
Abstract
Deep reinforcement learning methods have been applied to mobile robot navigation to find the optimal path to the target. The rewards are usually given when the task is completed, which may lead to the local optima during the training procedure. It seriously affects the training efficiency and navigation performance of the mobile robot. To this end, this paper proposes an intrinsic reward mechanism with intrinsic curiosity module and randomness enhanced module, combining the TD3 (twin-delayed deep deterministic policy gradient) reinforcement learning algorithm for mobile robot navigation. It effectively resolves the issue of slow convergence caused by sparse rewards in continuous action spaces. It also encourages mobile robots to explore unknown areas and reduces the occurrence of local optima. The experimental results show that the proposed navigation method significantly improves the training efficiency of mobile robots. Out of 1000 test episodes, only 3 exceeded the maximum step limit. This approach significantly reduces the occurrence of local optima. Furthermore, it increases the success rate to an impressive 83.5%, outperforms the existing navigation methods.
Introduction
Recent advancements in robotics technology 1 have led to a surge of robot applications across various domains, with mobile robots emerging as essential tools in both daily life and industrial operations. 2 Navigation is one of the critical technologies for intelligent mobile robots. Traditional navigation methods for robots struggle to adapt to new environments, and their performance typically degrades as the complexity of the tasks increases. 3 In recent years, researchers have turned to deep reinforcement learning (DRL) 4 algorithms to improve the performance of mobile robot navigation. By leveraging the inherent trial-and-error mechanism in DRL, robots can learn to perceive and navigate in unknown environments. 5 Through iterative refinement guided by reward functions, the optimal path can be obtained to reach the target. 6
However, DRL-based navigation 7 for mobile robots is a challenging task when operating in unexplored regions with limited rewards, leading to frequent falling into the trap with local optima. 8 This issue stems from the scarcity of consistent rewards during the process of completing the task. 9 This sparsity of rewards severely hinders the robot's ability to obtain meaningful rewards during its exploration. Consequently, it is crucial to design a mechanism that provides more consistent rewards, improving the performance of mobile robot navigation in environments with infrequent rewards.
To address the aforementioned challenges, this paper proposes an intrinsic reward mechanism which consists of the intrinsic curiosity module (ICM) and the randomness enhanced module (REM). This enables robots to autonomously navigate to their destination in unknown environments. The TD3 (twin-delayed deep deterministic policy gradient (DDPG)) reinforcement learning algorithm serves as the foundational framework for navigation, addressing the challenges of continuous action spaces. The ICM calculates the difference between the predicted next state and the actual next state to provide an intrinsic reward signal for the mobile robot, guiding its exploration of unknown regions. However, due to the inevitable interference of environmental noise when the robot predicts the next state, the intrinsic rewards are not always accurate. This imprecision hinders the full potential of the intrinsic reward mechanism, leading the robot occasionally falling into the trap with local optima. To address this, this paper proposes the REM. By estimating the randomness in unknown regions of the environment, it provides an additional reward signal for exploration. This approach diminishes the emergence of local optima traps, thereby enhancing the exploration efficiency of the algorithm.
Additionally, a novel reward function has been designed to encourage the mobile robot to develop better navigation strategies within its environment. During the training process, the mobile robot obtains external rewards from the state of the mobile robot within the environment and internal rewards generated through the intrinsic reward mechanism. By integrating external rewards and internal rewards, the reward during the mobile robot's training phase is increased, promoting sustained exploration and learning in subsequent trials. The combined use of the intrinsic reward mechanism and the new reward function significantly enhances the efficiency and robustness of the DRL algorithm. This ensures that the mobile robot actively explores unknown regions, thereby enhancing its capability to navigate in complex environments.
The main contributions of this paper are summarized as follows:
By integrating the TD3 reinforcement learning algorithm with the ICM for mobile robot navigation, the intrinsic reward mechanism effectively addresses the slow convergence issue caused by sparse rewards in continuous action spaces and motivates the mobile robot to explore unknown regions. REM has been designed on the foundation of the ICM. By estimating the randomness in unknown regions of the environment, it amplifies the impact of intrinsic rewards on navigation strategies. This approach diminishes the chances of the mobile robot falling into the trap with local optima. A novel reward function that combines both external rewards and internal rewards has been designed to enhance the mobile robot's navigation strategies. This integrated reward function increases the rewards for the mobile robot during its training, motivating continued exploration and learning in subsequent trials.
Related work
Algorithms of mobile robot navigation are categorized into global and local strategies based on acquired environmental data. 10 Global path planning chooses a path using a known static environmental map, where methods like A-star 11 and rapidly exploring random trees 12 are less effective in unknown environments. Local path planning methods such as dynamic window approaches 13 are commonly used to navigate in dynamic environments. However, traditional navigation algorithms are sensitive to sensor noise and require high accuracy, 14 limiting robots in complex environments.
