
Abstract
Reinforcement learning has developed as a promising approach for robot locomotion control, which can save engineering effort compared to conventional approaches. This article presents the implementation of Reinforcement learning on a low-cost, 12 degree of freedom robot known as a quadruped (spider) to optimize locomotion control, enabling the robot to move on different surfaces such as flat surfaces, ramps, speed bumps, and rough terrain. A MATLAB Simulink model is developed as a digital twin of the spider robot. The dynamics of the model were studied and validated using an open-loop algorithm. Then, the model is utilized in a training simulation environment to apply the reinforcement learning algorithm, showing its ability to move along a predefined path as a replacement for conventional motion control systems. Moreover, the work compares the performance and effectiveness of machine learning-based locomotion control with traditional motion control systems regarding navigation accuracy, speed, and adaptability in challenging environments. The minimum hardware requirements are also studied to move the experiment from simulation to reality.
Introduction
One of the greatest challenges in rescue missions is the uncertainty of victims’ existence under tons of rubble, where it is hard to measure any vital indicator. Also, the same challenges are found in the maintenance of giant machines or drainpipes where space is limited. 1 Generally, robots are needed to handle complex tasks for humans, and they come in different designs. Robot design mainly depends on the task that the robot will do, the environment where the robot will operate, and the human–robot interaction. Moving from one place to another is the main task of any mobile robot, and the various methods used to accomplish this task are called locomotion. The study of robot locomotion involves understanding how robots navigate and interact with their environment to perform tasks or reach specific destinations. Mobile robots need locomotion mechanisms that enable them to move freely without constraints throughout their environment. 2 Moreover, locomotion control defines the form or nature of the commands between humans and robots. For example, employing a joystick to control the desired speed and direction is more straightforward for the operator than controlling each actuator’s position (angle) in a four-wheeled robot. But there are a large variety of possible ways to move.
Traditional wheeled robots have significant limitations in terms of locomotion. They have poor obstacle-surmounting ability, poor terrain adaptability, low turning efficiency, or large outer radius, which makes them easy to slip. A legged robot can adapt to almost all kinds of complex terrain, avoid obstacles, and have a wide range of degrees of freedom (DOFs), flexible movement, and even more stability in some cases. With this capability, leg-based robots can be used to rescue humans in all kinds of rocky places, explore all types of complex environments, and potentially perform any physical activity that humans or animals can perform. 3
Embedded machine learning (ML) is a rapidly growing field of ML technologies and applications, such as algorithms, hardware, and software, designed to execute sensor data analytics and decision-making directly on devices with minimal power consumption. In robotics, this unleashes the potential of a wide range of applications, and it makes the robot more capable of adapting to environmental changes, using the data, learning from experience, identifying patterns, and optimizing its performance to accomplish a specific task. That applies to all types of robots. For instance, industrial robots powered with ML can be safer, and they are more efficient in obstacle detection, predicting risks, taking real-time decisions to ensure safety, and even predicting their failure. Mobile robots can also be more efficient using ML, optimizing navigation and reducing energy consumption.
As a type of ML, reinforcement learning (RL) has developed as a promising approach for robot learning, which can save engineering effort in conventional approaches. Robots can learn to accomplish tasks by trial and error without previous knowledge of the environment. RL involves discovering optimal actions to take in various situations, aiming to maximize a numerical reward signal. Many RL algorithms have been created to handle continuous action spaces and tested across a diverse set of simulated physics tasks like legged locomotion. There is a growing interest among researchers in applying RL to control robot locomotion instead of conventional control approaches, especially in the case of complex designs such as legged robots, which are considered multi-input, multi-output systems. These robots often present complex systems that demand significant engineering effort for motion control. Yet, the implementation of RL in robotics presents its unique set of challenges. This begins with modeling the environment, which can be a real-world or a