
Abstract
Online platforms are experimenting with interventions such as content screening to moderate the effects of fake, biased, and incensing content. Yet, online platforms face an operational challenge in implementing machine learning algorithms for managing online content due to the labeling problem, where labeled data used for model training are limited and costly to obtain. To address this issue, we propose a domain adaptive transfer learning via adversarial training approach to augment fake content detection with collective human intelligence. We first start with a source domain dataset containing deceptive and trustworthy general news constructed from a large collection of labeled news sources based on human judgments and opinions. We then extract discriminating linguistic features commonly found in source domain news using advanced deep learning models. We transfer these features associated with the source domain to augment fake content detection in three target domains: political news, financial news, and online reviews. We show that domain invariant linguistic features learned from a source domain with abundant labeled examples can effectively improve fake content detection in a target domain with very few or highly unbalanced labeled data. We further show that these linguistic features offer the most value when the level of transferability between source and target domains is relatively high. Our study sheds light on the platform operation in managing online content and resources when applying machine learning for fake content detection. We also outline a modular architecture that can be adopted in developing content screening tools in a wide spectrum of fields.
INTRODUCTION
Increasingly, online platforms like social media and review websites are applying machine learning techniques to screen user‐generated content for quality control (Lee et al., 2018; X. Zhang et al., 2022). This is in response to surging societal concerns about the spread of fake content that fuel extreme emotions (Allcott & Gentzkow, 2017; Ng et al., 2021; Vosoughi et al., 2018). In 2016, Facebook began to tag articles that were identified as fake by third‐party fact‐checkers. 1 Similarly, in early 2020, Twitter started to flag what it judged to be inappropriate content related to COVID‐19. 2 Without proper quality control, the value of the platforms will be reduced (Choi et al., 2018; Cui et al., 2018; Wei et al., 2021; Yan & Pedraza‐Martinez, 2019). Hence, content screening will be one of the most crucial processes of the backend operations for platforms, especially those specializing in content provision.
In quality management, the value loss in a value chain is measured as the deviation between the expected and the actual product characteristics (Taguchi, 1985), with the expense of quality control processes such as costs of sampling and inspection (Kanyamibwa & Ord, 2000). In a traditional supply chain with physical goods, such value loss could be reduced by contractual agreement with the upstream business partners, like deterred payment (Rui & Lai, 2015) and price negotiation based on defective rate (Leng et al., 2016). However, online platforms typically have a much larger upstream (i.e., users who generate content) with anonymous identity, making contractual agreement practically infeasible.
As a result, interventions to curb the propagation of fake content will be necessary for platforms. To efficiently routinize such inventions, real‐time assessment built on computational models will be required. The capability of machine learning in fake content detection has been reported in the literature, in which fake content has been found to contain linguistic cues that reveal its dissociation from genuine content (Clarke et al., 2021; D. Zhang et al., 2016; X. Zhang et al., 2022; L. Zhou & Zhang, 2008), and these cues could be captured by machine learning and natural language processing (NLP) techniques (Bloomfield, 2012; Clarke et al., 2021; Sharma et al., 2019; Q. Wang et al., 2018).
Despite the effectiveness of machine learning in fake content detection, online platforms always suffer from a lack of accurately labeled data to train machine learning models for content screening as these data are limited and costly to obtain (Ganin et al., 2016; Van Vlasselaer et al., 2017; Zhu et al., 2020). As summarized in Supporting Information Appendix A, our literature review reveals two challenges in developing machine learning models for fake content detection: (1) constructing a large sample of labeled examples for discriminant analysis is difficult because many domains have few confirmed cases of fake content and (2) collecting labeled fake content is laborious and costly. These challenges raise important operational issues for online platforms in utilizing machine learning for managing and exploiting online content (Wei et al., 2021). To address this issue, this study adopts an augmented artificial intelligence (AI) perspective, defined as a type of human–AI hybrid where humans and AI augment one and another (A. Rai et al., 2019), to advance fake content detection. Specifically, we augment fake content detection by identifying discriminating and domain invariant linguistic features based on a large collection of human judgments and perceptions of truth and deception, representing an approach that incorporates collective human intelligence to enhance AI (Yau et al., 2021).
In a nutshell, the idea is to (1) identify a news domain (source domain) where there is an abundance of human judgments and opinions in fake news detection, (2) distill the common linguistic features of news that are effective in discriminating against fake and non‐fake news based on the collective human inputs in the source domain, (3) transfer these linguistic features to another domain (target domain) where verified fake cases and human inputs are scare, and (4) augment these transferred features with traditional AI techniques to alleviate the problems associated with limited/unbalanced verified cases for model development in the target domain. In this regard, our work connects to the nascent literature on human–AI interaction (Fügener et al., 2021; Ge et al., 2021; A. Rai et al., 2019; Raisch & Krakowski, 2021) by contributing a unique form of human‐in‐the‐loop case that leverages collective human intelligence to augment fake content detection as part of a regular platform operation.
To rigorously validate the proposed approach, we identify three target domains: political news, financial news, and online reviews. All three domains have insufficient accurately labeled samples but to differing degrees. Fake political news is defined as “news articles that are intentionally and verifiably false and could mislead readers” (Allcott & Gentzkow, 2017, p. 213). It has received much attention since the 2016 U.S. presidential election, and a body of fake political news data has been manually assembled. Since fake or manipulated political news can undermine social media's credibility and users’ experience, flagging this content is important to platform operations (Lee et al., 2018). On the other hand, fake financial news articles are written with malicious intentions to manipulate the financial market (Clarke et al., 2021; X. Zhang et al., 2022). Unlike political news, wrongly labeled financial news could have significant legal consequences. Besides, financial news generally contains domain knowledge and insider information, causing ground‐truth labeling to be hard to verify (X. Zhang et al., 2022). These explain why financial news verified by the respective regulator as fake are very few (Clarke et al., 2021; X. Zhang et al., 2022). As firms increasingly incorporate various online information into their operations (Wei et al., 2021), identifying fake financial news provides valuable insights into the operational risk in financial services (Xu et al., 2017). Lastly, fake online reviews are defined as “deceptive reviews provided with an intention to mislead consumers in their purchase decision making, often by reviewers with little or no actual experience with the products or services being reviewed” (D. Zhang et al., 2016, p. 457). Fake online reviews can significantly influence platform operations by shaping consumers’ purchasing decisions and affecting merchants’ revenue (Wu et al., 2020). They also serve as an appropriate context in the current study as their ground truth is difficult to establish, and the usual practice of manually labeling fake reviews is inefficient (D. Zhang et al., 2016).
To represent human intelligence, we consider linguistic features associated with deception and truth extracted from a large general news dataset constructed based on the consensus of human labelers. We regard these linguistic features as opinion based because they reveal the difference between deceptive and trustworthy news according to human heuristic judgment. Specifically, we collect three sets of deceptive news (fake, biased, and clickbait news) from a comprehensive list of labeled deceptive news sites (Zimdars, 2016) and combine these with trustworthy news collected from a list of reliable news sites maintained by Wikipedia. In total, we obtain more than 2.2 million deceptive news articles and more than 1.9 million trustworthy news articles to serve as source domain data for extracting opinion‐based linguistic features. In a way, labeling these 4 M+ articles corresponds to the collective wisdom of human labelers in judging whether a piece of news is fake or not from a linguistic standpoint.
To augment fake content detection with human intelligence, we propose an advanced model that combines deep learning, transfer learning, domain adaptation, and adversarial training within a single framework. Under the framework, we first apply deep learning to extract discriminating linguistic features from the source domain. We then use transfer learning with domain adaptation via adversarial training to transfer domain invariant linguistic features to the three target domains (political news, financial news, and online reviews). Lastly, we fine‐tune the domain adaptive transfer learning with labeled target domain data to allow for AI adjustment in reducing human biases and errors. We refer to this model framework as the “augmented AI” approach. For comparison, we consider three machine learning models (multi‐layer perceptron, random forest, and multinomial naïve Bayes) directly trained on target domain data for fake content detection, which we regard as the “pure AI” approach. Figure 1 gives an overview of the two approaches.