During the “Man vs. Machine Go Match,” researchers overcame limitations of conventional obstacle avoidance methods by employing DRL techniques for autonomous navigation tasks. 15 This approach expanded navigation capabilities to complex tasks, offering advantages such as map-free navigation, strong learning capabilities, and reduced reliance on sensor accuracy. 16 Navigation techniques based on DRL algorithms frame the navigation process as a Markov decision process. Neural networks are employed to process sensor data, utilizing sensor observations as the state representation. To maximize expected action rewards, optimal strategies are generated through interactions with the environment to guide the robot to its target location.
The DRL networks can generate action policies for mobile robots in continuous action spaces and be applied to local obstacle avoidance scenarios. For example, Feng et al. 17 developed a local path planning approach based on deep double Q-learning (DDQN) reinforcement learning algorithm, combining the DDQN algorithm with topology-based global planning. Wang et al. 18 proposed an improved method based on DDPG. These DRL techniques have demonstrated remarkable performance in local obstacle avoidance scenarios. However, due to the environmental information being local, these methods are susceptible to local optima issues, especially in unknown regions, resulting in increased training times. To address the lack of global information, Pokle et al. 19 proposed a hierarchical motion planning approach, dividing navigation into local planning, global planning, and velocity control module. Besides, recent advancements for reinforcement learning have further addressed exploration challenges. Methods such as Savinov et al. 20 used episodic memory to create novelty bonuses by comparing current observations with past ones based on the number of steps needed to reach target point. This technique incorporates environment dynamics and mitigates issues where agents exploit actions leading to unpredictable consequences. Hafez et al. 21 proposed a behavior self-organization which supports task inference for continual robot learning by performing unsupervised learning of behavior embeddings. Burda et al. 22 and Wu et al. 23 introduced an exploration bonus for DRL methods based on the error of a neural network predicting features of observations given by a fixed randomly initialized neural network, which enhances exploration capabilities in complex tasks. Zhao et al. 24 used sound as a modality to guide exploration and improve representation learning in unsupervised reinforcement learning. Sekar et al. 25 leveraged self-supervised world models to plan and seek out expected future novelty, improving both exploration and fast adaptation to new tasks. Despite the integration of local and global planning, the computed path does not consider the process of robot's exploration and perception of its environment. In summary, although DRL-based methods show potential in improving robot navigation skills and applicability, 26 challenges remain in overcoming local optima issues, achieving comprehensive exploration, and navigating in unknown environments.
Method
Inspired by human curiosity, this paper proposes an intrinsic reward mechanism and integrates it into the autonomous navigation of mobile robots. This integration aims to improve the robot's capability to explore its environment and address the challenge of limited rewards in reinforcement learning. Unlike traditional exploration methods, the intrinsic reward mechanism closely mirrors human cognitive processes, generating a more thoughtful exploration strategy and improving learning effectiveness. The paper begins with an analysis of the intrinsic reward mechanism, followed by its integration with the TD3 DRL algorithm. It then investigates the analysis of the curiosity module and the REM. Finally, the design of a reward function combining the external rewards and internal rewards is presented. This comprehensive approach ultimately leads to a significant improvement in navigation efficiency.
Analysis of intrinsic reward mechanism
The intrinsic reward mechanism involves an internally generated reward signal within the mobile robot, which evaluates its current behavior quality. Traditional DRL-based navigation methods usually only offer rewards when the robot takes correct actions and penalizes it otherwise. Most of these methods focus solely on the outcome of the task, overlooking details such as speed, direction, and exploration of the environment during movement. This leads to reduced learning efficiency and frequent falling into the trap with local optima. In contrast, the intrinsic reward mechanism guides the robot's learning process even when external reward is lost, thereby enhancing both learning efficiency and navigation performance.
During the training phase, the intrinsic reward mechanism is commonly designed based on state-value rewards. State-value rewards assign a numerical value to each state, allowing the mobile robot to assess the current state and the expected outcomes of different actions. These state-value rewards act as intrinsic signals, effectively guiding the robot's learning process and improving learning efficiency. By motivating the robot to explore unknown regions, the intrinsic reward mechanism promotes the accumulation of additional environmental knowledge, ultimately boosting the anticipated long-term rewards.
Figure 1 depicts the intrinsic reward module. Here, S signifies the environmental state, a denotes the mobile robot's action, and R stands for the intrinsic reward. The intrinsic reward is determined by assessing the difference between the predicted subsequent state

