
Abstract
Visual simultaneous localization and mapping (SLAM) is well-known to be one of the research areas in robotics. There are many challenges in traditional point feature-based approaches, such as insufficient point features, motion jitter, and low localization accuracy in low-texture scenes, which reduce the performance of the algorithms. In this article, we propose an RGB-D SLAM system to handle these situations, which is named Point-Line Fusion (PLF)-SLAM. We utilize both points and line segments throughout the process of our work. Specifically, we present a new line segment extraction method to solve the overlap or branch problem of the line segments, and then a more rigorous screening mechanism is proposed in the line matching section. Instead of minimizing the reprojection error of points, we introduce the reprojection error based on points and lines to get a more accurate tracking pose. In addition, we come up with a solution to handle the jitter frame, which greatly improves tracking success rate and availability of the system. We thoroughly evaluate our system on the Technische Universität München (TUM) RGB-D benchmark and compare it with ORB-SLAM2, presumably the current state-of-the-art solution. The experiments show that our system has better accuracy and robustness compared to the ORB-SLAM2.
Introduction
Simultaneous localization and mapping (SLAM) is an extensively researched topic in robotics 1 and has been widely applied in service robot, autonomous driving, Unmanned Aerial Vehicle (UAV), virtual reality, and other fields. 2 –4 The SLAM system mainly contains laser-based and vision-based methods according to its sensor type. In recent years, the theoretic research of laser-based SLAM has achieved extraordinary results in localization, 5 mapping, autonomous navigation, and independent exploration. 6 Meanwhile, visual information has the advantage of much quantity information, low cost, and intuitive effects, visual simultaneous localization and mapping (vSLAM) has gradually become the hot research field. 7
Visual odometry is the process of determining the position and orientation of a robot by analyzing the associated camera images. It has been used in a wide variety of robotic applications. According to its different principles, there are mainly feature-based method and direct method, such as the line segment detector (LSD)-SLAM proposed by Engel et al., 8 which is able to build large-scale semi-dense maps, using direct methods instead of bundle adjustment over features. It achieves the reconstruction of semi-dense scene on standard Central Processing Unit (CPU)s, without Graphic Processing Unit (GPU) acceleration, and guarantees the final stability and real-time, but it still needs to rely on the feature point method for loop detection. Since the direct method is extremely sensitive to illumination and it is difficult to satisfy the strong assumption that the gradation is invariant, the research of feature-based SLAM has become popular currently. In recent years, optimization-based 9,10 approaches have emerged endlessly due to its superior accuracy per computational unit as compared with filtering-based approaches. The first real-time application was the visual odometry work of Mouragnon et al., 11 followed by the ground-breaking SLAM work of Klein and Murray 12 known as parallel tracking and mapping.
Many algorithms can be performed with only a monocular camera. However, depth information cannot be directly observed, which results in a lack of the scale. In addition, multi-view or filtering techniques are required to produce an initial map, and the pure rotation problem cannot be effectively solved. In recent years, various low-priced depth cameras have been launched, such as Microsoft’s Kinect, 13 Intel’s RealSense, 14 and Asus’s Xtion, which make up for the defects caused by monocular SLAM. 15
