
Abstract
Self-supervised learning is a reliable learning mechanism in which a robot uses an original, trusted sensor cue for training to recognize an additional, complementary sensor cue. We study for the first time in self-supervised learning how a robot’s learning behavior should be organized, so that the robot can keep performing its task in the case that the original cue becomes unavailable. We study this persistent form of self-supervised learning in the context of a flying robot that has to avoid obstacles based on distance estimates from the visual cue of stereo vision. Over time it will learn to also estimate distances based on monocular appearance cues. A strategy is introduced that has the robot switch from flight based on stereo to flight based on monocular vision, with stereo vision purely used as “training wheels” to avoid imminent collisions. This strategy is shown to be an effective approach to the “feedback-induced data bias” problem as also experienced in learning from demonstration. Both simulations and real-world experiments with a stereo vision equipped ARDrone2 show the feasibility of this approach, with the robot successfully using monocular vision to avoid obstacles in a 5 × 5 m room. The experiments show the potential of persistent self-supervised learning as a robust learning approach to enhance the capabilities of robots. Moreover, the abundant training data coming from the own sensors allow to gather large data sets necessary for deep learning approaches.
Introduction
It is generally acknowledged that robots operating in the real world benefit greatly from learning mechanisms. Learning allows robots to adapt to environments or circumstances not specifically foreseen at design time. However, the outcome of learning and its influence on the learning robot’s behavior can by definition not be predicted completely. This is a major reason for the delay in introducing successful learning methods such as Reinforcement Learning (RL) in the real world. For instance, with RL it is a major challenge to ensure an exploratory behavior that is safe for both the robot and its environment. 1
Learning from demonstration (LfD) can in this respect be regarded as more reliable. However, in the case of a mobile robot, LfD faces a “feedback-induced data bias” problem.2,3 If the robot executes its trained policy on real sensory inputs, its actions will be slightly different from the expert’s. As a result, the trajectory of the robot will be different to when the human expert was in control, leading to a test data distribution that is different from the training distribution. This difference worsens the performance of the learned policy, further increasing the discrepancy between the data distributions. The solution proposed in Ross et al.2,3 is to have the human expert provide novel training data for the sensory inputs experienced by the robot when being in control itself. This leads to an iterative process that requires quite a time investment of the human expert.
There is a relatively new learning mechanism for robots that combines reliability with the advantage of not needing any human supervision. Self-supervised learning (SSL) does not learn a control policy as LfD and RL, but rather focuses on improving the sensory inputs used in control. Specifically, in SSL, the robot uses the outputs of an original, trusted sensor cue to learn recognizing an additional, complementary sensor cue. The reliability comes from the fact that the robot has access to the trusted cue during the entire learning process, ensuring a baseline performance of the system.
Until now, the purpose of SSL has mostly been the exploitation of the complementarity between the sensor cues. To illustrate, perhaps the most well-known example is the use of SSL on Stanley, the car that won the grand DARPA challenge. 4 Stanley used a laser scanner to detect the road ahead. The range of the laser scanner was rather limited, which placed a considerable restriction on the robot’s driving speed. SSL was used in order to extend the road detection beyond the range of the laser scanner. In particular, the laser scanner-based road classifications were used to train a color model of drivable terrain in the images from a camera. This color model was then applied to image regions not covered by the laser scanner. These image regions higher up in the image allowed to detect the road further away. The use of SSL permitted Stanley to speed up considerably and was an important factor in winning the competition.
A characterizing feature of many of the earlier SSL studies,4–10 is that the complementary cue is always used in combination with the original sensor cue. More recent studies aim to replace the function of the original cue with that of the complementary cue.11–14 For instance, in Baleia et al., 11 the sense of touch is used to teach a vision process how to recognize traversable paths through vegetation with the goal of gradually reducing time-intensive haptic interaction. Hence, the learning of recognizing the complementary cue will have to persist in time. However, the consequences of this persistent form of SSL on the robot’s behavior when acting on the complementary cue have not been addressed in the above-mentioned studies.
The main contribution of this article is that we perform an in-depth study of the behavioral aspects of persistent SSL. We do so in the context of a scenario in which the robot should keep performing its task even when the supervisory cue becomes completely unavailable. Importantly, when the robot relies only on the complementary cue, it will encounter the feedback-induced data bias problem known from LfD. We suggest a novel behavior strategy during learning to handle this problem in persistent SSL. Specifically, we study a flying robot with a stereo vision system that has to avoid obstacles in a global positioning system (GPS)-denied environment. The robot uses SSL to learn a mapping from monocular appearance cues to stereo-based distance estimates. We have chosen this context because it is relevant for any stereo-based robot that needs to be robust to a permanent failure of one of its cameras. In computer vision, monocular distance estimation is also studied. There, the main challenges are the gathering of sufficient data (e.g., for deep neural networks) and the generalization of the learned distance estimation to an unforeseen operation environment. Both of these challenges are addressed to some extent by SSL, as learning data are abundant and the robot learns in the environment in which it operates. We regard SSL as an important supplement to machine learning for robots. Therefore, we end the study with a discussion on the position of (persistent) SSL in the broader context of robot and machine learning, comparing it among others with RL, LfD, and supervised learning.
The remainder of the article is set up as follows. First, we discuss related work. Then, we more formally introduce persistent SSL and explain our implementation for the stereo-to-mono learning. We analyze the similarity of the specific SSL case studied in this article with LfD approaches. Subsequently, we perform offline vision experiments in order to assess the performance of various parameter settings. Thereafter, we compare various learning strategies in simulation. The best learning strategy is implemented for experiments with a Parrot ARDrone2, and the results of these robotic experiments are analyzed. Finally, the broader implications of the findings on persistent SSL are discussed, and conclusions are drawn.
Related work
We study persistent SSL in the context of a stereo-vision equipped robot that has to learn to navigate with a single camera. In this section, we discuss the state-of-the-art in the most relevant areas to the study: monocular navigation and SSL.
Monocular navigation
The large majority of monocular navigation approaches focuses on motion cues. The optical flow of world points allows for the detection of obstacles 15 or even the extraction of structure from motion, as in monocular simultaneous localization and mapping (SLAM). 16 The main issue of using monocular motion cues for navigation is that optical flow only conveys information on the ratio between distance and the camera’s velocity. Additional information is necessary for retrieving distance. This information is typically provided by additional sensors, 16 but can also be retrieved by performing specific optical flow maneuvers.17,18
In contrast, it is well known that the appearance of objects in a single, still image does contain distance information. Successfully estimating distances in a single image allows robots to evaluate distances without having to move. In addition, many appearance extraction and evaluation methods are computationally efficient. Both these factors can aid the robot in the making of quick navigation decisions. Below, we give an overview of work in the area of monocular appearance-based distance estimation and navigation.
Appearance-based navigation without distance estimation
There are some appearance-based navigation methods that do not involve an explicit distance estimate. For instance, in de Croon et al., 19 an appearance variation cue is used to detect the proximity to obstacles, which is shown to be successful at complementing optical flow-based time-to-contact estimates. A threshold is set that makes the flying robot turn if the variation drops too much, which will lead to turns at different distances.