The intrinsic reward module.
Mobile robot navigation based on intrinsic reward mechanism
This section introduces a mobile robot navigation approach that combines the ICM and REM with the TD3 DRL algorithm. The method utilizes a laser rangefinder sensor to capture environmental data, covering a 180° frontal range and the robot's polar coordinates as input states. The sensor focuses on the forward region, with linear velocity limited to non-negative values and excluding backward movement. In new environments, the robot employs laser sensors to gather vital information, storing it for training purposes. Through optimizing its motion strategy, the robot seeks to achieve maximum rewards for task completion. Rewards consist of both external environmental rewards and internal rewards from the intrinsic reward mechanism. These reward components influence the robot's navigation strategy, refined over iterative training, enhancing task efficiency.
In the realm of network design, as shown in Figure 2, the mobile robot obtains state information such as
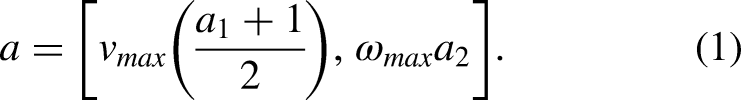

The framework for mobile robot navigation based on intrinsic reward mechanism.
Both critic networks utilize a similar three-layer fully connected structure and operate concurrently, allowing for differences in parameter values between the networks. The target critic networks take both the state-action pair s and a as inputs. The state s is fed into a fully connected layer, followed by a ReLU activation producing

ICM
The ICM consists of feature extraction, forward model, and inverse model, as shown Figure 3. In the input,

The intrinsic curiosity module.
In the forward model,


REM
The REM designed in this paper presents a novel network architecture. The central idea is to utilize the outputs of both the prediction and target modules to estimate the randomness of unknown areas in the environment, subsequently providing an additional reward signal for exploration. This supplementary reward signal amplifies the state randomness of the mobile robot, promoting the navigation algorithm to explore unknown regions. It reduces the occurrence of local optima traps without altering the intrinsic reward influence factor, thereby increasing the algorithm's exploration efficiency. For instance, when the mobile robot navigates to previously visited paths, it learns that the reward at its current position is significantly less compared with the reward of moving to unexplored regions. This inclines the mobile robot to depart from its current location and venture toward unknown regions. The structure of the REM is illustrated in Figure 4.

