
Abstract
An advanced driving assistant system is one of the most popular topics nowadays, and depth estimation is an important cue for advanced driving assistant system. Depth prediction is a key problem in understanding the geometry of a road scene for advanced driving assistant system. In comparison to other depth estimation methods using stereo depth perception, determining depth relation using a monocular camera is considerably challenging. In this article, a fully convolutional neural network with skip connection based on a monocular video sequence is proposed. With the integration framework that combines skip connection, fully convolutional network and the consistency between consecutive frames of the input sequence, high-resolution depth maps are obtained with lightweight network training and fewer computations. The proposed method models depth estimation as a regression problem and trains the proposed network using a scale invariance optimization based on L2 loss function, which measures the relationships between points in the consecutive frames. The proposed method can be used for depth estimation of a road scene without the need for any extra information or geometric priors. Experiments on road scene data sets demonstrate that the proposed approach outperforms previous methods for monocular depth estimation in dynamic scenes. Compared with the currently proposed method, our method has achieved good results when using the Eigen split evaluation method. The obvious prominent one is that the linear root mean squared error result is 3.462 and the δ < 1.25 result is 0.892.
Introduction
Estimating depth from a single image is a very important problem in the computer vision field. In general, depth estimation is a key problem for many research topics such as three-dimensional (3-D) modeling, 3-D reconstruction, scene understanding, object detection and robotics, semantic segmentation, human activity recognition, and so on.
Most of the depth estimation methods predict depth from stereo images and achieved good performances. Stereo methods rely on stereo images captured from multiple cameras to ensure that the problem of depth prediction is well-posed, where depths are estimated using geometrical computations, 1 additional sensors, 2 and photometric or consistency checks. 3 Although the stereo image method can obtain relatively accurate scene depth information, the depth result tends to be sparse. Furthermore, the estimated depth tends to be inaccurate when the distances considered are large, and a small matching error often causes a large depth estimation error.
Because of the ill-pose problem, estimate depth from a single image is much more challenging than depth estimation from stereo images. Previous studies using single image techniques focus on scene-dependent knowledge, for example, “Blocks World” model, 4 shape from shading, 5 and shape from the silhouette. Among these monocular methods, structure-from-motion (SfM) 6 is the most successful one. It predicts depth with multiple images captured from a single camera at different time intervals. That is, it estimates camera translation between sequence image pairs by different temporal intervals, and then, estimate depth through camera motion. However, these models typically work for images with particular scenes structures, and therefore, they are not applicable to road scene depth estimations.
A method suggested by Saxena et al. 7 considers each super-pixel extracted from the image as a plane with the same depth, and then infers the construction parameters of the super-pixel plane using a Markov random field (MRFs) to obtain the depth. In addition, the methods in the literature studies 8 –10 regard super-pixels as a plane of the same depth, and they estimate depth using the conditional random field (CRF). More recently, a data-driven method is often used to estimate the depth from the image, such as Karsch et al. 11,12 and Konrad et al. 13 These methods match image features with the RGBD data set and predict depth by exploiting the relationship between the image features and the depth. However, these methods use handcrafted features, which result in low accuracy.
In recent years, the monocular image depth estimation method based on convolutional neural networks (CNNs) has achieved considerable success. Most studies initialize their networks with AlexNet 14 or visual geometry group (VGG), 15 and then, optimize network parameters according to their requirements and data set. Eigen et al. 16 first proposed a solution for image depth estimation using CNNs. They estimate depth from a concise network with the photometric error between output and ground truth as loss function and pre-train the convolutional layers of the coarse-scale network on ImageNet. Eigen and Fergus 17 later extend their work and develop a well-designed network that uses three scales of inputs to generate the more general features and refine predictions to higher resolutions, including surface normal estimation and per-pixel semantic labeling.
