
Abstract
Indoor object detection is a very demanding and important task for robot applications. Object knowledge, such as two-dimensional (2D) shape and depth information, may be helpful for detection. In this article, we focus on region-based convolutional neural network (CNN) detector and propose a geometric property-based Faster R-CNN method (GP-Faster) for indoor object detection. GP-Faster incorporates geometric property in Faster R-CNN to improve the detection performance. In detail, we first use mesh grids that are the intersections of direct and inverse proportion functions to generate appropriate anchors for indoor objects. After the anchors are regressed to the regions of interest produced by a region proposal network (RPN-RoIs), we then use 2D geometric constraints to refine the RPN-RoIs, in which the 2D constraint of every classification is a convex hull region enclosing the width and height coordinates of the ground-truth boxes on the training set. Comparison experiments are implemented on two indoor datasets SUN2012 and NYUv2. Since the depth information is available in NYUv2, we involve depth constraints in GP-Faster and propose 3D geometric property-based Faster R-CNN (DGP-Faster) on NYUv2. The experimental results show that both GP-Faster and DGP-Faster increase the performance of the mean average precision.
Introduction
Indoor object detection is a very demanding and important task for robot applications. Generally, object detection contains two main tasks: the localization and classification problems. 1 Object detection is not an easy task due to the uncertainty of the location of the interest object. In this work, we focus on the indoor object detection.
Our work is motivated by two questions on the robot application. First, is the geometric property helpful for mobile robot to detect indoor object? Second, if the first answer is positive, how can the geometric property be used to detect indoor object? Since the depth information is not always available, we employ the shape of the bounding box as a universal geometric property to improve the performance of the indoor object detection.
In the last two decades, object detectors based on convolutional neural networks (CNNs) 2 –6 have achieved state-of-the-art results on various challenging benchmarks. 7,8 As a representative region-based CNN detector, Faster R-CNN 4 uses a region proposal network (RPN) to generate proposals. The regions of interest (RoIs) produced by RPN (RPN-RoIs) are chosen to train the proposals if (1) an RPN-RoI overlaps a ground-truth box with a highest intersection-over-union (IoU) overlap and (2) its IoU overlap is greater than a threshold. Every selected RPN-RoI is assigned a training label, which is the ground-truth label with the highest IoU overlap. Although the selection strategy of RPN-RoI is efficient, it does not focus on the geometric property of the candidates. The knowledge of the indoor object, such as geometric shape and context, may be helpful for detection. In this study, we use the shape of the bounding box as a two-dimensional (2D) geometric property to improve Faster R-CNN for the indoor object detection.
We first run over the indoor dataset to result in the widths and heights of the annotated bounding boxes. Then, we put them in the first quadrant of the Cartesian plane with their left-bottom points at the origin. The 2D geometric constraint of every classification is a convex hull region enclosing corresponding right-upper points. Figure 1 shows the 2D constraints of the 18 indoor classes collected from SUN2012 (http://groups.csail.mit.edu/vision/SUN/) database. 9 The black points show the coordinates composed by the widths and heights of the annotated bounding boxes.

