
Abstract
There are many ways to measure the efficiency of the storage area management in container terminals. These include minimising the need for container reshuffle especially at the yard level. In this paper, we consider the container reshuffle problem for stacking and retrieving containers. The problem was represented as a binary integer programming model and solved exactly. However, the exact method was not able to return results for large instances. We therefore considered a heuristic approach. A number of heuristics were implemented and compared on static and dynamic reshuffle problems including four new heuristics introduced here. Since heuristics are known to be instance dependent, we proposed a compatibility test to evaluate how well they work when combined to solve a reshuffle problem. Computational results of our methods on realistic instances are reported to be competitive and satisfactory.
Introduction
Containers are often stored temporarily in the yard between the time they arrive at the port either through vessels in the case of import and through external trucks in the case of export. In practice, containers for loading are placed in the export area and those unloaded from ships are placed in the import area. 1 Some ports stack export containers close to the quay and import containers close to the landside gate. Others have a dedicated area for marshalling containers just unloaded from or to be loaded onto vessels. Fast access to stored containers is a major concern in container terminals. Choosing an appropriate location for a container that is to be relocated is essential in reducing the subsequent reshuffles. There are many ways of tackling this problem.
When containers arrive there is need to have a storage strategy to stack them in order to make retrieval efficient. Container types are stored in different places (for instance 20-foot containers are stored separate from 40-foot containers). Where they are stored together, the 20-foot containers are stacked beneath the 40-foot because the latter have a higher priority when loading onto a vessel. The storage location could also be based on whether the container is full or empty, the destination of vessel and even their weight. After storage, containers can be reshuffled/pre-marshalled in advance of retrieval. The aim here is to change the initial layout of the block to a desired layout to facilitate retrieval.2
If the containers are placed exactly where they can quickly be accessed, the retrieval process will be efficient. However, this is hardly the case due to many reasons especially inaccurate information as to when the containers will be retrieved when storing them. 3 Other reasons include change in vessels arrival time due to delay, external trucks arriving late due to traffic and the vessels stowage plan amongst others. Since only containers at the top of a stack are accessible, there is usually need to reshuffle containers in order to retrieve the desired container beneath them. This process takes time and thus hampers the operation of yard cranes YCs which will delay the trucks and/or the vessels.
We are interested in retrieving all the containers in a bay at minimal reshuffle. However, decision on where to place a reshuffled container is not as easy as it looks because it affects subsequent retrievals. Even in a static case where there is no arrival of new containers while stacking, the problem is still dynamic due to the fact that the configuration of the bay changes each time there is a retrieval. In Kim and Hong 4 it was suggested that in order to minimise reshuffles, the storage location of incoming container should be well assigned and the location of a reshuffled container should also be determined. For the purpose YC drivers are given work orders in the form of a movement sequence. The movement sequence contains the order of container movements, instructing the driver which container to move, where and when to move them Lee and Chao. 5
Containers can be classified using different attributes such as weight, port of destination, length, being inbound or outbound and full or empty. This determines where they are stored for easy retrieval. For instance, a container destined for a farther port has a higher priority when loading onto a vessel since it will be unloaded later than a container destined for a port that is nearer. Heavier containers are stored in higher tiers in the yard since they are loaded in lower parts of vessels and are thus retrieved earlier. Containers that are stored earlier are likely to need earlier retrieval but would be buried under later arriving containers. Hence, there is need for reshuffle.
Literature review
The literature on selecting a storage strategy includes Van Asperen et al. 6 which investigated the role truck arrival could have on the stacking policy of a container terminal. They concluded that it will be more beneficial to improve available information at the time of stacking than attempting to fix poor stacking decisions later. This was done using discrete-event simulation to evaluate expected departure time for an import container to schedule the pre-emptive remarshalling moves. It was a follow-up on the work of Dekker et al. 7 which examined various stacking strategies for an automated container terminal and Borgman et al. 8 where a study of the knowledge of departure and stacking further away or close to exits points were considered. It was discovered that the trade-off between where to stack and accepting more reshuffles leads to improvements over the benchmark. Simulation technique was deployed in Zhao and Goodchild 9 to investigate the truck arrival information and container rehandles in the import container retrieval process. They found that a complete arrival order is not required to significantly reduce rehandles. However, benefit can be obtained from information about truck arrival.
There are benefits in stacking higher and using a larger number of rows. A storage system was developed in Casey and Kozan 10 that simulates and optimises the movement and storage of containers within the terminal. A mathematical model was presented that minimises rehandling moves, while having total job times as the objective function. Using four heuristics and three meta-heuristics, they concluded that the model and optimisation should be used within a larger model. The focus was on optimising the movements of machines and ensures they arrive at their final destination on time.
The problem of assigning containers to storage spaces that minimizes the total expected number of relocations was investigated in Yang and Kim. 11 The paper addressed both dynamic and static location problems. The static model was solved using the Genetic Algorithm (GA) and the dynamic one by the minimum space waste rule, which was found to outperform GA. The problem of assigning locations to incoming containers and the need for reshuffle in a container terminal was examined in Wan et al. 12 Yard operations in some container terminals was investigated in Chen,13 it was concluded that higher container stacking have a direct impact on the number of unproductive moves. They claimed that the major impact was on the delivery operation. The use of heuristics that use ϵ- optimal policies was proposed in Li et al. 14 to compute a specific allocation of empty containers between different ports. The problem was formulated as a multi-port containerisation model.