simulated model. The first ensures accuracy as the robot interacts with the actual environment, but it comes with risks, as the robot may damage itself while trying to maximize rewards. On the other hand, the second approach enables a quicker learning process where a computing system with higher computation power can be used in training, then the optimal policy can be deployed to the robot hardware. It also minimizes the training cost since there is no risk of damage to the hardware. Still, it may deviate from reality since a gap may exist between the simulation and the real-world scenario. To address this, a well-defined simulation environment that closely mimics reality is essential. Nowadays, many tools and libraries are available for model optimization and to generate C or C++ code to deploy the optimal policy to a microcontroller or small computers. 4
The rest of this article is organized as follows. The “Literature review” section reviews the literature. The robot design and configurations are discussed in the “Robot design and configuration” section. The dynamic modeling of the spider robot is presented in the “Dynamic modelling of the spider robot” section. The “Reinforcement learning” section discusses the implementation of reinforcement learning. The simulation setup and results are discussed in the “Simulation and results” section. Finally, the article is concluded in the “Conclusion” section.
Literature review
Robot research and design have taken a new trajectory with the advancement of ML. Many researchers are concentrating on empowering robots with the ability to analyze their environment through ML techniques, including object detection and robot tracking,5,6 debris classification in floor-cleaning robots, 7 the detection of hazardous materials signs in high-risk operational areas with limited computational resources, 8 path planning optimization in autonomous guided vehicles, 9 and several other applications related to visual navigation. 10 In addition, many researchers are developing legged robots to tackle complex locomotion tasks. Achieving agile locomotion in quadruped robots is challenging. Traditional controllers typically require substantial expertise and significant time for debugging and parameter tuning. 3 RL offers the potential to address the limitations of conventional controllers by enabling robots to learn effective skills directly from practical trials. This holds great promise in overcoming the constraints posed by conventional controllers. Within this context, considerable efforts have been directed towards quadruped robots, with a more specific focus on mammalian forms of movement, such as dog robots.11–15 And there has been comparatively less emphasis on applying RL techniques to achieve arachnid-like movement in multi-legged robots. These robots, characterized by the potential for up to eight limbs 16 and the ability to climb and adjust their size, have received less attention in implementing RL-based control strategies. For example, a soft quadruped robot simulation environment was developed by Lagrelius. 17 The robots’ legs consist of a continuum actuator that is driven by three servo motors to achieve complex movements. Each servo motor pulls on a wire attached to the foot of that leg. The work builds upon implementing an RL algorithm based on the MATLAB Simulink environment to train the model’s different walking gaits. Moreover, a bio-inspired hexapod robot called Boogie and its adaptive locomotion controller were presented by Trotta, 18 where an artificial central pattern generator (CPG) was used to generate the robot’s locomotion. It is based on real neurobiological control systems, and it has two layers: The first layer generates typical movement patterns, coordinating the hexapod’s limbs. The second layer ensures adaptability by controlling each limb’s behavior. The adaptability aspect is enabled by an RL algorithm that tunes the parameters of the CPG. The walking behavior simulation was conducted using Simulink Simscape Multibody. In summary, previous works have shown that many real-world problems/applications create different constraints in legged robots’ design, such as size, weight, area, and power. In addition, the complexity of the design plays a significant role in the needed control system, algorithm, and communication hardware. RL-based control strategies show massive potential in controlling legged robots in different environments, but this comes with a price of computational power and how to empower these robots with embedded ML. Moreover, research shows that legged tiny robots are one of the most promising light industries in the world, and they have a diverse range of practical applications that include search and rescue, inspection, entertainment, and STEM education. The learning of tiny-legged robots combines three challenging fields: ML, robotics, and embedded systems. 19
