
Abstract
According to the lexical quality hypothesis, differences in the orthographic, semantic, and phonological representations of words will affect individual reading performance. While several studies have focused on orthographic precision and semantic coherence, few have considered phonological precision. The present study used a suite of individual difference measures to assess which components of lexical quality contributed to competition resolution in a masked priming experiment. The experiment measured form priming for word and pseudoword targets with dense and sparse neighbourhoods in 84 university students. Individual difference measures of language and cognitive skills were also collected and a principal component analysis was used to group these data into components. The data showed that phonological precision and NHD interacted with form priming. In participants with high phonological precision, the direction of priming for word targets with sparse neighbourhoods was facilitatory, while the direction for those with dense neighbourhoods was inhibitory. In contrast, people with low phonological precision showed the opposite pattern, but the interaction was non-significant. These results suggest that the component of phonological precision is linked to lexical competition for word recognition and that access to the mental lexicon during reading is affected by differing levels of phonological processing.
Spoken language is a uniquely human ability. Neurotypical children become skilled users of spoken language without explicit instruction. However, the ability to understand written language cannot be acquired in the same way. Reading acquisition is mastered via explicit instruction and supervised practice, and the level of expertise acquired can vary greatly; around 30% of children experience difficulties in reading despite explicit instruction via adequate schooling (Byrne et al., 2002; Castles et al., 2018). This indicates that there are individual differences underlying the effectiveness and speed of processing the written word, a skill that is important for occupational and educational attainment.
The lexical quality hypothesis (LQH; Perfetti, 1992, 2007, 2017; Perfetti & Hart, 2002) is a leading theory which aims to explain differences in reading skill. According to the LQH, there are two key principles that define lexical representation: precision and redundancy. The lexical representations of skilled readers contain highly specified orthographic and phonological representations which are linked to each other and to higher-level lexical-semantic knowledge. High-quality phonological representations are (partly) redundant, distinctive, and context-sensitive. The bond between a word’s spelling and pronunciation increases with use, so that, in fluent readers, when the written form of a word is encountered, its phonological counterpart is activated simultaneously (Ehri, 2005; Perfetti & Hart, 2002). Precision refers to the knowledge of the exact orthographic, phonological, and semantic properties of a specific word. Redundancy relates to the bonded connections between a word’s orthography and phonology. This link is thought to become stronger over time with increasing reading skill. Individuals with less stable, more variable bonds between word-specific orthography and phonology have less redundant and, thus, lower-quality lexical representations. In addition to individual differences, word-internal properties can affect redundancy as well; for instance, the word read has low redundancy, as a single orthographic representation is related to two phonological representations (the present and past tense of read). Precision is required to ensure that the written visual input directly accesses the appropriate representation with little interference from its neighbours (e.g., prude and prune and brake and brace; i.e., words that differ from the target word by one letter or sound; Coltheart et al., 1977), resulting in rapid and efficient visual word recognition. In contrast, less precise and less redundant representations are poorly specified, more variable and less integrated, making the process of relating orthographic to phonological forms more effortful (i.e., laboured decoding). This leads to more interference between the target and its neighbours. In turn, more time is required to suppress the target’s word neighbours to access the lexical representation.
The LQH model is based on interactive-activation (IA) models of word recognition (see review by Davis, 2003; Grainger & Holcomb, 2009; Jacobs & Grainger, 1992; McClelland & Rumelhart, 1981). According to these models, activation begins at the sublexical level, propagating the activation to words at the lexical level. Words are activated based on overlap with the input, such that similar words receive (partial) activation. Within-level lateral inhibition is required in order to select the most fitting candidate. Much of the evidence for this comes from the masked priming paradigm, wherein a prime word is briefly presented below conscious awareness. Following the presentation of the prime, a response, often a lexical decision (i.e., decide whether a letter string is a word or not; LDT), is made to a target letter string (Forster & Davis, 1984). In this task, responses to word targets can be inhibited by the brief presentation of a form-related word prime differing by one letter from the target word (e.g., wine-VINE) but not when the prime is a pseudoword (i.e., a pronounceable nonword; e.g., bine-VINE) (Andrews & Hersch, 2010; Davis & Lupker, 2006; Forster & Davis, 1991; Forster & Veres, 1998; Van Heuven et al., 2001). According to IA models, the lexical inhibition effect occurs because during the processing of the prime word, its neighbouring candidates are suppressed, including the word target. Once the word target appears, the pre-activated prime and the target compete, slowing down recognition before the visual information distinguishes the target from its prime (i.e., lexical competition; Davis & Lupker, 2006; Van Heuven et al., 2001). Several factors (discussed below) contribute to the magnitude of the inhibitory priming effect, such as prime-target frequency (e.g., Davis & Lupker, 2006; Segui & Grainger, 1990), neighbourhood density (NHD) (i.e., the number of neighbours; e.g., Andrews & Hersch, 2010; Davis & Lupker, 2006; Forster et al., 1987; Meade et al., 2018; Van Heuven et al., 2001) and individual differences within the participants, such as spelling ability, reading ability, and reading comprehension (e.g., see review by Andrews, 2012, 2015; Andrews & Hersch, 2010; Andrews & Lo, 2012, 2013; Frisson et al., 2014). These findings indicate that orthographic and semantic processing contribute to lexical competition. However, phonological processing has not received much attention, although it has repeatedly been shown to contribute to the development of skilled reading (e.g., Bradley & Bryant, 1983; Share, 1995; see review by Meade, 2020). In addition, the precision and redundancy components do not ignore the importance of the phonological constituent but in fact highlights its relationship with the orthographic and semantic constituents (Perfetti, 2007). These three constituents strengthen their bonds with each other, leading to a precise lexical representation (Perfetti, 2007). Hence, it is expected that phonology, and phonological skill, will also contribute to regular word recognition. Nevertheless, the degree to which individual phonological skill affects lexical competition is unknown. To address this research gap, the present study examined how neighbourhood structure and orthographic, phonological, and semantic processing contribute to lexical competition in a masked priming paradigm.
The magnitude of inhibitory priming has been found to be modulated by prime and target frequency (e.g., Davis & Lupker, 2006; Segui & Grainger, 1990). Segui and Grainger (1990) reported that if a prime has a higher frequency than the target, inhibitory priming ensues, while if the target has a higher frequency than the prime, facilitatory priming occurs, i.e., word targets that follow related primes take less time to respond to than when preceded by unrelated primes. This effect has also been demonstrated in simulations of IA models (see review by Davis, 2003). One explanation for this pattern of results is that a low-frequency prime (e.g., gear) would become activated along with its neighbouring words—including the higher-frequency target word (e.g., BEAR)—but may fail to suppress its neighbours prior to target presentation. In this case, as the prime pre-activates the target without suppressing it, facilitatory priming can be observed (Andrews & Hersch, 2010; Segui & Grainger, 1990). In contrast to low-frequency word primes (e.g., gear), a high-frequency word prime (e.g., fear) is processed more quickly. As a result, the prime can suppress its neighbours—including the target word (BEAR)—more strongly prior to target presentation (i.e., target neighbour suppression)—thus once the related word target is presented, the neighbouring candidates are re-activated, leading to inhibitory priming effects (Davis & Lupker, 2006; Segui & Grainger, 1990; Van Heuven et al., 2001).
The inhibitory priming effect is also sensitive to neighbourhood density (NHD), phonological and orthographic overlap and individual differences such as spelling and/or reading comprehension ability. Andrews and Hersch (2010) observed that NHD and spelling ability modulated the presence and magnitude of inhibitory priming effects and found that inhibitory priming was specific only to word targets with dense neighbourhoods (i.e., many neighbours; e.g., BEAR has BEER, GEAR, BEAT, BEAD, TEAR) in skilled spellers only. Skilled readers showed facilitatory priming only in word targets with sparse neighbourhoods (i.e., few neighbours; e.g., VEIL has only VEIN and VEAL). Poor spellers only demonstrated facilitatory priming, irrespective of NHD. In addition, a multiple regression analysis showed that spelling ability explained unique variance beyond reading comprehension and vocabulary for inhibitory priming in masked priming (see also Andrews & Lo, 2012, who used transposed primes and found a similar pattern of effects). This finding is compatible with the lexical quality hypothesis (Perfetti, 2007, 2017; Perfetti & Hart, 2001, 2002). Skilled spellers and readers have more precise lexical representations, allowing them to access the prime directly, while suppressing its neighbours. This leads to larger inhibitory priming in neighbouring and transposed-letter targets. The lexical representations of less skilled spellers overlap with neighbouring candidates, leading to difficulty in recognising the prime and suppressing neighbouring candidates. As a result, less skilled readers/spellers are more likely to show facilitation, as sole access to the prime is less efficient. This effect indicates that for these participants, the neighbouring and transposed-letter targets were pre-activated, though not (yet) inhibited, by the prime.
Many reading models (e.g., interactive-activation models and the LQH) propose that phonological and orthographic representations interact. It could therefore be argued that people with more precise lexical-orthographic representations are more likely to maintain phonological information over a longer period during text reading, thus accessing lexical-semantic representations more efficiently (e.g., Perfetti, 2017; Tan & Perfetti, 1999). Additional support for this LQH-like hypothesis is provided by Frisson et al. (2014), who observed in eye-tracking that reading comprehension abilities influenced lexical competition because of phonological overlap. The authors observed inhibitory priming only when the prime and target were close together (3 words on average) and overlapped at the phonological and orthographic levels in both skilled and less skilled comprehenders. However, when the distance between prime and target increased to 9 words on average, inhibitory priming was only observed for people with good reading comprehension skills. This aligns with Folk (1999), who observed that automatic phonological processing is difficult to suppress in skilled readers, even if it causes interference. Taken together, this evidence seems to indicate that lexical competition may occur because of phonological information being maintained over a longer period.
There is therefore converging evidence that inhibitory priming is reflective of lexical competition (e.g., Andrews & Hersch, 2010; Andrews & Lo, 2012; Davis & Lupker, 2006; Segui & Grainger, 1990) and that this is moderated by spelling (an orthographic measure) and/or reading comprehension and vocabulary (semantic measures). However, the role of phonology in lexical competition has received less attention. Phonology is a key component of reading acquisition, spelling, and reading ability (Bradley & Bryant, 1983; Hatcher et al., 1994; Share, 1995; see review by Meade, 2020; Perfetti, 1992, 1995; Unsworth & Pexman, 2003). Phonology has also been found to be accessed automatically during word recognition (e.g., Ashby, 2010; Ashby et al., 2009; Perfetti & Bell, 1991; Rastle & Brysbaert, 2006; Yates, 2005; Yates et al., 2004). For example, evidence from single word recognition studies using LDT has shown that once orthographic NHD is kept constant and phonological NHD is manipulated, words with dense phonological neighbourhoods are recognised faster than words with sparse phonological neighbourhoods (Yates, 2005; Yates et al., 2004). In masked priming studies, facilitatory priming has been observed for phonologically overlapping prime-target pairs when orthographic overlap is held constant (e.g., claune-CLOWN compared with cleant-CLOWN; e.g., Perfetti & Bell, 1991). In a megastudy masked priming experiment, Adelman et al. (2014) tested 14 university sites with more than 1,000 participants and 420 stimuli. They included the following predictors: orthographic NHD, bigram frequency, word frequency, phonological neighbourhood, number of phonemes, and number of syllables. They observed that orthographic NHD only contributed to priming effects if phonological NHD was excluded from the analysis. If phonological NHD was included in the analysis, orthographic NHD did not contribute to the priming effect. The authors concluded that orthographic competition is confounded with phonological competition and that phonological NHD explains more variance in masked priming than orthographic NHD. They also argued that the effects seen in masked priming are phonological in nature (see also Rastle & Brysbaert, 2006). These studies highlight that phonology is important for visual word recognition. However, it is difficult to attribute lexical competition to orthography, phonology, or semantics, as phonology has not been tested together with orthography and semantic individual difference measures. In addition, the underlying definition of phonology is unclear, as phonology can constitute a wide variety of different behaviours such as phonological working memory, measures of reading fluency, and phonological awareness (Melby-Lervåg et al., 2012); thus, it is important to include a suite of individual difference measures that assess phonological processing. The present study therefore investigated individual differences in phonological processing and their effects on inhibitory priming.
