
Abstract
Batch processing machines are often the bottleneck in semiconductor manufacturing and their scheduling plays a key role in production management. Pioneer researches on multi-objective batch machines scheduling mainly focus on evolutionary algorithms, failing to meet the online scheduling demand. To deal with the challenges confronted by incompatible job families, dynamic job arrivals, capacitated machines and multiple objectives, we propose a clustering-aided multi-agent deep reinforcement learning approach (CA-MADRL) for the scheduling problem. Specifically, to achieve diverse nondominated solutions, an offline multi-objective scheduling algorithm named Multi-Subpopulation fast elitist Non-Dominated Sorting Genetic Algorithm (MS-NSGA-II) is firstly developed to obtain the Pareto Fronts, and a clustering algorithm based on cosine distance is employed to analyze the distribution of Pareto frontier solution, which would be used to guide reward functions design in multi-agent deep reinforcement learning. To realize multi-objective optimization, several reinforcement learning base models are trained for different optimization directions, each of which composed of batch forming agent and batch scheduling agent. To alleviate time complexity of model training, a parameter sharing strategy is introduced between different reinforcement learning base model. By validating the proposed approach with 16 instances designed based on actual production data from a semiconductor manufacturing company, it has been demonstrated that the approach not only meets the high-frequency scheduling requirements of manufacturing systems for parallel batch processing machines but also effectively reduces the total job tardiness and machine energy consumption.
Keywords
Introduction
Batch Processing Machines (BPMs) are widely used in semiconductor manufacturing systems to improve productivity by handling multiple lots simultaneously. Many processes in semiconductor manufacturing, such as cleaning, diffusion, oxidation, etching, and ion implantation, are efficiently handled by BPMs.1–3 Moreover, BPMs often represent a critical bottleneck in manufacturing systems due to their high acquisition cost and long processing time. The implementation of effective scheduling strategies for BPMs can yield substantial improvements in on-time delivery and a reduction in production costs.4–6 The current developments in scheduling BPMs are usually classified as single BPM versus parallel BPMs, incompatible versus compatible job families, identical versus non-identical job sizes, identical versus arbitrary release times, and capacitated versus non-capacitated machines. 7 The scheduling of the parallel BPMs for semiconductor wafer fabrication studied in this paper involves incompatible job families, non-identical job sizes, arbitrary release times and capacitated machines to maximally approximate the real scenario. To be specific, dynamically arrived jobs are first formed into batches based on job families. The size of each batch cannot exceed the capacity of the BPM, and the processing time of each batch is equal to the processing time of the largest job within the batch. In wafer fabrication systems, on-time order delivery and production cost are two very important optimization objectives, and in this paper we consider both minimizing the total tardiness as well as the overall energy consumption. 8
Over the years, researchers have proposed various methods to solve the parallel BPMs scheduling problem, including heuristic rules, evolution algorithms, reinforcement learning (RL), and so on. Ikura and Gimple
9
first proposed the use of heuristic rules to solve the scheduling problem of BPMs. They introduced priority rules for the
When facing more complex or multi-objective scheduling problems, using evolution algorithms such as genetic algorithms, 14 particle swarm optimization, 15 ant colony optimization, 16 greedy algorithms, 17 etc., can lead to better performance in obtaining scheduling solutions. Damodaran et al. 18 propose a greedy random adaptive search procedure (GRASP) to minimize makespan for the single BPM scheduling problem with non-identical job sizes. The solutions showed that this approach outperformed simulated annealing and genetic algorithms. Lu et al. 19 designed a hybrid multi-objective optimization algorithm integrating iterative greedy and efficient local search for solving an energy-efficient scheduling problem for a distributed flow shop in a heterogeneous factory, with the objective of minimizing the completion time and total energy consumption. Shahvari and Logendran 20 propose four algorithms based on bi-objective particle swarm optimization to solve the dual-resource scheduling problem on unrelated parallel machines. Li et al. 21 address the parallel BPMs scheduling problem with incompatible job families and dynamic job arrivals. They utilize ant colony optimization algorithm to minimize TWT (total weighted tardiness) and makespan and the solutions demonstrate significant improvements compared to conventional ATC (Apparent Tardiness Cost) rule. But the performance of their algorithms are strongly influenced by the distribution of job arrival times and the number of jobs. Scheduling problems in dynamic environments are characterized by uncertainty and time variability. While evolutionary algorithms perform well in offline scheduling problems, fully exploring the solution space of the problem, they are cannot offer swift responses to dynamically incoming jobs. This entails adjustments not only in algorithm parameters but also in iterations and evaluations. Consequently, this leads to a notable increase in computational complexity and cost.
In conclusion, both heuristic rules and evolution algorithms have certain limitations in solving dynamic multi-objective parallel BPMs scheduling problems. Recent research in the field of machine learning indicates that RL has potential and applicability in complex scheduling in the manufacturing industry. 22 In dynamic environments, RL algorithms learn optimal action policies by actively interacting with the environment. These algorithms dynamically adapt their strategies in response to real-time feedback and environmental fluctuations, enabling them to effectively handle uncertain elements like the arrival of jobs and resource availability through iterative experimentation and exploratory learning.23,24 Consequently, RL algorithms are widely used in various complex production scheduling problems. Huang 25 designed a double-deep Q-learning network for the problem of scheduling massively parallel batch machines by defining four job sequencing rules and three scheduling time windows, thus generating twelve action rules in the operation space. Luo et al. 26 proposed a Deep Reinforcement Learning (DRL)-based approach for the Flow Shop Scheduling Problem with Batch Machines (FSSP-BPM), which mainly consists of a basic scheduling framework based on an encoder-decoder model and an attention mechanism. Wang et al., 27 on the other hand, studied the non-permutation flow-shop scheduling problem and proposed a DRL algorithm based on LSTM to minimize the total completion time. Wang et al. 28 propose a multi-agent RL method based on double deep Q-networks to address the scheduling problem in online hybrid flow shop problem with parallel BPMs and effectively reduces the total tardiness time. The RL algorithms proposed in the aforementioned literature exhibit satisfactory performance in the context of single-objective scheduling problems. However, when confronted with multi-objective scheduling problems, the convergence of the RL algorithm during the training process becomes challenging, as does the design of the reward function. Thus, further adjustments are necessary in order to address these problems. Wang et al. 29 design a composite multi-objective reward function based on weighted inventory cost and tardiness penalty cost in their RL algorithm, aiming to achieve multi-objective optimization scheduling under weighted optimization combinations. The key point of this approach lies in transforming the combination of multiple objectives into a single objective and incorporating it into the reward function of RL, in order to achieve a balance between different objectives at each decision step. Furthermore, Li et al. 30 utilize multi-strategy RL algorithms to design multiple reward functions by weighting the multi-objective functions with a uniform distribution of weights. Although this method allows for training multiple RL models and obtaining multiple scheduling solutions in different optimization directions for achieving dynamic multi-objective optimization, it poses a challenge in terms of ensuring the diversity of the Pareto frontier solution when using uniformly distributed weights. The issue arises from the fact that selecting weight values uniformly from a given range fails to cover the true Pareto front in the objective space. Consequently, this approach restricts the algorithm’s ability to explore the solution space, thereby potentially overlooking high-quality solutions that are not considered due to their associated weight combinations. This suggests that there is scope for further improvement. 31
To sum up, we propose a clustering-aided multi-agent deep reinforcement learning for multi-objective parallel BPMs scheduling. The main contributions of this paper can be summarized as follows:
(1) In order to explore the real problem solution space distribution, an evolutionary algorithm called MS-NSGA-II was developed to sample the multi-objective solution space of the problem. Subsequently, the distribution of Pareto frontier solutions is analyzed employing the cosine distance based K-means clustering algorithm, which decomposes the original multi-objective optimization problem into a number of sub-problems in different optimization directions.
(2) A multi-intelligent agent deep reinforcement learning model has been devised for addressing the two subproblems associated with batch forming and batch scheduling in parallel BPMs scheduling problem. To ensure effective memory and prediction of shop floor states, as well as facilitate collaborative communication between agents, a Long Short-Term Memory (LSTM) network has also been incorporated.
(3) To accelerate the algorithm’s convergence and guide the agents’ learning toward the optimal strategy, the weight parameters obtained from the clustering analysis are innovatively used to design the reward function of the deep reinforcement learning base model in different optimization directions. Additionally, a parameter sharing strategy is employed to speed up training and enhance training quality.
The remainder of this paper is organized as follows. The section 2 describes the parallel BPMs problem and formulates the optimization model. The section 3 proposes a clustering-aided multi-agent reinforcement learning for multi-objective parallel BPMs scheduling algorithm. The section 4 presents the numerical experiments and practical instances study to verify the effectiveness of the proposed approach. The section 5 discusses the conclusions and future research works.
Problem formulation
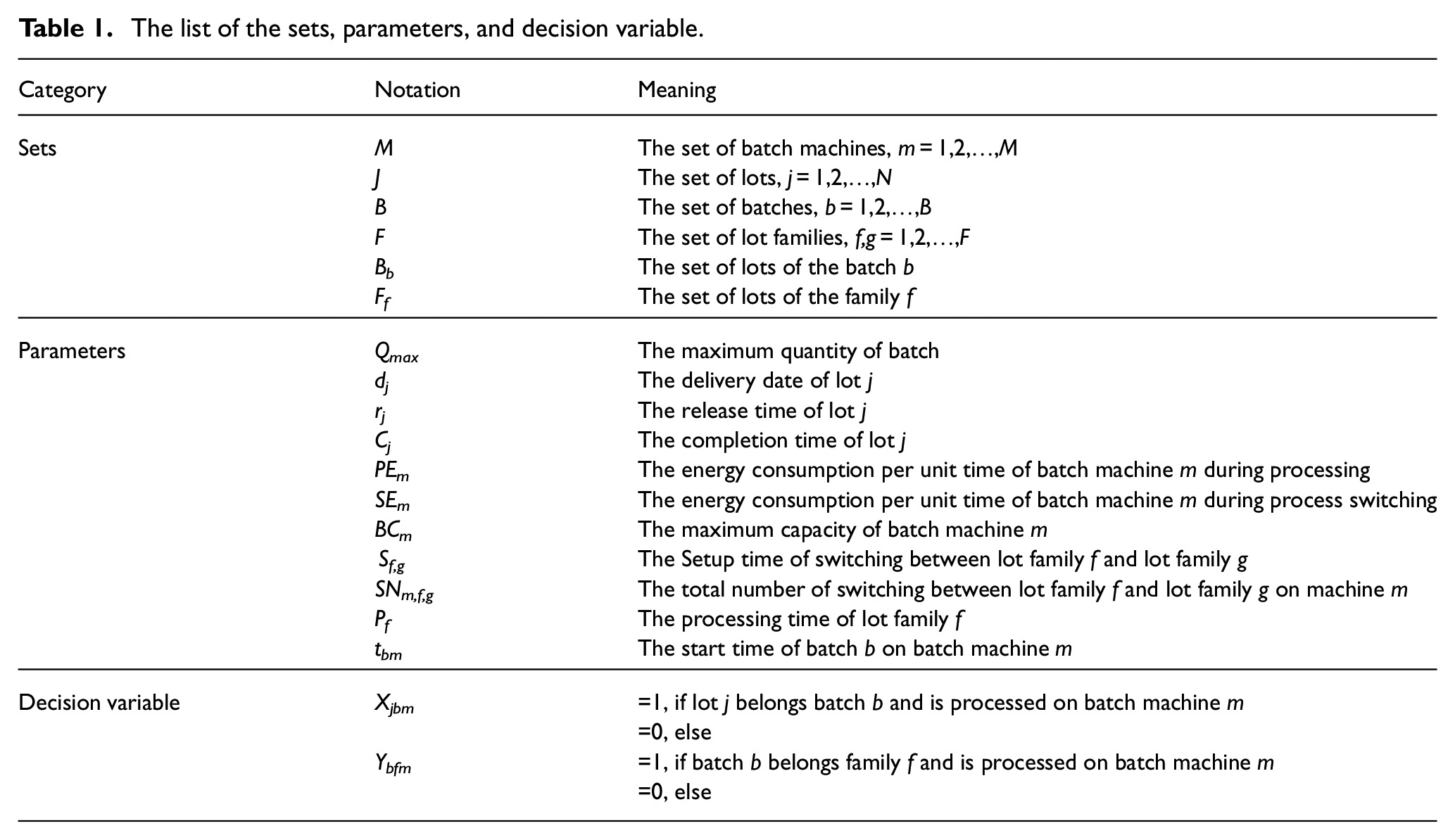
For the convenience of formal description, notations, sets, and parameters are defined as shown in Table 1.