The 2D geometric constraints of the 18 indoor classes of SUN2012. The black points show the width and height coordinates of the annotated bounding boxes. (a) wall, (b) window, (c) floor, (d) ceiling, (e) plant, (f) door, (g) curtain, (h) painting, (i) chair, (j) person, (k) table, (l) cushion, (m) bottle, (n) desk lamp, (o) bed, (p) pillow, (q) sofa, and (r) television.
From Figure 1, it can be seen that the scales and aspect ratios on the indoor classes vary in a large range. The “cushion,” “bottle,” “desk lamp,” “pillow,” and “television” are small objects. The “door” and “bottle” are thin objects with large aspect ratios, while “ceiling” and “table” are thick objects with small aspect ratios.
In this study, we propose 2D geometric property-based Faster R-CNN method (GP-Faster) for indoor object detection. For indoor applications, small objects, such as “bottle,” “pillow,” and “television”, are common targets in indoor scene. Because the coverage of the anchors generated from standard Faster R-CNN cannot fit the size of the small indoor objects, we first use mesh grids to generate appropriate anchors for small indoor objects, in which the grids are the intersections of direct and inverse proportion functions. After the anchors are regressed to RPN-RoIs, we then use the 2D constraints to refine the RPN-RoIs, that is, the width and height coordinates of the RPN-RoIs that fall in their 2D constraints are employed as inliers. The 2D constraints may remove outliers in RPN-RoIs. Extensive experiments implemented on SUN2012 9 and NYUv2 (https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html) 10 demonstrate that GP-Faster is able to improve detection performance for indoor object. The geometric property is helpful for region proposal.
Our main contributions are summarized as follows: We use mesh grids to generate anchors with the help of direct and inverse proportion functions. We use the shape of the bounding box as a universal geometric property to improve region proposals for classification. We use geometric constraints to remove the RPN-RoIs that may produce negative predictions. Compared with Faster R-CNN, our GP-Faster approach increases the performance of the mean average precision (mAP).
Related work
There are an increasing number of recent studies that focus on CNN-based indoor object detection. Gopan and Aarthi designed a CNN to identify bottles in the indoor environment. 11 Mordan et al. designed a context-based residual auxiliary block to combine ResNet and single-shot multibox detector for indoor object detection. 12 Zheng et al. combined CNN and recurrent neural network (RNN) to implement indoor semantic segmentation. 13 Ammirato et al. 14 first extracted CNN features from the target and scene images, and then, fed the features to a target-driven instance detector for object detection. Ehsan and Nahvi detected indoor people violence based on a combination of motion trajectory and spatiotemporal features. 15 Zhou et al. proposed a multimodal fusion deep CNN framework for object detection and segmentation. 16 The CNN-based indoor detectors usually pay much attention to the architectures of their networks and do not focus on application scenario. For indoor applications, the property of the indoor object may be helpful for detection.
Because mobile robot usually needs to detect indoor object for their navigation and service, many kinds of literature focus on vision-based object detection for robot. Reyes et al. proposed a CNN method based on You Only Look Once 5 to detect object for pepper. 17 Zhu et al. proposed a CNN-based indoor landmark detector with the help of a topological matching algorithm. 18 Together with classical classifier, Jiang et al. proposed a CNN-based tracking method for person-following robot. 19 Loghmani et al. proposed a two-stream fusion method for robot vision, 20 in which the features of the two CNN streams of RGB and depth images are fed into an RNN to detect objects. Sampedro et al. proposed a fully autonomous aerial robotic solution for search and rescue missions in indoor environments. 21 After employing Mask-RCNN 6 for image segmentation, Kowalewski et al. presented a full solution that produces object-level semantic perception of the environment for indoor mobile robot. 22 Although the vision-based detectors show advances in robot vision, many of them tend to assemble techniques.
Because geometric property is helpful for object understanding, geometric property is used in both traditional method 23 –25 and CNN-based method. 26 –28 Wu and Wang employed geometric property to detect elliptical object. 23 Batool and Chellappa applied geometric constraints to localize curvilinear shapes for wrinkles detection. 24 Ismail et al. estimated the indoor spatial layout using the vanishing point and then detected the object by studying the relation of the scene to the object. 25 Pham et al. first predicted a boundary map using a CNN and then employed a hierarchical segmentation tree to produce geometric and object segmentation. 26 Mizginov and Danilov combined generative adversarial networks and three-dimensional (3D) geometric modeling to detect traffic target. 27 Cai et al. employed geometric prior knowledge to improve a CNN-based method for planar object detection. 28 Since a kind of road object (e.g. car or bus) is usually in a standard size and the surveillance camera is static, the scale distribution of the class in the video frames can be estimated after the horizon is estimated by scene geometry. Amin and Galasso applied the scale distributions over the road classes to prune proposals. 29 However, the method is not appropriate for indoor objects due to the nonuniqueness of the scale distribution in indoor scene. The indoor robot moves in room and the indoor objects, such as wall, floor, or ceiling, may be not in standard size. A same object may be occurred in an image at the same position but in different pixel sizes. Although geometric properties are used for object detection, the CNN-based study of geometric property for indoor object detection is insufficient. Motivated by the application of the robot vision, we use geometric property to improve CNN-based detector in this study.
Proposed method
In our design, the main task of GP-Faster is to use 2D geometric property to improve region proposals. The main design of GP-Faster is shown in Figure 2. The blue modules show the loss of training. The red modules show our improvements. The FG prob in Figure 2 is the abbreviation of foreground probability, which is reshaped from a softmax layer. With the help of direct and inverse proportion functions, we first use mesh grids to generate appropriate anchors for indoor object location in the module of anchors generation. With the help of geometric prior knowledge, we then incorporate 2D geometric constraints in Faster R-CNN to train proposals for classification, as the module of geometric constraint shown in Figure 2.

