
Abstract
To enhance the performance of guiding an aircraft to a moving destination in a certain direction in three-dimensional continuous space, it is essential to develop an efficient intelligent algorithm. In this article, a pretrained proximal policy optimization (PPO) with reward shaping algorithm, which does not require an accurate model, is proposed to solve the guidance problem of manned aircraft and unmanned aerial vehicles. Continuous action reward function and position reward function are presented, by which the training speed is increased and the performance of the generated trajectory is improved. Using pretrained PPO, a new agent can be trained efficiently for a new task. A reinforcement learning framework is built, in which an agent can be trained to generate a reference trajectory or a series of guidance instructions. General simulation results show that the proposed method can significantly improve the training efficiency and trajectory performance. The carrier-based aircraft approach simulation is carried out to prove the application value of the proposed approach.
Introduction
The guidance of aircraft, including manned aircraft and unmanned aerial vehicles (UAVs), has become the research focus of scholars since it is widely utilized in realistic situations. For example, it can be applied for the guidance of carrier-based aircraft in the process of approach and landing for the maneuvering guidance of aircraft in air combat to reach the position of advantage, for aerial refueling guidance of UAVs, and so on. The guidance method is used to generate a trajectory or a set of instructions to guide a manned aircraft or a UAV to a moving destination in a certain direction in three-dimensional continuous space.
With the development of command and control technologies, various guidance methods have been proposed in aircraft guidance research. A visual/inertial integrated carrier landing guidance algorithm is presented, 1 which can obtain satisfactory accuracy results with less execution time. Wang et al. 2 establish a pilot behavior model for carrier landing operations based on realistic mechanisms and strategies. There are also some autonomous landing techniques for UAVs. 3 In air-to-air combat research community, many algorithms focus on automating maneuvering guidance to control UAVs or reduce the workload of pilots. 4 –6 Toubman et al. 4 adopt rule-based dynamic scripting in air combat, which requires hard coding the air combat tactics into a maneuver selection algorithm. Eklund et al. 5 present a nonlinear, online model predictive controller for pursuit and evasion of two fixed-wing autonomous aircraft, which requires a reliance on previous knowledge of the maneuvers. A virtual pursuit point-based combat maneuvering guidance law for an unmanned combat aerial vehicle is presented and is used in X-plane based nonlinear six-degrees-of-freedom air combat simulation. 6 The methods of trajectory optimization for UAV refueling in the air 7 and using a ground mobile refueling unit 8 are proposed.
These classical methods used in previous studies can accomplish the tasks for which they are programmed and require accurate models. However, in realistic situations, the accurate models usually do not exist or can be manually designed by human experts only. In this context, reinforcement learning (RL) 9 has proven to increasingly overcome this limitation and generated high expectations in the research community. RL is a type of artificial intelligence, which allows agents to learn directly from the environment through trial and error without a perfect knowledge of environment in advance. A well-trained RL agent can automatically determine the optimal or suboptimal behavior within a specific context to maximize its performance and it needs less computational time. Deep reinforcement learning (DRL) is a particular type of RL with deep neural networks for continuous state representation. Great achievements have been made in using the advanced DRL algorithms, such as deep Q-network (DQN), 10 deep deterministic policy gradient (DDPG), 11 and proximal policy optimization (PPO). 12 Mnih et al. introduce DQN and ignite the field of DRL. DQN uses experience replay and target networks to address instability issues and achieves outstanding results over many discrete Atari games. DDPG is an actor-critic, model-free algorithm, which is an extension of DQN and DPG. 13 It avoids the optimization of action-value function at every time and is feasible in complex continuous action spaces. PPO is proposed to benefit the stability and reliability from trust region policy optimization (TRPO), 14 and it is much simpler to implement, more general, and has better sample complexity. It achieves good performance on several continuous tasks and on discrete Atari games. DRL has been utilized in many decision-making fields. For example, it has been used in playing board games, 15 video games, 10 and robot control, 16,17 and obtained great achievements of human-level or super-human performance.