Taken together, phonological and orthographic overlap, NHD and individual differences in spelling and reading ability modulate the magnitude and direction of the inhibitory priming effect. In addition to these factors, the present study investigated whether phonological precision affects the magnitude and/or direction of inhibitory priming. In a masked form priming study, we manipulated neighbourhood density and prime lexicality. We predicted that word targets preceded by related word neighbour primes would produce slower responses than those preceded by unrelated primes, due to the activation of the prime with concomitant suppression of the target (e.g., Davis & Lupker, 2006). Following the results of Andrews and Hersch (2010), inhibitory priming is predicted to be larger for word targets with dense neighbourhoods relative to word targets with sparse neighbourhoods, as word targets with many neighbours are more likely to share neighbours with the prime, leading to larger lexical competition between the prime and target (Davis & Lupker, 2006). In order to assess the effects of sublexical overlap in the absence of lexical competition, it is important to include pseudoword primes and targets, as they have no lexical representation. Finally, we investigated the effect of individual differences in components of reading skill on lexical competition. We used a suite of individual difference measures to assess which component of phonology, orthography, and/or semantics modulated lexical retrieval. However, given that more skilled readers are better at reading than less skilled readers, as measured by print exposure, vocabulary size, reading comprehension, and phonological processing (e.g., Acheson et al., 2008; Burt & Fury, 2000 see review by Huettig et al., 2018; Martin-Chang & Gould, 2008), it becomes more difficult to assess which component of reading (e.g., orthography, phonology and semantics) modulates lexical retrieval, also because these individual differences measures are likely to be collinear. We therefore used Principal Component Analysis (PCA) to group together the individual difference tests, which exposed three latent components: phonological precision, orthographic precision, and semantic coherence. If orthographic precision contributes to lexical competition, we predicted lexical competition to be stronger in individuals scoring higher on a component that includes spelling (Andrews & Hersch, 2010; Andrews & Lo, 2012). If semantics contributes to lexical competition, inhibitory priming should manifest itself more strongly in individuals scoring higher on the semantic coherence component. If phonological skill modulates inhibitory priming, then we should see the strongest inhibitory priming for people with greater phonological precision, as phonology is argued to contribute to lexical competition (Tan & Perfetti, 1999).
Method
Participants
We aimed to detect a previously revealed effect size (i.e., the interaction between spelling, relatedness and NHD) from Andrews and Hersch’s (2010) study. A post hoc power analysis, using G*Power 3.1.9.4. (Faul et al., 2009) indicated that our sample size exceeded the number required to reach the desired level of power of 0.95 (minimum of 59 recommended, while we included the data from 84 participants in the analyses; see Supplementary Material 1 for the parameters used in the power analysis). Ninety-one participants took part in the study. Seven participants withdrew after the first two sessions. 1 We excluded two participants from the analyses who performed below 2SD in individual difference measures that assessed phonology, reading fluency, and spelling (see section on standardised tests), as they performed similarly to people with dyslexia. This left us with a final sample of 84 monolingual British undergraduate students (77 females and 7 left-handed) aged 19–23 years (M = 20.18 ± 1.04 years), who were given course credits in return for their participation. The experiment was conducted in accordance with British Psychological Society ethical guidelines and was approved by the University of Birmingham’s ethical committee (ERN_15-1236). All participants had normal or corrected-to-normal vision and signed a consent form to participate in the study.
Tests
General procedures for the tests
Each participant completed all of the components of the study over three sessions. Each session lasted approximately an hour (see Figure 1 and Table 1 for an overview of the experiment). All participants completed the tests in the same order. 3
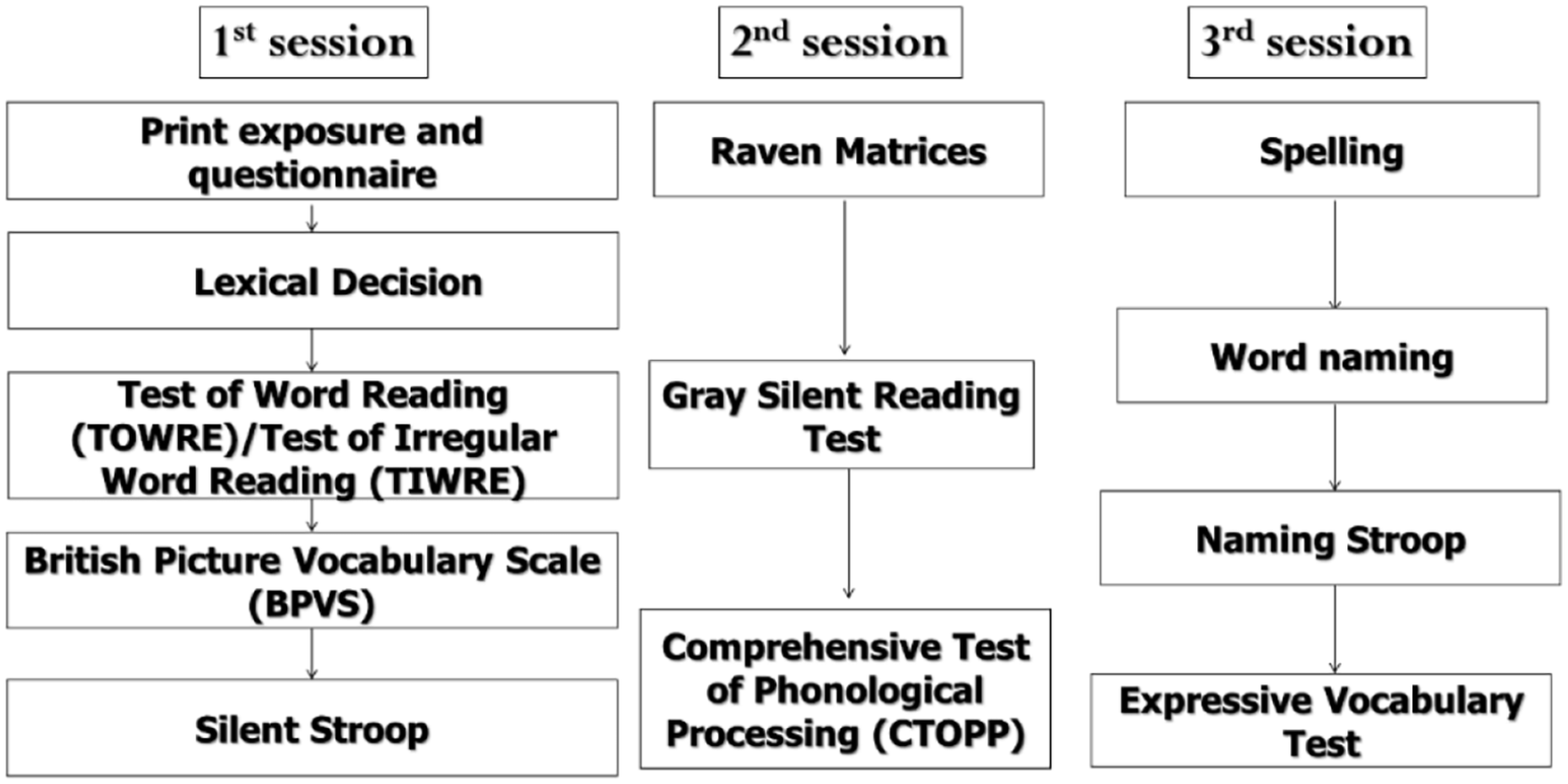
An overview of the three experimental sessions.
The individual difference measures used in the current experiment and their groupings.
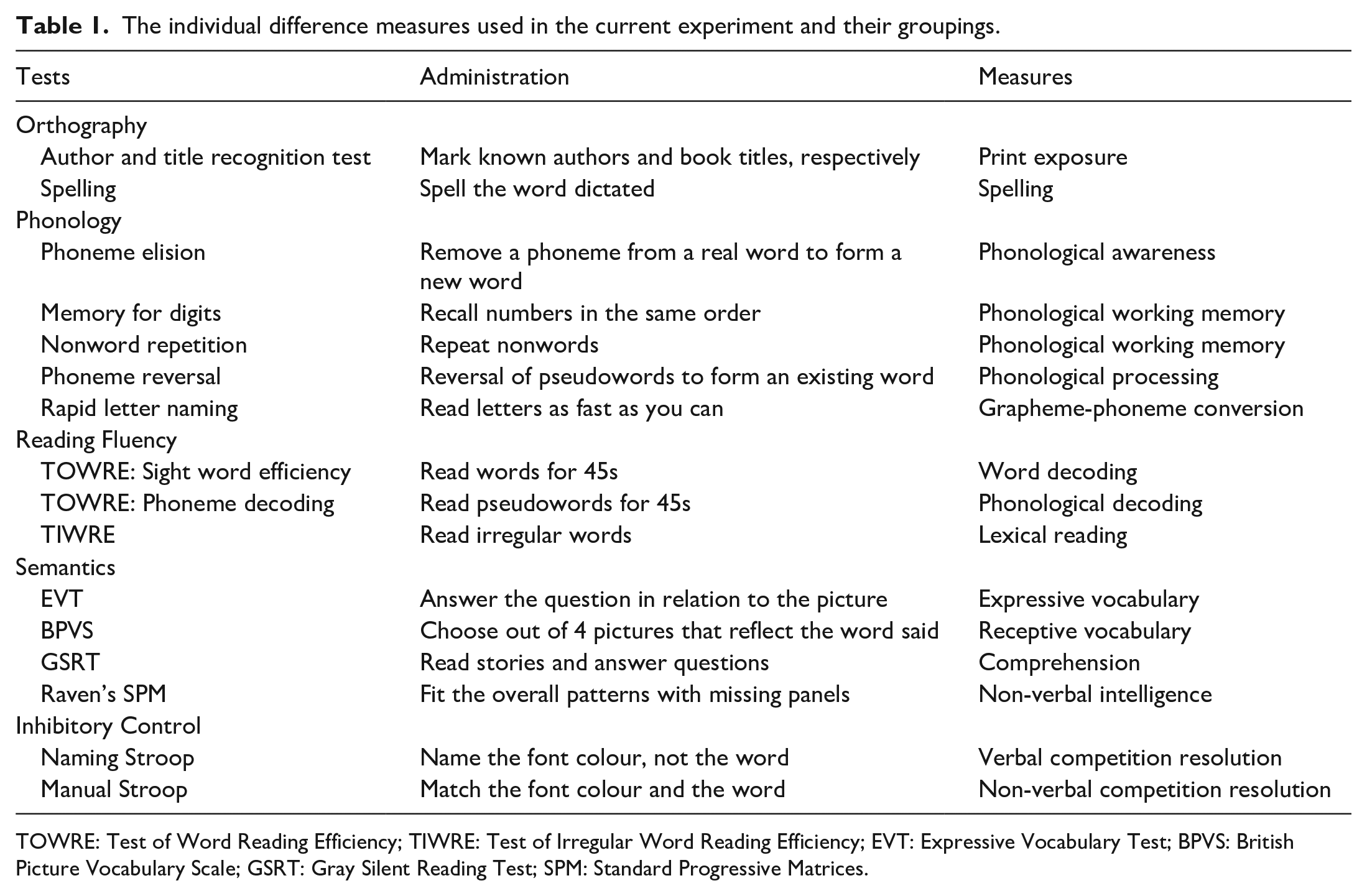
TOWRE: Test of Word Reading Efficiency; TIWRE: Test of Irregular Word Reading Efficiency; EVT: Expressive Vocabulary Test; BPVS: British Picture Vocabulary Scale; GSRT: Gray Silent Reading Test; SPM: Standard Progressive Matrices.