Unlike the above two methods, Roy and Todorovic 18 combine CNN with Regression Forest for predicting depths in the continuous domain via regression. At every tree node, they filter the sample with a CNN associated with that nod and design CNN at every node of convolutional regression trees (CRTs) to obtain significantly fewer parameters. That, in turn, allows for robust training on a smaller data set. Also, some methods often combine CNN with CRFs or MRFs to achieve the post-processing of depth estimation and optimize the estimation results of deep networks. Liu et al. 19 consider the continuous characteristic of the depth values formulated into a CRF learning problem. In particular, they use an end-to-end deep CNN network to learn the pairwise potentials of CRF with a deeply designed learning pipeline. Li et al. 8 use the CRF to optimize the super-pixel-level depth estimation results obtained by CNNs. Wang et al. 10 then proposed a method that predicts depth and semantic jointly. They first use a pre-trained CNN model to estimate the pixel-level depth and semantic labels. Then, they decompose the input image into segments to achieve further pixel-level results. By formulating the depth estimate and semantic problem into a hierarchical CRF, they achieve state-of-art results. Kim et al. 20 present a method for jointly predicting a depth map and intrinsic images from single-image input using a novel CNN architecture. The model includes a depth and intrinsic prediction network, a gradient scale network, and a joint CRF. The method in the literature 21 has also achieved good results by designing a new CNN implementation where training can be performed end-to-end. Compared with other methods, the image depth estimation method based on CNN learning can achieve better real-time performances and consequently obtain better accuracy. The method in the literature 22 treats the depth estimate as a multi-class classic problem and achieves a good depth estimation effect through a well-designed network.
Recently, the fully convolutional network (FCN) has achieved good results in object detection, 23,24 semantic segmentation, 25 –28 and depth estimation. 29,30 The skip connection structure used in FCN has been proven to merged the coarse and abstract information in different layers, this helps to extract the feature information of the input while making the output image the same size as the input image. Inspired by that, we use skip connection structure to learn the feature extraction in depth estimation problem and output pixel-level depth image. The methods in the literature studies 31,32 also use the FCN network structure for depth estimation, but the depth estimation part and pose estimation part of their network are separated. In their method, the deep estimation network part uses a single picture as input, and pose estimation network uses the front and back frame image of sequence or image pairs as input.
In this article, we are concerned with the challenge of monocular-based depth estimation. A fully CNN with skip connection based on a monocular video sequence is proposed to estimate depth. The network takes two neighboring images in a monocular video sequence as input and output pixel-level images. Skip connection and multi-layer deconvolution networks are used to preserve more information and output pixel-level results. With the integration framework that combines skip connection, FCN network and the consistency between consecutive frames of the input sequence, high-resolution depth maps are obtained with lightweight network training and fewer computations. The proposed method models depth estimation as a regression problem and trains the proposed network using a scale invariance optimization based on L2 loss function, which measures the relationships between points in the consecutive frames. The proposed method can be used for depth estimation of a road scene without the need for any extra information or geometric priors. Our network implicitly learns the pose relationship between the input images, which is conducive to the accuracy of the depth estimations results, and our method achieved good results on the KITTI data set.
The remainder of this article is organized as follows. Section “Network architecture” describes the details of our network architecture (subsection “Architecture”) and loss function (subsection “Loss function”) for depth estimation, and in section “Experiments,” the experimental setup (subsection “Experimental setup”), the evaluation metrics (subsection “Evaluation metrics”), the parameters settings (subsection “Experimental parameters”), and the experimental results (subsection “Experimental results”) are introduced. We conclude the article in the “Conclusion” section.
Network architecture
Architecture
Our purpose is to estimate the depth map corresponding to the road scene picture. Because of the ill-pose problem of a single picture, most methods now use additional information to constrain depth, such as optical flow information, CRF, motion information, and so on. Our method uses motion information, takes two pictures I and I −1 as input, and outputs a pixel-level depth map of single image I, where I and I −1 represent to two adjacent frames of the video sequence.
Inspired by the methods in literature studies, 16,33 we treat the depth estimation problem as a supervision problem. In other words, we have the picture of scenes and the corresponding ground truth of the scene during training. However, most monocular supervision methods take a single picture as input and have ill-pose problems and do not use important hidden information in the road scene video sequence. As shown in Figure 1, Eigen et al. 16 and Xu et al. 21 only take the single image as input and do not take advantage of the feature information of multiple images. We solve this problem by supervising the depth of prediction by taking two images I and I −1 as the input to the network.