Some RL methods have been proposed to solve aircraft guidance problems. 18 –22 An RL agent is developed for guiding a powered UAV from one thermal location to another quickly and efficiently by controlling bank angle 18 in the x-y plane. To solve guidance problem with many conflicting objectives, a voting Q-learning algorithm is proposed. 19 A model-based path-finding method is proposed using Q-learning to show the efficiency and reliability of the training methodology in solving guidance problems. 20 Rodriguez-Ramos et al. 21 propose a DRL strategy for UAV autonomous landing on a moving platform. However, the orientation of the landing platform is not considered, and the vertical velocity control is not included in the action set. A DQN algorithm is used to generate a trajectory to perform a perched landing on the ground. 22 In this DQN algorithm, noise is added to the numerical model of airspeed in the training environment, which is more in line with the actual scenario.
Previous research have shown the benefits of using RL to solve guidance problems while some limitations still exist. First, because of curse of dimensionality, RL is difficult to converge in three-dimensional continuous space, and the quality of generated trajectory does not meet the realistic requirement. Non-RL method is used to achieve the control of altitude 18,21 or trajectory smoothing. 23 Second, previous research did not consider the direction of the aircraft when it arrived at the destination, but only the location, 18,21 which could not completely solve the guidance problem. Last, current environments are mainly for video games 24 or robot control, 25,26 which do not have the ability to train a guidance agent. Previous studies did not have frameworks for solving guidance problems, either developing RL environment based on existing ones 21 or using a two-dimensional gridworld, 19,20 which are discrete and do not have the ability to solve three-dimensional problem.
Reward shaping 27 is usually used to modify reward function to facilitate learning while maintaining optimal policy, which is a manual endeavor. It is widely adopted in RL community and also used in aircraft planning and control. Toubman et al. 28 propose a reward function to remedy the false rewards and punishments for firing air combat missiles, which allow computer-generated forces to generate more intelligent behavior. Tummer and Agogino 29 propose difference reward functions in a multiagent air traffic system and show that agents can manage effective route selection and significantly reduce congestion. Two types of reward functions are developed to solve ground holding and air holding problems, 30 which assist air traffic controllers in maintaining high standard of safety and fairness between airlines.
The main contributions of this article are listed in the following: A novel reward function is proposed to improve the performance of the generated trajectories and the training efficiency. A pretrained PPO algorithm is presented for different kinds of moving destination guidance tasks. Using this algorithm, an agent that will be used in a new task can be trained quickly based on the existing agent. An RL framework is built, in which an agent can be trained to guide a manned aircraft or to control a UAV to a moving destination in a certain direction in three-dimensional continuous state space.
This article is organized as follows. The “Problem formulation” section introduces the guidance problem under consideration and shows how to formulate this problem as a DRL task. The proposed reward shaping method and pretrained PPO algorithm to solve this task are presented in “training optimization” section. The general simulation and the carrier-based aircraft approach simulation of the proposed method are given in “Simulation evaluation” section. The final section concludes the article.
Problem formulation
In this section, the problem of aircraft guidance in three-dimensional continuous space is introduced, and the RL-based algorithm and training framework are proposed to solve this problem.
Problem statement
The objective of aircraft guidance is to guide a manned aircraft or control a UAV from its current position
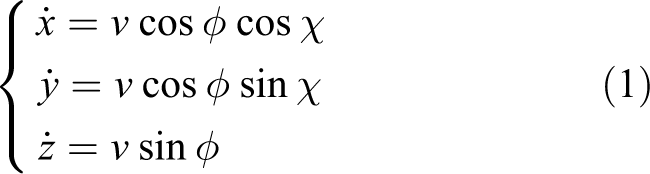
where

