
Abstract
The advantage of adversarial domain adaptation is that it uses the idea of adversarial adaptation to confuse the feature distribution of two domains and solve the problem of domain transfer in transfer learning. However, although the discriminator completely confuses the two domains, adversarial domain adaptation still cannot guarantee the consistent feature distribution of the two domains, which may further deteriorate the recognition accuracy. Therefore, in this article, we propose a deep adversarial domain adaptation network, which optimises the feature distribution of the two confused domains by adding multi-kernel maximum mean discrepancy to the feature layer and designing a new loss function to ensure good recognition accuracy. In the last part, some simulation results based on the Office-31 and Underwater data sets show that the deep adversarial domain adaptation network can optimise the feature distribution and promote positive transfer, thus improving the classification accuracy.
Keywords
Introduction
The training of deep neural networks requires a large amount of labelled data. However, the lack of a large amount of labelled data in real life limits its application. The proposal of transfer learning 1 solves the above problems well. It can apply knowledge or methods learned in other areas with large amounts of tagged data to areas where tagged data are scarce. Domain adaptation 2 is considered a representative method in transfer learning, which can use a considerable amount of labelled data from the related source domains to transfer the learned knowledge to the target domain.
The core idea of the domain adaptation method is to mitigate the problem of domain transfer between the source and the target domains. The domain-invariant features learned from the source domain with rich tagged data are transferred to the target domain. In recent years, in order to solve the problem of domain transfer between the source domain and the target domain, many domain adaptation methods have been proposed. The standard domain adaptation methods can be divided into the following two categories: (1) instance-based domain adaptation and (2) feature-representation domain adaptation. 3 The instance-based method is used to slow the error by weighting the source samples and train the weighted source samples. 4 The feature-based methods usually transform the features of the source and the target domains into a shared space where the feature distributions of the two data sets match. The domain adaptive method, based on feature representation, is the most commonly used method.
The transfer component analysis 5 (TCA) method was proposed previously, which utilises the feature extraction method and adopts the new parameter kernel for domain adaptation, projecting the data to the learned transfer component, which significantly reduces the distance between the domain distributions. In another study, a new kernel-based approach was proposed, which is a manifold learning method geodesic flow kernel (GFK), interpolating the bridge domain through infinite intermediate subspaces. 6 A deep domain confusion 7 (DDC) network structure was proposed, which was the first method to regularise the adaptive layer of AlexNet by using the linear kernel maximum mean discrepancy (MMD), to maximise the domain-invariant features and reduce the domain differences to realise domain adaptation. An extremely simple domain adaptive neural network 8 (DaNN) was proposed; this is a new method for domain adaptation in deep architecture and involves the addition of an MMD adaptation layer after the feature layer to measure the difference in the feature distribution between two domains. A new deep adaptive network 9 structure (DAN) was proposed, which extends deep convolutional neural networks to domain adaptation scenarios, copies the core Hilbert space reproducing kernel hilbert space (RKHS) by embedding the depth features of multiple task-specific layers and uses multi-kernel maximum mean discrepancy (MK-MMD) to optimise and match different distributions to learn transferable features. A new convolutional neural networks (CNN) structure was proposed, which simultaneously optimises domain invariants to promote domain migration and utilises soft tags to optimise the differences between the two tasks. 10 A new domain adversarial neural network 11 (DANN), was proposed, which was the first to introduce the idea of adversarial learning into transfer learning. The model minimises the loss function of the label classifier to extract features with distinguishing capabilities and maximises the loss function of a classifier to extract features with domain invariance, thereby reducing the domain migration. A deep network residual transfer network 12 (RTN) domain adaptation method was proposed, which can learn adaptive classifiers and transfer features from the data in two domains. A weighted MMD model 13 was proposed, which is defined by introducing an auxiliary weight for each class in the source domain, and a classification expectation-maximization (EM) algorithm based on pseudo-label assignment, auxiliary weight estimation and other updating of model parameters were proposed. The adversarial discriminative domain adaptation 14 (ADDA) model was proposed, which combines generative adversarial networks (GAN) 15 loss, weight sharing and discrimination modelling to optimise the domain differences. The joint adaptation network 16 (JAN) was also proposed, which is based on the joint maximum mean discrepancy (JMMD) standard. The method learns the transfer network by aligning the joint average of several domain-specific layers across multiple domains and maximises the JMMD by adopting the adversarial training strategy to make the distribution of the two domains easy to distinguish.
The domain transfer problem is solved by the different methods mentioned above. However, there are still some problems that remain to be solved. The MMD is used to optimise the domain transfer between two domains. Although the distribution of these two domains is generally the same, we cannot guarantee the complete alignment of each category’s feature distribution, resulting in low classification accuracy. Domain adaptation using adversarial 17 ideas is still a challenge, and even if the discriminator completely confuses the two domains, the feature distribution is not guaranteed to be sufficiently similar.
To further alleviate the distribution difference between the two domains, in this article, we propose deep adversarial domain adaptation network (DADAN), a new optimisation method. The MMD metric layer was added to the feature layer that was confused by the discriminator when adversarial training was used. In addition, weights of the class were established for each category to participate in the training, to maximise the differences between classes and to minimise the differences within classes, thereby improving classification accuracy.
The rest of this article is organised as follows: the second section introduces the related work; the third section explains the model architecture; the fourth section shows the experimental content, the simulation results and the analysis of the results; and finally, the fifth section concludes this article.
Related work
Maximum mean discrepancy
The MMD is usually the square distance between the kernel embedding of data distributions Ps and Pt in the RKHS. The smaller the MMD value is, the more similar are the feature distributions of the two domains. The distribution difference between the two domains can be estimated in many ways. The most commonly used non-parametric method used in transfer learning to measure the distribution difference between two domains is MMD. It measures the distance between two distributions in RKHS by a characteristic kernel K that maps the original variable to the RKHS space.
The characteristic distribution distance between the source domain and the target domain can be expressed as follows
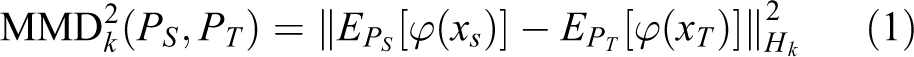