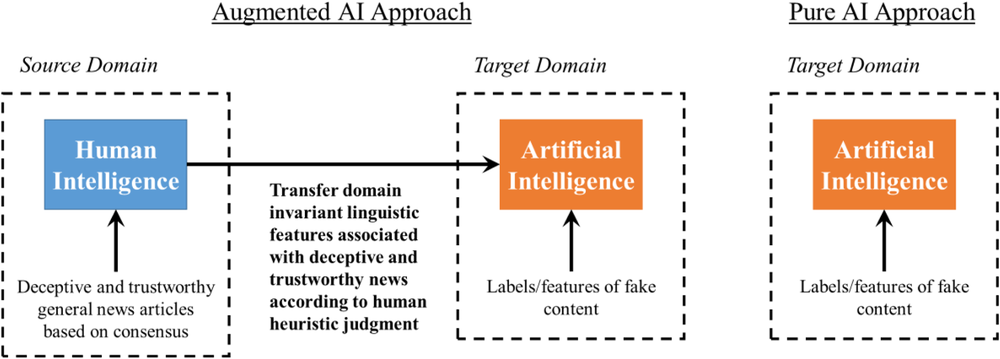
Augmented AI approach versus pure AI approach.
The domain adaptive transfer learning via adversarial training is the state‐of‐the‐art model (Chen et al., 2022; Y. Shi et al., 2022) that aims to extract discriminative and domain invariant features from one domain (source domain) and then transfer these features to another domain (target domain) to solve the same or different tasks (Pan & Yang, 2010; Zhuang et al., 2021). Transfer learning has been used in machine learning applications in technical and engineering domains where insufficient or no labeled data are available (Zhuang et al., 2021). The resulting trained models have generally performed well, requiring fewer data and less computational time than traditional models (Shin et al., 2020).
We illustrate the concept of domain adaptation in its simplest form using a sentiment classification task that comprises two review datasets: labeled reviews of smartphones and unlabeled reviews of hotels (see Figure 2). A typical machine learning model will discover several features that differentiate between positive and negative reviews of smartphones, such as “5G‐capable” and “fast,” as shown by examples 1 and 2 in Figure 2. However, these features are specific to smartphones (i.e., domain specific features) and are thus not useful to differentiate between positive and negative reviews of hotels. Conversely, features such as “best,” “expensive,” and “not worth,” as shown by examples 3 and 4, are applicable to both smartphones and hotels and can be used to differentiate between positive and negative reviews of smartphones and hotels. The goal of domain adaptation is to extract features from a source domain containing sufficient labeled examples and then transfer only discriminative and domain invariant features to a target domain. This transfer process can be achieved within a single learning design based on adversarial training that trains models in a competing way (Ganin et al., 2016). This approach requires null or only a very small percentage of labeled examples to be initially present in the target domain. Figure 2 illustrates a simple bag‐of‐words idea of domain adaptation, while more complex feature forms (e.g., latent features) are difficult to visualize but remain relevant and applicable.
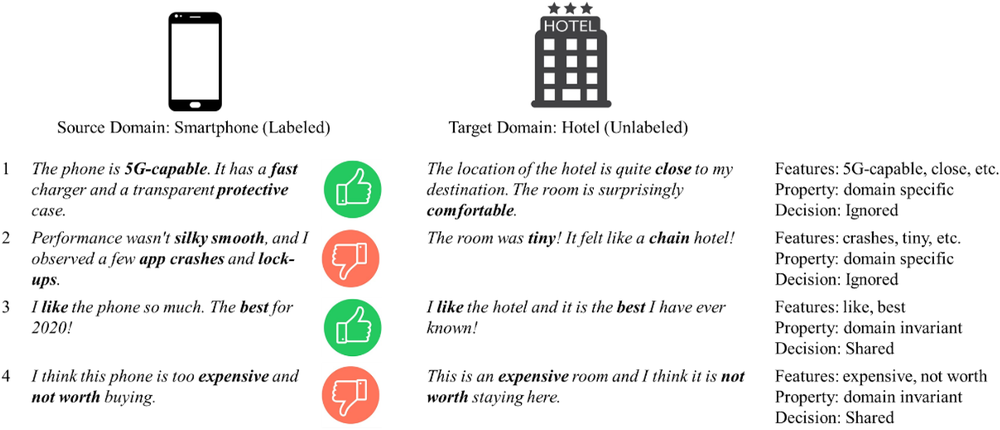
Illustration of a bag‐of‐words idea of domain adaptation.
In general, we expect the AI‐based fake content detection with augmentation to outperform the pure AI approach. Our empirical results confirm this expectation. To further explore the boundary condition of the augmented AI model, we examine how the performance of domain adaptive transfer learning varies according to the level of domain transferability. Specifically, domain adaptive transfer learning should be less effective in situations where the transferability between the source and target domains is low, as these domains will share few common features. As transferability increases, performance increases correspondingly until it reaches a point where incremental improvement starts to plateau. The reason is that when the source and target domains are highly similar, many features learned from the source domain are directly applicable to the target domain, and thus the benefit of transfer learning becomes marginal. Accordingly, we construct a simple and generalizable score to quantify domain transferability and show that the augmented AI approach's performance varies according to domain transferability.
In terms of operation support, the domain transferability score provides an implication for online platforms to allocate resources efficiently when applying machine learning for fake content detection. For instance, consider two product categories, with one containing limited labeled fake reviews as the target domain and another containing a sufficiently large amount of labeled fake reviews that can serve as the source domain. Using the transferability score as a guiding indicator, if domain transferability is above medium, the platform can consider applying domain adaptive transfer learning directly to detect fake content in the target domain without spending effort and time on manual labeling. However, if the domain transferability is very low, the platform needs to collect extra labels for training machine learning models. In this way, the transferability score guides online platforms through identifying domains that require extra resources (i.e., labels) when using machine learning to detect fake content.
This study makes several contributions to emerging research in operations management (OM) and information system (IS) interface, including AI, deep learning, social media, and digital platforms (S. Kumar et al., 2018). First, we propose an augmented AI approach that operationalizes collective human intelligence in assisting online platforms in identifying fake content as a routine practice. Our approach can also help online platforms resolve the inefficiency of labeling problem when applying machine learning models. Second, the idea of domain transferability implies a data‐driven solution to help online platforms effectively allocate resources for augmenting fake content detection in different domains or categories. Lastly, by recognizing an increasing number of research studies that employ machine learning and big data analytics in solving OM‐related problems (Choi et al., 2018; Cui et al., 2018; S. Kumar et al., 2018; Lee et al., 2018), our work contributes an early effort in applying advanced deep learning to improve online content management. To the best of our understanding, domain adaptive transfer learning via adversarial training has not been used in fake content detection for supporting platform operations (see Supporting Information Appendix A).