Kinematics model of aircraft: (a) kinematics model of aircraft on a horizontal plane and (b) kinematics model of aircraft on a vertical plane.

where m and g denote the mass of the aircraft and the acceleration due to the gravity, respectively.

where
In the scenario of UAV guidance, a continuous control vector
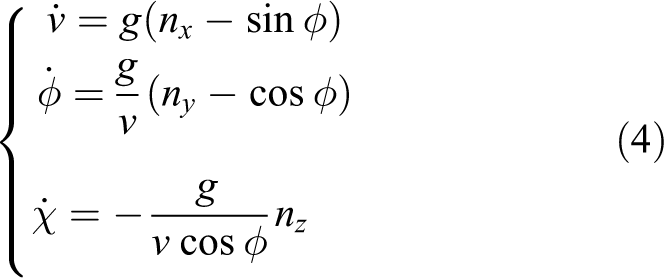
where

The continuous control variables are replaced with seven discrete control alternatives, 32 including steady flight, max load factor left turn, max load factor right turn, max long acceleration, max long deceleration, max load factor pull-up, and max load factor pushover, which are also the behaviors of the aircraft in realistic situations.
Proximal policy optimization-based algorithm for guidance agent training
In this article, the PPO-based algorithm is adapted to train an aircraft guidance agent, since it can be used in both discrete and continuous action spaces. The objective of PPO, 12 which is maximized at each iteration, is defined as follows

where

where

where

where
PPO algorithm is executed according to the training time step. However, there are not only training time step but also simulation time step. Because of the inconsistency in them, PPO algorithm needs to be improved to train a guidance agent. The pseudocode of PPO for aircraft guidance agent training is shown in Algorithm 1. The simulation results and their comparison with the proposed method are shown in “Simulation evaluation” section.
PPO for aircraft guidance agent training.


Reinforcement learning training framework
RL can be treated as Markov decision process (MDP).
33
An MDP is defined as a tuple
Unlike supervised learning agent, RL agents improve their abilities through continuous interaction with the environment. An aircraft guidance training framework is designed, as shown in Figure 2. Through training in the environment, the agent has the ability of guidance and then can be validated in special guidance simulation software or realistic situations.

Aircraft guidance training framework.
In the training process, at each time step t, the agent receives a state St
in a state space S and selects an action At
from an action space A, following a policy
For UAVs, the state set in this environment is a 10-dimensional vector, which is composed of the three-dimensional position and the heading angle of the aircraft as well as the destination, the flight path angle of the aircraft, and the number of control times remained. The action set is a three-dimensional continuous vector, which is defined as
It is called an episode from the time when the aircraft receives the start instruction to the time when it reaches the destination successfully or fails. Every episode starts with initialization. In the initialization process, the information of the aircraft and destination are initialized, including their positions and moving patterns, and the reward shaping value is initialized, which are explained in detail in the next section. After the parameter setting is completed, the situation information is sent to the guidance agent as a tuple of state, and the initialization is completed. In each training time step, the agent generates an action and sends it to the environment. The aircraft in the environment maneuvers according to the action in each simulation time step and the destination moves along its path. After the execution of the action, the environment sends the next state to the agent and judges whether the new state is a termination state or not. The termination state is composed of the successful arrival of the destination, the remaining number of control times being zero, and the aircraft flying out of the sector. The tuple of the current state, the action, the next state, and the reward in each step is used for the training of the guidance agent.
Training optimization
In this section, a reward shaping method is adopted to solve the slow convergence problem and improve the performance of the generated trajectories. In addition, a pretrained PPO algorithm is presented to further improve the training efficiency handling different kinds of moving destination guidance tasks.
Reward shaping
There are two problems when using RL method to train a guidance agent. One is that the only criterion to evaluate the guidance is the successful arrival to the destination, which is a sparse reward problem, leading to the slow convergence rate of training. The other is that different sequences which consist of the same actions have the same results in the training task. However, in realistic situations, it is very important to provide a smooth trajectory or instruction set with fewer changes for manned aircraft guidance. A reward shaping method is proposed to solve these two problems.
In this study, there are three rules to follow in reward shaping: Limited by sector scope and maximum number of control times, the aircraft is guided to the destination in a certain direction. The aircraft should be as close to the destination as possible and in the same direction as the destination. For manned aircraft guidance, the generated action should not be changed frequently.
According to the above rules, the reward function is defined as follows
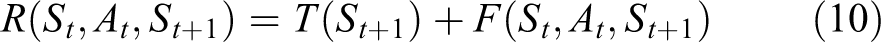
where
In this study, there are three kinds of termination states: the aircraft arrives at the destination with the same direction; the aircraft moves out of the sector; the maximum number of control times has been reached, and the aircraft is still in the sector and does not reach the destination. Termination reward is the reward obtained when the next state is termination, which is often used in the standard RL training. It is defined as