The list of the sets, parameters, and decision variable.
Problem description
The scheduling problem of parallel BPMs in semiconductor manufacturing systems is a well-known NP-hard problem.
32
It can be represented (
Figure 1 shows parallel BPMs scheduling in a semiconductor manufacturing system in two main steps, batch forming and batch scheduling. Batch forming refers to combining multiple lots into a single batch for processing in batch machines, batch scheduling refers to determining the order and timing of processing for each batch. The entire scheduling process is described as follows: N wafer lots arrive dynamically and need to form different batches in the buffer area based on their lot families. Lots within a batch belong to the same lot family, and the size of a batch cannot exceed the maximum capacity Q max of the BPMs that processes it. Only lots from the same lot family can be processed simultaneously as a batch on BPMs. Non-equivalent parallel BPMs consist of two or more different BPMs, and the machines are non-preemptive, which means that once a machine starts processing, it cannot be interrupted. During the processing, if the lot families of the current and subsequent batches differ, the BPMs will undergo a process type switch. This switch results in changes in the physical conditions, consequently impacting the setup time.
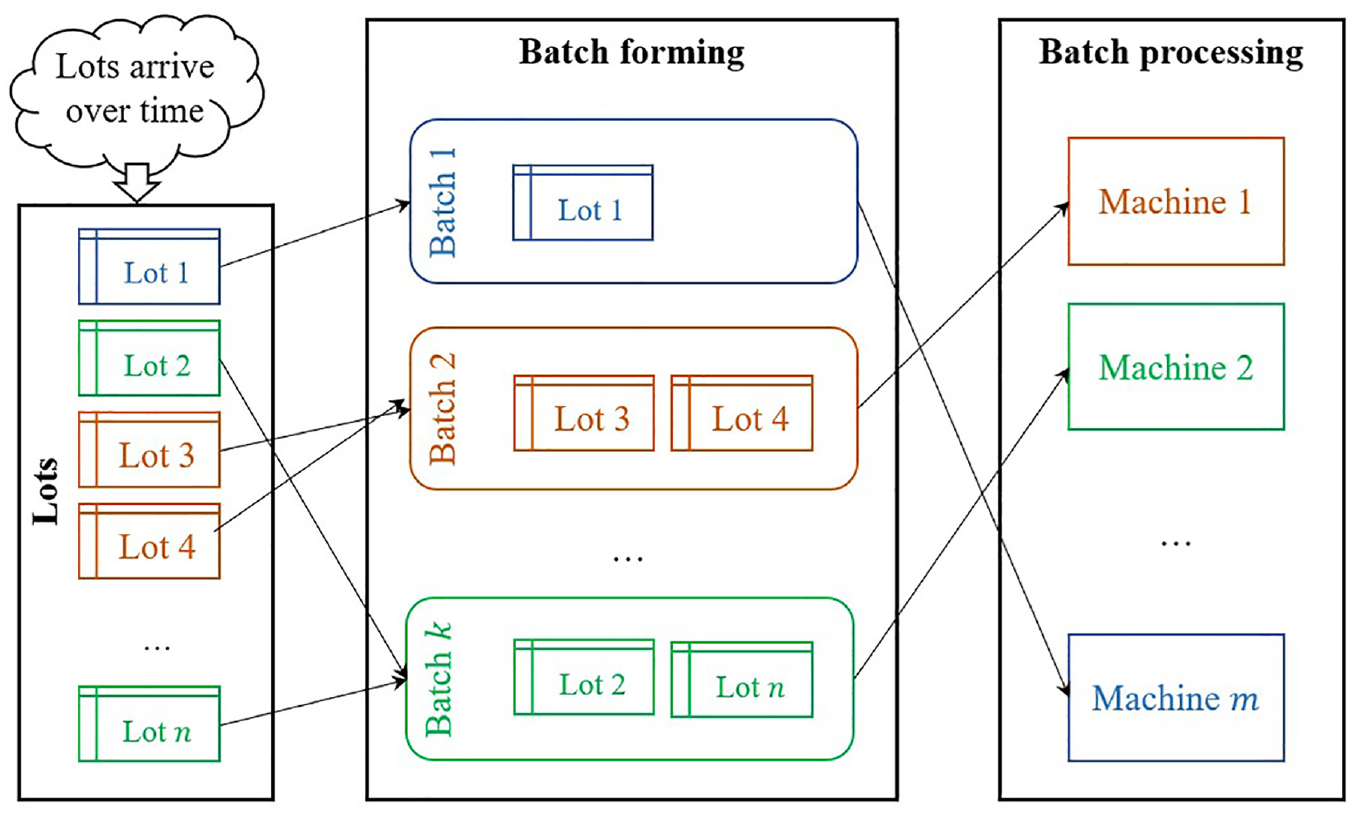
Parallel BPMs scheduling in semiconductor manufacturing systems.
Optimization model
To better address the parallel BPMs scheduling problem, this section establishes some reasonable assumptions and constraints that need to be met.
1) Problem assumptions:
Assumption: All wafer lots arrive dynamically. There are no special cases such as cancellations. Different BPMs have different maximum capacity limits. Batches with different process types are incompatible. Lots within the same family have the same processing time and can be batch processed. There are different setup times and energy consumption between consecutive batches due to different process types. A batch can only be processed by one machine at any given time.
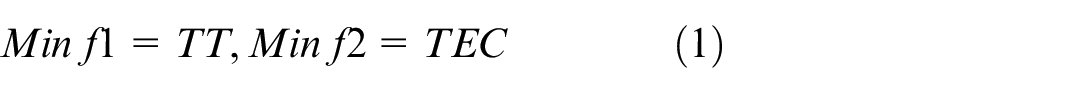

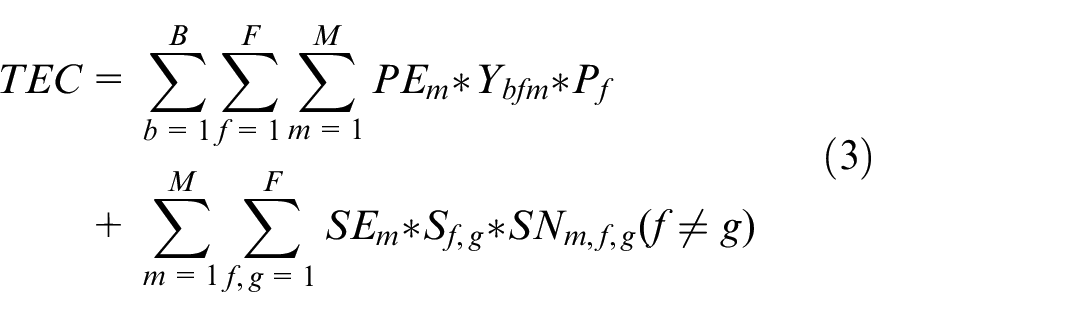
Equation (1) represents that the objective is to minimize the total tardiness (TT) time of batch and the total energy consumption (TEC).
Equations (2) and (3) represent the specific calculation steps for TT and TEC.

Equation (4) ensures that a lot can only participate in forming one batch and be processed on one machine.
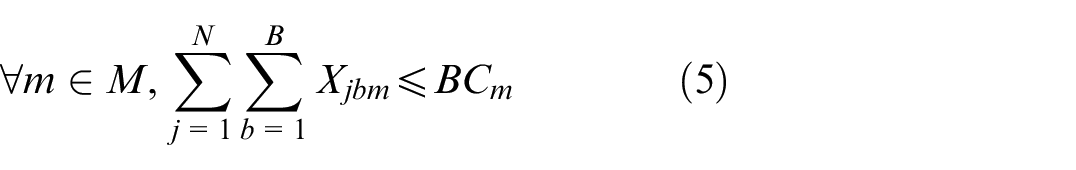
Equation (5) represents that the size of b batch cannot exceed the maximum capacity of the m machine processing that batch.
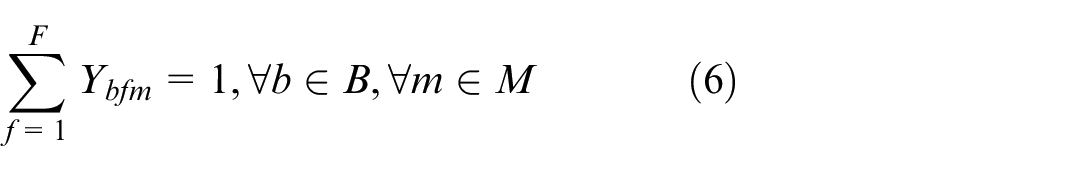
Equation (6) represents the lot family constraint, where the lot family of the lots in b batch processed on m machine is the same.
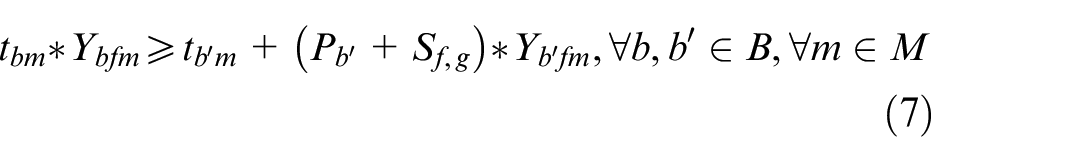
Equation (7) represents the constraint on the lot family switching time between adjacent batches. Batch b belongs to lot family g, and batch b′ belongs to family f.
