
Abstract
Applying the learning mechanism of natural living beings to endow intelligent robots with humanoid perception and decision-making wisdom becomes an important force to promote the revolution of science and technology in robot domains. Advances in reinforcement learning (RL) over the past decades have led robotics to be highly automated and intelligent, which ensures safety operation instead of manual work and implementation of more intelligence for many challenging tasks. As an important branch of machine learning, RL can realize sequential decision-making under uncertainties through end-to-end learning and has made a series of significant breakthroughs in robot applications. In this review article, we cover RL algorithms from theoretical background to advanced learning policies in different domains, which accelerate to solving practical problems in robotics. The challenges, open issues, and our thoughts on future research directions of RL are also presented to discover new research areas with the objective to motivate new interest.
Keywords
Introduction
Reinforcement learning (RL), 1 one of the most popular research fields in the context of machine learning, effectively addresses various problems and challenges of artificial intelligence. It has led to a wide range of impressive progress in various domains, such as industrial manufacturing, 2 board games, 3 robot control, 4 and autonomous driving. 5 Robot has become one of the research hot spots all over the world, which is widely used in industry, agriculture, service industry, medical treatment, aerospace, and other fields. 6 A large number of studies on RL algorithms for robots have attracted researchers’ interest and attention. Simultaneously, many well-known research institutes and companies (e.g. DeepMind, UC Berkeley, OpenAI, and Google Brain) have made some achievements in this field 7 –10 but still face enormous challenges.
RL and optimization control theory are studying how to enhance future manipulation of a dynamic system with past data. 11 The goal is to design systems that use richly structured perception, perform planning and control that adequately adapt to environmental changes. Optimal control is to design a controller to maximize the performance of the system in some indicators. 12 The solution of optimal control often uses value function and dynamic programming (DP). On the basis of Hamilton and Jacobi’s theory, Bellman et al. extended some solutions and gave some solutions with dynamic system state and value function, which is sometimes called optimal return function. 13 According to the Markov decision process (MDP), 14 we can conclude that all optimization problems can be classified as RL problems. In the past decades, some reviews discussed the application of robots, for example, environmental perception, 15 path planning, 16 behavior decision, 17 and motion control. 18 –20 Moreover, significant progress has been made in solving challenging problems across robotic domains using fuzzy control algorithms, 21 genetic algorithm (GA), 22 neural networks (NNs), 23 particle swarm optimization (PSO), 24 ant colony optimization (ACO), 25 and simulated annealing algorithm. 26 The aforementioned studies mainly focus on performance improvement, sampling efficiency, and robot manipulation (i.e. grabbing, handling, and route planning). These methods are often trapped in local optimum and difficult to converge. With the rise of deep learning (DL), 27 it brings a storm to the domain of robot vision. It promotes the rapid development of robot in indoor and outdoor scene recognition, industrial and family services, and multirobot cooperation. The surveys present DL approaches for robot in the literature. 10,28 Although DL effectively solves some problems of target recognition, grasping positioning, and cooperative learning of robots, it cannot autonomously make decision and control for robotics.
By contrast, the advantages of RL in online adaptability and self-learning features of complex systems for robots have attracted considerable attention. It converges to the optimal control strategy through trial-and-error interacting with environments. There are several typical robot research based on RL (Figure 1). To our knowledge, there is no profound survey specifically discussing RL methods for robot research, regardless of a number of reproducing existing work and interesting results. For convenience, a general taxonomy of the main research works of RL for robotics is shown in Figure 2. The combination of RL and artificial intelligence is of great significance to future studies of robots to solve general artificial intelligence. The list of abbreviations is represented in Table 1.

Several typical robot research based on RL. (a) Rotating a cross-shaped valve with multifingered hands, 29 (b) shadow dexterous hand, 30 (c) Cassie: walking on a treadmill, 31 (d) Rethnik robotics baxter, 32 (e) a quadruped robot, 33 (f) VelociRoACH (a millirobot), 34 (g) seven robots simultaneously perform grasp training, 35 and (h) PR2: learning to gently place a dish in a plate rack. 36
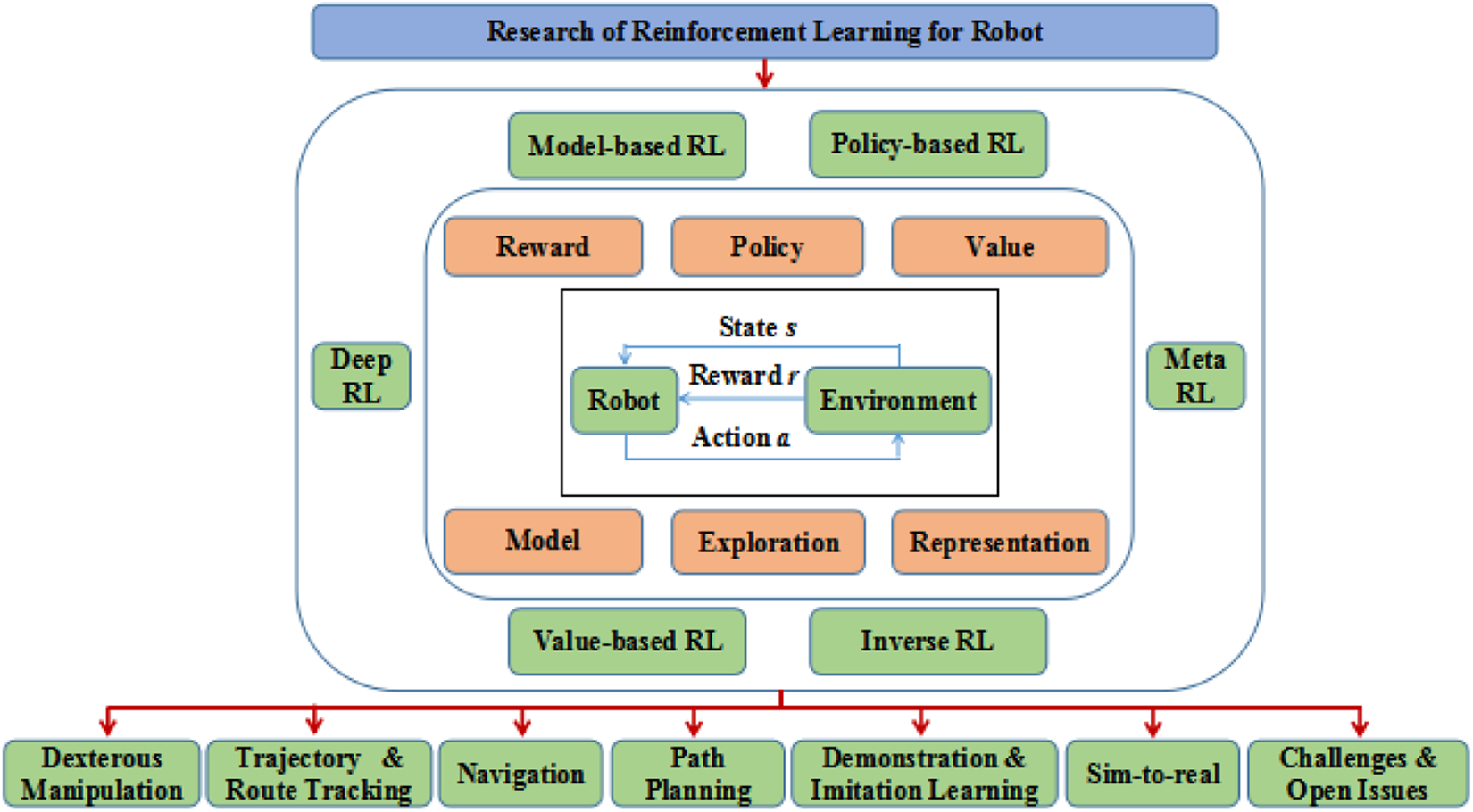
A general taxonomy of the main research work of RL for robotic. RL: reinforcement learning.
List of abbreviations.

