
Abstract
This study introduces the YORB-SLAM algorithm, a novel approach that integrates an enhanced ORB-SLAM2 framework with a lightweight YOLOv5 model to improve the robustness and accuracy of visual SLAM systems in indoor dynamic environments. By incorporating a variable threshold FAST corner detection algorithm, we optimize feature point extraction performance under unstable lighting conditions. An improved quadtree algorithm not only accelerates feature extraction but also retains richer image information. Further, we tailor a lightweight YOLOv5 model to our application scenario through self-training and devise a set of dynamic feature point elimination rules, significantly boosting performance in dynamic indoor scenes. Evaluations on six dynamic indoor sequences from the TUM dataset show that YORB-SLAM significantly outperforms the original ORB-SLAM2 in accuracy and exhibits better real-time capabilities than DS-SLAM and DynaSLAM.
Introduction
Simultaneous localization and mapping (SLAM) technology acquires external environmental information through sensors and determines its own position and establishes a map of the surrounding environment based on the matching relationship between information. 1 It is a key technology in various applications such as augmented reality, 2 mobile robotics, 3 autonomous driving, and drones. 4 SLAM technology is divided into visual SLAM and laser SLAM according to the type of sensor used. Visual SLAM has developed rapidly in recent years due to its low cost and rich information. Unlike laser SLAM, visual SLAM relies on image data to estimate position and build environmental maps, 5 requiring precise feature extraction and matching strategies in the face of lighting changes and dynamic obstacles.
The implementation techniques of the visual SLAM front-end visual odometry mainly include direct methods and feature point methods. Direct methods estimate camera motion using pixel value information of images, which are easily disturbed by external environmental factors. Feature point methods estimate camera motion through reprojection by tracking the position changes of representative information in images, offering good resistance to interference. Common feature point extraction algorithms include the ORB, 6 SIFT, 7 and SURF 8 algorithms. Among the existing feature point algorithms, the ORB feature due to its fast computation speed, meeting real-time requirements, is widely used in visual SLAM systems. However, the ORB algorithm tends to cluster, with unevenly distributed feature points extracted, which is not conducive to subsequent camera tracking. 9
Many researchers have improved the ORB detection algorithm. Mur-Artal et al. 10 used a quadtree division algorithm to segment images and then employed the Harris response value for nonmaximum suppression of feature points, effectively improving the uniformity of feature point distribution and enhancing the stability and reliability of feature points. Yao et al. 11 proposed an adaptive threshold ORB feature extraction algorithm based on an improved quadtree algorithm, showing better stability and speed in complex environments. Sun et al. 12 proposed an improved ORB algorithm based on regional segmentation, optimizing the uniformity of feature point distribution. Although issues with feature point mismatches persist, notable progress has been achieved.
In the field of visual SLAM, many excellent SLAM system frameworks have been proposed in recent years, such as DSO, 13 VINS-Fusion, 14 and the ORB-SLAM series. These algorithm frameworks can meet most application needs, especially in improving positioning accuracy and map construction efficiency. However, as the complexity of application scenarios increases, SLAM systems still have shortcomings in specific real-world scenarios, especially in indoor dynamic scenes with pedestrians and other dynamic objects, where existing SLAM systems often struggle to accurately handle these dynamic changes, affecting the system's positioning and mapping performance. 15
To address this challenge, many researchers have proposed numerous excellent algorithms based on the ORB-SLAM framework. Bescos et al. 16 introduced the DynaSLAM method, which precisely eliminates feature points of dynamic objects by combining semantic segmentation with multi-view geometry methods, thereby improving the performance of SLAM systems in dynamic environments. The DS-SLAM method integrates a semantic segmentation network and greatly improves positioning accuracy in dynamic scenes through motion consistency detection. 17 Dynamic-SLAM 18 uses the SSD network to detect dynamic objects and compensates for detection omissions using the velocity invariance of adjacent frames. This method improves the accuracy of dynamic object detection, especially in fast-moving scenes. Gong et al.'s method attempts to retain static feature points during dynamic and static detection crossover, improving SLAM performance in dynamic scenes to some extent but failing to completely correctly retain dynamic feature points. 19 Sun et al.'s VSLAM algorithm uses RGB-D information and dense optical flow tracking technology to remove dynamic foregrounds. 20 Although this method can handle dynamic objects to some extent, its performance is limited by the accuracy of the optical flow algorithm and high-speed moving scenes.
Addressing the issues with the ORB feature point algorithm, this article proposes optimization measures for the feature point extraction strategy of the front-end visual odometry in the ORB-SLAM2 system. Initially, we introduce an adaptive threshold calculation method based on image grayscale mean to mitigate the impact of environmental lighting changes on feature point extraction. By dynamically adjusting the threshold for feature point detection, this method maintains the stability and accuracy of feature point extraction under varying lighting conditions, thereby enhancing the robustness of the SLAM system. Furthermore, we optimized the quadtree splitting rules in ORB-SLAM2, limiting the number of splits and prioritizing feature points with high response values. This improvement strategy not only enhances the matching accuracy of feature points but also boosts the system's adaptability to complex scenes, particularly in feature-rich or texture-complex indoor environments.
To address the issue of positioning accuracy in indoor dynamic scenes for visual SLAM systems, we introduced the YOLOv5 object detection model. To balance the model size, accuracy, and efficiency, especially considering the deployment needs on embedded devices, we opted to replace YOLOv5's backbone network with MobileNetV3. This adjustment makes the entire SLAM system more suitable for operation on resource-constrained devices while maintaining good object detection and feature point elimination performance. Tailored for the specific needs of indoor dynamic scenes, we designed dynamic feature point elimination rules and pose estimation methods, significantly improving the system's positioning accuracy in dynamic environments.
The algorithm proposed in this article, named YORB-SLAM, builds on the ORB-SLAM2 foundation with a series of optimizations for feature extraction and dynamic feature point handling, significantly enhancing the system's robustness and positioning accuracy. By integrating advanced object detection algorithms, YORB-SLAM effectively addresses the challenges in indoor dynamic environments.
The rest of this article is organized as follows: the second section provides a detailed introduction to the design of the YORB-SLAM framework, optimization strategies for feature extraction, and the object detection network. The third section first analyzes the effectiveness of each optimization through experiments. It then compares the YORB-SLAM algorithm with other exemplary algorithms, showcasing YORB-SLAM's performance in various scenarios and discussing the significance of the research findings. The fourth section concludes the study, summarizing the work and looking forward to future research directions in the field of visual SLAM.
Materials and methods
Overview of the YORB-SLAM system
The YORB-SLAM framework innovatively extends the ORB-SLAM2 foundation, retaining its original architecture while incorporating a series of improvements to enhance adaptability to dynamic environments and overall performance. As illustrated in Figure 1, the optimizations designed by us are encompassed by the red dashed lines. The framework comprises four parallel threads: an optimized tracking thread, a newly added dynamic feature point removal thread, the original local mapping thread, and the loop closure detection thread. The collaborative operation of these threads enables YORB-SLAM to efficiently process image frames in real time within complex environments, effectively tracking the camera's position and orientation, and simultaneously constructing and maintaining a stable map of the environment.