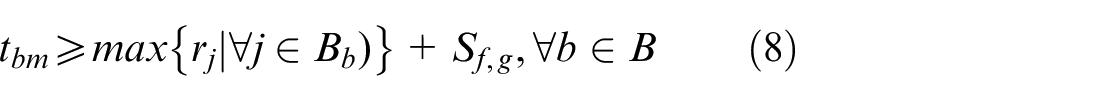
Equation (8) represents the constraint on the start time of batch b on machine m.
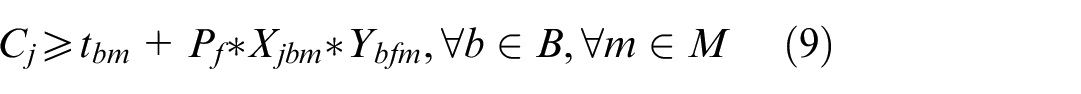
Equation (9) represents the constraint on the completion time of lot j.
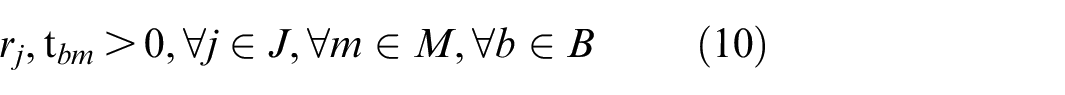
Equation (10) represents the constraint that the release time of lot j and the start time of batch b on machine m are greater than 0.
Parallel BPMs scheduling approach
For the dynamic multi-objective scheduling problem of parallel BPMs, the scheduling framework based on CA-MADRL is shown in Figure 2. This framework comprises three main components: offline scheduling algorithm MS-NSGA-II, K-means clustering algorithm, and MA-DRL model. Initially, the offline solving capability of MS-NSGA-II is employed to sample the Pareto frontier points in the multi-objective space. Subsequently, the sampled points are analyzed using the K-means clustering algorithm, which divides the objective space into multiple subspaces based on cosine distance. The central direction of each subspace is used as the optimization direction and is translated into the optimal combination of weights for the objective function of the multi-objective optimization subproblems. Furthermore, considering the specific characteristics of parallel BPMs problems, a multi-agent deep reinforcement learning (MADRL) base model is constructed. This model includes batch forming agent and batch scheduling agent, with interaction between agents achieved through an LSTM network. Finally, the optimal combination of weights in different optimization directions obtained after clustering is used to design the reward function of the agent. A parameter sharing strategy is then employed to train multiple MADRL base models, which are triggered in parallel during scheduling to achieve multi-objective optimization.
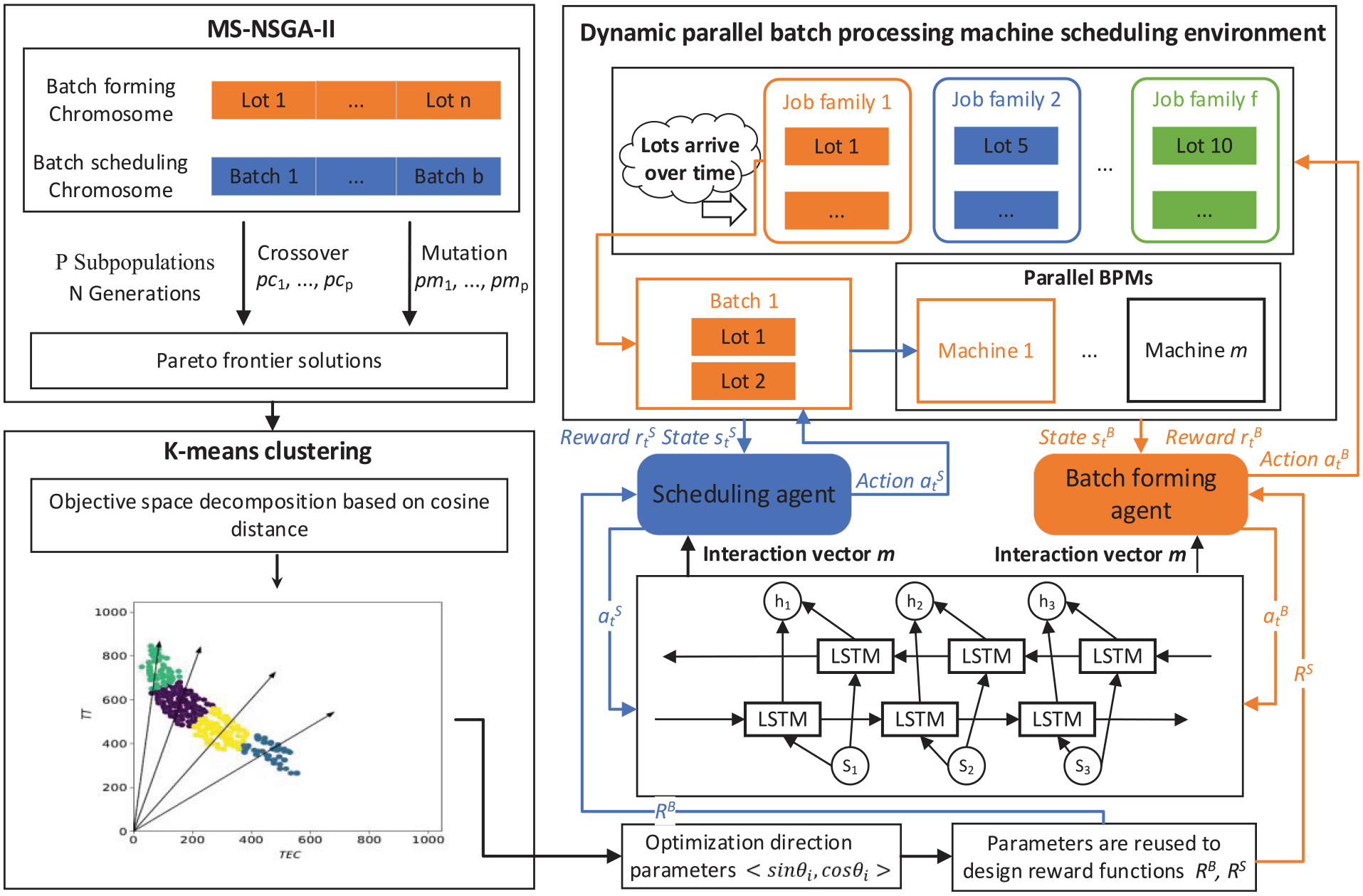
The overall framework of CA-MADRL approach.
MS-NSGA-II Pareto front sampling method
Metaheuristic algorithms offer distinct advantages in solving static multi-objective optimization problems, through an iterative process that consumes a tremendous amount of time, several optimization solutions are generated.33,34 Although this approach is not suitable for solving the dynamic BPMs scheduling problem, it can still provide us with excellent data and experience for training RL models. To prevent the utilization of uniformly distributed weight vectors for decomposing the multi-objective optimization problem and consequently impeding the quality of the Pareto solution set, it is crucial to devise an evolutionary algorithm that can comprehensively explore the solution space of the multi-objective parallel BPMs scheduling problem. Relative to NSGA-II, MS-NSGA-II is able to explore a wider solution space while better maintain population diversity through the parallel evolution of multiple independent populations. Based on this, we design batch forming chromosomes and batch scheduling chromosomes according to the characteristics of parallel BPMs problems to improve the evolution speed of the populations. Through iterative optimization of the multiple populations, which includes non-dominated sorting and crowding distance calculation, we are able to obtain the Pareto frontier solutions for the problem. This lays a solid foundation for addressing dynamic parallel BPMs multi-objective scheduling.
Encoding and initialization
For the two subproblems of batch forming and batch scheduling in parallel BPM scheduling, the chromosome is divided into two segments. The first segment describes the batch forming plan for lots, while the second segment describes the batch scheduling plan for batches. The batch forming segment uses integer encoding, with a segment length equal to the number of lots in the chromosome, each gene position represents a lot. The batch scheduling segment uses floating-point encoding, with a segment length equal to the number of batches, each gene position represents a batch.
The chromosome encoding for n lots and b batches consists of two segments. The first gene segment has a range of

An example of chromosome initialization.
Crossover and mutation operators
In the chromosome of the batch forming, we randomly select one lot family and exchange it with another. The crossover process in the batch forming section is shown in Figure 4. In this particular example, there are three lot families, and the lot family 2 is randomly selected for crossover, resulting in the exchange of genes between two lot families. However, this crossover operation may lead to incompatible conflicts between lot families in the grouping process. For instance, in offspring 2, lot 3, 4, 5 belong to different lot families but are formed to the same batch 3. To address the issue of generating a large number of illegal solutions after crossover, the chromosome segments after crossover are re-encoded to ensure compliance with the constraints related to incompatible lot families. We choose to split that batch and re-encode the batch numbers using a right-shift strategy, as shown in the re-encoding in the lower part of Figure 4.
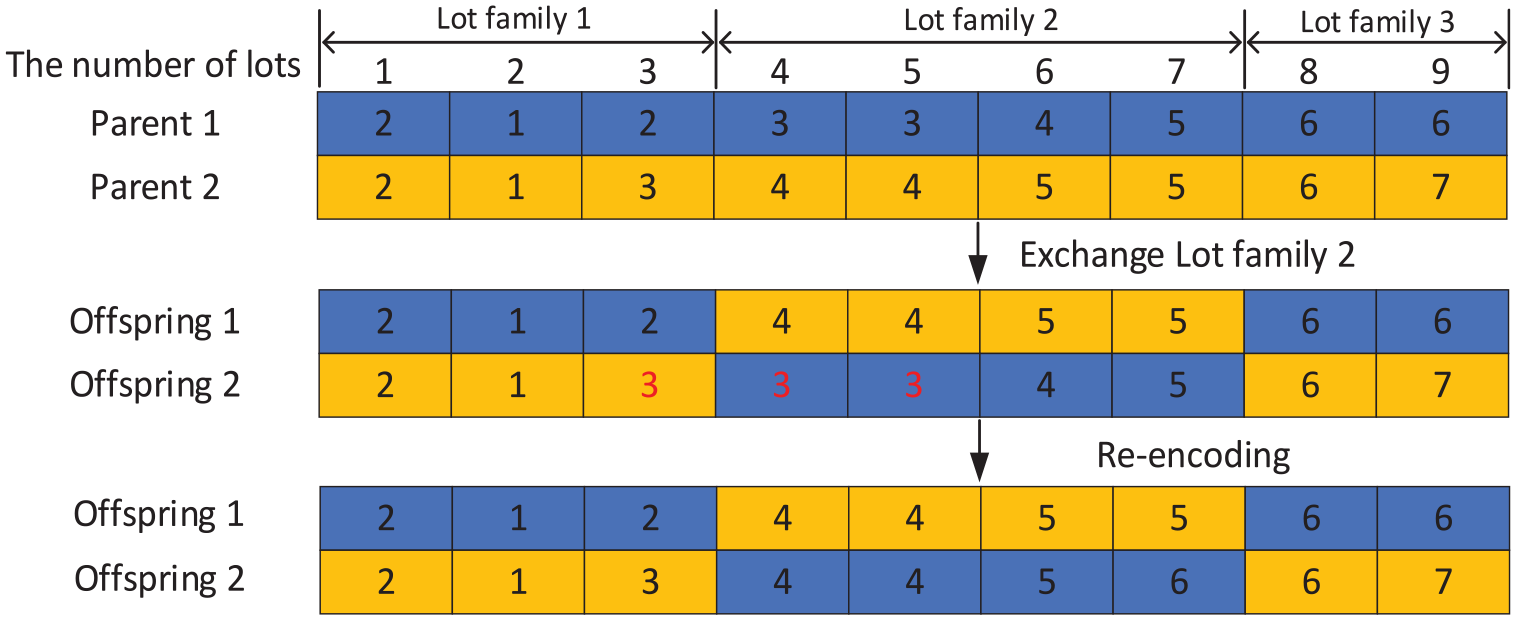
Example of crossover in batch forming chromosome.
