
Abstract
Balancing speed and quality during crises pose challenges for ensuring the value and utility of data in social science research. The COVID-19 pandemic in particular underscores the need for high-quality data and rapid dissemination. Given the importance of behavioural measures and compliance with measures to contain the pandemic, social science research has played a key role in policymaking during this global crisis. This study addresses two key research questions: How FAIR (findable, accessible, interoperable and reusable) are social science data on the COVID-19 pandemic? Which study features are related to the level of FAIRness scores of datasets?
We assess the FAIRness of n = 1131 articles, retrieved through a keyword search in the Web of Science database, employing both automated and manual coding methods. Our study inclusion criteria encompass empirical studies on the COVID-19 pandemic published between 2019 and 2023 with a social science focus and explicit reference to the underlying dataset(s). Our analysis of n = 45 datasets reveals substantial differences in FAIRness for different types of research on the COVID-19 pandemic. The overall FAIRness of data is acceptable, although particularly Reusability scores fall short, in both the manual and the automatic assessment. Further, articles explicitly linked to the Social Science concept in the OpenAlex database exhibit a higher mean overall FAIRness value. Based on these results, we derive recommendations for balancing ethical obligations and the potential tradeoff between speed and data (sharing) quality in social-scientific crisis research.
Keywords
Introduction
In recent years, we have experienced a phenomenon that the social sciences have named ‘polycrisis’. This refers to multiple shocks that occur in parallel or at short intervals, interact, and the consequences are greater than the sum of the individual crises (Whiting and Parker, 2023). Polycrisis is a term that first appeared in the 1970s, only to come back after the 2008–2009 financial crisis in Europe. However, the real turning point came with the COVID-19 pandemic when the term polycrisis entered the regular academic vocabulary. As local, national and global crises affect human behaviour in various ways, the social sciences, which study human behaviour, can provide important insights into the social or societal effects of crises. A social science perspective is also important as social, economic and political crises affect the world and different population segments simultaneously, but not necessarily symmetrically, meaning that inequalities can play a significant role. Ideally, insights from social science research can be drawn upon to develop or improve measures for handling crises and their consequences. Considering this, the COVID-19 pandemic can be analysed as a valuable case to understand how research can support crisis management.
The COVID-19 pandemic was a global challenge with high risks for the world population. Since COVID-19 was a novel virus, the pandemic was associated with many uncertainties, especially at the early outbreak stage. The highly contagious COVID-19 required the speedy implementation of measures to contain its spread and reduce the risk of harm to people worldwide. The combination of high levels of both risk/threat and uncertainty and the need to (re-)act rapidly presented severe challenges for policymakers and scientific research alike. For policymaking, the high-risk, high-uncertainty nature of the COVID-19 pandemic meant that it was important to be evidence-based. This entails that policy decisions – in this specific case, mainly regarding the development, implementation, adjustment or cessation of measures for containing the pandemic – should be informed by the rigorous consideration of available scientific evidence (Parkhurst, 2017). The general assumption behind evidence-based policymaking is that policies work better if we understand the mechanisms expected to function if implemented (Sanderson, 2002). Public health policymaking to mitigate the impact of COVID-19 was largely dominated by the epistemic hegemony of biomedicine (Sell et al., 2021). However, basing policymaking solely on evidence from biomedical research would have been problematic in at least two respects: Firstly, pandemics are multidimensional and have social and political aspects and consequences (Lohse and Canali, 2021). Secondly, when neither medication nor vaccination against COVID-19 was available at the beginning of the pandemic, the only measures that could be implemented were behavioural and studying human behaviour (as well as its antecedents and consequences) lies at the core of the social sciences. The second point was the basis for a widely discussed paper published early in the pandemic, which suggested ‘Using social and behavioural science to support COVID-19 pandemic response’ (Van Bavel et al., 2020). Specifically, in that paper, the authors propose 19 policy recommendations that could be backed by social science research. In response to that paper, however, another group of researchers recommended to ‘Use caution when applying behavioural science to policy’ (IJzerman et al., 2020). That paper proposed an evidence-readiness level for ascertaining whether findings from research in social and behavioural science are suitable for informing policy decisions.
Social science research and data on the COVID-19 pandemic
Among the topics commonly studied within the social and behavioural sciences identified by Van Bavel et al. (2020) as relevant to the COVID-19 pandemic are, for example, threat perception, trust, science communication, misinformation, conspiracy theories, social norms, polarization or stress and coping. The body of research on the pandemic and its effects on human behaviour is at least as diverse as this list. It shows the broad range of questions that social science research has investigated regarding the COVID-19 pandemic. Across social science disciplines, including, for example, psychology, political science, communication or sociology, studies have, for instance, addressed trust in science (Bromme et al., 2022; Rothmund et al., 2022), the information environment (Mach et al., 2021; Stier et al., 2022), misinformation (Hameleers et al., 2023; Yang et al., 2021) and news avoidance (de Bruin et al., 2021), polarization (Hart et al., 2020; Reiter-Haas et al., 2023), conspiracy theories (Batzdorfer et al., 2022; Hornsey et al., 2021), the psychological implications of telework (Schmitt et al., 2021) and self-isolation (Heffner et al., 2021), or the relationship between personality and responses to the pandemic (Anglim and Horwood, 2021).
Regardless of the specific question being investigated, providing reliable insights requires data. This is not different in the social sciences from any other area of scientific inquiry, including biomedical research. While not as varied as the topics, there is some variance in the types of data used in social science studies on the COVID-19 pandemic. As the cited examples show, the most common type is survey data, but researchers have, for instance, also analysed media content or posts and other types of data from social media platforms. What also differs widely is whether or in what form the research data collected or used for social science publications on the COVID-19 pandemic were published. There are different reasons for heterogeneous data publication practices. Important factors besides practical reasons, such as the required time and resources, include the ethical considerations.