An alternative approach is to directly learn the mapping from visual inputs to control actions. In order to fly a quad rotor through a forest, Ross et al. 3 use a variant of LfD 20 to acquire training data on avoiding trees in a forest. First a human pilot controls the drone, creating a training data set of sensory inputs and desired actions. Subsequently, a control policy is trained to mimic the pilot’s commands as good as possible. This control policy is then implemented on the drone.
A major problem of this approach is the feedback-induced data bias: A robot has a feedback loop of actions and sensory inputs, so its control policy determines the distribution of world states that it encounters (with corresponding sensory inputs and optimal actions). Small deviations between the trained controller and the human may bring the robot in unknown states for which it has received no training. Its control policy may generalize badly to such situations. The solution proposed in Ross et al. 3 is a transitional model called DAgger, 2 in which actions from the expert are mixed with actions from the trained controller. In the real-world experiments in Ross et al., 3 several iterations have been performed in which the robot flies with the trained controller, and the captured videos are labeled offline by a human. This approach requires skilled pilots and significant human effort.
Offline monocular distance learning
Humans are able to see distances in a single still image, and there is a growing body of work in computer vision utilizing machine learning to do the same. Interest in single image depth estimation was sparked by work from Hoiem et al. 23 and Saxena et al.24,25 Hoiem’s automatic photo pop-up tries to group parts of the image into segments that can be popped up at different depths. Saxena’s Make-3D uses a Markov random field (MRF) approach to classify a depth per image patch on different scales. These studies focus on creating a dense depth map with a machine learning computer vision approach. Both methods use supervised learning on a large training data set. Some work was done on adopting variants of Saxena’s MRF work for driving rovers and even for MAVs. Lenz et al. 26 proposed a solution based on a MRF to detect obstacles on board an MAV, but it does not infer how far the objects are. Instead, it is trained offline to recognize three different obstacle class types. Any different objects could hence lead to navigation problems.
Recently, again focusing on creating a dense depth map from a single image, Eigen et al. 27 propose a multi-scale deep neural network approach trained on the KITTI data set, making it more resilient for practical robot data. Training deep neural networks require a large data set, which is often obtained by deforming training data or by artificially generating training data. Michels et al. 28 use artificial data to learn recognizing obstacles on a rover, but in order to generalize well it requires the use of a very realistic simulator. In addition, the same work reports significant improvement if the artificial data are augmented with labeled real-world data.
Other groups acquire training data for supervised learning by having another separate robot or system acquire data. This data are then processed and learned offline, after which the learned algorithm is deployed on the target robot. Dey et al. 29 use an RC car with a stereo vision setup to acquire data from an environment, apply machine learning on this data offline, and navigate a similar but unseen environment with an MAV based on the trained algorithm. Creating and operating a secondary system designed to acquire training data, however, is no free lunch. Moreover, it introduces inconvenient biases in the training data, because an RC car will not behave in a similar way both in terms of dynamics, camera viewpoint, and the path chosen through the environment.
None of the above methods have the robot gather the data and learn while in operation.
Self-supervised learning
The idea of SSL has been around since the late 1990s, 30 but the successful application of it to terrain classification on the autonomously driving car Stanley 31 demonstrated its first major practical use. A similar approach was taken by Hadsell et al., 9 but now using a stereo vision system instead of a LIDAR system, and complex convolutional filters instead of simple and fixed color-based features. These approaches largely forgo the need for manually labeled data as they are designed to work in unseen environments.
In most studies on SSL for terrain classification, the ground truth is always used during operation. In contrast, two very recent studies have as goal that the robot takes some decisions based on the complementary sensor cue alone. Since the complementary cue then has to persist in the absence of the original cue, this form of SSL can be termed “persistent SSL.” Baleia et al. 11 study a rover with a haptic antenna sensor. In their application of terrain mapping, they try to map monocular cues to obstacles based on earlier events of encountering similar situations that resulted in either a hard obstacle, a traversable obstacle, or a clear path. The monocular information is used in a path-planning task, requiring a cost function for either exploring unknown potential obstacles or driving through a terrain on the current available information. Since checking whether a potential obstacle is traversable is costly (the rover needs to travel there in order for the antenna to provide ground truth on that), the robot learns to classify the terrain ahead with vision. On each sample an analysis is performed to determine whether the vision-based classifier is sufficiently confident: it either decides the terrain is traversable, not traversable, or unsure. In the unsure case, the sample is sensed using the antenna. Gradually this will become necessary less often, thus learning to navigate using its Kinect sensor alone. In Ho et al., 12 a flying robot first uses optical flow to select a landing site that is flat and free of obstacles. In order for this to work, the robot has to move sufficiently with respect to the objects on the landing site. While flying, the robot uses SSL to learn a regression function that maps an (appearance-based) texton distribution to the values coming from the optical flow process. The learned function extends the capabilities of the robot, as after learning it is also able to select landing sites without moving (from hover). The article shows that if the robot is uncertain on its appearance-based estimates, it can switch back to the original optical flow-based cue.
The main contribution of this article is that we focus on the behavioral aspects of persistent SSL. We study how to best set up the behavior during the learning process, so that the robot will be able to keep performing its task when the original sensor cue becomes completely unavailable. Furthermore, we use stereo vision as the trusted, original cue, something which has not been done before in SSL. Concerning a comparison with the largest body of work on SSL that deals with terrain traversability classification, learning depth estimates directly is likely more complex. To illustrate, the robot would not only have to recognize sand, but it also has to make the difference between sand at 1-m distance and at 3-m distance. As mentioned above though, successful algorithms exist even to estimate complete dense depth maps from single images. In this article, since the emphasis is on behavior, we will deal with simplified environments and the estimation is restricted to the average depth in the field of view of the camera.
Methodology overview
In this section, we describe the persistent SSL learning mechanism and describe our implementation of this mechanism for our specific proof of concept case, monocular depth estimation in flying robots. Note that since our interest is in the behavioral aspects of persistent SSL, it is most important that the robot flies and learns in real time. Moreover, for the applicability to small flying robots, it is important that the processing for such SSL can be performed onboard, even considering the significant restrictions in onboard processing. The focus here is not yet on dealing with complex environments or on the accomplishment of missions like exploration or navigation. In this study, we investigate a very simple environment and obstacle avoidance behavior. We end this section with a description of the three learning behaviors that we compare with each other.
Persistent SSL principle
The persistent SSL principle is schematically depicted in Figure 1. In persistent SSL, an original, pre-wired sensory cue provides supervised outputs to a learning process that takes a different, complementary sensory cue as input. The goal is to be able to replace the pre-wired cue if necessary. When considering the system as a whole, learning with persistent SSL can be considered as unsupervised; it requires no manual labeling or pre-training before deployment in the field. Internally it uses a supervised learning method that in fact needs ground truth labels to learn. This ground truth is, however, assumed to be provided online and autonomously without human or outside interference.