Usually, c 3 is positive value; c 4 and c 5 are negative values.

where

where

where
To alleviate the pressure of the controller, the guidance task should be finished with the least number of control times and the action should not be changed frequently. As mentioned in “Proximal policy optimization-based algorithm for guidance agent training” section, an action which is the same as the previous one is added and defines the continuous action reward as

Both c 6 and c 7 are negative values, and c 6 is larger than c 7.
For general training process, the position reward functions are given by

The training speed can be improved using the shaping reward function proposed above. For different tasks in realistic situations, training efficiency can be improved by adjusting one or more reward functions or coefficients.
Pretrained proximal policy optimization algorithm
For different tasks, the destinations have different moving patterns, such as straight-moving or curve-moving. In spite of reward shaping, there is still a problem of slow training speed. For complex scenarios, it will not even be able to train guidance agents successfully. Therefore, to speed up the training process and to train an agent quickly for the new task, it is necessary to propose an improved algorithm.
Considering the state space and action space, a pretrained PPO algorithm is proposed. The state space can be divided into two parts: the state of the aircraft and the state of the destination. The speed of the destination is far less than that of the aircraft, so the influence of the aircraft state on the agent is greater than that of the destination. Therefore, it can be assumed that the position of the destination is fixed, which means that four dimensions of the state space are unchanged, greatly reducing the complexity of the state space.
The pretrained PPO algorithm is adopted. By designing a greedy exploration policy, an agent can be trained in the fixed position destination environment and set as a baseline agent. Based on this agent, a conservative exploration strategy is set up to train an agent with guidance ability in the moving destination scenarios. This algorithm is more efficient than directly using PPO in moving destination scenario. The pseudocode of pretrained PPO is shown in Algorithm 2.
Pre-trained PPO.


Simulation evaluation
In this section, first of all, the feasibility and performance of the proposed method are verified by general simulations. Furthermore, the approach guidance simulation of carrier-based aircraft is carried out to illustrate the ability of this method to solve realistic problems.
Simulation setup
General simulation setup
Six guidance simulations are carried out and compared, including PPO for manned aircraft, PPO with continuous action reward function for manned aircraft, PPO with position reward function for manned aircraft, PPO with both reward functions for manned aircraft, PPO for UAV, and PPO with position reward function for UAV. Then, PPO with position reward function for UAV and PPO with both reward functions for manned aircraft using pretrained PPO algorithm are applied, and the simulation results are compared with that of PPO without pretraining.
In actual or simulated air guidance, an aircraft perceives the situation through multisensors. In this article, an assumption is made that a sensor with full situation perception ability is used, through which an aircraft can obtain the position and heading angle of itself and destination without error. The specific aircraft considered is the F-4 Phantom. 34 The simulation parameters are given in Table 1.
General simulation parameters.