Research ethics, research integrity and FAIR data
The FAIR principles specify that data should be Findable, Accessible, Interoperable and Reusable. Findable refers to readily discovering the metadata (data describing data) and data, typically with a unique identifier. Accessible means data are retrievable via an open and accessible protocol. Interoperable means the (meta)data can be exchanged (usually, this implies machine-readability). And finally, Reusable includes features, such as detailed description and provenance (Wilkinson et al., 2016). Before elaborating on FAIR data, it is useful to situate the FAIRness criteria within the broader frameworks of research ethics and research integrity. Scholars agree that there is broad overlap between the two, but also different emphases, with active debate as to the correct integration (Emmerich, 2020). Indeed, two widely recognized publications include both ‘Integrity’ and ‘Ethics’ in their titles (Iphofen, 2020; Israel, 2015). Ethics has primarily concerned research participants and risks of harm to them, whereas integrity often focuses on the role of host institutions and sponsors, and typically promotes honesty and independence while sanctioning research misconduct (e.g. fabrication or falsification of data) (Israel, 2015). Hence, research ethics tends to scrutinize research before it is undertaken, while integrity is typically assessed afterward. Within this framing, the FAIR principles are probably best seen as a method of enhancing research integrity. However, they have ethical implications as well, and these are becoming more prominent. The FAIR criteria of interoperability and reusability are both necessary for research transparency and the repurposing of data. Thus, by making research reproducible and replicable research, FAIR practices enable the implementation of the data management components of research integrity.
Other FAIR principles, Findability and Accessibility, are also directly relevant to research ethics. Social science research often uses individual-level data, most of which are typically personal data. The collected data can be sensitive, especially for crisis research. Hence, collecting, analysing and publishing social-scientific research data in crisis research is associated with legal and ethical concerns, such as privacy and data protection. For such data to be FAIR, it will typically be held and made available through a Trusted Digital Repository and meet requirements for legal and ethical processing.
Finally, the relevance of FAIR to ethics is strongest for matters concerning justice. Justice entails considerations of equity in research, ranging from equal opportunities to both participate in research and to benefit from its results. The motivation behind FAIR is usually understood as Open Data and Open Science, based on the assumption that openness and data sharing are positive. While this is broadly true, data sharing can ignore existing power inequities. The Global Indigenous Data Alliance developed the CARE principles that comprises Collective benefit from research, Authority to control their data, Responsibility to ensure that communities get enhanced data capabilities, and to promote Ethics, with special regard for the future (Carroll et al., 2020). The Research Data Alliance has been leading the effort to combine FAIR and CARE (Carroll et al., 2021). This integration could further align FAIRness with fundamental ethical frameworks, such as the Belmont Principles (National Commission for the Protection of Human Subjects of Biomedical and Behavioural Research, 1979). The call for collective benefit and the special regard for the future both support Beneficence. Accepting the authority of data subjects to control their own data undergirds Respect for Persons; and finally, enhancing the data handling skills and capacities of researched communities is one step towards greater equity and Justice, also for crisis research. This exemplifies the dynamic engagement of the FAIR communities with a range of research ethics and integrity concerns, including addressing tensions among competing ethical responsibilities.
Of course, there can be conflicts between different ethical obligations (Iphofen, 2020; Israel, 2015). The COVID-19 pandemic has highlighted the importance of being responsive while ensuring data quality for social science research (Kühne et al., 2020). Providing high-quality data in a timely manner was essential for implementing, assessing and adjusting policies, leading some researchers to argue that ‘Open science saves lives’ during a pandemic or in times of crisis more generally (Besançon et al., 2021). Accordingly, data sharing becomes even more critical during crises for science to be trustworthy and reliable. Hence, key questions for social science research in crises, such as the COVID-19 pandemic, include: Are the underlying data available? If so, can they potentially be re-used to check findings or conduct further research? Answering such questions requires a systematic evaluation of the data-sharing practices and the shared data.
Numerous institutions have adopted the FAIR Principles. While finding widespread support at a conceptual level, challenges emerged regarding translating the principles into action, specifically with regard to quantifying and measuring FAIRness (Bishop and Hank, 2018). One example of this effort in political science is a study by Eder and Jedinger (2019) in which the authors manually assessed the FAIRness of national election studies. In addition to such manual approaches, tools have been developed to measure FAIRness in an automated fashion, for example, the F-UJI assessment tool 1 (Devaraju and Huber, 2021), the FAIR-Checker, 2 the FAIR Evaluation Services 3 or the Fair-enough-metrics. 4 However, such assessments have not yet been conducted for the area of crisis research.
Aims and research questions
Our study aimed to assess how FAIR (Findable, Accessible, Interoperable and Reusable) social science data on the COVID-19 pandemic are and what implications this has for ethical questions related to data sharing in crisis research. We focused on these guiding principles as indicators of data-sharing practices and the value of shared data. To evaluate the FAIRness of the datasets, we employed a combination of automated and manual assessment. By synthesizing study-specific FAIRness scores of datasets and summarizing associated caveats, we could map the landscape of data sharing for social science research on the COVID-19 pandemic and identify best practices and potential issues to inform future practices. Based on existing research on data sharing and research ethics in the social sciences and the general considerations laid out above, we wanted to answer two research questions with our study:
Methods and data
The focus of our analyses are the FAIR criteria: Findability, Accessibility, Interoperability and Reusability. We employed a combination of automated and manual coding to assess the attributes of publications and the associated data (see Supplemental Appendix A for a complete list of variables, see (Batzdorfer et al., 2024) for our replication data and code). We based our manual coding scheme on the FAIR assessment items by Eder and Jedinger (2019). Accordingly, our manual coding assessed Findability by evaluating the availability of unique identifiers. Accessibility was measured by examining the extent to which datasets are openly and sustainably accessible and accompanied by open access modes and appropriate documentation. Interoperability was evaluated based on the level of standardized descriptive metadata. Reusability was assessed by evaluating the documentation and availability of code and the range of purposes for which the research data can be used (as well as its long-term integrity). Besides the FAIR variables, the manual coding added additional background variables: data collection date (month & year), the time lag between data collection and publication, the type of data used, the geography covered by the data, sample size and studied population for the case of survey data used (see Figure 1).
