
Abstract
Background:
The ulcerative colitis (UC) Mayo endoscopy score is a useful tool for evaluating the severity of UC in patients in clinical practice.
Objectives:
We aimed to develop and validate a deep learning-based approach to automatically predict the Mayo endoscopic score using UC endoscopic images.
Design:
A multicenter, diagnostic retrospective study.
Methods:
We collected 15120 colonoscopy images of 768 UC patients from two hospitals in China and developed a deep model based on a vision transformer named the UC-former. The performance of the UC-former was compared with that of six endoscopists on the internal test set. Furthermore, multicenter validation from three hospitals was also carried out to evaluate UC-former’s generalization performance.
Results:
On the internal test set, the areas under the curve of Mayo 0, Mayo 1, Mayo 2, and Mayo 3 achieved by the UC-former were 0.998, 0.984, 0.973, and 0.990, respectively. The accuracy (ACC) achieved by the UC-former was 90.8%, which is higher than that achieved by the best senior endoscopist. For three multicenter external validations, the ACC was 82.4%, 85.0%, and 83.6%, respectively.
Conclusions:
The developed UC-former could achieve high ACC, fidelity, and stability to evaluate the severity of UC, which may provide potential application in clinical practice.
Registration:
This clinical trial was registered at the ClinicalTrials.gov (trial registration number: NCT05336773)
Plain language summary
The development of an auxiliary diagnostic tool can reduce the workload of endoscopists and achieve rapid assessment of ulcerative colitis (UC) severity.
We developed and validated a deep learning-based approach to automatically predict the Mayo endoscopic score using UC endoscopic images.
The model that was developed in this study achieved high accuracy, fidelity, and stability, and demonstrated potential application in clinical practice.
Deep learning could effectively assist endoscopists in evaluating the severity of UC in patients using endoscopic images.
Introduction
Ulcerative colitis (UC) is a type of inflammatory bowel disease (IBD) characterized by chronic inflammation and ulcers in the colon and rectum on endoscopy. Common symptoms include diarrhea, abdominal pain, and cramps. 1 The worldwide incidence of UC is increasing, especially in newly industrialized countries. The annual incidence of UC ranges from 8.8 to 23.1 per 100,000 person-years in North America, 1.7 to 57.9 per 100,000 person-years in Northern Europe, and 7.3 to 17.4 in Oceania.2,3 Endoscopy is the core basis of the current management of UC.4,5 Endoscopic remission is both a long-term treatment target in daily clinical practice and a key component in clinical trials for the regulatory approval of novel therapeutic agents.6,7 Accurate evaluation of the severity of UC in patients is helpful for guiding clinical decision-making. 8 Note that the Mayo endoscopic score is the most prevalent, with details of image features collected during endoscopy and clinical symptoms reported by patients, of which the UC endoscopic score dominates. 9 Currently, the Mayo endoscopic score is widely employed as the standard of severity of UC under endoscopy; however, large errors are possible due to the subjective consciousness and lack of experience attributed to clinical evaluations of physicians, which may delay disease diagnosis and even miss the period of changing to the best treatment. 10 Moreover, endoscopic evaluation requires training, and the evaluation results often differ between two endoscopists. Thus, validated endoscopic indices enabling standardized, reproducible, and uniform reporting are essential for clinical practice and comprise an integral part of the clinical trial landscape.
Recent studies have suggested roles for artificial intelligence and deep learning in various fields including endoscopic field. For example, the development of deep learning-based auxiliary diagnostic tools to identify lesions in endoscopic images or videos has become a major research focus.11,12 Presently, deep learning technology has been gradually applied to the diagnosis of digestive system diseases due to its advantages of high efficiency and accuracy (ACC), such as the classification of gastric cancer invasion degree 13 and the identification of intestinal diseases, 14 showing good diagnostic performance and significantly reducing the work intensity of endoscopists. Ozawa 15 was the first to evaluate the performance of a convolutional neural network (CNN) in UC image recognition, the developed model based on GoogLeNet achieved an area under the curve (AUC) of 0.98 in distinguishing Mayo 0 or Mayo 1 disease from Mayo 2 or Mayo 3 disease; however, the performance consistency between the deep model and endoscopists was not assessed. Subsequently, Stidham et al. 16 demonstrated that their model performed similarly to experienced human reviewers. Considering that UC severity ratings have not been analyzed at the individual level, Bhambhvani and Zamora 17 conducted a three-level classification study (Mayo 1, Mayo 2, and Mayo 3) to explore the utility of CNNs in grading UC, but their sample size was too small with only 777 endoscopic images being included. Becker et al. 18 trained ResNet50 to perform multiple binary tasks; however, this study lacked four-level classification tasks. Note that these existing studies are limited to existing CNNs and generally lack validation of model generalization. Furthermore, the finite acceptance domain of the convolution operator makes it difficult to model remote dependence, and its static weight cannot flexibly adapt to the input content. 19 A vision transformer (ViT), 20 composed of attention modules, compensates for the above deficiency of CNNs and performs as well as or even better than CNNs in many computers’ vision tasks, such as classification, segmentation and object detection. Since Mayo endoscopic scoring of UC images is a more fine-grained classification task, and lesions with different classes are usually similar, it can easily cause confusion. Fortunately, ViT is able to capture more discriminative feature information from UC endoscopic images by modeling remote dependencies, which is beneficial for improving the classification performance. Note that Qi proposed a pyramid hybrid feature fusion framework to predict Mayo endoscopic score, 21 which had a dual-branch hybrid architecture with ResNet50 and a pyramid ViT; its disadvantage was the lack of comprehensive performance evaluation for the proposed framework. In this study, to assist in evaluating the severity of UC in patients, the UC-former was developed based on ViT with a constructed loss function to predict the Mayo endoscopic score using UC endoscopic images, and both internal validation and multicenter validation were introduced to evaluate the performance of the UC-former; moreover, the performance of the UC-former was also compared with that of endoscopists. Experimental results demonstrated the efficiency of the UC-formers in assessing UC severity.
