
Abstract
In this work, we introduce a new regularized logistic model for the supervised classification problem. Current logistic models have become the preferred tools for supervised classification in many situations. They mostly use either L1 or L2 regularization of the weight vector of parameters. Here we take a different approach by applying regularization not to the weight vector but to the gradient vector of the function representing the separating hyper-surface. We present the mathematical analysis of the model in its continuous setting and provide experimental evidence to show that the new model is competitive with state of the art models.
Introduction
In the last decades, many supervised learning methods have been developed and the ideas behind those models, reviewed consistently in literature.1–5 Among one of the most complete reviews is the one from Singh et al., 1 which tests many different methods on a single dataset and presents the results as a list of advantages and disadvantages of every tested method establishing their application areas. A different study, but also very complete, is the one from Fernández-Delgado et al. where 179 classifiers were evaluated on 121 datasets. 2
It is difficult to take one side and name the best performing supervised learning algorithm since usually this depends on many factors. The work of Kotsiantis et al. 3 brings some light in this direction. In this work the authors conducted a comprehensive review of different classification methods. The results showed that Support Vector Machines (SVM) and Neural Networks (NN) performed the best in terms of accuracy, classification speed and tolerance to parity problems. On the other hand, the very same algorithms presented lack of speed of learning, may have overfitting problems and there is the issue of selecting the best model parameters.
In this work we propose a new supervised binary classification method based in techniques from calculus of variations and functional analysis. By doing so, we are able to exploit the underlying mathematical theory and properties from each of these fields. Further, this allows us to obtain meaningful conditions in the continuous sense rather than just performing optimization discretely. By comparing the performance of our model against classical logistic regression models, SVM, and NN, we will show that the new method is competitive.
This work is organized as follows: first, we introduce the supervised learning problem and the new variational model. Then, we present the mathematical analysis of the model proving existence and uniqueness of the minimizer. Later, we present the numerical solution of the model by its first order optimality condition and the Levenberg-Marquardt method. Further, we present some results and discuss them before stating our conclusions. Finally, in Appendix 1 we present the proof of the Euler Lagrange partial differential equation.
A variational model for supervised learning
The problem
Given a training dataset of observations
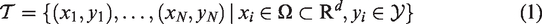
The most popular framework is the minimization of an energy functional like


The basic idea behind this variational model is to penalize wrong predictions through the loss function while allowing some relaxation through the regularizer. This is, the regularizer allows to control the smoothness of u representing the separating hypersurface. The regularizer also helps by making the problem well-posed and preventing overfitting. We will use a Lebesgue integrable function R(u) > 0 to somehow measure the complexity of u. The variational model (3) is then transformed into

A probabilistic interpretation of (4) is to notice that the empirical risk of choosing u among a space of hypothesis functions

Radial basis function approximation
Finding


Notice that in (7), the centers of the RBFs are the data observations xi. Due to this, the model will make predictions based on the Euclidean distance between points which class is known, and the new input for which its class is unknown while assigning a weight to each point. Therefore, some points will be more important than others when making the predictions. A similar idea to the one used in SVM.
Cross entropy as fitting term
A correct selection of the loss function in (4) is vital for the performance of the model. Here, since the model will be used for binary classification, we take a Bernoulli variable
The criteria to select an appropriate loss function is that it must maximize the likelihood that, given parameters wi, the model results in a prediction of the correct class for each input sample and this likelihood should be a function of these parameters. This can be achieved by the minimization of the cross-entropy
6
(also called negative log-likelihood) that effectively maximizes the likelihood. This function is given by:
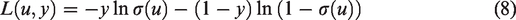
L2 function regularization
With the loss function for binary classification already chosen, we now proceed to select a regularizer. Most machine learning models mainly use parameter regularization by regularizing the weight vector

There is also the case of

More recently, Belkin et al.
10
proposed that under the assumption that the support of the marginal distribution of the dataset is a compact manifold embedded in