Decision trees was deployed in Kim et al. 15 from a set of optimal solutions to solve a dynamic programming model formulated to locate export containers considering weight. Simulated Annealing (SA) was used in Kang et al. 16 to derive the best stacking strategy for containers in a yard with uncertain weight information. Experiments showed that the strategy was able to reduce the number of re-handles compare to traditional same-weight group stacking strategy. They advised that more improvement can be obtained where the accuracy of the weight classification is done by machine learning. The integer programming model, a neighborhood search process and three functions were deployed in Lee and Chao 5 to minimise the number of container pre-marshalling and reduce re-handles. The pre-marshalling problem was modelled as an integer programming problem based on multi-commodity network flow in Lee and Hsu. 17 The optimization objective was to minimize the number of container movements during pre-marshalling. A heuristic called the tree search procedure was developed in Bortfeldt and Forster 18 for solving the container pre-marshalling problem. It is based on a natural classification of possible moves, making use of a lower bound and applying a branching scheme for move sequences rather than single moves. It proved effective on large real-world instances, according to the authors.
The problem of rearranging containers before they are shipped was examined in Kim and Bae19 using dynamic programming. The move planning was solved by using a transportation model. However, it was computationally demanding. Hence, heuristics were advised. A two-step SA was proposed in Choe et al. 20 to investigate intra-block remarshalling plan that is free from rehandles during both the loading and remarshalling, considering twin Automatic Straddle Carriers (ASCs). The first step identifies the slot that minimises reshuffles and the second step schedules ASC that minimises the interference between the ASCs. Integer programming was used in Lee et al. 21 to solve the terminal allocation problem for vessels and yard allocation problem for transhipment container movements for a port that has multiple terminals. A two level heuristic approach was adopted to solve the integrated problem. Work on the relocation problem includes Jin et al. 2 which proposed an improved greedy look ahead heuristic for the Container Relocation Problem (CRP). The objective of the CRP is to find an optimal operation plan for the crane with the fewest number of container relocations. The method was found to be efficient especially for large scale problems.
Three heuristic methods; index based, binary IP and beam search were developed in Hakan Akyüz and Lee1 to solve a binary integer programming model of the CRP. They concluded that the beam search heuristic outperformed the others. Emptying a stack without new arrivals was modelled as integer programming to derive an optimum reshuffle sequence. The problem was broken into parts and solved by four heuristics, IP-based, Lowest Slot (LS), Reshuffle Index (RI) and the Expected Number of Additional Relocations (ENAR). They claimed that their heuristic MRIP-Dk (MRIP that minimises the number of reshuffles in retrieving k containers plus estimated future reshuffles in stack after k containers are retrieved) outperformed other heuristics found in the literature. A tree search procedure was deployed in Forster and Bortfeldt 22 to solve CRP. The heuristic is based on natural classification of possible moves and used a branching scheme that moves sequences of promising single moves.
A meta-heuristic called the Corridor method was developed in Caserta et al. 23 to solve the CRP in stacking containers in a container terminal yard, pallets and boxes in a warehouse. The objective is to find the block location that minimises the number of movements that is required in the desired retrieval sequence. The imposition of exogenous constraints reduced the size of the problem and made use of constrained dynamic programming, a practical approach even for large instances. A three-phase heuristic was proposed in Lee and Lee 3 to optimise the work plan for a crane to retrieve containers from a yard according to a given order. They aimed at minimising the weighted sum of the number of container movements and the total cranes working time. The first phase generates an initial feasible movement sequence. The other two phases are iterative and terminate when a number of consecutive iterations cannot improve the current solution. This study is similar to that in Bortfeldt and Forster 18 on a tree search procedure for the pre-marshalling of containers.
The schedule of container movement by using an autonomous learning method was addressed in Hirashima. 24 This is based on a new learning model considering container groups and the Q-learning algorithm. The desired position of containers in a group is provided by an algorithm based on the Markov Decision Process (MDP). Using simulations, the proposed method was able to find solutions that had a smaller number of rehandles compared to conventional methods. This was a follow-up to previous works by Hirashima 25 where they discovered that the number of container arrangements increases exponentially with increase in the total count of containers. The desirable movements of containers was determined in Hirashima et al. 26 to reduce the total turnaround time of ships, using the Q-learning algorithm. Heuristics were deployed Expósito-Izquierdo et al. 27 to minimise the number of movements required to locate all containers. Features that consider the occupancy rate of the bays and the percentage with high priority are considered. An instance generator was also suggested for instances with varying degrees of difficulty.
After this exhaustive review, we believe that the heuristics we introduce here has the following advantages in particular over those described in Tang et al.
28
Four new simple but still effective heuristics are introduced. Compatibilty test between the different heuristics was undertaken.
Problem definition and modelling
Due to the limited space in a container yard, containers are stacked on top of each other. However, the higher containers are stacked on top of each the higher the likelihood that there will be need for reshuffle. On the other hand, lower stacking is likely to require less reshuffle but takes more space in the yard. Therefore, there is trade off between the need to manage space and minimise reshuffle. The time lag between when these containers are stored and when they are retrieved results in improper location. The result is that containers that are needed earlier are underneath containers that are needed later. In order to have access to the desired container, we need to reshuffle the container(s) on top. Reshuffles are only done within bays for safety and operational reasons. When a crane picks a container with its hoist either for retrieval, storing or reshuffle, it only moves the containers vertically or horizontally while the frame of the crane is kept still Wan et al. 12
The container reshuffle problem is made up of three basic decisions; Which container to move, when to move it and where to move it to. The configuration of a bay can be defined by the number of columns, the number of tiers, the number of containers and their position in the bay. Let S be the number of container in a bay with C columns and T tiers. The number of container S that should be in the bay for reshuffle to be feasible can be defined as follows;