Sampling strategies for feature extraction. Eigen et al. use the classic CNN network structure and Xu et al. and our method use the FCN network structure. Eigen et al. and Xu et al. use single image as input, while our method takes two images as input. CNN: convolutional neural network; FCN: fully convolutional network.
Our FCN is inspired by FCN in the literature studies, 17,34 but we doubled the number of input layers to accommodate the doubling of the number of input images and made some modifications to accommodate the depth estimation instead of the semantic segmentation. As shown in Figure 2, different from the Kuznietsov et al. 35 and SfM-net, 36 we use an FCN to simultaneously predict the depth and obtain motion implicitly. And Kuznietsov et al. 35 use binocular images as input and additional binocular targeting information as supervision, while we use the front and back frames as input. Unlike SfM-net, 36 because we treat depth estimation as supervised learning, we do not have a pose network part, which means we have fewer network parameters and shorter training time.

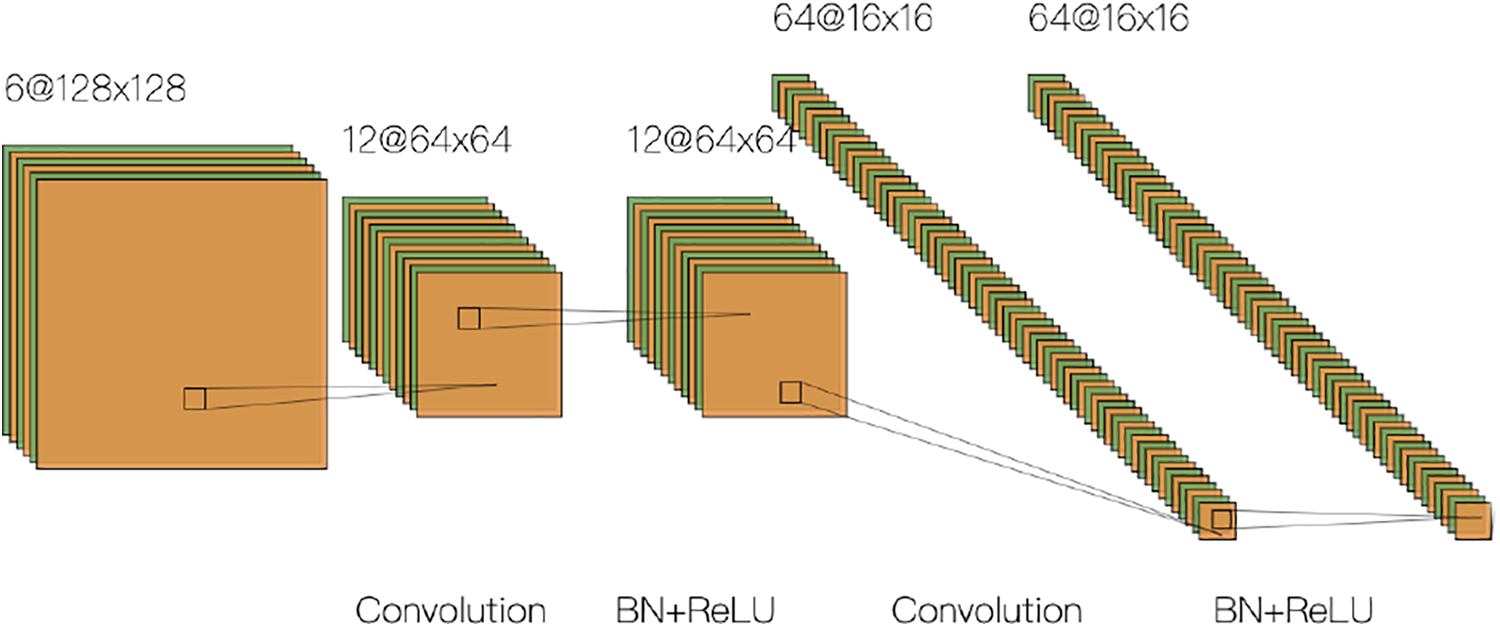
The proposed network architecture is illustrated in Figure 3. The network architecture consists of two parts: a convolution (encoder) part and a deconvolution (decoder) part.

