
Abstract
Humans maintain good memory and recognition capability of previous environments when they are learning about new ones. Thus humans are able to continually learn and increase their experience. It is also obvious importance for autonomous mobile robot. The simultaneous localization and mapping system plays an important role in localization and navigation of robot. The loop-closure detection method is an indispensable part of the relocation and map construction, which is critical to correct mappoint errors of simultaneous localization and mapping. Existing visual loop-closure detection methods based on deep learning are not capable of continual learning in terms of cross-scene environment, which bring a great limitation to the application scope. In this article, we propose a novel end-to-end loop-closure detection method based on continual learning, which can effectively suppress the decline of the memory capability of simultaneous localization and mapping system by introducing firstly the orthogonal projection operator into the loop-closure detection to overcome the catastrophic forgetting problem of mobile robot in large-scale and multi-scene environments. Based on the three scenes from public data sets, the experimental results show that the proposed method has a strong capability of continual learning in the cross-scene environment where existing state-of-the-art methods fail.
Introduction
Simultaneous localization and mapping (SLAM) is a key technology for autonomous mobile robots. 1,2 Visual-based SLAM has become a research hot spot because of the rich information acquired by visual sensors. The amount of training sample data learned by the visual SLAM system is always limited. So, the SLAM system encounters many problems, when the autonomous mobile robot works in a changeable real-world environment. 3,4 For example, when the visual SLAM system trained in scene A works in scene B, the catastrophic forgetting problem of the neural network causes a greater suppression of the memory capability of the visual SLAM system. Meanwhile, the visual SLAM lose the memory of the original scene when it learns map construction in the new environment. With the larger scene spanning, the longer running time, and the more new sample data, the memory capability of the existing visual SLAM system declines more severely. This cause the robot to fail to effectively and incrementally complete the map construction and need to relearn when it encounters cross-scene. 5
When the visual SLAM faces the cross-scene environment, how to make it have human-like continual learning capability is the key to the robot’s practical application. As a key module of visual SLAM, loop-closure detection (LCD) plays a crucial role in improving the human-like learning capability, if it can continually learn new knowledge from new scenes without forgetting the memory of previous scenes. Therefore, it is of great significance to study the method of visual LCD with cross-scene learning capability.
At present, most of the LCD methods mainly use image descriptors to visually describe the environment and then complete LCD by matching the current image with the keyframes of the map. Compared with the LCD methods based on handcrafted descriptors, 6 –10 the methods based on convolutional neural network (CNN) have significant advantages and also have received great attention. 11 –15 However, all LCD methods based on CNN have the problem of catastrophic forgetting, that is, they almost gradually forget the previously acquired content after learning new knowledge, which makes LCD methods lack the persistent adaptation to the environment and continual learning like human beings. 16 Existing LCD methods need to change the training data and retrain the model according to different application scenes. Although the model trained in the new scene can work well in the new scene, it partially forgets the old scene. As a result, the more new scenes are learned, the worse the capability of the model to recognize the old scene will be, or even completely unable to recognize the old scene. Figure 1 shows the state-of-the-art method of LCD NetVLAD 17 gradually lost its memory for old scenes after continually learning (a) Oxford night, (b) Pittsburgh, and (c) Oxford day.

