
Abstract
In the field of pattern recognition, using the symmetric positive-definite matrices to represent image set has been widely studied, and sparse representation-based classification algorithm on the symmetric positive-definite matrix manifold has attracted great attention in recent years. However, the existing kernel representation-based classification methods usually use kernel trick with implicit kernel to rewrite the optimization function and will have some problems. To address the problem, a neighborhood preserving explicit kernel representation-based classification-based Nyström method is proposed on symmetric positive-definite manifold by embedding the symmetric positive-definite matrices into a Reproducing Kernel Hilbert Space with an explicit kernel based on Nyström method. Thus, we can take full advantage of kernel space characteristics. Through the experimental results, we demonstrate the better performance of our method in the task of image set classification.
Keywords
Introduction
In the field of pattern recognition, the classification method based on image set has received a lot of attention.1–5 Each image set contains a number of images and may offer more discriminative and robust information. Compared to single-shot image-based classification, image set classification can better handle multi-angle cameras or intra-class divergence task.6,7 The commonly used image-set representation methods model image sets as covariance matrix,8–10 linear subspaces,11,12 and Gaussian mixture model, 13 among which, covariance matrix is obtained based on second-order statistics of image features which is a point lying on a Riemannian manifold spanned by symmetric positive definite (SPD) matrices and has been widely applied in action recognition, 14 pedestrian detection, 15 face recognition, 16 texture classification, 2 etc.
Sparse representation (SR) has a wide range of applications in the field of digital image processing and pattern recognition because of its robustness,17,18 which uses a linear combination of atoms in the dictionary to reconstruct the data, meanwhile keeping the reconstruction error as small as possible. In order to make the dictionary more discriminating, Yang et al. 18 proposed the FDDL method to obtain a dictionary that maintains the local discriminant information of the training data. Combined with the Locality Preserving Projection (LPP), Qiao et al. 19 proposed sparsity preserving projections method. In recent years, the kernel method has been widely applied which attempts to implicitly map training data into a high-dimensional Reproducing Kernel Hilbert Space (RKHS) by using the nonlinear mapping associated with a kernel function and can get an SR solution in high dimensional space.20,21
Most of the work mentioned above is based on vector-valued data. However, in many visual applications, visual data points actually lie in some Riemannian manifolds form such as the space of symmetric positive-definite (SPD) matrices. Because of the nonlinear Riemannian manifold of SPD matrices, the application of the SR of Euclidean space directly to the SPD matrix is applicable. One approach is to use Riemannian metric to calculate the reconstruction error; Sivalingam et al. 16 proposed a tensor SR method, the logdet divergence is used to measure the reconstruction error, and Sra and Cherian 22 proposed to use Frobenius norm as the error metric. An alternative approach is to embed the manifold data into tangent space with logarithmic mapping and then can make use of the existing SR methods. To exploit the Log-Euclidean metric of SPD manifold, Zhang et al. 23 obtained the vectorized form of original covariance matrices for SR.
In order to make use of the manifold structure of the SPD matrices, many people attempt to map these data into a high-dimensional RKHS by using the implicit kernel function. Harandi et al. 24 first used the Stein kernel to solve the Riemannian SR problem in kernel space. Subsequently, Li et al. 25 and Harandi et al. 26 also presented kernel SR by Log-Euclidean kernels and Jeffrey kernel. In order to strengthen the discriminability of the kernel space dictionary, similar to the Euclidean space, Li et al. 27 proposed semantic and neighborhood preserving dictionary learning. All of the above methods update the Riemannian dictionaries in Riemannian space.
The above kernel SR methods use implicit kernel functions to implement SR and dictionary update through kernel tricks. The data in kernel space have no explicit representation, which brings some inconvenience to the dictionary update, and may lead to the singular problem of the dictionary atom. Inspired by Nyström method,28,29 we propose an SR with explicit kernel function based on Nyström method. An approximate vector representation of the sample in the kernel space can be obtained by Nyström method, and then we can update sparse coefficients and dictionaries in kernel space. In order to maintain the local discriminant information of the original data, we also add the neighborhood preserving constraint on the sparse coefficients. Furthermore, to reduce information redundancy and improve operational efficiency, we use the (2D)2 principal component analysis (PCA) method to reduce the dimensionality of the SPD matrix. Different with Li et al., 27 our method use explicit kernel and Riemannian neighborhood graph.
This paper extends a neighborhood preserving explicit kernel SRC-based Nyström method on SPD manifold (NYSKSR) with application to image set classification. The contributions of our proposed method are threefold:
Using an explicit kernel mapping framework for kernel SR. Updating sparse coefficients and dictionaries in kernel space simultaneously. We apply our proposed method to several image set classification tasks where the data are depicted as covariance matrices.
The rest of this paper is organized as follows. “Related work” section is the review of the related works. In “Sparse representation based on Nyström method” section, we introduce our proposed method. We present experimental results in “Experiments and analysis” section and draw conclusions and future work in the final section.
Related work
Before we introduce our method, in this section, we briefly review the SPD manifold characteristic, the Nyström method, the
SPD manifold
Given an image set


