjustments. These limitations underscore the necessity for a new approach that combines proactive planning with reactive adaptability, enhanced by interactive graphical representations, to provide a robust, scalable, and user-induced scheduling solution capable of handling the dynamic nature of modern manufacturing environments.
This research devises an innovative scheduling tool designed specifically for dynamic parallel machine scheduling environments, markedly differing from traditional scheduling methodologies available in the relevant literature. Central to this innovation is a dual-phase strategy that combines proactive planning with reactive adaptability. At first, the tool explores and delineates a broad spectrum of potential schedules, employing a forward-looking stance that capitalizes on the anticipatory analysis of job slack times and machine availability. This is followed by a reactive phase, wherein the tool pivots in response to real-time operational disruptions, recalibrating and dynamically constructing schedules based on emergent data. A distinctive feature of the proposed tool is its integration of interactive graphical representations, which serve as a contemporary and dynamic alternative to conventional static Gantt Charts. These real-time visuals not only map out the selected schedule’s trajectory but also proactively signal the need for potential corrective actions, thereby substantially aiding in the decision-making processes. Furthermore, the tool’s design emphasizes user engagement and operational flexibility, offering both automated and manual options for schedule adjustments. Developed using Excel’s Visual Basic for Applications (VBA), the tool is crafted for ease of use, ensuring it can either stand alone or be integrated seamlessly within existing ERP systems. Through its distinctive features, the tool adeptly navigates the complexities of unforeseen events, bolstering the feasibility of schedules and enhancing decision-making efficacy in manufacturing operations.
This study bridges a shortfall in dynamic parallel machine scheduling environments via introducing a scheduling tool that integrates a unique proactive-reactive scheduling mechanism alongside a non-preemptive overlapping load adjustment approach, specifically tailored for identical parallel machine settings. This proposed tool marks a shift away from deterministic models commonly found in the current research, such as those proposed by De La Vega et al. 18 and Yanıkoğlu & Yavuz. 19 Our tool’s dual-phase nature is designed to proactively plan for and quickly adapt to potential disruptions, offering a flexible and robust alternative that improves upon traditional scheduling practices. This advancement allows for real-time schedule adjustments, highlighting a significant step forward in scheduling technology. Additionally, this work builds on the adaptive strategies suggested by Cohen et al. 20 and Novak et al., 21 which focus on reducing the impact of worst-case scenarios while considering uncertainties in task durations. These approaches are enhanced by adding a module that enables end-users to actively participate in making scheduling decisions based on up-to-date information. This feature ensures that schedules can be adjusted swiftly as changes occur. Building on the foundation of predictive-reactive scheduling methods identified by Baykasoğlu & Ozsoydan 33 and Juarez et al., 34 which deal with uncertainties such as order modifications and equipment failures, the approach proposed herein goes a step further. The provided solution is not only dynamic and adaptable but also user-friendly, routed in an interactive graphical interface. It facilitates active involvement from users in the scheduling process and improves the overall decision-making system.
Several gaps in existing studies are addressed, such as the lack of dual-phase scheduling solutions that both anticipate and react to disruptions, providing a more robust scheduling solution. The often-overlooked crucial role of end-user engagement in dynamic scheduling is also highlighted, an aspect that the tool caters for towards a more tailored and flexible scheduling process. Unlike classical tools that rely on static visualizations like Gantt Charts, the proposed approach employs interactive graphical displays for a more accurate and intuitive scheduling experience. Additionally, the tool’s scalability and flexibility are demonstrated through the computational experiments, addressing concerns present in previous studies.
Problem definition and description of the suggested scheduling methodology
Problem definition
Manufacturing processes are characterized by unpredictability and uncertainty, owing to their exposure to a broad spectrum of unforeseen events that can hamper or halt production. For instance, machines may temporarily cease to function during production due to breakdowns, or there may be a shortage of materials. In addition, production can be disrupted by order cancellations or delayed due to prolonged processing times. Such unexpected occurrences can severely impact a meticulously planned schedule, requiring prompt adjustments to avoid further delays. Conventional scheduling approaches rely merely on pre-existing data and do not account for the inherent instability of the manufacturing environment. Thus, static scheduling approaches, which aim to construct a single schedule beforehand without allowing for modifications to cater for the occurrence of unforeseen events, are highly inefficient and unsuitable for real-world dynamic scheduling scenarios.
In this study, we examine a set of jobs processed on three identical parallel machines. Each job has an estimated processing time in hours as well as ready and due dates. The objective is to develop an effective approach for scheduling jobs on the machines while accommodating changes in job attributes or machine availability as they arise. To that end, we propose a novel scheduling approach that divides the scheduling process into two separate phases, unlike the single-step approach used in traditional scheduling.
In the first phase, via an adaptation of the overlapping load adjustment approach presented in the next subsection, we use the given (estimated) data to establish a time window for scheduling each job. This enables the characterization of a set of potential solutions without creating an actual schedule. The second phase builds actual schedules dynamically over time and offers the end-user different scheduling options that account for the occurrence of unforeseen events.
The proposed scheduling approach is implemented as a semi-automated decision support tool that incorporates a dynamic, event-driven, and user-induced module. The developed tool progressively provides various schedule alternatives based on updated (actual) information, allowing the end-user to choose the most suitable alternative to implement on the shop floor. The efficacy of the proposed scheduling strategy will be assessed through a series of experiments measuring both the flexibility and the quality of the schedules produced. Flexibility will be gauged through evaluating the number of scheduling alternatives generated by the developed tool for the end-user, where a higher number of alternatives indicates greater flexibility. To assess the quality of the schedules, two criteria will be considered: the maximum completion time, and the number of tardy jobs.
An overlapping load adjustment-based scheduling solution
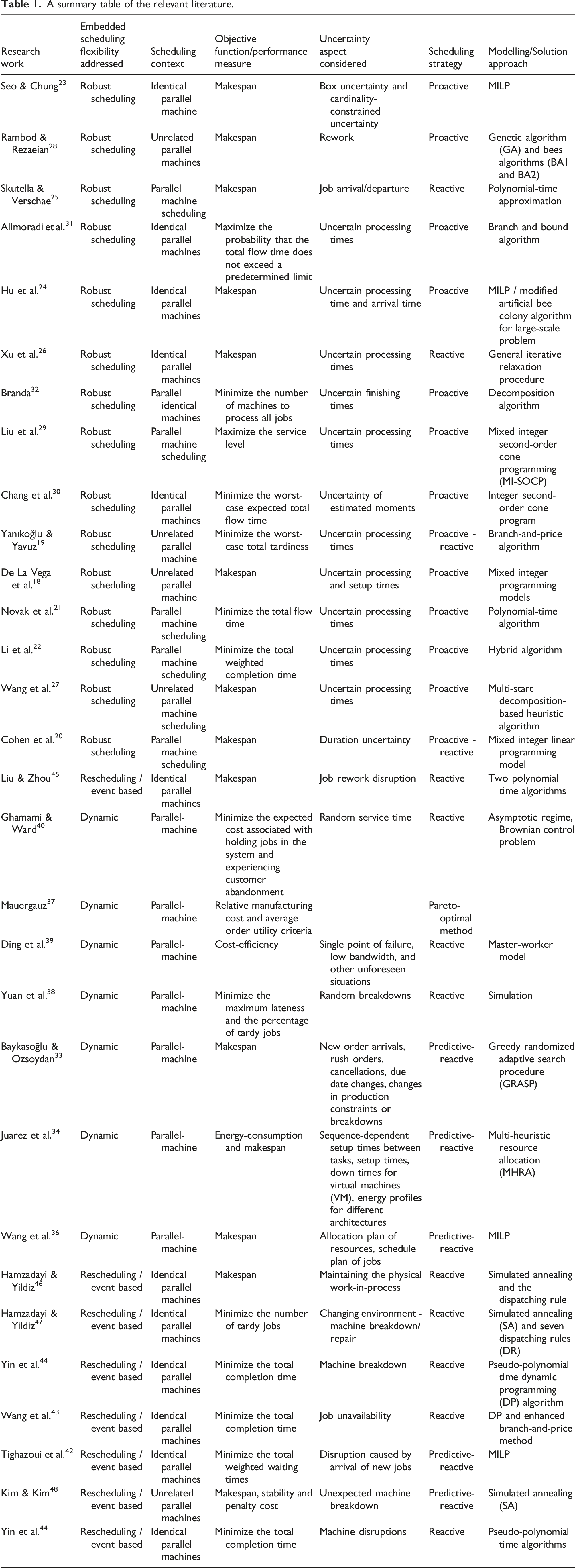
The Overlapping Load Adjustment Approach (OLAA), first introduced by Dillenseger,
50
is a method applied in dynamic single-machine and make-to-order production environments. This approach divides the planning horizon into equal intervals, each characterized by specific capacity and load metrics, essential for integrating new orders into existing schedules. Key elements of the OLAA include: • • •
For an elaborate discussion on the mechanism of the OLAA along with a detailed numerical example, interested readers are referred to the work of Bahroun et al. 51 In this paper, we introduce a flexible scheduling tool that utilizes the non-preemptive variant of OLAA to navigate the challenges of scheduling dynamic parallel machines. Initially, we distribute the jobs among three parallel machines, detailing the method for this assignment in Section 4.2. The OLAA technique, restricts preemption to one job per period. However, the tool developed in this study simulates a more realistic scheduling scenario where job interruptions are infeasible, mirroring many industrial processes like heat treatment. We assess the efficacy of both flexible and non-preemptive scheduling approaches for dynamic parallel machine scheduling settings, an area previously unexplored quantitatively to the best of the authors’ knowledge.