The training framework of our proposed GP-Faster. The red modules show our improvements. GP-Faster: geometric property-based Faster R-CNN method.
Generating appropriate anchors
Faster R-CNN produces anchors to regress the bounding boxes of objects. Each anchor is generated with a scale s and an aspect ratio r, where
Figure 3 shows the generation schedule of our design. The points show the widths and heights of the ground-truth boxes of the 18 indoor classes in SUN2012, in which the images are rescaled such that their shorter side is 600 and the other side is no more than 1000. The constraints of aspect ratios can be regarded as directly proportional functions as follows


The generation schedule of the anchors. The points show the widths and heights of the ground-truth boxes. The black lines show the aspect ratios of the anchors. The curves show the sizes of the anchors.
They are shown as the black lines in Figure 3. Similarly, the size constraints of the anchors can be regarded as inverse proportion functions

The curves in Figure 3 show the size constraints. The width and height of every anchor are determined by equations (1) and (2) with a certain combination

The anchors on each feature point are the intersections of the direct and inverse proportion functions, as the intersection of the lines and curves shown in Figure 3.
Different from the common dataset, there are a considerable number of small objects in the indoor dataset. As shown in Figure 3, there are a large number of black points near origin. Although Faster R-CNN uses bounding-box regression to adjust the error from an anchor box to a ground-truth box, the regression may be powerless when the error between them is too large. An anchor that overlaps a ground-truth box with a high IoU overlap is employed to train the regression. In other words, an object cannot be involved in training if there is no anchor overlapping it with a high IoU overlap. In this study, we design inverse proportion curves near origin to trap the small ground boxes, as the red curves shown in Figure 3.
GP-Faster designs the scales of the anchors as follows

where
2D geometric constraints
To improve the inliers ratio on RPN-RoIs, we use 2D geometric constraints to refine RPN-RoIs, as shown in Figures 1 and 2. We first prepare 2D geometric prior knowledge. For convenience, let the coordinate of the j’th annotated object in the i’th training image Ii
be Run over the training set to obtain the point sets Obtain
We then use the prepared prior knowledge to result in 2D constraint. Faster R-CNN uses anchors for bounding box regression. Not only the anchors inside of the region of Bk
but also the anchors near outside of the region of Bk
may be used for box regression. Let the current training image be Ii
, the anchors set of the resulting RPN-RoIs be

The 2D constraint of
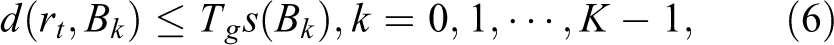
where Tg
is a threshold,
To implement the refinement of RPN-RoIs, let the number of RoIs we choose in RPN-RoIs be
Initialize
For
Add at
to
(a)
(b) the 2D constraint equation (6), where
Add at
to
Repeat steps 2 to 4 until all the at have been processed.
Update
Update
The set of RoIs is
The geometric constraints are only employed to train models. They are not used for model test. After the refinement of RPN-RoIs is implemented, the resulting RoIs are fed to full connections to result in training loss. Overall, GP-Faster generates appropriate anchors and implements 2D geometric refinement on the training set for improvement.
Implemental details
Besides thresholds
We tune the parameters on SUN2012 using VGG16. 31 After comparing the classes of the datasets Indoor09, 32 SUN2012, 9 and NYUv2, 10 we use 18 common indoor classes for implementation. They are “wall,” “window,” “floor,” “ceiling,” “plant,” “door,” “curtain,” “painting,” “chair,” “person,” “table,” “cushion,” “bottle,” “desk lamp,” “bed,” “pillow,” “sofa,” and “television” (Figure 1). The model is trained on the 18 classes of the SUN2012 training set. It is evaluated on corresponding classes of the SUN2012 test set using mAP. Because the object occluded is listed as a new class in SUN2012, the eight classes in SUN2012, including “person occluded,” “person sitting occluded,” “person,” “person standing,” “person walking,” “person crop,” “person sitting,” and “person sitting crop,” are fused to the class “person.” Similarly, the eight classes, including “chair occluded,” “chair,” “chair crop,” “armchair,” “armchair occluded,” “swivel chair,” “armchair crop,” and “deck chair,” are fused to the class “chair.”
The publicly available VGG16 model pretrained on ImageNet 2 is used for initialization. We train and test networks on images of a single scale in which the shorter side is 600 pixels. We initialize a learning rate of 0.001 and make the learning rate drop 10 times after every 80 k iterations on the dataset. A total of 100 k training iterations are run.
We run experiments to tune the training parameters
The ablation experiments of GP-Faster16 on the SUN2012 test set.