The rest of this article is organized as follows. The second section introduces the preliminaries of RL. The third section provides a conceptual overview of RL algorithms. The state-of-the-art research of RL for robots are outlined in the fourth section. The fifth section highlights some important challenges and open issues, and offers some perspectives to future research directions. Finally, the sixth section presents concluding remarks.
Preliminaries
Key concepts and terminology
RL is goal-oriented and based on a hypothesis. Robots can learn by trial and error in the process of interaction with the environment based on RL. The ultimate goal is to determine the best sequence of actions to maximize long-term benefits. For connectionist learning, learning algorithms are divided into three types: unsupervised learning, supervised learning, and RL. The characteristic of supervised learning is that the data of learning are labeled. The model is known, that is, we have already told the model what kind of action is correct in what state before learning. In short, we have a special teacher to guide it. It is usually used for regression and classification problems. On the contrary, RL is used to learn without a label but to explore the characteristics of data. It does not directly determine whether a state or action is good or bad but give a reward. Feedback is delayed, data are serialized, and there is a correlation between data and data. The behavior of the agent will affect the subsequent data.
With the exception of the agent and environment, there are eight main elements of an RL system: state St
, action At
, reward Rt
, policy

The learning process of robot based on RL. RL: reinforcement learning.
Markov decision process
Under uncertain and unstructured environments, MDP 14 is often used to model decision-making problems. Almost all RL problems can be expressed in the form of MDP. For example, optimal control mainly deals with continuous MDP problems, any part of observable problems can be transformed into MDP problems, and bandits are MDP problems with only one state. Here, bandit is the simplest Markov problem, that is, give you a set of actions and then you choose an action and immediately to get the reward. A typical example of MDP is playing Go (see Figure 4).

The simplest Markov decision process (Playing Go). According to the current state, the player performs action to the next step and gets an immediate reward.
RL is a process of running agents through a series of state-action pairs, just as iterative NNs. It extracts information from data by sampling and combines MDP with a large number of state-action pairs. The complex probability distribution model of the reward is associated with it.
23
A MDP is usually defined as a tuple
• S is a finite set of states.
• A is a finite set of actions.
• P is state transition probability, that is, the probability matrix of state transition for agent when selecting execution action to next state

R is the reward function

By collecting samples, the sequence H of observation, station, action, and reward are obtained

Informally, robot tends to search a policy π to maximize the discounted sum of future rewards Gt

The return Gt
, representing a good or bad state, is the attenuation sum of all rewards from the beginning to the end of sampling for an MDP. The greater the value, the better the state, so as to get more rewards. The cumulative reward value function of agent after state st
execution strategy π is

In the same way, we can also get the iterative relationship of action-value function

Finding an optimal strategy is better to solve the RL problem so that the robot can always gain more than other strategies in the process of interaction with the environment. This problem is transformed into solving the optimal action-value function
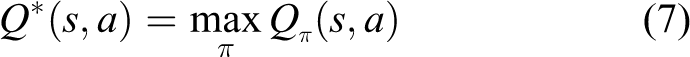
Therefore, the optimal strategy can be defined as