The randomness enhanced module.
Initially, the prediction module will forecast

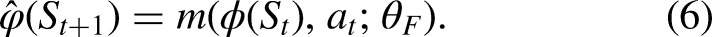


Design of the reward function
In this paper, at the end of a training episode, all intrinsic rewards stop accumulating, as illustrated in equation (9). Here, H represents the moment when the episode terminates. Data Input: The REM takes the current state Feature Extraction: The current state Prediction Module Network Update: The prediction module trains to forecast the output of the target module based on a vast amount of input data. It shares the same input data with the target network. During each training iteration, the mean squared error between the outputs of the two networks is used as the loss function to update the network parameters. Target Module Output: The target module produces a predicted value for the next state. This predicted output is compared with the output of the prediction module to compute the error. A larger error indicates a more novel environment, leading to a correspondingly larger reward value. Computing Intrinsic Reward: The intrinsic reward mechanism generates three reward signals. The first is derived from the error calculation between the next state's features and the output of the prediction module. The second is obtained from the computation between the prediction module and the target module. The final reward signal is determined based on the previous two rewards.

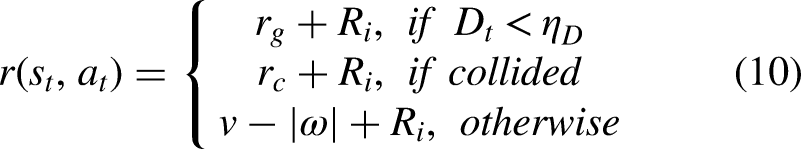

Experimental design and evaluation methodology
In this paper, a simulation environment was constructed within the Gazebo simulation simulator, and the Pioneer P3DX mobile robot platform was employed to train the navigation model and conduct experimental testing. Gazebo offers a physics-based simulation environment, enabling the simulation of interactions between mobile robots and their environments. Users can control the behavior of the mobile robot and utilize sensors to gather environmental data.
The method proposed in this paper is implemented based on the PyTorch framework and runs on a GeForce RTX 2080Ti GPU. During network training, batch processing is employed, with each batch comprising 40 sets of data randomly selected from the experience pool. In the training phase, the mobile robot moves a maximum of 300 steps per episode, either until it collides with an obstacle or reaches the target point. The maximum training movement is set to 3 ×
To validate the performance of the navigation method based on the intrinsic reward mechanism, this paper uses data from training episodes as a reference and conducts a statistical analysis of the data results from 1000 test episodes across different DRL navigation methods based on the ICM. Additionally, this paper places particular emphasis on analyzing episodes where the robot navigation method based on the intrinsic reward mechanism exceeds the maximum step limit, thereby verifying the effectiveness of the intrinsic reward mechanism.
This paper employs multiple metrics to assess the mobile robot's performance, including average success steps (ASS), success rate (SR), collision rate (CR), and collision steps (CS). Success steps represent the steps the robot takes to reach the target without collisions. CR is the ratio of collision episodes to total testing episodes. CS is the steps taken during episodes with collisions. The SR reflects the ratio of episodes in which the mobile robot successfully reaches the target point to the total number of test episodes. It is commonly used to assess the exploration strategy of the mobile robot, as depicted in equation (12).