It is remarkable that the point-based SLAM systems often fail to work properly and even lead to failure in low-texture or motion-jitter scenes in which it is difficult to find enough keypoint features. However, in addition to point shapes, there are planar elements that are rich in linear shapes and object-based 16 shapes, especially the former, even in low-texture scenes such as white walls and corridor edges.
In this work, we propose a point-line fusion method to deal with weak-matching objects in Red Green Blue - Depth (RGB-D) SLAM, where line features are joined in the feature extraction part. To solve the overlap and branch problem existing in the LSD 17 algorithm, we design an adaptive line extraction method which enhances the reliability of the line features. The camera pose is optimized by minimizing the point-line reprojection error. In addition, we set up an optimization mechanism for the motion-jitter sequences, which can effectively improve tracking success rate and improve the tracking accuracy indirectly. Compared with point-based SLAM, the accuracy and robustness of PLF-SLAM are greatly improved.
The rest of this article is organized as follows. The second section discusses the related work, the third section gives the details of our proposal, the fourth section details the experimental results, and the fifth section presents the conclusions and the future work.
Related work
The KinectFusion algorithm proposed by Newcombe et al. 18 merges the depth information measured by the sensor and uses the iterative closest point 19 (ICP) to calculate the camera pose. Due to its lack of loop detection, it is often applied to small workplaces. Endres et al. 20 propose using the ICP algorithm to compute frame-to-frame motion, and using the optimization-based method in the back end. Kerl et al. 21 propose a dense vSLAM method that minimizes both photometric and depth error of all pixels, which can make better use of the information available in the image compared to feature-based methods. The ElasticFusion algorithm proposed by Whelan et al. 22 is a dense 3-D reconstruction based on depth cameras which combines with relocation and is suitable for room-sized scene. Raul et al. propose Oriented FAST and Rotated BRIEF (ORB)-SLAM2 23 on the basis of their previous work, 24 and the whole system is built around the ORB features, 25 including the visual odometry and the visual vocabulary of loop closing. Although features such as Scale Invariant Feature Transform (SIFT) 26 and Speeded Up Robust Features (SURF) 27 are better in quality than ORB, their time consumption is difficult to meet the real-time requirements of vSLAM, and GPU acceleration is required. Compared with Harris, 28 ORB has good rotation invariance and can use the pyramid to achieve scale invariance. The system also adds the mechanism of loop closing, which can effectively prevent the error accumulated in the loop.
Gomez-Ojeda et al. 29 propose a vSLAM method based on a stereo camera that combines points and line segments to work in a wider range of scenes, especially in scenes where point features are scarce or not evenly distributed. Pumarola et al. 30 propose a visual SLAM based on a monocular camera, which improves the robustness of the system by processing points and lines simultaneously. In addition, it can complete the initialization of the map by processing the lines in three consecutive frames.
The LSD algorithm proposed by Rafael Grompone et al. can obtain detection results with sub-pixel precision in linear time, which can be applied to any digital image without debugging parameters. Its transform extraction speed is far faster than Hough speed, and it has strong robustness. Compared with the Mean-Standard Deviation Line Descriptor (MSLD) 31 descriptor, the line band descriptor (LBD) algorithm proposed by Zhang et al. 32 is fast and robust, which adds weight coefficients.
PLF-based vSLAM
Our work is based on ORB-SLAM2, and the algorithm consists of three threads that run in parallel: tracking, local mapping, and loop closing. In the tracking thread, point feature and line feature are used to estimate and optimize camera pose by reasonable weight, respectively. Figure 1 shows the flow chart of the tracking thread.