The legged robot designs found in the literature are quadruped and insect robots. Quadrupeds that are found by Fawcett et al., 11 Shi et al., 12 Li et al., 13 Choi et al., 14 and Lee et al. 15 are inspired by mammals such as dogs and horses. Quadrupeds benefit from a more straightforward gait pattern and the vertical weight distribution over the four legs, enhancing stability and making it easier to control these robots using motion planning algorithms, as found by Silva et al. 20 Still, these robots are considered excellent RL applications for controlling locomotion. However, the design of these robots cannot fit in tiny spaces such as tunnels or under rubble, which makes them not the best option for rescue and maintenance operations. In addition, the body cannot adjust its shape according to the environment; most of it weighs > 500 g, disqualifying them as tiny robots. The insect-inspired robot in the literature differs based on the number of legs. The early work on insect robots found by Neubauer 21 and Shoval et al. 22 shows the engineering effort needed to control the locomotion of these robots due to the complexity of the application, and they represent motion planning algorithms for limited situations and robot design. The hexapod presented by Uddin et al. 23 is remote-controlled, requires a communication circuit, and weighs 45 kg. According to Bapat, 24 the focus was on the robot design to make it more adaptable to the environment, increasing the complexity of locomotion control. Moreover, the previously discussed works use conventional control approaches that require more engineering effort and cannot generally be implemented in all types of environments. According to Lagrelius 17 and Trotta, 18 a successful implementation of RL to control locomotion on a flat surface is presented. However, hexapods are generally more stable than four-legged robots since the number of legs is higher. Also, they have more DOFs, meaning more actuators, weight, and power consumption. Another insect-inspired design discussed by Wang et al. 25 and Oh and Kim 26 is spider robots that have four legs and can move in an arachnid way; the work presents different gait algorithms based on the mathematical modeling effort for motion planning without implementing ML.
This study merges the benefits of a simplified quadruped robot design, achieved by using a minimal number of legs to minimize actuator efforts, with the inspiration derived from insects, enhancing the robot’s adaptability in size and locomotion to suit diverse environments. The main challenge is identifying a suitable gait pattern and control strategy to maintain stability during movement since coordinating leg movements, particularly during gait transitions or walking on uneven terrain, needs advanced control algorithms. Therefore, a RL algorithm is implemented to optimize locomotion across various terrains as a replacement for traditional locomotion control approaches.
Robot design and configuration
Robot design
An open-source four-legged robot (spider) design, presented by Swaminathan et al., 27 was built using 3D-printed parts and servo motors. It was controlled using Arduino and a mobile application that communicated via Bluetooth. This work takes the design to new stages: first, the robot is modeled in a MATLAB Simscape for simulation-based testing and evaluation. Second, the robot is trained to walk using RL. The robot is designed with a rectangular body architecture, offering increased area efficiency compared to a circular shape. This design facilitates the straightforward arrangement of essential components such as batteries, controllers, and drivers. The robot’s body is 10 cm in length, 8.5 cm in width, and 2.4 cm in height. The total mass of the robot is < 450 g, including all mechanical and electronic components. Four legs are attached to the corners of the rectangular body, with an assumption that the body’s mass is evenly distributed across these four legs. Moreover, the chosen leg type is inspired by arachnids, selected for its higher stability. Typically, an insect leg comprises six basic parts connected by five different joints. From proximal to distal, they are the coxa, trochanter, femur, tibia, tarsus, and pretarsus. 28 Due to its biological complexity, directly mimicking the exact anatomical arrangement of insect limbs would be challenging. Therefore, decreasing the DOFs is necessary to simplify both the mechanisms and control systems. 18
The leg design can be simplified into tibia, femur, and coxa links. The links are connected using three servo motors: body-coxa that rotates around the Z-axis, the coxa-femur joint that rotates around the X-axis, and the femur-tibia joint that rotates around the X-axis. This 3-DOF design guarantees a constant body height above the ground and enables the legs to move in all directions. The final design of the leg is shown in Figure 1. This configuration results in a four-legged robot with 12 joints and four friction contact points on the tip of each tibia, and the contact surface is < 3 mm in diameter. Moreover, the angle of each joint must be limited to avoid unwanted movements and collision between the legs.