Network architecture.
The convolution part takes two consecutive frames of a video sequence as input, and it uses the global view of the input scene to predict the structure of the overall depth map. It follows the typical architecture of a convolutional network. To accommodate twice the amount of input, we set the first layer of the conventional part as six channels, and the subsequent convolution layers are modified accordingly to fit the number of channels of the first layer. Further, the conventional part consists of repeated applications of unpadded convolutions. Each layer of the convolution part is a convolution block. To get better features, different convolution blocks use different filters for the input image to select relevant feature representations. Rectified Linear Units (ReLUs) are used as an activation function for the convolution block, and max-pooling layers are performed between these convolutional blocks to encode the global information. The number of features in the first convolution layer of each convolution block is twice the number of features in the last convolution layer of the upper layer convolution block. Specifically, the size of the first convolutional layer in each convolution block is half the size of the input layer before downsampling. Suppose the input size is
Convolution structure in the convolution block.
The deconvolution part results in an output image containing the depth of each pixel. Each layer of the deconvolution part includes several deconvolution layers, and each deconvolution layer contains two parts: upsampling layer obtained by upsampling the feature map through deconvolution and feature layer obtained by concatenating the corresponding feature map from the convolution part. The skip connection is added so that the information of the convolution layer is merged into the feature layer. The advantage is that more image information is integrated during the learning process of the upsampling parameter, thereby improving the accuracy of the learning of the upsampling parameter. And the final output of the deconvolution part is the depth information of each pixel of the input image.
During training, the network architecture consists of five convolutional blocks and five deconvolution layers. Specifically, the first two convolution blocks contain two convolutional layers, and the last three convolutional blocks contain three convolutional layers. The convolution kernel size in all five convolutional blocks is 3 * 3, and the convolution kernel of the convolutional layer in each convolution block is the same as the convolution kernel of the convolutional block. It should be noted that the size of the convolution kernel refers to the settings of other networks, such as Res-Net. It can be seen from another article that this parameter is a better parameter selected and is an empirical value. During the experiment, we also tried to use a 5 * 5 convolution kernel instead of a 3 * 3 convolution kernel, but the effect became worse. We think that the possible reason is that the size of different objects in the road scene dataset is quite different, and the 3 * 3 convolution kernel may have better feature extraction results.
A three-layer convolution connection layer is performed between the convolution part and the deconvolution part. The convolution kernel size used in the convolution connection layer is 1 * 1 to unify the channel of features. ReLU is used as activation functions for the convolution layer. At the same time, to prevent overfitting the model, a dropout is applied after the first two convolution connection layers.
Loss function
The conventional method of image depth estimation based on deep learning is often used to consider depth estimation as a classification problem, and the image depth value is treated as a category label or the super-pixels in the image. Then the CRF is used to further optimize the depth value of the pixels in each super-pixel or block. However, if each pixel in the image is directly subjected to deep estimation based on FCN deep learning, the depth estimation problem can be regarded as a regression problem, which can make the loss function simpler. A standard loss function for optimization in regression problems is the L2 loss function, which often achieves good results. Our method performs scale invariance optimization based on the standard L2 loss function. Suppose y and

where
λ parameter setting.

Rel: Abs relative difference; Linear RMSE: linear root mean squared error; Log RMSE: log root mean squared error.
During the training process, there are many pixel points with insufficient depth information or nonexistence in the target depth map, especially at the target edge, window, or smooth surface. These points are filtered out and only the valid points are used to calculate the loss function.