In the chromosome of the batch scheduling, we utilize single-point crossover, as shown in Figure 5. When a batch is scheduled to a machine and the batch size exceeds the maximum capacity of the machine, we handle the exceeding batches by randomly selecting a machine number from the set of machines
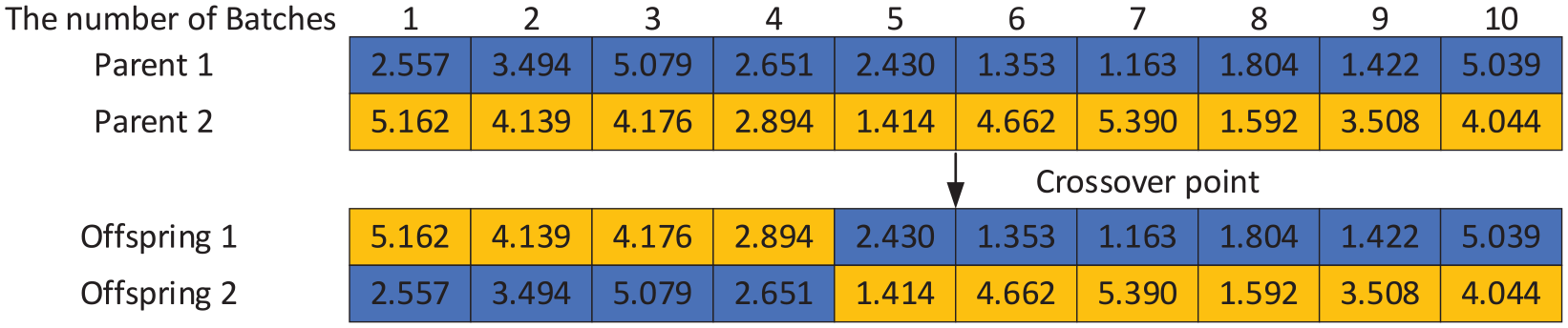
Example of crossover in batch scheduling chromosome.
Mutation in the batch forming chromosome serves the purpose of ensuring solution legality, increasing solution diversity, and escaping local optima. To achieve this, the mutation process is divided into two steps. In the first step, a random lot family is selected, and then two genes of that lot family are randomly chosen for numerical exchange. This exchange, as shown in Figure 6, occurs within the same lot family to avoid batch incompatibility issues and effectively enhance the evolution speed of the population. Mutation in the batch scheduling chromosome, on the other hand, involves randomly selecting one gene and regenerating it using an initialization method. This process is shown in Figure 7.
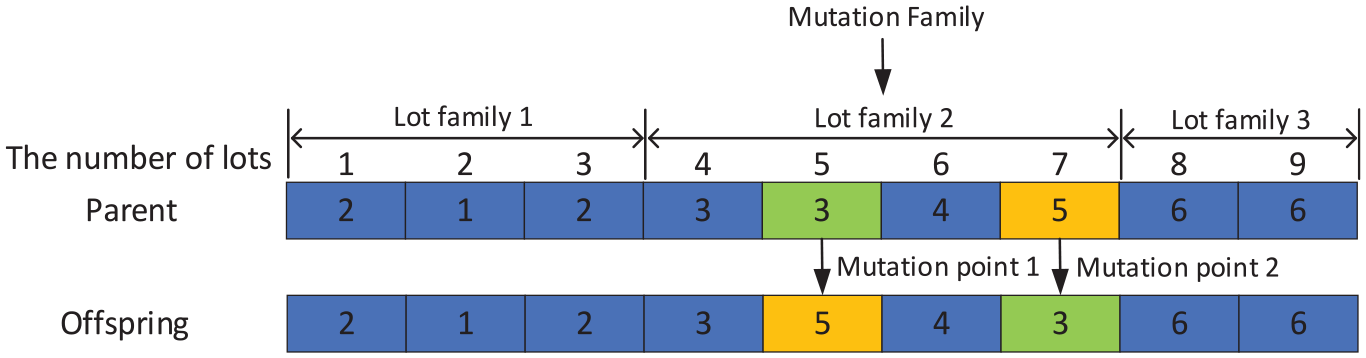
Example of mutation in batch forming chromosome.

Example of mutation in batch scheduling chromosome.
Multi-subpopulation
The convergence and diversity of the population search process of genetic algorithms can be affected by crossover rates, mutation rates and elite strategies. A higher mutation rate can increase the diversity of the solution set, but it may also prolong the convergence time of the algorithm. To address this issue, a single population of the traditional NSGA-II algorithm is divided into multiple sub-populations. Each subpopulation uses different crossover and mutation parameters. With this division, the convergence and diversity varies among the subpopulations. This approach increases the diversity of solutions and helps to get rid of local optima. Based on the above-designed MS-NSGA-II algorithm, the parallel BPMs scheduling problem is solved offline by iterative optimization to obtain a Pareto frontier solution set. Previous studies have shown that sampling the optimal and suboptimal solutions can better reflect the distribution of the Pareto frontier solution set. 35 Therefore, in this section, the output sampling points are the Pareto frontier solutions obtained from the first three layers of the algorithm.
K-Means clustering algorithm based on cosine distance for multi-objective space decomposition
After obtaining the Pareto front sampling points using the MS-NSGA-II algorithm, the distribution of the solution set can be analyzed by decomposing the objective space into several subspaces. Traditional methods use mature system scheme decomposition techniques proposed by Das and Dennis 36 to generate a set of uniformly distributed reference points on the unit hyperplane. However, the performance of solutions generated by uniformly distributed subspaces is poor due to the inconsistency with the distribution of the Pareto front. K-Means clustering is a widely used clustering algorithm with fast convergence and high interpretability. Some researchers have used reference vectors combined with the traditional Euclidean distance K-Means clustering method to select solutions. 37 However, the diversity of Pareto front solutions is essentially the diversity in the direction of weight vectors, and cosine distance is more suitable for measuring the differences in direction, as shown in Figure 8(a).
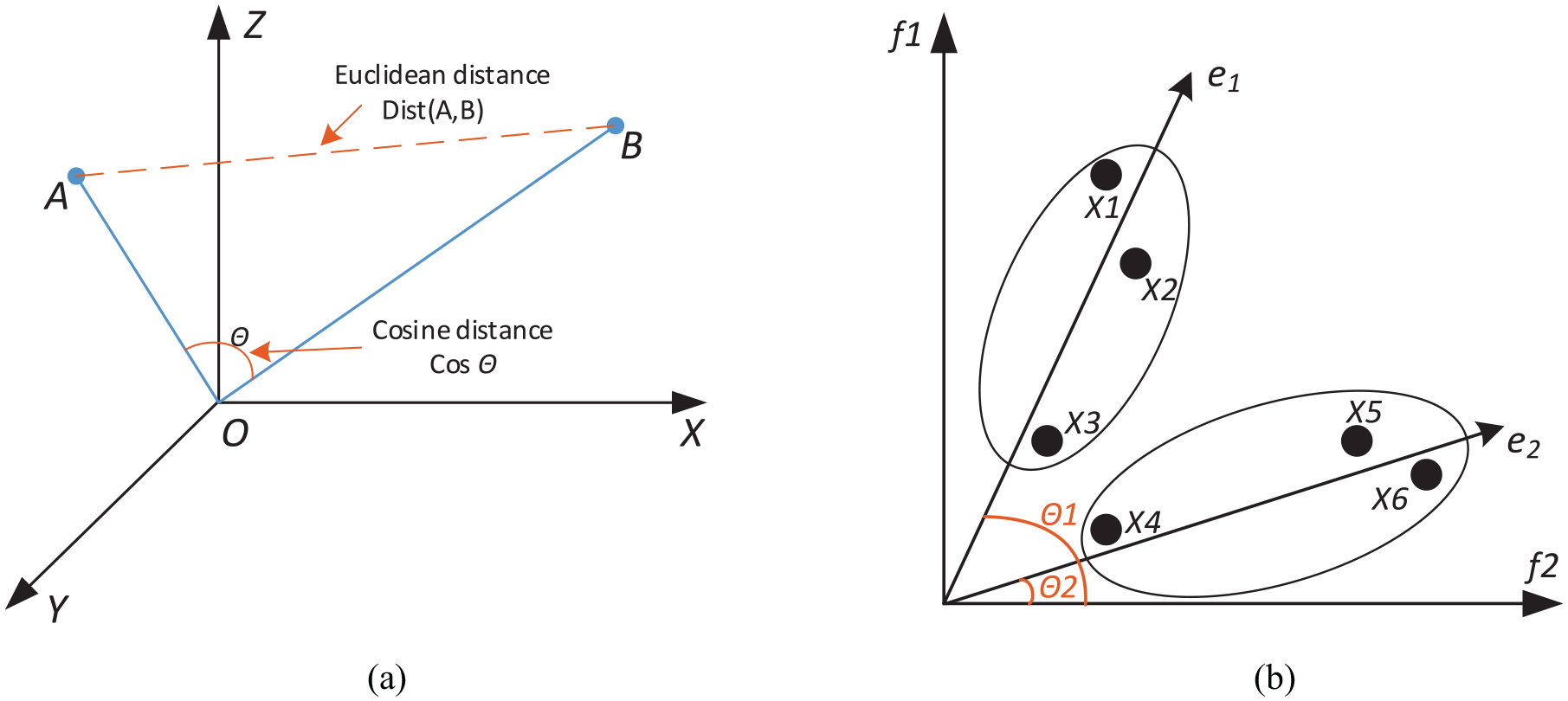
(a) Illustration of Euclidean distance and cosine distance and (b) illustration of clustering based on cosine distance.