It is noted that the tool operates on a dynamic event scheduling module, giving the user full control over its operation. It creates schedules dynamically and progressively, allowing the decision-maker to select one job from the pool of available jobs for processing at the end of each task. This selection is based on up-to-date information or disruptions. The tool generates CRP (Capacity Requirement Planning) and FCG (Feasibility Control Graph) reports to evaluate the feasibility of the solution and to identify infeasible solutions, specifically when the cumulative capacity surpasses the cumulative load. Furthermore, it suggests alternative solutions to the user, prioritizing feasibility, efficiency, and adaptability. Ultimately, the decision on which alternative to choose is left to the user’s discretion.
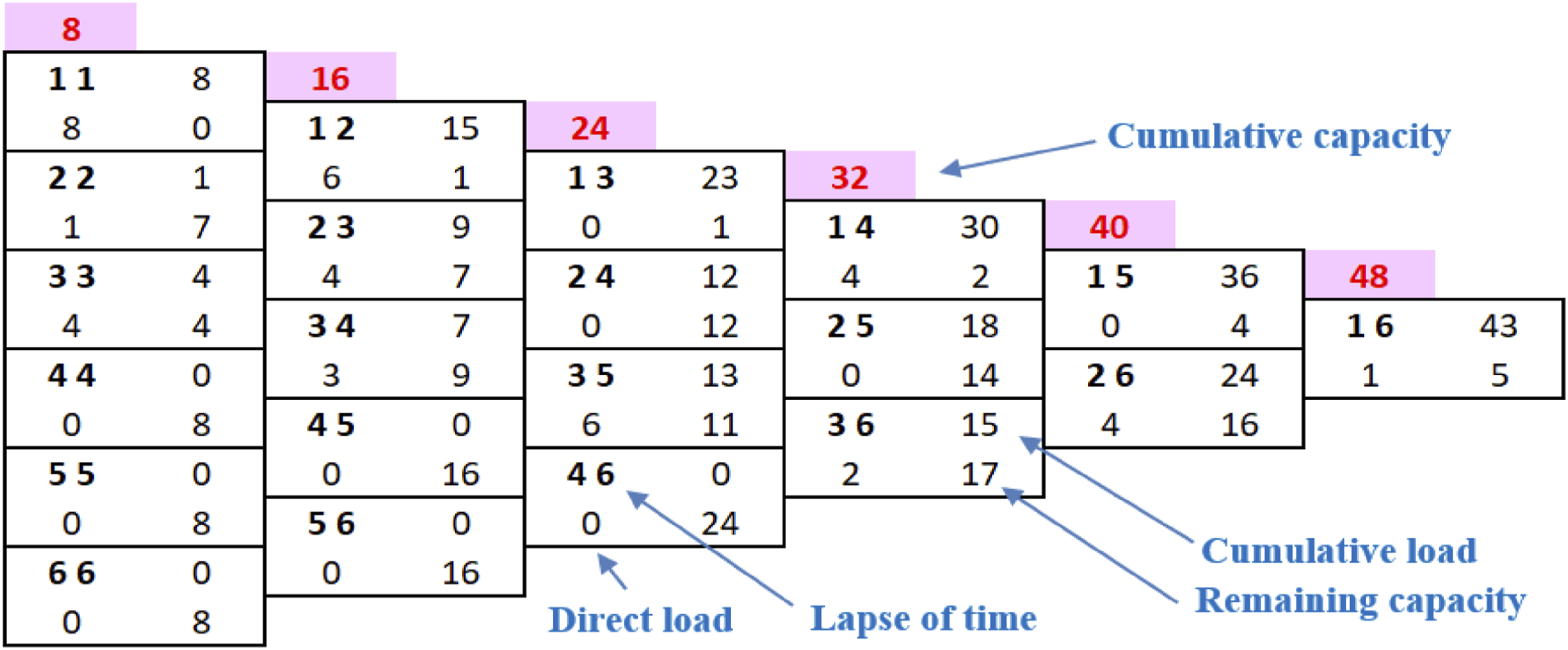
The flexible scheduling tool, developed in Microsoft Excel VBA, manages a list of current and/or upcoming jobs, each characterized by estimated processing times, start dates, and end dates. The tool’s mechanism is depicted in the flowchart given in Figure 1. Notably, we have encapsulated this approach in the form of a pseudocode, designated as Algorithm 1, to facilitate a better comprehension of the process. The initial step involves generating CRP (Capacity Requirement Planning) and FCG (Feasibility Control Graph) graphs to verify the feasibility of a proposed loading solution, without finalizing any schedules (Phase 1). The actual schedule construction takes place in the second phase, incorporating the latest relevant information. Starting with the first period, the user selects one of the jobs that can be loaded during that timeframe. When multiple tasks are available, priority dispatching rules are applied, and the tool typically favors the job(s) with the shortest scheduling intervals, considering them to be the most urgent. In situations where jobs have equal priority, it is recommended to begin with the lengthier tasks, thereby preserving flexibility for the end of the period by reserving shorter jobs for later. Flowchart of the scheduling tool for the parallel machine problem.
The end-user may adhere to these dispatching rules, but ultimately retains the final decision in selecting from the loadable jobs. Since tasks may extend over multiple periods, the decision to initiate a job is made either at the beginning of a period or upon the completion of a specific task. If unforeseen circumstances impede the start of a job, the decision-maker is offered alternative options to preserve the feasibility of the CRP. After completing period 1, the user moves on to period 2, repeating the process and continuing this real-time job allocation across all periods until the full schedule is established.
The developed tool closely aligns with the unpredictability of real-time scheduling by dynamically planning jobs as the scheduling horizon advances. It operates by promptly updating the CRP and FCG when selecting the next job to load. This process assesses the feasibility of various choices, at all times, and opts for the most suitable one. Consequently, once a job is loaded, its scheduling interval is adjusted to match the period(s) in which it will be processed.
The developed tool is well-suited to the unpredictability of real-time scheduling, dynamically planning jobs as the scheduling horizon progresses. It operates by promptly updating the CRP and FCG upon selecting the next job to be loaded. This process continuously assesses the feasibility of various options, always opting for the most suitable one. Consequently, once a job is loaded, its scheduling interval is adjusted to align with the period(s) during which it will be processed.

In case selecting a job leads to an infeasible FCG due to negative remaining capacity in specific lapses, the tool offers two resolution strategies. The first strategy involves manual correction, where users can either add capacity over time or delay specific processes to eliminate negative remaining capacities. The second strategy is automatic correction, wherein the system identifies tasks with scheduling intervals that end at the close of lapses exhibiting negative remaining capacity. It then ranks these tasks by decreasing task load and automatically extends the scheduling intervals for the minimum necessary number of tasks to eliminate negative capacity, thereby minimizing job postponement and resolving infeasibility.
In the manufacturing industry, scheduling approaches must adeptly handle a myriad of disruptions to maintain operational efficiency and meet production deadlines. The proposed novel scheduling tool is designed to address several critical types of disruptions that commonly impact parallel machine environments. These include (1) unexpected machine breakdowns, which necessitate immediate schedule adjustments to redistribute tasks among operational machines; (2) job delays due to late material arrivals or unforeseen job complexities, requiring real-time rescheduling to minimize impact; (3) order cancellations and modifications, where the tool flexibly alters or removes jobs from the schedule to reflect updated requirements; (4) urgent job requests, integrating high-priority tasks into existing schedules without significant disruption; and (4) variability in job processing times, which calls for adapting schedules to accommodate actual processing times that deviate from initial estimates. This comprehensive approach to managing disruptions through a proactive-reactive scheduling mechanism not only enhances the tool’s applicability in real-world manufacturing settings but also significantly contributes to its robustness and flexibility. By incorporating various disruption types into the scheduling tool, we offer a solution that goes beyond anticipating potential scheduling challenges to provide practical strategies for overcoming them, thereby ensuring that manufacturing processes remain as uninterrupted and efficient as possible.
Figure 2 demonstrates how the tool accommodates such scenarios. It integrates machine breakdowns or delays into the CRP and FCG, facilitating an impact analysis with the updated FCG. Based on the analysis of remaining capacity, if all lapses maintain positive remaining capacity, no action is necessary. However, if any lapse displays negative remaining capacity, users have the option of choosing either manual or automatic correction, either by delaying tasks or by adding extra capacity. This decision-making process, aligned with accommodating such contingencies, has been methodically translated into a pseudocode, delineated as Algorithm 2, to explain the adaptive scheduling mechanism that the tool provides. Integrating unplanned machine failure or delays into the schedule.
The tool’s adeptness at incorporating unexpected events into dynamic scheduling accurately mirrors the real-world challenges of manufacturing scheduling. Appendices B and C present a detailed numerical example that clearly illustrates the tool’s practical scheduling capabilities, providing a step-by-step overview of its functionality.