UAV: unmanned aerial vehicle.
The Adam
35
optimizer is used for learning the neural network parameters with a learning rate of
For each simulation, the reward shaping parameters c 3, c 4, and c 5 are set to 20, −20, −10, respectively. c 6 and c 7 are set to 0.01 and 0.1, respectively. a, b, and c are set to 0.0001, 0.5, and 0.1, respectively.
Carrier-based aircraft approach guidance simulation setup
Guiding aircraft to approach and land on the deck is one of the most important tasks in the use of aircraft carriers. 36 However, it may lead to a landing failure because of the carrier motion, small landing area, and low-visibility conditions. Under different visibility conditions, there are different approach guidance methods. This section mainly studies approach guidance under low-visibility conditions, which cannot be solved by a visual approach.
In the previous approach process, the aircraft should fly a holding pattern with fixed relative direction and position. 37 It is assumed that the carrier moves in a straight line at a constant velocity. The approach process of an aircraft is shown in Figure 3. All distances are in nautical miles, and the distance measurement equipment is radar 37 or satellite navigation system. 38

Carrier-based aircraft approach process: (a) approach from the stern of the carrier and (b) approach in front of the carrier bow.
Figure 3(a) shows the aircraft approach from the stern of the carrier. The aircraft is flying in a holding pattern, and it leaves the pattern and flies behind the carrier in a straight line with the runway after it receives the approach instruction. From 20 distance measuring equipment (DME) to 10 DME, the aircraft lowers its altitude from 5000 ft to 1200 ft and then flies straight to the final approach fix which is 3 DME from the carrier.
Figure 3(b) shows the aircraft approach in front of the carrier bow. The aircraft is flying in a holding pattern, and after receiving the approach instruction, it leaves the pattern and flies over the carrier and behind it. The aircraft began to descend after it left the carrier stern 4 to 5 DME. When it is 10 DME away from the carrier, the aircraft dropped to 1200 ft and flies straight to the final approach fix, which is 3 DME from the carrier.
The current holding pattern has not met the approach requirements due to the complex airspace around the carrier. Therefore, it is necessary to propose a new approach process so that the aircraft can approach at a moving carrier in arbitrary holding pattern. The method proposed in this section is to guide a manned aircraft from arbitrary arrival holding pattern to the final approach fix of a moving carrier. In actual approach process, altitude should not change frequently or intermittently. Therefore, the altitude reward shaping is needed to ensure that a reasonable flight trajectory can be generated. The altitude reward function is defined as in equation (17)

where h is the altitude of the aircraft,


The simulation is performed in a commercial software.
39
In this simulation, the range of the horizontal plane of the sector is
General simulation results
Simulation with reward shaping
Figure 4 shows the success rate in the training process using four kinds of reward functions. The training process of manned aircraft guidance training is shown in Figure 4(a). Using PPO, the system converges after training 200 iterations. The training speed of PPO with continuous action reward function is the slowest, and the system converges after more than 400 iterations. PPO with position reward function and with both reward functions has the fastest training speed. After about 120 iterations of training, the systems converged. For UAV guidance training, it is almost impossible to train successfully without reward shaping. Using reward shaping, the system converges after about 400 iterations, and the success rate can reach more than 99%, as shown in Figure 4(b).