mAP: mean average precision; Pre: precision; Rec: recall.
As shown the first three lines in Table 1, the mAP obtained by
Besides the four parameters, extended experiments show that
Experiments and results
We evaluate our method on two datasets: SUN2012
9
and NYUv2.
10
Our experiments are implemented based on the framework of Faster R-CNN.
4
Both VGG16
31
and ResNet101
33
are employed as our backbone networks. The VGG16-based and ResNet101-based experiments are, respectively, carried out on Caffe
34
and TensorFlow.
35
The publicly available VGG16 and ResNet101 models pretrained on ImageNet are used for corresponding initialization. For the sake of brevity, the standard Faster R-CNN implemented with the backbone networks of VGG16 and ResNet101 are, respectively, abbreviated as Faster16 and Faster101. We use a 1-GPU implementation, and thus, the minibatch size of RPN is 1. The VGG16 models are trained starting from conv3_1 using an end-to-end schedule. The ResNet101 models are trained starting from block2, that is, the parameter FIXED_BLOCKS is set to 1. We use a momentum of 0.9 and a weight decay of
Experiments and results on SUN2012
In this section, we evaluate GP-Faster on the SUN2012. We initialize a learning rate of 0.001 and make the learning rate drop 10 times after every 60 k iterations. A total of 100 k training iterations are run. To implement comparisons, we first run standard Faster R-CNN on the 18 classes collected from the SUN2012 set. Then, we run GP-Faster using the parameters in the aforementioned section. Table 2 presents our experimental results on the test set of SUN2012. The standard metric mAP is the average precision evaluated at IoU = 0.5. The columns of GP-Faster16 and GP-Faster101 show the results of our method using VGG16 and ResNet101 as the backbone networks, respectively.
Detection results on the SUN2012 test set (%).

mAP: mean average precision.
As provided in Table 2, we compare our method with the standard Faster R-CNN. GP-Faster outperforms Faster R-CNN. GP-Faster16 and GP-Faster101 achieve mAPs of 53.9% and 56.5%, respectively. Compared with the baseline Faster R-CNN, corresponding improvements of the mAPs are, respectively, 6.8% and 6.4%. It can be seen that the 2D geometric property provides extra auxiliary discrimination.
Figure 4 shows some detection results on the SUN2012 test set. The implementation models are Faster16 and GP-Faster16 (53.9% mAP). A score threshold of 0.6 is used to draw the detection bounding boxes. The blue and red colors, respectively, show the detections launched by Faster16 and GP-Faster16.

(a–j) Detection examples of Faster16 and GP-Faster16 on the SUN2012 test set. A score threshold of 0.6 is used to draw the detection bounding boxes. The blue and red colors, respectively, show the detections launched by Faster16 and GP-Faster16.
Figure 4 demonstrates that the 2D geometric property is helpful for indoor object detection. On the one hand, some positive objects are undetected by Faster16, but they are detected by GP-Faster16, such as “painting” and “door” in Figure 4(a), “desk lamp” in Figure 4(c), “window” and “door” in Figure 4(d), “door,” “plant,” and “chair” in Figure 4(e), “painting” and “curtain” in Figure 4(i), “pillow” in Figure 4(j). On the other hand, GP-Faster16 corrects some false detection of Faster16, such as “chair” in Figure 4(b), “person” in Figure 4(f), “desk lamp” in Figure 4(g), “table” and “chair” in Figure 4(h). The detection results suggest that GP-Faster is more powerful than Faster R-CNN on indoor object detection.
Experiments and results on NYUv2
In this section, we implement our proposed method on the NYUv2 dataset. The standard split of 795 training images and 654 testing images is employed for experiments in this work. To compare with the state-of-the-art methods
12,36,37
on the NYUv2 dataset, 19 classes are extracted for experiments. After the images are rescaled such that their shorter side is 600 pixels, Figure 5 shows the 2D constraints of the 19 classes. The scale parameter