Performance of state-of-the-art method of LCD continually learns of three scenes of (a), (b), and (c). The test data set is derived from the initial scene of (a). (a) RobotCar-Night scene; (b) Pittsburgh scene; (c) RobotCar-Day scene; (d) Recall@Top1. LCD: loop-closure detection.
In this article, a new cross-scene LCD method for visual SLAM is proposed to solve the problems of insufficient continual learning capability, loss of previously learned experience, and memory decline in terms of cross-scene learning. The proposed method learns image features by improving the learning strategy and CNN structure, then uses the improved NetVLAD to generate image descriptors with image feature aggregation, and finally adopts an efficient index structure to ensure the efficiency of the online LCD method. The most significant difference with the existing methods is that our method firstly adopts the parameter learning mechanism based on orthogonal weight modification, which effectively suppresses the memory decline of LCD.
The main contributions of this article include We integrate the orthogonal weight modification theory into the CNN for the first time and propose a new deep learning mechanism. The proposed method enables deep neural networks to obtain the ability to learn image features across scenes. The improvement of this basic learning ability has greatly improved the image matching performance of the robot in different scenes, which is of great significance to tasks such as LCD and visual place recognition. We propose a novel end-to-end LCD method, which has continual learning capability and generates more robust image descriptors. This method enables the nonlinear dynamic SLAM system to have the ability to build incremental maps across scene, which greatly improves the intelligence level of the SLAM system.
The rest of the article is organized as follows. We discuss the related work in the second section and introduce the proposed LCD method in the third section. The experiment is elaborated in detail in the fourth section and fifth section. In the sixth section, the work of the article is summarized and the future work is expected.
Related work
In this section, we briefly review the representative methods of LCD for visual SLAM and introduce the relationship between these methods and our work. Building a high-precision environmental map for visual SLAM is the most important and fundamental capability for its robust perception of the surrounding environment, and LCD is the key to correct mapping. 3 The LCD method can reduce the probability of incorrect representation of node of map and error accumulation brought by the front-end of visual SLAM, so as to obtain a globally consistent map. 18 LCD is to determine whether the robot has returned to a location that has been visited before, and it is, in essence, the same as global localization and place recognition. 19,20 So next we introduce these three aspects together.
Visual LCD can be roughly divided into two kinds of algorithms: those based on shallow features and those based on deep features. LCD based on shallow features mainly relies on handcrafted features which are mainly designed by expert experience. The GIST is a representative work based on the shallow features, which can describe the macroscopic feature of the whole image scene. 21 This method does not require any form of pretraining and only inputs an image to get the global feature vector. Therefore, this method is listed as one of the representative methods for the comparison experiment in our article. With the development of the methods in recent years, many local-based invariance features have appeared, such as SIFT, ORB, and SURF. 22 These methods can maintain a relatively stable matching accuracy in the face of camera rotation, translation, scale changes, and so on. They have also achieved certain effects in the SLAM system. 9,23 But these local feature-based methods not only need to construct bag-of-words, 10,18 and they are also weak when facing more complex changing environment such as light changes.
To address these challenges, researchers find that methods based on deep learning can find stable feature regions in a large number of scene samples and show stronger robustness when the appearance of environment changes dramatically due to changes in environmental light and seasons. Therefore, researchers try to introduce deep learning into the field of visual SLAM for detecting loop-closure, and many representative achievements appeared. The method proposed by Lopez-Antequera et al. uses a training model to map images in a low-dimensional space, so that images with similar scenes can be mapped close to each other. 15 Yin et al. introduce MDFL, a multi-domain feature learning method, to achieve end-to-end LCD. 24 Camara et al. integrate information such as semantics, geometric verification, and continuous frame time relationships to achieve performance improvements. 25 Those abovementioned methods are robust in specific environment but perform poorly in terms of efficiency. Therefore, Chancán et al. propose a LCD method combining FlyNet and CANN neural network models. 26 This method combines the compact pattern recognition capability of the FlyNet model with the powerful time filtering capability of CANN and greatly improves the efficiency. Khaliq et al. propose a lightweight visual LCD method that can achieve high performance at a lower computational cost, and the efficiency is increased by 12 times compared with state-of-the-art methods. 27 Although the above methods can solve some problems of LCD, they do not perform well in the face of long-term scene changes.
To cope with the challenge of long-term scene changes, researchers have proposed four different types of LCD methods. The first type is based on probability statistics and usually relies on a grid map model. It requires repeated observations of the environment to continuously update and maintain the map model and is only suitable for a small range of application scenes. 28 –30 The second type is based on “sampling” or “memory,” which divides the landmarks into temporary memory and permanent memory. These methods need to visit the same scene as much as possible to cover the changes of scene conditions, and it is easy to cause information explosion in a large range of scenes. 31,32 The third type is to build a stable semantic information model and use semantic information for matching. However, the current semantic segmentation precision is poor, and the effect of direct application in LCD is not very satisfactory. 14,33 –35 The fourth type is a learning-based method that uses long-term interaction and learning between mobile robots and the environment. It can improve the adaptability of loop-clousre detection to environment, which is the focus of current research. 17,36 –38 However, these learning methods based on CNNs suffer catastrophic forgetting problem as the number of scenes increase. The existing visual LCD methods still lack research in this aspect, which is the motivation of the research in this article.
Cross-scene training with continual learning
In this section, we introduce the principle and implementation process of the cross-scene LCD method in detail. In a typical LCD, given a query frame, Iq
, and a set of M database frames,