The selection of heuristics and algorithms for the proposed scheduling tool is grounded in the need to balance computational efficiency, adaptability, and ease of implementation in dynamic parallel machine environments. The proactive-reactive scheduling mechanism was chosen because it effectively addresses both the anticipation of potential disruptions and the need for real-time adjustments, which are crucial in dynamic manufacturing settings. The heuristic approach for job allocation, based on priority rules, ensures a balanced distribution of the workload across multiple machines while maintaining computational simplicity. In addition, the OLAA approach is very effective in handling dynamic scheduling aspects with an inherent focus on feasibility and flexibility. This approach, integrated with non-preemptive scheduling, aligns well with real-world constraints where job interruptions are often infeasible. The decision to use a hybrid algorithm combining proactive and reactive phases allows for the creation of robust baseline schedules that can be dynamically adjusted as new information becomes available. In contrast to more complex and computationally intensive methods, such as MILP models, the developed approach prioritizes scalability and real-time applicability. While MILP models offer exact optimization, they are often impractical for large-scale, real-time applications due to their high computational time requirements. Our heuristic and algorithmic choices strike a balance between optimality and practicality, ensuring that the tool can generate high-quality schedules efficiently, even under dynamic and uncertain conditions.
Performance analysis of the proposed scheduling tool
It is crucial to assess the effectiveness of the scheduling tool presented in the previous section in order to highlight the quality of the generated schedules and to emphasize the scheduling flexibility that the tool provides to the decision-maker. For the situation involving three identical parallel machines, 200 benchmark test instances with 24, 36 and 48 jobs are generated at random. The simulation process is run for each instance, where the number as well as the quality of the suggested schedules are recorded. Note that the quality of the schedules is evaluated through benchmarking with the results of the mathematical programming approach for 2 distinct performance measures: maximum completion time and the number of tardy jobs. These mathematical models are fully described in Appendix A. Second, in terms of flexibility, an algorithm is constructed that generates a large variety of non-preemptive feasible schedules based on validated CRP and FCG, as detailed in Section 4.1.
Schedules generation
Before generating schedules, job allocation to parallel machines is determined through a heuristic approach using priority rules. This process involves ranking the jobs in an increasing order of their ready dates and then descending order of their durations, followed by assigning the ranked jobs to the machine with the lowest total workload until all jobs are allocated, ensuring fair distribution of the workload across the machines. Then a feasible schedules generation algorithm is used to generate feasible schedules for each machine. Algorithm 3 has been developed to create a large number of non-preemptive feasible schedules by utilizing both the ready dates and due dates of the jobs, extracted from the validated CRP and FCG. The aim of this algorithm is to mimic the tool’s capability of providing the end-user with a broad selection of feasible options. Nevertheless, it is important to point out that when the tool is employed to address real-life problems, a single schedule is gradually built during the reactive phase. At the completion of each task, the tool will present a set of alternative solutions for the next task to be loaded and the end-user will make a selection.
The algorithm has been inspired from the algorithm’s basic principle is to create first groupings of jobs RD that have the same ready dates. The algorithm then creates all feasible permutations of the jobs in each set of jobs RDi (made out of jobs having the same ready date

Illustrative example for assessing the performance of the scheduling tool
An illustrative example of the overlapping approach for the three parallel machines problem.

Processing time, ready and due dates (machine 1).

Processing time, ready and due dates (machine 2).

Processing time, ready and due dates (machine 3).

The allocation of jobs to the three parallel machines follows the heuristic described in Section 4.2. This approach seeks to attain, to the best extent possible, an even distribution of workload across the different machines. Referring to Table 2, the total workload amounts to 128 h, based on the cumulative processing time of all jobs. Dividing this total by three yields approximately 42.67 h, suggesting the ideal load of each machine for a perfectly balanced schedule. The efficacy of the tool is evidenced in Tables 3–5, showing the first and second machines bearing a 43-hour load and the third machine with a 42-hour load. Moreover, the distribution of recurring ready dates, such as 1, 2, and 3 days, is relatively even across all machines. Additionally, we calculate the total margin (in days) for each job by subtracting the rounded-up number of periods required to complete the job from the length of the scheduling time window. For example, the total margin for Job C is 1 day, which is equal to the total scheduling time window (2 days) minus the number of days required for its completion (1 day, as it requires 4 h of processing time, rounded up to 1 day). The same concept is applied to the rest of the machines displayed in Tables 3–5.
The Capacity Requirement Planning (CRP), illustrating the scheduling time window for each job, is shown in Figure 3, specifically for the first parallel machine. To illustrate, consider Job C, which requires 4 h of processing time, and it can be scheduled at any time between days 1 and 2. Figure 4 exhibits the Feasibility Control Graph (FCG), a tool used to evaluate the viability of the allocation solution. Capacity requirement planning (CRP). Feasibility control graph (FCG).
Summary of the example results for machine 1.

Summary of the example results for machine 2.

Summary of the example results for machine 3.

The best solution generated for the first machine is a schedule that achieves a maximum completion time (Cmax) of 43 h without any tardy tasks. Out of the 100,000 schedules generated, 97,408 of them share the same Cmax of 43 h with no tardy jobs. Table 6 presents a summary of these schedules’ descriptive statistics. The minimum, maximum, and average Cmax values recorded are 43, 44, and 43.03 h, respectively, with a notably low standard deviation of 0.159 h. This indicates that the majority of the schedules closely align with the minimal Cmax value of 43 h. Among the 100,000 schedules generated, the total number of tardy jobs varies between 0 and 11, averaging at 5.98 with a standard deviation of 1.837. Notably, 5184 of the generated schedules do not contain any tardy jobs.
For the second machine, the best solution achieved a maximum completion time (Cmax) of 43 h with no tardy jobs. Within the 100,000 schedules generated, 95,392 maintain a Cmax of 43 h without any tardy job. An overview of these schedules’ descriptive statistics is presented in Table 7. The recorded minimum, maximum, and average Cmax values are 43, 46, and 43.12 h, respectively, with a standard deviation of 0.556 h. Considering the entire set of 100,000 generated schedules, the total number of tardy jobs varies between 0 and 9, with an average of 5.56 and a standard deviation of 1.594. Note that out of the 100,000 schedules created, 2304 schedules are not tardy.
For the third machine, the best-generated solution is a schedule achieving a maximum completion time (Cmax) of 42 h without any tardy jobs. Out of the 100,000 schedules generated, 3880 have a Cmax of 42 h and zero tardy jobs. The descriptive statistics of these schedules are outlined in Table 8. The observed minimum, maximum, and average Cmax values are respectively 42, 48, and 46.15 h, with a standard deviation of 2.772 h. Across the 100,000 schedules, the total number of tardy jobs varies between 0 and 6, with an average of 0.93 and a standard deviation of 1.47. Remarkably, 69,120 of the generated schedules do not include any tardy jobs.
For the optimal schedules, the three machines yielded similar results with optimal Cmax values of 43, 43, and 42, respectively. Figure 5 displays a sample of the best-generated schedules (highlighted in yellow) alongside other schedules. However, Machine 2 yielded the best results, having the least number of tardy schedules and a completion time of only 43 h. This example illustrates that once a validated CRP is in place, a variety of viable scheduling solutions become accessible. The primary advantage is the ability to develop a schedule that evolves dynamically, incorporating any unforeseen events on the shop floor, rather than relying on a predetermined schedule that may become outdated during the implementation stage. A sample of the generated schedules.
Experimental analysis
In this section, extensive computational experiments are performed which encompass 600 test instances of three different sizes in order to evaluate the performance of the scheduling tool for three identical parallel machines. Inspired by the methodology of Sels and Banjouke, 52 these instances are categorized into small size (200 instances of 24 jobs, averaging eight per machine), medium (200 instances of 36 jobs, 12 per machine), and large (200 instances of 48 jobs, 16 per machine). This range of job numbers better resembles real-world scenarios, reflecting a typical week’s production orders scheduling in a manufacturing company.
In the generation of these test instances, the following procedure is adopted: • The scheduling timeframe spans 10 working days. • Each machine’s workload approximates 8 h per day. • Working days are divided into eight one-hour segments. • Job processing times vary randomly: 1–8 h for small instances, 1–5 h for medium instances, and 1–4 h for large instances. The processing times are uniformly distributed within the specified ranges for each instance size. • The ready date for each job is randomly set within a range, starting from day 1 to a maximum determined by multiplying the total job processing time by a coefficient “a” (set at 0.09). The ready dates are generated using a uniform distribution within the specified range. • Each job’s deadline is also randomly determined, ranging from its ready date to a maximum calculated by multiplying the total processing time by a second coefficient “b,” set at 0.14, 0.125, and 0.16 for small, medium, and large instances, respectively. The due dates are generated based on a uniform distribution from the ready date to the calculated maximum deadline using the coefficient “b.”
