
Abstract
In the case that the background scene is dense map regularization complex and the detected objects are low texture, the method of matching according to the feature points is not applicable. Usually, the template matching method is used. When training samples are insufficient, the template matching method gets a worse detection result. In order to resolve the problem stably in real time, we propose a fast template matching algorithm based on the principal orientation difference feature. The algorithm firstly obtains the edge direction information by comparing the images that are binary. Then, the template area is divided where the different features are extracted. Finally, the matching positions are searched around the template. Experiments on the videos whose speed is 30 frames/s show that our algorithm detects the low-texture objects in real time with a matching rate of 95%. Compared with other state-of-art methods, our proposed method reduces the training samples significantly and is more robust to the illumination changes.
Keywords
Introduction
At present, the methods of pattern recognition, target classification, and detection based on local feature have been widely used in many aspects, such as in medicine, 1 in the industry, 2 in biology, 3 and so on. The main processes of these methods are to learn a large number of previous knowledge in features, then build a classifier, and use it for the recognition in-line. However, it is difficult to realize real-time objects detection because of the complexity. At the same time, in the case where the background scene is complex and the detected targets are texture-less, the local feature points are not enough to express the targets. Therefore, in this situation, this feature-based detection method is not applicable.
With the prosperity of the convolution neural network in recent years, it has achieved unprecedented success in the image classification, template detection, and other ways. 4 –6 However, it needs a complex computation environment and large data set with more salient features. Moreover, it needs to spend a long time to train the network, 7 which is not a good choice for detecting low-texture objects real time.
To solve these problems, we use the template matching method, because it has less computational complexity and it does not need to spend much time on training. 8 This method of area matching is suitable for the situations where the background is complex and the target texture is less. 9 We also maintain the traditional idea that builds a simple training set first, because this method is robust when the targets are rotated or deformed.
The outline of this article is arranged as follows: The second section discusses the related work on low-texture objects detection based on template matching. In the third section, we introduce our method with details. The fourth section indicates the evaluation results that compared to other two state-of-art methods. Finally, we give the conclusion in the last section.
Related work
The most common template matching method based on the pixel value is through sliding the template on another image to find the most similar area, 10,11 and fast template matching is achieved through normalized cross-correlation (NCC). The squared difference matching and standard squared difference matching are also widely used. These methods of template matching could be used easily by the open source visual library like OpenCV [version 3.4.1]. These methods are simple, but there are some disadvantages such as computation complex, poor target deformation robustness, and susceptible to noise interference. Therefore, there have been many improved algorithms.
Many people proposed different template matching methods based on geometric features because the pixel-based matching method has the problem of computational complexity and poor robustness. As mentioned in the study by Wu and Zou, 12 the template matching method based on the geometric features of the image has a stronger ability to express the template due to the combination of the geometrical characteristic information of the target, such as edge, corner, the center of gravity, and so on. At the same time, this method has a good robustness to light changes and noise interference as well as partial occlusion. Obviously, edge feature expression is an important factor in the effect of template matching. A lot of edge detection methods have been proposed such as classical Sobel operators, Prewitt operators, Canny operators, and Laplacian operators. There are also a lot of improvements for these operators. For example, Htet et al. 13 proposed an edge extraction method based on clustering. Solanki and Godfrey 14 proposed to use gradient uncertainty to obtain easily overlooked edge information. Muhlich et al. 15 proposed that the two filter templates are linearly combined to express the multi-directional image structure. In this article, we propose an edge feature extraction method, which is robust to light direction and intensity.
By using edge features, Lin and Xiu 16 proposed a method through mean absolute difference to improve rotation invariance. Lee and Hong 17 proposed a method of class-specific weighted dominant orientation templates (DOTs) to achieve fast matching. Dekel et al. 18 proposed a way to make it robust against complex geometric deformations by using a similarity measure between two sets of points. Korman et al. 19 proposed a fast template matching method for affine cases. Acharya 20 proposed a histograms of gradients (HOG)-based template matching method. Moreover, the HOG feature was proved to generalize well. 21 However, computational complexity of HOG made it hard to detect in real time. Hinterstoisser et al. 9,22,23 used DOT feature to detect targets with less textures in complex contexts, and it can be processed real time.
These methods have a good match effect in the scenario where training sets are sufficient. However, when the training sets are not enough to represent the targets at some situations where the targets are deformed or rotated large scale, the detection results obtained by those methods are inefficient. Therefore, we proposed a new template matching method based on the POD to solve those problems.
Proposed algorithm
As we know, the difference between the targets is mostly hidden on the edge of the targets. Therefore, we extract the target edge information first. If the number of edge is less than T and T is a threshold, then we discard the area. We let it half of the minimum number of edges in all template edges. In order to enhance the stability of our template matching approach and reduce interference with a low computation, we divided the template into several subregions, where the regional POD features, and we search the area around the template rather than in the entire image, which can reduce the computation. The entire flowchart of our proposed method is represented in Figure 1.