The persistent self-supervised learning principle.
In the schematic, the input variable

The function


Stereo-to-mono proof of concept
Figure 2 presents a block diagram of the proposed proof of concept system in order to visualize how the persistent SSL method is employed in our application: estimating monocular depth with a flying robot. Input is provided by a stereo vision camera, with either the left or right camera image routed to the monocular estimator. We use a Visual Bag of Words (VBoW) method for this estimator. The ground truth for persistent SSL in this context is provided by the output of a stereo vision algorithm. In this case, the average value of the disparity map is used, both for training the monocular estimator and as an input to the switch θ. Based on the switch, the system either delivers the monocular or the stereo vision average disparity to the behavior controller.

System overview. See the text for details.
Stereo vision processing
The stereo camera delivers a synchronized gray-scale stereo-pair image per time sample. A stereo vision algorithm first computes a disparity map, but often this is a far from perfect process. Especially in the context of an MAV’s size, weight and computational constraints, errors caused by imperfect stereo calibration, resolution limits, etc. can cause large pixel errors in the results. Moreover, learning to estimate a dense disparity map, even when this is based on a high quality and consistent data set, is already very challenging. Since we use the stereo result as ground truth for learning, we minimize the error by averaging the disparity map to a single scalar. A single scalar is much easier to learn than a full depth map and has been demonstrated to provide elementary obstacle avoidance capability.28,32,33
The disparity λ relates to the depth d of the input image:

Using averaged disparity instead of averaged depth fits the obstacle avoidance application better, because small but close by objects are emphasized due to the nonlinear relation of equation (4). However, linear learning methods may have difficulty mapping this relation. In our final design, we thus choose to learn the disparity with a nonparametric approach, which is resilient to nonlinearities.
Monocular disparity estimation
The monocular disparity estimator forms a function from the image’s pixel values to the average disparity in the image. Since the main goal of the article is to study SSL on board a drone in real time, efficiency of both the learning and execution of this function is very important. Hence, we converged to a computationally extremely efficient VBoW approach for the robotic experiments. We have also explored a deep neural network approach, but the hardware and time available for learning did not allow for having the deep neural learning on board the drone at this stage.
The VBoW method uses small image patches of w × h pixels, as successfully introduced in Varma and Zisserman 34 for a complex texture classification problem. First, a dictionary is created by clustering the image patches with Kohonen clustering (as in De Croon et al. 33 ). The n cluster centroids are called “textons.” In this work, two types of textons are used: normal intensity textons and gradient textons obtained similarly but based upon the gradient of the images. Gradient textures have been shown in Wu et al. 35 to be an important depth cue. An example dictionary of each is depicted in Figure 3. Gradient textons are shown with a color range (from blue = low, to red = high). The intensity textons in Figure 3 are based on grayscale intensity pixel values.

The texton library used in the experiments. The right set of textons is based on pixel intensities, the left set contains (artificially colored) gradient textons (i.e., textons based on gradient images).
When an image is received, m patches are extracted from the W × H pixel image. Each patch is compared to the dictionary by means of a distance function, in order to form a texton occurrence histogram for the image; the texton bin with the smallest Euclidean distance to a given patch is increased by 1. The histogram is normalized to sum to 1. Then, each normalized histogram is supplemented with its Shannon entropy, resulting in a feature vector of size n + 1. The idea behind adding the entropy is that the variation of textures in an image decreases when the camera gets closer to obstacles. 33 To illustrate the change in texton histograms when approaching an obstacle, a time series of texton histograms can be seen in Figure 4. Note how the entropy of the distribution indeed decreases over time, and that especially the fourth bin is much higher when close to the poster on the wall. A machine learning algorithm will have to learn to notice such relationships itself for the robot’s environment, by learning a mapping from the feature vector to a disparity scalar. We have investigated different function representations and learning methods to this end.

Approaching a poster on the wall. Left: monocular input. Middle: overlaid textons annotated with the color used in the histogram. Right: texton distribution histogram with the corresponding texton shown beneath it.
Control behavior
The proposed system uses a straightforward behavior heuristic to explore, navigate, and persistently learn a room. The heuristic is depicted as a finite state machine (FSM) in Figure 5. The FSM detects obstacles by means of a threshold t applied to the average disparity λ. In state 0, the robot flies in the direction of the camera’s principal axis. When an obstacle is detected (

The behavior heuristic FSM. λ is average disparity, e is the attitude error (meaning the difference between the newly picked direction and the current attitude), tn the respective thresholds.
Performance
The average disparity λ, coming either from stereo vision or from the monocular distance estimation function
This leads to the question how to determine what a “sufficient” TPR/FPR is. We evaluate this matter in the context of the robot’s obstacle avoidance task. In particular, we first look at the probability of a collision with a given TPR and then at the probability of a spurious turn with a given FPR.
In order to model the probability of a collision, consider a constant velocity approach with input samples (images)