Methods
Study design
This multicenter, diagnostic retrospective study was carried out in five hospitals in China. Patients with UC who underwent colonoscopy between 1 January 2018 and 31 December 2021 were identified from the Daping Hospital of Army Medical University (Army Medical Center of PLA), Sir Run Run Shaw Hospital of Zhejiang University, The First Affiliated Hospital of Chongqing Medical University, The Sixth Affiliated Hospital of Sun Yat-Sen University, and Tongji Hospital of Huazhong University of Science and Technology (Figure 1).

Graphic abstract of the study.
This study was approved by the Ethics Committee of Army Medical Center of PLA and was performed according to the Declaration of Helsinki. For patients whose colonoscopy images were stored in retrospective databases at each participating hospital, informed consent was exempted by the institutional review boards of the participating hospitals. The study protocol was approved by the clinical trial (ClinicalTrials.gov, ID: NCT05336773). The reporting of this study conforms to the STROBE statement. 22 In order to protect the patient’s privacy and rights, we have ensured that the patient’s personal information is deleted so that the identity of the patient may not be ascertained in any way.
Patients
Subjects were patients aged 18–72 years who had UC, and UC disease activity was assessed using the Mayo endoscopic score. The clinical manifestations of the enrolled patients with UC showed typical lesions. Patients with IBD unclassified were excluded. There were no exclusion criteria at the level of the input datasets.
Image quality control and dataset
All colonoscopy examinations were performed, usually with the patient under sedation, by well-trained endoscopists from the gastroenterology department using high-definition colonoscopes (CV290SL, Olympus Medical Systems, Tokyo, Japan). Colonoscopy records included a written description and a scheme representing the colon where the different lesions (frank erythema, aphtha, superficial and deep ulcerations, pseudopolyp, and stenosis) were displayed for each colonic segment (rectum and sigmoid, descending, transverse, and ascending colon).
We collected 15120 images of 768 patients from Army Medical Center of PLA (Chongqing, China) and Sir Run Run Shaw Hospital of Zhejiang University (Zhejiang, China) from January 2018 to December 2021. The dataset was randomly divided, including 13365 images (671 cases) in the training set and 1755 images (97 cases) in the internal test set (Supplementary Table 1).
In addition, 511 images (42 cases) from The First Affiliated Hospital of Chongqing Medical University, 234 images (45 cases) from The Sixth Affiliated Hospital of Sun Yat-Sen University, and 159 images (11 cases) from Tongji Hospital affiliated to Huazhong University of Science and Technology were selected as the external test sets.
Annotation of Mayo endoscopic score
For all collected UC endoscopic images, the Mayo endoscopic score of each image was independently annotated by two endoscopic experts with more than 20 years of working experience. If the labels of the identical image were not consistent between the two experts, the third expert was invited to assist in collectively making a final decision. Mayo endoscopic score annotated by the three endoscopic experts were considered as the Ground Truth labels in this study.
Training process
The structure diagram of the developed UC-former is shown in Figure 2. Firstly, the contrast-limited adaptive histogram equalization (Clahe) algorithm was utilized to highlight the features of each image. Second, we randomly cropped a 224 × 224 area, which was input into the ViT network after data enhancement operations such as random flipping and random brightness jitter. ViT decomposed the input image into a series of patches, linearly embedded each patch, added location information, and then fed the resulting vector sequence to the transformer encoder. In addition, an additional learnable class token was added to the vector sequence for subsequent image classification. The structure of each transformer encoder, consisting of two layerNorm layers, a multihead attention module, and a multilayer perceptron module, is shown on the right side of Figure 2.

Structure diagram of the developed UC-former.
Instead of dividing the image into 16 patches in the schematic, we divided each 224 × 224 image into 196 (14 × 14) patches, and the size of each patch was 16 × 16. To compensate for the class imbalances in the dataset while accommodating the input characteristics of ViT, we built a patch library for the category with a small sample size, which contained all the patches for splitting all images of that category in the training set. We then randomly selected patches in the patch library, rotated them, and rearranged them to generate new images. These newly generated images were added to the training set; they recombined the different image patches of that category, which was beneficial to improving the generalization of the deep model.