The following steps will be undertaken for each instance:
We then calculate the average, median, standard deviation, maximum and minimum values among all instances of the small, medium, and large sizes for each of the following measures, as shown in Tables 9 and 10: • The number of schedules that can be generated based on each instance’s CRP. • The number of best generated schedules. • For each instance, the percentage of best solutions compared to all created solutions. • For each instance, the minimum Cmax value obtained through all the generated schedules (optimal solution). • For each instance, the maximum Cmax value obtained through all the generated schedules. • For each instance, the average Cmax value obtained through all the generated schedules. • For each instance, the standard deviation of the Cmax across all the schedules generated. • The optimal Cmax obtained by running the instance using the first mathematical model on Cplex. • The percentage gap between the average Cmax and the optimal Cmax values. Experimental results for the makespan (Cmax). Experimental results for number of tardy jobs.
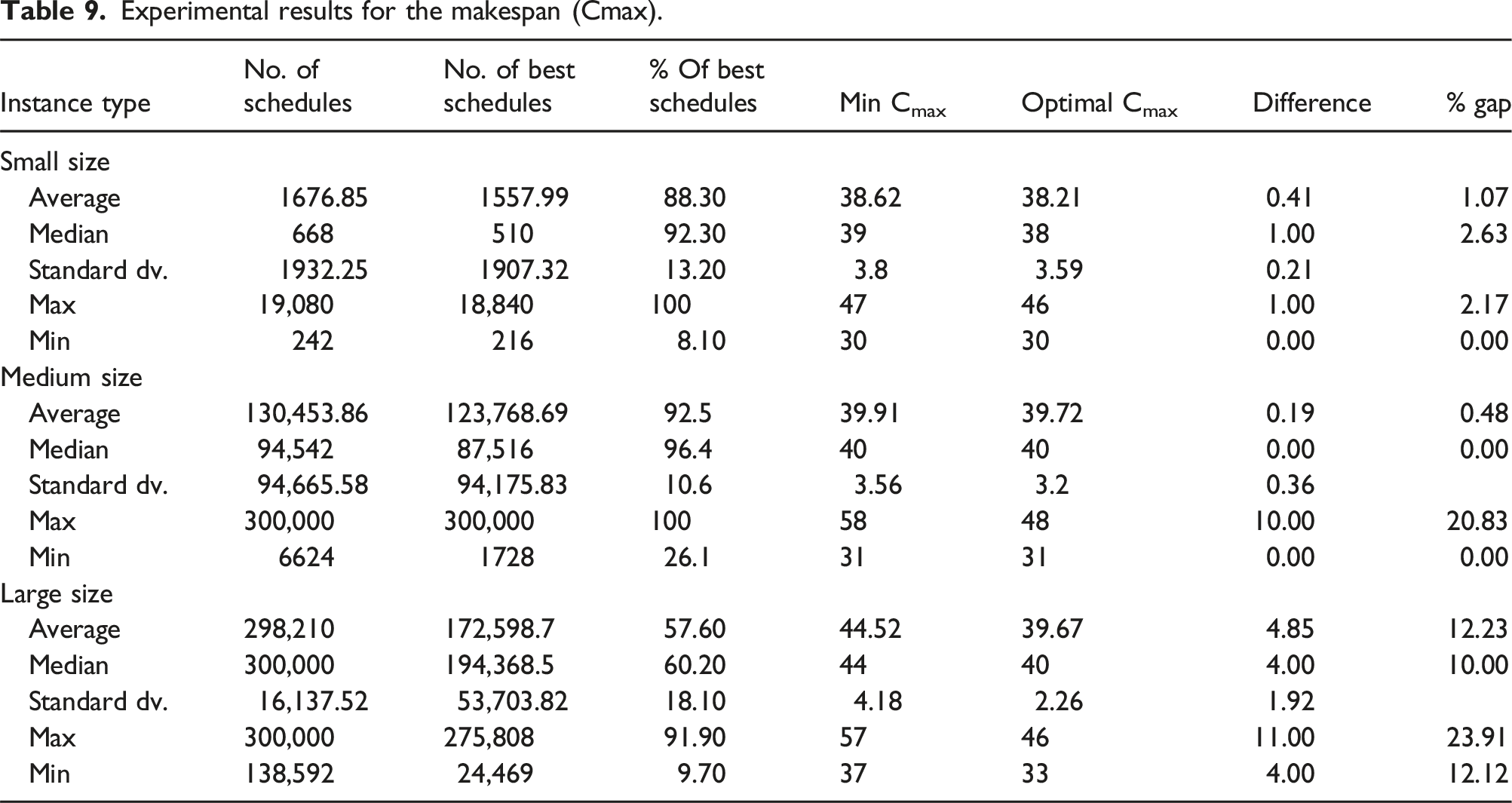

For the medium-sized instances, for example, 200 test instances were randomly generated, each comprising 36 jobs distributed as 12 jobs per machine. To determine the number of schedules generated for an instance, we added the schedules from all three machines. As Table 9 indicates, the average number of schedules for an instance is equal to 130,453 derived from 720, 4032, and 1872 schedules for machines 1, 2, and 3, respectively. Conversely, the maximum is 300,000 schedules, with each machine being limited to 100,000. The average number of schedules generated across the 200 instances is 130,453.86, with a median of 94,542.
The best generated schedules are those with the shortest completion time (Cmax). For each instance, the best schedules are those from the three machines that have the minimum Cmax. The average Cmax across the 200 instances is 123,768.7. The percentage of optimal schedules per instance is calculated by dividing the number of best schedules by the total schedules generated for all three machines. On average, 92.5% of the schedules are optimal across the 200 instances, with a standard deviation of 10.6%. These findings demonstrate the tool’s effectiveness in consistently generating schedules with the lowest Cmax. The large volume of schedules produced by the tool clearly highlights its considerable flexibility, providing numerous alternative scheduling options for the end-user.
Additionally, Table 9 indicates that the average of the lowest Cmax across the 200 instances is 39.91 h. This was calculated by first identifying the highest of the minimum Cmax values from the three machines for each instance, and then averaging these values across all instances. To confirm the minimal completion time, the Cplex optimizer was used to determine the optimal Cmax, which averaged 39.72 h. The difference between these two measurements is simply the optimal Cmax minus the minimum Cmax.
The average gap percentage between the mean Cmax of all solutions for each instance and the optimal solution varies, ranging from 1.07% for small-sized instances to 0.48% for medium-sized and 12.23% for large-sized instances (as detailed in Table 9). This range effectively demonstrates the high quality of the solutions generated by the scheduling tool. Additionally, Table 9 confirms this finding by showing that most instances exhibit a low standard deviation in Cmax across all generated solutions for each instance. Additionally, for each instance type, Table 9 displays both the number and percentage of the best-generated schedules. On average, these percentages are approximately 88% for small, 92% for medium, and 57% for large instances. This further exemplifies the high quality of solutions produced by the scheduling tool, which is also evidenced by the low average standard deviation in the completion time (Cmax) across all instance types.
Similarly, the average, median, standard deviation, maximum and minimum number of tardy jobs are depicted in Table 10 for each type of instance. It should be emphasized that the optimal solutions were found by running the second model through the Cplex optimizer. For medium-sized instances, for instance, the average number of tardy schedules over the 200 instances is 7634.45, which represents only 7.97% of the total number of schedules. The average number of tardy jobs is equal to 1.28 jobs compared to 0.25 jobs for the optimal solutions.
The average number of tardy jobs, along with their standard deviation, remains notably low for small-sized instances (1.28; 1.13), with a modest increase to (1.87; 0.25) for medium-sized instances, and further to (2.07; 1.96) for large instances. This indicates that even with a substantial number of possible scheduling solutions, reaching up to 300,000 for large-sized instances, the generated solutions maintain an acceptable level in terms of number of tardy jobs. These findings underscore the high quality of the scheduling options concerning the number of tardy jobs. Notably, the average number of tardy jobs remains within acceptable limits, despite the extensive range of schedules generated.
A comparative analysis of the tool’s performance across different instance sizes (small, medium, large) reveals notable trends and patterns that highlight its effectiveness and adaptability. The computational experiments conducted on 600 test instances show that the tool generates an extensive spectrum of scheduling alternatives, averaging from 1676 for small-sized instances to 298,210 for large-sized ones. This wide range demonstrates the tool’s capability to handle varying levels of complexity and workload efficiently. In terms of the average maximum completion time (Cmax), the tool closely mirrors the results obtained from the Cplex optimizer, with deviations of 1.07% for small, 0.48% for medium, and 12.23% for large instances. This indicates that the tool is quite efficient when it comes to minimizing Cmax, particularly for small and medium-sized instances. The larger deviation observed in large instances suggests that as the problem size increases, the complexity and variability of the scheduling alternatives also rise, potentially impacting the tool’s ability to consistently achieve near-optimal solutions. Additionally, the average number of tardy jobs remains low across all instance sizes, with 1.28, 1.87, and 2.07 for small, medium, and large instances, respectively. This consistency underscores the tool’s ability to minimize delays and yield high quality schedules even as the instance size grows. The tool’s performance in generating numerous scheduling alternatives ensures that end-users have plenty of viable options to choose from, enhancing flexibility and decision-making capabilities in dynamic environments.
In addition, the findings indicate that the computational time required by the tool is notably minimal, ranging from seconds for small instances to a few minutes for larger instances. Such low computational times demonstrate the tool’s capability to provide timely solutions, making it practical for use in dynamic and fast-paced manufacturing environments.