The similarity between two SPD matrices on the manifold can be described by the length of geodesic curve.
8
For points Ci and Cj on the SPD manifold, the affine invariant Riemannian metric
9
can be expressed as

The Riemannian kernel function
8
can be computed by the inner product of points in the tangent space based on logarithm mapping


Equation (4) represents the logarithm mapping of the SPD matrix, where
(2D) 2 Principal component analysis
Compared with the traditional PCA dimensionality reduction method,
Suppose there are m training image sets
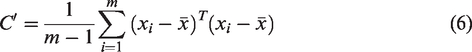
The

Nyström method
Existing kernel mappings are usually implicit mappings, which may cause some inconvenience, so the Nyström method was proposed to estimate the original kernel matrix in RKHS.
28
Given

SR on SPD matrices
Based on implicit mapping function
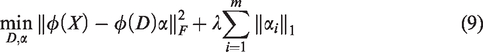
SR based on Nyström method
In this section, we start by introducing the SR based on Nyström method in kernel space. Then, we present the dictionary updating in kernel space. Finally, we introduce the classification via our SR. Figure 1 shows the flow chart of our method, and Algorithm 1 can summarize our method.

The flow chart of our method. (a) Input: image set, each image set is represented as an SPD matrix. (b) Dimensionality reduced samples by
Neighborhood preserving SR based on Nyström method
Let
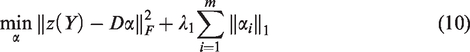
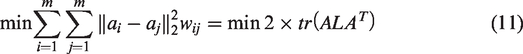
The wij is weight coefficient, which represents the neighborhood of yi and yj,



Adding the neighborhood preserving constraint to equation (10), our SR model can be rewritten as

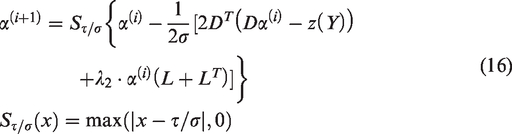
Dictionary updating
Based on the alternating direction method of multipliers, dictionary can be updated, such that the reconstruction error for each αi is minimized. The problem of learning a dictionary

Since the samples are embedded into the kernel space by Nyström method, we only need to update the dictionary in the kernel space. Equation (17) is a convergence problem. Based on the dictionary update method proposed in Rosasco et al.,
33
the solution of equation (17) can be solved iteratively, and the ith result is

Classification via sparse codes
Because the dictionary we have obtained is located in the kernel space, we should map the test samples into the kernel space by Nyström method. Let Training sample sets: Dimensionality reduction parameter The number of sampling training samples M and rank r in Nyström method The number of nearest neighbors nw and nb in equations (12) and (13) The regularization parameter λ1 and λ2 The number of iterations iter Dictionary Get the dimensionally reduced sample sets Compute the kernel space approximate vector representation Initialize the dictionary
Optimize α with fixed D, solve equation (15) by IPM method. Optimize D with fixed α, solve equation (17) by online dictionary learning method in Rosasco et al.
33
Testing sample sets: Class label Get the dimensionality reduced sample sets Compute the kernel space approximate vector representation Compute the reconstruction error of the test sample and the sample for class j by equation (19). Get the class label by equation (20).
Before classification, we first need to get the sparse coefficients of the test samples on the dictionary D. For a test sample belonging to the ith class, the residual error between it and the SR of the ith sample will be relatively small, the reconstruction error of the test sample and the sample for class j is

Experiments and analysis
This section presents comparative experimental results of our NYSKNP_SR method against the conventional methods used on SPD manifold for the task of face recognition, object categorization, virus cell classification, and dynamic scene classification.
Datasets and settings
To evaluate the proposed method, we have performed the experiments on four tasks: ETH-80, 34 Virus, 35 MDSD, 36 and YTC 8 datasets, respectively. Meanwhile, we compare our proposed method with other four conventional methods and two SR methods on SPD manifold including Covariance Discriminant Learning (CDL), 8 Projection Metric Learning (PML), 12 Grassmann Discriminant Analysis (GDA), 11 Log-Euclidean Metric Learning (LEML), 1 Generalized dictionary learning and sparse coding using Frobenius norm (Frob_SR), 22 and Log-Euclidean Kernels for SR (LogEK_SR). 25
The dataset of ETH-80 consists of eight categories: pears, tomatoes, dogs, cows, apples, cars, horses, and cups. Each category has 10 image sets, and each image set consists of 41 images. The size of each image is 256 × 256, in order to reduce the computational complexity, we resize each to 20 × 20, and each image set covariance matrix dimension is 400 × 400. Moreover, we randomly select five from each category as training samples and the rest for test. Table 1 shows the average classification accuracy of each method.
Average recognition rates and standard deviations of different methods on ETH-80. 34