Robot’s leg design.
Figure 2 represents the computer-aided design (CAD) model of the robot. This CAD model is an open source in STL files for 3D printing.

Four-legged 12 joint robot, computer-aided design (CAD) model.
Inverse kinematics
Kinematics, within the field of mechanics, analyses motion without examining the forces and torques behind it. It focuses on the analysis of position, velocity, and acceleration. Inverse kinematics employs kinematic equations to determine the movement of a robot or its limbs, guiding it toward a specified position. For instance, in the case of a spider leg robot, achieving a specific leg tip position involves calculating the joint angles using inverse kinematics equations. The inputs of the equations are the x and y coordinates of the leg tip and the desired position of the robot body. Therefore, inverse kinematics are utilized in robot modeling to create a logical initial condition that combines the joint’s angles, the desired XY coordinates of each leg, and the desired height of the robot. Also, it is important to randomize the initial states when implementing the RL training to allow exploration. Figure 3 presents the geometric analysis of the front-left robot leg,

Geometric analysis of spider robot leg.

Robot top view: Showing the left-front leg fully expanded.
The D displacement can be calculated from the targeted X and Y coordinates of the leg tip about the body-coxa joint, as shown in Figure 4, and the value of
Based on the targeted XY coordinates, the following equations calculate the D displacement and the






Sensors and actuators
The robot is provided with an inertial measurement unit (IMU) situated at the body’s center of gravity (CG), enabling the measurement of body attitude, velocity, and acceleration. Additionally, each joint has a servomotor capable of producing a maximum torque of 5 Nm. These motors have absolute encoders to measure relative joint angle, joint angle velocity, and the resulting torque. Furthermore, the robot employs force sensors for ground detection, represented as spherical ends and positioned at the tips of each leg. Sensors’ measurements play a crucial role in training deep reinforcement learning. They form the observation vector, which includes all sensor measurements from the robot’s surrounding environment.
Dynamic modeling of the spider robot
A recommended approach in implementing RL involves modeling the environment in a simulation format, reducing computational time, and mitigating the risk of potential damage to the robot hardware during training. Therefore, MATLAB-Simulink is employed in this work to model the spider robot and validate the dynamics of the mode.
Robot design and modeling
The spider model consists of the spider’s body, legs, and the ground, as shown in Figure 5. The inputs of this subsystem are the actions coming from the controller, which is the agent in the case of RL. Moreover, the outputs of this subsystem are the sensors’ readings from the environment. These values are taken from the Simulink-Simscape based on the real-time simulation, and they form the observation vector during the training of the RL agent.

Spider robot model in Simulink.
The robot’s four legs are linked to its body through the body-coxa joint. This link’s position and orientation are implemented using the frame transformation block based on the CAD design. Each leg contains another two joints: the coxa-femur joint and the femur-tibia joint. The joints are modeled using a revolute joint block acting between two frames with one rotational DOF. The model of the three links in the robot’s leg is shown in Figure 6. The links are connected using the revolute joint block, and the left side of the leg subsystem is connected to the robot’s body.

Robot’s leg Simulink model showing the frame transformation blocks and the Simscape solid blocks of each link in the leg.
Also, there is an input port for the joints’ torques. The ground contact point of the leg can be found on the right side of the model, and there is an output vector that represents the sensors’ values from the revolute joints, including the angular position and angular speed of each joint. The final robot model can be obtained by replicating the modeling of the remaining three legs using the same approach applied to the initial leg. Variances will exist in the connection points between the legs and the body, determined by the positioning of each leg, the joint’s orientation, and the legs’ components derived from the CAD model.
Design validation
To enable reinforcement learning training for the spider model, it is essential to validate the existing model’s capability to navigate and move in the designated environment. Therefore, a basic movement algorithm has been introduced to coordinate the motion of the four legs, facilitating forward movement along the x-axis. The algorithm contains a series of the x and z coordinates that outline the trajectory of the leg tip for forward motion. These coordinates are translated into joint angles and transmitted to each leg according to its orientation based on the inverse kinematics. Ensuring the forward movement involves transmitting angle values in a timed sequence with a specific delay between the legs. The y-coordinate of the tip is maintained at a constant 60 mm as it does not impact the robot’s movement and restricts the space it occupies during its motion. The desired height can be designated according to the surface, with a minimum value set at 0 mm where the robot touches the floor. For this experiment, it is set at 20 mm.
Forward movement is attained by forward-moving the front-left and rear-right legs along the x-coordinate and altering their positions in the z-coordinate (upward and downward). In contrast, the rear-left and front-right legs move backward in coordination with the other legs. This synchronous movement maintains the robot’s balance, preventing it from falling. Subsequently, the movement pattern reverses: the rear-left and front-right legs move forward in the x-coordinate and adjust their positions in the z-coordinate, while the front-left and rear-right legs move backward only. As a further step in physical model validation, the actual robot model was implemented by printing the CAD model using a 3D printer and assembling the robot parts using 12 servo motors. An Arduino mega is attached to the robot body as a physical model (plant) communicating with the Simulink model and sending the angle commands to the servo motors. The angle values are generated from the trajectory coordinates model shown in Figure 7 and sent to the actual hardware instead of the Simscape model. Figure 8 shows the implemented actual model in Simulink using the servo motor block from Arduino Matlab Support Package.

Trajectory coordinates model used to validate the design.

Actual robot subsystem consists of 12 servo motor blocks.
Figure 9 illustrates the resulting movement of the robot, transitioning from point A to point B to represent a single-step movement. The real robot has the same walking behavior as the one resulting from the Simscape simulation.