Experiments
In this section, we introduce the training and test data sets, the parameters during the training process, and the evaluation criteria of the prediction results. We train our model on the raw versions KITTI, 37 which is an open outdoor scenes data set. The binocular video sequence is used from the data set. During the training process, left and right image data are used as training samples respectively to increase the number of training images. Note that the left and right sequences in the binocular are only regarded as monocular video sequences of the road scene during the training process, and the left and right sequences are completely independent and do not affect each other. The reason for using the left and right sequences as the training data set is merely to increase the number and diversity of training samples.
Experimental setup
KITTI data set
The KITTI data set 37 is a widely used road scene data set, and it consists of a variety of outdoor scene pictures obtained from a binocular camera and ground truth obtained from radar sensor. To be able to perform comparison experiments fairly, we use the same training data and test data used by Eigen et al., 16 that is, 39,810 images for train and 4424 images for test split from 58 scenes from “City,” “Residential,” and “Road” categories.
Because the depth of the KITTI data set is obtained at different times using a rotating radar scanner. Therefore, there may be large errors in the ground truth depth used for training. We choose the average depth of the closest pixels to eliminate larger error pixels. Besides, radar only provides ground truth measures for the lower half of the scene. And to compare the fairness of the experiment, we use the same training set data processing method as Eigen et al., 16 we use the bottom part of the image as input to train our model. The output prediction results are only tested for the bottom half of the input test image.
Data augmentation
The training data were augmented with random online transformations to make the data set have more variability. For the data sets used in this study, the main data set expansions include: Rotation: Training images and ground truth are rotated by Color: RGB channels of training images are scaled globally by a random value Flips: Training images and ground truth images are flipped with 0.5 probability.
The rotation of the image can overcome the jitter of the image during the shooting to some extent. The change in color can reflect the evolution of illumination, which can reduce the precision of the prediction result. The flips of images are geometry-preserving, which can increase the diversity of training data.
Note that all data augmentation operations are performed for the two consecutive frames input into the system. In other words, the transformation of the input current frame and the consecutive previous frame is the same. Also, during data augmentation, the geometric space of the dataset is unchanged, and the coordinate system is stable. During the test, no transformation is performed on the input image.
Evaluation metrics
We compared our proposed approach with other state-of-the-art single-camera depth estimation methods. The comparison method was evaluated by the Accuracy with threshold thr (ACC), Abs relative difference (Rel), linear root mean squared error (Linear RMSE), and log root mean squared error (Log RMSE). The benchmark metrics for our comparisons are: Accuracy with threshold Abs relative difference: RMSE (linear): RMSE (log, scale-invariant):
where y and
Experimental parameters
We train our model using a single Nvidia GTX K40c GPU. The network parameters are initialized with random initialization. Specifically, we use 39,810 images of the KITTI data set for train and 4424 images as validation items and train our model using stochastic gradient descent (SGD) with a batch size of 12. The learning rate is set to 0.001 at the first 10 epochs and change to 0.0001 at the next 20 epochs. Because there is no additional re-projection process and pose-CNN or the process of generating super-pixels to obtain other information, our training time rarely takes only about 15 h. During the test, we can get the depth map of the input image in about 0.1 s.
In the training process, the input data is downsampled, and half of the size of the original image data is used as the input of the network structure. Furthermore, as the image size in the KITTI data set is 344 * 1152, and only the lower half of the image is used as the training sample so that the input image size is 86 * 576.
The FCN model is divided into a convolution part and a deconvolution part. The convolution part includes five convolution blocks and three convolution connection layers. Each convolution block is followed by a max-pooling layer; there is no max-polling layer between convolution layers in the same convolution block. The input of the convolution part is two consecutive frames with RGB channels, and the two images have a total of six channels. In our method, the stereo relationship in the left and right images is not required, and therefore, depth estimation can be completed only using the monocular image sequence. The deconvolution part consists of five layers of deconvolution. Each deconvolution layer is an upsampling process. The final output is the depth estimate of the gray channel, and some parameters of the convolution part of the deep network are set as listed in Tables 2 and 3; the parameters of the deconvolution part are listed in Table 4.
Convolution part parameter setting.