The 2D geometric constraint of 19 indoor classes on NYUv2.
Since NYUv2 is composed of pairs of RGB and depth frames that have been synchronized and annotated with dense labels for every image, we take the depth information into account in this section. After running over the depth frames of the dataset, we first extract the depths of all the objects with the help of the dense annotation. The depth constraint of every class is a maximum depth on corresponding objects. To avoid nontarget invasion from the background in the bounding box of RPN-RoI, a similar box with a quarter area centered in the RPN-RoI box is then cropped, and the depth values on the horizontal and vertical lines that are centered in the cropped box are used to approximate the object depth. The depth constraint is employed to refine RPN-RoI. In detail, the approximated object depth is required to be not greater than its corresponding class depth. Figure 6 shows our depth constraint. Figure 6(a) shows a depth frame. Figure 6(b) shows the depth of the “table” in Figure 6(a). Figure 6(c) shows an RPN-RoI of the “table” that overlaps with the “table” in Figure 6(a) with a certain IoU overlap. The color bar shows the depth values in meters in Figure 6(b) and (c). In Figure 6(c), the depth values on the red and white lines in the black box are employed to approximate the depth of the “table.”

(a–c) Illustration of the depth constraint.
After combining 2D geometry and depth constraints to refine RPN-RoIs, we propose 3D geometric property-based Faster R-CNN (DGP-Faster) in this section. DGP-Faster16 and DGP-Faster101 are, respectively, implemented with the backbone networks of VGG16 and ResNet101. For DGP-Faster, the geometric parameter Tg
is set to
Detection results on the NYUv2 test set (%).
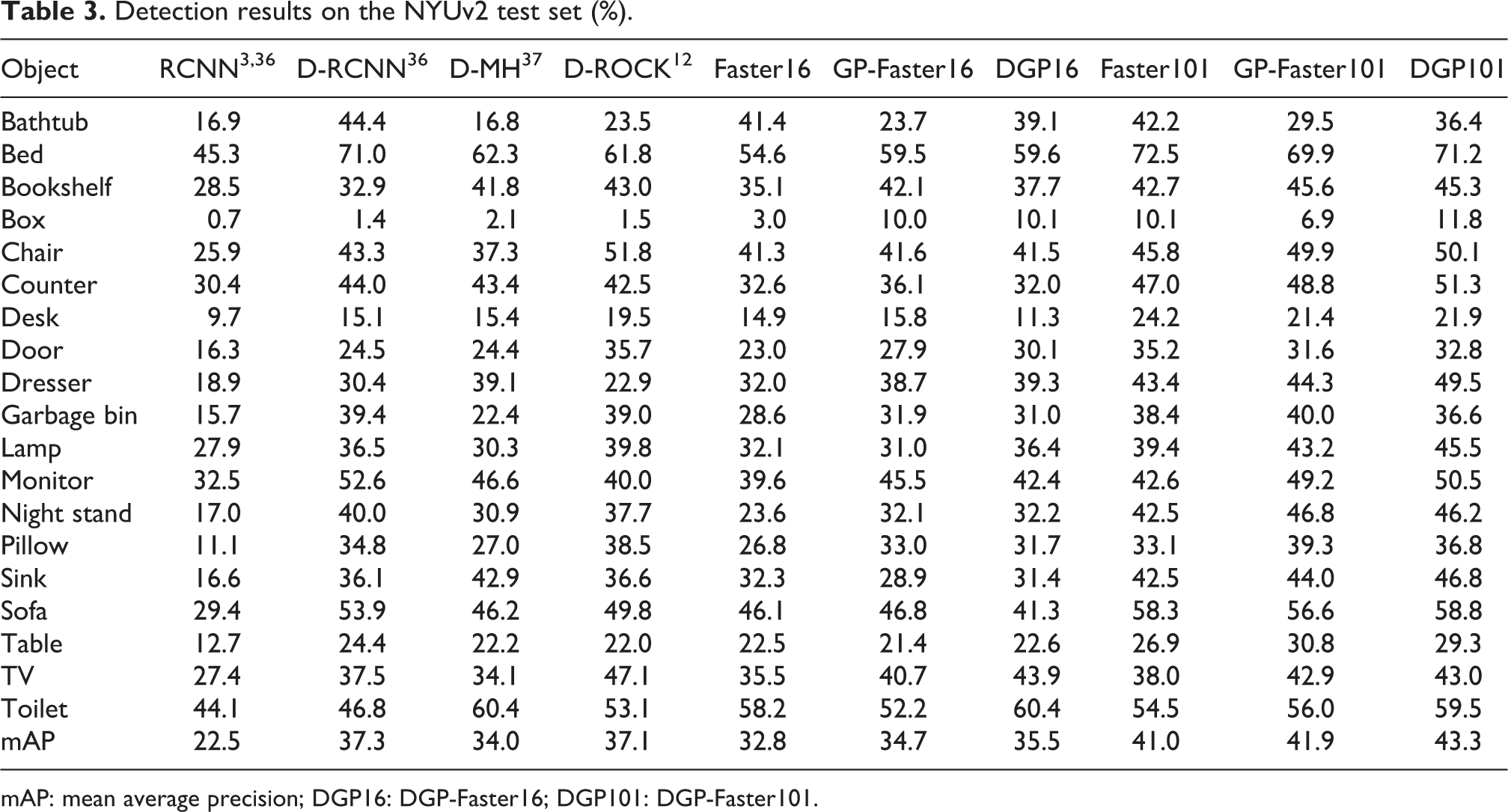
mAP: mean average precision; DGP16: DGP-Faster16; DGP101: DGP-Faster101.
As presented in Table 3, we compare our method with the state-of-the-art models. After implementing Faster16 and Faster101 on the dataset of NYUv2, we obtain the baseline results, which are, respectively, 32.8% and 41.0%. As given in Table 3, GP-Faster16 and GP-Faster101, respectively, achieve mAPs of 34.7% and 41.9%. Compared with the baseline results, corresponding improvements on mAP are, respectively, 1.9% and 0.9%. It can be seen that the 2D constraints are also helpful for indoor object detection on the NYUv2 dataset. In addition, DGP-Faster16 and DGP-Faster101, which involve depth constraints in training, achieve mAPs of 35.5% and 