The Virus dataset contains 15 categories, each consisting of five image sets, and each set has 20 images. The size of each cell image has been resized to 20 × 20. For each class, three image sets are chosen for training randomly and the rest two image sets are used as test samples. Table 2 summarizes the average identification accuracy of each method.
Average recognition rates and standard deviations of different methods on virus.35

The MDSD dataset is composed of 13 different categories of dynamic scenes, with each class consisting of 10 videos. We resize each frame to 20 × 20. We randomly select seven videos for training and the rest for testing in each class, the classification accuracies are given in Table 3.
Average recognition rates and standard deviations of different methods on MDSD.36

The YouTube Celebrities contains 1910 video clips of 47 subjects. Each clip consists of hundreds of frames. We resize each frame to 20 × 20. For the sample selection, we randomly choose three image sets in each subject for training and seven for testing, the mean recognition accuracies are given in Table 4.
Average recognition rates and standard deviations of different methods on YTC. 8

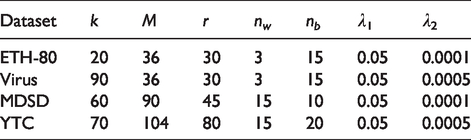
According to the experimental results, we resize each image to 20 × 20 and choose appropriate dimensionality reduction parameter k on the
Parameter setting in the experiment.
Result and analysis
The experimental results in the above tables are obtained by 10-iteration experiments on each data set, we take the average of 10-iterations. For the six methods used for comparison, CDL, 8 PML, 12 GDA, 11 and LEML 1 are conventional methods on SPD manifold, Frob_SR 22 is SR method on SPD manifold, and LogEK_SR 25 is a kernel SR method on SPD manifold. From the results in the four tables, the proposed method is the best in the classification accuracy rate on the five data sets. In the ETH-80, the best accuracy from the traditional method and SR method is CDL and LogEK_SR; however, our method is higher than these recognition rates with accuracy of 96.00% and has the smallest standard deviation of 2.69. This shows that on this data set, our method not only has a good recognition rate, but also has strong robustness. On the data set of Virus, our method has significantly improved the recognition rate; the highest recognition rate is 62.67%, far above LEML and LogEK_SR. The standard deviation 8.58 is not the smallest, but is relatively small in all methods, indicating that the robustness of our method on this data set is still guaranteed. About performance on the MDSD dataset, the recognition rate of all methods is generally low. However, our method still achieves the best recognition rate of 31.79% with a small standard deviation of 4.87. For the YTC data set, in addition to LogEK_SR method, our advantage is very obvious; the recognition rate reaches 74.58%, again with a relatively small standard deviation of 3.19.
The effect of dimensionality reduction parameter k
The original image set sample has a covariance matrix dimensionality of 400 × 400. If we directly use it for training, it will cause high dimensionality and large computational load; meanwhile, the recognition rate is not substantially improved. In order to make the method with good recognition rate and running efficiency, we should reduce dimensionality. The goal of dimensionality reduction is to obtain lower dimensional data and save the main information of the data set, and the performance and recognition rate of the algorithm cannot be significantly reduced. Figure 2 shows a graph of the recognition rates of different dimensionality reduction parameters. For the four data sets, the recognition rate of the algorithm fluctuates apparently when the parameters are small. This is mainly because when the dimensionality is too low, the effective information in the image set will be lost. Meanwhile, information redundancy occurs when the dimensionality is too large leading to the drop of the recognition rate, so we choose the most appropriate dimensionality reduction parameter for each image set by cross validation method.

Effects of different dimensionality reduction parameter on recognition rates.
Conclusion
In this paper, based on Nyström method, we map samples into kernel space by explicit kernel representation and propose a neighborhood preserving SR. Our method can maintain the neighbor’s information of the original data in SPD manifold. Compared with other conventional methods for SPD manifold, our method has high recognition rate. For the future work, we will consider how to extend our proposed method to the other types of manifolds and applications.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.