
Abstract
In this paper, a new method for vision-aided navigation based on trifocal tensor geometry is presented. The main goal of the proposed method is to estimate the position of vehicles in global positioning system-denied environments, using a standard inertial navigation system and only a single camera. The geometric trifocal tensor relationship between three images is used as measurement information from the camera, and the primary contribution of this work is the derivation of a measurement model that is able to express the geometric constraints of the trifocal tensor in the global frame. This measurement model does not require including the three-dimensional feature positions in the state vector. In other words, the proposed method does not entail reconstructing the environment. Rather, the method only considers the vehicle state. The vision-aided inertial navigation algorithm that we propose has computational complexity only with regard to the number of features at the current time, and the algorithm is capable of estimating the pose in real environments. Experiments were conducted to show the effectiveness of the proposed method in simulations and real environments.
Keywords
Introduction
Accurate estimations of the navigational state are essential in many fields, and a global positioning system (GPS) aided by an inertial measurement unit (IMU) is the primary method used today. In many cases, however, GPS might be unavailable or unreliable. For instance, navigation is important when operating indoors, in urban environments, under water, and on other planets. In these settings, vision-based methods are an attractive alternative for navigation, owing to their low cost, weight, and autonomous nature.
An important advantage of using a camera is that its images provide high-dimensional measurements with rich information content. By tracking feature points between several images, the motion of the camera can be estimated. However, the high volume of data poses a significant challenge when designing algorithms for such estimations. When real-time localization performance is required, we are faced with a fundamental trade-off between the computational complexity of the algorithm and the resulting accuracy of the estimation.
In this paper, we present an algorithm that is able to utilize the information provided by multiple measurements of visual features. The geometric trifocal tensor relationship between three images is used as measurement information from the camera. The primary contribution of our work is a measurement model that is able to express the geometric constraints of the trifocal tensor in the global frame. This measurement model does not require including the 3D feature positions in the state vector. Consequently, the computational complexity only relates to the number of features at the current time.
After a brief discussion of related work in the following section, the details of the proposed estimator are described in “Estimator description” section. In “Simulation and experimental results” section, the performance of the algorithm is verified by experiments in simulated and real environments. Finally, in the end section, the conclusions of this work are drawn.
Related work
Vision-aided navigation1,2 has become an active research field over the past few decades. Many works have addressed visual-inertial motion estimation, and several camera-IMU solutions have been proposed to track the state of a system in real time on computationally constrained platforms and in real environments.
One family of algorithms for fusing inertial measurements with observations of visual features follows the simultaneous localization and mapping (SLAM) paradigm. With this family of methods, the current IMU pose and the 3D positions of all visual landmarks are jointly estimated.3–6 These approaches treat the Scale-invariant feature transform (SIFT) features as the visual features. Sharing the same basic principles as SLAM-based methods for camera-only localization, Dong et al. 7 proposed that the integral channel image patch (ICIMGP) features 8 perform better than the others, including SIFT features. However, the main limitation to SLAM is its high computational complexity. Properly treating these correlations is computationally expensive. Thus, performing vision-based SLAM in environments with many features remains a challenging problem.
In contrast to SLAM, several algorithms have been proposed for estimating the pose of the camera exclusively, with the aim of achieving real-time operation. The most computationally efficient of these methods utilizes feature measurements to derive the constraints between pairs of images. Considering two images, epipolar constraints can be used as measurements. In Soatto et al., 9 epipolar geometry is employed in conjunction with a statistical motion model, while in Prazenica et al., 10 epipolar constraints are fused with a dynamical model of an airplane. In Indelman et al.,11,12 the constraints between the current and previous image are defined using epipolar geometry and combined with IMU measurements in an extended Kalman filter (EKF). With two-view based methods for aiding navigation, however, it is only possible to determine camera rotations and up-to-scale translations 13 (translations during the intervals are associated with an unknown scale). Therefore, two-view based methods are incapable of eliminating navigational errors in all states.
Given three overlapping images, it is possible to determine the camera motion up to a common scale 13 (translations during the intervals are associated with a common, unknown scale). Moreover, the familiar constraints are the trifocal tensor. Thus, we can express trifocal tensor constraints among multiple camera poses in order to improve the accuracy of the estimation. In 1997, Hartley 14 applied the trifocal tensor to compute the motion of a camera (along with the scene structure). For uncalibrated image sequences, Torr et al. 15 focused on the problem of structural degeneracy and motion recovery using the trifocal tensor. Guerrero et al. 16 solved the trifocal tensor directly using singular value decomposition for location and mapping. However, these trifocal tensor-based methods do not utilize IMU data. Based on an augmented state technique, 17 Hu and Chen 18 added the trifocal tensor to a multiview measurement model in order to estimate the current vehicle state and the state of the features during a particular interval. Nevertheless, this method estimates local features, increasing the computational time. Indelman et al. 19 presented a method based on three-view geometry. Their method differs from both SLAM and augmented state techniques. By linearizing the residual measurements and calculating the relevant Jacobian matrix, computational costs are reduced and accurate position results are obtained by applying the implicit extended Kalman filter (IEKF).
The constraints of the trifocal tensor and three-view geometry are both derived from three overlapping images. As such, there might be some connection between them. Indeed, the former is the sufficient condition for the latter (see “Estimator description” section for details). Motivated by this relation between the trifocal tensor and three-view geometry, we here propose a vision-aided navigation method based on trifocal tensor geometry. The proposed method is an effective vision/inertial navigation system (INS) estimation algorithm that is able to express the geometric constraints of the trifocal tensor in the global frame. It does not require the inclusion of 3D feature positions in the state vector, and its computational complexity only relates to the number of features at the current time. Moreover, our proposal is capable of pose estimations in real environments. The proposed algorithm is efficient, as demonstrated in “Simulation and experimental results” section, and capable of precise vision-aided inertial navigation in real environments.
Estimator description
The goal of the proposed method is to estimate the pose of a vehicle in the global frame. There are three reference frames used by the IEKF: the n—north-east-down coordinate system, whose origin is set at the location of the navigation system and points north and east, completing a Cartesian right-hand system; the b—body-fixed reference frame, whose origin is set at the center of the vehicles mass and points toward front of the vehicle, or right when viewed from above, completing the setup to yield a Cartesian right-hand system; and the c—camera-fixed reference frame, whose origin is set at the center of the camera’s projection, and points toward the center of the field of view (FOV), or toward the right-half of the FOV when viewed from the center of the cameras projection, completing the setup to yield a Cartesian right-hand system.
Structure of the EKF state vector
The evolving INS state is described by the vector
15