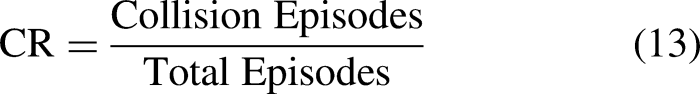
Experimentation and analysis
As illustrated in Figure 5, the chart depicts the range of steps taken by various methods to reach the target point.
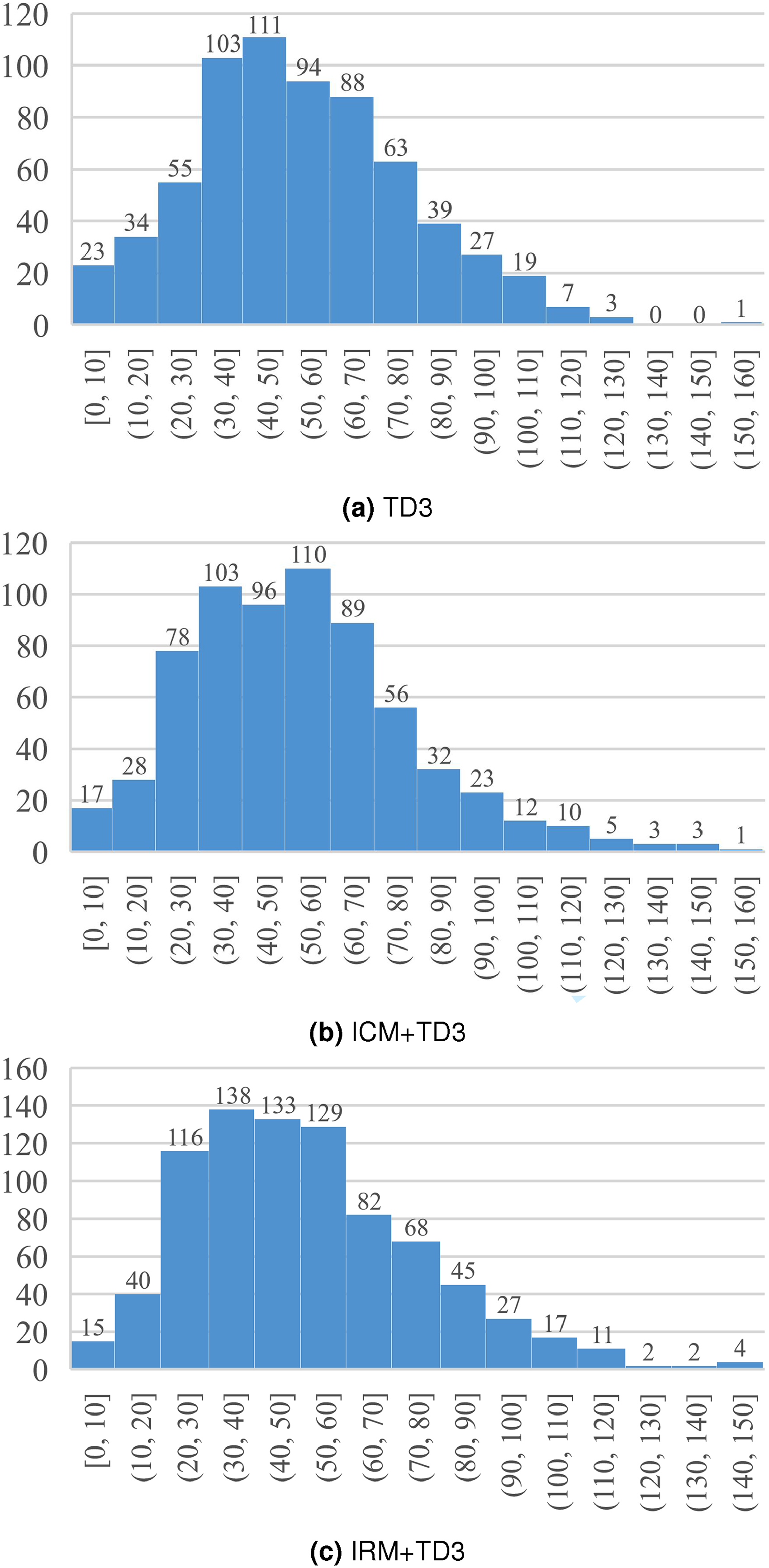
Steps counted for reaching destination. (a) TD3. (b) ICM + TD3. (c) IRM + TD3.
From the chart, it is evident that the mobile robot navigation method based on the intrinsic reward mechanism has a distinct advantage in terms of the overall step range. The steps required for the mobile robot to reach the target point are primarily distributed within the 20–60 step range, whereas the other two methods are more concentrated in the 30–80 step range. Moreover, within the 0–80 range, the navigation method based on the intrinsic reward mechanism accounts for 721 episodes, significantly surpassing the 569 episodes of navigation using only the TD3 algorithm and the 577 episodes of navigation based on the ICM.
The mobile robot navigation method based on the intrinsic reward mechanism exhibits a more compact step range, indicating more stable movement during training. The successful steps are primarily concentrated in the 20–60 range, while navigation using only the TD3 algorithm and navigation based on the ICM are more clustered in the 30–80 range. This demonstrates that the mobile robot navigation method based on the intrinsic reward mechanism not only enhances training efficiency but also improves the robustness of navigation to the target point.
Figure 6 presents a bar chart comparing the number of episodes exceeding the maximum step limit for the mobile robot navigation method based on the intrinsic reward mechanism, the navigation method based on the ICM, and navigation using only the TD3 DRL algorithm. The maximum step limit refers to the maximum number of steps required for a mobile robot to reach the target point. If the number of steps exceeds this limit, it is considered that the robot cannot reach the target point within this round of movement. From the results of 1000 test episodes, it is evident that the navigation method based on the intrinsic reward mechanism has the fewest episodes exceeding the maximum step limit, with only three episodes. This outcome is superior to the navigation method based on the ICM, validating the effectiveness of the intrinsic reward mechanism. It indicates that the mobile robot using the navigation method with the intrinsic reward mechanism, when exploring the environment, further reduces the likelihood of the robot getting trapped in local optima. This is attributed to the addition of the intrinsic reward mechanism in the navigation method, which employs two types of state errors as intrinsic motivation, continuously training the mobile robot to explore unknown environments, thus demonstrating the effectiveness of the intrinsic reward mechanism.

