
Abstract
This paper presents a vision-based, computationally efficient method for simultaneous robot motion estimation and dynamic target tracking while operating in GPS-denied unknown or uncertain environments. While numerous vision-based approaches are able to achieve simultaneous ego-motion estimation along with detection and tracking of moving objects, many of them require performing a bundle adjustment optimization, which involves the estimation of the 3D points observed in the process. One of the main concerns in robotics applications is the computational effort required to sustain extended operation. Considering applications for which the primary interest is highly accurate online navigation rather than mapping, the number of involved variables can be considerably reduced by avoiding the explicit 3D structure reconstruction and consequently save processing time. We take advantage of the light bundle adjustment method, which allows for ego-motion calculation without the need for 3D points online reconstruction, and thus, to significantly reduce computational time compared to bundle adjustment. The proposed method integrates the target tracking problem into the light bundle adjustment framework, yielding a simultaneous ego-motion estimation and tracking process, in which the target is the only explicitly online reconstructed 3D point. Our approach is compared to bundle adjustment with target tracking in terms of accuracy and computational complexity, using simulated aerial scenarios and real-imagery experiments.
Keywords
Introduction
Ego-motion estimation and target tracking are core capabilities required in a wide range of applications. While motion estimation is essential to numerous robotics tasks such as autonomous navigation1,2,3,4 and augmented reality,5,6 target tracking has been essential, amongst others, for video surveillance 7 and for military purposes. 8 Although researched for decades, target tracking methods have mostly assumed a known or highly predictable sensor location. Recent robotics applications such as autonomous aerial urban surveillance 9 or indoor navigation require the ability to track dynamic objects from platforms while moving in unknown or uncertain environments. The ability to simultaneously solve the ego-motion and target tracking problems becomes therefore an important task. Furthermore, attention has grown for cases in which external localization systems (e.g. GPS) are unavailable and the estimation process must be performed using on-board sensors only. In particular, the capability to perform those tasks based on vision sensors has become of great interest in the past two decades, mostly thanks to the ever-growing advantages these sensors present. 10
Vision-based ego-motion estimation is typically performed as part of a process known as bundle adjustment (BA) in computer vision, or simultaneous localization and mapping (SLAM) in robotics, where the differences between the actual and the predicted image observations are minimized. Therefore, the combined process of SLAM and tracking of a moving object usually involves an optimization over the camera’s motion states, the target’s navigation states, and the observed structure (3D landmarks). This optimization is performed incrementally as new information and variables are added to the process, constantly increasing the computational complexity of the problem. One of the main challenges in extended operation is thus keeping computational efforts to a minimum despite the growing number of variables. However, many robotics applications do not require actual online mapping of the environment. Avoiding this expensive task would therefore be beneficial in terms of processing time.
This work presents a computationally efficient approach for simultaneous camera ego-motion estimation and target tracking, while operating in unknown or uncertain GPS-deprived environments. Our focus lies on robotic applications for which online 3D structure reconstruction is of no interest, although recovering the latter offline from optimized camera poses is always possible. 11 We propose to take advantage of the recently developed incremental light bundle adjustment (iLBA)11–13 framework, which uses multi-view constraints to algebraically eliminate the (static) 3D points from the optimization, therefore allowing the dynamic target to become the only explicitly reconstructed 3D point in the process. The reduced number of variables involved in the optimization allows therefore for substantial savings in computational efforts. Incremental smoothing and mapping (iSAM) 14 technique is applied to re-use calculations, allowing to further reduce running time, in a similar fashion to the static-scene-oriented iLBA approach. We demonstrate, using simulations on synthetic datasets and real-imagery experiments, that while our methods provide similar levels of accuracy to full BA with target tracking, they compare favorably in terms of computational complexity.
The simultaneous ego-motion and dynamic object tracking relate to numerous works on SLAM and target tracking, both individually and combined. Early approaches used the extended Kalman filter (EKF) to solve the SLAM problem15,16 but were eventually overtaken by other techniques due to their quadratic computational complexity, which limits them to relatively small environments or to relatively small state vectors. Numerous SLAM methods have been proposed to overcome computational complexity, for example, by exploiting the sparsity of the involved matrices,17,18 or by approximating the full problem with a reduced non-linear system. 19 A more recent technique, used in the frame of this work, performs incremental smoothing 14 to recover the solution while recalculating only part of the variables at each optimization step and allows for a significant reduction of the computational cost. Still, full BA methods involve the reconstruction of the 3D observed structure, increasing unnecessarily the number of estimated variables in cases online mapping is of no interest. Several “structure-less” BA approaches have been developed, where the optimization satisfies constraints which do not involve 3D structure reconstruction. Rodríguez et al. 20 use epipolar constraints between pairs of views, while Steffen et al. 21 utilize trifocal tensor constraints. The recently developed LBA method, 12 used in this work, applies two kinds of multi-view constraints: the two-view and three-view constraints. Pose-SLAM techniques22,23 avoid explicit mapping by maintaining the camera trajectory as a sparse graph of relative pose constraints, which are calculated using the landmarks in a separate process. In contrast to standard Pose-SLAM, LBA formulates multi-view geometry constraints for each feature match, thereby avoiding to rely on the uncertainty of the abovementioned separate process.
The target tracking problem, referred more generally as detection and tracking of moving objects (DTMO) 24 in the robotics literature, has been extensively studied for several decades.25,26 The combined SLAM and DTMO problem, which is assessed in our work, has attracted considerable attention in the recent years, mostly in order to improve SLAM accuracy, which can be greatly degraded by the presence of dynamic objects in the environment, if the latter is considered as static. 27 The first mathematical framework to the combined process of simultaneous localization, mapping, and moving object tracking (SLAMMOT) was presented by Wang, 28 where the problem is decomposed into two separate estimators, one for the SLAM problem given the static landmarks and another for the tracking problem. Occupancy grid-based approaches were proposed later by Vu et al. 29 and Vu, 1 where SLAM was solved by calculating the maximum likelihood of occupancy grid maps. Ortega 30 introduced a geometric and probabilistic approach to the vision-based SLAMMOT problem, providing a comparison between the different kinds of optimization methods, while Hahnel et al. 31 used sampled-based joint probabilistic data association filter to track people and occupancy grids for static landmarks. An extensive overview of the literature concerning SLAM and DTMO is presented in Pancham et al. 32
The rest of this paper is structured as follows: First, we formulate the simultaneous ego-motion estimation and moving object tracking problem. Next, we review the LBA method, which is extended to address the mentioned problem. Then, we present experimental results, comparing our method with full BA in terms of computation time and accuracy. Finally, we conclude and share thoughts about further possible developments.
Problem formulation and notations
We consider a scenario where a monocular camera mounted on a mobile robot is tracking a dynamic target while operating in a GPS-deprived unknown environment.
The BA problem
The process of determining the camera poses and the stationary 3D structure given measurements is called BA or SLAM. Let xk represent the camera pose (i.e. 6DOF position and orientation) at time step tk, and denote all such states up to that time by
Using probabilistic representation, the BA problem can be expressed by the joint pdf