43.3%, respectively. Compared with 2D geometric property-based detectors, DGP-Faster16 improves the mAP by 0.8% and DGP-Faster101 improves the mAP by 1.4%. DGP-Faster101 achieves the greatest mAP and outperforms all the state-of-the-art detectors in mAP. It can be seen that the depth constraint provides extra auxiliary discrimination. Overall, both the 2D geometry and depth constraints are helpful for indoor object detection.
We evaluate the inference time of our detectors on NYUv2. Although geometric constraints are not used for model test, our detection parameters
Discussion
To improve the performance of the indoor mobile robot, we proposed GP-Faster and DGP-Faster, which incorporates geometric property in Faster R-CNN to improve the detection performance. Faster R-CNN chooses RPN-RoIs to train the proposals. However, on the one hand, some outliers in RPN-RoIs are chosen as candidates. On the other hand, some small indoor objects cannot be covered by anchors generated by the standard Faster R-CNN. In this study, we employed the shape of the bounding box as a universal property and used geometric constraint to refine RPN-RoIs. In addition, we use mesh grids to generate appropriate anchors for indoor objects with the help of direct and inverse proportion functions. The comparison experiments implemented on the SUN2012 and NYUv2 datasets showed that GP-Faster improved the performance of the mAP. The experiments on NYUv2 showed that DGP-Faster achieved a further step in performance. It suggests that both the 2D geometric property and depth information are helpful for mobile robot to detect indoor object. However, the depth information is not always available, DGP-Faster may be limited for implementation in some applications.
Conclusions
In this article, a geometric property-based Faster R-CNN is proposed for indoor object detection. With the help of direct and inverse proportion functions, we first use mesh grids to generate appropriate anchors for indoor objects. After the anchors are regressed to RPN-RoIs, we then use the geometric constraints to refine the RPN-RoIs, in which the geometric constraints may contain 2D size and depth information. The geometric constraints can remove some outliers in RPN-RoIs. With the help of geometric property, our proposed GP-Faster and DGP-Faster increase the mAP performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Anhui Provincial Natural Science Foundation (1808085MF171, 1908085MA07), and the National Natural Science Foundation of China (61672039, 61972439).