Overview of our proposed pipeline. It is mainly composed of an online phase and an offline phase. The entire process is described in subsection “Overview” and the details of the two phases in the pipeline are shown in subsections “Image descriptor generation” and “Loop-closure candidate selection.”
Overview
Figure 2 clearly shows the pipeline of the proposed cross-scene LCD method. The inspiration of this article comes from the fact that the capability to overcome catastrophic forgetting problem is the key to human-like cross-scene learning in LCD, and the latest continual learning work provides us with an idea. 39 Unlike most methods that only use pretrained models, 13 the pipeline designed in this article includes online and offline phases to make our method have stronger learning capability and adaptability. The model training in the offline learning phase is the basis and the main innovation of this article. To this end, this article proposes a novel cross-scene model training method (given in Algorithm 1) and a new network structure (as shown in Figure 4). By using the trained model, the image descriptors can be generated end-to-end.
In the pipeline of Figure 2, some of the links can be considered as part of the subsection “Loop-closure candidate selection.” In the offline phase, we extract the convolution features of all images in the database and implement feature vectorization and dimensionality reduction. Then the inverted index can be built to link the feature vectors to the database images. In the online phase, the convolution features of the query image are firstly extracted, then vectorized, and dimensioned. Lastly, the Top-N candidate images from the database are retrieved to utilize the inverted index and provided to the loop-closure verification link to determine the final loop-closure location.
Cross-scene learning
In fact, mobile robots are always working in a variety of different scenes or environments with changing conditions. For example, an SLAM system that has learned about the office environment in a bright day may need to continue to learn the map of the outdoor environment in a dark evening. However, at present, SLAM system based on deep learning does not have the ability to accumulate experience incrementally. This is mainly because they can only adapt to the autonomous positioning and map building in the environment after training in a specific working scene. When the robot enters into a new working environment, it cannot directly add learning content to the previously trained experience model but need to retrain the model. As the volume of data increases, the existing methods are learning new knowledge while increasing the experience, it leads to the loss of accumulated experience or memory decline, which greatly limits the incremental map building ability of mobile robot for different scenes, thus we propose a new cross-scene training method to overcome those disadvantages.
Model training.


Algorithm 1 describes the proposed method, which can improve the performance of LCD in terms of continual learning for multiple scenes. Firstly, the K-Means clustering algorithm is used to calculate the clustering center, and the obtained clustering center is used to initialize the NetVLAD layer. Since the high acquisition cost of label data, and easy acquisition of GPS data, we use GPS as ground-truth to realize weakly supervised learning, and the triplet loss function is also used to calculate the loss for back-propagation (BP). In the process of BP, the schematic of our cross-scene method is shown in Figure 3. Traditional methods, such as stochastic gradient descent (SGD), most likely search outside rather than the overlapping area. Thus, we define the orthogonal projector
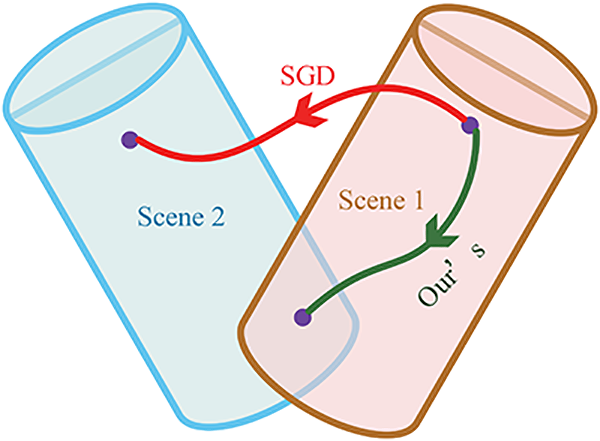
Schematic of our method. The training process searches for configurations that can learn scene 2 (blue area), within the subspace that enables the network to learn scene 1 (pale pink area). A successful search necessarily stops at a position inside the overlapping subspace. In comparison, the method obtained by stochastic gradient descent search (SGD) is more likely to end outside this overlapping area.
Consider a neural network of
According to character of Deriving Projection Matrices,
41
it can be easy to derive Orthogonal Projection Matrix of