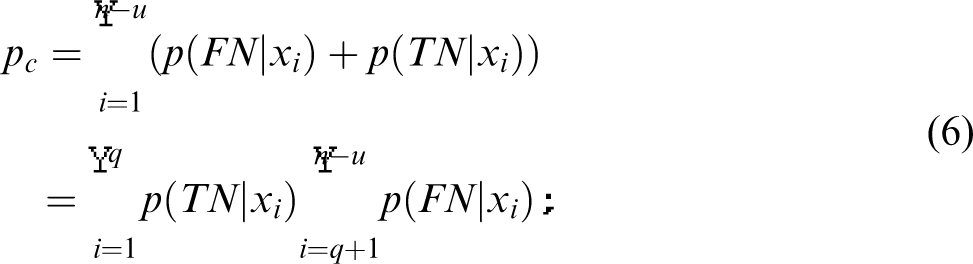
We can use equation (6) to choose an acceptable
The analysis of the effect of false positives is straightforward, as it can be expressed in the number of spurious turns per second or, equivalently if assuming a constant velocity, per meter traveled. With the same scenario as above, an FPR = 0.05 will on average lead to three spurious turns per traveled meter, which is unacceptably high. An FPR = 0.0017 will approximately lead to 1 spurious turn per 10 m.
The above analysis seems to indicate that quite many false negatives are acceptable, while there can only be very few false positives. However, there are two complicating factors. The first factor is that equation (6) only holds when X can be assumed i.i.d., which is unlikely due to the nature of the consecutive samples of an approach toward an obstacle. Some reasoning about the nature of the dependence is, however, possible. Assuming a strong correlation between consecutive samples results in a higher probability of xi being classified the same as
The system can be more realistically modeled as a Markov process as depicted in Figure 6. From this it can be seen that the system can be split in a reducible Markov process with an absorbing avoid state, and a chain of states that leads to the absorbing collision state. The values of the transition matrix Ω can be determined from the data gathered during operation. This would allow the robot to better predict the consequences of a chosen TPR and FPR.
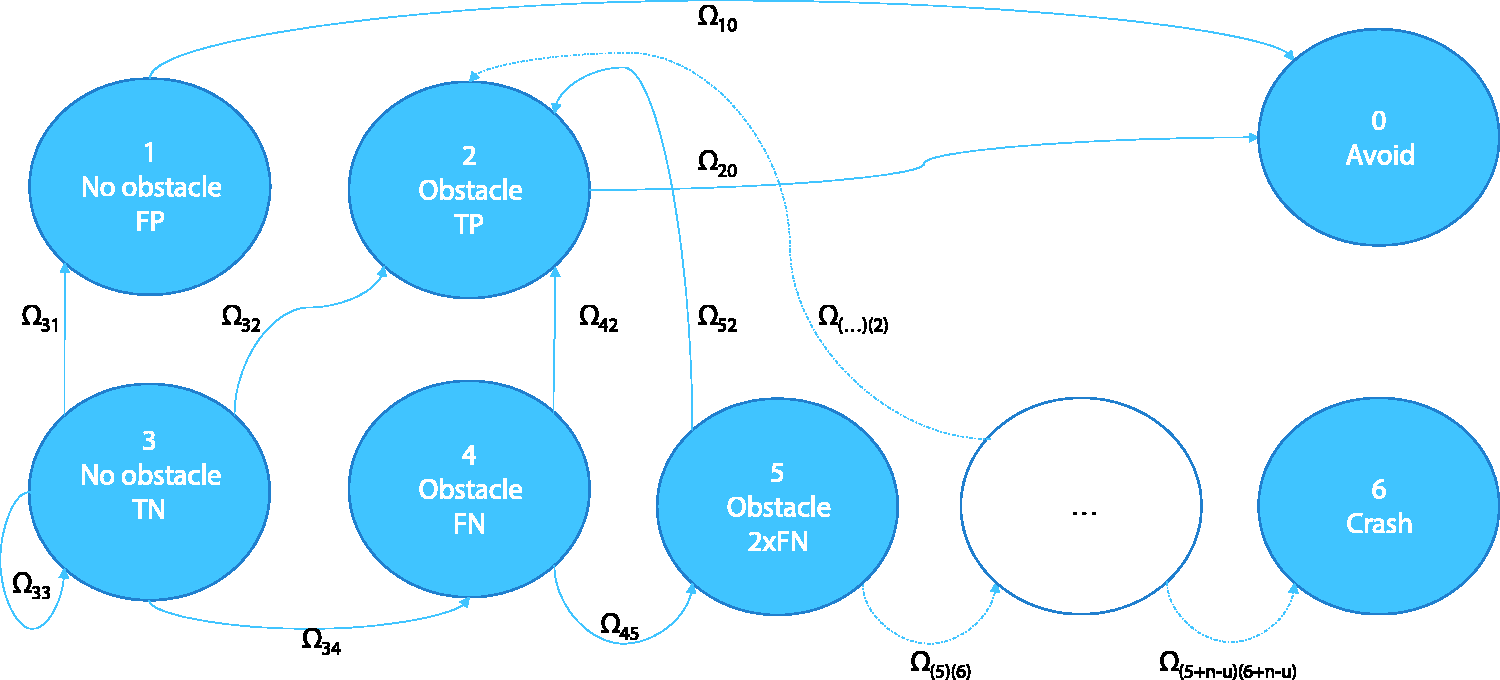
A Markov model of the probability of a collision. Due to the nature of the consecutive samples, state transition probabilities
As an illustration of the effects of sample dependence, let us suppose a model in which each classification has a probability of being identical to the previous classification,
This leads us to the second complicating factor, which is specific to our SSL setup. Since the robot operates on the basis of the ground truth, it should theoretically hardly ever encounter positive samples. Namely, the robot should turn when it detects a positive sample. This implies that the uncertainty on the estimated TPR is rather high, while the FPR can be estimated better. A potential solution to this problem is to purposefully have the mono-estimation robot turn earlier than the stereo vision-based one.
Similarity with LfD
The core of SSL is a supervised algorithm that learns the function
A similar problem of inducing a different state distribution is well known in the area of LfD.2,3 Actually, we will show that under some mild assumptions, the persistent SSL problem studied in this paper is equivalent to an LfD problem. Hence, we can draw on solutions in LfD such as DAgger. 2
The goal of LfD is to find a policy
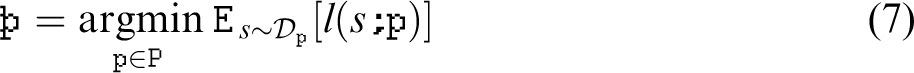
At first sight, SSL is quite different, as it focuses only on the state information that serves as input to the policy. Instead of optimizing a policy, the supervised learning in persistent SSL can be defined as finding the function

To see the similarity to equation (7), first realize that the stereo-based policy is in this case the teacher policy:

When we learn a function

Learning schemes
The interest of the above-mentioned similarity lies in the use of proven techniques from the field of LfD for training the persistent SSL system. In this article, we study a well-known method from this field, named DAgger,
2
and compare it with two additional methods. All three learning schemes start with an initial learning period in which the drone is controlled purely by means of stereo vision. The three methods are different though as follows.
In the first learning scheme, the drone will continue to fly based on stereo vision for the remainder of the learning time. After learning, the drone immediately switches to monocular vision. For this reason, the first scheme is referred to as “cold turkey.” In the second learning scheme, the drone will perform a stochastic policy, selecting the stereo vision-based actions with a probability βi and monocular-based actions with a probability In the third learning scheme, the drone will perform monocular-based actions, with stereo vision only used to override these actions when the drone gets too close to an obstacle. Therefore, we refer to this scheme as “training wheels.”
Offline vision experiments
In this section, we perform offline vision experiments. The goal of these experiments is to determine how good the proposed VBoW method is at estimating monocular depth, and to determine the best parameter settings.
To measure the performance, we use two main metrics: the mean square error (MSE) and the area under the curve (AUC) of an ROC curve. MSE is an easy metric that can be directly used as a loss function, but in practice many situations exist in which a low MSE can be achieved while inadequate performance is reached for the basis of reliable MAV behavioral control. The AUC captures the trade-off between TPR and FPR and hence is a good indication of how good the performance is in terms of obstacle detection.
We use two data sets in the experiments. The first data set is a video made on a drone during an autonomous flight using an onboard 128 × 96 pixels stereo camera. The second data set is a video made by manually walking with a higher quality 640 × 480 pixel stereo camera through an office cubicle in a similar fashion as the robot should move in the later online experiments. The data sets #1 and #2 used in this section are made available for download publicly. 36 An example image from each data set is shown in Figure 7.

Example from data set #1 (left, 128 × 96 pixels) and data set #2 (right, 640 × 480).
Our implementation of the VBoW method has six main parameters, ranging from the number of intensity and gradient textons to the number of samples used to smooth the estimated disparity over time. An exhaustive search of parameters being out of reach, we have performed various investigations of parameter changes along a single dimension. Table 1 presents a list of the final tuned parameter values. Note that these parameter values have not only been optimized for performance. Whenever performance differences were marginal, we have chosen the parameter values that saved on computational effort. This choice was guided by our goal to perform the learning on board of a computationally limited drone. Below we will show a few of the results when varying a single parameter, deviating from the settings in Table 1 in the corresponding dimension.
Parameter settings.