LITERATURE REVIEW
Fake content detection based on linguistic features and machine learning
There is a body of research in deception theory and computational linguistics demonstrating that deceptive content contains distinct linguistic features that can be used for its detection (Ho et al., 2016; Rashkin et al., 2017; Q. Wang et al., 2018; Zahedi et al., 2015). L. Zhou et al. (2004) showed that linguistic constructs are useful for detecting deception in text‐based asynchronous computer‐mediated communication. Larrimore et al. (2011) found that loan descriptions with extended narratives and concrete descriptions increased lenders’ perceptions of borrowers’ trustworthiness. Bloomfield (2012) leveraged linguistic features to identify deceptive messages relayed during quarterly earnings conference calls. Toma and D'Angelo (2015) showed that online medical advice was perceived as more trustworthy if it contained more words, especially long words, and fewer “I”‐pronouns and anxiety‐related words. Ho et al. (2016) identified that word counts and words that were associated with cognitive and affective processes were important factors for detecting deception in online communication. Rubin et al. (2016) highlighted that fake articles typically contained more humorous, ironic, and absurd words. Siering et al. (2016) studied fraudulent behavior in crowdfunding platforms and found that the content‐based and linguistic cues of suspended projects differed from those of non‐suspended projects. Rashkin et al. (2017) determined that compared with trustworthy news, fake news contained more first‐ and second‐person pronouns; more subjective, superlative, and modal adverbs; fewer assertive and “hear” category words (Tausczik & Pennebaker, 2010); and fewer hedging words. Furthermore, Yang et al. (2017) suggested that satirical political news was more emotional and unprofessional than trustworthy news and Clarke et al. (2021) reported that there were substantial differences between the linguistic features of fake news and those of legitimate financial news.
Previous studies have also attempted to use NLP and machine learning techniques to capture the linguistic features of fake content. For example, Abbasi et al. (2010) developed a design science framework based on a support vector machine to identify textual cues embedded in a web page, such as word phrases and grammar, and thus identify fake websites. Q. Wang et al. (2018) studied deception in the mobile app market and developed a machine learning model that used app descriptions and reviews to identify copycat apps. Several studies on the analysis of online reviews have demonstrated the utility of combining textual cues with machine learning models to detect fake or inauthentic reviews (N. Kumar et al., 2019; Ott et al., 2011; D. Zhang et al., 2016). Many studies in the political sphere have analyzed the language patterns associated with deception and extracted linguistic features from fake political news (Rashkin et al., 2017; Rubin et al., 2016; W. Y. Wang, 2017; Yang et al., 2017). These patterns and linguistic features have been used to develop advanced deep learning models to detect and assess the truthfulness of news (Sharma et al., 2019; X. Zhou & Zafarani, 2020). In the finance and accounting context, Clarke et al. (2021) used a psycholinguistic and word categories lexicon (Tausczik & Pennebaker, 2010) to develop machine learning models to detect deceptive financial news articles. Bloomfield (2012) used the same lexicon and logistic regression to detect deceptive conference calls.
The above studies show that combining linguistic features with machine learning for fake content detection is a burgeoning and promising field of research. However, previous studies on deceptive linguistic cues generally relied on small samples of deceptive data and on the direct application of standalone machine learning models (see Supporting Information Appendix A) that are susceptible to the inefficiency of labeling problem. To address this research gap, the current study aims to advance fake content detection in online platforms by augmenting domain invariant linguistic features representing collective human intelligence with the help of domain adaptive transfer learning via adversarial training.
Transfer learning and its application
Transfer learning has received increasing research attention in recent years and has been proven useful in various applications, such as pattern recognition and sentiment analysis (Zhuang et al., 2021). It involves using knowledge acquired in one task to solve a related task in the same or similar domains. According to a survey by Zhuang et al. (2021), there are several ways to categorize transfer learning based on different criteria. Given that our paper aims to address the labeling issue in fake content detection in online platforms, in the following, we adopt the label‐setting perspective of Pan and Yang (2010) and Zhuang et al. (2021) to categorize transfer learning into three types: inductive transfer learning, transductive transfer learning, and unsupervised transfer learning.
Inductive transfer learning is used when the source and target domains are the same (e.g., finance), and the source and target tasks are different but related (e.g., opinion mining vs. sentiment analysis). Accordingly, inductive transfer learning requires labeled data in the target domain but either labeled or unlabeled data in the source domain. For example, Zheng et al. (2020) observed that the distribution of credit card transactions changed with users’ transaction behavior over time, thus developed a boosting‐based transfer learning model to improve credit scoring. Peng (2020) proposed an inductive transfer learning model to improve public firms’ earnings forecasts within dynamic data environments. Kratzwald and Feuerriegel (2019) pioneered a transfer learning approach to transfer useful knowledge from other NLP tasks to improve the performance of question–answering systems.
Transductive transfer learning is used when the source and target tasks are the same (e.g., deception detection), while the source and target domains are different (e.g., political vs. finance). Unlike inductive transfer learning, transductive learning requires substantial labeled data in the source domain but few or no labeled data in the target domain. When a source and a target domain are very similar and highly related, a pre‐trained model based on the source domain data can be directly applied to solve the target domain task. For instance, Kraus and Feuerriegel (2017) used a deep learning model pre‐trained on Form 8‐K filings to analyze regulated ad hoc announcements for stock price prediction. In contrast, when a source and a target domain are different, domain adaptation is required to ensure that only domain invariant features are transferred to the target domain (Ganin et al., 2016). Zhu et al. (2020) illustrated that domain adaptive transfer learning improved motion sensor‐based human identification based on features extracted from rich sets of wearable motion sensor data. Our paper is connected to this type as we leverage state‐of‐the‐art transductive transfer learning (i.e., domain adaptive transfer learning via adversarial training) to resolve the labeling issue for platform operations.
Finally, unsupervised transfer learning is used when domains and tasks are different. It thus aims to solve unsupervised machine learning problems where the source and target domains contain no labeled data. For example, Shen et al. (2020) used unsupervised transfer learning in loan rejection inference analysis to estimate loan applicants’ possible repayments for better credit scoring.
A growing body of literature has demonstrated the potential of transfer learning. To realize its potential, it is imperative to understand the notion of source‐to‐target transferability and to develop techniques to quantify transferability to avoid negative transfer (Pan & Yang, 2010). Early works to quantify transferability were mainly theoretical studies (Bao et al., 2019; Ben‐David et al., 2007; Mansour et al., 2009). Later works have proposed various ways to construct an empirical measure of transferability (Achille et al., 2019; Bao et al., 2019; Nguyen et al., 2020; Tran et al., 2019; Zamir et al., 2019). However, the proposed measures were either very complex, not easy to interpret, or less generalizable due to the strong assumptions implied. Besides, these works mainly focused on computer vision and quantifying the transferability between source and target tasks (e.g., sentiment detection vs. deception detection) rather than the domains (e.g., fake general news vs. fake financial news).
This paper introduces a transferability score to quantify domain transferability using a similarity measure that is very simple to apply and calculate. This score is also informative and convenient as it falls between 0 and 1, which provides an easy and fast assessment of source–target domain transferability in transfer learning. Besides, this score is generalizable as it can be applied to any machine learning model that can generate a feature map/vector, which is very common in deep learning. Lastly, the score depends on “domain” only but not “class,” as it is generated from models that do not train on labeled target domain data. From a resource allocation perspective, online platforms can leverage our score to assess domain transferability first before starting to collect labels.
DOMAIN ADAPTIVE TRANSFER LEARNING VIA ADVERSARIAL TRAINING
In this study, we leverage collective human intelligence using domain invariant linguistic features extracted from a source domain consisting of three types of deceptive general news labeled as fake, biased, or clickbait. These news articles are classified as such by human labelers. Afterward, domain adaptive transfer learning via adversarial training is applied to transfer only relevant linguistic features to three target domains—political news, financial news, or online reviews. Our model works in a semisupervised way, with source and target domain data trained together. Specifically, we train a deep learning model to extract useful linguistic features to differentiate deceptive general news from trustworthy news (supervised learning) and then apply transfer learning within a domain adaptation framework to assess the deceptiveness of content in the three target domains (unsupervised learning). This approach assumes that the extracted linguistic features are discriminative in content and invariant across the source and target domains. Finally, we fine‐tune the pre‐trained domain adaptive transfer learning model with labeled target domain data to represent our augmented AI approach.