The resulting movement of the robot in the Simscape Animation and the actual robot.
Reinforcement learning
Four-legged spider robot locomotion can be formulated as a Markov decision process (MDP) since, at each time step, its state depends only on the previous state at the antecedent time step. At each time step t, the state vector
In RL, an intelligent agent operates in a dynamic environment, aiming to maximize cumulative rewards. The creation of agents contains the development of both the policy and the learning algorithm. In the case of the spider robot, the policy maps 56 observations from the environment to 12 torque actions. The learning algorithm continually updates the policy parameters to achieve the goal, which, in this context, controls locomotion along the x-axis. The agent operates without any pre-existing knowledge of the environment, relying solely on the learning policy for locomotion control. No additional controllers or guidelines are provided to the agent. Figure 10 illustrates the agent’s and the environment’s interaction.

Reinforcement learning general structure.
The agent is modeled in the Simulink environment using the RL agent block, which serves to simulate and train a reinforcement learning agent within Simulink. This block is connected to an agent stored either in the MATLAB workspace or a data dictionary. The block is configured to receive observations from the modeled environment and a computed reward, also sending actions represented as torques applied to the spider robot actuators. The agent block is also connected to a stopping criterion, which outlines conditions for terminating a training episode in case of poor performance, reducing computational costs associated with undesirable robot behaviors such as falling or losing track. The full model representing the agent and the robot environment is presented in Figure 11.
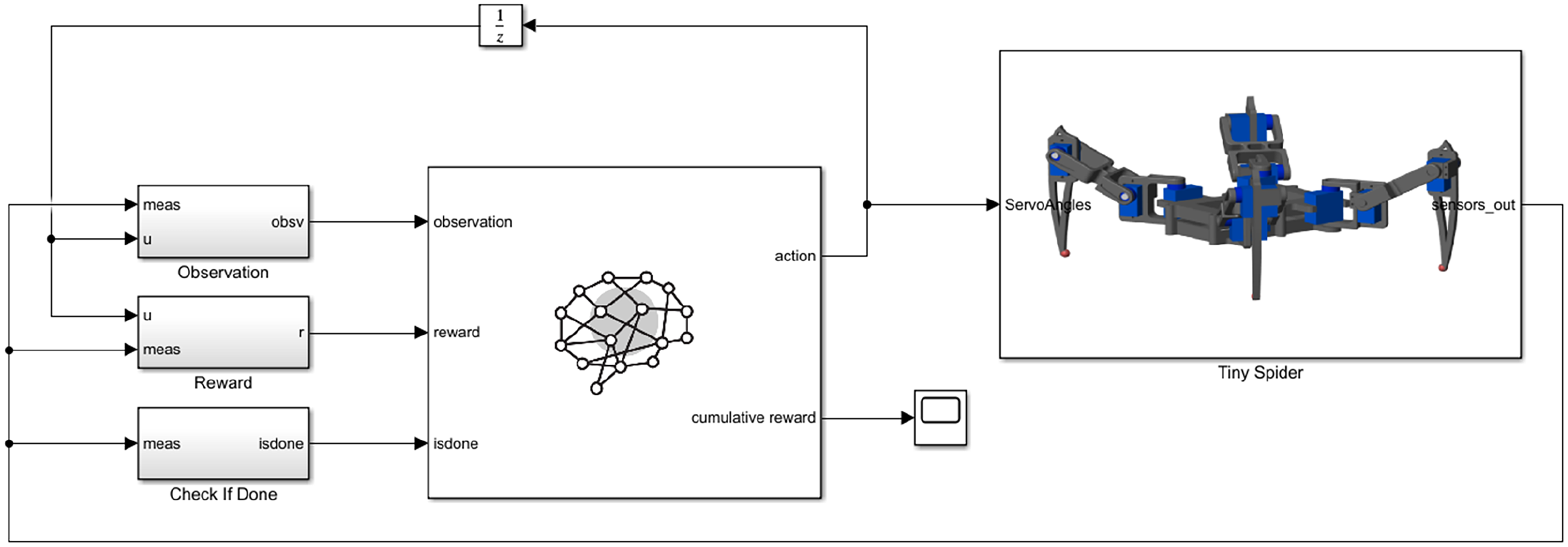
The top layer of the implemented Simulink model.
Choosing the agent learning algorithm depends on the nature of the problem, whether it has a discrete action space or continuous action space. Obviously, the spider robot has a continuous action space where different types of algorithms can be used. In this work, a deep deterministic policy gradient (DDPG) is implemented, showing sufficient results in training the spider agent. However, other options, such as twin delayed DDPG (TD3), can be used and evaluated.
Deep deterministic policy gradient
A DDPG is a model-free, off-policy actor-critic algorithm using deep function approximators that can learn policies in high-dimensional, continuous action spaces. It is based on the deterministic policy gradient (DPG) algorithm.
31
DDPG maintains four neural networks as function approximators: a Q network (critic) Initialize all the DDPG networks with random parameters and start with an empty experience buffer. The spider agent takes the current observation and passes it to the actor-network. The actor-network receives the state The agent gets a reward The critic is updated the same as in Q-learning, where the Q value is obtained by the Bellman equation. The value function target is the sum of the experience reward Then the mean squared loss between the updated Q value and the original Q value is minimized to update the critic: In the actor, the objective is maximizing the expected return by taking the mean of the sum gradients calculated from the mini-batch N:
Finally, the agent will update the target actor and critic parameters based on a defined target update method. The DDPG algorithm has significant computational resources requirements. Therefore, in this study, the robot is trained on a well-equipped computer presented in the “Simulation setup” section to minimize the learning time, and only the optimal actor policy, which has less computational requirements and can be handled by an embedded system, will be deployed to the robot to achieve locomotion.