Figure 8 shows the results for different numbers of textons,

MSE and AUC number of textons. Dashed/solid lines refer to results on train/test set.
The VBoW method involves choosing a regression algorithm. In order to determine the best learning algorithm, we have tested four regression algorithms, limiting the choice mainly based on feasibility for implementing the regression algorithm on board a constrained embedded system. We have tested two non-parametric (kNN and Gaussian process regression) and two parametric (linear and shallow neural network regression) algorithms. Figure 9 presents the learning curves for a comparison of these regressors. Clearly, in most cases the kNN regression comes out best. A naive implementation of kNN suffers from having a larger training set in terms of CPU usage during test time, but after implementation on the drone, this did not become a bottleneck.
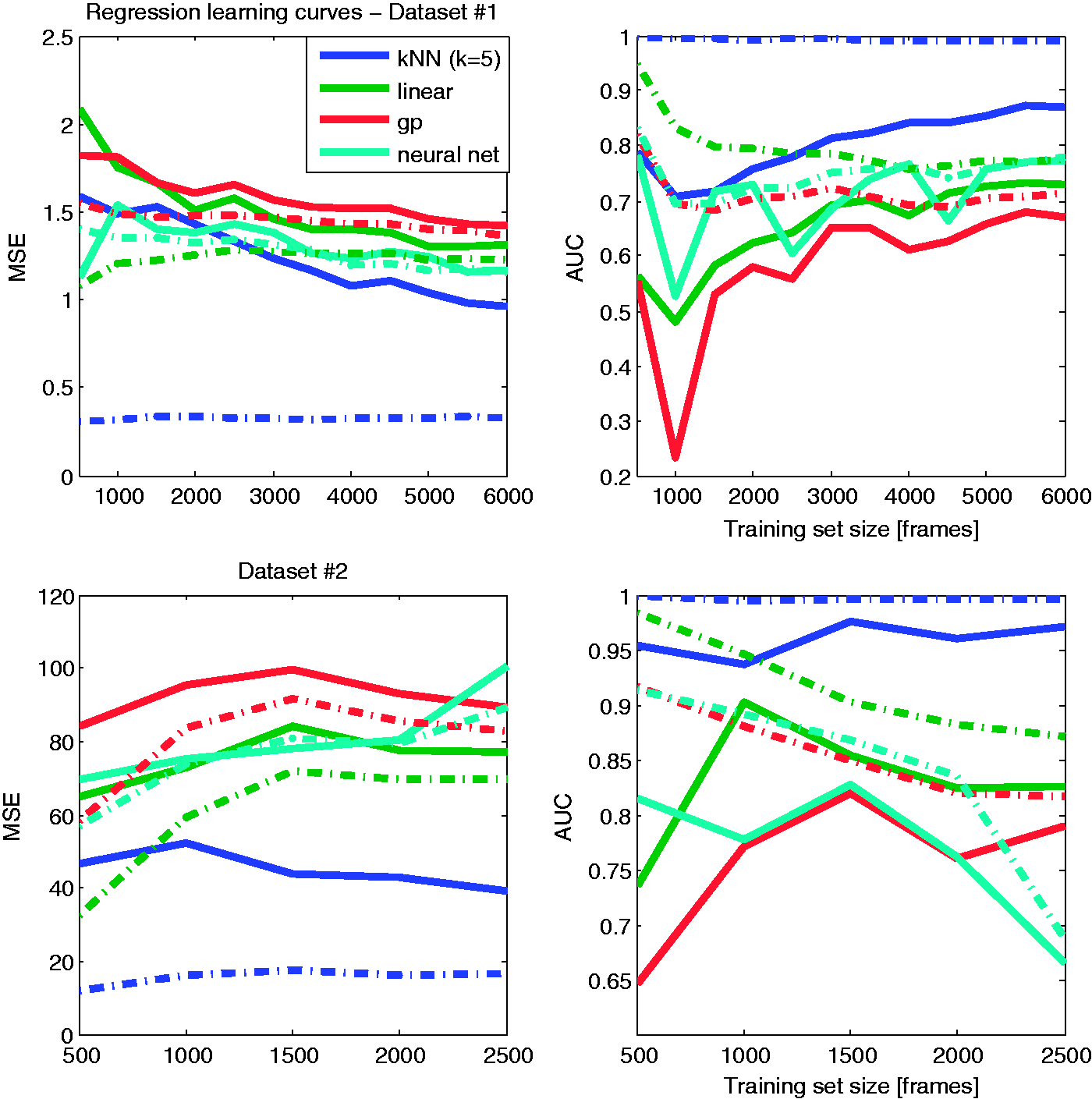
VBoW regression algorithms learning curves. Dashed/solid lines refer to results on train/test set.
The final offline results on the two data sets are quite satisfactory. They can be viewed online (note 1). After a training set of roughly 6000 samples, the kNN approximates the stereo vision-based disparities in the test set rather well. Given a desired TPR of 0.82, the learner has an FPR of 0.26. Considering the high inter-dependability of concurrent frames, this should be sufficient for usage of the estimated disparities in control.
Simulation experiments
We argued that a persistent form of SSL is similar to LfD. The relevance of this similarity lies in the behavioral schemes used for learning. In this section, we compare the three learning schemes, as introduced in the section Learning Schemes, in simulation.
Setup
We simulate a “flying” drone with stereo vision camera in SmartUAV, 37 an in-house developed simulator that allows for 3D rendering and simulation of the sensors and algorithms used on board the real drone. Figure 10 shows the simulated “office room.” The room has a size of 10 × 10 m, and the drone has an average forward speed of 0.5 m/s. All the vision and learning algorithms are exactly the same as the ones that run on board of the drone in the real experiments.

SmartUAV simulation environment.
We compare the three learning schemes, cold turkey, DAgger, and training wheels, in simulation. As mentioned, these schemes all have the same initial training period with stereo vision being in control, but they differ in the remaining learning period. After all learning, the drone will use its monocular disparity estimates for control. The stereo vision remains active only for overriding the control if the drone gets too close to a wall. During this testing period, we register the number of turns and the number of overrides. The number of overrides is a measure of the number of potential collisions. The performed number of turns during testing is compared to the number of turns performed when solely using stereo vision, to evaluate the number of spurious turns. The initial learning period is 1 min, the remaining learning period is 4 min, and the test time is 5 min. These times have been selected to allow a full experiment on a single battery of the real drone.
Results
Table 2 contains the results of 30 experiments with the three learning schemes and a purely stereo-vision-controlled drone. The first observation is that “cold turkey” gives the worst results. This result was to be expected on the basis of the similarity between persistent SSL and LfD: the learned monocular distance estimates do not generalize well to the test distribution when the monocular vision is in control. The originally proposed DAgger scheme performs better, while the third learning scheme termed “training wheels” seems most effective. The third scheme has the lowest number of overrides of all learning schemes, with a similar total number of turns as a pure stereo vision run. The intuition behind this method being best is that it allows the drone to best learn from samples when the drone is beyond the normal stereo vision turning threshold. The original DAgger scheme has a larger probability to turn earlier, exploring these samples to a lesser extent. Double-sided statistical bootstrap tests 38 indicate that all differences between the learning methods are significant with p < 0.05.
Test results for the three learning schemes.