Theoretical background
First, we outline why and how domain adaptive transfer learning works. Prior studies have devised theoretical measures to assess how well a domain adaptive model performs in a target domain (Ben‐David et al., 2007; 2010). Formally, we consider a binary classification task in which X denotes the input space and
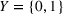
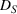
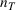
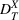
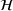
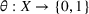
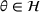
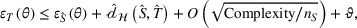
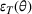
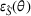
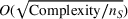
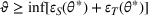
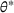
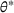
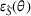
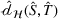
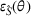
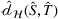
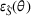
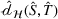
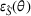
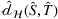
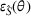
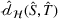
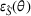
Fine‐tuning with labeled target domain data
As explained, the best model configuration for a situation where no information on the target label is available should achieve a minimum balance between the source error and domain divergence, as expressed in Equation (1). However, suppose a small number of labeled examples (e.g., verified deceptive examples) are present in the target domain. In that case, it may be possible to increase model performance by fine‐tuning the model parameters and supplementing target domain specific features for prediction (Daumé, 2007; Ganin et al., 2016). This involves replacing the original empirical source error in Equation (1) with a weighted average of the empirical source error and the empirical target error based on the small number of labeled target examples (Ben‐David et al., 2010; Daumé, 2007; Ganin et al., 2016; Mansour et al., 2009; P. Rai et al., 2010). Consequently, the theoretical target error bound defined by Equation (1) can be further reduced.
Overview of the model framework
A domain adaptive transfer learning via adversarial training framework is depicted in Figure 3. It is developed with reference to the domain adversarial training for transfer learning outlined by Ganin et al. (2016), which is the state‐of‐the‐art method in domain adaptation (Chen et al., 2022; Y. Shi et al., 2022). It consists of four modules: an embedding layer, a feature extractor, a label predictor, and a domain classifier (the adversarial part). Learning occurs as training data are channeled through these modules, from left to right. The embedding layer module transforms text content (e.g., deceptive and non‐deceptive text) into meaningful numerical representations. Various methods can be used in this module, such as traditional methods based on bag‐of‐words, term frequency‐inverse document frequency, or more advanced techniques based on word embedding. Next, the feature extractor (represented by
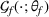
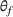
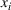
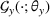
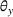
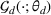
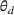
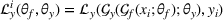
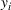
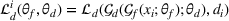
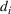
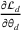
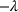
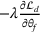
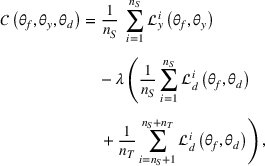
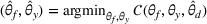
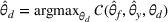
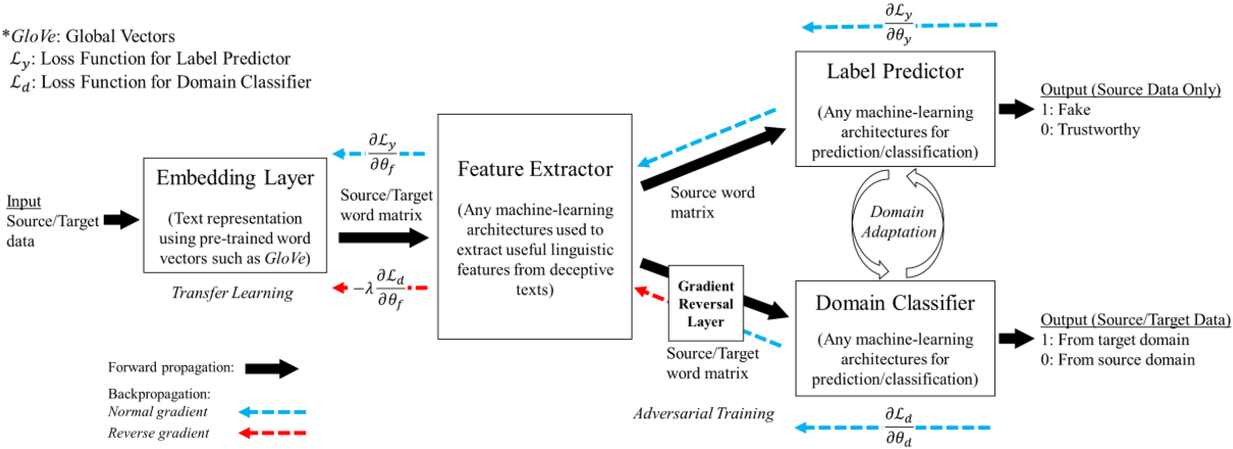
A model framework for fake content detection.
In sum, the label predictor and the domain classifier function to simultaneously train a model that is able to identify fake data (i.e., is discriminative) but unable to differentiate between source and target domains (i.e., is domain invariant), which ensures that the model only transfers invariant features. In other words, we can perceive this training approach as introducing a domain regularizer that prevents the model from distinguishing the origin of the input data, which is achieved by the inclusion of the domain classifier and the gradient reversal layer. Equation (1) shows that the divergence term
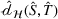
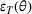
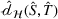
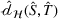
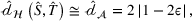
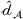
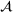
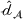
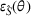
We develop a domain adaptive transfer learning model that instantiates the framework (Figure 3) and uses the model (and its variants) for analysis and validation in the remainder of this paper. More details of the model are provided in Supporting Information Appendix B.
MODEL DEVELOPMENT
This section provides more information on data collection, model construction, and model training.
Source domain data
To construct the source domain dataset, we collect labeled deceptive general news articles from a comprehensive list of deceptive websites (Zimdars, 2016), which are curated by volunteers from the OpenSources project. This list is derived from various lists from the Internet and fact‐checking sites (e.g., Wikipedia 3 and Snopes.com 4 ) and compiled using six heuristic rules, including writing style analysis, which reflects opinion‐based linguistic features of deceptive news. This list has been referenced in various university libraries (e.g., NDNU library 5 and NJS library 6 ) and research studies (Allcott et al., 2019; Grinberg et al., 2019; Guess et al., 2018). It contains 1001 news websites, each tagged with various labels (e.g., fake, biased) that indicate the types of deception. We focus on news sites with one of three identified labels (“fake,” “biased,” or “clickbait”), which results in 223 sites for news collection. Our focus on these three labels is in line with the definition of fake content stated earlier, and these labels capture the intentions to achieve various goals, such as distorting facts, misleading the audience, and attracting attention (see Table 1). We first collected content from these 223 labeled sites to create three datasets of deceptive news corresponding to fake, biased, and clickbait to provide insights into their differences in the prediction task in the three target domains. We then combine these three datasets to form a single dataset of deceptive news of the source domain to conduct further analyses. By doing so, we aim to identify as many opinion‐based linguistic features as possible in the source domain and transfer them to the target domains to identify fake content. A complete list of each type of deceptive news site is given in Supporting Information Appendix C.
Definitions and descriptive statistics for source domain data
Note: Standard deviations are shown in parentheses.
To collect trustworthy news articles, we refer to a Wikipedia list 7 of 80 reliable news sites that are frequently referred to by readers with high consensus. Table 1 summarizes the definitions and descriptive statistics for the news article data collected for the source domain. We collect news articles from these sites over a period from 2014 to 2018. In brief, the labeled general news dataset, serving as the source domain data, is constructed from lists of deceptive and trustworthy websites agreed upon by diverse human opinions. We thus extract and transfer linguistic features from these news articles to represent human opinion on truth and deception.
Target domain data
We consider three target domains for fake content detection to conduct a comprehensive analysis. The first domain is political news, and the corresponding dataset, which contains fake and authentic political news articles, is obtained from data repositories like FakeNewsNet (Shu et al., 2017; 2020). Both fake and authentic political news articles are identified by PolitiFact.com, which is a reputable source for fact‐checking political news. We collect 856 fake political news articles and 8767 authentic articles from the repositories, and these comprise our first target domain dataset. We observe that fake and authentic political news articles have similar word statistics, such as word count, average words per sentence, and function words.