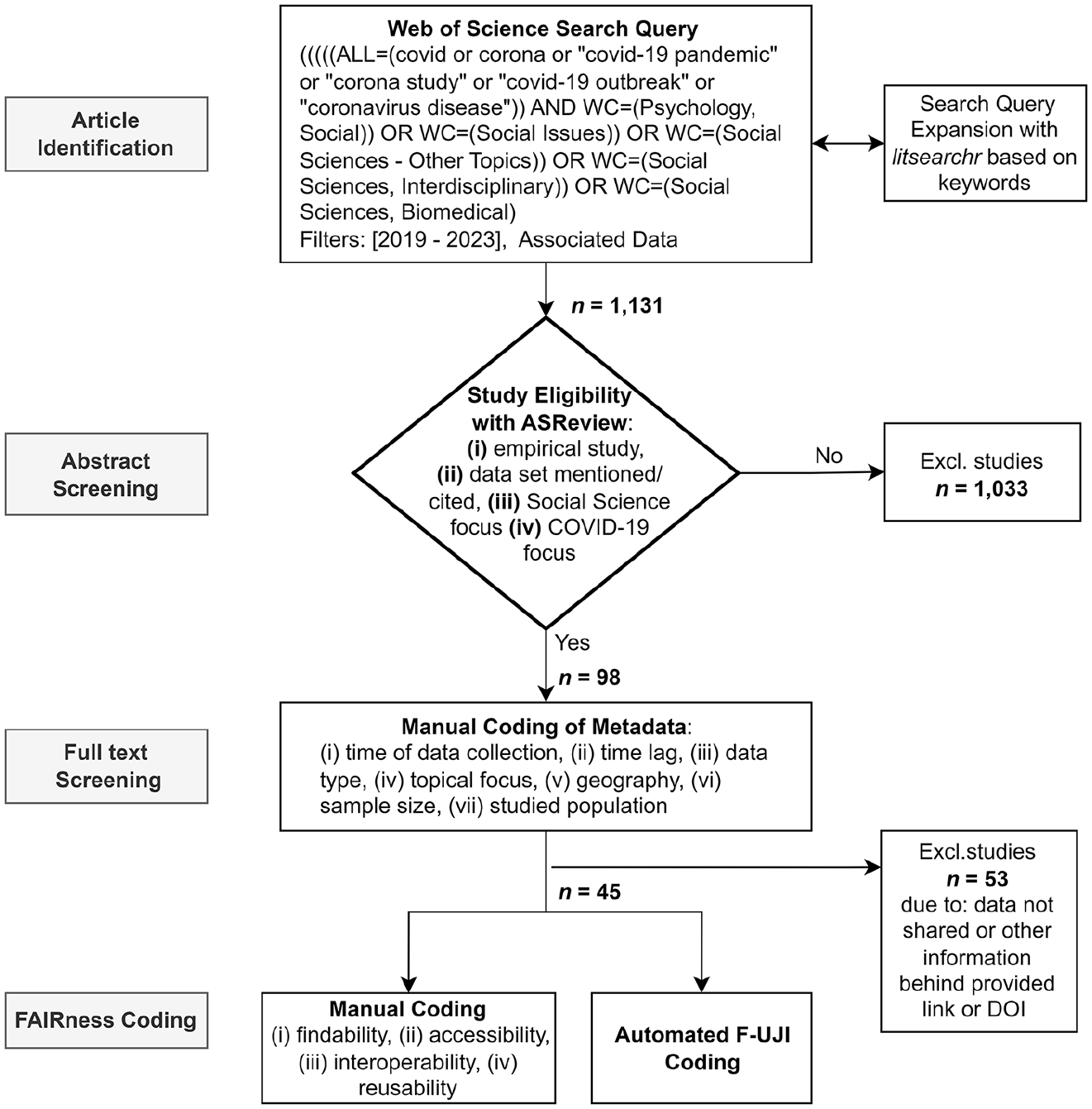
Flow-chart of article screening and data coding.
We employed a systematic multistep approach to identify social science publications on the COVID-19 pandemic and the associated data. The identification of relevant journal articles from social science research was based on a keyword search in the Web of Science database, with filters for the social science domain and associated data being available. Our first search query involved explicit COVID-19 terms, such as ‘covid or corona or covid-19’. This naïve Web of Science search was expanded using the R package litsearchr version 1.0.0 (Grames et al., 2019), which uses a network of word co-occurrences to optimize the coverage of relevant articles based on extracted keywords from titles and abstracts (see Figure 1). Using this keyword list in a Web of Science query yielded a dataset comprising 1131 search results. These results were semi-automatically coded for inclusion via the ASReview tool (van de Schoot et al., 2021). This approach facilitated the scalability of manual abstract screening by integrating active learning techniques. The process involved manual labelling for the relevance of titles and abstracts, augmented by a machine learning model—a naïve Bayes classifier based on TF-IDF (Term Frequency-Inverse Document Frequency) feature extraction. Using the relevance scores from manual labelling, the machine learning model predicted articles that were most likely relevant (van de Schoot et al., 2021) and this labelling and training loop was incrementally scaled up until the data-driven stopping criterion proposed by the authors of the tool (100 consecutive irrelevant articles) was reached.