Because the Bellman equation
13
is not linear, nonlinear max function is introduced. Thus, it cannot be solved directly like Bellman expectation equation to obtain a closed-form solution, which can be iterated by value. It can be solved by value iteration, Q-learning,
37
strategy iteration, or SARSA.
1
When
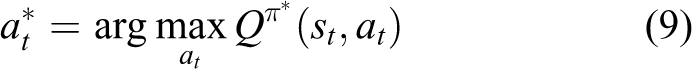
State-of-the-art reinforcement learning algorithms in robotics
Robot research involves many RL algorithms. The generation of training data determines the specific methods used in robot learning. The data needed for robot learning can be generated by the interaction between robot and environment or provided by experts. Then, a modern intelligent robot with autonomous decision-making and learning ability is studied by combining artificial intelligence technology with RL methods. Therefore, value-based RL, policy-based RL, model-based RL, deep reinforcement learning (DRL), meta-RL, and inverse RL (IRL), which have been applied to robots, are reviewed in this section. In addition, Table 2 shows a summary of the strengths and weaknesses of RL methods.
Summary of the strengths and weaknesses of RL algorithms.
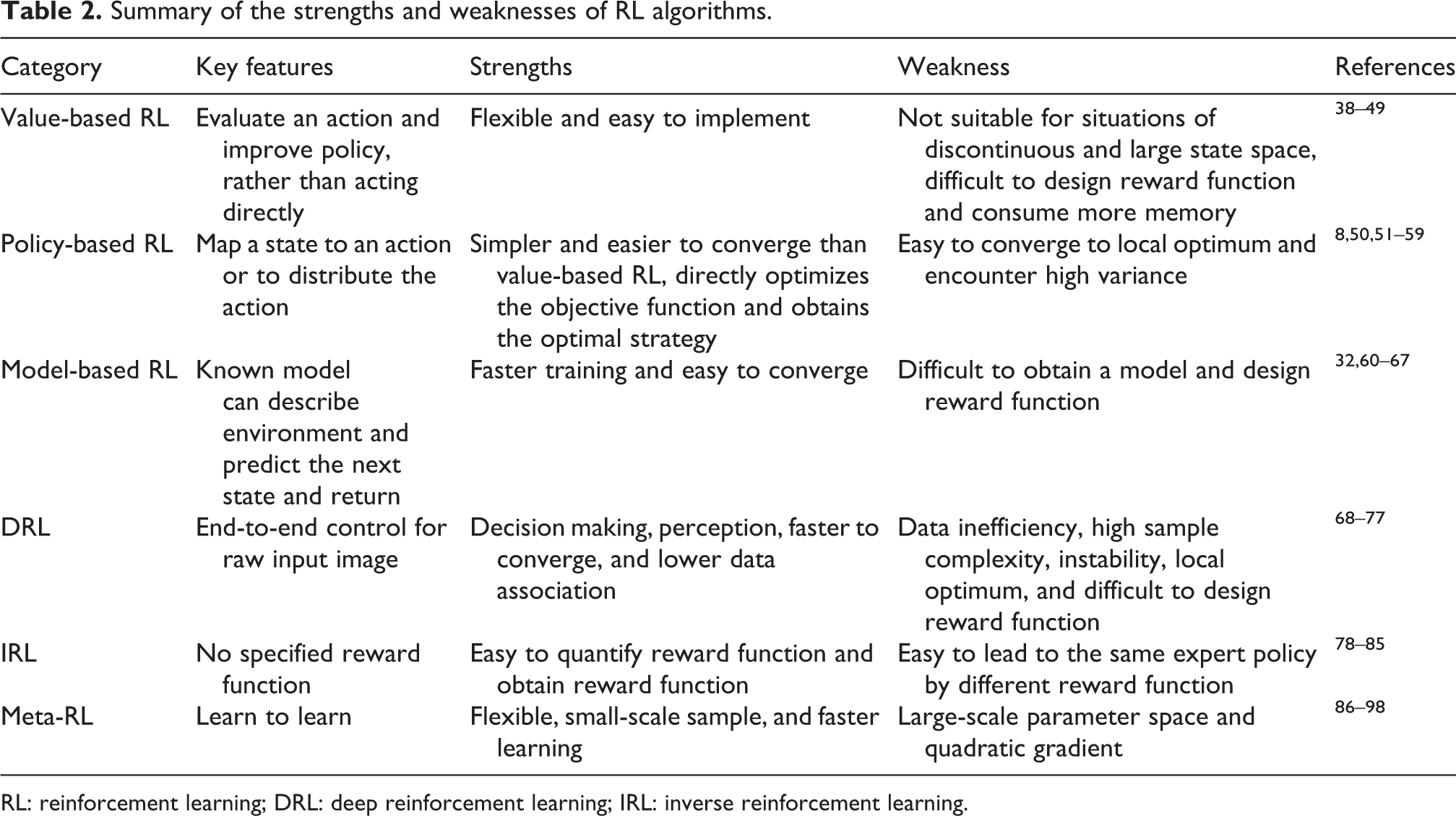
RL: reinforcement learning; DRL: deep reinforcement learning; IRL: inverse reinforcement learning.
Value-based reinforcement learning
The value function is the prediction of expectation, accumulation, discount, and future return. Generally, the optimal state- and action-value function

DP, Monte Carlo (MC), temporal difference (TD) learning, SARSA, and Q-learning are classical model-free RL algorithms for learning state and action value function. Once the value function is derived, we may get the optimal policy for robot actions.
MC 39 estimated the real value of the state by sampling several episodes. The more complete the episode, the better the learning effect without depending on the state transition probability model. The history and theory of DP algorithms were reviewed by Rust, 38 which is used to solve sequential decision problems under uncertainty based on Markov hypothesis and Bellman expectation equation of the state function. Peidró et al. presented Gaussian growth method to improve the precision of poorly defined regions of the workspace for the 10-degrees-of-freedom robot. The incomplete state sequence 40,41 used TD learning to solve it without executing the policy. Similar to MC method, TD method is a model-free RL method. A series of RL problems for prediction and control may be solved with only two consecutive states and corresponding rewards. RL and DRL methods are mostly reproduced based on the idea of TD learning to realize robot applications, such as 42 least-squares temporal difference algorithm. 43
There are two main methods of TD learning, that is, on-policy and off-policy, which differ from the way of the Q-value updating. On-policy approach, like SARSA, 44 exploring while learning the optimal strategy, is a model-free online control algorithm of TD. The state space is modeled by a dynamic Bayesian network and updated using a region-based particle filter in the literature. 45 This work makes high-level decisions on the player/stage simulator and the Pioneer robot. The learning process will be smoother and not trapped in a local optimal solution. In addition, the SARSA (λ) 46 based on reverse recognition will be able to effectively learn online for robot, and the data can be discarded after learning. The off-policy methods, like Q-learning, 47 usually update value function with ε-greedy policy but greedy. It directly learns the optimal strategy depending on a series of data generated during training. Thus, it will be greatly affected by sample data and variance of training data, and even affects the convergence of Q function. Tai and Liu adopted a method to explore a corridor environment with the depth information from an RGB-D sensor only, which is used to build such an exploring strategy for robotics by a supervised DL structure and a Q-learning network. 48 Zimmer and Doncieux extract representations dedicated to discrete RL from learning traces generated by neuroevolution results for a faster learning on two simulated robotics tasks. 49 Q-learning and SARSA are recommended for training RL model in a simulated environment and online production environment, respectively.
Policy-based reinforcement learning
In contrast to value-based RL, policy-based RL is to map a state to an action or to distribute the action and then find the best mapping relationship by strategic optimization. The policy search methods mainly include random policy search and deterministic policy search. Assuming that the expectation of initial state harvest is taken as the optimization objective

Without a clear initial state, the optimization objective can define the average value

where
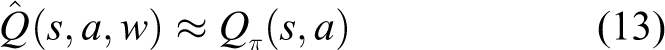
The function is described by the parameter w, and the state s and action a are taken as input. After calculation, the approximate action value is obtained.