The average and standard deviation are given for the number of overrides and turns during the testing period. A lower number of overrides is better. In the table, the best results are shown in boldface.
The differences between the learning schemes are well illustrated by the positions the drone visits in the room during the test phase. Figure 11 contains “heat maps” that show the drone positions during turning (top row) and during straight flight (bottom row). The position distribution has been obtained by binning the positions during the test phase of all 30 runs. The results for each scheme are shown per column in Figure 11. Right is the pure stereo vision scheme, which shows a clear border around the straight flight trajectories. It can be observed that this border is best approximated by the “training wheels” scheme (second from the right).

Simulation heatmaps, from left to right: cold turkey, DAgger, training wheels, stereo only. Top images are turn locations, lower images are the approaches.

The used multicopter.
Robotic experiments
The simulation experiments showed that the “training wheels” setup resulted in the fewest stereo vision overrides when switching to monocular disparity estimation control. In this section, we test this online learning setup with a flying robot.
The experiment is set up in the same manner as the simulation. The robot, a Parrot ARDrone2, first explores the room with the help of stereo vision. After 1 min of learning, the drone switches to using the monocular disparity estimates with stereo vision running in the background for performing potential safety overrides. In this phase, the drone still continues to learn. After learning 4 to 5 min, the drone stops learning and enters the test phase. Again, also for the real robot the main performance measure consists of the number of safety overrides performed by the stereo vision during the testing phase.
The ARDrone2 is standard not equipped with a stereo vision system. Therefore, an in-house-developed 4 g stereo vision system is used, 39 which sends the raw images over USB to the ARDrone2 (see figure 12). The grayscale stereo camera has a resolution of 128 × 96 px and is limited to 10 fps. The ARDrone2 comes with a 1 GHz ARM cortex A8 processor and 128 MB RAM, and normally runs the Parrot firmware as an autopilot. For the experiments, we replace this firmware with the the open source Paparazzi autopilot software.39,40 This allowed us to implement all vision and learning algorithms on board the drone. The length of each test is dependent on the battery, which due to wear has considerable variation, in the range of 8–15 min.
The tests are performed in an artificial room that has been constructed within a motion-tracking arena. This allows us to track the trajectory of the drone and facilitates post-experiment analysis. The room is approximately 5 × 5 m, as delimited by plywood walls. In order to ensure that the stereo vision algorithm gave reliable results, we added texture in the form of duct-tape to the walls. In five tests, we had a textured carpet hanging over one of the walls (Figure 13 left, referred to as “room 1”), in the other five tests it was on the floor (Figure 13 right, referred to as “room 2”).

Two test flight rooms.
Results
Table 3 shows the summarized results obtained from the monocular test flights. Two main observations can be made from this table. First, the average number of stereo overrides during the test phase is 3, which is very close to the number of overrides in simulation. The monocular behavior also has a similar heat map to simulation. Figure 14 shows a heat map of the drone’s position during the approaches and the avoidance maneuvers (the turns). Again, the stereo-based flight performs better in the sense that the drone explores the room much more thoroughly and the turns happen consistently just before an obstacle is detected. On the other hand, especially in room 2, the monocular performance is quite good in the sense that the system is able to explore most of the room.

Room 1 (plain texture) position heat map. Top row is the binned position during the avoidance turns, bottom row during the obstacle approaches, right column during stereo ground truth based operation, left column during learned monocular operation.
Test flight summary.

Second, the selected TPR and FPR are on average 0.47 and 0.11. The TPR is rather low compared to the offline tests. However, this number is heavily influenced by the monocular estimator-based behavior. Due to the goal of the robot, avoiding obstacles slightly before the stereo ground truth recognizes them as positives, positives should hardly occur at al. Only in cases of FNs where the estimator is slower or wrong, positives will be registered by the ground truth. Similarly, the FPR is also lower in the context of the monocular-based behavior.
ROC curves of the 10 flights are shown in Figure 15. A comparison based on the numbers between the first five flights (room 1) and the last five flights (room 2) does not show any significant differences, leading to the suggestion that the system is able to learn both rooms equally well. However, when comparing the heat maps of the two situations in the monocular system in Figures 14 and 16, it seems that the system shows slightly different behavior. The monocular system appears to explore room 2 better, getting closer to copying the behavior of the stereo-based system. This is also pointed out by the peak in the heat map in the bottom row, left column of Figure 14; the binned position occurrence of the monocular behavior during the straights. It shows the behavior was affected by false positives, it sometimes turned too soon and too far from the walls, resulting in a peak in the middle of the room. Similarly, this is also visible when comparing the monocular turn locations (Figure 14, top row) to the stereo turn locations (Figure 14 top right). The stereo algorithm turns consistently close to the walls, while the monocular behavior shows a lot of spread and turns often quite far away from the walls. Interestingly, this problem partly disappears when more varied and natural texture is applied to the same room as shown by the results in Figure 16.