The underlying inclusion criteria for the manual coding of the relevance of a publication for our study were as follows: (i) empirical studies, (ii) thematic focus on COVID-19, (iii) social science research focus and (iv) an unambiguous reference to at least one dataset in the paper. The resultant sample comprised n = 98 articles and was further subjected to full-text screening. We screened the referenced datasets for this set of eligible articles and extracted the Digital Object Identifier (DOI) or URL for each dataset. Some articles referenced software or other research outputs, such as visualizations, with a DOI but not the actual research data. These records were excluded, leaving N = 45 articles with dataset references. We used the first-mentioned dataset for articles with more than one dataset reference. The identified datasets were automatically analysed according to the FAIR principles using the automatic F-UJI assessment tool (Devaraju and Huber, 2021).
The F-UJI assessment tool with automated tests relies on machine-evaluable criteria to assess the higher-level metadata of the dataset according to the so-called ‘FAIRsFAIR’ metrics (Devaraju and Huber, 2021). The method defines metrics for each of the four FAIR principles and includes a set of tests for each metric. These tests can be run by evaluating a dataset DOI or URL, as well as querying services from re3data 5 and DataCite, 6 and result in a score for each of the four principles and an overall FAIR score. By calculating the percentage of the maximum score possible, an evaluation of the overall FAIRness of the four individual principles can be undertaken. 7 By using the percentage only, we simplify the evaluation for this paper. We used version 2.2.5 of the F-UJI tool 8 combined with version 0.5 of the metrics definition (Devaraju et al., 2022). The assessment comprises 45 tests for 16 (out of 17 defined 9 ) metrics. It applies them to available datasets and metadata in a machine-actionable way (see Supplemental Appendix B for the complete list of metrics).
As a third type of data, we also collected bibliometric data. For this, we used the R package openalexR version 1.2.3 (Aria and Le, 2023), which queries the API of the OpenAlex catalog 10 and allows article data augmentation with metadata, such as associated concepts (we used a threshold of >0.5 for the concept assignment confidence score) or citation count. OpenAlex provides concepts and confidence scores based on a concept tagger model of the title and abstract of articles (Aria and Le, 2023). We used the concepts for group comparisons of FAIRness scores and citation counts for additional correlational analyses.
Results
Descriptive results
In our final sample of articles (n = 45), the majority were published in 2023 (n = 17, 37.8%) and 2022 (n = 15, 33.3%), with fewer publications in 2021 (n = 11, 24.4%) and 2020 (n = 2, 4.4%). Data coverage spanned multiple continents, predominantly Europe (n = 19, 42.2%) and North America (n = 14, 31.1%). Fewer articles encompassed Asia (n = 6, 13.3%), Africa (n = 5, 11.1%), South America (n = 3, 6.7%) and Australia (n = 2, 4.4%). As several studies covered more than one geography, the assignment of multiple regions per publication was possible in our coding. For analytical purposes, we grouped Asia, South America, Africa and Australia (n = 8, 17.8%). The time lag between data collection and publication ranged from 1 to 38 months, averaging 18 months (SD = 10 months). Regarding data type, survey data was, by far, the most common type in our sample (n = 25, 55.6%), followed by experiments (n = 2, 4.4%), mixed methods (n = 4, 8.9%) and digital trace data (n = 3, 6.7%). Among survey articles (n = 20), sample sizes varied from 467 to 89,798, with a mean of 22,059 (SD = 27,273).
Based on OpenAlex concept data, articles were categorized into three main domains, again allowing for multiple concepts per article: Psychology (n = 30, 66.7%), Medicine (n = 24, 53.3%) and Political Science (n = 22, 48.9%) were the most frequent disciplines in our final sample. Additionally, the sample included publications associated with the concepts Sociology (n = 12, 26.7%) and Economics (n = 8, 17.8%). For analytical clarity, categories were consolidated into ‘Social Science’, encompassing Political Science, Sociology and Economics (n = 32, 71.1%). Regarding accessibility and citation metrics, among the 45 sampled articles, 41 were identified in OpenAlex. Of these, 27 (65.9%) were published open access, and 37 (90.2%) were accessible in open access formats elsewhere, including pre-/postprints. Citation counts for these articles varied from zero to 124, with an average of 14.4 citations (SD = 29.9).
To address research question
Manual and F-UJI FAIRness assessment.