When the angle between two Pareto front points is small in a multi-objective optimization space, the direction of the weight vectors is roughly the same, as shown in Figure 8(b). If clustering is performed directly based on Euclidean distance, the result would be three clusters:
The expression for the cosine of the angle between two weight vectors

Since the cosine value of the angle between two vectors approaches 1 as the angle approaches 0, equation (12) is used as the quantified expression of cosine distance:
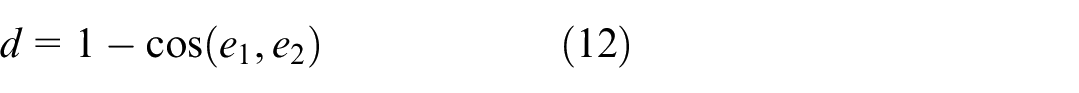
The cost function of the K-Means clustering algorithm based on cosine distance can be defined as the sum of the cosine distances between the directions of each Pareto front point and the direction of the centroid in its corresponding subspace, expressed as equation (13).
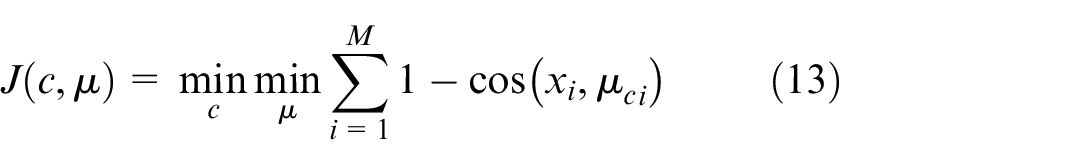
In the equation (13),

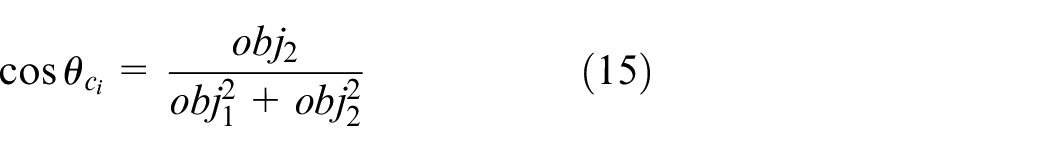
By iterating through subspace allocation and updating the subspace centers, the Pareto front points are divided into multiple subspaces, where the Pareto front solutions are concentrated in the direction of the subspace centers, which represents the optimal optimization direction. The pseudocode for the algorithm is shown in Algorithm 1.

After obtaining the optimal direction of the centers for multiple subspaces, the parallel batch processing multi-objective scheduling problem is transformed into a finite number of fixed-weight optimization subproblems. The target weights for each subspace center direction can be represented as
Parameter sharing based multi-objective deep reinforcement learning scheduling
After performing Pareto front point sampling with MS-NSGA-II and decomposing the objective space with the K-means clustering algorithm to obtain different weight parameter combinations for the objective functions, it is used in the design of the reward function of agents for the MADRL base model. The base model is trained using a parameter sharing strategy, namely, after training the sub-model in the current direction, the parameters of that model are directly utilized as the initialization parameters for the model in the subsequent direction. This strategy significantly reduces training time and enhances the overall training quality. Essentially, this represents an improved multi-strategy RL approach. As shown in Figure 9, when a scheduling is triggered, the dynamic scheduling base models of multiple subspaces are computed in parallel. This computation yields multiple solutions in the dynamic environment, thereby achieving multi-objective optimization in RL.
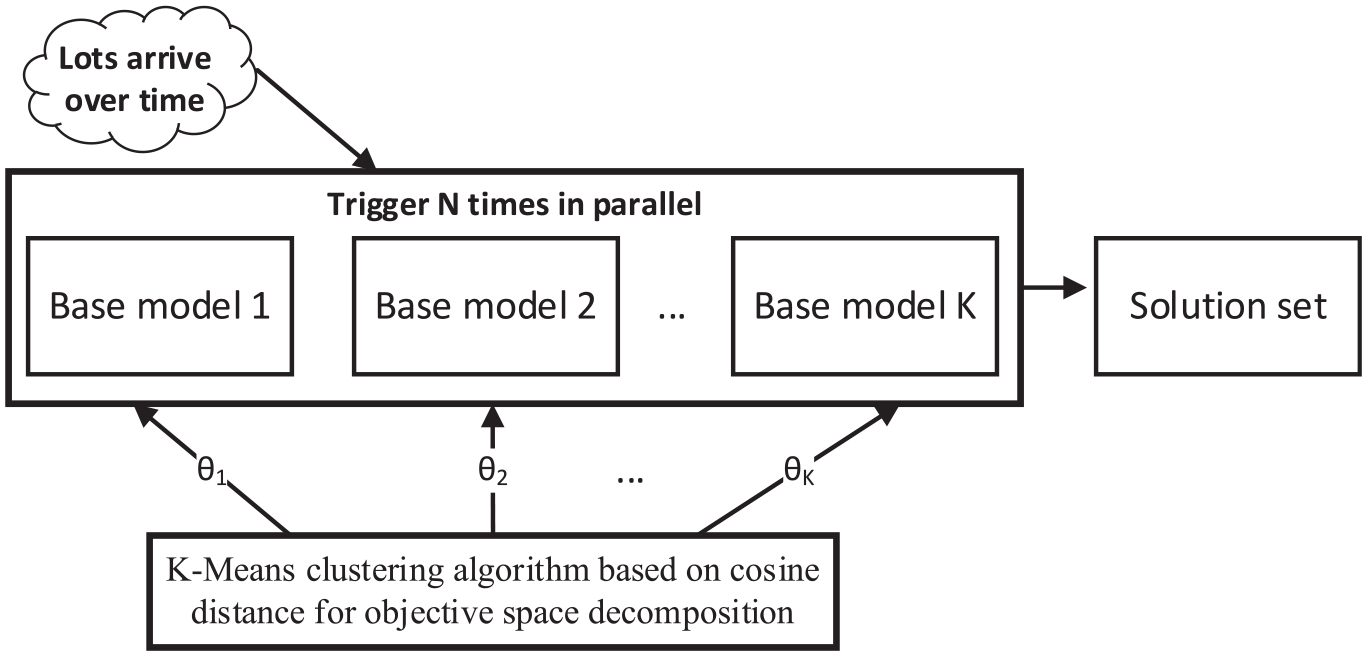
Implementing multi-objective scheduling using reinforcement learning.
State space and action space
To address the two sub-problems of parallel BPMs scheduling, batch forming and batch scheduling, we have designed batch forming agent and batch scheduling agent. The agents make scheduling decisions based on the state information of the scheduling environment and they perceive the dynamic changes in the environment through the state information.
1) State space
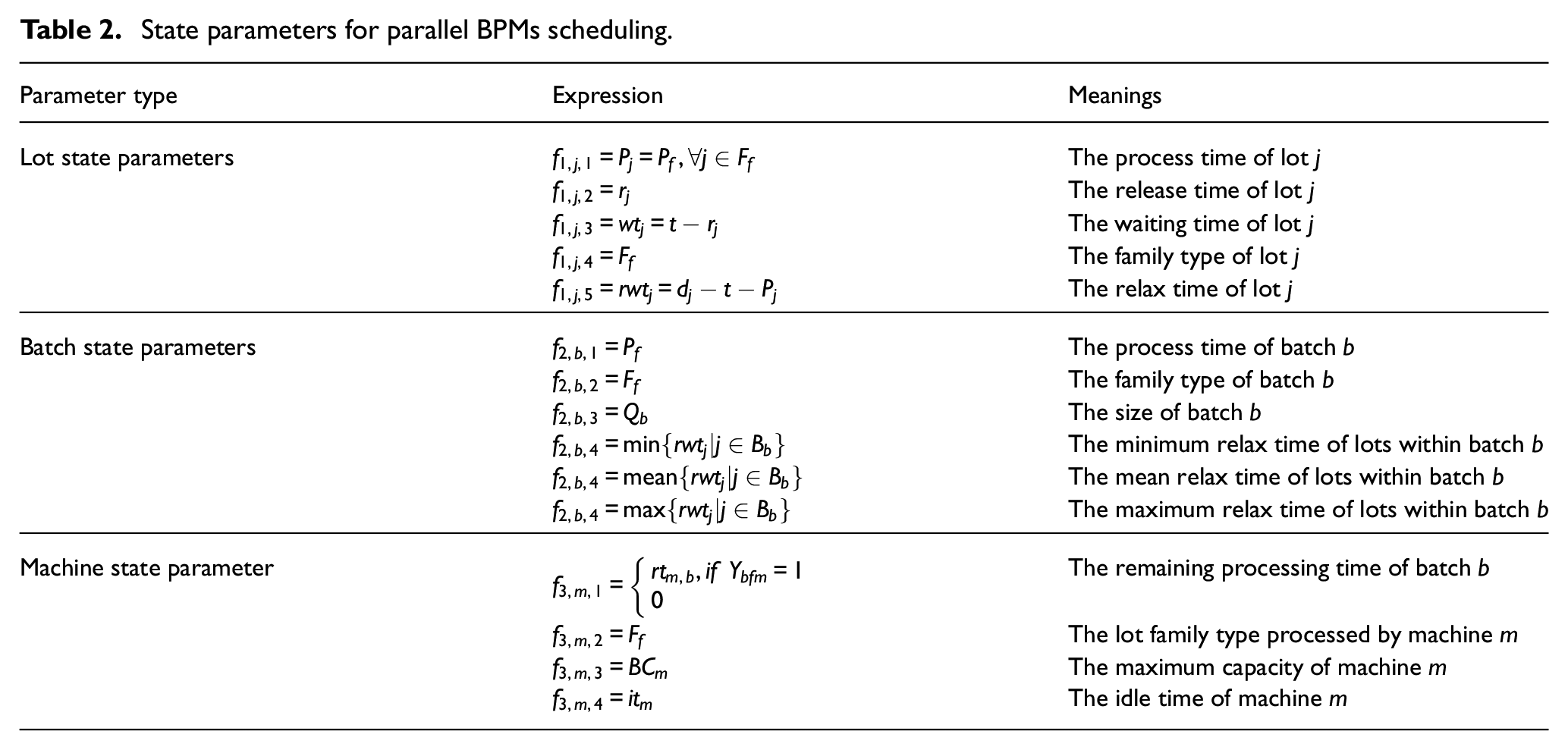
Design state matrix
2) Action space
State parameters for parallel BPMs scheduling.
The action space of parallel BPMs scheduling primarily includes the action space of batch forming agent and the action space of batch scheduling agent.
In the action space of batch forming agent, a batch buffer is set up, and the action determines whether to form a batch with the current pending lots or keep lots in the buffer. The action space of batch forming agent is defined as follows:
Action 1: Selecting a certain number of lots for batch forming

Action 2: Wait
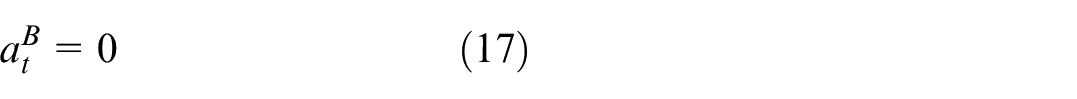
In the action space of batch scheduling, when there is idle machine, the action is made to select the appropriate batch for processing. Choosing to wait indicates not selecting any batch for processing. The machine matching rule is set to select the machine with the minimum switching time from the set of machines that meet the capacity requirements.