The second domain is financial news, for which we obtain 383 verified fake financial articles from Clarke et al. (2021) and X. Zhang et al. (2022). The Securities and Exchange Commission (SEC) has verified that these financial news articles are biased news written for monetary compensation to promote stocks. 8 These fake financial news articles were published on various financial websites from August 1, 2011, to December 31, 2013. We also use the Factiva API to obtain legitimate financial news articles published in The Wall Street Journal, and these comprise a dataset of 68,409 news articles from the same period as above. We then construct the second target domain dataset by combining the 383 verified fake items with the 68,409 legitimate items. We observe that legitimate financial news articles contain fewer words overall and fewer words per sentence than verified fake financial news articles.
The third domain is online reviews, for which we collect fake and authentic online reviews from Yelp that have been used in other studies (Mukherjee et al., 2013; Rayana & Akoglu, 2015; D. Zhang et al., 2016). Yelp uses its own review filtering algorithm to identify fake or suspicious reviews, which are added to a filtered list that is publicly available. It has been shown that Yelp's fake review detection algorithm is sufficiently accurate and reliable, such that the reviews it identifies as fake are close to the ground truth (Mukherjee et al., 2013; D. Zhang et al., 2016). We obtain a random sample of 4268 fake reviews and 34,818 authentic reviews from the filtered list of Yelp and use these reviews to construct our third target domain dataset. We observe that authentic reviews contain more words overall and more words per sentence than fake reviews, while fake and authentic reviews contain similar numbers of complex words (words with more than six letters), function words, and punctuation marks. All three domains exhibit the labeling problem to various degrees.
As shown in previous studies in Supporting Information Appendix A, machine learning models have typically been trained on relatively small datasets in fake content detection, as few verified fake examples are available. Although some studies have used balanced datasets, these datasets did not correspond to actual population distributions. We validate our approach using highly imbalanced datasets in target domains to mimic real scenarios for which verified fake data are scarce.
Model preparation and training
Before preparing the models, we first compile four versions of source domain datasets. The first three source domain datasets are constructed by combining deceptive news articles of each type with randomly sampled trustworthy news articles of equal number. For example, we combine 894,746 fake news articles with 894,746 randomly sampled trustworthy news articles. The remaining source domain news dataset is constructed by combining deceptive news articles (i.e., 231,949 randomly sampled fake news articles + 231,949 randomly sampled biased news articles + 231,949 clickbait news articles) with an equal number of randomly sampled trustworthy news articles (i.e., 695,847 randomly sampled trustworthy news articles).
To comprehensively compare different models under the general transfer learning framework in Figure 3, we consider four specific types of transfer learning models to be described in detail below. We provide complete pseudocode for training each type of transfer learning in Supporting Information Appendix D.
Baseline: Transfer learning without domain adaptation
The first type is simple transfer learning without domain adaptation. Specifically, we train this type of model using the architecture depicted in Supporting Information Appendix B by discarding the domain‐classifier module and using only the source domain dataset. We then apply the trained models to directly score the deceptiveness of content in the three target domains. No target domain data are used for model training. To simplify the interpretation of results, we label each model as follows. We first use the following symbols to indicate which version of the source domain dataset is used for model training: “Fake_” for fake and trustworthy news dataset, “Bias_” for biased and trustworthy news dataset, “Ckbt_” for clickbait and trustworthy news dataset, and “Pool_” for pooled all deceptive and trustworthy news dataset. We then use the symbol “TLnoDA” to indicate that these models are transfer learning without domain adaptation. In sum, we end up with four models denoted by Fake_TLnoDA, Bias_TLnoDA, Ckbt_TLnoDA, and Pool_TLnoDA.
Baseline: Transfer learning with domain adaptation
The second type is transfer learning with domain adaptation. We follow the procedures described in Section 3 to train the model on source domain data and non‐fake data in the target domains. The source domain data ensure that the model has sufficient predictive power to discriminate deceptive from trustworthy news articles, while the non‐fake data in the target domains guide the training process to extract only domain invariant features. We merge the source domain dataset with 8767 authentic political news articles, 68,409 legitimate financial news articles, or 34,818 authentic online reviews that represent the three target domains. To emphasize again, no data labeled as fake in the target domains are used for model training. Similarly, we denote models in this type by changing the symbol to “TLDA,” for example, Fake_
In brief, we regard these two types of transfer learning with/without domain adaptation as baselines for comparison since they only rely on opinion‐based linguistic features without leveraging the labeling information of the target domains. These two types of models simulate the situation where the target domain's label on fake versus non‐fake is unavailable. In addition, we consider a random guess classifier (RG) that predicts the two classes with equal probability and is thus the simplest classification baseline.
Augmented AI: Transfer learning with domain adaptation and fine‐tuning on a small sample of the target domain
The third and fourth types of transfer learning models represent the augmented AI approach proposed in this study. The third type is transfer learning with domain adaptation, fine‐tuned with a few labeled data in the target domain. We use this type to illustrate that the performance of a domain adaptive model comprised of opinion‐based linguistic features can be increased by supplementation with a very small number of target fake examples. Thus, after preparing the pre‐trained domain adaptive model (the second type of model described above), we randomly sample a very small amount of labeled data in an approximate ratio of 1:10 from the target domain, resulting in random samples of 172 labeled political news articles, 80 labeled financial news articles, and 860 labeled online reviews. We consider a ratio of 1:10 as it is consistent with the 10‐fold cross‐validation applied to the pure AI models described later. These small samples of fake content are used to fine‐tune the label predictor of the pre‐trained models, with the other model parameters, held constant. Based on the second type of model, we denote models belonging to the third type by extending the symbol with “_FTsmall” to indicate that they are fine‐tuned with a small amount of labeled data in the target domain. We thus have four models named Fake_TLDA
Augmented AI: Transfer learning with domain adaptation and fine‐tuning on full sample of the target domain
The fourth type is an extension of the third type and uses all labeled target domain data. Specifically, we fine‐tune the trained domain adaptive models using all available fake content and randomly sampled non‐fake samples of equal size. This type of model is the ultimate augmented AI model to enable comparison with the direct application of traditional machine learning to the target domain dataset. We denote models based on this type by Fake_TLDA_FT
For each transfer learning model and each training epoch, we randomly split the source domain news into two sets of 75% and 25% each. The 75% set is used for training, and the 25% set is used to test the performance of the model and to calculate the empirical source error. We combine the training set generated from the source domain news articles with an equal number of random target domain data items to form the final training set for the domain adaptive models. Except for models that incorporate fine‐tuning, only non‐fake target domain data are used. We run each model for at least 50 epochs to ensure that appropriate model convergence is achieved. In all cases, we use Python with the PyTorch and TorchText libraries and run the model on a server using Intel Xeon E5 CPUs and four Nvidia Tesla P100 GPU cards.
Pure AI and evaluation metrics
As detailed in Supporting Information Appendix F, we consider two direct machine learning approaches (pure AI) for comparison. The first approach is a machine learning model trained directly on the full target dataset using all the available labeled data. This approach corresponds to the best performance a direct machine learning model can achieve when it uses all the available information. The second approach is a machine learning model trained using a small subset (10%) of verified fake content in the target dataset. Thus, we envision a situation in which the first approach corresponds to the actual population distribution of fake content in the target domain, which is unknown in practice, whereas the second approach corresponds to the sample distribution of the target domain, which represents only a small subset of observable and verified fake content that is scarce and hard to obtain in practice. To minimize algorithmic bias, three popular machine learning techniques (a multi‐layer perceptron classifier, a random forest classifier, and a multinomial naïve Bayes model) are implemented, and their average performance is used as the performance measure of each approach.