Demographic questionnaire
This questionnaire collected background information on participants, including age, gender, and handedness (https://osf.io/6pd4b/).
Language measures
Print exposure
Print exposure included Author recognition test (ART) and Magazine recognition test (MRT) adapted with Stanovich and West (1989) and Title recognition test (TRT) adapted from Cunningham and Stanovich (1990) (see https://osf.io/ja8r6/ for print exposure measure). The ART is a checklist which requires participants to choose whether they are familiar with the name of a popular author by ticking their name. The ART checklist consists of 100 authors (50 real and 50 foils). The MRT and TRT followed the same procedures as the ART, with participants ticking familiar magazines (MRT) and book titles from plays, poetry, and novels (TRT). The TRT checklist had 100 book titles (50 real and 50 foils) and the MRT was a checklist of 100 magazines (50 real and 50 foils). 2 We modified the lists, which were constructed about 30 years ago for a US audience, to include current and classic authors, together with book titles from Amazon’s top 100 authors and book titles and UK magazines from Wikipedia to adapt to a British audience. We tested this version of ART, TRT, and MRT using a total of 100 additional participants from the same undergraduate population, none of whom participated in the present study. Pilot testing showed a normal distribution among the participants. This confirms that the modifications of the ART, MRT, and TRT were suitable to measure print exposure in the present population. There was no time limit for completing the checklists. For each participant, a score was calculated by subtracting the correct score (i.e., hits) from the number of foils (i.e., false alarms) ticked.
Receptive vocabulary
The British Picture Vocabulary Scale (BPVS; Dunn et al., 1997) was used to measure the participants’ receptive vocabulary. Participants heard a word and selected the corresponding picture from a choice of four. Each participant completed six vocabulary sets (Sets 9–14, with 12 words per set). E-prime (E-studio, E-prime 2.0) software was used to implement this task. The number of correct answers out of 71 was used in the analyses.
Phonological decoding
The sight word efficiency and non-word reading (phonemic decoding) subtests from the Test of Word Reading Efficiency (TOWRE; Torgesen et al., 1999) were used as a measure of phonological decoding (i.e., grapheme-phoneme conversion) skill. The tests required participants to read out loud as many printed words out of 108 (TOWRE sight word reading efficiency) or pronounceable pseudowords out of 66 (TOWRE phonemic decoding subtest) as possible within 45 s.
Lexical reading
The Test of Irregular Word Reading Efficiency (TIWRE; Reynolds & Kamphaus, 2007) was used as a measure of lexical reading skill (see Cortese & Simpson, 2000). For the TIWRE, participants had to read 25 irregular words with no time limit. The number of correct answers in each test was recorded for each participant.
Phonological processing
The following subtests from the CTOPP (Wagner et al., 1999) were used: phoneme elision, rapid letter naming (RLN), memory for digits, non-word repetition and phoneme reversal. In the phoneme elision task, participants had to remove the stated phoneme from a word and report the resulting word (e.g., mat without /m/ is at). In the non-word repetition task, participants heard pseudowords and had to repeat them back to the experimenter. In the phoneme reversal task, participants heard a pseudoword and had to reverse the pseudoword to form a real word (e.g., na forms an). In all three tasks, there were 18 items and the number of correct answers was recorded. In the RLN, participants had to name 36 printed letters as quickly as possible. In the memory for digits test, participants heard a string of digits which they had to repeat to the experimenter immediately and in verbatim. There were 20 items and the number of correct answers was used in the analyses.
Reading comprehension
In the Gray Silent Reading Test (GSRT; Wiederholt & Blalock, 2000), each participant read six brief stories (i.e., Stories 4–9) silently. The stories increased in complexity. The participant had to answer five multiple choice questions per story with no time limit. E-prime software was used to implement this task. The number of correct answers was used in the analyses.
Expressive vocabulary
In the Expressive Vocabulary Test (EVT; Williams, 2007), participants had to name objects (e.g., binoculars) or to describe what a person was doing (e.g., singing) with reference to a picture. There were 109 items and the number of correct answers was used in the analyses.
Spelling
The spelling subtest was based on the British Ability Scale (BAS, Elliott et al., 1996). Twenty words were dictated to the participant, which they had to spell accurately. The number of correctly spelled words was used in the analyses.
We also included measures of executive functioning, tested with the manual and naming Stroop (1935) and a test of non-verbal intelligence (Raven’s Standard Matrices test; Raven, 1960). These were included as control measures to ensure that the differences between the groups did not result from differences in non-verbal intelligence or inhibitory control (Elsherif et al., 2021; see Supplementary Material 1 for further details). These tests were not included in the PCA.
Materials for masked priming
Word target set
The experimental targets were a set of 80 monosyllabic words. There were 78 four-letter and two five-letter words. The targets were divided into two equal sets that differed in their orthographic and phonological neighbourhood densities (NHD) (see Tables 2 and 3). The High NHD set had nine or more orthographic neighbours (ON) and 14 or above phonological neighbours (PN), whereas the Low NHD set had between two and eight ON and between three and 13 PN. The low NHD had 3.5 phonographic neighbours (SD = 1.76, range = 1–8), while the high NHD had 7.03 phonographic neighbours (SD = 2.78, range = 2–12). Both sets significantly differed from each other, ON: t(78) = 17.72, p < .001, d = 4.01; PN: t(78) = 15.26, p < .001, d = 3.46; PgN: t(78) = 6.64, p < .001, d = 1.50. High- and low-N targets did not differ significantly in mean word frequency per million (t < 1), log frequency, t(78) = 1.84, p = .07, d = 0.42, SUBTLEX-UK Frequency, t(78) = 1.91, p = .06, d = 0.43, or word length (number of graphemes; t < 1). The high and low NHD target sets differed in length on average by less than one phoneme; however, this difference was significant, t(78) = 9.35, p < .001, d = 2.11. All frequency and N values were obtained from the CELEX database (Baayen et al., 1995) using Davis’s (2005) N-Watch and to check the robustness of the frequency values, we obtained the Zipf values from the SUBTLEX-UK database (Van Heuven et al., 2014). The full set of material can be found in Table A1 and A2 in Supplementary Material 2 for a complete list of stimuli.
Descriptive statistics for word target characteristics.
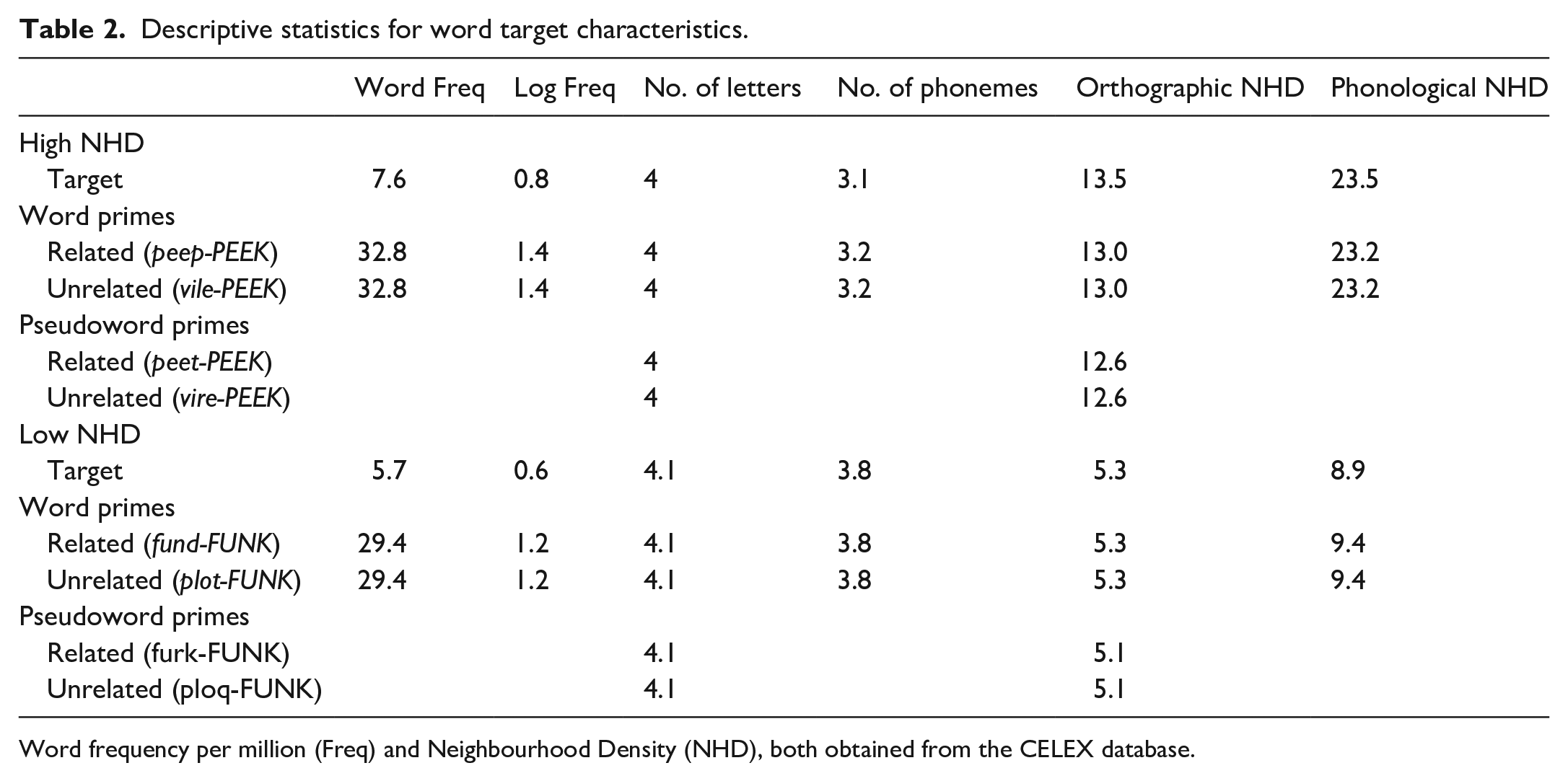
Word frequency per million (Freq) and Neighbourhood Density (NHD), both obtained from the CELEX database.
Descriptive statistics for pseudoword target characteristics.