Action 1: Selecting batches for processing on machines
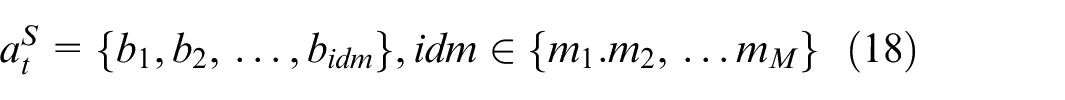
Action 2: Wait
Reward function
The reward function should consider both objectives in this chapter. Based on the obtained weight vector, the objectives are weighted to obtain a composite multi-objective function as equation (20):
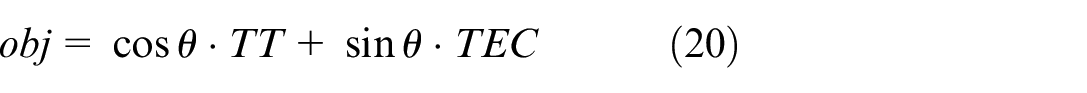
1) Reward function of batch forming agent:
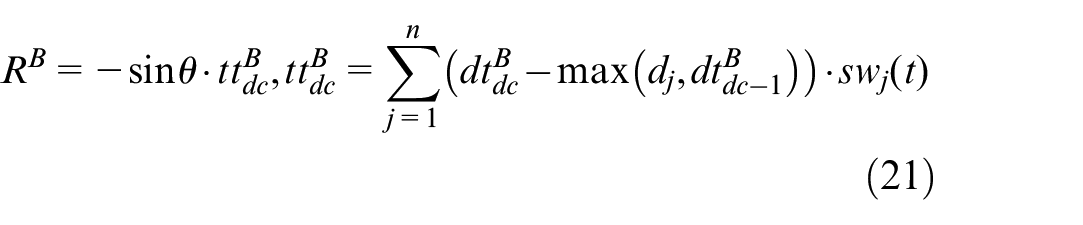
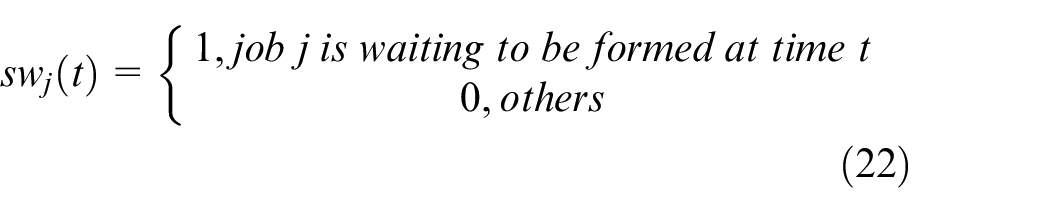
2) Reward function of batch scheduling agent:
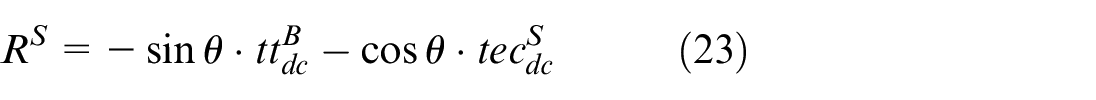
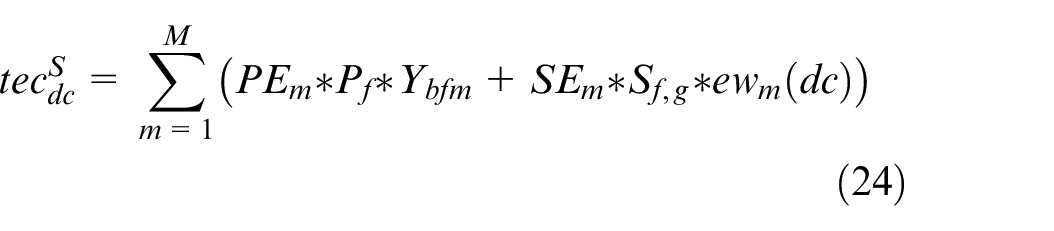

Multi-agent reinforcement learning
The interaction process between the RL agents and the parallel BPMs can be effectively described using Markov Decision Processes (MDP). When scheduling events are triggered, the agents begin by observing the current state of the scheduling environment, denoted as
Figure 10 illustrates the multi-agent RL model. The model comprises two agents: the batch forming agent and the batch scheduling agent. Each agent is equipped with an Actor module responsible for generating scheduling strategies. The agents engage in sequential scheduling using a dynamic scheduling mechanism. They interact with the parallel BPMs scheduling environment and continuously optimize their scheduling strategies based on the learned scheduling experiences. Both agents share a global Critic and a global LSTM network. The Critic represents the action-value function, which evaluates the quality of scheduling decisions. The global LSTM network maps the environment’s global state and the agents’ scheduling decisions to the strategy evaluation. This multi-agent RL model allows the agents to collaborate and learn from each other’s experiences, leading to improved scheduling strategies and overall performance.
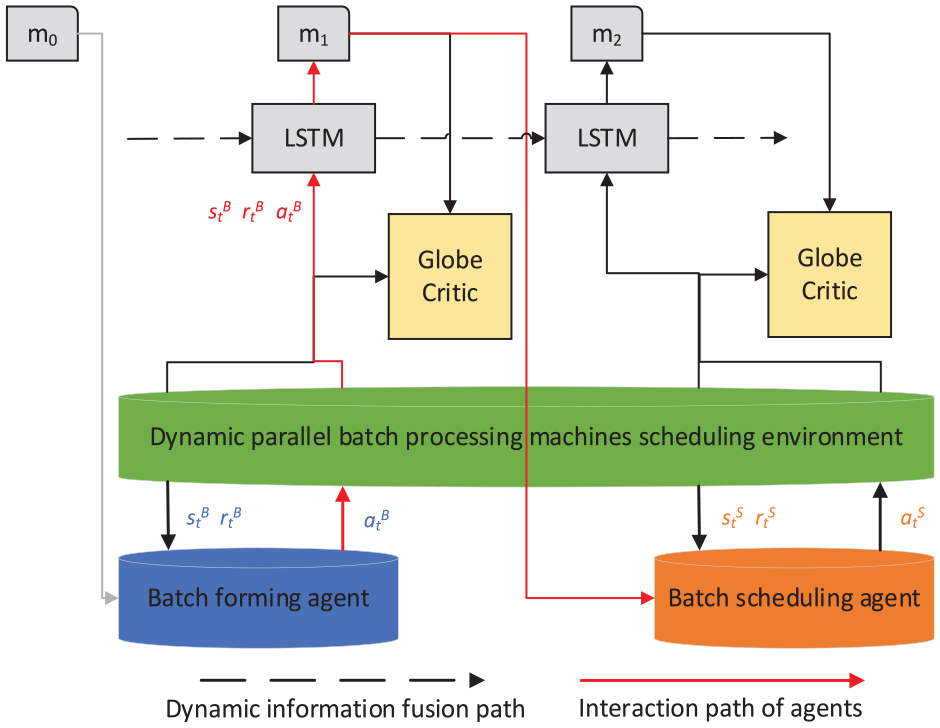
Multi-agent reinforcement learning model.
Parameter sharing based model training
As shown in Figure 2 and Algorithm 2, the process of multi-agent interacting with the MDP is defined. After designing the individual reward functions based on different optimization weights, it is necessary to train the models to ensure that each base model can find near-optimal or optimal solutions in each optimization direction. A parameter sharing strategy is used in the training process, that is, the different base models are trained in order of θ from largest to smallest, when the first base model is trained, that is, its network parameters have been optimized to be near optimal. The next base model is trained with the optimal network parameters of the previous model as a starting point, which speeds up the training speed and improves the training quality. In short, the network parameters are sequentially transferred from the previous subproblem to the next.

The main processes of Algorithm 2 include: initializing weight combinations and agent parameters, determining training parameters and experience pool initialization, batch forming phase, batch scheduling phase, calculating global discounts, and updating the policy network and value network. Through the above process CA-MADRL algorithm is able to achieve optimization in batch processing and scheduling tasks through multi-agent deep reinforcement learning, and continuously improves its strategies to obtain better solutions. Additionally, the LSTM network plays a crucial role in storing environment states, making predictions, and facilitating communication among agents. Hence, prior to model training, the LSTM network is frozen and the LSTM modules of multiple base models are consolidated into a shared module. This allows the LSTM network to consistently capture the scheduling records of different base models during the training process.
Numerical experiments
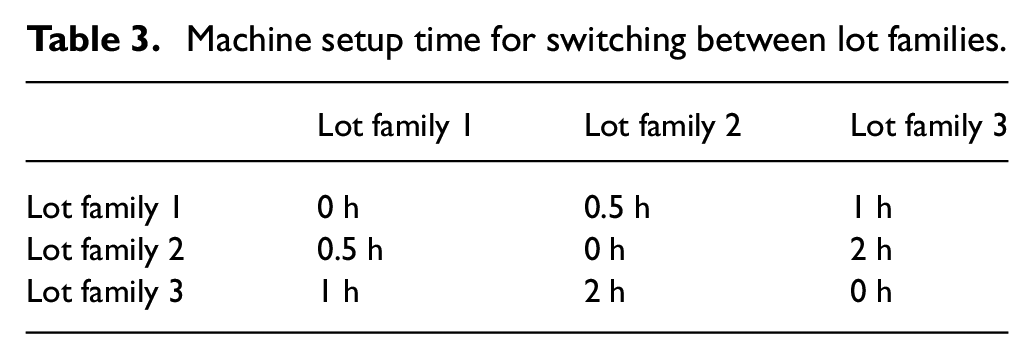
To verify the effectiveness of the CA-MADRL approach proposed in this paper, we conducted experiments using 16 instances designed based on actual production historical data of the diffusion area from a semiconductor manufacturing company. The diffusion area is a typical parallel BPMs scheduling workshop, where wafers are usually processed in batches on carriers. These carriers can accommodate multiple wafers and can be processed simultaneously in the parallel BPMs. The scheduling workshop’s lot data includes parameters such as lot families, processing times of lot families, and due dates of lots. The machine data includes parameters such as lot families that the machine can process, maximum capacity of machines, processing and idle power consumption of machines. Production setup time when switching lot families, as shown in Table 3. We set up four different types of machines and lot combinations
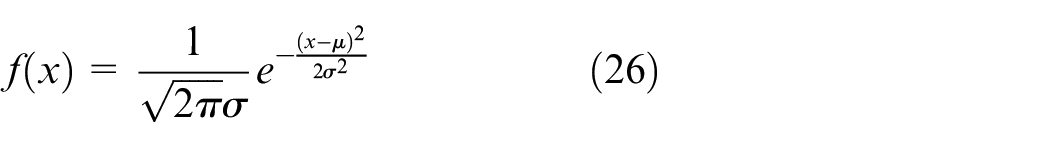
Machine setup time for switching between lot families.