where ϕ is the feature mapping and Hk stands for RKHS with the feature kernel k.
Partial adversarial domain adaptation
Partial adversarial domain adaptation (PADA)
18
can be improved using the traditional DANN network. We are given a source domain
The PADA method can promote the positive transfer of the relevant source domain and slow down the negative transfer of the irrelevant source domain. The overall objective of PADA 18 is as follows

where yi is the original label of the source domain sample and di is the domain tag of input xi and γ is used to represent the overall distribution weight of the source domain data. The Gf represents the feature extractor, the Gy represents the source classifier and the Gd represents the domain discriminator.
The PADA method has achieved good results in partial domain adaptation. 18 –20 However, in the case of the traditional domain adaptation, the data feature distribution of the domain discriminator confusion cannot be guaranteed to be the same; therefore, in the present study, we improved this. In this article, we propose to add an MMD measurement layer to the domain-invariant feature extracted by the feature extractor and add it to the optimisation target. Further optimisation of the characteristic distribution of the two domains is confused by the domain discriminator.
Proposed method
The quality of the extracted deep domain-invariant features will influence the model’s performance and reduce the difference in the feature distribution between the two domains that are confused by the domain discriminator and improve the performance of the model. In this article, we propose the combination of PADA and MK-MMD to further reduce the distribution difference between the two domains, confused by the domain discriminator. When the distribution difference is smaller, the larger the amount of useful information carried by the extracted domain-invariant features is, the better is the transfer effect.
In this article, we propose to add the MK-MMD measurement layer on the feature layer extracted by the feature extractor and confused by the domain discriminator and add its loss to the overall optimisation goal of the model, thereby further reducing the difference in the feature distribution of the two domains confused by the domain discriminator.
Network structure
We propose a new DADAN model structure. After pre-processing the collected original image data, the result was input into the network for model training. The network structure is shown in Figure 1.