Overall framework of the YORB-SLAM algorithm.
The tracking thread is responsible for real-time tracking of the camera's position and orientation, utilizing ORB feature points for matching to estimate the camera pose. YORB-SLAM optimizes the feature point extraction strategy within the tracking thread to enhance the quality and robustness of feature point extraction.
In the introduced dynamic feature point removal thread, image recognition technology based on the self-trained YOLO-Mo network is employed to effectively identify and eliminate dynamic feature points in image frames, reducing the impact of dynamic environmental factors on system performance and enhancing stability and accuracy.
The local mapping thread uses observed new data to create and update the local map, performs local bundle adjustment to optimize the scene's structure and camera motion, and manages and maintains map points.
The loop closure detection thread is tasked with identifying loop closures in the environment, divided into loop closure detection and correction phases, using a bag-of-words model for detection and global bundle adjustment (BA) for loop closure correction, thereby improving the global consistency of the map.
Optimization of ORB feature extraction algorithm
The ORB algorithm, a widely applied method for feature point extraction in the field of image processing, combines the strengths of FAST feature point detection and BRIEF feature description to offer a fast and stable solution for image feature recognition and description. 21 The quality of ORB feature point extraction is directly linked to the YORB-SLAM system's estimation of camera pose.
Optimization of the FAST corner detection algorithm
The FAST corner detection algorithm bases its judgment on the idea that for a target pixel, a circle is drawn with a radius of 3 pixels around it, using 16 pixels on the circumference for comparison, as shown in Figure 2. Here, p represents the target pixel, and 1∼16 are the comparison points. If among these 16 comparison points, there are consecutively n pixels whose grayscale value is either higher than the target pixel's by a threshold T, as in formula (1), or lower than the threshold T, as in formula (2), then the target pixel p is identified as a FAST corner. The value of n is typically set to 12. This comparison considers not only the grayscale differences between pixels but also the continuity of these differences, which is crucial for corner identification.