To improve the training efficiency, in addition to adopting the transfer learning strategy, we employed three loss functions to encourage the deep model to learn as many correlations between two patches as possible to improve its ability to assess the severity of UC. Since the classification of Mayo 1 and Mayo 2 is less consistent with the evaluation of endoscopists, 16 we combined Mayo 0 and Mayo 1 into one category (mild) and Mayo 2 and Mayo 3 into another category (severe). We expected the classification of both mild and severe, which was used to assist the final four-level classification task, to be as accurate as possible, and their loss was applied to update the network parameters. The cross-entropy loss functions between the ground truth labels and the predicted probabilities are given as follows

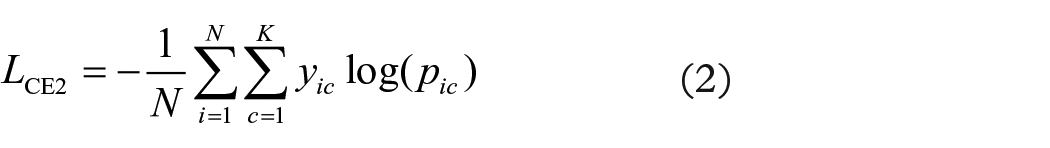
where LCE1 and LCE2 represent the cross-entropy loss of the auxiliary task and that of the primary task, respectively; yi and yic represent the true label; pi and pic represent the corresponding predicted probability; K represents the number of categories; and N represents the sample size of a batch.
Note that the output of each transformer encoder in ViT, which contains the high-dimensional features of 196 patches, has the same size. Inspired by Gong’s work, 23 we hope that the shallow features and deep features in the training process should be as similar as possible for the identical patch and as different as possible for different patches so that the representation of patches can be diversified. The UC-former employs a contrast loss function to achieve the above purpose. Let q[1] and q[G] denote the output patch set of the first layer and last layers, respectively, and let Q denote the number of patches. Next, the contrast loss function can be expressed as follows

We trained the UC-former by simply minimizing the constructed loss function which was obtained by weighting the above three loss functions as follows

where α + β + γ = 1. In particular, the values of α, β, and γ were set to 0.5, 0.4, and 0.1, respectively. Note that 10-fold cross-validation was repeated five times on the training set to tune the hyperparameters of the UC-former. This task was carried out based on the PyCharm 2020.1.3 platform, with PyTorch framework version 1.7.0 and Python version 3.8.5. Eight NVIDIA GeForce RTX 2080 Ti graphics cards were used to train the deep network. During the process of model training, the initial learning rate was set to 0.01, which was adjusted by the exponential attenuation method. Stochastic gradient descent optimizer with the momentum of 0.9 and the weight decay of 1 × 10−5 was used to train the deep model for maximally 50 epochs.
Test process
Once the UC-former was trained, 1755 images from the internal test set were utilized to evaluate its performance. According to the standard definition, we calculated the AUC, ACC, sensitivity (SEN), specificity (SPE), positive prediction value (PPV), and negative prediction value (NPV). To better understand the decision-making basis of the network, heatmaps produced by the method in the study by Chefer et al., 24 which can intuitively show the more important parts related to the decision-making, were given. In addition, the attention maps in the multihead attention modules were extracted to observe patch areas that the model paid more attention to as the network deepened.
The performance of the UC-former was also compared with that of six endoscopists, including three junior endoscopists with approximately 7 years of working experience and three senior endoscopists with more than 15 years of working experience. All endoscopists have experienced professional training in colonoscopy diagnosis and can skillfully operate colonoscopy, judge intestinal mucosal lesions, accurately write endoscopic diagnosis and collect endoscopic images. All six endoscopists independently scored each UC image on the internal test set. Moreover, to evaluate the generalization of the UC-former, external datasets collected from three hospitals were employed.
Statistical analysis
We chose ACC, SEN, SPE, PPV, and NPV to evaluate the classification performance. The McNemar test was used to assess significant differences among ACC, SEN, and SPE, while the Chi-square test was applied to the PPV and NPV, wherein a p value less than 0.05 was considered to be a significant difference. The 95% Wilson confidence interval was applied for each evaluating indicator. All statistical analyses were implemented by IBM SPSS statistical software 25.0.
Results
Patient enrollment
Between January 2018 and December 2021, 15,120 images from 768 patients were obtained from two hospitals. Overall, 13,365 endoscopic images from 671 patients were selected to build the UC-former, and 1755 endoscopic images from 97 patients were selected to evaluate its performance. Moreover, the performance of the UC-former was also compared with that of six endoscopists. Colonoscopy images from 98 patients in three hospitals were employed as the external datasets to evaluate the generalization capability (Supplementary Figure 1). After randomized allocation, the four groups of patient and image characteristics in the training and test sets had similar background data regarding age, sex, bowel preparation, and clinical severity (Table 1).