DADAN network structure. DADAN: deep adversarial domain adaptation network.
The feature extractor Gf discussed in this article was obtained by fine-tuning the pre-trained ResNet-50 in the ImageNet model, which could make the most of the advantages of the pre-trained model and the original network parameters. The deep domain-invariant features f of the input data were extracted by the feature extractor Gf , and the weight of the feature extractor was shared between the two domains. Here, Ms represents the features extracted from the source domain, and Mt denotes the features extracted from the target domain.
The source classifier Gy took the domain-invariant features f obtained from the feature extractor Gf as the input for detection and shared the weight of the source classifier to target the domain classifier.
The domain discriminator Gd was used to confuse the domain-invariant feature f of the two domains extracted by the feature extractor Gf . The gradient reversal layer acted between the feature extractor Gf and the domain discriminator Gd , and thus, the gradient direction was automatically reversed during the back-propagation process.
In order to obtain the domain-invariant feature f, we learnt the parameter
MK-MMD 9,21 was developed from MMD. The original MMD maps the features of two domains to an RKHS and calculates the average difference after mapping. This kernel is fixed; thus, we can choose either a Gaussian kernel or a linear kernel, but we cannot determine which kernel is necessarily better. Therefore, in this study, we adopted MK-MMD. The MK-MMD model assumes that we can obtain the optimal kernel through a linear combination of multiple kernels. The most popular method of using MK-MMD is DAN. 9
Loss function
1. Source supervision loss
The feature f extracted from the feature extractor Gf was fed into the source classifier Gy to optimise the classification loss of the labelled data in the source domain. The loss function can be expressed as follows
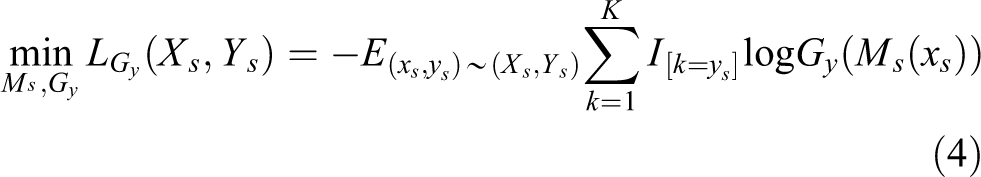
The source classifier

where γ is a vector that measures the class contribution of the source domain. Irrespective of whether the number of categories in the source domain was equal to the number of target domains, the contribution weight of the source domain categories could be obtained, thus guiding the target domain data to reduce the classification errors.
2. Domain discriminator loss
The domain discriminator Gd was used to identify which domain the domain-invariant features extracted from each input data item xi originated from. If the domain discriminator Gd could not distinguish which domain the extracted domain-invariant features belonged to, then the features extracted by the feature extractor Gf were domain invariant. The loss function can be written as follows

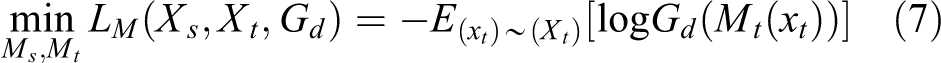
Here,
3. Maximum average difference loss
MK-MMD was the same as MMD; the feature map ϕ was associated with the characteristic kernel, and
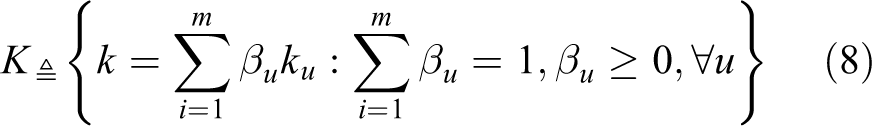
The correlation constraint of the coefficient

The overall objectives of DADAN were as follows

Here, yi
is the original label of the source domain sample and di
is the domain from which the sample originated. Furthermore, λ is a hyper-parameter that trades off
The optimisation problem found the optimal parameters

Simulation
We conducted an experimental validation to evaluate our approach and several advanced deep transfer learning methods. Our method was simulated with an underwater object detection task.
Data set description
1. Office-31 data set
Office-31 22 is one of the most commonly used image data sets in domain adaptation, containing a total of 4652 images in 31 categories from three different domains: Amazon (A), Webcam (W) and DSLR (D). We evaluated the accuracy of the following six transfer tasks in different methods: A → W, D → W, W → D, A → D, D → A and W → A.
2. Underwater data set
According to the method of generating the underwater data set proposed in Yu et al., 23 three types of Office-31 underwater data sets with a turbidity of 0.5, 1.0 and 2.0 were obtained, as shown in Figure 2. In this study, the Office-31 data set and the generated underwater data set were taken as the source and the target domains. We evaluated nine transfer tasks for each turbidity. They were A → U_A, A → U_D, A → U_W, D → U_A, D → U_D, D → U_W, W → U_A, W → U_D and W → U_W.