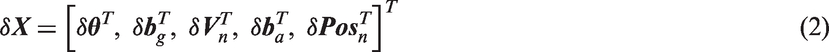
For the position, velocity, and biases, the error is defined as the standard additive error, i.e. the estimate

System model
The linearized continuous time model
15
for the IMU error state is



Measurement model
The measurement model employed to update the estimate of the filter state is given by the trifocal tensor. The trifocal tensor encapsulates the geometric relationships between the three different viewpoints, and it is independent of the scene structure.
13
Figure 1 shows the so-called point–point–point correspondence between the three views. This correspondence can be used to transfer the image point with the trifocal tensor. Where Three-view point correspondence among three camera images.
Assuming the camera calibration matrix is known, then the camera projection matrices can be defined as follows
11

According to the projection matrices and a line in 3D space, the trifocal tensor can be derived as follows

Next, we use the trifocal tensor to transfer the point


The variables used in equation (9) are expressed in camera systems, in order to estimate the pose of the vehicle in the global frame, by rearranging equation (9), we can yield point–point–point correspondence in the navigation system as follows (the proof for which is provided in Appendix 1)

Define matrix


The model in equation (13) contains nine trilinearites, but only four are linearly independent. Geometrically, these four trilinearites 11 arise from special line choices in the second and third images for the point–line–line relation.
Here, we select
First consider a single feature observed in the three images captured at times t1, t2, and t3 (where

In typical scenarios, there is more than one matching pair of features. Indeed, we assume that there are N matching features from all the three views. Thus, the measurement model can be written as

As we explained in “Related work” section, the constraints of the trifocal tensor geometry and the three-view geometry are both derived from three overlapping images. Therefore, there should be some connection between them. Through our analysis, we have obtained the following lemma (the detailed proof is listed in Appendix 2):
Lemma 1
The trifocal tensor constraints are the sufficient conditions for the three-view geometric constraints.
According to Indelman et al.,
12
given multiple matching features, one can determine the translation vectors
Implicit EKF
In this section, we present the IEKF used to analyze the performance of the fusion with a navigation system.
Equation (15) shows that the measurement model



During the time interval

The propagation covariance is similarly calculated by numerical integration of the Lyapunov equation