Parameters tuning
The designed MS-NSGA-II algorithm is used to sample the Pareto frontier for multiple test instances. The parameters in MS-NSGA-II are set according to the relevant experience of genetic algorithm parameter setting in the literature 14 and the number of decision variables in batch machines scheduling, taking into account the diversity of populations and exploration ability. The parameters are set as follows: population size is set to 100, maximum number of iterations is set to 500. The combination of crossover and mutation rates for the three subpopulations are set as (0.8, 0.02), (0.9, 0.01), and (0.7, 0.03) respectively. Through iteratively calculating, frontiers point sampling was performed for each instance, resulting in a set of sample points.
In this section, the elbow method 38 is used to optimize the value of K. The results are shown in Figure 11(a). As K increases, the clustering error gradually decreases. When K > 4, the curve tends to flatten, indicating that increasing the number of clusters no longer significantly improves the clustering effect. Therefore, K = 4 is determined to achieve a small clustering error with a relatively small number of clusters, ensuring diversity among the clusters. The visualization of the clustering results using Instance 1 is shown in Figure 11(b).
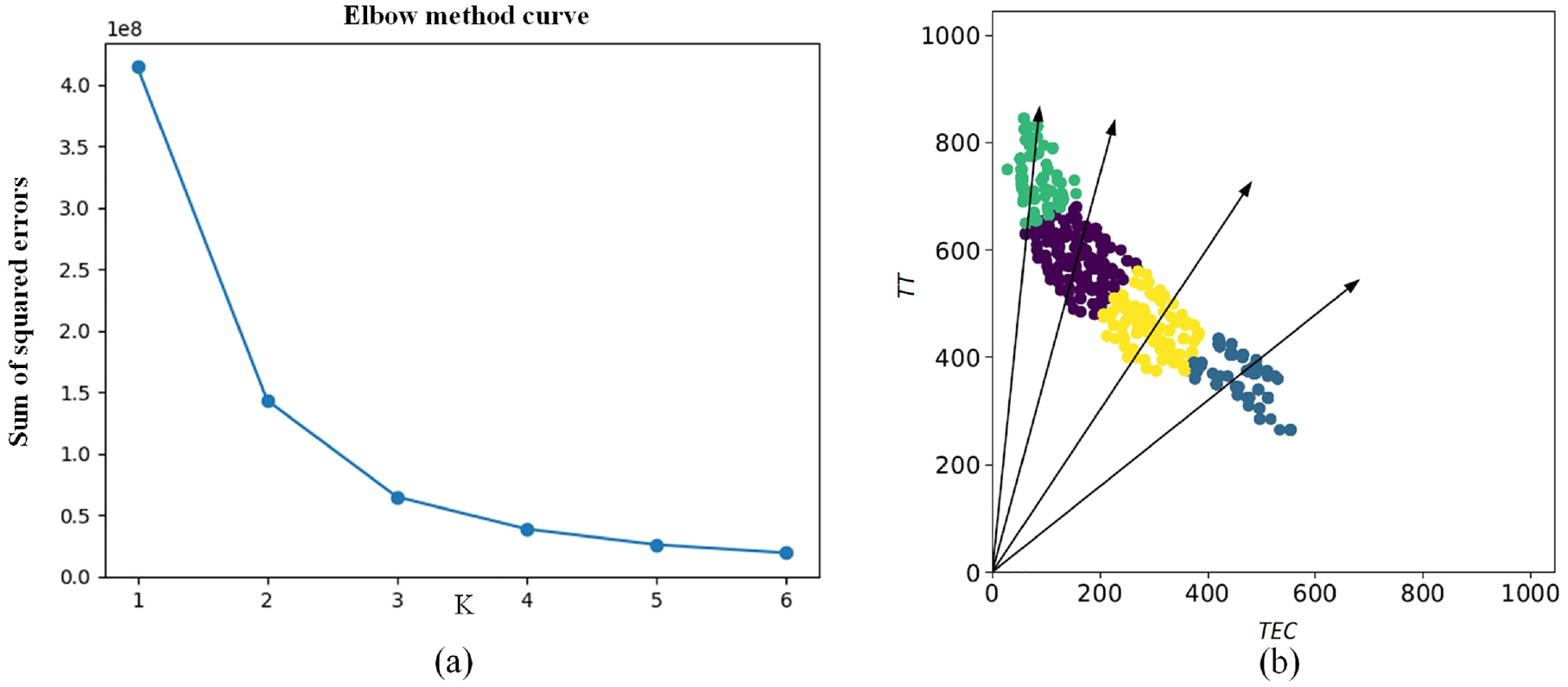
(a) Curve for optimizing the parameter K and (b) clustering results.
In the RL algorithm experiment, it is necessary to optimize the performance of the algorithm by determining some key parameters. Firstly, probability matching is used to randomly sample candidate scheduling decisions based on the weights of policy outputs,
40
in order to avoid the agent getting stuck in local optima and improve the diversity of the solution set. A suffix of 0 or 1 is added after the state matrix to differentiate between batch forming and scheduling for the global Critic. Two agents with the same network structure are built to optimize parameters such as learning rate
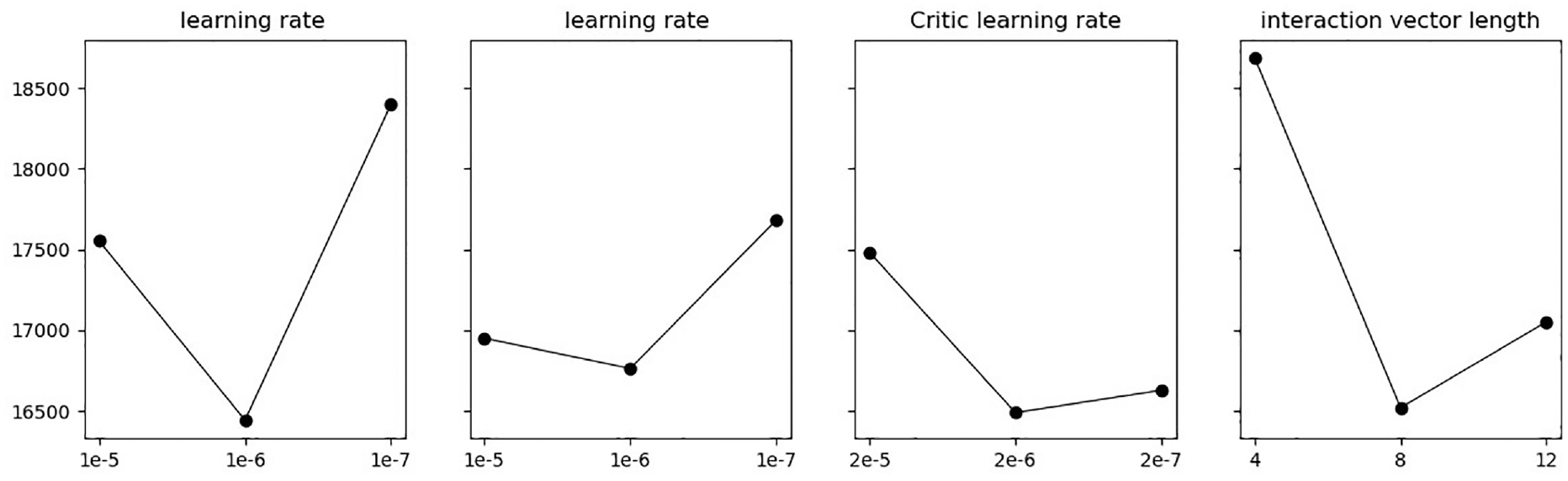
Orthogonal experiments in reinforcement learning.
The batch size and experience buffer capacity are determined based on the interaction data during the algorithm scheduling process. Since the interaction data can be reused after parameter updates, the experience buffer capacity is set to 3–5 times the number of interaction data obtained in one round, which improves the efficiency of agent scheduling interactions and accelerates the learning process. The time window size and time scaling factor
Reinforcement learning experimental parameters.
The training process of multi-agent
The various parameters of the RL model training process can reflect the correctness of the algorithm design and the effectiveness of improvements. Set the algorithm according to the parameters in Table 4 and train it on the training set. Record the changes in the agent’s parameters during the iteration process. Figure 13(a) shows that the global cumulative discounted reward value of the CA-MADRL algorithm gradually increases during the training process. Additionally, both Figure 13(b) for the batch forming agent and Figure 13(c) for the scheduling agent exhibit a good upward trend in average cumulative discounted rewards. This indicates that the two agents have formed a good cooperative relationship through information interaction centered around LSTM units, achieving global optimization. The total tardiness and total energy consumption in Figure 13(d) gradually decrease, validating the consistency between the reward function designed with optimal weights and the global optimization objective. The value network loss in Figure 13(e) converges gradually, indicating that the global critic’s evaluation error of the scheduling made by the two agents decreases over time, establishing a global evaluation system for the dyeing workshop scheduling. In Figure 13(f), the evaluation of the agent’s action values by the global critic gradually increases, indicating that as the evaluation error decreases, the scheduling performance of the agent improves.