where
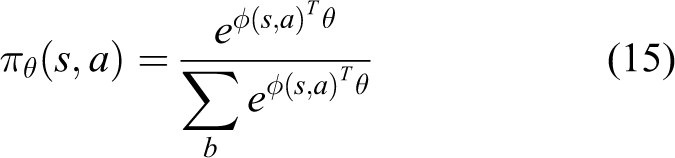

and the score function was calculated by Gauss policy (16).
Silver et al. presented a framework for DPG algorithms to ensure adequate exploration and learn a deterministic target policy from an exploratory behavior policy in high-dimensional action spaces. 53 UCB proposed trust region policy optimization (TRPO) to effectively optimize large nonlinear policies such as NNs. 52 The TRPO algorithm outperforms prior methods on a range of challenging policy learning tasks, for example, learning simulated robotic swimming, hopping, and walking gaits. DeepMind used the idea of deep Q-network (DQN) extended from Q-learning algorithm to modify their deterministic strategy gradient method and proposed a deep deterministic strategy gradient algorithm (DDPG) based on actor-critic (AC) framework. 54 In the simulation environment MuJoCo, the target of the robot grasping operation in continuous action space is realized. The robust model-free approach attacks the limitation of a large number of training episodes to find solutions for robotics dexterous manipulation and legged locomotion.
Mnih et al. found that asynchronous advantage AC algorithm can adapt to both discrete and continuous space. 55 Levine et al. trained complex manipulation skills for a PR2 robot end-to-end with guided policy search. 8 Policy gradient with Q-learning significantly outperformed AC and Q-learning on Atari games testing. 57 Additionally, path consistency learning minimized a notion of soft consistency error along multistep action sequences extracted from both on-policy and off-policy traces. 58 Haarnoja et al. derived a soft Q-learning algorithm by applying deep energy-based policies to maximum entropy policies so that skills can be transferred between tasks for simulated swimming and walking robots. 59 In a recent study, 50 the generalization of the learned policy is successfully verified on physical robots in rich and complex environments using policy-gradient-based method. In addition, a state-of-the-art survey focuses on leveraging prior knowledge on the policy structure and creating data-driven surrogate models of the expected reward to find effective policy search algorithms. 99 Therefore, although policy-based RL usually converges to local optimum and encounters high variance, it directly optimizes the objective function and obtains the optimal strategy.
Model-based reinforcement learning
The value-based and policy-based RL is model free, which learns directly from value function and policy function. The state s and action a are used as input to predict the next state s′, that is, state transition probability model

The block diagram of model-based RL. RL: reinforcement learning.
Sutton integrated a Dyna architecture for learning, planning, and reacting based on approximating DP. 60 In contrast to Dyna, the Dyna-2 architecture 61 is designed, which separates the experience of interacting with the environment and model predictions. A unified framework that ranges from model-based to model-free methods was designed for learning the continuous control policies by backpropagation. 62 A variety of challenging, underactuated, physical control problems are solved, including reaching, grabbing, and tracking of a robot arm. Model-based methods improved model-free RL for continuous control tasks of simulated robot using Q-learning with experience replay and effectively accelerated learning by Gu et al. 63 Polydoros and Nalpantidis reviewed the applications of model-based RL for robotics and outlined the state-of-the-art in both algorithms and hardware. 32 Unlike classical model-based RL and planning methods, the model-based RL and model-free RL were combined to interpret predictions from a dynamic model to construct implicit plans in arbitrary ways by NN architecture. 64,65 Since the state transition models need to be known in model-free RL, the deficiencies of the learned models have limited the utility for robot learning and planning. An advanced study on discrete-action domains using TreeQN and ATreeC has been presented by Farquhar et al., 67 which is training end-to-end and shows the benefit of a box-pushing domain and a set of Atari games over previous approaches. Remarkably, in a study, 66 authors trained temporal difference models to train with model-free learning and that was used for model-based control on a range of robot continuous control tasks, for example, reaching target locations (real-world Sawyer robot), pushing a puck to a random target, and training the cheetah to run at target velocities.
Deep reinforcement learning
DL,
27
another branch of machine learning, usually consists of multilayer nonlinear operation units. Regarding the output of the lower layer as input, the deep abstract feature representation is automatically acquired from a large number of training data. Significant successes have been achieved in image processing, speech recognition, natural language processing, robot control, and other domains.
10,68,69,71
Compared to traditional multilayer NN algorithms, DL is conducive to alleviating the gradient dispersion and local optimum and eliminating the curse of dimension caused by high dimensional data. The representative structures for DL include as aboard as deep belief network, stacked autoencoder, recurrent neural network, and convolutional neural network (CNN). RL permits agents or robots to learn decision making by millions of interactions with the environment across a variety of different domains. Consequently, as an artificial intelligence method closer to human thinking, various DRL combining the perceptive ability of DL with the decision-making ability of RL achieves direct control from raw input to output by end-to-end learning
Mnih et al. pioneered a DQN algorithm that combined CNN with traditional Q-learning for approaching Q-learning method with nonlinear functions. 72 There are three main aspects for DQN to improve traditional Q-learning based on experience replay mechanism: (1) approximating the value function with deep CNN; (2) training the learning process of RL by experience replay; and (3) setting up the target network independently to deal with TD error. Figure 6(a) shows the DQN architecture and the training process is given by Figure 6(b), and the detailed learning processes are as follows
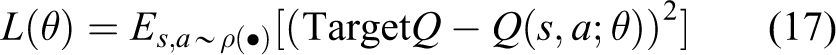

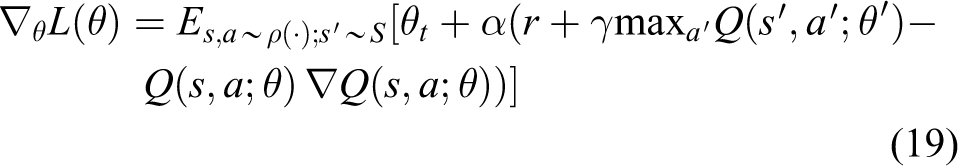
where

(a) DQN architecture and (b) the training framework of DQN. DQN: deep Q network.
For the problem of overestimation in Q-learning, Van Hasselt et al. 74 proposed deep double Q-network based on DQN and online network evaluation greedy strategy, instead of using target network to evaluate the value. Updating parameters in the form of the formula

