
Abstract
With the wide application of advanced information technology and intelligent equipment in the manufacturing system, the decisions of design and operation have become more interdependent and their integration optimization has gained great concerns from the community of operational research recently. This article investigates an optimization problem of integrating dynamic resource allocation and production schedule in a parallel machine environment. A meta-heuristic algorithm, in which heuristic-based partition, genetic-based sampling, promising index calculation, and backtracking strategies are employed, is proposed for solving the investigated integration problem in order to minimize the makespan of the manufacturing system. The experimental results on a set of random-generated test instances indicate that the presented model is effective and the proposed algorithm exhibits the satisfactory performance that outperforms two state-of-the-art algorithms from literature.
Keywords
Introduction
In manufacturing systems, there are usually existing two different categories of production activities.1–7 One is the design activity such as allocating the resources into the production units to determine the production capacity. The other is the operation activity such as scheduling the jobs in the production units to satisfy the production demand. The decisions of design and operation activities are typically made independently. The decision-maker first determines the allocation plan of resources (workers, electric power, and so on) and then determines the schedule plan of jobs according to the allocated resources.8–13 However, these two activities require to be closely related in practice. The available resources are always limited, and the allocation plan of resources in the production unit (or machine) can affect the efficiency of processing jobs. In recent years, the integrated resource allocation and production schedule problems have received more and more attention from the operational research (OR) community. The similar works that are termed as the scheduling problem with flexible resource constraints have been reported in literature.14–17 It is noticeable that the most works only focus on the static resource allocation plan, in which the allocated resources in a machine always remain fixed during the whole production horizon. With the recent development of advanced information technology and intelligent equipment, such as manufacturing execution system (MES), industrial robots, and so on, the production process in the manufacturing system must be able to re-operate, even re-design dynamically. Therefore, this article aims at investigating the optimal integration of dynamic resource allocation and production schedule in a parallel machine manufacturing environment.
Parallel machine scheduling can usually be defined as a set of identical machines employed to process the jobs in parallel so as to optimize a given scheduling criterion. 18 In general, this parallel machine scheduling problem can be broken down into two subproblems: first, assign each job to any of the machines and then determine the process sequence of jobs on each machine. Many real-world problems can be translated into parallel machine scheduling, for example, operation room scheduling in hospitals, 19 gate assignment scheduling in airports, 20 and process scheduling in CPUs. 21 It is noticeable that these studies only focused on the scheduling problem, neither involve in the allocation of resources. Daniels et al.22,23 first broadened the scope of the traditional scheduling function to include both job sequencing and processing time control through allocating a flexible resource among the parallel machines. In their works, the processing time of each job was to depend on the amount of resource allocated to the associated machine. Parallel machine scheduling problems with resource allocation constraints had begun to gain more and more concerns in recent years.24–26 Based on the distinct characteristics of resources, the relevant research works could be grouped into two categories. In the first category, processing of job was associated with the allocated amount of nonrenewable resource, for example, electric power or water. A constraint of the total amount or resource or an objective function in terms of resource cost was usually utilized when deciding job assignment among machines and jobs sequence on machines.27–33 The second category focused on parallel machine scheduling under the allocation constraint of reusable and renewable resources.34–37 Resource allocation among machines and jobs was known in advance, and thus, a schedule plan should include three decisions, that is, job assignment among machines, job sequence, and start time on machines. It is noticeable that the most works only concerned the allocation of resources among machines and jobs in a static way. In this static way, the resources always remained fixed once they were allocated upon a machine processing a job, or job assignment among machines always required to be known in advance.
In this article, a parallel machine scheduling problem that enables to allocate a reusable and renewable resource dynamically in a production horizon will be studied. In the investigated problem, integrated optimal decision of job assignment among machines, resource allocation among jobs, job sequence, and start time on machines will be considered simultaneously. A nested partition (NP) algorithm will be developed to deal with this complicated optimization problem effectively and efficiently. In the proposed algorithm, four special operations, including heuristic-based partition, genetic-based sampling, promising index calculation, and backtracking strategy, will be designed based on the problem characteristics.
The remainder of this article is organized as follows. Section “Problem statement” states the investigated problem and presents its mathematical model. Section “Solution method” introduces the proposed algorithm and gives its detailed design. Section “Experimental study” conducts the numeric experiments and analyzes the experimental results. Section “Conclusion” draws the conclusions with a brief outlook of the future work together.
Problem statement
In this section, we introduce a parallel machine scheduling problem with dynamic resource allocation. There are
Notations used are listed as follows:

It is noted that the processing modes in
According to these notations and definitions, an integer programming model can be established as follows

s.t.



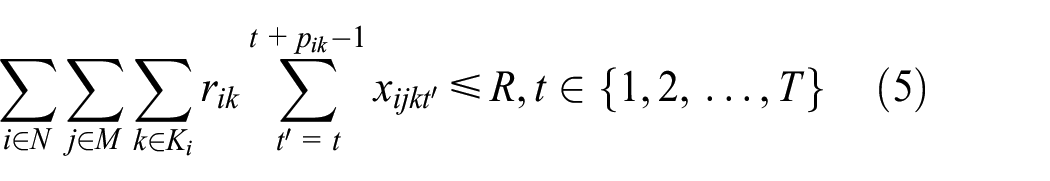



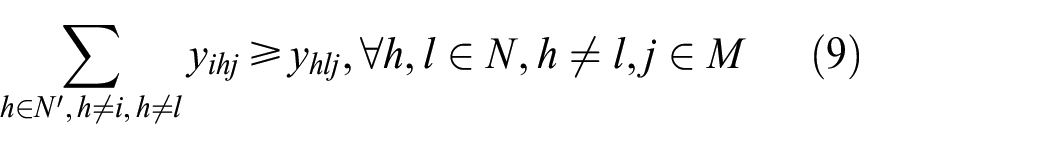


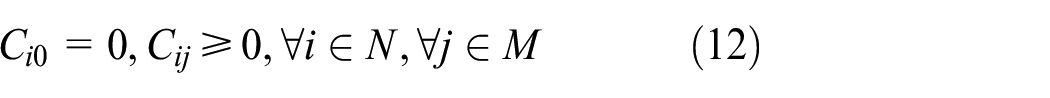
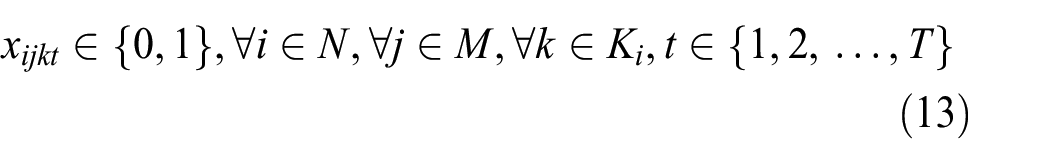

where equation (1) means that the objective function is to minimize the makespan. As shown in equation (11), the makespan of a schedule is equal to the maximum completion time of all jobs. Constraints (2) and (3) define the processing time and the completion time of job, respectively. Constraint (4) guarantees that each job must be processed on one machine in one mode. Constraint (5) ensures that the total amount of allocated resource at any time cannot exceed its limit. Constraint (6) stipulates that each job only has one predecessor on one machine. Constraint (7) guarantees that each job has only one immediately precedence job. Constraint (8) shows that each machine has only one dummy job. Constraint (9) defines the sequence relation of jobs on one machine. Constraint (10) means that each machine can only process one job at any time. The left constraints give the range of decision variables.
A general parallel machine scheduling problem with objective of minimizing the makespan has been proved to be NP-hard. 38 The investigated problem in this article is also NP-hard since more decisions, such as resource allocation among jobs and job start time on machines, have to be considered with the traditional schedule decisions together. Therefore, a meta-heuristic algorithm is proposed as an optimizer for solving this complicated parallel machine scheduling problem with dynamic resource allocation effectively in the next section.
Solution method
Meta-heuristic algorithm has been well known as one of best optimizers for the complex optimization problems.39–41 NP is a new meta-heuristic algorithm introduced by Shi and Olafsson. 42 It has been successfully applied to solve many complex optimization problems, for example, traveling salesman problem, 43 buffer allocation problem, 44 product design problem, 45 and production scheduling problems.46,47
Basic algorithm framework
In NP algorithm, there are four operations, that is, partitioning, sampling, promising index calculation, and move. Let
Step 1: Partitioning. Partition the most promising region
Step 2: Sampling. Randomly generate