All the models (augmented AI models, pure AI models, and the baselines) are compared in terms of four metrics: balanced accuracy, precision, recall, and F1 score, with a focus on balanced accuracy. We also conduct paired t‐tests to assess whether there are statistically significant differences between model performances (Abbasi et al., 2015). More details on the construction of pure AI models and the evaluation metrics are provided in Supporting Information Appendix F.
MODEL VALIDATION
Based on the model setup described before, we compare the prediction performance of the augmented AI approach, represented by the domain adaptive transfer learning with fine‐tunning, and the pure AI approach in three target domains (political news, financial news, and online reviews) that contain highly unbalanced examples with different levels of domain transferability.
Domain adaptation performance
We first assess the effectiveness of domain adaptation, as reported in Table 2. For reference, we also train models using the same target domain as the source domain so that there will be no divergence between domains. The value of the empirical source error 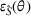
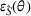
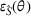
Domain adaptation performance
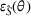
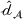
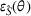
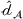
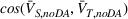
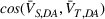
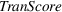
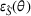
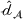
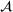
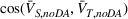
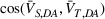
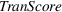
We train models using the same target domain as the source domain for reference to examine the ideal best performance of domain adaptation when there is no divergence between domains.
Next, we examine the proxy
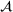
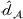
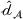
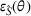
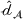
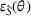
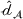
For the political news domain, the average value of 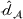
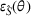
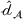
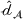
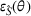
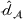
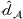
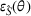
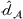
Domain transferability
Although a small sum of 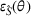
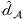
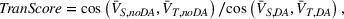
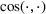
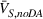
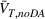
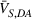
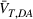
The transferability scores of all three domains are shown in Table 2. We also provide a visual analysis of domain transferability in Supporting Information Appendix G for robustness check. First, from the table, we observe that the cosine similarity between source and target domain centroids are all very near to 1 after domain adaptation, suggesting that domain adaptive models are successful in adapting the feature space of source and target domains. Next, we observe that the average transferability score is 0.89 for the political news domain, which indicates that the source and political news domains are similar and contain many shareable features. The average transferability score for the financial news domain is 0.86, which is just slightly lower than that of the political domain. Finally, the average transferability score for the online review domain is 0.74 that is the lowest among the three target domains. Based on this gradation of the transferability scores, we denote the domain transferability in the order of political news, financial news, and online reviews, respectively.
Relative performance based on three target domains
We now assess the overall performance of augmenting fake content detection by domain invariant linguistic features in three target domains. It is expected that (1) all learning models (both augmented AI and pure AI models) will outperform the random guess model, (2) the domain adaptive transfer learning model will outperform the non‐domain adaptive transfer learning model, and (3) the domain adaptive transfer learning model fine‐tuned with a set of fake content (augmented AI models) will outperform the direct machine learning models that use the same set of fake content (pure AI models). The relative performance of the four transfer learning models depends on how well common opinion‐based linguistic features are transferred from the source domain to the target domain. Thus, we hypothesize that the relative performance of the different models for a particular target domain will follow an order as depicted in Table 3. To test our hypothesis, we consider the version of the source domain dataset that combines all types of opinion‐based deceptive news. Therefore, when we compare the relative performance of various models, we mainly focus on these seven models: two augmented AI models (Pool_TLDA_FTsmall and Pool_TLDA_FTfull), two pure AI models, and three baselines (Pool_TLnoDA, Pool_TLDA, and RG).
Summary of three different learning perspectives
Notes: Domain transferability: political news ∼ financial news > online reviews.
Abbreviation: AI, artificial intelligence.
Results for fake political news
We first examine the results of the political news validation (a high transferability domain), which are summarized in Table 4. We confirm that the non‐domain adaptive transfer learning model (Pool_TLnoDA) is the worst‐performing transfer learning model, with low precision and only approximately 50% balanced accuracy. Nevertheless, it still outperforms a random guess classifier.
Validation results for fake political news
Notes: The results are based on 9623 political news articles, 856 of which are fake political news.
Abbreviation: RG, random guess.
Average value is reported with the standard deviation shown in parentheses.
Fine‐tuning is based on 856 fake news articles and 856 randomly sampled real political news articles.
Fine‐tuning is based on a random sample of 86 fake news articles and 86 real political news articles.
p‐values significant at α = 0.05.
As expected, the domain adaptive transfer learning model (Pool_TLDA) performs better than the non‐domain adaptive model (Pool_TLnoDA), as the former achieves a higher value of balanced accuracy and has better precision and high recall. In addition, the domain adaptive model (Pool_TLDA) that does not include examples of fake news articles in the target domain performs similarly to the direct learning models trained on a small sample.
We then consider the transfer learning model with domain adaptation that is fine‐tuned using a small subset of the available fake political news articles (Pool_TLDA_FTsmall) and find that Pool_TLDA_FTsmall has approximately 2.93% better balanced accuracy than the corresponding transfer learning model with domain adaptation that is not fine‐tuned (Pool_TLDA). Furthermore, the direct learning models trained on a small sample have an average balanced accuracy and F1 score of 52.49% and 15.40%, respectively, and achieve low precision and moderate recall. Interestingly, we observe that the performance of the domain adaptive model (Pool_TLDA_FTsmall), which is fine‐tuned with a small subset of fake content, is significantly better than the direct learning on a small sample and approaches the direct learning models that use all fake content in its target domain.
Finally, we consider the case in which all labeled target domain data are used to fine‐tune the domain adaptive model. We observe that the resulting model (Pool_TLDA_FTfull) significantly outperforms the pure AI models, which provides further evidence of the effectiveness of augmented AI models. The results of the first target domain confirm our expectations regarding the relative performance of these transfer learning models (Table 3).
Results for fake financial news
Table 5 summarizes the results from our analysis of financial news articles (a domain with transferability slightly lower than the political news domain). Similar to the analysis of the political news domain, we observe that the non‐domain adaptive transfer learning model (Pool_TLnoDA) significantly outperforms a random guess classifier (by >6.41%) in identifying fake financial news articles with respect to balanced accuracy. The Pool_TLDA model has significantly better performance than the Pool_TLnoDA model, as shown by its balanced accuracy and F1 scores.
Validation results for fake financial news
Notes: The results are based on 68,792 financial news articles, 383 of which are fake financial news articles.
Abbreviation: RG, random guess.
Average value is reported with the standard deviation shown in parentheses.
Fine‐tuning is based on 383 fake financial news articles and 383 randomly sampled legitimate financial news articles.
Fine‐tuning is based on a random sample of 40 fake news articles and 40 legitimate financial news articles.
p‐Values significant at α = 0.05.
In addition, the domain adaptive model (Pool_TLDA) outperforms the direct learning models trained on a small sample in terms of balanced accuracy, without any fake financial news articles present in its target domain. Similarly, we find that fine‐tuning substantially improves its performance, as the Pool_TLDA_FTsmall model has approximately 17.94% higher balanced accuracy than the Pool_TLDA model and a higher F1 score. The fine‐tuned domain adaptive model (Pool_TLDA_FTsmall) achieves better results than the Pool_TLDA model by more accurately identifying fake financial news articles. Furthermore, we observe that the Pool_TLDA_FTsmall model substantially outperforms the direct learning models trained on a small sample (by approximately 41.40% on average) and has a balanced accuracy close to the direct learning models using all available fake financial news articles.
The performance of the domain adaptive model fine‐tuned using all labeled data (Pool_TLDA_FTfull) is slightly lower than the performance of direct learning models based on full datasets. This may be attributable to a small set of labeled target domain data (comprising a random sample of 40 fake financial news articles) being sufficient for the domain adaptive model such that supplementation with additional labeled target domain data is of no additional benefit. The results obtained from the financial news domain are largely consistent with those obtained from the political news domain, further confirming the relative performance order depicted in Table 3.