Comparison of episodes exceeding the maximum step limit.
In conclusion, from the statistical data of 1000 test episodes, which includes ASS, SR, CR, and CS for the mobile robot navigation method based on the intrinsic reward mechanism, the navigation method based on the ICM, and other DRL algorithm navigation, it can be identified from the analysis that the results of the navigation method based on the intrinsic reward mechanism have shown significant improvement compared with other methods. A comparison was made between the mobile robot navigation method based on the intrinsic reward mechanism and the method proposed, as well as other reinforcement learning navigation methods, as shown in Table 1.
Performance comparison using different deep reinforcement learning methods.

From the perspective of the SR, the method proposed in this section has an SR of 83.5%, which is 5.6% higher than the navigation method based on the ICM. It significantly surpasses navigation methods solely based on DDPG, A3C, and TD3. The CR is also the lowest among the compared methods, at only 16.2%. The CS provides a more direct indication of the improvement in navigation efficiency brought about by the method proposed in this section. This demonstrates that the combination of the intrinsic reward mechanism with reinforcement learning navigation algorithms not only enhances the exploration efficiency of the mobile robot during navigation, further reducing the occurrence of local optima traps, but also improves the overall navigation performance of the mobile robot.
Conclusion
In this paper, DRL mobile robots replaced the localization and map-building modules as well as the local path planning module in traditional navigation frameworks. This allows for movement toward the target point while avoiding obstacles. By integrating the intrinsic reward mechanism with DRL navigation algorithms, the final intrinsic reward value is obtained by calculating two types of state errors. This effectively reduces the likelihood of the mobile robot getting trapped in local optima during exploration and enhances both training efficiency and navigation performance. Experimental results demonstrate that the navigation algorithm based on the intrinsic reward mechanism significantly reduces instances where the mobile robot falls into local optima traps. Only three episodes encountered local optima in 1000 training episodes, and the SR increased to 83.5%. However, the following limitations exist in our method, and we aim to address them in future work:
This study conducted training and testing in a static obstacle environment. In the future, dynamic obstacles can be incorporated to improve the obstacle avoidance performance of mobile robots, making the simulation more applicable to real-world scenarios. The intrinsic reward mechanism is proposed based on state errors. It can lead to inaccuracies in generating intrinsic rewards, affecting the mobile robot's ability to judge the novelty of the environment.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, Beijing Nova Program (grant numbers 62272322, 62272323, 20230484409).
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.