A typical bay configuration.
Containers are ranked from 1 to S, indicating the priority order for retrieval. Where containers are not stored while retrieval is going on, we have a static state i.e. the number of containers only decreases. We have a dynamic state when containers are stored while retrieval is in process. Each time a container is retrieved, the configuration of the bay changes due to reshuffles. This dynamic nature of the problem even for a static case shows the complexity of the problem. Even for a small instance, the number of states grows exponentially with the increase in the number of containers.
According to Carraro and de Castro,
29
let

It is important to note that s is the container to be retrieved and also the stage of the retrieval. The number of reshuffles necessary to retrieve container s in stage xs can be defined as follows;

The total number of reshuffles in retrieving all the containers is thus;

We are interested in determining the minimum reshuffle possible in retrieving containers from a given bay.
The model formulation
The first binary integer programming (BIP) model for a container reshuffle problem was presented in Wan et al.
12
The model introduced column-relationship variables that check whether a container to be retrieved is in the same column as the container reshuffled. Due to the long computational time needed to solve problems with large number of containers, the model was improved in Tang et al.
28
The improved model removed all the column-relationship variables and added reshuffle related constraints. This reduced the number of decision variables by
The model we suggest here is a further improvement on the two previous ones found in Tang et al.
28
and Wan et al.
12
We have made the following modification in view of the limitations of these models. We observed that the last two constraints in the the two models force containers to keep the same location they had at the first stage of retrieval. We have removed them and introduced a bay configuration constraint to reflect the change arising from each container reshuffled. The two constraints are now replaced by a new one as shown in constraint (18). This constraint assigns binary values to
Parameters
Decision variables



The model

subject to:






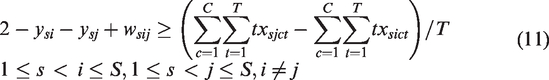
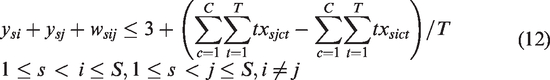