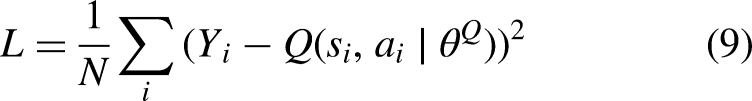

Observation vector
The spider robot interacts with its surrounding environment through receiving observations and executing actions. The actor is responsible for taking actions and learning the task by receiving information from the real robot through an observation vector.
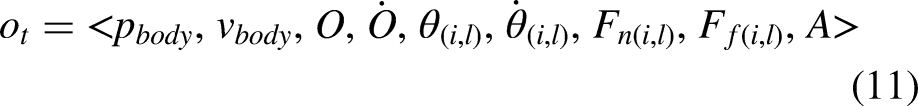
Action vector
The agent generates twelve actions according to the number of the robot’s joints normalized between
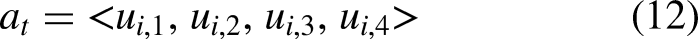
Reward function
The agent receives the reward function at every time step during training. Positive rewards incentivize the agent to execute correct actions, while negative penalties discourage it from doing what is wrong. In this work, implementing the RL agent aims to find a locomotion policy that allows the robot to move forward. The reward function motivates the robot to move forward by providing a positive reward for positive forward velocity (

Episode stopping criteria
Episode stopping criteria are essential techniques for implementing the training of the control policy. The training algorithm has the complete freedom to explore the action space, and it could select some actions that could lead to unstable and unwanted states. A logical flag, called the “isdone” flag in the RL agent block, is used when at least one of the modeled stopping criteria is true. The modeled stopping criteria are two: the first one is when the height of the body’s CG from the ground is below a certain
Simulation and results
Simulation setup
The training process and the simulation were conducted in MATLAB. Simulink-Simscape is used to model the environment and the RL agent. Deep learning and RL Toolboxes are utilized to create the agent neural networks and perform the RL training. The simulations were performed on a computer equipped with an Intel®CoreTM i9-13900K Processor with 24 cores, a frequency of 3 GHz, and 64 GB RAM. During the training process, RL agents depend on hyperparameters, which are configurations that determine key aspects of the learning process. These parameters control elements like the balance between exploration and exploitation, the discount factor, the learning rate, and the frequency of policy updates. Table 1 shows the hyperparameters that are implemented using the RL toolbox.
Hyperparameter values for the implemented simulation.