Clinical statistical characteristics in the training and test set.

SD, standard deviation.
Performance of UC-former
The average results of 10-fold cross-validation repeated 5 times on the training set is shown in Table 2, with the overall ACC reaching 0.871 (95% CI, 0.865–0.876). In the internal test, we plotted the confusion matrix and the receiver operating characteristic (ROC) curves for Mayo 0,
Results of 10-fold cross-validation on the training set.
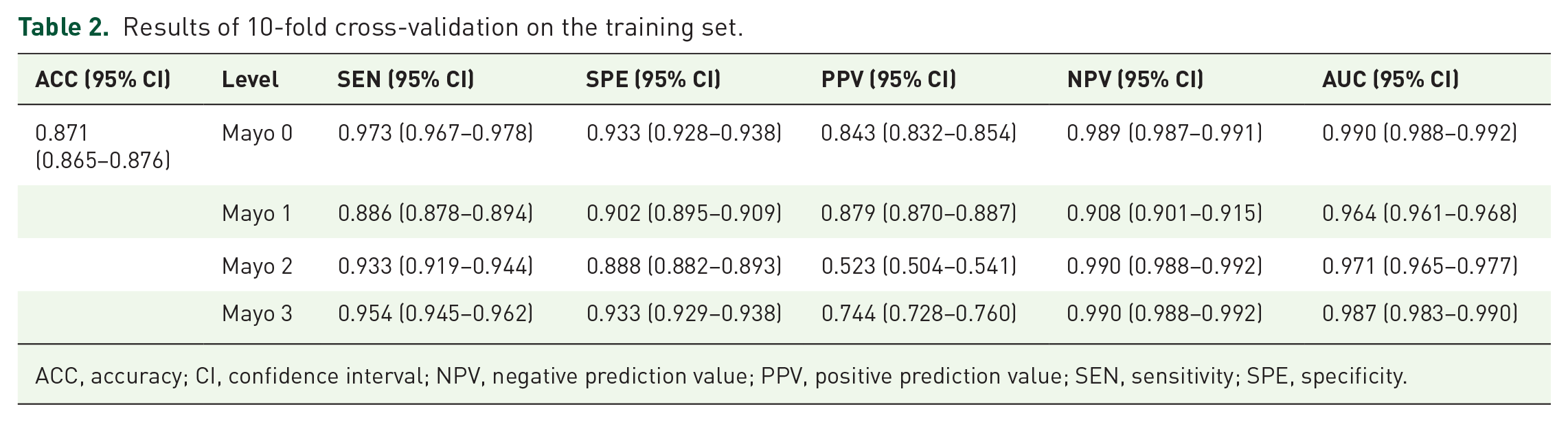
ACC, accuracy; CI, confidence interval; NPV, negative prediction value; PPV, positive prediction value; SEN, sensitivity; SPE, specificity.
Mayo 1, Mayo 2, and Mayo 3 (Figure 3), where the corresponding AUCs for each level were 0.998 (95% CI, 0.995–1.000), 0.984 (95% CI, 0.978–0.991), 0.973 (95% CI, 0.958–0.989), and 0.990 (95% CI, 0.981–0.998), respectively (Supplementary Table 2).
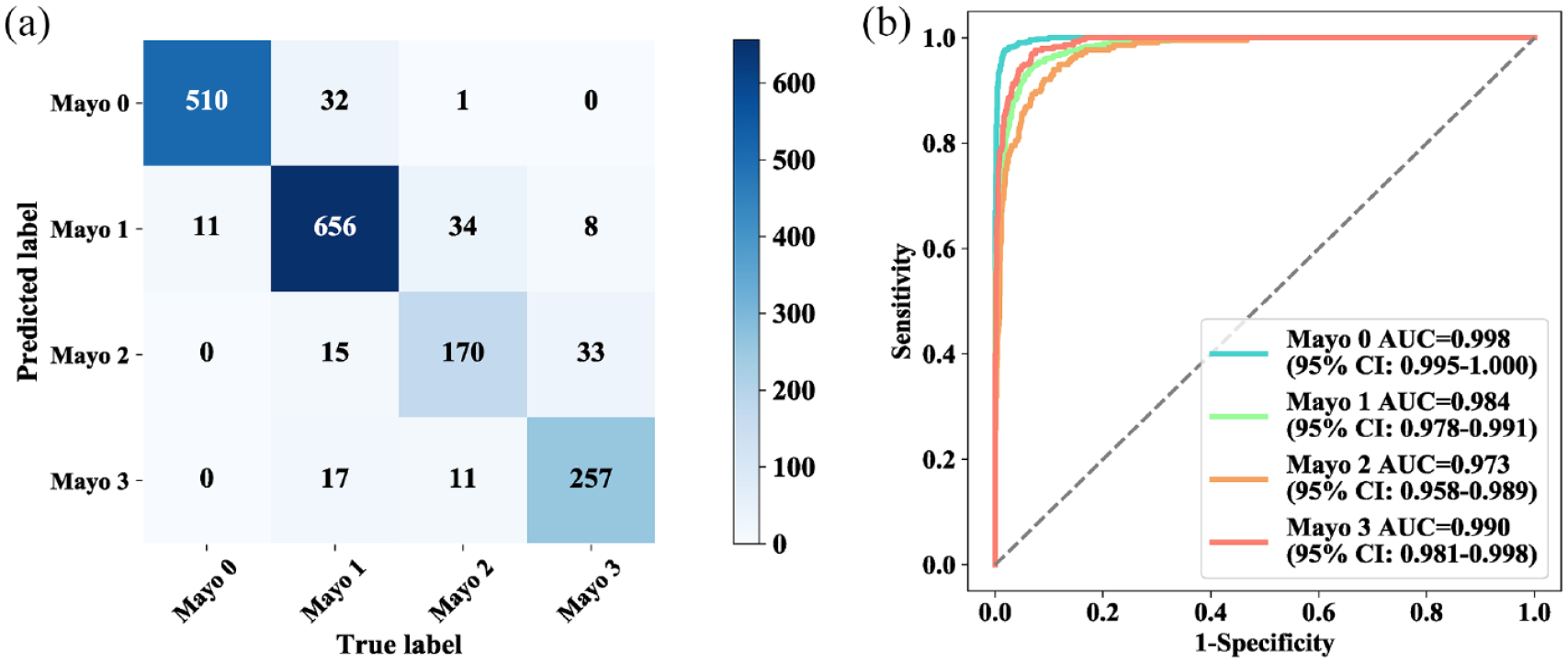
Confusion matrix and ROC curves for UC-former. Confusion matrix (a) and ROC curves (b) for the test results of four groups.
The comparison of performance between the UC-former and the endoscopists is shown in Table 3 and Figure 4. The classification performance varies for different Mayo endoscopic scores, whether they are UC-formers or endoscopists. Notably, the performance of senior endoscopists was significantly higher than that of junior endoscopists in terms of overall ACC. Note that the overall ACC of