Flow chart of the tracking thread.
Adaptive line segment extraction
The time needed for feature extraction occupies a large part in the whole algorithm. Efficient feature extraction method is the premise to ensure the real-time performance of the SLAM system. LSD 17 is a linear-time LSD, which is much faster than the Hough transform 33 method and requires no parameter tuning. However, compared to extracting ORB features, it takes two to three times longer to extract line features by the LSD method, which will greatly affect the real-time performance of the algorithm. And some of the extracted lines are redundant and useless, resulting in lower reliability. We propose a new line extraction method based on LSD and define a line segment response value function as follows
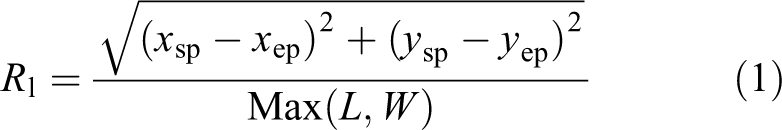
where
By setting the adaptive threshold, the line segment with response value less than

(a to c) LSD detection sample. LSD: line segment detector.
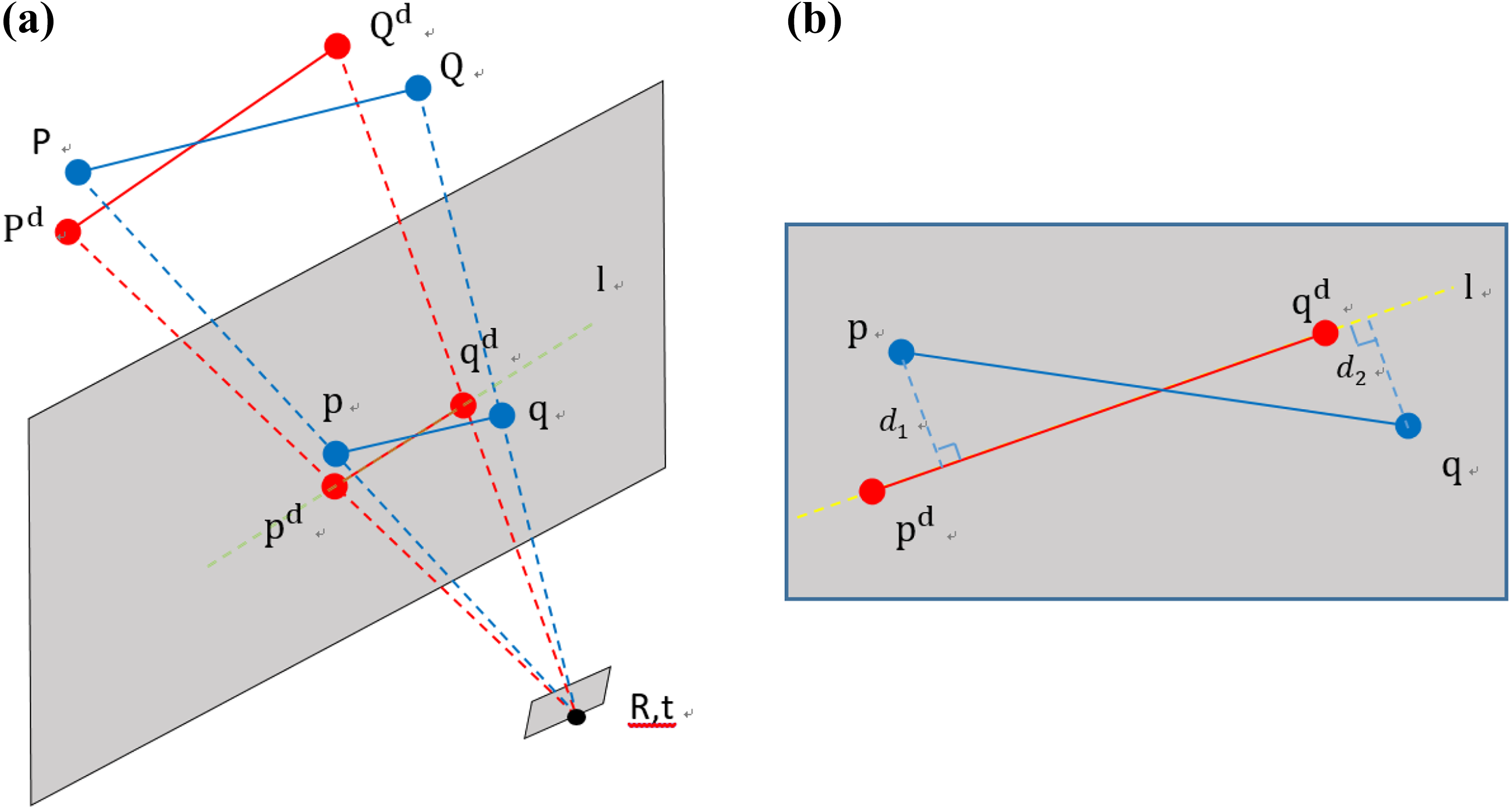
Among them, Figure 2(a) is the original sample, Figure 2(b) is the line segment extracted by the original algorithm, and Figure 2(c) is the enlarged result of Figure 2(b). The line segment on the floor is mistakenly considered to be the overlap of two or more line segments, and this error occurs in most of the frames, which will affect the reliability of the matching. Therefore, we propose an improved method for this flaw and merge the overlapped line segments through appropriate conditions. First, the above situation is abstracted into a geometric problem, as shown in Figure 3.