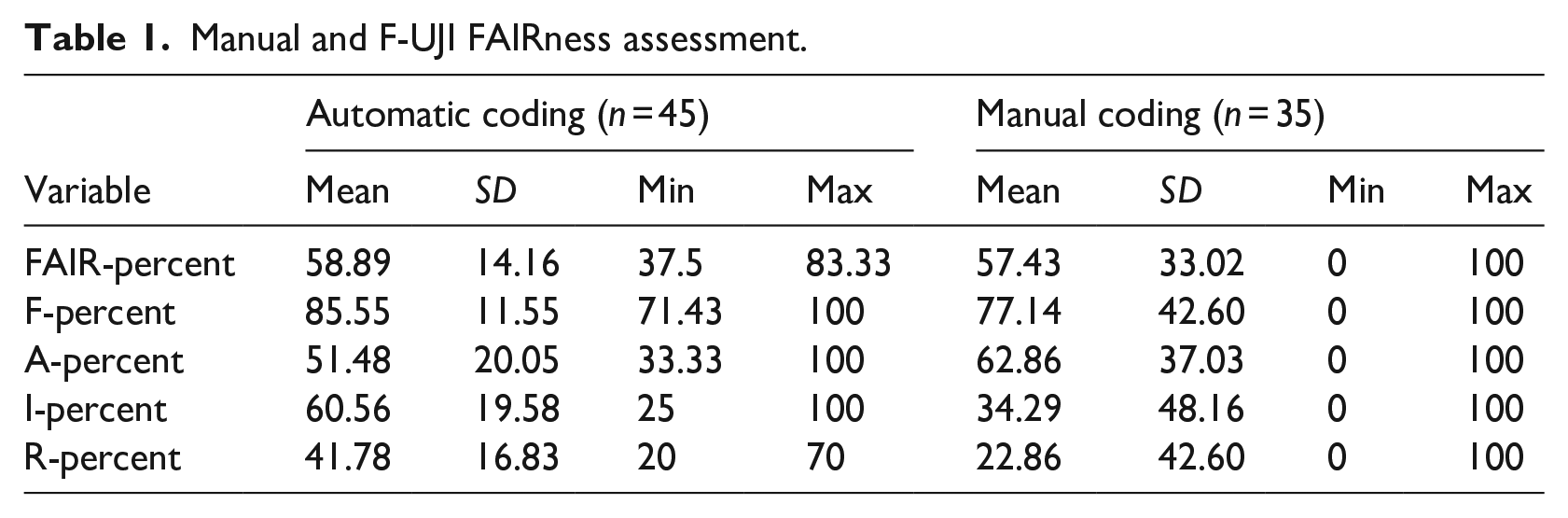
Assessing the FAIRness manually resulted in excluding some of the data DOIs as they were referencing some data but not the data used for the main analyses in the articles. As a result, there are only 35 articles with manually evaluated FAIRness in our final analysis. The manually coded FAIR values were also transformed into percentages (Table 1). The overall FAIRness from the manual coding has a mean value of 57.4% and a standard deviation of 33.0%. The findability mean is 77.1% (SD = 42.6%), the mean for Accessibility is 62.9% (SD = 37 %), the mean Interoperability is 34.3% (SD = 48.2%) and the Reusability mean is 22.9% (SD = 42.6%).
Regarding the FAIRness assessment of
To depict the FAIRness distribution, we categorized studies into quartiles using both manual and automated FAIR values (see Figures 2 and 3). Manual coding predominantly allocated datasets to the highest quartile (⩾75%), though some also fell into the lowest quartile (<25%). In contrast, automated coding led to a more balanced distribution, with datasets primarily falling into the 50% and below 75% quartile and none categorized in the lowest quartile.
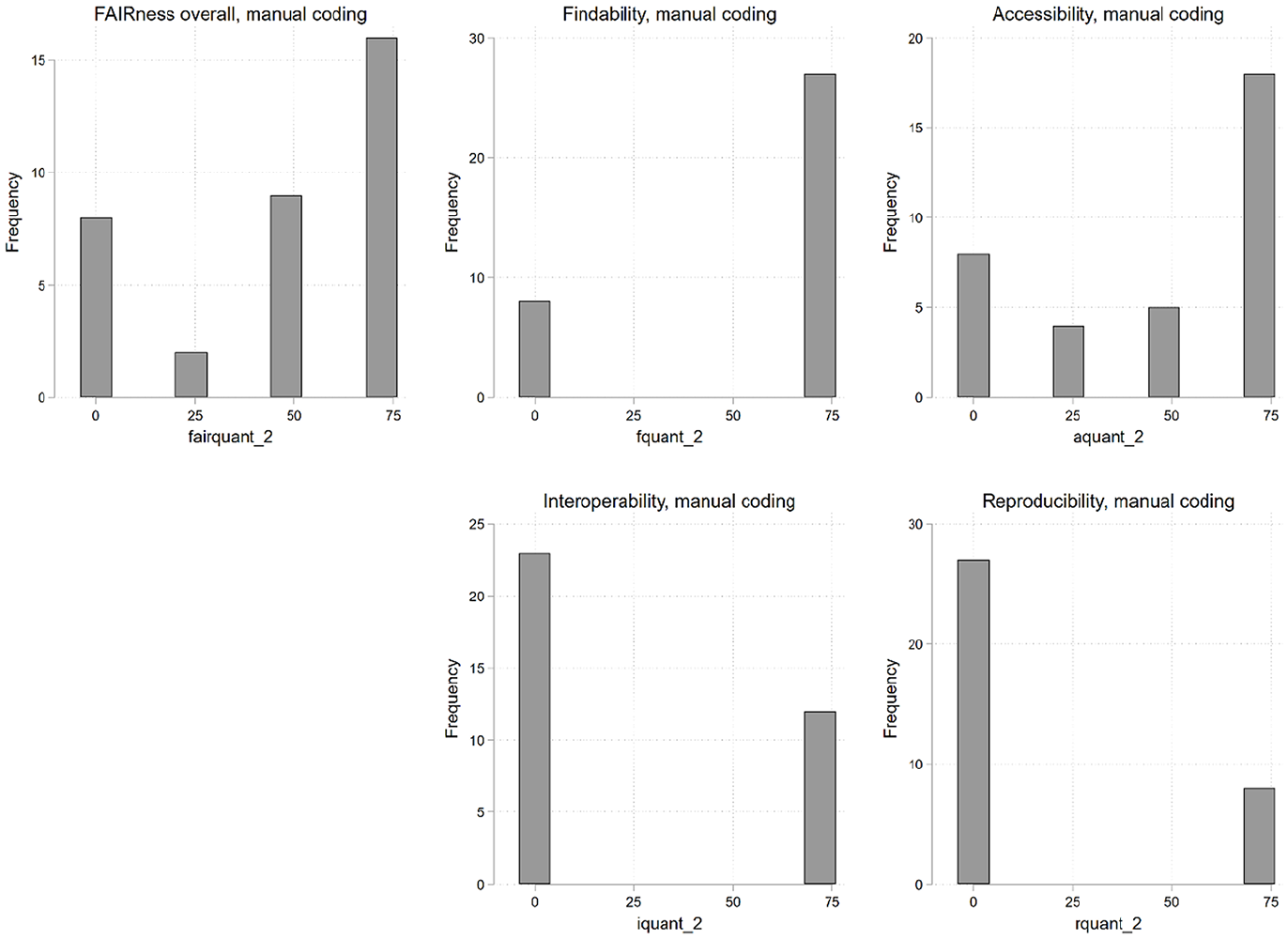
Number of datasets in quartile groups of FAIRness, manual coding.