Flowchart of our proposed algorithm.
Extract target edges
We know that the difference between the targets is mostly hidden on the edge of the targets. Therefore, we extract the target edge information first. There are many ways to obtain image edges. The usual method is to use edge detection operators such as Sobel operator, Prewitt operator, Canny operator, and so on. Those methods detect the edges based on the gradient information, which is less useful in extracting edges from textureless objects. Therefore, in order to deal with this problem, we adopt a new method to extract edge features. And our method has some evident differences with Kirsch edge detector. First of all, Kirsch edge detector uses eight 3 × 3 operators to convolve with an image. Then the biggest value of the gradients is used to be the edge value of a point. However, our method is based on the comparison of eight adjacent pixels. If the result is the same as the predetermined result, the direction of the point is reserved, and the point is represented by the direction.
Our inspiration came from local binary patterns features.
24
In order to remove the interference of Gaussian white noise in the image, the Gaussian filter is utilized. Then the image is gray scale. We compare each pixel of the filtered image with its eight-neighborhood pixel. Figure 2(a) shows that p0 is compared with

Using of eight-neighborhood binary to find the edge point.



In Figure 2(b), the number which is next to each 3 × 3 check box indicates the LIB value of the center point. In order to make the edge features are robust to the directions of illumination, we choose to compare the four LIBs of 7, 124, 227, and 224 to indicate the four edge directions of 0°, 45°, 90°, and 135°, respectively. As observed, these binarization distributions are similar to the edge directions. We use red arrows to indicate the direction of the edges of these points. In order to generalize the boundary points, we consider the LIB {3,6,7,48,96,107,108, 119,136,159,207,248,249,252} are the points in the direction 0°. {4,56,64,68,124,131,187,191,199,251} are the points on the edge whose direction is 45°. {12,24,28,34,62, 63,126,129,192,193,221,227,231,243} are the points on the edge whose direction is 90°. {1,14,16,17,31,224,238, 239,241,254} are the points on the edge whose direction is 135°. Obviously, the edge direction whose direction is 0° shows that those edge points have the same orientation in the background with different brightness. Therefore, this method is robust to the illumination changes when it is used to extract edges.
Regional division
In order to enhance the stability of our template matching approach and reduce the interference with a low computation, we regionalize the template that is used in our method. At the same time, in order to be robust to the rotational deformation, the DAISY feature is used to divide the template.
25
As shown in Figure 3(a), the area in the red circle is a template that is divided into three layer areas. As shown in Figure 3(b), each layer in the three layers consists of eight circular areas with the same size. Figure 3(c) shows the processing of the regional principal orientation difference. Moreover, the direction and distance between the centers of the adjacent layer circular regions are the same. As the red arrow distance shows, we let the distance between the center of each layer in the same direction to be l. The circle diameter of the target template is

Regional division.

where the radius of each circle of the ith layer is ri. And ri is a coefficient which is determined by the current layer, which is shown in equation (5). In equation (4), b is a cost weight for controlling ri. In our experiment, b equals 0.7 based on our tests. After many experiments, this value can get the best matching results