(a and b) Geometry of overlapping lines.
In Figure 3, d 1 is the distance from the midpoint on line l 1 to line l 2, we define the conditions for merging the line segments as follows

The included angle of the two line segments should be smaller than

where x and y are the abscissa and ordinate of the end point of the line segment, respectively. For case (b), the shortest distance from end point b to c is less than the experience threshold
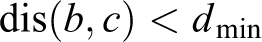
As described above, if the extracted line segments satisfy the above conditions, line segment merging is performed. We propose the least squares method for merging line segments and generate a 2-D point set according to the given line segments.
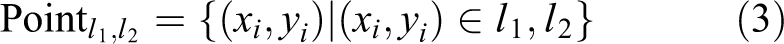
Suppose that the approximate line function of the merged line

Let the fitting formula be

Then the sum of squared deviations is as follows

Calculating partial derivatives for a and b, respectively, we obtain the simultaneous equations

Finally, the above formula is solved to obtain the linear function of the merged line segment.
Line matching method
Line features can be matched by comparing the similarity of LBD descriptors. The common feature matching methods contain the brute force match (BFM) algorithm and fast library for approximate nearest neighbors (FLANN) algorithm. FLANN can easily lead to matching failure when tracking in low-texture scenes, thus we use BFM in our work.
Compared with the point feature, the BFM algorithm has a higher error rate when matching line features. The main reasons are as follows: The matched lines have low similarity, and some of them are wrongly matched. Since the line features of the edge part of the image are often only partially matched in the image, it is difficult to use for the subsequent pose estimation later. In low-texture scenes, the extracted line features are not reliable enough.
Therefore, we filter the line features extracted by the BFM algorithm and reject the inaccurate matches. All matching pairs are needed to be filtered by the following conditions (Figure 4):

The motion of line segments in two adjacent images.
Considering that the edge line features are often partially missing, we present a method to remove the edge feature line matching pairs is proposed. The narrow area around the image is divided into edge areas, when the end point of the matched line falls into the area, the line feature is classified as edge feature and discarded.
In addition, the line feature mentioned above compares the similarity by comparing the Hamming distance between LBD descriptors, and we obtain the minimum descriptor distance by BFM. On this basis, when the minimum descriptor distance exceeds a certain range, the matched line will be discarded.
Point-line reprojection error
The optimization of camera pose first needs to find an error model of the points and lines. The variable of the error model is the camera pose and spatial coordinate of the features. The camera pose is calculated by minimizing the point-line reprojection error. In our work, the distance between the two end points of the spatial line projection and the detected line segments in the image is used as the reprojection error.
As shown in Figure 5, let

(a and b) Line reprojection error model.
After obtaining the normalized line coefficients, we define the point-line error

where

Since there is accumulated errors in camera pose obtained in visual odometry, and the noise cannot be eliminated, the projection of 3-D points and lines on the image is necessarily different from the points and lines detected on the image, so we define the following error formula
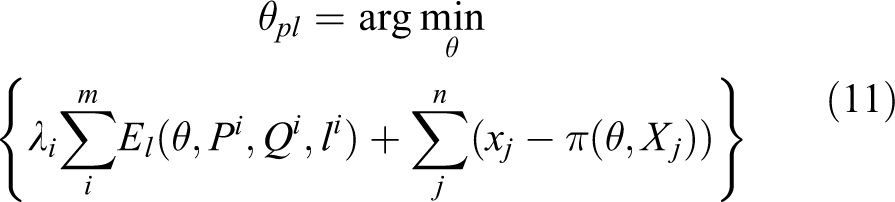
where i is the ith line feature, j is the jth point feature, and
Point-line Optimization Algorithm of PLF-SLAM