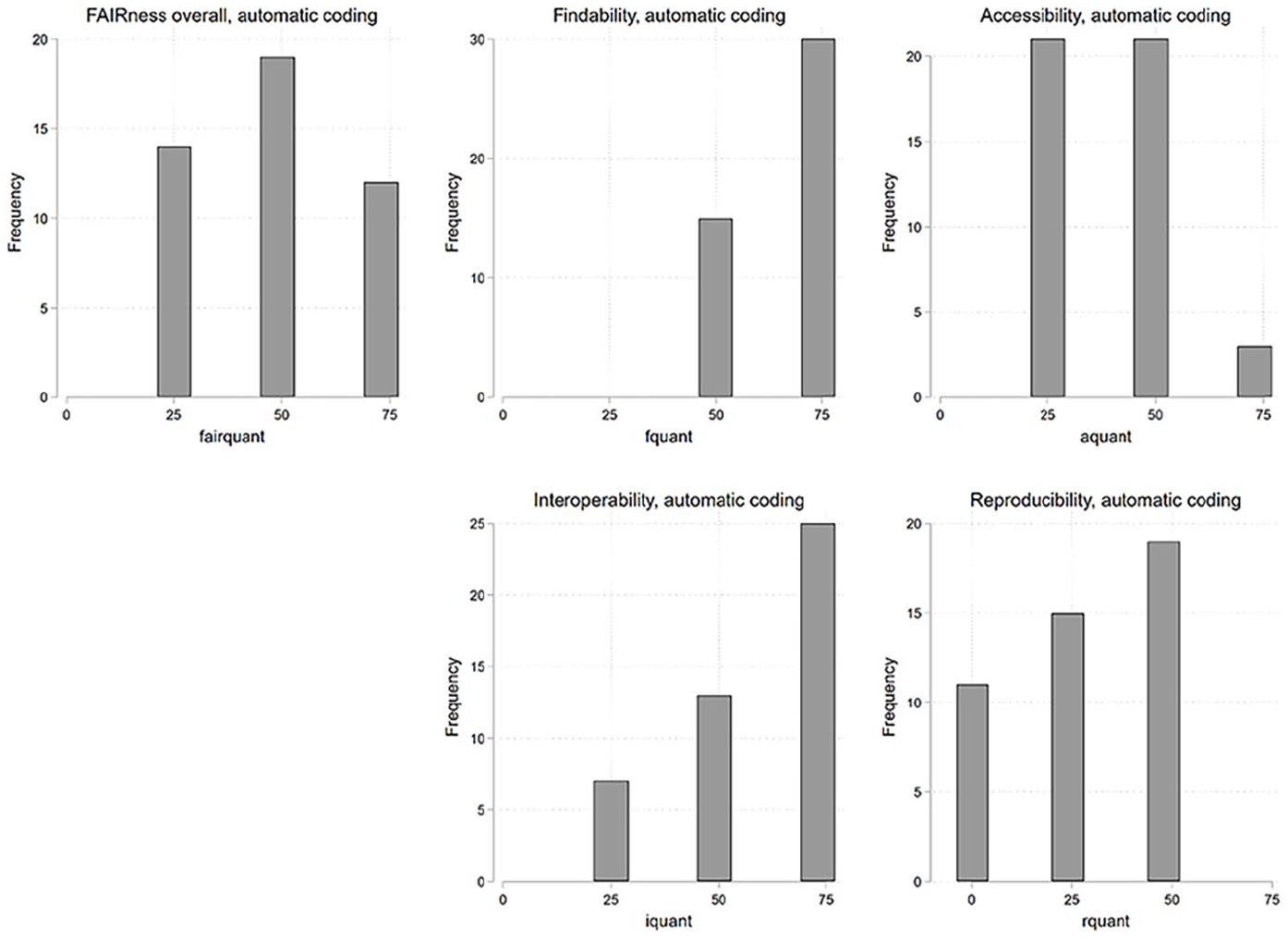
Number of datasets in quartile groups of FAIRness, automatic coding.
Most datasets have high Findability levels, as the manual and automatic coding shows. Similarly, a significant portion of datasets demonstrates acceptable or high Accessibility, as determined through manual and automated evaluations. However, a divergence emerges in the assessment of Interoperability; manual coding predominantly yields low Interoperability ratings, whereas automated methods frequently identify datasets with acceptable or high Interoperability. Regarding Reusability, the prevailing assessment across datasets is either low or mediocre, consistent across manual and automated analyses. 11
Correlational analyses and group comparisons
To assess the FAIRness attributes of research data within our sample, we utilized automated FAIRness scores represented as percentages. Group comparisons were conducted employing two-tailed t-tests (for details, cf. Supplemental Appendix C). Pearson’s pairwise correlation coefficients were employed for metric variables. No association could be found between FAIRness scores and publication year. Notably, no significant correlation was observed between the temporal gap from data collection to publication and FAIRness. Upon grouping articles based on geographical data origin, European datasets show inferior overall FAIRness (t(43) = 2.65, p = 0.0055). Moreover, European articles display lower Interoperability (t(43) = 4.04, p = 0.001) and Reusability values (t(43) = 2.54, p = 0.0073) in comparison to other continents.