In this study, the comparison with the solutions of the MILP models seeks to establish a meaningful benchmark for evaluating the effectiveness of the proposed scheduling tool, particularly in the context of dynamic scheduling environments. In particular, the aim is to demonstrate that the proposed tool, which is tailored to handle the dynamic and uncertain nature of manufacturing operations, can still generate solutions that are competitive in terms of key performance metrics, such as maximum completion time (Cmax) and the number of tardy jobs. This benchmarking approach underlines the unique contribution of the tool to the field of dynamic scheduling. Via enabling the generation of multiple feasible scheduling alternatives and providing a mechanism for real-time adjustments in response to unforeseen disruptions, the tool offers a practical, adaptable, and efficient solution for modern manufacturing systems. The results from the extensive computational experiments illustrate close alignment between the average maximum completion time and the average number of tardy jobs generated by the tool and the benchmarks obtained from the Cplex optimizer. This highlights the tool’s capability to balance flexibility and robustness while enhancing operational efficiency in environments characterized by uncertainty and frequent disruptions.
The performance analysis of the proposed scheduling tool reveals its robustness and flexibility to cater for various scenarios, particularly in environments characterized by dynamic and uncertain conditions. The tool’s performance can be attributed to several key factors. Firstly, the proactive-reactive scheduling mechanism allows for the anticipation of potential disruptions and quick adaptation to real-time changes, ensuring continuous feasibility whilst minimizing the impact of unforeseen events. This dual-phase approach enables the tool to generate a broad spectrum of scheduling alternatives, providing end-users with multiple options to select the most suitable schedule. Secondly, the characteristics of the jobs play a significant role in the tool’s efficiency. For instance, jobs with higher slack times provide greater flexibility in scheduling, allowing the tool to better accommodate disruptions without compromising the overall schedule. Additionally, the tool’s ability to handle varying job processing times, ready dates, and due dates ensures that it can adapt to different job profiles while maintaining high scheduling quality. Thirdly, machine availability and the distribution of workload across machines contribute to the tool’s effectiveness. Via using a heuristic approach to allocate jobs to machines based on priority rules and workload balancing, the tool ensures an even distribution of tasks, which enhances overall system performance. The integration of CRP and FCG graphs further aids in maintaining feasible schedules by providing real-time graphical displays and facilitating informed decision-making. Lastly, the extensive computational experiments demonstrate that the tool consistently generates high-quality schedules, with a low average number of tardy jobs and minimal deviations from optimal completion times. This is evident from the close alignment between the average maximum completion time (Cmax) and the results obtained from the Cplex optimizer, indicating the tool’s capability to generate competitive solutions while offering the flexibility needed to handle dynamic scheduling environments.
During the computational experiments, a few outliers and unexpected results were observed, particularly in the large-sized instances. One notable outlier was the deviation in the average maximum completion time (Cmax) for large instances, which reached up to 12.23%, compared to much smaller deviations for small and medium instances (1.07% and 0.48%), respectively. This larger deviation can be attributed to the increased complexity and variability associated with scheduling a greater number of jobs. As the size of the instance increases via the incorporation of additional jobs, the scheduling tool must then manage significantly higher potential conflicts and dependencies, which could partially impact the tool’s capability towards achieving optimal solutions. Another unexpected result was the occasional higher number of tardy jobs in specific large instance scenarios. While the average number of tardy jobs remained low (1.28 for small, 1.87 for medium, and 2.07 for large instances), certain large instances exhibited a slightly higher count of tardy jobs. This anomaly can be linked to the distribution of job processing times and the stochastic nature of job arrivals and deadlines. In some large instances, a clustering of jobs with similar due dates or longer processing times may have caused temporary bottlenecks, leading to delays and eventually an increase in the number of tardy jobs. In addition, the computational time for some large instances occasionally spiked beyond the average of 1–2 min. These spikes were primarily due to the tool’s efforts to explore and evaluate an extensive set of scheduling alternatives in quest of high-quality solutions. When the scheduling problem becomes more complex, with several interdependent tasks coupled with tight deadlines, the tool requires additional time to process and optimize the schedules.
Novelties and limitations of the proposed scheduling tool
This study introduces a dynamic scheduling tool tailored for parallel machine environments, addressing the evolving challenges characterizing today’s manufacturing organizations. Traditional scheduling methods, which develop complete production schedules in advance, fall short in dynamic conditions whereby material shortages, unexpected orders, or machine failures are likely events. The novelties of the tool proposed in this work are briefly listed below: • Proactive-Reactive Approach: Offers a novel two-phase scheduling method, balancing pre-planning with reactive adjustments. • Dynamic Scheduling: Facilitates real-time scheduling of jobs, including new job arrivals, while accommodating unexpected events. • Graphical Interface: Utilizes CRP and FCG for a dynamic, user-friendly experience and as an innovative alternative to traditional static Gantt Charts. • Ease of Integration: Coded in Microsoft Excel VBA for easy adoption as a standalone tool or via integration into existing ERP systems. • Flexibility and Robustness: Extensive computational experimentation illustrated both aspects through generating a large number of high-quality schedules across 600 test instances of various sizes.
Despite the above novelties, the tool suffers from the following limitations: • Proactive Phase: Relies on predicted processing times, which may not accurately reflect real-time conditions in the presence of frequent disturbances. • Reactive Phase Challenges: Managing a high number of machines or jobs may complicate decision-making due to the abundance of scheduling alternatives.
The proposed decision support tool marks a significant advancement in managing parallel machine scheduling environments, offering a flexible and dynamic solution that aligns well with the realities of modern manufacturing processes.
In this paper, the extension of proactive scheduling strategies from single-machine contexts to cater for the complexities associated with parallel machine environments is presented, which is still inspired by the OLAA approach for single machines. Specialized heuristic rules and optimization algorithms have been developed, tailored for scheduling tasks across multiple parallel machines while addressing the challenges posed by the increased complexity and inherent interdependencies. Unlike the original approach that included preemption, the adaptations made for parallel machines incorporate non-preemptive scheduling to better suit real-world scenarios where preemption is not permissible. Innovative coordination strategies that optimize job distribution have been incorporated, minimizing completion times and tardy orders. Through rigorous computational experiments in the context of parallel machines, it has been demonstrated that these methodologies significantly improve scheduling efficiency and flexibility.
Concluding remarks and directions for future research
In this study, a dynamic and flexible proactive-reactive scheduling tool for parallel machine environments has been introduced, based on a non-preemptive variant of the overlapping load adjustment approach. Feasible schedules are characterized in the tool’s proactive phase by leveraging job margins, without the establishment of any fixed schedules. In the reactive phase, the progressive construction of a short-term schedule is facilitated, with the flexibility being provided to end-users to select tasks from a range of available options, particularly in response to unforeseen events. Real-time assessment and decision support are offered through interactive graphical displays, such as CRP and FCG, thereby enhancing the tool’s capability to be monitored and dynamically adapted. Developed in Microsoft Excel VBA, the tool can be seamlessly integrated into existing ERP systems or scheduling software, representing a dynamic alternative to traditional static Gantt charts. It is found to be especially well-suited for managing schedules in dynamic and fast-paced parallel machine environments.
The computational experiments conducted on 600 instances of small, medium, and large sizes have clearly demonstrated the efficiency of the scheduling tool in handling parallel machine scheduling problems. Notably, for medium-sized instances, the average number of schedules generated was 130,453.86, indicating a wide range of scheduling scenarios. The tool proved its efficiency, with an average of 92.5% of the schedules being optimal. The average minimum Cmax was closely aligned with the results from the Cplex optimizer, showing a minor difference of only 0.19 h. Furthermore, the low average number of tardy jobs per instance reflected the tool’s scheduling accuracy. The additional results obtained underscore the tool’s robustness and adaptability in managing complex, real-world manufacturing schedules. In particular, the average gap percentage between the mean Cmax of all solutions and the optimal solution showed acceptable values (1.07% for small, 0.48% for medium, and 12.23% for large instances). This is further supported by the low standard deviation in Cmax for each instance type. These statistics collectively demonstrate the tool’s ability to consistently produce high-quality scheduling solutions.
A comprehensive analysis was conducted on the tardiness of jobs for each instance type, and the optimal solutions obtained through the Cplex optimizer show that, for medium-sized instances, for example, the average number of tardy schedules equals 7.97% of the total. This equates to an average of 1.28 tardy jobs, which is close to the 0.25 tardy jobs obtained from the Cplex optimizer. Across the various instance sizes, the average number of tardy jobs remains low: 1.28 for small, 1.87 for medium, and 2.07 for large instances, all with low standard deviations. This pattern is maintained even with up to 300,000 potential scheduling solutions for large instances, which highlights consistency in generating high-quality solutions. The findings reveal that, despite the diversity in the generated schedules, the average number of tardy jobs remains within reasonable limits, underscoring the effectiveness of the scheduling tool in this aspect.