Underwater data sets.
Compared approaches and results analysis
For the Office-31 data set, we compared the traditional and advanced transfer learning and deep learning methods: TCA 5 , GFK 6 , DDC 7 , DAN 9 , RTN 12 , DANN 11 , ADDA 14 and JAN 16 . AlexNet and ResNet are both classic networks and are widely used in image classification. We adopted AlexNet 24 and ResNet-50 25 as the base networks. On the one hand, for the convenience of comparison with other mainstream methods; on the other hand, these two network structures can obtain better results in image feature extraction.
As the amount of data in domain A was considerably larger than that in domains W and D, it was impossible to learn more features in the W and D domains for tasks W → A and D → A, resulting in a less accurate result than that for other tasks.
Tables 1 and 2 show the AlexNet-based and ResNet-based results of different methods in the Office-31 data set, respectively. These tables show that our approach had the best results for different transfer tasks. Furthermore, for all of the transfer learning tasks, the proposed method was obviously superior to the other methods. The boldface values in the tables are the best results.
Accuracy (%) of the Office-31 data set based on AlexNet. 24

TCA: transfer component analysis; DDC: deep domain confusion; DAN: deep adaptive network; RTN: residual transfer network; DANN: domain adversarial neural network; ADDA: adversarial discriminative domain adaptation; JAN: joint adaptation network; DADAN: deep adversarial domain adaptation network.
Accuracy (%) of the Office-31 data set based on ResNet. 25

TCA: transfer component analysis; DDC: deep domain confusion; DAN: deep adaptive network; RTN: residual transfer network; DANN: domain adversarial neural network; ADDA: adversarial discriminative domain adaptation; JAN: joint adaptation network; DADAN: deep adversarial domain adaptation network.
Figures 3 and 4 show the average accuracy of different transfer learning methods based on AlexNet and ResNet. It was evident that the DADAN method proposed in this article was superior to all of the comparison methods for all of the transfer learning tasks.

Average accuracy (%) of the Office-31 data set based on AlexNet.

Average accuracy (%) of the Office-31 data set based on ResNet.
For the underwater image data set, the DADAN method proposed in this article was compared with the AlexNet-based method. 23
As the amount of data in domain A was considerably larger than that in domains U_W and U_D, it was impossible to learn more features in the U_W and U_D domains for tasks W → U_A and D → U_A, resulting in a less accurate result than that for the other tasks.
The AlexNet-based method 23 only verified the accuracy of task A → U_A under three different turbidity values and the maximum accuracy of less than 50%. Figure 5 clearly shows that the DADAN method was considerably more accurate than the AlexNet-based method in the case of the transfer task A → U_A under three different types of turbidity. In addition to the migration task A → U_A, Figure 5 shows the results of DADAN facing different turbidity values for different transfer learning tasks. We observed that the DADAN method could achieve not only high accuracy for the same transfer task under different turbidity conditions but also stable accuracy for different transfer tasks under different turbidity conditions. Compared with the previous methods, the DADAN method dramatically improved the accuracy of the transfer of in-air image data knowledge for underwater target detection tasks. Moreover, it had strong applicability and provided more possibilities for underwater target detection.

Accuracy (%) on the Underwater data set for the DADAN method. DADAN: deep adversarial domain adaptation network.
Conclusion
In this article, a new DADAN was proposed. On the basis of the features and advantages of adversarial learning and MK-MMD, DADAN put them together and designed a new loss function to further optimise the feature distribution of two domains in order to maintain their consistency. We conducted some comparative experiments on the Office-31 and Underwater data sets by using DAN, RTN, DANN and other methods. The experimental results showed that this method could effectively optimise the feature distribution confused by the domain discriminator, thus promoting the positive transfer and obtaining a higher accuracy classification than the current mainstream methods.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Natural Science Foundation of China, No. 61973103, Henan province Central plains thousand talents plan: top young talents and Key scientific research project of Henan University with No. 19A120002.