Calculate the corresponding performance values

Step 3: Calculating the promising index. For each region

Step 4. Move. Calculate the promising region index with the best performance value

If more than one region is equally promising, the tie can be broken arbitrary. If this index corresponds to a region that is a subregion of
By repeating Steps 1–4, the NP method can deal with an optimization problem effectively. If the most promising region includes only one solution, it stops and outputs the obtained solution and objective value. Next, NP algorithm combining with some heuristic rules and genetic algorithm (NP-HGA) is designed and discussed.
Solution representation
There are four decisions when solving the investigated problem, that is, job assignment among machines, resource allocation among jobs, jobs’ sequence, and start time on machines. A solution should represent them simultaneously, and thus, this study applies a permutation vector to denote a feasible solution. In this vector, each position denotes a job index and each element contains three parts that represent the schedule of its corresponding job. In detail, a solution can be represented by
NP partitions a feasible region of an optimization problem at its first iteration. This feasible region is named as initial feasible region. The initial feasible region can be a whole or partial solution space. The former can realize a global search that has to consume more computational cost, while the latter utilizes a local initial feasible region to ensure the solution quality with less computation cost. This study employs the latter approach and proposes a heuristic rule to produce an initial feasible region as follows. First, sort all jobs in the descending order as the processing time difference of their first and second modes and stored in
Partitioning operation
In NP-HGA, the partitioning operation is used to arrange one job based on the current promising region. It constructs a set of subregions, and each subregion is developed by determining the assignment, resource allocation, and start time of a job. If there is a promising region where
Input: current feasible region
Output: subregions of
Step 1:
Step 2: Choose a job
Step 3: Identify the earliest available machine
Step 4: Determine the earliest schedule time
Step 5: Calculate the number of available resources
Step 6: Determine the feasible schedules
Step 7: If
Sampling operation
Sampling operation aims to find the better solutions in a region which can represent this region’s promising index. This study designs a heuristic rule to generate a set of solutions, and then, a partheno genetic algorithm is employed to search a better solution to calculate the promising index of this region.
The heuristic rule is developed based on longest processing time first and it is described as follows:
Input: the feasible region in
Output: a feasible solution.
Step 1:
Step 2:
Step 3: Identify the first available machine
Step 4: Calculate the number of available resources
Step 5: Generate a number
(1) If
(2) If
Step 6: If
By repeating this heuristic rule, we can generate
Index calculation and move operations
The promising index of subregions denotes their own probability that contains the optimal solution. A subregion with the best promising index is chosen as the promising region in the next iteration. Thus, it guides the algorithm’s search direction. In this study, the objective function value of the best solution found in sampling operation is taken as the promising index of its corresponding subregion. As this approach, we can calculate the promising index of all subregions.
Based on the above approach, NP-HGA can select a promising region. If one of the subregions has the best promising index, it moves to this subregion to perform the next iteration. If the complementary region has the best promising index, it indicates that the algorithm falls into a local optimal. Thus, a backtracking strategy is used to make the algorithm return to one of the previous searched regions. This study designs four backtracking strategies as follows: (1) backtrack to the previous region of the current most promising region; (2) backtrack to the initial promising region; (3) backtrack to the previous region containing the best solution found so far; and (4) backtrack to the previous region containing the best solution found in the complementary region.
Experimental study
To examine the performance of NP-HGA in solving the investigated problem, two state-of-the-art algorithms in literature are employed as its comparison algorithms. The hybrid nested partition (h-NP) 47 method was initially designed for the parallel machine scheduling problem in static resource allocation way, while master-slave genetic algorithm (MSGA) 49 was used to solve the scheduling problem with dynamic resource allocation in parallel machine manufacturing environment.
Test instances
The following method is used to generate a set of random test instances in the experiments. The number of machines is set to