Future research directions could include several enhancements to further improve the tool’s scalability, adaptability, and applicability. First, scalability enhancements could expand the tool to accommodate more complex parallel machine environments with an increased number of machines and jobs. This can be achieved by optimizing the heuristic algorithms and leveraging parallel processing techniques to manage larger datasets more efficiently. Another avenue for future research is the integration of machine learning techniques to predict disruptions and learn from historical scheduling data towards enhancing the tool’s adaptability and robustness. Through the use of predictive analytics, the tool can better anticipate potential issues and adjust schedules proactively. Furthermore, developing machine learning-based decision support systems that provide real-time recommendations to users based on patterns and trends identified in the data can improve the accuracy and efficiency of scheduling decisions. Extending the tool to handle different types of scheduling problems, such as job shop scheduling, flow shop or hybrid flow shop scheduling, would broaden its applicability across various manufacturing and service industries. Additionally, exploring the integration of the tool with other scheduling environments, such as project management and workforce scheduling, could provide a versatile solution for diverse operational needs. Enhancements to the user interface and customization options are also important future extensions. Improving usability and customization options includes developing intuitive dashboards, customizable scheduling views, and interactive features that cater to specific industry needs. Incorporating user feedback mechanisms to continuously improve the tool based on real-world usage and user experiences will ensure it remains relevant and effective in addressing industry challenges. Lastly, expanding the range of performance metrics used to evaluate the tool’s impact on production efficiency, cost savings, and delivery timeliness will provide a deeper understanding of the tool’s effectiveness and identify areas for further improvement.
Footnotes
Acknowledgements
The authors acknowledge the support of the American University of Sharjah under the Open Access Program. This paper represents the opinions of the authors and does not mean to represent the position or opinions of the American University of Sharjah.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research supported by the American University of Sharjah FRG Grant N° FRG16-R-19.
Disclaimer
The authors express their gratitude to Yasmin Elshaarawy and Benita Davy, undergraduate students, for their assistance in conducting the literature review.
Mathematical models
In this appendix, we introduce the mixed-integer linear programming formulations for the two previously mentioned quality performance indicators. We then proceed to compare the results generated by these mathematical models versus those obtained from the scheduling tool. Below, we present the notation used in these models, followed by the two specific models: minimization of the completion time of the last job (Cmax) and minimization of the number of tardy jobs.
Indices:
i Index for job, where
j Index for the position in the sequence, where
k Index for machine, where
Parameters:
p
i
Processing time of job
r
i
Release/ready date of job
d
i
Due date of job
Decision variables:
An example illustrating the tool’s dynamic schedule build-up feature
This appendix provides a numerical example based on the data shown in Table 2. We have divided the instance of 48 jobs into three sets of equal loads, each to be handled by one of the parallel machines. In what follows, Machine 1 is being used to illustrate the step-by-step development of the schedule, a key feature of the scheduling tool. This detailed walkthrough, despite its length, aims to clearly mimic the tool’s application in real-world dynamic parallel machine scheduling scenarios. As described in Section 3, scheduling is dynamic, building progressively over time until all jobs are allocated.
To showcase the tool’s ability to progressively build schedules, Figure 6’s CRP indicates that seven jobs are available for initial loading. This suggests starting with any of the following jobs: C1, P1, k1, t1, b1, L1, or n1 in the first period. Jobs H1, f1, and W1 will be scheduled at the beginning of period 2, along with any jobs not processed in period 1. A similar approach applies to tasks Q1, V1, d1, B1, N1, and p1 at the start of period 3. Validated CRP and FCG before processing any of the jobs.