Room 2 (carpet natural texture) position heat map. Top row is the binned position during the avoidance turns, bottom row during the obstacle approaches, right column during stereo ground truth based operation, left column during learned monocular operation.
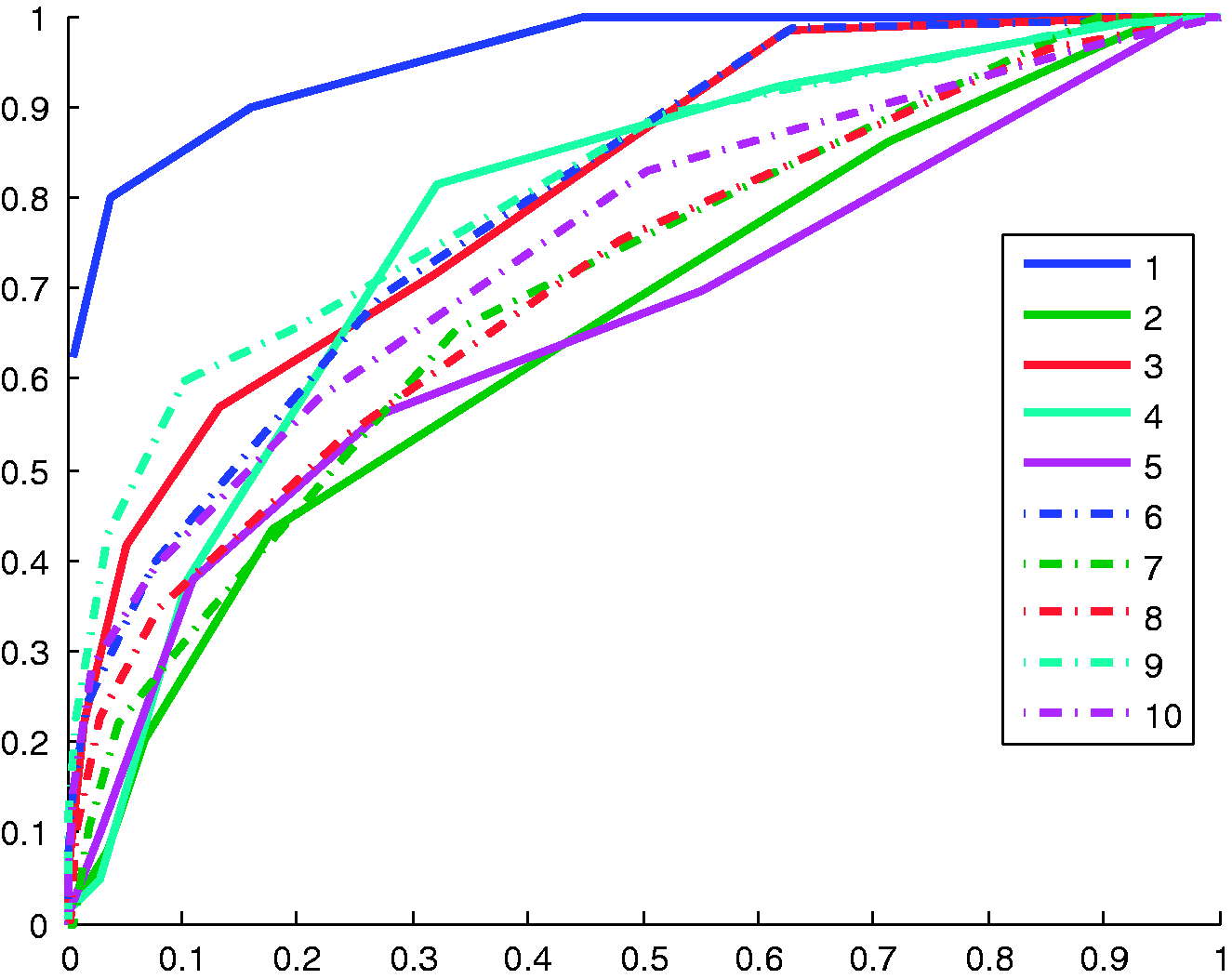
ROC curves of the 10 test flights. Dashed/solid lines refer to results on room #1/#2.
The experimental setup with the room in the motion tracking arena allows for a more in-depth analysis of the performance of both stereo and monocular vision. Figure 17 shows the spatial view of the flight trajectory of test #10 (note 2). The flight is segmented into approaches and turns which are numbered accordingly in these figures. The color scale in Figure 17(a) is created by calculating the theoretically visible closest wall based on the tracking the systems measured heading and position of the drone, the known position of the walls, and the FOV angle of the camera. It is clearly visible that the stereo ground truth in Figure 17(b) does not capture this theoretical disparity perfectly. Especially in the middle of the room, the disparity remains high compared to the theoretical ground truth due to noise in the stereo disparity map. The results of the monocular estimator in Figure 17(c) show another decrease in quality compared to the stereo ground truth.