in which α is the relatively minor constant.
For the case of

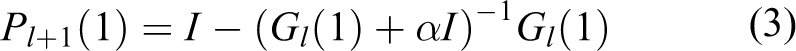
in which


It can be easily derived that
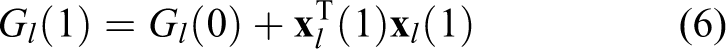

According to equations (6) and (7), the relationship of kth scene and

According to the Woodbury matrix identity
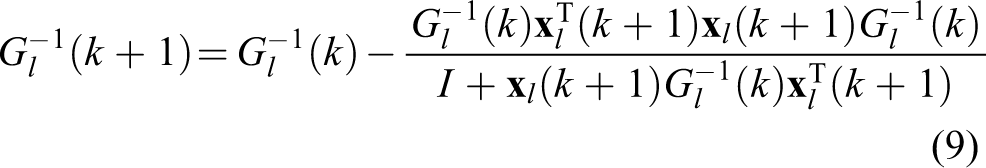
Thus we can get the orthogonal projection matrix P
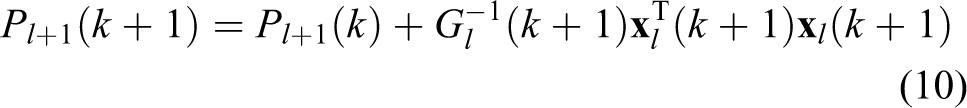
Traditional method such as SGD update the weight matrix by

where lr denotes the learning rate.
In our method, the weight matrix(

Image descriptor generation
As shown in the NetVLAD module in Figure 4, the original NetVLAD method doesn’t take into account the effects of some low-quality features such as ambiguity. These low-quality features don’t contribute much to the recognition and have side effects, and the weight of this low-quality information to the final aggregation should be reduced. The simplest method is to find out the low-quality images in the preprocessing stage and reduces theirs contribution weight, but this can’t achieve the goal of intelligence. In this article, the method of end-to-end automatic training is implemented so that the network itself can optimize the identification and reduce the weight of this part of the sample. We increase the number of clustering centers to
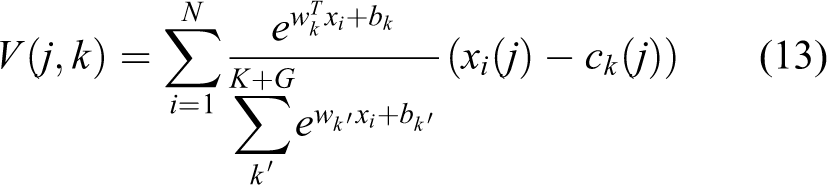
where
The network structure designed in our experiment is shown as Figure 4, and the proposed method can also be used to improve the continual learning performance of other network structure such as ResNet 42 and Xception. 43 As shown in the middle part of Figure 4, we have improved the network structure based on AlexNet 44 . AlexNet is oriented to image classification task, using five convolutional layers (among which three convolutional layers are connected to the max-pooling layer), three fully connected layers, containing a total of 630 million connections, 60 million parameters, and 650,000 neurons. Due to the limited computational resource of mobile robots, the algorithm should ensure lightweight and high real-time performance. However, the fully connected layer has a huge number of parameters and considerable computational complexity, so we remove all the fully connected layers from the network structure. The max-pooling layer can reduce the size of the model and improve the computing speed, but it loses a lot of information that is irreversible. We remove the final max-pooling layer from the network structure, which can enhance the robustness of the network model. In this way, the output of the convolutional layer can be conveniently used as the input of the NetVLAD module.