Lin et al. 11 took this idea further and explored with success the use of the Total Variation and Euler elastica as regularizers.
We argue that this way of directly regularizing the separating hypersurface u is better than regularizing the vector of parameters w. Our argument is that while penalizing w has the objective of controlling the values wi individually which in some cases may growth indiscriminately, penalizing u or its gradient as in (11) has the intention of controlling the smoothness of the separating hypersurface. The second, has the immediate impact of reducing overfitting.
The model
Let
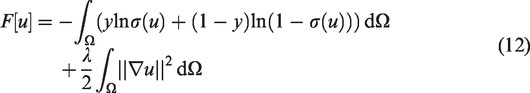
Then our supervised learning models amounts to solving (5) with
Analysis of the model
Existence and uniqueness of a minimizer
In this section, we shall determine existence of a minimizer of our model. Our proof of existence consists in showing that some minimizing sequence
(Existence of a Minimizer). Let

has at least one minimizer Assume
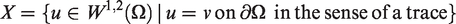
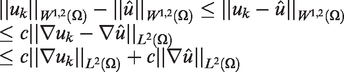
where c is some positive constant. We know that


Since uk is a minimizing sequence for m finite, we have that
To show that
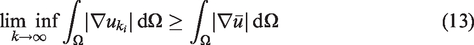

This is straightforward using the convexity of the functionals. In other words, we know that for some

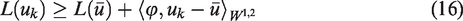
By taking the limit


This completes our proof for the existence of a minimizer. We will end this section by stating a theorem about the uniqueness of the minimizer which follows by the convexity of the functional. The proof is elementary and therefore will not be presented. (Uniqueness of Minimizer). If L is strictly convex, then the functional
The solution
In order to solve the expression in (4), we proceed to compute the functional derivative and equate to zero i.e. the first order optimality condition

To this end, let

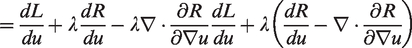
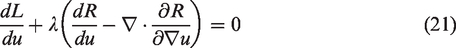
From the definition of L in (8) we get


Then the condition of optimality is the elliptic PDE

To solve the problem numerically, we recall that u depends on w. Then the problem is reduced to finding the weight vector

Having N datum pairs (xi, yi) it is possible to write the problem of finding




Note we have defined
Training with LM
The LM algorithm consists in estimating
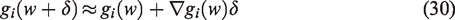

Equation (31) is the gradient of g with respect to w. By looking at the expression of the linearisation of the function, we can expand it to get

Taking the derivative of (32) with respect to δ, we see that


x such that λ is a regularization parameter c is the fitting degree η is a dampening parameter M is the number of iterations
Solve
We now proceed to give the expressions used in the algorithm.

Results
In this section we present some results to illustrate the performance of our Regularized Logistic Regression (RLR) model. We tested RLR against the nine binary datasets shown in Table 1. For comparison purposes we decided to compare the results against those obtained from L1 and L2 regularized logistic regression (classical regularization over the weights), SVM and NN.
In this Table, we present the datasets we used for testing.

BT: blood transfusion; BC: breast cancer; VC: vertebral column.
The datasets were standardized, i.e. all features in each dataset were centered to zero mean and unit variance. No dimensionality reduction was used in the experiments.
For each dataset we calculated two metrics: Accuracy and Area under the ROC curve (AUC).
13
The 5-fold cross validation scheme was also used in both metrics. In the experiments, we took care of selecting the different parameters of each method fairly. For our RLR model we have to choose the triplet
RLR
The triplet c is searched on (0, 5) with step λ is searched on η = 1 was used for each dataset. This value was empirically found to be the best.
L1 and L2 regularized logistic regression
C is searched on (0, 5) with step
SVM
The pair C is searched on (0, 5) with step
NN
The parameter
Accuracy
In Table 2 we present the classification results in terms of accuracy. The first thing to notice is that both classical L1 and L2 regularized logistic regression models performed poorly. Other than the Heart dataset, where the accuracy was similar to that one obtained from the other models (meaning that the Heart dataset is linearly separable), they consistently delivered low accuracy values. Due to this, we will not discuss more about these two models in the rest of the paper.
The accuracy (%) of each method is outlined in this table.