Using Bayes’ rule, the general recursive Bayesian formula for BA can be derived as
33

Considering a standard pinhole camera, the corresponding observation model can be defined as
34

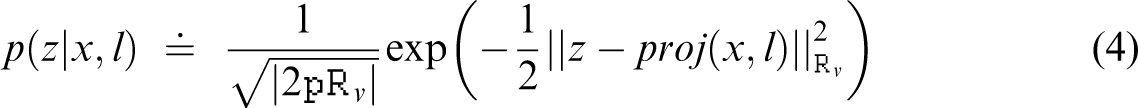
Solving the BA problem would therefore consist in calculating the maximum a posteriori estimate over the joint pdf, defined as
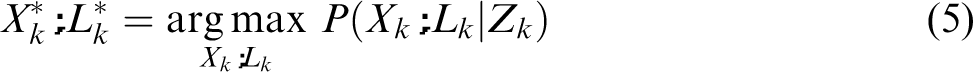
Due to the monotonic characteristics of the logarithmic function, calculating the MAP estimate
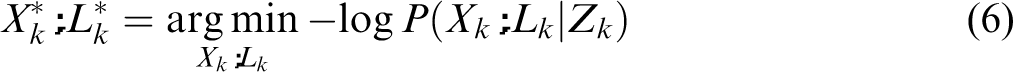
This leads to a non-linear least-squares optimization, where the cost function

BA and target tracking
We investigate scenarios in which a dynamic target is tracked by the camera. Based on the camera’s observations of the target, we seek to estimate its trajectory and velocity over time. We assume the target moves randomly; however, its motion is assumed to follow a known stochastic kinematic model (e.g. constant velocity or constant acceleration).
Let yk represent the target state at time step tk, defined generally as


We denote
Assuming a known Markovian motion model for the target, which likelihood is represented by

In this work, as in many robotics applications, we consider a constant velocity model,
35
characterized by the equation

The target state linear continuous propagation is generally noted as


Finally, solving the combined BA and target state estimation process consists in calculating the MAP estimate over the joint pdf from equation (10)