Here, θt
and
The problems of a huge amount of data and exploration with sparse rewards limit the applicability of DRL to many robot tasks. In the literature, 56,100 a small set of demonstration was leveraged to overcome the above situation and accelerate the learning process, which has better initial performance than previous methods. 75 –77 To bridge the gap to reality, 101,102 the sample efficiency of experiences for human–robot interaction and multirobot collaboration was improved. Experimentally, compared to DRL based on value function, this approach is more efficient for strategy optimization.
Inverse reinforcement learning
Most multistep decision-making problems are difficult to obtain reward functions in complex environments. IRL 78 that has made a breakthrough in the field of robotics reversely solves reward function in MDP based on the hypothesis of optimal expert decision trajectories. 79 –81 Robot is able to learn how to make complex decisions while the reward function is not specified.
When the dimension of state space is very large and high dimension, the classical IRL methods have been proven exceptionally not effective enough. The states and actions in the model are replaced by DNN, 83 which has achieved significant performance in large and complex systems. Similarly, another comprehensive study of a practical and scalable IRL algorithm, that is, adversarial inverse reinforcement learning (AIRL), was presented in Fu et al. 84 This approach is able to recover robust reward functions and policies under variation in the underlying domain. Peng et al. 85 applied an adaptive stochastic regularization method for adversarial learning to AIRL to yield variational AIRL algorithm, which tends to recover smoother reward functions that is closer to the ground truth reward. More fluent interactions between human and robot were effectively performed for specified human–robot collaboration task based on co-operative IRL. 70 A robot successfully learned to set a table according to a demonstrator’s preferences by Brown et al. 103 Experimentally, a recent study improves navigation performance for human-aware robot in a limited visual field. 82
Meta-reinforcement learning
Generally, a good reward function is often difficult to design, and a large number of training samples are needed to make the performance of the model a certain height. To reduce the excessive dependence on big data and realize small sample learning, Berkeley Blog published an article called learning to learn (i.e. meta-learning). The goal of meta-learning (MTL) is to learn and quickly train an adaptive model to a new task from a series of learning tasks. Some recent studies mainly focus on model-based MTL, metric-based MTL, and gradient descent-based learning. 104 –106
Romera-Paredes et al. presented zero-shot learning approaches with the aim of addressing automatic classification problems. 91 The researchers from OpenAI obtained a general system by one-shot imitation learning, which turned any demonstrations into robust policies. 92 Another study on few-shot learning (FSL) from the definition to core issues was proposed by Wang et al. 93 FSL, mimics human, combines prior knowledge with few supervised experience to rapidly generalize to a new task. In a recent study, 94 the latest development of MTL is briefly introduced and developed an off-policy meta-RL algorithm to improve sample efficiency and the effectiveness in sparse reward problems. Hence, advances in MTL have led to great breakthroughs and a flurry of research to robotic systems. 95 –98
Reinforcement learning for various robotic applications
The above-outlined techniques provide an operable method for robotics technology. By means of prior knowledge, behavior discretization, approximation of value function, mental rehearsal, and preconstructed strategies, the robots have the abilities of decision-making and self-learning. The state-of-the-art research to robot in recent years, as reported in the literature, is summarized in Table 3. Table 3 outlines the applications of RL in robots.
A summary of reinforcement learning applications to robotics in recent years.

RL: reinforcement learning.
Dexterous manipulation
At present, the dexterous manipulation of robot is a huge challenge in continuous motion space with respect to complex environments. Using model-free and pure vision-based RL method to perform high-sensitivity manipulator was first proposed by Katya et al., 115 which got grid of the dependence on precise models of robot, for example, kinematics model, dynamics model, interaction force, high fidelity tactile sensor, or joint position sensor. The robot successfully controls a pneumatic five-fingered hand rotating object in a Gazebo simulation environment. The Hindsight Experience Replay technique that can be combined with an arbitrary off-policy RL algorithm was exploited by Andrychowicz et al. 108 to achieve the manipulation tasks. Similarly, various types of robot manipulation problems were solved very efficiently even though in cluttered environments, for example, shifting, sliding, and pick-and-place. 109,154
Normally, a certain amount of training data is needed to be sampled to update policies in every iteration step of policy optimization, and the cost of acquiring training data is higher in real robotic scenarios. A low-priced and highly flexible multifingered RIO hand with multiple operational skills was successfully developed, 110 which can rotate valve, push abacus, grab objects, and so on. Later, the asynchronous normalized advantage functions with safety constraints represented one of the few algorithms that are capable of alleviating the human intervention for complex 3D manipulation tasks in simulation environment and training on real physical robots. 114 To learn more complex operation skills, faster learning and less interaction with the environment are the key to real-world applications by a handful of trials. 99,101,113
Rajeswaran et al. only utilized a small number of artificial demonstrations to perform relocation and door opening (see Figure 7(b)). 116 Using distributed RL to learn operating skills in the simulator by Andrychowicz et al. 111 to achieve an unprecedented level of dexterity on a five-fingered manipulator without relying on human demonstrations (see Figure 7(c)). A recent study improved sampling efficiency and learning stability with deep P network (DPN) and double DPN. 117 The two-arm cooperative robot successfully flips the handkerchief and folds the T-shirt with a limited number of samples (see Figure 7(a)). Li et al. solved various maneuvering dynamics and uncertain external disturbances of the humanoid-like mobile manipulator based on the advanced online kinematics redundancy solution of the neural dynamic optimization algorithm. 112