Success rate during the training process using PPO with different reward functions: (a) manned aircraft guidance training and (b) UAV guidance training. UAV: unmanned aerial vehicle; PPO: proximal policy optimization.
Each well-trained agent is tested for 1000 simulations. The success rate, average number of control times, and average computational time to generate an instruction are given in Table 2. Typical trajectories are shown in Figure 5. The number of control times is an important parameter for evaluating the performance of an agent in the guidance of manned aircraft. The less the number of control times, the less pressure the pilot will have, and the smoother the flight trajectory will be. As shown in Figure 5(b), the aircraft only needs to be controlled four times to successfully reach the destination. For the flight trajectory shown in Figure 5(a), the aircraft is controlled more than 10 times to reach the destination, which will bring greater pressure to the pilot.
Training results of PPO with reward shaping.
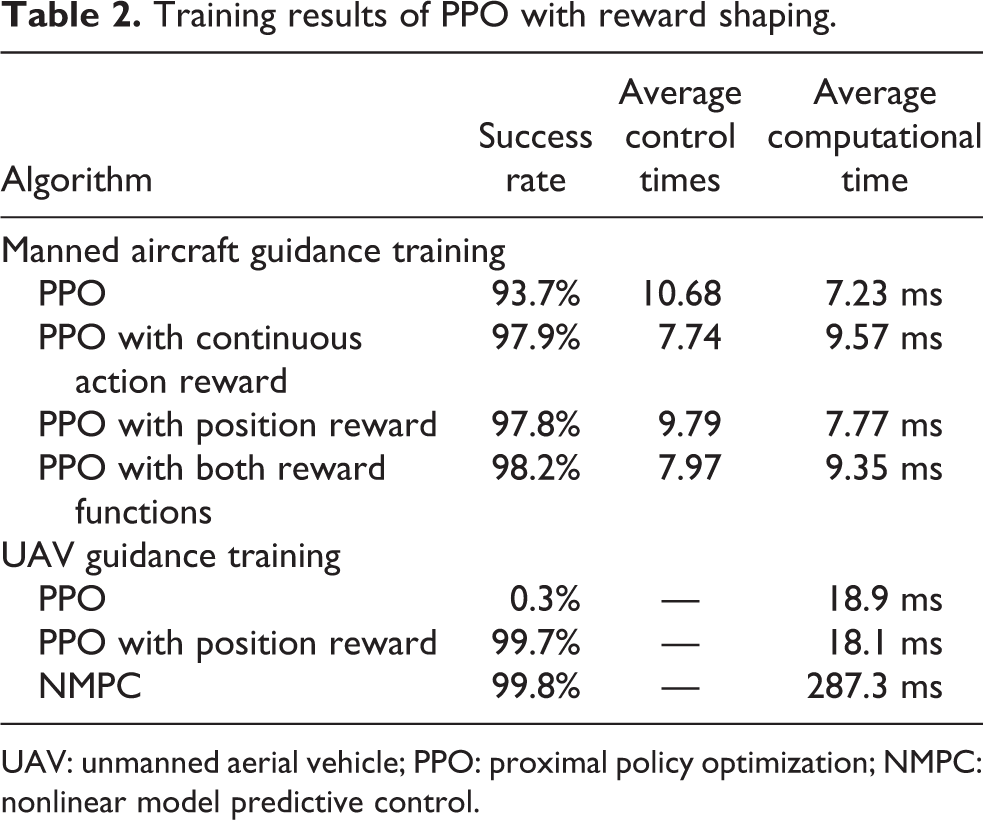
UAV: unmanned aerial vehicle; PPO: proximal policy optimization; NMPC: nonlinear model predictive control.

Typical trajectory results of PPO with different reward functions: (a) manned aircraft, PPO; (b) manned aircraft, PPO with continuous action reward; (c) manned aircraft, PPO with position reward; (d) manned aircraft, PPO with both rewards; (e) UAV, PPO; and (f) UAV, PPO with position reward. UAV: unmanned aerial vehicle; PPO: proximal policy optimization.
For manned aircraft guidance training, using the continuous action reward function, the quality of the trajectory has been greatly improved, as shown in Figure 5(b). The number of control times is reduced by 27.5% while the training speed slowed down. The position reward function can be used to improve the training speed by 40%, but it still needs a lot of number of control times and the trajectory quality remains low performance, as shown in Figure 5(c). Using both reward functions can improve the success rate by 4.5%, accelerate the training speed by 40% and reduce the number of control times by 25.4% to make the generated trajectory smoother, as shown in Figure 5(d). It takes less than 10 ms to generate an instruction using an agent, which is very efficient.
For UAV guidance agent training, simulation results are compared with the mainstream traditional algorithm NMPC. 40 Using standard PPO, it is impossible to train successfully, as shown in Figure 5(e). Using PPO with reward shaping, the success rate can reach 99.7%, as shown in Figure 5(f), which is almost the same as that of using NMPC, 99.8%. However, using the proposed method, the instruction generation time can be reduced from nearly 300 ms to within 20 ms.
Simulation using pretrained proximal policy optimization
Using reward shaping, agents can be trained for different destinations to generate reasonable trajectories. However, destinations under different tasks have a variety of moving patterns. It takes a lot of time to train different agents from scratch for different tasks. Using pretrained PPO algorithm, based on the agent of static destination, the training efficiency for a new agent can be greatly improved.
Two scenarios of straight and curve moving destinations are set up for manned aircraft and UAV guidance agent training using pretrained PPO algorithm with the proposed reward functions. The success rates in the training process are shown in Figure 6. Using well-trained agents, the success rate, average number of control times, and average computational time to generate an instruction are presented in Table 3. The typical trajectories are shown in Figure 7.