Parameter settings
The parameter settings of all algorithms are set as follows. In h-NP, the number of sampled solutions from each subregion is set to 20,
Experimental results and discussions
In this section, we carry out three experiments to choose an effective backtracking strategy for NP-HGA in solving the investigated problem.
To examine the performance of four strategies, we choose an instance with 9 machines and 56 jobs. The experimental results are shown in Table 1, where “NP-HGA-X” means that the backtracking strategy
Comparison of four backtracking strategies.
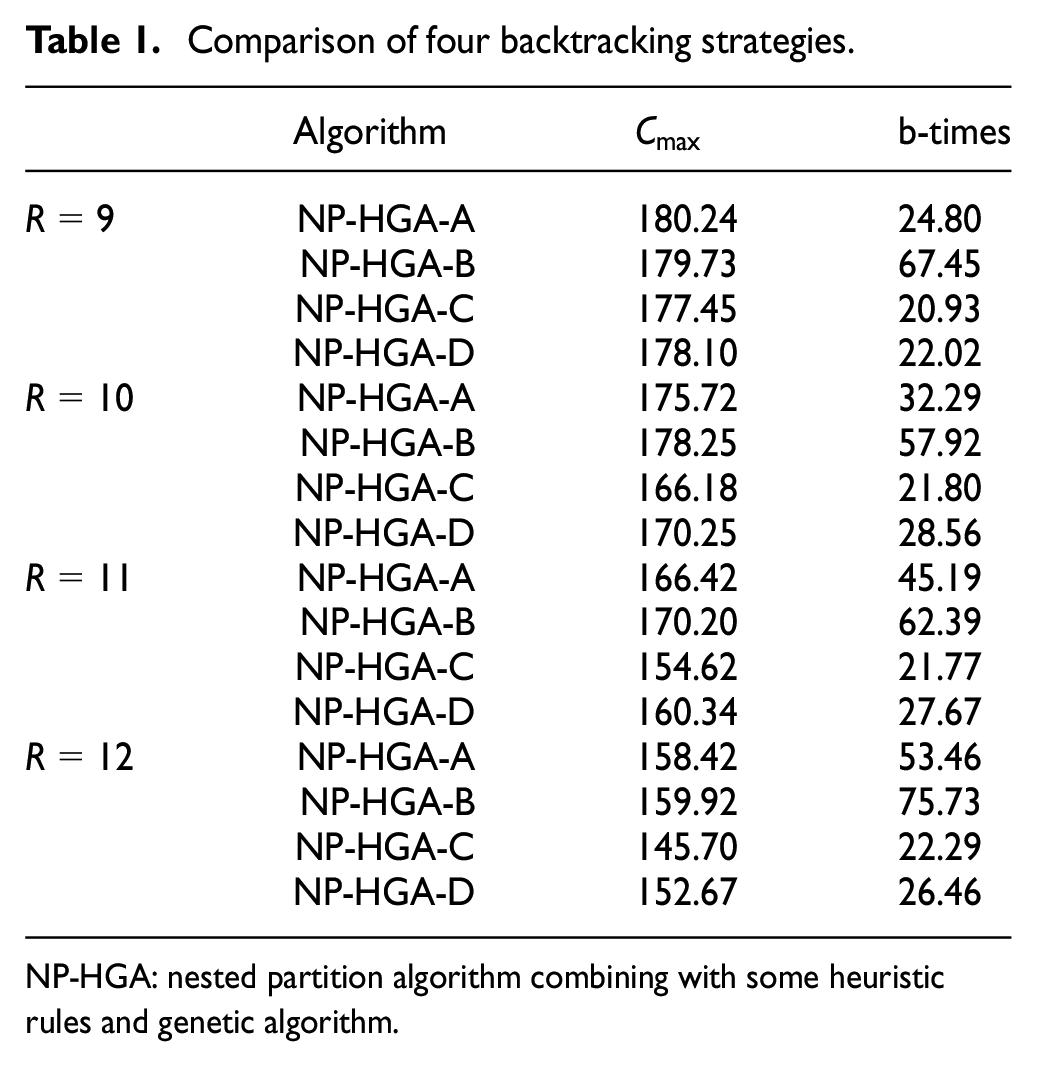
NP-HGA: nested partition algorithm combining with some heuristic rules and genetic algorithm.
The second experiment chooses an instance in Daniels et al.
34
to compare the NP-HGA with the static resource allocation case by using h-NP. In this instance, there are 4 machines and 15 jobs. Each job has three processing modes 1, 2, and 3 that need 1, 2, and 3 unit amount of resource, respectively. The processing time of job in the three processing modes is shown in Table 2. Figure 1 shows the Gantt charts via h-NP and NP-HGA, respectively. In this figure, a symbol “
The processing time of jobs in the three processing modes.