The center and radius of each circle can be determined when the center position and the diameter
Regional principal orientation difference
According to the approach proposed in the “Extract target edges” section, we judge each pixel in the template whether it is an edge point and determine its edge orientation. Then, according to the “Regional division” section, we divide each template into three layers and calculate the number of pixels in each edge orientation for each circular area of each layer. The orientations of the two edges that own the most pixels are chosen as the main orientation and the second orientation of the circular area, respectively. The number of pixels in the main orientation of each circular area is recorded as
By comparing
Although we have rotated the initialized direction to the main direction of each layer, the direction of each circular area in the template has been changed into the same size because the orientation of the template has been changed. In order to represent stably the continuous relationship between the orientations of circular areas in each layer, we use a different approach to solve this problem. Although the rotational deformation changes the direction of the template object, the angular relationship of the main directions between the two adjacent circular areas in each layer is maintained

where
Finally, we use the vector
Template matching
According to our study, the moving range of target between the two frames is not too large during the real-time target detection process. Therefore, we search the area around the template rather than in the entire image, which can reduce the computation.
As shown in Figure 4, the shaded portion is the position of the target template in the previous frame. We search the target template within the range of

Template search range.
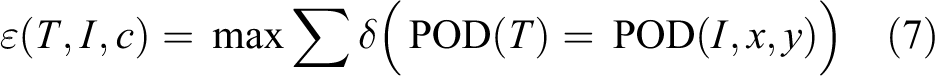
where T is the template and I is the area to be matched in the next frame. x and y are the steps in horizontal and vertical directions, respectively. δ(A) is a binary function that returns 1 if A is true, otherwise A is false. POD(T) is the POD features of template, and POD(I,x,y) is the POD features in the search area of moving x and y steps.
Experiment
In this section, we designed four tests to evaluate the performance of our proposed algorithm in the robustness to the illumination change and the rotational deformation. Moreover, the performance in real-time target detection is also evaluated. Our proposed algorithm is coded in MATLAB2015b. All experiments are achieved on a personal computer that integrated a single core Intel CPU with 3.0 GHz and 4 GB RAM.
In order to evaluate our proposed method, we compared our approach called POD to DOT, 18 to patch rectification method the NCC 10,11 and to the histogram-based template matching approach HOG. 21
We did the performance evaluation on the Oxford Wall image data set. 26 It is noted that no video sequence is available, and we synthesized a training set by scaling and rotating images by adding random noise and affine illumination change. In order to test our method for the video, we asked two students to take 100 video sequences in our lab.
Moreover, our three groups of experiments compare the detection results under different light intensities and the results from different methods under different rotation angles (0°–60°). Furthermore, we tested the same target in 30 images with different light intensities and directions and selected seven experimental results with high light intensity discrimination and put it in the article. Similarly, we tested the same target after rotating nearly 30 different angles and took four different experimental results from different angles in the article.
Edge extraction comparison
After using non-maximal suppression, we use double-threshold detection. Figure 5 shows the filter results for different double-threshold coefficients. We use the coefficient r1 multiplied the maximum value of the gradient after the non-maximum value suppressing as the low threshold. And the coefficient r2 corresponds to high threshold. The coefficient (r1, r2) of the three figures are (0.01, 0.1), (0.01, 0.2), and (0.05, 0.1). Figure 5(d) in our article adopted coefficient (0.05, 0.1). We think this is a proper coefficient.

Comparison results of the edge extracted. (a) Original image, (b) Sobel, (c) Canny, and (d) proposed method.
Comparing with the Sobel operator, Figure 5(b) indicates that our method removes a large number of non-edge information, which decreases the running time. Comparing with the Canny operator, Figure 5(c) shows that our method retains more edge information. Therefore, we can find that our method is more describable to each edge and can classify the edges by their directions.
The matching results under illumination changes
The first image in Figure 6 is an original image and the rest images are the matching results with the template object, which is in the first image under different illuminations. The images in the first row indicate the light attenuation. The images of the second row indicate the enhancement images. The results show that in the case of drastic changes in light, light attenuation has a better match stability. With increasing light intensity, more and more interference is created, and there has been a certain match bias. According to our analysis, the reason for the deviation is the cost weight b in equation (5) and the background interference.

The matching results under different illuminations.
Matching results under rotational deformations
Figure 7 displays a target existing in four different directions and the template matching results by four methods. It is noted that the red rectangle box is the detection result by POD, the green rectangle box is the detection result by HOG, the blue rectangle box is the detection result by DOT, and the yellow rectangle box is the detection result by the NCC. The purple rectangle box is the searching range. The picture on the lower left corner is the template.