In examining articles associated with distinct concepts, we compared their mean FAIRness values with other articles. Notably, articles linked to the Social Science concept exhibited a higher mean overall FAIRness (t(43) = −1.81, p = 0.0387). The same is true across individual components, such as Findability (t(43) = −1.82, p = 0.0380), Accessibility (t(43) = −1.72, p = 0.0463) and Interoperability (t(43) = −1.94, p = 0.0292). Similarly, articles with the Political Science concept demonstrated higher mean Interoperability (t(43) = -1.84, p = 0.0362). Furthermore, a noteworthy observation emerged in the context of data Accessibility, with open-access articles displaying a significantly higher mean (t(39) = −2.16, p = 0.0186) compared to other access-type counterparts. No significant difference could be found for articles that are available open access elsewhere (e.g. with pre- or post-print). Additionally, our analysis revealed no significant correlation between the number of citations and FAIRness values. The correlation of sample size for the survey datasets with FAIRness is significant for the Accessibility (r = -0.50, p = 0.0233) and the Reusability (r = -0.47, p = 0.0384), indicating lower FAIRness for higher sample sizes.
Overall, our analyses provided several insights that can help answer our
Discussion
In this section, we first summarize and discuss the empirical findings from our study. Subsequently, we contextualize FAIRness within the overarching framework of research ethics and conclude by offering specific recommendations pertinent to crisis research.
Empirical findings
In evaluating the FAIR principles of selected articles focused on COVID-19 within the realm of social science data, the overall FAIRness is deemed ‘acceptable’ but falls short of excellence. To contextualize this finding, we compare our results with those of Eder and Jedinger (2019) concerning national election studies. We quantify equivalent FAIRness percentages for comparison based on data from Eder and Jedinger (2019) (Table 2).
FAIRness percentage of election datasets.
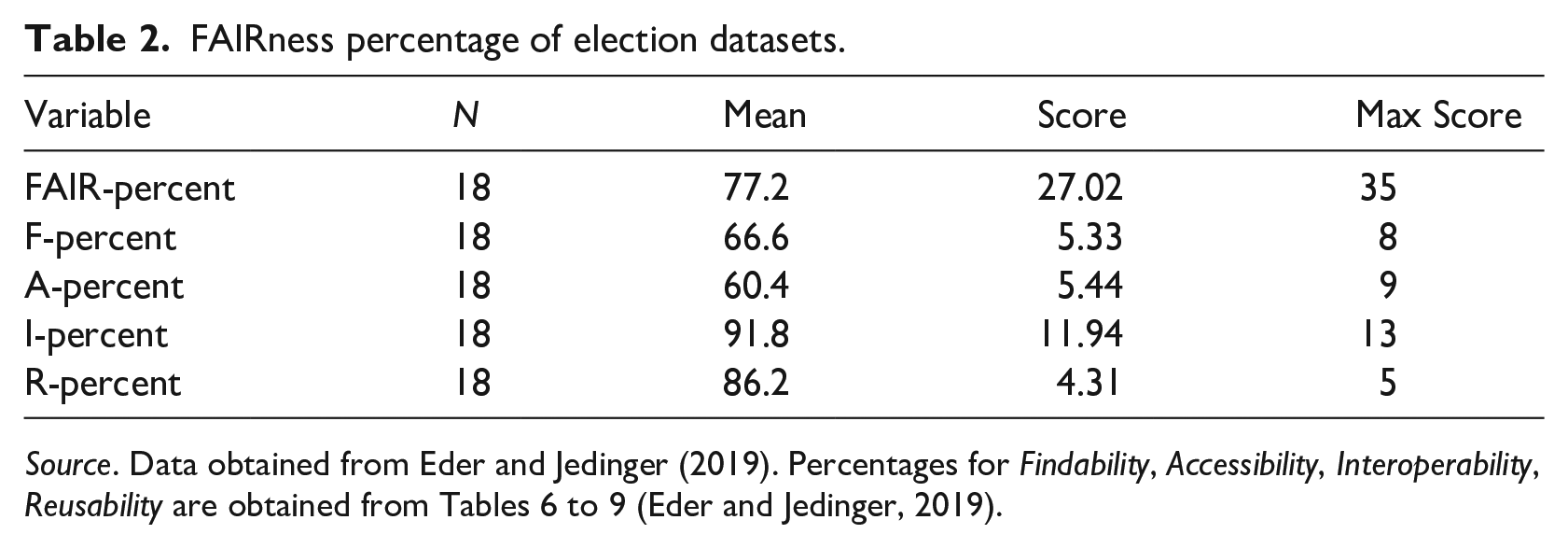
Source. Data obtained from Eder and Jedinger (2019). Percentages for Findability, Accessibility, Interoperability, Reusability are obtained from Tables 6 to 9 (Eder and Jedinger, 2019).
Eder and Jedinger reported an overall FAIR score of 77.2% for national election studies, categorized as ‘high’ based on our criteria. In contrast, our COVID-19 studies yielded a FAIR score of 58.9%, denoted as ‘acceptable’. A detailed breakdown across the four FAIR principles reveals similar trends in Accessibility, Interoperability and Reusability, with COVID-19 studies trailing behind national election studies. Notably, for Findability, there is a higher value for COVID-19 studies (85.6%) than for election studies (66.6%). In summary, while our COVID-19 studies show superior Findability, they do not attain the FAIRness levels observed in national election studies.