Despite the powerful capability of an individual robot, there are significant breakthroughs in the field of multirobot object manipulation and robot-assisted surgery. 155 Excitingly, a recent study significantly improves performance for human–robot collaboration. 107
Trajectory and route tracking
To realize dynamic obstacle avoidance, the robot tracks the reference route in a certain error range according to a specific certain control law and finally reaches the reference point of a preset geometric route in a partially observable nonlinear dynamic environment. Therefore, it is critical to improve the real time and adaptability of obstacle avoidance and navigation by trajectory and route tracking techniques. Figure 8 shows the sketch map of robotic trajectory and route tracking. Conventional algorithms are easy to fall into local optimum, oscillate in similar obstacle groups, swing in narrow channels, and even cannot identify the path. Additionally, target reference points are not reachable, which eventually leads to errors and instability in tracking and dynamic obstacle avoidance.
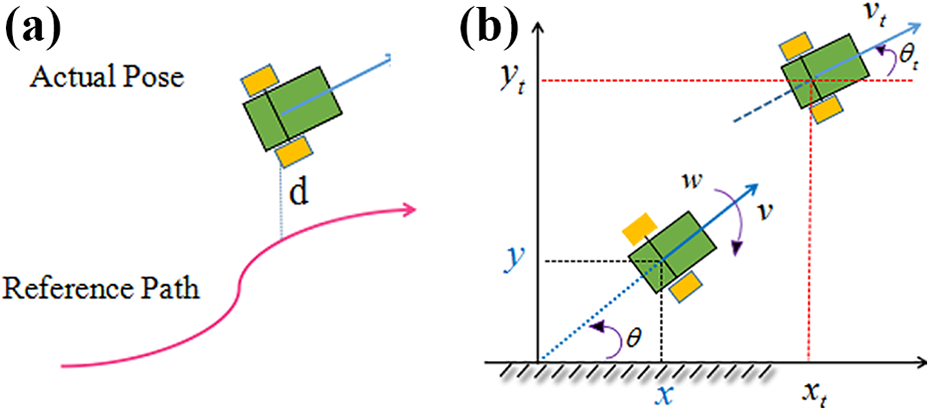
The sketch map of robotic route and trajectory tracking: (a) Route tracking: d is the error distance between robot and reference route. (b) Trajectory tracking: For arbitrary robot pose
AC compensators were designed, 120 which was used to reduce tracking error of a multiple DOF industrial robot manipulator. A variety of real-world robotic manipulation tasks, such as dish placement and pouring, used policy optimization to adaptively sample trajectories and effectively to learn good global costs for complex robotic motion skills from user demonstrations. 36 Compared to traditional PID control, the improved DRL algorithm was employed to effectively handle the control problem of trajectory tracking for autonomous underwater vehicle. 126 A study by Nagabandi et al. presented a hybrid algorithm that training NN dynamic models along with a small number of samples was able to accelerate learning and follow arbitrary trajectories. 124 A DDPG model was trained to track the optimal route towards large-scale outdoor applications. 125 Long et al. presented a safe and efficient collision avoidance policy. 127 This decentralized sensor-level collision avoidance policy is implemented using a policy gradient to directly map raw sensor measurements to robot steering commands of movement velocity, which enables multiple robots to quickly track collision-free paths.
To ensure adaptability without an accurate dynamic model, the controller was trained online by the Q-learning algorithm to directly learn action policy. 121 They argue that their adaptive 3D path-following control method has a more intelligent decision-making ability. How to generate smooth and dynamically feasible trajectories for most robotic systems? How to keep time optimal while tracking path or trajectory? Ota et al. proposed that a 6-DoF manipulator arm trained with a good reference trajectory to quickly track a designed trajectory in configuration space. 122 In a recent study, an improved Q-learning algorithm is exploited to form a reward and penalty mechanism, 123 which effectively tackles the problem of robotic time-optimal route tracking with prior knowledge. The prior knowledge of leg trajectories was embedded into the action space during safe exploration with only less data collection to achieve walking on a quadruped robot. 113 Kim et al. handled the issues of actuating speeds and controllability for soft mobile robots based on entropy adaptive RL. 156 The important contributions are that the method narrows down the search space during training and accelerates data collection.
Navigation
Fast and robust autonomous navigation under various scenarios by means of environmental perception and location techniques becomes a major topic in researchers. Generally, in all these applications, the robot complete navigation on the basis of the sketch map can be seen in Figure 9. Over the past decades, all sorts of algorithms that require cameras, radars, and other sensors are developed for robot to detect obstacles in the navigation environment. And the perceptual information is to build the map for the robot to plan a path around obstacles. 157 –161 Currently, the representative method is the simultaneous localization and mapping technology that builds maps incrementally by estimating the moving positions. 162 However, the calculation and the adaptability of traditional methods are both difficult to navigate when some special signs or specific environmental characteristics are unknown.

The schematic of general robot navigation.
The RL methods that search an optimal or suboptimal path from the start point to the goal point enable mobile robots to self-explore and self-learn by interacting with the environment. Huang et al. improved Q-learning algorithm to reduce the probability of collisions under dynamic environments. 128 A method of end-to-end training with mapless motion planner was employed for mobile robots in unseen virtual and real environments without any prior demonstrations. 133 It would be better if the model is more generalizable when transferring to unseen environments, thus, a hybrid RL model was presented to solve a real-world vision-language navigation task. 131 The target-driven robot navigation technique was used to memorize valuable points’ information about the environment and generalize to a real robot scenario with a model trained in simulation. 129,134 Another study presented an end-to-end differentiable neural architecture to successfully navigate along paths not encountered. 135 To acquire the multifaceted navigation skills, Chen et al. mapped height-map image observations to motor commands of wheel-legged robot, which significantly improved the quality of obstacle avoidance. 136
Service robot that is capable of autonomous long-range navigation and motion greatly enhances the ability of transporting goods, medicines, luggage, and so on. Assume that the NN architecture and the process of RL search reward are combined with motion planning control algorithm, the robot can navigate in a long range. Hao-Tien et al. employed AutoRL to automatically search for the best feedback and network architecture by means of large-scale hyper-parameter optimization and to learn path-following navigation behaviors. 137 This method better generalizes to new environments, though it has sampling inefficiency. Similarly, the robot learned point-to-point navigation policies end-to-end. 138 The authors designed the probabilistic roadmaps for sampling-based path planning to enable long-range navigation. After training, it can adapt to a variety of different environments. Combining probabilistic roadmaps and AutoRL instead of manual adjusted RL local planner successfully completed long-range indoor navigation. 139 To better verify the effectiveness of the algorithm, the physical platform was utilized to verify navigation and obstacle avoidance in complex scenarios. 50 Experimentally, 156,132 the robustness, controllability, and precision of robots have been fully studied in practical applications.
Li et al. proposed a role playing learning scheme by collecting a large number of maps and pedestrian trajectory data. 130 The mobile robot navigates socially toward a target using TRPO to optimize NN end-to-end. Another similar study on human–robot interaction focused on developing natural social navigation behavior algorithms, 140 which enabled collision avoidance, leader–follower, and split-and-rejoin based on expert demonstration. A visual navigation control method made up of low-level behaviors and a metalevel policy was presented for three different simulated robots to avoid obstacles in new compound environments with both learn and sequence robot behaviors. 141 In a recent study, 142 the authors hold a self-adaptive visual navigation method based on meta-RL to learn and adapt novel scenes.
Path planning
The changeability and complexity of the robot motion environment put forward higher requirements for dynamic obstacle avoidance and path planning. The purpose of path planning is to plan a collision-free optimal or suboptimal path from the starting point to the target point in a given space, and to be as smooth and safe as possible. Path planning mainly consists of global path planning based on a known model environment and local path planning on the basis of unknown sensor environment. Although traditional algorithms have obtained a series of achievements, 24,159,163,164 there are still many shortcomings in accuracy, stability, and robustness. The environment model of robotic path planning is shown in Figure 10.