Matching results under rotational deformations among three methods.
We can see that the method we proposed is robust to rotational deformations. Therefore, we can reduce many training samples through this method.
Runtime comparison
In order to illustrate that the algorithm proposed in this article is real time, we test the runtime for the template with different sizes. Figure 8 shows the results of the average running time by multiple measurements. Figure 8 shows that the method we proposed can meet real time when the image resolution increases. The runtime is less than 25 ms for detecting the object in each frame even the video is 720p.

Running time of different template sizes.
Matching rate under different rotation angles
In our proposed algorithm, we introduce matching rate which is described by equation (8) to assess the performance in the rotation invariant. Figure 9 shows the comparison results of the template matching rate between POD and the other two state-of-art algorithms under six different rotational angles, which is shown in Figure 8. In this test, we make an experiment to compare our method with the NCC template matching method
10,11
and the template matching method based on HOG features.
20
As shown in Figure 9, this method is superior to the conventional template matching method in case of rotational deformation for the Oxford data set. The matching score of the POD method is more than 95%. The matching rate of the POD method has a little jitter. The reason is background interference and the edges cannot be described adequately under partial angles.
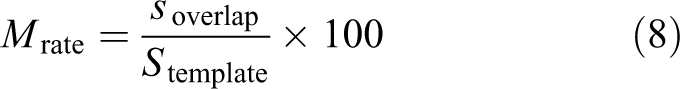
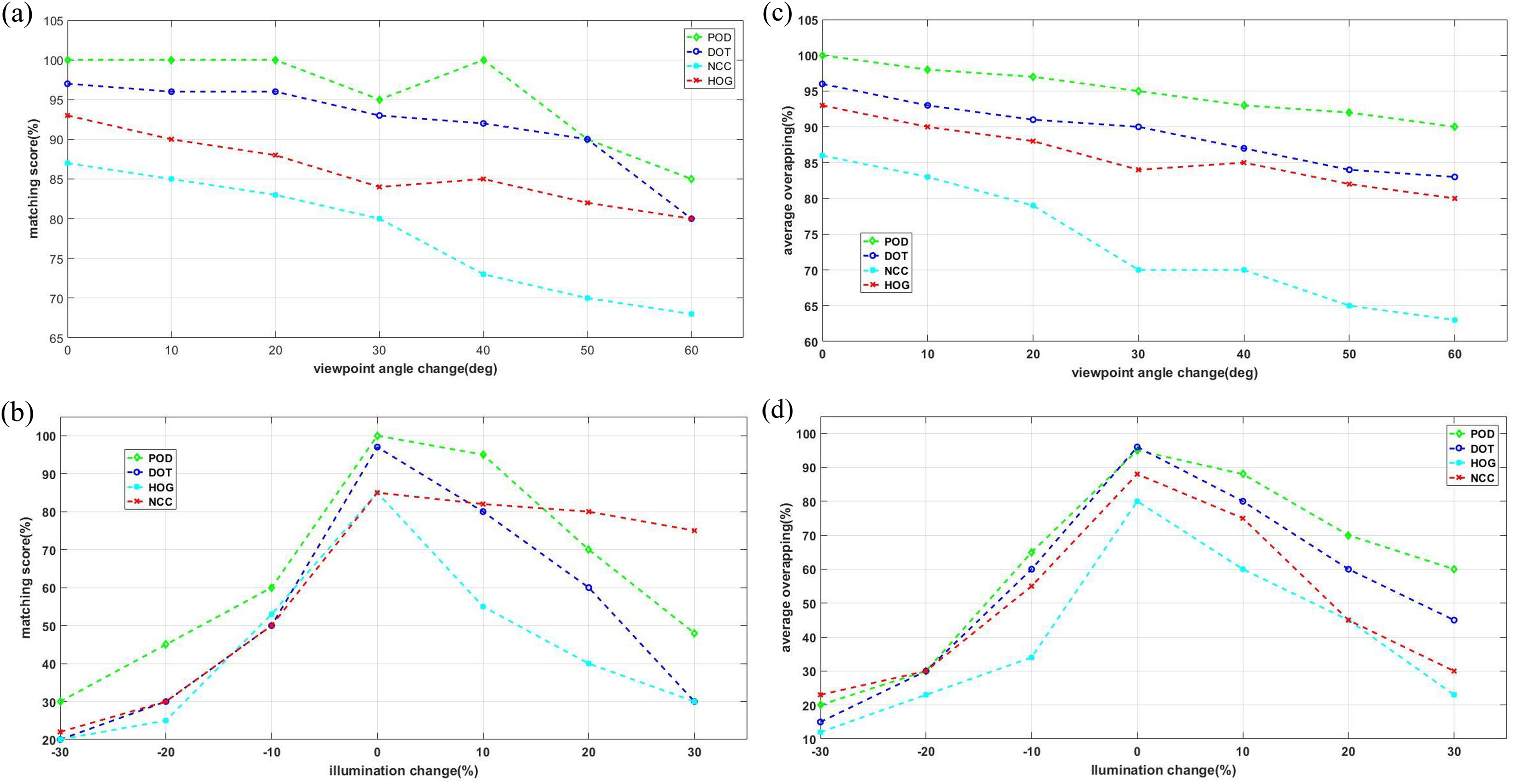
Methods comparisons on the Oxford data set. (a and b) Matching score for Oxford data set when increasing the viewpoint angle and changing the illumination. (c and d) The overlaps between the retrieved and expected regions as an accuracy measure when increasing the viewpoint angle and changing the illumination.
where soverlap is the number of overlap pixels and Stemplate is the number of pixels in the template.
Figure 9 shows the methods comparisons on Oxford data set. Comparing Figure. 9(a) and (b), we can find that the illumination change makes the performance of all of the methods worse than the viewpoint change, especially the low illumination reduces the matching scores. Figure 9(a) indicates that the matching score of our proposed method POD can achieve 100% when the viewpoint changes are 0°, 10°, 20°, and 40°. Moreover, according to Figure 9(c) and (d), we can also get the same conclusion on the average overlapping. This is because the low or the high illumination makes it difficult to extract useful image features. Even though changing the viewpoint or the illumination, the proposed method can obtain the best performance among the four introduced methods.
Figure 10 shows the methods comparisons on our lab data. Comparing Figure 10(a) and (b), we can find that the illumination change makes the performance of all of the methods worse than the viewpoint change, especially the low illumination reduces the matching scores. Moreover, according to Figure 10(c) and (d), we can also get the same conclusion on the average overlapping. This is because the low or the high illumination makes it difficult to extract useful image features. Even though changing the viewpoint or the illumination, the proposed method can obtain the best performance among the four introduced methods.