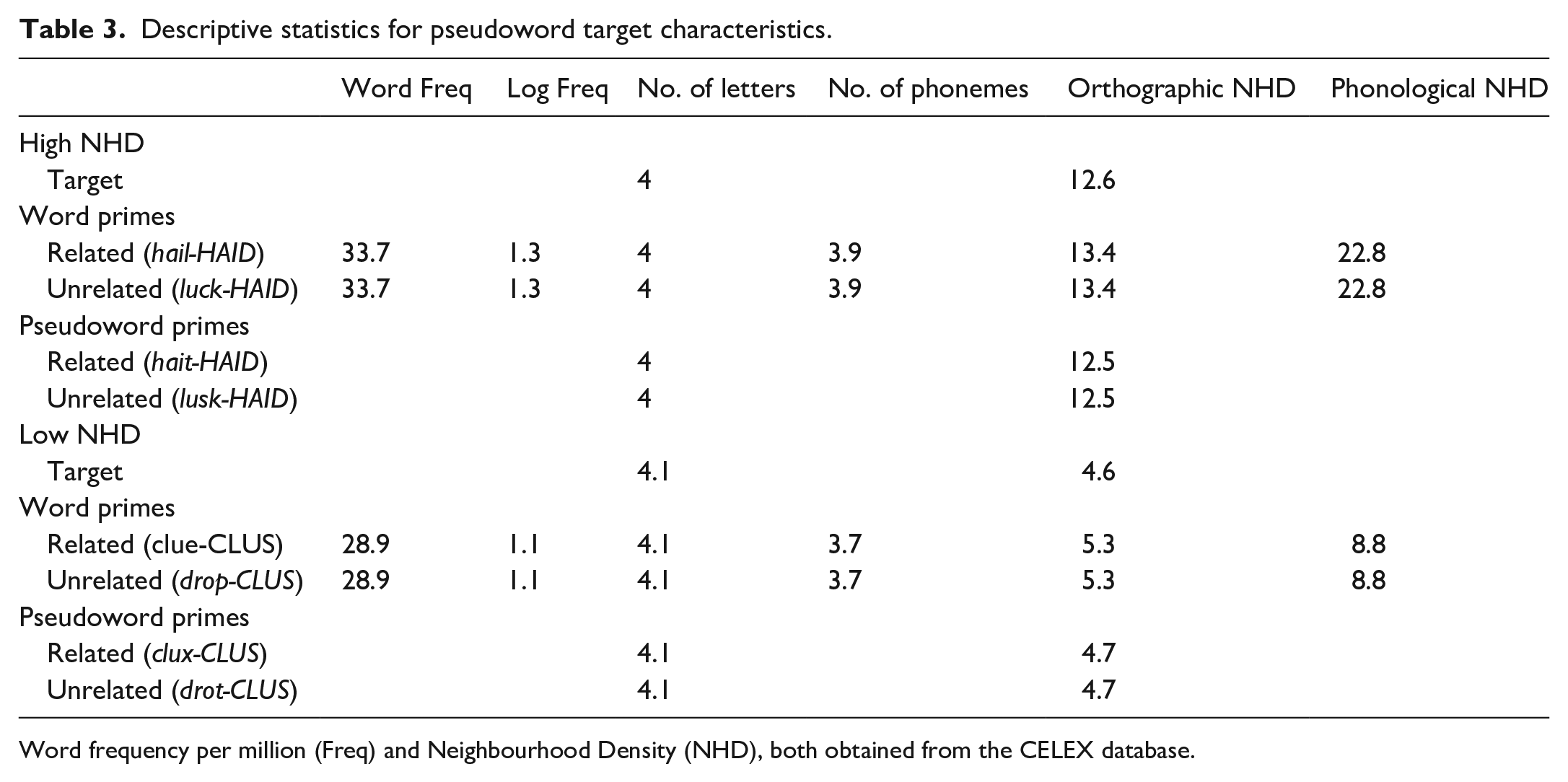
Word frequency per million (Freq) and Neighbourhood Density (NHD), both obtained from the CELEX database.
Pseudoword target set
Eighty monosyllabic pseudoword targets were created to provide the no trials for the lexical decision task. There were 78 four-letter and two five-letter pseudowords. All pseudowords were orthographically legal and pronounceable letter strings in English. The targets were divided into two equal sets differing in orthographic NHD. The high NHD set for pseudowords had eight or above orthographic neighbours, while the low NHD set had between two and seven orthographic neighbours. Both sets were significantly different (t(78) = 12.31, p < .001, d = 2.8). For both sets, there were no significant differences between the word target and pseudoword target for orthographic density (high NHD: t(78) = 1.22, p = .23, d = 0.28; low NHD: t(78) = 1.67, p = .10, d = 0.38). Neighbourhood density could, therefore, not be used as a strategy to indicate whether the target stimulus was a word or pseudoword.
For each word and pseudoword target, related and unrelated word and pseudoword primes were selected (see Tables 2 and 3). All word and pseudoword primes were monosyllabic and had the same number of letters as their targets.
Word prime set
Related and unrelated word primes had a higher word frequency per million and log word frequency than their target words (all ps < .001) as primes with higher frequency than the target tend to produce the strongest inhibitory NHD effect (see review by Grainger, 1992). The related word primes differed from their targets by one letter (either the last or penultimate, e.g., peep-PEEK/fate-FAGE). For each NHD set, the primes were selected according to the same NHD criteria as their targets. The primes and targets did not differ significantly from each other in mean orthographic and phonological NHD (word prime-word target: all ts < 1; word prime-pseudoword target for high NHD: t(39) = 1.57, p = .12, d = 0.50; word prime-pseudoword target for low NHD: t(39) = 1.61, p = .12, d = 0.52). The high and low NHD prime sets differed significantly from each other in mean orthographic and phonological NHD (word targets: ON: t(78) = 16.8, p < .001, d = 3.80; PN: t(78) = 15.47, p < .001, d = 3.50; pseudoword target: ON: t(78) = 15.19, p < .001, d = 3.44; PN: t(78) = 13.5, p < .001, d = 3.05). However, the high and low NHD prime sets did not differ significantly in word frequency (word and pseudoword target: t < 1) and log word frequency (word target: t(78) = 1.9, p = .06, d = 0.43; pseudoword target: t(78) = 1.79, p = .08, d = 0.41). For each NHD set, the number of phonemes between prime and target was not significantly different (dense and sparse NHD: t < 1). The high and low NHD prime sets differed in length on average by 1/10th of a phoneme; however, this difference was significant (t(78) = 7.1, p < .001, d = 1.61). To create the unrelated word primes, the related primes were re-ordered for each NHD set with an additional criterion of no orthographic overlap (i.e., no letter in the same position) between prime and target (e.g., vile-PEEK/plot-FUNK). The means and p values were therefore the same as the related word primes.
Pseudoword prime set
The related pseudoword primes were matched on the same criteria as the related word primes. The high and low NHD pseudoword prime sets differed significantly from each other in mean orthographic NHD (pseudoword prime-word target: t(78) = 13.87, p < .001, d = 3.14; pseudoword prime-pseudoword target: t(78) = 16.04, p < .001, d = 3.63). For each NHD set, the pseudoword primes and targets did not differ in mean orthographic NHD (word target: dense: t(39) = 1.35, p = .18, d = 0.43; sparse: t < 1; pseudoword target: both t < 1).
Design
The masked priming experiment had a between-item factor: target lexicality (word vs. pseudoword) and 2 (prime lexicality: word versus pseudoword) × 2 (NHD: dense versus sparse) × 2 (related versus unrelated) nested within-subject design for each between-item factor. The pseudoword targets and word targets were divided into two lists to reduce target repetition but allow data collection for all targets in all of the priming conditions. Each target was presented twice in each list. The two stimulus lists had rotated prime-target combinations across the different conditions; thus, all targets occurred in all four prime conditions. For example, list one contained vire-PEEK and peep-PEEK, while list two included vile-PEEK and peet-PEEK. The two lists were further separated into four experimental blocks per list, resulting in a total of eight paired blocks. To accomplish the counterbalancing, we divided half of the items for each condition into these eight paired blocks. The order of presentation of paired blocks was rotated across participants. Within each paired block, the two lists had a different order to reduce any systematic effects of the sequencing of items.
Procedures
Masked priming
Participants were informed that they would be presented with a letter string. The participant had to press the YES key on the button box if the letter string was a word and the NO key if the letter string was a pseudoword. The YES response was always made with the participant’s dominant index finger. The participants were told that they had to complete the lexical decision task as fast as possible without compromising accuracy. E-prime (E-Prime 2.0) software was used to create the experiment and collect the responses. All stimuli were written in Arial font size 34. No mention was made of the primes. No feedback was provided.
A trial of the masked priming task had the following sequence: a forward mask (#####) was presented for 500 ms, which was followed by a prime stimulus in lower case for 50 ms and finally, the target stimulus in upper case for 1,500 ms. Participants were instructed to respond within 1,500 ms. Following the participant’s response, there was an inter-trial interval of 1,500 ms. Participants first completed 10 practice trials with a similar structure to the experimental trials. The experiment started after the practice trials. After every 40 trials, participants had a short break.
Results
Demographic variables, attrition, and cognitive and language tests
Our participants were homogeneous in their demographics. All 84 participants were first language English speakers and monolingual. All participants, 83 undergraduate and 1 graduate students, had a similar level of education. As can be seen in Table 4, there is an appropriate level of variability in all of the tests.
Means and standard deviation of all measures.
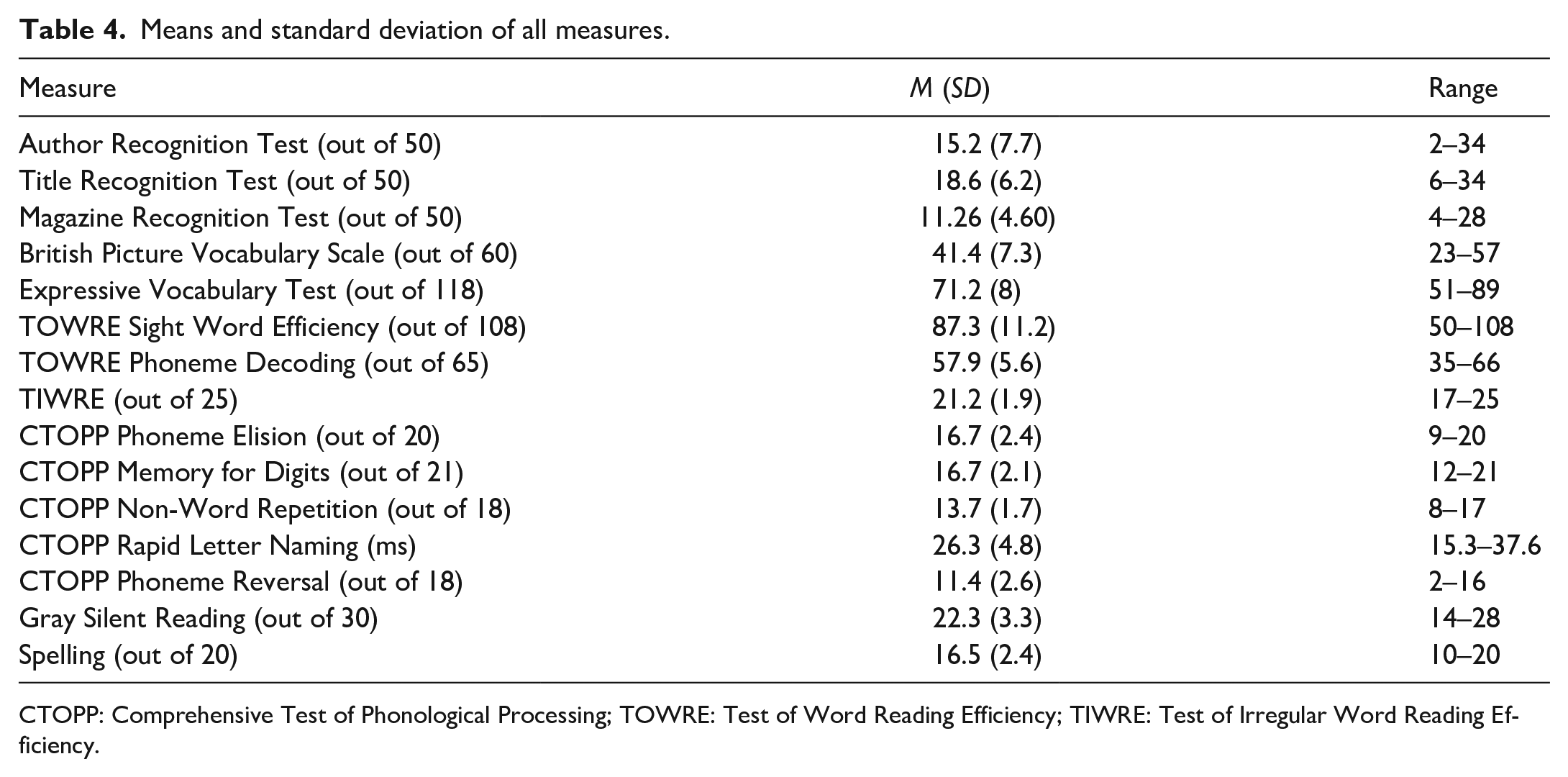
CTOPP: Comprehensive Test of Phonological Processing; TOWRE: Test of Word Reading Efficiency; TIWRE: Test of Irregular Word Reading Efficiency.