Results for fake online reviews
The fake online reviews dataset represents a relatively lower transferability scenario. The corresponding results are detailed in Table 6. We observe that the non‐adaptive transfer learning (Pool_TLnoDA) achieves reasonable performance in this context, compared with that of a random guess classifier, as the Pool_TLnoDA model affords a balanced accuracy of 51.47% and an F1 score of 20.11%. The Pool_TLDA model performs similarly to the Pool_TLnoDA model. Again, we find that fine‐tuning improves transfer learning performance. The domain adaptive model (Pool_TLDA_FTsmall), which is fine‐tuned with a small sample of the target dataset, significantly outperforms the direct learning models that are trained on the same small sample of fake reviews, as the former achieve similar accuracy to the latter but a higher recall. However, a comparison of the performance of the domain adaptive model fine‐tuned with the full target dataset (Pool_TLDA_FTfull) against the direct machine learning models based on full samples shows that the latter performs better. As expected, the effectiveness of transfer learning declines as transferability decreases; this is also an indication of negative transfer (Pan & Yang, 2010), as applying transfer learning reduces the predictive accuracy of models, such that transfer learning models perform worse than models (multi‐layer perceptron and random forest) trained directly on the full data sample. Figure 4 summarizes the main comparisons shown in Tables 4–6.
Validation results for fake online reviews
Notes: The results are based on 39,086 online reviews, 4,268 of which are fake online reviews.
Abbreviation: RG, random guess.
Average value is reported with the standard deviation shown in parentheses.
Fine‐tuning is based on 4268 fake and 4268 randomly sampled authentic online reviews.
Fine‐tuning is based on a random sample of 430 fake online reviews and 430 authentic online reviews.
p‐Values significant at α = 0.05.
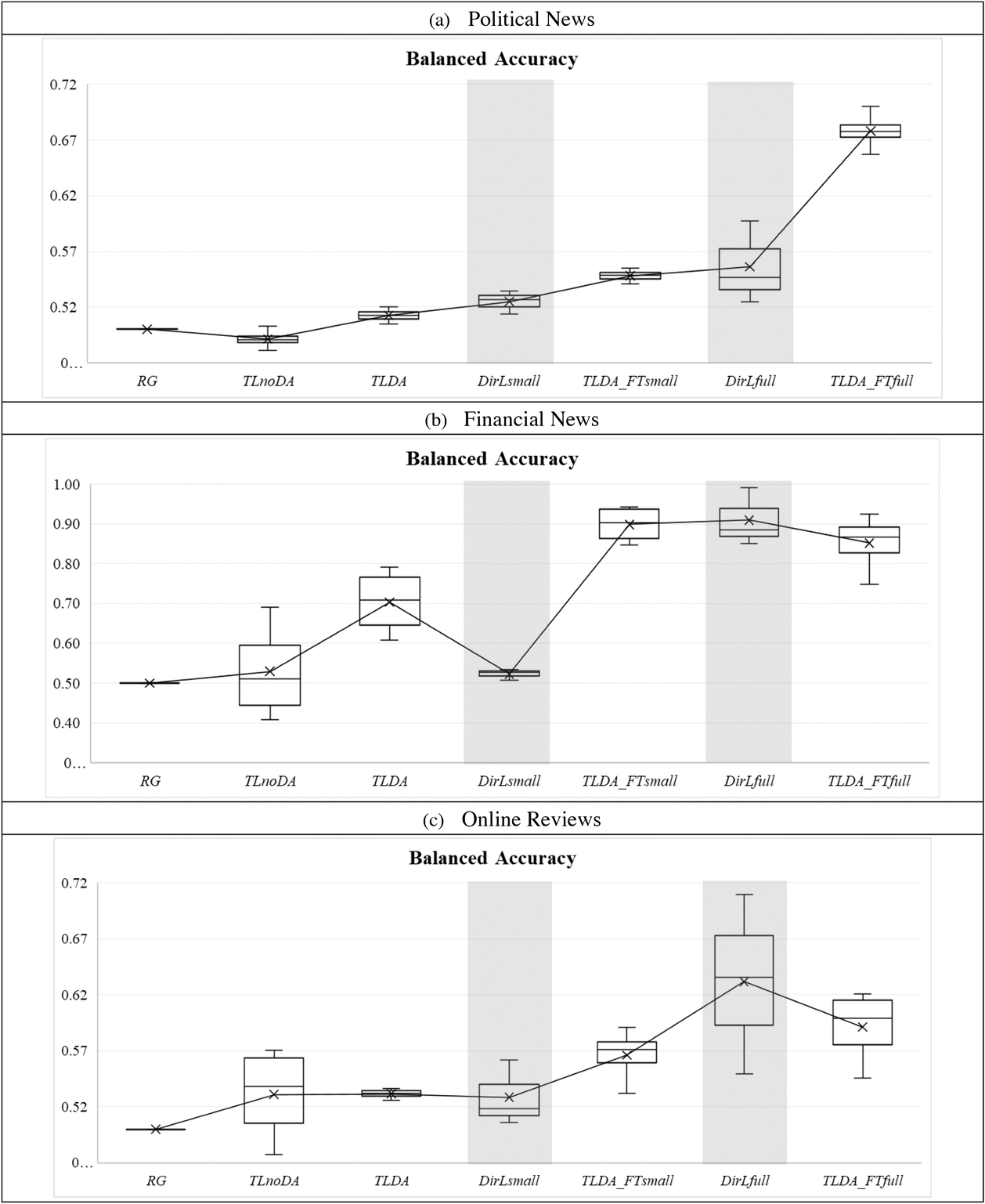
Summary of validation results. (a) Political news. (b) Financial news. (c) Online reviews. RG: random guess; TLnoDA: transfer learning without domain adaptation; TLDA: transfer learning with domain adaptation; DirLsmall: direct learning trained on a small sample; TLDA_FTsmall: transfer learning with domain adaptation and fine‐tuning on a small sample; DirLfull: direct learning trained on the full sample; TLDA_FTfull: transfer learning with domain adaptation and fine‐tuning on the full sample. The shaded areas represent the two pure AI approaches
To conclude, the validation results largely match our general expectations regarding the relative performance of the various transfer learning models, as depicted in Table 3. A comparison of the pure AI approach using traditional machine learning models shows that the augmented AI approach based on domain adaptive transfer learning effectively alleviates the problem of insufficient labeled data for fake content detection, provided that there is an appropriate level of transferability between domains, as indicated by the transferability score.
DISCUSSION AND CONCLUSION
Online platforms are experimenting with fact‐checking and content screening interventions as a regular operation to moderate the adverse effects of deceptive and incensing content (Moravec et al., 2019; Papanastasiou, 2020). However, platforms have limited capacity for manual fact‐checking, as it is labor‐ and time‐intensive (Sharma et al., 2019). To effectively curb the spread of fake content, intelligent screening systems must be developed that can maximize the accuracy of assessing deceptive content, as failure to do so may lead to devastating consequences that undermine the value of online content (Cui et al., 2018; S. Kumar et al., 2018). Failing to stop fake content from spreading on online platforms will reinforce filter bubbles and generate extreme emotions and highly polarized opinions (Allcott & Gentzkow, 2017; Ng et al., 2021; Vosoughi et al., 2018), or being exploited by threat actors to manipulate the business environment (Lee et al., 2018). However, legitimate content could be wrongly labeled with the presence of false alarms. This may create an impression of censorship and exaggerated filtering, potentially leading to backlash from the user community (Freeze et al., 2020).