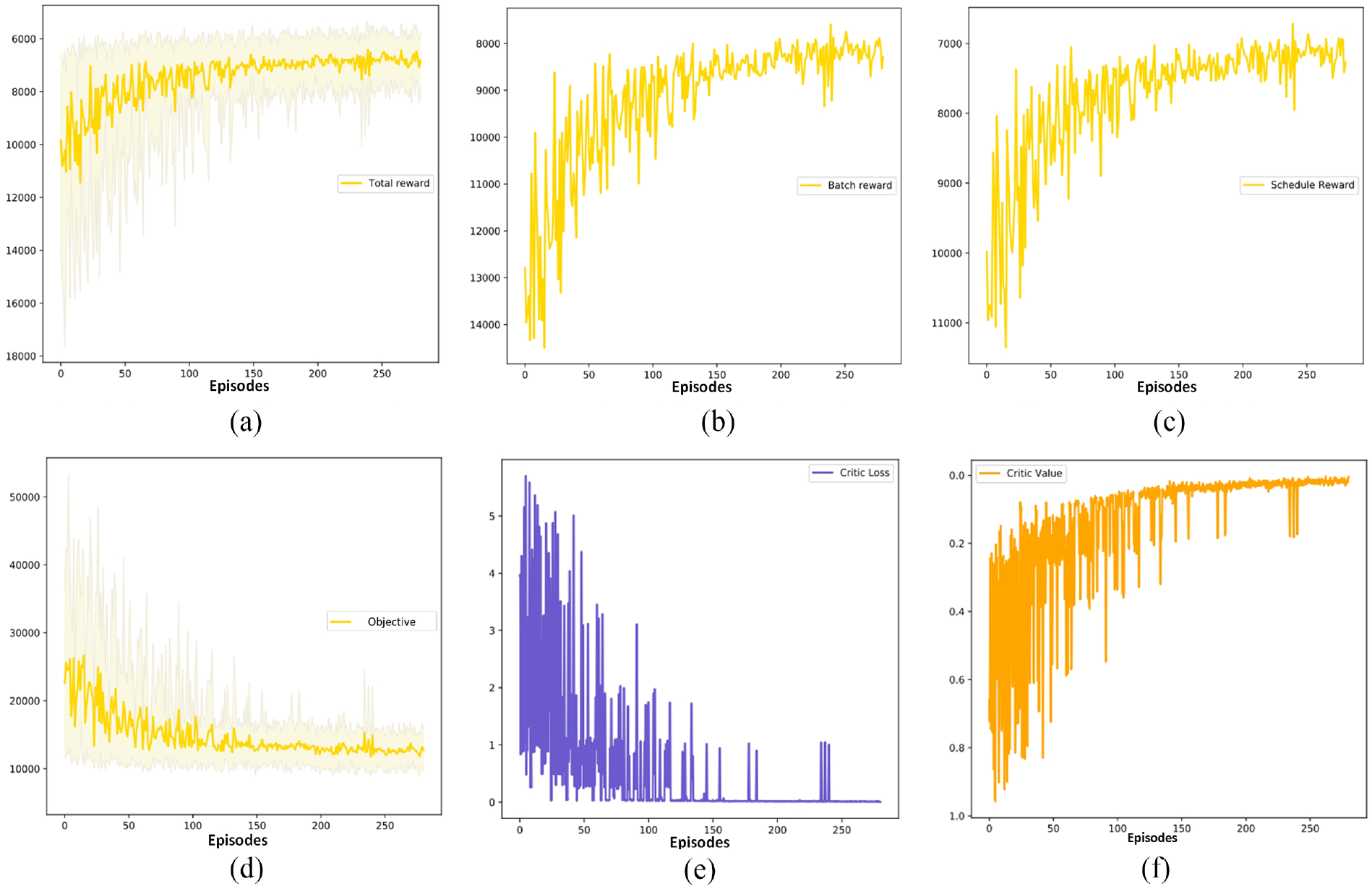
(a) Global cumulative discounted reward, (b) reward of batch forming agent, (c) reward of batch scheduling agent, (d) weighted objective function value, (e) loss of value network, and (f) estimated values of the value network.
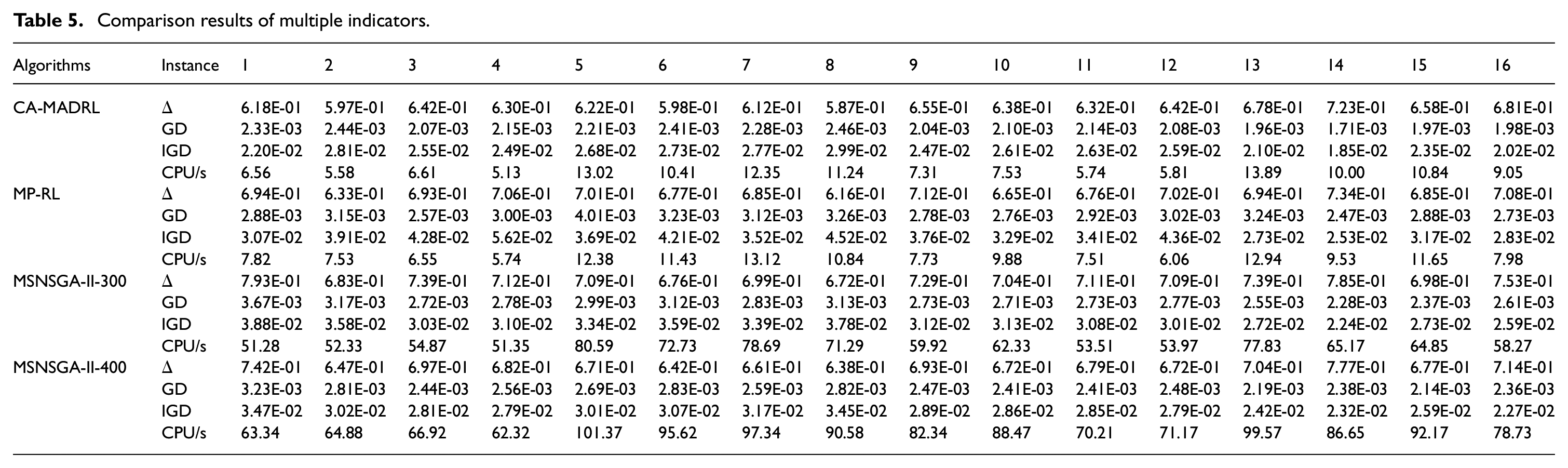
Algorithm performance comparison experiment
To evaluate the performance of the proposed CA-MADRL algorithm, a traditional multi-policy reinforcement learning (MP-RL) algorithm and the MS-NSGA-II proposed in this paper as comparison algorithms. MS-NSGA-II has a population size of 100 and maximum iterations of 300 and 400. The traditional MP-RL uses weight combinations with uniformly distributed optimization directions. The number of optimization directions is the same as the value obtained from the clustering algorithm. Other parameters of the base model are the same as the parameter design of the proposed approach. Since the RL base model can only obtain one solution in each run, each base model for each optimization direction is independently run 5 times to obtain multiple solutions.
Multi-objective optimization cannot be simply judged based on the objective values obtained. Referring to the evaluation system for the solution set of multi-objective optimization established in existing research,
41
the evaluation of multi-objective optimization results mainly relies on the following three indicators:
Comparison results of multiple indicators.
To visually demonstrate the impact of clustering assistance on multi-objective scheduling of RL agents, we plot the Pareto frontiers obtained by CA-MADRL and MP-RL when solving Instance 5. In Figure 14, the solutions obtained from the MP-RL algorithm guided by a uniform distribution of directions show a significant deviation from the
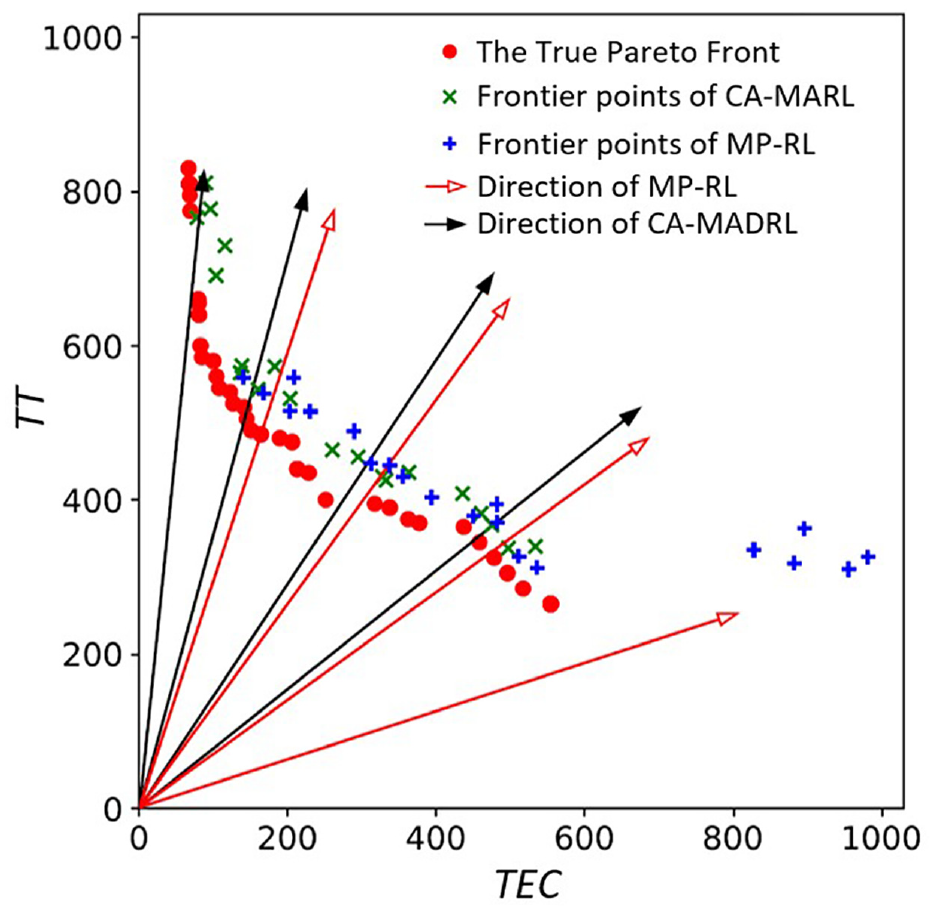
Pareto frontier comparison.
Conclusion
This paper presents a novel approach called CA-MADRL to solve multi-objective scheduling problems. It effectively addresses the issue of RL algorithms lacking diversity in solutions when faced with multi-objective optimization, as well as the computational time problem faced by evolution algorithms in dynamic environments. The multi-objective scheduling problem is solved by MS-NSGA-II algorithm and analyzed by cosine based clustering algorithm to obtain the distribution of Pareto solutions in the real solution space. Further, the original problem is decomposed into multiple sub-problems and multiple MADRL base models are trained to solve it, where the weights obtained from the clustering analysis are used for the design of the reward function of the agents and a parameter sharing strategy is used to speed up the training process.
The proposed multi-objective BPMs scheduling approach is validated using 16 test instances designed based on actual production data from a semiconductor manufacturing company and the results show that the trained multi-objective scheduling model can effectively approximate the true Pareto front, resulting in a reduction in total tardiness time and total energy consumption. Furthermore, the response time of the method is greatly reduced compared to the time-consuming exact solution process of evolutionary algorithms, which makes it more suitable for practical scheduling applications in factories. The proposed approach provides multiple optimization solutions, but among these solutions, how to automatically select the optimal weights for workshop scheduling based on the actual production status in the aggregated optimization directions is of great practical significance. It is a research direction for achieving fully automated scheduling in parallel BPMs for multi-objective optimization. At the same time, big data from the production process is used in conjunction with artificial intelligence technology to predict future production demand and machine status for advance scheduling and optimization, further improving the performance of the scheduling system.
Footnotes
Acknowledgements
We thank the editors and the anonymous reviewers for their fruitful comments and suggestions in improving the quality of this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Key R&D Program of China [grant number 2022YFB3305003], the Open Project of Henan Key Laboratory of Intelligent Manufacturing of Mechanical Equipment, Zhengzhou University of Light Industry [grant number IM202303], National Natural Science Foundation of China [grant number 52005099], and the Shanghai Science and Technology Innovation Action Plan [grant number 22511101903].
Data availability statement
The data that has been used is confidential.