Convolution connection part parameter setting.

Deconvolution part parameter setting.

Experimental results
Experimentation was performed using random 28 scenes from the “City,” “Road,” “Campus,” and “Residential” scenes of the KITTI data set. Figure 5 shows examples of the results obtained during the test. Every three rows of the figure constitute a group. The top row of each group is the input; the middle row is the ground truth, and the bottom of each group is the output of our proposed network. The value of the depth is normalized to [0–255].

Example predictions from our algorithm. Every three rows of the figure constitute a group. For each input image, we show input (top row of each group), ground truth (middle row of each group), and output (bottom of each group). The values of the depth are normalized to [0–255].
As shown in Figure 5, the proposed method accurately predicts the depth of road scene images. It is also good for deep prediction in some details, such as small target objects in road scenes. Furthermore, the method can fill the holes existing in the real depth map of the road scene and obtain continuous depth information.
In Table 5, we compare our model with several popular methods. Besides, we set our method as a baseline and change our model to “single image input with skip connection” and “image sequence input without skip connection” as two comparative experiments. All the methods in the table used the same evaluation indicators, namely six indicators of
Comparison on the KITTI data set.

Rel: Abs relative difference; Linear RMSE: linear root mean squared error; Log RMSE: log root mean squared error; 3-D: three dimensional; DDVO: differentiable direct visual odometry. Best performance is indicated with bold.
When compared to other methods, it can be observed that our method achieved the best evaluation results, when the thresholds
When compared to different versions of our methods, Table 5 shows that the results of the model with consecutive frames and skip connection is better than the incomplete models. The model of image sequence input without skip connection achieves better performance than the model of single image input with skip connection in
Of course, there are some methods that have achieved good results, such as Fu et al. 33 and Li et al. 22 By comparison, we find that our method is not as good as the above two methods. We think the reasons may be as follows. First, the method proposed in this article is our earliest experiment. Second, we did not introduce additional information, nor did we perform detailed feature extraction on the ground truth values.
Conclusion
We proposed a method for depth estimation of road scene video images based on the FCN network and skip connection. The method takes continuous image frames and corresponding real depth information as input, and skip connection and multi-layer deconvolution networks are used to preserve more information and output pixel-level results. With the integration framework that combines skip connection, FCN network and the consistency between consecutive frames of the input sequence, high-resolution depth maps are obtained with lightweight network training and fewer computations. The proposed method models depth estimation as a regression problem and trains the proposed network using a scale invariance optimization based on L2 loss function, which measures the relationships between points in the consecutive frames. The whole neural network is constructed by image convolutional coding and deconvolution decoding, which overcomes the problem that the traditional method based on CNN cannot output a full-scale depth estimation map. Further, the method adopts the convolutional coding part and the deconvolution decoding part of the convolutional layer hopping link to realize a more flexible network structure, and it provides more reference information for the subsequent decoding part, compared with simple upsampling. The method can achieve better depth estimation results. In the experimental part of this article, we demonstrated that our approach performs surprisingly well.
In future work, we think that unsupervised learning or half-supervised learning is very important for depth estimation due to the lack of annotation data. Compared with supervised approaches, unsupervised approaches or half-supervised approaches could predict depth through minimizing the image reconstruction error without ground truth of input images during train. The key areas of our future work include unsupervised learning methods and multi-sensor fusion. The spacing-increasing discretization 33 strategy and deep attention-based classification 22 strategy give us a lot of inspiration. We believe that the methods are very worthy of reference for our future work.
Footnotes
Acknowledgement
The authors would like to thank the reviewers for spending their valuable time on this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (61773245, 61603068, 61806113), Natural Science Foundation of Shandong Province (ZR2018ZC0436, ZR2018PF011, ZR2018BF020), Key Research and Development Program of Shandong Province (2018GGX101053), Scientific Research Foundation of Shandong University of Science and Technology for Recruited Talents (2017RCJJ061, 2017RCJJ062, 2017RCJJ063), and Taishan Scholarship Construction Engineering.