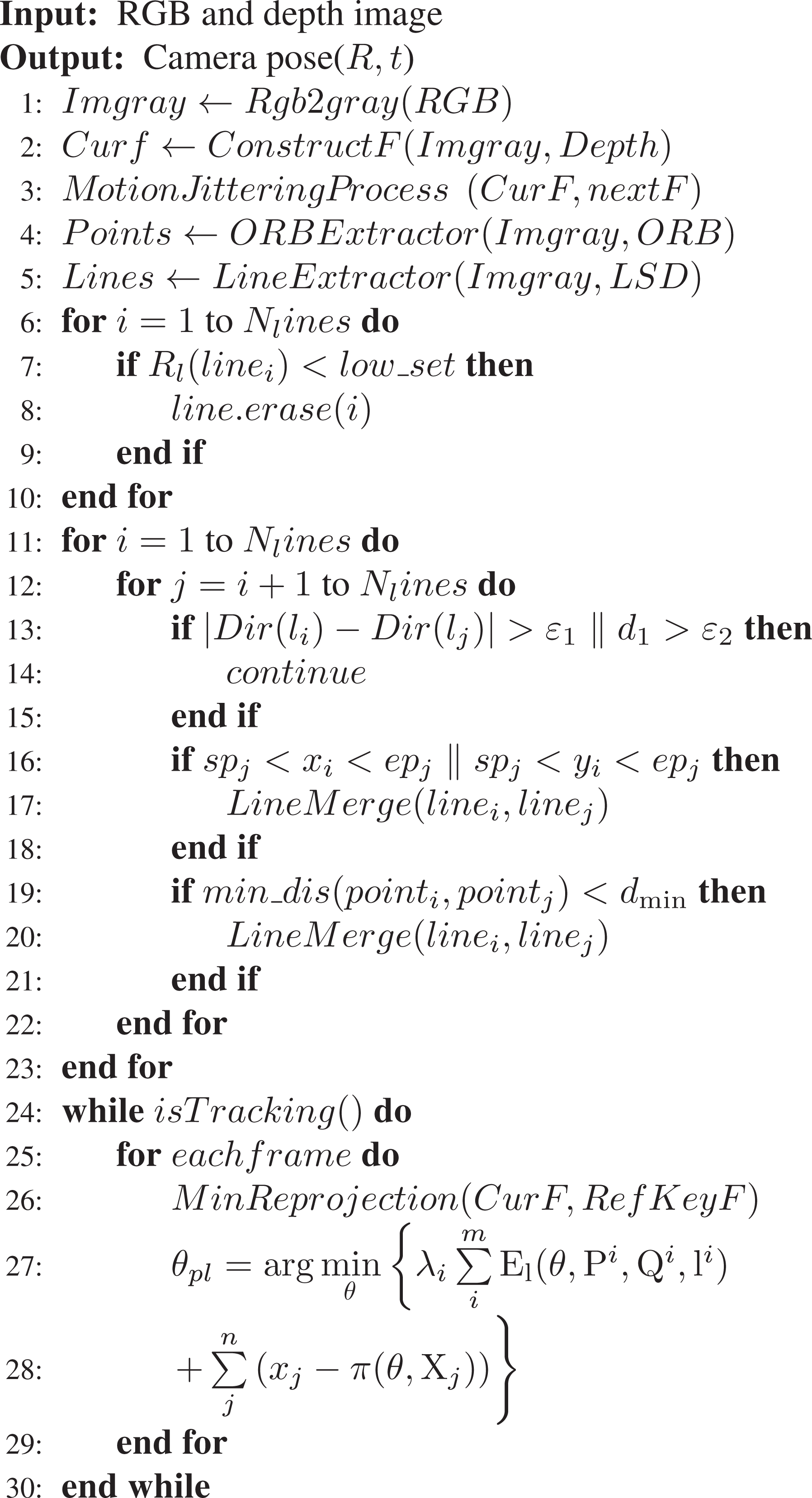
Motion jittering
In the tracking process, the camera often moves fast or shakes, which results in blurred images. As shown in Figure 6, it is easy to cause the failure of feature matching, and finally, the tracking will be lost. Tracking loss requires relocation to make adjustments. If the relocation fails after the loss, it will lead to tracking failure. The main reason for the tracking loss is that the texture of the image is not obvious or the feature difference is too large due to motion jittering, which makes it impossible to match correctly. There are two solutions to the above situation:

(a and b) Blurry image caused by motion jitter.
Under the premise of obtaining the blur kernel, the image with jittering is applied to the linear convolution, which makes the original blurred image clearer, but calculating the blur kernel is a major difficulty. Using the Gauss filter to deal with the image captured by the camera, which can reduce the difference between adjacent images and effectively improve the success rate of feature matching. This feature can effectively reduce the probability of tracking loss.
In this article, we propose a method to select motion-blurred images automatically. In tracking, we pre-match the features of the current image and the next image to calculate the success rate of the tracking in advance. When the matching degree of the two images is lower than the given threshold, Gaussian blur is used to reduce the image noise and detail, which reduces the difference between the two images and improves the matching success rate later.
When the size of blur kernel increases in a certain range, the image blur degree will also increase, so the number of feature matching will also increase. But beyond this range, the difference between adjacent images will be larger than the original image, resulting in matching failure. We propose the following improvement methods in Algorithm 2
Motion Jittering Proccess


Through the improvement of the above method, the tracking success rate is obviously improved, and the error of pose estimation is indirectly reduced, which improves the robustness of the SLAM system.
Experiments and results
We experiment and evaluate the performance of our method on the Technische Universität München (TUM) 34 dataset, which provides several image sequences with accurate ground truths obtained by external motion capture systems. These image sequences also include specific scenes such as normal motion, fast motion, low texture, no structure, etc. We perform our experiments on the computer which has an Intel core i5 (@2.6 GHZ) processor and 8 GB RAM with no GPU acceleration to reduce the running cost of SLAM.
Tracking accuracy
The evaluation of SLAM system performance mainly includes localization accuracy and mapping accuracy, and the latter mainly depends on the former. Therefore, we mainly focus on the localization accuracy of the algorithm in this article. To verify the effectiveness and superiority of the proposed method, we compare it with ORB-SLAM2.
In this article, we select different types of image sequences and carry out multiple groups of the same experiments on each sequence and then take the average value to avoid contingency. Finally, we calculate the root mean square error (RMSE) between the estimated pose and the true pose. We obtain the average of these RMSE data to effectively compare the results. A variety of image sequences such as fr1/360 and fr1/desk are selected as experimental comparison sequences and compared with ORB-SLAM2. The results are presented in Table 1.
Table 1 shows the absolute trajectory error result of different methods for tracking the above dataset sequences separately. From the experimental results, it can be known that the RMSE data obtained by our method is lower than that of ORB-SLAM2 at different degrees in most datasets. As shown in Figure 7(a) and (b), the tracking results of PLF-SLAM are significantly better than ORB-SLAM2 on the fr1/room sequence, which is benefited from the adaptive line segment extraction method proposed in this article. When the number of point features is insufficient, the line features can be simultaneously extracted to participate in the tracking, which makes up for the lack of point features.
Results of the comparisons in the TUM data set.