Constraints (5) and (6) determine the reshuffle variable ysi.
Constraints (10) imply a reshuffled container cannot be in the same column after reshuffle. If container i is above container s and both are in the same column then, container i must be reshuffled i.e., ysi and
Constraints (15) address the relative positions of two containers before and after both are reshuffled. Suppose container i, j and s are in the same column and container j is above container i before reshuffle. If containers i and j are reshuffled in retrieving container s then, ysi, ysj and wsij are all one. If both containers i and j are reshuffled to same new column therefore, container i will be above container j in the new column. Constraints (16) and (17) ensure that a container not reshuffled keep its position. If container i is not reshuffled at stage s therefore ysi = 0. This means
Illustration
Consider a bay with seven containers, three columns and three tiers. The initial position is as shown in stage (a) of Figure 2 adapted from Carraro and de Castro. 29 The first reshuffle is done in stage (b) where container 7 moves from top of container 1 to top of container 2. At stage (c), container 1 is retrieved. Container 7 moves again from top of container 2 to the slot vacated by container 1; this is the second reshuffle at stage (d). At stage (e), container 2 is then retrieved. The third reshuffle is done in stage (f) where container 6 moves to top of container 7 and that is the last reshuffle. If container 6 had been moved to the top of container 4 that would have necessitated another reshuffle. This would have led to four reshuffles instead of three. Subsequently all the remaining containers can be retrieved without need for reshuffle.

Reshuffle process.
A heuristic approach
Due to the computational complexity of the model, the exact approach is only able to solve small scale problems. This is at variance with real world situations where medium to large scale instances are encountered and fast results are required. There is thus need to seek an approximate approach solution. In this section, we review some heuristics found in literature and propose four new ones based on the least priority rule. They are referred to as LPH1, LPH2, LPH3 and LPH4.
Reshuffle index (RI) heuristic
This is based on the rule that a blocking container should be moved to a column having the least number of containers that have to be retrieved earlier than the blocking container as described in Murty.30 Identify the blocking container and compare it to the minimum numbered container in each column that has empty space. Put the blocking container in a column that has the least number of container to be retrieved earlier than the blocking container. Where there is a tie, the container is put in the column with higher tier and by arbitrary choice for a further tie.
H1 and H2 heuristic
H1 and H2 are each based on two conditions as described in Tang et al.
28
The difference between the two heuristics is the decision rule for moving blocking container. The first condition which is common to both is to identify the blocking container referred to as k and compare it to the minimum numbered container referred to as nc in each column c that has empty space. Put k in column c that satisfies
Framework for RI, H1 and H2
The number of containers in the bay is initially numbered from 1 to S. The first container to be picked is container 1, once that is done, the remaining container is renumbered from 1 to S-1. At each stage, the container to pick is always container 1. M denotes the cumulative reshuffle at a stage and M1 is the number of reshuffles in retrieving a container. The reshuffle process for the three heuristics above as described in Tang et al. 28 can be summarised as follows;
The least priority heuristic (LPH1)
It is based on the fact that the highest numbered container should be retrieved last hence, it is given the least priority. The algorithm starts by inputting a matrix of dimension t x c representing the initial state of the bay with t being the number of tiers and c the number of columns. Empty slot is represented by zero which can be randomly generated or input manually. The minimum numbered container is always the one to be retrieved at each stage hence, this indicates the priority order i.e retrieval is done in ascending order. At each stage, the minimum numbered container refer to as the desired container s is identified and retrieved if there is no container blocking it. If there is a blocking container refer to as k, the container s has to be moved to another column.
The decision on where to put k is determined by calculating the sum of the reciprocal for containers in those columns where there is empty spaces. These sums will be compared, and the column that returns the lowest sum of reciprocal is chosen as the column where k should be moved to. Where a column has all slots empty, k is placed in this column. This is done for all k blocking the s until there is no container blocking it at which stage such container can now be retrieved. Since at each stage, the minimum numbered container is always the one to be retrieved the algorithm updates the configuration and the process is repeated until all containers are retrieved.
The least priority heuristic (LPH2)
The blocking container k is compared to the minimum numbered container nc in each column having empty spaces. Put k in a column that satisfies the condition
The least priority heuristic (LPH3)
The blocking container k is compared to the minimum numbered container nc in each column having empty spaces. Put k in a column that satisfies the condition
The least priority heuristic (LPH4)
Apply the first condition in LPH3 where
Framework for LPH
Computational experiments
Experiments were conducted to investigate the performance of the model on different problem instances randomly generated. The model is coded in GMPL and executed on an Intel Core i7-4790 3.60 GHz CPU with 16 GB RAM. For an exact solution, each of the problems has been solved using GLPSOL while the heuristic is coded in MATLAB R2018b. The results given in Tables 1 to 6 are for the static reshuffle scenario, i.e., emptying all container in the bay. 600 instances were randomly generated for 12 problem classes each having 50 cases. 1-hour was set as the benchmark for a solution to be generated for each instance of the problems.
Comparison between model and heuristics for small problems.