FAST feature point.
Here, Ip represents the grayscale of the target pixel, Ix the grayscale of the 16 comparison pixels, with x ranging from 1 to 16, and T the comparison threshold. To enhance detection speed, a subset of points may be examined initially. For instance, if n is set to 12, the 1st, 5th, 9th, and 13th pixels can be checked first. If at least three of these points satisfy the formulas above, the pixel is considered a candidate corner; otherwise, it is not. This method effectively eliminates most noncorners, reducing unnecessary comparisons and significantly accelerating corner detection speed.
The uncertainty of lighting conditions in environments, where intensity changes can directly affect image grayscale, is particularly crucial in image processing, especially when using algorithms like FAST corner detection that rely on grayscale value comparisons. Consequently, the number of feature points extracted using traditional FAST corner detection algorithms may vary significantly across different lighting and contrast conditions of the same scene. To achieve the desired number of feature points, thresholds often need to be readjusted, which may lead to instability in feature point quality, thereby affecting subsequent processing steps. Changes in image grayscale caused by lighting can be divided into local and global grayscale variations. Local grayscale variations refer to changes in grayscale values in specific areas, affecting the accuracy of fixed threshold detection; global grayscale variations mean adjustments in the grayscale values of the entire image, where setting thresholds simply based on a percentage of the target pixel's grayscale value may no longer be suitable.
To address this, we propose an adaptive threshold determination method based on the average grayscale value of the image. This method first calculates the total grayscale of the 16 pixels on the circumference, excluding extreme values to mitigate the impact of abnormal data under extreme lighting conditions. It then introduces a calculation based on the average grayscale value of the remaining pixels to accommodate situations with multiple extreme values, ultimately determining an adaptive grayscale threshold according to the variation in this average grayscale value, as shown in formula (3). This approach not only considers the overall grayscale level of the image but also improves the flexibility and accuracy of threshold setting by excluding extreme values and calculating averages.

Quadtree algorithm optimization
The quadtree algorithm is a common method for feature point uniformization, suitable for the balanced processing of ORB feature points with weak discreteness. The implementation of the quadtree algorithm comprises the following steps:
Initialize the entire image as the root node; Split the node into four equal-sized child nodes; Remove child nodes that do not contain any feature points; Repeat steps 2 and 3 until the number of feature points in each child node is less than or equal to 1 or the extracted feature points reach the desired number; and Retain the feature point with the highest response value in each node and remove the rest.
The quadtree algorithm effectively balances the distribution of feature points and enhances their discreteness. However, while making the feature point extraction more uniform, the quadtree algorithm may also lead to two issues: firstly, in cases of feature point accumulation, the quadtree may undergo multiple splits, reducing the speed of the feature point extraction algorithm and leading to tracking loss
12
; secondly, this strategy only considers retaining high-response feature points in the last step, resulting in the loss of some high-response feature points, especially in areas dense with high-response points. As indicated by the red boxes in Figure 3, the deeper the color of a point, the higher its response value. During the final step of feature point deletion, some high-response points in the same node are deleted, implying the loss of some significant feature information in the image.

Demonstration of limitations of the quadtree algorithm.
To address these deficiencies in the ORB-SLAM2 quadtree algorithm, this article proposes an improved quadtree algorithm.
The algorithm initially performs conventional quadtree splits, then checks after each round of splitting whether the current number of nodes exceeds 70% of the target number of feature points. If this criterion is met, the splitting stops; otherwise, it continues. After splitting ends, nodes with only one feature point are retained, and all feature points from the remaining nodes are collected into an array, sorted by response value from highest to lowest, and the top n feature points are selected. The value of n is the difference between the target number of feature points and the number of single feature point nodes after splitting, as shown in equation (4).