FAIRness in the context of research ethics
Arguably, one of the most widely accepted statements of research ethics for the protection of humans in research is the Belmont Report (National Commission for the Protection of Human Subjects of Biomedical and Behavioural Research, 1979). It defines three basic ethical principles: respect for persons, beneficence and justice. Against these criteria, how does FAIRness stand up? Some critics of FAIR find fault with the concept as overly technical or legalistic (see the Conclusion section below for one example), but can anything substantive be said regarding the extent to which making data FAIR also enhances other ethical objectives?
Respect for persons is expressed via respect for autonomy. Thus, informed consent is vital to the process that makes research with humans morally permissible. FAIRness has very little obvious connection with this principle. However, this is not the case for beneficence and justice. The principle of beneficence requires that we ‘do no harm’ or, more realistically, ‘maximize benefits and minimize harms’. FAIRness advances this aim; the principles of Interoperability and Reusability are specifically intended to ensure that the maximum value can be extracted from research data by making its reuse easier. The final Belmont principle is justice. Again, here, FAIRness is strongly aligned with and supportive of this principle. The purpose of enhancing Accessibility is to make access to the valuable resource of data more equitable and not the preserve of well-funded scholars and institutions. To be certain, there is no one-to-one mapping here. FAIRness does not ensure that research meets all ethical standards. Adherence to the FAIR principles alone does not guarantee that research will be conducted in an ethical fashion. Even if research generates data that are findable, accessible, interoperable and reusable, this does not guarantee that all ethical norms and standards were adhered to in the research process, for example, with regards to privacy standards. FAIR principles concentrate on measurable attributes, on formal and technical aspects. However, there is substantial overlap between FAIR principles and principles of research ethics. Moreover, as the example of the CARE principles above indicates, there is growing advocacy for greater integration between FAIR and key ethics principles of collective beneficence and justice.
Recommendations for crisis research data management
Drawing insights from our study, we propose strategic guidelines for the effective handling of research data in future social science crisis research throughout the data life cycle:
Notably, these recommendations are valid for all research data, not only crisis data. However, how they are weighted shifts in a crisis. For example, the need to share information quickly may justify taking shortcuts on the comprehensiveness of documentation, which can be minimal at first and augmented at a later date. What is important to consider when it comes to sharing research data is that, while we are focusing on research on crises, research itself – in the social sciences and beyond – has also been facing a crisis. A key reason for the widely discussed ‘replication crisis’ is the limited availability of the underlying research data (Freese and Peterson, 2017). Given the high relevance of social-scientific crisis research for policymaking (Ruggeri et al., 2023; Van Bavel et al., 2020), not addressing the reasons for the replication crisis would be especially problematic. This further highlights the importance of making research data available and reusable.
Limitations
As with every empirical study, ours has several limitations that should be taken into account when considering its results. These limitations relate to, firstly, the choice of the database and the specificity of search criteria, which may affect the generalizability of our results to other settings. While our selection was guided by careful consideration of relevance and accessibility, variations in database structures and search algorithms across platforms could influence the reproducibility of our study in different contexts. Secondly, the strict assumptions inherent in the F-UJI tool scoring system pose a limitation. The requirement for available DOIs for scoring introduces a potential bias, as not all datasets adhere to this standard. Moreover, the existence of grey areas in data-sharing practices may introduce subjectivity in scoring, impacting the reliability of our results. Also, the data policy of the journal in which a study is published may influence the extent of FAIR data sharing (Zenk-Möltgen et al., 2018). Lastly, numerous other influencing factors that we did not consider in our study, such as repository selection, associated metadata requirements, or study topic, may significantly impact the FAIRness of datasets.
Conclusion
Given its global scale and the challenges it entailed for both scientific research and policymaking, the COVID-19 pandemic presents an instructive case for crisis research. Notably, the pandemic has substantially impacted how science is disseminated and perceived. Going even further, it has also transformed how science is done. This pertains to the need for open and rapid data sharing as well as the increased relevance of preprints (Watson, 2022). Overall, the case of the COVID-19 pandemic shows that incorporating social science research in policymaking in times of crisis avoids the creation of simple or blanket solutions to public health problems and raises awareness of the undesirable or counter-productive outcomes of such policies (Pickersgill et al., 2022). In addition, social science research enables policymakers to become more aware of the effectiveness of a policy to achieve a pre-defined goal and minimize or balance the potential inequalities and unwanted asymmetries that these policies might bring (Lohse and Canali, 2021).
Of course, the COVID-19 pandemic was unique in many ways. But as climate change accelerates, it is to be expected that various localized and potentially more global crises lie ahead. While many of the substantive research findings on the COVID-19 crisis are quite likely not generalizable to others, many of the meta-scientific ones quite likely are. Based on their ‘synthesis of evidence for policy from behavioural science during COVID-19’, Ruggeri et al. (2023) propose a general approach to analysing policy evidence that could be useful for future crises. Likewise, we believe that while not all findings from our study can be generalized to other and especially future crises, the recommendations we derive from them are useful for other and future crisis research.
Supplemental Material
sj-docx-1-rea-10.1177_17470161241257575 – Supplemental material for Between urgency and data quality: assessing the FAIRness of data in social science research on the COVID-19 pandemic
Supplemental material, sj-docx-1-rea-10.1177_17470161241257575 for Between urgency and data quality: assessing the FAIRness of data in social science research on the COVID-19 pandemic by Veronika Batzdorfer, Wolfgang Zenk-Möltgen, Laura Young, Alexia Katsanidou, Johannes Breuer and Libby Bishop in Research Ethics
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
All articles in Research Ethics are published as open access. There are no submission charges and no Article Processing Charges as these are fully funded by institutions through Knowledge Unlatched, resulting in no direct charge to authors. For more information about Knowledge Unlatched please see here: ![]()
Ethical approval
The authors declare that research ethics approval was not required for this study.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.