Factor graph representation
As mentioned earlier, the factorization of the joint pdf described in equation (10) can be represented using a factor graph,
36
which will be used later to efficiently solve the optimization problem using incremental inference. Using the same observation (equation (3)) and motion (equation (12)) models, this pdf is expressed in factor graph notation as

An illustration expressing the above factorization for a small example is shown in Figure 1. The corresponding factors in equation (15) are straightforwardly defined as follows: The factor


Factor graph representing a factorization of the joint pdf for bundle adjustment with single target tracking.
The projection factors


Similarly to the previous section, the MAP estimate is defined as

This corresponds to the state of the art where inference is performed over camera poses, landmarks, and target states. Yet, when the primary focus is navigation rather than mapping, explicit estimation of the observed landmarks in an online process is not actually required. Conceptually, estimating only the camera poses and the dynamic target (but not the landmarks) involves less variables to optimize and could be attractive from a computational point of view. In this work, we develop an approach based on this idea.
LBA and dynamic target tracking
BA is a non-linear iterative optimization framework typically applied for estimating camera poses and observed landmarks. In this section, we integrate target tracking to a structure-less BA technique called light bundle adjustment (LBA). 13 First, we formulate the LBA equations while considering a static scene. These equations are then extended to incorporate the dynamic target tracking problem.
Using factor graph notations, the joint pdf

As mentioned, this works considers robotics applications in which the online reconstruction of the 3D structure is of no interest. One way to avoid explicit estimation of the landmarks in the solution is by marginalizing out the latter from the joint pdf as in

However, this involves a series of calculations which, in the case of online operation, could be penalizing: First, performing the exact marginalization would initially require to solve the full BA problem, including landmarks, before applying a Gaussian approximation to compute the marginal. Secondly, marginalization in the information form involves the expensive calculation of the Schur complement over the variables we wish to keep. 22 Moreover, marginalization introduces fill-in, destroying the sparsity of the information matrix.
In contrast, structure-less BA methods approximate the BA cost function, allowing for estimation of the camera poses without involving the reconstruction of the 3D structure.20,21 In this work, we use the recently developed LBA approach,11,12 which algebraically eliminates the landmarks from the optimization, using multi-view constraints and in particular, three-view constraints.
LBA
LBA allows for reduction of the number of variables involved in the optimization compared to standard BA. By algebraically eliminating the landmarks from the problem, the optimization can be performed over the camera poses only. The key idea is to use geometrical constraints relating three views from which the same landmark is observed.
Considering a set of three overlapping poses k, l and m from which a common landmark is observed, it is possible to derive constraints that relate the three poses while eliminating the landmark.
37
These constraints can be formulated as two two-view constraints



The resulting probability distribution




Figure 2 shows a comparison between the factor graph representation of LBA and standard BA for a small example.

Factor graph representation for a small example including three views xk, xl, xm. (a) The BA problem, where the three views are related to the landmark l with projection factors. (b) The LBA problem, where the landmark l has been eliminated, and the three views are related by two- and three-view constraints.
Therefore, rather than optimizing the cost function 7, that involves the camera and landmark states, the optimization is performed on the cost function
11
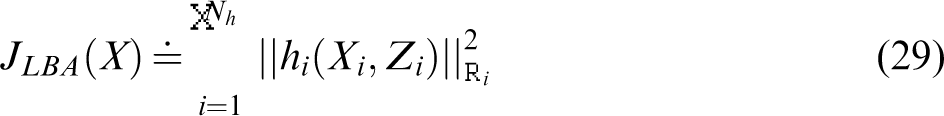
Practically, when a landmark is observed by a new view xk and some earlier views xl and xm, a single two-view (between xk and one of the two other views) and a single three-view constraint are added (between the three views). The reason for not adding the second two-view constraint (between views xl and xm) is that this constraint was already added when processing these past views. In case a landmark is observed by only two views, we add a single two-view constraint.
LBA and dynamic target tracking
In this section, we integrate dynamic target tracking into the LBA framework. As will be shown, the resulting approach provides comparable accuracy for both target tracking and camera pose estimation while significantly reducing running time, compared to an equivalent BA approach.
The idea behind the proposed method is to incorporate the target tracking problem into the LBA framework in order to yield a proxy for the joint pdf
We integrate the factors

Solving the localization and target tracking problem then corresponds to estimating the MAP


An illustration expressing the above factorization for the same example as in Figure 1 is shown in Figure 3.