the UC-former was 0.908 (95%CI, 0.893–0.920), which is much higher than that of the best senior endoscopist [0.773 (95%CI, 0.753–0.792)] and the best junior endoscopist [0.849 (95%CI, 0.831–0.865)], both with significant differences.
Comparison of classification performance between UC-former and endoscopists.

ACC, accuracy; CI, confidence interval; NPV, negative prediction value; PPV, positive prediction value; SEN, sensitivity; SPE, specificity; UC, ulcerative colitis.
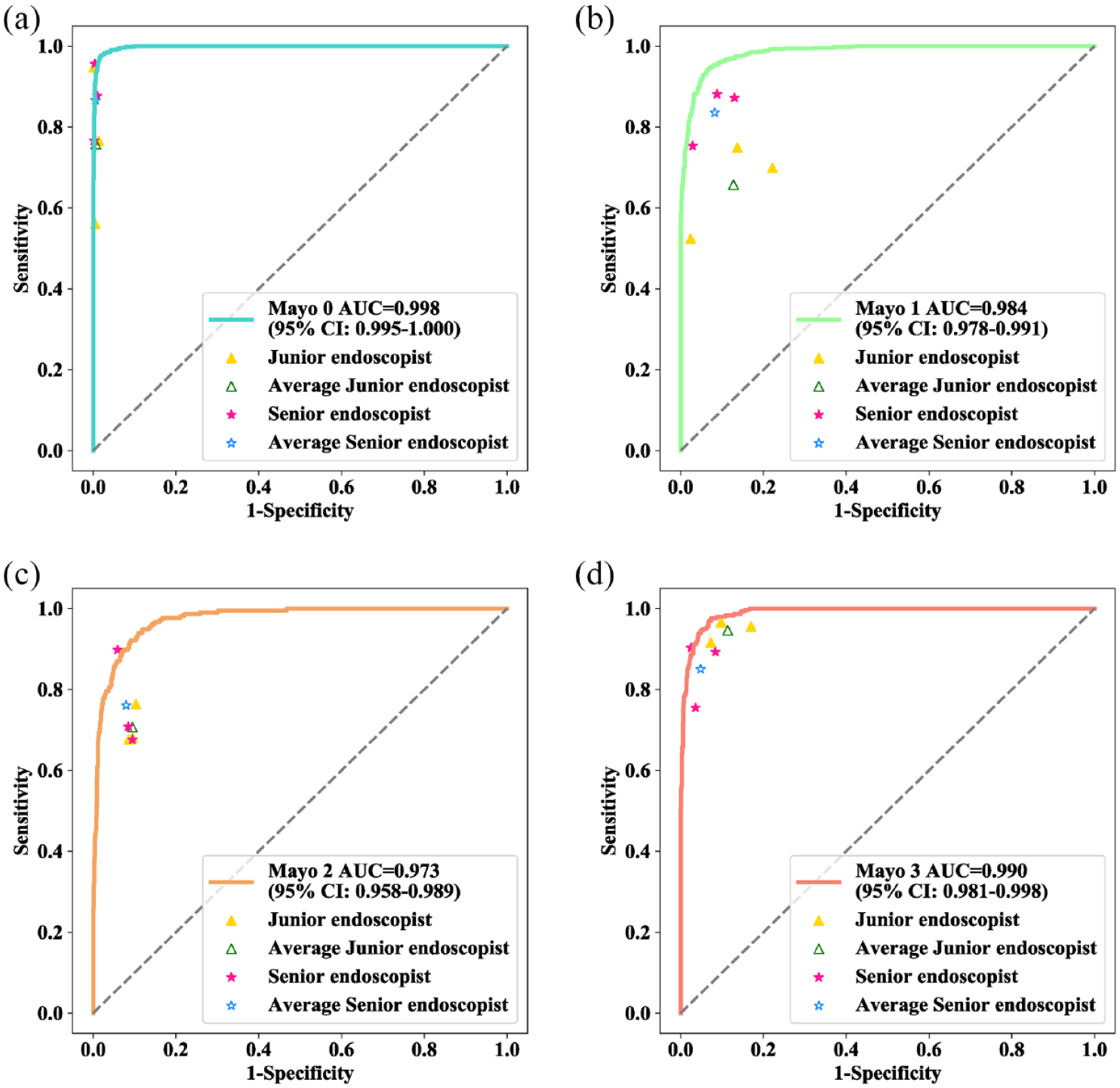
Comparison of performance between UC-former and endoscopists on the internal test set. ROC curve for Mayo 0 (a), Mayo 1 (b), Mayo 2 (c), and Mayo 3 (d). The yellow triangles indicate the diagnostic sensitivities and specificities of the junior endoscopists, the blue triangle indicates the pooled sensitivities and specificities of all junior endoscopists, the pink stars indicate the diagnostic sensitivities and specificities of the senior endoscopists, and the blue star indicates the pooled sensitivities and specificities of all senior endoscopists.
Feature visualization is widely employed to explore the working mechanism and judgment basis of deep networks. The feature maps in the multihead attention module in each transformer encoder are shown in Supplementary Figure 2. For the UC-former, the number of multiheads was 12, and each head was used to extract different correlations between two patches, so for each