Calculation of composite scores and correlations
The number of variables was reduced by calculating composite scores (see Supplementary Material 1 for the correlation tables and a PCA with variables that were not combined). This was conducted as there were 15 variables and 84 participants, thus we would require 15 participants for each variable to be placed in a PCA. First, scores for the suite of individual difference measures were z-transformed to allow comparison between the different scores. Bivariate correlations (Pearson’s product-moment correlation) were then used to investigate the relationship between the individual difference measures in the entire sample. If correlations are strong, a composite score can be calculated by averaging z-scores for the specific measure but have to be measuring a similar skill (e.g., nonword repetition and memory for digits are both measures of phonological working memory). Following this composite score, a PCA was conducted to isolate common constructs between the remaining individual difference measures and the composite variables. The composite measure was chosen to be entered in the PCA to avoid entering multiple highly-correlated measures (e.g., Andrews & Lo, 2012; Elsherif et al., 2020; Holmes et al., 2014).
A composite measure of vocabulary (ZVocab) was formed by averaging the standard scores of the vocabulary scores, as these measures were two strongly correlated variables (r = .59) to provide a more comprehensive measure of vocabulary ability. A composite measure of phonological working memory (ZMemory) was formed by combining the two highly correlated measures of phonological working memory (i.e., nonword repetition and memory for digits; r = 0.43). A composite measure of reading fluency (ZReadingFluency) was formed by averaging the standard scores of three highly correlated measures of reading fluency (TOWRE word reading and Rapid Letter Naming, r = .47; TOWRE phonemic decoding and Rapid Letter Naming, r = .51; and TOWRE word reading and phonemic decoding, r = .56). Finally, a composite measure of print exposure (ZPrintexposure) was formed by aggregating two strongly related measures of print exposure (ART and TRT, r = .76).
Table 5 summarises the correlations between the composite standard scores with the other individual difference measures. The correlations reflect relationships shown in previous studies, including the relationship between print exposure and vocabulary (e.g., Martin-Chang & Gould, 2008 ) and print exposure and spelling (e.g., Burt & Fury, 2000). Critically, the degree of collinearity among these various individual difference measures is relatively high (rs ⩾ .3). A multi-variate approach, such as PCA, is therefore appropriate.
Correlations between tasks.
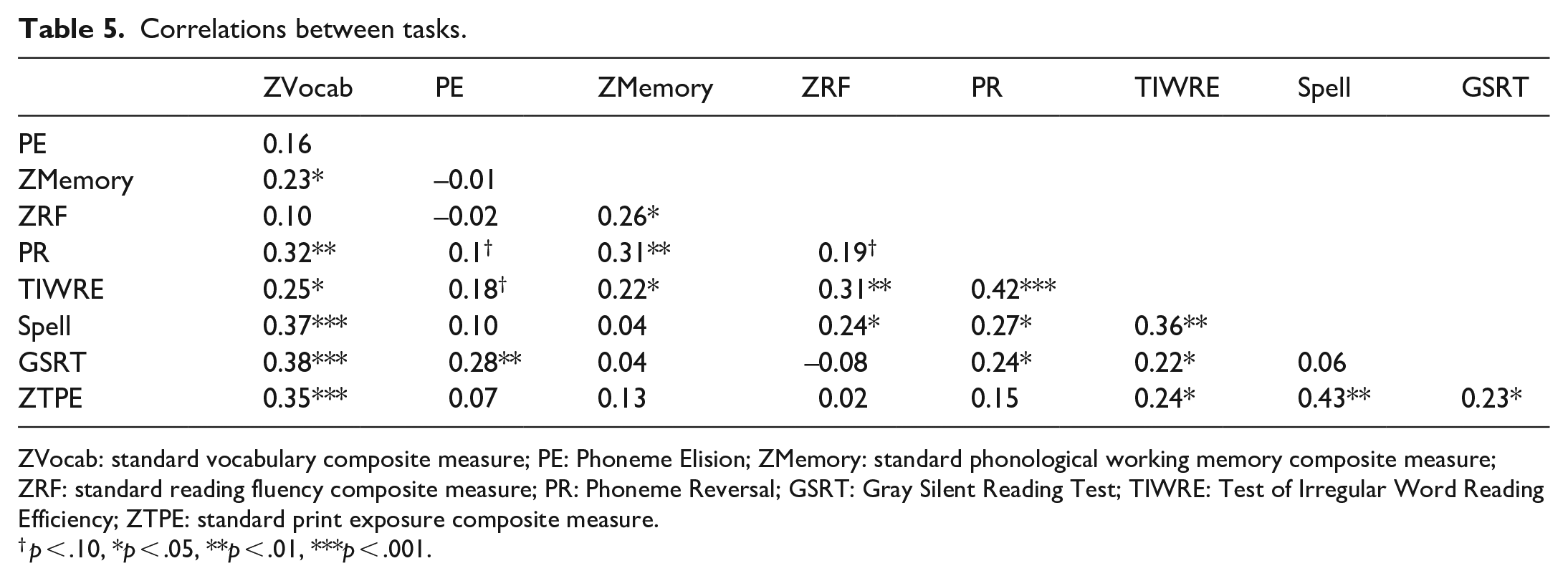
ZVocab: standard vocabulary composite measure; PE: Phoneme Elision; ZMemory: standard phonological working memory composite measure; ZRF: standard reading fluency composite measure; PR: Phoneme Reversal; GSRT: Gray Silent Reading Test; TIWRE: Test of Irregular Word Reading Efficiency; ZTPE: standard print exposure composite measure.
p < .10, *p < .05, **p < .01, ***p < .001.
Principal component analysis
The PCA analysis determined the statistical clustering of the individual difference measures. This analysis was carried out using the software package GPA rotation (Bernaards & Jennrich, 2005), within the R statistical programming open code software (R Development Core Team, 2017). The data from Table 5 were entered into a PCA. One variable, CTOPP phoneme elision, which correlated less than .3, was dropped from the analysis. The Kaiser–Meyer–Olkin measure of sampling adequacy was .68, above the commonly recommended value of .50 (Field, 2009). The Bartlett’s test of sphericity was significant (χ2 (28) = 113.47, p < .001). This showed the correlations between the remaining eight variables were appropriate for PCA.
We calculated both varimax and oblique rotations. Table 6 presents the results of the varimax analysis. The initial analysis extracted three components with eigenvalues greater than Kaiser’s criterion of 1, accounting for a total of 62% of variance in reading behaviours. Component loadings were similar, irrespective of rotation (except that the variable Zvocab was only found in varimax rotation) and the highest inter-component correlation produced by an oblique rotation was .26 between the second and third components. A varimax rotation was therefore performed as the components did not correlate with each other above .32 (Tabachnick et al., 2007). Only variables with loadings of higher than 0.45 were considered. Based on the loadings, these three components were assigned construct names indicative of their component variables and are listed in the order of variance explained in Table 6. Components show positive or negative loadings. Positive loadings give inclusionary criteria and describe the underlying construct of the component. Negative loadings provide exclusionary criteria and show an inverse relationship to the construct of the component.
Components produced by the PCA.
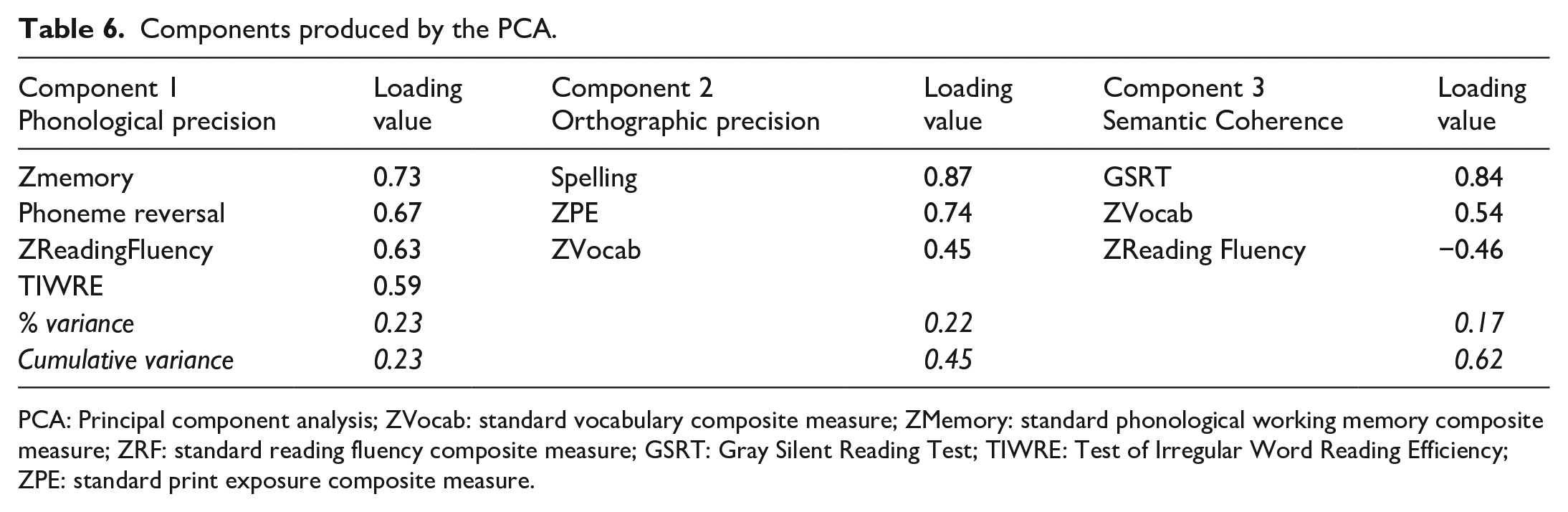
PCA: Principal component analysis; ZVocab: standard vocabulary composite measure; ZMemory: standard phonological working memory composite measure; ZRF: standard reading fluency composite measure; GSRT: Gray Silent Reading Test; TIWRE: Test of Irregular Word Reading Efficiency; ZPE: standard print exposure composite measure.
The first component, accounting for the most variance, includes the composite measure of phonological working memory and the composite measures of reading fluency, phoneme reversal, and TIWRE (all positive components). These positive loadings indicate that higher phonological working memory and phonological awareness might benefit from redundant word-specific phonology and context-sensitive grapheme-phoneme phonology, leading to more efficient access to the phonological representation (Perfetti, 2007). These variables contribute to a component that primarily reflects phonological precision.
The second component (in order of variance explained) includes the composite measure of print exposure, the composite measure of vocabulary, and spelling. The positive loadings of the recognition test variables, along with spelling and vocabulary, suggest that larger vocabulary size might benefit from stronger and richer connections between sublexical orthographic and phonological representations and lexical-semantic representations, resulting in more efficient bottom-up processing, which is in line with the definition of orthographic precision (Perfetti, 2007), despite the fact that vocabulary measures are not orthographic in nature. This component primarily reflects a general index of orthographic precision.
The third component includes Gray Silent Reading comprehension and the composite measure of vocabulary (positive loadings), together with the composite score of reading fluency (negative loadings). The loadings could be interpreted primarily as an index of semantic coherence. The negative loading of ZReadingFluency is somewhat unexpected given that reading fluency is thought to play a positive role in comprehension, at least in younger readers (see Silverman et al., 2013, for discussion). However, the influence of fluency/decoding on comprehension weakens with age (Language & Reading Research Consortium, 2015), and Jackson (2005) showed that similar measures as those comprising ZReadingFluency did not correlate with a passage comprehension measure. Finally, it should be noted that ZReadingFluency was the weakest loading factor on the semantic coherence component and that this component did not interact with any of the LDT results reported below.