Object detection
YOLOv5 algorithm light-weighting
In the domain of object detection, the YOLO (You Only Look Once) algorithm has been revolutionary. Since its inception, YOLO has evolved into many versions, with YOLOv5 and YOLOv8 being the most prominent. Each version boasts unique features and advantages, making them stand out in their respective areas. Given the scenario of deploying an object detection network on an indoor mobile robot, YOLOv5 was chosen after considering factors like computational resources, network model size, and accuracy, aligning with our deployment needs for indoor settings.
The design of YOLOv5 centers around four main components: the input stage, backbone network, neck network, and prediction stage, each optimized for enhanced performance and flexibility. 22 In the input stage, YOLOv5 employs various data augmentation techniques such as mosaic augmentation, dynamic anchor calculations, and adaptive image scaling, improving anchor generation and enhancing the diversity and quality of input images. The backbone network extracts features from the input images, combining convolutional layers, C3 layers, and SPPF (Spatial Pyramid Pooling Fast) to efficiently enhance feature extraction. 23 The neck network, utilizing PAN (Path Aggregation Network) and FPN (Feature Pyramid Network) structures, performs feature fusion, enriching the information across different feature levels. In the prediction stage, the algorithm processes loss calculations for bounding boxes and nonmaximum suppression to finalize and refine detection results. 24
To accommodate varying performance and resource requirements, YOLOv5 offers five network models of different sizes: YOLOv5n, YOLOv5 s, YOLOv5 m, YOLOv5 l, and YOLOv5x, each with varying width and depth coefficients. This study employs YOLOv5 l v6.1, referred to as YOLOv5 l. Although subsequent community research has introduced several new YOLO models, the YOLOv5 model remains favored for its lightweight, ease of use, and deployment suitability for mobile devices.
Further, to reduce the network size and complexity of the YOLOv5 l model, this study substitutes its backbone network with MobileNetV3. Announced by Google in 2019, MobileNetV3, the latest in the MobileNet series, inherits advantageous features from MobileNetV1 and MobileNetV2 and optimizes them further. Comprising bneck structures, MobileNetV3 incorporates depthwise separable convolutions from MobileNetV1 and inverted residual structures from MobileNetV2, introduces a lightweight SE (Squeeze-and-Excitation) attention mechanism, and replaces the original activation function with h-swish, 25 as shown in Figure 4. The modified YOLOv5 model significantly reduces network size and complexity while meeting computational power requirements, enhancing algorithm speed, and providing a viable solution for efficient object detection on embedded devices.

MobileNetV3 network structure diagram.
The lightweight network proposed in this article is referred to as the YOLO-Mo network. Table 1 presents the backbone network structure of YOLO-Mo.
YOLO-Mo Backbone network structure.

Table 1 offers an overview of the YOLO-Mo network structure, with “From” indicating input sources, “-1” denoting input from the previous layer's output, “Param” for the number of parameters, “Module” for module names, and “Arguments” for model parameter settings. The “conv_bn_hswish” module includes three adjustable parameters: input channels, output channels, and stride information. The “MobileNet_Block” module features seven adjustable parameters: input channels, output channels, expanded convolution channels, kernel size, stride, SE attention mechanism inclusion, and h-swish activation function usage.
Table 2 compares the network layers and parameter counts between YOLO-Mo, YOLOv5n, and YOLOv5 s. Despite YOLO-Mo having more layers, its parameter count is only about half that of YOLOv5 s.
Comparison of network models.