LSD: line segment detector; SLAM: simultaneous localization and mapping. The bold values highlight the experimental results of the method in this paper to show the advantages of the paper.
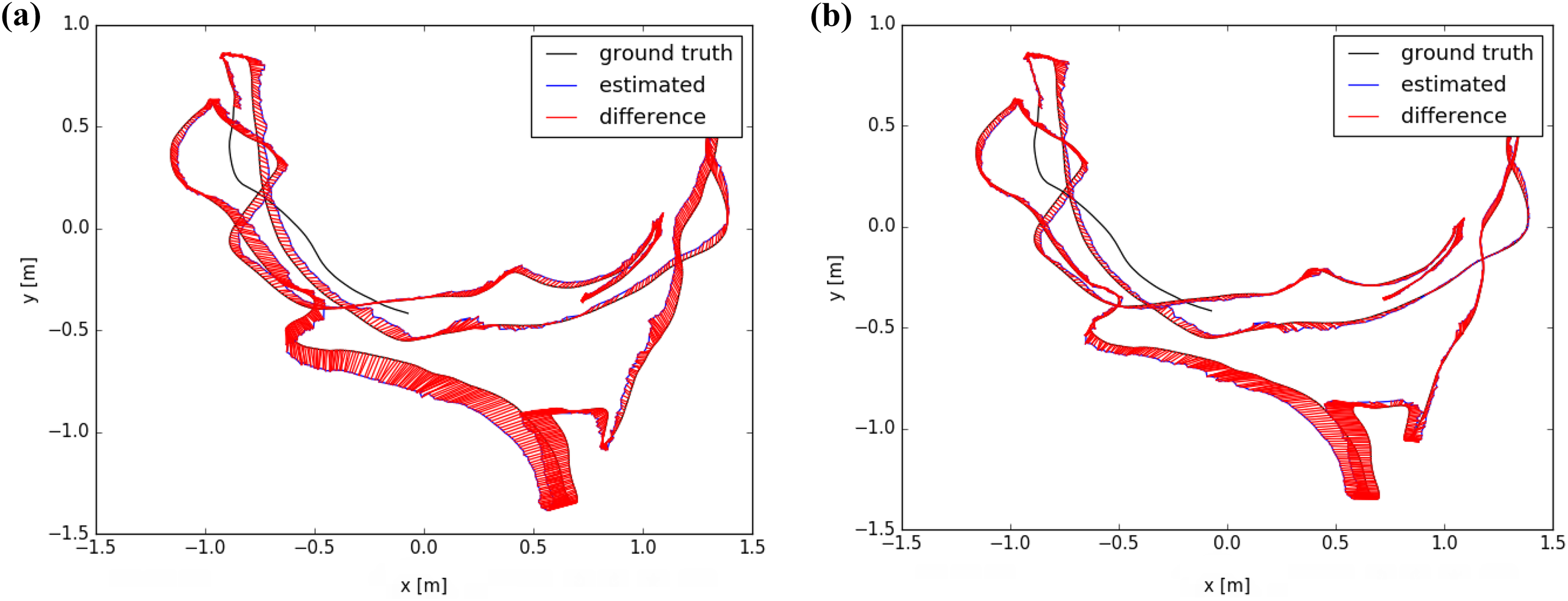
Results of fr1/room sequence in different methods: (a) ORB-SLAM2 and (b) PLF-SLAM. SLAM: simultaneous localization and mapping.
In addition, we also compare our method with ORB-SLAM2 based on the original LSD method. It can be seen from the experimental data in the table that, when we use the adaptive line segment extraction method in this article, most of the trajectory errors are significantly reduced, and the pose estimation is more accurate. The reason is that the line features extracted by the original LSD method have a series of situation such as overlap, segmentation. So that the difference in line features extracted between the adjacent images is large, resulting in poor matching. In our work, we deal with the overlap and segmentation, and more stringent conditions are imposed in the matching, which makes the line matching more reliable and lays a good foundation for the back-end optimization.
Motion jitter evaluation
In the second section, when the camera is quickly shaken, the images taken will often affect feature matching due to the motion blur problem, so it is difficult to calculate the camera pose between the current frame and the next frame in the tracking process. When that happens, we need to perform the relocalization method to find the camera pose, otherwise, the entire tracking process will fail.
When the above TUM sequences are tested, it is found that there are different degrees of motion jitter in multiple sets of sequences. In the fr1/desk sequence, ORB-SLAM2 typically has tracking loss during the 170th and 171st images. The reason is that the image of the previous image is drifted due to the camera’s fast jitter, and the difference between the current frame and the next frame is too huge, so that there are not enough matching pairs, resulting in tracking failure. Although the camera pose can be restored by relocalization, the previous trajectory will be lost, which will inevitably increase the overall trajectory error, as is the fr2/large_loop sequence.
We found two images of the sequence that caused tracking loss and then extracted and matched the features separately. We find that there are few valid matches. For example, the matches of jitter frames in the fr1/desk sequence are only 76, which are difficult to meet the needs of tracking. After our method is used, the matches grow to 117 pairs, and the matching success rate is obviously improved. This is due to the optimization of the jitter images. When the matches are sufficient, the tracking success rate will be greatly improved.
Figure 8 shows the matching of two images in the fr1/desk sequence, where (a) is the matching image before processing and (b) is the processed matching image. It is easy to find that the feature matching after processing by this method is better.