The convolutional neural network structure diagram proposed by this article. This network can extract the global image descriptor end-to-end, which provides convenience for the subsequent construction of index structure and keyframe query.
Loop-closure candidate selection
The ultimate goal of the proposed online phase is to search the most similar N keyframes for current observed image from the map, which are the candidate loop-closure keyframes. The process can be described as: given x which is D-dimensional vector (current observed image) and set
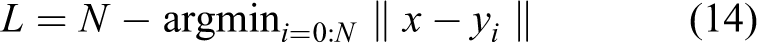
The simplest way is to compare the query frame with all the images in the map one by one and then select the N nearest candidates. The time complexity of constructing distance matrix and finding N nearest neighbors in the minimum heap algorithm for distance matrix are
But this is not the focus of this article, so our experiment directly adopts the product quantization inverted method 43 to ensure experimental efficiency of the whole method for validating effectiveness of the proposed cross-scene method with continual learning. Algorithm 2 describes the process of obtaining the loop-closure candidate, and the most similar N keyframes can be searched according to the current observed image. In line 3 of Algorithm 2, it is the process of inverted indexing of all images in the map, while line 4 is the process of a real-time query of the observed images in the index structure.
Loop-closure candidate selection.


Experimental setup
We perform a number of comparative experiments to evaluate the performance of the proposed LCD method in the cross-scene environment. The operating system of the experimental environment is Ubuntu 18.04, and the graphics card type is Nvidia RTX 2080Ti. In this section, the data sets related to the experiment are firstly described, then the adopted evaluation protocols and methods are introduced, and finally the comparison methods are listed.
Data sets
Oxford RobotCar data set
45
and Pittsburgh data set
46
have been used as standard testing data sets in many papers. In this article, three challenging scenes are selected to evaluate the performance of the proposed LCD method. In our experiments, two scenes are taken from the Oxford RobotCar data set, in which the RobotCar-Day scene is collected from the day images, the RobotCar-Night scene is from the night images, and the third scene is collected from the Pittsburgh. The learning data include three parts: training set, validation set, and test set.
In detail, the training data set, validation data set, and test data set of RobotCar-Day scene data set and RobotCar-Night scene data set, and Pittsburgh scene data set are following as Table 1, Table 2, and the reference, 46 respectively. In the following, the three scene data sets of RobotCar-Day scene data set, RobotCar-Night scene data set, and Pittsburgh scene data set are introduced.
Detailed composition of the training set, validation set, and test set in the RobotCar-Day scene.

Detailed composition of the training set, validation set, and test set in the RobotCar-Night scene.

For the different experiment aims, it should be noted that the test data sets of the following specific experiments are changed. For subsection “Evaluation of overall performance,” the test set of every learning scene is test data sets combined with all of the scenes. For subsection “Evaluation of cross-scene ability,” the every learning scene of test data set is the initial scene.
Evaluation index
Our experiment adopted three typical indexes to evaluate the performance of the algorithm, which are Precision-recall curve, Recall@N, and Average searching time per query. Precision-recall curve is used to evaluate the overall performance of LCD. Recall@N curve is used to show the tendency to continually learn multiple scenes. Average searching time is used to test the real time of the algorithm

LCD classification.