Discussion on feature point removal rules
The Dynamic Feature Point Removal Thread is designed to optimize feature point identification and processing through four main tasks, thereby enhancing the overall performance and efficiency of the system. These tasks include semantic segmentation of input image frames, receiving feature point identification results from the tracking thread, removing dynamic feature points, and sending the remaining feature points back to the tracking thread.
To accurately determine the state of objects in the environment, the system utilizes YOLO-Mo for semantic segmentation to identify object types and locations. However, semantic segmentation alone is insufficient for recognizing the dynamic state of objects, necessitating the introduction of prior judgments to assist in determining whether objects are in motion. Objects are classified into three categories based on their motion characteristics: high dynamic objects, low dynamic objects, and static objects. High dynamic objects are defined as objects capable of autonomous movement, such as people, animals, and certain mechanical products like robot vacuums; low dynamic objects are defined as objects that do not move autonomously but often move with high dynamic objects, such as mobile phones, cups, and chairs; static objects are defined as objects that rarely move, such as tables, air conditioners, and computers.
The criterion for determining dynamic feature points is based on the classification and state of the object they reside in: if a feature point is located within a high dynamic object and not within a static object, it is deemed a dynamic feature point; if a feature point is located within a low dynamic object that overlaps with a high dynamic object, it is also considered a dynamic feature point. All others are considered static feature points.
To address potential shortages of static feature points following the removal of dynamic feature points, the system adopts an over-extraction strategy for feature points. This means that initially, the system extracts more feature points than anticipated and later decides whether to delete some of the feature points with lower response values based on the actual number of static feature points. This strategy ensures that there are enough static feature points for stable camera pose estimation even after removing some dynamic feature points, while optimizing the efficiency of the system's operation.
Experimental results and discussion
In this section, we validate the efficacy of our work through experiments conducted across multiple public datasets, divided into three parts.
Part 1 compares the original ORB-SLAM2 algorithm with its enhanced version, which solely optimizes the feature point extraction strategy of ORB-SLAM2. Initially, the stability of feature point extraction under various lighting conditions is assessed, followed by a discussion on the dispersion and extraction speed of feature points, and concluding with the verification of feature matching accuracy.
Part 2 involves training a lightweight target detection network introduced on a custom dataset and comparing its performance with other target detection networks to further validate its effectiveness in real indoor scenes.
Part 3 tests the performance of the proposed YORB-SLAM algorithm on six dynamic sequences from the TUM dataset, comparing it with ORB-SLAM2 and other dynamic scene SLAM systems. Subsequently, the error metrics and real-time performance of each algorithm are discussed.
Experimental platform
The experiments in this article were conducted on a computing platform equipped with an AMD Ryzen 5 4600H CPU, which includes an integrated Radeon Graphics processing unit with a base clock of 3.00 GHz, and a dedicated NVIDIA GeForce GTX 1650 GPU. The system is complemented with 16GB of RAM.
In terms of the software environment, the experiments were carried out using the Ubuntu 20.04 operating system. The experiment utilized OpenCV 3.4.15 and OpenCV Contrib 3.4.15 as foundational libraries for image processing and computer vision tasks. PyTorch 1.12.0 served as the deep learning framework, and Python 3.6 was employed as the programming language. Additionally, CUDA 11.3 was used to accelerate deep learning computations.
Stability comparison of feature point extraction quantity under different lighting conditions
To verify the effectiveness of optimizations to the FAST corner detection algorithm, we use the Oxford 5k dataset to compare the original and improved algorithms in terms of light sensitivity and feature point dispersion. This dataset features high-quality images of various Oxford landmarks, divided into predefined categories, making it a standard benchmark for fine-grained recognition and location identification tasks in computer vision research.
The experiments are conducted in three sets under three different conditions: 60%, 100%, and 140% of the original image brightness, aiming to simulate the variations in lighting intensity that might be encountered in real-world environments. Regarding threshold settings, the original FAST corner extraction algorithm's thresholds were fixed at 40 and 30; in contrast, the improved algorithm's FAST corner extraction threshold's weight parameter was set to 0.7. To evaluate the algorithm's performance under different brightness levels, the number of feature points extracted from the same image under different brightness levels was used as the criterion for judging the algorithm's light sensitivity. Figure 5 compares the improved algorithm with the original ORB-SLAM2 algorithm under the “bikes” sequence in the Oxford 5k dataset.

Comparison of feature point extraction under different lighting conditions.
Table 3 compares the feature point extraction results of the original and the improved algorithm in four subsets of the Oxford 5k dataset. The results indicate that the original algorithm experienced significant fluctuations in the number of feature points with changes in brightness, specifically, a 63% average decrease in feature points at 60% of the original image brightness, and a 48% average increase at 140%. This outcome demonstrates the original algorithm's high sensitivity to light changes, leading to unstable feature point extraction. In contrast, the improved algorithm exhibited smaller fluctuations in the number of feature points with changes in brightness, with a 4% average decrease at 60% brightness and an 11% average increase at 140%. These results suggest that the improved FAST corner detection algorithm significantly enhances robustness to changes in lighting, resulting in more stable feature point extraction. This improvement enhances the algorithm's adaptability under different lighting conditions, reducing the risk of tracking failure due to lighting changes, especially in environments with varying light intensity and dim scenes, demonstrating better adaptability.
Feature point extraction results under different brightness conditions.