Noting that we are only interested in estimating the navigation errors at the current time instant
Then the Kalman gain matrix
16
can be given by

Since
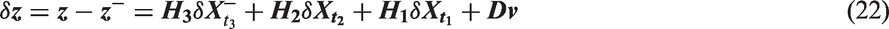
Hence

Then the corrected state and covariance are given as

The estimated state
Referring to equation (23), the matrices

The other two cross-correlation terms,
Computation requirements
It is interesting to examine the computational complexity of the operations needed during the IEKF.
Assume that at some step k there are N features included in the three overlapping images. The computational complexity of carrying out the algorithm IEKF at step k involves the computation of the predicted state
Note that during the IEKF process we do not estimate the state of the features, and the state dimension r remains unchanged. Here the state dimension r = 15, so the computation of the predicted state
Simulation and experimental results
In this section, we analyze the performance of the IEKF fused with a navigation system with a simulation and an experiment.
Simulation results

Initial navigation errors and IMU errors.

IMU: inertial measurement unit.
Assume that the simulated trajectory is a loop repeated once, as shown in Figure 2. In order to demonstrate the performance of the algorithm in loop scenarios, two different update modes were evaluated: (1) a sequential update, in which all three images were acquired closely together; and (2) a loop update, in which the first two images were captured when the platform passed a given region for the first time, and the third image was obtained during the second passing of the same region. The total running time was approximately 215 s. At Loop path.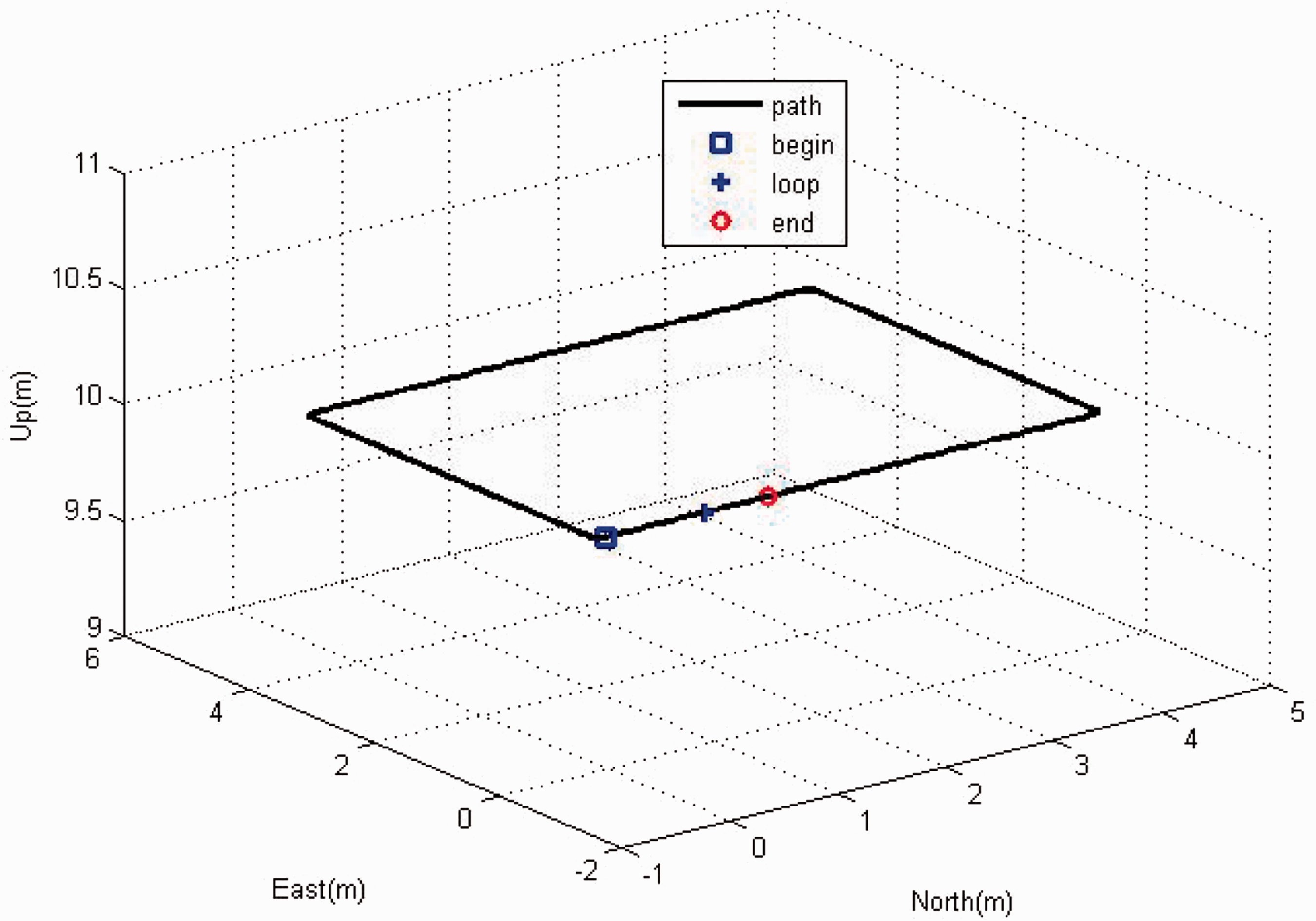
Figure 3 shows the Monte Carlo results (200 runs) using the proposed trifocal tensor. The curve is the square root of the filter covariance, defined for the ith component in the state vector as Two hundred Monte Carlo results error estimations (covariance) using the trifocal tensor, three-view geometry and INS. (a) Position errors, (b) velocity errors, (c) accelerate bias, (d) attitude errors, and (e) gyro bias.
Experimental results
In this section, we describe the results of an experiment we conducted to evaluate the proposed method in a real environment. A dataset package collected by Lee et al. 25 at the Swiss Federal Institute of Technology in Zurich was applied to validate the proposed method. There are five synchronized datasets in this package. We selected the 1LoopDown dataset (the flight trajectory for which is a loop repeated once using a downward-looking camera). The inertial sensor measurements and camera images were recorded for postprocessing at 200 and 50 Hz, respectively. The true position of the quadrotor was obtained with a VICON system that was set up in the room for comparison. The features were detected and matched using the SIFT algorithm 26 coupled with the RANSAC method, 27 and an additional comparison experiment between SIFT features and ICIMGP features using the trifocal tensor method is conducted in the end.
Figure 4(a)
25
shows the quadrotor collecting the dataset package in the indoor flight environment, and Figure 4(b)
25
shows the flight trajectory. The quadrotor flew for approximately 32 s and returned to its original position at Experiment processing. (a) The quadrotor and flight environment and (b) flight trajectory.
Figure 5 shows the matched features detected during the experiment. Indeed, sometimes there were no matching features, e.g. at Number of detected features.
Figure 6 shows the computational complexity of the IEKF during the experiment, using MATLAB 7.1. As shown in the figure, the computational time does not relate to the total detected features (as it does with SLAM). Rather, it relates to the detected features at each step. The longest calculation time was approximately 0.058 s at Computational complexity.
The estimated positions are shown in Figure 7. Indeed, the position errors increased considerably with the INS-only method. However, they reset to meters with both the proposed trifocal tensor and three-view geometry. At time Estimated position errors using different methods.
The position errors.