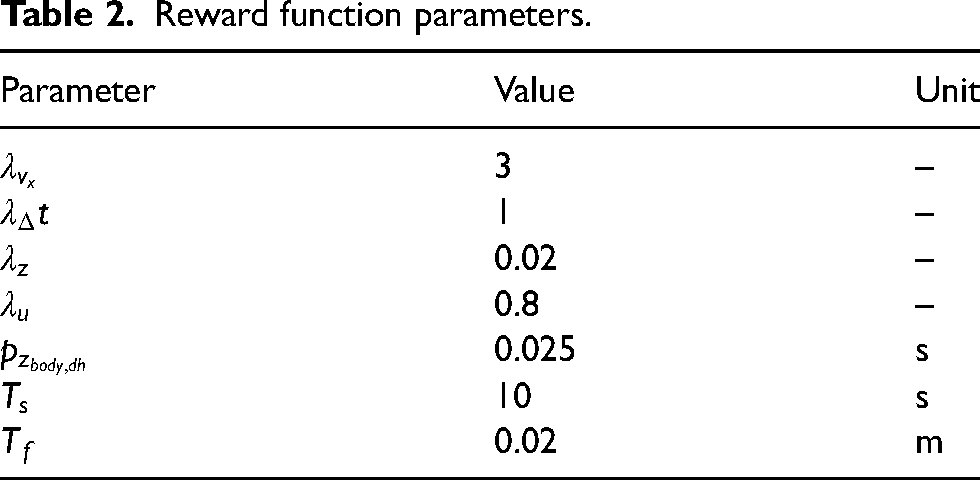
The weight values in the reward function equation (13) are used to assign relative importance or priority to different components or features of the environment state. The choice of weights depends on the specific task and the desired behavior of the agent. Calculating the weights involves trial and error, starting by initializing the weights to some initial values, then training the agent and evaluating the agent’s behavior to adjust the weights and repeat. Table 2 shows the gain values in the reward function subsystem, the simulation time, the sampling time, and the desired height presented in equation (13).
Reward function parameters.
Simulation environments
Simulation environments represent different terrains the robot could interact with in real life based on the required application. These scenarios showcase the efficacy of RL training in developing policies for locomotion control across varied terrains. In this work, the agent was trained on five different terrains. The first terrain is a flat surface where the robot must be able to move forward without any change in the surface elevation. The second terrain is called Ramp 1, where the robot must be able to move on a ramp tilted

The implemented simulation scenarios in reinforcement learning (RL) training.
Simulation results
The training was done separately for each scenario. The training on the flat surface took almost 13 h and reached 8182 episodes. The adopted stopping criteria was an average reward equal to or higher than 50. In the first 2000 episodes, The reward value fluctuates within negative values ranging from

Episode average reward on different types of surfaces.
The optimal actor policy in each scenario controlled the spider robot to move forward along the x-axis, achieving effective locomotion. The agent demonstrated excellent adaptability in adjusting both speed and torque based on the surface. It showed caution by moving slowly on ramps, and unexpectedly, the average torque values on challenging surfaces were lower than on flat surfaces, as shown in Table 3. This unexpected behavior affected the power consumption of the actuators, highlighting the agent’s capability to adapt torque, speed, and power consumption according to the environment.
Average speed, average torque, and cumulative reward.

Simulation to reality
The final step in implementing RL is transitioning from the simulated environment to the actual physical environment, known as deployment. The actor optimal policy can be deployed on the robot hardware to test the optimal policy in controlling locomotion or fine-tune the optimal policy using online learning to get better performance. In MATLAB, a C/C++ code can be generated from the policy evaluation function, which maps the observations to actions based on the developed policy. The generated code can be deployed to the robot hardware, which can be an embedded system and act like a traditional controller. The minimum requirement of such hardware can be specified by analyzing the actor policy using the MATLAB deep neural network analyzer. The number of learnable parameters for the optimal policy model is 146.7k, and since the learnable parameters are stored in a single precision format, taking 32 bits in memory, this neural network has a size of only 0.573 MB.
Conclusion
In this work, a simulation model of a four-legged robot with 12 joints was developed. The dynamics of the model were validated using a basic open-loop algorithm. Subsequently, a RL model employing DDPG was introduced to control the robot’s locomotion. Effectively, the agent exhibited the ability to learn locomotion across various surfaces without the need for conventional control methods nor relying on prior environmental data, showcasing remarkable adaptability and reliability. The training included flat surfaces, ramps, speed bumps, and rough terrains. Moreover, the resulting policies were successfully tested in diverse random scenarios for which the agent had not been trained.
Results and Simulink model availability
The system’s code is public and can be accessed through (https://github.com/ZaidHJaber/Four-legged-Spider-Robot-RL-locomotion). Furthermore, the system demonstration is available. See (https://www.youtube.com/playlist?list=PLrXurzH_oKpuT00fxP0ZjtIjLz9AAMmnC). This transparent sharing aims to expedite model development among fellow researchers and ensure the swift reproduction of results.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.