transformer encoder, there were 12 feature maps. In the shallow layer, the features learned by the UC-former were scattered, while as the network deepened, the features became increasingly focused, and the patches with lesions appeared to be highlighted. Heatmaps generated by the UC-former are shown in Figure 5; they partly explain the classification results achieved by the UC-former.

Heatmaps generated by UC-former.
Multicenter validation
The UC-former showed better generalization performance on the external test sets (Table 4). In the First Affiliated Hospital of Chongqing Medical University, the Sixth Affiliated Hospital of Sun Yat-Sen University, and Tongji Hospital, the overall ACC was 0.824 (95% CI, 0.788–0.854), 0.850 (95% CI, 0.799–0.890), and 0.836 (95% CI, 0.771–0.886), respectively. The SEN and SPE of all categories were higher than 0.8 in the three multicenter datasets. Note that the PPV of Mayo 2 was low in the results of the First Affiliated Hospital of Chongqing Medical University, possibly because the number of images belonging to Mayo 2 was too small, accounting for only 7.828% in the entire dataset. The confusion matrix and ROC curves of multicenter validation were shown in Figure 6.
Results of multicenter validation achieved by UC-former.

ACC, accuracy; CI, confidence interval; NPV, negative prediction value; PPV, positive prediction value; SEN, sensitivity; SPE, specificity; UC, ulcerative colitis.