Static case
Here we compare the results from the model solved with B&C and the heuristics for a small size problem defined as a bay with 50% utilisation capacity. We observe that they all return the same results for problem classes 
In Table 1, we compare the model with original version of the heuristics for small size problems. While Table 2 shows comparison with the extended versions. The extended version of each heuristic as defined in Wan et al.
12
is obtained by considering each possible slot for a reshuffled container based on the original rule of the heuristic and the one that gives the minimum possible reshuffle to empty the bay is chosen. They are denoted by E for each of the heuristic. For problem class
Comparison between model and heuristics for small problems.

‘- ’: Out of time.
Medium size problems are considered in Tables 3 and 4. We compared the model with the heuristics for 80% utilisation capacity. H1_E, H2_E and LPH2_E performed better than other heuristics for problem classes
Comparison between model and heuristics for medium problems.

Comparison between model and heuristics for medium problems.

In Tables 5 and 6, we compare all heuristics for large size problems defined as bay with 100% capacity. As expected, all the heuristics return the same average reshuffle for problem class
Comparison between the heuristics for large problems.

Dynamic case
The true test of a reshuffle process is the application to a dynamic situation. In container terminal, reshuffle is done while both retrieval and storage is taking place. 50 instances were generated for four problem classes with 80% utilisation capacity. 1000 containers were retrieved and 650 containers stored for each problem class. The retrieval of containers is the same as static case except that an incoming container will affect the priority order based on the expected departure time of the new container. In view of this, every container in the bay will be re-assigned a new index each time there is an incoming container. The heuristic rule determines where the container will be stored similar to how reshuffles are treated. The RTG is assumed to be positioned close to the sixth column hence, the incoming container is stored from right to left of the bay. Note, since the extended heuristics has been shown to be better than the original version, only the extended are treated here.
The average number of reshuffle for the 50 instances and the CPU time in seconds is shown in Table 7. It can be observed that LPH1 has the best performance for problem class
Comparison between the heuristics for large problems.

Dynamic.

Compatibility
Here we check how well the different heuristics work together when they are combined to solve a given problem. Since heuristics are known be instance dependent, it is not surprising to observe some heuristics performing well on some instance and very poorly on some others. In view of this, it is worthwhile investigating how well the heuristics perform individually compare to when they are combined to solve an instance of a problem. We have chosen the problem class
Table 8 show the average reshuffle when the heuristics are used individually as well as when they are combined to solve the problems. Entries along the main diagonal are results when each of the heuristics are used alone and other entries indicate pairing of the heuristics. Once again we observe LPH2 returning the best result either as a stand alone heuristics or when combined with other heuristics.
Compatibility.

Conclusion
Container reshuffle is a potent way to measure the efficiency of operations in container ports. Basically, the fewer the reshuffles made to retrieve needed containers, the better since a reshuffle, when necessary, is a waste of effort. The problem of minimising the number of reshuffles has therefore, been recognised for some time now and has been approached by many. Integer programming models of the binary type have been constructed for it and solved both exactly and approximately using heuristics and meta-heuristics. The issue is that these models are less than satisfactory for the following reasons.
The models are too big; they have too many unnecessary variables and/or constraints. The heuristics use arbitrary rules to resolve issues of ties to determine storage position of reshuffled containers.
We have, thus addressed these issues by considering an alternative model to fit our requirements. This alternative model has been given and described extensively. Given the computational complexity of the problem (NP-hard, since it is represented as an ILP), papers relying on exact methods are not realistic. Those using heuristics are more realistic in that sense although some of the heuristics are crude. We have, therefore carried out experiments on realistic instances using the model as well as some of the prominent heuristics found in the literature and used on the reshuffle problem namely H1, H2 and RI. Moreover, we have designed four novel heuristics LPH1, LPH2, LPH3 and LPH4 which has been tested and compared with others on static and dynamic reshuffle problems. We also presented a compatibility test to check how well the heuristics work when combined to solve a problem. The results show that LPH2 is superior to other heuristics.
Footnotes
Acknowledgements
The authors would also like to thank the anonymous reviewers for their valuable comments and suggestions to improve the quality of the paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We are grateful to ESRC for funding this work within the “Smart Data Analytics for Business and Local Government” project, Grant ES/L011859/1.