This study adopts an augmented AI with a human intelligence perspective and proposes the domain adaptive transfer learning via an adversarial training framework to address the inefficiency in labeling as well as maximize fake content detection performance. We find that transfer learning with domain adaptation and fine‐tuning can effectively extract and transfer opinion‐based linguistic features to augment AI‐based fake content detection, as domain adaptation ensures only relevant features are transferred and fine‐tuning reduces human biases and errors in features learned from crowd‐based opinions. We also derive a measure to operationalize the notion of domain transferability. We show that domain adaptive transfer learning offers the most value when the level of transferability is high. In our validation analyses, both augmented AI and pure AI models are tested against the general expectations depicted in Table 3; these expectations are largely confirmed, as shown in Figure 4.
Theoretical implications
Our study contributes to research on applying machine learning to detect fake content in online platforms and, to some extent, the literature on human–AI interaction (A. Rai et al., 2019; Yau et al., 2021). The literature has discussed a wide range of scenarios of how we can keep humans and AI in a loop to achieve maximum performance (Fügener et al., 2021; Ge et al., 2021; Lou & Wu, 2021; Raisch & Krakowski, 2021). Our research empirically compares augmented and pure AI approaches using an important and highly relevant context of fake content detection. Our findings largely confirm that fake content detection based on machine learning models can achieve better performance when augmenting domain invariant linguistic features extracted from deceptive and trustworthy news identified based on consensus. We thus contribute a unique use case of having collective human intelligence (opinion‐based linguistic features) to supplement the AI model (fake content detection) when there is limited and even no labeled data for training the AI model. This implication is important to online platforms in applying machine learning to operationalize fake content detection on a regular basis.
Second, we explain the efficacy of transfer learning with respect to the transferability between a source domain and a target domain. To this end, a transferability score is developed to quantify the transferability between domains. A low transferability (close to 0) means that few features are shared by the source and target domains, and thus the utility of domain adaptive transfer learning is highly limited. Similarly, a very high transferability (nearly 1) means that the utility of domain adaptive transfer learning is also limited. In this situation, a transfer learning model developed with examples from the source domain already incorporates many shared features of the source and target domains and can thus be applied directly to the target domain. For example, if the comparison depicted in Figure 2 is between smartphones and digital notepads (instead of hotels), which are similar in many ways, models developed using smartphone examples could be applied directly to digital notepads. Thus, the performance gain delivered by domain adaptation would be limited. This finding addresses a research gap regarding the condition that underscores transfer learning performance.
Third, in a more general sense, features extracted from domain adaptation training can be regarded as universal features, as they hold across different domains and contexts (Hao, 2019). These features are particularly useful for increasing the generalizability of machine learning algorithms, as the trained models can be deployed in multiple applications. The invariant property of these features also facilitates a certain amount of model interpretation, as it avoids spurious features that undermine the performance of machine learning models and thus enables better evaluation of the behavior of AI systems (Meske et al., 2022). As an illustration, we outline an approach to interpret and visualize domain invariant linguistic features and present it in Supporting Information Appendix H. Invariant features can be identified by performing domain adaptation via adversarial training using multi‐context data, which can be collected at different times, from different locations, or on different subjects. In this regard, important universal information is retained, and spurious correlations are filtered out, leading to more robust and trustworthy machine learning models.
Practical implications
A direct practical implication of the result of this study is to illustrate a cost‐effective way to implement an AI‐based fake content detection model for online platforms such as social media and review websites. On the one hand, domain experts’ judgments are required to determine whether domain specific content is fake or not, which is costly to collect for building an AI model. On the other hand, platform users’ feedbacks on the content (e.g., like, downvote, flag as inappropriate) are relatively easier to collect. Still, the quality cannot be guaranteed and may result in a poor and biased AI model when these data are used directly for model training. To address the dilemma, platforms could adopt the augmented AI model to leverage inputs from the crowd (in this study, opinion‐based linguistic features) to supplement the costly domain specific task. In our empirical analysis, results suggest that when the transferability score is not low, the model performance of a pure AI model based on direct learning with full sample of the target domain is actually close to that of an augmented AI model based on transfer learning with domain adaptation and fine‐tuning using a small fraction of the target sample. Given that this augmented AI approach only uses 10% data of the target domain, platforms can save up to 90% cost on expert judgment while maintaining a similar model performance when this approach is adopted.
The findings of this study also have practical implications beyond the detection of fake content on online platforms. Our study sheds light on big data research focused on extracting information signals from unstructured text data coming from different sources (Choi et al., 2018; Einav & Levin, 2014; Z. M. Shi et al., 2020). Big data analytics is at the core of OM since many OM‐related problems need to deal with data of high volume, high variety, and high velocity (Choi et al., 2018; Jha et al., 2020). Our proposed domain adaptive transfer learning via adversarial training approach can thus advance big data analytic techniques in OM when addressing uncertainty with learning (e.g., limited or missing label problem). Our model also provides insights into emerging topics like fintech at the interface between OM and IS (S. Kumar et al., 2018). For instance, financial technology applications increasingly rely on NLP to deliver novel financial services to customers (Jagtiani & John, 2018; Jagtiani & Lemieux, 2019). Thomson Reuters News Analytics aggregates various news sentiment analysis techniques to support trading and investment decisions, whereas Sentifi delivers actionable insights by analyzing large‐scale financial news data from 13 million media outlets. In these contexts, domain adaptive transfer learning facilitates efficient and scalable inferencing of the information content of news. For example, analyzing the market reaction to domain invariant linguistic features is a novel way to utilize transfer learning, illustrating the potential utility of domain adaptive transfer learning in deciphering financial news for market signaling applications.
Limitations and future research
While the current study opens a new avenue for online fake content and business analytics research, it also has several limitations that warrant future research. First, in situations whereby human judgments must be used to determine the veracity of information, our model can be used as an initial screening mechanism to aid fact‐checkers. Content with very high/low scores (as determined by the domain adaptive transfer learning model) could be labeled automatically, while content with scores in the intermediate range could be forwarded to checkers for final judgment. The resulting human decisions could then serve as training samples for regular updating of the model. Second, the ability to deceive continuously improves, as deceivers constantly learn from authentic and legitimate content (Moravec et al., 2019; D. Zhang et al., 2016). Therefore, the source domain data used to extract human opinion‐based features must be updated regularly. Third, our domain adaptive transfer learning model is likely sensitive to the domain itself as moving content categorized from one domain to another will affect the domain transferability and the amount of domain specific features. While our work leverages datasets from various sources and assumes that text contents are categorized according to the predefined domains (general news, political news, financial news, and online review), a promising direction for future research is to define a domain for a piece of content using machine learning and NLP techniques, such as clustering analysis and topic modeling. We can thus examine the relationship between transfer learning and domain sensitivity. Lastly, this paper considers a purely data‐driven approach to identifying domain specific and domain invariant features. In this regard, we consider the linguistic features to be latent and unobservable and do not make any presumption about the forms of features (e.g., lexical, syntactic, semantic, thematic). Future research can directly investigate what kind of linguistic features are regarded as domain invariant in different domains for advancing theoretical understanding. We illustrate this idea in Supporting Information Appendix H to stimulate future studies that seek to build on our work.
Footnotes
ACKNOWLEDGMENTS
The authors are grateful to the department editor, the senior editor, and two anonymous reviewers for their insightful and constructive comments that greatly improve the content and the exposition of the paper. The authors also thank Dr. Hailiang Chen from the University of Hong Kong for sharing the fake financial news dataset. This project was supported by the Theme‐based Research Grant on Fintech (T31‐608/18N) of the Research Grant Council of Hong Kong.
1
2
3
4
5
6
7
8
A copy of the complete list of fake financial news items is available at ![]() ).
).
9
Cosine similarity between vectors is defined as
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.