General linear mixed effect model (GLMM)
A general mixed linear analysis was conducted on the reaction time data for word and pseudoword targets using the lme4 package (Bates et al., 2010). The reaction times were log-transformed. GLMM models were run, including neighbourhood density (sum coded with sparse as intercept), relatedness (sum coded with unrelated as intercept) and prime lexicality (sum coded with pseudoword prime as intercept) as a fixed effect with all slopes and intercepts allowed to vary at random by subject and items. With regard to the lexical decision dataset, word targets and pseudoword targets were analysed separately to identify which components drove the processing and recognition of words and pseudowords. Furthermore, the three components from the PCA were entered into the model as a fixed effect and analysed as a continuous variable. If interactions between the components from the PCA and any other fixed effects arose, the continuous PCA data were then logged as binary variables (high vs. low). The recoding was done by splitting the data from a variable into two sets so that the number of data points per set was as closely matched as possible.
All continuous variables were centred prior to analysis. In all cases, the maximal random structure model included the interactions of all three conditions with both subjects and items (Barr et al., 2013). A fully random model was used whenever possible. However, fully specified models often fail to converge. If the model failed to converge, we simplified the random slopes, removing interactions before main effects in the order of least variance explained until the model converged (Veldre & Andrews, 2014). The minimal model in the fixed effects structure was isolated using the drop1 function, which identifies the most complex fixed effect explaining the least variance. Fixed effects were removed until the model with the minimal Bayesian Information Criterion (BIC) was reached (Schwarz, 1978). ΔBIC implies the difference between the full model and reduced model; a positive ΔBIC indicates that the reduced model is better than the null model. We have included Bayes factor (BF) approximations, using the formula (exp(ΔBIC/2); Raftery, 1995); by using the BF, we compared the relative evidence for different models. For instance, a BF value of 5 implies that the reduced model is five times more likely than the full model. In general, the higher the ΔBIC and BF, the more likely the reduced model is in comparison to the full model. Based on these tests, we created a minimal model, which included the combination of components that provided the best fit of our data. In the reduced model, components with a t-value of greater than 2 are considered significant at the alpha = .05 level (Baayen et al., 2008). When interactions were observed, each fixed effect was logged as a binary variable and significance values were calculated using the afex package (Singmann et al., 2015). Finally, Cohen’s d = ∆M/ σ effect sizes for the within-group comparisons were computed with estimated marginal means (for calculation of ∆M) and total variance from covariance model estimates (for standardisation of σ; Cohen, 1988; Westfall et al., 2014).
Word targets
The reaction times (RTs) were trimmed, excluding all errors, response times below 200 ms and responses ±2.5SD or above from participant’s mean response time. Five word items (i.e., BARD, BIDE, BOLL, CRAG, and NOOK) produced more than 50% errors and so were removed from the lexical decision analyses, leaving 35 target words per condition. This led to 17.8% of the data being removed in total. Only correct trials were included in the RT analyses. Average RTs, SDs, and the proportion of correct responses for each condition are shown in Table 7.
Mean response times and proportion correct for prime lexicality, relatedness, and NHD condition.
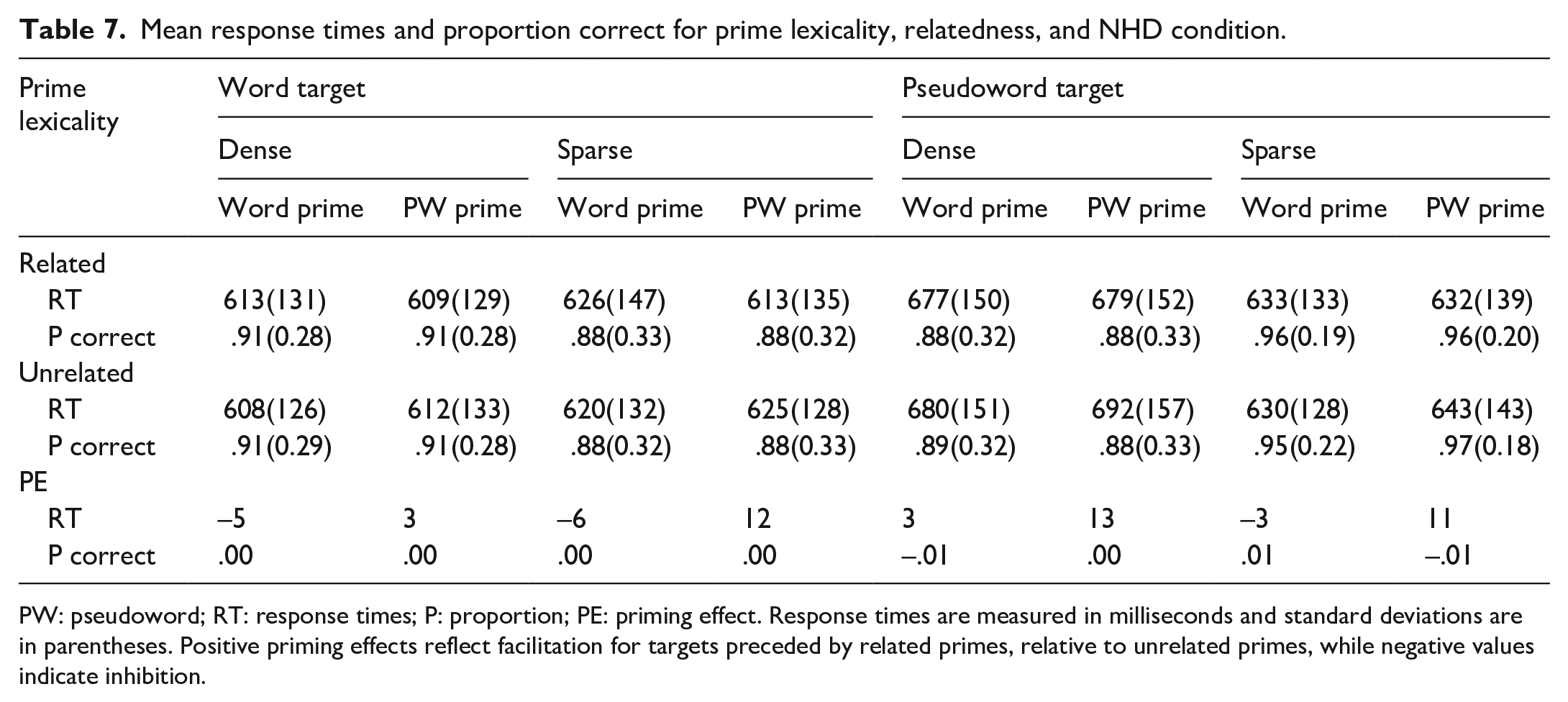
PW: pseudoword; RT: response times; P: proportion; PE: priming effect. Response times are measured in milliseconds and standard deviations are in parentheses. Positive priming effects reflect facilitation for targets preceded by related primes, relative to unrelated primes, while negative values indicate inhibition.
Accuracy was high for all conditions, with only minute variability between them, making it difficult to compare conditions. Since the model for the accuracy data did not reach convergence, and since the research questions were concerned with the influence of individual difference measures on the priming effect in word targets (which shows in latency outcomes but not necessarily in accuracy outcomes), we will not discuss the accuracy data in further detail. However, it can be observed from Table 7 that word targets with sparse neighbourhoods produced more errors than word targets with dense neighbourhoods.
For word targets, the effects were inhibitory in direction for word primes and facilitatory in direction for pseudoword primes. The model for the lexical decision for the word target did not converge until the item slope was removed, leaving only an item intercept; the three-way interaction was reduced to NHD as an individual factor by itself in the random structure (see Supplementary Material 2B for the final model code for word target and pseudoword target). The output of this model is shown in Table 8.
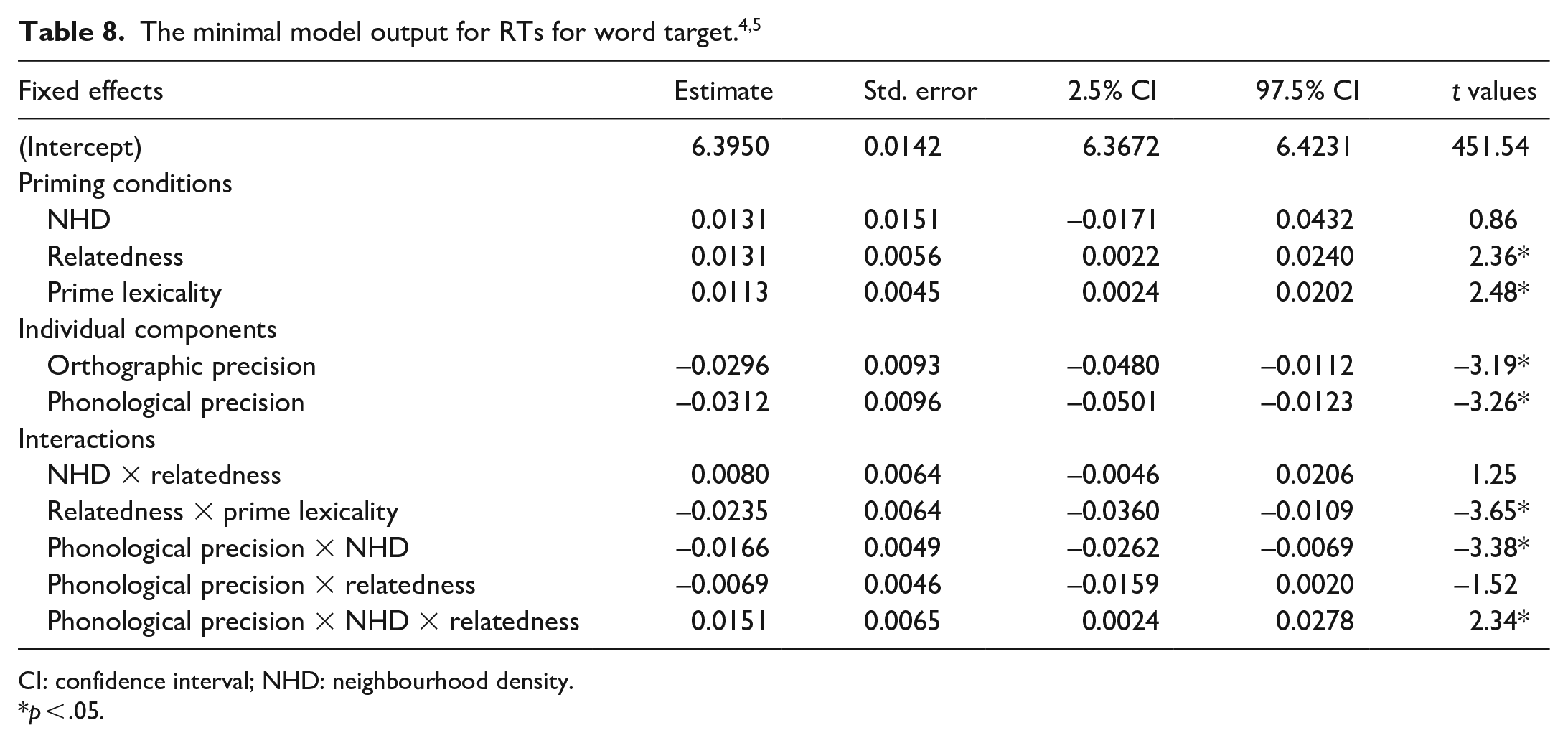
CI: confidence interval; NHD: neighbourhood density.
p < .05.