The environment model of robot path planning: (a) The robot sketch map of moving towards the target point and (b) the distribution domains of obstacles.
Generally, it is difficult to address the problems of mobile robot path planning in dynamic scene by classical methods. Jaradat et al. applied Q-learning algorithm to limit the number of states and successfully reached its target without collision. 143 Later, many improved Q-learning algorithms were presented to save storage and decrease the searching scope. The proposed method reduced the energy consumption and time complexity instead of repeatedly updating Q-table by Konar et al. 144 Experimentally, the ε-greedy exploration and Boltzmann exploration were used to shrink orientation angle and path length under heuristic searching strategies by Li et al. 145 Roy et al. utilized image processing techniques and RL methods to plan the shortest path for mobile robots. 146 Another similar study, 165 in which robot followed the observed demonstration trajectories by visual servo tracking control, tended to design a new robot demonstration learning framework with image-based planning method. To avoid the policy degradation caused by the method based on the value function 147 was to optimize the strategy with parameters by the idea of gradient rising and maximizing the cumulative expected reward.
To find feasible collision-free and time-efficient paths, the authors hold a decentralized multiagent collision avoidance algorithm that encoded the estimated time and searched for a collision-free velocity vector by Chen et al. 118 Wu et al. robustly overcame the problems of robot local trajectory planning based on data-driven representation learning. 148 Similar to previous studies, the perceptive ability of convolutional NNs and end-to-end learning mode of RL is critical to robot path planning. For the instability of the robot training stage and the sparsity of the environment state space, updating NN and increasing the greedy rule probability enhanced the ability of local planning by inputting lidar signal and local target position. 149 The raw sensor measurements were directly mapped to robot commands to find time-efficient and collision-free paths for multirobot systems by Long et al. 127 Thus, the applicability and scalability were experimentally demonstrated in a large-scale scenario with 100 robots. Later, Francis et al. proposed a sampling-based robot path planning algorithm combining DRL with long-range motion planning methods for different navigation tasks. 139
On a real robotic wheelchair platform, Kim et al. attempted to adopt three-layer architecture for socially adaptive path planning. 151 A large number of demonstration trajectories generated by experts are utilized to infer the cost function and then plan an optimal path for robot in various dynamic environments. For planetary rovers, a recent study developed a soft value iteration network, 152 which represented policy with the action probability distribution and effectively trained gradients based on IRL. Wu et al. successfully proposed a policy for online trajectory planning for free-floating space robot without dynamic and kinematic models. 166 Recent practical experiments 150,153,167,168 make a series of huge breakthroughs for mobile robot, sake-like robot, cleaning, and maintenance robot. These great achievements of real-world greatly promote the development of robotic applications in the future.
Demonstration and imitation learning
Traditional RL algorithms are generally high computational cost, high complexity, time consuming, and poor scalability for policy acquisition. Imitation learning, similar to supervised learning, is an available way for transferring movement skills from a human expert demonstrations to the robot. Although model-free RL is widely used, the supervised information provided by human experts can promote robot learning to imitate the next skill. Robots quickly determine strategies for new scenarios if they learn from their own peer experts (i.e. through teleoperation or demonstrations) or human expert demonstrations, and even generalize models in the underlying assignment of tasks, such as learning to manipulate new objects by watching a video. Moreover, demonstration learning can avoid directly modeling environment and reduce the complexity of robot action programming.
To reduce the system interaction time for approaching, grasping, and picking up complex objects, Duan et al. proposed one-shot imitation learning. 92 The authors hold a neural net trained with pairs of demonstrations, where input the first demonstration and a state sampled from the second demonstration on a family of block stacking experiments. The meta-imitation learning, 96 unlike the prior one-shot imitation, inclined to learn new manipulation tasks end-to-end from a single visual demonstration in complex unstructured environments without learning each skill from scratch. Another similar research built up prior knowledge through MTL. 119 APR2 arm and a Sawyer arm successfully learn to place, push, and pick-and-place new objects combining prior knowledge with a single video of human manipulation demonstration.
Pfeiffer et al. firstly employed NN to learn a target-oriented end-to-end navigation model, which directly learned from the demonstration for motion planning of autonomous ground robots. 169 It is difficult to design a scripted motion planner or controller in previous work. Therefore, only a small amount of demonstration data was leveraged to train end-to-end visuomotor policies with large visual and dynamics variations for robot manipulation tasks by Zhu et al. 170 In response to the challenges of disaster relief, constrained personnel and equipment, 171 a system of learning from minimal human demonstration was built to fast perform actions and learn to mimic navigation behaviors. Additionally, Nguyen et al. developed a general framework of imitation learning with indirect intervention based on visual navigation and language assistance to search for objects in photorealistic indoor environments. 172
For dexterous multifingered hands, the pretrain policies with behavior cloning were derived based on demonstration argument policy gradients. 116 To tackle the problems of achieving compound and multistage tasks without providing any direct supervision, Yu et al. presented a method for earning and composing convolutional NN policies. 173 It is better to prevent policies from deviating from human demonstrations and guide the exploration of the manipulator with trajectory tracking assistant reward. In a recent study, 174 the human demonstration used for imitation learning provided an intuitive way to evaluate state representation methods for robot hand–eye coordination learning in both state dimension reduction and controllability. A variety of order fulfillment and kitchen serving tasks were successfully learned in the context of decomposing a human demonstration into primitives at metatest stage (see Figure 11). The recent advances of novel robot tasks via imitation learning from demonstration were reviewed in a survey. 175 The updated taxonomy and classification of current methods are helpful for future research both in theory and in practice.

One-shot hierarchical imitation learning of compound visuomotor tasks. (Left): training robot by learning primitive behaviors from human demonstrations. (Right): testing the skills of performing compound tasks by PR2 robot. 35
Sim-to-real
Running, climbing, falling, and climbing are inherent instincts of human beings. To our knowledge, the performance of robots has been unsatisfactory with respect to walking gracefully or grasping naturally. The coordination of gait movement and dexterity of robotic manipulator has always been a difficult problem in the industry. Over the past decades, it is easier to trap in seemingly smaller obstacles in the physical world than in simulation. The universal simulation environments are given in Table 4. Almost none of these unpredictable obstacles, that is, surface friction, structural flexibility, vibration, sensor delay, and poor actuator transformation of the robot itself, and so on, can be assumed in advance by mathematical models. With the development of technology, the gap between simulation and reality is gradually bridged.
The simulation environments.