On the other hand, although RLR just outperformed SVM and NN on three datasets out of nine, in general we see that RLR is quite competitive when compared against these two fully stablished methods.
We also calculated the accuracy distances for a better insight. This is, the absolute value of the residual between each method’s accuracy and the one of the top performer. The results are shown in Table 3. On average RLR was down by 0.73%, SVM by 0.51% and NN by 0.89%. With this in mind, we can say that in terms of accuracy, SVM is the best method, while RR is second and NN comes a close third.
The absolute value of the residual between the method’s accuracy and the method with the highest accuracy.

AUC score
The AUC score is another way to evaluate the performance of a classifier. 15 In Table 4, we present the AUC values obtained for the different models and datasets. We also applied a similar analysis to the one presented above for the accuracy values. This is, we calculated the AUC distances (the differences between AUC values) for each dataset. In order to compare the models, we computed the sum of the distances (instead of the averages) obtaining the values that can be seen at the bottom of Table 5: RLR = 0.12, SVM = 0.02 and NN = 0.17. The result suggest that SVM is the best performer, RLR the second and NN is third. This is consistent with what was obtained when analyzing the accuracy values.
In this Table, we show the values for the area under the ROC curve (AUC) for each method over each dataset. Between brackets is the assigned grade; A being excellent performance, while F is catalogued as a fail. Bold numerals are the highest values.

This Table shows the AUC distances. This is, the absolute value of the residual between each method’s AUC and the method with the highest AUC for each dataset.

Grading
Here we introduce a more intuitive analysis based on the AUC. We consider this analysis more robust than the previous. The analysis consists in assigning a “grade” to the results of a classifier by specifying the following grading scheme:

By following the above grading scheme, we are partitioning discretely the interval
The number in each column indicates the number of times each method got the grade on the leftmost column. By assigning the values A = 1, B = 2, C = 3, D = 4, F = 5, we can calculate a weighted final grade.

In the bottom row in Table 6 it is the weighted total of the grades. The lowest the total value, the better the method. Again SVM obtained the best score. This time, RLR came a close second with only a 1 point difference and NN was very far by 4 points.
Conclusion
In this work, we have shown the way a new method for the supervised learning problem can be developed from a variational point of view. We have seen that it is very possible to formally formulate the problem as the minimization of a functional which has an associated PDE that describes the necessary conditions that a minimizer must meet. This equation proved to be easy to solve numerically with the least-squares algorithm Levenberg Marquardt. Tests were conducted and we compared the performance of our own model with the classical L1 and L2 regularized logistic regression models, NN and an RBF SVM. Both classical regularized models performed poorly as expected in every non linearly separable dataset. By regularizing u instead of w we were able to improve results substantially. From this analysis, it was clear that while SVM beat both our model and NN, our model outperformed NN while staying relatively close to the performance of SVM.
Finally, like all formal analyses, it was necessary to prove the existence and uniqueness of a solution for our functional. The validity of this claim turned out to be true by Theorem 3.1. Even more, we were able to prove that, indeed, a solution of the PDE is a minimizer of a functional, thereby, formally justifying our argument that we could minimize our functional by solving the condition of optimality. By and large, our true intention was to showcase that a variational approach can be used and should be used for tackling the supervised learning problem. A variational approach encompasses the areas of functional analysis and the calculus of variations, both of which permitted us to make this work possible. Using the methods of the calculus of variations we were able to guarantee a solution which was facilitated by the theory of functional analysis. Therefore, we can only conclude that the choice of a variational approach in solving the supervised learning problem was satisfactory.
The implementations for the RLR model, benchmarking scripts and datasets may all be found at https://github.com/carlosb/thesis.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Appendix 1.
In this section, we aim to derive the weak Euler-Lagrange equation and see that solutions of it are in fact minimizers of