LCD: loop-closure detection.
Comparative study
In the follow experiments, we compare our approach with different state-of-the-art LCD methods including NetVLAD, Max-Pool, Off-the-Shelf, and GIST.
To distinguish, we denote the abbreviation of our method as follows. The Cross-Scene Descriptor (
Experimental results
In this section, all the experimental results are showed. To ensure the objectivity and completeness of the experimental data, we construct the data sets in accordance with subsection “Data sets” and did not eliminate the useless data in the data sets. Therefore, some figures show that the area below the precision-recall curve is less than 0.5. We firstly demonstrate the effectiveness of two key modules NetVLAD and Off-the-Shelf. Next, we evaluate the convergence of CSDesc method, the overall performance, the cross-scene performance, and the efficiency of our method.
Evaluation of key-modules effectiveness
In this section, we evaluate the role of two key modules NetVLAD and Off-the-Shelf. NetVLAD module or the Off-the-Shelf module in traditional methods can significantly improve performance. We change the traditional weight update way of CNN during the learning process, so it is necessary to evaluate these two modules. This comparison involves two scene data sets, RobotCar-Day and RobotCar-Night, and the results in terms of precision and recall are shown in Figure 5 and Figure 6.

Evaluation of the impact of the NetVLAD module and Off-the-Shelf on the RobotCar-Day data set.

Evaluation of the impact of the Off-the-Shelf module on the RobotCar-Night data set.
Firstly, we evaluate the effectiveness of adding NetVLAD module. We use the RobotCar-Day scene and RobotCar-Night scene in the experiments and get the same results. Due to space limitations, we only show the RobotCar-Day results. As shown in Figure 5, the importance of the NetVLAD module is obvious. Examining CSDesc-Pi versus CSDesc-N-Pi and CSDesc-Pp versus CSDesc-N-Pp, we observe a significant improvement in performance when NetVLAD (N) is employed.
Then we evaluate the effectiveness of adding the Off-the-Shelf module. As shown in Figure 6, in some cases, without the Off-the-Shelf module, CSDesc-N is able to outperform CSDesc-N-Pi (cyan vs. magenta). That’s due to perceptual aliasing becomes more pronounced in a night scene. In terms of different pretrained models, Figure 5 shows that under different thresholds, the recognition accuracy is mutually competitive (CSDesc-Pi vs. CSDesc-Pp or CSDesc-N-Pi vs. CSDesc-N-Pp).
In summary, the result demonstrates the usefulness of NetVLAD and Off-the-Shelf independently, and they are both used in our final CSDesc LCD method.
Evaluation of convergence of CSDesc
In LCD, robots repeatedly go back to the same place that may show significant visual appearance differences. The changes (e.g. daytime vs night) are often repetitive during robot navigation. Continual learning can be problematic due to osculation and may never converges. Given the repeated changes, the convergence of continual learning is quite considerable. For example, robots work in the same place during the day and at night. As shown in Figure 7, we compare with a traditional non-learning method, typical CNN methods, and NetVLAD methods based on different pretrained models. Surprisingly, the performance of the Max-Pool method and NetVLAD which adopt the ImageNet pre-trained model is even worse than that of the non-learning method GIST. It indicates that the existing representative learning method is insufficient in the face of such cross-scene testing. CSDesc with cross-scene capability has achieved remarkable results in the face of this challenge. Although the NetVLAD with pre-trained model Places365 is slightly better than our CSDesc-N-Pp method when we have higher requirements for recall, it still fails to match our CSDesc-N-Pi method. We also conduct a qualitative analysis on the results of the experiment. Figure 8 shows some example matches using the proposed approach and other comparisons.

Evaluation of the convergence on continual learning scenes RobotCar-Day

Matched place examples from Figure 7 with under different environmental conditions. (a) is a query image from a RobotCar-Day scene, and (b), (c), (d), and (e) are images matched by different methods. It can be seen intuitively that only our method (CSDesc-N-Pi) can get the best matching result. (a) Query image; (b) Matched by CSDesc-N-Pi; (c) Matched by NetVLAD-Pp; (d) Matched by GIST; (e) Matched by MaxPool-Pi.
Evaluation of overall performance
In the following experiment, we analyze the overall performance of our method in continually learning multiple scenes. We design two cases:
from the night with bright lights to Pittsburgh with the diverse environment, namely RobotCar-Night
first experienced the two scenes in (1), and then to the sunny noon, that is, RobotCar-Night
As shown in Figure 9, it is very gratifying that our CSDesc-N-Pi and CSDesc-N-Pp methods significantly surpass the comparative methods. Meanwhile, the NetVLAD method almost fails, while the Max-Pool method and GIST had certain effects. We attribute it to its learning layer with clustering capability, which lost more memory in the learning process because of its lack of cross-scene capability.