Factor graph representing a factorization of the joint pdf for LBA and target tracking.
LBA and multi-target tracking
The considered problem can be straightforwardly extended to multi-target tracking by integrating the additional targets into the formulation from equation (30). Considering n targets, the corresponding joint pdf can be written

Incremental smoothing
Solving the abovementioned non-linear least square problems is achievable using several optimization methods. Online operation requires this task to be performed efficiently, and therefore, cost-efficient techniques were implemented in this work.
Batch optimization performs factorization of the Jacobian matrix A from scratch each time new variables are added to the problem. In contrast, incremental smoothing updates the problem as new measurements and variables arrive, by directly updating the square root information matrix R and recalculating only the matrix entries that actually change. 39 Furthermore, instead of performing batch re-ordering, eliminating the corresponding factor graph into a Bayes tree 14 allows for incremental variable ordering, which keeps the R matrix sparsity at a relatively constant level. Additionally, rather than fully re-linearizing the whole set of variables at a determined point in time, iSAM2 performs fluid re-linearization, which triggers re-linearization of a variable only when the deviation between its current estimate and the linearization point is larger than a defined threshold, set heuristically or as part of a “tuning” process.
Results
We demonstrate the benefits of the proposed method with simulations performed on synthetic datasets and with real-imagery experiments. Experiments were performed considering a downward-facing camera mounted on a flying vehicle, which tracks a single target, for the sake of simplicity. For each scenario, target tracking and ego-pose estimation using LBA and full BA are compared in terms of accuracy and processing time. All experiments were run on an Intel i7-4720HQ quadcore processor with 2.6 GHz clock rate and 8GB of RAM. The methods used for comparison were implemented using the GTSAM library (https://research.cc.gatech.edu/borg/download).
Experimental evaluation with synthetic datasets
A series of simulations were performed on synthetic datasets in order to compare our method with full BA technique and to demonstrate its capability in terms of computational performance and estimation accuracy for both camera and target states. We present two types of studies: A statistical performance study on an approximately 3-km long aerial scenario (Figure 4), and a case study in a larger aerial scenario (Figure 6(a)). In both cases, the downward-facing camera operates in GPS-denied environments and occasionally re-visits previously explored locations, providing occasional loop-closure measurements. The priors