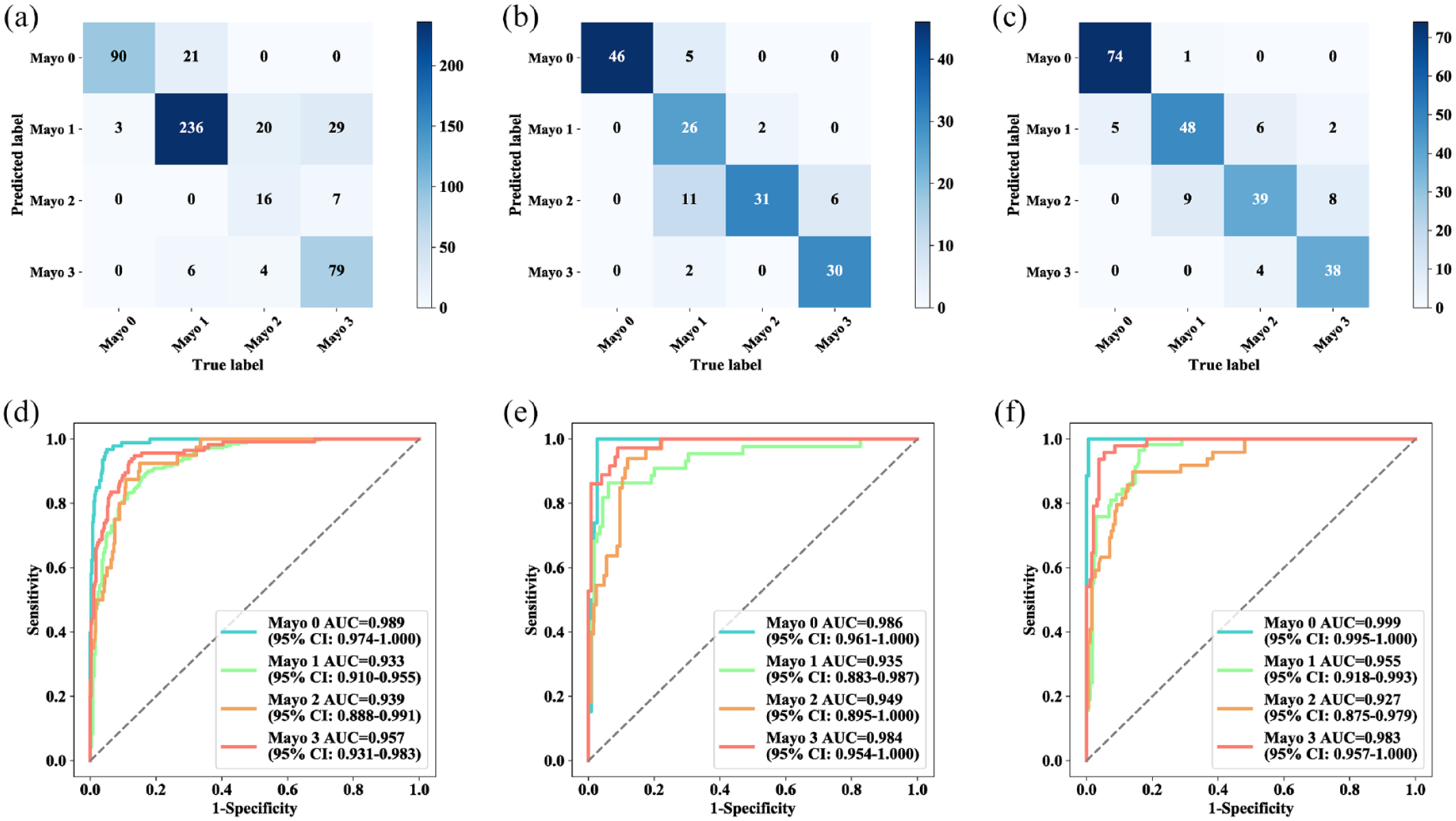
Confusion matrix and ROC curves of multicenter validation. Confusion matrix (a–c) and ROC curves (d–f) for three hospitals. (a and d) The First Affiliated Hospital of Chongqing Medical University. (b and e) Tongji Hospital Affiliated with Huazhong University of Science and Technology (c and f) The Sixth Affiliated Hospital of Sun Yat-Sen University.
Discussion
Artificial intelligence techniques have been widely utilized in an increasing number of medical fields, such as the accurate diagnosis of pathology, ultrasound, and cardiac imaging.25,26 In the field of diagnosis of UC, it has been reported that artificial intelligence is introduced to evaluate the histological activity of UC. 12 In the clinical treatment of UC, recovery under endoscopy can be regarded as the gold standard to evaluate the efficiency of clinical treatment. Manual interpretation is limited to experienced clinicians who also exhibit great differences. A few clinical studies have evaluated the severity of UC under endoscopy. A recent study proposed UC-DenseNet can effectively diagnose UC and assist the endoscopist in formulating the treatment strategy. 27 However, it is still necessary to be validated by the multicenter dataset in clinical practice, and compared with endoscopists in order to more effectively demonstrate the efficiency of the deep model in clinical experiments.
In our study, based on retrospective stored images, the developed UC-former demonstrated high ACC, SEN and SPE for the prediction of the Mayo endoscopic score of UC images. As a kind of supervised learning, accurate annotation of Mayo endoscopic score for each UC image is crucial for training an effective deep model. In this study, a more reliable annotation mode was introduced. Two experts were invited to annotate all UC images independently, and the participation of the third expert mainly solved those inconsistent labels for the identical image annotated by the first two experts. Note that it is also a popular annotation mode to extract keywords from diagnostic reports using natural language processing, which could significantly reduce the annotation workload; however, it inevitably introduces annotation noise. In contrast to previous efforts using deep learning to grade UC severity, we adopted a more advanced deep learning architecture, that is, ViT. Furthermore, we designed auxiliary branches to enable the model to better learn the subtle features of UC images with different Mayo endoscopic scores. Note that a common problem in clinical practice is that there are fewer positive samples than negative samples, which is manifested in our study, as the number of samples for Mayo 2 was much less than the number of samples for Mayo 0 and Mayo 1. Although we designed a data enhancement method for UC-former to compensate for the class imbalance problem in the dataset, the experimental results show that the classification of Mayo 2 still remains difficult. Notably, there were significant differences in both SEN and SPE between junior endoscopists and senior endoscopists. Furthermore, there were differences between two different senior endoscopists or between two different junior endoscopists because the clinical experience and cognition of each endoscopist were different. In terms of average ACC, the classification performance of senior endoscopists was better than that of junior endoscopists. Compared with endoscopists, the UC-former achieved much higher classification ACC, demonstrating its advantages in the four-level classification of the Mayo endoscopic score. In terms of SEN, SPE, PPV, and NPV, the UC-former still outperformed most endoscopists. In addition, compared with endoscopists, the UC-former made decisions much faster, with an average speed of about 0.017 s per image. Therefore, it is believed that it is feasible to apply this deep model to real-time classification of endoscopic videos in the future. Note that changes in the brightness, color, and contrast of endoscopic images will greatly affect the classification performance of the deep model, which can be demonstrated in the results of multicenter validation. Generally, endoscopic images collected by different medical centers have various colors, brightness, and contrast, so the performance of the UC-former on the multicenter test dataset is usually worse than that on the internal test dataset. Note that data enhancement can increase the diversity of data, thus improving the generalization ability of the deep model. Since the UC-former employed a patch-based data enhancement method, it still achieved excellent performance on the three multicenter external datasets, indicating that it had better generalization ability.