The reduced model was significantly different from the full model (full model BIC: −6930.8; reduced model = BIC: −7286.2 p < .001, ΔBIC: 355.38, approx. BF > 10,000), thus the final model is based on the reduced model. In the reduced model, there was a significant three-way interaction between phonological precision, NHD, and relatedness (see Figure 2). In people with high phonological precision, the direction of the priming effects for word targets with dense neighbourhoods was inhibitory, while the direction of the priming effect was facilitatory for word targets with sparse neighbourhoods. People with low phonological precision showed the opposite pattern.
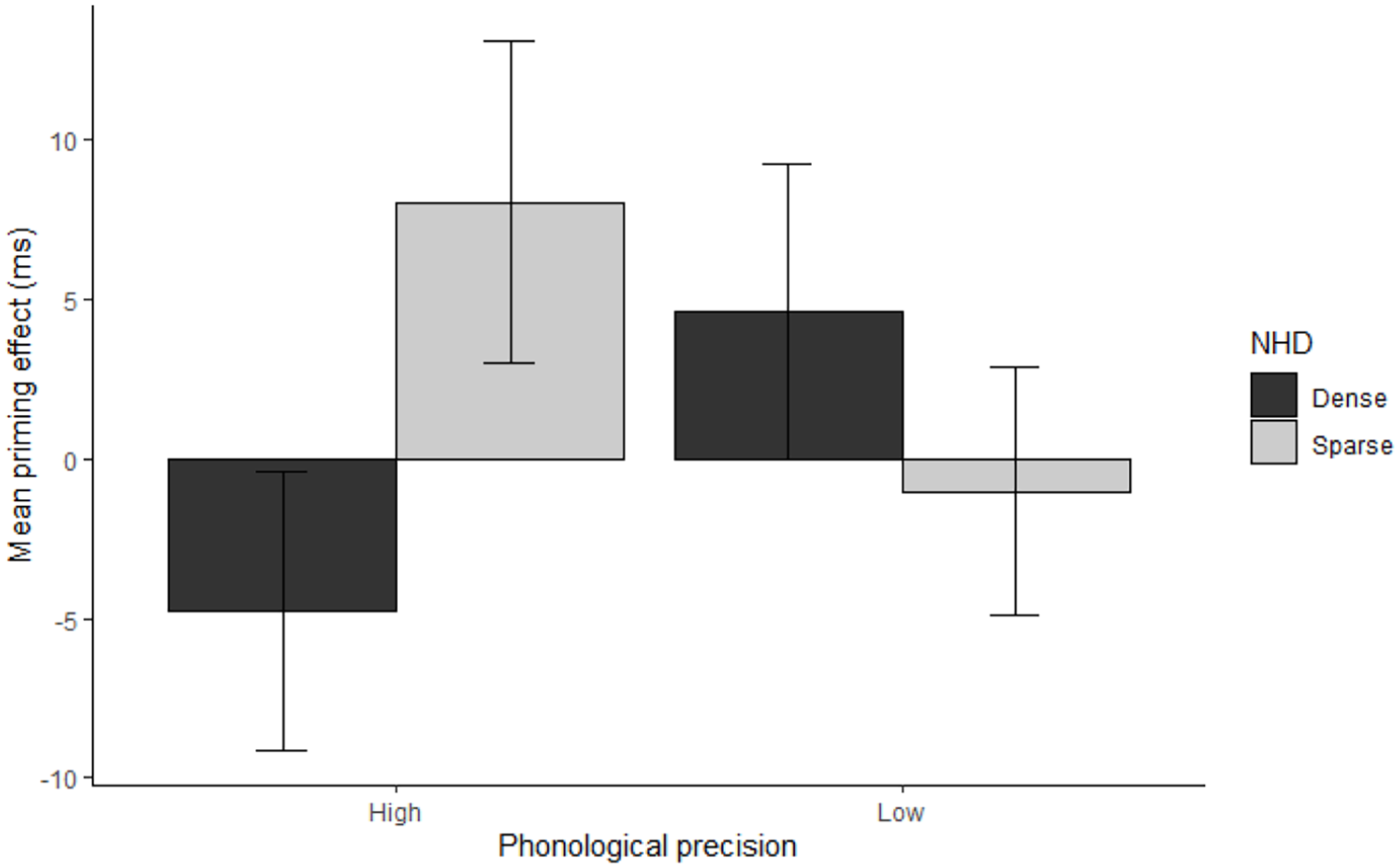
Reaction time (RT) priming effects (in ms) for high- and low-N targets, averaged over prime lexicality and separated by the phonological precision composite. Positive priming effects reflect facilitation for targets preceded by related primes, relative to unrelated primes, while negative values indicate inhibition. Error bars represents 95% confidence interval for each condition.
The reduced model was split into two sub-models: high phonological precision and low phonological precision. Phonological precision was removed from the equation and the same procedures for the analyses and random structure from the reduced model were applied to the sub-models. In the high phonological precision sub-model, the NHD and relatedness interaction was significant (b = 0.023, t = 2.60, p = .0095). No main effects of NHD (b = −0.002, t = −0.13, p = .90) or relatedness (b = −0.006, t = −1.02, p = .31) were found. For the participants with low phonological precision, no interaction between NHD and relatedness was observed (b = −0.007, t = −0.78, p = .44), relatedness (b = 0.01, t = 1.46, p = .14), and the NHD approached significance (b = 0.03, t = 1.67, p = .10).
The reduced model also produced a significant interaction of relatedness with prime lexicality (Table 8). The reduced model was split into two sub-models: word targets preceded by word primes and word targets preceded by pseudoword primes. Prime lexicality was removed from the equation and the same procedures for the analyses from the reduced model were applied to the sub-models. An effect of relatedness was significant for the pseudoword priming condition (b = 0.02, t = 3.89, p = .00102, d = 0.08), but not the word priming condition (b = −0.007, t = −1.43, p = .15, d = −0.03). For pseudoword primes, related primes led to shorter reaction times (M = 612, SE = 14.6) than unrelated primes (M = 620, SE = 14.0).
With regard to the individual components, the model output showed that there was a significant effect of orthographic precision and phonological precision on log RT. Unsurprisingly, the higher the components of orthographic precision and phonological precision, the shorter the reaction times. No main effect or interaction of semantic coherence contributed to the reaction times.
Pseudoword targets
The reaction times (RTs) were trimmed similar to the word target analyses, resulting in the loss of 9.8% of the data. Average RTs, SDs, proportion correct, and 95% confidence interval of reaction times for each condition are shown in Table 8. Accuracy for the pseudoword targets was high with minimal variation between the different conditions. Since the model did not reach convergence, no further analyses are reported. It can be noted that, in contrast to the accuracy for word targets, sparse neighbourhoods produced fewer errors than dense neighbourhoods in pseudoword targets.
The direction of priming was inhibitory for pseudoword targets preceded by word primes and facilitatory for pseudoword targets preceded by pseudoword primes. The model for the lexical decision focusing on the pseudoword target did not converge until the item-slope was removed, leaving only an item-intercept, and the three-way interaction for subjects was reduced to individual effects with prime lexicality being removed in the random structure. The minimal model output is shown in Table 9. Participants responded more slowly to pseudowords with dense neighbourhoods than pseudowords with sparse neighbourhoods.
The minimal model output for RTs for pseudoword targets.
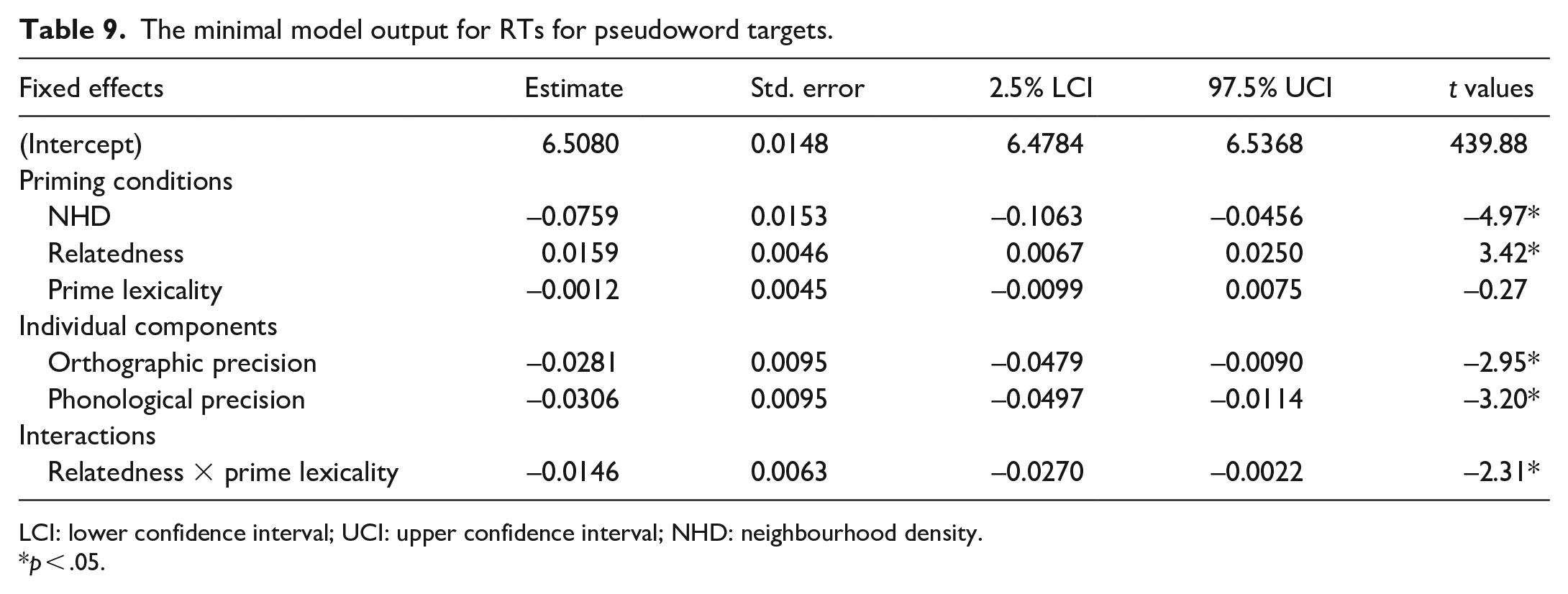
LCI: lower confidence interval; UCI: upper confidence interval; NHD: neighbourhood density.
p < .05.
The reduced model for pseudoword targets was significantly different from the full model (Full model BIC: −6959.8; reduced model = BIC: −7309.0, p < .001, ΔBIC: 394.25, Approx. BF > 10,000). We therefore chose the reduced model for our analyses. The reduced model produced a significant interaction for relatedness and prime lexicality. The reduced model was split into two sub-models: pseudoword targets preceded by a word prime and pseudoword targets preceded by a pseudoword prime. Prime lexicality was removed from the equation and the same procedures for the analyses from the reduced model were applied to the sub-models. The effect of relatedness was not significant for pseudoword targets preceded by a word prime condition (b = 0.0001, t = 0.03, p = .98, d = .001), while an effect of relatedness was significant for the pseudoword targets preceded by a pseudoword prime condition (b = 0.016, t = 2.9, p = .005, d = .07). For pseudoword primes, related primes resulted in shorter reaction times (M = 655, SE = 2.68) than unrelated primes (M = 666, SE = 2.76). For word primes, there was no difference in reaction times between related (M = 654, SE = 2.59) and unrelated primes (M = 654, SE = 2.58).
With regard to the individual components, the model output showed that there was a significant effect of orthographic precision and phonological precision on log RT. As expected, the higher the phonological precision and orthographic precision, the shorter the reaction times (see Supplementary Material 1 for the pseudoword equivalent of Figure 2). No main effect or interaction of semantic coherence contributed to the reaction times.