Scenario used for statistical study. Camera and target trajectories are shown in red and blue, respectively. At this scale, ground truth and estimated trajectories are indistinguishable (see Figure 5).
Statistical simulation results
A performance comparison between the proposed method and BA with target tracking is presented in a 45-run Monte-Carlo study. The scenario used in this simulation, shown in Figure 4, contains 52 frames, gathered over ∼160 s. Loop-closures can be noticed around views 20 and 38. The simulated target takes a similar course on the ground and for the sake of simplicity, stays in the camera’s field of view throughout the process. The comparisons presented in Figure 5(a) to (c) are given in terms of root-mean-square error (RMSE), calculated over the norms of the error vectors. All results refer to incremental estimations, i.e. at each time tk performance is evaluated given Zk, which is in particular important for online navigation.
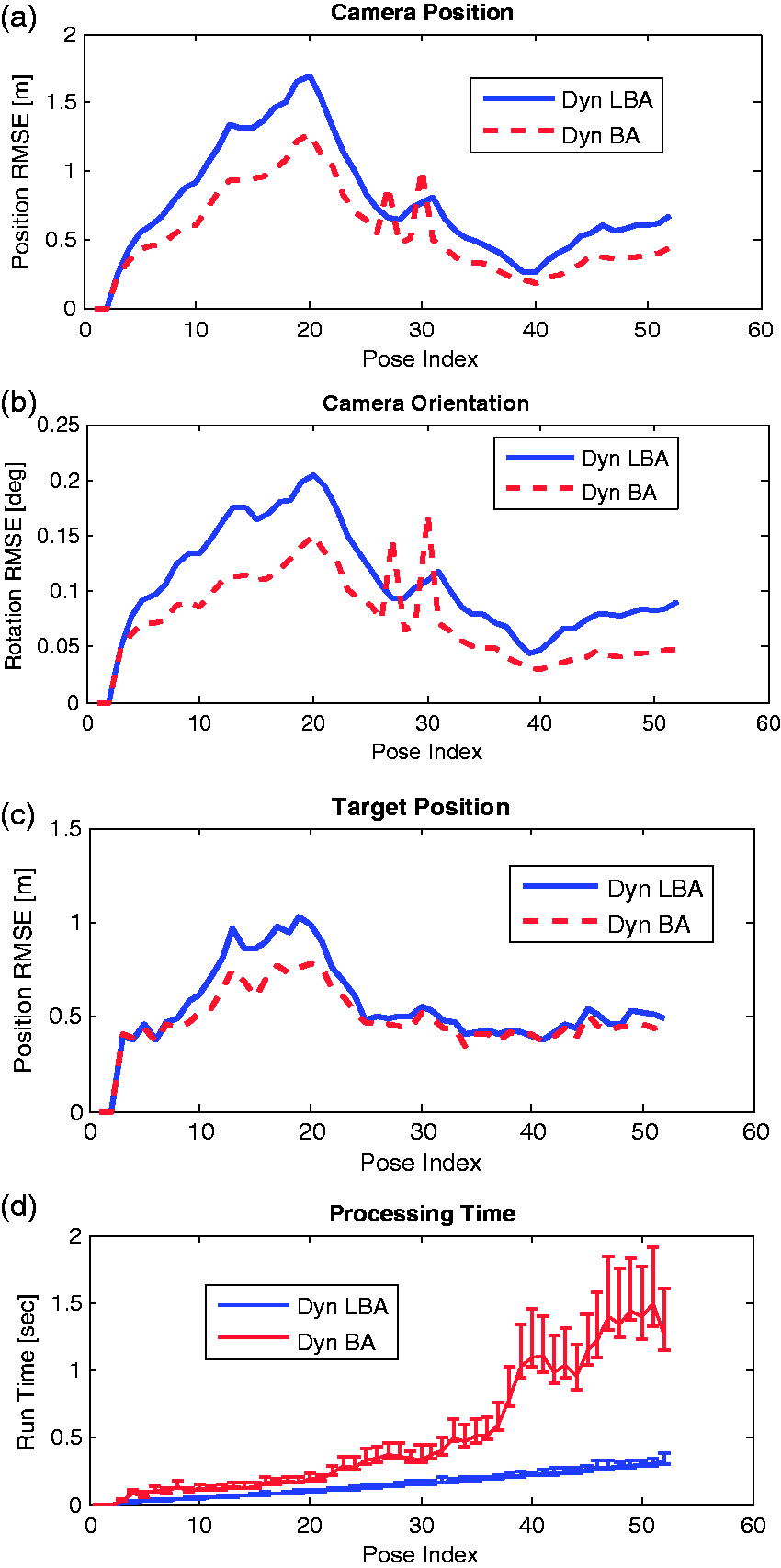
Monte-Carlo study results comparing between the proposed method and full BA with target tracking (a) camera position RMSE; (b) camera orientation RMSE (including close-up); (c) target position RMSE; (d) running time average with lower and upper boundaries.
Figure 5(a) and (b) describes the camera incremental position and orientation errors and Figure 5(c) shows the target position error. We observe similar levels of accuracy with the two techniques. The camera pose and target trajectory errors are bounded, with clear negative trend in both the camera and target position errors around view 20, upon loop closure. We note that, in this case, the navigation is performed relatively to the camera’s and target’s initial positions. Those were initialized from their ground truth values, causing initial errors to be zero for all the estimated states.
Figure 5(d) shows statistics over running time between the proposed method and full BA with target tracking. For BA, a distinct increase in computational time can be observed at view 38, where a loop closure occurs. While one can already observe a significant difference in running time between the two methods in favor of LBA, we confirm this observation further in a larger scenario and with real imagery experiments in the next sections.
Large scenario
The large scenario, shown in Figure 6(a), simulates an approximately 14.5-km-long aerial path and involves a series of loop closures, resulting in variables recalculation during optimization. The target takes a different course on the ground (as shown in Figure 6(b)), which causes losses of target sight for approximately a seventh of the frames. In these cases, only the motion model factor is taken into consideration.