James et al. proposed a simple and highly scalable approach to compute robot trajectories in simulator and successfully achieve end-to-end manipulation and control in the real world. 176 To avoid tedious manual tuning or calibration, Tan et al. and Bharadhwaj et al. did a good job of porting what the policies learned from the simulator and off-policy data to the real robot. 33,177 The simulation environment provides a basic platform for the analysis, synthesis and offline programming of robot system with high real-time, versatility and authenticity, and low cost. The simulation models of various tasks in virtue of the large amount of randomized simulation data help us enhance the real-world data, which speeds up the process of robot learning and training. How to transfer simulation to reality is still critical and challenging for robotics. Recently, Liu et al. obtain appealing performance by transferring the trained policy in simulation environments to the real-world scenarios, which significantly reduce training costs and improve the generalization capability for robot control tasks. 178
Challenges, open issues, and directions
Real-world challenges and open issues
Overall, RL methods have recently made notable progress for robotic application due to supercomputational power, frontier algorithms, and large-scale dataset. However, sample inefficiency, higher training costs, uncertain models, dimensional disaster, and so on, have restricted the development of RL in robotic domain. Furthermore, a large amount of RL research of robots are still at the stage of simulation, which are far from performing well for real-word problems. There still a long way to go for robot to learn and master various skills that human does in a shorter time. In general, the challenges and open issues needed to be solved for future research are as follows: In research on robot, data play an important role in decision making and the evaluation of learning. The scale of action and state space increase exponentially with the increase of the number of features for RL tasks, which leads to dimension disaster. More data and computation will be needed when exploring states and actions. Exploration and exploitation face a central issue: either exploitation gives more knowledge about the environment to make the best decision or exploring for more current information. To date, because random behavior cannot generate rewards, the problem of sparse rewards is difficult to solve, and it is impossible to learn. It is necessary to have an effective benchmark and standard environment, otherwise testing and evaluating the generalization of RL algorithms will not be feasible. Although the robot simulation platforms (Table 4) can accelerate the learning process and provide a reliable evaluation for control and physical behavior, there is still a big gap between the simulation data and the real-world data. Additionally, it cannot completely transfer to the real world under the condition of visual and physical differences, for example, transfer learned skills to other tasks and share learned skill with other robots. It takes a long time to obtain a result in terms of large-scale experiments. Developing simpler computational models for robotic operation tasks in the physical world and minimizing human intervention for robotic exploration have become one of the most significant issues. Various investigations of the application of RL for robots are that the hardware is generally expensive and easy to wear and tear. Maintaining and repairing robots require costs, physical labor, long waiting cycles, and so on. In a way, these have an adverse effect on the progress of robot intelligence. The robot optimization based on RL is extremely complex nonconvex optimization problems. It is designed under convex assumption and then applied to nonconvex objective function.
179
These nonconvex optimization algorithms are still lemmas or extensions of convex optimization (convex analysis). The breakthroughs in algorithmic theory of these nonconvex optimization problems are generally attributed to finding the “convex” structure and sometimes impossible to solve the optimal control problem. The NN is a kind of nonlinear approximation. The disadvantage of nonlinear approximation is the existence of local minimum and the difficulty of optimization. In the process of RL, the data are generated by the interaction between agents and environment, and the adjacent data are not independent and identically distributed. It is not stable to use the data directly to train the NN. Due to the influence of obstacles in workspace, complex coupling characteristics, and nonlinearity, the trajectory planning and control of robot are faced with many problems. The challenges at the interface of nonlinear coupling and learning must be solved before we can build robust, safe robot learning systems that interact with an uncertain physical environment.
Future research directions
Maximum entropy DRL: We expect RL methods to show good performance for robot decision making and control in the real world. However, complex sample, the higher dimension of data space, and poor convergence restrict the development of general artificial intelligence. Therefore, it is necessary to optimize the hyperparameters, which limits the applicability of the robot for an unstructured and complex environment. Maximum entropy deep reinforcement learning (MEDRL) provides a basis for constructing hierarchical strategies that can solve complex and sparse reward tasks through probabilistic reasoning while eliminating the trouble of adjusting hyperparameters. 180 It is used for improving the search strategy and preventing convergence to a local optimum. Compared with the deterministic policy search method, 181 the MEDRL has stronger consistency and robustness. Learning expressive energy policy from soft Q-learning and combining nonstrategic updates with soft AC is to maximize expected returns and entropy in random situations.
Semantics to operations: Designing reward functions and exploring time are the obstacles for robot to applying RL methods to the real world. Previous research on robotic learning skills require manually preset the reward functions, which are then applied to be optimized. Although robots cannot understand tasks by observing or depending on human language, researchers have helped robots understand semantic concepts and complete tasks by combining a small amount of annotated data with RL methods. 182,183 Learning to use experience to understand events of human demonstrations, imitating and learning human actions and understanding semantic categories (e.g. toys and pens) have become a prevalent trend in the future development for robots.
Shared system of clouds robot: Although the research of RL has made great progress for robots, such as grasping, stacking, navigation, and so on, the kinds of behaviors that robot master are limited. In addition, it takes a long time for a single robot to collect sufficient training data sets. Recording these actions, by which robots iteratively improve the network for evaluating different states and action values through RL, are expected for robots while exploring different ways to accomplish a task. Learning motor skills and intrinsic physical models directly from experience enable each robot to obtain a copy of the updated network before performing the next stage of action. For robots with different locations and configurations in the real world, the shared system of clouds robot appears to be an efficient approach for collecting large amounts of data in a short time, accelerating robot learning 184 and even constructing highly generalized representations of individual robot.
Bio-inspired learning: The computation and energy consumption generated by training robot increases exponentially, which is not sustainable development. For example, the maximum entropy optimization and RL algorithms are utilized to successfully predict the metabolite concentration of erythrospora. 185 Additionally, the ACO 25 and PSO 24 have solved the intelligent optimization problem of multiagent cluster. There are also many key technologies in artificial intelligence, such as artificial neural network, 186 artificial immune system, GA, 22 and so on, which come from the study of biological science. In the future, bio-inspired learning based on RL is a topic worthy of study, it will provide new ideas and technical means to solve the problems of robot applications.
Conclusions
Over the past few decades, robots have been unable to achieve high intelligence due to the constraints of algorithms and hardware. This article presents a comprehensive survey on various kinds of RL algorithms and models to robot research. We first give a tutorial of RL from fundamental concepts to advanced methods and highlight their advantages in addressing the challenges brought about by robot research. Subsequently, this article discusses the state-of-the-art robot research on the basis of RL, for example, dexterous manipulation, navigation, trajectory and route tracking, path planning, demonstration and imitation learning and sim-to-real. Despite this article has laid a solid foundation and opened up new research interests to robots, there remain many different factors affecting reproducibility of RL algorithms for real-world robot tasks. Finally, the existing challenges, open issues as well as important future research directions are highlighted to push the important research forward.
Footnotes
Acknowledgments
This work was supported in part by my tutor and lab classmates. We thank the authors of Figures 1, ![]() , and 9 for authorizing us to use their pictures in this article.
, and 9 for authorizing us to use their pictures in this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.