The heatmaps are used to display which part of the input image has a role in the final classification of the image. Note that most responses of heatmaps generated by UC-former were in the lesion area of UC images, which were relatively significant areas, showing that UC-former learned significant areas and more distinguishing features during the training process. These findings also suggested that UC-former was a reliable and robust deep model in this study.
In this study, we developed and validated a deep learning-based approach to predict the Mayo endoscopic score of UC images. Due to its high ACC, fidelity, and stability, the developed UC-former may assist endoscopists in improving prediction ACC in clinical settings. This approach may lay a foundation for the study of the Mayo endoscopic score predicted by deep learning to evaluate the severity of UC in patients. However, our study still has some limitations. First, we collected data from only two centers to construct the training set, and the data diversity was still insufficient for deep learning. Due to differences in equipment, lighting, and endoscopist manipulation, training data should include as many UC images in various situations as possible to improve the generalization performance of the UC-former. Second, in terms of performance, although we performed both internal validation and multicenter validation, performance validation with larger cohorts or prospective clinical trials is warranted.
In summary, the developed UC-former may be an original and welcome step for the automatic and accurate prediction of the Mayo endoscopic score in UC patients. In the future, in addition to further expanding the dataset, we will continue to improve UC-former and to enhance its feature extraction capability to better extract key features that distinguish UC images with different Mayo endoscopic scores, which may further improve the classification performance of UC-former.
Supplemental Material
sj-docx-3-tag-10.1177_17562848231170945 – Supplemental material for Development and validation of a deep learning-based approach to predict the Mayo endoscopic score of ulcerative colitis
Supplemental material, sj-docx-3-tag-10.1177_17562848231170945 for Development and validation of a deep learning-based approach to predict the Mayo endoscopic score of ulcerative colitis by Jing Qi, Guangcong Ruan, Yi Ping, Zhifeng Xiao, Kaijun Liu, Yi Cheng, Rongbei Liu, Bingqiang Zhang, Min Zhi, Junrong Chen, Fang Xiao, Tingting Zhao, Jiaxing Li, Zhou Zhang, Yuxin Zou, Qian Cao, Yongjian Nian and Yanling Wei in Therapeutic Advances in Gastroenterology
Supplemental Material
sj-tif-1-tag-10.1177_17562848231170945 – Supplemental material for Development and validation of a deep learning-based approach to predict the Mayo endoscopic score of ulcerative colitis
Supplemental material, sj-tif-1-tag-10.1177_17562848231170945 for Development and validation of a deep learning-based approach to predict the Mayo endoscopic score of ulcerative colitis by Jing Qi, Guangcong Ruan, Yi Ping, Zhifeng Xiao, Kaijun Liu, Yi Cheng, Rongbei Liu, Bingqiang Zhang, Min Zhi, Junrong Chen, Fang Xiao, Tingting Zhao, Jiaxing Li, Zhou Zhang, Yuxin Zou, Qian Cao, Yongjian Nian and Yanling Wei in Therapeutic Advances in Gastroenterology
Supplemental Material
sj-tif-2-tag-10.1177_17562848231170945 – Supplemental material for Development and validation of a deep learning-based approach to predict the Mayo endoscopic score of ulcerative colitis
Supplemental material, sj-tif-2-tag-10.1177_17562848231170945 for Development and validation of a deep learning-based approach to predict the Mayo endoscopic score of ulcerative colitis by Jing Qi, Guangcong Ruan, Yi Ping, Zhifeng Xiao, Kaijun Liu, Yi Cheng, Rongbei Liu, Bingqiang Zhang, Min Zhi, Junrong Chen, Fang Xiao, Tingting Zhao, Jiaxing Li, Zhou Zhang, Yuxin Zou, Qian Cao, Yongjian Nian and Yanling Wei in Therapeutic Advances in Gastroenterology
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.