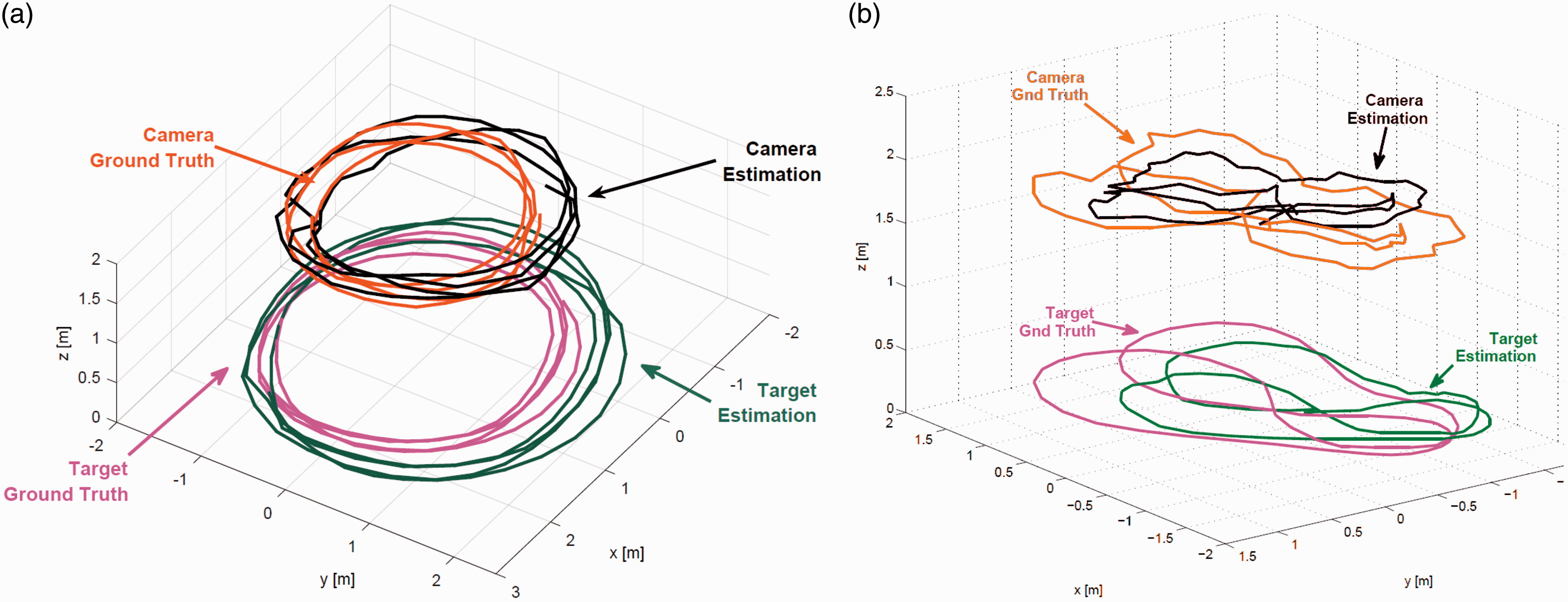
(a) Estimated camera (red) and target (blue) trajectories for the large synthetic scenario with 24,500 observed landmarks (shown in black). (b) Top view of the target and camera estimated trajectories for the large-scale synthetic scenario. At this scale, ground truth and estimated trajectories are indistinguishable (see Figure 7).
The obtained average camera position incremental errors for LBA and BA are 1.27 and 0.51 m, respectively, with a maximum error of 5.11 and 2.33 m. While the accuracy levels are similar, one can easily notice the difference in running time. Loop closures have a high impact on BA running time due to the landmark re-elimination and re-linearization they trigger; this process is avoided with LBA. It results in an average processing time of 3.3 s for LBA with target tracking, versus 22.2 s for BA method. The obtained overall processing time for the same scenario is 809 s for the proposed method, versus 5329 s with BA.
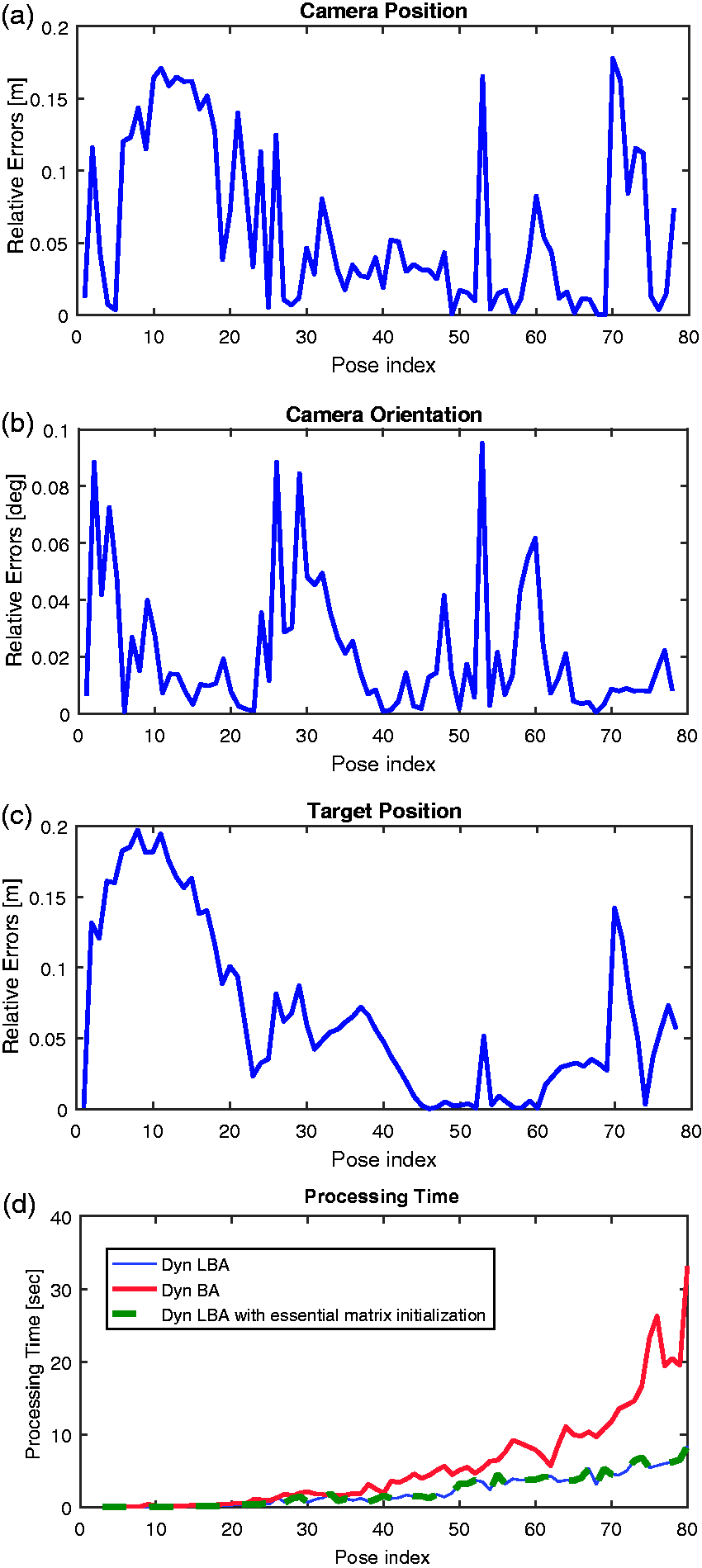
Since we are interested to assess the similarity in terms of accuracies between the two techniques, we show in Figure 7(a) to 7(c) the relative errors between LBA and BA methods, meaning the difference between the estimation errors using both methods. Then, a comparison of the processing time is shown in Figure 7(d).