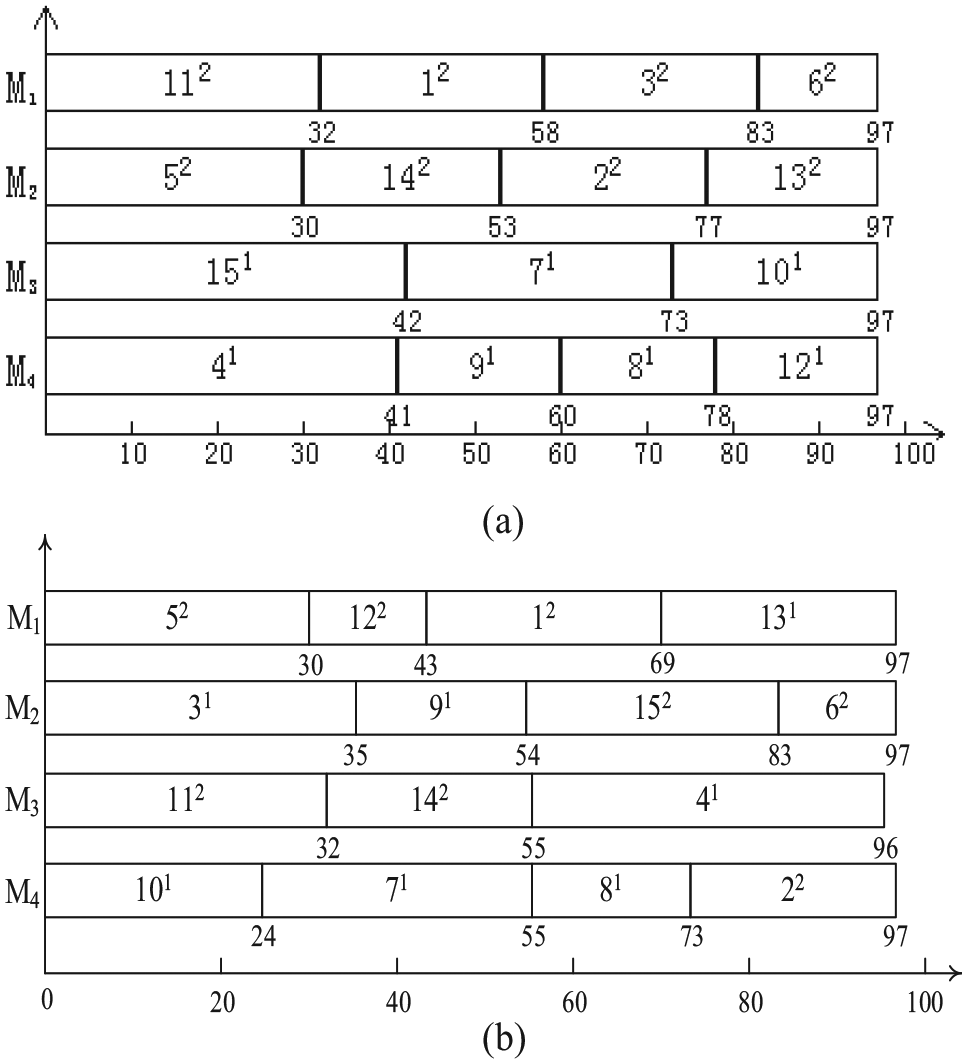
Illustration of the experimental results via Gantt charts: (a) h-NP, (b) NP-HGA.
In the third experiment, we compare NP-HGA with h-NP and MSGA by using all test instances. For each test instance, each algorithm executes 20 times independently. The average value (mean) and standard deviation (SD) are recorded to evaluate their performance. In addition, equation (16) is employed to compare NP-HGA with MSGA