Feature point extraction validation
Under the experimental conditions described in the Experimental Platform section, a comparative validation was conducted between the original ORB-SLAM2 feature extraction algorithm and the improved algorithm using the “freiburg2/xyz” subset of indoor images from the TUM dataset. The TUM dataset, developed by the Computer Vision Group at the Technical University of Munich, is widely utilized for evaluating and benchmarking the performance of visual SLAM systems. It is specifically designed to provide indoor environment data of varying complexity, including scenarios with different lighting conditions, rapid movement, and diverse structures. The experiment detailed a comparative analysis of 10 consecutive pairs of indoor image frames. Figure 6 illustrates a comparative visualization of feature extraction results between the original and the improved ORB-SLAM2 algorithms.

Feature point extraction comparison.
To quantify the dispersion of feature points, the experiment divided each image into nine equal regions and counted the number of feature points within them. The standard deviation of these counts was computed to effectively evaluate the uniformity of feature point distribution across the image frames. The formula for calculating the dispersion of feature points is shown in equation (5):
Feature point extraction data comparison.
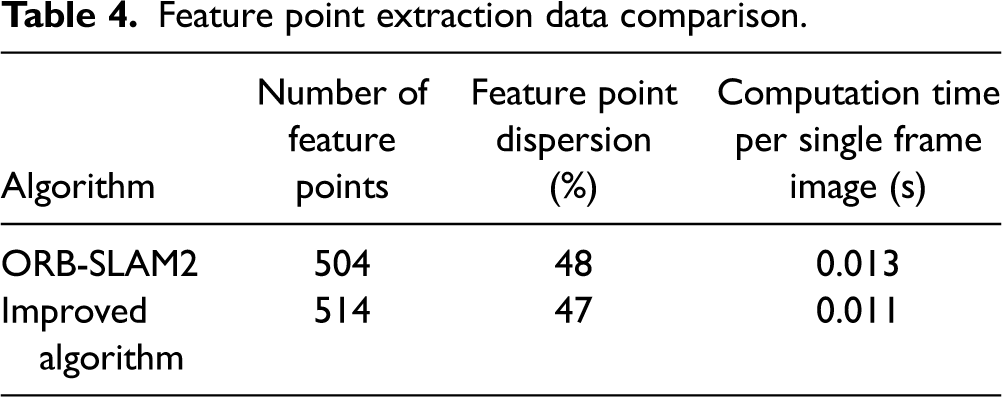
The results indicate that the improved algorithm surpasses the original ORB-SLAM2 in terms of computation time per single frame image, demonstrating a significant efficiency advantage and enhancing the real-time capabilities of the visual SLAM system. Although the feature point dispersion of the improved algorithm is slightly inferior to that of the original ORB-SLAM2, this is attributed to the improved algorithm's preference for retaining feature points with higher response values and representativeness, at the cost of some dispersion. This approach preserves more image features, thereby increasing the accuracy of subsequent feature matching.
Feature point matching experiment
In the feature point matching experiment, the same experimental setup as in the feature point extraction experiment was utilized. Figure 7 compares the matching effectiveness between the original ORB-SLAM2 algorithm and the improved algorithm.

Comparison of feature point matching effectiveness.
The comparison focuses on the correct match count and matching precision PM of two feature point extraction algorithms, using indoor images from the TUM dataset freiburg2/xyz. The matching algorithm employs a brute-force method calculating Hamming distance. Matching precision PM is defined by equation (6):
Comparison of feature point matching data.