Incremental relative errors of LBA method with respect to BA method for the (a) camera position, (b) camera orientation, (c) target position, in the large-scale synthetic scenario. (d) a comparison of the processing times per frame.
Experimental evaluation with real-imagery datasets
Further evaluations were performed through real-world experiments conducted at the Autonomous Navigation and Perception Lab (ANPL). Similarly to the synthetic dataset evaluation, these experiments involve a downward-facing camera which performed an aerial pattern while tracking a dynamic target moving on the ground. Ground truth data were gathered for the camera and the dynamic target using an independent real-time 6DOF optical tracking system. A scheme of the lab setup is presented in Figure 8 and two samples of typical captured images are presented in Figure 9. The recorded datasets are available online and can be accessed at http://vindelman.net.technion.ac.il.

Conceptual scheme of the lab setup for the real-imagery experiments. The camera was manually held facing downwards and moved around the lab, in pre-defined patterns. Trackers, represented by yellow dots, were installed on the camera and on the target, allowing for detection by the ground truth system and measurement of their 6DOF poses. Images were scattered on the floor to densify the observed environment. Best seen in colour.

Typical images from the ANPL1 real-imagery dataset.
Two different datasets were studied. In the first dataset, ANPL1, the camera and the target perform circular patterns, while in the second, ANPL2, they move in a more complex and unsynchronized manner, with occasional loss of target sight. Both cover an area of approximately
Dataset details.