Success rate during the training process using pretrained PPO: (a) manned aircraft guidance training and (b) UAV guidance training. UAV: unmanned aerial vehicle; PPO: proximal policy optimization.
Training results of pre-trained PPO with reward shaping.

UAV: unmanned aerial vehicle; PPO: proximal policy optimization.

Typical trajectory results of pretrained PPO: (a) manned aircraft, straight-moving destination; (b) manned aircraft, circle-moving destination; (c) UAV, straight-moving destination; and (d) UAV, circle-moving destination. UAV: unmanned aerial vehicle; PPO: proximal policy optimization.
For straight-moving destination, the performance of agents with or without pretraining is comparable. The number of iterations needed to train a static destination guidance agent (baseline) and a straight-moving destination guidance agent based on it is slightly less than that required for direct training. However, based on this baseline, only less than 10 iterations are needed to make the training successful, which greatly improves the training efficiency. Meanwhile, the results show that based on this agent, for other types of tasks, such as reaching the curve-moving destination, high-performance agents can also be trained efficiently. Compared with NMPC, the time required to generate an instruction is greatly reduced with a small reduction in the success rate.
Carrier-based aircraft approach guidance simulation results
The success rate during the process of carrier-based aircraft guidance training is shown in Figure 8. An agent for static carrier approach guidance is gained through 100 iterations of training. Based on this agent, after 20 iterations, an agent for straight-moving carrier approach guidance is gained. The well-trained agent is tested in the scenario of an aircraft with random initial position and a carrier in the map center. The success rate and average number of control times are presented in Table 4.

Success rate during the process of aircraft approach guidance training.
Success rate and average number of control times of aircraft approach guidance agent.

The well-trained agent is applied in a general combat simulation platform, which can be used for individual and tactical simulation. The typical simulation results are shown in Figure 9.

Simulation results of carrier-based aircraft approach: (a) approach from the stern of the carrier and (b) approach in front of the carrier bow.
The simulation results show that the trajectory can be generated to guide a manned aircraft approaching at a moving carrier. The generated trajectory satisfies the approach requirements by the proposed method, and the aircraft can approach from anywhere without waiting in the unique holding pattern, which is used now.
Conclusion
This article proposed a pretrained PPO algorithm for aircraft guidance to reach a moving destination in a certain direction in three-dimensional continuous space. An RL-based framework is built, which can be used to train a manned aircraft guidance agent or a UAV control agent. Continuous action reward function and position reward function are proposed to improve the performance of the generated trajectories and the training efficiency. For different kinds of moving destination guidance tasks, an agent can be trained quickly based on the existing agent using pretrained PPO algorithm. The general simulation and carrier-based aircraft approach guidance simulation results show that the proposed approach can fulfill guidance tasks and has high training efficiency as well as performance.
Future work could focus on two different aspects to improve the proposed approach. One is to train agents for destinations with multiple moving patterns. The other is to improve the proposed algorithm that can be used to train a general agent to fit most of the application conditions.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China under grant no. 91338107.