Flight path of test 10 in room 2. Monocular flight starts form approach 23. The meaning of the color of the flightpath differs per image; (a): the approximated disparity based on the external tracking system. (b): the measured stereo average disparity, (c): the monocular estimated disparity, (d): the error between the stereo disparity and monocular estimated disparity with dark blue meaning zero error, (e): error during FP, (f): error during FN. (e and f) only show the monocular part of the flight.
Discussion
We start the discussion with an interpretation of the results from the simulation and real-world experiments, after which we proceed by discussing persistent SSL in general and provide a comparison to other machine learning techniques.
Interpretation of the results
Using persistent SSL, we were able to autonomously navigate our multicopter on the basis of a stereo vision camera, while training a monocular estimator on board and online. Although the monocular estimator allows the drone to continue flying and avoiding obstacles, the performance during the approximately 10-min flights is not perfect. During monocular flight, a fairly limited amount of (autonomous) stereo overrides was needed while at the same time the robot was not fully exploring the room like when using stereo.
Several improvements can be suggested. First, we can simply have the drone learn for a longer time, accumulating training data over multiple flights. In an extended offline test, our VBoW method shows saturation at around 6000 samples. Using additional features and more advanced learning methods may result in improved performance if training set sizes increase.
During our tests in different environments, it proved unnecessary to tune the VBoW learning algorithm parameters to a new environment as similar performance was obtained. The learned results on the robot itself may or may not generalize to different environments; however, this is of less concern as the robot can detect a new environment and then decide to continue the learning process if the original cue is still available. In order to detect an inadequacy of the learned regression function, the robot can occasionally check the estimation error against the stereo ground truth. In fact our system already does so autonomously using its safety override. Methods on checking the performance without using the ground truth, e.g. by employing a learner that gives an estimate of uncertainty, are left for future work.
Deep learning
At the time of our robotic experiments, implementing state-of-the-art deep learning methods on-board a flying drone was deemed infeasible due to hardware restrictions. One of the major advantages of persistent SSL is the unprecedented amount of available training data. This amount of data will be more useful to more complex learning methods such as deep learning methods than to less complex, but computationally efficient methods such as the VBoW method used in our experiments. Today, with the availability of strongly improved hardware such as the NVidia Jetson TX1, close-to state-of-the-art models can be trained and run on-board a drone, which may significantly improve the learning results.
Persistent SSL in relation to other machine learning techniques
In order to place persistent SSL in the general framework of machine learning, we compare it with several techniques. An overview of this comparison is presented in Figure 18.
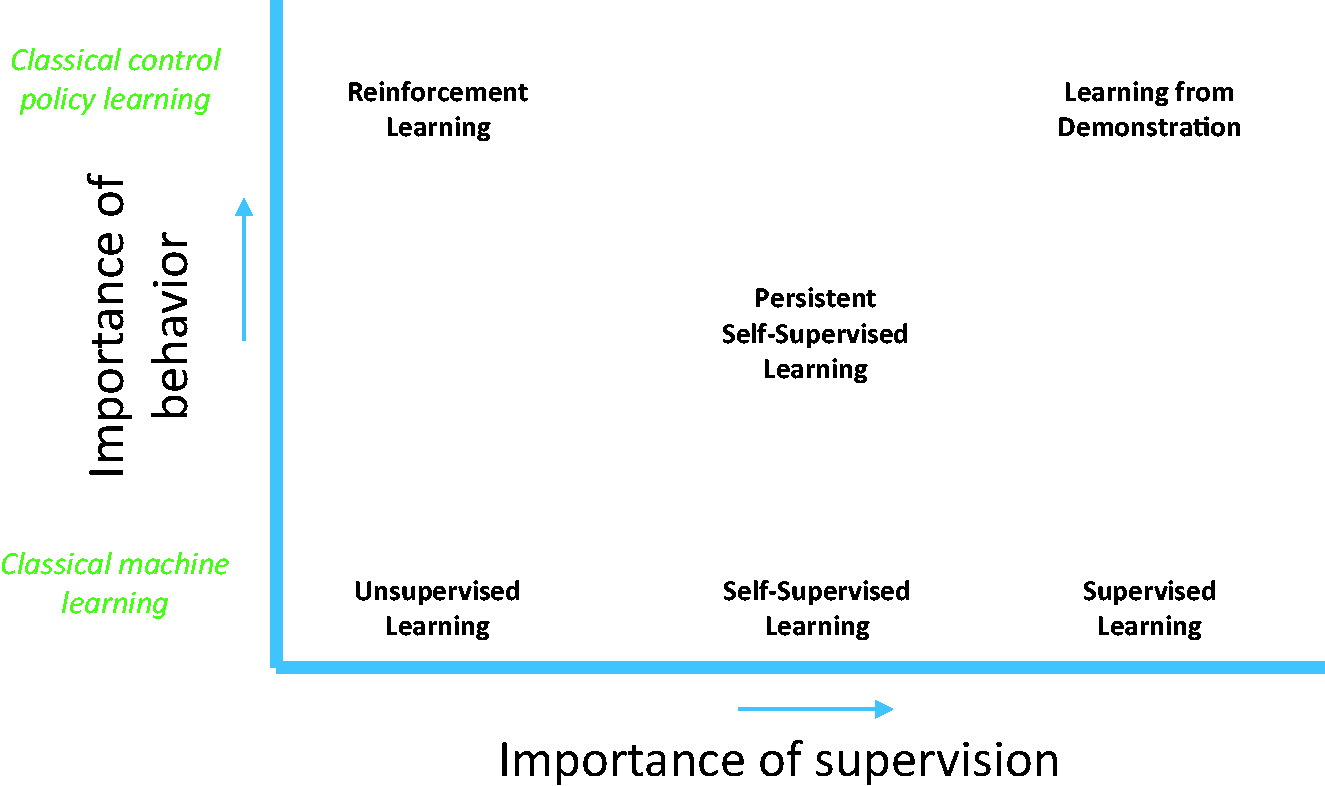
Lay of the machine learning land.
Un-/semi-/supervised learning
Unsupervised learning does not require labeled data, semi-supervised learning requires only an initial set of labeled data, 41 and supervised learning requires all the data to be labeled. Internally, persistent SSL uses a standard supervised learning scheme, which greatly facilitates and speeds up learning. The typical downside of supervised learning—acquiring the labels—does not apply to SSL, since the robot continuously provides these labels itself.
A major difference between the typical use of supervised learning and its use in persistent SSL, is that the data for learning are generally assumed to be i.i.d. However, persistent SSL controls a behavioral component which, in turn, affects both the data set obtained during training as well as during testing time. Operation based on ground truth induces a certain behavior that differs significantly from behavior induced from a trained estimator, even more so for an undertrained estimator.
SSL
The persistent form of SSL is set apart in the figure from “normal” SSL, because the persistence property introduces a much more significant behavioral component to the learning. While normal SSL expects the trusted cue to remain available, persistent SSL assumes that the robot may sometimes act in the absence of the trusted cue. This introduces the feedback-induced data bias problem, which, as we have seen, requires specific behavior strategies for best learning the robot’s task.
Learning from demonstration
Imitation learning, or LfD, is a close relative to persistent SSL. Consider for instance teleoperation, an LfD scheme in which a (human or robot) teacher remotely operates a robot in order for it to learn demonstrated actions in its environment.
20
This can be compared to persistent SSL if we consider the teacher to be the ground truth function
Reinforcement learning
Lastly, we compare persistent SSL with RL, which is a distinctively different technique.
43
In RL, a policy is learned using a reward function. Due to the evaluative feedback provided in RL, defining a good reward function is one of fundamental difficulties of RL known as reward shaping.43,44 Since persistent SSL uses supervised feedback, reward shaping is less of an issue in persistent SSL, only requiring a choice of a loss function between
Persistent SSL differs from other learning techniques in the sense that no complete training data set is needed to train the algorithm beforehand. Instead it requires a ground truth
Feedback-induced data bias
The robot induces how its environment is perceived, meaning it influences the acquired training samples based on its behavior. The problems arising from this feedback-induced data bias are known from other machine-learning disciplines, such as RL and LfD. 43 In particular, Ross et al. have proposed DAgger 2 to solve a similar problem in the LfD domain, which iteratively aggregates the data set with induced training samples and the experts reaction to it. However, in the case of LfD, obtaining the induced training samples requires a careful engineered and often additional setup, while in persistent SSL, this functionality is inherently available. Secondly, the performance of the LfD expert (i.e., in many cases, a human) is not easy to control, often reacting too late or too early. The control policy of the persistent SSL ground truth override system can, on the other hand, be very deterministic. In the case of a DAgger application with drones flying through a forest, 3 it proved infeasible to reliably sample the expert in an online fashion. Acquired videos had to be processed offline by the expert, hence the need for (offline ↔ online) iterations. Moreover an additional online human safety override interface was still necessary to prevent damage to the drone while learning. Thirdly, due to the cost of (and need for) iterative demonstration sessions, the emphasis of DAgger is on converging fast with needing as little expert sessions as possible. In persistent SSL, there are no costs for using the teacher signals coming from the original sensor cue. With persistent SSL, we can directly focus on effectively using the available amount of training samples instead of minimizing the number of iterations like in DAgger.
Another reason why persistent SSL handles the induced training sample issue better than other state of the art robot learning methods, is that in persistent SSL part of the learning problem itself can be easily separated and tested from the behavior; i.e. in a traditional supervised learning setting. In our proof of concept, this has allowed us to test the learning algorithms and thoroughly investigate its limits before deployment.
Conclusion
We have investigated the behavioral aspects of an SSL scheme, in which the supervisory signal is switched off after an initial learning period. In particular, we have studied an instance of such “persistent SSL” for the task of obstacle avoidance, in which the robot uses trusted stereo vision distance estimates in order to learn appearance-based monocular distance estimation. We have shown that this particular setup is very similar to LfD. This similarity has been corroborated by experiments in simulation, which showed that the worst learning strategy is to make a hard switch from stereo vision flight to mono vision flight. It is best to have the robot fly based on mono vision and using stereo vision only as “training wheels,” to take over when the robot would otherwise collide with an obstacle. The real-world robot experiments show the feasibility of the approach, giving acceptable results already with just 4–5 min of learning.
The findings also indicate interesting future venues of investigation. First, and perhaps most importantly, in the 4–5 min of the real-world experiments, the robot already experiences roughly 7000–9000 supervised learning samples. It is clear that longer learning times can lead to very large supervised data sets, which are suitable for deep learning approaches. Such approaches likely allow the learning to extend to much larger and more varied environments, such as outdoor forests or multiple rooms inside larger buildings. In addition, they could allow the learning to improve the resolution of disparity estimates from a single value to a full image size disparity map. Second, in the current experiments, the robot stayed in a single environment. We mentioned that a different environment can make the learned mapping invalid, and that this can be detected by means of the ground truth. Another venue, as studied in Ho et al., 12 is to use a machine learning method with an associated uncertainty value. For instance, one could obtain uncertainty estimates by using a learning method such as a Gaussian Process or by using dropout with deep neural networks. This can help with a further integration of the behavior with learning, for instance by tuning the forward velocity based on the certainty. These venues together could allow for persistent SSL to reach its full potential, significantly enhancing the robustness of robots operating in real-world environments.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.