ANPL: Autonomous Navigation and Perception Lab.
Data association is performed using an implementation of the RANSAC algorithm 40 on the SIFT features that were extracted from the images and stored for potential loop closures. Since the experiments were conducted in a relatively constrained area with a wide field-of-view camera, numerous loop closures occur, as locations are often re-visited. For LBA, a single three-view constraint is added for each landmark observed more than twice in the past. This three-view constraint involves the current observation, the earliest observation and the one in the middle. A similar concept is used for 3D points triangulation, meaning the current observation and the earliest observation are taken into account. The target is detected by identification of the most highly recurrent SIFT feature, meaning we assumed that the SIFT feature which was detected in the highest number of frames belongs to the target. Although more advanced techniques exist, they are outside the scope of this work.
We compare the pose estimation errors of the camera and the position errors of the dynamic target with respect to ground truth for both LBA with target tracking and full BA cases. Incremental smoothing was applied for both methods in ANPL1 dataset and standard batch optimization in ANPL2. QR factorization was used in all cases. We assume priors
Figure 10 shows the estimated trajectories and ground truth for the camera and the dynamic target in both datasets, using LBA method. We calculate an average error in position estimation of 22 and 38 cm for the camera and the target, respectively, in ANPL1 dataset, and of 49 and 47 cm in the ANPL2 dataset. The same level of position accuracy is calculated for the BA method. These errors are due (at least partially) to a specific practical data synchronization issue (ground truth data vs. image sequence) during the experiment. Similarly to the large-scale simulation case, we show in Figures 11(a) to (c), the relative errors between LBA and BA methods and a comparison of the processing time in Figure 11(d).
Estimated vs. ground truth 3D trajectories with real-imagery datasets for LBA approach in (a) ANPL1 dataset (b) ANPL2 dataset. BA approach produces similar results in terms of estimation errors, as shown in Table 2.
Incremental relative errors for the (a) camera position, (b) camera orientation, (c) target position, in ANPL1 dataset, (d) a comparison of the processing times per frame.
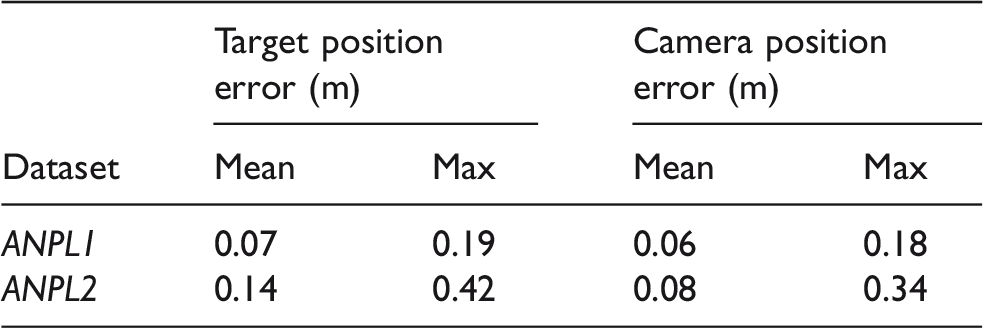
Tables 2 and 3 summarize the absolute values of the relative errors and the processing times for the two datasets. In both cases, the two methods show similar levels of accuracy: The average values for target and camera positions are 7 and 6 cm, respectively, for ANPL1 dataset, and 14 and 8 cm for ANPL2 dataset. In contrast, LBA with dynamic target tracking shows consequently better computational performances. The mean processing time per step is reduced by 61% for ANPL1 and by 39% for ANPL2.
Relative estimation errors summary of LBA method with respect to BA method for the camera and target positions in ANPL1 and ANPL2 datasets.
Note: The table entries are absolute values.
ANPL: Autonomous Navigation and Perception Lab.
Summary of the processing times with LBA and BA methods for the ANPL1 dataset.

LBA: light bundle adjustment; BA: bundle adjustment; ANPL: Autonomous Navigation and Perception Lab.
Conclusions and future work
We presented an efficient method for simultaneous ego-motion estimation and target tracking using the LBA framework. By algebraically eliminating the observed landmarks from the optimization, we allow the target to become the only reconstructed 3D point in the process. This reduces significantly the number of variables compared to full BA methods, and thus, allows for processing time improvements. We presented the mathematical process involved in the integration of the target tracking problem into the LBA framework, leading to a cost function that is formulated in terms of multi-view constraints, target motion model, and observations of the target. Computational efforts are further reduced by applying incremental inference over factor graphs representing the optimization problem, thus performing partial calculations at each optimization step.
We investigate the performance of the proposed approach and compare it to the corresponding BA formulation using synthetic and real-imagery datasets. While the two approaches exhibit similar accuracy levels, a significantly reduced running time was obtained for the proposed approach with both experimental methods. In particular, the presented method was up to seven times faster than full BA in the simulations and up to two and a half times faster in the real-imagery experiments. This difference, however, is expected to vary with the number of landmarks observed per frame. The created real-imagery datasets have been made available to the research community through the ANPL website. These datasets include recorded images with synchronized ground truth for both the camera and the target, and is seen as a contribution by itself.
As for future work, aerial experiments including scale estimation for both BA and LBA methods (potentially using fusion with additional sensors such as IMU) could further improve the realism of the scenario. Also, an experimental implementation of our method to the multi-target tracking problem seems a natural continuation. In this case, the method used for targets detection and data-association represents a real challenge.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.