The experimental results of the third experiment are shown in Table 3, where a symbol “
Experimental results of three algorithms.

h-NP: hybrid nested partition; MSGA: master-slave genetic algorithm; NPHGA: nested partition algorithm combining with some heuristic rules and genetic algorithm; SD: standard deviation.
From the experimental results, we can find that NP-HGA can achieve the better results on all instances than those of h-NP. MSGA also performs better than h-NP in most of the instances. The results indicate that the dynamic resource allocation way is better than the static allocation one. In addition, we can find that NP-HGA outperforms MSGA in all instances by comparing their mean, standard deviation, and ratio values. This demonstrates that dynamic resource allocation on parallel machine scheduling can efficiently utilize the limited resources, and NP-HGA has a better performance in solving the investigated problem.
To evaluate the algorithms’ performance in terms of computational time, the average computational time is examined when solving a test instance with different amounts of resource, and their computational time is shown in Table 4. Because the dynamic resource allocation case is more complex than the static one, the computational time of MSGA and NP-HGA consumes more time than h-NP. By comparing NP-HGA with MSGA, we can find that NP-HGA uses less time than MSGA in all instances.
Comparison of the algorithms’ computational time.

h-NP: hybrid nested partition; MSGA: master-slave genetic algorithm; NP-HGA: nested partition algorithm combining with some heuristic rules and genetic algorithm.
By conducting the above experiments and analyzing the experimental results, we can find that NP-HGA is a better solver in dealing with the parallel machine scheduling problem with dynamic resource allocation. NP-HGA is designed by introducing some special strategies for the investigated problem such as a heuristic-based partition, genetic-based sampling, promising index calculation, and backtracking approaches. These strategies do strengthen and balance the algorithm’s exploration and exploitation abilities and, thus, make the proposed algorithm perform better in solving the investigated problem.
Conclusion
This study investigates dynamic resource allocation in a parallel machine scheduling problem with objective of minimizing the makespan. To deal with it effectively, this study designs a nest partition algorithm that employs several specially designed operations, that is, heuristic-based partition, genetic-based sampling, promising index calculation, and backtracking strategies based on the problem characteristics. Numerical experiments are carried out on a set of random-generated test instances, and algorithm comparisons are made among the proposed algorithm and two state-of-the-art peer algorithms in literature. Experimental results demonstrate that dynamic resource allocation is much better than the static one, and the proposed algorithm performs better in solving the investigated problem.
For the future work, it is very necessary to extend the single time-related objective into multi-objective models that can take the cost- and revenue-oriented objectives into account together to help decision-makers find a flexible schedule plan. It is also an interesting work to design more efficient meta-heuristic algorithms to cope with the complicated parallel machine scheduling problems with dynamic resource allocation.
Footnotes
Handling Editor: James Baldwin
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported partly by National Natural Science Foundation of China (NSFC) under Grant No. 61703290, No. 71671032 and No. 61703220; the Natural Science Fund Guidance Program of Liaoning Province under Grant No. 2019-ZD-0478; the Fundamental Research Funds for the Central Universities Grant No. N160402002 and No. N180408019.