(a and b) Matching before and after image processing.
Figure 9(a) shows the comparison between the estimated trajectory and the actual trajectory in ORB-SLAM2. We can find that the tracking in the red rectangle box has been lost. Figure 9(b) shows the comparison between the estimated trajectory and the actual trajectory in PLF-SLAM. It can be seen that the tracking effect of this method in this sequence is obviously better than the former.

Results of fr1/desk sequence in different methods: (a) ORB-SLAM2 and (b) PLF-SLAM. SLAM: simultaneous localization and mapping.
Table 2 shows the comparison of the two methods in tracking success rate, which includes multiple groups of image sequences with good tracking and bad tracking. From the table, we can see that our method has good tracking results for most image sequences. Compared with ORB-SLAM2, the tracking success rate has been improved to some extent. This proves that our method improves the robustness of slam system to a certain extent.
Success rate comparison results.

LSD: line segment detector; SLAM: simultaneous localization and mapping. The bold values highlight the experimental results of the method in this paper to show the advantages of the paper.
Conclusion
In this article, a point-line fusion SLAM method based on depth camera is presented. Aiming at the unreliability of SLAM based on point feature in low-texture environment, a new line segment extraction, and matching method are proposed, which solve the overlap and branch problem of the original LSD method and improve the reliability of the line matching and robustness. For the motion jitter problem often encountered in tracking, a method of autonomously selecting and optimizing the motion jitter frame is proposed, which greatly improves the success rate of tracking, and the method does not require additional sensor support. We have carried out many experimental evaluations on the TUM dataset, and most of the experimental results have been greatly improved compared with ORB-SLAM2. We have specifically verified the image sequence with motion blur, and the experimental results prove the article. The experimental results verify the rationality and effectiveness. In the future, we will optimize the tracking process and improve the real-time performance of the proposed method by detecting the current tracking environment to choose when to join the line feature estimation. In addition, we will combine the depth sensor to build a dense point cloud map in real time, and further build an octree-based grid map to enhance the intuitiveness and reusability of mapping for subsequent navigation work and other corresponding work.
Footnotes
Acknowledgments
We would like to express our gratitude to all those who helped us during the writing of this thesis. We acknowledge the help of Professor Wang Hao, who has offered suggestions in academic studies. We awe a special debt of gratitude to Han Jianying, a partner in the same research field. Finally, thanks to all the partners of the lab for their company and support.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Anhui Province [Grant No. 1708085MF146], the university synergy Innovation Prograln of Anhui Province [GXXT-2019-003], the special fund for basic scientific research in central colleges and universities [Grant No. ACAIM190102], and the Project of Innovation Team of Ministry of Education of China [Grant No. IRT17R32].