Methods comparisons on our data set. (a and b) Matching score for Oxford data set when increasing the viewpoint angle and changing the illumination. (c and d) The overlaps between the retrieved and expected regions as an accuracy measure when increasing the viewpoint angle and changing the illumination.
Furthermore, comparing Figures 9 and 10, we can find that the introduced methods can obtain a better performance on the Oxford data set than on our lab data, which means that the practice scenarios are much more complex than the Oxford data set. Therefore, the evaluation on our lab data displays the robustness and precision of the proposed algorithm.
Conclusion
In this article, we presented an algorithm for detecting low-texture objects under complex environment based on POD. In order to inhibit the change of illumination direction and intensity, we proposed a new edge extraction approach based on comparing central point with the neighborhood point to extract edge features. Besides, we introduced the DAISY for dividing area and principal orientation difference to create a new feature descriptor, which is to inhibit object rotational deformation. Experimental results on the Oxford data set and our lab data demonstrate that the presented algorithm is robust to the lighting changes and the rotational deformation. Therefore, the method can deal with the situation where training samples are insufficient. Moreover, our method can detect the object in real time because of requiring little computation, which would assist the acquisition of complete scene models. In the future, we intend to improve the circular area division to make the matching more stable in much more complex scenarios including noise background, scale.
Footnotes
Authors' Note
Weihua Tang is now affiliated to China State Construction Engineering Corporation Ltd, Beijing, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The project was sponsored by the National Key Research and Development Program (No. 2016YFB0502002), the National Natural Science Foundation of China (No. 61401040), and the Beijing University of Posts and Telecommunications Young Special Scientific Research Innovation Plan (2016RCGD11).