The related work7,8 showed that the performance of ICIMGP features is better than SIFT features. Here we conducted an additional comparison experiment between them. Because during the whole process, the number of the detected features is not many using these two methods, in order to illustrate the performance of ICIMGP features, here we just compare the loop update mode at Loop experimental results using SIFT and ICIMGP. (a) Position error and (b) position error zoom. ICIMGP: integral channel image patch; SIFT: Scale-invariant feature transform.
Conclusion and future work
This paper presented a new method for vision-based/INS applications based on the trifocal tensor. The trifocal tensor constraints we derived were the sufficient conditions for the three-view geometric constraints. The proposed method utilizes three overlapping images to formulate the related constraints between platform motions at the time instances of three images. These constraints were fused with an INS using the IEKF. Simulated and real experimental results indicated that the performance of the proposed trifocal tensor constraints exceeded that of the three-view geometric constraints. Moreover, the performance of the trifocal tensor method is better using the ICIMGP features than the SIFT ones.
This paper applied the IEKF to analyze navigation systems. As we know, the UKF uses a selected set of points to map the probability distribution of the measurement model more accurately than the linearization of the IEKF. This results in faster convergence from inaccurate initial conditions in estimation problems. Therefore, in future research, we shall use the UKF method (ICIMGP features) to analyze the performance of navigation systems in an effort to further improve their accuracy.
Footnotes
Acknowledgment
The authors thank in particular Xinghui Dong from the University of Manchester for his discussions and code on ICIMGP. They are also grateful to the editors and anonymous reviewers for their useful suggestions and detailed comments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.