The validated CRP and FCG presented in Figure 6 indicate that the decision-maker has the choice between seven jobs at the start of period 1 (C1, P1, k1, t1, b1, L1, and n1). As per the tool, tasks with long processing times and short scheduling segments would be prioritized for processing, but in reality, the decision-maker might still overwrite these rules and launch any job based on his or her personal preference. In this case, three jobs (P1, t1, and n1) have the shortest scheduling interval of one period out of the seven jobs. When compared to other loadable jobs, these three tasks have the highest priority to be started during period 1. Assuming the decision-maker chooses to begin with job P1, then t1 and n1 in that order, given their processing times of 4, 3, and 1 h, respectively. The CRP and FCG are then promptly updated, as seen in Figure 7. It shall be noted that this decision had no effect on the FCG because the scheduling segment of tasks P1, t1, and n1 remains unchanged. As a result, the decision-maker can confirm this option and begin production of jobs P1, t1, and n1 at the start of period 1, as shown in Figure 7. Updated CRP and FCG after completing the first three jobs.
Now that the first scheduling interval [11] capacity of 8 h is completed given the sum of the processing times of the first three jobs is 8 h, we next move to period 2. All unprocessed tasks with a scheduling segment starting at period 1 are updated and moved to the beginning of period 2 (Figure 8. All such tasks, with a scheduling segment starting at period 2, may now be launched. As noted in Figure 8, these are C1, k1, b1, L1, H1, f1, and W1. However, Jobs C1, b1, and W1 have higher priority than the rest of the jobs due to their smaller time scheduling segment. The manager chooses to process job C1 then b1 and W1 since C1 has a longer processing time. Following the adopted schedule (Job C1 then b1 and W1), the CRP, FCG is then updated as shown in Figure 9. Updated CRP and FCG after completing the first three jobs in period 1. Updated CRP and FCG after completing the jobs 4–6.

Referring to the updated CRP and FCG (Figure 9), the decision-maker is presented with several options for the next job to launch after completing tasks C1, b1, and W1. These options include tasks k1, L1, H1, or f1. The manager can select any of these loadable jobs, ensuring that the choice does not lead to negative capacity once the scheduling segment for the selected task is lowered. The green schedule in Figure 10, where task f1 is chosen for processing in period 2, contains negative remaining capacity for scheduling intervals [1,2] and [2,2]. Notably, for interval [2,2], the total load reaches 11 h, surpassing the daily allocated capacity of 8 h. Updated CRP and FCG after completing job f1.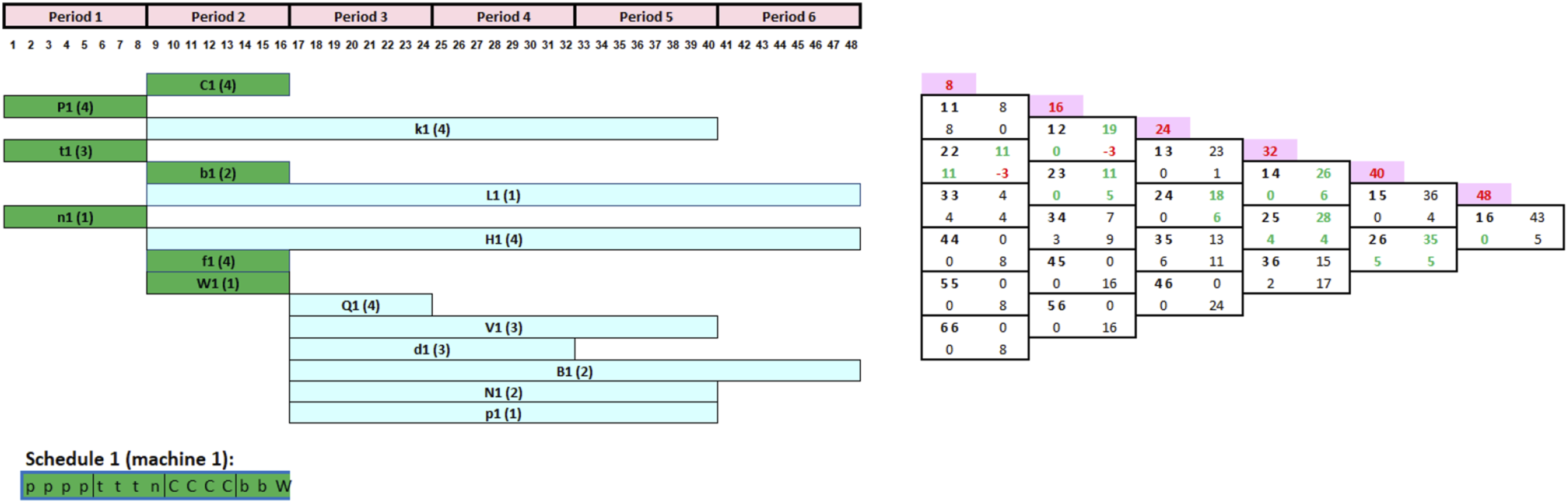
To address this issue, the manager could schedule another loadable job (with 1 h of processing time), and task f1 should be extended beyond period 2 to overlap between periods 2 and 3, as shown in Figure 10. The manager then assumes that job L1 will be processed in period 2 because it has the least processing time of 1 h. The CRP and FCG are then promptly updated, as seen in Figure 11. Updated CRP and FCG after completing job L1.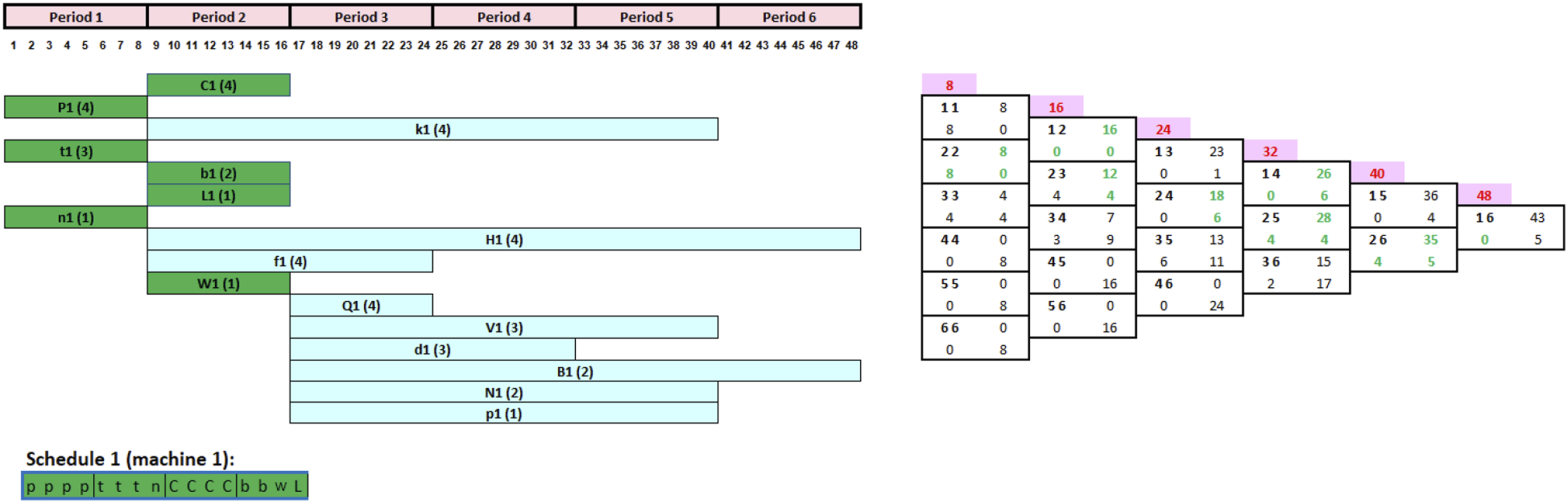
The remaining unprocessed tasks with a scheduling segment starting at period 2 are updated and moved to the beginning of period 3 and scheduled (Figure 12). The tasks f1 and Q1 will be chosen to be processed in period 3 and to be completed by the end of period 3. In this manner, the 8 h capacity of period 3 is exhausted and we can move on to period 4 by moving all the unprocessed tasks starting at the beginning of period 3 (k1, H1, V1, d1, B1, N1, and p1) to the beginning of period 4, as shown in Figure 13. Updated CRP and FCG after completing jobs in period 2. Updated CRP and FCG after processing jobs f1 and Q1 in period 3.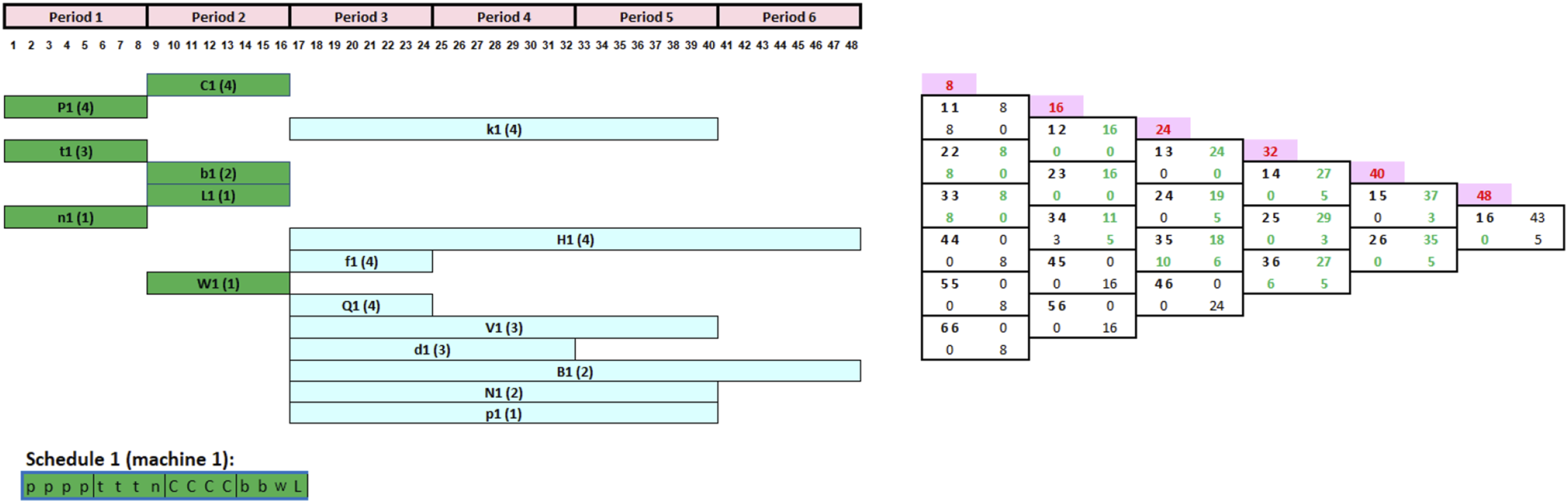
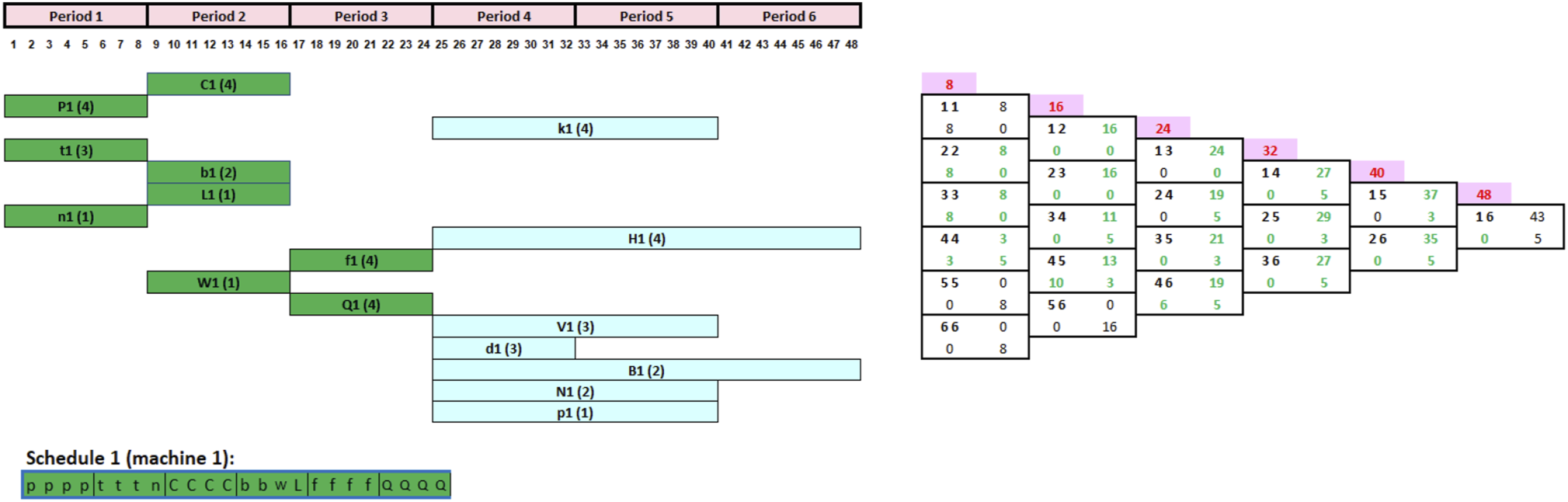
With reference to the updated CRP and FCG (Figure 13), the decision-maker has several choices for the next task to launch in period 4, including k1, H1, V1, d1, B1, N1, or p1. Figure 13 indicates that job d1 is urgent, as its scheduling segment ends in the same period. Given that the segment allows for selecting additional jobs, the green schedule in Figure 14 assumes the decision-maker opts to process tasks p1 and k1 following d1. Consequently, the capacity for period four is filled, and all unprocessed tasks are moved to the start of period 5. The CRP and FCG are accordingly updated, as shown in Figure 14. Updated CRP and FCG after completing jobs in period 4.
At the beginning of period 5, it is clear that jobs V1 and N1 will be processed first as they start and end within period 5. Since there is more production capacity remaining in period 5, job H1 is launched and will be processed over periods 5 and 6. The unprocessed task in period 5 (B1) will be moved to the beginning of period 6. As B1 is the last task to be processed, it will simply complete in period 6. The final CRP and FCG are shown in Figure 15. Updated CRP and FCG after completing all jobs.