In the feature point matching experiment, the improved algorithm demonstrated higher numbers of matches and better matching precision. These results further validate the superiority of the improved algorithm in selecting feature points, enabling more effective identification and matching of identical feature points between images, which is crucial for enhancing the tracking and reconstruction accuracy of visual SLAM systems.
In summary, by making moderate sacrifices in the dispersion of feature points, the improved ORB feature point extraction algorithm has achieved significant advantages in terms of quality retention of feature points, computational efficiency, and matching performance. These optimizations not only enhance the algorithm's adaptability to environmental changes but also its application efficiency and accuracy in real-time visual SLAM systems. Therefore, the improved algorithm shows excellent adaptability and efficiency in processing image feature point extraction and matching, offering a more reliable and efficient solution for real-time visual SLAM systems.
Object detection algorithm
YOLO-Mo network training
Given the indoor work scenario envisaged in this study, a substantial indoor dataset was curated and annotated, supplemented with select indoor data from the COCO dataset, totaling 2000 images for training. To ensure the accuracy and consistency of data annotation, we used Labelimg as the annotation tool.
The custom dataset was randomly divided into training and testing sets at a 4:1 ratio, with the training platform as outlined in the Experimental Platform section, and key training parameters presented in Table 6.
Training parameter settings.

Throughout the training, particular attention was paid to two critical metrics: Loss (accuracy loss) and mAP (mean Average Precision). The training process' loss and precision curves are depicted in Figure 8, where Loss indicates accuracy loss, and mAP represents mean Average Precision.

Training process.
The results demonstrate that our model exhibited robust performance throughout the training cycle, with a gradual and stabilizing decrease in accuracy loss and a steady increase in mAP, showing no signs of overfitting or underfitting. This indicates effective model training, achieving anticipated outcomes with the YOLO-Mo model on the custom dataset.
Comparative training with YOLOv5 s and YOLOv5n under identical conditions yielded the performance data in Table 7.
Comparison of network detection results.

Table 7 reveals that the YOLO-Mo model's size and framerate are between those of YOLOv5n and YOLOv5 s. Its recall and precision significantly improve compared to YOLOv5n and are very close to YOLOv5 s, indicating its higher accuracy in recognizing objects in indoor scenes.
Due to its lightweight network, YOLO-Mo experiences a slight drop in detection precision compared to YOLOv5 s. However, it reduces the model size by 5.8MB and increases the framerate by 26 fps compared to YOLOv5 s. Therefore, the YOLO-Mo algorithm achieves a balanced trade-off between detection precision and speed, facilitating easier deployment on mobile devices, aligning with the application scenarios of YORB-SLAM.
Experimental validation
The YOLO-Mo model, trained on the custom dataset, was compared with the YOLOv5 s model using default weights for indoor scene detection. The results, illustrated in Figure 9, show that YOLOv5 s, trained on the COCO dataset encompassing 80 categories of labels, fails to detect certain common indoor objects, such as cabinets and trash bins, and also produce some detection errors. This is attributed to the COCO dataset not being specifically designed for indoor scenes. In contrast, YOLO-Mo, trained on the custom dataset, accurately identifies common objects within indoor scenes, meeting the accuracy requirements for indoor object detection set forth in this study.

Real scene detection results.
YOLO-SLAM system
To assess the performance and robustness of YORB-SLAM in indoor dynamic scenarios compared to the original ORB-SLAM2 system, the study selected six dynamic scene sequences from the TUM dataset in the experimental environment described in the Experimental Platform section. These sequences encompass a range of scene dynamics from high to low, including movements of people in offices, camera motion along various paths and directions, and minor movements of seated individuals. A comprehensive evaluation of high-dynamic (walking sequences) and low-dynamic (sitting sequences) scenarios aimed to test the YORB-SLAM system's performance under different levels of dynamics and motion patterns. The sequences, including freiburg3_walking_xyz, freiburg3_walking_halfsphere, freiburg3_walking_rpy, freiburg3_walking_static, freiburg3_sitting_halfsphere, and freiburg3_sitting_static, encompass a range of scene dynamics from high to low and a variety of motion patterns from simple to complex, such as XYZ translation, hemispherical motion, RPY rotations (around the x, y, and z axes), and static scenes, providing a comprehensive testing environment for the experiments. For convenience, subsequent discussions use abbreviations fr3, w, half, and s to denote freiburg3, walking, halfsphere, and sitting, respectively, as sequence names.
In terms of performance evaluation, the study used the root mean square error (RMSE), mean error, and standard deviation of absolute trajectory error (ATE) as key performance indicators. RMSE measures the deviation of estimated poses from actual poses based on actual positions, as shown in equation (7):