Evaluation of the overall performance on continual learning scenes RobotCar-Night
Then, we increase the number of scenes to make experiments more challenging and set the continual learning of autonomous mobile robots in three scenes of Robotcar-Night

Evaluation of the overall performance on continual learning scenes RobotCar-Night

Matched place examples from Figure 10 with under different environmental conditions. (a) is a query image from a RobotCar-Night scene, and (b), (c), (d), and (e) are images matched by different methods. Query image: It can be seen intuitively that only our method (CSDesc-N-Pi) can get the best matching result. Very surprised that the GIST method actually matched the images in the Pittsburgh data set (In subsection “Data sets”). (a) Query image; (b) Matched by CSDesc-N-Pi; (c) Matched by GIST; (d) Matched by DBoW2; (e) Matched by NetVLAD-Pi; (f) Matched by MaxPool-Pi.
Evaluation of cross-scene ability
To demonstrate the continual learning capability of the method proposed in this article more clearly, we use the recall curve with respect to a varying N or the so-call Recall@N as the performance metric. The experiments based on the three cases in subsection “Evaluation of overall performance” and the test sets are RobotCar-Day, RobotCar-Night, and RobotCar-Night, respectively.
Take the Case (2) in subsection “Evaluation of overall performance” as an example to illustrate the evaluation steps, which are mainly divided into three steps:
After learning the RobotCar-Night scene, we got model A, and used model A to evaluate the RobotCar-Night test set;
After learning the Pittsburgh scene based on model A, model B was obtained, and model B was used to conduct experiments on the RobotCar-Night test set to evaluate the memory capability of the model;
After learning the RobotCar-Day scene based on the model B, the model C is obtained, and the RobotCar-Night test set is evaluated using the model C. It can be seen that our test method is to train each scene in turn and use the model obtained by each training to evaluate the initial scene. In this way, we can see the trend of recognition accuracy.
As can be seen from Figure 12, CSDesc still has a strong recognition capability for the RobotCar-Day scene after successively learning two scenes. The NetVLAD method has better performance in single scene learning, but after continual learning two scenes, performance decreases obviously. While the performance of the Max-Pool method also decreases slightly, but the decrease is smaller than that of NetVLAD. The traditional non-learning methods have certain competitiveness, which can be attributed to the relative simplicity of the two scenes.

Evaluation of the capability of continual learning on the RobotCar-Day and RobotCar-Night data sets in terms of Recall@N curves. In the case where the recall decreases after other methods have continually studied two scenes, the CSDesc-N-Pp method not only doesn’t decrease the recall but also has a slight increase.
As can be seen from Figure 13, the CSDesc method has prominent advantages. After continually learning the RobotCar-Night and Pittsburgh scenes, it has a strong recognition capability for the RobotCar-Night scene. Although the NetVLAD method has good performance when learning a single scene, the performance significantly decreases after undergoing cross-scene learning, and at this time the Max-Pool method has surpassed NetVLAD. The recall performance of the traditional non-learning method is still the worst, which can be attributed to the fact that the Pittsburgh has too many scenes, resulting in insufficient GIST representation.

Evaluation of the capability of continual learning on the RobotCar-Night and Pittsburgh data sets in terms of Recall@N curves. In the case where the recall rate decreases after other methods have continually studied two scenes, the recall of the CSDesc-N-Pi method not only does not decrease but also increases slightly.
Figure 14 is the evaluation result of multiple methods in the RobotCar-Night test set when the number of recalls N = 1 is adopted. During the continual learning of three scenes, the performance of the CSDesc shows a slight increase or maintenance, while the NetVLAD shows the most obvious decline, and that of Max-Pool shows a slow decline.