Discussion
Summary of findings
The current study used a suite of individual difference measures to assess which facets of LQH modulate lexical decision times. In order to investigate competition resolution during the processing of words, we manipulated NHD and prime and target lexicality in a masked form priming experiment, controlling for both orthographic and phonological neighbourhoods. We observed that phonological precision and NHD interacted with form priming, such that in people with high phonological precision, the direction of the priming effects for word targets with dense neighbourhoods was inhibitory, while for those with sparse neighbourhoods, it was facilitatory. The opposite pattern was observed for people with low phonological precision, but the interaction was non-significant. This finding is in line with Andrews and Hersch (2010) and Andrews and Lo (2012), although we found that the component of phonological precision, rather than spelling, affected the priming pattern observed. We also noted a significant interaction between prime lexicality and relatedness such that the direction of priming for word targets preceded by word neighbour primes was inhibitory, while the direction of priming for word targets that followed pseudoword neighbour primes was facilitatory. This interaction is consistent with the findings of Davis and Lupker (2006), supporting their claim that inhibitory priming for word targets following word primes indicates lexical competition, while facilitatory priming for word targets preceded by pseudoword primes suggests sublexical facilitation.
Pseudoword targets with dense neighbourhoods were rejected more slowly than those with sparse neighbourhoods (also in line with Davis & Lupker, 2006), indicating that it is harder to reject a pseudoword when the pseudoword activates several neighbouring word candidates. Furthermore, pseudoword neighbour primes produced significant facilitatory priming for pseudoword targets, and no significant priming effects were shown for those that followed word primes (in line with Forster & Veres, 1998). Finally, several components (i.e., phonological precision and orthographic precision) moderated the speed at which pseudowords were rejected. Participants with higher phonological and orthographic precision took less time to reject pseudowords compared with people with lower phonological and orthographic precision. However, none of the individual difference measures interacted with the priming effect.
The role of LQH in masked priming for word targets
One of the main contributions of the present study is the inclusion of a suite of individual difference measures, as previous research has tended to focus on either a single measure or a few measures. The present study used a suite of individual difference measures and grouped them into different components using PCA. The PCA for the current neurotypical population suggests there are three components, which are related to phonology, orthography, and semantics, and that the different measures loaded differently onto these components. The observation of three components highlights that these processes are distinct from one another. However, as suggested by the LQH (Perfetti, 2007), proficient processing involves integrating these different components online and our study shows that individuals do this to different extents.
Concerning the role of the individual difference measures on competition resolution, previous studies have shown that spelling and semantics moderate the size and direction of the priming effect with regard to the NHD (Andrews & Hersch, 2010; Perfetti, 2007). The present study is the first to include measures of phonological processing and showed that the priming effects depended significantly on the component of phonological precision. People with high phonological precision showed facilitatory priming only in word targets with sparse neighbourhoods. This was not modulated by any measures related to orthography or semantics. Our findings support Adelman et al. (2014) and Rastle and Brysbaert (2006), who argue that phonological processing moderates priming effects from neighbouring candidates. It should be noted that while orthographic precision did not modulate our results, we do not want to argue on the basis of these null results that orthographic knowledge is unimportant in word recognition (see also Elsherif et al., 2020, described below). However, our results do indicate that phonological knowledge also plays an important role in visual word recognition.
Perfetti (1992) and Andrews and colleagues (Andrews, 2015; Andrews & Hersch, 2010; Andrews & Lo, 2012) posited that greater lexical precision is a property of a good lexical representation. Greater lexical precision would lead to a quick inhibition of lexical competitors, thus increasing the speed of lexical access, while poor lexical precision would lead to a slow suppression of neighbouring candidates, slowing down lexical access. Andrews and Hersch argued that the quality of lexical representations is best reflected by measures of spelling, as spelling is linked to measures of lexical competition, since the representations have to be robust and stable to allow direct lexical access. Representations that are fully specified and precise have redundant mapping between letters and sounds. The more redundant the letter-sound correspondence, the more likely the reader can directly access the mental lexicon and recognise the word. The present study found that the phonological precision component may be a more appropriate measure of lexical precision than components including spelling or lexical-semantic processing.
However, we used one spelling measure, while Andrews and Hersch (2010) used two spelling measures that were aggregated. As a result, our spelling data may be somewhat less sensitive. Nevertheless, our results extend the research of Andrews and Hersch (2010), as we found that lexical retrieval is driven by orthography (as found in Andrews & Hersch) and phonology (the present study) in addition to vocabulary. This is important as it confirms one of the notions of the LQH that redundancy and lexical precision are mutually dependent and are a graded notion. Put simply, the higher the level of phonological precision, the more strongly bonded the orthographic and phonological features so that they are intrinsic to each other, leading to faster lexical retrieval. This finding has obvious implications for masked priming experiments. It is consistent with a strong relationship between orthographic and phonological processing. Yang et al. (2021) used homophonic prime-target pairs that had no character overlap to investigate whether phonology modulated the priming effects in the same-different task when using Japanese (Experiment 1) or Chinese (Experiment 2) script. They observed phonological priming effects in both experiments, concluding that although same-different tasks have a strong orthographic basis, the priming effects are also driven by phonological codes. They argued that it is therefore not possible to conclude that any masked priming effects in logographic, and even alphabetic languages, are solely driven by orthographic processing. Our findings confirm that phonology also contributes to the neighbourhood priming effects for word targets in English.
The role of LQH in masked priming for pseudoword targets
Although word targets allowed us to test the impact of phonological precision on lexical competition, pseudoword targets allowed us to examine the effects of sublexical overlap without lexical competition playing a role. Regarding the rejection of pseudowords, the literature on the processing of pseudoword targets is limited and the LQH does not make precise predictions for these types of stimuli. However, pseudoword targets provide a viable measure of the redundancy facet concerning the LQH. The LQH states that less skilled readers have weakly bonded orthographic and phonological features, as the phonological and orthographic representations have many-to-one mappings. Skilled readers would try to access the pseudoword target directly. However, as pseudowords have no lexical representation, skilled readers would reject pseudowords more easily. In contrast, for less skilled readers, the orthographic and phonological features are weakly bonded. The graphemes do not have a one-to-one mapping, as the grapheme of <ai> in the pseudoword “haid” activates several phonemic representations: /ai/, /a/, and perhaps /ae/. Less skilled readers would therefore treat pseudowords more like words and may take longer to access the mental lexicon and notice that the pseudoword does not exist. Several individual difference measures (i.e., phonological precision and orthographic precision) moderated the speed of rejecting pseudowords in our study. Consistent with the LQH, people with higher phonological and orthographic precision rejected pseudowords more quickly than those with lower phonological precision and orthographic precision. Skilled readers with stronger grapheme-phoneme correspondences can allocate more resources to higher-level mechanisms (cf. LaBerge & Samuels, 1974). In contrast, less skilled readers use additional attentional resources to decode words, thus taking more time to reject pseudowords.
In addition, it was observed that pseudoword targets with dense neighbourhoods took longer to reject than pseudoword targets with sparse neighbourhoods, irrespective of reading ability. One explanation is that pseudoword targets with dense neighbourhoods face sustained co-activation from many word neighbours making them difficult to reject. Alternatively, pseudowords with sparse neighbourhoods receive activation from fewer word neighbours and are therefore easier to reject (Andrews, 1997; Meade et al., 2018). In addition, no individual component was found to moderate the priming effects for the rejection of pseudowords. This partially supports Andrews and Hersch’s (2010) findings, who showed that vocabulary knowledge drove the speed of rejecting pseudowords and that priming effects for pseudowords were not affected by any of the individual difference measures. There are two tenable explanations as to why individual differences do not moderate priming effects in pseudoword targets. It could be argued that “yes” and “no” decisions are processed differently, as “no” decisions require more cognitive resources than “yes” decisions (e.g., Rayner et al., 2006). However, Perea et al. (2010) assessed whether masked nonword priming effects were greater when the task involved a “yes” response to nonwords than when it entailed a “no” response. The magnitude of priming effects for nonword targets was similar between yes and no responses. They concluded that the priming effect is a lexical process. A second explanation is that word primes are more likely to produce stronger competitors than pseudoword primes, as the latter have no lexical entries. Pseudoword primes may therefore only weakly activate word neighbours, thus once the pseudoword target appears, inhibitory priming is minimal. This indicates that the inhibitory priming effects are lexical in nature, as such effects are only shown in the current study for word recognition, not the rejection of pseudowords. It is important to note that phonological precision is a measure of lexical precision, as the component of phonological precision was found to be limited to only word, not pseudoword, targets.
Theoretical implication
It should be noted, though, that the present findings might reflect the later stages of lexical retrieval. The LDT has been argued to be a measure of the later stages of visual word recognition, while visual word naming assesses the earlier stages (Schilling et al., 1998). Using a collection of methods, Schilling et al. (1998) found that the later measures of eye-tracking were strongly correlated to the LDT, whereas the earlier measures of eye-tracking were related to visual word naming. If this is correct, then it would indicate that phonology may contribute to the later stages of lexical retrieval. Elsherif et al. (2020) used the same stimuli, standardised tests, and participant pool as the current study but replaced the LDT with visual word naming. The authors observed that the component of orthographic rather than phonological precision contributed to the priming effects in visual word naming, such that people with high orthographic precision showed smaller facilitatory priming for word targets with dense neighbourhoods than those with sparse neighbourhoods. This indicates that the early stages of visual word recognition (i.e., grapheme-phoneme conversion) is moderated by orthography, while access to the mental lexicon (i.e., the later stages) is moderated by phonology. These findings can be accommodated straightforwardly in Grainger and Holcomb’s (2009) bi-interactive model. In this model, on presentation of a printed word, perceptual features are mapped onto pre-lexical orthographic representations (~150 ms, letters and letter clusters: O-units) which are then mapped onto whole-word orthographic representations (~250 ms, O-words) and simultaneously onto pre-lexical and lexical phonological representations via the central interface between orthography and phonology (~250 ms–325 ms; O ↔ P). Whole-word form representations subsequently activate semantic representations (~400 ms, S-units). The more general conclusion is that lateral inhibition is primarily driven by phonology, while orthography contributes to sublexical facilitation. Future research should use a subtraction approach to assess the sequential activation processes from LDT to visual word naming and subtract the latencies of visual word naming from the latencies of LDT to provide a phonological access value (Catling & Elsherif, 2020; Santiago et al., 2000), assess which component affects lexical retrieval, especially when details of the specific item is unidentified or unretrieved (e.g., recognition without identification paradigm; Catling et al., 2021) or using a creative destruction approach (i.e., pre-specifying alternative results by competing hypotheses on a complex set of experimental findings; Tierney et al., 2020; Tierney et al., 2021).
Conclusion
In summary, the current study partially replicated previous findings from the literature and found a significant interaction of phonological precision, NHD, and relatedness. In individuals with high phonological precision, the direction of the priming effects for word targets with dense neighbourhoods was inhibitory, whereas it was facilitatory for those with sparse neighbourhoods. The opposite pattern was observed for people with low phonological precision, but the interaction was not significant. In addition, we found that the speed of pseudoword rejection was affected by the components of phonological precision and orthographic precision. However, there were no effects of the individual components on the priming effect for pseudoword rejection. This indicates that phonological precision is important for the processing of words and that the inhibitory priming effects in recognition tasks are lexical in nature.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218211046350 – Supplemental material for Phonological precision for word recognition in skilled readers
Supplemental material, sj-docx-1-qjp-10.1177_17470218211046350 for Phonological precision for word recognition in skilled readers by Mahmoud M Elsherif, Linda Ruth Wheeldon and Steven Frisson in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
We thank all the participants for their involvement in the study. This study constituted part of the first author’s doctoral thesis. Sections of this study were presented at the Psycholinguistics in Flanders (Ghent, Belgium, June 2018) and the Experimental Psychological Society (London, January 2019).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.