Illustrative example of incorporating machine breakdown via the scheduling tool
In this example, the reactive capabilities of the scheduling tool are illustrated by an unexpected machine breakdown during a production schedule, as shown to the end-user. Referring back to Figure 9, let us assume there was an unforeseen one-hour machine breakdown at the end of day 1. This event is reflected in the updated CRP of Figure 16, with the updated accompanying FCG. The FCG indicates that the breakdown affects all intervals starting with period 1, specifically [1,1], [1,2], [1,3], [1,4], and [1,5], adding a cumulative load of 1 h. The only negatively impacted interval is [1,1], where the extra hour of breakdown causes the cumulative load to exceed capacity (9 > 8), resulting in a negative capacity of (−1). In such situation, the manager should consider adding extra capacity to period 1 or postponing one of the jobs with a time scheduling segment ending in period 1, such as jobs P1, t1, or n1. Updated CRP and FCG with 1 h breakdown.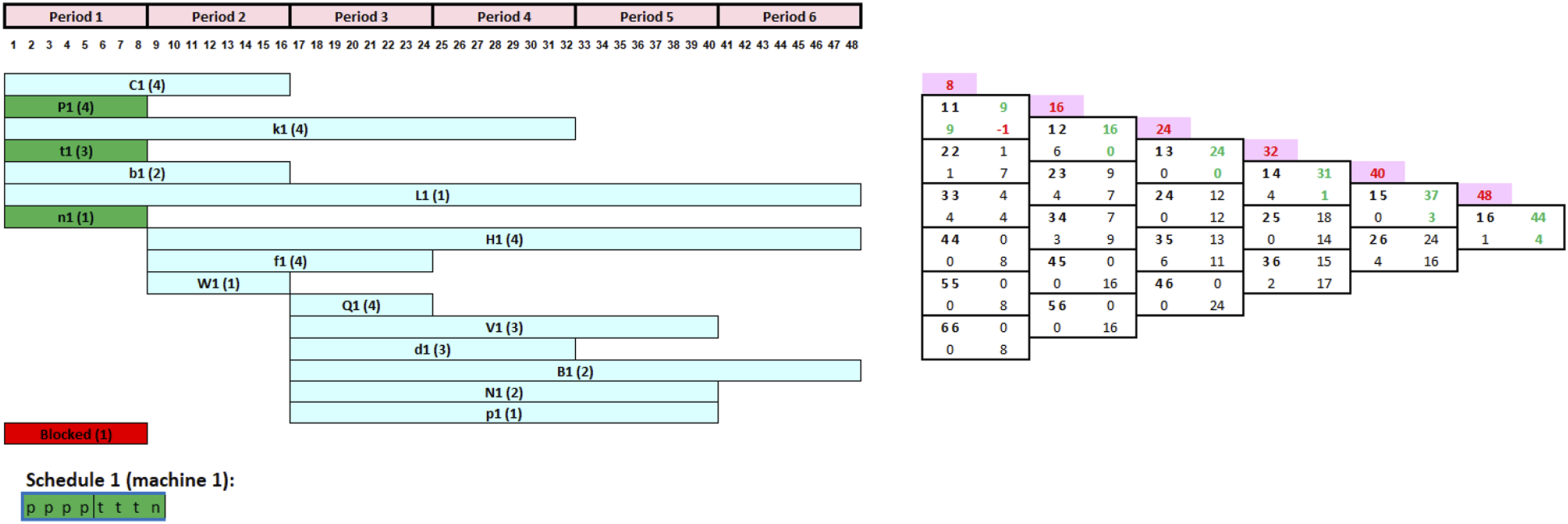
The postponed task’s duration should be larger than or equal to the breakdowns. The scheduling interval of tasks P1, t1, and n1 ends exactly at period 1 in the case presented in Figure 16, hence one of these tasks should be delayed. Any of those tasks can be postponed, but we must establish a feasible schedule with no additional negative capacity when deciding which task to postpone. As a result, it is recommended to select the task with the lowest load, which is task n1 with a load of 1 hour. Delaying job n1 and extending its scheduling interval to the end of day 2 has resolved the negative capacity in scheduling interval [1,1], as illustrated in Figure 17. An alternative solution for breakdown is reported in Figure 18 which calls for delaying job n1 to start at period 2 and end at period 3. Updated CRP and FCG with resolved 1-hour machine breakdown situation. An alternative CRP and FCG with resolved 1-hour machine breakdown situation.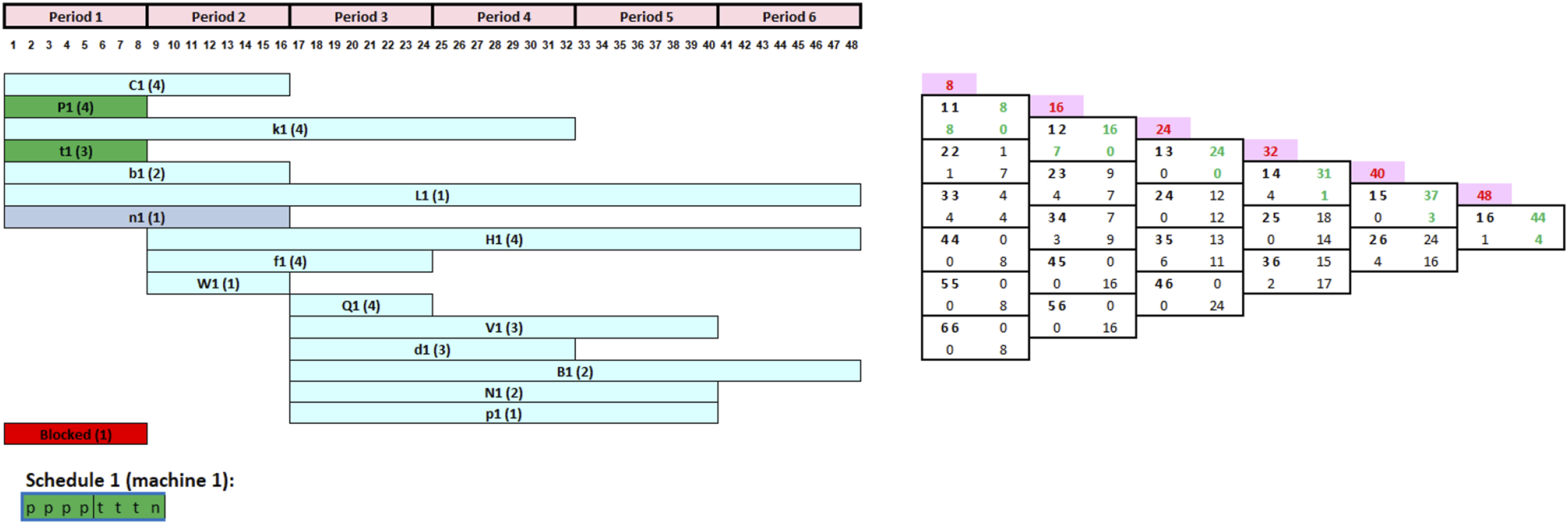
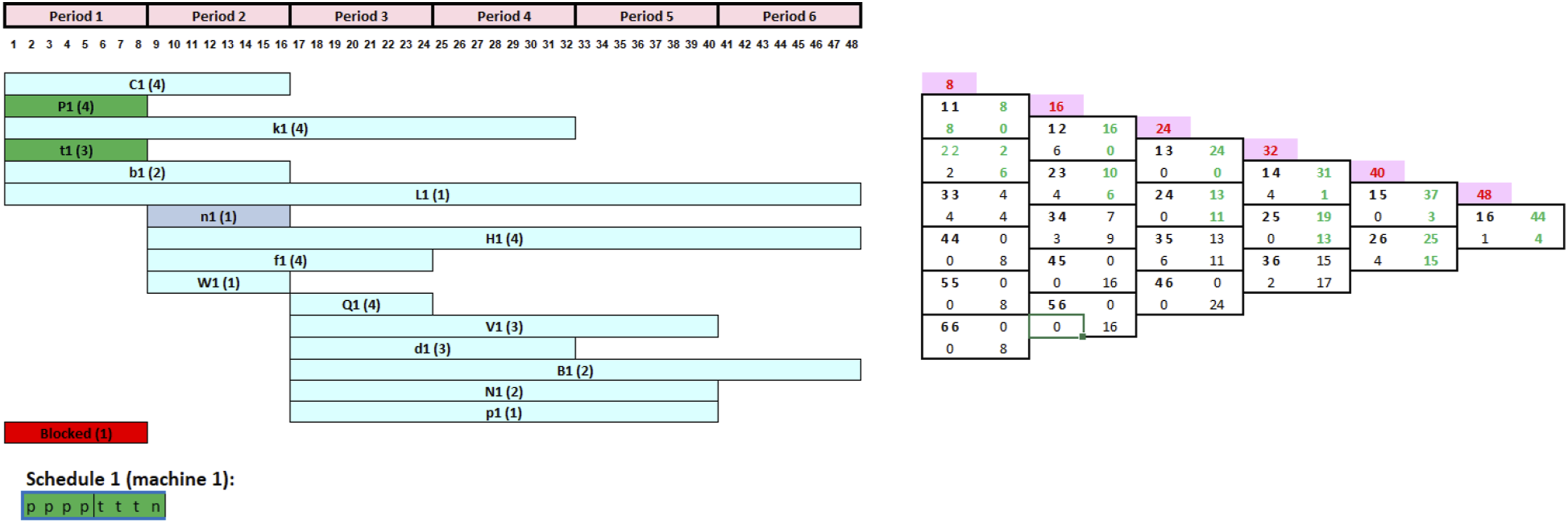
The tool’s dynamically changing graphical representations help the end-user manage an ongoing schedule on real-time basis and examine the impact of every scheduling decision. This example shows how this scheduling tool might be useful when determining the impact of unforeseen events on a company’s capacity to make timely deliveries.