Evaluation of the capability of continual learning on the RobotCar-Night, Pittsburgh, and RobotCar-Day data sets in terms of Recall-1 curves. The horizontal axis is the data sets’ name that needed to continually learn. The CSDesc method doesn’t show a significant downward trend in recall performance, and the performance of the MaxPool-Pi, NetVLAD, and NetVLAD-Pp methods that don’t have continual learning capability drop sharply.
Evaluation of the efficiency
In this subsection, we evaluate our method in terms of its matching efficiency. Note that the reported times in this article were those on a workstation with 10-core CPU at 2.2 GHz and 64 GB of RAM. We are most interested in the time it takes to match the map keyframes for the current observed view, which is the most critical step in the algorithm, and all the steps are constant time complexity. We use the data sets on three scenes from Case (3) in subsection “Evaluation of overall performance,” and the map contains a total of 23,796 keyframes. We report the details of the average matching time for each query in Table 4. It can be seen in Table 4 that for each query, our algorithm takes 18.28 ms at 20% of the entire map size, which is 4.7 k, and 43.52 ms at 23.8 k. On average, our algorithm is therefor able to handle approximately 0.44 million images per second or a map of 1 million images in 2.27 s. It is sufficient for real-time LCD, since a large number of invalid frames have to be removed. If the distance traveled by a robot between two consecutive keyframes is one meter, the proposed method is able to handle a topological appearance map that covers a distance of 1000 kilometers in real time.
Average searching time per query at different size maps.

Conclusion and future work
In fact, only if the SLAM system has the ability of continual learning can the robot realize incremental map construction in a real scene. Those existing LCD methods have memory forgetting defects, so the existing SLAM cannot achieve incremental mapping, but to learn all the scene data at one time. However, it is almost impossible for practical application, which also limits the intelligent navigation level of robot system.
In this article, we introduce a novel cross-scene LCD method with continual learning for visual SLAM, which can enhance the capability of continual mapping by restraining the memory decay of robot SLAM system. The greatest contribution of this article is to introduce the continual learning mechanism into the process of LCD. We also achieved automatic optimization and reduced the weight of low-quality features in the scene, aiming at the side-effect problem. We propose a lightweight network structure and add the inverted product quantization index in searching, which can conduct real-time online LCD.
To evaluate the cross-scene performance of our method, lots of experiments were conducted on three kinds of scene data sets RobotCar-Day, RobotCar-Night, and Pittsburgh. Evaluation results have demonstrated that our method completely outperforms NetVLAD, Max-Pool, and GIST by a large margin across the three scene data sets and achieves state-of-the-art LCD accuracy.
In terms of matching efficiency, the average matching time of our method is 43.52 ms per query on the data set and its growth rate is extremely low as the database size increases. In summary, the proposed method is able to robustly perform LCD under practical and challenging conditions with a high efficiency that is highly scalable to large environments.
In the future, we plan to expand the current work with more complex neural network structures such as VGG, ResNet, and DenseNet et al. We intend to develop a deep learning framework to further improve the recognition performance of our current system by utilizing semantic visual information and cross-scene description. SVSF-SLAM is robust face parameters uncertainties and error modeling, thus SVSF-SLAM is very suitable for combining with our method to improve the robustness of the SLAM system. 1,2 We will also study more effective human–robot interaction methods based on the similarity between semantic systems and human navigation. In summary, we hope our research can contribute to the further development of intelligent navigation, semantic cognition, and robust localization for mobile robots.
Footnotes
Acknowledgment
The authors would like to thank the reviewers for their constructive comments and suggestions to improve the quality of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Key Area Research Projects of Universities of Guangdong Province under Grant 2019KZDZX1026 and Grant 2018KZDXM074, in part by the Natural Science Foundation of Guangdong under Grant 2020A1515110255, in part by the National Natural Science Foundation of China under Grant 61603103, in part by the Innovation Team Project of Universities of Guangdong Province under Grant 2020KCXTD015.