Track diagrams of different dynamic scenes.
Results in Table 8 show that YORB-SLAM's performance improvement in low-dynamic scenes is limited, with an average reduction of 28.19% in RMSE, 37.40% in mean error, and 18.37% in variance. This is because, in low-dynamic scenes, where human movement is minimal, ORB-SLAM2's visual odometry can use the RANSAC algorithm to eliminate some mismatches. However, in high-dynamic scenes with larger human movement, relying solely on ORB-SLAM2's mismatch elimination algorithm is insufficient, and YORB-SLAM's performance significantly improves, with an average reduction of 92.08% in RMSE, 97.14% in mean error, and 85.38% in variance. These statistics convincingly demonstrate YORB-SLAM's robustness in dynamic indoor scenes, particularly under high-dynamic conditions, marking a significant improvement.
Comparison between ORB-SLAM2 and YORB-SLAM in TUM sequences.

RMSE: root mean square error.
Beyond comparing with ORB-SLAM2, this study also benchmarks the YORB-SLAM approach against DynaSLAM and DS-SLAM, two popular dynamic scene SLAM systems in recent years, as shown in Table 9. The data for DynaSLAM is taken from the paper by Bescos et al., 16 and for DS-SLAM from the paper by Yu et al., 17 where the “-” symbol indicates data not provided in their respective publications.
Comparison of absolute trajectory error between YORB-SLAM and other dynamic SLAM methods.

RMSE: root mean square error.
According to Table 9, in low-dynamic scenes, YORB-SLAM's positioning accuracy is comparable to DynaSLAM and DS-SLAM. In high-dynamic scenes, YORB-SLAM outperforms DS-SLAM and is slightly inferior to DynaSLAM.
Real-time performance is another critical metric for evaluating SLAM systems. A SLAM system that sacrifices real-time capabilities for accuracy is challenging to apply in real-world scenarios. To quantify the real-time performance of the YORB-SLAM system, the study compared the processing time per frame in different sequences using the open-source codes of DynaSLAM and DS-SLAM on the same hardware, as presented in Table 10.
Comparison of real-time performance between YORB-SLAM and other dynamic SLAM methods.

Data from Table 10 indicates that the YORB-SLAM system exhibits superior real-time performance compared to other dynamic SLAM systems. Although it takes more time than ORB-SLAM2 due to the added object detection process, it still operates at a lower level. In contrast, DynaSLAM, despite its excellent accuracy in handling dynamic environments, shows slightly insufficient real-time performance. Due to its multi-view nature, the DynaSLAM algorithm spends a considerable amount of time on multi-view geometry, suggesting that DynaSLAM may not be the best choice for applications requiring rapid processing and real-time feedback. 16
In summary, YORB-SLAM significantly enhances indoor dynamic positioning capabilities while maintaining efficient operation of the SLAM system. In dynamic indoor environments, YORB-SLAM's comprehensive performance surpasses ORB-SLAM2, DynaSLAM, and DS-SLAM.
Conclusion
This study addresses the issue of reduced positioning accuracy of the ORB-SLAM2 algorithm in indoor dynamic scenes by designing a vision SLAM system based on object detection, aimed at minimizing the impact of dynamic objects in the environment on the SLAM system. Initially, by proposing a variable threshold FAST corner detection algorithm and an enhanced quadtree strategy, the ORB feature extraction algorithm was optimized, enhancing the speed of feature extraction while retaining more image information. Subsequently, we lightened YOLOv5 with MobileNetV3, training the network on a custom indoor dataset tailored to our application scenario. Integrating the lightened YOLOv5 model, we introduced the YORB-SLAM algorithm and devised dynamic feature point elimination rules. Comparative experiments with the ORB-SLAM2 algorithm on the TUM dataset demonstrated that our system could reduce the absolute trajectory error by 97%. Compared to dynamic SLAM systems like DS-SLAM and DynaSLAM, our system also showed improved accuracy without sacrificing speed. We conclude that YORB-SLAM surpasses ORB-SLAM2, DS-SLAM, and DynaSLAM in terms of overall performance.
For future work, we aim to further refine the dynamic information judgment rules of the YORB-SLAM system to maintain its performance in more complex environments. First, we consider combining the object detection algorithm with optical flow methods to overcome the limitation of only detecting pretrained objects in the network. Secondly, acknowledging the vision SLAM system's sensitivity to environmental brightness, we propose enhancing the system's localization and mapping capabilities through multisensor fusion under various lighting conditions.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.